AST-SED: An Effective Sound Event Detection Method Based on Audio Spectrogram Transformer
https://arxiv.org/abs/2303.03689
AST-SED: An Effective Sound Event Detection Method Based on Audio Spectrogram Transformer
In this paper, we propose an effective sound event detection (SED) method based on the audio spectrogram transformer (AST) model, pretrained on the large-scale AudioSet for audio tagging (AT) task, termed AST-SED. Pretrained AST models have recently shown
arxiv.org
초록
본 논문에서는 대규모 오디오 태깅(Audio Tagging, AT) 작업을 위해 AudioSet으로 사전학습된 오디오 스펙트로그램 트랜스포머(Audio Spectrogram Transformer, AST) 모델을 기반으로 한 효과적인 소리 이벤트 탐지(Sound Event Detection, SED) 방법을 제안한다. 우리는 이 방법을 AST-SED라 명명한다. 최근 사전학습된 AST 모델은 실제 주석 데이터(real annotated data)의 부족 문제를 완화하는 데 도움을 주며, DCASE2022 챌린지 Task 4에서 가능성을 보여주었다. 그러나 AT와 SED 작업 간의 차이로 인해, 사전학습된 AST 모델의 출력을 그대로 사용하는 것은 최적이 아니다. 이에 따라, 본 연구에서는 AST 모델을 재설계하거나 재학습하지 않고도 효과적이고 효율적인 미세조정(fine-tuning)을 가능하게 하는 인코더-디코더(encoder-decoder) 아키텍처인 AST-SED를 제안한다.
구체적으로, Frequency-wise Transformer Encoder (FTE)는 주파수 축을 따라 셀프 어텐션(self-attention)을 적용한 트랜스포머로 구성되며, 하나의 클립 내에서 다수의 오디오 이벤트가 겹치는 문제를 해결하도록 설계되었다. Local Gated Recurrent Units Decoder (LGD)는 최근접 이웃 보간(Nearest-Neighbor Interpolation, NNI)과 양방향 GRU(Bidirectional Gated Recurrent Unit, Bi-GRU)를 활용하여, 사전학습된 AST 모델의 출력에서 손실된 시간 해상도를 보완한다.
DCASE2022 Task 4 개발 세트에서의 실험 결과, FTE-LGD 아키텍처를 적용한 제안 모델 AST-SED는 우수한 성능을 입증하였다. 특히, 이벤트 기반 F1 점수(Event-Based F1-score, EB-F1) 59.60%와 다성 소리 탐지 점수 시나리오 1(Polyphonic Sound Detection Score scenario1, PSDS1) 0.5140은 CRNN 및 다른 AST 기반 사전학습 시스템들보다 현저히 높은 성능을 기록했다.
색인어 — 소리 이벤트 탐지, 트랜스포머, 게이트 순환 유닛(GRU), 인코더-디코더, 파인튜닝
1. 서론
소리 이벤트 탐지(Sound Event Detection, SED)는 주어진 오디오 클립 내에서 동시에 발생하는 여러 이벤트의 범주(category)와 발생 시점(timestamp)을 모두 판별하는 것을 목표로 한다. 이 기술은 스마트 홈 기기 [1]나 자동 감시 시스템 [2]과 같은 실제 시스템에서 널리 활용될 수 있다. 최근에는 SED 연구의 발전을 평가하기 위해 DCASE 챌린지에서 일련의 태스크들이 제시되고 있다[^1].
기존 시스템들은 주로 mean teacher [3, 4, 5]와 같은 반지도 학습(semi-supervised learning) 방법을 활용하여, 약하게 주석된(weakly labeled) SED 태스크를 다룬다. 대부분의 방법은 합성곱 순환 신경망(Convolutional Recurrent Neural Network, CRNN) 구조 [6, 7]와 그 변형 모델들(SK-CRNN [8], FDY-CRNN [9])을 사용하여 프레임 단위 특징 추출과 문맥(context) 모델링을 수행한다. 2020년, Miyazaki 외 [10]는 국소(local) 및 전역(global) 문맥 정보를 모두 모델링하기 위해 합성곱 기반 트랜스포머 구조인 Conformer를 도입하였다. 강하게 주석된 데이터와 합성 데이터의 도움을 받으면, SED 성능은 더욱 향상될 수 있다.
DCASE2022에서는 대규모의 외부 약하게 주석된 AudioSet [11] 데이터를 활용하려는 다양한 연구들이 발표되었다. 예를 들어, Ebbers와 Haeb-Umbach [12]는 FB-CRNN(forward-backward CRNN)과 Bi-CRNN(bidirectional CRNN)을 AudioSet에서 사전학습(pretrain)한 뒤, 자가 학습(self-training) 방식으로 SED에 파인튜닝하였다. Xiao [13]는 사전학습된 오디오 신경망(PANN) 및 오디오 스펙트로그램 트랜스포머(AST) [14, 15]의 출력을 기반으로 RNN을 활용해 문맥 모델링을 수행하였다. 본 논문은 [13]에 영감을 받아, Fig.1(a)에서 보여주듯 사전학습된 AST 모델을 기반으로 AST-GRU를 SED에 확장하였다. CRNN처럼, AST 출력은 먼저 주파수 축에 대해 평균 풀링(mean pooling)된 후, Bi-GRU로 전달되어 문맥을 모델링한다.
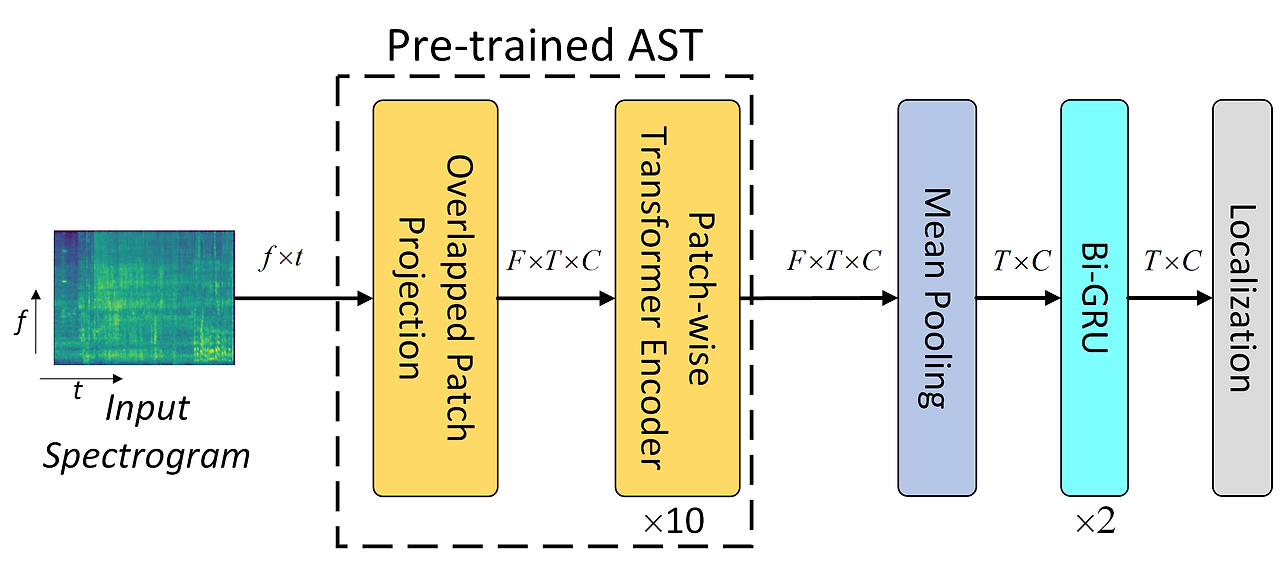
(a) AST-GRU (기존 베이스라인): AST 출력에서 주파수 축으로 평균 풀링하여 프레임 시퀀스를 구성한 뒤 Bi-GRU에 입력해 문맥 모델링 수행.
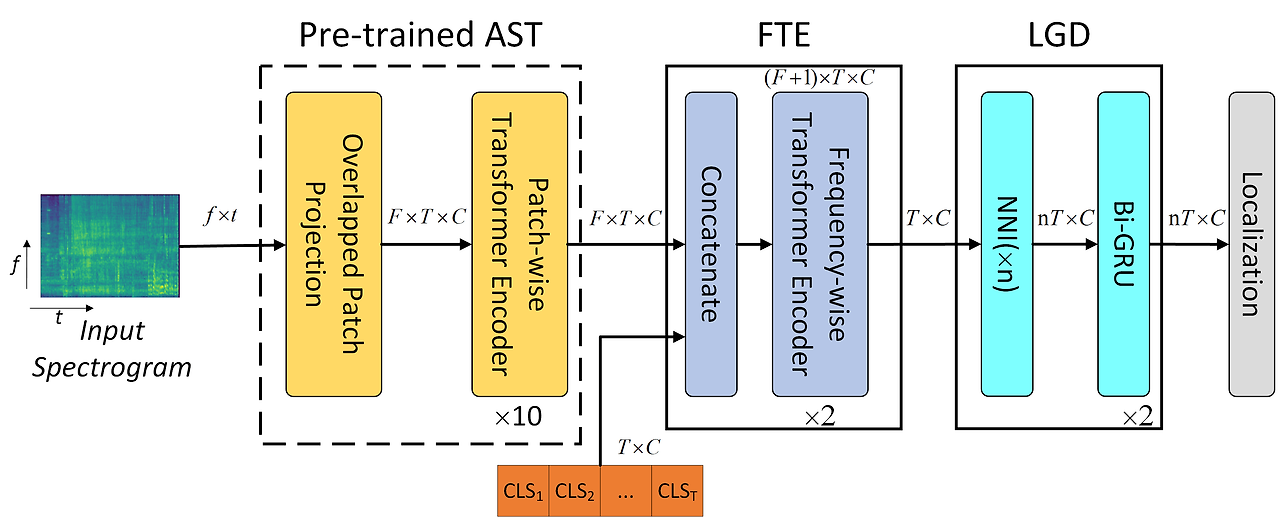
(b) AST-SED (본 논문 제안 모델): 주파수 축 셀프 어텐션을 적용한 FTE로 프레임 시퀀스를 생성하고, NNI(Nearest Neighbour Interpolation) 및 Bi-GRU로 구성된 LGD(Local GRU Decoder)를 통해 높은 시간 해상도 특징을 출력. (a) 평균 풀링: AST-GRU에서 주파수 축을 따라 단순 평균. (b) FTE: 주파수 축에 셀프 어텐션을 적용한 구조.
AST-GRU가 보여주는 가능성에도 불구하고, 앞서 언급했듯이 사전학습된 AST의 출력을 직접 사용하는 것은 최적의 방법이 아니다. 그 이유는 AT와 SED 작업 간의 근본적인 차이에 있다. 첫째, 하나의 클립에 다양한 주파수 대역을 가지는 여러 오디오 이벤트가 동시에 발생하므로, 단순한 평균 풀링과 같은 집계 방식은 주파수 정보를 손실시킬 수 있다. 둘째, AST 모델은 AudioSet에서 오디오 태깅(Audio Tagging, AT) 작업을 위해 클립 단위 표현(clip-wise representation)을 학습하였기 때문에, 시간 해상도(temporal resolution)가 손실될 수 있다.
이에 따라 본 논문에서는 Fig.1(b)에 제시된 바와 같이, 대규모 AudioSet에서 사전학습된 AST 모델을 기반으로 인코더-디코더 구조의 AST-SED 방법을 제안한다. 구체적으로, Frequency-wise Transformer Encoder (FTE)에서는 AST 출력에 프레임 단위 클래스 토큰(frame-level class tokens)을 연결하고, 일련의 트랜스포머 블록을 통과시킨다. 셀프 어텐션은 주파수 축(frequency axis)을 따라 적용되며, 다중 이벤트가 겹치는 상황에 적합한 프레임 단위 표현을 생성한다.
이후, Local GRU Decoder (LGD)에서는 먼저 Nearest Neighbour Interpolation (NNI)을 이용해 프레임 시퀀스를 입력 스펙트로그램의 시간 해상도에 맞게 확장한 뒤, 양방향 GRU(Bi-GRU) [16]를 통해 문맥 모델링을 수행한다. 기존 시스템 [4]들처럼, mean teacher 방식을 활용하여 약하게 주석되거나 미주석(unlabeled)된 데이터로부터 학습한다.
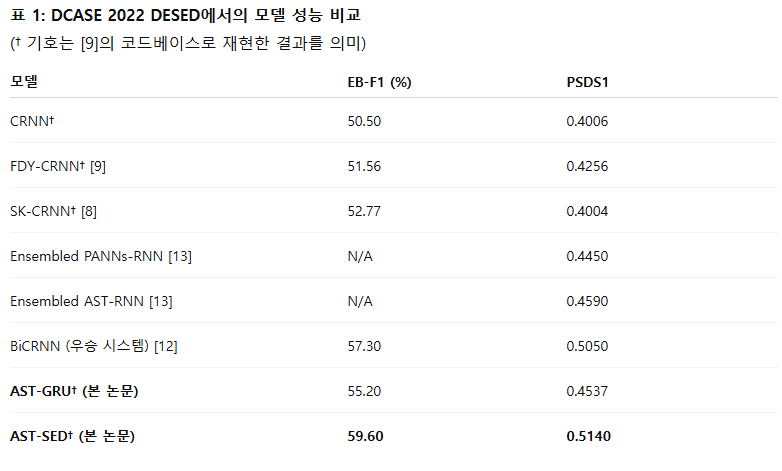
DCASE2022 Challenge Task4의 개발 세트에서 제안한 FTE-LGD 아키텍처 기반 AST-SED의 성능을 평가하기 위한 광범위한 실험을 수행하였다. 그 결과, Event-Based F1 (EB-F1) 59.60%, PSDS1 (Polyphonic Sound Detection Score - Scenario 1) 0.5140을 기록하여, DCASE2022 우승 시스템의 성능(EB-F1 57.30%, PSDS1 0.5050)을 뛰어넘는 우수한 결과를 달성하였다.
2. 방법
이 절에서는 먼저 사전학습된 AST를 사용하는 기본 베이스라인 시스템인 AST-GRU를 간략히 소개하고, 그 한계점을 분석한다. 이어서, AST 모델을 재설계할 필요 없이 효율적으로 파인튜닝할 수 있도록 설계된 제안된 인코더-디코더 구조(FTE-LGD) 기반의 AST-SED 시스템을 자세히 설명한다.
2.1 사전학습된 AST 기반 베이스라인 시스템: AST-GRU
[15, 17]에서는 오디오 태깅(Audio Tagging, AT) 작업을 위해 AST(Audio Spectrogram Transformer) 아키텍처가 제안되었다. AST-GRU 시스템은 Fig.1(a)에 나타난 것처럼 사전학습된 AST의 출력을 기반으로 구축된다. 입력 스펙트로그램은 크기 16×16, 보폭(stride) 10×10의 패치로 분할되며, 이 패치들은 768차원의 패치 토큰(patch-token)으로 선형 투영(linear projection)된다. [18, 19]를 따라, 이 패치 토큰들에 위치 임베딩(positional embedding)을 더하여 PI ∈ ℝ^F×T×C 형태의 입력 시퀀스를 구성한다.
이후, Fig.1(a)와 같이, 멀티헤드 셀프 어텐션(Multi-Head Self-Attention, MHSA)이 적용된 패치 단위 트랜스포머 인코더(Patch-wise Transformer Encoder, PTE)를 통해 패치 수준의 문맥(context) 정보를 모델링한다.
트랜스포머 기반 모델의 학습은 일반적으로 많은 연산 자원을 요구하는 것으로 알려져 있다. 예를 들어, 패치 시퀀스 길이 n에 대해 셀프 어텐션(self-attention)의 계산 복잡도는 O(n^2)이며, 충분한 양의 학습 데이터가 필요하다 [19]. 이러한 특성은, 시퀀스 길이 n이 긴 경우, 비록 대규모의 약하게 주석된 AudioSet을 사용할 수 있더라도, 트랜스포머 기반 모델을 SED 작업에 직접 활용하는 데 제약이 될 수 있다.
AST-GRU에서는 이러한 문제를 해결하기 위해 먼저 주파수 축(frequency axis)에 대해 평균 풀링(mean pooling)을 적용하여, 훨씬 짧은 시퀀스 길이 n을 갖는 프레임 시퀀스(frame sequence)를 형성하고, 이후 양방향 GRU(Bi-GRU)를 통해 SED 작업을 수행한다. 이후, 시그모이드(Sigmoid) 활성화 함수가 적용된 선형 분류기(linear classifier)를 사용하여 프레임 단위 SED 예측값을 생성하며, 오디오 태깅(AT) 작업에는 소프트맥스(softmax) [20]가 적용된다.
또한, PTE(Patch-wise Transformer Encoder) 부분은 10개의 트랜스포머 블록을 갖는 사전학습된 AST-base 모델로 초기화된다. 이 후, AST-GRU는 약하게 주석된 데이터와 미주석 데이터에 대해 Mean Teacher [3] 기법을 사용하여 파인튜닝(fine-tuning)되며, 사용되는 손실 함수는 다음과 같이 정의된다.
손실 함수는 다음과 같이 정의된다:

AST-GRU는 기존 CRNN 구조보다 SED 성능이 더 우수할 수 있지만, 앞서 언급한 것처럼 AT와 SED 작업의 차이로 인해 여전히 최적의 구조는 아니다. 다음 절에서는, AST-GRU의 주파수 및 시간 정보 손실 문제를 해결하기 위해 제안된 FTE-LGD 인코더-디코더 아키텍처 기반 AST-SED 시스템을 상세히 설명한다.
2.2 제안된 FTE-LGD 아키텍처 기반 AST-SED
2.2.1 FTE: 주파수 축 기반 트랜스포머 인코더 (Frequency-wise Transformer Encoder)
FTE의 설계 동기를 설명하기 위해, 먼저 이벤트별 주파수 축 활성화 분포를 분석한다. 이를 위해 AST-GRU에서 사용된 평균 풀링(mean pooling)을 하나의 주파수 밴드(frequency band)로 대체하여, 각 이벤트 클래스에 대한 탐지 성능을 평가한다. 다양한 주파수 밴드를 사용할 때의 클래스별 이벤트 기반 F1 점수(EB-F1)를 계산하고 이를 [0, 1] 범위로 정규화하여 주파수 축 활성 분포를 시각화한다.
Fig.3은 네 가지 이벤트 유형에 대한 주파수 축 분포를 탐색하기 위한 히스토그램을 보여준다:
- Alarm_bell_ringing: 주로 고주파(high frequency) 영역에서 활성화됨.
- Speech: 주로 저주파(low frequency) 영역에서 활성화됨.
- Dog, Dishes, Cat 등의 이벤트: 주로 중간 주파수대(middle frequency)에서 활성화됨.
- Electronic_shaver, Blender, Vacuum_cleaner, Frying 등: 모든 주파수 밴드에 걸쳐 고르게 활성화됨.
이처럼 이벤트마다 활성화되는 주파수 분포가 다르다는 점을 확인할 수 있다. 이는 단순한 평균 풀링(mean pooling)과 같은 집계 방식이, SED에서 판별력을 가지는 주파수 정보를 손실할 수 있음을 시사한다. 따라서, 보다 정교한 주파수 축 기반 모델링이 필요하며, 이는 FTE의 동기이기도 하다.
이를 해결하기 위해, 트랜스포머 내에 주파수 축 기반 멀티헤드 셀프 어텐션(frequency-wise Multi-Head Self-Attention, fMHSA)을 도입한 FTE 블록(Frequency-wise Transformer Encoder block)이 제안되었다. 구체적으로, PTE(Patch-wise Transformer Encoder)의 출력 PO ∈ ℝ^F×T×C에 대해, 학습 가능한 CLS 토큰 시퀀스 CLS ∈ ℝ^T×C를 주파수 축(frequency axis) 방향으로 PO와 결합하여 FTE 입력 FI ∈ ℝ<sup>(F+1)×T×C</sup>을 구성한다. [18, 19]를 따라, FTE 블록은 fMHSA가 적용된 다층 퍼셉트론(MLP)과 레이어 정규화(Layer Normalization, LN)로 이루어진다. 계산 방식은 다음과 같다:

여기서 주목할 점은, fMHSA에서는 각 토큰 E_{t,f}가 동일 시간 위치 t에서만 다른 주파수 위치 f들과 상호작용한다는 것이다(Fig.2(b) 참조).
FTE의 출력 FO ∈ ℝ^(F+1)×T×C에서 CLS 토큰 시퀀스만을 추출하면, 최종적인 프레임 시퀀스 C ∈ ℝ^{T×C}가 된다. FTE는 총 2개의 트랜스포머 블록으로 구성되며, 각 블록에는 4개의 헤드를 가진 fMHSA가 사용된다. 중간 임베딩 차원은 768로 설정된다.

(a) Alarm_bell_ringing

(b) Dog
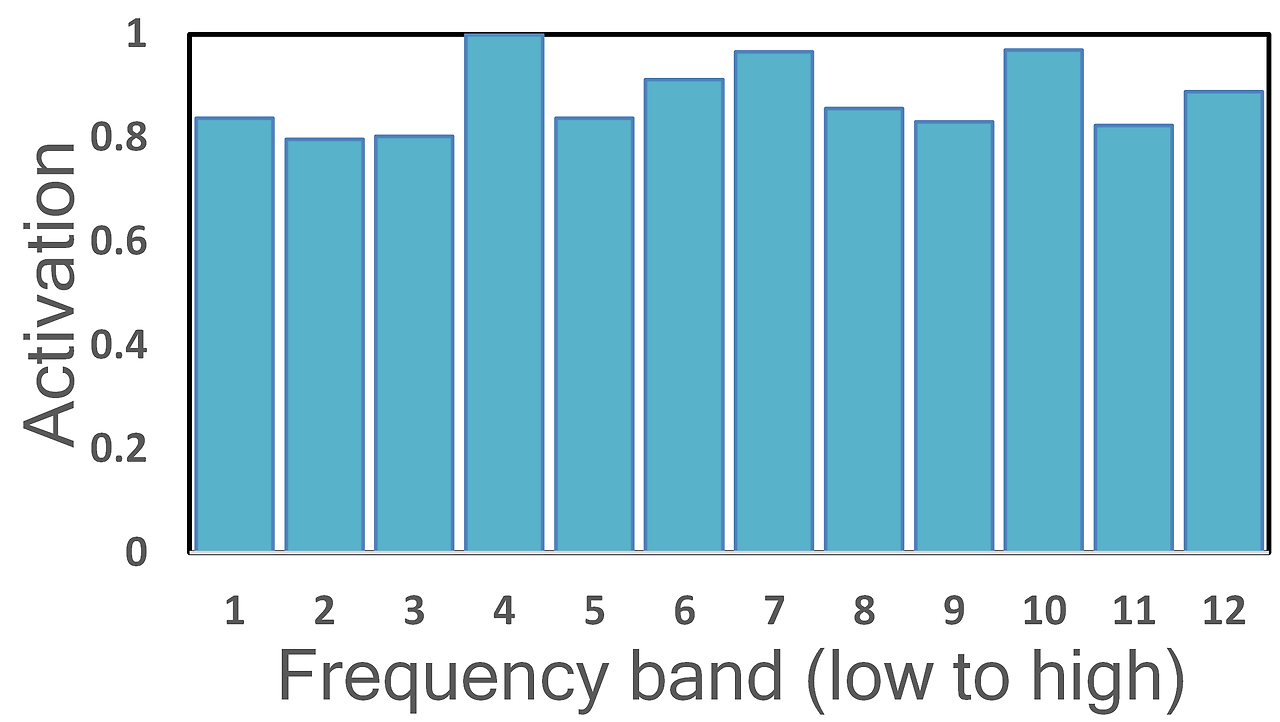
(c) Blender

(d) Speech
그림 3: 주파수 차원에 따른 정규화된 활성화 분포.
2.2.2 LGD: Local GRU Decoder
AST의 출력은 시간 해상도(temporal resolution)가 낮기 때문에, 이를 그대로 Bi-GRU에 입력하여 문맥(context)을 모델링하면 SED 성능이 제한적일 수 있다. 이에 따라, LGD(Local GRU Decoder)는 NNI 블록(Nearest Neighbour Interpolation)과 Bi-GRU로 구성되며, Fig.1(b)에서 보이듯 FTE 출력 시퀀스 C ∈ ℝ^{T×C}에 적용되는 로컬 디코더(local decoder) 역할을 한다.
만약 NNI 업샘플링 비율(up-sampling ratio)을 n이라 하면, LGD의 단순한 구현은 다음과 같다:

출력 O ∈ ℝ^{nT×C}는 높은 시간 해상도(high temporal resolution)를 요구하는 정밀한 SED 작업(fine-grained SED task)에 적합할 수 있다.
기존의 CRNN 구조에서는 GRU의 디코딩 능력 [16]이 크게 주목받지 못했는데, 이는 CNN 부분이 이미 높은 시간 해상도의 출력을 생성하도록 설계되어 디코딩이 필요하지 않았기 때문이다. 그러나 AST 기반 SED에서는, 레이블된 데이터와 연산 비용 등 막대한 자원이 필요하기 때문에, 고해상도 트랜스포머를 사전학습(pretraining)이나 파인튜닝(fine-tuning)에 사용하는 것이 비효율적이다 [19]. 이러한 이유로, Conformer [10]에서도 Transformer 대신 Bi-GRU를 SED를 위한 디코더로 채택하게 된 것이다.
3. 실험 및 결과
3.1 데이터셋 및 실험 설정
평가를 위해 DCASE2022 Task4 개발 세트(DESED) [21]를 사용하였다.
훈련 데이터셋은 다음과 같은 구성으로 이루어져 있다:
- 약하게 라벨링된(weak) 클립: 1,578개
- 라벨이 없는(unlabeled) 클립: 14,412개
- 실제 강한 라벨(real-strong) 클립: 3,470개
- 합성된 강한 라벨(synthetic-strong) 클립: 10,000개
검증(validation) 데이터셋은 총 1,168개의 클립으로 구성되어 있다. PSDS1 [22]과 EB-F1 점수가 정밀한 SED 성능 평가 지표로 사용된다.
16kHz 오디오 입력 파형은 먼저 25ms 윈도우 크기와 10ms 프레임 시프트를 적용하여 128차원의 로그 Mel 스펙트로그램으로 변환되며, 이후 평균 0, 표준편차 0.5로 정규화된다.
MixUp [23], time-mask, time-shift, FilterAugment [24] 등의 데이터 증강 기법이 적용되며, 고정된 시간 길이의 중앙값 필터(median filter)가 후처리(post-processing)로 사용된다. 모든 이벤트 타입에 대해 0.5의 임계값(threshold)을 적용하여 hard prediction을 생성하고, 이를 기반으로 EB-F1을 계산한다. 데이터 증강 및 중앙값 필터 설정은 [9]와 동일하게 적용되었다.
AST-GRU와 AST-SED는 모두 AdamW 옵티마이저 [25]를 사용하여 10 에폭 동안 학습되며, 배치 구성은 real-strong : synthetic-strong : weak : unlabeled = 1:1:2:2의 비율로 설정된다.
학습률(learning rate, lr)은 사전학습된 AST에는 5e-6, 나머지 부분에는 1e-4로 설정되며, 처음 5 에폭 동안은 고정된 학습률을 사용하고, 이후에는 지수적으로 감소시킨다.
또한, Mean Teacher 기반의 반지도 학습(SSL)을 활용하여 AST-GRU와 AST-SED를 DCASE2022 DESED에 대해 파인튜닝한다.
3.2 AST-GRU와 AST-SED 성능 비교
Table 1에서 보이듯, AST-GRU는 DCASE 2022 DESED에서 EB-F1 55.20%, PSDS1 0.4537을 기록하며, 각각 CRNN 베이스라인(CRNN†)의 성능인 50.5%, 0.4006을 크게 상회하는 성과를 보였다. 이는 AudioSet에서 사전학습된 AST 모델이 강력한 특징 추출기(feature extractor)로 작동함을 보여준다.
한편, FTE-LGD 인코더-디코더 구조를 포함한 AST-SED는 더욱 뛰어난 결과를 달성한다. 특히, EB-F1 59.60%, PSDS1 0.5140이라는 최고 성능을 기록하며, 최근 보고된 최첨단(state-of-the-art) 결과들을 능가한다. 주목할 점은, 이전 우승 시스템 [12] 또한 자가 학습(self-training) 방식으로 학습되었다는 점이다.



3.3 FTE-LGD 구조를 활용한 AST-SED의 구성요소 분리 실험 (Ablation Study)
우리는 다양한 아키텍처 구성과 파라미터 선택의 효과를 평가하기 위해 일련의 구성요소 분리 실험(ablation study)을 수행하였다. 표 2는 FTE 또는 LGD를 적용한 다양한 구성을 보여주며, 이들 구성은 베이스라인인 AST-GRU보다 우수한 성능을 보일 수 있음을 나타낸다.
특히, FTE-LGD 인코더-디코더 아키텍처를 적용한 AST-GRU/AST-SED는 가장 뛰어난 성능을 기록하며, AST-GRU 대비 EB-F1에서 4.40%p, PSDS1에서 0.06의 절대적인 향상을 달성했다.
또한 표 2에서는 다양한 업샘플링 비율(up-sampling ratio)에 따른 LGD의 성능을 비교하였으며, 5배 및 10배 업샘플링이 가장 우수한 결과를 나타냄을 확인하였다.
표 3은 오디오 이벤트 유형별 성능 차이를 나타낸다. Speech, Dog와 같이 짧은 길이의 이벤트(short duration events)에서는
AST-SED가 각각 9.62%, 9.61%의 상대적으로 큰 성능 향상을 보였다.
반면, Running_water, Vacuum_cleaner와 같은 긴 길이의 이벤트(long duration events)에서는 향상폭이 상대적으로 작았으며, 이는 LGD에 사용된 단순한 NNI 연산의 한계로 인한 것으로 해석할 수 있다.
향후 연구에서는 보다 강력한 디코더 구조를 도입하여 긴 이벤트에 대한 성능 향상을 도모할 계획이다.
4. 결론
본 논문에서는 사전학습된 AST 모델을 기반으로 한 효과적인 SED 방법(AST-SED)을 제안하였다. 특히, AST 모델을 수정하지 않고도 효율적으로 학습할 수 있는 인코더-디코더 구조를 설계하였다.
- 인코더인 FTE(Frequency-wise Transformer Encoder)는 주파수 축 기반 셀프 어텐션을 활용한 트랜스포머 블록으로 구성되어, 프레임 단위 특징 추출을 효과적으로 수행한다.
- 디코더인 LGD(Local GRU Decoder)는 NNI 연산과 양방향 GRU 블록으로 구성되어, 정밀한 시간 해상도 기반 SED 수행이 가능하다.
DCASE2022 Task4에서의 실험 결과는, FTE-LGD 구조를 활용한 제안된 AST-SED가 기존 최신 기법들(state-of-the-art)을 능가하는 성능을 달성함을 입증하였다.