MatFormer: Nested Transformer for Elastic Inference
https://arxiv.org/abs/2310.07707
MatFormer: Nested Transformer for Elastic Inference
Foundation models are applied in a broad spectrum of settings with different inference constraints, from massive multi-accelerator clusters to resource-constrained standalone mobile devices. However, the substantial costs associated with training these mod
arxiv.org
구글에서 소규모 모델에서 사용했다고 말하는 matformer를 리뷰할것이다.
초록
파운데이션 모델(Foundation Models)은 대규모 멀티 가속기 클러스터부터 리소스가 제한된 독립형 모바일 기기까지 다양한 추론 제약 조건을 가진 환경에서 활용되고 있습니다. 하지만 이러한 모델을 훈련하는 데 드는 막대한 비용은 제공할 수 있는 모델 크기의 다양성을 제한하는 요인이 됩니다. 그 결과, 실사용자는 자신이 원하는 지연 시간(latency)이나 비용 요구 사항에 최적화되지 않은 모델을 선택할 수밖에 없는 상황에 놓이게 됩니다.
이에 우리는 MatFormer를 소개합니다.
※ MatFormer는 Matryoshka Transformer의 줄임말로, 모델이 본질적으로 중첩된(nested) 구조를 가진다는 점에서 이름이 유래되었습니다.
MatFormer는 다양한 배포 제약 조건을 고려해 탄력적인 추론(elastic inference)을 제공할 수 있도록 설계된 새로운 형태의 Transformer 아키텍처입니다. 이 모델은 표준 Transformer 구조 내에 중첩된 Feed Forward Network (FFN) 블록 구조를 통합함으로써 이를 구현합니다. 학습 시, 크기가 서로 다른 여러 중첩 FFN 블록의 파라미터를 함께 최적화함으로써 추가 연산 비용 없이 수백 개의 정확한 소형 모델들을 추출할 수 있습니다.
우리는 MatFormer의 효용성을 디코더와 인코더 등 다양한 모델 유형뿐 아니라, 언어와 비전 등 다양한 모달리티에 걸쳐 실험적으로 검증했습니다. 그 결과, 실제 환경에서도 효과적으로 활용될 수 있는 가능성을 보여줍니다.
예를 들어, 파라미터 수 8억 5천만 개(850M)의 디코더 전용 MatFormer 언어 모델(MatLM)에서 5억 8천 2백만 개(582M)에서 8억 5천만 개 사이의 여러 소형 모델을 추출할 수 있으며, 각각은 독립적으로 학습한 동등한 크기의 모델보다 더 나은 검증 손실 및 단발(one-shot) 다운스트림 성능을 보였습니다.
또한, 범용 MatFormer 기반의 비전 Transformer(MatViT) 인코더에서 추출한 소형 인코더들도 대규모 적응형 검색(adaptive large-scale retrieval)에 필요한 거리 기반 임베딩 구조(metric-space structure)를 잘 보존하는 것을 확인했습니다.
마지막으로, MatFormer에서 추출한 정확하고 일관된 서브모델을 활용한 사전 추론(speculative decoding) 기법을 통해 추론 지연 시간(inference latency)을 크게 줄일 수 있음을 입증했습니다.
자세한 내용은 프로젝트 웹사이트에서 확인할 수 있습니다.
1 서론

Figure 1: MatFormer는 Transformer의 FFN 블록에 중첩(nested) 구조를 도입하고, 모든 서브모델을 함께 학습함으로써, 수백 개의 정확한 서브모델을 자유롭게 추출할 수 있게 하여 탄력적인 추론(elastic inference)을 가능하게 한다.
대규모 파운데이션 모델(FM, Foundation Model) [49, 45, 17]은 모바일 환경의 실시간 응답부터 웹 규모 배치 처리(batch serving)를 위한 멀티 클러스터 GPU에 이르기까지, 다양한 연산 및 정확도 요구사항을 가진 환경에서 활용됩니다. 그러나 일반적인 모델 계열(family)은 서로 다른 크기의 모델을 몇 개만 독립적으로 훈련하여 제공합니다. 예를 들어, Llama-2 모델 계열은 70억(7B), 130억(13B), 340억(34B), 700억(70B) 파라미터 모델만을 제공합니다 [59]. 이로 인해 실제 사용자는 자신의 지연 시간이나 비용 제약에 비해 더 작은(그리고 일반적으로 덜 정확한) 모델을 선택해야 하는 경우가 많습니다. 또는 압축(compression)이나 프루닝(pruning)을 활용해 더 큰 모델을 주어진 예산 안에 맞춰 넣는 방법도 있지만 [19, 36, 53], 이 경우 추가적인 학습이 필요합니다.
우리는 이러한 문제를 해결하기 위해 MatFormer를 소개합니다. 이는 기본적으로 탄력성(elasticity)을 내장한 Transformer 아키텍처 [61]로, 하나의 범용(universal) 모델을 학습한 뒤, 추가 학습 비용 없이 수백 개의 소형 서브모델을 추출할 수 있도록 설계되어 있습니다 (그림 1 참조). MatFormer는 인코더와 디코더 모두에 적용 가능하며, 도메인에 무관하게 사용 가능하고, 기존 파운데이션 모델 훈련 파이프라인과도 호환됩니다.
MatFormer는 Matryoshka 표현 학습(Metryoshka Representation Learning) [34] 원리를 기반으로, 표준 Transformer 블록 내부에 중첩된 하위 구조(nested substructure)를 도입합니다. 형식적으로는 Transformer 블록들을
T₁ ⊂ T₂ ⊂ ⋯ ⊂ T_g
와 같이 정의하며, 여기서 g는 중첩 블록의 수를 의미하고, T_i ⊂ T_i+1 관계는 T_i의 파라미터가 T_i+1에 포함된다는 것을 뜻합니다. MatFormer는 Transformer의 attention 블록과 Feed Forward Network (FFN) 블록 양쪽 모두에 이러한 중첩 구조를 도입할 수 있습니다 (그림 1 참조).
예를 들어, FFN 블록의 hidden layer에 d_ff개의 뉴런이 있다고 할 때, MatFormer는 이들 뉴런에 대해 matryoshka 구조를 유도하여, T_i는 상위 m_i개의 뉴런만 포함합니다. 이때,
1 ≤ m₁ < m₂ < ⋯ < m_g = d_ff
로 설정되며, 각 단계별 서브모델에 포함되는 뉴런 수를 의미합니다. 직관적으로, 처음 m₁개의 뉴런이 가장 중요하며, 이후의 뉴런은 점차 더 큰 모델에만 포함됩니다.
기존 연구들과 달리 (2절 참고), 우리는 단지 g개의 크기(세분화 수준, granularity)에 대해 학습했음에도 불구하고, 학습 이후 지수적으로 많은 수의 서브모델을 추출할 수 있습니다. 학습된 MatFormer 블록 T₁, …, T_g를 각 층에서 조합함으로써 새로운 모델을 구성할 수 있는데, 이를 우리는 Mix’n’Match 방식이라고 부릅니다 (3.3절 참조). 예컨대, 첫 번째 층에서 T_g, 두 번째 층에서 T₂, 세 번째 층에서 T₄ 등의 조합을 선택하여 총 g_l개의 조합이 가능하며, 여기서 l은 층의 수입니다. 놀랍게도, 다양한 모델 크기와 설정에서 이러한 방식으로 추출된 모델들이 높은 정확도를 보이며, 추출된 모델의 크기에 따라 정확도도 자연스럽게 향상됨을 확인했습니다.
우리는 최대 8억 5천만 개의 파라미터를 가진 디코더 전용 언어 모델(MatLM)을 MatFormer 기반으로 학습하여 다음과 같은 결과를 관찰했습니다:
- g개의 세분화 수준으로 학습된 MatLM은, 각각 독립적으로 학습된 동일 크기의 모델들보다 검증 손실과 다운스트림 one-shot 성능에서 더 우수했습니다.
- Mix’n’Match 방식으로 추출된 모델들은, g개의 명시적 학습 모델들이 형성한 정확도-파라미터 트레이드오프 곡선 상에 존재합니다.
- 다양한 크기의 MatFormer 모델에 대해 손실-연산량 법칙(loss vs. compute law)이 일반 Transformer와 유사하게 유지됨을 확인했습니다.
- MatLM에서 추출된 서브모델은 일관성이 높아, 추론 최적화 및 다양한 규모의 환경에 배포하기에 매우 적합합니다.
우리는 ViT 기반의 MatFormer 모델(MatViT)도 추가로 실험했습니다. 예를 들어, MatViT-L/16은 ImageNet-1K에서 표준 ViT-L/16보다 더 높은 정확도를 달성했으며, 추출된 모든 서브모델 또한 각각의 독립 학습 모델과 같거나 더 나은 성능을 보였습니다. 특히, MatViT는 일관성이 매우 높기 때문에, 탄력적 이미지 검색(elastic image retrieval)을 위한 "탄력적 인코더(elastic encoder)"로 활용할 수 있습니다. 즉, 가장 큰 MatViT 모델로 인코딩된 이미지의 임베딩 공간(metric space)은, 서브모델에 의해서도 잘 보존됩니다. 이에 따라, 질의 복잡도나 시스템 부하 등의 조건에 따라, 서브모델 중 하나를 선택하여 고정된 코퍼스에서 검색을 수행할 수 있고, 이 경우 계산량을 40% 이상 줄이면서도 정확도 손실은 0.5% 이하로 유지됩니다.
주요 기여 내용은 다음과 같습니다:
- 표준 Transformer 내에 중첩 구조를 도입하고, g개의 세분화 수준을 최적화하여 하나의 범용 탄력 모델을 구성하는 MatFormer를 제안합니다.
- 추가 계산 비용 없이 파라미터 제약 내에서 최적의 서브모델을 찾아주는 간단한 휴리스틱인 Mix’n’Match 기법을 소개합니다. 이 기법은 복잡한 NAS 기법보다 우수한 결과를 보이며, 수백 개의 정확하고 일관된 서브모델을 추가 학습 없이 생성할 수 있습니다 (3절 참조).
- MatFormer는 디코더 전용 언어 모델(MatLM)과 비전 인코더(MatViT) 모두에 잘 일반화되며, 표준 Transformer와 유사한 수준의 성능과 확장성을 가지면서도, 훨씬 더 빠른 오토레그레시브 생성과 대규모 적응형 밀집 검색을 가능하게 합니다 (4절 참조).
🔍 구조적으로는 좋아 보이지만 실제로는 다음이 걱정된다는 관점:
1. 학습 안정성 문제
- 중첩 구조(nested FFN) 안에 여러 개의 서브모델을 한꺼번에 학습하므로,
- 특정 서브모델의 파라미터가 전체 모델에 중복 포함되면서 gradient conflict가 발생할 수 있음.
- 특히 작은 서브모델이 성능을 내기 위해 집중된 학습을 받아야 하는데, 큰 모델이 그 파라미터를 공유하면 균형 잡힌 학습이 어렵고 오버핏/언더핏 혼란 가능성 있음.
- 논문에서는 이를 다층 Mix’n’Match로 커버한다고 했지만, 그게 정말 안정적으로 작동할지는 별도 검증이 필요함.
2. 학습 효율성
- **“추가 연산 없이 여러 모델을 한 번에 학습한다”**는 주장을 하는데, 사실상 g개의 granularity에 대해 loss를 따로 최적화해야 하므로,
- 일반 Transformer 대비 학습 속도 자체는 느릴 수 있고, 메모리 사용량도 늘어날 가능성 있음.
- 논문에서는 scaling law 측면에서 vanilla transformer와 비슷하다고 주장하지만, 학습 efficiency에 대한 absolute comparison은 부족함.
3. 모델 압축(MOE/MOA) 방식 대비 실용성
- 말씀하신 것처럼, 큰 모델 하나만 잘 학습시키고 그걸 부분적으로 선택적으로 사용하는 Mixture of Experts (MoE), Mixture of Activations (MoA), 혹은 pruning/trimming 기법이 오히려:
- 더 단순하고,
- 서브모델 선택이 명시적이며,
- 하위 모델의 품질이 예측 가능한 경우가 많음.
- 반면 MatFormer는 "서브모델이 잘 작동한다"고 주장하지만, 그 신뢰성과 일관성은 실제 환경에서는 검증이 더 필요함.
🔧 요약하면:
- 좋은 구조 아이디어는 맞지만,
- 학습 안정성과 서브모델 간 충돌,
- 실제 학습 시간과 효율성,
- MOE류와 비교한 실질적 이점 등은 좀 더 엄밀히 따져봐야 할 듯합니다.
2 관련 연구
Transformer [61]는 언어 [8], 비전 [17], 오디오 [47] 등 다양한 모달리티의 파운데이션 모델 [7]을 위한 통합 모델 아키텍처로 자리잡았습니다. 하지만 강력한 성능에도 불구하고, 표준 Transformer 블록은 다양한 리소스 제약 환경에서의 대규모 적응적(deployment-adaptive)이고 유연한 추론을 자연스럽게 지원하지는 못합니다. 이러한 다양한 배포 요구를 충족시키기 위해 기존에는 다음과 같은 접근들이 활용되었습니다:
- 서로 다른 크기의 모델 패밀리를 직접 훈련 [49, 2],
- 훈련 이후(post-hoc)에 효율화를 적용하는 방식으로 양자화 [19], 프루닝 [36], 지식 증류(distillation) [53] 등이 있습니다.
그러나 이들 기법은 보통 하나의 제약 조건에 특화되어 있고, 새로운 다운스트림 작업마다 별도의 학습이 필요하므로, 진정한 의미의 탄력적인(adaptive) 솔루션이라고 보기는 어렵습니다.
마지막으로, Transformer 기반의 LLM들은 추론 속도를 높이기 위해 보통 다음과 같은 기법들을 사용합니다:
- Speculative decoding [39, 12]: 작은 draft 모델과 큰 verifier 모델 간의 일관된 동작을 이용한 방식,
- Early exiting [54]: 실시간 추론을 가능하게 하기 위한 조기 종료 기법 등.
표 1: MatFormer와 관련 기법들의 학습 및 추론 측면 비교
우리는 MatFormer가 기존 기법들과는 달리, 학습 시 소수의 모델만 최적화하면서도, 추론 시 지수적으로 많은 모델을 추가 학습이나 NAS 없이 추출할 수 있다는 점을 강조합니다. 또한 MatFormer는 서브네트워크가 중첩(nested) 구조로 되어 있어, 적응형 검색(adaptive retrieval) 및 모델 공존(colocation)을 추론 중에 가능하게 합니다. 여기서 l은 모델의 레이어 수, exp(l)은 레이어 수에 대한 지수 함수를 의미합니다.

CNN 기반 구조에서 Transformer로의 확장
하나의 모델로부터 여러 개의 소형 모델을 추출하는 아이디어는 이전부터 존재해 왔습니다 [66, 65, 9, 23, 10]. 대부분의 기존 연구는 CNN 기반 인코더에 초점을 맞추었으나, 본 논문에서는 Transformer 기반 디코더 전용 언어 모델 및 사전학습된 비전 모델에 초점을 둡니다.
예를 들어, OFA [9]는 teacher CNN 모델을 학습시킨 뒤, 범용 student CNN 내에서 중첩되지 않은 랜덤 서브모델들을 증류(distillation) 방식으로 미세조정합니다. OFA는 주로 엣지 디바이스에 배포될 소형 모델에 집중합니다. 반면, MatFormer는 증류를 필요로 하지 않으며, 중첩된 구조를 사용하므로 메모리 사용량을 줄이고, 여러 서브모델을 동시에 호스팅할 수 있어, 질문을 서로 다른 서브네트워크로 라우팅하는 상황에서 유리합니다.
Slimmable Networks [66]는 일부 고정된 width 조합만을 함께 최적화하며, Universal Slimmable Network [65]는 이를 연속적인 서치 공간으로 확장합니다. 그러나 MatFormer는 이러한 서브모델을 미리 정의된 g개의 granularity 중 하나만 최적화한다는 점에서 다릅니다.
HAT [63]은 다양한 아키텍처의 상대적 성능만을 학습하는 범용 네트워크를 훈련한 뒤, NAS를 통해 최적의 아키텍처를 선택하고 새로 학습합니다. 이에 비해, MatFormer는 추가 학습 없이도 Mix’n’Match (3.3절)을 통해 NAS 수준의 결과를 얻을 수 있습니다.
DynaBERT [27]는 정해진 서브모델 집합만 공동으로 학습하고, 별도의 서치 전략은 없습니다. 명시적으로 학습된 서브모델만 사용하므로, 경량화는 가능하지만 MatFormer보다 성능은 떨어지며, 계산량과 메모리는 동일하게 소모됩니다 (4절 참조).
MatFormer의 핵심 차별점
대부분의 기존 기법은 지수적으로 많은 서브모델을 직접 최적화하는 반면, MatFormer는 단 g=4개의 서브모델만 학습하여 추론 시 수백~수천 개의 모델을 추출할 수 있습니다. 이는 특히 대규모 데이터셋에서 더 나은 정확도를 제공합니다.
최근에는 Transformer 인코더에도 이러한 아이디어를 확장한 연구들이 존재합니다 [11, 52]. 하지만 이들 중 일부는 디코더 전용 모델로 확장되지 않거나 [52], MatFormer보다 성능이 낮은 경우가 많습니다 (4절 참조). 또한, weight 공간은 아니지만 Matryoshka representation learning [34]나 FlexiViT [5]는 각각 출력 공간 또는 입력 공간에서 탄력성을 제공하여 배포 제약을 부드럽게 넘기도록 설계되어 있습니다.
MatFormer는 이와 달리 weight 공간 내에 중첩 구조를 직접 구현하여 디코더 및 인코더 Transformer 모델을 모두 대상으로 하는 진정한 탄력성 + 적응성을 구현합니다. 이를 통해 정확도 vs 계산량 트레이드오프를 정적(static) 또는 동적(dynamic)으로 자유롭게 조절할 수 있으며, 훈련 방식도 간결합니다 (그림 1 참조).
SortedNet [60]은 MatFormer와 유사한 목표를 가진 동시대 연구이지만, MatFormer처럼 소수의 서브모델을 중첩 최적화하지 않고 기존 방식처럼 여러 개의 랜덤 서브모델을 개별 최적화합니다. 또한 Flextron [64]은 MatFormer를 기반으로 MLP와 Attention Head 양쪽에 중첩 구조를 도입하고, 레이어별 토큰을 다른 granularity로 자동 라우팅하는 router를 포함해 MatFormer 방식을 확장한 최신 연구입니다.
표 1에서 우리는 MatFormer와 위의 관련 기법들을 요약 비교했습니다. 이들 연구는 크게 두 가지 공통 아이디어를 따릅니다:
- 여러 서브모델을 공동 학습(joint training)
- 랜덤 서브모델 샘플링
우리는 이 중 가장 유사한 기법으로 DynaBERT [27]와 OFA [9]를 선정하였으며, 이들과 MatFormer의 실험적 비교는 4장에서 다룹니다.
3 MatFormer
이 장에서는 MatFormer의 중첩된 서브구조(nested substructure)를 정의하고 (3.1절), 선택된 g개의 모델 세분화 수준(granularities)에 대한 학습 절차를 설명합니다 (3.2절). 이후 MatFormer로부터 Mix’n’Match 방식으로 추출한 서브모델을 활용한 탄력적 추론(elastic inference)과 그 배포 고려사항에 대해 논의합니다 (3.3절).
3.1 MatFormer 구조
MatFormer는 다음과 같이 g개의 Transformer 블록
T₁ ⊂ T₂ ⊂ ⋯ ⊂ T<_g
를 정의합니다. 여기서 T_i ⊂ T_i+1 관계는 T_i의 파라미터가 T_i+1에 포함된다는 것을 의미합니다.
이러한 중첩 구조는 Transformer의 어느 부분에도 적용할 수 있으나, 본 논문에서는 FFN (Feed-Forward Network) 블록에 집중하여 기법을 정의하고 실험의 대부분도 이에 기반합니다. 이는 Transformer의 전체 파라미터 수와 연산량 중 약 60% (LLM과 ViT 기준)가 FFN 블록에서 발생하기 때문입니다 (Appendix C 및 F.2에서는 Attention 블록에 MatFormer를 적용한 실험도 포함되어 있음).
따라서 이 논문에서는 FFN 블록에 MatFormer의 중첩 서브구조를 도입하는 데 중점을 둡니다. 이후 이러한 블록을 l개의 층으로 쌓아, 공유된 파라미터를 가지는 g개의 중첩 모델
ℳ₁ ⊂ ℳ₂ ⊂ … ⊂ ℳ_g
을 구성합니다.
Transformer의 FFN 블록은 hidden layer 하나를 가지며, 은닉 뉴런 수는 d_ff, 입력과 출력은 ℝ_dmodel 공간에 존재합니다. 또한 FFN의 고정 비율은 다음과 같이 정의됩니다:

MatFormer는 FFN 블록의 hidden representation에 대해 g개의 세분화 수준을 갖는 matryoshka 중첩 구조를 도입합니다. 구체적으로, Transformer의 중첩 블록 T_i는 FFN의 처음 m_i개의 뉴런을 포함합니다. 여기서

는 각 세분화 수준 또는 서브모델의 뉴런 수를 의미합니다.
이때 선택된 세분화 수준 T_i에 따라 입력 x ∈ ℝ_dmodel에 대한 FFN 연산은 다음과 같이 정의됩니다:

여기서:
- W₁, W₂ ∈ ℝ_d_ff × d_model는 FFN의 가중치 행렬,
- W₁[0:k]는 W₁의 앞쪽 k개 행을 의미하는 서브매트릭스,
- σ는 비선형 함수로, 보통 GELU [24]**나 **squared ReLU [56]가 사용됩니다.(편의상 bias 항은 생략)
본 논문에서는 g = 4개의 지수 간격을 갖는 세분화 수준을 사용하며, FFN 비율은 {0.5, 1, 2, 4} 로 설정됩니다. 즉, 중첩된 hidden 뉴런 수는 {d_ff/8, d_ff/4, d_ff/2, d_ff}입니다.
이로써,
ℳ₁ ⊂ ℳ₂ ⊂ … ⊂ ℳ_g
의 g개 서브모델이 생성되며, 각 모델 ℳ_i는 T_i를 l개 층으로 쌓은 구조입니다. 또한 입력/출력 임베딩 행렬은 이 모델들 간에 공유됩니다.
추가적으로, 우리는 attention head에서도 유사한 중첩 서브구조를 구성할 수 있음을 주목합니다. 여기서 attention head는 “중요도 순”으로 정렬되며, 더 중요한 head일수록 더 많은 서브모델에 공유됩니다. 즉, i번째 세분화 수준에서는 처음 m_i개의 attention head를 사용합니다.
또한, 각 Transformer 블록에 공급되는 토큰 임베딩(d_model)에도 이러한 중첩 구조를 도입할 수 있습니다.
3.2 학습 (Training)
Transformer 모델 ℳ에 대해, 입력 x에 대한 순전파(forward pass)는
ℳ(x)
로 표기하며, 출력과 목표값 y 간의 손실 함수는
ℒ(ℳ(x), y)
로 정의됩니다.
MatFormer는 학습 과정에서 g개의 중첩된 서브모델을 무작위로 샘플링하는 간단한 학습 전략에 기반합니다. 구체적으로, 매 스텝마다 MatFormer의 세분화 수준(granularity) 중 하나인
i ∈ {1, 2, …, g}
를 무작위로 선택하여, 해당 서브모델에 대해 표준 확률적 경사 하강 기반 옵티마이저 [55]를 사용해 학습합니다:

여기서:
- ℳ_i는 i번째 세분화 수준에 해당하는 서브모델의 파라미터 집합이며,
- 이 i는 확률 분포 {p₁, p₂, …, p_g}로부터 샘플링됩니다.
본 논문의 대부분의 실험에서는 이 확률 분포를 균등 분포로 설정하여 서브모델을 동일 확률로 샘플링합니다. 다만, Appendix F.3에서는 이 확률 분포를 조정하는 것이 일부 서브모델의 성능을 향상시킬 수 있음을 보입니다.
이와 같은 MatFormer 학습 방식은 하나의 범용 모델 ℳ_g 내부에
g개의 정확한 중첩 서브모델 ℳ₁, …, ℳ_g
을 형성하며, 더 나아가 3.3절에서 소개할 Mix’n’Match 방식으로 수백 개의 소형 서브모델을 추가 연산이나 학습 없이 정확도-계산량 곡선(accuracy-vs-compute curve)을 따라 자유롭게 추출할 수 있도록 합니다.
이러한 방식은 추론 시 다양한 모델을 무료로 얻을 수 있게 하며, MatFormer를 통해 얻어진 모델당 평균 학습 비용(amortized training cost)을 크게 절감할 수 있게 합니다.
또한, 이로부터 추출된 소형 서브모델들은 범용 모델과 매우 일관된 동작 특성을 가지며 (3.4절), 다양한 환경에서 신뢰 가능한 추론 성능을 제공합니다.
✅ “표준 확률적 경사 하강 기반 옵티마이저”가 뭔가요?
사실 이건 너무 거창하게 표현된 말이에요. 그냥 우리가 평소에 쓰는:
- Adam, SGD, AdamW, Lion 이런 옵티마이저들을 말하는 겁니다.
즉, 문장에서 말하는 건 단지:
"우리는 서브모델 중 하나를 선택해서, 그걸 Adam 같은 걸로 학습시켜요"
라는 아주 단순한 말이에요.
✅ 그래서 기존 학습 파이프라인 그대로 쓰면 된다는 뜻입니다.
🔧 MatFormer 학습 방식을 “운동기구” 비유로 이해하기
가령 헬스장에서 운동기구가 4개 있다고 해보죠:
- 기구 A (작은 모델)
- 기구 B (중간 모델)
- 기구 C (큰 모델)
- 기구 D (제일 큰 모델)
이제 매일 운동을 할 때:
- 오늘은 A 기구만 써서 운동 (== 작은 서브모델만 학습)
- 내일은 C 기구 써서 운동 (== 큰 모델로 학습)
- 모레는 B 기구...
- …랜덤으로 하나만 골라서 매번 운동함
➡️ 그러면 시간이 지나면 모든 기구가 골고루 쓰이게 되겠죠?
- 즉, 각 모델이 다른 날에 번갈아 학습됨
- 전체 모델 하나만 학습한 게 아니라
→ 작은 모델도, 중간 모델도 전부 적절히 훈련됨
이게 바로 MatFormer의 학습 전략입니다.
3.3 Mix’n’Match
추론(inference) 단계에서는 g개의 서브모델 중 하나인
ℳ₁ ⊂ ℳ₂ ⊂ … ⊂ ℳ_g
를 선택하여, 해당하는 Transformer 블록 T_i를 각 레이어에 쌓는 방식으로 쉽게 추출할 수 있습니다.
하지만, MatFormer의 각 레이어마다 서로 다른 세분화 수준(granularity)을 선택함으로써, 조합적으로 매우 많은 수의 정확한 소형 모델을 추가 비용 없이 생성할 수 있습니다. 우리는 이 간단한 절차를 Mix’n’Match라고 부르며, 이때 생성된 추가적인 서브모델들은 명시적으로 학습된 적이 없음에도 불구하고 높은 성능을 발휘한다는 것을 확인했습니다.
🎯 서브모델 선택 문제: NAS vs Mix’n’Match
주어진 계산 자원 또는 파라미터 예산 내에서 만들 수 있는 서브모델 조합은 여러 개가 존재합니다. 이 중 최적의 서브모델을 고르기 위한 일반적인 접근은 신경망 아키텍처 탐색(NAS, Neural Architecture Search) [48, 68]입니다. 하지만 NAS는 계산 비용이 매우 크다는 단점이 있습니다 (Appendix D.2 참조).
이에 비해 Mix’n’Match는 훨씬 간단한 대안을 제시합니다:
"기울기가 가장 완만한 방향으로 서브블록 크기를 점진적으로 증가시켜라"
즉, 레이어 간 granularity 변화가 작을수록 좋다는 직관입니다. 구체적으로는, j번째 레이어의 크기 ≥ i번째 레이어의 크기 (j > i)가 되도록 구성하는 것을 추천합니다.
예시를 들어보면,
- 어떤 모델이 앞 절반의 레이어에는 granularity g₂,
- 나머지 절반에는 granularity g₃를 사용하는 것이,
- 비슷한 파라미터 크기를 가지면서도 g₁과 g₄를 섞는 모델보다 더 좋은 성능을 낼 가능성이 높습니다.
이러한 휴리스틱은 MatFormer의 학습 방식에서 기인합니다:
- 학습 중 각 샘플된 서브모델은 모든 레이어에서 동일한 granularity를 유지하며 학습됩니다.
- 따라서, uniform하거나 점진적으로만 변화하는 구조에 대해 모델이 더 잘 적응합니다.
이러한 통찰은 NAS에서도 확인됩니다. NAS 역시 불균형한 구조보다는 균형 잡힌 구성을 선호하며 (Appendix D.1), 그 중에서도 기울기가 최소인 증가 구조가 가장 뛰어난 성능을 보이는 것으로 실험적으로 나타났습니다.
4.1.1절 및 Appendix D.1에서는, Mix’n’Match 방식이 OFA [9]에서 사용하는 진화 기반 NAS 기법 [48]과 비슷하거나 더 좋은 성능을 낸다는 점을 보여줍니다.
✅ 요약
- Mix’n’Match는 단순하면서도 비용이 거의 들지 않는 휴리스틱으로,
- 주어진 계산 예산 하에서 성능이 뛰어난 서브모델을 선택할 수 있는 효과적인 방법입니다 (4.1.1절 및 4.2절).
- 더 자세한 내용과 직관은 Appendix D.1에 기술되어 있습니다.
🔍 용어 정리 먼저
- 각 레이어마다 g개의 sub-block 크기 선택 가능 (예: small, medium, large, x-large)
- 예를 들어, [g1, g1, g2, g3, g4] 처럼 작은 블록에서 점차 큰 블록으로 이동하는 구조가 기울기 완만한 증가입니다.
- 반면 [g1, g4, g2, g3, g1]은 기울기 급변, 불규칙한 구조입니다.
🤔 왜 점진적으로 증가하는 구조가 낫다고 주장할까?
1. 학습 방식의 일관성 가정
- 학습 중에는 매번 하나의 granularity만 골라서 모델 전체를 통째로 학습합니다 (예: ℳ₁ 또는 ℳ₃ 하나만 전체에 적용).
- 즉, 모델은 **“모든 레이어가 같은 granularity일 때”**에만 제대로 최적화됩니다.
➡️ 따라서,
Mix’n’Match로 섞을 때도, 학습 당시 분포와 가까운 (즉, 연속적인) 조합일수록 더 잘 작동합니다.
2. 표현 공간의 정합성
- 예를 들어 FFN의 hidden layer 크기가 [64 → 128 → 512]처럼 갑자기 바뀌면,
→ 앞 레이어의 feature 표현이 뒷 레이어에서 부적절하게 과도하게 확장되거나 낭비될 수 있습니다. - 반면 [64 → 128 → 256 → 512]처럼 점진적으로 크기를 늘리면,
→ representation 공간이 점진적으로 확장되며, 정보 흐름도 안정적으로 유지됩니다.
➡️ 즉, 모델 내부에서 정보가 부드럽게 흐를 수 있다는 점에서 정합성이 생깁니다.
✅ 정리
- “기울기 완만한 증가”는 학습 방식의 일관성과 표현 공간의 부드러운 확장이라는 직관에 기반한 경험적 규칙입니다.
- 논문에선 이를 수식적으로 증명하지 않고, 실험(NAS vs Mix’n’Match)을 통해 성능이 낫다고 주장하는 방식입니다.
- 따라서 실제 활용 시에는 → 여러 조합을 실험해보고 “기울기 완만한 구조”를 베이스라인으로 쓰는 것이 합리적입니다.
3.4 배포 (Deployment)
MatFormer의 설계는 정적(static) 워크로드와 동적(dynamic) 워크로드 모두에 유리하게 작용합니다.
📌 정적 워크로드 (Static Workloads)
1장에서 Llama-2 모델을 예로 들었던 상황을 확장해 보겠습니다. 예를 들어 어떤 배포 환경에서는 지연 시간(latency) 예산이 400억(40B) 파라미터짜리 Llama 모델을 감당할 수 있지만, 실제로는 다음 크기인 700억(70B) 모델의 지연 시간이 너무 커서, 340억(34B)짜리 모델만 배포할 수 있다고 가정해 봅시다.
- 40B 모델을 처음부터 훈련시키는 데는 4.8 × 10²³ FLOPs가 필요합니다.
- 그런데 34B와 70B 모델의 훈련 비용도 이미 각각 4.08 × 10²³ FLOPs와 8.4 × 10²³ FLOPs에 달합니다.
결과적으로, 지연 시간 여유가 있음에도 불구하고, 성능이 떨어지는 모델(34B)을 사용할 수밖에 없는 상황이 됩니다.
➡️ 하지만 MatFormer를 사용하면, 추가적인 학습 FLOPs 없이도 정확도가 높은 40B 모델을 추출할 수 있습니다.
즉, 정적 워크로드—즉, 사전에 연산 자원이 정해져 있고, 입력 난이도도 비교적 일정한 경우—에서는 Mix’n’Match를 활용해 주어진 제약 조건 하에서 가장 정확한 서브모델을 선택할 수 있습니다.
📌 동적 워크로드 (Dynamic Workloads)
동적 워크로드는 연산 자원이나 입력의 난이도가 실시간으로 변화하는 환경을 말합니다. 이러한 환경에서는 MatFormer의 범용 모델을 기반으로, 토큰 또는 질의(query) 단위로 최적의 서브모델을 동적으로 추출할 수 있습니다.
이 방식이 MatFormer에서 특히 잘 작동하는 이유는 다음과 같습니다:
- MatFormer로부터 추출된 서브모델들은 범용 모델과 매우 높은 행동 일관성(behavioral consistency)을 가지기 때문입니다 (4.1절 참조).
- 덕분에 다양한 서브모델 간 예측 드리프트(prediction drift)가 최소화됩니다.
모델 간 일관성(consistency)은 다음 방식으로 측정합니다:
- 동일한 prefix에 대해 생성된 토큰 일치율(percentage of matching tokens)
- 또는 작은 모델의 출력 분포와 큰 모델의 출력 분포 간의 KL 발산(KL divergence)
→ 이는 디코딩 시 샘플링 전략의 영향을 고려합니다.
이러한 높은 일관성은 다음과 같은 데서 특히 효과를 발휘합니다:
- Speculative decoding [39]과 같은 추론 가속화 기법에서 더 뛰어난 속도 향상 제공 (4.1.1절)
- 서로 다른 플랫폼 간 배포에서 예측 드리프트를 줄이는 데에도 기여
또한, 4.2.2절에서는 다음도 보입니다:
- 모델 일관성이 높을수록, 인코더 모델의 metric-space 구조 유지 능력도 향상됨
마지막으로, MatFormer의 중첩 구조 덕분에 여러 서브모델을 함께 배치(model colocation)할 때에도 메모리 효율이 더 뛰어날 수 있습니다.
정적 워크로드의 설정이 억지스러움
4 실험 (Experiments)
이 절에서는 MatFormer를 다양한 모달리티(언어: 4.1절, 비전: 4.2절)와 모델 클래스(디코더, 인코더)에서 실험적으로 평가합니다.
우리는 MatFormer 기반 모델이 탄력적으로 배포(elastic deployment)될 수 있음을 입증하며, 그 대상은 one-shot 생성 평가부터 적응형 이미지 검색(adaptive image retrieval)에 이르기까지 폭넓은 작업을 포함합니다 (4.1.1절 및 4.2절).
또한, MatFormer 모델이 신뢰할 수 있는 스케일링 법칙(scaling behavior)을 따르는지도 함께 분석합니다 (4.1.2절).
진짜 중요한 건 "scaling 법칙을 어떻게 설계에 반영하느냐"
4.1 MatLM: MatFormer 기반 언어 모델
실험 설정:
우리는 MatFormer 구조를 기반으로 한 디코더 전용 언어 모델(MatLM)을 구축하고, 이를 일반적인 Transformer 기반 언어 모델(LM) [41]과 비교합니다.
각 MatLM은 고정된 d_model 값을 가지며, FFN 비율이 {0.5, 1, 2, 4}인 g=4개의 중첩 세분화(nested granularities)에 대해 최적화됩니다.즉, 변하는 것은 FFN 블록의 hidden representation 크기뿐입니다.
우리는 이 서브모델들을 모델 크기 순서에 따라 다음과 같이 표기합니다: MatLM – {S, M, L, XL}, 여기서 MatLM-XL은 전체 모델(universal MatLM)을 의미합니다.
비교 기준(Baseline)으로는, 동일한 아키텍처를 기반으로 각 FFN 비율 {0.5, 1, 2, 4}에 대해 각각 독립적으로 학습한 4개의 일반 Transformer 모델을 훈련시킵니다. 이들을 Baseline – {S, M, L, XL}로 명명합니다.
또한, OFA [9]와 DynaBERT [27]를 언어 모델링 실험 환경에 맞게 변형하여, MatFormer와 같은 파라미터 규모에서 성능을 비교합니다.
이 모든 모델은:
- 검증 손실(validation loss),
- 25개의 영어 태스크 [8, 22, 3]에 대한 평균 정확도(1-shot 평가)
를 기준으로 평가됩니다.
모든 학습은 독립적으로 학습된 베이스라인과 동일한 연산 및 메모리 비용 내에서 수행됩니다. 자세한 학습 설정, 베이스라인, 평가 방식 및 데이터셋은 부록 B(Appendix B)를 참조하십시오.

Figure 2:
850M 규모의 MatLM 및 베이스라인 모델에 대한 검증 손실과 one-shot 다운스트림 평가 결과. Mix’n’Match는 MatLM에서 성능-연산량 트레이드오프 곡선을 따라 정확하고 일관성 높은 서브모델들을 생성하는 데 도움이 됩니다.
📊 베이스라인 대비 결과
MatFormer의 우수성을 입증하기 위해, 우리는 850M 규모 MatLM 모델을 대응하는 베이스라인들과 비교하여 Figure 2에 나타냅니다.
전반적으로 Figure 2(a), (b)를 보면, MatLM의 모든 서브모델(granularity)은 동일 규모의 베이스라인 모델보다 더 좋은 성능을 보입니다.
특히,
- DynaBERT는 MatFormer보다 로그 퍼플렉서티(log-perplexity) 기준으로 약 0.01 차이의 성능 격차를 보이며,
- 이는 DynaBERT가 모든 세분화 수준을 동시에 최적화(joint optimization)하기 때문에,
- 각 서브모델에 대한 gradient update가 줄어들어 성능이 저하된다는 점에서 기인합니다.
이를 MatFormer 수준까지 맞추기 위해서는,
- DynaBERT는 약 15% 이상의 추가 연산량이 필요합니다.
OFA는 MatFormer처럼 하나의 범용 모델을 유지하되, 훈련 시 랜덤 서브네트워크 샘플링을 사용합니다. 이로 인해 S나 XL granularity 쪽 모델이 충분히 학습되지 않아 성능이 떨어집니다. 이 현상은 그림 2(a)의 종(bell) 모양 손실 곡선으로 나타나며,
→ OFA가 범용성과 모델 탄력성 사이의 균형을 제대로 유지하지 못하는 단점을 드러냅니다.
또한 OFA는 서브모델 선택을 위해 복잡한 NAS 기법이 필요합니다. 그러나 NAS를 확장 적용하는 것은 비용이 많이 들고 오류 가능성도 높으며, 이에 대한 상세 논의는 부록 D.2에서 다룹니다.
MatFormer의 성능, 베이스라인과의 비교, 각 방법의 장단점에 대한 자세한 논의는 부록 B.4를 참고하시기 바랍니다.
4.1.1 MatLM을 활용한 탄력적 추론 (Elastic Inference with MatLM)
Mix’n’Match로 어떤 제약 조건에도 정확한 서브모델을 추가 비용 없이 생성
Mix’n’Match는 MatLM으로부터 고정된 네 가지 세분화 수준({S, M, L, XL})을 넘어서, S에서 XL 사이의 모든 연산 자원 제약 조건에 맞는 정확한 서브모델을 생성할 수 있도록 해줍니다.
우리는 850M 파라미터 규모의 MatLM을 기반으로 Mix’n’Match의 성능을 평가하였으며, 이때 생성된 서브모델을 독립적으로 학습된 베이스라인 모델들 {S, M, L, XL}과 비교하여 검증 손실 및 다운스트림 성능을 비교하였습니다.
Figure 2(a)는 Mix’n’Match가 추가 비용 없이 최적의 손실-연산량 트레이드오프를 달성함을 보여주며, Figure 2(b)의 다운스트림 평가 결과도 이러한 경향을 강화합니다.
예를 들어, MatLM-XL 모델의 연산 자원의 55%만 사용할 수 있는 배포 환경에서, Mix’n’Match로 생성한 서브모델은 정확도가 약 1% 하락한 수준으로 XL의 성능을 근접하게 따라갑니다. 반면, 같은 조건에서 MatLM-M 모델을 사용할 경우 정확도는 2% 하락합니다.
→ 이는 Mix’n’Match가 성능 곡선 상에서 수많은 최적 모델을 생성할 수 있다는 점을 잘 보여줍니다.
우리는 다양한 서브모델 선택 휴리스틱을 실험했으며, 깊은 레이어로 갈수록 점진적으로 더 큰 granularity를 사용하는 방식이 가장 우수하다는 결과를 일관되게 얻었습니다 (3.3절 참조).
이 휴리스틱은 OFA [9]에서 사용하는 진화 기반 탐색 기법(evolutionary search) [48]보다 더 나은 성능을 보여주며, 이는 Figure 2(a), (b)에 나타나 있습니다. 또한 Figure 6에서는, MatFormer에 NAS를 적용해도 Mix’n’Match보다 더 나은 성능을 제공하지 못함을 보여줍니다. Mix’n’Match에 대한 추가적인 설명은 부록 D.1에 상세히 정리되어 있습니다.
🚀 MatLM 서브모델은 speculative decoding을 가속시킴
Speculative decoding은 가벼운 정확한 언어 모델을 draft로 활용하여, 몇 개의 토큰을 오토리그레시브하게 먼저 생성한 뒤,
이를 더 큰 모델(verifier)로 병렬 검증하는 방식입니다. 만약 draft가 부정확하면, verifier의 출력으로 롤백됩니다.
→ 결과적으로, 큰 모델과 같은 정확도를 유지하면서도 추론 속도를 높일 수 있는 기법입니다.
자세한 원리는 원 논문 [39]를 참조하십시오. 이 알고리즘의 병목은 다음 상황에서 발생합니다:
- 작은 draft 모델의 예측이 큰 모델과 불일치할 경우,
→ 롤백이 자주 발생하면서 속도가 느려짐
하지만 draft와 verifier의 일관성이 높을수록 롤백이 줄어들고, 지연 시간(latency)도 감소합니다.
Figure 2(c)에서 확인할 수 있듯, MatLM 서브모델은 베이스라인 모델들보다 최대 11.5% 더 일관성 있는 결과를 보입니다.
이는 KL divergence 기반의 일관성 측정 결과로도 유지되며 (Appendix Figure 7 참조),
→ MatLM 기반 draft와 verifier 조합이 더 적은 오차, 더 빠른 추론을 가능하게 한다는 것을 시사합니다.

표 LABEL:tab:spec은 MatLM의 S(393M) 모델을 draft로, XL(850M) 모델을 verifier로 사용한 speculative decoding의 추론 시간 속도 향상을 보여줍니다.
- 독립적으로 학습된 베이스라인 모델을 이용한 speculative decoding은
→ 기존 850M-XL 모델의 오토리그레시브 추론에 비해 최대 10% 속도 향상을 보여줍니다. - 하지만 MatLM 기반 speculative decoding은 이보다도 최대 6% 더 빠르며,
이는 다음과 같은 점에서 기인합니다:- MatLM의 draft/verifier가 더 일관적이기 때문
- MatLM 서브모델 간에는 attention cache 공유가 가능한데,
이건 베이스라인 모델들에서는 불가능합니다 (Appendix C.1 참조)
또한, MatLM은 추론 시 두 개의 모델을 따로 로딩할 필요가 없어, 자원 제약 환경에서 메모리 오버헤드도 줄일 수 있습니다.
4.1.2 MatLM은 일반 Transformer 언어 모델만큼 잘 확장된다

Figure 3:
우리는 78M에서 850M 파라미터 범위의 다양한 디코더 전용 MatLM 모델을 학습하고, 모든 세분화 수준({S, M, L, XL})에 대한 검증 손실 및 1-shot 다운스트림 평가 점수의 스케일링 경향을 관찰합니다. 그 결과, 모든 크기의 MatLM-XL 모델은 Baseline-XL 모델과 유사한 학습 추세를 따릅니다. 흥미롭게도, 모든 세분화 수준에서 검증 손실 및 다운스트림 평가 결과가 XL 모델의 scaling trend를 그대로 따릅니다.
850M MatLM 모델과 그 서브모델들이 기존 Transformer LMs와 최소한 동등한 정확도를 보인다는 점을 확인한 후, 이번에는 MatLM의 훈련 확장성(scalability)을 분석하고자 합니다.
우리는 MatLM의 스케일링 특성 [29, 25]을 일반 Transformer 베이스라인 LMs와 비교합니다. 이를 위해 78M에서 850M 파라미터의 모델들을 10B ~ 80B 토큰(각 granularity별)을 학습하며, Figure 9에서 MatLM {S, M, L, XL}의 검증 손실을 독립적으로 학습된 베이스라인과 비교합니다.

표 3: 스케일링 방정식의 추정된 계수
Figure 3(a)를 보면, MatLM-XL 모델의 학습 추세는 파라미터 수 증가에 따라 Baseline-XL 모델과 유사한 scaling behavior를 보입니다.
또한 Figure 3(b)는 MatLM과 베이스라인 모두에서 {S, M, L, XL} 모든 세분화 수준의 모델이 동일한 스케일링 경향을 따름을 보여줍니다.
이에 따라, 비임베딩(non-embedding) 파라미터 수 N과 훈련 토큰 수 D에 기반하여 모든 가능한 서브모델들에 대해 스케일링 법칙을 피팅했고, 그 결과는 표 3에 정리되어 있습니다.
→ 추정된 계수가 매우 유사하므로, MatLM도 일반 Transformer LMs와 유사하게 스케일링됨을 알 수 있습니다.
Figure 3(c)에서는 MatLM이 평균적으로 베이스라인보다 0.3% 더 높은 다운스트림 평가 성능을 보이며, 특히 작은 서브모델들은 최대 1.4%까지 더 우수한 성능을 발휘합니다.
마지막으로, Appendix Figure 9(f)는 MatLM 서브모델들이 베이스라인 대비 XL 모델과 더 높은 예측 일관성을 보인다는 점을
모델 크기 전반에 걸쳐 보여줍니다.
우리는 현재의 scaling law는 MatLM이 여러 서브모델을 동시에 최적화하고, 심지어 명시적으로 학습되지 않은 모델들도 잘 작동한다는 점을 충분히 반영하지 못함을 인지하고 있습니다 (4.1.1절 참조). 이러한 복잡성을 더 잘 반영하는 수식적 정식화는 후속 연구로 남겨두며, 이와 관련한 추가 논의는 부록 E.1에 포함되어 있습니다. 모든 세분화 수준 별 실험 결과는 부록 E에 정리되어 있습니다.

Figure 4:
MatViT 모델들은 ImageNet-1K 분류 작업에서 표준 ViT 모델과 동등하거나 더 나은 성능을 보이며, Mix’n’Match를 통해 정확도-연산량 곡선을 아우르는 서브모델들을 추가 비용 없이 제공할 수 있습니다.
4.2 MatViT: MatFormer 기반 비전 Transformer
우리는 MatFormer를 Vision Transformer (ViT) [21] 기반의 컴퓨터 비전 인코더 모델로 확장합니다. MatFormer 기반 ViT(MatViT)는 이미지 분류 및 검색과 같은 기본적인 컴퓨터 비전 작업에서 탄력적 추론(elastic inference)을 가능하게 합니다.
우리는 표준 ViT-B/16 및 ViT-L/16 모델의 MatFormer 버전인 MatViT-B/16 및 MatViT-L/16을 훈련하며, 이 모델들은 FFN 비율이 {0.5, 1, 2, 4}인 g = 4개의 중첩 세분화(nested granularities)를 사용합니다.
- B/16 모델은 ImageNet-1K [50]에서 AugReg [57] 기법을 적용해 학습되며,
- L/16 모델은 ImageNet-21K [18]에서 사전학습(pretraining)한 후, ImageNet-1K에서 파인튜닝(finetuning)됩니다.
모든 모델은 Scenic 라이브러리 [16]에서 제공하는 표준 ViT 변형 모델의 학습 설정 및 최적 하이퍼파라미터를 그대로 사용합니다.
4.2.1 이미지 분류 (Image Classification)
우리는 ImageNet-1K 데이터셋에서 ViT 및 MatViT 모델의 이미지 분류 성능을 평가합니다. Figure 4(a)는 B/16 모델의 경우, MatViT에서 명시적으로 최적화된 granularities가 독립적으로 학습된 베이스라인과 동등한 정확도를 달성함을 보여줍니다.
하지만 L/16 모델에서는, Figure 4(b)에 나타난 바와 같이, 동일한 추론 비용 조건 하에서 MatViT가 최대 0.35% 더 높은 정확도를 기록합니다.
우리는 또한 MatFormer를 사전학습(pretraining)과 파인튜닝(finetuning)의 다양한 조합에서 적용해 보았습니다. 이를 위해 2×2 그리드 형태의 조합 실험을 수행하였고 (부록 G.1의 Table LABEL:tab:vit-2x2 참조), 그 결과, 사전학습 단계에서 MatFormer를 사용하는 것이 다운스트림 활용에 더 정확하고 유연한 인코더를 가져오는 데 유리함을 확인했습니다.
또한, 파인튜닝 시 MatFormer를 사용하면 Mix’n’Match를 통해 주어진 제약 조건에 따라 탄력적인 배포(elastic deployment)를 할 수 있게 됩니다.
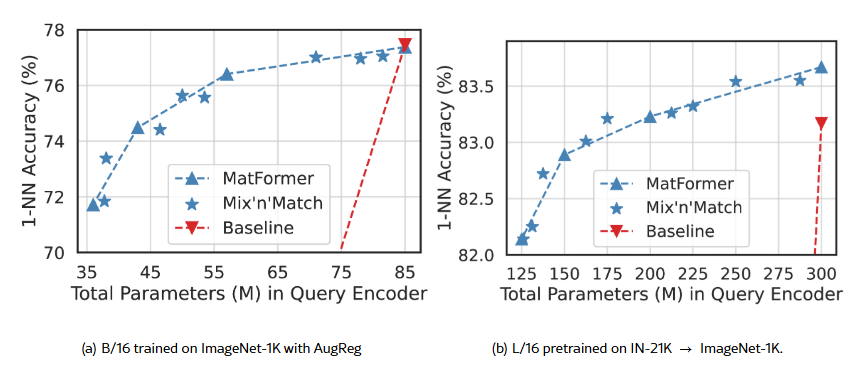
Figure 5:
MatViT는 베이스라인과 달리 적응형 검색(adaptive retrieval)을 위한 탄력적 인코더(elastic encoder)를 자연스럽게 제공하며, 실시간 질의 처리(real-time query side computation)에서도 ImageNet-1K에서 높은 정확도를 유지할 수 있습니다.
🔁 Mix’n’Match 기반 적응형 인코더
또한, Mix’n’Match로 생성된 서브모델들의 정확도는 명시적으로 학습된 granularities를 연결하는 정확도-곡선 선상에 거의 정확히 위치합니다.
예를 들어, 어떤 애플리케이션이 파라미터 수 5천만(50M) 이하의 B/16 모델만을 탑재할 수 있는 경우, MatViT는 기존 방법(50M 이하 베이스라인 중 가장 큰 모델 탑재)보다 0.8% 더 정확한 모델을 제공할 수 있습니다.
배포(deployment) 시에는 범용 MatViT 모델 하나만 메모리에 올려두고, 현재 사용 가능한 연산 자원에 따라 적응형 서브모델을 동적으로 추출해 그 순간 가능한 자원 내에서 최대한의 정확도를 확보할 수 있습니다.
현재는 Mix’n’Match 조합 중 어떤 모델이 가장 적합한지 검증셋에 대한 빠른 추론을 통해 선택하고 있지만, 이 방식은 확장성이 있으며 동시에 신경망 내 레이어 간 최적의 자원 할당(budget allocation)에 대한 필요성을 시사합니다 [33].
4.2.2 적응형 이미지 검색 (Adaptive Image Retrieval)
이미지 검색(image retrieval)의 목적은 사전학습된 인코더에서 얻은 표현(representation)을 이용해 예를 들어 같은 클래스의 이미지처럼 의미적으로 유사한 이미지를 찾는 것입니다 [13].
표준적인 접근은 다음과 같습니다:
- 데이터베이스 이미지를 인코더로 임베딩하고,
- 질의(query) 이미지도 같은 인코더로 임베딩한 후,
- query 임베딩과 가장 가까운 이웃(Nearest Neighbor)을 검색하는 방식입니다.
이때 일반적으로는:
- 데이터베이스 이미지는 고성능(비싼) 인코더로 임베딩할 수 있지만,
- 질의 이미지는 실시간 추론이 필요하기 때문에 경량 인코더를 사용해야 합니다.
더 나아가, 질의 인코딩 환경은 다음과 같이 다양할 수 있습니다:
- 디바이스 내 처리(on-device) vs. 클라우드 처리(cloud processing)
- 질의 부하(query load)나 질의 복잡도(query complexity)의 변화
하지만 기존 솔루션은 고정된 하나의 인코더만 사용하기 때문에, 다양한 상황에서 정확도 또는 비용 측면에서 타협이 불가피합니다.
MatViT는 탄력적인 성격(elastic nature)을 가지기 때문에, 이러한 상황에서 질의 인코더(query encoder)로 이상적인 후보가 될 수 있습니다. 하지만 이미지 검색에서는 다음이 반드시 보장되어야 합니다:
질의 임베딩과 데이터베이스 임베딩 간의 거리 정보가 유지되어야 한다. 즉, 큰 인코더로 임베딩된 고정된 데이터베이스와
다양한 서브모델로 임베딩된 질의 이미지 사이에서도 거리 구조(metric space)가 세분화 수준(granularity)에 관계없이 유지되어야 합니다.
하지만,
- 작은 ViT 베이스라인 모델만으로 질의 이미지를 인코딩하면
- 임베딩 간의 거리 구조가 보존되지 않아, 검색 정확도가 거의 0에 수렴합니다 (Figure 5 참조).
우리는 ViT와 MatViT 인코더를 대상으로 ImageNet-1K에서 이미지 검색 성능을 평가했습니다. 평가 방식은 [CLS] 토큰의 표현 벡터를 이용한 1-NN (1-Nearest Neighbor) 정확도이며 (Appendix G.2 참조),
Figure 5는 다음을 보여줍니다:
- MatViT로부터 추출한 서브모델들은 거리 정보를 상당히 잘 보존하며,
- 동시에 훨씬 더 높은 유연성(flexibility)을 제공합니다.
예를 들어,
- 정확도 손실이 0.5% 미만인 조건에서,
- MatViT-L/16은 연산 비용을 40% 줄일 수 있습니다.
이 사례는 Figure 5(b)에서의 Mix’n’Match로 생성된 1억 7천 5백만(175M) 파라미터 모델로, 이는 XL 모델(3억 파라미터)보다 40% 작으면서도, 정확도 손실은 0.5% 미만에 불과합니다.
우리가 아는 한, 이는 이런 형태의 결과로는 최초이며, 대규모 의미 기반 검색(semantic search)을 위한 다양한 적응형 추론 전략(adaptive inference strategies)의 가능성을 새롭게 열어줍니다.
5 결론 (Conclusion)
본 연구에서는 MatFormer를 제안하였습니다. MatFormer는 탄력성(elasticity)을 본질적으로 내장한 Transformer 아키텍처로,
하나의 범용(universal) 모델을 학습한 후, 배포 시점에서 추가 비용 없이 수백 개의 정확한 소형 서브모델을 추출할 수 있도록 설계되어 있습니다.
우리는 MatFormer 언어 모델(MatLM)이 독립적으로 학습된 모델들과 동등한 수준의 perplexity 및 1-shot 정확도를 달성함을 확인하였습니다.
더 나아가, MatLM은 훈련된 granularities에 거의 무관하게 안정적인 손실-계산량 스케일링 곡선(loss-vs-compute scaling curve)을 보여주며, 이는 MatFormer가 초대형 모델로도 강력하게 일반화될 수 있음을 시사합니다.
마지막으로, MatFormer의 서브모델들은 다음과 같은 다양한 추론 시간 개선을 가능하게 합니다:
- Speculative decoding을 활용한 더 빠른 오토리그레시브 생성
- 모달리티 전반에서 적응형 밀집 검색(adaptive dense retrieval)을 위한 탄력적인 질의 인코더(elastic query encoder)
향후 연구에서는, 이러한 모델들을 동적으로 라우팅하여 추론 지연 시간(inference latency)을 조절하는 방법 [32, 40, 20]과,
이를 지원하기 위한 하드웨어 최적화 기술 개발이 매우 유망한 방향이라 판단합니다.
감사의 글 (Acknowledgments)
훈련 파이프라인 설정을 도와준 Aishwarya P S, Yashas B.L. Samaga, Varun Yerram, Lovish Madaan, Anurag Arnab에게 감사를 전합니다. 또한, 유익한 논의와 지원, 피드백을 제공해준 Matthew Wallingford, Praneeth Netrapalli, Orhan Firat, Rohan Anil, Tom Duerig, Luke Zettlemoyer, Manish Gupta, Rahul Sukthankar, Jeff Dean에게도 감사드립니다.
본 연구는 다음 기관의 컴퓨팅 자원 및 지원을 일부 활용하였습니다:
- University of Washington의 HYAK
- Harvard University의 FAS RC
- Kempner Institute
- Google Cloud Platform의 초기 단계 연구 크레딧 지원
Ali Farhadi는 다음의 지원을 받았습니다:
NSF (미국국립과학재단) 연구 과제 IIS 1652052, IIS 1703166, DARPA 과제 N66001-19-2-4031, W911NF-15-1-0543, Allen Institute for AI 및 Google의 연구 기부금. Sham Kakade는 미 해군연구청(ONR) 과제 N00014-22-1-2377의 지원을 받았습니다.
본 연구는 Chan Zuckerberg Initiative Foundation의 기부를 통해 설립된 Kempner Institute for the Study of Natural and Artificial Intelligence의 일부 지원으로도 수행되었습니다. Yulia Tsvetkov은 NSF CAREER 과제 IIS2142739, NSF 과제 IIS2125201, IIS2203097 및 Google, MSR(Microsoft Research), OpenAI의 연구 지원을 받았습니다. Hannaneh Hajishirzi는 Allen Institute for AI의 기부를 통한 지원을 받았습니다.