XXt Can Be Faster
https://arxiv.org/abs/2505.09814?ref=mail.bycloud.ai&_bhlid=77b4be6f732dbeaa5cbd4eb23d6dc4ce93c750ee
$XX^{t}$ Can Be Faster
We present RXTX, a new algorithm for computing the product of matrix by its transpose $XX^{t}$ for $X\in \mathbb{R}^{n\times m}$. RXTX uses $5\%$ fewer multiplications and $5\%$ fewer operations (additions and multiplications) than State-of-the-Art algorit
arxiv.org

1 서론
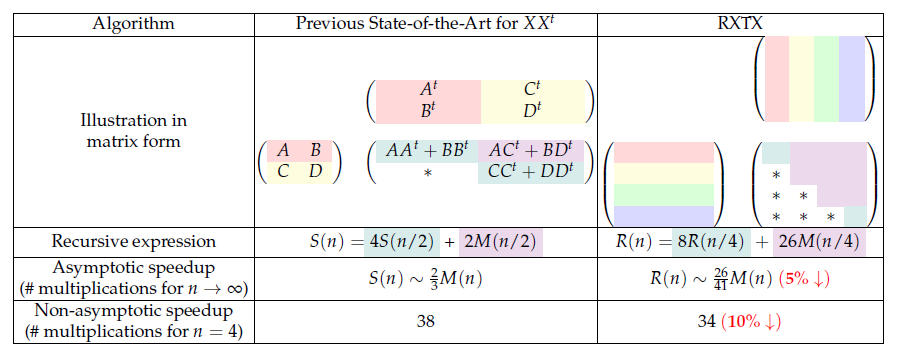

더 빠른 행렬 곱셈 알고리즘을 찾는 것은 컴퓨터 과학과 수치 선형대수학에서 중심적인 도전 과제이다. 일반 행렬 곱 AB를 계산할 때 필요한 곱셈 횟수를 획기적으로 줄일 수 있음을 보여준 [Strassen, 1969]와 [Winograd, 1968]의 선구적인 결과 이후, 이 문제를 탐구하는 광범위한 연구가 진행되어 왔다. 이 분야의 접근법은 경사 하강법 기반의 최적화 기법 [Smirnov, 2013], 휴리스틱 [Éric Drevet 외, 2011], 군론 기반 방법 [Ye and Lim, 2018], 그래프 기반의 랜덤 워크 [Kauers and Moosbauer, 2022], 그리고 딥 강화학습 [Fawzi 외, 2022] 등 매우 다양하다.



1.1 관련 연구
기존 연구들 [Ye and Lim, 2016, 2018]은 표현론(representation theory)과 Cohn–Umans 프레임워크를 활용하여 구조화된 행렬 곱에 대한 새로운 곱셈 방식(multiplication schemes)을 도출하였다. 강화학습 기법도 이 분야에 적용된 바 있다. 예를 들어, Fawzi 외 [2022]는 딥 강화학습(deep RL)을 활용하여 텐서의 랭크를 계산하고 새로운 곱셈 알고리즘을 발견하였다. 적절한 학습 설정 하의 신경망(Neural Networks)은 작은 크기의 행렬에 대해 Strassen 알고리즘과 Laderman 알고리즘을 재발견할 수 있다 [Elser, 2016].

2 RXTX의 분석
다음과 같이 기호를 정의한다:
- R(n): RXTX 알고리즘이 n×n 행렬에 대해 수행하는 곱셈의 수
- S(n): Arrigoni 외 [2021]의 재귀적 Strassen 알고리즘이 n×n 행렬에 대해 수행하는 곱셈의 수
- M(n): 일반적인 n×n 행렬 곱에 대해 Strassen–Winograd 알고리즘이 수행하는 곱셈의 수
- R^+: RXTX 알고리즘이 n×n 행렬에 대해 수행하는 덧셈과 곱셈의 총합
- S^+(n): 재귀적 Strassen 알고리즘(Arrigoni 외 [2021])이 n×n 행렬에 대해 수행하는 덧셈과 곱셈의 총합
- M^+(n): Strassen–Winograd 알고리즘이 일반 n×n 행렬 곱에 대해 수행하는 덧셈과 곱셈의 총합
여기서 opt 상첨자(superscript)는 최적 차단 조건(optimal cutoff)을 의미하며, 즉, 행렬 크기가 충분히 작을 경우 더 이상의 재귀 호출 대신 표준 행렬 곱셈을 사용하는 것을 나타낸다.


그림 1에서는 n이 4의 거듭제곱일 때의 R(n)/S(n) 비율을 확인할 수 있다. 이 비율은 항상 100% 이하를 유지하며 점차 점근적인 95%에 수렴한다. 이는 곱셈 횟수가 약 5% 감소했음을 의미한다. 그림 2에서도 동일한 현상이 나타나는데, 이 경우에는 최적 차단 조건(optimal cutoff)을 적용하여, 행렬 크기가 충분히 작을 경우에는 재귀 호출 대신 표준 행렬 곱셈을 사용하는 방식이다.

그림 1: RXTX와 기존 최신(State-of-the-Art) 알고리즘, 그리고 순진한(naive) 알고리즘 간의 곱셈 횟수 비교

그림 2: 최적 차단 조건(optimal cutoff)을 적용한 RXTX와 기존 최신 알고리즘, 순진한 알고리즘 간의 곱셈 횟수 비교




그림 3: RXTX와 재귀적 Strassen 알고리즘, 그리고 순진한(naive) 알고리즘 간의 연산 수 비교. RXTX는 n≥256일 때 재귀적 Strassen보다 우수하며, n≥1024일 때 순진한 알고리즘보다 우수하다.

그림 4: 최적 차단 조건(optimal cutoffs)을 적용한 알고리즘 간 비교. 즉, 재귀 과정에서 행렬 크기가 충분히 작아지면 연산 수가 가장 적은 알고리즘으로 전환함. RXTX는 n≥32일 때 순진한 알고리즘보다, n≥256일 때 최신(State-of-the-Art) 알고리즘보다 더 우수하다.




그림 5: RXTX의 평균 실행 시간은 2.524초로, 특정 BLAS 루틴의 평균 실행 시간인 2.778초보다 9% 더 빠르다. 전체 실행 중 99%에서 RXTX가 더 빨랐다.
3 발견 방법론 (Discovery Methodology)
3.1 RL 기반 대규모 이웃 탐색 (RL-guided Large Neighborhood Search)
이 절에서는 제안하는 방법론의 개요를 간략히 소개한다. 전체 방법론 및 다른 가속화 기법들은 [Rybin et al., 2025]에서 자세히 설명될 예정이다. 우리는 RL 기반 대규모 이웃 탐색(RL-guided Large Neighborhood Search) [Wu et al., 2021; Addanki et al., 2020]을 두 단계 MILP 파이프라인과 결합하였다:
- RL 에이전트가 (잠재적으로 중복되는) 랭크-1 쌍선형 곱(rank-1 bilinear product)의 집합을 제안한다.
- MILP-A는 이러한 후보 랭크-1 쌍선형 항들과 목표 표현식(target expressions) 사이의 수만 개의 선형 관계를 철저하게 열거(exhaustively enumerate)한다.
- MILP-B는 이후, 모든 목표 표현식을 만족시키는 관계들을 유도하는 가장 작은 곱셈 집합을 선택한다.



감사의 말 (Acknowledgements)
Z.-Q. Luo의 연구는 다음의 지원을 받았다:
- 중국 광둥성 기초 및 응용 기초 연구 중대 프로젝트(No.2023B0303000001),
- 광둥성 빅데이터 컴퓨팅 핵심 연구소,
- 중국 국가 핵심 연구개발 프로젝트 (과제 번호: 2022YFA1003900).