How much do language models memorize?
https://arxiv.org/abs/2505.24832?_bhlid=6015c87a2128aa76e108898443aa2727b63d9786
How much do language models memorize?
We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. W
arxiv.org
초록 (Abstract)
우리는 모델이 특정 데이터 포인트에 대해 “얼마나 알고 있는지”를 추정하는 새로운 방법을 제안하고, 이를 통해 최신 언어 모델의 용량(capacity)을 측정합니다. 우리는 메모리제이션(memorization)을 두 가지 구성 요소로 공식적으로 분리합니다:
- 비의도적 메모리제이션(unintended memorization): 모델이 특정 데이터셋에 대해 포함하고 있는 정보
- 일반화(generalization): 모델이 실제 데이터 생성 과정에 대해 포함하고 있는 정보
일반화 요소를 제거함으로써, 주어진 모델의 총 메모리제이션을 계산할 수 있으며, 이는 모델 용량에 대한 추정치를 제공합니다. 우리의 측정 결과에 따르면, GPT 계열 모델의 용량은 파라미터당 약 3.6 비트(bits-per-parameter)로 추정됩니다.
우리는 점차 커지는 크기의 데이터셋을 사용해 언어 모델을 학습시키며, 모델이 용량이 다 찰 때까지 데이터를 암기하고, 그 시점에서 “grokking” 현상이 시작되며, 일반화가 시작됨에 따라 비의도적 메모리제이션이 감소함을 관찰했습니다. 우리는 50만에서 15억 개 파라미터에 이르는 수백 개의 Transformer 언어 모델을 학습시켰고, 모델 용량과 데이터 크기를 멤버십 추론(membership inference)과 연관짓는 스케일링 법칙(scaling laws)을 도출했습니다.

그림 1: 무작위 데이터를 대상으로 한 비의도적 메모리제이션 (3절). GPT 계열의 다양한 크기의 모델들은 파라미터당 약 3.6 비트 수준에서 메모리제이션이 포화되며, 이 값은 경험적 용량 한계를 나타냅니다.

그림 2: 모델 크기 및 데이터셋 크기에 따른 텍스트의 비의도적 메모리제이션 (4절). 모든 수치는 전체 데이터 분포에 대해 학습된 대규모 오라클 모델을 기준으로 계산되었습니다.
1 서론 (Introduction)
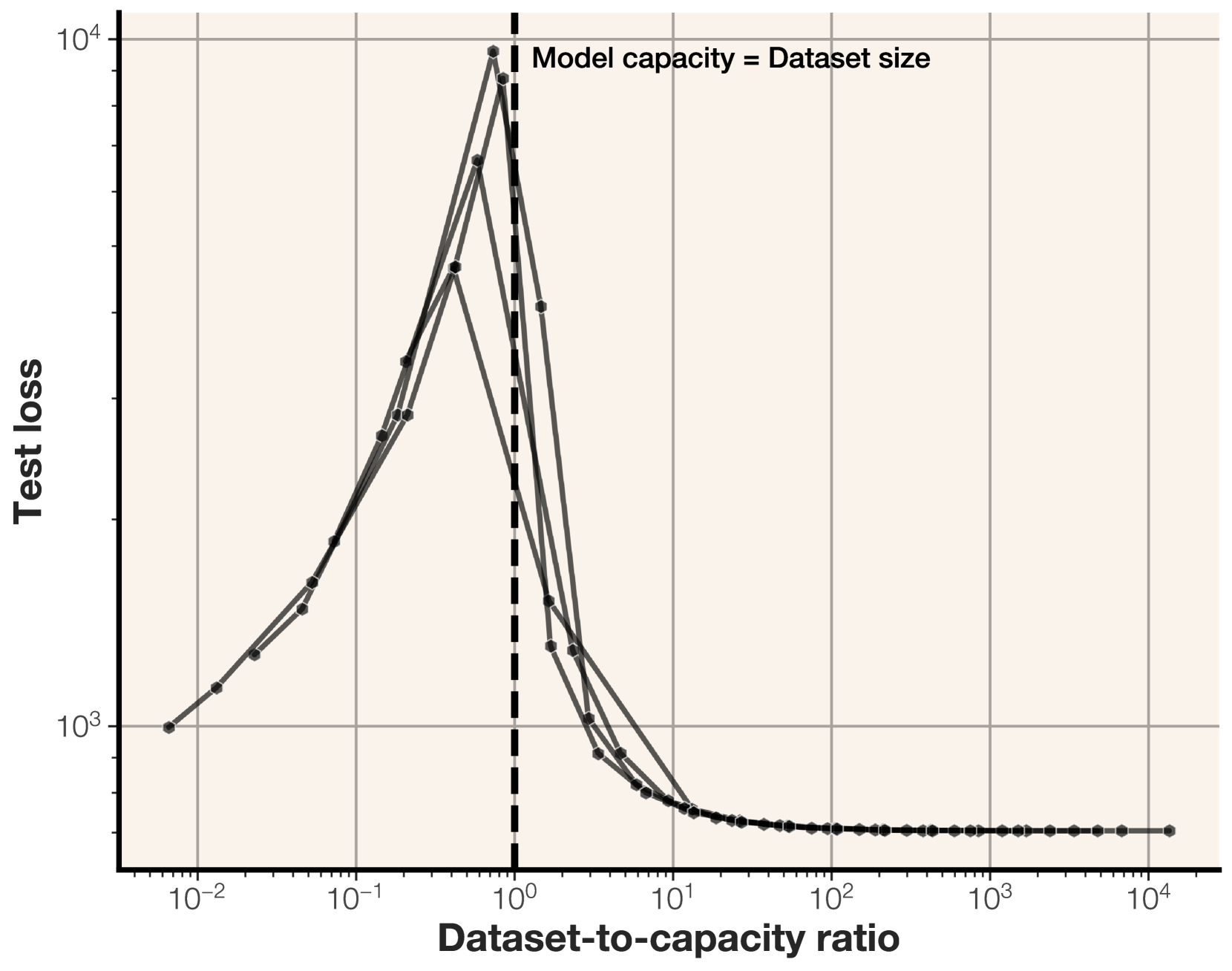
그림 3: 합성된 비트 문자열에 대한 실험에서, 더블 디센트(double descent) 현상은 데이터셋 크기가 모델의 용량(capacity)을 초과하기 시작할 때 정확히 발생합니다. 이 시점부터는 비의도적 메모리제이션(unintended memorization)이 손실 감소에 더 이상 유리하지 않게 됩니다.

그림 4: 실제 텍스트 데이터에 대해 훈련된 다양한 모델 및 데이터셋 크기의 학습 손실 및 테스트 손실. 데이터셋 크기가 모델의 용량을 초과할 때 더블 디센트가 발생합니다.
최근 수년간 현대의 언어 모델들은 점점 더 방대한 양의 데이터로 훈련되어 왔으며, 그에 비해 파라미터 수는 수십억 규모에서 정체되어 있습니다. 예를 들어, 최신 SOTA 모델 중 하나(Dubey 외, 2024)는 80억 개의 파라미터(디스크 기준 약 32GB)를 가지며, 15조 개의 토큰(약 7TB)을 학습 데이터로 사용합니다.
여러 연구(Carlini et al., 2019; Mireshghallah et al., 2022; Nasr et al., 2023; Zhang et al., 2023; Carlini et al., 2023b; Schwarzschild et al., 2024)에서는 이러한 사전학습 언어 모델들이 학습 데이터를 의미 있게 암기하는지에 대한 의문을 제기합니다. 대부분의 연구는 다음 두 가지 관점 중 하나로 접근합니다:
- 데이터 추출(extraction): 모델의 파라미터에서 전체 학습 데이터를 복원하는 시도
- 멤버십 추론(membership inference): 특정 데이터 포인트가 학습 데이터에 포함되어 있었는지를 판별
데이터 추출 연구들은, 모델로부터 특정 데이터를 생성할 수 있다면 해당 데이터가 암기된 것으로 간주합니다(Carlini et al., 2023b; Nasr et al., 2023; Schwarzschild et al., 2024). 그러나 우리는 단순히 모델이 어떤 출력을 생성했다고 해서 그것이 반드시 암기의 증거는 아니라고 주장합니다. 최근 연구(Geiping et al., 2024)는 언어 모델이 거의 어떤 문자열이든 생성할 수 있음을 보여줍니다. 따라서 특정 문장을 출력했다는 사실만으로는 메모리제이션을 확정할 수 없습니다.
이 문제를 해결하기 위해 일부 연구자들은 입력을 정규화하는 방식—예: 입력 길이 제한(Schwarzschild et al., 2024) 또는 특정 접두사(prefix)를 포함시키는 방식(Carlini et al., 2023b)—을 제안했습니다. 하지만 이러한 제약이 있더라도, 모델의 일반화 능력 때문에 메모리제이션 여부를 확실히 입증하긴 어렵습니다. 예를 들어, 훌륭한 언어 모델은 두 수의 합을 묻는 질문에, 그 식을 본 적이 없어도 정확한 답을 낼 수 있습니다.
실제로 최근 연구(Liu et al., 2025)는 이전에 ‘암기된 것’으로 간주되었던 예시 중 일부가 학습 데이터에 실제로 존재하지 않으며, 그 출력 가능성은 일반화의 결과라고 보고합니다. 또한, 텍스트를 완전히 동일하게 재생산하는 것(verbatim reproduction)은 메모리제이션의 필요조건이 아닙니다. 모델은 단어 하나 걸러 하나씩 암기하는 등 특정 패턴을 기억할 수도 있습니다.
이처럼 데이터 추출만으로는 메모리제이션을 정의하기에는 불충분하며, 보다 정확한 정의가 필요합니다. 기존 수학적 정의들—예: 멤버십 추론(Shokri et al., 2017) 또는 차등 개인정보 보호(Dwork, 2006)—은 데이터셋/분포 수준에서 정의되며, 특정 인스턴스(예: 특정 교과서 한 문장)에 대한 메모리 측정에는 적합하지 않습니다. 개별 인스턴스 수준에서 메모리제이션을 정의하려는 시도(Feldman, 2020; Feldman & Zhang, 2020)도 있었지만, 이들 정의는 학습 알고리즘 전체의 메모리 용량에 초점을 맞추고 있으며, 특정 모델 내에서 특정 데이터가 얼마나 암기되었는지를 측정하고자 하는 우리의 목적에는 부합하지 않습니다.
이에 따라, 우리는 모델이 특정 데이터 포인트에 대해 보유한 정보량을 정량화하는 새로운 메모리제이션 정의를 제안합니다. 이 정의는 “압축률(compression rate in bits)” 개념에 기반하며, 모델이 주어진 입력을 매우 짧은 인코딩으로 압축할 수 있다면, 해당 입력을 암기한 것으로 간주합니다. 이 프레임워크는 Kolmogorov 정보 이론(Kolmogorov, 1963) 및 Shannon 정보 이론(Shannon, 1948)에 영감을 받았지만, 모델의 우도(likelihood)를 통해 실제로 쉽게 측정할 수 있습니다.
우리는 메모리제이션과 일반화의 구분이라는 핵심 문제(Prashanth et al., 2024)에 대응하기 위해, 메모리제이션을 다음 두 가지 구성요소로 분해합니다:
- 비의도적 메모리제이션(unintended memorization): 모델이 특정 데이터셋에 대해 저장한 정보
- 일반화(generalization): 모델이 데이터 생성 과정에 대해 학습한 지식
이 두 개념을 이해하기 위해, 우리는 다양한 용량의 언어 모델들을 서로 다른 크기의 데이터셋으로 훈련시켜 비의도적 메모리제이션과 일반화를 측정합니다. 먼저, 균일 무작위 비트 문자열로 구성된 데이터셋을 사용하여 일반화 요소를 제거한 후, 모델이 데이터에 대해 얼마만큼의 정보를 담고 있는지를 정확히 측정합니다. 이 실험을 통해 정확히 정보량이 알려진 데이터셋으로 학습했을 때의 언어 모델 용량을 정의할 수 있습니다. 실험 결과, GPT 스타일의 Transformer는 파라미터당 약 3.5~4 비트의 정보를 저장할 수 있으며, 이는 모델 구조 및 정밀도(precision)에 따라 다릅니다.
이후 우리는 실제 텍스트로 실험을 반복합니다. 이 경우 일반화가 가능하고, 학습에 도움이 되기도 합니다. 실제 텍스트에서는, 모델이 특정 용량까지는 데이터를 암기하다가, 이후에는 비의도적 암기를 일반화로 대체하며, 개별 샘플 수준이 아닌 일반화 가능한 패턴을 학습하기 시작합니다. 우리 프레임워크는 이 시점에서 더블 디센트(double descent) 현상이 시작됨을 보여주며, 이는 데이터 크기가 모델 용량(비트 기준)을 초과하는 지점에서 발생합니다.
마지막으로, 우리는 모델 용량과 데이터셋 크기를 기반으로 멤버십 추론 성능에 대한 스케일링 법칙(scaling law)을 도출합니다. 실험 결과, 멤버십 추론 성능은 모델 용량 및 데이터 크기와 정확한 함수적 관계를 따르며,
- 더 큰 모델은 더 많은 샘플을 암기할 수 있고,
- 더 큰 데이터셋은 멤버십 추론을 어렵게 만든다는 사실을 확인했습니다.
우리가 도출한 스케일링 법칙은 대형 모델로도 확장 가능하며, 대부분의 현대 언어 모델은 평균적인 데이터 포인트에 대해서는 신뢰할 만한 멤버십 추론이 어려울 정도로 많은 데이터를 학습한 것으로 예측됩니다.

그림 5: 학습 도중 암기된 비트 수. 이 모델은 GPT 스타일 Transformer이며, 686만 파라미터와 약 23.9MB의 용량(capacity)을 가집니다.

그림 6: 합성 데이터로 학습한 모델들의 파라미터당 비트 용량. GPT 모델을 half precision으로 학습했을 때, α = 3.64 비트/파라미터로 추정됩니다.
2 의도된 암기와 비의도적 암기 (Memorization, intended and unintended)
모델 θ = L(x) 은 학습 알고리즘 L과 데이터셋 x ∼ X를 사용하여 학습될 때, 샘플 x로부터 일부 정보가 모델 θ로 전달됩니다.
메모리제이션(memorization) 관련 문헌에서 핵심 질문 중 하나는, 이 저장된 정보 중 얼마나 많은 부분이 의도된 것인지, 혹은 비의도적인 것인지를 규명하는 것입니다.
이 연구에서는 다음과 같은 특성을 만족하는 엄밀한 메모리제이션 정의를 제시하는 것을 목표로 합니다:
- 일반화와의 분리
우리가 정의하는 비의도적 메모리제이션(unintended memorization)은, 의도된 암기(intended memorization)와 명확히 구별되어야 하며, 이 의도된 암기를 우리는 일반화(generalization)라고 부릅니다.
예를 들어, 다음과 같은 훈련 샘플을 학습한 언어 모델을 생각해보십시오:
Q: 2의 100제곱은 무엇인가요?
A: 1267650600228229401496703205376
이 모델이 이 훈련 샘플을 얼마나 암기했는지를 평가할 때, 기초적인 수학 연산을 수행하는 능력은 언어 모델에서 기대되는 일반화된 기능이라는 점을 고려해야 합니다. - 샘플 수준의 암기 정의
우리는 확률변수 자체가 아니라, 확률변수의 구체적인 실현(realization)에 대해 메모리제이션을 정의해야 합니다.
다시 말해, 특정 샘플 x가 모델 θ 안에 얼마나 비의도적으로 암기되었는지를 정의하고자 합니다. - 학습 알고리즘으로부터의 독립성
우리의 정의는 학습 알고리즘 L에 의존하지 않고, 최종 모델 θ와 특정 샘플 x만을 기반으로 정의되어야 합니다.
이는 특히 언어 모델과 같이, 우리가 최종 모델과 특정 입력 샘플에만 접근할 수 있는 상황에서 매우 중요합니다.
이전 연구들 또한 머신러닝 모델에 대한 메모리제이션 정의를 시도해왔습니다. 본 논문에서는 위의 기준을 만족하는 보다 정확한 메모리제이션 정의와 이를 측정하는 방법을 제시하고자 합니다. 메모리제이션의 다양한 정의에 대한 더 폭넓은 논의는 부록 A.2를 참조하십시오.
2.1 통계적 관점에서 본 메모리제이션 (A statistical view of memorization)
표기법.
이 절에서는 대문자(예: X, Θ)는 확률변수를 나타내고, 소문자(예: x ∼ X, θ ∼ Θ)는 확률변수의 구체적인 실현값(instance)을 나타냅니다.
정보 이론(information theory)에서는 확률변수에 대한 정보량 개념이 잘 정립되어 있습니다. 확률변수 X에 대해, 우리는 일반적으로 H(X)—즉 X의 엔트로피(entropy)—를 사용하여 X가 포함하고 있는 정보량을 정의합니다. 또한, 두 개의 서로 다른 확률변수 X, Y에 대해, X | Y는 Y가 고정되었을 때 X에 남아 있는 불확실성을 의미합니다. 이제 이를 바탕으로, X와 Y 사이의 상호정보(mutual information)를 다음과 같이 정의할 수 있습니다:

이제 머신러닝 학습 파이프라인을 가정해 봅시다. 우리는 데이터셋 분포 X를 반영하는 모델에 대한 사전 분포(prior) Θ를 갖고 있고, 학습 알고리즘 L은 X로부터 샘플을 받아 훈련된 모델 Θ^를 생성합니다. 이때, Θ^가 X에 대해 보존하고 있는 정보량을 이해하기 위해, 우리는 상호정보 개념을 사용할 수 있습니다:

이는 훈련된 모델 Θ^ 안에 X에 대한 모든 정보량을 측정하는 방식입니다. 그러나 앞서 언급했듯, 우리는 이 메모리제이션 정의가 일반화(generalization)까지 고려하길 원합니다. 따라서, 비의도적 메모리제이션(unintended memorization)을 측정할 때는, Θ가 고정된 후에도 X에 남아 있는 불확실성—즉 X | Θ에 포함된 정보만을 고려합니다.
이를 바탕으로, 비의도적 메모리제이션은 다음과 같이 정의할 수 있습니다:

그리고 일반화(또는 의도된 암기, intended memorization)는 다음과 같이 정의됩니다:

이제 우리는 의도된 암기와 비의도적 암기에 대한 정의를 갖췄으며, 실제로 이를 어떻게 측정할 수 있는지를 논의해봅니다. 먼저 비의도적 메모리제이션을 측정할 수 있게 해주는 정리를 소개합니다:

이 명제는 다음과 같은 사실을 시사합니다:
- 데이터셋 수준에서의 비의도적 메모리제이션의 하한(lower bound)은 각 샘플 단위의 메모리제이션을 더함으로써 측정할 수 있으며,
- 훈련된 모델 자체의 정보 엔트로피(H(Θ^))는 비의도적 메모리제이션의 상한(upper bound)을 제공합니다.
또한, 이 명제는 비의도적 메모리제이션이 데이터셋 크기에 따라 증가할 수는 있지만, 모델의 총 용량(capacity)을 넘을 수는 없다는 점도 함의합니다.
2.2 Kolmogorov 복잡도를 이용한 비의도적 메모리제이션 측정
지금까지 제시한 메모리제이션 및 일반화의 정의는 엔트로피 기반(entropy-based) 정보 개념에 기반하고 있습니다. 이는 곧, 해당 정의들이 확률변수(random variables)에 대해서만 적용 가능함을 의미합니다. 하지만 이는 메모리제이션을 실제로 측정할 때 큰 어려움을 초래합니다. 정의에 포함된 변수들은 모두 단일 샘플(singleton)이기 때문입니다. 우리는 하나의 모델 θ, 하나의 데이터셋 x = (x₁, ..., xₙ), 하나의 훈련된 모델 θ^만을 가지고 있으며, 단일 샘플만으로는 엔트로피(또는 조건부 엔트로피)를 측정하는 것이 불가능합니다.
이 문제를 해결하기 위해, 우리는 정보의 또 다른 개념인 압축 기반(compression-based) 접근으로 전환하며, 이후 이 방식이 앞서 정의한 메모리제이션 개념과 근사적으로 유사함을 보일 것입니다.
Kolmogorov 복잡도(Kolmogorov complexity)는 문자열 x의 정보량을 H_K(x)로 정의하며, 이는 주어진 계산 모델에서 x를 표현하는 가장 짧은 프로그램(표현)의 길이로 정의됩니다. 마찬가지로, x | θ는 θ라는 참조 정보가 주어진 상태에서 x를 가장 짧게 표현하는 방식이며, 이때의 정보량은 H_K(x | θ)로 나타냅니다. 그렇다면, 상호정보(mutual information)는 다음과 같이 정의할 수 있습니다:




이러한 결과는 Kolmogorov 기반 정의가 실질적으로 Shannon 기반 메모리제이션과 얼마나 잘 들어맞는지를 수학적으로 보장해줍니다.
2.3 우도를 이용한 Kolmogorov 복잡도 추정
앞서 정의한 Kolmogorov 기반 메모리제이션 개념을 고정한 상태에서, 이제 우리는 Kolmogorov 복잡도 H_K를 다양한 설정에서 어떻게 추정할 수 있는지를 설명합니다. Kolmogorov 복잡도는 정확하게 계산하는 것이 계산 불가능(uncomputable)하다는 것이 알려져 있으며, 결정 문제(decision version)는 판정 불가능(undecidable)합니다. 하지만, 현존하는 최적의 압축 방식(compression scheme)을 이용하여 이를 근사할 수는 있습니다.
아래에서는 정의에 사용된 각 항을 어떻게 근사하는지를 요약합니다:


표 1: 다양한 네트워크 너비(width)와 깊이(depth), 정밀도 설정(full 및 half-precision)에 따른 모델 용량 추정값. 정밀도를 bfloat16에서 float32로 2배 증가시켰을 때, 모델 용량은 파라미터당 3.51비트에서 3.83비트로 소폭 증가합니다.

그림 7: 멤버십 추론(membership inference)에 대한 스케일링 법칙 곡선(scaling law curve)과 실제 실험 데이터(원 표시)를 함께 시각화한 그래프.
3 메모리제이션을 위한 모델 용량 (Model Capacity for Memorization)
비의도적 메모리제이션(unintended memorization)은 모델 θ가 데이터 포인트 x에 대해 알고 있는 정확한 비트 수를 원칙적으로 측정할 수 있는 방법을 제공합니다. 데이터셋에 있는 각 데이터 포인트에 대해 이 정보를 합산하면, 모델이 전체 데이터셋에 대해 알고 있는 총 정보량(비트 수)을 측정할 수 있습니다. 그리고 각 데이터 포인트가 서로 완전히 독립적이어서 일반화가 불가능한 경우, 데이터 포인트별 비의도적 메모리제이션을 합산함으로써 모델 θ의 용량(capacity)을 추정할 수 있습니다.
3.1 모델 용량 정의
우리는 먼저 특정 언어 모델 θ에 대한 메모리제이션 용량(capacity) 개념을 수학적으로 정식화합니다. 모델의 용량이란, 모델 θ의 모든 파라미터에 걸쳐 저장될 수 있는 최대 메모리제이션 정보량(비트 수)을 의미합니다.


3.2 합성 시퀀스를 이용한 모델 용량 측정
이 절에서는 Transformer 언어 모델의 용량(capacity)을 측정합니다. 우리의 목표는 다양한 데이터셋 및 분포를 구성한 후, 단일 모델 θ를 훈련시켜 각각에 대한 메모리제이션을 측정하는 것입니다. 이후, 모든 데이터셋에 대한 최대 메모리제이션 양을 기준으로 모델의 용량을 근사합니다.
데이터셋을 생성할 때, 각 토큰은 사전 정의된 토큰 집합으로부터 균일하게(random uniform) 독립적으로 샘플링됩니다.
H_K(x | θ, θ^)를 근사하기 위해, 우리는 θ^ 하에서의 엔트로피를 직접 계산하여 해당 데이터셋의 가장 짧은 기술(description)을 추정할 수 있습니다. 이 값을 전체 Shannon 정보에서 빼면, 비의도적 메모리제이션 mem<sub>U</sub>(X, L(X))을 근사할 수 있습니다.


실험 세부사항 (Experimental details)
Kaplan et al. (2020)을 따라, 우리는 GPT-2 아키텍처(Radford et al., 2019)를 기반으로 모델을 스크래치부터 훈련시킵니다.
모델 구성은 다음과 같습니다:
- 층 수: 1~8개
- 히든 차원: 32~512
- 파라미터 수: 10만~2천만 개
- 학습 스텝: 10⁶
- 배치 크기: 2048
- 옵티마이저: Adam
- 정밀도: bfloat16, A100 GPU 단일 장비 사용
- 메모리 초과 시 gradient accumulation 사용
기본 설정은 다음과 같습니다:
- 어휘 크기 V = 2048
- 시퀀스 길이 S = 64
- 데이터셋 크기만 변화
- 각 모델 및 데이터셋 조합에 대해 5개의 랜덤 시드로 반복 (모델 초기화 및 데이터 샘플링에 영향을 줌)
실험 결과 (Results)
그림 2는 모델 크기와 데이터 크기별 메모리제이션 양을 보여줍니다.
- Y축: 비의도적 메모리제이션
- X축: 데이터셋 크기
- 선 색상: 모델 크기
결과적으로, 모델이 자신의 용량에 도달하면 메모리제이션이 포화되고 더 이상 증가하지 않음을 확인할 수 있습니다. 작은 데이터셋은 모델의 용량이 충분할 경우 완전히 암기됩니다.
우리는 모델의 비의도적 메모리제이션의 최대값을 측정하여 용량을 추정했고, 이를 그림 6에 시각화했습니다. 흥미롭게도, 매우 작은 규모에서도 모델 파라미터 수와 메모리제이션 용량 사이에 매우 부드럽고 선형적인 관계가 나타납니다. 측정 결과, 이 실험 조건에서 모델은 파라미터당 약 3.5~3.6 비트의 정보를 암기하는 것으로 나타났습니다. 이는 이전 연구(Roberts et al., 2020; Lu et al., 2024)가 지적한 것처럼, 사실 저장량이 모델 용량에 비례한다는 가설을 지지합니다. 다만, Allen-Zhu & Li (2024)가 양자화 기반으로 추정한 2비트/파라미터보다 다소 높게 나타났습니다.
최적 도달 여부와 수렴 분석
모델은 경사 하강법(gradient descent)으로 학습되었기 때문에, 전역 최적(global optima)에 도달하지 못했을 수 있으며,
결과적으로 측정된 용량은 하한(lower bound)입니다. 우리는 8M 파라미터 모델의 훈련 곡선을 자세히 분석했고, 그림 6에 시각화했습니다.
모든 데이터셋(샘플 수 16,000~400만)은 3.56~3.65 × 10⁶ 비트의 메모리제이션 범위에 수렴했으며, 이는 측정값이 상당히 안정적이며, 더 많은 학습을 해도 암기량이 크게 증가하지 않을 것임을 시사합니다. 가장 큰 두 데이터셋(400만, 800만 샘플)은 각각 2.95M, 1.98M 비트를 암기했으며, 더 많은 epoch을 진행했다면 용량에 근접할 때까지 더 암기했을 것으로 예상됩니다.
정밀도가 모델 용량에 미치는 영향
자연스럽게 떠오르는 질문은, 정밀도(precision)가 α (비트/파라미터)에 어떤 영향을 주는가입니다. 최근 연구에 따르면, 모델은 2비트 이하로 양자화되어도 여전히 유용함을 유지할 수 있습니다.
이전 실험은 모두 bfloat16으로 수행되었으므로, 우리는 이를 float32(full precision)로 다시 수행하여 정밀도가 용량에 미치는 영향을 측정했습니다.
그 결과,
- 모델 전반적으로 약간의 용량 증가가 관찰되었고,
- α 값은 평균 3.51 → 3.83 비트/파라미터로 증가했습니다.
하지만 이는 정밀도(16 → 32비트)의 2배 증가에 비해 매우 작은 변화이며, 이는 정밀도 증가로 추가된 비트 중 대부분은 실제 정보 저장에는 활용되지 않는다는 것을 의미합니다.
4 비의도적 메모리제이션과 일반화의 분리
앞선 실험에서는 합성된 비트 문자열을 대상으로 메모리제이션과 멤버십 추론 특성을 분석했습니다. 이번에는 텍스트 데이터에 대한 메모리제이션을 측정합니다. 무작위로 생성된 시퀀스와 달리, 텍스트 데이터로부터의 학습은 비의도적 메모리제이션(샘플 수준)과 일반화(분포 수준)가 혼합된 형태로 존재합니다.
일반화(분포 수준)가 혼합된 형태로 존재합니다. 따라서, 우리는 동일한 파라미터 수로 전체 데이터셋을 학습한 모델을 참조 모델(reference model)로 사용합니다.
<sup>3</sup>
참조 모델의 계산 능력을 제한하는 것은 𝒱-정보(Xu et al., 2020)와 관련되며, 이는 모델 크기를 고려했을 때 신호에서 “실제로 사용 가능한 정보”를 측정합니다.
또한, 오라클 참조 모델(oracle reference model)도 고려합니다. 이는 평가 데이터셋에서 가장 낮은 손실(최고 압축률)을 달성한 모델로, 매우 많은 파라미터를 가질 수 있습니다.
실험 세부사항
3.2절에서 수행한 실험을 합성 데이터 대신 실제 텍스트 데이터를 사용하여 반복합니다. 실제 세계의 텍스트 분포를 얻기 위해, 우리는 최신 FineWeb 데이터셋(Penedo et al., 2024)을 사용합니다. 이 데이터셋은 최신의 중복 제거(deduplication) 기준을 따릅니다.
- 시퀀스 길이는 64토큰이며,
- 64토큰으로 자를 때 1~2%의 시퀀스가 중복되는 현상을 방지하기 위해 추가적인 중복 제거 단계를 수행합니다.
- 이는 추출률(extraction rate)을 정확히 측정하기 위해 매우 중요합니다.
이전과 동일하게, 다양한 크기의 텍스트 데이터셋에 대해 여러 크기의 모델을 사전학습(pretrain)하고, 각 모델-데이터셋 조합에 대해 비의도적 메모리제이션을 측정합니다.
추가로,
- 표준 손실 기반 절차에 따른 멤버십 추론 성능
- 다양한 길이의 prefix를 사용한 정확한 추출률(그리디 디코딩)도 측정합니다.
실험 결과
- 샘플 수준의 비의도적 메모리제이션은 모델 파라미터 수가 클수록 증가하고, 학습 데이터셋 크기가 클수록 감소합니다 (그림 4).
- 오라클 참조 모델 기준으로 측정한 경우(그림 2),
- 모델이 작을 때는 작은 데이터셋에서 오라클보다 더 많은 정보를 학습할 수 있어 메모리제이션이 증가하다가,
- 모델이 일반화하기 시작하면서 오라클보다 성능이 떨어지게 되고, 그 시점부터 메모리제이션은 감소합니다.
데이터셋 크기 대비 모델 용량 비율이 더블 디센트를 예측함
훈련 손실 및 테스트 손실을 보면, 데이터셋이 충분히 클 경우, 모델이 일반화를 시작하는 시점(즉, 평가 손실이 감소하기 시작하는 시점)은 모델의 용량에 도달했을 때입니다. 이 시점은 대략 10⁵개의 샘플로, 모델의 파라미터 수에 따라 달라집니다.
Nakkiran et al. (2019)과 같이, 우리는 데이터셋 크기와 모델 용량의 비율을 그림 4에 플롯했습니다.
기존 연구와 달리, 우리는
- 참조 모델의 압축률을 기반으로 정확한 데이터셋 크기,
- α 추정을 통해 정확한 모델 용량을 계산할 수 있습니다.
데이터셋 크기가 모델 용량에 가까워질수록 평가 성능이 일시적으로 감소(더블 디센트)하며, 그 이후 모델 용량을 초과하면 평가 손실이 급격히 향상되는 현상이 나타납니다. 이는 Belkin et al. (2019), Nakkiran et al. (2019)의 더블 디센트 관찰을 뒷받침하며,
더블 디센트는 데이터의 정보량이 모델 용량을 초과할 때 정확히 시작된다는 직관적인 설명을 제공합니다.
하나의 이론은 다음과 같습니다:
모델이 더 이상 개별 샘플을 직접 암기할 수 없게 되면, 여러 샘플 간 정보를 공유하며 압축하게 되고, 이 과정에서 일반화가 발생한다는 것입니다.

그림 8: 64-토큰 학습 시퀀스에 대해, prefix 길이별로 측정한 train/test 추출률

그림 9: 데이터셋 크기별 멤버십 추론 F1 점수 (F1 = 0.5는 무작위 추론과 동일)

그림 10: 32-토큰 prefix를 기준으로 한 suffix 추출률과 멤버십 추론 성능 비교. (일반적으로 멤버십 추론이 추출보다 쉬움)
일반화는 0이 아닌 추출률을 설명함
우리는 전체 훈련 데이터셋과 겹치지 않는 1만 개의 테스트 샘플에 대해 추출률을 측정했습니다 (그림 17).
- 32-토큰 prefix 기준으로, 매우 작은 훈련 데이터셋에서는 100% 추출 가능했습니다.
- 예측 가능하게, 데이터셋 크기가 커질수록 추출률은 감소했습니다.
그러나 데이터셋이 충분히 커졌을 때도 추출률은 0까지 떨어지지 않고, 테스트 샘플에 대한 추출률과 거의 동일한 수준으로 수렴합니다. 즉, 중복이 제거된 상태에서 훈련 데이터셋이 충분히 크면, 성공적인 추출은 전적으로 일반화에 기인한 것임을 시사합니다.
5 메모리제이션과 멤버십 추론 (Memorization and Membership)
우리의 학습 설정은 훈련 데이터와 테스트 데이터를 완전히 제어할 수 있으며, 완벽한 중복 제거(deduplication)가 적용되어 있습니다. 이로 인해 본 실험 환경은 모델 크기, 데이터셋 크기, 멤버십 추론 성공률 사이의 관계를 연구하기에 이상적입니다.
모든 멤버십 추론 결과는 표준 손실 기반 멤버십 추론(loss-based membership inference) 방식(Yeom et al., 2018; Sablayrolles et al., 2019)을 따릅니다.
방법은 매우 간단합니다:
손실(loss) 값의 임계값(cutoff)을 설정하여, 샘플이 학습 데이터셋의 멤버인지 여부를 예측합니다.
5.1 합성 데이터 및 텍스트 데이터에서의 멤버십 추론
합성 데이터:
합성 데이터로 학습된 각 모델에 대해, 데이터셋 크기별로 멤버십 추론 공격의 성공률을 시각화했습니다 (그림 14). 특정 크기 이상의 데이터셋부터는, 평균적인 경우의 멤버십 추론이 실패하기 시작합니다. 이는 모델 크기에 비해 데이터셋이 너무 클 경우, 평균적인 훈련 샘플에 대한 멤버십 추론은 불가능할 수 있음을 시사합니다.
텍스트 데이터:
텍스트로 학습된 각 모델에 대해, FineWeb에서 겹치지 않는 미사용 데이터를 사용해 표준 손실 기반 멤버십 추론(Yeom et al., 2018; Sablayrolles et al., 2019)을 수행하고, 데이터셋 크기에 따른 성능 변화를 그림 10에 시각화했습니다.
- 모델 크기가 고정된 경우, 데이터 크기가 커질수록 멤버십 추론이 더 어려워집니다.
- 멤버십 추론과 추출(extraction)을 비교하면 (그림 10), 모든 경우에 멤버십 추론의 성능이 더 높았습니다.
예를 들어, 추출률이 0인 경우에도 멤버십 추론 F1 점수가 0.97에 이를 정도로 높은 성능을 보이기도 했습니다.
5.2 멤버십 추론을 위한 스케일링 법칙
이 절에서는 메모리제이션에 대한 예측 모델을 수립합니다. 특히, 우리는 다음 요소들에 따라 손실 기반 멤버십 추론의 F1 점수를 예측합니다:
- 토큰 수(token count)
- 샘플 수(number of examples)
- 모델 파라미터 수(model size)
이후, 500K부터 15억(1.5B) 파라미터까지의 모델에 대해 우리의 예측을 검증합니다.
5.2.1 함수 형태 (Functional Forms)
모델 용량이 고정되어 있을 때, 멤버십 추론 성능은 데이터셋 크기에 따라 시그모이드(sigmoid) 형태를 따르는 경향이 있습니다.
이는 직관적으로 다음과 같이 설명할 수 있습니다:
- 작은 데이터셋에 과적합된 큰 모델은 멤버십 추론이 매우 쉬워 초기 F1 점수는 1에 가깝습니다.
- 그러나 데이터셋 크기가 증가함에 따라, 손실값만으로 훈련/비훈련 데이터를 구별하기 어려워지고,
- 결국 F1 점수는 0.5 (무작위 추론 수준)로 수렴합니다.



5.2.2 대형 모델에서의 검증
우리는 다음 사실에 주목합니다:
현대 언어 모델 대부분은 토큰 수 대비 파라미터 수 비율(token-per-parameter ratio)이 10² 이상이며, 우리의 스케일링 법칙에 따르면 이는 멤버십 추론 F1 점수가 0.5, 즉 통계적으로 유의미한 손실 기반 멤버십 추론이 불가능함을 의미합니다.

표 2: 우리 스케일링 법칙이 예측한 멤버십 추론 F1 점수에 대응하는 데이터셋 크기와 실제 측정값.
우리는 F1 점수가 각각 0.55, 0.75, 0.95가 될 것으로 예측되는 모델들을 학습시켜 이를 검증했습니다. 모델은 GPT-2 Small (약 1.25억 파라미터)과 GPT-2 XL (약 15억 파라미터)을 선택했습니다. 우리의 스케일링 법칙을 이용해, 주어진 모델 크기에서 목표 F1 점수를 얻기 위해 필요한 데이터셋 크기를 계산하고 (표 2 참조), 이 크기로 모델을 학습한 뒤 F1 점수를 측정했습니다 (그림 7의 원(circle)으로 표시됨).
예측값은 실제 F1 점수와 대체로 ±1.5포인트 이내로 일치합니다. 가장 오차가 컸던 구간은 예측 F1이 0.75인 경우로, 이는 시그모이드 곡선에서 기울기가 가장 가파른 부분이기 때문입니다. 전반적으로, 이러한 결과는 우리의 경험적 모델이 멤버십 추론을 잘 설명하고 있으며, 매우 큰 데이터셋으로 학습된 모델에서는 멤버십 추론 공격이 실패할 수밖에 없는 이유를 설명합니다 (Das et al., 2024; Duan et al., 2024; Maini et al., 2024 참조).
6 관련 연구 (Related Work)
언어 모델과 압축
Shannon의 소스 코딩 정리(Shannon, 1948)는 예측과 압축 사이의 이중성을 처음으로 정식화했습니다. 언어 모델링과 압축의 관계는 Shannon (1950)부터 연구되었으며, 영어에 대해 더 정확한 모델일수록 더 적은 비트로 텍스트를 압축할 수 있다는 사실이 밝혀졌습니다. 또한 Kolmogorov 복잡도(Kolmogorov, 1965)와 Shannon 정보 사이의 관계도 Grunwald & Vitányi (2004)에 의해 자세히 논의되었습니다. Delétang et al. (2024)은 현대 Transformer 기반 언어 모델을 압축기로 활용하는 방법을 탐색했습니다.
본 연구에서는 모델 내 메모리제이션을 측정하는 도구로서 압축 개념을 사용했습니다.
언어 모델의 용량
Arpit et al. (2017)은 모델의 실효 용량(effective capacity) 개념을 정식화하고, 표현력과 학습 시간 모두가 모델 용량에 큰 영향을 준다는 점을 관찰했습니다. 또한 여러 연구에서는 RNN (Collins et al., 2017; Boo et al., 2019) 및 Transformer (Roberts et al., 2020; Heinzerling & Inui, 2021; Allen-Zhu & Li, 2024) 모델의 용량을 기억 가능한 사실(fact) 또는 랜덤 라벨 수로 측정했습니다. 일부는 양자화(quantization) 조건 하에서 측정되었습니다.
Yun et al. (2019), Curth et al. (2023), Mahdavi et al. (2024), Kajitsuka & Sato (2024) 등은 다양한 모델 아키텍처의 이론적 용량 추정치를 제안했지만, 아직까지 현대적인 다층 Transformer에 대해 스케일 확장이 이뤄진 연구는 없습니다. 본 연구는 모델 용량에 대한 명확한 상한(upper bound)을 측정한 최초의 시도입니다.
메모리제이션의 대안적 정의
비의도적 메모리제이션은 기존 문헌에서 제안된 다양한 메모리제이션 정의들과 깊은 관련이 있습니다. 이에 대한 상세 비교는 부록 A.2에서 제공합니다.
7 결론 (Conclusion)
우리는 모델이 데이터셋에 대해 알고 있는 정확한 비트 수를 측정할 수 있는 새로운 메모리제이션 정의를 제안합니다. 이 정의를 바탕으로 현대 Transformer 언어 모델의 용량을 측정하고, 추출률(extraction rate) 및 F1 점수와 같은 지표가 모델 크기 및 데이터셋 크기에 따라 어떻게 변화하는지 분석합니다. 또한 멤버십 추론에 대한 스케일링 법칙을 제안하고, 이를 대형 모델에서도 검증하였습니다.
우리의 결과는 언어 모델이 어떻게 정보를 암기하는지, 그리고 어떤 정보는 암기하고 어떤 정보는 하지 않는지에 대한 실무자들의 이해를 넓히는 데 도움을 줍니다.
8 감사의 말 (Acknowledgements)
Karen Ullrich, Niloofar Mireshghallah, Mark Ibrahim, Preetum Nakkiran, Léon Bottou 등 논문 개선에 도움을 준 많은 분들께 감사드립니다.