https://arxiv.org/abs/2405.11473
FIFO-Diffusion: Generating Infinite Videos from Text without Training
We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without additional training. This is achie
arxiv.org
초록 우리는 텍스트 조건 비디오 생성을 위한 사전 학습된 확산 모델에 기반한 새로운 추론 기술을 제안합니다. 우리 접근 방식인 FIFO-Diffusion은 개념적으로 추가 훈련 없이 무한히 긴 비디오를 생성할 수 있습니다. 이는 큐에서 일련의 연속적인 프레임을 증가하는 노이즈 수준으로 동시에 처리하며 대각선 디노이징을 반복 수행함으로써 달성됩니다. 우리 방법은 큐의 앞머리에서 완전히 디노이징된 프레임을 제거하면서 꼬리에 새로운 무작위 노이즈 프레임을 추가합니다. 그러나 대각선 디노이징은 양날의 검으로, 꼬리에 가까운 프레임이 더 깨끗한 프레임을 참조함으로써 이점을 취할 수 있지만, 이러한 전략은 훈련과 추론 간의 불일치를 유발합니다. 따라서 우리는 훈련-추론 간격을 줄이기 위해 잠재적 파티셔닝을 도입하고, 전방 참조의 이점을 활용하기 위해 선견 디노이징을 도입합니다. 실질적으로 FIFO-Diffusion은 기준 모델을 제공하는 경우 목표 비디오 길이에 관계없이 일정한 메모리를 소비하며, 여러 GPU에서 병렬 추론에 적합합니다. 우리는 기존 텍스트-비디오 생성 기준에서 제안된 방법의 유망한 결과와 효과를 입증했습니다. 생성된 비디오 샘플 및 소스 코드는 우리의 프로젝트 페이지에서 확인할 수 있습니다.

FIFO-Diffusion: 텍스트로부터 무한 비디오 생성, 추가 훈련 없이
Figure 1: FIFO-Diffusion이 사전 학습된 텍스트 조건 비디오 생성 모델인 VideoCrafter2(Chen et al., 2024)를 기반으로 생성한 10,000프레임 길이의 비디오 일러스트레이션. 각 이미지의 왼쪽 상단에 있는 숫자는 프레임 인덱스를 나타냅니다. 결과는 FIFO-Diffusion이 짧은 클립(16프레임)으로 훈련된 모델을 기반으로 장기간 비디오를 효과적으로 생성할 수 있으며, 품질 저하 없이 장면의 동적 요소와 의미를 유지함을 명확히 보여줍니다.
1. 소개
확산 확률 모델(Diffusion probabilistic models)은 이미지 생성에서 큰 성공을 거두었습니다(Ho et al., 2020; Song et al., 2021b; Dhariwal & Nichol, 2021; Rombach et al., 2022). 이미지 분야에서의 성공을 바탕으로 비디오 생성에서도 빠른 진전이 있었습니다(Ho et al., 2022; Singer et al., 2022; Zhou et al., 2022; Wang et al., 2023b).
그럼에도 불구하고, 긴 비디오 생성은 여전히 이미지 생성에 비해 뒤쳐져 있습니다. 그 이유 중 하나는 비디오 확산 모델(VDMs)이 비디오를 시간 축이 추가된 단일 4D 텐서로 간주하는 경향이 있어, 모델이 비디오를 대규모로 생성하는 것을 방해하기 때문입니다. 긴 비디오를 생성하는 직관적인 접근 방식은 자동회귀 생성(autoregressive generation)으로, 이전 프레임을 바탕으로 미래 프레임을 반복적으로 예측하는 것입니다. 그러나 트랜스포머 기반 모델(Hong et al., 2023; Villegas et al., 2023)과 달리, 확산 기반 모델은 단일 프레임 생성을 위한 반복적인 디노이징 단계로 인해 막대한 계산 비용을 발생시키므로 자동회귀 생성 전략을 직접 채택할 수 없습니다. 대신, 많은 최근 연구들(Ho et al., 2022; He et al., 2022; Voleti et al., 2022; Luo et al., 2023; Chen et al., 2023b; Blattmann et al., 2023)은 청크드 자동회귀 생성 전략(chunked autoregressive generation strategy)을 채택하여, 소수의 선행 프레임을 조건으로 여러 프레임을 병렬로 예측함으로써 계산 부담을 줄이고 있습니다. 이러한 접근 방식은 계산적으로 실현 가능하지만, 실제로는 소수의—대부분 하나 또는 두 개의—프레임에서 사용 가능한 제한된 시간적 맥락을 모델이 포착하기 때문에 청크로 예측된 부분들 간의 시간적 일관성 및 연속적인 움직임이 종종 부족하게 됩니다.
제안된 추론 기술인 FIFO-Diffusion은 추가 훈련 없이 긴 비디오 생성을 실현합니다. 이는 짧은 클립으로 사전 학습된 비디오 생성 확산 모델을 기반으로 임의의 길이의 비디오를 생성할 수 있게 합니다. 또한, FIFO-Diffusion은 청크드 자동회귀 방법의 한계를 효과적으로 극복하며, 모든 프레임이 충분한 수의 선행 프레임을 참조할 수 있게 합니다. 우리 접근 방식은 큐를 사용하여 시간 경과에 따라 단조롭게 증가하는 다양한 노이즈 수준을 가진 프레임 시퀀스를 유지하면서, 첫 번째 프레임이 완전히 디노이징될 때마다 큐의 앞부분에서 제거되고 새로운 무작위 노이즈 이미지가 꼬리에 추가되는 방식으로 프레임을 대각선 디노이징(Section 4.1)을 통해 생성합니다. 대각선 디노이징은 이점과 단점을 모두 제공합니다. 더 노이즈가 많은 프레임은 이전 디퓨전 단계에서 더 깨끗한 프레임을 참조함으로써 이점을 얻지만, 모델은 동시에 처리되는 프레임들의 노이즈 수준 차이로 인해 훈련-추론 간격에서 어려움을 겪을 수 있습니다. 이러한 한계를 극복하고 대각선 디노이징의 이점을 수용하기 위해, 우리는 잠재적 파티셔닝(Section 4.2)과 선견 디노이징(Section 4.3)을 제안합니다. 잠재적 파티셔닝은 노이즈 입력 이미지의 노이즈 수준 범위를 제한하고, 디퓨전 과정을 더 세밀하게 이산화하여 비디오 품질을 향상시킵니다. 추가적으로, 선견 디노이징은 기본 모델의 능력을 향상시켜 더욱 정확한 노이즈 예측을 제공합니다. 또한, 잠재적 파티셔닝과 선견 디노이징은 모두 여러 GPU에서 병렬 처리가 가능합니다.
우리의 주요 기여는 다음과 같이 요약됩니다.
- 짧은 클립으로 훈련된 VDMs를 위한 훈련이 필요 없는 비디오 생성 기술인 대각선 디노이징을 통한 FIFO-Diffusion을 제안합니다. 우리 접근 방식은 각 프레임이 충분한 수의 선행 프레임을 참조할 수 있게 하여 임의 길이의 비디오 생성을 가능하게 합니다.
- 생성 품질을 향상시키는 잠재적 파티셔닝과 선견 디노이징을 도입하고, 이 두 기술의 이론적 및 경험적 효과를 입증합니다.
- FIFO-Diffusion은 기준 모델을 제공하는 경우 생성 비디오 길이에 관계없이 일정한 양의 메모리를 사용하며, 여러 GPU에서 병렬 추론을 쉽게 수행할 수 있습니다.
- U-Net(Ronneberger et al., 2015) 또는 DiT(Peebles & Xie, 2023) 아키텍처를 기반으로 한 네 가지 강력한 기준에서 우리의 실험은 FIFO-Diffusion이 시간이 지남에 따라 품질 저하 없이 자연스러운 움직임을 포함한 매우 긴 비디오를 생성함을 보여줍니다.
2 관련 연구
이 섹션에서는 기존의 확산 기반 비디오 생성 모델을 논의하고, 긴 비디오 생성 기술을 요약합니다.
2.1 비디오 확산 모델
비디오 생성은 종종 확산 모델에 의존합니다(Ho et al., 2022; Singer et al., 2022; Zhou et al., 2022; Wang et al., 2023b; Chen et al., 2023a). 확산 기반 기술 중 VDM(Ho et al., 2022)은 U-Net(Ronneberger et al., 2015)의 구조를 수정하여 디노이징을 위해 시간 정보를 고려하는 3D U-Net 아키텍처를 제안합니다. 반면, Make-A-Video(Singer et al., 2022)는 2D 공간 대응 후 1D 시간적 합성곱 레이어를 추가하여 3D 합성곱을 근사합니다. 이러한 아키텍처는 처음에 이미지-텍스트 쌍으로 공간 레이어를 학습한 후 비디오의 시간적 맥락을 위해 1D 시간적 레이어를 추가함으로써 시각-텍스트 관계를 이해할 수 있게 합니다. 최근에는 (Peebles & Xie, 2023)에서 DiT로 불리는 변환기 아키텍처를 확산 모델에 도입했습니다. 추가적으로, 대규모 텍스트-이미지 및 텍스트-비디오 데이터셋으로 학습된 여러 오픈소스 텍스트-비디오 모델들이 있습니다(Wang et al., 2023b; Chen et al., 2023a; Wang et al., 2023c; Chen et al., 2024).
2.2 긴 비디오 생성
He et al. (2022); Voleti et al. (2022); Yin et al. (2023); Harvey et al. (2022); Blattmann et al. (2023); Chen et al. (2023b)는 긴 비디오를 생성하기 위해 가시적인 프레임을 기반으로 마스킹된 프레임을 예측하도록 모델을 학습시킵니다. NUWA-XL(Yin et al., 2023)은 계층적 접근 방식을 제안하여, 글로벌 확산 모델이 희소한 키 프레임을 생성하고 로컬 확산 모델이 그 사이를 보간합니다. 그러나 계층적 프레임워크는 무한히 긴 비디오를 생성하는 데 한계를 보입니다. 반면, LVDM(He et al., 2022)과 MCVD(Voleti et al., 2022)와 같은 모델은 몇 개의 초기 프레임을 기반으로 후속 프레임을 자동회귀적으로 예측하며, FDM(Harvey et al., 2022)과 SEINE(Chen et al., 2023b)은 예측 또는 보간을 수행하기 위해 마스킹 전략을 일반화합니다. 자동회귀적 프레임워크는 무한히 긴 비디오를 생성할 수 있지만, 오류 누적과 프레임 간 시간적 일관성 부족으로 인한 품질 저하에 종종 시달립니다. LGC-VD(Yang et al., 2023)는 이러한 한계를 해결하기 위해 글로벌 및 로컬 맥락을 모두 고려합니다.
Wang et al. (2023a); Qiu et al. (2023)은 조정이 필요 없는 긴 비디오 생성 기술을 제안합니다. Gen-LVideo(Wang et al., 2023a)는 비디오를 중첩된 짧은 클립으로 보고, 한 프레임에 대해 여러 예측을 평균화하는 시간적 공동 디노이징을 제안합니다. FreeNoise(Qiu et al., 2023)는 윈도우 기반 주의 집중 융합을 사용하여 주의 집중 범위 문제를 회피하고, 긴 비디오 초기화를 위한 로컬 노이즈 셔플 유닛을 제안합니다. 그러나 이는 교차 주의 집중을 계산하기 위해 비디오 길이에 비례하는 메모리가 필요하여 무한히 긴 비디오를 생성하기 어렵습니다.
3. 텍스트-비디오 확산 모델

4 FIFO-Diffusion

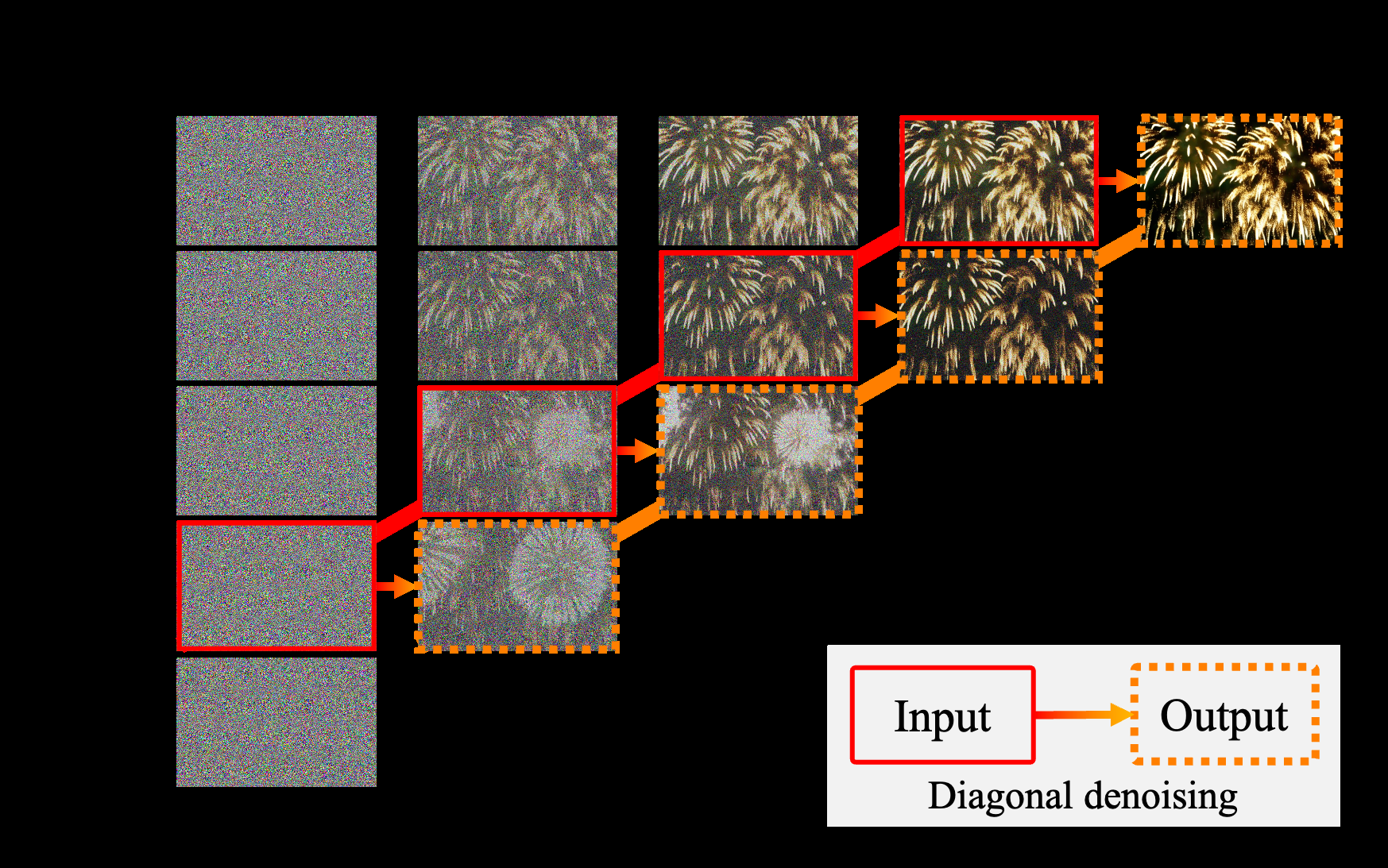
Figure 2 설명
Figure 2: 대각선 디노이징(diagonal denoising)을 f = 4로 설명한 그림입니다. 실선으로 둘러싸인 프레임들은 모델 입력을 나타내며, 점선으로 둘러싸인 프레임들은 디노이징된 버전을 나타냅니다. 디노이징 후, 오른쪽 상단 모서리에 완전히 디노이징된 인스턴스가 큐에서 제거되고 새로운 무작위 노이즈가 큐에 추가됩니다.
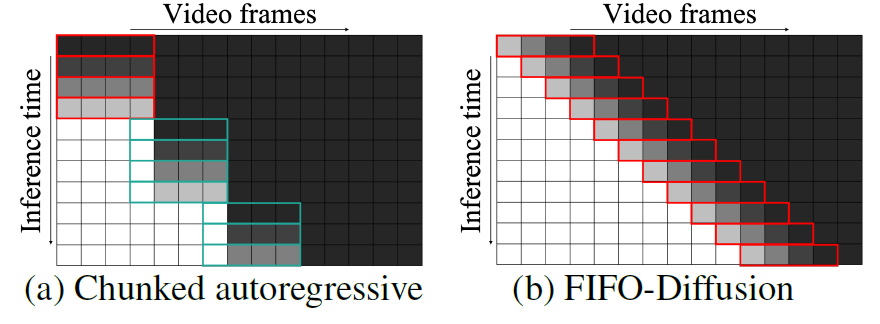
Figure 3 설명
Figure 3: 긴 비디오 생성을 위해 제안된 청크드 자동회귀(chunked autoregressive) 방법과 FIFO-Diffusion의 비교입니다. 무작위 노이즈(검정색)는 모델에 의해 반복적으로 디노이징되어 이미지 잠재 공간(흰색)으로 변환됩니다. 빨간 상자는 사전 학습된 기본 모델의 디노이징 네트워크를 나타내고, 녹색 상자는 추가 훈련으로 얻어진 예측 네트워크를 나타냅니다.
4.1 대각선 디노이징

-----------------------------------------------------------------------------------------------------------------------------------------------------------------

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
FIFO-Diffusion은 이후 프레임으로 맥락을 순차적으로 전파함으로써 일관된 비디오를 생성하는 데 뛰어납니다. 그림 3은 청크드 자동회귀 방법(Ho et al., 2022; He et al., 2022; Voleti et al., 2022; Luo et al., 2023; Chen et al., 2023b; Blattmann et al., 2023)과 우리의 접근 방식 간의 개념적 차이를 설명합니다. 전자는 마지막으로 생성된 프레임만 조건으로 하기 때문에 청크 사이에서 장기적인 맥락을 유지하지 못하는 경우가 많습니다. 그러나 FIFO-Diffusion에서는 모델이 프레임 시퀀스를 1씩 이동하여 생성 과정 전체에서 각 프레임이 충분한 수의 이전 프레임을 참조할 수 있게 합니다. 이는 모델이 몇 개의 프레임의 로컬 일관성을 자연스럽게 더 긴 시퀀스로 확장할 수 있게 합니다.
또한, FIFO-Diffusion은 서브네트워크나 추가 훈련이 필요하지 않으며, 기본 모델에만 의존합니다. 이는 마스킹된 프레임 외삽(outpainting)을 위한 추가 예측 모델이나 미세 조정이 필요한 기존의 자동회귀 방법과 다릅니다.
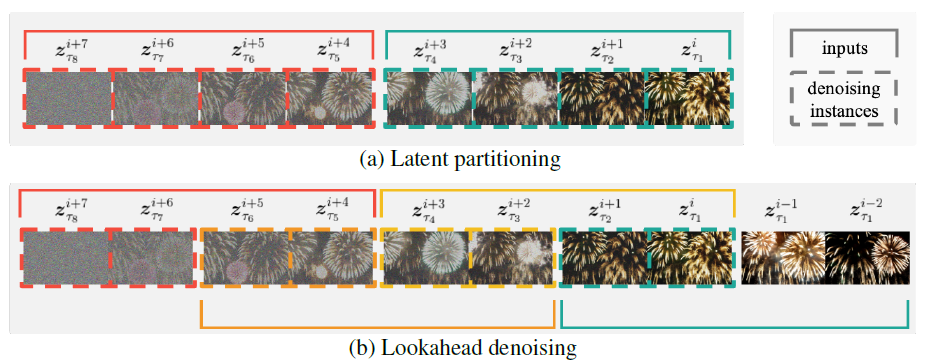
Figure 4 설명
Figure 4: 잠재적 파티셔닝과 선견 디노이징을 설명한 그림으로, 여기서 f= 및 n=입니다. (a) 잠재적 파티셔닝은 확산 과정을 n부분으로 나누어 최대 노이즈 수준 차이를 줄입니다. (b) (a)에서 선견 디노이징을 통해 모든 프레임이 적절한 수의 이전 프레임과 함께 디노이징될 수 있으며, (a)보다 두 배 더 많은 계산이 필요합니다.
4.2 잠재적 파티셔닝


-----------------------------------------------------------------------------------------------------------------------------------------------------------------

-----------------------------------------------------------------------------------------------------------------------------------------------------------------



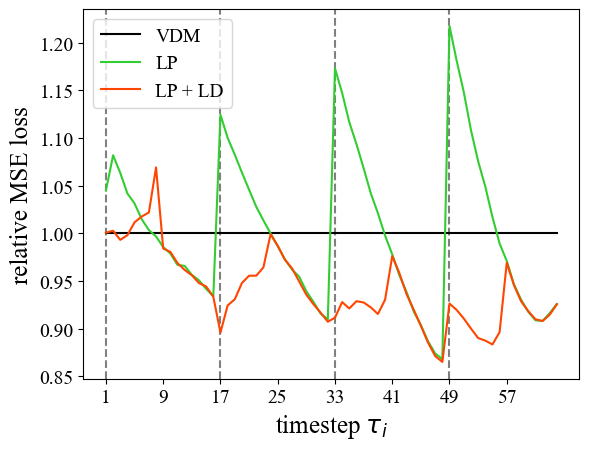
Figure 5 설명

4.3 Lookahead Denoising
대각선 디노이징은 훈련-추론 간격을 초래하지만, 더 깨끗한 프레임을 관찰함으로써 노이즈가 많은 프레임이 이점을 얻어 더 정확한 디노이징을 가능하게 한다는 점에서 또 다른 이점을 제공합니다. 경험적 증거로, 그림 5는 대각선 디노이징이 원래 디노이징 전략에 비해 노이즈 예측에서의 상대적 MSE 손실을 보여줍니다. 상대적 MSE의 공식 정의는 다음과 같습니다:

몇몇 초기 시간 단계를 제외하고, Lookahead Denoising을 통한 노이즈 예측은 기본 모델의 디노이징 능력을 향상시켜, 4.2절에서 설명한 훈련-추론 간격을 거의 완전히 극복합니다. 모델 출력의 절반만을 사용하기 때문에 이 접근 방식은 대각선 디노이징의 두 배의 계산이 필요합니다. 그러나 계산 오버헤드에 대한 우려는 잠재적 파티셔닝과 동일한 방식으로 병렬화를 통해 쉽게 해결할 수 있습니다 (표 1 참조).

Figure 6 설명
Figure 6: (a) Open-Sora Plan과 (b) VideoCrafter2를 기반으로, 그리고 (c) VideoCrafter2를 기반으로 한 여러 프롬프트에 의해 FIFO-Diffusion으로 생성된 긴 비디오 일러스트레이션. 각 프레임의 왼쪽 상단에 있는 숫자는 프레임 인덱스를 나타냅니다.
5. 실험
이 섹션에서는 FIFO-Diffusion을 포함한 긴 비디오 생성 방법으로 생성된 비디오를 제시하고, 이를 정성적 및 정량적으로 평가합니다. 또한, FIFO-Diffusion에 도입된 잠재적 파티셔닝과 Lookahead Denoising의 이점을 검증하기 위해 소거 연구를 수행합니다.
5.1 구현 세부 사항
우리는 짧은 비디오 클립으로 훈련된 기존의 오픈 소스 텍스트-비디오 확산 모델을 기반으로 FIFO-Diffusion을 구현합니다. 여기에는 세 가지 U-Net 기반 모델인 VideoCrafter1 (Chen et al., 2023a), VideoCrafter2 (Chen et al., 2024), zeroscope2와 DiT 기반 모델인 Open-Sora Plan3이 포함됩니다. 우리는 η ∈ {0.5, 1}로 DDIM 샘플링(Song et al., 2021a)을 사용합니다. 구현에 대한 자세한 내용은 부록 B의 표 3에 있습니다.
5.2 정성적 결과
우리는 먼저 제안된 접근 방식의 성능을 정성적으로 평가합니다. 그림 1은 VideoCrafter2를 기반으로 FIFO-Diffusion에 의해 생성된 10,000 프레임 이상의 매우 긴 비디오 예시를 보여줍니다. 이는 짧은 비디오 클립으로 훈련된 모델에만 의존하여 임의의 길이의 비디오를 생성할 수 있는 FIFO-Diffusion의 능력을 보여줍니다. 개별 프레임은 비디오 후반부에서도 품질 저하 없이 뛰어난 시각적 품질을 보여주며, 비디오 전체에 걸쳐 의미적 정보가 일관됩니다. 그림 6 (a)와 (b)는 자연스러운 장면 및 카메라 움직임을 가진 생성된 비디오를 제시합니다. 움직임의 일관성은 생성 과정에서 이전 프레임을 참조함으로써 잘 제어됩니다.
또한, 그림 6 (c)는 FIFO-Diffusion이 프롬프트를 연속적으로 변경하여 많은 움직임을 포함한 비디오를 생성할 수 있음을 보여줍니다. 여러 움직임을 생성하고 장면 간 원활한 전환을 할 수 있는 능력은 우리의 방법의 실용성을 강조합니다. 다중 프롬프트 생성을 더 자세히 설명한 내용은 부록 E.1에 있습니다. 추가 예제와 다른 기준 모델을 기반으로 한 비디오 데모는 부록 D와 E 및 우리의 프로젝트 페이지1에서 확인할 수 있습니다.

Figure 7 설명
Figure 7: FIFO-Diffusion을 적용한 VideoCrafter2(첫 번째), VideoCrafter2에 적용한 FreeNoise(두 번째), VideoCrafter2에 적용한 Gen-L-Video(세 번째), 그리고 LaVie + SEINE(마지막)에 의해 생성된 샘플 비디오. 각 프레임의 왼쪽 상단에 있는 숫자는 프레임 인덱스를 나타냅니다.
그림 7에서는 VideoCrafter2에 적용된 두 가지 훈련이 필요 없는 기술인 FreeNoise(Qiu et al., 2023)와 Gen-L-Video(Wang et al., 2023a) 및 훈련 기반 청크드 자동회귀 방법인 LaVie(Wang et al., 2023c) + SEINE(Chen et al., 2023b)와 우리의 결과를 비교합니다. 청크드 자동회귀 방법은 T2V를 위한 LaVie와 I2V를 위한 SEINE 두 가지 모델이 필요합니다. 우리의 방법은 움직임의 부드러움, 프레임 품질 및 장면 다양성 측면에서 다른 방법보다 훨씬 뛰어나다는 것을 관찰했습니다. 훈련이 필요 없는 방법 중에서, Gen-L-Video는 배경이 흐릿해지는 문제를 보이며, FreeNoise는 동적 장면을 생성하지 못하고 움직임이 부족합니다. LaVie + SEINE의 경우, 자동회귀 생성 중 오류 누적으로 인해 비디오가 점차 품질이 저하되고 텍스트에서 벗어납니다. 또한, 이들은 청크 간 주기적인 불연속성을 보여주며, 마지막 단일 프레임의 제한된 맥락 정보로 인해 어려움을 겪습니다. 추가 샘플은 부록 F의 그림 17과 18에 제공됩니다.
우리는 또한 사용자 연구를 통해 FIFO-Diffusion이 긴 비디오 생성에서 기존 방법인 FreeNoise와 비교하여 성능을 평가했습니다. 그림 8은 사용자들이 모든 기준에서 특히 움직임과 관련된 기준에서 FreeNoise보다 FIFO-Diffusion을 상당히 선호한다는 것을 보여줍니다. 움직임은 이미지에 비해 비디오에서 가장 두드러진 특성 중 하나이기 때문에, 이러한 기준에서 FIFO-Diffusion의 강력한 결과는 매우 고무적이며 더욱 자연스러운 동적 비디오를 생성할 잠재력을 보여줍니다. 사용자 연구에 대한 자세한 내용은 부록 B.1에 있습니다.
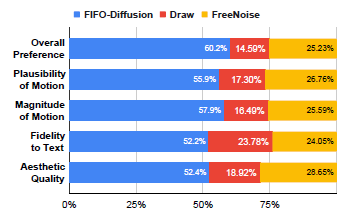
Figure 8 설명
Figure 8: FIFO-Diffusion과 FreeNoise 간의 사용자 연구 결과를 다섯 가지 기준으로 비교한 그래프.
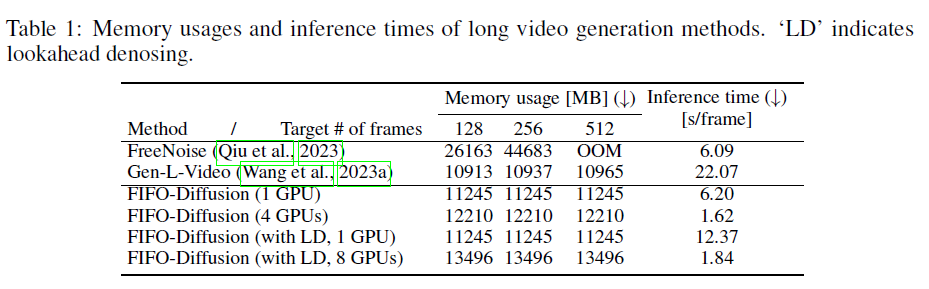
표 1
표 1: 긴 비디오 생성 방법의 메모리 사용량과 추론 시간. 'LD'는 Lookahead Denoising을 나타냅니다.
5.3 계산 비용
우리는 확장성과 시간 효율성을 분석하기 위해 FIFO-Diffusion을 포함한 훈련이 필요 없는 긴 비디오 생성 방법의 메모리 사용량과 프레임당 추론 시간을 측정합니다. 표 1은 FIFO-Diffusion이 고정된 메모리 할당으로 임의의 길이의 비디오를 생성하는 반면, FreeNoise는 목표 비디오 길이에 비례하여 메모리를 소비한다는 것을 보여줍니다. Gen-L-Video도 거의 일정한 메모리를 소비하지만, 프레임당 중복된 계산으로 인해 많은 시간이 소요됩니다. 더욱이, FIFO-Diffusion은 병렬화된 계산을 통해 시간을 절약할 수 있으며, 이는 우리 방법에만 독점적으로 사용할 수 있습니다. 비록 Lookahead Denoising을 포함하는 것이 더 많은 계산을 요구하지만, 여러 GPU에서 병렬 추론을 통해 샘플링 시간을 크게 줄일 수 있습니다. 실험을 위해 우리는 VideoCrafter2를 기본 모델로 사용하고 A6000 GPU에서 64번의 추론 단계가 있는 DDPM 스케줄러를 사용합니다.
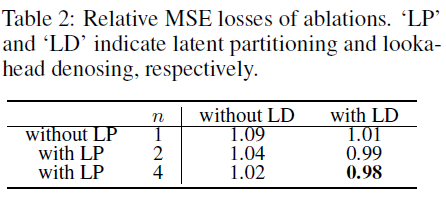
표 2
표 2: 소거 연구의 상대적 MSE 손실. 'LP'와 'LD'는 각각 잠재적 파티셔닝과 Lookahead Denoising을 나타냅니다.
5.4 소거 연구
우리는 잠재적 파티셔닝과 Lookahead Denoising이 FIFO-Diffusion의 성능에 미치는 영향을 분석하기 위해 소거 연구를 수행했습니다. 부록 H의 그림 20과 21은 잠재적 파티셔닝이 생성된 비디오의 품질과 시간적 일관성을 크게 개선하는 반면, Lookahead Denoising은 비디오를 더욱 자연스럽고 부드럽게 만들어 깜빡임 효과를 줄여줍니다.
또한, 표 2는 소거 간의 모든 시간 단계에서 평균 상대적 MSE 손실(식 (7) 참조)을 비교합니다. 결과는 잠재적 파티셔닝이 대각선 디노이징으로 인한 훈련-추론 간격을 분할 수가 증가함에 따라 효과적으로 줄임을 보여줍니다. 더 나아가 Lookahead Denoising은 모델의 노이즈 예측 정확도를 더욱 향상시켜 원래 예측 성능을 능가합니다.
5.5 자동 평가
우리는 MSR-VTT(Xu et al., 2016) 테스트 세트에서 무작위로 샘플링된 프롬프트로 생성된 비디오의 FVD(Untherthiner et al., 2018) 점수를 측정합니다. 생성된 긴 비디오의 평가를 위해, 우리는 FIFO-Diffusion과 FreeNoise로 생성된 긴 비디오의 16프레임 참조 비디오와 1의 스트라이드를 가진 16프레임 창의 시퀀스 간의 FVD 점수를 계산합니다. 더 많은 논의는 부록 G에 제공됩니다.
6 한계
잠재적 파티셔닝은 대각선 디노이징의 훈련-추론 간격을 완화하고 Lookahead Denoising은 표 2에 나타난 것처럼 더 정확한 디노이징을 가능하게 하지만, 모델 입력 분포의 변화로 인해 간격은 여전히 남아 있습니다. 그러나 우리는 대각선 디노이징의 이점이 훈련에도 유망하다고 믿으며, 이 간격은 훈련에 대각선 디노이징 패러다임을 통합함으로써 해결될 수 있다고 생각합니다. 이 통합은 향후 작업으로 남겨둘 것입니다. 훈련과 추론 환경이 정렬되면 FIFO-Diffusion의 성능은 크게 향상될 수 있습니다.
7 결론
우리는 짧은 비디오 클립으로 사전 학습된 비디오 확산 모델을 조정하지 않고 텍스트에서 무한히 긴 비디오를 생성할 수 있는 새로운 추론 알고리즘인 FIFO-Diffusion을 제안했습니다. 우리의 방법은 첫 번째 들어간 것이 첫 번째 나오는 방식으로 노이즈 수준이 증가하는 잠재 변수를 처리하는 대각선 디노이징을 수행함으로써 실현됩니다. 각 단계에서 완전히 디노이징된 인스턴스가 큐에서 제거되고 새로운 무작위 노이즈가 큐에 추가됩니다. 대각선 디노이징에는 트레이드오프가 있지만, 우리는 그 고유한 한계를 완화하기 위해 잠재적 파티셔닝을, 그 강점을 활용하기 위해 Lookahead Denoising을 제안했습니다. 이들을 결합하여, FIFO-Diffusion은 높은 품질의 긴 비디오를 성공적으로 생성하며, 훌륭한 장면 맥락 일관성과 동적 움직임 표현을 나타냅니다.
'일상생활' 카테고리의 다른 글
| 이미지 prompt 추축 (0) | 2024.06.25 |
|---|---|
| 인공지능 분야 모델 분석 (0) | 2024.06.25 |
| 사족보행 로봇을 위한 다중제약 강화학습 알고리즘 (0) | 2024.06.15 |
| storydiffusion (0) | 2024.05.06 |
| [Kaggle] 키 발급 (0) | 2024.05.02 |
