https://haidog-yaqub.github.io/EzAudio-Page/
EzAudio
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer 1Johns Hopkins Unversity, Baltimore, MD, USA 2Tencent AI Lab, Bellevue, WA, USA *This work was done while J. Hai was an intern at Tencent AI lab, USA. EzAudio is an advanced t
haidog-yaqub.github.io
https://arxiv.org/abs/2409.10819
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
Latent diffusion models have shown promising results in text-to-audio (T2A) generation tasks, yet previous models have encountered difficulties in generation quality, computational cost, diffusion sampling, and data preparation. In this paper, we introduce
arxiv.org
요약
잠재 확산 모델(latent diffusion models)은 텍스트-오디오(T2A) 생성 작업에서 유망한 결과를 보여주었으나, 이전 모델들은 생성 품질, 계산 비용, 확산 샘플링, 데이터 준비와 같은 문제에 직면해 왔습니다. 본 논문에서는 이러한 문제를 해결하기 위해 EzAudio라는 Transformer 기반의 T2A 확산 모델을 소개합니다. 우리의 접근 방식은 몇 가지 주요 혁신을 포함합니다:
(1) 1차원 파형 Variational Autoencoder (VAE)의 잠재 공간(latent space)에서 T2A 모델을 구축하여 2차원 스펙트로그램 표현을 다루거나 추가적인 신경 보코더를 사용하는 복잡성을 피했습니다.
(2) 오디오 잠재 표현 및 확산 모델링에 최적화된 확산 Transformer 아키텍처를 설계하여, 수렴 속도, 학습 안정성, 메모리 사용량을 향상시켰고, 그 결과 학습 과정을 더욱 쉽고 효율적으로 만들었습니다.
(3) 데이터 부족 문제를 해결하기 위해, 음향 종속성을 학습하기 위해 비라벨 데이터(unlabeled data)를 활용하고, 오디오-언어 모델이 주석을 달아 생성한 오디오 캡션 데이터를 텍스트-오디오 정렬 학습에 활용하며, 인간이 주석을 단 데이터를 미세 조정(fine-tuning)에 사용하는 데이터 효율적인 학습 전략을 채택했습니다.
(4) EzAudio를 간소화하고 더 큰 CFG(Classifier-Free Guidance) 점수를 사용할 때 우수한 프롬프트 정렬을 유지하면서도 훌륭한 오디오 품질을 달성할 수 있도록 CFG 스케일링 방법을 도입하여, 최적의 CFG 점수를 찾는 어려움을 해소했습니다. EzAudio는 기존 오픈 소스 모델들보다 객관적 지표 및 주관적 평가 모두에서 우수한 성능을 보여주며, 현실적인 청취 경험을 제공하는 동시에 단순한 모델 구조, 낮은 학습 비용, 따라 하기 쉬운 학습 파이프라인을 유지합니다. 코드, 데이터, 사전 학습된 모델은 다음 링크에서 제공됩니다: https://haidog-yaqub.github.io/EzAudio-Page/.
색인 용어: 확산 Transformer, 텍스트-오디오 생성
1. 서론
Stable Diffusion [1]과 같은 잠재 확산 기반 텍스트-이미지(T2I) 생성 모델의 급속한 발전은 고품질 이미지 합성 분야에 혁신을 가져왔습니다. 이러한 방법의 성공을 기반으로 확산 기반 텍스트-오디오(T2A) 생성이 유망한 연구 분야로 부상하고 있습니다. 이전 연구 [2, 3, 4, 5, 6]에서는 2D 멜 스펙트로그램을 이미지로 간주하고, 2D U-Net을 사용하여 오디오 콘텐츠를 생성하는 방식으로 T2I의 기술을 T2A에 적용했습니다.
최근 Diffusion Transformer(DiT) [7, 8, 9]가 전통적인 CNN 기반 U-Net을 능가하는 이미지 생성 성능을 보여주었습니다. 그러나 T2A, 특히 2D 멜 스펙트로그램을 사용하는 경우 DiT는 몇 가지 어려움에 직면하게 됩니다. 주요 문제는 계산 비용과 시간적 해상도 간의 균형을 맞추는 것입니다. 또한, 2D 멜 기반 방법은 ControlNet과 같이 일반적으로 1D 조건에 의존하는 일부 다운스트림 애플리케이션과 완벽히 호환되지 않을 수 있습니다. 최근 Make-An-Audio-2 [10]는 멜 스펙트로그램을 위해 1D 변분 오토인코더(VAE)를 도입하여, 2D 표현보다 우수한 생성 품질을 보이는 Transformer 기반 아키텍처를 활용했습니다. 그러나 [11, 12]에서 언급된 바와 같이 멜 스펙트로그램의 재구성은 여전히 소리 효과나 음악과 같은 오디오 품질 저하로 이어질 수 있습니다. 이러한 문제를 해결하고 DiT를 T2A에 통합하기 위해, 우리는 파형 E [13, 14]를 사용하여 계산 비용을 줄이고, 높은 시간적 해상도를 유지하며, 추가적인 신경 보코더 없이도 강력한 재구성을 제공합니다.
파형 잠재 표현, 확산 모델링에서의 예측 대상, T2A에서의 조건 방식 등을 결합하여, 우리는 DiT를 새롭게 재설계하였으며, 이를 위해 새로운 적응형 계층 정규화(AdaLN) 방법을 도입하고, 긴 스킵 연결(long-skip connections)을 통합하며, RoPE [15] 및 QK-Norm [16]과 같은 기법을 활용했습니다. 제안된 EzAudio-DiT는 빠른 수렴과 안정적인 학습을 달성하며, 더 적은 파라미터를 사용하고 메모리 소비를 줄였습니다.

그림 1: 제안된 EzAudio의 프레임워크와 EzAudio-DiT의 아키텍처 세부 사항.
T2A 생성에서 또 다른 주요 도전 과제는 대규모 주석 데이터셋의 부족입니다. AudioLDM [4]는 비라벨 오디오에 CLAP [17] 임베딩을 사용하지만, 텍스트와 오디오 임베딩 간의 불일치로 인해 생성 성능에 어려움을 겪습니다. Make-an-Audio-1&2 [6, 10]는 합성 오디오 데이터를 사용하는 것을 제안하지만, 데이터셋이 완전히 오픈 소스가 아니며, 새로운 데이터를 합성하는 것은 시간이 많이 걸릴 수 있습니다. 또한, 합성 데이터는 음원 샘플의 불일치한 녹음 환경 때문에 눈에 띄는 아티팩트를 도입하여 오디오 생성의 품질을 제한합니다. Tango [2]는 합성 캡션 데이터셋 모음인 TangoPromptBank를 도입했지만, 여러 데이터셋의 일관성 없는 품질과 시간 소모적인 조직이 여전히 장애물로 남아 있습니다. 이러한 문제를 해결하기 위해 우리는 Audioset [18], VGGSound [19], AudioCaps [20]과 같은 오픈 소스 데이터셋을 사용하여 세 단계의 학습 파이프라인을 제안합니다. 먼저, 마스크 모델링을 통합하여 모델이 음향 종속성을 학습하도록 합니다. 다음으로, 오디오-언어 모델과 언어 모델이 자동 생성하고 정제한 오디오 캡션 데이터를 사용하여 텍스트-오디오 정렬 학습을 진행합니다. 마지막으로 인간이 주석을 단 데이터로 모델을 미세 조정하여 정확한 오디오 생성을 수행합니다. 우리의 전략은 생성 품질과 프롬프트 정렬을 모두 향상시킵니다. 생성된 캡션은 공개되며, 오디오 데이터도 오픈 소스이기 때문에 향후 연구에 쉽게 접근할 수 있습니다.
또한, 확산 모델 샘플링에서 널리 사용되는 classifier-free guidance (CFG) [21]는 CFG 점수를 높이면 프롬프트 정렬을 향상시킬 수 있지만 과노출로 인해 생성 품질이 저하될 수 있습니다. 이 문제는 특히 잠재 파형 표현에서 두드러지며, 파형의 피크 분포는 음량 및 동적 범위뿐만 아니라 주파수 특성에도 영향을 미치기 때문입니다. 이 문제를 해결하기 위해 우리는 CFG 리스케일링 기술 [22]을 도입했습니다. 이 접근 방식은 더 높은 CFG 점수를 사용할 때도 오디오 충실도에 미치는 영향을 최소화하면서 강력한 프롬프트 정렬을 보장합니다. 결과적으로 CFG 점수를 신중하게 균형 잡을 필요가 없어 모델 사용이 간소화됩니다.
요약
우리는 EzAudio라는 혁신적이고 따라 하기 쉬운 T2A 프레임워크를 소개합니다. EzAudio는 (1) 파형 잠재 공간에서 동작하고, (2) 새롭게 설계된 효율적인 T2A DiT 아키텍처를 특징으로 하며, (3) 새로운 학습 전략을 통합하고, (4) 확산 샘플링에서 CFG를 개선합니다. EzAudio는 기존의 오픈 소스 모델보다 객관적 및 주관적 평가 모두에서 우수한 현실적인 오디오 샘플을 생성합니다. 코드는 물론 데이터셋과 모델 체크포인트도 공개되어 연구자와 스타트업들이 쉽게 T2A 모델을 구축할 수 있도록 도와줍니다. 또한, EzAudio가 비디오-오디오 합성과 같은 다른 오디오 생성 작업에서도 발전을 이끌 수 있기를 기대합니다.
II. 방법
이 섹션에서는 EzAudio의 기반이 되는 주요 구성 요소와 기술, 즉 아키텍처 설계, 분류기-프리 가이던스 리스케일링, 그리고 다단계 학습 전략에 대해 소개합니다.
II-A. EzAudio 개요
EzAudio는 세 가지 주요 구성 요소로 이루어져 있습니다: (1) 텍스트 인코더, (2) 잠재 확산 모델(LDM), 그리고 (3) 파형 VAE입니다. 텍스트 인코더는 입력된 오디오 설명을 처리하며, 이 설명은 잠재 확산 모델에 의해 오디오 파형의 잠재 표현을 생성하는 데 사용됩니다. 이 과정은 표준 가우시안 노이즈에서 역확산(reverse diffusion)을 거쳐 수행됩니다. 마지막으로 파형 VAE 디코더는 이 잠재 표현을 오디오 파형으로 재구성합니다.
EzAudio는 T2A 작업에서 뛰어난 성능을 보여준 FLAN-T5 [23]를 텍스트 인코더로 사용합니다. LDM은 속도(velocity) 예측 [24]과 Zero-SNR 확산 스케줄러 [22]를 사용하며, 이 두 가지 모두 확산 기반 이미지 및 오디오 생성에서 성공적으로 사용되었습니다 [25, 26]. LDM의 신경망은 T2A에 맞춰 특별히 설계된 Transformer 모델인 EzAudio-DiT를 기반으로 합니다.
파형 VAE는 Stable Audio [27]와 DAC [28]를 기반으로 하며, Snake 활성화 함수 [29]를 사용하는 완전 합성곱 오토인코더를 활용합니다. 여기서 잔여 벡터 양자화(RVQ) 대신 VAE 병목을 사용합니다. VAE는 KL 발산, 재구성, GAN 손실의 조합으로 학습하여 가우시안 분포의 잠재 공간을 보장하고 고품질의 오디오 재구성을 달성합니다. 우리는 AudioSet [18]을 이용해 파형 VAE를 학습하여 다양한 종류의 오디오를 처리할 수 있게 했습니다.
II-B. 효율적인 EzAudio-DiT 설계 제안
EzAudio는 DiT를 T2A에 더 적합하게 만들기 위해 파라미터 및 메모리 효율성, 수렴 속도, 학습 안정성을 개선하는 몇 가지 혁신적인 설계를 제안합니다. 이러한 혁신에는 다음이 포함됩니다:
- AdaLN-SOLA: DiT에서 AdaLN 계층은 이미지 클래스 조건 및 확산 단계 모두를 관리하기 때문에 많은 파라미터를 차지합니다. 텍스트 입력 처리는 교차-어텐션으로 관리되므로, AdaLN이 수행하는 작업이 단순해져 AdaLN의 간소화가 가능합니다. [9]에서 소개된 AdaLN-Single은 모든 DiT 블록에 대해 단일 공유 AdaLN을 사용하여 DiT의 모델 크기와 메모리 사용량을 줄이는 것을 목표로 합니다. 그러나 우리는 AdaLN-Single이 성능 저하와 DiT 학습의 불안정성을 초래한다는 것을 발견했습니다. 이를 해결하기 위해, 우리는 AdaLN-SOLA (AdaLN-Single Orchestrated by Low-rank Adjustment)를 제안합니다. AdaLN-SOLA는 하나의 공유 AdaLN 모듈을 사용하지만, 각 블록은 확산 단계를 입력으로 하는 저랭크 행렬을 사용해 공유 AdaLN을 적응적으로 조정합니다. 이렇게 함으로써 모델 파라미터와 메모리 사용량을 줄이면서도 모델 성능과 수치적 안정성을 유지할 수 있습니다.
- 긴 스킵 연결(Long-skip Connection): 확산 모델에서 입력 저수준 특징은 정확한 노이즈 또는 속도 추정에 필수적인 정보를 포함합니다. 128개의 채널을 가진 파형 잠재 임베딩을 사용할 때, 이는 일반적인 이미지 표현보다 훨씬 많아 Transformer가 세부 정보를 유지하기 어려워집니다. 이러한 부담을 완화하기 위해, 우리는 Transformer의 나중 블록에서 저수준 특징이 도달할 수 있도록 하는 긴 스킵 연결을 적용합니다(Fig. 1.b 참조).
- 기타 기법: DiT의 학습 안정성을 높이기 위해, 어텐션 레이어에 QK-Norm [16]을 적용하고 긴 스킵 연결의 융합 후 LayerNorm [30]을 도입했습니다. 또한, Transformer의 수렴 속도를 높이고 모델 성능을 개선하는 것으로 알려진 RoPE [15]를 오디오 잠재 표현의 위치 인코딩을 처리하는 데 사용했습니다.
II-C. 마스크 모델링 및 합성 캡션을 통한 사전 학습
T2I와 비교했을 때, T2A는 데이터 부족 문제가 있습니다. 확산 Transformer의 잠재력을 발휘하고 모델 성능을 개선하기 위해, 우리는 [31] 및 [9]와 같은 다단계 학습 접근 방식을 채택했습니다. 이 접근 방식은 다음과 같은 단계로 구성됩니다:
- II-C1. 마스크 확산 모델링
마스크 모델링은 Transformer [32, 33] 및 확산 Transformer [34]에서 효율적인 자기 지도 학습 사전 학습으로 성공적으로 적용되었습니다. 이 단계에서 우리는 다양한 오디오 클래스를 포함하지만 노이즈가 많은 주석이 있는 대규모 데이터셋인 AudioSet [18]을 사용합니다. 학습 중 무작위로 25%에서 100% 범위의 토큰을 최소 0.2초 단위로 마스킹하고, 확산 노이즈를 추가합니다. 모델은 텍스트 조건 없이 마스킹되지 않은 토큰을 사용해 마스크된 토큰을 재구성하도록 학습됩니다. 완전히 마스크되었을 때, 모델은 무조건적 모델로 작동합니다. - II-C2. 합성 캡션 데이터 생성
다음으로, 우리는 텍스트-오디오 정렬 학습을 위해 합성 캡션 데이터를 사용합니다. 오디오와 언어의 다양성을 높이기 위해, 우리는 여러 소스의 합성 데이터를 통합했습니다:- Auto-ACD [35]: AudioSet 및 VggSound에 대한 150만 개의 캡션이 포함된 오픈 소스 데이터셋입니다. 캡션 생성 시, 오디오 및 비디오 캡션 모델이 초기 캡션을 생성하고, 이를 언어 모델이 자연스러운 오디오 캡션으로 정제합니다.
- AS-Qwen-Caps: AudioSet에 대해 Qwen-Audio2 [36]를 사용해 생성된 오디오 캡션입니다. 이는 주요 오디오-언어 모델 중 하나입니다.
- AS-SL-GPT4-Caps: AudioSet의 강력한 레이블이 있는 부분의 시간 주석을 기반으로, OpenAI의 GPT-4o-mini API 3을 사용해 생성된 오디오 캡션입니다.
- 첫 번째 단계의 모델을 기반으로, 우리는 각 DiT 블록에 교차-어텐션 모듈을 통합하여 텍스트 조건을 처리하도록 합니다. 안정적인 학습 재개를 보장하기 위해 교차-어텐션 모듈의 출력 투사 레이어를 0으로 초기화합니다. 또한, 텍스트 입력에 더 의존하도록 하기 위해 완전한 마스크를 적용할 확률을 높였습니다. 이와 더불어, 텍스트의 10%는 무조건적 모델링을 위해 빈 입력으로 대체됩니다.
- II-C3. 미세 조정(Fine-tuning)
마지막으로 Tango에서 사용된 접근 방식을 따르며, 수작업으로 라벨링된 오디오 캡션 데이터셋인 AudioCaps [20]을 사용해 모델을 미세 조정하여 정확하고 고품질의 오디오 생성을 보장합니다.
II-D. 분류기-프리 가이던스 리스케일링을 통한 샘플링 개선
CFG [21]는 확산 샘플링을 지시하는 데 사용됩니다. 이는 역과정에서만 출력 속도(vc)을 다음과 같이 조정합니다:

여기서 w는 가이던스 스케일이며, v_{pos}와 v_{neg}는 각각 긍정적 프롬프트와 부정적 프롬프트 하에서의 모델 출력을 나타내며, v_{cfg}는 조정된 속도를 나타냅니다. 기본적으로 부정적 프롬프트는 빈 값으로 설정되어 무조건적인 경우와 같습니다.
높은 가이던스 스케일은 프롬프트 정렬을 향상시키지만, 과노출로 인해 생성 품질이 저하될 수 있습니다. 이를 해결하기 위해 CFG 리스케일링 기법 [22]을 사용하여 큰 w를 사용할 때도 방향을 유지하면서 v_{cfg}의 크기를 조정합니다.

여기서 phi는 리스케일링 인자이며, v_{cfg}'는 확산 샘플링을 위한 개선된 CFG 속도를 나타냅니다.
III. 실험
III-A. 실험 환경
우리는 파형 VAE와 T2A 모델 모두에 대해 24kHz 오디오 샘플 레이트를 사용하여 실험을 수행했습니다. 파형 잠재 표현은 50Hz에서 동작하며, 128개의 채널로 구성됩니다. DiT 변형 모델의 경우, DiT-L은 1024 채널을 가진 24개의 DiT 블록으로 구성되며, DiT-XL은 1152 채널을 가진 28개의 DiT 블록으로 구성됩니다. 모든 모델은 AdamW 옵티마이저로 학습되었습니다. 확산 샘플링 중에는 기본적으로 50개의 샘플링 단계와 CFG 점수 3을 사용합니다.
이전의 T2A 연구들 [4, 5, 2, 10]을 따라, 우리는 모델을 평가할 때 사전 학습된 PANNs [39]를 특징 추출기로 사용하여 프레셰 거리(FD), 쿨백-라이블러(KL) 발산, 그리고 인셉션 점수(IS)를 사용했습니다. 추가적으로, 생성된 오디오와 텍스트 프롬프트 간의 정렬을 평가하기 위해 최신 버전의 CLAP [17]을 사용합니다. 모든 오디오 샘플은 평가 전에 16kHz로 리샘플링됩니다.
AudioCaps 테스트 세트, 900개의 오디오 클립으로 구성되며 현재 882개의 클립이 사용 가능, 이 평가에 사용됩니다. 각 클립은 사람이 작성한 다섯 개의 캡션을 가지며, [2, 4]의 접근 방식을 따라 각 클립마다 하나의 캡션을 무작위로 선택합니다. 일부 연구 [10]에서는 모든 캡션을 평가에 사용하여 더 낮은 FD를 보이기도 합니다.
III-B. T2A에서의 DiT 아키텍처 비교
우리는 AudioCaps 데이터셋을 사용하여 128의 배치 크기와 1e-4의 학습률로 80k 스텝 동안 훈련하며, 다양한 DiT 변형에 대해 소거 연구(ablation study)를 수행했습니다. DiT-L 설정은 III-A 섹션에서 설명한 블록 수와 Transformer 채널 구성을 따릅니다. 변형 모델에는 기본 DiT [7]에 교차-어텐션 레이어를 추가한 CrossDiT, AdaLN을 AdaLN-Single로 교체한 Pixel-Art-DiT [9], 텍스트-음악 생성을 위해 설계된 RoPE 및 QK-Norm을 통합한 Stable-Audio-DiT [27], 그리고 II-B 섹션에서 설명한 제안된 EzAudio-DiT가 포함됩니다.
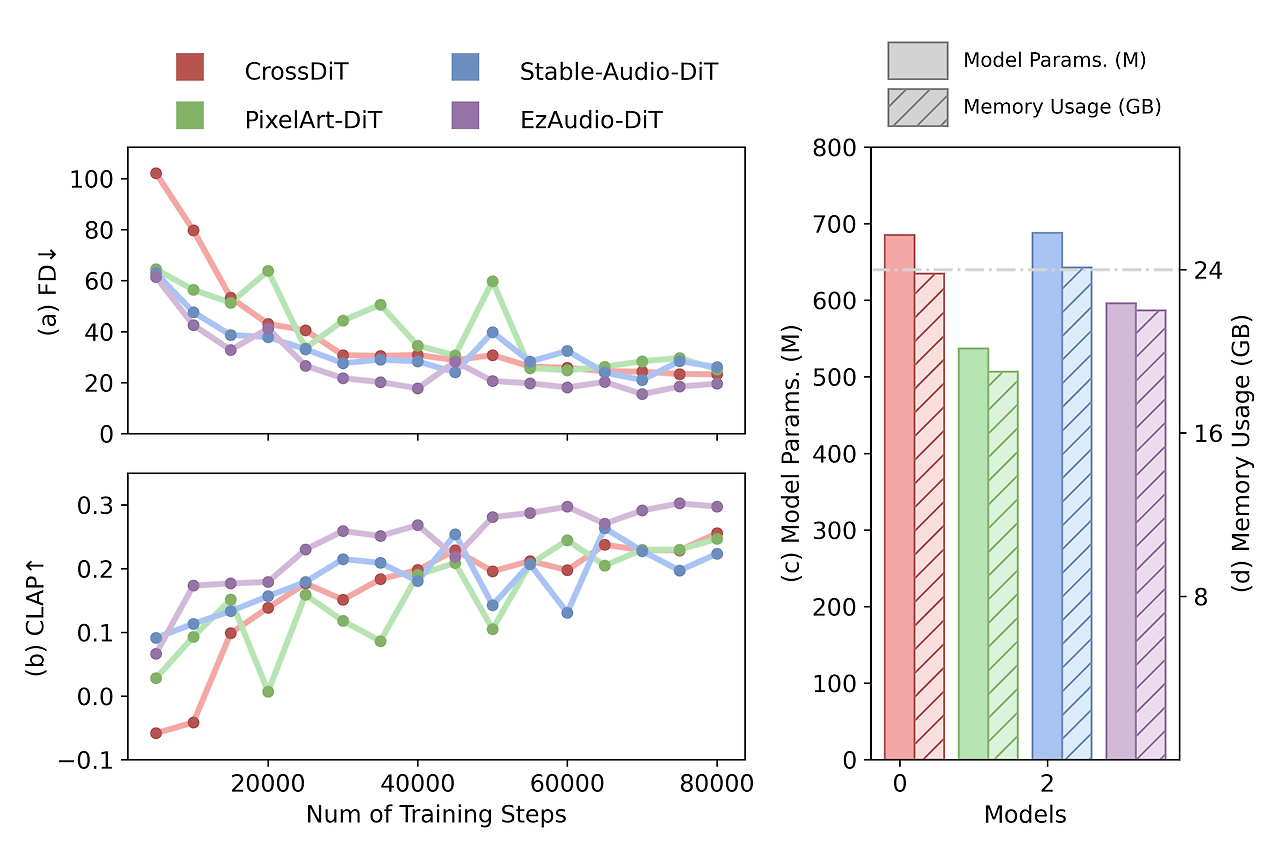
그림 2: 확산 Transformer 아키텍처의 비교.
그림 2.a에서 보듯이 PixelArt-DiT는 초기 학습 단계에서 빠르게 수렴하지만, 학습이 진행됨에 따라 불안정해집니다. RoPE의 도움으로 Stable-Audio-DiT는 초기에는 CrossDiT보다 더 빠르게 수렴하지만, 두 모델의 성능은 나중에 비슷해지며 Stable-Audio-DiT가 더 불안정해집니다. 제안된 EzAudio-DiT는 DiT 변형 모델들 중에서 빠르고 일관된 수렴을 보여주며, 궁극적으로 더 나은 성능을 달성합니다. 우리는 빠른 수렴을 긴 스킵 연결(long-skip connections)과 RoPE 덕분으로, 안정적인 학습은 AdaLN-SOLA, QK-Norm, 그리고 Skip-Norm 덕분이라고 보고 있습니다.
그림 2에서는 배치 크기 16으로 학습할 때의 모델 파라미터와 메모리 사용량을 비교했습니다. AdaLN-Single을 사용하는 PixelArt-DiT는 가장 적은 파라미터 수와 낮은 메모리 사용량을 보입니다. AdaLN-SOLA와 스킵 연결을 특징으로 하는 EzAudio-DiT는 PixelArt-DiT보다 약간 더 많은 파라미터와 메모리 사용량을 보이지만, Cross-DiT 및 Stable-Audio-DiT보다는 상당히 낮습니다. 특히 배치 크기 16에서는 EzAudio-DiT의 메모리 사용량이 24GB 이하로 유지되어 Nvidia 4090과 같은 GPU에서 효율적인 미세 조정이 가능합니다.
-----
논문이나 실험에서 **"step"**을 사용한 이유는 다음과 같은 경우일 수 있습니다:
- 미니 배치 학습을 강조: 데이터셋이 매우 크거나 GPU 메모리 제약이 있는 경우, 미니 배치를 사용해 학습하는 것이 일반적입니다. 이러한 상황에서는 모델이 전체 데이터를 몇 번 반복하는지보다는 미니 배치를 얼마나 많이 처리했는지를 설명하는 것이 더 적절할 수 있습니다. 그래서 "step" 단위를 사용하는 것이 자연스럽습니다.
- Fine-tuning과 같이 특정 상황에서 자주 사용: 특히 큰 모델을 미세 조정(fine-tuning)하거나 일정한 단계에서 성능을 관찰할 때, "step" 단위로 학습 진행 상황을 평가하는 것이 더 의미 있는 경우가 많습니다. 왜냐하면 작은 데이터셋에 대해 fine-tuning을 진행하면 몇 epoch가 지나기 전에 충분히 학습이 완료될 수 있기 때문입니다. 이럴 때는 학습 단계를 세밀하게 기록하는 것이 중요하므로 "step"을 사용합니다.
- 컨버전스 모니터링: 학습이 점차 수렴(converge)하는 과정을 모니터링할 때, 모델이 매 몇 step마다 수렴 속도나 손실 감소를 기록하는 경우가 많습니다. 따라서 step 단위로 학습 과정을 보고하는 것이 더 직관적일 수 있습니다.
결론적으로, **"step"**을 사용한 이유는 미니 배치 기반 학습 방식에서 학습이 어떻게 진행되고 있는지 더 정확히 나타내기 위함이며, 더 세밀하게 학습 과정을 기록하고 모니터링하기 위한 목적이라고 볼 수 있습니다. 반면 **"epoch"**은 전체 데이터셋을 기준으로 한 반복 횟수를 나타내므로, 데이터의 크기나 배치 크기에 비례해 한 번 학습을 끝내는 단위로 사용할 때 유리합니다.
따라서, 실험 설계나 연구 목표에 따라 적절한 단위를 선택하는 것이죠. "step"을 사용할 때는 특히 세밀한 미니 배치 단위의 학습 상황을 다룬다는 점에서 더 적절했을 가능성이 큽니다.
-----
III-C. 학습 방법 비교
이 섹션에서는 III-A 섹션에서 설명한 EzAudio-DiT의 DiT-XL 설정을 사용하여, 더 큰 데이터셋을 활용한 다양한 사전 학습 전략을 비교합니다. 학습 과정은 세 단계로 나누어지며, 모든 단계에서 배치 크기는 128입니다. 1단계에서는 180만 개의 샘플을 사용하여 100K 학습 스텝 동안 학습하며, 학습률은 1e-4입니다. 2단계에서는 학습률 5e-5로 50K 스텝을 수행하며, 임계값이 0.35, 0.40, 0.45에 따라 각각 58만, 27만, 11만 개의 샘플을 사용합니다. 3단계에서는 학습률 1e-5로 30K 스텝을 완료하며, 4만 8천 개의 샘플을 사용합니다. 전체 학습 과정은 8개의 A100-40G GPU를 사용하여 5일이 소요됩니다.
표 I: 다양한 사전 학습 방법에 따른 평가 결과

표 I에서는 Tango [2]와 우리의 제안된 학습 전략을 비교합니다. Tango는 오디오 캡션 데이터셋 모음인 TangoPromptBank를 사전 학습에 사용하고, AudioCaps를 미세 조정에 사용합니다. TangoPromptBank의 경우, 배치 크기 128로 150K 스텝 동안 학습하고, 학습률 1e-4로 수행한 후 30K 미세 조정 스텝을 학습률 1e-5로 진행했습니다. 우리의 방법은 Tango에 비해 더 우수한 생성 품질과 강력한 텍스트-오디오 정렬을 달성했습니다. 또한, 합성 캡션을 필터링할 때의 다양한 임계값을 평가했습니다. 낮은 임계값은 더 다양하지만 노이즈가 많은 데이터를 허용해 모든 지표에 부정적인 영향을 미쳤고, 높은 임계값은 대부분의 지표를 개선했지만 FD와 데이터 다양성은 감소시켰습니다. 우리는 데이터 다양성과 모델 성능 간의 최적의 균형을 제공하는 0.40 임계값을 선택했습니다.
III-D. CFG와 CFG 리스케일링의 영향
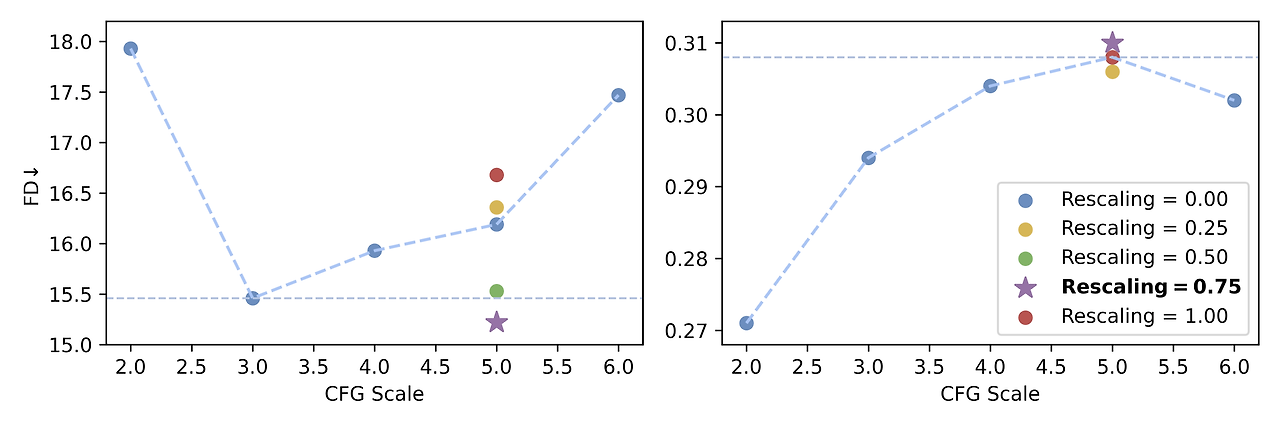
그림 3: 다양한 CFG 스케일 및 리스케일링 인자에 따른 FD 및 CLAP 점수.
그림 3에서 보듯이, 높은 CFG 값은 텍스트-오디오 정렬을 향상시키지만 FD를 증가시켜 오디오 품질이 감소함을 나타냅니다. CFG가 5일 때 가장 높은 CLAP 점수를 얻고 FD의 저하가 미미하므로, 우리는 이 수준에서 리스케일링을 적용합니다. 리스케일링 인자 0.50~0.75 범위를 사용하면 모델이 강력한 텍스트 정렬을 유지하면서도 오디오 품질에 대한 부정적인 영향을 완화할 수 있습니다.
III-E. 최신 기술과의 비교
우리는 III-A 섹션에서 설명한 제안된 전략으로 학습된 EzAudio-L과 EzAudio-XL을 최근 오픈 소스 T2A 모델과 비교했습니다. Tango-1&AF [2, 3], AudioLDM-1&2 [4, 5], 그리고 Make-An-Audio [6]는 모두 2D U-Net 기반의 확산 접근 방식을 사용하여 멜 스펙트로그램 오디오 표현을 사용합니다. AudioLDM과 Make-An-Audio는 텍스트 인코더로 CLAP을 사용하며, Tango-1과 Tango-AF는 FLAN-T5를 사용합니다. AudioLDM-2는 CLAP과 FLAN-T5 입력을 모두 처리할 수 있는 GPT-2 기반 인코더를 도입했습니다. Make-An-Audio-2 [10]는 멜 스펙트로그램 표현을 위해 1D-VAE를 사용하고, Transformer 아키텍처를 채택해 CLAP으로 원본 텍스트 프롬프트를 처리하고 GPT-3.5로 처리된 프롬프트에 대해 미세 조정된 FLAN-T5를 사용합니다. 공정한 비교를 위해 각 모델의 공개된 리포지터리에서 공식 체크포인트를 사용하여 AudioCaps 테스트 세트에서 평가를 수행했습니다(III-A 섹션 참고). 각 방법의 논문이나 리포지토리에서 권장하는 샘플링 스텝과 CFG 점수를 사용하였으며, Tango-1&AF와 AudioLDM-1&2에는 200 스텝을, Make-An-Audio-1&2에는 100 스텝을 적용했습니다. EzAudio의 경우, 100 스텝과 CFG 점수 5를 사용하며 리스케일링 인자는 0.75로 설정했습니다.
표 II: AudioCaps 데이터셋에서 EzAudio와 T2A 모델의 비교
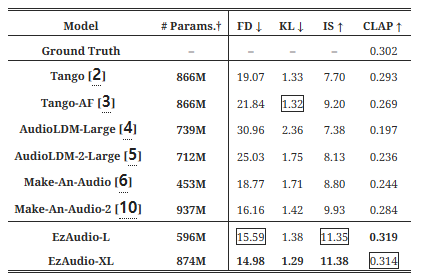
표 II에서 보듯이, AudioLDM-1&2는 다른 기준 모델들과 비교했을 때 전반적인 성능이 약한 것으로 나타났습니다. Make-An-Audio 2는 더 높은 FD와 IS 점수를 달성했지만, 텍스트-오디오 정렬에서는 약간 뒤처졌습니다. 이는 사운드 이벤트를 폭넓게 분류하는 데 언어 모델에 의존하기 때문일 가능성이 큽니다. Tango는 정렬 측면에서는 좋은 성능을 보였으나, 현실적인 오디오 생성에서는 부족함을 보였고, Tango-AF는 IS를 개선했으나 FD와 CLAP 점수에서는 열세를 보였습니다. 이에 반해, EzAudio-L과 EzAudio-XL은 품질과 텍스트-오디오 정렬 측면에서 기준 모델들보다 우수한 성능을 보였으며, EzAudio-XL이 대부분의 지표에서 EzAudio-L보다 약간 더 우수한 성능을 보여주었습니다.

그림 4: 평균 주관적 점수 및 95% 신뢰 구간.
우리는 30개의 무작위로 선택된 텍스트 프롬프트에 대해 5점 척도의 평균 의견 점수(MOS)를 사용하여 전반적인 오디오 품질(OVL)과 텍스트 프롬프트 관련성(REL)을 평가하는 주관적 실험을 수행했습니다. 음악 제작이나 오디오 엔지니어링 배경을 가진 12명의 참가자가 이 실험에 참여했습니다. EzAudio-XL을 Tango, AudioLDM-2, Make-An-Audio-2, 그리고 AudioCaps의 오디오 샘플과 비교했습니다. 그림 4에서 볼 수 있듯이, 결과는 객관적 결과와 일치하며, EzAudio-XL이 텍스트 정렬과 오디오 품질 측면에서 기준 모델들보다 우수한 성능을 보여주었습니다. Make-An-Audio 2는 Tango보다 높은 FD와 IS 점수를 보였으나, 합성 데이터를 사용한 탓에 간헐적으로 아티팩트를 생성하는 경우가 있었습니다. 특히, EzAudio-XL의 OVL 점수는 실제 녹음에 근접하여 현실적인 오디오를 생성하는 능력을 강조합니다.
IV. 결론
본 논문에서는 EzAudio라는 새로운, 배포와 사용이 쉬운 T2A 프레임워크를 소개했습니다. EzAudio는 효율적인 DiT 아키텍처와 합성 캡션 데이터를 활용한 간소화된 학습 파이프라인, 그리고 CFG 리스케일링 기법을 통해 정밀하고 고품질의 오디오 생성을 달성합니다. 제안된 프레임워크는 매우 현실적인 오디오를 생성하며 최신 성능을 달성합니다. 향후, 우리는 ControlNet과 DreamBooth의 통합을 계획하고 있으며, EzAudio의 음성 및 음악 생성 응용에 대해 더 탐구할 예정입니다.
'일상생활' 카테고리의 다른 글
| Gen-3 Alpha Video to Video (0) | 2024.11.23 |
|---|---|
| NotebookLM으로 만들어본 것 (0) | 2024.11.12 |
| 배틀퀸(BattleQueen) 다운로드 링크 공유 (1) | 2024.09.01 |
| The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (1) | 2024.08.15 |
| Luma-ai (0) | 2024.07.02 |
