Source: https://github.com/sh02092/unity-ml-agents-self-driving-car
GitHub - sh02092/unity-ml-agents-self-driving-car: final project in university
final project in university. Contribute to sh02092/unity-ml-agents-self-driving-car development by creating an account on GitHub.
github.com
Result: https://github.com/cs20131516/Unity-ml-agents-self-driving-car
1. 프로젝트 개요
프로젝트 목적 및 목표:
본 프로젝트의 목적은 Unity ML-Agents를 사용하여 PPO(Proximal Policy Optimization)를 이용한 자율 주행 자동차를 구현하는 것입니다. 이를 통해 인공지능 기반 자율 주행 시스템의 성능을 개선하고, PPO 알고리즘이 자동차 학습에 얼마나 효과적인지 평가하고자 합니다.
기존 DQN 기반 구현에서 PPO로 전환한 이유:
DQN(Deep Q-Network)은 Q-learning을 기반으로 한 딥러닝 알고리즘이지만, 학습이 비교적 느리고 안정성이 낮은 문제가 있습니다. 반면, PPO는 적응형 학습 속도와 안정적인 성능으로 더 높은 효율성을 제공합니다. 이러한 이유로 본 프로젝트에서는 PPO를 선택했습니다.
Unity ML-Agents 및 PPO의 간단한 소개:
Unity ML-Agents는 Unity를 기반으로 한 머신러닝 툴킷으로, 게임 및 시뮬레이션 환경에서 인공지능 에이전트를 개발하고 학습할 수 있게 해줍니다. PPO는 강화학습 알고리즘 중 하나로, 큰 스텝을 사용하여 업데이트 하는 것을 통해 안정적으로 학습할 수 있게 한 알고리즘입니다.
2. 기술적 세부사항
사용한 기술 스택: Unity, ML-Agents, Python
PPO 알고리즘의 간략한 원리 및 장점:
PPO는 강화학습 알고리즘 중 하나로, 이전 정책과 새 정책 사이의 변화를 제한함으로써 안정적인 학습을 제공합니다. 이는 큰 스텝을 사용하여 빠른 학습 속도와 안정성을 동시에 보장할 수 있습니다.
PPO YAML 파일 설정 설명:
본 프로젝트에서 사용한 YAML 파일은 PPO 알고리즘의 하이퍼파라미터와 네트워크 설정, 보상 신호 등을 정의합니다. 이를 통해 학습 과정 및 결과에 영향을 주는 다양한 요소를 조절할 수 있습니다.
3. 학습 과정
학습 데이터 및 환경에 대한 설명:
본 프로젝트에서는 Unity ML-Agents를 사용하여 자율 주행 자동차의 학습 환경을 구축했습니다. 에이전트는 가상 도로에서 다양한 교통 상황을 경험하며, 최적의 주행 전략을 학습하게 됩니다.
학습 과정에서의 주요 도전 과제 및 해결 방법:
학습 과정에서 발생한 주요 도전 과제 중 하나는 하이퍼파라미터 튜닝이었습니다. 최적의 하이퍼파라미터를 찾기 위해 여러 번의 실험을 진행하여 가장 높은 성능을 보이는 파라미터를 선택했습니다. 또한, 보상 함수를 설계하는 것도 중요한 과제였으며, 자동차가 도로를 따라 정확하게 주행하도록 적절한 보상을 설정했습니다.
학습 과정 동안의 성능 개선 및 최적화 전략:
성능 개선 및 최적화를 위해 다양한 전략을 적용했습니다. 이에는 하이퍼파라미터 튜닝, 네트워크 구조 변경, 보상 함수 개선 등이 포함됩니다. 이러한 전략들을 통해 에이전트의 학습 속도를 높이고, 자율 주행 성능을 개선할 수 있었습니다.
4. 결과 및 성능
학습 완료된 동영상 제공:
학습이 완료된 후, 자율 주행 자동차가 실제로 잘 작동하는 것을 시각적으로 보여주는 동영상을 제공합니다. 이 동영상에서는 에이전트가 다양한 상황에서 안전하고 효율적으로 주행하는 모습을 확인할 수 있습니다.
학습 과정 동안의 성능 지표 변화:
학습 과정 동안 성능 지표(예: 보상, 에피소드 길이 등)를 그래프 또는 표로 표시하여 에이전트의 학습 진행 상황을 시각적으로 보여줍니다.

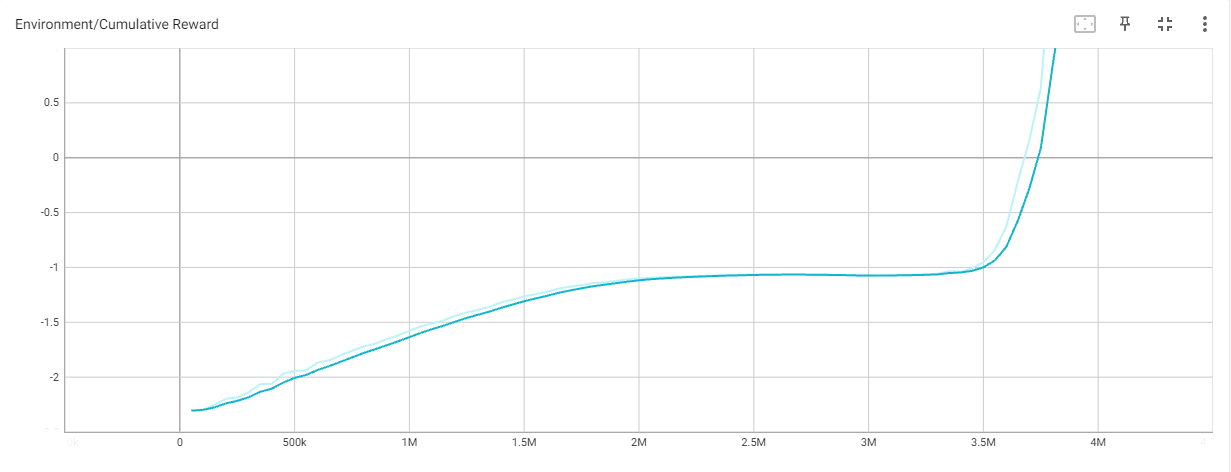


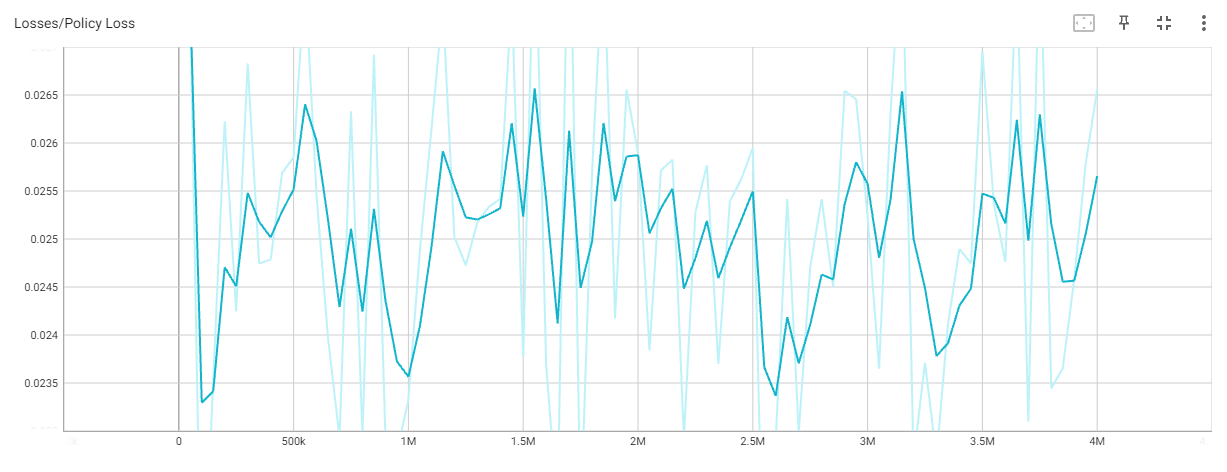

5. 프로젝트의 한계 및 향후 계획
프로젝트의 한계점 및 개선 가능한 부분:
본 프로젝트에서는 기본적인 자율 주행 자동차 구현에 중점을 두었지만, 현실 세계의 복잡한 교통 상황에 대응하기에는 부족한 부분이 있습니다. 예를 들어, 다양한 날씨 조건, 도로 표지판 인식, 차량 간 통신 등에 대한 고려가 필요합니다.
향후 계획 및 확장 가능성:
향후 프로젝트를 확장하기 위해 다음과 같은 계획을 세울 수 있습니다.
- 더 다양한 도로 및 교통 상황을 반영하는 학습 환경 구축
- 날씨 변화, 도로 표지판, 신호등 등의 요소를 포함하여 보다 현실적인 시뮬레이션 개발
- 차량 간 통신을 통한 협동 주행 기능 추가
- 다양한 강화학습 알고리즘과의 성능 비교를 통한 최적의 알고리즘 선택
해당 프로젝트를 통해 얻은 인사이트 및 경험:
본 프로젝트를 통해 강화학습 알고리즘 중 PPO의 효과성을 확인할 수 있었습니다. 또한, Unity ML-Agents를 사용하여 머신러닝 기반의 자율 주행 시스템을 구축하는 방법을 경험하였습니다. 이를 통해 현실 세계의 다양한 문제에 대한 인공지능 솔루션을 개발하는 데 기여할 수 있습니다.
'프로젝트' 카테고리의 다른 글
| 유니티 ML-Agents를 이용한 drl-crawler 개선 (0) | 2023.03.22 |
|---|---|
| 유니티 ML-Agents를 이용한 AutoParkSimulation (0) | 2023.03.22 |
| 유니티 ML-Agents를 이용한 드론 제어 강화학습 (0) | 2023.03.16 |
| 유튜브 동영상 다운로드 및 srt 파일 생성 (0) | 2023.03.15 |
| 유튜브 다운로드 및 자막 생성 (0) | 2023.03.07 |