https://github.com/OSUPCVLab/SegFormer3D/tree/653faa6b44c67cebd27a02de5fe08ee4072dd230
GitHub - OSUPCVLab/SegFormer3D: Official Implementation of SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentati
Official Implementation of SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation (CVPRW 2024) - OSUPCVLab/SegFormer3D
github.com
https://arxiv.org/abs/2404.10156
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While
arxiv.org
초록(Abstract)
Vision Transformer(ViT) 기반 아키텍처의 도입은 3D 의료 영상(MI) 분할 분야에서 전통적인 컨볼루션 신경망(CNN) 모델을 뛰어넘어 전역적 맥락 이해를 강화함으로써 큰 진전을 이뤄냈습니다. 그러나 이러한 패러다임 전환으로 3D 분할 성능이 크게 향상되었음에도, 최첨단(State-of-the-Art, SOTA) 아키텍처들은 훈련과 배포 과정에서 대규모 컴퓨팅 자원을 요구하는 매우 크고 복잡한 구조를 필요로 합니다. 더욱이 의료 영상 분야에서 자주 직면하는 제한된 데이터셋 환경에서는, 모델 규모가 클수록 일반화와 학습 수렴에 장애가 될 수 있습니다. 이러한 과제를 해결하고, 동시에 경량 모델의 연구 가치가 3D 의료 영상 분야에서 중요함을 보여주고자, 우리는 다중 스케일 볼륨 특징에 대해 어텐션을 계산하는 계층적 트랜스포머인 SegFormer3D를 제안합니다. 또한 SegFormer3D는 복잡한 디코더를 지양하고 전부 MLP 기반(all-MLP) 디코더를 사용하여 지역(local) 및 전역(global) 어텐션 특징을 효과적으로 결합함으로써 매우 정확한 분할 마스크를 생성합니다. 제안된 메모리 효율적인 트랜스포머는 훨씬 큰 모델이 가진 성능적 특성을 컴팩트한 설계로 유지합니다. SegFormer3D는 현재 SOTA 모델 대비 33배 적은 파라미터 수와 13배 낮은 GFLOPS로 3D 의료 영상 분할에서 딥러닝의 민주화를 실현합니다. 우리는 SegFormer3D를 세 가지 널리 사용되는 데이터셋(Synapse, BRaTs, ACDC)에서 현재 SOTA 모델들과 비교하여 벤치마크를 수행하였으며, 경쟁력 있는 결과를 달성했습니다.
코드: https://github.com/OSUPCVLab/SegFormer3D.git
GitHub - OSUPCVLab/SegFormer3D: Official Implementation of SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentati
Official Implementation of SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation (CVPRW 2024) - OSUPCVLab/SegFormer3D
github.com

그림 1: BraTs 데이터셋에서의 파라미터 수 대비 성능
위 그림은 SegFormer3D와 기존 3D 볼륨 영상 분할 아키텍처를 비교하여, 파라미터 수에 대한 모델 성능을 평가한 것입니다. 초록색 막대는 모델의 파라미터 수를 나타내고, 보라색 곡선은 각 아키텍처의 평균 다이스 계수를 나타냅니다. 우리는 약 450만 개(4.5M) 파라미터로 구성된 SegFormer3D가 3D 의료 영상 분할 분야에서 매우 경쟁력 있는 경량 아키텍처임을 입증합니다.
1 서론(Introduction)
의료 분야에서의 딥러닝 도입은 매우 큰 변혁을 가져왔으며, 복잡한 의료 데이터를 학습하고 분석할 수 있는 전례 없는 능력을 제공합니다. 3D 볼륨 영상 분할은 의료 영상 분석에서 핵심적인 과제로, 진단 및 치료 시 종양이나 다기관(多器官)의 위치를 파악하기 위해 매우 중요합니다. 일반적으로는 인코더-디코더 구조[23, 18]를 사용하여, 먼저 영상을 저차원 표현으로 변환한 뒤 해당 표현을 복셀별(segmentation mask)로 매핑해 분할을 수행합니다. 그러나 이러한 구조는 제한된 수용영역(receptive field)으로 인해 정확한 분할 마스크를 생성하기가 쉽지 않습니다. 최근에는 비전 트랜스포머(ViT)의 전역 관계를 포착하는 능력을 활용한 트랜스포머 기반 기법[11, 32]이 우수한 분할 성능을 보이며 각광받고 있습니다. 이는 지역 유도 편향(local inductive bias)을 가진 CNN과는 확연히 대비되는 부분입니다.


TransUnet[5]와 UNETR[11]의 선구적인 작업 이후, 의료 영상 분야에서는 ViT의 강력한 인코딩 능력과 CNN의 피처(feture) 정제 능력을 디코딩 단계에 결합하려는 다양한 트랜스포머 기반 아키텍처 연구가 활발히 이뤄졌습니다. 예를 들어 [10, 11, 32]는 합성곱의 국소화된 수용영역과 전역 어텐션을 융합했습니다. 하지만 ViT는 작은 규모의 데이터셋에서 학습할 경우 CNN이 가진 일반화 능력을 따라가기 어렵고, 종종 대규모 데이터셋에서 사전 학습(pretraining)을 요구하는데[7], 이는 의료 영상 분야에서 흔하지 않습니다. 또한 ViT의 계산 효율성은 멀티 헤드 자기 어텐션 블록에서 발생하는 부동소수점 연산량과 원소별(element-wise) 연산에 의해 제약을 받습니다[17]. 특히 3D 의료 영상의 경우, 3D 볼륨 입력을 시퀀스 형태로 변환했을 때 길이가 매우 길어져 이러한 문제가 더욱 두드러집니다. 게다가 의료 영상 데이터는 반복적인 구조가 많은 특성을 보이는데[6], 이는 3D 의료영상 SOTA ViT 아키텍처에서 종종 간과되는 부분입니다.
본 논문에서는 SegFormer3D라는 볼륨 기반 계층적 ViT를 제안합니다. 이는 2D 기반 SegFormer[27]를 3D 의료 영상 분할 작업에 확장한 것입니다. Vanilla ViT[7]가 고정 스케일로만 피처 맵을 생성하는 것과 달리, Segformer3D는 Pyramid Vision Transformer[26] 기반 설계를 적용하여 입력 볼륨을 여러 스케일로 인코딩합니다. 이를 통해 트랜스포머가 입력의 여러 해상도 스케일에서 거친(coarse) 정보부터 세밀한(fine-grained) 정보까지 효과적으로 포착할 수 있도록 합니다. 또한 SegFormer3D는 효율적인 자기 어텐션 모듈[26]을 활용하여, 내장된(embedded) 시퀀스를 일정 비율로 압축함으로써 모델 복잡도를 크게 낮추면서도 성능은 저하되지 않도록 했습니다(그림 1 참조). 게다가 중첩(overlapping) 패치 임베딩 모듈[27]을 활용해 입력 복셀의 국소적 연속성(local continuity)을 보존합니다. 이 임베딩에서는 위치 정보가 없는(positional-free) 인코딩 방식[14]을 적용하여, 의료 영상 분할에서 흔히 발생하는 학습 및 추론 시 해상도가 불일치할 때 생기는 정확도 손실을 방지합니다. 마지막으로 고품질의 분할 마스크 생성을 위해, SegFormer3D는 [27]에서 도입된 All-MLP 디코더를 사용합니다. 우리는 세 가지 벤치마크 데이터셋(Synapse[15], ACDC[1], BRaTs[20])에서 정량적/정성적 평가를 통해 SegFormer3D의 효과를 입증했습니다. 본 논문의 기여 사항은 다음과 같이 요약할 수 있습니다.
- 경량의 메모리 효율적 분할 모델을 제안하여, 3D 의료 영상 분야에서 기존 대규모 모델이 가진 성능적 특성을 유지합니다.
- 파라미터 수 450만 개와 17 GFLOPS로, SegFormer3D는 SOTA 대비 각각 34배, 13배 감소된 파라미터와 모델 복잡도를 달성합니다.
- 사전 학습 없이도 매우 경쟁력 있는 결과를 보이며, 경량 비전 트랜스포머(ViT)의 일반화 능력과 의료 영상에서 SegFormer3D 같은 아키텍처를 탐색하는 것이 가치 있는 연구 분야임을 보여줍니다.
2 관련 연구(Related Work)
Unet[23]이 도입된 이후, Dense-Unet[2], Deep-supervised CNN[33] 등 다양한 의료 영상 분석 기법이 제안되었습니다. Unet은 3D 의료 영상 분석 분야로도 확장되어, 예를 들어 3D-Unet[6], V-net[21], nn-Unet[13], 그리고 [9, 8, 24] 등과 같은 모델이 발표되었습니다. 연구자들은 문맥 정보를 포착하기 위해 계층적 아키텍처도 고안했습니다. 예를 들어 [21]에서는 Milletari 등 이 V-net을 이용하여 유용한 영상 특징을 보존하기 위해 볼륨을 낮은 해상도로 다운샘플링하는 방식을 제안했습니다. Cicek 등[6]은 3D-Unet에서 2D 합성곱을 3D 합성곱으로 대체하였고, Isensee 등[13]은 다중 스케일에서 특징을 추출할 수 있는 범용적인 분할 아키텍처 nn-Unet을 제안했습니다. 또한 [16]에서 PGD-UNet은 변형 가능한(deformable) 합성곱을 사용해 불규칙한 장기 형태나 종양을 처리하는 방법을 선보였습니다.
최근에는 TransUnet[5], Unetr[11], SwinUnetr[10], TransFuse[30], nnFormer[32], LoGoNet[22] 등 트랜스포머와 합성곱을 결합한 아키텍처에 대한 연구가 활발합니다. TransUnet[5]는 트랜스포머와 U-Net을 결합해 이미지 패치를 인코딩하고, 고해상도 업샘플된 CNN 특징을 활용해 객체의 위치를 파악합니다. Hatamizadeh 등[11]이 제안한 UNETR은 3D 모델로서, 트랜스포머가 가진 장거리 공간 종속성(long-range spatial dependencies)과 CNN의 내재적 유도 편향(inductive bias)을 ‘U-형’ 인코더-디코더 구조에서 결합합니다. UNETR에서는 트랜스포머 블록이 일관된 전역 표현(global representation)을 인코딩하고, 이를 CNN 기반 디코더의 여러 해상도 단계에 걸쳐 통합합니다. LoGoNet[22]은 Large Kernel Attention(LKA)와 이중 인코딩 전략(dual encoding strategy)을 활용해 3D 의료 영상 분할에서 장거리 및 단거리 특징 의존성을 포착합니다. Zhou 등[32]이 제안한 nnFormer는 Swin-UNet[3] 아키텍처에서 파생된 기법입니다. Wang 등[25]은 TransBTS를 제안했는데, 이는 일반적인 합성곱 기반 인코더-디코더 구조에 트랜스포머 레이어를 병목(bottleneck)으로 추가한 방식입니다. 그러나 이들 모델은 높은 모델 복잡도와 계산 복잡도라는 단점을 안고 있습니다.

(a) 그림 2: BRaTs에 대한 정성적(qualitative) 결과
각 행은 MRI 시퀀스의 서로 다른 프레임이며, 각 열은 3D 볼륨 영상 분할 결과를 나타냅니다. SegFormer3D는 경량성과 효율성을 유지하면서도, 최신 기법(SOTA)과 견줄 만한 높은 정확도의 분할 성능을 정성적으로 보여줍니다.

(b) 표 2: BRaTs 비교 표
모든 클래스에 대한 평균 성능을 기준으로 순위를 매긴 결과입니다. SegFormer3D는 여러 부문에서 이미 널리 알려진 솔루션들을 뛰어넘는 매우 경쟁력 있는 성능을 보입니다.
3 방법(Method)
트랜스포머(Transformer)의 도입으로 볼륨 의료 영상 분할(3D medical image segmentation)의 성능이 크게 향상되었습니다. 하지만 현재 높은 성능을 보이는 모델들은 모델 성능을 높이기 위해 파라미터 수를 과도하게 증가시키는 경향이 있어, 효율성이 저하됩니다. 이에 우리는 성능을 희생하지 않으면서도 경량성과 효율성을 지닌 트랜스포머의 이점을 입증하기 위해 Segformer3D를 소개합니다. Segformer3D는 450만(4.5M) 파라미터와 17 GFLOPS로 기존 대비 파라미터 수는 34배, 복잡도는 13배 감소하였으며, 이는 3D 의료 영상 분할 분야에서 제안된 아키텍처의 중요성을 보여줍니다 1.

표 1: Segformer3D와 SOTA 모델의 크기(단위: M) 및 복잡도 비교.
Segformer3D는 성능 손실 없이도 파라미터 수와 계산 복잡도를 크게 줄인 모습을 보입니다.
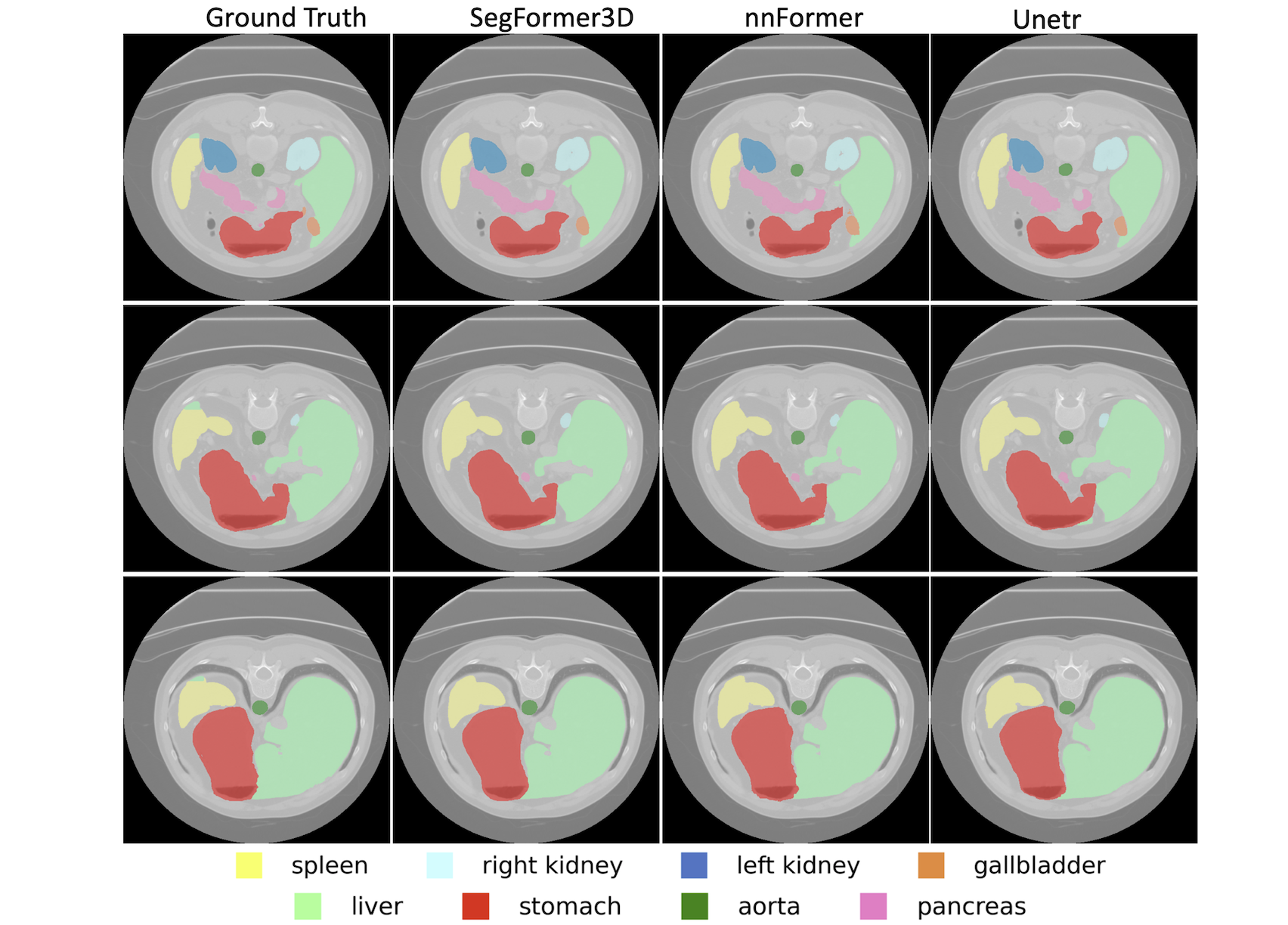
(a) 그림 3: Synapse 데이터셋에 대한 정성적 결과
각 행은 CT 시퀀스의 다른 프레임이며, 각 열은 서로 다른 3D 볼륨 영상 분할 결과를 나타냅니다. 각 장기 마스크는 고유한 색상으로 표시되었습니다. Segformer3D는 경량 설계를 유지하면서도, 기존에 잘 확립된 SOTA 기법들과 비교했을 때 매우 높은 정확도의 분할 성능을 정성적으로 보여줍니다.
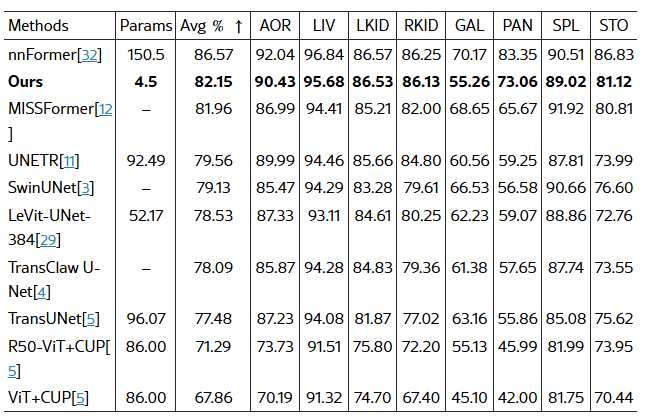
(b) 표 3: Synapse 비교 표
클래스별 평균 성능을 기준으로 순위를 매긴 결과입니다. Segformer3D는 매개변수 수가 34배나 많은 nnFormer보다 근소한 차이로 뒤를 이을 정도로 경쟁력을 갖추어, 이미 널리 알려진 여러 솔루션보다 우수한 성능을 보입니다.




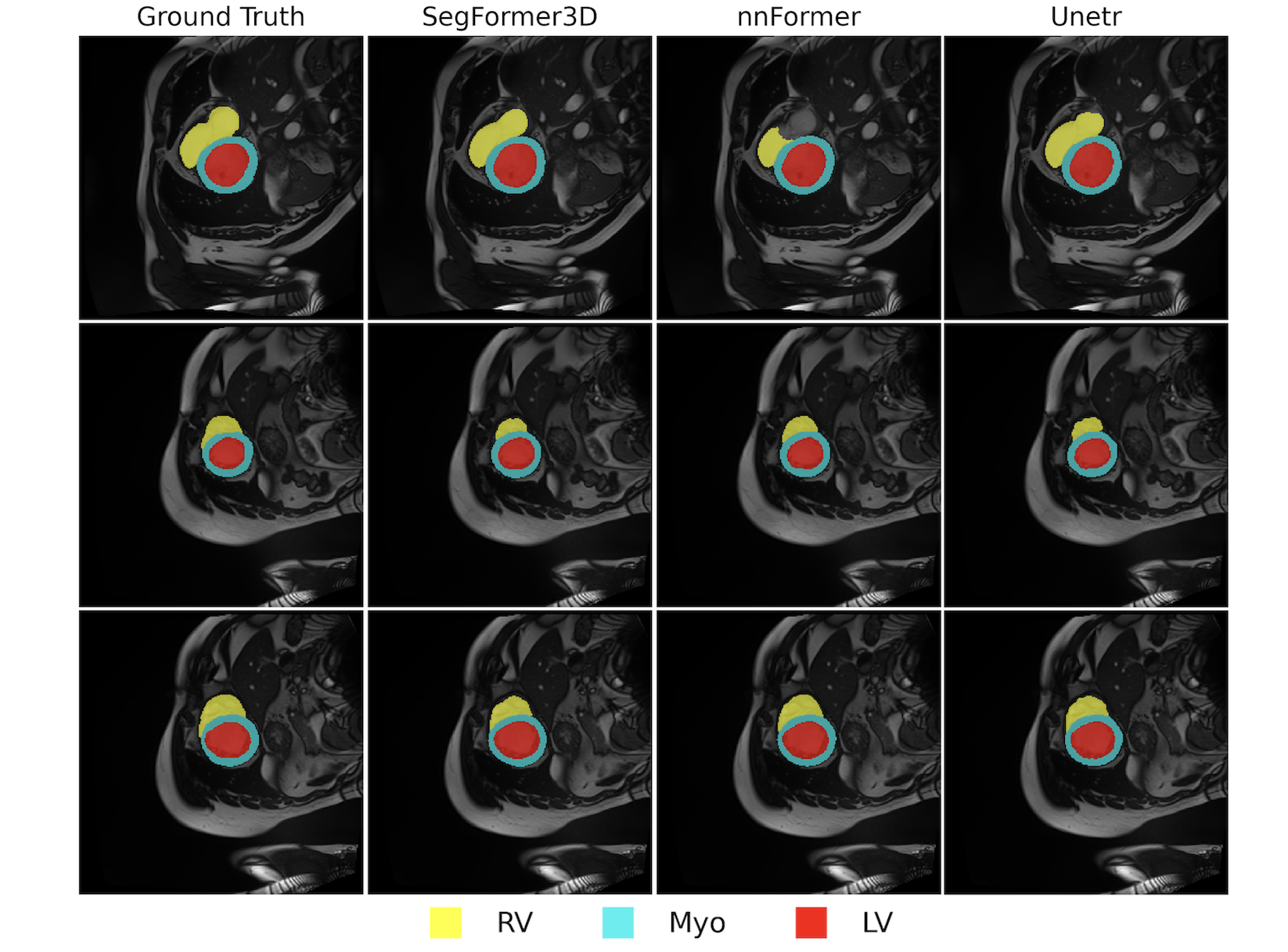
(a) 그림 4: ACDC 데이터셋에 대한 정성적 결과
각 행은 시네 MRI(cine-MRI) 시퀀스의 서로 다른 프레임이며, 각 열은 다양한 3D 볼륨 영상 분할 결과를 나타냅니다. SegFormer3D는 경량성과 효율성을 유지하면서도, 최신 기법(SOTA)과 견줄 만한 높은 정확도의 분할 성능을 보여줍니다.

(b) 표 4: ACDC 비교 표
클래스별 평균 성능 기준 순위를 매긴 결과입니다. SegFormer3D는 이미 널리 알려진 여러 솔루션보다 우수하며, 1억 5천만(150M) 파라미터가 넘는 SOTA 모델에 비해 불과 1% 이내의 성능 차이를 보일 정도로 경쟁력이 높습니다.
4 실험 결과(Experimental Results)
최신 3D 볼륨 분할 아키텍처의 표준을 따르기 위해, 본 연구에서는 동일한 데이터셋과 평가 방식을 사용하여 모든 아키텍처를 공정하고 일관되게 비교했습니다. 우리는 사전 학습(pretraining)에 외부 데이터를 사용하지 않고, 널리 쓰이는 세 가지 데이터셋(Brain Tumor Segmentation (BraTS) [20], Synapse Multi-Organ Segmentation (Synapse) [15], Automatic Cardiac Diagnosis (ACDC) [1])에서 제안 모델을 학습하고 평가했습니다.
학습, 실시간(online) 증강, 추론은 모두 PyTorch 환경에서 단일 Nvidia RTX 3090 GPU를 사용해 수행했습니다. 모든 모델은 동일한 학습률 정책을 적용했으며, 여기에는 선형적으로 학습률을 4×10^−6에서 4×10^−4까지 증가시키는 워밍업(warm-up) 단계와, 이후 PolyLR 감쇠(learning rate decay) 전략이 포함됩니다. 최적화에는 AdamW[19] 옵티마이저를 학습률 3×10^−5로 사용했습니다. 손실 함수로는 동일한 가중을 갖는 Dice와 Cross Entropy를 결합해, 각 손실 함수의 장점을 결합하고 학습 수렴성을 향상했습니다. 배치 크기는 4로 설정했고, SOTA 모델과 동일하게 1000 에폭(epoch) 동안 모델을 학습했습니다. 추가 데이터 없이도 실제 의료 영상 데이터셋에서 제안 아키텍처의 성능을 확인하고자 사전 학습 없이 모든 실험을 진행했습니다.
4.1 Brain Tumor Segmentation (BraTs) 결과
BraTs[20]는 MRI 영상을 활용한 의료 영상 분할 데이터셋입니다. 이 데이터셋은 총 484개의 MRI 영상을 포함하고, FLAIR, T1w, T1gd, T2w 네 가지 모달리티로 구성됩니다. 데이터는 19개 기관에서 수집되었으며, 부종(ED), 증강 종양(ET), 비증강 종양(NET) 등 세 가지 종류의 종양 하위 영역(lesion subregions)에 대한 라벨이 제공됩니다. nnFormer[32] 등 주요 문헌과 동일하게 데이터 전처리, 증강, 결과 보고 방식을 따랐으며, Whole Tumor (WT), Enhancing Tumor (ET), Tumor Core (TC) 항목에 대한 결과를 보고합니다. 표 3(a)에서 확인할 수 있듯이, Segformer3D는 CNN 및 트랜스포머 기반의 기존 대형 아키텍처에 비해 4.5백만(4.5M) 파라미터와 17.5 GFLOP라는 경량 구조로도 매우 경쟁력 있는 세그멘테이션 성능을 보입니다. 이는 모든 패치를 압축 없이 처리하는 전통적인 ViT와 달리, 효율적 자기 어텐션 모듈을 활용해 표현 학습 능력을 높였기 때문입니다. 마지막으로 그림 3(a)는 제안한 아키텍처가 이미 확립된 모델 대비 뛰어난 정성적(segmentation mask) 결과를 제공함을 시각적으로 보여줍니다.
4.2 Multi-Organ CT Segmentation (Synapse) 결과
Synapse 데이터셋[15]은 총 30개의 CT 영상을 포함하며, [32]에서 정의된 데이터 처리 및 학습, 데이터 분할 방식을 따라 결과를 생성했습니다. 비장(spleen), 췌장(pancreas), 담낭(gallbladder) 등 여러 장기의 주석이 포함되어 다기관(多器官) 분할이 필요한 복잡한 멀티 클래스 세그멘테이션 문제입니다. 표 4(a)에 제시된 정량적 결과에서 Segformer3D는 1억 5천만(150M) 파라미터를 가진 nnFormer[32] 다음으로 2위를 차지했습니다. 또한 그림 4(a)는 현재 SOTA 아키텍처들과 비교했을 때, 매우 정확한 장기 분할 마스크를 시각적으로 확인할 수 있습니다. 마지막으로, [11, 12, 10] 등 널리 사용되는 아키텍처 대비 Segformer3D는 불과 4.5M 파라미터만으로도 경쟁력 있는 결과를 달성하며, 특히 데이터가 제한된 환경에서 과도한 파라미터 증가가 꼭 큰 성능 향상으로 이어지지 않는다는 점을 시사합니다.
4.3 Automated Cardiac Diagnosis (ACDC) 결과
ACDC[1]는 100명의 환자 데이터를 기반으로, 좌심실(LV), 우심실(RV), 심근(Myo)을 3D 볼륨으로 분할하기 위한 데이터셋입니다[1]. [32]와 동일한 학습 및 추론 파이프라인을 적용했으며, Dice 계수를 이용해 분할 정확도를 측정했습니다. 표 5(a)에 나타난 결과를 보면, Segformer3D는 매우 크고 복잡한 모델들과 견주어도 매우 경쟁력 있는 성능을 보입니다. 제안 모델은 평균적으로 파라미터 수가 34배, 계산 복잡도가 13배 높은 모델들과 1% 이내 성능 차이를 보일 정도입니다. 그림 5(a)에서는 정성적인(segmentation mask) 비교 결과를 제시하며, 추가 대규모 사전 학습 없이도 높은 성능을 달성함을 확인할 수 있습니다.
4.4 결론(Conclusion)
UNETR, TransUNet, nnFormer와 같은 아키텍처는 ViT 프레임워크를 적용해 3D 볼륨 의료 영상 분할에 혁신을 가져왔습니다. 이로 인해 전통적인 CNN 기반 모델에 비해 맥락(Context) 이해 능력이 현저히 향상되었지만, 자기 어텐션 모듈의 복잡성으로 인해 파라미터 수와 모델 복잡도가 크게 증가했습니다. 이러한 대형 모델은 대규모 연산 자원에 대한 접근이 제한된 의료 연구자들에게는 활용이 어려울뿐더러, 제한된 데이터셋 환경에서는 모델 일반화와 학습 수렴에도 부정적인 영향을 줄 수 있습니다.
본 논문에서는 이러한 문제들을 해결하면서도 성능을 희생하지 않기 위해, SOTA 아키텍처 대비 파라미터 수가 34배, 계산 복잡도가 13배 작은 경량 모델인 Segformer3D를 제안했습니다. 우리는 최신 SOTA 모델 및 다른 널리 인용되는 연구들과의 비교를 통해, 추가 사전 학습이나 대규모 컴퓨팅 자원 없이도 경량 · 효율적 아키텍처가 대형 모델에 필적하는 우수한 성능을 발휘할 수 있음을 입증했습니다. 마지막으로, 특히 의료 영상처럼 실질적인 이점이 있는 분야에서 고성능 경량 아키텍처 연구에 주력하는 것은 접근성을 높이고 실제 활용성을 증진한다는 점에서 중요한 의미를 지닌다고 강조합니다.
'인공지능' 카테고리의 다른 글
| Instance Normalization: The Missing Ingredient for Fast Stylization (3) | 2025.01.30 |
|---|---|
| Group Normalization (2) | 2025.01.24 |
| AutoVFX: Physically Realistic Video Editing from Natural Language Instructions (2) | 2025.01.20 |
| NeRFactor: neural factorization of shape and reflectance under an unknown illumination (2) | 2025.01.17 |
| Titans: Learning to Memorize at Test Time (3) | 2025.01.16 |



