https://poloclub.github.io/transformer-explainer/
Transformer Explainer: LLM Transformer Model Visually Explained
An interactive visualization tool showing you how transformer models work in large language models (LLM) like GPT.
poloclub.github.io
Transformer란 무엇인가?
Transformer는 인공지능(AI) 접근 방식을 근본적으로 바꾼 신경망 아키텍처다. Transformer는 2017년 발표된 획기적인 논문 "Attention is All You Need" 에서 처음 소개되었으며, 이후 OpenAI의 GPT, Meta의 LLaMA, Google의 Gemini와 같은 텍스트 생성 모델의 핵심 구조로 자리 잡았다. 현재는 텍스트뿐 아니라 오디오 생성, 이미지 인식, 단백질 구조 예측, 게임 플레이 등 다양한 분야에서 활용되며 그 범용성을 입증하고 있다.
본질적으로, 텍스트 생성형 Transformer 모델은 다음 단어 예측(next-word prediction) 원리에 기반해 작동한다. 즉, 사용자가 입력한 텍스트 프롬프트가 주어졌을 때, 그 뒤에 올 가능성이 가장 높은 단어를 예측하는 방식이다. Transformer의 핵심 혁신은 자기 주의(Self-Attention) 메커니즘에 있으며, 이를 통해 전체 시퀀스를 한 번에 처리하고, 이전 아키텍처보다 장기 의존성(long-range dependency)을 훨씬 효과적으로 포착할 수 있다.
GPT-2 계열 모델은 대표적인 텍스트 생성형 Transformer의 예시다. 예를 들어, Transformer Explainer는 1억 2천4백만 개의 파라미터를 가진 GPT-2(small) 모델로 구동된다. 이 모델은 최신이거나 가장 강력한 Transformer는 아니지만, 현재 최첨단 모델들이 사용하는 아키텍처 구성 요소와 원리를 대부분 공유하고 있어 Transformer의 기초를 이해하기 위한 좋은 출발점이 된다.
Transformer 아키텍처
텍스트 생성형 Transformer는 다음 세 가지 핵심 구성 요소로 이루어진다.
- 임베딩(Embedding)
텍스트 입력은 토큰(token) 이라 불리는 더 작은 단위로 나뉘는데, 이는 단어 또는 하위 단어(subword)일 수 있다. 각 토큰은 임베딩(embedding) 이라 불리는 수치 벡터로 변환되며, 이 벡터는 단어의 의미적 정보를 담는다. - Transformer 블록(Transformer Block)
모델의 입력 데이터를 처리하고 변환하는 기본 단위이다. 각 블록은 다음과 같은 구성 요소를 포함한다.- 어텐션 메커니즘(Attention Mechanism): Transformer 블록의 핵심 요소로, 토큰들이 서로 정보를 주고받아 문맥 정보와 단어 간 관계를 포착할 수 있도록 한다.
- MLP(다층 퍼셉트론, Multilayer Perceptron) 레이어: 각 토큰을 독립적으로 처리하는 전방향 신경망(feed-forward network)이다. 어텐션 레이어가 토큰 간 정보를 전달하는 역할이라면, MLP는 각 토큰의 표현을 더욱 정교하게 다듬는 역할을 한다.
- 출력 확률(Output Probabilities)
마지막의 선형 변환(Linear)과 소프트맥스(Softmax) 레이어는 처리된 임베딩을 확률로 변환하여, 시퀀스에서 다음에 올 토큰을 예측할 수 있도록 한다.
임베딩(Embedding)
예를 들어, Transformer 모델을 사용해 텍스트를 생성하려고 한다고 해보자. 다음과 같이 프롬프트를 입력한다고 하자.
“Data visualization empowers users to”
이 입력은 모델이 이해하고 처리할 수 있는 형식으로 변환되어야 한다. 바로 이때 임베딩(embedding) 이 필요하다. 임베딩은 텍스트를 모델이 다룰 수 있는 수치 표현으로 변환한다. 프롬프트를 임베딩으로 변환하려면 다음 네 단계를 거친다.
- 입력 토큰화(Tokenization)
- 토큰 임베딩(Token Embedding)
- 위치 정보(Positional Encoding) 추가
- 토큰 임베딩과 위치 인코딩을 합산하여 최종 임베딩 생성
아래는 각 단계의 구체적인 과정이다.

그림 1. 임베딩 레이어 확장 뷰 — 입력 프롬프트가 벡터 표현으로 변환되는 과정. (1) 토큰화, (2) 토큰 임베딩, (3) 위치 인코딩, (4) 최종 임베딩 단계로 구성됨.
1단계: 토큰화(Tokenization)
토큰화는 입력 텍스트를 토큰(token) 이라 불리는 더 작은 단위로 나누는 과정이다. 토큰은 단어일 수도 있고, 하위 단어(subword)일 수도 있다. 예를 들어, "Data"와 "visualization"은 각각 고유한 토큰이지만, "empowers"는 두 개의 토큰으로 분리될 수 있다.
모델을 학습하기 전에 전체 토큰 어휘(vocabulary)가 미리 정의되는데, 예를 들어 GPT-2의 어휘 크기는 50,257개의 고유 토큰으로 구성된다. 입력 텍스트를 고유 ID를 가진 토큰으로 분리하면, 해당 토큰의 벡터 표현을 임베딩에서 불러올 수 있다.
2단계: 토큰 임베딩(Token Embedding)
GPT-2(small) 모델에서는 각 토큰이 768차원 벡터로 표현된다. 이 벡터 차원 수는 모델 크기에 따라 달라진다. 모든 토큰의 임베딩은 크기가 (50,257 × 768)인 행렬에 저장되며, 이는 약 3,900만 개의 파라미터를 포함한다. 이 방대한 임베딩 행렬 덕분에 모델은 각 토큰에 의미적 정보를 부여할 수 있다.
3단계: 위치 인코딩(Positional Encoding)
임베딩 레이어는 각 토큰이 입력 프롬프트 내에서 어떤 위치에 있는지도 함께 인코딩한다. 위치 인코딩 방식은 모델마다 다르다. GPT-2는 위치 인코딩 행렬을 처음부터 학습하며, 이를 훈련 과정에 직접 통합한다.
4단계: 최종 임베딩(Final Embedding)
마지막으로, 토큰 임베딩과 위치 인코딩을 더해 최종 임베딩 표현을 만든다. 이 결합된 표현은 토큰의 의미 정보뿐 아니라, 입력 시퀀스 내에서의 위치 정보까지 함께 담고 있다.
Transformer 블록(Transformer Block)
Transformer의 핵심 처리 단위는 Transformer 블록이며, 이 블록은 멀티헤드 자기 주의(Multi-Head Self-Attention) 와 다층 퍼셉트론(MLP, Multi-Layer Perceptron) 으로 구성된다. 대부분의 Transformer 모델은 이러한 블록을 여러 개 쌓아 순차적으로 배치하며, 각 블록을 거칠수록 토큰 표현이 점점 진화하여 입력 토큰에 대한 정교한 이해를 쌓게 된다. 이러한 계층적 접근을 통해 모델은 입력에 대한 고차원 표현을 형성한다. 예를 들어, 우리가 살펴보고 있는 GPT-2(small) 모델은 이러한 블록을 총 12개 포함한다.
1. 멀티헤드 자기 주의(Multi-Head Self-Attention)
자기 주의(Self-Attention) 메커니즘은 모델이 입력 시퀀스에서 중요한 부분에 집중할 수 있도록 하여, 데이터 내 복잡한 관계와 의존성을 포착한다. 자기 주의 계산은 다음과 같은 단계로 진행된다.
단계 1: Query, Key, Value 행렬 생성

각 토큰의 임베딩 벡터는 Query(Q), Key(K), Value(V)라는 세 벡터로 변환된다. 이는 입력 임베딩 행렬에 Q, K, V에 해당하는 학습 가능한 가중치 행렬을 곱해 얻는다.
웹 검색에 비유하면:
- Query(Q): 검색창에 입력한 검색어 — 모델이 더 많은 정보를 찾고 싶은 토큰
- Key(K): 검색 결과의 각 웹 페이지 제목 — Query가 어떤 토큰에 주의를 기울일지 결정하는 단서
- Value(V): 웹 페이지의 실제 내용 — Query와 Key가 매칭되면, 해당 Key에 대응하는 Value가 핵심 정보
이 Q, K, V를 이용해 어텐션 스코어(Attention Score) 를 계산하고, 이를 통해 예측 시 각 토큰이 얼마나 주목받아야 할지 결정한다.
단계 2: 멀티헤드 분할(Multi-Head Splitting)
Query, Key, Value 벡터를 여러 개의 헤드로 분할한다. GPT-2(small) 의 경우 12개 헤드로 나누며, 각 헤드는 임베딩의 일부만 독립적으로 처리한다. 이렇게 하면 다양한 문법적·의미적 관계를 병렬로 학습할 수 있어 표현력이 강화된다.
단계 3: 마스킹된 자기 주의(Masked Self-Attention)

각 헤드에서 마스킹된 자기 주의 계산이 이루어진다. 이 과정은 모델이 시퀀스를 생성할 때 미래 토큰을 참조하지 못하게 막으면서, 입력 내 관련 부분에 집중하도록 한다.
- 어텐션 스코어 계산: Query와 Key의 내적(dot product)을 통해 각 Query가 각 Key와 얼마나 잘 맞는지 측정하여, 모든 입력 토큰 간 관계를 나타내는 행렬을 만든다.
- 마스킹(Masking): 어텐션 행렬의 상삼각 부분(미래 토큰)에 마스크를 씌워 값이 -∞가 되게 하여, 모델이 미래를 "미리 보기" 못하게 한다.
- 소프트맥스(Softmax): 마스크를 적용한 뒤, 각 스코어에 지수를 취하고 정규화하여 확률로 변환한다. 각 행의 합은 1이 되며, 해당 토큰이 왼쪽에 있는 다른 토큰들과 얼마나 관련 있는지를 나타낸다.
단계 4: 출력과 결합(Output & Concatenation)
마스킹된 자기 주의 스코어를 Value 행렬에 곱해 최종 자기 주의 출력을 얻는다. GPT-2에서는 12개 헤드 각각이 다른 관계를 학습하며, 이들의 출력을 병합(concatenate) 한 뒤 선형 변환(Linear Projection)을 거쳐 하나의 벡터로 만든다.
2. 다층 퍼셉트론(MLP: Multi-Layer Perceptron)
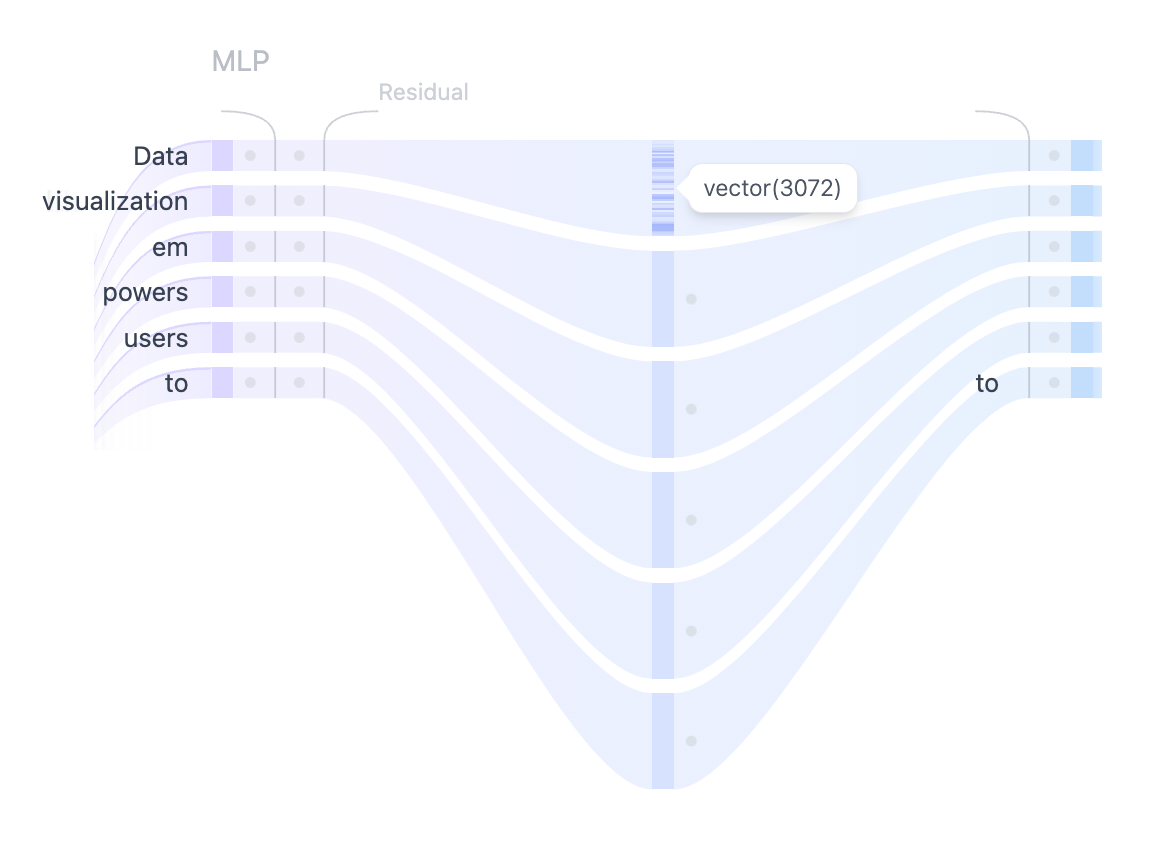
멀티헤드 자기 주의가 다양한 토큰 간 관계를 포착한 뒤, 이 결합된 출력은 MLP 레이어로 전달되어 표현력을 한층 강화한다.
- 구조: MLP 블록은 두 개의 선형 변환(Linear Transformation) 과 그 사이의 GELU 활성화 함수로 구성된다.
- 첫 번째 선형 변환: 차원을 768 → 3072로 4배 확장
- 두 번째 선형 변환: 차원을 3072 → 768로 다시 축소
- 목적: 다음 블록으로 전달되는 입력 차원을 일정하게 유지하면서, 중간에 더 풍부한 표현을 학습하도록 함
- 특징: 자기 주의가 토큰 간 관계를 다루는 반면, MLP는 각 토큰을 독립적으로 처리해 표현을 다른 공간으로 매핑한다.
출력 확률(Output Probabilities)
입력이 모든 Transformer 블록을 거쳐 처리된 후, 최종적으로 선형 레이어(Linear Layer) 를 통해 토큰 예측을 준비한다. 이 레이어는 최종 표현을 50,257차원 공간으로 투영(projection)하며, 여기서 어휘집(vocabulary)의 모든 토큰은 하나씩 해당하는 로짓(logit) 값을 갖는다.
다음 단어가 될 수 있는 후보는 모든 토큰이므로, 이 로짓 값을 기반으로 토큰들을 다음 단어가 될 가능성 순서로 정렬할 수 있다. 이후 소프트맥스(Softmax) 함수를 적용하여 로짓을 확률 분포로 변환한다. 이 확률의 총합은 1이 되며, 이를 이용해 다음 토큰을 확률적으로 샘플링한다.

그림 5. 어휘집의 각 토큰은 모델이 출력한 로짓을 기반으로 확률이 할당된다. 이 확률은 각 토큰이 다음 단어가 될 가능성을 나타낸다.
다음 토큰 생성 과정
마지막 단계는 이 확률 분포에서 다음 토큰을 샘플링하는 것이다. 이때 온도(temperature) 하이퍼파라미터가 중요한 역할을 한다. 수학적으로는 간단한 연산으로, 모델의 로짓을 temperature 값으로 나누기만 하면 된다.
- temperature = 1: 로짓을 1로 나누므로 소프트맥스 출력에 변화가 없다.
- temperature < 1: 확률 분포를 더 날카롭게(sharpen) 만들어 모델의 확신(confidence)을 높이고, 출력이 더 결정론적(deterministic) 으로 변한다. 예측이 더 안정적이고 반복적인 결과를 낸다.
- temperature > 1: 확률 분포를 완화시켜(soften) 더 무작위성(randomness) 을 높인다. 일부에서는 이를 모델의 “창의성(creativity)”이 높아진다고 표현한다.
추가 샘플링 기법
온도 조절 외에도, 샘플링 과정에서 다양성과 품질을 조율하기 위해 다음 두 가지 기법을 사용할 수 있다.
- top-k 샘플링: 확률이 가장 높은 상위 k개 토큰만 후보로 제한하고, 나머지는 제외한다.
- top-p 샘플링(nucleus sampling): 누적 확률이 p 이상이 되는 가장 작은 토큰 집합만 고려한다. 이렇게 하면 가능성이 높은 후보에 집중하면서도 일정 수준의 다양성을 유지할 수 있다.
고급 아키텍처 특징(Advanced Architectural Features)
Transformer 모델의 성능을 향상시키는 여러 고급 아키텍처 요소들이 있다. 이들은 모델의 전반적인 성능에 중요하지만, Transformer의 핵심 개념을 이해하는 데 반드시 필수적이지는 않다. 그중 레이어 정규화(Layer Normalization), 드롭아웃(Dropout), 잔차 연결(Residual Connections) 은 특히 학습 단계에서 중요한 역할을 한다.
- Layer Normalization: 학습을 안정화하고 더 빠르게 수렴하도록 돕는다.
- Dropout: 일부 뉴런을 무작위로 비활성화하여 과적합을 방지한다.
- Residual Connections: 그래디언트가 네트워크를 직접 통과할 수 있도록 하여 기울기 소실 문제를 방지한다.
1. 레이어 정규화(Layer Normalization)
Layer Normalization은 학습 과정에서 활성값을 특성(feature) 단위로 정규화하여 평균과 분산이 일정하도록 만든다. 이렇게 하면 내부 공변량 변화(Internal Covariate Shift) 문제를 완화하고, 초기 가중치에 대한 민감도를 줄이며, 모델이 더 효과적으로 학습하도록 돕는다.
Transformer 블록에서는 자기 주의(Self-Attention) 전에 한 번, MLP 레이어 전에 한 번, 총 두 번 적용된다.
2. 드롭아웃(Dropout)
Dropout은 학습 중에 일부 뉴런의 출력을 무작위로 0으로 만들어 과적합을 방지하는 정규화 기법이다. 이렇게 하면 모델이 특정 뉴런에 의존하지 않고, 보다 강건한 특징을 학습하게 되어 새로운 데이터에 더 잘 일반화한다.
추론(inference) 시에는 드롭아웃이 비활성화되며, 이는 학습된 여러 서브네트워크의 앙상블을 사용하는 것과 같은 효과를 낸다.
3. 잔차 연결(Residual Connections)
Residual Connection은 2015년 ResNet에서 처음 도입되어, 매우 깊은 신경망 학습을 가능하게 한 혁신적인 구조다. 이는 한 층의 입력을 출력에 더해 우회 경로(shortcut) 를 만드는 방식이다.
이 연결은 기울기 소실(Vanishing Gradient) 문제를 줄여주어, 여러 개의 Transformer 블록을 쌓더라도 안정적으로 학습할 수 있게 한다. GPT-2에서는 Transformer 블록마다 MLP 전과 후 두 번 사용되며, 이를 통해 그래디언트가 더 원활히 흐르고, 초기 층도 충분한 업데이트를 받는다.
인터랙티브 기능(Interactive Features)
Transformer Explainer는 사용자가 Transformer의 내부 동작을 직접 탐구할 수 있도록 설계된 인터랙티브 도구다. 다음과 같은 기능들을 실험해볼 수 있다.
- 사용자 입력 텍스트 실험
원하는 텍스트 시퀀스를 입력하면, 모델이 이를 어떻게 처리하고 다음 단어를 예측하는지 확인할 수 있다. 어텐션 가중치, 중간 연산 과정, 최종 출력 확률 계산 과정을 탐구할 수 있다. - 온도(temperature) 슬라이더 조절
모델 예측의 무작위성을 조절할 수 있다. 값을 낮추면 출력이 더 결정론적(deterministic)이 되고, 값을 높이면 창의성(creativity)이 높아진다. - Top-k 및 Top-p 샘플링 선택
추론 시 샘플링 방식을 조정할 수 있다. 다양한 값으로 실험하며 확률 분포가 어떻게 변화하고 예측 결과에 어떤 영향을 주는지 확인할 수 있다. - 어텐션 맵 시각화
입력 시퀀스 내에서 모델이 어떤 토큰에 주목하는지 확인할 수 있다. 특정 토큰에 마우스를 올리면 해당 토큰의 어텐션 가중치가 강조 표시되며, 모델이 문맥과 단어 간 관계를 어떻게 포착하는지 볼 수 있다.
비디오 튜토리얼
이 기능들을 활용하는 방법을 영상으로도 확인할 수 있다.
https://www.youtube.com/watch?v=ECR4oAwocjs&t=1s&ab_channel=PoloClubofDataScience%40GeorgiaTech
Transformer Explainer 구현 방식
Transformer Explainer는 브라우저에서 직접 실행되는 실시간 GPT-2(small) 모델을 기반으로 한다. 이 모델은 Andrej Karpathy의 nanoGPT PyTorch 구현을 기반으로 하며, ONNX Runtime으로 변환되어 원활한 브라우저 실행이 가능하다.
프론트엔드는 Svelte 프레임워크로 제작되었고, 시각화는 D3.js를 이용해 동적으로 구현되었다. 사용자의 입력에 따라 수치 값이 실시간으로 업데이트된다.
개발자
Transformer Explainer는 조아리(Aeree Cho), Grace C. Kim, Alexander Karpekov, Alec Helbling, Jay Wang, 이성민(Seongmin Lee), Benjamin Hoover, Polo Chau가 조지아 공과대학교(Georgia Institute of Technology)에서 개발했다.
'개인용' 카테고리의 다른 글
| kaiber.biz (0) | 2025.08.25 |
|---|---|
| asanAI (0) | 2025.08.21 |
| 콜랩 완료시 자동 다운로드 코드 (1) | 2025.07.12 |
| RAG의 시대는 곳 갈 것이다 (0) | 2025.06.27 |
| 최신 MoE 모델 아키텍처 리뷰 (0) | 2025.05.20 |