https://github.com/fudan-generative-vision/hallo
GitHub - fudan-generative-vision/hallo: Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation - fudan-generative-vision/hallo
github.com
시작전 알아두면 좋을 것
종단 간 확산 모델(End-to-End Diffusion Model)은 최신 인공지능 기술 중 하나로, 이미지와 같은 데이터를 생성하거나 복원하는 데 사용됩니다. 이 모델은 데이터에 노이즈를 점진적으로 추가하는 전진 과정과, 노이즈로부터 원래 데이터를 점진적으로 복원하는 역과정을 통해 작동합니다. 여기서는 종단 간 확산 모델의 주요 개념과 특징을 설명하겠습니다.
주요 개념
- 확산 과정 (Diffusion Process)
- 전진 과정 (Forward Process): 원본 데이터(예: 이미지)에 점진적으로 노이즈를 추가하여 데이터의 잠재 표현을 점점 더 무작위화합니다. 이 과정은 특정 단계 수만큼 반복되며, 각 단계마다 소량의 노이즈가 추가됩니다.
- 역과정 (Reverse Process): 노이즈가 추가된 데이터를 원본 데이터로 복원하는 과정입니다. 이는 전진 과정의 역순으로 진행되며, 각 단계마다 노이즈를 제거하여 점진적으로 원본 데이터를 재구성합니다.
- 잠재 공간 (Latent Space)
- 데이터의 잠재 표현을 다루는 공간으로, 원본 데이터의 중요한 특징을 압축된 형태로 표현합니다. 이 잠재 공간에서 데이터는 보다 효율적으로 처리되고, 생성 과정의 효율성을 높입니다.
- 확산 모델 (Diffusion Model)
- 데이터의 확산 및 역확산 과정을 모델링한 신경망으로, 일반적으로 딥러닝 모델의 하나인 U-Net 아키텍처를 사용합니다. 이 모델은 전진 및 역과정 모두를 학습하여 원본 데이터와 노이즈 간의 변환을 수행합니다.
특징
- 고품질 데이터 생성
- 종단 간 확산 모델은 매우 고해상도의 이미지를 생성할 수 있으며, 생성된 이미지의 품질이 뛰어납니다. 이는 노이즈를 점진적으로 제거하는 역과정을 통해 보다 세밀한 디테일을 복원할 수 있기 때문입니다.
- 시간적 일관성
- 특히 비디오 생성이나 애니메이션 생성에 있어서 시간적 일관성을 유지하는 데 효과적입니다. 이는 각 프레임 간의 변화가 부드럽고 자연스러운 전환을 가능하게 합니다.
- 적응형 제어
- 데이터 생성 과정에서 다양한 제어 변수를 도입하여, 예를 들어 특정한 스타일이나 속성(예: 입술 움직임, 표정 등)을 조절할 수 있습니다. 이는 개인화된 데이터 생성에 유용합니다.
응용
종단 간 확산 모델은 다양한 응용 분야에서 사용됩니다. 예를 들어:
- 이미지 및 비디오 생성: 고해상도의 현실적인 이미지와 비디오를 생성하는 데 사용됩니다.
- 의료 영상 처리: 의료 이미지를 복원하거나 향상시키는 데 효과적입니다.
- 음성 합성 및 애니메이션: 오디오 입력에 맞춰 입술 움직임 및 표정을 동기화시키는 애니메이션을 생성합니다.
종단 간 확산 모델은 최신 인공지능 연구에서 중요한 위치를 차지하고 있으며, 데이터 생성 및 복원에서 높은 성능을 보여줍니다. 이 모델은 특히 중간 표현 없이 직접 데이터를 생성하는 능력 덕분에 많은 연구자와 개발자들에게 주목받고 있습니다.
VideoP2P [21]
**VideoP2P (Point-to-Point Video Editing)**는 비디오 편집을 위해 개발된 기술로, 비디오 내 특정 지점 간의 편집을 쉽게 할 수 있도록 설계되었습니다. 주요 특징은 다음과 같습니다:
- 교차 주의 맵 조작: VideoP2P는 교차 주의(cross-attention) 맵을 조작하여 비디오의 특정 부분을 정밀하게 편집합니다. 이로 인해 사용자는 비디오의 다양한 요소를 세밀하게 조정할 수 있습니다.
- 포인트 투 포인트 편집: 이 기술은 비디오의 특정 지점 간의 전환을 부드럽게 만들어, 자연스러운 편집을 가능하게 합니다. 이는 비디오의 흐름을 방해하지 않으면서 원하는 변경을 적용할 수 있게 합니다.
- 적용 예시: 예를 들어, 비디오 클립의 특정 프레임에서 객체를 추가하거나 제거하거나, 특정 장면의 색조를 변경하는 등의 작업을 수행할 수 있습니다.
vid2vid-zero [44]
vid2vid-zero는 비디오 편집 및 생성 기술로, 주로 다음과 같은 기능을 포함합니다:
- 텍스트 및 이미지 입력을 통한 비디오 생성: vid2vid-zero는 텍스트 및 이미지 입력을 기반으로 비디오를 생성할 수 있습니다. 이는 사용자가 원하는 내용의 텍스트와 이미지 입력을 제공하면, 해당 내용을 바탕으로 비디오를 생성하는 방식입니다.
- 교차 주의 맵 활용: VideoP2P와 마찬가지로 교차 주의 맵을 사용하여 비디오 생성 및 편집의 정밀도를 높입니다. 이는 입력된 텍스트와 이미지가 비디오 내에서 어떻게 표현되는지를 세밀하게 조정할 수 있게 합니다.
- 자연스러운 전환 및 일관성 유지: vid2vid-zero는 비디오 프레임 간의 전환이 자연스럽고 일관되게 유지되도록 설계되어, 생성된 비디오가 시각적으로 매끄럽고 현실감 있게 보입니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
무조건 알아야됨 (수식 이해 필요시) -- ddim인가 ddpm거인데 ddpm 논문으로 기억
잠재 확산 모델(Latent Diffusion Model)
잠재 확산 모델은 입력 데이터를 잠재 공간(latent space)으로 변환하여 그 공간 내에서 확산 과정(diffusion process)을 수행한 다음, 역확산 과정을 통해 원본 데이터를 재구성하는 방식으로 작동합니다. 이 과정은 다음과 같은 주요 단계로 구성됩니다:


하다마드 곱의 정의 (element-wise multiplication)

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
요약
**VideoP2P [21]**는 특정 비디오 지점 간의 편집을 용이하게 하는 기술로, 교차 주의 맵을 통해 비디오의 세밀한 부분을 조정할 수 있게 합니다. **vid2vid-zero [44]**는 텍스트 및 이미지 입력을 기반으로 비디오를 생성하며, 교차 주의 맵을 사용하여 자연스럽고 일관된 비디오 출력을 제공합니다. 이 두 기술은 모두 고품질 비디오 편집 및 생성에 중점을 두고 있으며, 사용자에게 정밀하고 유연한 비디오 편집 도구를 제공합니다.
초록
음성 입력을 통해 인물 이미지 애니메이션 분야는 현실적이고 동적인 초상화를 생성하는 데 있어 상당한 발전을 이뤘습니다. 본 연구는 얼굴 움직임을 동기화하고 확산 기반 방법론의 틀 내에서 시각적으로 매력적이고 시간적으로 일관된 애니메이션을 생성하는 복잡성을 탐구합니다. 중간 얼굴 표현을 위한 매개변수 모델에 의존하는 전통적인 패러다임에서 벗어나, 우리의 혁신적인 접근 방식은 종단 간 확산 패러다임을 수용하고 오디오 입력과 시각적 출력 간의 정밀한 정렬을 향상시키기 위해 계층적 오디오 구동 시각 합성 모듈을 도입합니다. 여기에는 입술, 표정 및 자세 움직임이 포함됩니다. 제안된 네트워크 아키텍처는 확산 기반 생성 모델, UNet 기반 노이즈 제거기, 시간 정렬 기술 및 참조 네트워크를 원활하게 통합합니다. 제안된 계층적 오디오 구동 시각 합성은 표현과 자세 다양성에 대한 적응형 제어를 제공하여 다양한 정체성에 맞춘 더 효과적인 개인화를 가능하게 합니다. 정성적 및 정량적 분석을 포함하는 종합적인 평가를 통해 우리의 접근 방식은 이미지 및 비디오 품질, 입술 동기화 정확도 및 움직임 다양성에서 뚜렷한 향상을 보여줍니다. 추가 시각화 및 소스 코드에 대한 액세스는 다음에서 확인할 수 있습니다: https://fudan-generative-vision.github.io/hallo.
1.서론
초상화 이미지 애니메이션, 일명 토킹 헤드 이미지 애니메이션은 하나의 정적 이미지와 해당 음성 오디오로부터 말을 하는 초상화를 생성하는 것을 목표로 합니다. 이 기술은 비디오 게임과 가상 현실, 영화 및 TV 제작, 소셜 미디어와 디지털 마케팅, 온라인 교육 및 훈련, 인간-컴퓨터 상호작용 및 가상 비서 등 다양한 분야에서 상당한 가치를 지닙니다. 이 분야에서의 중요한 발전은 Stable Diffusion [31]과 DiT [27]과 같은 작업들로 입증됩니다. 이러한 작업들은 잠재 공간에서 훈련 데이터에 점진적으로 노이즈를 포함시킨 후, 이 노이즈로부터 신호를 점진적으로 재구성하는 역과정을 거칩니다. 입술 움직임 [28, 52], 얼굴 표정 [13, 24, 34], 머리 자세 [24, 37, 38]의 매개변수적 또는 암묵적 표현과 잠재 공간에서의 확산 기술 [6, 22, 39, 46, 47]을 결합하여 고품질의 생생한 동적 초상화를 종단 간 방식으로 생성할 수 있습니다.
이 연구는 초상화 이미지 애니메이션에서 두 가지 주요 과제에 중점을 둡니다: (1) 오디오 입력에 의해 구동되는 입술 움직임, 얼굴 표정 및 머리 자세의 동기화 및 조정. (2) 시각적으로 매력적이고 시간적으로 일관된 고충실도 애니메이션 생성.
첫 번째 과제를 해결하기 위해, 매개변수 모델 기반 접근 방식 [6, 24, 28, 34, 38, 46, 52]은 처음에 입력 오디오를 사용하여 3DMM [1], FLAME [19], HeadNeRF [16]과 같은 중간 표현으로 얼굴 랜드마크 또는 매개변수적 움직임 계수를 도출하여 시각적 생성을 수행합니다. 그러나 이러한 방법의 효과는 중간 표현의 정확성과 표현력에 의해 제한됩니다. 반면, 또 다른 접근 방식은 잠재 공간에서 분리된 표현 학습 [13, 22, 47]을 포함하여 얼굴 특징을 정체성 및 비정체성 요소로 분리하여 독립적으로 학습하고 프레임 간 통합합니다. 이 접근 방식의 주요 장애물은 정적 및 동적 얼굴 속성을 포괄하면서 다양한 초상화 요소를 효과적으로 분리하는 것입니다. 또한, 앞서 언급한 방법의 잠재 공간에서 중간 표현 또는 분리된 표현의 도입은 높은 현실성과 다양성을 가진 시간적으로 일관된 시각적 출력을 생성하는 것을 저해합니다.
시각적으로 매력적이고 시간적으로 일관된 고품질 애니메이션을 생성하기 위해, 종단 간 확산 모델 [39]( 이 모델은 데이터에 노이즈를 점진적으로 추가하는 전진 과정과, 노이즈로부터 원래 데이터를 점진적으로 복원하는 역과정을 통해 작동합니다 )의 활용은 이미지와 오디오 클립에서 직접 초상화 비디오를 합성하는 데 있어 최근의 발전을 활용합니다. 이 접근 방식은 중간 표현이나 복잡한 전처리 단계를 제거하여 고해상도, 상세하고 다양한 시각적 출력을 생성할 수 있게 합니다. 그러나 생성된 얼굴 시각 합성과 오디오 간의 입술 움직임, 표정 및 자세를 정밀하게 일치시키는 것은 여전히 과제로 남아 있습니다.

그림 1: 제안된 방법론은 시간적으로 일관되고 시각적으로 고충실도의 초상화 이미지 애니메이션을 생성하는 것을 목표로 합니다. 이는 참조 이미지, 오디오 시퀀스, 그리고 선택적으로 시각 합성 가중치를 계층적 오디오 구동 시각 합성 접근 방식에 기반한 확산 모델과 함께 활용하여 달성됩니다. 이 방법의 결과는 중간 얼굴 표현에 의존하는 이전 접근 방식과 비교하여 개선된 충실도와 시각적 품질을 보여줍니다. 또한, 제안된 방법론은 입술 동기화 측정의 정확성을 향상시키고 움직임 다양성에 대한 제어를 강화합니다.
이 연구에서는 종단 간 확산 모델의 틀을 준수하며, 표현과 자세의 다양성을 제어할 수 있는 능력을 통합하면서 정렬 문제를 해결하는 것을 목표로 합니다. 이 과제를 해결하기 위해, 입술, 표정 및 자세와 관련된 오디오 및 시각적 특징 간의 대응을 확립하기 위해 교차 주의 메커니즘을 사용하는 계층적 오디오 구동 시각 합성 모듈을 도입합니다. 그런 다음, 이러한 교차 주의는 적응형 가중치를 사용하여 융합됩니다. 이 계층적 오디오 구동 시각 합성 모듈을 기반으로, 확산 기반 생성 모델과 UNet 기반 노이즈 제거기 [32], 일련의 일관성을 위한 시간 정렬 [11], 시각적 생성을 안내하는 ReferenceNet을 통합하는 네트워크 아키텍처를 제안합니다. 그림 1에서 보여지듯이, 이 통합 접근 방식은 오디오 신호와 효과적으로 동기화되는 입술 및 표정 움직임을 향상시키며, 표현 및 자세의 세밀도를 적응형으로 제어하여 다양한 시각적 정체성에 걸쳐 일관성과 현실성을 보장합니다.
실험 섹션에서는 이미지 및 비디오 품질, 입술 동기화 및 움직임 다양성에 대한 평가를 포함한 정성적 및 정량적 관점에서 우리의 제안된 접근 방식을 종합적으로 평가합니다. 특히, 우리의 방법은 이전 방법론과 비교하여 FID 및 FVD 지표로 정량화된 이미지 및 비디오 품질에서 상당한 향상을 보여줍니다. 또한, 우리의 접근 방식은 이전 확산 기반 기술과 비교했을 때 입술 동기화에서 유망한 발전을 보입니다. 나아가, 우리의 방법은 특정 요구사항에 따라 표현과 자세의 다양성을 조절할 수 있는 유연성을 제공합니다. 관련 연구 분야에서의 추가 연구를 촉진하기 위해 소스 코드와 샘플 데이터를 오픈 소스 커뮤니티에 제공하는 것에 전념하고 있습니다.
2. 관련 연구
확산 기반 비디오 생성
최근 확산 기반 비디오 생성의 발전은 텍스트-이미지 확산 모델의 기본 원리를 활용하여 유망한 결과를 보여주고 있습니다 [2, 7, 12, 15, 18, 23, 48, 56]. 주목할 만한 노력으로는 Video Diffusion Models (VDM) [15], 공간-시간 분해된 U-Net을 이용해 이미지와 비디오 데이터를 동시에 훈련시키는 방법과, 고해상도 출력을 위해 계단식 확산 모델을 활용하는 ImagenVideo [14]가 있습니다. Make-A-Video [36]와 MagicVideo [54]는 이러한 개념을 확장하여 원활한 텍스트-비디오 변환을 가능하게 합니다. 비디오 편집을 위해 VideoP2P [21]와 vid2vid-zero [44]는 교차 주의 맵을 조작하여 출력을 세밀하게 조정하며, Dreamix [25]는 이미지-비디오 혼합 미세 조정을 사용합니다. 또한, Gen-1 [9]은 깊이 맵과 교차 주의를 통해 구조적 지침을 통합하고, MCDiff [5]와 LaMD [17]는 모션 유도 비디오 생성을 통해 인간 동작의 현실성을 향상시킵니다. VideoComposer [45], AnimateDiff [4], 그리고 VideoCrafter [4]는 이미지와 비디오 생성의 합성을 탐구하여 이미지를 조건으로 하여 확산 과정을 혼합합니다. 이러한 확산 모델의 고충실도 및 시간적으로 일관된 시각 생성 성능을 고려하여, 본 연구에서는 종단 간 확산 모델을 채택합니다.
얼굴 표현 학습
잠재 공간에서 얼굴 표현을 학습하는 것은 특히 정체성과 관련된 외모와 입술 움직임, 표정, 자세와 같은 비정체성 움직임을 분리하는 것이 컴퓨터 비전 분야에서 중요한 과제입니다. 이와 관련된 표현 학습은 명시적 방법과 암묵적 방법 두 가지로 나뉩니다. 명시적 방법은 종종 얼굴 랜드마크를 사용합니다. 얼굴 랜드마크는 입, 눈, 눈썹, 코, 턱선 등 중요한 영역을 로컬라이제이션하고 표현하는 데 사용되는 얼굴의 주요 지점들입니다 [35, 50]. 또한 3D 매개변수 모델 [10, 30, 51], 예를 들어 3D 변형 모델(3DMM)은 통계적 형상 모델과 텍스처 모델을 결합하여 인간 얼굴의 변동성을 포착합니다. 그러나 이러한 명시적 방법은 표현 능력과 재구성의 정밀도에 의해 제한됩니다. 반면, 암묵적 방법은 외모 정체성, 얼굴 동작 및 머리 자세와 같은 측면에 집중하여 2D [3, 20, 26, 41, 49, 55] 또는 3D [8, 43] 잠재 공간에서 분리된 표현을 학습하는 것을 목표로 합니다. 이러한 접근법은 표현력 있는 얼굴 표현에서 유망한 결과를 내었지만, 다양한 얼굴 요소를 정확하고 효과적으로 분리하는 것은 여전히 큰 도전 과제로 남아 있습니다.
초상화 이미지 애니메이션
최근 몇 년간, 초상화 이미지 애니메이션 분야는 정적 이미지와 오디오 입력을 쌍으로 하여 현실적이고 표현력 있는 토킹 헤드 애니메이션을 생성하는 데 상당한 진전을 이루었습니다. 발전의 시작은 LipSyncExpert [28]로, 정적 이미지와 특정 정체성의 비디오에서 음성 세그먼트와의 입술 동기화를 개선하여 높은 정확도를 달성했습니다. 이후 SadTalker [52]와 DiffTalk [34]와 같은 개발은 3D 정보와 제어 메커니즘을 통합하여 머리 움직임과 표정의 자연스러움을 향상시켰습니다. 중요한 변화는 추가 참조 비디오 없이 자연스러운 머리 움직임과 얼굴 표정을 특징으로 하는 고충실도 토킹 헤드 비디오의 생성을 촉진하는 Diffused Heads [37]와 GAIA [13]와 같은 확산 모델의 도입과 함께 발생했습니다. 이러한 모델은 다양한 정체성에 걸쳐 개인화되고 일반화된 합성을 위한 강력한 기능을 입증했습니다. 이 발전을 이어 DreamTalk [24]와 VividTalk [38]는 확산 모델을 활용하여 표현력 있고 고품질의 오디오 구동 얼굴 애니메이션을 생성하여 입술 동기화와 다양한 발화 스타일을 개선했습니다. 추가적으로 Vlogger [6]와 AniPortrait [46]는 가변적인 비디오 길이와 사용자 정의 가능한 캐릭터 표현을 수용하기 위해 공간적 및 시간적 제어를 도입했습니다. 최근의 혁신인 VASA-1 [47]과 EMO [39]는 정적 이미지와 오디오로부터 감정적으로 표현력 있고 현실적인 토킹 얼굴을 생성하기 위한 프레임워크를 개발하여 다양한 얼굴 미묘함과 머리 움직임을 포착했습니다. 마지막으로 AniTalker [22]는 라벨링된 데이터의 필요성을 최소화하고 실제 응용에서의 동적 아바타 생성 가능성을 강조하여 상세하고 현실적인 얼굴 움직임을 생성하는 획기적인 프레임워크를 도입했습니다.
본 연구에서는 EMO [39]에서 제시한 잠재 확산 형식을 채택하고, 오디오 입력과 입술 움직임, 표정, 자세와 같은 비정체성 움직임 간의 상관성을 높이기 위해 계층적 교차 주의 메커니즘을 도입합니다. 이러한 형식은 표현과 자세 다양성에 대한 적응형 제어를 제공할 뿐만 아니라 생성된 애니메이션의 전반적인 일관성과 자연스러움을 향상시킵니다.

그림 2: 제안된 파이프라인의 개요. 구체적으로, 우리는 초상화가 포함된 참조 이미지와 해당 오디오 입력을 통합하여 초상화 애니메이션을 구동합니다. 선택적으로 시각 합성 가중치를 사용하여 입술, 표정, 자세 가중치의 균형을 맞출 수 있습니다. ReferenceNet은 일관되고 제어 가능한 캐릭터 애니메이션을 위해 글로벌 시각 텍스처 정보를 인코딩합니다. 얼굴 및 오디오 인코더는 각각 고충실도의 초상화 정체성 특징을 생성하고 오디오를 움직임 정보로 인코딩합니다. 계층적 오디오 구동 시각 합성 모듈은 오디오와 시각적 구성 요소(입술, 표정, 자세) 간의 관계를 설정하며, UNet 노이즈 제거기가 확산 과정에서 사용됩니다.
3. Methodology
3.1 Preliminary


3.2 계층적 오디오 구동 시각 합성
얼굴 임베딩:

Audio Embedding

Hierarchical Audio-Visual Cross Attention (계층적 오디오-비주얼 크로스 어텐션)



간단하게 다음과 같다

각 영여별 스케일의 잠재 표현을 얻는 것
3.3 네트워크 아키텍처
마지막으로, 본 논문에서 제안하는 계층적 오디오-비주얼 크로스 어텐션을 활용한 확산 기반 생성 모델의 네트워크 아키텍처를 소개합니다. 우리는 기존의 참조 이미지를 사용하여 생성 과정을 안내하기 위해 ReferenceNet을 활용하여 Stable Diffusion을 기반으로 한 비디오 생성을 위한 표준 시각적 생성 모델을 사용했습니다. 시간적 정렬은 생성된 비디오 시퀀스의 일관성과 일관성을 향상시키며, 이전에 설명한 바와 같이 오디오와 입술, 표정, 자세 간의 정교한 매핑을 설정하는 계층적 오디오 구동 시각 합성 모듈을 포함합니다.
확산 백본 (Diffusion Backbone)
Stable Diffusion 1.5는 잠재 확산 모델을 기반으로 하며, 세 가지 주요 구성 요소로 이루어져 있습니다: 벡터 양자화 변이형 오토인코더(Vector Quantised Variational AutoEncoder, VQ-VAE), Unet 기반의 디노이징 모델, 그리고 조건 모듈입니다. 텍스트-이미지 응용 프로그램의 경우, 잠재 이미지 입력은 무작위 초기화로부터 생성되고 확산 모델에 의해 처리되어 새로운 잠재 이미지 출력을 생성합니다. 본 연구에서는 오디오 신호가 주요 모션 구동 요소로 사용되므로 Stable Diffusion의 조건에서 텍스트 특징을 제외합니다.
ReferenceNet
ReferenceNet은 생성 과정에서 기존 이미지를 참조하여 생성된 비디오의 품질을 향상시키기 위해 설계되었습니다. 이는 초상화와 배경의 시각적 텍스처 정보를 포함합니다. ReferenceNet은 디노이징 모델 네트워크와 동일한 레이어 수를 가진 Unet 기반의 Stable Diffusion 네트워크입니다. 이러한 구조에서 특정 레이어에서 생성된 특징 맵은 잠재적으로 유사한 의미론적 특징을 나타내며, ReferenceNet에 의해 추출된 특징을 확산 백본에 통합하는 데 도움이 됩니다. 이러한 통합은 초상화와 배경의 시각적 텍스처 정보를 포함하여 생성된 비디오의 품질을 향상시킵니다. 모델 훈련 동안, 비디오 클립의 첫 번째 프레임이 참조 이미지로 사용됩니다.
시간적 정렬 (Temporal Alignment)
확산 모델을 기반으로 한 비디오 생성 작업에서 시간적 정렬은 생성된 비디오 시퀀스의 일관성과 일관성을 보장하는 데 중요한 역할을 합니다. 보다 구체적으로, 이전 추론 단계에서 일부 프레임(우리 구현에서는 2개)을 모션 프레임으로 지정하여 잠재 노이즈와 함께 시간 축을 따라 연결합니다. 이러한 시간적 조작은 비디오 프레임의 시간 순서 요소를 처리하는 데 능숙한 여러 자기-어텐션 블록을 통해 이루어집니다.
이와 같은 네트워크 아키텍처는 비디오 생성 과정에서 오디오와 시각적 요소 간의 정교한 매핑을 보장하며, 고품질의 일관된 비디오 출력을 생성하는 데 기여합니다.
3.4 훈련 및 추론
훈련 (Training)
훈련 과정은 두 개의 별개 단계로 구성됩니다:
- 첫 번째 훈련 단계: 개별 비디오 프레임은 참조 이미지와 대상 비디오 프레임 쌍을 이용하여 생성됩니다. VAE 인코더와 디코더, 얼굴 이미지 인코더의 파라미터는 고정된 상태로 유지되며, ReferenceNet의 공간 크로스 어텐션 모듈과 디노이징 UNet의 가중치를 최적화하여 단일 프레임 생성 능력을 향상시킵니다. 입력 데이터로 14 프레임이 포함된 비디오 클립이 추출되며, 얼굴 비디오 클립에서 랜덤으로 한 프레임이 참조 프레임으로 선택되고 같은 비디오의 또 다른 프레임이 대상 이미지로 사용됩니다.
- 두 번째 훈련 단계: 참조 이미지, 입력 오디오, 대상 비디오 데이터를 사용하여 비디오 시퀀스를 훈련합니다. ReferenceNet과 디노이징 UNet의 공간 모듈은 고정된 상태로 유지되며, 비디오 시퀀스 생성 능력을 향상시키는 데 집중합니다. 이 단계에서는 주로 계층적 오디오-비주얼 크로스 어텐션을 훈련하여 오디오를 모션 가이드로 삼아 입술, 표정, 자세의 시각 정보와의 관계를 설정합니다. 또한, 모션 모듈이 도입되어 모델의 시간적 일관성과 부드러움을 향상시키며, AnimateDiff [11]의 기존 가중치로 초기화됩니다. 이 단계에서는 비디오 클립에서 랜덤으로 한 프레임이 참조 이미지로 선택됩니다.
추론 (Inference)
추론 단계에서는 네트워크가 단일 참조 이미지와 구동 오디오를 입력으로 받아 해당 오디오에 기반한 비디오 시퀀스를 생성하여 참조 이미지를 애니메이션으로 만듭니다. 시각적으로 일관된 긴 비디오를 생성하기 위해, 이전 비디오 클립의 마지막 2 프레임을 다음 클립의 초기 k 프레임으로 사용하여 비디오 클립 생성에 대한 점진적 추론을 가능하게 합니다.
이와 같은 훈련 및 추론 과정은 고품질의 일관된 비디오 출력을 보장하며, 참조 이미지와 오디오 입력을 기반으로 정교한 애니메이션을 생성합니다.

그림 4: 학습 및 추론을 위한 데이터 세트의 통계
4. 실험
4.1 실험 설정
구현 세부 사항: 훈련 및 추론을 포함한 실험은 8개의 NVIDIA A100 GPU가 장착된 컴퓨팅 플랫폼에서 수행되었습니다. 초기 및 후속 단계는 각각 30,000번의 훈련 스텝으로 구성되었으며, 배치 크기는 4이고 비디오 해상도는 512 × 512로 설정되었습니다. 두 번째 단계의 각 훈련 인스턴스는 14개의 비디오 프레임을 생성하였으며, 모션 모듈의 잠재 변수는 비디오 연속성을 위해 첫 2개의 실제 프레임과 연결되었습니다. 두 훈련 단계 모두에서 학습률은 1e-5로 설정되었고, 모션 모듈은 Animatediff의 가중치로 초기화되었습니다. 비디오 생성 향상을 위해, 참조 이미지, 가이드 오디오 및 모션 프레임은 훈련 중에 0.05의 확률로 드롭되었습니다. 추론 시, 연속성은 모션 모듈 내의 마지막 2개의 모션 프레임의 특징 맵과 노이즈가 있는 잠재 변수를 연결함으로써 보장되었습니다.
데이터셋: 그림 4에서 보듯이, 데이터셋은 HDTF (190 클립, 8.42 시간) 및 추가로 인터넷에서 수집한 데이터 (2019 클립, 155.90 시간)로 구성됩니다. 이러한 비디오는 다양한 연령, 인종 및 성별의 개인들이 실내외 배경에서 반신 또는 클로즈업 샷으로 촬영되었습니다. 고품질의 훈련 데이터를 보장하기 위해, 우리는 강한 입술 및 오디오 일관성을 보이는 단일 인물 스피킹 비디오를 유지하면서 장면 변경, 큰 카메라 이동, 과도한 얼굴 움직임, 그리고 완전히 측면을 향한 샷이 포함된 비디오를 제외하는 데이터 정리 과정을 거쳤습니다. Mediapipe를 사용하여 훈련 비디오에서 표정 및 입술 활동 범위를 결정하였으며, 이를 통해 훈련 및 추론에 사용된 표정 및 입술 마스크를 구성했습니다. 데이터 정리 후, 정제된 훈련 데이터셋은 HDTF (188 클립, 6.47 시간) 및 인터넷에서 수집한 데이터 (1635 클립, 102.39 시간)로 구성되며, 각 훈련 비디오 클립은 해상도 512 × 512에서 15 프레임으로 이루어져 있습니다.
평가 메트릭: 초상화 이미지 애니메이션 접근법에서 사용된 평가 메트릭에는 Fréchet Inception Distance (FID), Fréchet Video Distance (FVD), Synchronization-C (Sync-C), Synchronization-D (Sync-D), 그리고 E-FID가 포함됩니다. 구체적으로, FID와 FVD는 생성된 이미지와 실제 데이터 간의 유사성을 측정하며, 값이 낮을수록 성능이 더 좋고 현실적인 출력을 나타냅니다. Sync-C와 Sync-D는 생성된 비디오의 입술 동기화를 콘텐츠와 다이내믹스 측면에서 평가하며, Sync-C 값이 높고 Sync-D 값이 낮을수록 오디오와의 정렬이 더 잘 된 것을 나타냅니다. E-FID는 Inception 네트워크에서 추출된 특징을 기반으로 생성된 이미지의 품질을 평가하여 충실도의 정제된 평가를 제공합니다.
베이스라인: 정량적 실험에서 우리는 제안된 방법을 SadTalker [53], DreamTalk [24], Audio2Head [42], AniPortrait [46]의 공개 구현과 비교 분석했습니다. 평가에는 HDTF, CelebV 및 제안된 데이터셋을 사용하였으며, 90%의 정체성 데이터를 훈련 목적으로 할당하는 훈련 및 테스트 분할을 활용했습니다. 정성적 비교에서는 참조 이미지, 오디오 입력 및 각 방법이 제공하는 결과 애니메이션 출력을 고려하여, 이러한 선택된 접근 방식들과 우리의 방법을 비교 평가했습니다. 이러한 정성적 평가는 현실적이고 표현력 있는 토킹 헤드 애니메이션을 생성하는 데 있어 우리의 방법의 성능과 기능에 대한 통찰을 제공하는 것을 목표로 했습니다.

표 1: HDTF 데이터 세트에서 기존의 인물 이미지 애니메이션 접근 방식과 정량적으로 비교한 결과입니다. 우리가 제안한 방법은 우수한 입술 동기화 성능으로 시간적으로 일관된 고품질의 말하는 머리 애니메이션을 생성하는 데 탁월합니다.

그림 5: HDTF 데이터 세트에 대한 기존 접근 방식과의 정성적 비교.
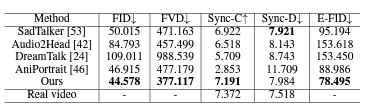
표 2: CelebV 데이터 세트의 기존 인물 이미지 애니메이션 접근 방식과 정량적 비교.

그림 6: CelebV 데이터 세트에 대한 기존 접근 방식과의 정성적 비교.
4.2 정량적 결과
HDTF 데이터셋 비교 표 1은 HDTF 데이터셋에서 다양한 초상화 이미지 애니메이션 기술의 종합적인 정량 평가를 제시합니다. 제안된 방법은 여러 지표에서 우수한 성능을 보여주며, 특히 FID (20.545), FVD (173.497), E-FID (7.951)에서 가장 낮은 점수를 기록했습니다. 이러한 결과는 생성된 토킹 헤드 애니메이션의 높은 품질과 시간적 일관성을 강조합니다. 또한, 제안된 방법은 Sync-C (7.750)와 Sync-D (7.659) 지표에서 실제 비디오 벤치마크와 유사한 우수한 입술 동기화 능력을 보여줍니다. 이러한 성과는 고충실도의 시각적 생성과 시간적 일관성을 유지하면서 입술 동기화를 향상시키는 우리의 접근 방식의 효과를 강조합니다. 이러한 발견을 보완하기 위해, 그림 5는 다양한 방법의 비교 성능을 시각화합니다.
CelebV 데이터셋 비교 표 2에 제시된 정량적 평가 결과는 CelebV 데이터셋을 사용한 다양한 초상화 이미지 애니메이션 기술의 비교 분석을 제공합니다. 제안된 접근 방식은 가장 낮은 FID (44.578)와 FVD (377.117) 점수를 기록하였으며, 가장 높은 Sync-C 점수 (7.191)를 달성했습니다. 또한, 우리의 방법은 경쟁력 있는 Sync-D 값 (7.984)과 가장 낮은 E-FID 점수 (78.495)를 확보하여 높은 품질의 애니메이션과 주목할 만한 시간적 일관성 및 정밀한 입술 동기화를 나타냅니다. 이러한 결과는 현실적인 애니메이션을 생성하는 데 있어 우리의 기술의 견고성과 효율성을 입증합니다. 더 포괄적인 분석을 제공하기 위해, 그림 6에는 시각적 비교 검토가 제시됩니다.
이 정량적 결과는 제안된 방법이 초상화 이미지 애니메이션에서 다른 기존 기술들보다 우수한 성능을 보임을 보여주며, 특히 시각적 충실도와 입술 동기화에서 큰 향상을 가져왔음을 강조합니다.
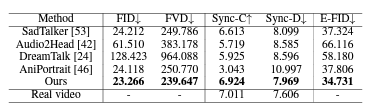
표 3: 제안된 '야생' 데이터 세트에서 기존의 인물 이미지 애니메이션 접근 방식과 정량적으로 비교한 결과입니다.

그림 7: 다양한 인물 스타일을 고려한 제안된 접근 방식의 비디오 생성 결과
제안된 "야생" 데이터셋 비교
야생 데이터셋 비교 표 3에 제시된 정량적 평가는 제안된 "야생" 데이터셋(그림 4의 통계에서 HDTF를 제외한 데이터셋)을 사용하여 다양한 초상화 이미지 애니메이션 기술의 비교 분석을 제공합니다. 우리의 방법론은 우수한 성능을 보여주며, FID (23.266)와 FVD (239.647)에서 가장 낮은 점수를 기록하고, Sync-C 점수 (6.924)에서 가장 높은 점수를 달성했습니다. 또한, 우리의 접근 방식은 E-FID 점수 (34.731)에서 가장 낮은 점수를 기록하고, Sync-D 값 (7.969)에서 경쟁력 있는 성과를 보이며, 실제 비디오 데이터가 설정한 벤치마크에 가깝게 접근합니다. 이러한 결과는 다양한 어려운 조건 하에서도 시간적 일관성과 정밀한 입술 동기화가 특징인 고품질 애니메이션을 생성하는 데 있어 우리의 기술의 견고성과 효율성을 강조합니다.

그림 8: 다양한 오디오 스타일을 고려한 제안된 접근 방식의 비디오 생성 결과.

그림 9: 기존 방법론과 제안된 접근 방식 간의 헤드 및 표정 모션 다양성의 정성적 비교.

그림 10: 개인화를 미세 조정하는 아이덴티티의 시각화. 개인화된 데이터 미세 조정을 통해 아이덴티티별 표정 및 포즈 기능을 향상하면 타겟 아이덴티티와 매우 유사한 애니메이션을 쉽게 생성할 수 있습니다.
4.3 정성적 결과
다양한 초상화 스타일 그림 7에 묘사된 연구는 스케치, 페인팅, AI 생성 이미지, 조각 등 다양한 초상화 스타일이 제안된 방법론을 사용한 비디오 합성에 미치는 영향을 탐구합니다. 결과는 다양한 시각적 및 청각적 출력을 생성하는 데 있어 접근 방식의 다재다능함과 견고함을 강조합니다.
다양한 오디오 스타일 그림 8은 다양한 오디오 스타일과 관련된 정성적 결과를 제시합니다. 결과는 우리의 방법이 다양한 오디오 입력을 효율적으로 처리하여 오디오 콘텐츠와 완벽하게 일치하는 고충실도 및 시각적으로 일관된 비디오를 생성할 수 있음을 보여줍니다.
오디오-비주얼 크로스 어텐션 그림 3은 원래의 전체 오디오-비주얼 크로스 어텐션과 제안된 계층적 오디오-비주얼 크로스 어텐션 간의 비교를 보여줍니다. 제안된 계층적 오디오-비주얼 크로스 어텐션이 오디오, 입술 움직임, 얼굴 표정 간의 정밀하고 세밀한 정렬을 효과적으로 달성함을 관찰할 수 있습니다. 이 정렬은 훈련 중의 관련성을 높이고 추론 과정에서 오디오를 기반으로 한 보다 정밀한 모션 제어를 가능하게 합니다.
머리와 표정 움직임의 다양성 그림 9는 기존 방법론과 우리의 제안된 접근 방식 간의 머리와 표정 움직임의 다양성에 대한 정성적 비교를 제시합니다. 분석 결과, 우리의 방법이 표정과 자세 움직임의 다양성이 향상된 애니메이션을 생성하는 데 있어 뛰어난 성능을 보여줍니다.
정체성 미세 조정 개인화 그림 10은 각 정체성에 특정한 데이터를 사용하여 다양한 정체성을 미세 조정한 결과를 제시합니다. 분석 결과, 제안된 계층적 오디오 구동 시각 합성이 개별 정체성의 독특한 특징을 능숙하게 포착하여 미세 조정 절차 후 각 정체성의 고유한 특성을 반영하는 개인화된 애니메이션을 생성함을 알 수 있습니다.
이와 같은 정성적 결과는 우리의 방법이 다양한 스타일과 조건에서 높은 품질의 애니메이션을 생성하는 능력을 보여줍니다.
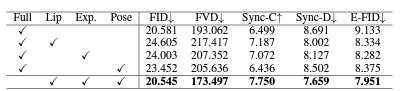
표 4: 계층적 시청각(입술, 표정, 포즈) 교차 주의에 대한 제거 연구. '전체'라는 명칭은 전체 시각-청각 교차 주의의 기본 구성을 나타냅니다. 그 후, 이 연구에서는 입술, 표정, 포즈 특징을 개별적으로 도입하여 오디오와 시각 양상 간의 영역별 교차 주의를 점진적으로 통합했습니다. 실험 설정에서는 표의 마지막 행에 명시된 구성을 준수했습니다.


4.4 절삭 연구 (Ablation Study)
계층적 오디오-비주얼 크로스 어텐션 표 4에 제시된 절삭 연구는 입술, 표정, 자세 특징을 체계적으로 통합하여 계층적 오디오-비주얼 크로스 어텐션의 영향을 면밀히 조사합니다. 결과 분석은 입술 특징을 단독으로 포함했을 때 특정 지표에서 개선이 이루어짐을 보여주지만, 평가 기준 전반에 걸쳐서는 개선 정도가 다양합니다. 또한, 얼굴 특징과 입술 특징을 함께 포함하면 혼합된 결과를 보이지만 동기화 신뢰도를 높이고 E-FID를 줄이는 데 주목할 만한 개선을 보여줍니다. 특히, 입술, 표정, 자세의 세 가지 모달리티를 모두 포함하면 전반적인 성능이 가장 크게 향상되어 오디오-비주얼 합성의 품질과 일관성을 높입니다. 이러한 반복적 개선은 여러 특징에 걸친 계층적 크로스 어텐션의 효능을 강조하여 향상된 오디오-비주얼 통합을 달성합니다. 그림 12(a)는 계층적 오디오-비주얼(입술, 표정, 자세) 크로스 어텐션에 대한 추가 정성적 통찰을 제공합니다.
다양한 어텐션 가중치 메커니즘 표 5는 계층적 오디오 구동 시각 합성 모듈에서 사용되는 다양한 어텐션 가중치 메커니즘에 대한 정량적 평가를 제공합니다. 조사된 메커니즘 중 "직접 더하기" 접근 방식이 19.580의 가장 낮은 FID 점수로 뛰어난 이미지 품질을 나타냅니다. 주목할 만하게도, 우리의 "제로 컨볼루션" 전략은 모든 주요 지표에서 최고의 성능을 보여줍니다. 구체적으로, 가장 높은 FVD (173.497), Sync-C (7.750), Sync-D (7.659), E-FID (7.951) 점수를 기록하여 동기화된, 시간적으로 일관된 애니메이션을 생성하는 데 있어 최고의 견고함을 보여줍니다. 그림 12(b)는 계층적 오디오 구동 시각 합성에서 다양한 어텐션 가중치 메커니즘의 추가 정성적 비교를 제공합니다.
계층적 가중치 조정을 통한 표현 제어 그림 11은 계층적 가중치 조정을 통해 달성된 표현 제어의 정성적 결과를 보여줍니다. 다양한 합성 가중치 설정에 대한 평가 결과는 뚜렷한 경향을 나타냅니다: 입술 가중치를 증가시키면 입술 동기화 정확도가 향상되지만 전체 충실도와 비디오 품질은 약간 저하됩니다. 반면, 표정 가중치를 높이면 이미지와 비디오 품질이 약간 향상되지만 동기화 지표에는 약간의 부정적인 영향을 미칠 수 있습니다. 따라서 가중치 설정의 선택은 충실도, 비디오 품질, 동기화 사이에서 특정 응용 프로그램의 요구 사항에 따라 신중한 균형을 필요로 합니다. 본 연구에서는 적응 가중치 프로세스를 통해 결정된 기본 설정을 따릅니다.
오디오 및 이미지 CFG 스케일 표 6은 다양한 오디오 및 이미지 CFG 스케일 구성에서 생성된 비디오의 정량적 분석을 제공합니다. 구성 중 λa = 3.5 및 λi = 3.5 설정이 경쟁력 있는 FID (23.167), FVD (195.179), Sync-C (7.658), Sync-D (7.894), E-FID (7.951) 점수로 균형 잡힌 성능을 달성합니다. 시각적 충실도와 모션 다양성 사이의 이러한 균형은 고품질, 동기화된 비디오를 생성하는 데 있어 이 구성이 효과적임을 강조합니다.
효율성 분석 표 7은 제안된 접근 방식의 다양한 구성에 대한 효율성 분석을 제공합니다. 계층적 오디오 구동 시각 합성을 사용한 추론에는 9.77 GB의 GPU 메모리가 필요하며 1.63초가 소요됩니다. 반면, 계층적 오디오 구동 시각 합성 없이 추론할 경우 GPU 메모리 사용량은 9.76 GB로 약간 줄어들며 동일한 1.63초의 추론 시간을 유지합니다. 비디오 해상도의 변화는 GPU 메모리 사용량과 추론 시간 모두에 크게 영향을 미칩니다. 256 × 256 해상도에서 처리할 경우 6.62 GB의 GPU 메모리와 0.46초가 소요되며, 1024 × 1024 해상도에서는 20.66 GB의 GPU 메모리와 10.29초가 필요합니다.
이와 같은 분석은 제안된 접근 방식의 효율성과 다양한 구성에서의 성능을 강조하며, 고품질의 동기화된 비디오를 생성하는 데 있어 견고함과 유연성을 보여줍니다.
4.5 한계점 및 향후 연구 방향
이 연구에서 제안된 초상화 이미지 애니메이션의 발전에도 불구하고, 추가 탐구와 고려가 필요한 몇 가지 한계점이 존재합니다. 이러한 한계점은 미래 연구가 제시된 방법론을 개선하고 확장할 수 있는 영역을 강조합니다:
- 향상된 시각-오디오 동기화: 향후 연구는 더 고급 동기화 기술을 탐구할 수 있습니다. 이는 정교한 오디오 분석 방법을 통합하거나 더 깊은 크로스 모달 학습 전략을 활용하는 것을 포함할 수 있습니다. 이러한 발전은 특히 복잡한 언어 패턴이나 미묘한 감정 표현이 있는 상황에서 얼굴 움직임과 오디오 입력의 정렬을 개선할 가능성이 있습니다.
- 견고한 시간적 일관성: 급격하거나 복잡한 움직임이 포함된 시퀀스에서의 불일치를 해결하기 위해 고급 시간적 일관성 메커니즘에 대한 추가 탐구가 필요합니다. 장기 종속성을 기반으로 하는 정렬 전략을 개발하거나 순환 신경망 모델을 활용하여 프레임 간의 안정성을 강화할 수 있습니다.
- 계산 효율성: 확산 기반 생성 모델과 UNet 기반 디노이저의 계산 효율성을 최적화하는 것이 중요합니다. 경량 아키텍처, 모델 가지치기 또는 효율적인 병렬화 기술에 대한 연구는 실시간 응용 프로그램에서 접근 방식을 더 실용적으로 만들면서 자원 사용을 최소화하는 데 기여할 수 있습니다.
- 다양성 제어 향상: 표정과 자세의 다양성과 시각적 정체성의 무결성 유지 사이의 균형은 여전히 중요한 과제입니다. 미래 연구는 보다 미세한 제어 매개변수나 정교한 다양성 메트릭을 통합하여 적응형 제어 메커니즘을 개선하는 데 집중할 수 있습니다. 이러한 개선은 얼굴 정체성의 진정성을 유지하면서 보다 자연스럽고 다양한 애니메이션 출력을 보장할 것입니다.
4.6 사회적 위험과 완화 방안
본 논문에서 제시된 연구의 맥락에서, 오디오 입력에 의해 구동되는 초상화 이미지 애니메이션 기술의 개발 및 구현과 관련된 사회적 위험이 존재합니다. 잠재적인 위험 중 하나는 딥페이크와 같은 속이거나 악의적인 목적으로 오용될 수 있는 매우 현실적이고 동적인 초상화를 생성하는 것에 대한 윤리적 문제입니다. 이러한 위험을 완화하기 위해서는 기술에 대한 윤리적 가이드라인과 책임 있는 사용 관행을 확립하는 것이 필수적입니다. 또한, 애니메이션 초상화 생성에 개인의 이미지와 목소리를 사용하는 것과 관련된 프라이버시 및 동의 문제도 우려됩니다. 이러한 우려를 완화하려면 투명한 데이터 사용 정책을 보장하고, 정보에 입각한 동의를 얻으며, 개인의 프라이버시 권리를 보호하는 것이 필요합니다. 이러한 사회적 위험을 해결하고 적절한 완화 조치를 구현함으로써, 연구는 사회적 맥락 내에서 초상화 이미지 애니메이션 기술의 책임 있고 윤리적인 개발을 촉진하고자 합니다.
5 결론
본 논문은 종단 간 확산 모델을 사용하여 초상화 이미지 애니메이션을 위한 새로운 방법을 소개하며, 오디오 구동 얼굴 동작 동기화 및 시간적 일관성이 있는 고품질 애니메이션 생성의 과제를 해결합니다. 제안된 계층적 오디오 구동 시각 합성 모듈은 크로스 어텐션 메커니즘과 적응형 가중치를 통해 오디오-비주얼 정렬을 강화합니다. 확산 기반 생성 모델링, UNet 디노이징, 시간 정렬 및 ReferenceNet을 통합하여 애니메이션의 품질과 현실감을 향상시킵니다. 실험 평가를 통해 우수한 이미지 및 비디오 품질, 향상된 입술 동기화, 증가된 모션 다양성이 FID 및 FVD 메트릭을 통해 검증되었습니다. 이 방법은 다양한 시각적 정체성을 수용하기 위해 표정과 자세의 다양성에 대한 유연한 제어를 허용합니다.
'인공지능' 카테고리의 다른 글
| Nemotron-4 340B Technical Report (2) | 2024.06.20 |
|---|---|
| Mixture-of-Agents Enhances Large Language ModelCapabilities (1) | 2024.06.19 |
| Will we run out of data? Limits of LLM scaling based on human-generated data (1) | 2024.06.17 |
| xLSTM: Extended Long Short-Term Memory (2) | 2024.06.16 |
| ToonCrafter: Generative Cartoon Interpolation (2) | 2024.06.15 |



