https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
NVIDIA Releases Open Synthetic Data Generation Pipeline for Training Large Language Models
Nemotron-4 340B, a family of models optimized for NVIDIA NeMo and NVIDIA TensorRT-LLM, includes cutting-edge instruct and reward models, and a dataset for generative AI training.
blogs.nvidia.com
요약
우리는 Nemotron-4 340B 모델 패밀리를 공개합니다. 여기에는 Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, Nemotron-4-340B-Reward가 포함됩니다. 우리의 모델은 NVIDIA 오픈 모델 라이선스 계약하에 공개되며, 이는 모델과 그 출력물을 배포, 수정 및 사용할 수 있는 허용적인 모델 라이선스입니다. 이 모델들은 다양한 평가 벤치마크에서 공개 액세스 모델들과 경쟁할 만한 성능을 발휘하며, FP8 정밀도로 배포될 때 8개의 GPU가 장착된 단일 DGX H100에 적합하도록 크기가 조정되었습니다. 우리는 커뮤니티가 이러한 모델을 다양한 연구 및 상업적 응용 프로그램에서, 특히 작은 언어 모델을 훈련시키기 위한 합성 데이터를 생성하는 데 활용할 수 있다고 믿습니다. 특히, 우리의 모델 정렬 과정에서 사용된 데이터의 98% 이상이 합성적으로 생성되어, 합성 데이터 생성에서 이러한 모델의 효과를 보여줍니다. 공개 연구를 지원하고 모델 개발을 촉진하기 위해, 우리는 모델 정렬 과정에서 사용된 합성 데이터 생성 파이프라인도 오픈 소스로 공개하고 있습니다.
1. 서론
대형 언어 모델(LLM)은 다양한 응용 분야에서 많은 작업을 효과적으로 수행할 수 있습니다. 최근에는 더 많은 고품질의 토큰을 사전 학습하여 이러한 모델의 정확성을 높이는 데 주력하고 있습니다. 예를 들어, Llama-2 시리즈(Touvron et al., 2023)는 2조 개의 토큰으로 학습되었으며 Llama-3 시리즈(MetaAI, 2024)는 15조 개의 토큰으로 학습되었습니다. Nemotron-4 340B 기본 모델은 9조 개의 고품질 데이터셋 토큰으로 학습되었으며, 이에 대한 세부 사항은 Parmar et al. (2024)에 제공되어 있습니다. 우리는 기본 LLM을 감독된 미세 조정(SFT)과 강화 학습 기반의 인간 피드백(RLHF)(Ouyang et al., 2022; Bai et al., 2022) 및 직접 선호 최적화(DPO)(Rafailov et al., 2024)와 같은 선호도 미세 조정을 통해 정렬합니다. 정렬 과정은 모델이 지시를 더 잘 따르고, 대화를 효과적으로 수행하며, 문제를 더 잘 해결할 수 있게 합니다. 정렬 과정은 응답의 품질을 정확하게 식별할 수 있는 보상 모델에 의존합니다. 이 보상 모델은 RLHF의 중요한 구성 요소이며 합성 데이터 생성에서 품질 필터링과 선호도 순위 매기기에도 유용한 도구입니다.

그림 1: 네모트론-4-340B-베이스, 네모트론-4-340B-인스트럭트, 네모트론-4-340BR워드의 비교. 자세한 평가 결과는 각각 섹션 2.4, 섹션 3.4, 섹션 3.1을 참조하세요.
LLM의 지속적인 개발을 지원하기 위해, 우리는 Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, Nemotron-4-340B-Reward를 공개 액세스 모델로 제공하며, 허가가 자유로운 라이센스로 배포합니다. 그림 1은 선택된 작업에서 Nemotron-4 340B 모델 패밀리의 정확도를 강조합니다. 특히, Nemotron-4-340B-Base는 ARC-Challenge, MMLU, BigBench Hard 벤치마크와 같은 상식적 추론 작업에서 Llama-3 70B(MetaAI, 2024), Mixtral 8x22B(Mistral-AI-Team, 2024b), Qwen-2 72B 모델과 경쟁력을 갖추고 있음을 보여줍니다. Nemotron-4-340B-Instruct는 지시 수행 및 채팅 기능 면에서 해당 지시 모델들(MetaAI, 2024; Mistral-AI-Team, 2024b; Qwen-Team, 2024)을 능가합니다. Nemotron-4-340B-Reward는 발표 시점 기준으로 RewardBench(Allen AI, 2024)에서 GPT-4o-0513 및 Gemini 1.5 Pro-0514와 같은 독점 모델을 능가하며 최고의 정확도를 달성합니다. 우리는 커뮤니티의 지속적인 LLM 개발을 지원하기 위해 우리의 보상 모델을 공개합니다.
이 모델들의 유망한 응용 분야 중 하나는 합성 데이터 생성으로, 이는 이미 사전 학습을 위한 데이터 품질 향상에 상당한 가치를 입증했습니다. 예를 들어, 데이터 합성은 웹 텍스트의 재구성(Maini et al., 2024), 텍스트 품질 분류기를 위한 학습 데이터 생성(MetaAI, 2024; Guilherme Penedo, 2024), 사전 학습 세트에 잘 나타나지 않는 도메인을 위한 데이터 생성에 사용되었습니다. 또한, 합성 데이터 생성은 인간 주석 데이터를 수집하는 데 드는 높은 비용 때문에 정렬에 필수적입니다. 우리는 Nemotron-4-340B-Instruct를 만드는 데 합성 데이터를 많이 사용했으며, 우리의 훈련 데이터 중 98% 이상이 정렬 과정 전반에 걸쳐 합성되었습니다. 모델과 정렬 전략을 공유함과 동시에 합성 데이터 생성 파이프라인도 공개합니다. 여기에는 합성 프롬프트 생성, 응답 및 대화 생성, 품질 필터링, 선호도 순위 매기기가 포함됩니다. 이 파이프라인은 감독된 미세 조정과 선호도 미세 조정을 모두 지원하도록 설계되었으며, 다양한 도메인에 적응할 수 있는 고품질 데이터를 생성하는 데 커뮤니티에 큰 도움이 될 것입니다.
Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, Nemotron-4-340B-Reward를 출시하고, 우리의 합성 데이터 생성 파이프라인을 공유함으로써, 우리는 AI 응용 프로그램 개발 및 LLM의 책임 있는 사용을 위한 연구 진보를 가속화하기 위해 대형 모델에 대한 폭넓은 접근성을 장려하고자 합니다. 우리는 책임 있는 개발 관행을 준수할 것이며, 모델이 유독하거나 유해한 콘텐츠를 생성하는 데 사용되지 않도록 할 것입니다.
공헌 요약:
- Nemotron-4 340B 모델 패밀리(Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, Nemotron-4-340B-Reward)를 NVIDIA 오픈 모델 라이선스 계약 하에 출시하며, 이는 상업적 용도로 허용됩니다.
- 투명성과 재현성을 촉진하기 위해 이러한 모델의 훈련 및 추론에 대한 코드를 공개합니다.
- 우리의 합성 데이터 생성 파이프라인에 대한 포괄적인 세부 사항을 제공하고, 모델 정렬에서의 효과를 보여줍니다. 또한 우리의 생성 프롬프트, 인간 주석 선호도 데이터셋, 품질 필터링 및 선호도 순위를 위한 Nemotron-4-340B-Reward를 공유합니다. 앞으로는 합성 데이터 생성을 위한 NVIDIA 추론 마이크로서비스(NIMs)와 같은 더 많은 도구를 공유할 것입니다.
2. 사전 학습
2.1 데이터
우리의 사전 학습 데이터 혼합은 세 가지 유형의 데이터로 구성됩니다: 영어 자연어 데이터(70%), 다국어 자연어 데이터(15%), 소스 코드 데이터(15%). 영어 코퍼스는 웹 문서, 뉴스 기사, 과학 논문, 책 등을 포함한 다양한 출처와 도메인의 선별된 문서로 구성됩니다. 다국어 데이터는 53개의 자연어로 구성되며, 단일 언어 코퍼스와 평행 코퍼스에서 가져온 문서들로 이루어져 있습니다. 코드 데이터셋은 43개의 프로그래밍 언어로 구성됩니다. 우리는 총 9조 개의 토큰을 사용해 이 데이터를 학습하며, 처음 8조 개는 공식적인 사전 학습 단계에서, 마지막 1조 개는 계속된 사전 학습 단계에서 학습합니다. 우리의 학습 코퍼스와 선별 절차에 대한 자세한 설명은 Parmar et al. (2024)를 참고하십시오. Nemotron-4-340B-Base는 Nemotron-4-15B-Base와 동일한 데이터 혼합을 따릅니다.

2.2 아키텍처 세부 사항
Nemotron-4-340B-Base는 Nemotron-4-15B-Base(Parmar et al., 2024)와 유사한 아키텍처를 가지고 있습니다. 이는 인과적 주의 마스크를 사용하는 표준 디코더 전용 Transformer 아키텍처(Vaswani et al., 2017)이며, 회전 위치 임베딩(RoPE) (Su et al., 2021), SentencePiece 토크나이저(Kudo and Richardson, 2018), MLP 계층의 제곱 ReLU 활성화 함수를 사용합니다. 이 모델은 바이어스 항을 가지지 않으며, 드롭아웃 비율은 0이고, 입력-출력 임베딩이 연결되지 않습니다. 또한 그룹화된 쿼리 주의(GQA)(Ainslie et al., 2023)를 사용합니다. Nemotron-4-340B-Base의 하이퍼파라미터는 표 1에 나와 있습니다. 이 모델은 94억 개의 임베딩 파라미터와 3,316억 개의 비임베딩 파라미터를 가지고 있습니다.

2.3 훈련 세부 사항
Nemotron-4-340B-Base는 768개의 DGX H100 노드를 사용하여 훈련되었습니다. 각 노드는 NVIDIA Hopper 아키텍처(NVIDIA, 2022)를 기반으로 하는 8개의 H100 80GB SXM5 GPU를 포함합니다. 각 H100 GPU는 희소성을 제외한 16비트 부동 소수점(bfloat16) 연산 시 989 테라FLOP/s의 최대 처리량을 가집니다. 각 노드 내에서 GPU는 NVLink 및 NVSwitch(nvl)에 의해 연결되며, GPU 간 대역폭은 900 GB/s(각 방향에서 450 GB/s)입니다. 각 노드는 노드 간 통신을 위한 8개의 NVIDIA Mellanox 400 Gbps HDR InfiniBand 호스트 채널 어댑터(HCAs)를 가지고 있습니다.
우리는 모델을 훈련하기 위해 8-way 텐서 병렬화(Shoeybi et al., 2019), 인터리빙을 사용한 12-way 파이프라인 병렬화(Narayanan et al., 2021) 및 데이터 병렬화를 결합하여 사용했습니다. 또한 데이터 병렬 복제본 전체에 옵티마이저 상태를 분할하여 훈련의 메모리 풋프린트를 줄이는 분산 옵티마이저를 사용합니다. 데이터 병렬화 정도는 배치 크기가 증가함에 따라 16에서 64까지 확장되었습니다. 표 2는 배치 크기 증가의 3단계를 요약하며, 각 반복 당 시간과 모델 FLOP/s 활용률(MFU)을 포함합니다(Chowdhery et al., 2022; Korthikanti et al., 2022). MFU는 모델 훈련에서 GPU가 얼마나 효율적으로 활용되는지를 정량화하며, 100%는 이론적 최대치를 의미합니다.
계속된 훈련
우리는 모델 훈련이 끝날 때 데이터 분포와 학습률 감쇠 일정을 변경하면 모델 품질이 크게 향상된다는 것을 발견했습니다. 구체적으로, 8조 개의 토큰을 사전 학습한 후 동일한 손실 목표를 사용하여 추가 1조 개의 토큰으로 계속된 훈련을 수행합니다. 이 추가 훈련 단계에서는 두 가지 다른 데이터 분포를 활용합니다. 첫 번째 분포는 계속된 훈련 토큰의 대부분을 구성하며, 사전 학습 중에 이미 소개된 토큰을 사용하지만 더 높은 품질의 출처에 큰 샘플링 가중치를 둡니다. 두 번째 분포는 질문-응답 스타일의 정렬 예제를 소수 포함하여 모델이 다운스트림 평가에서 이러한 질문에 더 잘 응답할 수 있도록 하고, 모델 정확도가 낮은 영역에서 데이터를 상향 가중치합니다. 학습률 일정은 학습률의 크기보다 더 가파른 감쇠 기울기를 우선시하며, 이러한 데이터 분포와 일정은 모델이 사전 학습 데이터셋에서 부드럽게 전환하고 최종 훈련 단계에서 도입된 데이터에서 더 잘 학습할 수 있게 합니다.
2.4 기본 모델 평가
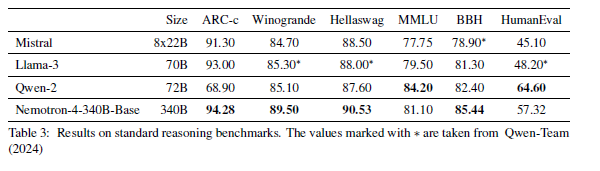
이 섹션에서는 Nemotron-4-340B-Base의 결과를 보고합니다. 우리는 우리의 모델을 Llama-3 70B(MetaAI, 2024), Mistral 8x22(Mistral-AI-Team, 2024b), Qwen-2 72B(Qwen-Team, 2024)와 같은 다른 공개 액세스 기반 모델들과 비교합니다. 다음은 우리가 평가한 작업의 목록, 그 카테고리 및 설정입니다:
- 인기 있는 집계 벤치마크: MMLU (5-shot)(Hendrycks et al., 2020) 및 BBH (3-shot)(Suzgun et al., 2022).
- 상식적 추론: ARC 챌린지(25-shot)(Clark et al., 2018), Winogrande(5-shot)(Sakaguchi et al., 2020), Hellaswag(10-shot)(Zellers et al., 2019).
- 코드: HumanEval에서 Pass@1 점수(0-shot)(Chen et al., 2021a)
우리는 모든 평가에서 표준화된 작업 설정을 따릅니다. Nemotron-4-340B-Base는 모든 상기 작업을 LM-Evaluation Harness(Gao et al., 2021)를 사용하여 평가합니다. 표 3은 Nemotron-4-340B-Base가 상식적 추론 작업 및 BBH와 같은 인기 있는 벤치마크에서 최고의 정확도를 달성했음을 보여줍니다. 또한, MMLU 및 HumanEval과 같은 코드 벤치마크에서도 경쟁력 있는 성능을 보입니다.
각각의 벤치마크는 다음과 같은 의미와 목적을 가지고 있습니다:
ARC-c (AI2 Reasoning Challenge - Challenge Set)
- 의미: ARC(초등과학 능력평가, AI2 Reasoning Challenge)는 초등학교 과학 문제를 통해 AI의 상식적 추론 능력을 평가하는 벤치마크입니다. 이 벤치마크는 "이해"와 "추론" 능력을 테스트하기 위해 개발되었습니다.
- 목적: 주어진 과학 문제를 정확히 해결할 수 있는 AI 모델의 능력을 측정합니다. ARC-c는 특히 난이도가 높은 "챌린지" 세트로 구성되어 있습니다.
Winogrande
- 의미: Winogrande는 Winograd Schema Challenge를 기반으로 한 벤치마크로, 상식적 추론과 언어 이해 능력을 평가합니다.
- 목적: 두 문장 중 올바른 문장을 선택하는 문제를 통해 AI가 문맥을 이해하고 적절한 추론을 수행할 수 있는지를 평가합니다. 예를 들어, "The trophy doesn't fit in the suitcase because it is too large"에서 "it"이 가리키는 것이 무엇인지 파악해야 합니다.
Hellaswag
- 의미: Hellaswag는 인간의 일상적 상식과 물리적 세계에 대한 이해를 평가하는 벤치마크입니다.
- 목적: 짧은 이야기나 시나리오를 주고, 그 다음에 이어질 일을 맞추는 문제를 통해 AI의 예측 능력을 테스트합니다. 이는 특히 AI가 연속적인 사건을 이해하고 추론하는 능력을 측정하는 데 중점을 둡니다.
MMLU (Massive Multitask Language Understanding)
- 의미: MMLU는 다양한 주제와 난이도의 문제를 포함하는 대규모 멀티태스크 언어 이해 벤치마크입니다.
- 목적: 여러 도메인에서의 지식과 추론 능력을 평가합니다. 이 벤치마크는 AI 모델이 여러 분야에서 동시에 잘 수행할 수 있는지를 테스트합니다.
BBH (Big-Bench Hard)
- 의미: BBH는 Big-Bench 벤치마크의 일부로, 특히 어려운 문제들로 구성된 세트입니다.
- 목적: 다양한 고난이도 문제를 통해 AI 모델의 상식적 추론, 문제 해결 능력, 창의적 사고 등을 평가합니다. 이 벤치마크는 모델의 전반적인 지능과 적응력을 측정하는 데 사용됩니다.
HumanEval
- 의미: HumanEval은 프로그래밍 문제를 통해 AI의 코드 작성 능력을 평가하는 벤치마크입니다.
- 목적: 주어진 자연어 설명에 따라 코드를 작성하고, 그 코드가 올바르게 동작하는지를 평가합니다. Pass@1 점수는 첫 시도에서 정확한 코드를 작성할 수 있는지를 나타냅니다.
이 벤치마크들은 각각의 특성에 맞추어 AI 모델의 다양한 능력을 측정하는 데 사용됩니다.
3. 정렬
3.1 보상 모델링
보상 모델은 모델 정렬에서 중요한 역할을 하며, 강력한 지시 따르기 모델을 훈련하는 데 있어 선호도 순위 매기기와 품질 필터링을 위한 중요한 심판 역할을 합니다. 강력한 보상 모델을 개발하기 위해 우리는 HelpSteer2라 불리는 10,000개의 인간 선호 데이터셋을 수집했으며, 이는 HelpSteer(Wang et al., 2023b)에서 설명된 방법론과 유사한 방식으로 수집되었습니다. 이 데이터셋은 공개적으로 배포되며 자세한 내용은 Wang et al. (2024)에서 찾을 수 있습니다.
Ouyang et al. (2022)와 Touvron et al. (2023)에서 사용된 쌍별 랭킹 모델과 달리, 우리는 다속성 회귀 보상 모델이 길지만 도움이 되지 않는 응답을 길이만으로 선호하는 등의 무관한 특성을 실질적인 도움으로부터 분리하는 데 더 효과적이라는 것을 발견했습니다. 또한 회귀 모델은 세밀한 보상을 예측하는 데 더 우수하며, 유사한 응답 간의 도움 정도의 미묘한 차이를 포착합니다. 회귀 보상 모델은 Nemotron-4-340B-Base 모델의 최종 소프트맥스 층을 새로운 보상 “헤드”로 대체하여 구축됩니다. 이 “헤드”는 마지막 층의 은닉 상태를 HelpSteer 속성(도움 정도, 정확성, 일관성, 복잡성, 장황함)의 5차원 벡터로 매핑하는 선형 투영입니다. 추론 시 이러한 속성 값들은 가중 합계를 통해 전체 보상으로 집계될 수 있습니다. 자세한 내용은 Wang et al. (2024)에 포함되어 있습니다. 우리는 이러한 모델이 RewardBench(Lambert et al., 2024)에서 매우 잘 작동하며, 발표 시점에서 최고 정확도를 달성한 것을 확인했습니다. 다양한 카테고리의 점수는 표 4에 나와 있습니다.

Nemotron-4-340B-Reward의 강력한 전체 점수는 우리의 Nemotron-4-340B-Base 모델의 강력함, HelpSteer2 데이터셋의 높은 품질, 그리고 우리의 방법론의 효능을 입증합니다. 더욱이, 이 보상 모델은 후속 섹션에서 논의될 Nemotron-4-340B-Instruct 훈련을 위한 탄탄한 기반을 제공합니다.
3.2 정렬 데이터
모델이 계속 발전함에 따라 기존의 허용된 데이터셋은 가장 잘 정렬된 모델을 훈련하기에는 점점 더 불충분해지고 있습니다. 게다가, 인간으로부터 고품질의 데이터를 수집하는 것은 시간과 비용이 많이 드는 작업입니다. 이 문제를 해결하기 위해, 우리는 합성 데이터 생성(SDG)에 대한 심도 있는 탐구를 수행했습니다. 특히, 전체 정렬 과정에서 우리는 약 20,000개의 인간 주석 데이터를 사용했습니다(감독된 미세 조정을 위한 10,000개, 보상 모델 훈련 및 선호도 미세 조정을 위한 HelpSteer2 데이터 10,000개), 반면 데이터 생성 파이프라인은 감독된 미세 조정과 선호도 미세 조정을 위해 사용된 데이터의 98% 이상을 합성했습니다. 이 섹션에서는 우리의 합성 데이터 생성 파이프라인에 대한 상세 설명과 추가 인간 데이터와의 통합 방법을 설명합니다.
3.2.1 프롬프트 준비
기존의 프롬프트, 예를 들어 LMSYS-Chat-1M 프롬프트(Zheng et al., 2023)와 같은 프롬프트가 있긴 하지만, 합성 프롬프트를 생성하는 것은 SDG의 중요한 첫 번째 단계입니다. 이 접근 방식은 다양한 시나리오를 포함하도록 프롬프트 분포를 제어할 수 있게 해줍니다. 프롬프트 다양성은 다차원적입니다. 여기에는 작업 다양성(예: 글쓰기, 개방형 Q&A, 폐쇄형 Q&A), 주제 다양성(예: STEM, 인문학, 일상 생활) 및 지시 다양성(예: JSON 출력, # 단락, 예-아니오 답변)이 포함됩니다. 이러한 차원에서 프롬프트의 다양성을 보장하기 위해, 우리는 UltraChat 데이터셋(Ding et al., 2023)의 생성 방식과 유사한 접근 방식을 채택했습니다. 구체적으로, 우리는 Mixtral-8x7B-Instruct-v0.1(Jiang et al., 2024)를 생성기로 사용하여 개방형 Q&A, 글쓰기, 폐쇄형 Q&A, 수학 및 코딩 등의 작업을 위해 별도로 합성 프롬프트를 생성했습니다. 각 프롬프트 작업에 대해 다양한 주제나 키워드를 시드로 사용하여 프롬프트가 다양한 주제를 다루도록 했습니다. 또한 "출력은 JSON 형식이어야 합니다."와 같이 예상되는 응답 형식을 명시적으로 정의하는 지시 프롬프트도 생성했습니다. 또한 모델의 대화 능력을 향상시키기 위해 사용자-도우미 상호 작용 기록을 포함하는 두 턴 프롬프트도 생성했습니다. 다음 단락에서는 단일 턴 합성 프롬프트, 지시 따르기 프롬프트, 두 턴 프롬프트를 생성하는 파이프라인에 대해 설명합니다.

그림 2: 왼쪽부터 공개 Q&A, 쓰기, 비공개 Q&A, 수학 및 코딩을 위한 합성 단일 턴 프롬프트 생성.
합성 단일 턴 프롬프트
그림 2에서는 합성 프롬프트를 생성하는 고수준 파이프라인을 보여줍니다. 다양한 주제를 수집하기 위해, 우리는 생성기에게 다양한 매크로 주제를 출력하도록 프롬프트를 작성합니다. 그런 다음 생성기에게 각 합성 매크로 주제와 관련된 하위 주제를 출력하도록 요청합니다. 합성 매크로 주제, 합성 하위 주제, 수동으로 수집된 주제를 포함하여 총 3,000개의 주제를 수집했습니다. 우리는 생성기에게 각 주어진 주제와 관련된 질문을 생성하도록 프롬프트를 작성하여 합성 개방형 Q&A 프롬프트(예: "기계 학습이란 무엇인가?")를 생성했습니다. 그런 다음 생성기에게 질문을 더 구체적이고 자세하게 다듬도록 요청합니다. 처음 생성된 질문은 보통 매우 짧기 때문입니다. 글쓰기와 관련된 프롬프트(예: "기계 학습에 관한 에세이를 작성하라.")의 경우, 프롬프트는 주어진 주제에 대한 특정 유형의 문서(예: 뉴스레터, 에세이)의 생성을 지시하는 내용을 포함합니다. 마찬가지로, 생성기에게 생성된 작업을 더 세부적으로 포함하도록 다듬도록 요청합니다. 폐쇄형 Q&A 프롬프트를 생성하기 위해 우리는 C4 데이터셋(Raffel et al., 2020)의 텍스트를 사용합니다. 각 주어진 문서에 대해 생성기에게 적절한 지시 사항(예: "주어진 텍스트를 요약하라." 또는 "주어진 텍스트를 기반으로 xxx는 무엇인가?")을 출력하도록 요청합니다. 그런 다음 수동으로 정의된 템플릿을 사용하여 문서와 생성된 지시 사항을 연결합니다. 수학 및 코딩 프롬프트를 생성하기 위해, 우리는 수학 및 파이썬 프로그래밍에서 다양한 키워드(예: 나눗셈, 루프, 람다 함수)를 수집합니다. 그런 다음 수학 및 파이썬 프로그래밍에 대한 고수준 주제와 하위 주제를 생성합니다. 다음으로, 우리는 생성기에게 위키피디아 엔티티가 수학 또는 파이썬 프로그래밍과 관련이 있는지 분류하도록 프롬프트를 작성합니다. 또한 우리의 파이썬 사전 학습 데이터에서 자주 사용되는 파이썬 키워드를 수집하고 수동으로 수집한 수학 관련 키워드를 포함합니다. 전체적으로 우리는 12,000개의 파이썬 관련 키워드와 17,000개의 수학 관련 키워드를 수집했습니다. 그런 다음 각 키워드와 관련된 문제를 생성하도록 생성기를 프롬프트합니다. 보충 자료 B에서는 합성 프롬프트 생성을 위한 이 파이프라인에서 사용한 프롬프트를 공유합니다.
합성 지시 따르기 프롬프트
지시 따르기는 정렬된 모델에서 매우 중요합니다. 우리의 모델이 지시를 따르는 능력을 향상시키기 위해, 우리는 합성 지시 따르기 프롬프트를 생성합니다. 예를 들어, "기계 학습에 관한 에세이를 작성하라. 응답은 세 단락으로 구성되어야 한다."와 같은 프롬프트를 생성합니다. 구체적으로, 우리는 무작위로 선택된 합성 프롬프트 세트를 사용합니다. 각 합성 프롬프트에 대해 Zhou et al. (2023)에서 "검증 가능한" 지시 템플릿 중 하나를 무작위로 선택하여 합성 지시를 생성합니다(예: "응답은 세 단락으로 구성되어야 한다."). 그런 다음 프롬프트와 지시를 수동으로 정의된 템플릿과 함께 연결합니다. 단일 턴 지시 따르기 프롬프트 외에도, 모든 향후 대화에 적용되는 다중 턴 지시 따르기 프롬프트를 구성합니다. 예를 들어, "질문에 답하고 모든 후속 질문에 다음과 같이 답하십시오: [지시 시작] 세 단락으로 답하십시오. [지시 끝]"와 같은 형태입니다. 또한, 두 번째 턴 지시 따르기 프롬프트를 구성하여 주어진 지시에 따라 이전 응답을 수정하도록 요청합니다.
합성 두 턴 프롬프트
감독된 미세 조정 단계에서 대화 데이터셋은 보통 다중 턴으로 구성되지만, 선호도 미세 조정을 위한 선호 데이터는 보통 단일 턴입니다(Bai et al., 2022; Cui et al., 2023). 선호도 미세 조정에서 모델의 다중 턴 대화 능력을 향상시키기 위해, 우리는 선호 데이터셋을 구축하기 위해 두 턴 프롬프트를 구성합니다. 구체적으로, 프롬프트는 한 사용자의 질문, 하나의 도우미 응답, 그리고 또 다른 사용자의 질문으로 구성됩니다. 예를 들어, "User: XXX; Assistant: XXX; User: XXX;" 형태입니다. 첫 번째 사용자 프롬프트는 ShareGPT(RyokoAI, 2023)에서 가져오고, 도우미 응답과 다음 턴 질문은 우리의 중간 지시 모델로 생성합니다.
실제 세계의 LMSYS 프롬프트
실제 세계의 사용자 요청을 더 잘 반영하기 위해, 우리는 LMSYS-Chat-1M(LMSYS) (Zheng et al., 2023)에서 프롬프트를 가져옵니다. 모든 프롬프트를 균형 잡힌 비율로 결합하고 이를 감독 학습과 선호 학습을 위한 두 개의 별도 세트로 나눠 서로 겹치지 않도록 합니다. 감독 학습 분할에서는 LMSYS에서 잠재적으로 안전하지 않은 것으로 표시된 프롬프트를 제거하여 원치 않는 대화를 유도하지 않도록 합니다. 그러나 선호 학습 분할에서는 이러한 프롬프트를 유지하여 모델이 안전한 응답과 안전하지 않은 응답을 구별할 수 있도록 합니다.

그림 3에서는 합성 단일 턴 프롬프트와 LMSYS 프롬프트 간의 비교를 제공합니다. 구체적으로, 각 프롬프트 세트에 대해 Mixtral-8x7B-Instruct-v0.1 모델을 사용하여 응답을 생성하고, Nemotron-4-340B-Reward를 사용하여 응답의 도움 정도 점수를 주석 처리합니다. 합성 프롬프트와 LMSYS 프롬프트의 도움 정도 분포를 플로팅합니다. 우리는 합성 프롬프트의 평균 도움이 LMSYS 프롬프트보다 높다는 것을 관찰합니다. 이는 간단한 프롬프트일수록 "도움이 되는" 것이 더 쉽기 때문에, LMSYS 프롬프트가 평균적으로 합성 단일 턴 프롬프트보다 더 어렵고 복잡함을 의미합니다.
3.2.2 합성 대화 생성
감독된 미세 조정은 모델이 대화 형식으로 사용자와 상호작용하는 방법을 배우도록 합니다. 우리는 지시 모델에 입력 프롬프트를 기반으로 응답을 생성하도록 프롬프트를 제공하여 합성 대화를 시작합니다. 다중 턴 대화 기능을 촉진하기 위해, 각 대화를 세 턴으로 구성하여 더 역동적이고 상호작용적인 대화 흐름을 만듭니다. 모델은 역할 놀이를 통해 도우미와 사용자의 역할을 번갈아가며 시뮬레이션합니다. 사용자 턴에서 원하는 행동을 유도하기 위해, 우리는 명확하게 정의된 사용자 성격과 대화 역사를 모델에 제공하는 것이 중요하다는 것을 발견했습니다(부록 C에서 설명됨). 또한, 사용자의 턴을 실제 사용자 질문을 모방하도록 후처리하여 예의 바른 문구(예: "감사합니다...", "물론, 기꺼이...")를 제외합니다. 시연 데이터 생성을 위해 그리디 샘플링을 사용합니다. 또한, 우리는 Nemotron-4-340B-Reward를 활용하여 대화의 품질을 평가하고, 각 샘플에 점수를 할당하며, 사전 설정된 임계값 이하의 샘플을 필터링합니다. 이는 추가적인 품질 제어 층을 제공하여 고품질 데이터만 유지되도록 합니다.
3.2.3 합성 선호 데이터 생성
우리는 10,000개의 인간 주석 HelpSteer2 선호 데이터를 사용하여 Nemotron-4-340B-Reward를 훈련하지만, 더 다양한 도메인의 프롬프트와 우리의 최상위 중간 모델로부터 더 고품질의 응답을 포함하는 선호 데이터도 필요합니다. 따라서, 우리는 (프롬프트, 선택된 응답, 거부된 응답)의 삼중 형식으로 합성 선호 데이터를 생성하려고 노력합니다.
응답 생성
선호 데이터는 합성 단일 턴 프롬프트, 지시 따르기 프롬프트, 두 턴 프롬프트뿐만 아니라 ShareGPT 프롬프트, LMSYS 프롬프트, GSM8K(Cobbe et al., 2021) 및 MATH(Hendrycks et al., 2021) 훈련 데이터셋의 프롬프트와 같은 실제 세계 프롬프트도 포함합니다. 각 프롬프트에 대해 여러 랜덤 중간 모델을 사용하여 응답을 생성합니다. 여러 모델을 사용하여 응답을 생성하면 선호 데이터셋이 모델이 학습할 수 있는 다양한 응답을 포함하게 됩니다. 또한, MT-Bench에 따라 최상위 성능 모델의 여러 랜덤 생성 응답으로 더 도전적인 합성 선호 예제를 만들기도 합니다. 이러한 도전적인 선호 예제는 모델이 더욱 향상될 수 있도록 합니다.
정답을 심판으로 활용
각 프롬프트에 대해 여러 응답을 제공하면 선호 순위를 판단하고 선택된 응답과 거부된 응답을 선택해야 합니다. 일부 작업은 정답 레이블(예: GSM8K 및 MATH 훈련 데이터셋의 정답)이나 검증기(예: 지시 따르기 응답은 파이썬 프로그램으로 검증 가능)를 사용하여 평가할 수 있습니다. 우리는 정답/검증기를 사용하여 각 응답의 정확성을 판단합니다. 올바른 응답을 선택된 응답으로, 잘못된 응답을 거부된 응답으로 선택합니다.
LLM을 심판으로 활용 및 보상 모델을 심판으로 활용
대부분의 프롬프트는 객관적인 답변이 없습니다. 우리는 LLM을 심판으로 활용한 방법과 보상 모델을 심판으로 활용한 방법을 모두 실험했습니다. LLM을 심판으로 활용하는 경우, 프롬프트와 두 응답을 심판 LLM에 제공하고 두 응답을 비교하도록 요청합니다. 위치 편향을 피하기 위해, 응답 순서를 바꿔 두 번 LLM에 요청합니다. LLM이 두 번 모두 일관된 판단을 내릴 때 유효한 (프롬프트, 선택된 응답, 거부된 응답) 삼중 항목을 선택합니다. 심판 프롬프트는 부록 D에 있습니다. LLM을 심판으로 활용한 초기 선호 데이터셋의 반복을 통해 우리는 보상 모델을 심판으로 활용하는 방법도 탐구했습니다. 보상 모델을 심판으로 활용하는 경우, Nemotron-4-340B-Reward를 사용하여 각 (프롬프트, 응답) 쌍의 보상을 예측하고 보상을 기반으로 선호 순위를 결정합니다. 보상 벤치마크 점수(Lambert et al., 2024)에 따르면 보상 모델을 심판으로 활용한 방법이 LLM을 심판으로 활용한 방법보다 더 높은 정확도를 보였습니다. 특히, 선택된 응답과 거부된 응답을 구분하기 어려운 Chat-Hard 카테고리에서는 보상 모델을 심판으로 활용한 방법이 평균 정확도 0.87 대 0.54로 LLM을 심판으로 활용한 방법보다 훨씬 더 뛰어났습니다. 우리는 Chat-Hard 카테고리 점수가 합성 데이터 생성에서 선호 순위를 매기는 데 특히 중요하다는 점을 주목합니다. 따라서 후속 데이터셋 반복에서는 보상 모델을 심판으로 활용하는 방법을 사용하기로 했습니다.
3.2.4 반복적인 약-to-강 정렬
앞서 논의한 바와 같이, 고품질 데이터는 모델 정렬에 필수적입니다. 데이터 합성에서는 정렬된 LLM이 생성 파이프라인 전반에 걸쳐 지시를 정확히 따르는 것이 요구됩니다. 이는 어떤 모델이 생성기로 가장 적합한지, 생성기의 강도가 데이터 품질과 어떻게 관련되는지, 그리고 데이터 생성기를 어떻게 개선할 수 있는지와 같은 중요한 질문을 제기합니다. 약-to-강 일반화(Burns et al., 2023)에서 영감을 받아, 우리는 데이터를 최적화 상태로 점진적으로 정제하기 위한 새로운 반복적 접근 방식을 개발했습니다. 이 접근 방식은 정렬 훈련과 데이터 합성의 강점을 결합하여 서로를 상호 강화하고 지속적인 개선을 추진할 수 있게 합니다.

그림 4는 반복적인 약-to-강 정렬의 워크플로를 보여줍니다. 여기서 모델의 품질(약한 모델인지 강한 모델인지는)은 모델 크기와 관계없이 여러 평가 지표(기본 모델에 대한 2.4절 및 지시 모델에 대한 3.4.1절 참조)의 조합으로 정의됩니다. 초기 정렬된 모델은 대화 및 선호 데이터 모두의 생성기로 사용됩니다. 이 데이터는 감독된 미세 조정 및 선호 조정을 사용하여 더 나은 기본 모델을 정렬하는 데 사용됩니다. 흥미롭게도, 우리는 교사 모델이 학생 모델의 한계를 설정하지 않는다는 것을 발견했습니다. 구체적으로, 기본 모델과 정렬 데이터가 정제됨에 따라, 새로 정렬된 모델은 초기 정렬된 모델을 상당한 차이로 능가할 수 있습니다.
정렬 절차는 기본 모델 사전 학습과 병행하여 수행됩니다. 첫 번째 반복에서는 허가가 자유로운 라이센스를 가진 강력한 모델로 입증된 Mixtral-8x7B-Instruct-v0.1을 초기 정렬 모델로 선택합니다. 생성된 데이터는 Nemotron-4-340B-Base의 중간 체크포인트인 340B-Interm-1-Base를 훈련하는 데 사용됩니다. 주목할 만하게도, 340B-Interm-1-Base는 Mixtral 8x7B 기본 모델을 능가하며, 결과적으로 340B-Interm-1-Instruct 모델이 Mixtral-8x7B-Instruct-v0.1 모델을 능가하게 합니다. 이는 약한 감독으로도 강력한 능력을 이끌어낼 수 있음을 반영합니다.
두 번째 반복에서는 340B-Interm-1-Instruct 모델을 새로운 데이터 생성기로 활용합니다. Mixtral-8x7B-Instruct-v0.1에 비해 향상된 능력을 가진 이 모델을 통해 두 번째 반복에서 생성된 합성 데이터는 첫 번째 반복에서 생성된 데이터보다 더 높은 품질을 나타냅니다. 결과 데이터는 340B-Interm-2-Base를 340B-Interm-2-Chat으로 훈련하는 데 사용됩니다. 이 반복적 과정은 자체 강화 플라이휠 효과를 만들어내며, 이는 두 가지 측면에서 개선을 가져옵니다: (1) 동일한 데이터셋을 사용할 때, 기본 모델의 강도가 지시 모델에 직접적인 영향을 미쳐, 더 강력한 기본 모델이 더 강력한 지시 모델을 만들어냅니다; (2) 반대로, 동일한 기본 모델을 사용할 때, 데이터셋의 품질이 지시 모델의 효과를 결정하는 중요한 역할을 하여, 더 높은 품질의 데이터가 더 강력한 지시 모델을 이끌어냅니다. 정렬 절차 전반에 걸쳐, 우리는 여러 라운드의 데이터 생성 및 정제를 수행하여 모델의 품질을 지속적으로 개선합니다.
3.2.5 추가 데이터 소스
우리는 모델에 특정 능력을 부여하기 위해 여러 보충 데이터셋을 통합했습니다. 아래는 그 목록입니다.
- 주제 따르기: 주제 일관성과 세밀한 지시 따르기는 지시 모델에 중요한 능력입니다. 우리는 CantTalkAboutThis(Sreedhar et al., 2024)의 훈련 세트를 통합했습니다. 이 데이터셋은 주제를 벗어나게 하는 방해 턴을 의도적으로 섞어 다양한 주제를 다루는 합성 대화를 포함합니다. 이 데이터셋은 작업 지향 상호작용 동안 모델이 의도된 주제에 집중하는 능력을 향상시키는 데 도움을 줍니다.
- 불가능한 작업: 특정 작업은 인터넷 접속이나 실시간 지식과 같은 특정 능력이 필요하기 때문에 모델이 자체적으로 완료할 수 없습니다. 이러한 경우의 환각을 줄이기 위해 우리는 소수의 인간이 작성한 예시(부록 A 참조)를 사용하여 LLM이 다양한 질문을 생성하도록 유도합니다. 그런 다음 LLM에게 명시적으로 거부 응답을 하도록 요청하여 이러한 응답을 수집하고 해당 질문과 짝지어 모델을 훈련합니다. 이를 통해 모델이 불가능한 작업을 더 잘 처리할 수 있도록 합니다.
- STEM 데이터셋: Open-Platypus(Lee et al., 2023)는 STEM과 논리적 지식을 향상시키는 것으로 입증되었습니다. 우리는 PRM800K(Lightman et al., 2023), SciBench(Wang et al., 2023a), ARB(Sawada et al., 2023), openbookQA(Mihaylov et al., 2018)와 같은 허가가 자유로운 라이센스를 가진 서브셋을 훈련 데이터에 포함했습니다.
- 문서 기반 추론 및 QA: 문서 기반 QA는 LLM의 중요한 사용 사례입니다. 우리는 FinQA 데이터셋(Chen et al., 2021b)을 활용하여 수치적 추론 능력을 향상시키고, (Liu et al., 2024)에서 수집한 인간 주석 데이터를 사용하여 맥락화된 QA의 정확성을 높이며, wikitablequestions 데이터셋(Pasupat and Liang, 2015)을 사용하여 반구조적 데이터에 대한 모델의 이해를 강화합니다.
- 함수 호출: 함수 호출 능력을 향상시키기 위해 (Glaive AI, 2023)에서 일부 샘플을 포함했습니다.
3.3 정렬 알고리즘
우리는 모델 정렬을 위해 두 단계를 포함하는 표준 프로토콜(Ouyang et al., 2022)을 채택합니다: 감독된 미세 조정과 선호도 미세 조정. 이 섹션에서는 기본 알고리즘을 설명하고 우리의 혁신적인 훈련 전략을 제시합니다.
3.3.1 단계적 감독된 미세 조정
감독된 미세 조정(SFT)은 정렬의 첫 번째 단계입니다. 전통적으로 SFT는 모든 작업의 샘플 혼합으로 구성된 데이터셋을 사용하여 단일 단계로 수행됩니다. 그러나 우리의 실험 결과는 여러 행동을 동시에 학습하는 것이 때로는 이들 간의 충돌을 초래하여 모델이 모든 작업에서 최적의 정렬을 달성하는 것을 방해할 수 있음을 시사합니다. 이 현상은 특히 코딩 작업에서 두드러지며, 데이터 혼합의 샘플링 가중치를 조정해도 모든 코딩 작업에 모델을 정렬하지 못합니다. 이를 해결하기 위해, 우리는 모델이 다른 행동을 순차적이고 신중하게 습득할 수 있도록 하는 두 단계의 SFT 전략을 고안했습니다. 이 접근 방식은 모든 다운스트림 작업에서 우수한 결과를 가져옵니다.
코딩 SFT
다른 작업에 방해받지 않고 코딩 및 추론 능력을 향상시키기 위해, 우리는 첫 번째 단계로 순수하게 코딩 데이터를 사용하여 SFT를 수행합니다. 모델의 코딩 능력을 효과적으로 향상시키기 위해서는 상당한 양의 데이터가 필요합니다. 코딩 데이터를 효과적으로 합성하기 위해, 우리는 진화 과정을 모방한 Genetic Instruct 접근 방식을 개발하여, 자체 지시(Wang et al., 2022)와 마법사 코더 변이(Luo et al., 2023)를 활용하여 소수의 고품질 시드로부터 많은 합성 샘플을 생성합니다. 이 접근 방식에서는 생성된 지시와 그 솔루션의 정확성과 품질을 평가하기 위해 LLM을 활용하는 적합도 함수를 도입합니다. 이러한 평가와 검사를 통과한 샘플은 인구 풀에 추가되며, 진화 과정은 목표 인구 크기에 도달할 때까지 계속됩니다. 전체 파이프라인은 여러 개의 인구 콜로니를 사용하여 효율적으로 병렬 실행되도록 설계되어 필요에 따라 확장 가능합니다. 광범위한 중복 제거 및 필터링 후, 약 80만 개의 샘플로 구성된 데이터셋이 Code SFT 훈련을 위해 유지됩니다. 우리는 일정한 학습률 3e-7과 전역 배치 크기 128로 모델을 한 에포크 동안 훈련합니다.
일반 SFT
두 번째 단계에서는 섹션 3.2에서 설명한 다양한 작업을 포함하는 20만 개의 샘플로 구성된 혼합 데이터셋을 활용하여 일반 SFT를 진행합니다. 망각 위험을 줄이기 위해, 데이터 혼합에는 이전 Code SFT 단계에서 가져온 코드 생성 샘플의 2%도 포함됩니다. 우리는 전역 배치 크기 128로 모델을 세 에포크 동안 훈련하고, 학습률을 [1e-7, 5e-7] 범위에서 탐색합니다. 두 단계 모두에서 사용자 턴을 마스킹하고 도우미 턴에서만 손실을 계산합니다.
3.3.2 선호도 미세 조정
감독된 미세 조정 단계 이후, 우리는 선호도 미세 조정을 통해 모델을 계속 개선합니다. 여기서 모델은 (프롬프트, 선택된 응답, 거부된 응답) 삼중항의 형태로 선호도 예제를 학습합니다 (Ouyang et al., 2022; Bai et al., 2022). 구체적으로, 우리의 선호도 미세 조정 단계는 Direct Preference Optimization (DPO) (Rafailov et al., 2024)과 새로운 정렬 알고리즘인 Reward-aware Preference Optimization을 사용하여 모델 개선의 여러 반복을 포함합니다.
Direct Preference Optimization (DPO)
DPO (Rafailov et al., 2024) 알고리즘은 선택된 응답과 거부된 응답 사이의 내재적 보상 격차를 최대화하도록 정책 네트워크를 최적화합니다. 정책이 선택된 응답과 거부된 응답을 구별하는 동안, 우리는 선택된 응답이 고품질임에도 불구하고 선택된 응답과 거부된 응답 모두의 가능성이 격차가 증가함에 따라 일관되게 감소하는 것을 관찰했습니다. 경험적으로, 정책 네트워크가 충분히 오래 훈련되면 과적합되는 경향이 있으며, 한 메트릭(예: MT-Bench)의 개선은 다른 메트릭(예: 0-shot MMLU)의 저하와 함께 나타나는 경우가 많습니다. 이러한 문제를 완화하기 위해, 우리는 기본 DPO 손실에 추가하여 선택된 응답에 대한 가중된 SFT 손실을 추가합니다. 추가된 SFT 손실은 특히 우리의 선호도 데이터가 참조 정책에서 생성되지 않았기 때문에 정책 네트워크가 선호도 데이터로부터 크게 벗어나는 것을 방지하는 데 도움이 됩니다. 모델이 저품질의 선택된 응답을 학습하는 것을 방지하기 위해, 우리는 Nemotron-4-340B-Reward를 사용하여 참값이 없을 때 고품질의 선택된 응답을 포함한 예제를 선택합니다. 이를 통해 다양한 작업을 포함하는 16만 개의 예제 선호도 데이터셋을 확보하게 됩니다. 우리는 모델을 전역 배치 크기 256과 일정한 학습률로 한 에포크 동안 훈련합니다. 학습률은 [3e-8, 3e-7], DPO 손실의 kl 정규화 계수는 [3e-4, 3e-3], SFT 손실의 가중치는 [1e-5, 1e-3] 범위 내에서 조정합니다.
eward-aware Preference Optimization (RPO)
보상 인식 선호도 최적화(RPO): 3.2.3절에서 설명한 바와 같이, 우리의 선호도 데이터의 대부분은 합성 데이터이며, 그 선호도 순위는 Nemotron-4-340B-Reward 모델의 보상에 따라 판단됩니다. DPO는 두 응답 간의 이진 순위만 사용하지만, 응답 간의 차이에는 더 많은 정보가 포함되어 있습니다. 경험적으로, 일부 거부된 응답이 선택된 응답보다 약간 나은 경우도 있으며, 일부 거부된 응답은 훨씬 뒤처지는 경우도 있습니다. 이러한 차이를 무시하면, DPO는 선택된 응답과 거부된 응답 간의 내재적 보상 격차를 최대화하지만, 이는 고품질의 거부된 응답을 "잊어버리는" 현상을 초래합니다. 이를 극복하기 위해, 우리는 보상 인식 선호도 최적화(RPO)라는 새로운 알고리즘을 제안합니다. 이는 정책 네트워크가 정책 참조와의 보상 격차를 근사하도록 시도하며, 구체적으로는 정책 네트워크가 정의한 보상 격차를 근사하려고 합니다. 이는 다음과 같은 새로운 손실 함수를 도입하게 됩니다:

로그 비율은 확률의 상대적인 차이를 나타내지만, 보상 모델에서 실제 보상 차이를 반영하지 않습니다. 여기서 추가적인 정규화와 거리 메트릭이 필요합니다.
로그 비율은 확률 간의 차이를 명확하게 드러내지만, 실제 응답의 품질 차이를 반영하지 않습니다. 따라서, 보상 차이를 반영한 거리 메트릭과 정규화를 추가하여 모델이 더 나은 응답을 선택하도록 최적화하는 것입니다. 이렇게 함으로써, 모델이 단순한 확률 차이뿐만 아니라 응답의 실제 품질을 반영하여 학습할 수 있습니다.
3.4 지시 모델 평가
3.4.1 자동 벤치마크
우리는 Nemotron-4-340B-Instruct를 다양한 자동 벤치마크에서 포괄적으로 평가했습니다. 이 섹션에서는 우리 모델의 결과를 보고하고, 공개된 모델(Llama-3-70B-Instruct (MetaAI, 2024), Mixtral-8x22B-Instruct-v0.1 (Mistral-AI-Team, 2024b), Qwen-2-72B-Instruct (Qwen-Team, 2024))과 독점 모델(GPT-4-1106-preview (OpenAI, 2023), Mistral Large (Mistral-AI-Team, 2024a), Claude-3-Sonnet (Anthropic, 2024))과 비교합니다. 다음은 평가한 작업, 그 카테고리 및 설정입니다:
- 단일 턴 대화: AlpacaEval 2.0 LC (Dubois et al., 2024) 및 Arena Hard (Li et al.).
- 다중 턴 대화: MT-Bench (GPT-4-Turbo) (Wang et al., 2024). 이는 원래 MT-Bench (Zheng et al., 2024a)의 수정된 버전으로, 점수가 평균적으로 원래 MT-Bench 점수보다 0.8 포인트 낮습니다. 특히, 추론, 수학, 코딩 카테고리에서 30개의 참조 응답 중 13개가 잘못된 것으로 나타나 정확한 평가에 큰 영향을 미쳤습니다. 수정된 답변은 여기에서 확인할 수 있습니다.
- 인기 있는 집계 벤치마크: MMLU (0-shot) (Hendrycks et al., 2020).
- 수학: GSM8K (0-shot) (Cobbe et al., 2021).
- 코드: HumanEval (0-shot) (Chen et al., 2021a) 및 MBPP (0-shot) (Austin et al., 2021)에서 Pass@1 점수.
- 지시 따르기: IFEval (Zhou et al., 2023).
- 주제 따르기: TFEval (Sreedhar et al., 2024).

표 5에서 볼 수 있듯이, Nemotron-4-340B-Instruct는 현재 사용 가능한 공개 액세스 모델과 경쟁력을 갖추고 있습니다. 지시 모델의 경우, 우리는 제로샷 평가가 가장 중요한 설정이라고 믿습니다. 이는 사전 예시 없이 지시를 정확히 따르는 모델의 능력을 평가하기 때문입니다. 이 설정은 사람들이 실제 세계에서 LLM과 상호작용하는 방식과 더 유사합니다. 투명성과 재현성을 위해, 우리는 평가에 사용된 프롬프트를 부록 E 1에 포함했습니다.
섹션 3.3에서 논의한 바와 같이, 우리의 정렬 훈련은 여러 단계를 포함합니다: 코드 SFT, 일반 SFT, DPO, 그리고 세 번의 RPO. 우리는 최종 모델의 결과를 측정하고, 각 정렬 단계 동안 각 중간 모델의 강도를 표 6에 정량화했습니다. 우리는 코드 SFT 단계가 기본 모델의 57.3에서 HumanEval 점수를 70.7로 크게 향상시키는 것을 관찰했습니다. 그 다음의 일반 SFT는 MT-Bench와 MMLU와 같은 다른 카테고리에서 정확도를 크게 향상시키며, HumanEval에서는 약간의 저하가 있었습니다. DPO 단계는 대부분의 메트릭을 추가로 향상시키며, MT-Bench에서는 약간의 감소가 있었습니다. 마지막으로, RPO 단계는 모든 메트릭을 고르게 향상시켰습니다. 특히, MT-Bench 점수는 7.90에서 8.22로 증가했고, IFEval Prompt-Strict-Acc는 61.7에서 79.9로 증가했습니다.
3.4.2 인간 평가
자동 평가 외에도, 우리는 훈련된 평가자 팀을 통해 모델의 인간 평가를 실시했습니다. 이 평가자들은 10개의 서로 다른 작업 카테고리로 분류된 136개의 프롬프트를 제시받았으며, 6점 척도의 리커트 유형 척도를 사용해 응답을 평가했습니다. 이 척도는 다섯 수준의 품질과 모델이 지시를 완전히 따르지 못한 경우를 위한 추가 수준을 포함했습니다. 프롬프트 카테고리는 주로 InstructGPT (Ouyang et al., 2022)에서 파생되었으며, 다중 턴 채팅 카테고리가 추가되어 마지막 도우미 턴만 평가했습니다. 기타 "기타" 카테고리에는 순수 추론 및 적대적 프롬프트에 관한 프롬프트가 포함되었습니다. 프롬프트의 자세한 분포는 보충 자료 G에 포함되어 있습니다.
평가 지침은 주로 두 가지 축으로 구성됩니다: 도움성(helpfulness)과 진실성(truthfulness). 이 축을 기반으로 각 5단계 품질이 주로 포함해야 할 사항을 상세히 설명했습니다. 이는 일반적인 Poor/Excellent 극단 비교보다 주관성을 줄여 신뢰성을 높이는 데 도움이 됩니다 (Joshi et al., 2015). 지침의 반복적인 정제 과정에서 응답 길이에 대한 평가자들의 인식을 고려한 보조 기준을 포함하면 결과가 개선된다는 것을 발견했습니다. 이 접근 방식은 모델의 지시 따르기와 유용한 응답 제공 능력에서 평가자 개인의 장황함 선호도를 분리하는 데 도움이 되었습니다.

평가 디자인 측면에서, 각 프롬프트는 고정된 모델 세트에서 세 가지 다른 응답과 짝을 이루었습니다. 응답의 순서는 각 프롬프트마다 무작위로 배치되었으며, 모든 프롬프트와 응답은 동일한 평가자 그룹에 의해 평가되었습니다. 평가가 완료된 후, 점수는 GPT-4-1106-preview와 비교하여 상대적인 승/무/패 비율로 변환되었습니다. 결과는 표 5에 나와 있습니다. 추출 및 재작성 작업을 제외하고, Nemotron-4-340B-Instruct의 승률이 GPT-4-1106-preview와 비교할 때 비슷하거나 더 좋은 성과를 보였으며, 특히 다중 턴 채팅에서 강력한 결과를 보였습니다. 전체 평가 세트에서 모델의 전체 비율은 승 : 무 : 패 = 28.19% : 46.57% : 25.24%입니다.
인간 평가에서의 보조 기준으로, 평가자들의 길이 인식을 표 7에서 확인할 수 있습니다. 결과는 평가자들이 Nemotron-4-340B-Instruct의 응답 길이를 적절하다고 여기는 비율이 약간 더 높다는 것을 보여줍니다 (79.41% vs 74.02%). 주목할 만한 점은 이러한 이득이 주로 긴/장황한 응답 비율의 감소에서 비롯된다는 것입니다 (20.10% vs 25.74%).

3.4.3 안전성 평가
대형 언어 모델(LLM)이 널리 사용됨에 따라, 이들의 사용과 관련된 콘텐츠 안전성 위험도 증가하고 있습니다. 우리의 모델의 안전성을 평가하기 위해, 우리는 NVIDIA의 고품질 콘텐츠 안전 솔루션 및 평가 벤치마크인 AEGIS(Ghosh et al., 2024)를 사용합니다. AEGIS는 인간-LLM 상호작용에서의 12가지 주요 위험을 다루는 포괄적인 콘텐츠 안전성 위험 분류 체계를 기반으로 합니다(세부 사항은 부록 H 참조). 이 분류 체계는 여러 콘텐츠 안전성 위험 분류 체계를 고려하여 만들어졌으며, NVIDIA의 조직적 가치와 일치하여 혐오 및 괴롭힘의 보호 특성을 정의하고, 아동 성학대를 별도의 주요 위험 범주로 정의합니다. 또한 우리는 "주의 필요"라는 새로운 범주를 도입하여 안전성을 판단하기에 충분한 맥락이 없는 모호한 상황을 다룹니다. 이 범주는 보다 방어적인 모드가 필요할 때 특히 유용하며, 필요에 따라 "주의 필요"를 안전하거나 안전하지 않은 것으로 매핑할 수 있습니다.
AEGIS는 사용자 프롬프트, 단일 턴 및 다중 턴 대화의 인간 주석 데이터셋과 후보 LLM의 응답이 안전한지 여부를 예측하고, 응답이 안전하지 않은 경우 위반 범주를 제공할 수 있는 AEGIS 안전 모델로 구성된 벤치마크입니다. AEGIS 안전 모델은 오픈 소스 LlamaGuard(Inan et al., 2023) LLM 기반 분류기 그룹으로, AEGIS 안전 분류 체계 및 정책과 함께 파라미터 효율적인 방식으로 추가 지시 조정을 거쳤습니다.

AEGIS 테스트 분할에서 프롬프트를 사용하여 Nemotron-4-340B-Instruct와 Llama-3-70B-Instruct로부터 응답을 유도합니다. 그런 다음 AEGIS 안전 모델이 응답을 평가합니다. 그림 6에서는 Nemotron-4-340B-Instruct와 Llama-3-70B-Instruct의 총 응답 수 대비 안전하지 않은 응답의 비율을 보고합니다. 우리는 Nemotron-4-340B-Instruct의 매우 낮은 안전하지 않은 응답 비율을 보여줍니다. 기록된 안전하지 않은 응답 중에서 Nemotron-4-340B-Instruct는 폭력, 자살 및 자해, 아동 성학대, 개인 정보, 괴롭힘, 위협 및 주의 필요 범주에서 무시할 수 있는 수준입니다. 안전하지 않은 응답 중 일부는 범죄 계획 및 규제 물질 범주에 속합니다. 우리는 이후 모델 업데이트에서 이를 완화할 계획입니다. 전반적으로, Nemotron-4-340B-Instruct는 안전성 면에서 Llama-3-70B-Instruct와 비교할 만합니다.
4. 결론
우리는 Nemotron-4 340B 모델 패밀리(Nemotron-4-340B-Base, Nemotron-4-340B-Instruct 및 Nemotron-4-340B-Reward)를 소개합니다. 이 모델들은 허가가 자유로운 오픈 액세스 라이센스로 제공되며, 다양한 작업에서의 능력을 상세히 설명합니다. 우리는 이 모델들의 훈련 및 추론 코드를 공개합니다. 또한 우리의 합성 데이터 생성 파이프라인에 대한 포괄적인 세부 사항을 제공하고 그 효과를 입증합니다. 우리는 이러한 모델들이 LLM 및 AI 응용 프로그램의 개발을 촉진할 것이라고 믿습니다.



