https://arxiv.org/abs/2301.00808
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrat
arxiv.org
다른 분야의 일을하면서 논문을 읽다보니 정신이 없다
https://github.com/facebookresearch/ConvNeXt-V2
GitHub - facebookresearch/ConvNeXt-V2: Code release for ConvNeXt V2 model
Code release for ConvNeXt V2 model. Contribute to facebookresearch/ConvNeXt-V2 development by creating an account on GitHub.
github.com
초록
개선된 아키텍처와 더 나은 표현 학습 프레임워크로 인해 시각 인식 분야는 2020년대 초반에 급격한 현대화와 성능 향상을 이루었습니다. 예를 들어, ConvNeXt [52]로 대표되는 현대적인 컨볼루션 신경망(ConvNet)은 다양한 시나리오에서 강력한 성능을 보여주었습니다. 이러한 모델들은 원래 ImageNet 라벨을 사용한 지도 학습을 위해 설계되었지만, 마스크 오토인코더(MAE) [31]와 같은 자가 지도 학습 기술로부터도 잠재적인 이점을 얻을 수 있습니다. 그러나 단순히 이 두 가지 접근 방식을 결합하는 것은 기대에 못 미치는 성능을 보였습니다. 본 논문에서는 완전한 컨볼루션 마스크 오토인코더 프레임워크와 ConvNeXt 아키텍처에 추가하여 채널 간 특징 경쟁을 향상시킬 수 있는 새로운 글로벌 응답 정규화(GRN) 층을 제안합니다. 자가 지도 학습 기술과 아키텍처 개선의 공동 설계는 다양한 인식 벤치마크에서 순수 컨볼루션 신경망의 성능을 크게 향상시키는 새로운 모델군인 ConvNeXt V2를 탄생시켰습니다. 여기에는 ImageNet 분류, COCO 탐지 및 ADE20K 분할이 포함됩니다. 또한, ImageNet에서 76.7%의 상위-1 정확도를 기록하는 효율적인 3.7M 파라미터 Atto 모델부터 공개된 훈련 데이터만을 사용하여 88.9%의 최첨단 정확도를 달성하는 650M Huge 모델에 이르기까지 다양한 크기의 사전 학습된 ConvNeXt V2 모델을 제공합니다.
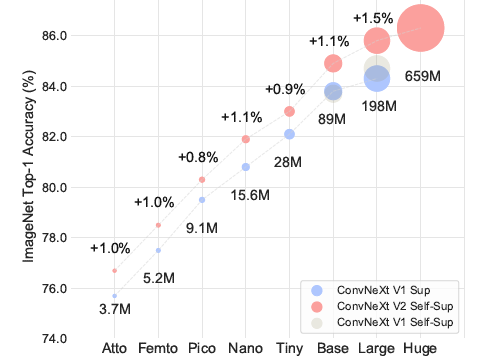
그림 1. ConvNeXt V2 모델 확장. 완전한 컨볼루션 마스크 오토인코더 프레임워크를 사용하여 사전 학습된 ConvNeXt V2 모델은 다양한 모델 크기에서 이전 버전보다 훨씬 나은 성능을 발휘합니다.
1. 서론
이전 수십 년간의 연구 돌파구를 바탕으로 [34,44,47,60,68], 시각 인식 분야는 대규모 시각 표현 학습의 새로운 시대를 맞이했습니다. 사전 학습된 대규모 비전 모델은 특징 학습과 다양한 시각 응용 프로그램을 가능하게 하는 필수 도구가 되었습니다. 시각 표현 학습 시스템의 성능은 주로 세 가지 주요 요소에 의해 영향을 받습니다: 선택된 신경망 아키텍처, 사용된 학습 방법, 데이터의 규모. 시각 인식 분야에서는 이러한 각 영역에서의 진보가 전체 성능 개선에 기여합니다.
신경망 아키텍처 설계의 혁신은 표현 학습 분야에서 일관되게 중요한 역할을 해왔습니다. 컨볼루션 신경망 아키텍처(ConvNets) [34, 44, 47]는 다양한 시각 인식 작업에 대해 일반적인 특징 학습 방법을 사용할 수 있게 함으로써 컴퓨터 비전 연구에 상당한 영향을 미쳤습니다 [25, 33]. 최근 몇 년 동안, 원래 자연어 처리용으로 개발된 트랜스포머 아키텍처 [68]는 모델 및 데이터셋 크기에 대한 강력한 확장 행동으로 인해 인기를 얻었습니다 [21]. 더 최근에는 ConvNeXt [52] 아키텍처가 전통적인 ConvNet을 현대화하여 순수 컨볼루션 모델도 확장 가능한 아키텍처가 될 수 있음을 보여주었습니다. 그러나 신경망 아키텍처 설계 공간을 탐색하는 가장 일반적인 방법은 여전히 ImageNet에서 지도 학습 성능을 벤치마킹하는 것입니다.
시각 표현 학습에 대한 별도의 연구 라인에서는 레이블이 있는 지도 학습에서 전제 목표를 가진 자가 지도 사전 학습으로 초점이 이동하고 있습니다. 다양한 자가 지도 알고리즘 중에서 마스크 오토인코더(MAE) [31]는 최근 언어 모델링에서의 성공을 시각 도메인으로 가져와 빠르게 시각 표현 학습의 인기 있는 접근 방식이 되었습니다. 그러나 자가 지도 학습의 일반적인 관행은 지도 학습을 위해 설계된 사전 결정된 아키텍처를 사용하고, 그 설계가 고정되어 있다고 가정하는 것입니다. 예를 들어, MAE는 비전 트랜스포머 [21] 아키텍처를 사용하여 개발되었습니다.
아키텍처와 자가 지도 학습 프레임워크의 설계 요소를 결합하는 것은 가능하지만, ConvNeXt와 마스크 오토인코더를 사용할 때는 도전 과제가 발생할 수 있습니다. 한 가지 문제는 MAE가 트랜스포머의 순차 처리 능력에 최적화된 특정 인코더-디코더 설계를 가지고 있다는 점입니다. 이는 무거운 계산이 필요한 인코더가 보이는 패치에 집중할 수 있게 하여 사전 학습 비용을 줄여줍니다. 이 설계는 밀집된 슬라이딩 윈도우를 사용하는 표준 ConvNet과 호환되지 않을 수 있습니다. 또한, 아키텍처와 학습 목표 간의 관계를 고려하지 않으면 최적의 성능을 달성할 수 있을지 불분명할 수 있습니다. 실제로 이전 연구에서는 마스크 기반 자가 지도 학습으로 ConvNet을 학습하는 것이 어려울 수 있음을 보여주었고 [43], 경험적 증거는 트랜스포머와 ConvNet이 표현의 질에 영향을 미칠 수 있는 다른 특징 학습 행동을 가질 수 있음을 시사합니다.
이를 해결하기 위해 우리는 네트워크 아키텍처와 마스크 오토인코더를 동일한 프레임워크 하에 공동 설계하여 ConvNeXt 모델에 대한 마스크 기반 자가 지도 학습을 효과적으로 만들고 트랜스포머를 사용할 때와 유사한 결과를 달성하고자 합니다. 마스크 오토인코더를 설계할 때 우리는 마스크된 입력을 희소 패치 집합으로 취급하고 희소 컨볼루션 [28]을 사용하여 보이는 부분만 처리합니다. 이 아이디어는 대규모 3D 포인트 클라우드를 처리할 때 희소 컨볼루션을 사용하는 것에서 영감을 받았습니다 [15,76]. 실제로 우리는 ConvNeXt를 희소 컨볼루션으로 구현할 수 있으며, 미세 조정 시 가중치는 특별한 처리 없이 표준 밀집 레이어로 다시 변환됩니다. 사전 학습 효율성을 더욱 높이기 위해 트랜스포머 디코더를 단일 ConvNeXt 블록으로 교체하여 전체 설계를 완전히 컨볼루션화했습니다. 이러한 변경으로 혼합된 결과를 관찰했습니다: 학습된 특징은 유용하고 기본 결과를 개선하지만, 미세 조정 성능은 여전히 트랜스포머 기반 모델만큼 좋지 않습니다.
다음으로 ConvNeXt의 다양한 학습 구성에 대한 특징 공간 분석을 수행했습니다. 우리는 ConvNeXt를 마스크된 입력에 직접 학습시킬 때 MLP 층에서 특징 붕괴의 잠재적인 문제를 확인했습니다. 이 문제를 해결하기 위해 채널 간 특징 경쟁을 향상시키기 위해 글로벌 응답 정규화(GRN) 층을 추가하는 것을 제안합니다. 이 변경은 모델이 마스크 오토인코더로 사전 학습될 때 가장 효과적이며, 지도 학습에서 고정된 아키텍처 설계를 재사용하는 것이 최적이 아닐 수 있음을 시사합니다.
요약하자면, 우리는 마스크 오토인코더와 함께 사용할 때 성능이 향상된 ConvNeXt V2를 소개합니다. 이 모델은 ImageNet 분류 [60], COCO 객체 탐지 [49], ADE20K 분할 [81]을 포함한 다양한 다운스트림 작업에서 순수 ConvNet의 성능을 크게 향상시킵니다. ConvNeXt V2 모델은 다양한 계산 체제에서 사용할 수 있으며, ImageNet에서 76.7%의 상위-1 정확도를 달성하는 효율적인 3.7M 파라미터 Atto 모델부터 IN-22K 레이블을 사용하여 최첨단 88.9% 정확도에 도달하는 650M Huge 모델에 이르기까지 다양한 복잡도의 모델을 포함합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
마스크 오토인코더(Masked Autoencoder)는 자가 지도 학습(self-supervised learning) 기법 중 하나로, 이미지나 텍스트 데이터의 일부를 마스크(mask) 처리하여 가리고, 모델이 그 가려진 부분을 예측하도록 학습하는 방식입니다. 이는 특히 비전 트랜스포머(Vision Transformer)에서 많이 사용되며, 자연어 처리에서 마스크 언어 모델링(Masked Language Modeling)의 성공을 시각 도메인으로 확장한 것입니다.
마스크 오토인코더의 작동 원리
- 입력 데이터 마스킹:
- 입력 이미지의 일부 패치를 무작위로 선택하여 마스크 처리합니다. 예를 들어, 이미지의 25% 패치를 가린다고 가정합니다.
- 인코딩 단계:
- 마스크된 이미지를 인코더에 입력합니다. 인코더는 보이는(마스크되지 않은) 패치들로부터 특징을 추출합니다.
- 디코딩 단계:
- 추출된 특징을 기반으로 디코더가 마스크된 부분을 복원하도록 학습합니다. 디코더는 마스크된 패치들을 복원하여 원래 이미지와 최대한 가깝게 만듭니다.
- 재구성 손실:
- 디코더가 생성한 복원 이미지와 원본 이미지 간의 차이를 계산하여 손실(loss)을 구합니다. 이 손실을 최소화하도록 모델을 학습시킵니다.
마스크 오토인코더의 장점
- 자가 지도 학습: 레이블된 데이터 없이도 대량의 데이터로 학습이 가능하므로, 라벨링 비용을 절감할 수 있습니다.
- 일반화 능력 향상: 모델이 더 다양한 특징을 학습할 수 있어, 다양한 다운스트림 작업(예: 이미지 분류, 객체 탐지 등)에서 좋은 성능을 발휘할 수 있습니다.
- 효율성: 가려진 부분을 복원하는 작업을 통해 모델이 데이터의 중요한 패턴을 학습하게 되어, 더 효율적인 특징 표현을 가능하게 합니다.
마스크 오토인코더는 이러한 특성들 덕분에 최근 시각 인식 분야에서 많은 주목을 받고 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
2. 관련 연구
컨볼루션 신경망(ConvNets): 1980년대에 처음 소개된 ConvNets [46]는 역전파를 사용하여 학습되었으며, 최적화, 정확성, 효율성 측면에서 수년간 많은 개선을 거쳤습니다 [35, 36, 39, 44, 58, 61, 63, 75]. 이러한 혁신은 주로 ImageNet 데이터셋을 사용한 지도 학습을 통해 발견되었습니다. 최근에는 UnNAS [50]와 같이 회전 예측 및 색상화와 같은 자가 지도 사전 과제를 사용하여 아키텍처 검색을 수행하려는 노력도 있었습니다. 최근 ConvNeXt [52]는 설계 공간을 종합적으로 검토하고, 순수 ConvNet이 비전 트랜스포머 [21, 51]만큼 확장 가능할 수 있음을 입증했습니다. 비전 트랜스포머는 많은 응용 프로그램에서 지배적인 아키텍처가 되었습니다. ConvNeXt는 특히 낮은 복잡성이 요구되는 시나리오에서 우수한 성능을 보였습니다 [7, 70, 71]. 자가 지도 학습을 기반으로 한 우리의 ConvNeXt V2 모델은 기존 모델을 업그레이드하고 다양한 사용 사례에서 성능을 크게 향상시키는 간단한 방법을 제공합니다.
마스크 오토인코더(Masked Autoencoders): 마스크 이미지 모델링은 마스크 오토인코더 [31]로 대표되는 최신 자가 지도 학습 전략 중 하나입니다. 마스크 오토인코더는 신경망 사전 학습 프레임워크로서 시각 인식에 광범위한 영향을 미쳤습니다. 그러나 원래의 마스크 오토인코더는 비대칭 인코더-디코더 설계 때문에 ConvNet에 직접 적용할 수 없습니다. [3,77]과 같은 대체 프레임워크는 ConvNet에 이 접근 방식을 적용하려고 시도했지만, 혼합된 결과를 보였습니다. MCMAE [23]는 입력 토크나이저로 몇 개의 컨볼루션 블록을 사용합니다. 우리가 알기로는, 자가 지도 학습이 ConvNeXt의 최고 지도 학습 결과를 개선할 수 있음을 보여주는 사전 학습된 모델은 없습니다.
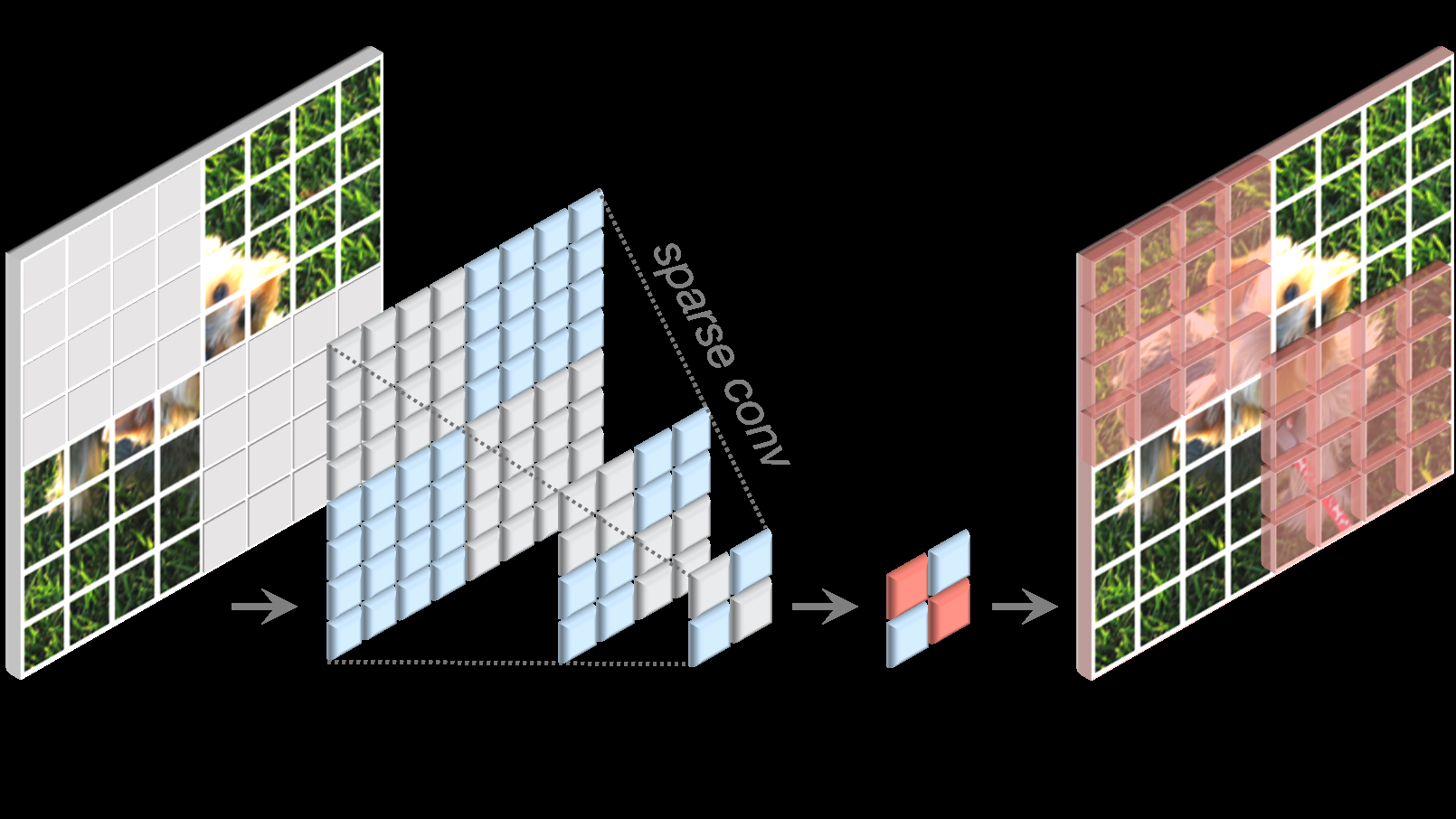
3. 완전 컨볼루션 마스크 오토인코더
우리의 접근 방식은 개념적으로 간단하며 완전 컨볼루션 방식으로 실행됩니다. 학습 신호는 원시 입력 비주얼을 높은 마스킹 비율로 무작위로 마스킹하고, 남은 컨텍스트를 기반으로 모델이 누락된 부분을 예측하게 하여 생성됩니다. 우리의 프레임워크는 그림 2에 설명되어 있으며, 이제 주요 구성 요소를 더 자세히 설명하겠습니다.
마스킹: 우리는 마스킹 비율 0.6으로 무작위 마스킹 전략을 사용합니다. 컨볼루션 모델은 계층적 설계를 가지고 있어 특징이 다양한 단계에서 다운샘플링되므로, 마스크는 마지막 단계에서 생성되고 가장 높은 해상도로 재귀적으로 업샘플링됩니다. 실제 구현에서는 원본 입력 이미지의 32×32 패치 중 60%를 무작위로 제거합니다. 최소한의 데이터 증강을 사용하며, 무작위 크기 조정 크롭만 포함합니다.
그림 2. 우리의 FCMAE 프레임워크
우리는 완전 컨볼루션 마스크 오토인코더(FCMAE)를 소개합니다. 이 프레임워크는 희소 컨볼루션 기반의 ConvNeXt 인코더와 가벼운 ConvNeXt 블록 디코더로 구성됩니다. 전체적으로, 우리의 오토인코더 아키텍처는 비대칭적입니다. 인코더는 보이는 픽셀만 처리하고, 디코더는 인코딩된 픽셀과 마스크 토큰을 사용하여 이미지를 재구성합니다. 손실은 마스크된 영역에서만 계산됩니다.
인코더 설계: 우리는 ConvNeXt [52] 모델을 인코더로 사용합니다. 마스크 이미지 모델링을 효과적으로 만드는 한 가지 과제는 모델이 마스크된 영역에서 정보를 복사하여 붙여넣는 지름길을 학습하지 않도록 하는 것입니다. 이는 트랜스포머 기반 모델에서는 상대적으로 쉽게 방지할 수 있는데, 보이는 패치만 인코더에 입력으로 남길 수 있기 때문입니다. 그러나 ConvNet에서는 2D 이미지 구조를 유지해야 하므로 이를 달성하기가 더 어렵습니다. 단순한 해결책은 입력 측에 학습 가능한 마스크 토큰을 도입하는 것이지만 [3,77], 이러한 접근 방식은 사전 학습의 효율성을 떨어뜨리고, 테스트 시에는 마스크 토큰이 없으므로 학습 및 테스트 시간의 일관성을 저해합니다. 이는 마스킹 비율이 높을 때 특히 문제가 됩니다.
이 문제를 해결하기 위해, 우리의 새로운 통찰력은 "희소 데이터 관점"에서 마스크된 이미지를 보는 것입니다. 이는 3D 작업에서 희소 포인트 클라우드 학습에서 영감을 받았습니다 [15,76]. 우리의 주요 관찰은 마스크된 이미지를 2D 희소 배열의 픽셀로 표현할 수 있다는 것입니다. 이 통찰력을 바탕으로, 희소 컨볼루션을 프레임워크에 통합하여 마스크 오토인코더의 사전 학습을 용이하게 하는 것이 자연스럽습니다. 실제로 사전 학습 중에 인코더의 표준 컨볼루션 레이어를 서브매니폴드 희소 컨볼루션으로 변환하여 모델이 보이는 데이터 포인트만 작동하도록 제안합니다 [15,27,28]. 희소 컨볼루션 레이어는 추가 처리가 필요 없이 미세 조정 단계에서 표준 컨볼루션으로 다시 변환될 수 있습니다. 대안으로는 밀집 컨볼루션 작업 전후에 이진 마스킹 작업을 적용하는 것도 가능합니다. 이 작업은 숫자적으로 희소 컨볼루션과 동일한 효과를 가지며, 이론적으로는 더 많은 계산이 필요하지만 TPU와 같은 AI 가속기에서는 더 친화적일 수 있습니다.
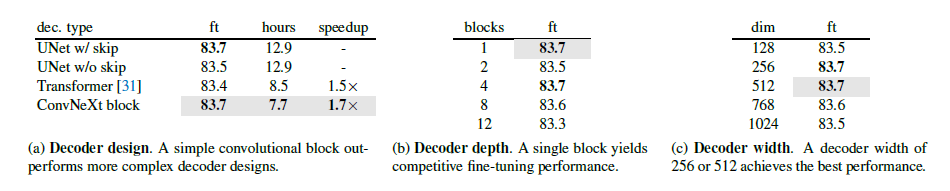
표 1. ImageNet-1K에서 ConvNeXt-Base로 MAE 디코더 소거 실험
우리는 미세 조정(ft) 정확도(%)를 보고합니다. 사전 학습 일정은 800 에포크입니다. 디코더 설계 탐색에서는 JAX를 사용하여 256코어 TPU-v3 팟에서 실제 시간(wall-clock time)을 벤치마크했습니다. 속도 향상은 UNet 디코더 기준에 상대적인 것입니다. 논문에서 사용된 최종 설계 선택 사항은 회색으로 표시되었습니다.
디코더 설계
우리는 가볍고 간단한 ConvNeXt 블록을 디코더로 사용합니다. 이는 전체적으로 비대칭 인코더-디코더 아키텍처를 형성하며, 인코더가 더 무겁고 계층적입니다. 계층형 디코더 [48, 59] 또는 트랜스포머 [21, 31]와 같은 더 복잡한 디코더도 고려했지만, 단순한 단일 ConvNeXt 블록 디코더가 미세 조정 정확도 측면에서 잘 작동했고, 사전 학습 시간을 상당히 줄였습니다. 이는 표 1에 나와 있습니다. 디코더의 차원은 512로 설정합니다.
재구성 목표
재구성된 이미지와 목표 이미지 간의 평균 제곱 오차(MSE)를 계산합니다. MAE [31]와 유사하게, 목표는 원본 입력의 패치 단위로 정규화된 이미지이며, 손실은 마스크된 패치에만 적용됩니다.
완전 컨볼루션 마스크 오토인코더 (FCMAE)
위에서 설명한 제안들을 결합하여 완전 컨볼루션 마스크 오토인코더(FCMAE)를 제시합니다. 이 프레임워크의 효과를 평가하기 위해 ConvNeXt-Base 모델을 인코더로 사용하고 일련의 소거 연구(ablation studies)를 수행합니다. 논문 전체에서 전이 학습에서의 실용적 관련성 때문에 끝에서 끝으로 미세 조정 성능에 중점을 두고, 학습된 표현의 품질을 평가합니다. 우리는 ImageNet-1K (IN-1K) 데이터셋을 사용하여 각각 800과 100 에포크 동안 사전 학습과 미세 조정을 수행하고, 단일 224×224 중심 크롭에 대한 상위-1 IN-1K 검증 정확도를 보고합니다. 실험 설정에 대한 추가 세부 사항은 부록에서 찾을 수 있습니다.
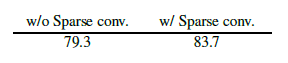
우리의 FCMAE 프레임워크에서 희소 컨볼루션 사용의 영향을 이해하기 위해, 마스크된 이미지 사전 학습 동안 학습된 표현의 품질에 어떻게 영향을 미치는지 조사합니다. 경험적 결과에 따르면, 좋은 결과를 얻기 위해서는 마스크된 영역에서 정보 누출을 방지하는 것이 필수적임을 보여줍니다.
다음으로, 자가 지도 학습 접근 방식을 지도 학습과 비교합니다. 구체적으로, 동일한 레시피를 사용한 100 에포크 지도 학습 기준 결과와 원래 ConvNeXt 논문 [52]에서 제공된 300 에포크 지도 학습 기준 결과를 얻습니다. 우리의 FCMAE 사전 학습이 무작위 기준 초기화보다 더 나은 초기화를 제공한다는 것을 발견했습니다(즉, 82.7에서 83.7로), 하지만 원래 지도 학습 설정에서 얻은 최고의 성능에 도달하기 위해서는 여전히 개선이 필요합니다.

이는 트랜스포머 기반 모델을 사용한 마스크 이미지 모델링의 최근 성공과는 대조적입니다 [3, 31, 77], 여기서 사전 학습된 모델이 지도 학습된 모델보다 훨씬 뛰어납니다. 이는 마스크 오토인코더 사전 학습 동안 ConvNeXt 인코더가 직면하는 고유한 문제를 조사하게 만드는 동기가 됩니다. 다음으로 이러한 문제에 대해 논의합니다.

그림 3. 특징 활성화 시각화
각 특징 채널의 활성화 맵을 작은 사각형으로 시각화합니다. 명확성을 위해, 각 시각화에 64개의 채널을 표시합니다. ConvNeXt V1 모델은 채널 전반에 걸쳐 중복된 활성화(죽거나 포화된 뉴런)가 존재하는 특징 붕괴 문제를 겪습니다. 이 문제를 해결하기 위해, 우리는 학습 중 특징 다양성을 촉진하는 새로운 방법인 글로벌 응답 정규화(GRN) 층을 도입합니다. 이 기술은 각 블록의 고차원 특징에 적용되어 ConvNeXt V2 아키텍처의 개발로 이어집니다.
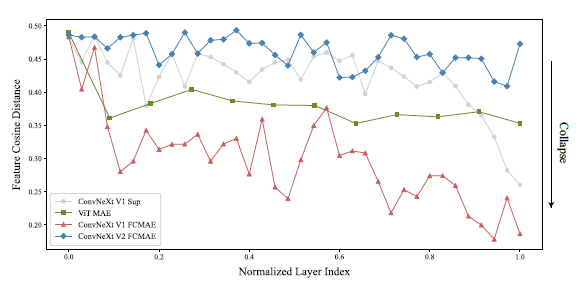
그림 4. 특징 코사인 거리 분석
총 레이어 수가 아키텍처마다 다르기 때문에, 정규화된 레이어 인덱스에 대해 거리 값을 플로팅합니. ConvNeXt V1 FCMAE 사전 학습된 모델은 심각한 특징 붕괴 행동을 보입니다. 지도 학습된 모델도 마지막 레이어에서만 특징 다양성 감소를 보입니다. 지도 학습된 모델에서의 이러한 다양성 감소는 교차 엔트로피 손실 사용 때문일 가능성이 높으며, 이는 모델이 클래스 구분 특징에 집중하고 다른 특징을 억제하도록 유도합니다.
4. 글로벌 응답 정규화 (Global Response Normalization)
이 섹션에서는 FCMAE 사전 학습이 ConvNeXt 아키텍처와 함께 더 효과적으로 작동하도록 하기 위해 새로운 글로벌 응답 정규화(GRN) 기법을 소개합니다. 우리는 먼저 질적 및 양적 특징 분석을 통해 접근 방식을 설명합니다.
특징 붕괴: 학습 행동에 대한 더 깊은 통찰을 얻기 위해, 우리는 특징 공간에서 정성적 분석을 수행합니다. 우리는 FCMAE 사전 학습된 ConvNeXt-Base 모델의 활성화를 시각화하고, "특징 붕괴" 현상을 관찰합니다: 여러 채널에 걸쳐 죽거나 포화된 특징 맵이 많아지며 활성화가 중복됩니다. 그림 3에서 이러한 시각화의 일부를 보여줍니다. 이 현상은 ConvNeXt 블록의 차원 확장 MLP 레이어에서 주로 관찰되었습니다 [52].

분석 수행 방법
우리는 ImageNet-1K 검증 세트의 다양한 클래스에서 임의로 1,000개의 이미지를 선택하고, FCMAE 모델, ConvNeXt 지도 학습 모델 [52], MAE 사전 학습된 ViT 모델 [31]을 포함한 각 모델의 모든 레이어에서 고차원 특징을 추출합니다. 그런 다음 각 이미지의 레이어별 거리를 계산하고 모든 이미지에 걸쳐 평균 값을 계산합니다. 결과는 그림 4에 플롯되어 있습니다. FCMAE 사전 학습된 ConvNeXt 모델은 특징 붕괴 경향을 명확히 나타내며, 이는 이전 활성화 시각화에서의 관찰과 일치합니다. 이는 학습 중에 특징을 다양화하고 특징 붕괴를 방지하는 방법을 고려하도록 동기를 부여합니다.




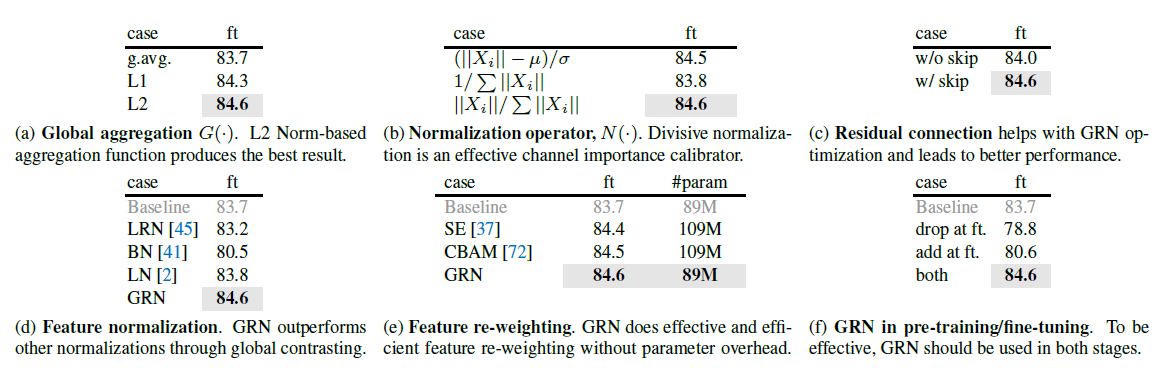
표 2. ConvNeXt-Base를 사용한 GRN 절제. ImageNet-1K에서 미세 조정 정확도를 보고합니다. 최종 제안은 회색으로 표시되어 있습니다.
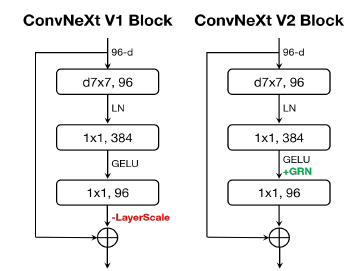
그림 5. ConvNeXt 블록 설계
ConvNeXt V2에서는 차원 확장 MLP 레이어 후에 GRN 레이어를 추가하고, 불필요해진 LayerScale [65]을 제거합니다.
ConvNeXt V2
우리는 GRN 레이어를 원래 ConvNeXt 블록에 통합하였으며, 이는 그림 5에 설명되어 있습니다. 경험적으로, GRN이 적용될 때 LayerScale [65]이 불필요해져 제거할 수 있음을 발견했습니다. 이 새로운 블록 설계를 사용하여, 우리는 다양한 효율성과 용량을 가진 모델들을 만들었으며, 이를 ConvNeXt V2 모델군이라고 부릅니다. 이 모델들은 경량형 (예: Atto [70])부터 고연산형 (예: Huge)까지 다양합니다. 자세한 모델 구성은 부록에서 찾을 수 있습니다.
GRN의 영향
우리는 FCMAE 프레임워크를 사용하여 ConvNeXt V2를 사전 학습하고 GRN의 영향을 평가합니다. 그림 3의 시각화와 그림 4의 코사인 거리 분석에서 ConvNeXt V2가 특징 붕괴 문제를 효과적으로 완화함을 관찰할 수 있습니다. 코사인 거리 값은 일관되게 높아, 레이어 전반에 걸쳐 특징 다양성이 유지됨을 나타냅니다. 이 행동은 MAE 사전 학습된 ViT 모델 [31]과 유사합니다. 전반적으로, 이는 ConvNeXt V2의 학습 행동이 유사한 마스크 이미지 사전 학습 프레임워크 하에서 ViT와 유사할 수 있음을 시사합니다. 다음으로, 우리는 미세 조정 성능을 평가합니다.
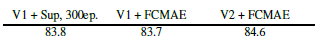
GRN을 장착한 FCMAE 사전 학습된 모델은 300 에포크 지도 학습된 모델보다 성능이 크게 우수할 수 있습니다. GRN은 V1 모델에서는 없었지만, 마스크 기반 사전 학습에 중요함이 입증된 특징 다양성을 향상시킴으로써 표현의 질을 향상시킵니다. 이 개선은 추가적인 파라미터 오버헤드나 증가된 FLOPS 없이 달성됩니다.
특징 정규화 방법과의 관계
다른 정규화 레이어 [2,41,45,67,73]가 글로벌 응답 정규화(GRN) 레이어만큼 잘 작동할 수 있을까요? 표 2d에서 우리는 GRN을 세 가지 널리 사용되는 정규화 레이어와 비교합니다: 국소 응답 정규화(LRN) [45], 배치 정규화(BN) [41], 및 레이어 정규화(LN) [2]. 우리는 GRN만이 지도 학습 기준을 크게 능가할 수 있음을 관찰합니다. LRN은 근처 이웃 채널 내에서만 대조를 이루므로 글로벌 컨텍스트가 부족합니다. BN은 배치 축을 따라 공간적으로 정규화하여 마스크된 입력에는 적합하지 않습니다. LN은 글로벌 평균과 분산 표준화를 통해 암묵적으로 특징 경쟁을 유도하지만 GRN만큼 잘 작동하지 않습니다.
특징 게이팅 방법과의 관계
뉴런 간의 경쟁을 강화하는 또 다른 방법은 동적 특징 게이팅(dynamic feature gating) 방법을 사용하는 것입니다 [37, 56, 69, 72, 78]. 표 2e에서 우리는 GRN과 두 가지 고전적인 게이팅 레이어: squeeze-and-excite(SE) [37] 및 convolutional block attention module(CBAM) [72]을 비교합니다. SE는 채널 게이팅에 중점을 두고, CBAM은 공간 게이팅에 중점을 둡니다. 두 모듈 모두 GRN이 하는 것과 유사하게 개별 채널의 대조를 증가시킬 수 있습니다. GRN은 추가적인 파라미터 레이어(예: MLP)를 필요로 하지 않으므로 훨씬 더 간단하고 효율적입니다.
사전 학습/미세 조정에서 GRN의 역할
마지막으로, 우리는 사전 학습과 미세 조정에서 GRN의 중요성을 검토합니다. 우리는 표 2f에 GRN을 미세 조정에서 제거하거나 미세 조정 시점에 새로 초기화된 GRN을 추가한 결과를 제시합니다. 어느 쪽이든, 우리는 성능 저하가 현저하게 나타남을 관찰하여, 사전 학습과 미세 조정 모두에서 GRN을 유지하는 것이 중요하다는 것을 시사합니다.
5. ImageNet 실험
이 섹션에서는 마스크 기반 자가 지도 사전 학습을 성공적으로 만들기 위해 공동 설계된 두 가지 주요 제안, FCMAE 사전 학습 프레임워크와 ConvNeXt V2 아키텍처를 제시하고 분석합니다. 이러한 설계들이 시너지를 발휘하여 다양한 크기의 모델로 확장하는 강력한 기반을 제공함을 보여줍니다. 또한, 우리의 접근 방식을 이전의 마스크 이미지 모델링 접근 방식과 비교하여 실험을 통해 검증합니다. 추가로, FCMAE 프레임워크를 사용하여 사전 학습하고 ImageNet-22K 데이터셋에서 미세 조정한 우리의 가장 큰 ConvNeXt V2 Huge 모델이 공개된 데이터만을 사용하여 ImageNet-1K 데이터셋에서 88.9%의 최첨단 상위-1 정확도를 달성할 수 있음을 보여줍니다.
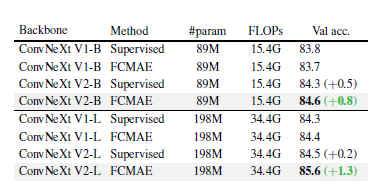
표 3. 공동 설계가 중요하다
아키텍처와 학습 프레임워크가 공동 설계되어 함께 사용될 때, 마스크 이미지 사전 학습은 ConvNeXt에 효과적입니다. 우리는 800 에포크 FCMAE 사전 학습된 모델에서의 미세 조정 성능을 보고합니다. 더 큰 모델일수록 상대적 개선이 더 큽니다.
공동 설계의 중요성
이 논문에서는 자가 지도 학습 프레임워크(FCMAE)와 모델 아키텍처 개선(GRN 레이어)을 공동 설계하는 독특한 연구를 수행합니다. 표 3에 제시된 결과는 이 접근 방식의 중요성을 보여줍니다. FCMAE 프레임워크를 모델 아키텍처를 수정하지 않고 사용하는 경우 표현 학습의 질에 대한 영향이 제한적임을 발견했습니다. 마찬가지로, 새로운 GRN 레이어는 지도 학습 설정에서 성능에 미치는 영향이 다소 작습니다. 그러나 두 가지를 결합하면 미세 조정 성능에서 큰 향상을 가져옵니다. 이는 모델과 학습 프레임워크가 특히 자가 지도 학습의 경우 함께 고려되어야 한다는 아이디어를 뒷받침합니다.
모델 확장
이 연구에서 우리는 3.7M의 저용량 Atto 모델부터 650M의 고용량 Huge 모델까지 다양한 크기의 8가지 모델을 평가했습니다. 이러한 모델들은 제안된 FCMAE 프레임워크를 사용하여 사전 학습되었으며, 완전 지도 학습된 모델과 미세 조정 결과를 비교했습니다. 그림 1에 표시된 결과는 모든 모델 크기에서 지도 학습 기준보다 일관되게 성능이 향상되는 강력한 모델 확장 행동을 보여줍니다. 이는 효과성과 효율성 측면에서 매우 광범위한 모델 스펙트럼에서 마스크 이미지 모델링의 이점이 처음으로 입증된 것입니다. 완전한 표 형태의 결과는 부록에서 찾을 수 있습니다.
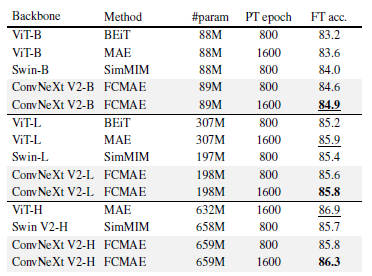
표 4. 이전 마스크 이미지 모델링 접근법과의 비교
사전 학습 데이터는 IN-1K 훈련 세트입니다. 모든 자가 지도 학습 방법은 224 크기의 이미지로 끝에서 끝 미세 조정 성능을 기준으로 벤치마킹됩니다. 우리는 각 모델 크기별로 가장 높은 정확도를 밑줄로 표시하고, 우리의 최고 결과를 굵게 표시합니다.
이전 방법들과의 비교
우리는 우리의 접근 방식을 트랜스포머 기반 모델을 위해 설계된 이전의 마스크 오토인코더 방법들 [3, 31, 77]과 비교합니다. 결과는 표 4에 요약되어 있습니다. 우리의 프레임워크는 모든 모델 크기에서 SimMIM [77]으로 사전 학습된 Swin 트랜스포머를 능가합니다. MAE [31]로 사전 학습된 단순 ViT와 비교했을 때, 우리의 접근 방식은 파라미터 수가 훨씬 적음에도 불구하고(198M vs 307M) Large 모델 범위까지 유사한 성능을 보입니다. 그러나, Huge 모델 범위에서는 우리의 접근 방식이 약간 뒤처졌습니다. 이는 큰 ViT 모델이 자가 지도 사전 학습에서 더 큰 이점을 얻을 수 있기 때문일 수 있습니다. 다음으로, 추가적인 중간 미세 조정을 통해 이 격차를 좁힐 수 있을 것입니다.
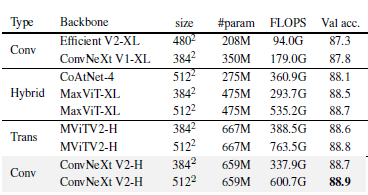
표 5. IN-21K 라벨을 사용한 ImageNet-1K 미세 조정 결과
FCMAE 사전 학습을 갖춘 ConvNeXt V2 Huge 모델은 다른 아키텍처를 능가하며, 공개 데이터만을 사용한 방법 중 88.9%의 새로운 최첨단 정확도를 설정합니다.
ImageNet-22K 중간 미세 조정
우리는 또한 ImageNet-22K 중간 미세 조정 결과를 제시합니다 [3]. 훈련 과정은 다음의 세 단계를 포함합니다: 1) FCMAE 사전 학습, 2) ImageNet-22K 미세 조정, 3) ImageNet-1K 미세 조정. 우리는 사전 학습과 미세 조정에 384² 해상도의 이미지를 사용합니다 [38]. 우리는 우리의 결과를 컨볼루션 기반 [52, 64], 트랜스포머 기반 [22], 및 하이브리드 디자인 [20, 66]을 포함한 최첨단 아키텍처 설계와 비교합니다. 이러한 모든 결과는 ImageNet-22K 지도 라벨을 사용하여 훈련되었습니다. 결과는 표 5에 요약되어 있습니다. 우리의 방법은 공개 데이터만을 사용하여(즉, ImageNet-1K와 ImageNet-22K) 새로운 최첨단 정확도를 설정했습니다.
6. 전이 학습 실험
이제 전이 학습 성능을 벤치마크합니다. 먼저, 공동 설계의 영향을 평가합니다, 즉 ConvNeXt V1 + 지도 학습 vs. ConvNeXt V2 + FCMAE를 비교합니다. 또한, SimMIM [77]으로 사전 학습된 Swin 트랜스포머 모델과 우리의 접근 방식을 직접 비교합니다. 훈련 및 테스트에 대한 세부 사항은 부록에 제공됩니다.
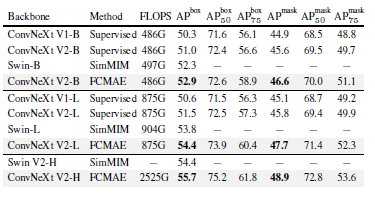
표 6. Mask-RCNN을 사용한 COCO 객체 탐지 및 인스턴스 세그멘테이션 결과
FLOPS는 이미지 크기(1280, 800)로 계산됩니다. Swin의 결과는 [77]에서 가져왔습니다. 모든 COCO 미세 조정 실험은 ImageNet-1K 사전 학습된 모델을 기반으로 합니다.
COCO에서의 객체 탐지 및 세그멘테이션
우리는 COCO 데이터셋 [49]에서 Mask R-CNN [33]을 미세 조정하고, COCO val2017 세트에서 탐지 mAPbox와 세그멘테이션 mAPmask를 보고합니다. 결과는 표 6에 나와 있습니다. 우리의 제안이 적용됨에 따라 점진적인 성능 향상을 확인할 수 있습니다. V1에서 V2로 넘어가면서, GRN 레이어가 새로 도입되어 성능이 향상됩니다. 여기에 더해, 지도 학습에서 FCMAE 기반 자가 지도 학습으로 이동할 때 더 나은 초기화로 인해 모델이 추가적인 혜택을 봅니다. 두 가지가 함께 적용될 때 최고의 성능이 달성됩니다. 또한, 우리의 최종 제안인 FCMAE로 사전 학습된 ConvNeXt V2는 모든 모델 크기에서 Swin 트랜스포머를 능가하며, 특히 큰 모델 범위에서 가장 큰 격차를 보입니다.
ADE20K에서의 의미론적 세그멘테이션
요약하자면, 우리는 UperNet 프레임워크 [74]를 사용하여 ADE20K [82] 의미론적 세그멘테이션 작업에서 실험을 수행합니다. 우리의 결과는 객체 탐지 실험과 유사한 경향을 보여주며, 최종 모델은 V1 지도 학습된 모델보다 크게 개선되었습니다. 또한, 기본 및 큰 모델 범위에서 Swin 트랜스포머와 동등한 성능을 보이지만, 큰 모델 범위에서는 Swin을 능가합니다.
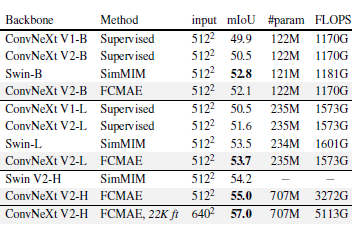
표 7. UPerNet을 사용한 ADE20K 의미론적 세그멘테이션 결과
FLOPS는 입력 크기(2048, 512) 또는 (2560, 640)을 기준으로 합니다. 모든 ADE20K 미세 조정 실험은 ImageNet-1K 사전 학습된 모델을 기반으로 합니다. FCMAE, 22K ft의 경우 ImageNet-1K 사전 학습 후 ImageNet-22K 지도 미세 조정이 이어집니다.
7. 결론
이 논문에서는 ConvNeXt V2라고 불리는 새로운 ConvNet 모델 군을 소개하며, 이는 더 넓은 복잡성을 다룹니다. 아키텍처는 최소한의 변경만 있지만, 자가 지도 학습에 더 적합하도록 설계되었습니다. 우리의 완전 컨볼루션 마스크 오토인코더 사전 학습을 사용하여, ImageNet 분류, COCO 객체 탐지 및 ADE20K 세그멘테이션을 포함한 다양한 다운스트림 작업에서 순수 ConvNet의 성능을 크게 향상시킬 수 있습니다.
감사의 말
우리는 작은 계산량을 필요로 하는 ConvNeXt 모델 변형의 초기 설계와 관련된 훈련 레시피를 제공해 주신 Ross Wightman에게 감사드립니다. 또한, Kaiming He가 제공한 유익한 토론과 피드백에도 감사드립니다.
'인공지능' 카테고리의 다른 글
| Adding Conditional Control to Text-to-Image Diffusion Models (1) | 2024.06.27 |
|---|---|
| DiT: Self-supervised Pre-training for Document Image Transformer (1) | 2024.06.26 |
| Diffusion On Syntax Trees For Program Synthesis (1) | 2024.06.23 |
| Relightable Gaussian Codec Avatars (1) | 2024.06.23 |
| Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild (1) | 2024.06.22 |



