https://arxiv.org/abs/2203.02378
DiT: Self-supervised Pre-training for Document Image Transformer
Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose \textbf{DiT}, a self-supervised
arxiv.org
요약
이미지 변환기는 최근 자연 이미지 이해를 위해 감독 학습(ViT, DeiT 등) 또는 자가 지도 학습(BEiT, MAE 등) 사전 학습 기술을 사용하여 상당한 진전을 이루었습니다. 이 논문에서는 문서 AI 작업을 위해 대규모 레이블 없는 텍스트 이미지를 사용하여 자가 지도 학습된 문서 이미지 변환기 모델인 DiT를 제안합니다. 이는 인간이 레이블을 지정한 문서 이미지의 부족으로 인해 감독 학습된 대응 모델이 존재하지 않기 때문에 필수적입니다. 우리는 DiT를 문서 이미지 분류, 문서 레이아웃 분석, 표 검출 및 OCR을 위한 텍스트 검출을 포함한 다양한 시각 기반 문서 AI 작업의 백본 네트워크로 활용합니다. 실험 결과, 자가 지도 학습된 DiT 모델이 문서 이미지 분류(91.11 → 92.69), 문서 레이아웃 분석(91.0 → 94.9), 표 검출(94.23 → 96.55) 및 OCR을 위한 텍스트 검출(93.07 → 94.29)과 같은 다운스트림 작업에서 새로운 최첨단 결과를 달성했음을 보여줍니다. 코드와 사전 학습된 모델은 https://aka.ms/msdit에서 공개적으로 이용 가능합니다.
1. 소개
자가 지도 학습 사전 훈련 기술은 지난 몇 년간 문서 AI에서 사실상의 일반적인 관행이었습니다 [10]. 이 기술은 이미지, 텍스트, 레이아웃 정보를 통합된 변환기(Transformer) 아키텍처를 사용하여 공동으로 훈련시킵니다 [2, 19, 21, 25, 28, 32, 33, 38, 41–44, 48]. 이러한 접근 방식 중 대부분은 문서 AI 모델의 사전 훈련 파이프라인이 시각 기반 이해(예: 광학 문자 인식(OCR) 또는 문서 레이아웃 분석)로 시작되며, 이는 여전히 인간이 라벨링한 훈련 샘플을 사용하는 감독 컴퓨터 비전 백본 모델에 크게 의존하고 있습니다. 벤치마크 데이터셋에서 좋은 결과가 나왔지만, 이러한 비전 모델은 도메인 전이 및 훈련 데이터의 템플릿/형식 불일치로 인해 실제 응용에서 성능 격차에 직면하는 경우가 많습니다. 이러한 정확도 저하는 [26, 46] 사전 훈련된 모델과 다운스트림 작업에 필수적인 영향을 미칩니다. 따라서, 문서 이미지 이해의 백본에 자가 지도 사전 훈련을 활용하는 방법을 조사하는 것은 필수적입니다. 이는 다양한 도메인에 대한 일반적인 문서 AI 모델을 더 잘 지원할 수 있습니다.
최근 이미지 변환기 [3, 9, 12, 13, 17, 31, 36, 47]는 자연 이미지 이해를 위해 큰 성공을 거두었습니다. 여기에는 분류, 검출 및 분할 작업이 포함되며, 이는 ImageNet에서 감독 사전 훈련 또는 자가 지도 사전 훈련을 통해 이루어집니다. 사전 훈련된 이미지 변환기 모델은 유사한 파라미터 크기에서 CNN 기반 사전 훈련 모델과 비교하여 동등하거나 더 나은 성능을 달성할 수 있습니다. 그러나 문서 이미지 이해를 위해서는 ImageNet과 같은 대규모 인간 라벨링 벤치마크가 흔히 사용되지 않기 때문에 대규모 감독 사전 훈련이 실현 불가능합니다. 약하게 지도된 방법이 문서 AI 벤치마크를 만드는 데 사용되었지만 [26, 27, 45, 46], 이러한 데이터셋의 도메인은 비슷한 템플릿과 형식을 공유하는 학술 논문에서 주로 유래하며, 이는 실제 문서(예: 양식, 청구서/영수증, 보고서 등)와 다릅니다. 이는 일반적인 문서 AI 문제에 대해 만족스럽지 못한 결과를 초래할 수 있습니다. 따라서, 일반적인 도메인의 대규모 레이블 없는 데이터를 사용하여 문서 이미지 백본 모델을 사전 훈련하는 것이 중요하며, 이는 다양한 문서 AI 작업을 지원할 수 있습니다.

그림 1: 다양한 레이아웃과 형식의 시각적으로 풍부한 비즈니스 문서로 사전 교육용 DiT.
이 목적을 달성하기 위해, 우리는 일반적인 문서 AI 작업을 위한 자가 지도 사전 학습된 문서 이미지 변환기 모델인 DiT를 제안합니다. DiT는 어떤 인간 라벨링된 문서 이미지에도 의존하지 않습니다. 최근 제안된 BEiT 모델 [3]에서 영감을 받아, 문서 이미지를 사용한 유사한 사전 학습 전략을 채택했습니다. 입력 텍스트 이미지는 먼저 224 × 224 크기로 조정된 후, 이미지를 16 × 16 패치 시퀀스로 분할하여 이미지 변환기의 입력으로 사용합니다. DALL-E [34]에서의 비주얼 토큰을 사용하는 BEiT 모델과는 달리, 우리는 대규모 문서 이미지를 사용하여 이산 VAE(dVAE) 모델을 재훈련하여 생성된 비주얼 토큰이 문서 AI 작업에 더 관련성이 있도록 했습니다. 사전 학습 목표는 손상된 입력 문서 이미지를 사용하여 BEiT의 마스크드 이미지 모델링(MIM)을 통해 dVAE에서 비주얼 토큰을 복구하는 것입니다. 이 방식으로 DiT 모델은 인간 라벨링된 문서 이미지에 의존하지 않고, 대규모 레이블 없는 데이터를 사용하여 각 문서 이미지 내의 글로벌 패치 관계를 학습합니다. 우리는 사전 학습된 DiT 모델을 문서 이미지 분류를 위한 RVL-CDIP 데이터셋 [16], 문서 레이아웃 분석을 위한 PubLayNet 데이터셋 [46], 표 검출을 위한 ICDAR 2019 cTDaR 데이터셋 [15], 그리고 OCR 텍스트 검출을 위한 FUNSD 데이터셋 [22]을 포함한 네 가지 공개된 문서 AI 벤치마크에서 평가했습니다. 실험 결과, 사전 학습된 DiT 모델이 기존의 감독 및 자가 지도 사전 학습 모델을 능가했으며, 이러한 작업에서 새로운 최첨단 성과를 달성했음을 보여주었습니다.
이 논문의 기여는 다음과 같이 요약됩니다:
- 대규모 레이블 없는 문서 이미지를 사전 학습에 활용할 수 있는 자가 지도 사전 학습된 문서 이미지 변환기 모델 DiT를 제안합니다.
- 문서 이미지 분류, 문서 레이아웃 분석, 표 검출, OCR을 위한 텍스트 검출을 포함한 다양한 문서 AI 작업의 백본으로 사전 학습된 DiT 모델을 활용하여 새로운 최첨단 성과를 달성합니다.
- 코드와 사전 학습된 모델은 https://aka.ms/msdit에서 공개적으로 이용 가능합니다.
2. 관련 연구
이미지 변환기는 최근 컴퓨터 비전 문제에서 분류, 객체 검출 및 분할을 포함한 상당한 진전을 이루었습니다. [12]는 가장 적은 수정으로 이미지를 직접 표준 변환기에 적용한 최초의 연구입니다. 그들은 이미지를 16 × 16 패치로 나누고 이러한 패치의 선형 임베딩 시퀀스를 ViT(비전 변환기)라는 변환기에 입력으로 제공합니다. ViT 모델은 이미지 분류를 위해 감독 학습 방식으로 훈련되었으며, ResNet 기반 모델을 능가합니다. [36]는 주의력을 통한 데이터 효율적 이미지 변환기 및 디스틸레이션인 DeiT를 제안했으며, 이 모델은 ImageNet 데이터셋에만 의존하여 감독 사전 학습을 수행하고 ViT와 비교하여 최첨단 성과를 달성합니다. [31]은 시프트된 윈도우를 사용하여 표현을 계산하는 계층적 변환기를 제안했습니다. 시프트된 윈도우 방식은 비중첩 로컬 윈도우로 자기 주의 계산을 제한하여 효율성을 가져오면서도 크로스-윈도우 연결을 허용합니다.
감독 사전 학습 모델 외에도, [8]은 2D 입력 구조의 지식 없이 픽셀을 자동 회귀적으로 예측하는 시퀀스 변환기인 iGPT를 훈련했으며, 이는 자가 지도 이미지 변환기 사전 학습의 첫 시도입니다. 이후 이미지 변환기의 자가 지도 사전 학습은 컴퓨터 비전에서 핫 토픽이 되었습니다. [7]은 레이블 없이 자기 증류를 사용하여 이미지 변환기를 사전 학습하는 DINO를 제안했습니다. [9]은 자가 지도 학습을 위해 시암 네트워크 기반의 MoCov3를 제안했습니다. 최근에는 [3]이 BERT 스타일의 사전 학습 전략을 채택하여 원본 이미지를 비주얼 토큰으로 토큰화한 다음, 일부 이미지 패치를 무작위로 마스킹하고 백본 변환기에 입력합니다. 마스킹 언어 모델링과 유사하게, 그들은 사전 학습 목표로 마스킹 이미지 모델링 작업을 제안하여 최첨단 성과를 달성합니다. [47]은 온라인 토크나이저를 사용하여 마스킹 예측을 수행할 수 있는 자가 지도 프레임워크 iBOT을 제시했습니다. 온라인 토크나이저는 MIM 목표와 함께 공동 학습이 가능하며, 사전 학습된 토크나이저가 있는 다단계 파이프라인을 필요로 하지 않습니다.
비전 기반 문서 AI는 일반적으로 OCR, 문서 레이아웃 분석 및 문서 이미지 분류와 같은 문서 분석 작업을 컴퓨터 비전 모델을 사용하여 수행하는 것을 의미합니다. 이 도메인에서 대규모 인간 라벨링 데이터셋의 부족으로 인해, 기존 접근 방식은 일반적으로 ImageNet/COCO 데이터셋으로 사전 학습된 ConvNets 모델에 기반합니다. 그런 다음 모델은 특정 작업에 맞는 라벨링 샘플로 계속 훈련됩니다. 우리가 아는 한, 사전 학습된 DiT 모델은 비전 기반 문서 AI 작업을 위한 최초의 대규모 자가 지도 사전 학습 모델입니다. 동시에, 이는 문서 AI를 위한 멀티모달 사전 학습에도 활용될 수 있습니다.

그림 2: MIM 사전 학습이 포함된 DiT의 모델 아키텍처.
3. 문서 이미지 변환기
이 섹션에서는 DiT의 아키텍처와 사전 학습 절차를 먼저 설명합니다. 그 다음, DiT 모델을 다양한 다운스트림 작업에 적용하는 방법을 설명합니다.
3.1 모델 아키텍처
ViT [12]를 따라, 우리는 DiT의 백본으로 기본 변환기(Transformer) 아키텍처 [37]를 사용합니다. 문서 이미지를 겹치지 않는 패치로 나누고, 패치 임베딩 시퀀스를 얻습니다. 1차원 위치 임베딩을 추가한 후, 이 이미지 패치들은 멀티헤드 어텐션이 있는 변환기 블록 스택에 전달됩니다. 최종적으로, 변환기 인코더의 출력을 이미지 패치의 표현으로 사용합니다. 이는 그림 2에 나타나 있습니다.
3.2 사전 학습
BEiT [3]에서 영감을 받아, 우리는 마스크드 이미지 모델링(MIM)을 사전 학습 목표로 사용합니다. 이 절차에서는 이미지를 각각 이미지 패치와 비주얼 토큰으로 두 가지 뷰에서 표현합니다. 사전 학습 동안, DiT는 이미지 패치를 입력으로 받아 출력 표현으로 비주얼 토큰을 예측합니다.
자연어의 텍스트 토큰처럼, 이미지는 이미지 토크나이저에 의해 얻어진 일련의 이산 토큰으로 표현될 수 있습니다. BEiT는 DALL-E [34]의 이산 변분 오토인코더(dVAE)를 이미지 토크나이저로 사용하며, 이는 4억 개의 이미지를 포함한 대규모 데이터 컬렉션에서 훈련되었습니다. 그러나 자연 이미지와 문서 이미지 간의 도메인 불일치가 존재하여, DALL-E 토크나이저는 문서 이미지에 적합하지 않습니다. 따라서, 문서 이미지 도메인에 더 적합한 이산 비주얼 토큰을 얻기 위해, 우리는 IIT-CDIP [24] 데이터셋의 4,200만 문서 이미지로 dVAE를 훈련합니다.
DiT 모델을 효과적으로 사전 학습하기 위해, 우리는 이미지 패치 시퀀스를 주어진 상태에서 입력의 일부를 특별 토큰 [MASK]로 무작위로 마스킹합니다. DiT 인코더는 위치 임베딩이 추가된 선형 투영을 통해 마스킹된 패치 시퀀스를 임베딩한 후, 변환기 블록 스택을 통해 문맥화합니다. 모델은 마스킹된 위치에서 출력으로 비주얼 토큰의 인덱스를 예측해야 합니다. 원시 픽셀을 예측하는 대신, 마스킹된 이미지 모델링 작업은 모델이 이미지 토크나이저로 얻은 이산 비주얼 토큰을 예측하도록 요구합니다.
3.3 미세 조정(Fine-tuning)
우리는 문서 이미지 분류를 위한 RVL-CDIP 데이터셋, 문서 레이아웃 분석을 위한 PubLayNet 데이터셋, 표 검출을 위한 ICDAR 2019 cTDaR 데이터셋, 그리고 텍스트 검출을 위한 FUNSD 데이터셋을 포함한 네 가지 문서 AI 벤치마크에서 모델을 미세 조정합니다. 이러한 벤치마크 데이터셋은 이미지 분류 및 객체 검출의 두 가지 일반적인 작업으로 형식화될 수 있습니다.
이미지 분류
이미지 분류의 경우, 이미지 패치의 표현을 집계하기 위해 평균 풀링을 사용합니다. 그런 다음, 전역 표현을 간단한 선형 분류기에 전달합니다.
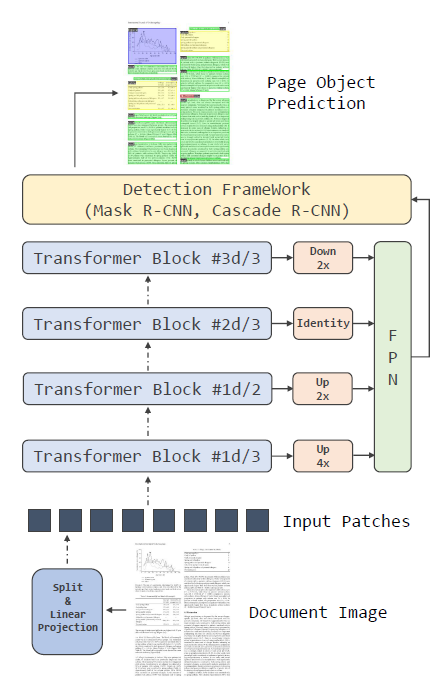
그림 3: 다양한 탐지 프레임워크에서 백본 네트워크로서로 적용하는 그림
객체 검출
객체 검출을 위해, 그림 3에서 보이듯이 Mask R-CNN [18]과 Cascade R-CNN [5]을 검출 프레임워크로 사용하고, ViT 기반 모델을 백본으로 사용합니다. 우리의 코드는 Detectron2 [39]를 기반으로 구현되었습니다. [14, 29]를 따라, 단일 스케일 ViT를 멀티 스케일 FPN에 적응시키기 위해 네 개의 다른 변환기 블록에서 해상도 수정 모듈을 사용합니다. 총 블록 수를 𝑑라고 하면, 1𝑑/3번째 블록은 2개의 스트라이드 2 2×2 전이 컨볼루션을 사용하는 모듈로 4배 업샘플링됩니다. 1𝑑/2번째 블록의 출력은 단일 스트라이드 2 2×2 전이 컨볼루션을 사용하여 2배 업샘플링됩니다. 2𝑑/3번째 블록의 출력은 추가 작업 없이 사용됩니다. 마지막으로, 3𝑑/3번째 블록의 출력은 스트라이드 2 2×2 맥스 풀링으로 2배 다운샘플링됩니다.
4. 실험
4.1 작업
섹션 3.3에서 언급한 데이터셋을 간략히 소개합니다.
RVL-CDIP
RVL-CDIP [16] 데이터셋은 16개의 클래스에 40만 개의 그레이스케일 이미지로 구성되며, 각 클래스 당 2만 5천 개가 포함됩니다. 훈련 이미지 32만 개, 검증 이미지 4만 개, 테스트 이미지 4만 개가 있습니다. 16개 클래스는 다음과 같습니다: {편지, 양식, 이메일, 필기, 광고, 과학 보고서, 과학 출판물, 사양, 파일 폴더, 뉴스 기사, 예산, 송장, 프레젠테이션, 설문지, 이력서, 메모}. 평가 기준은 전체 분류 정확도입니다.
PubLayNet
PubLayNet [46]은 대규모 문서 레이아웃 분석 데이터셋입니다. 36만 개 이상의 문서 이미지는 PubMed XML 파일을 자동으로 파싱하여 생성되었습니다. 생성된 주석은 텍스트, 제목, 목록, 그림, 표와 같은 일반적인 문서 레이아웃 요소를 다룹니다. 모델은 할당된 요소의 영역을 검출해야 합니다. 우리는 경계 상자의 교차 영역 (IOU) [0.50:0.95]의 카테고리별 및 전체 평균 정밀도(MAP)를 평가 지표로 사용합니다.
ICDAR 2019 cTDaR
cTDaR 데이터셋 [15]은 표 검출 및 표 구조 인식을 포함한 두 가지 트랙으로 구성됩니다. 이 논문에서는 하나 이상의 표 주석이 있는 문서 이미지를 제공하는 트랙 A에 초점을 맞춥니다. 이 데이터셋은 보관 문서와 현대 문서의 두 개 하위 집합을 포함합니다. 보관 하위 집합에는 600개의 훈련 이미지와 199개의 테스트 이미지가 포함되며, 손으로 그린 회계 장부, 주식 거래 목록, 기차 시간표, 생산 센서스 등을 포함한 다양한 표가 있습니다. 현대 하위 집합에는 600개의 훈련 이미지와 240개의 테스트 이미지가 포함되며, 과학 저널, 양식, 재무 보고서 등 다양한 PDF 파일이 포함됩니다. 데이터셋에는 스캔한 문서 이미지와 디지털 형식으로 된 다양한 형식의 중국어 및 영어 문서가 포함됩니다. 이 작업을 평가하는 지표는 모델의 랭크된 출력과 다른 교차 영역 (IoU) 임계값에 대한 정밀도, 재현율 및 F1 점수입니다. 우리는 각각 0.6, 0.7, 0.8 및 0.9의 IoU 임계값으로 값을 계산하고, 이를 최종 가중 F1 점수로 병합합니다.

이 작업은 모델이 최종 평가 결과를 얻기 위해 현대 및 보관 세트를 결합할 것을 요구합니다.
FUNSD
FUNSD [22]는 텍스트 검출, 광학 문자 인식(OCR)을 통한 텍스트 인식 및 양식 이해를 위한 세 가지 작업으로 라벨링된 노이즈가 많은 스캔된 문서 데이터셋입니다. 이 논문에서는 스캔된 양식 문서의 텍스트 경계 상자를 검출하는 작업 #1에 초점을 맞춥니다. FUNSD에는 31,485개의 단어가 포함된 199개의 완전히 주석이 달린 양식이 있으며, 훈련 세트에는 150개의 양식이, 테스트 세트에는 49개의 양식이 포함됩니다. 평가 지표는 IoU@0.5에서의 정밀도, 재현율 및 F1 점수입니다.

그림 4: 다양한 토큰화 도구를 사용한 문서 이미지 재구성. 왼쪽부터: 원본 문서 이미지, 자체 학습된 dVAE 토큰라이저를 사용한 이미지 재구성, DALL-E 토큰라이저를 사용한 이미지 재구성
4.2 설정
사전 학습 설정
우리는 DiT를 IIT-CDIP 테스트 컬렉션 1.0 [24]에서 사전 학습합니다. 다중 페이지 문서를 단일 페이지로 분할하여 데이터셋을 전처리하고, 4,200만 개의 문서 이미지를 얻습니다. 또한 훈련 중에 데이터를 증강하기 위해 무작위 크기 조정을 도입합니다. 우리는 ViT 기본 아키텍처와 동일한 12계층 변환기, 768 히든 크기, 12개의 어텐션 헤드를 가진 DiT-B 모델을 훈련합니다. 피드포워드 네트워크의 중간 크기는 3,072입니다. 더 큰 버전인 DiT-L은 24계층, 1,024 히든 크기, 16개의 어텐션 헤드를 가지고 있으며, 피드포워드 네트워크의 중간 크기는 4,096입니다.
dVAE 토크나이저
BEiT는 DALL-E에서 훈련된 이미지 토크나이저를 차용하지만, 이는 문서 이미지 데이터와 일치하지 않습니다. 이 경우, 우리는 IIT-CDIP 데이터셋의 4,200만 개 문서 이미지를 최대한 활용하여 비주얼 토큰을 얻기 위해 문서 dVAE 이미지 토크나이저를 훈련합니다. DALL-E 이미지 토크나이저처럼, 문서 이미지 토크나이저는 8,192 코드북 차원과 3계층의 이미지 인코더를 가집니다. 각 계층은 2 스트라이드의 2D 컨볼루션과 ResNet 블록으로 구성됩니다. 따라서 토크나이저는 최종적으로 8의 다운샘플링 계수를 가집니다. 112×112 이미지를 주어지면, 14×14 이산 토큰 맵과 14×14 입력 패치에 맞게 조정됩니다.
우리는 오픈 소스 DALL-E 구현에서 dVAE 코드베이스를 구현하고, 4,200만 개 문서 이미지가 포함된 전체 IIT-CDIP 데이터셋으로 dVAE 모델을 훈련합니다. 새로운 dVAE 토크나이저는 입력 이미지를 재구성하기 위한 MSE 손실과 양자화된 코드북 표현의 사용을 증가시키기 위한 당혹감 손실을 조합하여 훈련됩니다. 입력 이미지 크기는 224×224이며, 학습률은 5e-4, 최소 온도는 1e-10으로 3 에포크 동안 훈련합니다. 우리는 다운스트림 작업의 문서 이미지 샘플을 재구성하여 DALL-E 토크나이저와 우리의 dVAE 토크나이저를 비교합니다. PubLayNet 및 ICDAR 2019 cTDaR 데이터셋에서 이미지를 샘플링한 후, DALL-E와 우리의 토크나이저로 재구성된 이미지를 비교합니다. DALL-E의 이미지 토크나이저는 선과 토큰의 경계를 구분하기 어렵지만, 우리의 dVAE 토크나이저는 원본 이미지에 더 가깝고 경계가 더 선명하고 명확합니다. 우리는 더 나은 토크나이저가 원본 이미지를 더 잘 설명하는 더 정확한 토큰을 생성할 수 있음을 확인했습니다.
사전 학습 데이터와 이미지 토크나이저를 갖춘 우리는 DiT를 50만 단계 동안 배치 크기 2,048, 학습률 1e-3, 웜업 단계 10K, 가중치 감소 0.05로 사전 학습합니다. Adam [23] 옵티마이저의 𝛽1과 𝛽2는 각각 0.9와 0.999입니다. 우리는 확률적 깊이 [20]를 0.1의 비율로 사용하고 BEiT 사전 학습과 마찬가지로 드롭아웃을 비활성화합니다. 또한 BEiT처럼 40% 패치를 마스킹한 상태로 DiT 사전 학습에서 블록 단위 마스킹을 적용합니다.
RVL-CDIP에서의 미세 조정
우리는 문서 이미지 분류를 위해 RVL-CDIP에서 사전 학습된 DiT 모델과 다른 이미지 백본을 평가합니다. 이미지 변환기를 배치 크기 128, 학습률 1e-3으로 90 에포크 동안 미세 조정합니다. 모든 설정에서 원본 이미지를 RandomResized-Crop 작업으로 224 × 224로 크기 조정합니다.

그림 5: ICDAR 2019 cTDaR 아카이브 하위 집합에서 적응형 이미지 이진화를 사용한 사전 처리 예시
ICDAR 2019 cTDaR에서의 미세 조정
우리는 표 검출을 위해 ICDAR 2019 데이터셋에서 사전 학습된 DiT 모델과 다른 이미지 백본을 평가합니다. 객체 검출 작업의 이미지 해상도가 분류보다 훨씬 크기 때문에 배치 크기를 16으로 제한합니다. 학습률은 보관 하위 집합과 현대 하위 집합에 대해 각각 1e-4와 5e-5입니다. 예비 실험에서, 보관 하위 집합의 원본 이미지를 직접 사용하는 것은 DiT 미세 조정 시 최적의 성능을 발휘하지 못한다는 것을 발견했으므로, OpenCV [4]로 구현된 적응형 이미지 이진화 알고리즘을 적용하여 이미지를 이진화합니다. 전처리 예는 그림 5에 나와 있습니다. 훈련 중에, 우리는 DETR [6]에서 사용된 데이터 증강 방법을 다중 스케일 훈련 전략으로 적용합니다. 구체적으로, 입력 이미지는 확률 0.5로 무작위 직사각형 패치로 잘리고, 그런 다음 최단 변이 최소 480에서 최대 800 픽셀, 최장 변이 최대 1,333 픽셀이 되도록 다시 크기 조정됩니다.
PubLayNet에서의 미세 조정
우리는 문서 레이아웃 분석을 위해 PubLayNet 데이터셋에서 사전 학습된 DiT 모델과 다른 이미지 백본을 평가합니다. ICDAR 2019 cTDaR 데이터셋과 유사하게, 배치 크기는 16이며, 기본 버전의 학습률은 4e-4, 큰 버전의 학습률은 1e-4입니다. 또한 DETR [6]에서 사용된 데이터 증강 방법을 사용합니다.
FUNSD에서의 미세 조정
우리는 FUNSD에서 텍스트 검출 작업을 위해 사전 학습된 DiT 모델과 다른 백본들을 미세 조정하기 위해 동일한 객체 검출 프레임워크를 사용합니다. 문서 레이아웃 분석 및 표 검출에서 검출 프로세스에 앵커 박스 크기 [32, 64, 128, 256, 512]를 사용합니다. 이는 검출된 영역이 보통 단락 수준이기 때문입니다. 문서 레이아웃 분석과는 달리, 텍스트 검출은 문서 이미지에서 단어 수준의 더 작은 객체를 위치 지정하는 것을 목표로 합니다. 따라서, 검출 프로세스에서 앵커 박스 크기 [4, 8, 16, 32, 64]를 사용합니다. 배치 크기는 16으로 설정하고, 기본 모델의 학습률은 1e-4, 큰 모델의 학습률은 5e-5입니다.
기준으로 선택된 이미지 백본 모델들은 DiT-B와 비교 가능한 파라미터 수를 가지고 있습니다. 여기에는 두 가지 종류가 포함됩니다: CNN과 이미지 변환기. CNN 기반 모델로는 ResNext101-32×8d [40]를 선택했습니다. 이미지 변환기로는 ImageNet-1K 데이터셋에서 224×224 입력 크기로 사전 학습된 DeiT [36], BEiT [3], MAE [17]의 기본 버전을 선택했습니다. 우리는 모든 기준 모델들의 미세 조정을 다시 실행했습니다.

표 1: RVL-CDIP에서 문서 이미지 분류 정확도 (%)
모든 모델은 텍스트 정보 없이 순수 이미지 정보(해상도 224×224)를 사용합니다.

표 2: PubLayNet 검증 세트에서 IOU [0.50:0.95]에 따른 문서 레이아웃 분석 mAP
ResNext-101-32×8d는 ResNext로, Cascade는 C로 줄여서 표시됩니다.
FUNSD에서의 미세 조정
우리는 FUNSD에서 텍스트 검출 작업을 위해 사전 학습된 DiT 모델과 다른 백본들을 미세 조정하기 위해 동일한 객체 검출 프레임워크를 사용합니다. 문서 레이아웃 분석 및 표 검출에서 검출 프로세스에 앵커 박스 크기 [32, 64, 128, 256, 512]를 사용합니다. 이는 검출된 영역이 보통 단락 수준이기 때문입니다. 문서 레이아웃 분석과는 달리, 텍스트 검출은 문서 이미지에서 단어 수준의 더 작은 객체를 위치 지정하는 것을 목표로 합니다. 따라서, 검출 프로세스에서 앵커 박스 크기 [4, 8, 16, 32, 64]를 사용합니다. 배치 크기는 16으로 설정하고, 기본 모델의 학습률은 1e-4, 큰 모델의 학습률은 5e-5입니다.
기준으로 선택된 이미지 백본 모델들은 DiT-B와 비교 가능한 파라미터 수를 가지고 있습니다. 여기에는 두 가지 종류가 포함됩니다: CNN과 이미지 변환기. CNN 기반 모델로는 ResNext101-32×8d [40]를 선택했습니다. 이미지 변환기로는 ImageNet-1K 데이터셋에서 224×224 입력 크기로 사전 학습된 DeiT [36], BEiT [3], MAE [17]의 기본 버전을 선택했습니다. 우리는 모든 기준 모델들의 미세 조정을 다시 실행했습니다.

표 3: ICDAR 2019 cTDaR에서 표 검출 정확도 (F1)
4.3 결과
RVL-CDIP
RVL-CDIP에서의 문서 이미지 분류 결과는 표 1에 나와 있습니다. 공정한 비교를 위해, 표에 있는 접근법들은 데이터셋의 이미지 정보만을 사용합니다. DiT-B는 선택된 단일 모델 기준치들보다 상당히 뛰어난 성능을 보였습니다. DiT는 다른 이미지 변환기 기준 모델들과 동일한 모델 구조를 공유하기 때문에, 더 높은 점수는 문서 특화 사전 학습 전략의 효과를 나타냅니다. 더 큰 버전인 DiT-L은 단일 모델 설정에서 이전 SOTA 앙상블 모델과 비슷한 점수를 얻었으며, 이는 문서 이미지에서의 모델링 능력을 더욱 강조합니다.
PubLayNet
PubLayNet에서의 문서 레이아웃 분석 결과는 표 2에 나와 있습니다. 이 작업은 많은 훈련 및 테스트 샘플을 가지고 있으며, 일반적인 문서 요소에 대한 포괄적인 분석이 필요하기 때문에, 다양한 이미지 변환기 모델의 학습 능력을 명확히 보여줍니다. DeiT-B, BEiT-B, MAE-B가 ResNeXt-101보다 현저히 우수하며, DiT-B는 이러한 강력한 이미지 변환기 기준 모델들보다도 더 뛰어납니다. 결과에 따르면, 향상은 주로 목록과 그림 카테고리에서 발생했으며, DiT-B를 기반으로 한 DiT-L은 훨씬 더 높은 mAP 점수를 제공합니다. 우리는 또한 다양한 객체 검출 알고리즘의 영향을 조사했으며, 결과는 더 발전된 검출 알고리즘(우리 경우에는 Cascade R-CNN)이 모델 성능을 더 높은 수준으로 끌어올릴 수 있음을 보여줍니다. 우리는 또한 ResNeXt-101-32×8d 기준 모델에 Cascade R-CNN을 적용했으며, DiT는 기본 및 큰 설정에서 각각 1% 및 1.4%의 절대 점수로 이를 능가하여, DiT의 다른 검출 프레임워크에서의 우수성을 나타냅니다.
ICDAR 2019 cTDaR
ICDAR 2019 cTDaR 데이터셋에서의 표 검출 결과는 표 3에 나와 있습니다. 이 데이터셋의 크기는 상대적으로 작아, 저자원 시나리오에서 모델의 소수 샷 학습 능력을 평가하는 데 목적이 있습니다. 우리는 먼저 보관 및 현대 하위 집합에서 모델 성능을 개별적으로 분석합니다. 표 3b에서, DiT는 보관 하위 집합에서 BEiT를 제외한 모든 기준 모델을 능가합니다. 이는 BEiT의 사전 학습에서 4억 개의 다양한 색상의 이미지로 훈련된 DALL-E dVAE를 직접 사용하기 때문입니다. DiT의 경우, 이미지 토크나이저는 회색조 이미지로 훈련되어, 색상이 있는 역사적 문서 이미지에는 충분하지 않을 수 있습니다. Mask R-CNN에서 Cascade R-CNN으로 전환할 때의 향상도 PubLayNet 설정과 유사하게 관찰되었으며, DiT는 여전히 다른 기준 모델을 크게 능가합니다. 결론은 표 3c의 현대 하위 집합 결과와 유사합니다. 우리는 두 하위 집합의 예측을 단일 집합으로 결합합니다. 표 3a의 결과는 DiT-L이 모든 Mask R-CNN 방법 중에서 가장 높은 wF1 점수를 달성했음을 보여주며, 이는 DiT가 다양한 문서 범주에서의 다용성을 나타냅니다. IoU@0.9의 메트릭이 현저히 더 우수하다는 점에 주목할 만하며, 이는 DiT가 더 세밀한 객체 검출 능력을 가지고 있음을 의미합니다. 세 가지 설정 모두에서, 우리는 우리의 최고의 모델과 Cascade R-CNN 검출 알고리즘을 통해 SOTA 결과를 2% 이상 (94.23→96.55) 절대 wF1 점수로 새로운 수준으로 끌어올렸습니다.
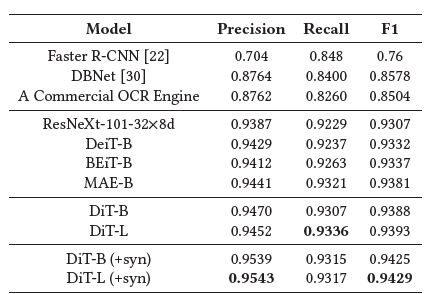
표 4: 마스크 R-CNN이 다양한 백본(ResNeXt, DeiT, BEiT, MAE 및 DiT)과 함께 사용되는 FUNSD 작업 #1의 텍스트 감지 정확도(IoU@0.5). "+syn"은 1백만 개의 문서 이미지를 포함한 합성 데이터 세트로 DiT를 학습시킨 다음 FUNSD 학습 데이터로 미세 조정했음을 나타냅니다.
FUNSD (텍스트 검출)
FUNSD 데이터셋에서의 텍스트 검출 결과는 표 4에 나와 있습니다. OCR을 위한 텍스트 검출은 오랜 기간 동안 실세계 문제로 존재해 왔기 때문에, 우리는 인기 있는 상업용 OCR 엔진에서 단어 수준의 텍스트 검출 결과를 얻어 높은 수준의 기준을 설정했습니다. 또한, DBNet [30]은 온라인 OCR 엔진을 위한 널리 사용되는 텍스트 검출 모델로, 우리는 사전 학습된 DBNet 모델을 FUNSD 훈련 데이터로 미세 조정하고 정확성을 평가했습니다. 두 모델 모두 IoU@0.5에서 약 0.85의 F1 점수를 달성했습니다.
다음으로, 우리는 Mask R-CNN 프레임워크를 사용하여 ResNeXt-101, DeiT, BEiT, MAE, DiT를 포함한 다양한 백본 네트워크(CNN 및 ViT)를 비교했습니다. CNN 기반 및 ViT 기반 텍스트 검출 모델은 진보된 모델 설계와 더 많은 파라미터 덕분에 기준 모델들을 크게 능가했습니다. 우리는 또한 DiT 모델들이 다른 모델들과 비교하여 새로운 SOTA 결과를 달성했음을 확인했습니다. 마지막으로, 우리는 100만 개의 문서 이미지를 포함한 합성 데이터셋으로 DiT 모델을 추가로 훈련하여, DiT-L 모델이 0.9429의 F1 점수를 달성하게 했습니다.
결론 및 미래 작업
이 논문에서는 일반 문서 AI 작업을 위한 자가 지도 기반의 기본 모델인 DiT를 소개했습니다. DiT 모델은 다양한 템플릿과 형식을 포함한 대규모 레이블 없는 문서 이미지로 사전 학습되어, 다양한 도메인에서의 다운스트림 문서 AI 작업에 이상적입니다. 우리는 테이블 검출, 문서 레이아웃 분석, 문서 이미지 분류 및 텍스트 검출을 포함한 여러 시각 기반 문서 AI 벤치마크에서 사전 학습된 DiT를 평가했습니다. 실험 결과, DiT는 여러 강력한 기준 모델을 전반적으로 능가하며 새로운 SOTA 성능을 달성했습니다. 우리는 사전 학습된 DiT 모델을 공개하여 문서 AI 연구를 촉진할 예정입니다.
향후 연구에서는 훨씬 더 큰 데이터셋으로 DiT를 사전 학습하여 문서 AI에서 SOTA 결과를 더욱 향상시킬 것입니다. 또한, 우리는 DiT를 다중 모드 사전 학습의 기본 모델로 통합하여, LayoutLM과 같은 차세대 레이아웃 기반 모델에서 시각적으로 풍부한 문서 이해를 위해 통합된 변환기 기반 아키텍처가 문서 AI의 CV 및 NLP 응용 프로그램 모두에 충분할 수 있도록 할 것입니다.
'인공지능' 카테고리의 다른 글
| Revisiting Feature Prediction for Learning Visual Representations from Video (1) | 2024.06.28 |
|---|---|
| Adding Conditional Control to Text-to-Image Diffusion Models (1) | 2024.06.27 |
| ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders (1) | 2024.06.25 |
| Diffusion On Syntax Trees For Program Synthesis (1) | 2024.06.23 |
| Relightable Gaussian Codec Avatars (1) | 2024.06.23 |



