https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
What are Diffusion Models?
[Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of several key papers in the references)]. [Updated on 2022-08-27: Added classifier-free guidance, GLIDE, unCLIP and Imagen. [Updated on 2022-08
lilianweng.github.io
[2021-09-19 업데이트: 여러 주요 논문의 저자인 Yang Song이 작성한 스코어 기반 생성 모델링에 대한 이 블로그 포스트를 강력히 추천합니다.] [2022-08-27 업데이트: classifier-free guidance, GLIDE, unCLIP 및 Imagen 추가.] [2022-08-31 업데이트: 잠재 확산 모델 추가.] [2024-04-13 업데이트: progressive distillation, consistency models, 그리고 모델 아키텍처 섹션 추가.]
지금까지 저는 세 가지 유형의 생성 모델, GAN, VAE 및 Flow 기반 모델에 대해 작성했습니다. 이들은 고품질 샘플을 생성하는 데 큰 성공을 거두었지만 각각 고유의 한계가 있습니다. GAN 모델은 적대적 훈련 특성 때문에 잠재적으로 불안정한 훈련과 생성물의 다양성이 적다는 단점이 있습니다. VAE는 대리 손실에 의존합니다. Flow 모델은 가역 변환을 구성하기 위해 특수한 아키텍처를 사용해야 합니다.
확산 모델은 비평형 열역학에서 영감을 받았습니다. 이들은 데이터에 무작위 노이즈를 천천히 추가하는 마르코프 체인의 확산 단계를 정의하고, 노이즈로부터 원하는 데이터 샘플을 구성하기 위해 확산 과정을 역으로 학습합니다. VAE나 Flow 모델과 달리, 확산 모델은 고정된 절차로 학습되며 잠재 변수는 고차원(원본 데이터와 동일)입니다.
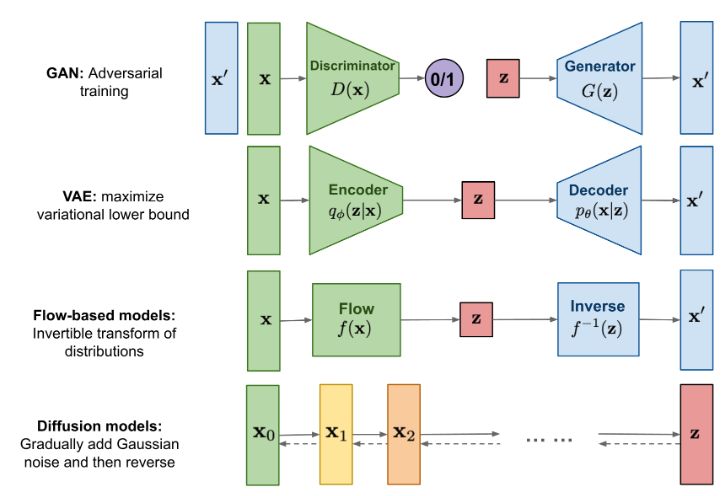
그림 1. 다양한 유형의 생성 모델 개요.
확산 모델이란 무엇인가요? 유사한 아이디어를 기반으로 한 여러 확산 기반 생성 모델이 제안되었습니다. 여기에는 확산 확률 모델(Sohl-Dickstein et al., 2015), 노이즈 조건 스코어 네트워크(NCSN; Yang & Ermon, 2019), 및 노이즈 제거 확산 확률 모델(DDPM; Ho et al. 2020)이 포함됩니다.

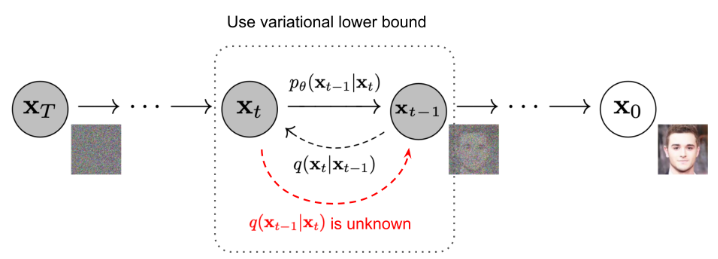
그림 2. 노이즈를 천천히 추가(제거)하여 샘플을 생성하는 순방향(역방향) 확산 과정의 마르코프 체인. (이미지 출처: Ho 외. 2020, 몇 가지 주석 추가)



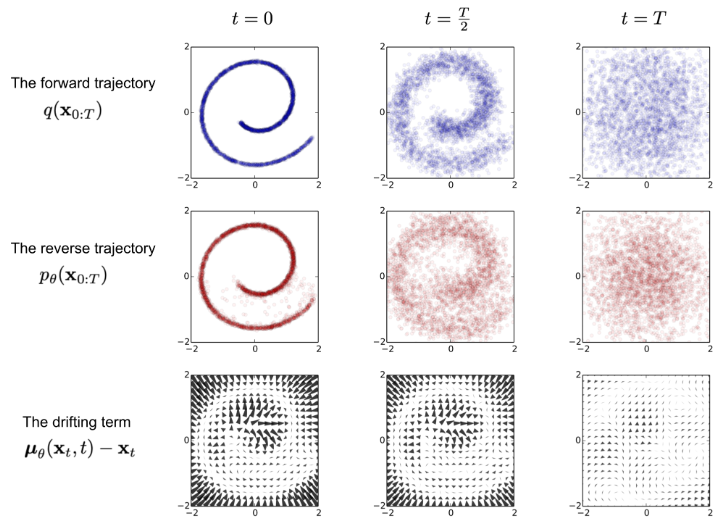
그림 3. 2D 스위스 롤 데이터를 모델링하기 위한 확산 모델 훈련의 예. (이미지 출처: Sohl-Dickstein 외., 2015)










그림 4. DDPM의 트레이닝 및 샘플링 알고리즘(이미지 출처: Ho et al. 2020)



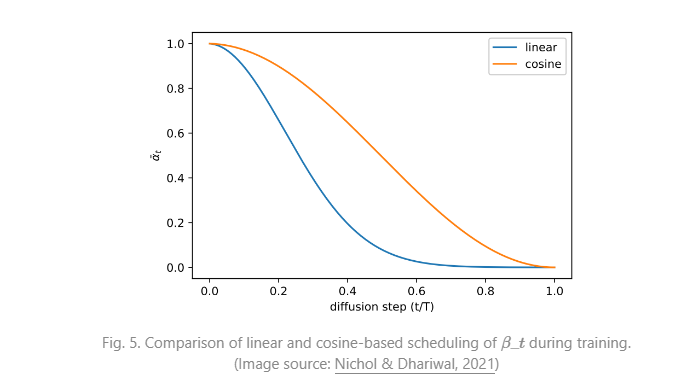


그림 6. 개선된 DDPM의 음의 로그-확률을 다른 확률 기반 생성 모델과 비교. NLL은 비트/딤 단위로 보고됩니다. (이미지 출처: Nichol & Dhariwal, 2021)
Conditioned Generation
ImageNet 데이터셋과 같이 조건 정보를 포함한 이미지로 생성 모델을 훈련할 때, 클래스 레이블이나 설명 텍스트의 조각에 조건을 부여하여 샘플을 생성하는 것이 일반적입니다.



그림 7. 이 알고리즘은 분류기의 지침을 사용하여 DDPM 및 DDIM으로 조건부 생성을 실행합니다. (이미지 출처: Dhariwal & Nichol, 2021])







DDPM에 비해 DDIM은 다음을 수행할 수 있습니다:
1. 훨씬 적은 수의 단계로 더 높은 품질의 샘플을 생성할 수 있습니다.
2. 생성 프로세스가 결정론적이기 때문에 '일관성' 속성을 가지며, 이는 동일한 잠재 변수를 조건으로 하는 여러 샘플이 유3사한 상위 수준의 특징을 가져야 함을 의미합니다.
3. 이러한 일관성 덕분에 DDIM은 잠재 변수에서 의미적으로 의미 있는 보간을 수행할 수 있습니다.
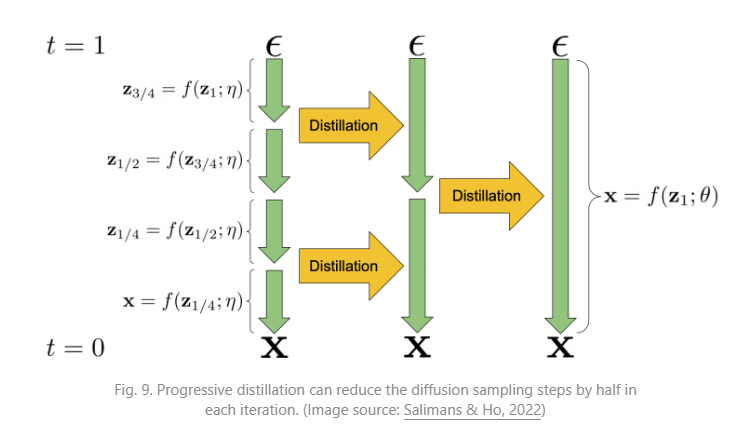



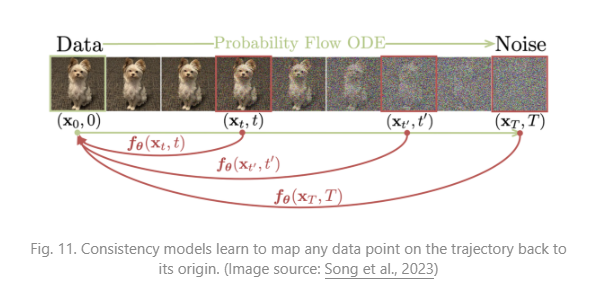


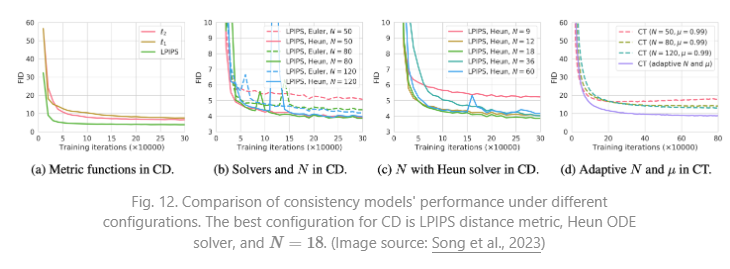
잠재 가변 공간
잠재 확산 모델(LDM; Rombach & Blattmann 등, 2022)은 픽셀 공간 대신 잠재 공간에서 확산 과정을 실행하여 훈련 비용은 낮추고 추론 속도는 더 빠르게 만듭니다. 이는 이미지의 대부분의 비트가 지각적 디테일에 기여하고 공격적인 압축 후에도 의미 및 개념적 구성이 여전히 남아 있다는 관찰에서 착안한 것입니다. LDM은 먼저 자동 인코더로 픽셀 수준의 중복성을 제거한 다음, 학습된 잠복에 대한 확산 과정을 통해 의미적 개념을 조작/생성함으로써 지각적 압축과 의미적 압축을 생성 모델링 학습으로 느슨하게 분해합니다.










모델 아키텍처
확산 모델에는 두 가지 일반적인 백본 아키텍처를 선택할 수 있습니다: U-Net과 트랜스포머입니다.
U-Net(Ronneberger 등, 2015)은 다운샘플링 스택과 업샘플링 스택으로 구성됩니다.
다운샘플링: 각 단계는 두 개의 3x3 컨볼루션(패딩되지 않은 컨볼루션)을 반복적으로 적용한 다음 각각 ReLU와 최대 2x2 풀링(보폭 2)을 적용하는 것으로 구성됩니다. 각 다운샘플링 단계마다 특징 채널 수가 두 배가 됩니다.
업샘플링: 각 단계는 특징 맵의 업샘플링과 2x2 컨볼루션으로 구성되며, 각 단계마다 특징 채널 수가 절반으로 줄어듭니다.
바로 가기: 바로 가기 연결은 다운샘플링 스택의 해당 레이어와 연결되며 업샘플링 프로세스에 필수적인 고해상도 피처를 제공합니다.




트랜스포머 아키텍처는 쉽게 확장할 수 있는 것으로 잘 알려져 있습니다. 이는 더 많은 컴퓨팅에 따라 성능이 확장되고 실험에 따르면 더 큰 DiT 모델이 더 컴퓨팅 효율적이기 때문에 DiT의 가장 큰 장점 중 하나입니다.
빠른 요약
장점: 확장성과 유연성은 제너레이티브 모델링에서 상충되는 두 가지 목표입니다. 추적 가능한 모델은 분석적으로 평가할 수 있고 가우스 또는 라플라스 등을 통해 저렴하게 데이터를 맞출 수 있지만, 풍부한 데이터 세트의 구조를 쉽게 설명할 수 없습니다. 유연한 모델은 데이터의 임의의 구조에 맞출 수 있지만, 이러한 모델을 평가, 학습 또는 샘플링하는 데는 일반적으로 많은 비용이 듭니다. 확산 모델은 분석적으로 추적 가능하고 유연합니다.
단점: 확산 모델은 샘플을 생성하기 위해 긴 확산 단계의 마르코프 체인에 의존하기 때문에 시간과 계산 비용이 상당히 많이 들 수 있습니다. 프로세스를 훨씬 빠르게 만드는 새로운 방법이 제안되었지만, 샘플링 속도는 여전히 GAN보다 느립니다.
References
[1] Jascha Sohl-Dickstein et al. “Deep Unsupervised Learning using Nonequilibrium Thermodynamics.” ICML 2015.
[2] Max Welling & Yee Whye Teh. “Bayesian learning via stochastic gradient langevin dynamics.” ICML 2011.
[3] Yang Song & Stefano Ermon. “Generative modeling by estimating gradients of the data distribution.” NeurIPS 2019.
[4] Yang Song & Stefano Ermon. “Improved techniques for training score-based generative models.” NeuriPS 2020.
[5] Jonathan Ho et al. “Denoising diffusion probabilistic models.” arxiv Preprint arxiv:2006.11239 (2020). [code]
[6] Jiaming Song et al. “Denoising diffusion implicit models.” arxiv Preprint arxiv:2010.02502 (2020). [code]
[7] Alex Nichol & Prafulla Dhariwal. “Improved denoising diffusion probabilistic models” arxiv Preprint arxiv:2102.09672 (2021). [code]
[8] Prafula Dhariwal & Alex Nichol. “Diffusion Models Beat GANs on Image Synthesis.” arxiv Preprint arxiv:2105.05233 (2021). [code]
[9] Jonathan Ho & Tim Salimans. “Classifier-Free Diffusion Guidance.” NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications.
[10] Yang Song, et al. “Score-Based Generative Modeling through Stochastic Differential Equations.” ICLR 2021.
[11] Alex Nichol, Prafulla Dhariwal & Aditya Ramesh, et al. “GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.” ICML 2022.
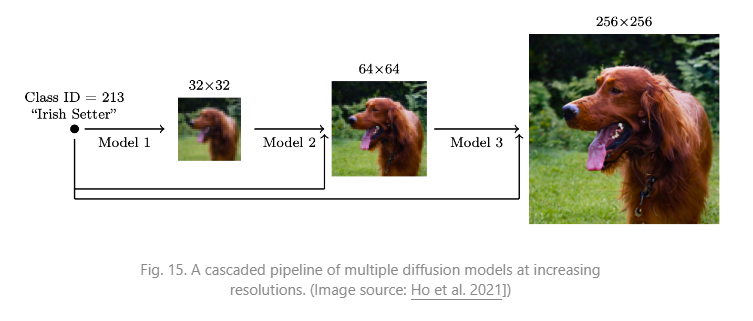
[12] Jonathan Ho, et al. “Cascaded diffusion models for high fidelity image generation.” J. Mach. Learn. Res. 23 (2022): 47-1.
[13] Aditya Ramesh et al. “Hierarchical Text-Conditional Image Generation with CLIP Latents.” arxiv Preprint arxiv:2204.06125 (2022).
[14] Chitwan Saharia & William Chan, et al. “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding.” arxiv Preprint arxiv:2205.11487 (2022).
[15] Rombach & Blattmann, et al. “High-Resolution Image Synthesis with Latent Diffusion Models.” CVPR 2022.code
[16] Song et al. “Consistency Models” arxiv Preprint arxiv:2303.01469 (2023)
[17] Salimans & Ho. “Progressive Distillation for Fast Sampling of Diffusion Models” ICLR 2022.
[18] Ronneberger, et al. “U-Net: Convolutional Networks for Biomedical Image Segmentation” MICCAI 2015.
[19] Peebles & Xie. “Scalable diffusion models with transformers.” ICCV 2023.
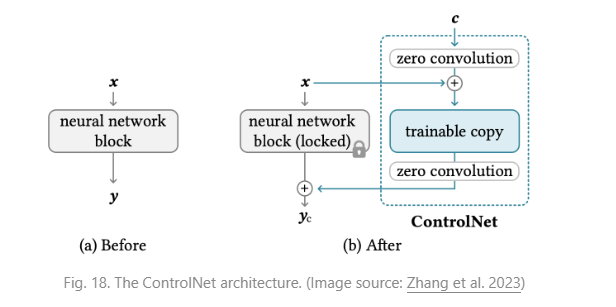
[20] Zhang et al. “Adding Conditional Control to Text-to-Image Diffusion Models.” arxiv Preprint arxiv:2302.05543 (2023).



