https://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
요약
자연어 처리의 중요한 패러다임은 일반 도메인 데이터에 대한 대규모 사전 학습과 특정 작업 또는 도메인에 대한 적응으로 구성됩니다. 우리가 더 큰 모델을 사전 학습할수록 모든 모델 파라미터를 재학습하는 전체 미세 조정(full fine-tuning)은 덜 실현 가능해집니다. 예를 들어, GPT-3 175B 모델을 독립적으로 미세 조정한 인스턴스를 각각 배포하는 것은 비용이 매우 많이 듭니다. 우리는 Low-Rank Adaptation(LoRA)을 제안하는데, 이는 사전 학습된 모델 가중치를 고정하고, Transformer 아키텍처의 각 층에 학습 가능한 랭크 분해 행렬을 주입하여 다운스트림 작업에 필요한 학습 가능한 파라미터 수를 크게 줄입니다. Adam을 사용하여 미세 조정된 GPT-3 175B와 비교할 때, LoRA는 학습 가능한 파라미터 수를 10,000배, GPU 메모리 요구 사항을 3배 줄일 수 있습니다. LoRA는 학습 가능한 파라미터가 더 적고 학습 처리량이 높으며, 어댑터와 달리 추가적인 추론 지연이 없음에도 불구하고 RoBERTa, DeBERTa, GPT-2 및 GPT-3에서 모델 품질이 미세 조정보다 동등하거나 더 우수합니다. 우리는 또한 언어 모델 적응에서 랭크 부족(rank-deficiency)에 대한 경험적 조사를 제공하여 LoRA의 효과를 설명합니다. 우리는 LoRA를 PyTorch 모델에 통합할 수 있는 패키지를 제공하고, RoBERTa, DeBERTa 및 GPT-2에 대한 구현 및 모델 체크포인트를 https://github.com/microsoft/LoRA에서 제공합니다.
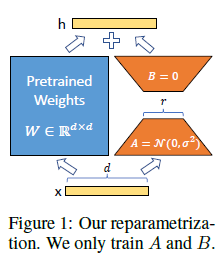
Figure 1: 우리의 재파라미터화. 우리는 A와 B만 훈련합니다.
1 서론
자연어 처리의 많은 응용 프로그램은 하나의 대규모 사전 학습된 언어 모델을 여러 다운스트림 응용 프로그램에 적응시키는 데 의존합니다. 이러한 적응은 보통 모든 사전 학습된 모델의 파라미터를 업데이트하는 미세 조정을 통해 이루어집니다. 미세 조정의 주요 단점은 새로운 모델이 원래 모델과 동일한 수의 파라미터를 포함한다는 점입니다. 몇 달마다 더 큰 모델이 훈련되면서, 이는 GPT-2나 RoBERTa large에서는 단순한 “불편함”에서, 1750억 개의 학습 가능한 파라미터를 가진 GPT-3에서는 중요한 배포 문제로 변화합니다.
많은 사람들은 일부 파라미터만 적응시키거나 새로운 작업을 위한 외부 모듈을 학습하여 이를 완화하려고 했습니다. 이렇게 하면 각 작업에 대해 사전 학습된 모델 외에 소수의 작업별 파라미터만 저장하고 로드하면 되므로, 배포 시 운영 효율성이 크게 향상됩니다. 그러나 기존 기술들은 종종 모델 깊이를 확장함으로써 추론 지연을 초래하거나 모델의 사용 가능한 시퀀스 길이를 줄이는 경우가 많습니다. 더 중요한 것은, 이러한 방법들이 종종 미세 조정 기준선에 도달하지 못하여 효율성과 모델 품질 간의 트레이드오프를 초래한다는 것입니다.
Li et al. (2018a)와 Aghajanyan et al. (2020)에서 영감을 받아, 과학자들은 학습된 과매개변수화된 모델이 실제로는 낮은 고유 차원에 존재한다고 보여줍니다. 우리는 모델 적응 동안 가중치의 변화도 낮은 "고유 랭크"를 가진다고 가정하여 Low-Rank Adaptation(LoRA) 접근 방식을 제안합니다. LoRA는 사전 학습된 가중치를 고정하면서, 적응 동안의 밀집 층의 변화를 랭크 분해 행렬로 최적화함으로써 밀집 층의 일부를 간접적으로 훈련할 수 있게 합니다. GPT-3 175B를 예로 들어, 매우 낮은 랭크(r)가 충분하며, 이는 전체 랭크(d)가 12,288에 이르더라도 LoRA를 저장 및 계산 효율적으로 만듭니다.
LoRA는 몇 가지 주요 이점을 가지고 있습니다:
- 사전 학습된 모델은 공유될 수 있으며, 다양한 작업을 위한 여러 작은 LoRA 모듈을 구축하는 데 사용될 수 있습니다. 공유된 모델을 고정하고, Figure 1에서 A와 B 행렬을 교체하여 효율적으로 작업을 전환함으로써 저장 요구 사항과 작업 전환 오버헤드를 크게 줄일 수 있습니다.
- LoRA는 훈련을 더 효율적으로 만들고, 대부분의 파라미터에 대해 그라디언트를 계산하거나 옵티마이저 상태를 유지할 필요가 없기 때문에, 적응형 옵티마이저를 사용할 때 최대 3배까지 하드웨어 진입 장벽을 낮출 수 있습니다. 대신에, 주입된 훨씬 작은 저랭크 행렬만 최적화하면 됩니다.
- 우리의 간단한 선형 디자인은, 배포 시에 학습 가능한 행렬을 고정된 가중치와 병합할 수 있게 하여, 구조적으로 완전 미세 조정된 모델과 비교하여 추론 지연을 도입하지 않습니다.
- LoRA는 많은 이전 방법들과 독립적이며, prefix-tuning과 같은 많은 방법들과 결합될 수 있습니다. 부록 E에서 예를 제공합니다.

2 문제 설명
우리의 제안은 학습 목표와는 무관하지만, 우리는 언어 모델링을 우리의 동기 사용 사례로 삼습니다. 아래는 언어 모델링 문제에 대한 간단한 설명이며, 특히 특정 작업 프롬프트가 주어진 조건부 확률의 최대화에 관한 것입니다.


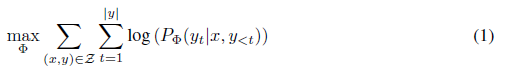

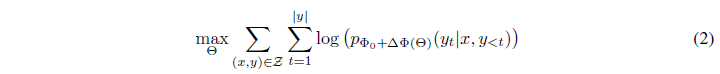

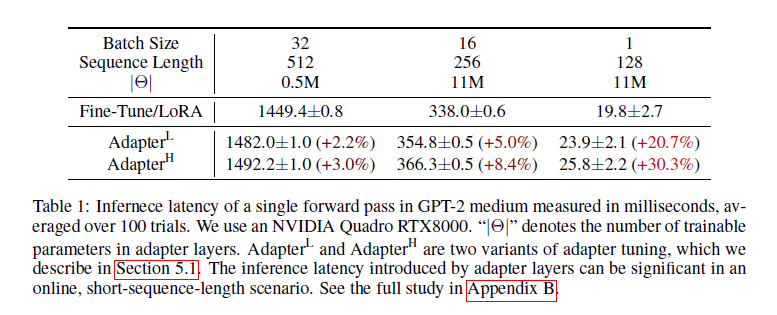
표 1
GPT-2 medium에서 단일 포워드 패스의 추론 지연 시간(밀리초 단위), 100번의 시도에서 평균. NVIDIA Quadro RTX8000을 사용했습니다. “|Θ|”는 어댑터 레이어의 학습 가능한 파라미터 수를 나타냅니다. AdapterL과 AdapterH는 5.1장에서 설명하는 어댑터 튜닝의 두 가지 변형입니다. 온라인, 짧은 시퀀스 길이 시나리오에서 어댑터 레이어가 초래하는 추론 지연은 상당할 수 있습니다. 전체 연구는 부록 B를 참조하십시오.
3 기존 솔루션이 충분히 좋은가?
우리가 해결하려는 문제는 새로운 것이 아닙니다. 전이 학습이 처음 도입된 이후로, 수십 개의 연구들이 모델 적응을 더 파라미터 및 계산 효율적으로 만들기 위해 노력해왔습니다. 잘 알려진 연구들에 대한 개요는 6장을 참조하세요. 언어 모델링을 예로 들어보면, 효율적인 적응을 위한 두 가지 주요 전략이 있습니다: 어댑터 레이어 추가(Houlsby et al., 2019; Rebuffi et al., 2017; Pfeiffer et al., 2021; Rücklé et al., 2020) 또는 입력 레이어 활성화의 일부 형태를 최적화하는 것(Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021). 그러나 두 전략 모두 대규모 및 지연 민감한 생산 시나리오에서는 한계가 있습니다.
어댑터 레이어는 추론 지연을 초래합니다
어댑터에는 여러 변형이 있습니다. 우리는 Transformer 블록당 두 개의 어댑터 레이어를 갖춘 Houlsby et al. (2019)의 원래 디자인과, 블록당 하나의 레이어와 추가 LayerNorm (Ba et al., 2016)을 포함한 Lin et al. (2020)의 최근 디자인에 초점을 맞춥니다. 레이어를 가지치기 하거나 멀티태스크 설정을 활용하여 전체 지연 시간을 줄일 수 있지만(Rücklé et al., 2020; Pfeiffer et al., 2021), 어댑터 레이어에서 추가 계산을 피할 직접적인 방법은 없습니다. 어댑터 레이어는 작은 병목 차원을 가지고 있어 추가할 수 있는 FLOPs를 제한함으로써 종종 원래 모델의 1% 미만의 파라미터를 가지도록 설계되었기 때문에, 이는 큰 문제가 아닌 것처럼 보입니다. 그러나 대규모 신경망은 지연 시간을 낮추기 위해 하드웨어 병렬 처리에 의존하며, 어댑터 레이어는 순차적으로 처리해야 합니다. 이는 배치 크기가 일반적으로 하나인 온라인 추론 설정에서 차이를 만듭니다. 모델 병렬 처리가 없는 일반적인 시나리오, 예를 들어 단일 GPU에서 GPT-2 medium(Radford et al., b)으로 추론을 실행할 때, 매우 작은 병목 차원에서도 어댑터를 사용할 때 지연 시간이 눈에 띄게 증가하는 것을 볼 수 있습니다(표 1).
Shoeybi et al. (2020); Lepikhin et al. (2020)에서 수행된 것처럼 모델을 분할해야 할 때 이 문제는 악화됩니다. 왜냐하면 추가 깊이는 AllReduce 및 Broadcast와 같은 동기화된 GPU 작업을 더 많이 요구하기 때문입니다. 어댑터 파라미터를 여러 번 중복 저장하지 않는 한 말입니다.
프롬프트를 직접 최적화하는 것은 어렵습니다
다른 방향인 프리픽스 튜닝(Li & Liang, 2021)은 다른 도전에 직면합니다. 우리는 프리픽스 튜닝이 최적화하기 어렵고, 학습 가능한 파라미터에서 성능이 비단조적으로 변화한다는 것을 관찰하였으며, 이는 원래 논문에서도 유사한 관찰을 확인한 것입니다. 더 근본적으로, 적응을 위해 시퀀스 길이의 일부를 예약하는 것은 다운스트림 작업을 처리하는 데 사용할 수 있는 시퀀스 길이를 필연적으로 줄이며, 이로 인해 프롬프트 튜닝이 다른 방법들에 비해 성능이 떨어진다고 추정합니다. 작업 성능에 대한 연구는 5장에서 다루도록 하겠습니다.
4. 우리의 방법
LoRA의 간단한 설계와 실질적인 이점에 대해 설명합니다. 여기에 설명된 원칙은 딥 러닝 모델의 모든 고밀도 레이어에 적용되지만, 실험에서는 트랜스포머 언어 모델의 특정 가중치에만 초점을 맞춰 동기를 부여하는 사용 사례로 삼았습니다.

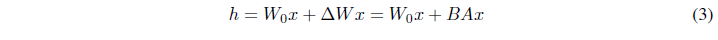

전체 미세 조정의 일반화
더 일반적인 형태의 미세 조정은 사전 학습된 파라미터의 부분 집합을 학습하는 것입니다. LoRA는 한 걸음 더 나아가 적응 동안 풀 랭크를 유지하기 위해 가중치 행렬에 누적된 그라디언트 업데이트를 필요로 하지 않습니다. 이는 모든 가중치 행렬에 LoRA를 적용하고 모든 편향을 유지할 수 있음을 의미합니다. 전체 미세 조정의 장점을 유지하면서 LoRA의 랭크를 사전 학습된 가중치 행렬의 랭크로 설정함으로써, 학습 가능한 파라미터의 수가 증가함에 따라, LoRA는 점진적으로 원래 모델에 수렴하고, 더 길고 복잡한 시퀀스를 처리하기 위해 MLP 및 프리픽스 기반 방법으로 수렴합니다.



5. 실험 연구
우리는 RoBERTa (Liu et al., 2019), DeBERTa (He et al., 2021) 및 GPT-2 (Radford et al., b)에서 LoRA의 다운스트림 작업 성능을 평가한 후, GPT-3 175B (Brown et al., 2020)로 확장합니다. 우리의 실험은 자연어 이해(NLU)에서 생성(NLG)까지 다양한 작업을 다룹니다. 구체적으로, RoBERTa와 DeBERTa에 대해서는 GLUE (Wang et al., 2019) 벤치마크를 평가합니다. GPT-2에 대해서는 Li & Liang (2021)의 설정을 따라 직접 비교를 수행하고, GPT-3에 대한 대규모 실험으로 WikiSQL (Zhong et al., 2017) (NL에서 SQL 쿼리로)과 SAMSum (Gliwa et al., 2019) (대화 요약)을 추가합니다. 사용한 데이터셋에 대한 자세한 내용은 부록 C를 참조하세요. 모든 실험에서는 NVIDIA Tesla V100을 사용합니다.
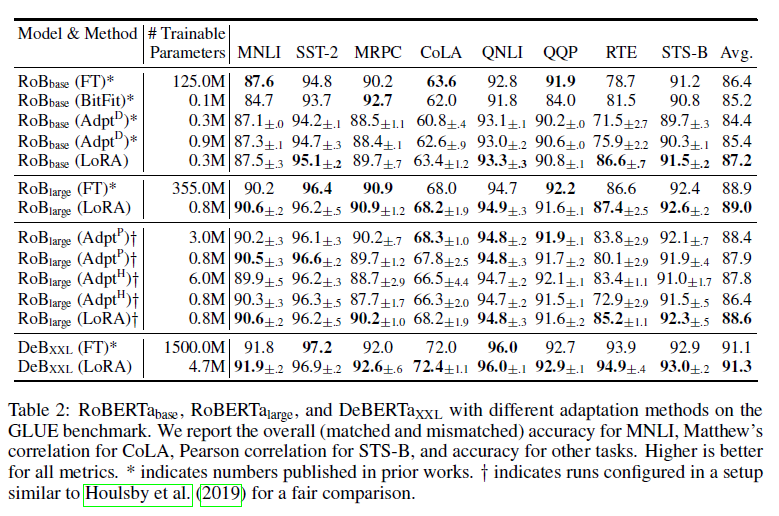
표 2: GLUE 벤치마크에서 다양한 적응 방법을 사용한 RoBERTa base, RoBERTa large, DeBERTa XXL
우리는 MNLI에 대해 전체(일치 및 불일치) 정확도, CoLA에 대해 Matthew’s 상관계수, STS-B에 대해 Pearson 상관계수, 다른 작업에 대해서는 정확도를 보고합니다. 모든 지표에서 높을수록 좋습니다. *는 이전 연구에서 발표된 숫자를 나타냅니다. y는 공정한 비교를 위해 Houlsby et al. (2019)와 유사한 설정으로 구성된 실행을 나타냅니다.
5.1 기준선
다른 기준선과 비교하기 위해, 우리는 이전 연구에서 사용된 설정을 복제하고 가능한 경우 보고된 숫자를 재사용합니다. 그러나 이는 일부 기준선이 특정 실험에서만 나타날 수 있음을 의미합니다.
**미세 조정(FT)**은 적응을 위한 일반적인 접근 방식입니다. 미세 조정 동안, 모델은 사전 학습된 가중치와 바이어스로 초기화되고, 모든 모델 파라미터가 그라디언트 업데이트를 거칩니다. 간단한 변형은 일부 레이어만 업데이트하고 나머지는 동결하는 것입니다. 우리는 GPT-2에서 마지막 두 레이어만 적응시키는 이전 연구(Li & Liang, 2021)에서 보고된 기준선을 포함합니다 (FTTop2).
바이어스 전용(Bias-only) 또는 BitFit은 다른 모든 것을 동결한 채 바이어스 벡터만 학습하는 기준선입니다. 최근에 이 기준선은 BitFit (Zaken et al., 2021)에서 연구되었습니다.


LORA

-----------------------------------------------------------------------------------------------------------------------------------------------------------------





-----------------------------------------------------------------------------------------------------------------------------------------------------------------
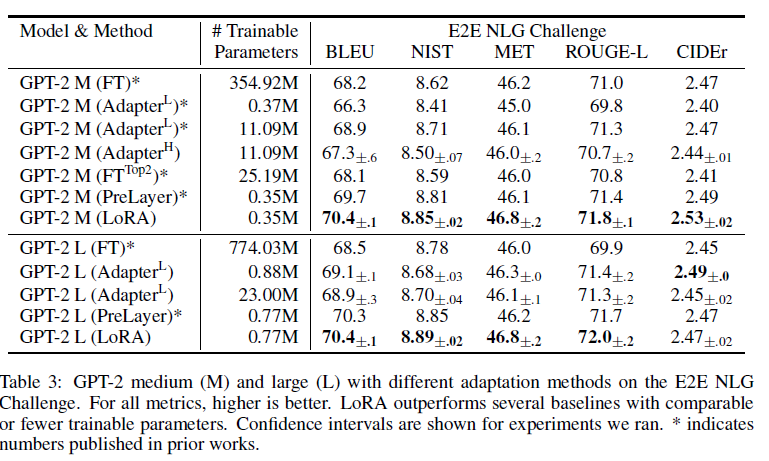
표 3: E2E NLG 챌린지에서 GPT-2 Medium(M) 및 Large(L)의 다양한 적응 방법
모든 메트릭에서 높을수록 좋습니다. LoRA는 비교 가능한 또는 더 적은 학습 가능한 파라미터를 가진 여러 기준선을 능가합니다. 우리가 실행한 실험에 대한 신뢰 구간이 표시되어 있습니다. *는 이전 연구에서 발표된 숫자를 나타냅니다.
5.2 RoBERTa Base/Large
RoBERTa(Liu et al., 2019)는 BERT(Devlin et al., 2019a)에서 처음 제안된 사전 학습 방식을 최적화하여 더 많은 학습 가능한 파라미터를 추가하지 않고도 BERT의 작업 성능을 향상시켰습니다. RoBERTa는 최근 몇 년 동안 GLUE 벤치마크(Wang et al., 2019)와 같은 NLP 리더보드에서 더 큰 모델들에 의해 추월되었지만, 여전히 크기 면에서 실무자들 사이에서 경쟁력 있고 인기 있는 사전 학습된 모델입니다. 우리는 HuggingFace Transformers 라이브러리(Wolf et al., 2020)에서 사전 학습된 RoBERTa base(125M)와 RoBERTa large(355M)를 사용하여 GLUE 벤치마크 작업에서 다양한 효율적인 적응 방법의 성능을 평가합니다. 또한 Houlsby et al. (2019)와 Pfeiffer et al. (2021)의 설정을 복제합니다. 어댑터와 비교할 때 LoRA를 평가하는 방법에 두 가지 중요한 변경 사항을 추가하여 공정한 비교를 보장합니다. 첫째, 모든 작업에 동일한 배치 크기를 사용하고 어댑터 기준선과 일치시키기 위해 시퀀스 길이 128을 사용합니다. 둘째, 모델을 MNLI에 적응된 모델이 아닌 사전 학습된 모델로 초기화합니다. Houlsby et al. (2019)의 이 더 제한된 설정을 따르는 실행에는 y 레이블을 붙입니다. 결과는 표 2(상위 섹션)에 제시되어 있습니다. 사용된 하이퍼파라미터에 대한 자세한 내용은 섹션 D.1을 참조하세요.
5.3 DeBERTa XXL
DeBERTa(He et al., 2021)는 훨씬 큰 규모로 훈련된 BERT의 최근 변형으로, GLUE(Wang et al., 2019)와 SuperGLUE(Wang et al., 2020)와 같은 벤치마크에서 매우 경쟁력 있는 성능을 보입니다. 우리는 LoRA가 GLUE에서 완전히 미세 조정된 DeBERTa XXL(1.5B)의 성능을 여전히 맞출 수 있는지 평가합니다. 결과는 표 2(하위 섹션)에 제시되어 있습니다. 사용된 하이퍼파라미터에 대한 자세한 내용은 섹션 D.2를 참조하세요.
5.4 GPT-2 Medium/Large
LoRA가 NLU에서 완전 미세 조정의 경쟁력 있는 대안이 될 수 있음을 보여준 후, 우리는 LoRA가 GPT-2 medium 및 large(Radford et al., b)와 같은 NLG 모델에서도 여전히 우세한지 답하고자 합니다. 직접 비교를 위해 Li & Liang(2021)의 설정에 최대한 가깝게 유지합니다. 공간 제약으로 인해 이 섹션에서는 E2E NLG Challenge(표 3)에서의 결과만 제시합니다. WebNLG(Gardent et al., 2017)와 DART(Nan et al., 2020)에 대한 결과는 섹션 F.1을 참조하세요. 사용된 하이퍼파라미터 목록은 섹션 D.3에 포함되어 있습니다.

표 4: GPT-3 175B에서의 다양한 적응 방법의 성능
우리는 WikiSQL에서의 논리 형식 검증 정확도, MultiNLI-matched에서의 검증 정확도, SAMSum에서의 Rouge-1/2/L을 보고합니다. LoRA는 전체 미세 조정을 포함한 이전 접근 방식을 능가합니다. WikiSQL에서의 결과는 약 ±0.5%, MNLI-m에서 약 ±0.1%, 그리고 SAMSum에서의 세 가지 메트릭에 대해 각각 약 ±0.2/±0.2/±0.1의 변동성을 보입니다.
5.5 GPT-3 175B로 확장
LoRA의 최종 스트레스 테스트로, 우리는 1750억 개의 파라미터를 가진 GPT-3로 확장합니다. 높은 훈련 비용 때문에, 우리는 주어진 작업에 대해 무작위 시드에 대한 일반적인 표준 편차만 보고하며, 각 항목에 대해 제공하지는 않습니다. 사용된 하이퍼파라미터에 대한 자세한 내용은 섹션 D.4를 참조하십시오. 표 4에서 알 수 있듯이, LoRA는 세 가지 데이터셋 모두에서 미세 조정 기준선을 맞추거나 초과합니다. 그림 2에서 보여지듯이, 모든 방법이 더 많은 학습 가능한 파라미터로부터 단조롭게 이익을 얻는 것은 아닙니다. 우리는 프리픽스 임베딩 튜닝에 대해 256개 이상의 특별 토큰을 사용하거나 프리픽스 레이어 튜닝에 대해 32개 이상의 특별 토큰을 사용할 때 성능이 크게 떨어지는 것을 관찰합니다. 이는 Li & Liang (2021)에서 유사한 관찰을 확인시켜줍니다. 이 현상에 대한 철저한 조사는 이 작업의 범위를 벗어나지만, 우리는 더 많은 특별 토큰이 입력 분포를 사전 훈련 데이터 분포에서 더 멀어지게 한다고 의심합니다. 별도로, 우리는 섹션 F.3에서 적은 데이터 환경에서의 다양한 적응 접근 방식의 성능을 조사합니다.
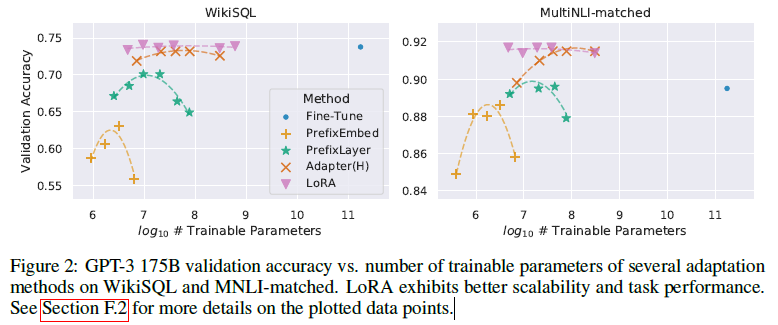
그림 2: WikiSQL 및 MNLI-matched에서의 여러 적응 방법의 GPT-3 175B 검증 정확도 대 학습 가능한 파라미터 수
LoRA는 더 나은 확장성과 작업 성능을 보여줍니다. 그림에 대한 더 자세한 데이터 포인트는 섹션 F.2를 참조하십시오.
6. 관련 연구
Transformer 언어 모델
Transformer(Vaswani et al., 2017)는 자기 주의를 많이 사용하는 시퀀스-투-시퀀스 아키텍처입니다. Radford et al. (a)는 이를 자기 회귀 언어 모델링에 적용하여 Transformer 디코더 스택을 사용했습니다. 그 이후로 Transformer 기반 언어 모델은 NLP를 지배하며 많은 작업에서 최첨단 성과를 달성했습니다. BERT(Devlin et al., 2019b)와 GPT-2(Radford et al., b)와 같은 대형 Transformer 언어 모델이 등장하면서 새로운 패러다임이 생겨났습니다. 이는 일반 도메인 데이터에 대한 사전 학습 후, 작업별 데이터에 대해 미세 조정을 통해 직접 작업별 데이터로 훈련하는 것보다 성능을 크게 향상시키는 방식입니다. 더 큰 Transformer를 훈련하면 일반적으로 더 나은 성능이 나와서 활발한 연구 방향으로 남아 있습니다. GPT-3(Brown et al., 2020)는 현재까지 훈련된 가장 큰 단일 Transformer 언어 모델로, 1750억 개의 파라미터를 가지고 있습니다.
프롬프트 엔지니어링 및 미세 조정
GPT-3 175B는 몇 가지 추가적인 훈련 예제만으로도 그 행동을 조정할 수 있지만, 결과는 입력 프롬프트에 크게 의존합니다(Brown et al., 2020). 이는 원하는 작업에 대해 모델의 성능을 최대화하기 위해 프롬프트를 구성하고 형식화하는 경험적 기술인 프롬프트 엔지니어링 또는 프롬프트 해킹을 필요로 합니다. 미세 조정은 사전 학습된 모델을 특정 작업에 맞추어 재학습하는 것입니다(Devlin et al., 2019b; Radford et al., a). 그 변형에는 일부 파라미터만 학습하는 것이 포함됩니다(Devlin et al., 2019b; Collobert & Weston, 2008), 하지만 실무자들은 종종 다운스트림 성능을 최대화하기 위해 모든 파라미터를 재학습합니다. 그러나 GPT-3 175B의 방대함 때문에, 이는 큰 체크포인트를 생성하고 높은 하드웨어 진입 장벽을 가지므로 일반적인 방식으로 미세 조정하는 것이 어렵습니다.
파라미터 효율적인 적응
많은 연구자들이 신경망의 기존 레이어 사이에 어댑터 레이어를 삽입하는 방법을 제안했습니다(Houlsby et al., 2019; Rebuffi et al., 2017; Lin et al., 2020). 우리의 방법은 가중치 업데이트에 저랭크 제약을 가하기 위해 유사한 병목 구조를 사용합니다. 주요 기능적 차이는 학습된 가중치를 추론 중에 주요 가중치와 병합할 수 있어 어댑터 레이어처럼 지연을 초래하지 않는다는 점입니다(3장 참조). 어댑터의 현대적 확장은 COMPACTER(Mahabadi et al., 2021)로, 본질적으로 Kronecker 제품을 사용하여 어댑터 레이어를 파라미터화하며, 일부 사전 결정된 가중치 공유 방식을 사용합니다. 유사하게, LoRA를 다른 텐서 제품 기반 방법과 결합하면 파라미터 효율성을 향상시킬 수 있으며, 이는 향후 연구 과제로 남겨둡니다. 최근에는 프롬프트 엔지니어링의 연속적이고 미분 가능한 일반화와 유사하게, 미세 조정을 대신하여 입력 단어 임베딩을 최적화하는 방법이 많이 제안되었습니다(Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021). 우리는 실험 섹션에서 Li & Liang (2021)과의 비교를 포함합니다. 그러나 이러한 연구들은 프롬프트에서 더 많은 특별 토큰을 사용하여 확장할 수밖에 없으며, 이는 작업 토큰에 사용할 수 있는 시퀀스 길이를 차지하게 됩니다.
딥러닝에서의 저랭크 구조
저랭크 구조는 머신 러닝에서 매우 흔합니다. 많은 머신 러닝 문제는 특정 내재 저랭크 구조를 가지고 있습니다(Li et al., 2016; Cai et al., 2010; Li et al., 2018b; Grasedyck et al., 2013). 또한, 많은 딥러닝 작업, 특히 과매개변수화된 신경망의 경우, 학습 후 신경망은 저랭크 특성을 가지게 됩니다(Oymak et al., 2019). 일부 이전 연구들은 원래 신경망을 훈련할 때 저랭크 제약을 명시적으로 부과하기도 합니다(Sainath et al., 2013; Povey et al., 2018; Zhang et al., 2014; Jaderberg et al., 2014; Zhao et al., 2016; Khodak et al., 2021; Denil et al., 2014). 그러나, 우리의 지식으로는 이러한 연구들 중 어느 것도 다운스트림 작업에 적응하기 위해 고정된 모델에 저랭크 업데이트를 고려하지 않았습니다. 이론 문헌에서는, 기저 개념 클래스가 특정 저랭크 구조를 가질 때 신경망이 다른 고전적 학습 방법을 능가하는 것으로 알려져 있습니다(Ghorbani et al., 2020; Allen-Zhu & Li, 2019; Allen-Zhu & Li, 2020a). Allen-Zhu & Li (2020b)에서의 또 다른 이론적 결과는 저랭크 적응이 적대적 훈련에 유용할 수 있음을 시사합니다. 요컨대, 우리가 제안한 저랭크 적응 업데이트는 문헌에서 잘 정당화되고 있다고 믿습니다.
7. 저랭크 업데이트 이해하기
LoRA의 경험적 이점을 고려할 때, 우리는 다운스트림 작업에서 학습된 저랭크 적응의 특성을 더 설명하고자 합니다. 저랭크 구조는 하드웨어 진입 장벽을 낮추어 여러 실험을 병렬로 수행할 수 있게 할 뿐만 아니라, 업데이트된 가중치가 사전 학습된 가중치와 어떻게 상관되는지를 더 잘 해석할 수 있게 합니다. 우리는 GPT-3 175B에 초점을 맞추었으며, 여기서 학습 가능한 파라미터를 최대 10,000배까지 줄이면서도 작업 성능에 부정적인 영향을 미치지 않았습니다.
우리는 다음 질문에 답하기 위해 일련의 경험적 연구를 수행합니다: 1) 파라미터 예산 제약이 주어졌을 때, 사전 학습된 Transformer의 어느 가중치 행렬의 부분집합을 적응시켜 다운스트림 성능을 최대화해야 할까요? 2) “최적”의 적응 행렬 ΔW가 정말로 랭크 부족인가요? 그렇다면, 실제로 사용하기 좋은 랭크는 무엇인가요? 3) ΔW사이의 연결은 무엇인가요? Δ는 W와 높은 상관관계를 가지나요? ΔW는 W에 비해 얼마나 큰가요?
질문 (2)와 (3)에 대한 우리의 답변은 다운스트림 작업을 위한 사전 학습된 언어 모델을 사용하는 기본 원칙에 대한 통찰을 제공한다고 믿습니다. 이는 NLP에서 중요한 주제입니다.
7.1 Transformer의 어느 가중치 행렬에 LoRA를 적용해야 하는가?
제한된 파라미터 예산이 주어졌을 때, 다운스트림 작업에서 최상의 성능을 얻기 위해 LoRA로 적응시켜야 할 가중치 유형은 무엇인가요? 4.2장에서 언급했듯이, 우리는 자기 주의 모듈의 가중치 행렬만 고려합니다. GPT-3 175B에서 18M의 파라미터 예산(FP16으로 저장 시 약 35MB)을 설정했으며, 이는 96개의 레이어 모두에 대해 한 가지 유형의 주의 가중치를 적응시킬 경우 r=, 두 가지 유형을 적응시킬 경우 r=에 해당합니다. 결과는 표 5에 제시되어 있습니다.
모든 파라미터를 ΔW_q 또는 ΔWk_에 두는 것은 성능을 크게 낮추는 반면, W_q와 W_v를 모두 적응시키는 것이 최고의 결과를 제공합니다. 이는 네 개의 랭크만으로도 ΔW에서 충분한 정보를 포착하여, 더 큰 랭크로 한 가지 유형의 가중치를 적응시키는 것보다 더 많은 가중치 행렬을 적응시키는 것이 더 낫다는 것을 시사합니다.
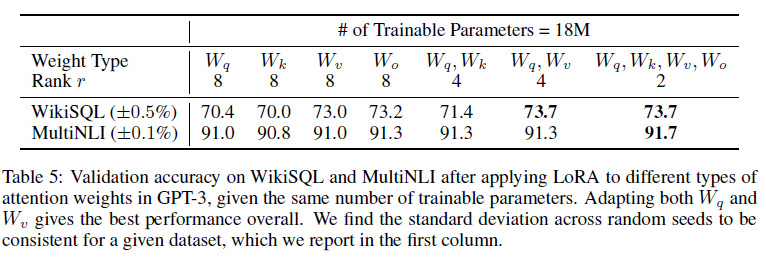
표 5: 같은 수의 학습 가능한 파라미터가 주어졌을 때, GPT-3에서 다양한 주의 가중치 유형에 LoRA를 적용한 후 WikiSQL 및 MultiNLI의 검증 정확도
W_q와 W_v를 모두 적응시키는 것이 전반적으로 최고의 성능을 제공합니다. 주어진 데이터셋에 대해 무작위 시드에 따른 표준 편차가 일관됨을 확인하였으며, 이는 첫 번째 열에 보고됩니다.
7.2 LoRA에 대한 최적의 랭크 r는 무엇인가?
우리는 모델 성능에 대한 랭크 r의 효과에 주목합니다. 비교를 위해 { W_q,W_v}, {W_q,W_k,W_v,W_c}그리고 {W_만을 적응시킵니다.
표 6은 놀랍게도 매우 작은 r에서도 LoRA가 이미 경쟁력 있는 성능을 보인다는 것을 보여줍니다(특히 { W_q,W_v} 보다 {W_ 만을 적응시킬 때 더 그렇습니다). 이는 업데이트 행렬 ΔW가 매우 작은 "내재 랭크"를 가질 수 있음을 시사합니다. 이 발견을 더 지지하기 위해, 우리는 서로 다른 값과 무작위 시드에 의해 학습된 부분 공간의 겹침을 확인합니다. 우리는 r을 증가시켜도 더 의미 있는 부분 공간을 커버하지 않으며, 이는 저랭크 적응 행렬이 충분하다는 것을 시사합니다.
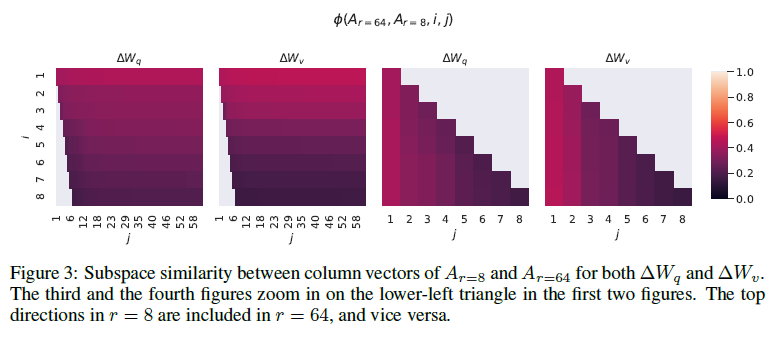



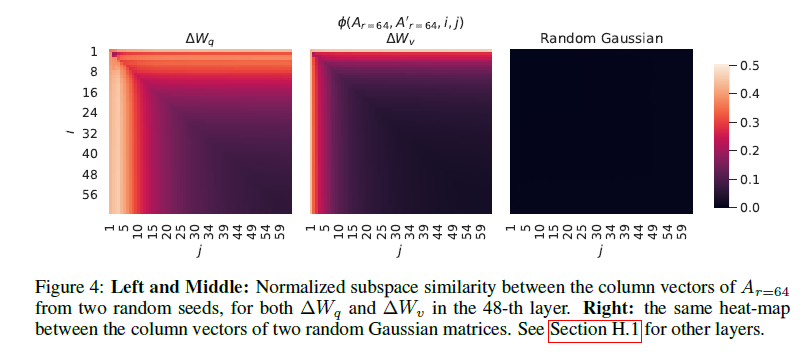





8. 결론 및 향후 작업
거대한 언어 모델을 미세 조정하는 것은 필요한 하드웨어와 다양한 작업을 위해 독립적인 인스턴스를 호스팅하는 데 드는 저장/전환 비용 면에서 매우 비쌉니다. 우리는 LoRA라는 효율적인 적응 전략을 제안하며, 이는 추론 지연을 초래하지 않고 입력 시퀀스 길이를 줄이지 않으면서 높은 모델 품질을 유지합니다. 중요한 점은, 대부분의 모델 파라미터를 공유함으로써 서비스로 배포될 때 빠른 작업 전환을 가능하게 한다는 것입니다. 우리는 Transformer 언어 모델에 초점을 맞추었지만, 제안된 원칙은 밀집 레이어가 있는 모든 신경망에 일반적으로 적용될 수 있습니다.
미래 연구를 위한 여러 방향이 있습니다:
- 다른 효율적인 적응 방법과의 결합: LoRA는 다른 효율적인 적응 방법과 결합되어 상호 보완적인 개선을 제공할 수 있습니다.
- 미세 조정 또는 LoRA의 메커니즘: 미세 조정 또는 LoRA의 메커니즘은 아직 명확하지 않습니다. 사전 학습 중 학습된 특징들이 다운스트림 작업에서 잘 수행되도록 어떻게 변환되는가? 우리는 LoRA가 전체 미세 조정보다 이 질문에 답하는 데 더 용이하다고 믿습니다.
- 가중치 행렬 선택 방법: 우리는 대부분의 경우 Heuristic에 의존하여 LoRA를 적용할 가중치 행렬을 선택합니다. 이를 더 원칙적으로 수행할 수 있는 방법이 있을까요?
- 랭크 부족의 활용: ΔW의 랭크 부족은 W도 랭크 부족일 수 있음을 시사하며, 이는 미래 연구의 영감이 될 수 있습니다.
'인공지능' 카테고리의 다른 글
| Generative Image Dynamics (1) | 2024.07.05 |
|---|---|
| Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild (2) | 2024.07.04 |
| Parameter-Efficient Transfer Learning for NLP (1) | 2024.07.02 |
| LLM Critics Help Catch LLM BugsNat (1) | 2024.07.01 |
| Robust Speech Recognition via Large-Scale Weak Supervision (1) | 2024.06.30 |



