https://generative-dynamics.github.io/
Generative Image Dynamics
We present an approach to modeling an image-space prior on scene motion. Our prior is learned from a collection of motion trajectories extracted from real video sequences depicting natural, oscillatory dynamics such as trees, flowers, candles, and clothes
generative-dynamics.github.io
요약
우리는 장면 운동에 대한 이미지 공간 사전 모델링 접근 방식을 제시합니다. 우리의 사전 모델은 나무, 꽃, 촛불, 그리고 바람에 흔들리는 옷과 같은 자연적인 진동 동역학을 묘사하는 실제 비디오 시퀀스에서 추출한 운동 궤적 컬렉션에서 학습됩니다. 우리는 푸리에 도메인에서 스펙트럴 볼륨으로 밀집하고 장기적인 운동을 모델링하며, 이는 확산 모델을 사용한 예측에 적합하다는 것을 발견했습니다. 단일 이미지가 주어지면, 훈련된 모델은 주파수에 맞춘 확산 샘플링 프로세스를 사용하여 스펙트럴 볼륨을 예측할 수 있으며, 이는 비디오 전체에 걸쳐 움직임 텍스처로 변환될 수 있습니다. 이미지 기반 렌더링 모듈과 함께, 예측된 운동 표현은 정지 이미지를 매끄럽게 반복되는 비디오로 변환하거나, 실제 이미지에서 객체와 상호 작용하여 현실감 있는 시뮬레이션 동역학을 생성하는 등 여러 다운스트림 응용 프로그램에 사용될 수 있습니다 (스펙트럴 볼륨을 이미지 공간 모달 기저로 해석함으로써). 더 많은 결과는 우리 프로젝트 페이지를 참조하십시오: generative-dynamics.github.io.

그림 1 설명
우리는 장면 운동에 대한 생성적 이미지 공간 사전을 모델링합니다. 단일 RGB 이미지에서, 우리의 방법은 푸리에 도메인에서 밀집하고 장기적인 픽셀 궤적을 모델링하는 운동 표현인 스펙트럴 볼륨 [23]을 생성합니다. 우리의 학습된 운동 사전은 단일 이미지를 매끄럽게 반복되는 비디오로 또는 점을 끌고 놓는 것과 같은 사용자 입력에 반응하는 동적 시뮬레이션으로 변환하는 데 사용될 수 있습니다. 오른쪽에서는 출력 비디오를 시간-공간 X-t 슬라이스 (왼쪽에 표시된 입력 스캔라인을 따라)로 시각화합니다.
1. 서론
자연 세계는 항상 움직이고 있으며, 겉보기에 정적인 장면조차도 바람, 물의 흐름, 호흡 또는 다른 자연적 리듬의 결과로 미묘한 진동을 포함하고 있습니다. 이러한 움직임을 모방하는 것은 시각적 콘텐츠 합성에서 매우 중요합니다. 사람들은 움직임이 없거나 약간 비현실적인 움직임을 가진 이미지를 보았을 때, 그것이 불쾌하거나 비현실적으로 보일 수 있습니다. 인간은 장면에서의 움직임을 해석하거나 상상하는 것이 쉽지만, 모델이 현실적인 장면의 움직임을 학습하거나 생성하도록 훈련하는 것은 결코 간단하지 않습니다. 우리가 관찰하는 움직임은 장면의 기저 물리적 동역학, 즉 물체에 적용되는 힘과 그것이 고유한 물리적 특성(질량, 탄성 등)에 따라 반응하는 결과입니다. 이러한 양을 대규모로 측정하고 포착하는 것은 어렵습니다.
다행히도, 일부 응용 프로그램에서는 이를 측정할 필요가 없습니다. 예를 들어, 몇 가지 관찰된 2D 움직임을 분석하여 장면에서 그럴듯한 동역학을 시뮬레이션할 수 있습니다. 이러한 관찰된 움직임은 장면 간 동역학을 학습하는 데 감독 신호로도 사용할 수 있습니다. 관찰된 움직임은 복합적인 물리적 효과에 기초하고 있지만, 종종 예측 가능하기 때문입니다. 예를 들어, 촛불은 특정 방식으로 깜박이고, 나무는 흔들리고, 잎은 바스락거릴 것입니다. 인간에게 이러한 예측 가능성은 우리의 지각 시스템에 내재되어 있습니다. 정지 이미지를 보면서 우리는 그럴듯한 움직임을 상상할 수 있으며, 이러한 움직임이 여러 가지 있을 수 있기 때문에 그 이미지에 조건부로 자연스러운 움직임의 분포를 상상할 수 있습니다. 인간이 이러한 분포를 모델링하는 능력을 고려할 때, 이를 컴퓨터적으로 모델링하는 것은 자연스러운 연구 문제입니다.
최근 생성 모델, 특히 조건부 확산 모델의 발전은 텍스트에 조건부로 실제 이미지의 분포를 모델링하는 능력을 포함한 풍부한 분포를 모델링할 수 있게 했습니다. 이러한 능력은 텍스트에 조건부로 다양한 현실적인 이미지 콘텐츠를 생성하는 새로운 응용 프로그램을 가능하게 했습니다. 이러한 이미지 모델의 성공을 바탕으로, 최근 연구는 이러한 모델을 비디오 및 3D 기하학과 같은 다른 도메인으로 확장했습니다.
이 논문에서는 이미지 공간 장면 운동에 대한 생성적 사전, 즉 단일 이미지 내 모든 픽셀의 움직임을 모델링합니다. 이 모델은 실제 비디오 시퀀스의 대규모 컬렉션에서 자동으로 추출한 운동 궤적을 학습합니다. 특히, 각 훈련 비디오에서 밀집하고 장기적인 픽셀 궤적의 주파수 도메인 표현인 스펙트럴 볼륨 형태로 운동을 계산합니다. 스펙트럴 볼륨은 바람에 흔들리는 나무와 꽃과 같이 진동 동역학을 나타내는 장면에 적합합니다. 우리는 이 표현이 장면 운동을 모델링하는 확산 모델의 출력으로도 매우 효과적임을 발견했습니다. 단일 이미지에 조건부로 학습된 분포에서 스펙트럴 볼륨을 샘플링할 수 있는 생성 모델을 훈련합니다. 예측된 스펙트럴 볼륨은 이미지 애니메이션에 사용할 수 있는 장기적인 픽셀별 운동 궤적 세트인 움직임 텍스처로 직접 변환될 수 있습니다. 또한, 스펙트럴 볼륨은 상호작용 동역학 시뮬레이션에서 사용할 수 있는 이미지 공간 모달 기저로 해석될 수 있습니다.
우리는 주파수에 맞춘 확산 모델을 사용하여 입력 이미지에서 스펙트럴 볼륨을 예측하며, 주파수 대역 전체에 걸쳐 예측을 조정하는 공유 주의 모듈을 통해 이러한 예측을 조정합니다. 예측된 움직임은 이미지 기반 렌더링 모델을 통해 미래 프레임을 합성하여 정지 이미지를 현실적인 애니메이션으로 변환하는 데 사용할 수 있습니다. 이는 그림 1에 설명된 바와 같습니다.
원시 RGB 픽셀보다 움직임에 대한 사전은 픽셀 값의 장기 변동을 효율적으로 설명하는 더 근본적이고 저차원적인 구조를 포착합니다. 따라서 중간 움직임을 생성하면 더 일관된 장기 생성과 애니메이션에 대한 세밀한 제어가 가능합니다. 우리는 여러 다운스트림 응용 프로그램에서 훈련된 모델의 사용을 시연하며, 이는 매끄럽게 반복되는 비디오 생성, 생성된 움직임 편집, 그리고 이미지 공간 모달 기저를 통한 상호작용 동적 이미지 활성화, 즉 사용자 적용 힘에 대한 객체 동역학의 반응을 시뮬레이션하는 것을 포함합니다.
2. 관련 연구
생성적 합성
최근 생성 모델의 발전으로 텍스트 프롬프트에 조건부로 포토리얼리스틱 이미지를 합성할 수 있게 되었습니다[16, 17, 24, 72–74]. 이러한 텍스트-이미지 모델은 생성된 이미지 텐서를 시간 차원으로 확장하여 비디오 시퀀스를 합성할 수 있습니다[7, 9, 43, 62, 83, 105, 110]. 이러한 방법들은 실제 영상의 시공간 통계를 포착하는 비디오 시퀀스를 생성할 수 있지만, 종종 일관되지 않은 움직임, 비현실적인 텍스처의 시간적 변이, 질량 보존과 같은 물리적 제약을 위반하는 등의 아티팩트가 발생합니다.
이미지 애니메이션
텍스트에서 비디오를 완전히 생성하는 대신, 다른 기술들은 정지 이미지를 입력으로 받아 이를 애니메이션화 합니다. 최근 많은 딥 러닝 방법들은 3D-유넷 아키텍처를 채택하여 비디오 볼륨을 직접 생성합니다[27, 36, 40, 47, 53, 92]. 이러한 모델들은 기본적으로 이미지 정보 대신 텍스트에 조건부로 비디오를 생성하는 모델과 동일하며, 앞서 언급한 유사한 아티팩트를 나타냅니다. 이러한 한계를 극복하는 한 가지 방법은 비디오 콘텐츠 자체를 직접 생성하는 대신, 외부 소스에서 파생된 움직임에 따라 이미지 콘텐츠를 이동시키는 이미지 기반 렌더링을 통해 입력 소스 이미지를 애니메이션화하는 것입니다[51, 79–81, 98]. 이러한 방법들은 추가적인 안내 신호나 사용자 입력이 필요하거나 제한된 움직임 표현을 사용합니다.
운동 모델 및 운동 사전
컴퓨터 그래픽스에서는 자연적이고 진동하는 3D 운동(예: 물결이나 바람에 흔들리는 나무)을 푸리에 도메인에서 형성된 노이즈로 모델링하고 이를 시간 도메인 운동 필드로 변환할 수 있습니다[78, 87]. 일부 방법은 시뮬레이션되는 시스템의 기저 동역학에 대한 모달 분석을 사용합니다[22, 25, 88]. 이러한 스펙트럴 기술은 사용자 주석을 통해 단일 2D 이미지에서 식물, 물, 구름을 애니메이션화하는 데 적응되었습니다[20]. 우리의 작업은 특히 장면의 모달 분석과 그 장면의 비디오에서 관찰된 움직임을 연결하고 이를 사용하여 비디오에서 상호작용 동역학을 시뮬레이션한 Davis [23]의 연구에서 영감을 받았습니다. 우리는 Davis 등의 연구에서 주파수 공간 스펙트럴 볼륨 운동 표현을 채택하여 대규모 훈련 비디오 세트에서 이 표현을 추출하고, 스펙트럴 볼륨이 확산 모델을 통해 단일 이미지에서 움직임을 예측하는 데 적합함을 보여줍니다.
다양한 운동 표현을 사용한 예측 작업
여러 방법들은 이미지나 비디오를 사용하여 결정론적 미래 운동 추정[34, 70]이나 더 풍부한 가능한 운동의 분포를 예측하는 작업에서 다양한 운동 표현을 사용했습니다[93, 95, 103]. 그러나 많은 이 방법들은 전체 운동 궤적이 아닌 순간적인 픽셀 운동을 예측하는 광류 운동 추정을 수행합니다. 또한, 많은 이전 작업은 합성 작업보다는 활동 인식과 같은 작업에 중점을 두고 있습니다. 최근 연구는 인간과 동물과 같은 폐쇄 도메인 설정에서 생성 모델을 사용하여 운동을 모델링하고 예측하는 장점을 입증했습니다[2, 19, 28, 71, 90, 106].
텍스처로서의 비디오
일부 움직이는 장면은 일종의 텍스처—동적 텍스처[26]—로 간주될 수 있으며, 이는 영상을 확률적 프로세스의 시공간 샘플로 모델링합니다. 동적 텍스처는 파도, 불꽃, 움직이는 나무와 같은 부드럽고 자연스러운 움직임을 나타내며, 비디오 분류, 세분화 또는 인코딩에 널리 사용됩니다[12–15, 75]. 관련된 텍스처 유형인 비디오 텍스처는 입력 비디오 프레임 집합과 프레임 쌍 간 전환 확률로 움직이는 장면을 나타냅니다[65, 77]. 많은 방법들이 장면 운동과 픽셀 통계를 분석하여 동적 또는 비디오 텍스처를 추정하고, 매끄럽게 반복되거나 무한히 변화하는 출력 비디오를 생성하는 것을 목표로 합니다[1, 21, 32, 58, 59, 77]. 우리의 방법은 사전 학습된 사전을 사용하여 단일 이미지에 적용할 수 있다는 점에서 이러한 많은 작업과 대조됩니다.

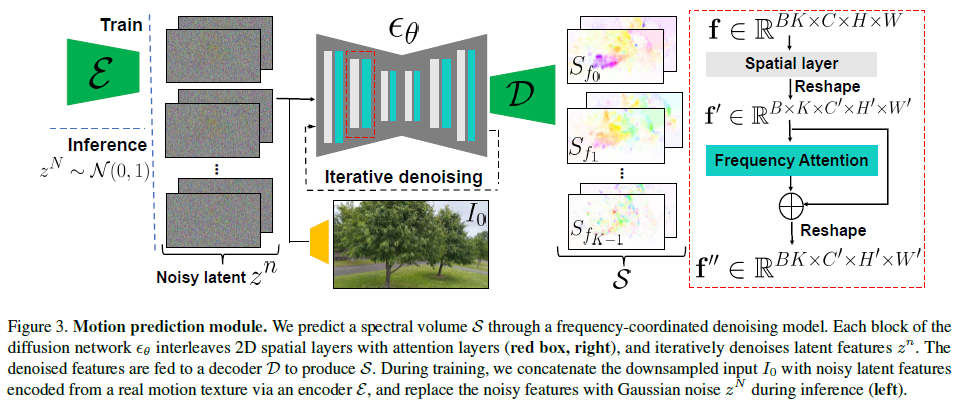
4. 예측 움직임

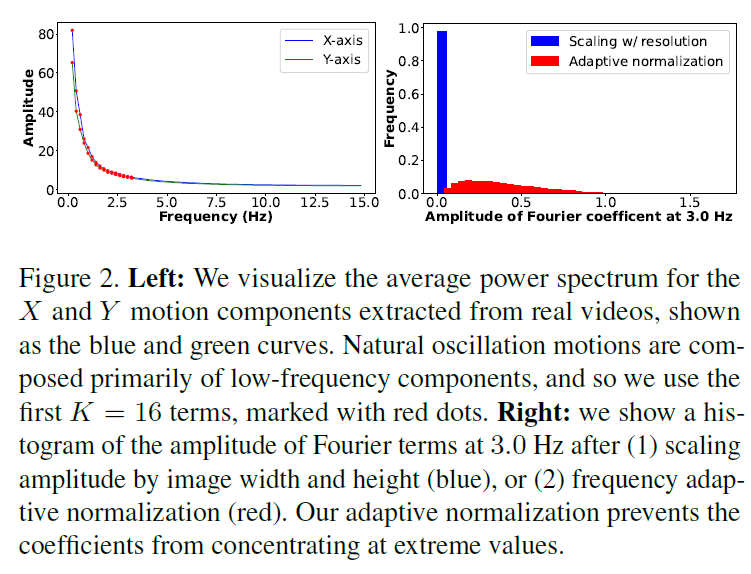
그림 2. 왼쪽: 실제 동영상에서 추출한 X 및 Y 모션 구성 요소의 평균 파워 스펙트럼을 파란색과 녹색 곡선으로 시각화하여 표시합니다. 자연 진동 모션은 주로 저주파 성분으로 구성되어 있으므로 빨간색 점으로 표시된 첫 번째 K = 16 항을 사용합니다. 오른쪽: (1) 이미지 폭과 높이에 따라 진폭을 스케일링(파란색) 또는 (2) 주파수 적응형 정규화(빨간색)한 후 3:0Hz에서 푸리에 항의 진폭 히스토그램을 표시합니다. 적응형 정규화는 계수가 극단적인 값에 집중되는 것을 방지합니다.

-----------------------------------------------------------------------------------------------------------------------------------------------------------------

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
우리는 어떻게 K 출력 주파수를 선택해야 할까요? 실시간 애니메이션에 대한 이전 연구는 대부분의 자연 진동 운동이 주로 저주파 성분으로 구성된다는 것을 관찰했습니다[25, 68]. 이 관찰을 검증하기 위해, 우리는 무작위로 샘플링된 1,000개의 5초짜리 실제 비디오 클립에서 추출한 운동의 평균 파워 스펙트럼을 계산했습니다. 그림 2의 왼쪽 그래프에서 보여지듯이, 운동의 파워 스펙트럼은 주파수가 증가함에 따라 지수적으로 감소합니다. 이는 대부분의 자연 진동 운동이 저주파 항으로 잘 표현될 수 있음을 시사합니다. 실제로, 우리는 첫 K=16 개의 푸리에 계수가 다양한 실제 비디오와 장면에서 원래의 자연 운동을 현실적으로 재현하기에 충분하다는 것을 발견했습니다.


주파수 적응 정규화
우리가 관찰한 한 가지 문제는 운동 텍스처가 주파수에 따라 특정 분포 특성을 가진다는 것입니다. 그림 2의 왼쪽 그래프에 시각화된 것처럼, 스펙트럴 볼륨의 진폭은 0에서 100까지 범위를 가지며 주파수가 증가함에 따라 대략적으로 지수적으로 감소합니다. 확산 모델은 안정적인 훈련과 노이즈 제거를 위해 출력의 절대값이 -1과 1 사이에 있어야 하므로[44], 훈련에 사용하기 전에 실제 비디오에서 추출한 S의 계수를 정규화해야 합니다. 이전 연구[29, 76]에서처럼 이미지 크기를 기준으로 이러한 계수의 크기를 [0,1]로 스케일링하면, 높은 주파수에서 거의 모든 계수가 0에 가깝게 됩니다. 이는 그림 2의 오른쪽 그래프에 나타나 있습니다. 이러한 데이터를 기반으로 훈련된 모델은 부정확한 운동을 생성할 수 있습니다. 추론 중에 작은 예측 오류도 비정규화 후 큰 상대적 오류를 유발할 수 있기 때문입니다.

주파수-조정 노이즈 제거
K 주파수 대역을 가진 스펙트럴 볼륨 S를 예측하는 가장 간단한 방법은 단일 확산 U-Net에서 4K 채널의 텐서를 출력하는 것입니다. 그러나 이전 연구[7]와 마찬가지로, 많은 수의 채널을 생성하도록 모델을 훈련하면 과도하게 평활화되고 부정확한 출력이 나올 수 있음을 관찰했습니다. 대안으로는 각 개별 주파수 슬라이스를 독립적으로 예측하기 위해 LDM에 추가 주파수 임베딩을 주입하는 방법이 있지만[4], 이 설계 선택은 주파수 도메인에서 상관되지 않은 예측을 초래하여 비현실적인 움직임을 유발할 수 있습니다.

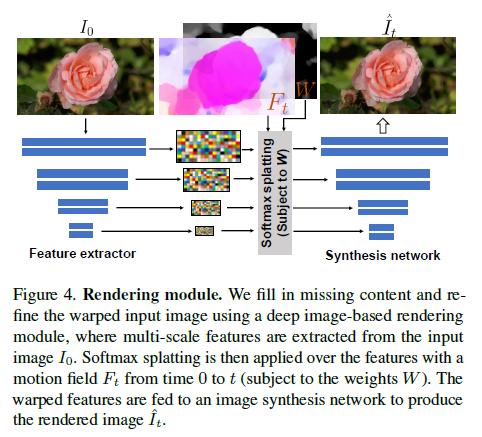



6. 응용
이미지에서 비디오로
우리 시스템은 입력 이미지에서 먼저 운동 스펙트럴 볼륨을 예측하고, 스펙트럴 볼륨에서 변환된 운동 텍스처에 이미지 기반 렌더링 모듈을 적용하여 애니메이션을 생성함으로써 단일 정지 사진을 애니메이션화할 수 있게 합니다. 우리는 명시적으로 장면 운동을 모델링하기 때문에, 운동 텍스처를 선형적으로 보간하여 슬로우 모션 비디오를 생성하거나 예측된 스펙트럴 볼륨 계수의 진폭을 조정하여 애니메이션 동작을 확대(또는 축소)할 수 있습니다.
매끄러운 반복
많은 응용 프로그램은 비디오의 시작과 끝 사이에 불연속성이 없는 매끄럽게 반복되는 비디오를 필요로 합니다. 불행히도, 훈련을 위해 매끄럽게 반복되는 비디오의 큰 컬렉션을 찾는 것은 어렵습니다. 대신, 우리는 정규 비순환 비디오 클립으로 훈련된 우리의 운동 확산 모델을 사용하여 매끄럽게 반복되는 비디오를 생성하는 방법을 고안했습니다. 최근의 이미지 편집 가이드 연구[3, 30]에서 영감을 받아, 우리의 방법은 명시적인 반복 제약을 사용하여 운동 노이즈 제거 샘플링 프로세스를 안내하는 운동 자가 안내 기술입니다. 특히, 추론 동안 각 반복적인 노이즈 제거 단계에서, 우리는 표준 분류기 없는 가이드[45]와 함께 추가적인 운동 가이드 신호를 통합하여 각 픽셀의 시작 프레임과 끝 프레임에서 위치와 속도가 가능한 한 비슷하도록 강제합니다.



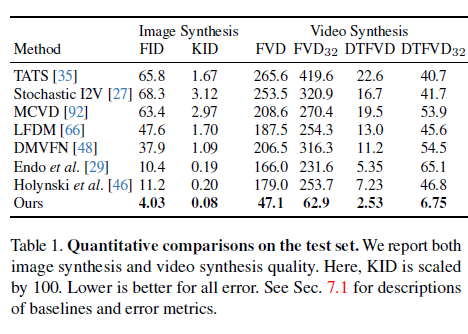
표 1. 테스트 세트에 대한 정량적 비교
우리는 이미지 합성 및 비디오 합성 품질을 모두 보고합니다. 여기서 KID는 100으로 스케일됩니다. 오류가 낮을수록 좋습니다. 베이스라인 및 오류 메트릭의 설명은 섹션 7.1을 참조하십시오.
7. 실험
구현 세부 사항

데이터
우리는 온라인 소스와 자체 캡처를 통해 진동 운동을 보이는 자연 장면의 3,015개의 비디오 세트를 수집하고 처리합니다. 우리는 비디오의 10%를 테스트용으로 남겨두고 나머지를 훈련에 사용합니다. 실제 운동 궤적을 추출하기 위해, 우리는 비디오의 각 선택된 시작 이미지와 모든 미래 프레임 사이에 거친-세부 흐름 방법[10, 61]을 적용합니다. 훈련 데이터로서, 우리는 10번째 비디오 프레임을 입력 이미지로 사용하고 다음 149프레임에 걸쳐 계산된 운동 궤적을 사용하여 해당하는 실제 스펙트럴 볼륨을 도출합니다. 총합하여, 우리의 데이터는 150,000개 이상의 이미지-운동 쌍으로 구성됩니다.
Baselines
우리는 우리의 접근 방식을 최근의 단일 이미지 애니메이션 및 비디오 예측 방법들과 비교합니다. Endo et al. [29]와 DMVFN [48]은 순간적인 2D 운동 필드를 예측하고, 미래 프레임을 자기회귀적으로 렌더링합니다. Holynski et al. [46]은 대신 단일 정적 오일러리언 운동 설명을 통해 운동을 시뮬레이션합니다. 다른 최근 작업들, 예를 들어 Stochastic Image-to-Video (Stochastic-I2V) [27], TATS [35], MCVD [92]는 VAE, 트랜스포머 또는 확산 모델을 채택하여 원시 비디오 프레임을 직접 예측합니다. LFDM [66]은 흐름 볼륨을 예측하고 확산 모델에서 잠재 변수를 워핑하여 미래 프레임을 생성합니다. 우리는 모든 위의 방법들을 각각의 오픈 소스 구현을 사용하여 우리의 데이터에 대해 훈련합니다.
우리는 우리의 접근 방식과 이전 기준선에 의해 생성된 비디오의 품질을 두 가지 방법으로 평가합니다. 첫째, 이미지 합성 작업을 위해 설계된 메트릭을 사용하여 개별 합성 프레임의 품질을 평가합니다. 우리는 Fréchet Inception Distance (FID) [42]와 Kernel Inception Distance (KID) [5]를 채택하여 생성된 프레임과 실제 프레임의 분포 간 평균 거리를 측정합니다. 둘째, 합성된 비디오의 품질과 시간적 일관성을 평가하기 위해, Human Kinetics 데이터셋 [52]에서 훈련된 I3D 모델 [11]을 기반으로 한 창 크기 16 (FVD) 및 32 (FVD32)의 Fréchet Video Distance [91]를 채택합니다. 우리가 생성하려는 자연 진동 운동의 합성 품질을 보다 충실하게 반영하기 위해, 우리는 Dynamic Textures Database [37]에서 주로 자연 운동 텍스처로 구성된 데이터셋을 사용하여 창 크기 16 (DTFVD) 및 32 (DTFVD32)의 Dynamic Texture Frechet Video Distance [27]도 채택합니다.
우리는 또한 [57, 60]과 같이 창 크기 30 프레임의 슬라이딩 윈도우 FID와 창 크기 16 프레임의 슬라이딩 윈도우 DTFVD를 사용하여 생성된 비디오 품질이 시간이 지남에 따라 어떻게 저하되는지 측정합니다. 모든 방법에 대해, 우리는 256 x 128 해상도에서 중앙 자르기를 통해 메트릭을 평가합니다.

그림 5. 다양한 접근 방식으로 생성된 비디오의 X-t 슬라이스
왼쪽에서 오른쪽으로: 입력 이미지와 해당하는 실제 비디오의 X-t 비디오 슬라이스, 세 가지 기준선 [27, 29, 46, 92]에 의해 생성된 비디오, 그리고 우리의 접근 방식으로 생성된 비디오.
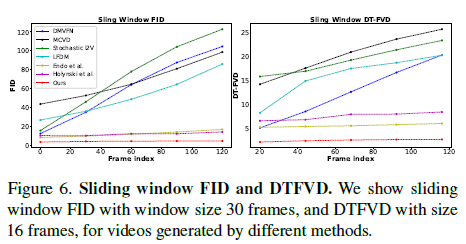
그림 6. 슬라이딩 윈도우 FID 및 DTFVD
우리는 창 크기 30 프레임의 슬라이딩 윈도우 FID와 창 크기 16 프레임의 DTFVD를 보여줍니다.
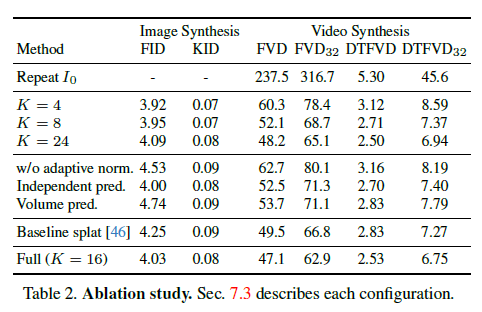
표 2. 소거 연구
각 구성에 대한 설명은 섹션 7.3에 있습니다.
7.1. 정량적 결과
표 1은 우리의 접근 방식과 기준선들이 테스트 세트에서의 정량적 비교를 보여줍니다. 우리의 접근 방식은 이미지 및 비디오 합성 품질 측면에서 이전 단일 이미지 애니메이션 기준선보다 훨씬 뛰어납니다. 구체적으로, 훨씬 낮은 FVD와 DT-FVD 거리는 우리의 접근 방식으로 생성된 비디오가 더 현실적이고 시간적으로 더 일관성이 있음을 시사합니다. 또한, 그림 6은 다른 방법으로 생성된 비디오의 슬라이딩 윈도우 FID와 슬라이딩 윈도우 DT-FVD 거리를 보여줍니다. 글로벌 스펙트럴 볼륨 표현 덕분에, 우리의 접근 방식으로 생성된 비디오는 시간이 지남에 따라 품질 저하가 발생하지 않습니다.
7.2. 정성적 결과
우리는 생성된 비디오를 시공간 X-t 슬라이스로 시각화하여 비디오의 작은 움직임을 시각화하는 표준 방법으로 정성적 비교를 수행합니다[94]. 그림 5에 나타난 바와 같이, 우리의 접근 방식으로 생성된 비디오 동역학은 다른 방법들보다 해당 실제 참조 비디오(두 번째 열)에서 관찰된 운동 패턴과 더 강하게 유사합니다. Stochastic I2V [27]와 MCVD [92]와 같은 기준선은 시간이 지남에 따라 외관과 운동을 현실적으로 모델링하지 못합니다. Endo et al. [29]와 Holynski et al. [46]은 적은 아티팩트를 가진 비디오 프레임을 생성하지만, 시간이 지남에 따라 과도하게 평활화되거나 비진동적인 운동을 나타냅니다. 생성된 비디오 프레임과 다양한 방법에 걸쳐 추정된 운동의 품질을 평가하기 위해 독자들은 보충 자료를 참조하십시오.

그림 7
우리는 세 가지 최근 대규모 비디오 확산 모델[31, 36, 97]에서 생성된 미래 프레임을 보여줍니다.

그림 8
제한 사항. 우리는 렌더링된 미래 프레임(짝수)과 입력 이미지와 렌더링된 이미지를 겹쳐놓은 예시(홀수)를 보여줍니다. 우리의 방법은 얇은 객체나 큰 움직임이 있는 영역, 그리고 많은 새로운 콘텐츠를 채워야 하는 영역에서 아티팩트를 생성할 수 있습니다.
7.3. 소거 연구
우리는 운동 예측 및 렌더링 모듈에서 주요 설계 선택을 검증하기 위해 소거 연구를 수행하여, 우리의 전체 구성과 다양한 변형을 비교합니다. 구체적으로, 우리는 주파수 대역의 수 K를 4, 8, 16, 24로 다르게 설정한 결과를 평가합니다. 주파수 대역 수를 늘리면 비디오 예측 품질이 향상되지만, 16개 이상의 주파수에서는 향상이 미미합니다. 다음으로, 우리는 실제 스펙트럴 볼륨에서 적응형 주파수 정규화를 제거하고 대신 입력 이미지의 너비와 높이에 따라 스케일링만 수행합니다 (적응형 정규화 없음). 추가로, 주파수 조정 노이즈 제거 모듈을 제거하거나 (독립적 예측), 4K 채널 스펙트럴 볼륨의 텐서 볼륨을 단일 2D U-net 확산 모델을 통해 공동으로 예측하는 더 간단한 DM으로 대체합니다 (볼륨 예측). 마지막으로, 학습 가능한 가중치에 따라 단일 스케일 피처에 소프트맥스 스플래팅을 적용하는 기준 렌더링 방법을 사용하는 결과와 비교합니다 (기준 스플래트). 우리는 또한 생성된 비디오가 입력 이미지를 N번 반복하여 볼륨을 형성하는 기준을 추가합니다 (입력 이미지 반복). 표 2에서 볼 수 있듯이, 모든 더 간단한 또는 대체 구성은 우리의 전체 모델과 비교하여 성능이 저하됩니다.
7.4. 대규모 비디오 모델과의 비교
우리는 사용자 연구를 수행하여 최근 대규모 비디오 확산 모델인 AnimateDiff [36], ModelScope [97] 및 Gen-2 [31]와 생성된 애니메이션을 비교합니다. 테스트 세트에서 무작위로 선택된 30개의 비디오에 대해 사용자들에게 "어떤 비디오가 더 현실적인가요?"라는 질문을 합니다. 사용자들은 우리의 접근 방식을 다른 방법들보다 80.9% 선호한다고 보고했습니다. 또한, 그림 7에 나타난 바와 같이, 이러한 기준선에서 생성된 비디오는 입력 이미지 콘텐츠를 제대로 따르지 못하거나 시간이 지남에 따라 색상 드리프트 및 왜곡을 나타냅니다. 전체 비교는 보충 자료를 참조하십시오.
8. 토론 및 결론
제한 사항
우리의 접근 방식은 스펙트럴 볼륨의 저주파만 예측하므로, 비진동 운동이나 고주파 진동을 모델링하지 못할 수 있습니다—이는 학습된 운동 기저를 사용하여 해결할 수 있습니다. 또한, 생성된 비디오의 품질은 기본 운동 궤적의 품질에 의존하며, 이는 얇은 움직이는 객체나 큰 변위를 가진 객체가 있는 장면에서 저하될 수 있습니다. 옳다 하더라도, 많은 양의 새로운 보이지 않는 콘텐츠를 생성해야 하는 운동은 저하를 일으킬 수 있습니다 (그림 8).
결론
우리는 단일 정지 사진에서 자연 진동 동역학을 모델링하기 위한 새로운 접근 방식을 제시합니다. 우리의 이미지 공간 운동 사전은 각 픽셀 운동 궤적의 주파수 표현인 스펙트럴 볼륨으로 표현되며, 이는 확산 모델을 사용한 예측에 효율적이고 효과적임을 발견했으며, 실제 세계 비디오 컬렉션에서 학습되었습니다. 스펙트럴 볼륨은 주파수 조정 잠재 확산 모델을 사용하여 예측되며, 이미지 기반 렌더링 모듈을 통해 미래 비디오 프레임을 애니메이션화하는 데 사용됩니다. 우리의 접근 방식은 단일 사진에서 포토리얼리스틱 애니메이션을 생성하며, 이전 기준선을 상당히 능가하며, 매끄럽게 반복되거나 상호작용하는 이미지 동역학을 생성하는 등의 여러 다운스트림 응용 프로그램을 가능하게 합니다.
감사의 말
우리는 풍부한 논의와 유익한 의견을 제공해 준 Abe Davis, Rick Szeliski, Andrew Liu, Boyang Deng, Qianqian Wang, Xuan Luo, 그리고 Lucy Chai에게 감사드립니다.
'인공지능' 카테고리의 다른 글
| Mip-Splatting: Alias-free 3D Gaussian Splatting (1) | 2024.07.07 |
|---|---|
| Rich Human Feedback for Text-to-Image Generation (1) | 2024.07.06 |
| Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild (2) | 2024.07.04 |
| LoRA: Low-Rank Adaptation of Large Language Models (1) | 2024.07.03 |
| Parameter-Efficient Transfer Learning for NLP (1) | 2024.07.02 |



