https://arxiv.org/abs/2301.11325
MusicLM: Generating Music From Text
We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeli
arxiv.org
요약
우리는 MusicLM이라는 모델을 소개합니다. 이 모델은 "왜곡된 기타 리프에 의해 뒷받침되는 차분한 바이올린 멜로디"와 같은 텍스트 설명으로부터 고음질 음악을 생성합니다. MusicLM은 조건부 음악 생성을 계층적 시퀀스-투-시퀀스 모델링 작업으로 처리하며, 여러 분에 걸쳐 일관된 24kHz의 음악을 생성합니다. 우리의 실험은 MusicLM이 오디오 품질과 텍스트 설명에 대한 준수에서 이전 시스템들을 능가함을 보여줍니다. 더 나아가, MusicLM은 텍스트와 멜로디 모두에 조건부로 적용될 수 있음을 증명하였으며, 이는 휘파람이나 허밍 멜로디를 텍스트 캡션에 설명된 스타일에 맞게 변형할 수 있음을 의미합니다. 미래 연구를 지원하기 위해, 우리는 5.5k개의 음악-텍스트 쌍으로 구성된 데이터셋인 MusicCaps를 공개합니다. 이 데이터셋에는 인간 전문가들이 제공한 풍부한 텍스트 설명이 포함되어 있습니다. MusicLM 예제 보기.
1. 서론
조건부 신경망 오디오 생성은 텍스트-음성 변환(Zen et al., 2013; van den Oord et al., 2016)부터 가사 조건부 음악 생성(Dhariwal et al., 2020) 및 MIDI 시퀀스로부터의 오디오 합성(Hawthorne et al., 2022b)까지 다양한 응용 분야를 포함합니다. 이러한 작업들은 조건 신호와 해당 오디오 출력 간의 일정 수준의 시간적 정렬을 통해 가능해집니다. 반면에 텍스트-이미지 생성의 진보(Ramesh et al., 2021; 2022; Saharia et al., 2022; Yu et al., 2022)에서 영감을 받아 최근에는 "바람이 부는 소리와 함께 휘파람을 부는"과 같은 시퀀스 전반에 걸친 고수준 캡션으로부터 오디오를 생성하는 연구(Yang et al., 2022; Kreuk et al., 2022)가 탐구되고 있습니다. 이러한 거친 캡션으로부터 오디오를 생성하는 것은 큰 진전을 나타내지만, 이러한 모델들은 몇 초에 걸친 소수의 음향 이벤트로 구성된 단순한 음향 장면에 제한되어 있습니다. 따라서 단일 텍스트 캡션을 장기 구조와 다수의 스템을 가진 풍부한 오디오 시퀀스로 변환하는 것은 여전히 미해결 과제입니다.
최근 AudioLM(Borsos et al., 2022)이 오디오 생성을 위한 프레임워크로 제안되었습니다. AudioLM은 오디오 합성을 이산 표현 공간에서 언어 모델링 작업으로 간주하고, 거친 단계에서 세밀한 단계로의 오디오 이산 단위(또는 토큰)의 계층을 활용하여 수십 초에 걸친 고품질과 장기 일관성을 달성합니다. 또한 오디오 신호의 내용에 대해 어떤 가정도 하지 않음으로써 AudioLM은 주석 없이 음성이나 피아노 음악과 같은 오디오 전용 코퍼스로부터 현실적인 오디오를 생성하는 법을 학습합니다. 다양한 신호를 모델링하는 능력은 적절한 데이터로 학습되었을 때 더 풍부한 출력을 생성할 수 있음을 시사합니다.
고품질의 일관된 오디오를 합성하는 본질적인 어려움 외에도 또 다른 방해 요인은 오디오-텍스트 쌍 데이터의 부족입니다. 이는 이미지 분야와는 극명한 대조를 이룹니다. 이미지 분야에서는 방대한 데이터셋의 가용성이 최근에 달성된 놀라운 이미지 생성 품질에 크게 기여했습니다(Ramesh et al., 2021; 2022; Saharia et al., 2022; Yu et al., 2022). 게다가 일반적인 오디오에 대한 텍스트 설명을 만드는 것은 이미지를 설명하는 것보다 훨씬 어렵습니다. 첫째, 몇 마디의 말로 음향 장면(예: 기차역이나 숲에서 들리는 소리)이나 음악(예: 멜로디, 리듬, 보컬의 음색 및 반주에 사용되는 다양한 악기)의 두드러진 특성을 명확하게 포착하는 것은 간단하지 않습니다. 둘째, 오디오는 시간적 차원에 따라 구조화되어 있어 시퀀스 전반에 걸친 캡션이 이미지 캡션보다 훨씬 약한 수준의 주석이 됩니다.
본 연구에서는 고음질 음악을 텍스트 설명으로부터 생성하는 모델인 MusicLM을 소개합니다. MusicLM은 생성 요소로 AudioLM의 다단계 자회귀 모델링을 활용하며, 이를 확장하여 텍스트 조건을 포함합니다. 주된 과제인 페어링 데이터의 부족 문제를 해결하기 위해, 우리는 MuLan(Huang et al., 2022)을 사용합니다. MuLan은 음악과 해당 텍스트 설명을 임베딩 공간에서 서로 가깝게 투영하도록 훈련된 공동 음악-텍스트 모델입니다. 이 공유 임베딩 공간은 훈련 시 캡션의 필요성을 완전히 없애주며, 대규모 오디오 전용 코퍼스를 사용한 훈련을 가능하게 합니다. 즉, 우리는 훈련 중에는 오디오에서 계산된 MuLan 임베딩을 조건으로 사용하고, 추론 시에는 텍스트 입력에서 계산된 MuLan 임베딩을 사용합니다.
라벨이 없는 대규모 음악 데이터셋에서 훈련된 MusicLM은 "기억에 남는 색소폰 솔로와 솔로 가수가 있는 매혹적인 재즈곡" 또는 "저음과 강한 킥이 있는 베를린 90년대 테크노"와 같은 복잡한 텍스트 설명에 대해 24kHz에서 길고 일관된 음악을 생성하는 법을 학습합니다. 이 작업을 위한 평가 데이터가 부족한 문제를 해결하기 위해, 우리는 전문 음악가들이 준비한 5.5k 예제로 구성된 새로운 고품질 음악 캡션 데이터셋인 MusicCaps를 소개하며, 이는 향후 연구를 지원하기 위해 공개합니다.
우리의 실험은 정량적 지표와 인간 평가를 통해 MusicLM이 Mubert(Mubert-Inc, 2022)와 Riffusion(Forsgren & Martiros, 2022)과 같은 이전 시스템들보다 품질과 캡션에 대한 충실도 면에서 뛰어남을 보여줍니다. 더 나아가, 음악의 일부 측면을 단어로 설명하는 것이 어렵거나 불가능할 수 있기 때문에, 우리는 우리의 방법이 텍스트 이외의 조건 신호도 지원할 수 있음을 보여줍니다. 구체적으로, 우리는 MusicLM이 추가적인 멜로디를 오디오(예: 휘파람, 허밍)의 형태로 조건으로 받아들이고, 텍스트 프롬프트에 설명된 스타일로 원하는 멜로디를 따르는 음악 클립을 생성할 수 있도록 확장합니다.
우리는 음악 생성과 관련된 위험, 특히 창의적 콘텐츠의 부적절한 사용 가능성을 인식합니다. 책임 있는 모델 개발 관행에 따라, 우리는 Carlini et al.(2022)이 텍스트 기반 대형 언어 모델을 위해 사용한 방법론을 적용하고 확장하여 암기 현상에 대한 철저한 연구를 수행합니다. 우리의 연구 결과는 MuLan 임베딩을 MusicLM에 입력할 때, 생성된 토큰의 시퀀스가 훈련 세트의 해당 시퀀스와 상당히 다르다는 것을 보여줍니다.
이 연구의 주요 기여는 다음과 같습니다:
- MusicLM을 소개합니다. 이 모델은 텍스트 조건 신호에 충실하면서도 몇 분 동안 일관된 24kHz의 고품질 음악을 생성합니다.
- 우리의 방법을 다른 조건 신호, 예를 들어 텍스트 프롬프트에 따라 합성된 멜로디에 확장합니다. 또한 최대 5분 길이의 길고 일관된 음악 생성을 시연합니다.
- 텍스트-음악 생성 작업을 위해 수집된 최초의 평가 데이터셋을 공개합니다: MusicCaps는 음악가들이 준비한 5.5k 음악-텍스트 쌍으로 구성된 손수 제작된 고품질 데이터셋입니다.
2. 배경 및 관련 연구
다양한 분야에서 생성 모델링의 최첨단 기술은 주로 Transformer 기반 자회귀 모델(Vaswani et al., 2017) 또는 U-Net 기반 확산 모델(Ho et al., 2020)에 의해 주도되고 있습니다. 이 섹션에서는 MusicLM과 유사한 이산 토큰을 사용하는 자회귀 생성 모델에 중점을 두고 관련 연구를 검토합니다.
2.1. 양자화 (Quantization)
이산 토큰 시퀀스를 자회귀적으로 모델링하는 것은 자연어 처리(Brown et al., 2020; Cohen et al., 2022)와 이미지 또는 비디오 생성(Esser et al., 2021; Ramesh et al., 2021; Yu et al., 2022; Villegas et al., 2022)에서 강력한 접근 방식으로 입증되었습니다. 양자화는 연속 신호(이미지, 비디오, 오디오 포함)를 위한 자회귀 모델의 성공에 중요한 요소입니다. 양자화의 목표는 높은 충실도의 재구성을 가능하게 하면서도 컴팩트하고 이산적인 표현을 제공하는 것입니다. VQ-VAE(Van Den Oord et al., 2017)는 다양한 도메인에서 낮은 비트율로 인상적인 재구성 품질을 보여주었으며, 많은 접근 방식의 기본 양자화기로 사용됩니다.
SoundStream(Zeghidour et al., 2022)은 일반 오디오를 낮은 비트율로 압축하면서도 높은 재구성 품질을 유지할 수 있는 범용 신경망 오디오 코덱입니다. 이를 달성하기 위해 SoundStream은 잔여 벡터 양자화(RVQ)를 사용하여, 높은 비트율과 품질로의 확장성을 큰 계산 비용 없이 가능하게 합니다. 구체적으로, RVQ는 일련의 벡터 양자화기로 구성된 계층적 양자화 방식이며, 타겟 신호는 양자화기 출력의 합으로 재구성됩니다. 양자화기의 구성 덕분에 RVQ는 타겟 비트율이 증가함에 따라 코드북 크기의 기하급수적인 증가를 피합니다. 또한, 각 양자화기가 더 거친 양자화기의 잔여에 맞춰지는 사실은 양자화기에 계층적 구조를 도입하여, 더 거친 단계가 높은 충실도의 재구성에 더 중요하게 만듭니다. 이 속성은 생성에 바람직한데, 이는 과거의 맥락을 거친 토큰에만 집중함으로써 정의할 수 있기 때문입니다. 최근에 SoundStream은 EnCodec(Défossez et al., 2022)에 의해 더 높은 비트율과 스테레오 오디오로 확장되었습니다. 이 연구에서 우리는 SoundStream을 오디오 토크나이저로 사용하며, 이는 6 kbps의 비트율로 24 kHz의 음악을 높은 충실도로 재구성할 수 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
적당한 precision을 요구한다면 양자화는 합리적 선택
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
2.2. 오디오를 위한 생성 모델
고품질의 오디오를 장기적인 일관성을 가지고 생성하는 도전에도 불구하고, 최근 몇 가지 접근 방식들이 어느 정도 성공을 거두었습니다. 예를 들어, Jukebox(Dhariwal et al., 2020)는 다양한 시간 해상도에서 VQ-VAE의 계층 구조를 제안하여 높은 시간적 일관성을 달성하려 하지만, 생성된 음악에는 눈에 띄는 아티팩트가 나타납니다. 반면, PerceiverAR(Hawthorne et al., 2022a)는 SoundStream 토큰의 시퀀스를 자회귀적으로 모델링하여 고품질 오디오를 생성하지만, 장기적인 시간 일관성을 희생합니다.
이러한 접근 방식들에 영감을 받아, AudioLM(Borsos et al., 2022)은 계층적 토큰화 및 생성 방식을 사용하여 일관성과 고품질 합성 간의 균형을 맞추려 합니다. 구체적으로, 이 접근 방식은 두 가지 토큰 유형을 구분합니다: (1) 장기 구조를 모델링할 수 있도록 오디오 데이터로 사전 훈련된 모델에서 추출한 의미적 토큰, (2) 신경망 오디오 코덱이 제공하는 음향 토큰으로, 세밀한 음향 세부 사항을 캡처합니다. 이를 통해 AudioLM은 전사본이나 상징적 음악 표현에 의존하지 않고도 일관되고 고품질의 음성 및 피아노 음악을 생성할 수 있습니다.
MusicLM은 AudioLM을 기반으로 세 가지 중요한 추가 기여를 합니다: (1) 생성 과정을 설명적인 텍스트로 조건화, (2) 멜로디와 같은 다른 신호로 조건화를 확장할 수 있음을 보여줌, (3) 드럼 앤 베이스, 재즈, 클래식 음악 등 피아노 음악을 넘어 다양한 긴 음악 시퀀스를 모델링.
2.3. 조건부 오디오 생성
텍스트 설명(예: "배경에서 웃음소리가 나는 휘파람 소리")으로부터 오디오를 생성하는 것은 최근 몇 가지 연구에서 다뤄졌습니다. DiffSound(Yang et al., 2022)는 CLIP(Radford et al., 2021)을 텍스트 인코더로 사용하고, 확산 모델을 적용하여 텍스트 임베딩을 기반으로 타겟 오디오의 양자화된 멜 스펙트로그램 특징을 예측합니다. AudioGen(Kreuk et al., 2022)은 텍스트 임베딩을 위해 T5(Raffel et al., 2020) 인코더를 사용하고, EnCodec(Défossez et al., 2022)에 의해 생성된 타겟 오디오 코드를 예측하기 위해 자회귀 Transformer 디코더를 사용합니다. 두 접근 방식 모두 AudioSet(Gemmeke et al., 2017) 및 AudioCaps(Kim et al., 2019)와 같은 페어링된 훈련 데이터에 의존하며, 필터링 후 총 5천 시간 이하의 데이터입니다.
MusicLM과 유사한 접근 방식으로는 텍스트 조건에 따른 음악 생성을 다루는 연구들이 있습니다. Mubert(Mubert-Inc, 2022)는 텍스트 프롬프트를 Transformer로 임베딩하여, 인코딩된 프롬프트와 가까운 음악 태그를 선택하고 이를 사용하여 노래 생성 API를 쿼리합니다. 선택된 태그를 기반으로 Mubert는 음악가와 사운드 디자이너가 생성한 소리들의 조합을 생성합니다. Riffusion(Forsgren & Martiros, 2022)은 페어링된 음악-텍스트 데이터셋의 음악 조각의 멜 스펙트로그램에 Stable Diffusion 모델(Rombach et al., 2022a)을 미세 조정하여 음악을 생성합니다. 우리는 Mubert와 Riffusion을 우리의 기준선으로 사용하여, 오디오 생성 품질과 텍스트 설명에 대한 충실도를 개선했음을 보여줍니다.
음악의 상징적 표현(예: MIDI)도 강력한 조건화의 한 형태로 생성 과정을 이끌 수 있습니다(Huang et al., 2019; Hawthorne et al., 2019; Engel et al., 2020). MusicLM은 허밍 멜로디와 같은 더 자연스럽고 직관적인 방식으로 조건 신호를 제공할 수 있으며, 이는 텍스트 설명과 결합될 수도 있습니다.
2.4. 텍스트 조건부 이미지 생성
텍스트 조건부 오디오 합성의 전신은 텍스트 조건부 이미지 생성 모델로, 이는 스트럭처 개선과 방대한 고품질 페어링 훈련 데이터의 가용성 덕분에 품질 면에서 상당한 진전을 이루었습니다. 주목할 만한 Transformer 기반 자회귀 접근 방식으로는 Ramesh et al. (2021)과 Yu et al. (2022)가 있으며, Nichol et al. (2022), Rombach et al. (2022b), Saharia et al. (2022)는 확산 기반 모델을 제시합니다. 텍스트-이미지 접근 방식은 텍스트 프롬프트로부터 비디오를 생성하는 것으로 확장되었습니다(Wu et al., 2022a; Hong et al., 2022; Villegas et al., 2022; Ho et al., 2022).
이들 작업 중 우리 접근 방식에 가장 가까운 것은 DALL-E 2 (Ramesh et al., 2022)입니다. 특히, DALL-E 2가 텍스트 인코딩을 위해 CLIP (Radford et al., 2021)에 의존하는 방식과 유사하게, 우리는 같은 목적으로 공동 음악-텍스트 임베딩 모델을 사용합니다. DALL-E 2가 디코더로 확산 모델을 사용하는 것과는 달리, 우리의 디코더는 AudioLM을 기반으로 합니다. 또한, 우리는 텍스트 임베딩을 음악 임베딩으로 매핑하는 사전 모델을 생략하여 AudioLM 기반 디코더가 오디오 전용 데이터셋에서 훈련될 수 있도록 하고, 추론 시 음악 임베딩을 텍스트 임베딩으로 단순히 교체합니다.
2.5. 음악과 텍스트를 위한 공동 임베딩 모델
MuLan(Huang et al., 2022)은 각각의 모달리티를 위한 두 개의 임베딩 타워로 구성된 음악-텍스트 공동 임베딩 모델입니다. 이 타워들은 대조 학습을 사용하여 두 모달리티를 128차원의 공유 임베딩 공간으로 매핑하며, 이는 (Radford et al., 2021; Wu et al., 2022b)와 유사한 설정입니다. 텍스트 임베딩 네트워크는 대규모 텍스트 전용 데이터 코퍼스에서 사전 훈련된 BERT(Devlin et al., 2019)를 사용하며, 오디오 타워는 ResNet-50 변형을 사용합니다.
MuLan은 음악 클립과 해당 텍스트 주석 쌍에 대해 훈련됩니다. 중요한 것은 MuLan이 훈련 데이터 품질에 대해 약한 요구사항만 부과하며, 음악-텍스트 쌍이 약하게 연관되어 있는 경우에도 크로스 모달 연관성을 학습할 수 있다는 점입니다. 자연 언어 설명과 음악을 연결하는 능력은 이를 검색 또는 제로샷 음악 태깅에 적용 가능하게 만듭니다. 본 연구에서는 Huang et al. (2022)의 사전 훈련된 모델을 사용합니다.
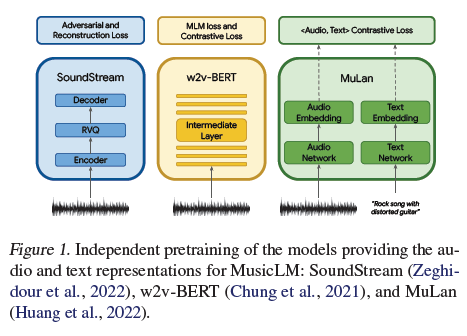
그림 1. MusicLM의 오디오 및 텍스트 표현을 제공하는 모델들의 독립적인 사전 훈련: SoundStream(Zeghidour et al., 2022), w2v-BERT(Chung et al., 2021), MuLan(Huang et al., 2022).
3. 방법론
이 섹션에서는 MusicLM과 그 구성 요소들을 설명합니다. 3.1절에서는 오디오 표현을 제공하는 모델들을 설명합니다. 이후 3.2절에서는 이러한 표현을 텍스트 조건부 음악 생성에 어떻게 사용하는지 보여줍니다.
3.1 오디오 및 텍스트의 표현과 토큰화
우리는 조건부 자회귀 음악 생성을 위해 오디오 표현을 추출하는 세 가지 모델을 사용합니다. 이 모델들은 그림 1에 설명되어 있습니다. 특히, AudioLM 접근 방식을 따라, 우리는 고품질 합성을 가능하게 하는 음향 토큰으로 SoundStream(Zeghidour et al., 2022)의 자기 지도 학습 오디오 표현을 사용하고, 장기적 일관된 생성을 촉진하는 의미 토큰으로 w2v-BERT(Chung et al., 2021)를 사용합니다. 조건 신호를 표현하기 위해, 훈련 중에는 MuLan 음악 임베딩을, 추론 시에는 MuLan 텍스트 임베딩을 사용합니다. 이 세 모델 모두 독립적으로 사전 훈련된 후 고정되어 시퀀스-투-시퀀스 모델링을 위한 이산 오디오 및 텍스트 표현을 제공합니다.
SoundStream: 우리는 24 kHz 단일 음향 오디오에 대해 스트라이딩 팩터가 480인 SoundStream 모델을 사용하여 50 Hz 임베딩을 생성합니다. 이러한 임베딩의 양자화는 12개의 양자화기를 가진 RVQ에 의해 훈련 중 학습되며, 각 양자화기는 1024개의 어휘 크기를 가집니다. 이는 6 kbps의 비트레이트를 가지며, 1초의 오디오는 600개의 토큰으로 표현됩니다. 이를 음향 토큰(A)이라고 합니다.
w2v-BERT: AudioLM과 유사하게, 우리는 600M 파라미터를 가진 w2v-BERT 모델의 MLM 모듈 중간 레이어를 사용합니다. 모델을 사전 훈련하고 고정한 후, 7번째 레이어에서 임베딩을 추출하고 학습된 k-means의 중심을 사용하여 이를 양자화합니다. 우리는 1024개의 클러스터와 25 Hz의 샘플링 속도를 사용하여, 매 초당 25개의 의미 토큰(S)을 얻습니다.
MuLan: MusicLM을 훈련하기 위해, 우리는 MuLan의 오디오 임베딩 네트워크에서 타겟 오디오 시퀀스의 표현을 추출합니다. 이 표현은 연속적이며 Transformer 기반 자회귀 모델에서 조건 신호로 직접 사용할 수 있습니다. 그러나 우리는 오디오와 조건 신호가 모두 이산 토큰 기반의 동질적인 표현을 가지도록 MuLan 임베딩을 양자화하기로 결정하여, 조건 신호를 자회귀적으로 모델링하는 추가 연구를 지원합니다.
MuLan은 10초 오디오 입력에 대해 작동하며, 우리는 더 긴 오디오 시퀀스를 처리해야 하기 때문에, 1초의 스트라이드로 10초 창에서 오디오 임베딩을 계산하고 결과 임베딩을 평균화합니다. 그런 다음, 12개의 벡터 양자화기를 가진 RVQ를 적용하여 결과 임베딩을 이산화합니다. 이 과정은 오디오 시퀀스에 대해 12개의 MuLan 오디오 토큰(MA)을 생성합니다. 추론 중에는 텍스트 프롬프트에서 추출한 MuLan 텍스트 임베딩을 조건으로 사용하고, 오디오 임베딩에 사용된 것과 동일한 RVQ로 양자화하여 12개의 토큰(MT)을 얻습니다.
훈련 중에 MA로 조건화하는 것에는 두 가지 주요 이점이 있습니다. 첫째, 텍스트 캡션의 필요성에 제한되지 않기 때문에 훈련 데이터를 쉽게 확장할 수 있습니다. 둘째, 대조 손실을 사용하여 훈련된 MuLan과 같은 모델을 활용함으로써, 노이즈가 있는 텍스트 설명에 대한 강건성을 높일 수 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
예를 들어, 당신이 바이올린 연주를 녹음했다고 가정해 보겠습니다. 이 녹음은 매우 고품질의 24 kHz 단일 음향 오디오로 제공됩니다. 이 오디오를 SoundStream을 사용하여 처리하면, 매 1초마다 600개의 작은 조각(토큰)으로 변환됩니다. 이렇게 변환된 토큰들은 원래의 바이올린 연주를 고품질로 재구성할 수 있는 정보들을 담고 있습니다. 이러한 토큰들은 **음향 토큰(A)**이라고 부릅니다.
w2v-BERT 모델은 바이올린 연주를 들으면서, 연주가 진행되는 동안의 중요한 의미적 특징들을 추출합니다. 예를 들어, 연주가 어떻게 전개되는지, 어떤 멜로디가 반복되는지 등을 이해합니다. 그리고 이러한 중요한 특징들을 1초당 25개의 의미 토큰(S)으로 변환합니다. 이 토큰들은 연주의 전체적인 맥락을 유지하면서도 중요한 세부 사항을 캡처합니다.
바이올린 연주와 관련된 텍스트 설명이 있다고 가정해 봅시다. 예를 들어, "우아한 바이올린 솔로"라는 설명이 있다고 해보겠습니다. MuLan 모델은 이 텍스트 설명을 임베딩(수치화된 표현)으로 변환합니다. 그런 다음, 이 임베딩을 오디오 임베딩과 동일한 방식으로 양자화하여 12개의 MuLan 텍스트 토큰(MT)으로 변환합니다. 이 토큰들은 "우아한 바이올린 솔로"라는 텍스트 설명을 수치적으로 표현한 것입니다.
훈련 중에는, MuLan은 바이올린 연주와 그에 해당하는 텍스트 설명을 연결하여, 모델이 텍스트 설명을 기반으로 오디오를 생성할 수 있도록 돕습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
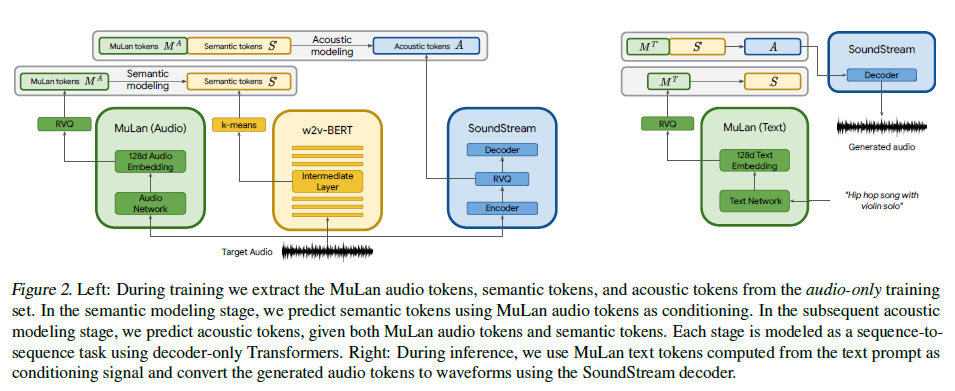
그림 2.
- 왼쪽: 훈련 중에는 오디오 전용 훈련 세트에서 MuLan 오디오 토큰, 의미 토큰, 음향 토큰을 추출합니다. 의미적 모델링 단계에서는 MuLan 오디오 토큰을 조건으로 사용하여 의미 토큰을 예측합니다. 이어지는 음향적 모델링 단계에서는 MuLan 오디오 토큰과 의미 토큰을 주어진 조건으로 음향 토큰을 예측합니다. 각 단계는 디코더 전용 Transformers를 사용하여 시퀀스-투-시퀀스 작업으로 모델링됩니다.
- 오른쪽: 추론 중에는 텍스트 프롬프트로부터 계산된 MuLan 텍스트 토큰을 조건 신호로 사용하고, 생성된 오디오 토큰을 SoundStream 디코더를 사용하여 파형으로 변환합니다.
3.2. 오디오 표현의 계층적 모델링
우리는 앞서 소개한 이산 오디오 표현을 AudioLM과 결합하여 텍스트 조건부 음악 생성을 달성합니다. 이를 위해, 우리는 각각의 단계가 별도의 디코더 전용 Transformer에 의해 자회귀적으로 모델링되는 계층적 시퀀스-투-시퀀스 모델링 작업을 제안합니다. 제안된 접근 방식은 그림 2에 설명되어 있습니다.
첫 번째 단계는 의미적 모델링 단계로, MuLan 오디오 토큰에서 의미 토큰(S)으로의 매핑을 학습합니다. 이는 시퀀스에서 시간 단계에 해당하는 위치인 t에서의 분포 p(St|S<t; MA)를 모델링하는 것입니다. 두 번째 단계는 음향적 모델링 단계로, MuLan 오디오 토큰과 의미 토큰을 조건으로 하여 음향 토큰(Aq)을 예측합니다. 이는 분포 p(At|A<t; S; MA)를 모델링하는 것입니다.
특히, 긴 토큰 시퀀스를 피하기 위해, AudioLM은 음향적 모델링 단계를 더 세분화하여 거친(coarse) 단계와 세밀한(fine) 단계로 나누는 것을 제안했습니다. 우리는 동일한 접근 방식을 따르며, 거친 단계는 SoundStream RVQ 출력의 첫 4개 레벨을 모델링하고, 세밀한 단계는 나머지 8개 레벨을 모델링합니다. 자세한 내용은 Borsos et al. (2022)를 참조하십시오.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
여기서 분포라는 개념은 우리가 다음 토큰을 예측하는 방식과 관련이 있습니다. 예를 들어, 우리가 "음악"을 생성하고 있다고 가정해봅시다. MusicLM은 현재 시퀀스에서 다음 토큰(음표나 음향)을 예측하는데, 이는 현재 시퀀스의 이전 토큰들과 조건(텍스트나 이전 토큰)에 기반합니다.
의미적 모델링 단계
의미적 모델링 단계는 MuLan 오디오 토큰을 사용하여 의미 토큰을 예측합니다. 이때 모델은 "현재 시퀀스의 이전 의미 토큰"과 "MuLan 오디오 토큰"을 사용하여 다음 의미 토큰을 예측합니다.
예를 들어보겠습니다:
- 현재 시퀀스: [의미 토큰1, 의미 토큰2, 의미 토큰3]
- MuLan 오디오 토큰: [MuLan 토큰1, MuLan 토큰2]
이 상황에서 모델은 다음 의미 토큰(의미 토큰4)을 예측하려고 합니다. 이를 분포 p(St|S<t; MA)로 나타냅니다. 여기서 S<t는 현재 시퀀스의 이전 의미 토큰들(의미 토큰1, 의미 토큰2, 의미 토큰3)을 의미하고, MA는 MuLan 오디오 토큰을 의미합니다. 모델은 이전 토큰들과 MuLan 오디오 토큰을 기반으로 의미 토큰4가 무엇이 될지를 예측합니다.
음향적 모델링 단계
음향적 모델링 단계는 MuLan 오디오 토큰과 의미 토큰을 사용하여 음향 토큰을 예측합니다. 이때 모델은 "현재 시퀀스의 이전 음향 토큰"과 "의미 토큰" 및 "MuLan 오디오 토큰"을 사용하여 다음 음향 토큰을 예측합니다.
예를 들어보겠습니다:
- 현재 시퀀스: [음향 토큰1, 음향 토큰2, 음향 토큰3]
- 의미 토큰: [의미 토큰1, 의미 토큰2, 의미 토큰3]
- MuLan 오디오 토큰: [MuLan 토큰1, MuLan 토큰2]
이 상황에서 모델은 다음 음향 토큰(음향 토큰4)을 예측하려고 합니다. 이를 분포 p(At|A<t; S; MA)로 나타냅니다. 여기서 A<t는 현재 시퀀스의 이전 음향 토큰들(음향 토큰1, 음향 토큰2, 음향 토큰3)을 의미하고, S는 의미 토큰들(의미 토큰1, 의미 토큰2, 의미 토큰3)을 의미하며, MA는 MuLan 오디오 토큰을 의미합니다. 모델은 이전 음향 토큰들, 의미 토큰들, 그리고 MuLan 오디오 토큰을 기반으로 음향 토큰4가 무엇이 될지를 예측합니다.
요약
- 의미적 모델링 단계: 이전 의미 토큰들과 MuLan 오디오 토큰을 기반으로 다음 의미 토큰을 예측합니다.
- 음향적 모델링 단계: 이전 음향 토큰들, 의미 토큰들, 그리고 MuLan 오디오 토큰을 기반으로 다음 음향 토큰을 예측합니다.
결국 다음 토큰을 예측하는 방안을 논의함
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4. 실험 설정
4.1. 모델
의미적 단계와 AudioLM의 음향적 단계를 모델링하기 위해 디코더 전용 Transformers를 사용합니다. 모델들은 동일한 아키텍처를 공유하며, 이는 24개의 레이어, 16개의 어텐션 헤드, 1024의 임베딩 차원, 4096의 피드포워드 레이어 차원, 0.1의 드롭아웃 및 상대적 위치 임베딩(Raffel et al., 2020)으로 구성되어 있습니다. 각 단계는 4억 3천만 개의 파라미터를 가집니다.
4.2. 훈련 및 추론
사전 훈련되고 고정된 MuLan에 의존함으로써, MusicLM의 다른 구성 요소를 훈련하기 위해 오디오 전용 데이터만 필요합니다. SoundStream과 w2v-BERT는 Free Music Archive(FMA) 데이터셋(Defferrard et al., 2017)에서 훈련되며, 의미적 및 음향적 모델링 단계를 위한 토크나이저와 자회귀 모델은 500만 개의 오디오 클립으로 구성된 데이터셋에서 훈련됩니다. 이 데이터셋은 24 kHz에서 28만 시간의 음악을 포함합니다. 각 단계는 훈련 데이터를 여러 번 반복하여 훈련됩니다. 우리는 의미적 단계와 음향적 단계를 위해 각각 30초와 10초 길이의 타겟 오디오 랜덤 크롭을 사용합니다. AudioLM 세밀 음향 모델링 단계는 3초 크롭으로 훈련됩니다.
추론 중에는 MuLan이 학습한 오디오와 텍스트 간의 공동 임베딩 공간을 사용합니다. 즉, MA를 MT로 대체합니다. 그런 다음 위에서 설명한 단계를 따라 MT를 기반으로 A를 얻습니다. 모든 단계에서 자회귀 샘플링을 위해 온도 샘플링을 사용하며, 의미적 모델링 단계에서는 1.0, 거친 음향 모델링 단계에서는 0.95, 세밀 음향 모델링 단계에서는 0.4의 온도를 사용합니다. 이러한 온도 값은 생성된 음악의 다양성과 시간적 일관성 간의 균형을 제공하기 위해 주관적 검사를 기반으로 선택되었습니다.
4.3. 평가 데이터셋
MusicLM을 평가하기 위해 우리는 MusicCaps라는 고품질 음악 캡션 데이터셋을 준비하여 공개합니다. 이 데이터셋에는 AudioSet(Gemmeke et al., 2017)에서 추출한 5.5천 개의 음악 클립이 포함되어 있으며, 각각 10명의 전문 음악가가 작성한 영어 텍스트 설명과 짝을 이룹니다. 각 10초 음악 클립에 대해 MusicCaps는 (1) 음악을 설명하는 평균 4문장으로 구성된 자유 텍스트 캡션과 (2) 장르, 분위기, 템포, 가수의 목소리, 악기 구성, 불협화음, 리듬 등을 설명하는 음악 측면 목록을 제공합니다. 평균적으로, 데이터셋은 클립당 11개의 측면을 포함합니다. 캡션 및 측면 목록 예시는 부록 A를 참조하십시오.
MusicCaps는 AudioCaps(Kim et al., 2019)를 보완하며, 둘 다 AudioSet에서 텍스트 설명과 짝을 이룬 오디오 클립을 포함합니다. 그러나 AudioCaps가 비음악 콘텐츠를 포함하는 반면, MusicCaps는 오직 음악에만 초점을 맞추고 있으며, 전문가가 제공한 매우 상세한 주석을 포함합니다. 예제는 AudioSet의 학습 및 평가 분할에서 추출되었으며, 다양한 장르의 분포를 다룹니다. 자세한 내용은 부록 A를 참조하십시오. MusicCaps는 또한 장르 균형 데이터 분할을 제공하여 1천 개의 예제를 포함합니다.
4.4. 평가 지표
우리는 MusicLM을 평가하기 위해 다양한 지표를 계산하며, 음악 생성의 두 가지 중요한 측면인 오디오 품질과 텍스트 설명에 대한 충실도를 포착합니다.
프레셰 오디오 거리(FAD)
프레셰 오디오 거리(FAD, Fréchet Audio Distance, Kilgour et al., 2019)는 참조 없이 오디오 품질을 평가하는 지표로, 인간의 인식과 잘 일치합니다. FAD 점수가 낮은 모델은 그럴듯한 오디오를 생성할 것으로 기대됩니다. 그러나 생성된 샘플이 제공된 텍스트 설명에 반드시 충실하지는 않을 수 있습니다.
우리는 두 가지 공개적으로 이용 가능한 오디오 임베딩 모델을 기반으로 FAD를 보고합니다:
- Trill2 (Shor et al., 2020): 음성 데이터로 훈련된 모델
- VGGish (Hershey et al., 2017): YouTube-8M 오디오 이벤트 데이터셋(Abu-El-Haija et al., 2016)으로 훈련된 모델
훈련 데이터의 차이로 인해, 이 모델들은 각각 오디오 품질의 다른 측면(음성과 비음성)을 측정할 것으로 기대됩니다.
KL 발산(KLD)
텍스트 설명과 해당 텍스트와 호환되는 음악 클립 간에는 다대다 관계가 있습니다. 따라서 생성된 음악을 오디오 파형 수준에서 참조와 직접 비교하는 것은 불가능합니다. 입력된 텍스트 설명에 대한 충실도를 평가하기 위해, 우리는 Yang et al. (2022) 및 Kreuk et al. (2022)이 제안한 방법과 유사한 프록시 방법을 채택합니다. 구체적으로, 우리는 AudioSet에서 다중 라벨 분류를 위해 훈련된 LEAF(Zeghidour et al., 2021) 분류기를 사용하여 생성된 음악과 참조 음악에 대한 클래스 예측을 계산하고, 클래스 예측의 확률 분포 간의 KL 발산을 측정합니다. KL 발산이 낮을 때, 생성된 음악은 분류기에 따르면 참조 음악과 유사한 음향적 특성을 가질 것으로 기대됩니다.
MuLan 주기 일관성(MCC)
MuLan은 음악-텍스트 공동 임베딩 모델로, 음악-텍스트 쌍 간의 유사성을 정량화하는 데 사용할 수 있습니다. 우리는 MusicCaps의 텍스트 설명과 이를 기반으로 생성된 음악에서 MuLan 임베딩을 계산하고, 이러한 임베딩 간의 평균 코사인 유사성으로 MCC 지표를 정의합니다.
질적 평가
궁극적으로, 우리는 생성된 샘플이 텍스트 설명에 얼마나 잘 부합하는지를 평가하기 위해 주관적인 테스트에 의존합니다. 우리는 A-vs-B 인간 평가 과제를 설정합니다. 여기서 평가자들은 텍스트 설명과 두 개의 음악 샘플을 제시받는데, 이 샘플들은 두 개의 다른 모델 또는 하나의 모델과 참조 음악에 의해 생성된 것입니다. 평가자들은 다음 다섯 가지 중 하나를 선택할 수 있습니다: A 또는 B에 대한 강한 선호, 약한 선호, 그리고 선호 없음. 평가자들은 결정할 때 음악의 품질을 고려하지 않도록 지시받는데, 이는 FAD 지표로 이미 평가되었기 때문입니다.
우리는 참조 음악을 포함하여 n개의 다른 모델의 출력을 고려하며, 따라서 총 n+1개의 조건과 n(n+1)/2 쌍이 있습니다. 쌍별 테스트 결과를 집계하고 조건을 순위 매기기 위해, 우리는 한 조건이 얼마나 자주 강하게 또는 약하게 선호되는지를 "승리" 횟수로 계산합니다. 샘플은 평가 데이터의 장르 균형 1천 개 하위 집합에서 선택됩니다.
훈련 데이터 암기
대형 언어 모델은 훈련 데이터에서 본 패턴을 암기할 수 있는 능력이 있습니다(Carlini et al., 2020). 우리는 MusicLM이 음악 세그먼트를 얼마나 암기할 수 있는지를 연구하기 위해 Carlini et al. (2022)에서 사용된 방법론을 적용합니다. 우리는 의미적 모델링을 담당하는 첫 번째 단계에 집중합니다. 훈련 세트에서 무작위로 N개의 예제를 선택합니다. 각 예제에 대해, MuLan 오디오 토큰 MA와 첫 번째 T 의미 토큰 S의 시퀀스를 포함하는 프롬프트를 모델에 입력합니다. 여기서 T는 0에서 250까지이며, 최대 10초에 해당합니다. 우리는 탐욕적 디코딩을 사용하여 125개의 의미 토큰(5초)의 연속을 생성하고, 생성된 토큰을 데이터셋의 타겟 토큰과 비교합니다. 우리는 생성된 토큰과 타겟 토큰이 전체 샘플링된 세그먼트에서 동일한 예제의 비율을 정확한 일치로 측정합니다.
또한, 우리는 유사한 오디오 세그먼트로 이어질 수 있는 서로 다른 토큰 시퀀스를 감지하기 위해 근사 일치를 탐지하는 방법론을 제안합니다. 즉, 생성된 토큰과 타겟 토큰의 어휘 {0; : : : ; 1023}에 대한 의미 토큰 수의 히스토그램을 계산하고, 히스토그램 간의 일치 비용을 다음과 같이 정의합니다. 먼저, 의미 토큰 쌍 간의 거리 행렬을 계산하며, 이는 w2v-BERT를 의미 토큰으로 양자화하는 데 사용된 k-평균 중심 간의 유클리드 거리로 채워집니다(섹션 3.1 참조). 그런 다음, 두 히스토그램의 비-제로 토큰 수에 해당하는 하위 행렬만 고려하여 Sinkhorn 알고리즘(Cuturi, 2013)을 사용하여 히스토그램 쌍 간의 일치 비용을 찾기 위한 최적 운송 문제를 해결합니다. 두 시퀀스가 근사 일치일 가능성이 있는지를 결정하는 데 사용되는 임계값을 보정하기 위해, 타겟 토큰이 있는 예제를 교환하여 음성 쌍을 구성하고 이러한 음성 쌍에 대한 일치 비용의 경험적 분포를 측정합니다. 우리는 근사 일치의 허위 양성률을 0.01% 미만으로 유지하기 위해 일치 임계값 tau를 0.85로 설정합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
임계값 au를 0.85로 설정한다는 것은, MusicLM의 훈련 데이터 암기 여부를 평가할 때, 두 시퀀스가 "근사 일치"로 간주될 수 있는지를 결정하는 기준을 설정하는 것을 의미합니다. 이 임계값을 통해 모델이 생성한 음악 토큰 시퀀스와 훈련 데이터에 있는 토큰 시퀀스가 어느 정도 유사한지를 측정할 수 있습니다.
구체적으로:
- 히스토그램 기반 일치 비용 계산:
- 의미 토큰의 히스토그램을 생성합니다. 예를 들어, 특정 토큰이 몇 번 나타나는지를 세는 것입니다.
- 히스토그램 간의 거리를 계산합니다. 이 거리는 w2v-BERT 모델의 k-평균 중심 간의 유클리드 거리를 기반으로 합니다.
- Sinkhorn 알고리즘을 사용하여 최적 운송 문제를 해결하여 히스토그램 간의 일치 비용을 찾습니다.
- 음성 쌍 생성:
- 음성 쌍은 훈련 데이터의 예제를 교환하여 만듭니다. 이는 실제로 서로 관련이 없는 토큰 시퀀스를 비교하여 음성 일치 비용의 분포를 생성하는 과정입니다.
- 경험적 분포 측정:
- 음성 쌍에 대해 계산된 일치 비용의 분포를 측정합니다. 이 분포는 두 시퀀스가 서로 다른 경우에 일치 비용이 어떻게 분포되는지를 나타냅니다.
- 임계값 τ\tau 설정:
- 이 분포를 사용하여, 두 시퀀스가 근사 일치로 간주될 수 있는 임계값 tau를 설정합니다. 여기서는 tau를 0.85로 설정하여, 근사 일치로 간주될 수 있는 일치 비용의 최대 값을 정합니다.
- 근사 일치의 허위 양성률을 0.01% 미만으로 유지합니다. 즉, 실제로 다른 시퀀스들이 임계값을 초과하여 잘못 근사 일치로 간주되는 확률을 매우 낮게 유지합니다.
이렇게 함으로써, 모델이 생성한 시퀀스와 훈련 데이터의 시퀀스가 유사한지를 보다 엄격하게 평가할 수 있습니다
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
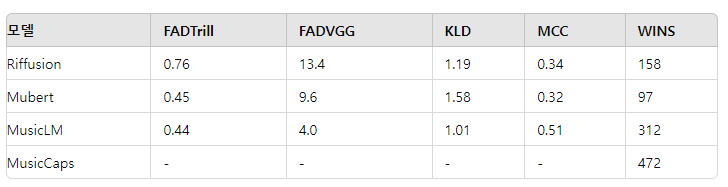
표 1. MusicCaps 데이터셋의 캡션을 사용하여 생성된 샘플 평가
모델은 오디오 품질 측면에서 프레셰 오디오 거리(FAD)와 텍스트 설명에 대한 충실도를 사용하여 Kullback–Leibler 발산(KLD)과 MuLan 주기 일관성(MCC) 및 쌍별 인간 청취 테스트에서의 승리 횟수(Wins)로 비교됩니다.
이 표는 MusicLM이 다른 모델들보다 우수한 성능을 보임을 명확히 보여줍니다.
5. 결과
우리는 MusicLM을 기술적 텍스트로부터 음악을 생성하는 두 개의 최근 기준 모델, 즉 Mubert(Mubert-Inc, 2022)와 Riffusion(Forsgren & Martiros, 2022)과 비교하여 평가합니다. 특히, 우리는 Mubert API를 통해 오디오를 생성하고, Riffusion 모델에서 추론을 수행합니다. 우리의 평가 데이터셋인 MusicCaps에서 평가를 수행하며, 이 데이터셋은 이 논문과 함께 공개합니다.
기준 모델과의 비교
표 1에는 본 논문의 주요 정량적 및 정성적 결과가 보고되어 있습니다. FAD 지표로 측정된 오디오 품질 측면에서, FADVGG 기준으로 MusicLM은 Mubert와 Riffusion보다 더 나은 점수를 기록했습니다. FADTrill 기준으로는 MusicLM이 Mubert와 유사한 점수(0.44 대 0.45)를 기록했고, Riffusion(0.76)보다 더 나은 점수를 기록했습니다. 이 지표들에 따르면, MusicLM은 음악가와 사운드 디자이너가 준비한 사전 녹음된 소리에 의존하는 Mubert와 비교하여 고품질 음악을 생성할 수 있습니다. 입력 텍스트 설명에 대한 충실도 측면에서는, KLD와 MCC 지표로 측정된 결과 MusicLM이 가장 높은 점수를 기록했으며, 이는 MusicLM이 기준 모델들에 비해 텍스트 설명으로부터 더 많은 정보를 포착할 수 있음을 시사합니다.
우리는 텍스트 충실도의 평가를 인간 청취 테스트로 보완했습니다. 참가자들은 두 개의 10초 클립과 텍스트 캡션을 제시받고, 캡션의 텍스트로 가장 잘 설명된 클립을 5점 Likert 척도로 평가하도록 요청받았습니다. 우리는 1200개의 평가를 수집했으며, 각 소스는 600쌍의 비교에 참여했습니다. 표 1은 총 "승리" 횟수를 보고하며, 이는 인간 평가자들이 한 모델을 나란히 비교했을 때 얼마나 자주 선호했는지를 나타냅니다. MusicLM은 두 기준 모델보다 명확히 선호되었으며, 여전히 실제 음악 참조와의 측정 가능한 격차가 있습니다. 청취 연구의 전체 세부 사항은 부록 B에서 확인할 수 있습니다.
MusicLM보다 실제 음악이 선호된 예제를 청취한 결과, 다음과 같은 패턴이 나타났습니다:
- 캡션이 매우 상세하여 다섯 개 이상의 악기를 언급하거나 "바람 소리, 사람들이 말하는 소리"와 같은 음악 외적인 측면을 설명합니다.
- 캡션이 재생되는 오디오의 시간적 순서를 설명합니다.
- MuLan이 잘 포착하지 못하는 부정을 사용합니다.
전반적으로, 우리는 다음과 같은 결론을 내립니다:
- 우리의 접근 방식은 MusicCaps의 풍부한 자유 텍스트 캡션으로부터 세밀한 정보를 포착할 수 있습니다.
- KLD와 MCC 지표는 텍스트 설명에 대한 충실도를 정량적으로 측정하며, 이는 인간 평가 연구와 일치합니다.
의미 토큰의 중요성
의미적 모델링을 음향적 모델링과 분리하는 유용성을 이해하기 위해, 우리는 MuLan 토큰에서 직접 거친 음향 토큰을 예측하는 Transformer 모델을 훈련했습니다. 이 모델은 분포 p(At∣A<t;MA)를 모델링합니다. 우리는 FAD 지표가 유사하게 나타나지만(0.42 FADTrill과 4.0 FADVGG), 의미적 모델링 단계를 제거하면 KLD와 MCC 점수가 나빠지는 것을 관찰했습니다. 특히, KLD 점수는 1.01에서 1.05로 증가하고, MCC 점수는 0.51에서 0.49로 감소하며, 이는 의미 토큰이 텍스트 설명에 대한 충실도를 촉진함을 나타냅니다. 또한, 우리는 샘플을 청취하여 이 점을 정성적으로 확인했습니다. 추가로, 장기 구조에서 저하가 관찰되었습니다.
오디오 토큰이 나타내는 정보
우리는 의미 토큰과 음향 토큰이 포착하는 정보를 연구하기 위해 추가 실험을 수행했습니다. 첫 번째 연구에서는 MuLan 텍스트 토큰과 의미 토큰을 고정하고, 음향 모델링 단계를 여러 번 실행하여 여러 샘플을 생성했습니다. 이 경우, 생성된 음악을 청취함으로써 샘플들이 다양하지만 동일한 장르, 리듬적 특성(예: 드럼), 그리고 주요 멜로디의 일부를 공유하는 것을 관찰할 수 있습니다. 샘플들은 특정 음향적 특성(예: 리버브, 왜곡 수준)과 유사한 음역대를 가진 다른 악기들 측면에서 다릅니다. 두 번째 연구에서는 MuLan 텍스트 토큰만 고정하고 의미 토큰과 음향 토큰을 모두 생성했습니다. 이 경우, 멜로디와 리듬적 특성 측면에서 훨씬 더 높은 수준의 다양성을 관찰할 수 있지만, 여전히 텍스트 설명과 일관성이 있습니다. 우리는 이 연구에서 얻은 샘플들을 동반 자료에 제공합니다.
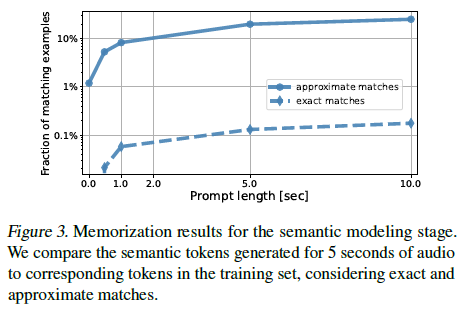
그림 3. 의미적 모델링 단계의 암기 결과. 우리는 5초 오디오에 대해 생성된 의미 토큰을 훈련 세트의 해당 토큰과 비교하여 정확 일치와 근사 일치를 고려합니다.
암기 분석
그림 3은 의미 토큰 프롬프트 길이가 0초에서 10초 사이에서 변할 때 정확 일치와 근사 일치를 모두 보고합니다. 우리는 의미 토큰 프롬프트가 10초일 때 5초의 연속을 생성할 때조차도 정확 일치의 비율이 항상 매우 작음(< 0.2%)을 관찰했습니다. 그림 3에는 τ=0.85를 사용한 근사 일치 결과도 포함되어 있습니다. 이 방법론으로 감지된 일치의 수가 더 많으며, MuLan 토큰만 입력으로 사용했을 때(프롬프트 길이 T = 0)도 일치 예제의 비율이 증가합니다. 우리는 이러한 일치를 더 면밀히 조사하고, 가장 낮은 일치 점수를 가진 경우가 낮은 수준의 토큰 다양성을 특징으로 한다는 것을 관찰했습니다. 즉, 125개의 의미 토큰 샘플의 평균 경험적 엔트로피는 4.6 비트인 반면, 일치 점수가 0.5 미만인 근사 일치로 감지된 시퀀스를 고려할 때는 1.0 비트로 감소합니다. 우리는 T = 0에서 얻은 근사 일치 샘플을 동반 자료에 포함시켰습니다. 음향 모델링이 의미 토큰이 정확히 일치할 때에도 생성된 샘플에 더 많은 다양성을 도입한다는 점을 주목하십시오.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
암기 분석의 목적은 MusicLM이 훈련 데이터의 특정 음악 세그먼트를 그대로 암기하고 재생하는지 여부를 평가하는 것입니다. 이를 위해, 두 가지 유형의 일치(정확 일치와 근사 일치)를 분석합니다.
정확 일치 분석
- 설정: 모델에 MuLan 오디오 토큰(MA)과 첫 번째 T 의미 토큰(S)을 입력합니다. 여기서 T는 0초부터 10초까지의 프롬프트 길이를 의미합니다.
- 생성: 모델이 125개의 의미 토큰(5초 길이)을 생성하도록 합니다.
- 비교: 생성된 토큰이 훈련 데이터의 타겟 토큰과 정확히 일치하는 비율을 계산합니다.
결과: 정확 일치의 비율은 항상 매우 작습니다(0.2% 미만). 이는 모델이 훈련 데이터를 그대로 재생하지 않는다는 것을 의미합니다.
근사 일치 분석
- 설정: 이전과 동일하게 MuLan 오디오 토큰과 첫 번째 T 의미 토큰을 입력합니다.
- 생성: 모델이 125개의 의미 토큰을 생성하도록 합니다.
- 히스토그램 계산: 생성된 토큰과 타겟 토큰의 의미 토큰 수의 히스토그램을 계산합니다. 이는 각 토큰이 얼마나 자주 나타나는지를 보여줍니다.
- 일치 비용 계산: 두 히스토그램 간의 일치 비용을 계산합니다. 이 비용은 w2v-BERT의 k-평균 중심 간의 유클리드 거리로 계산됩니다. Sinkhorn 알고리즘을 사용하여 최적의 히스토그램 일치를 찾습니다.
- 근사 일치 감지: 계산된 일치 비용이 임계값 τ=0.85 이하인 경우를 근사 일치로 간주합니다.
결과: 근사 일치의 비율은 정확 일치보다 더 높게 나타납니다. 특히, MuLan 토큰만을 사용할 때(프롬프트 길이 T = 0)도 일치 비율이 증가합니다. 또한, 일치 비용이 낮은 경우에는 토큰의 다양성이 낮습니다. 예를 들어, 평균 엔트로피는 일반적으로 4.6 비트이지만, 일치 비용이 0.5 미만인 경우에는 1.0 비트로 떨어집니다. 이는 일부 생성된 시퀀스가 낮은 다양성을 가진다는 것을 의미합니다.
요약
- 정확 일치: 모델이 훈련 데이터를 그대로 재생하는 경우는 매우 드뭅니다.
- 근사 일치: 일부 생성된 시퀀스는 훈련 데이터와 비슷하지만, 이는 토큰 다양성이 낮은 경우에 해당합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
6. 확장
멜로디 조건
MusicLM을 확장하여 텍스트 설명뿐만 아니라 허밍, 노래, 휘파람, 악기 연주 등의 형태로 제공되는 멜로디에 기반한 음악을 생성할 수 있도록 했습니다. 이를 위해 목표 멜로디를 포착하는 방식으로 조건 신호를 확장해야 합니다. 이를 위해 동일한 멜로디를 가지지만 음향이 다른 오디오 쌍으로 구성된 합성 데이터셋을 만듭니다. 이러한 쌍을 만들기 위해, 같은 음악 클립의 다양한 버전(예: 커버, 기악, 보컬)을 사용합니다. 추가적으로, 사람들이 허밍하고 노래하는 데이터 쌍도 수집합니다. 그런 다음 두 오디오 클립에 동일한 멜로디가 포함되어 있을 때, 해당 임베딩이 서로 가까워지도록 공동 임베딩 모델을 훈련합니다. 구현 세부 사항은 부록 C를 참조하십시오.
MusicLM의 멜로디 조건을 추출하기 위해, 우리는 멜로디 임베딩을 RVQ로 양자화하고, 결과 토큰 시퀀스를 MuLan 오디오 토큰(MA)과 연결합니다. 추론 중에는 입력 오디오 클립에서 멜로디 토큰을 계산하고 이를 MuLan 텍스트 토큰(MT)과 연결합니다. 이 조건을 기반으로, MusicLM은 입력 오디오 클립에 포함된 멜로디를 따르면서 텍스트 설명에 충실한 음악을 성공적으로 생성할 수 있습니다.
장기 생성 및 스토리 모드
MusicLM에서 생성은 시간적 차원에서 자회귀적이기 때문에 훈련 중에 사용된 시퀀스보다 더 긴 시퀀스를 생성할 수 있습니다. 실제로 의미적 모델링 단계는 30초의 시퀀스로 훈련됩니다. 더 긴 시퀀스를 생성하기 위해, 우리는 15초의 스트라이드로 진행하여, 15초를 접두사로 사용하여 추가 15초를 생성하며 항상 동일한 텍스트 설명에 조건을 둡니다. 이 접근 방식으로 몇 분 동안 일관된 긴 오디오 시퀀스를 생성할 수 있습니다.
작은 수정으로, 시간 경과에 따라 텍스트 설명을 변경하면서 긴 오디오 시퀀스를 생성할 수 있습니다. 비디오 생성 맥락에서 Villegas et al. (2022)로부터 차용하여, 이 접근 방식을 스토리 모드라고 부릅니다. 구체적으로, 우리는 여러 텍스트 설명에서 MT를 계산하고 조건 신호를 15초마다 변경합니다. 모델은 텍스트 설명에 따라 음악의 맥락을 변경하면서 템포가 일관되고 의미론적으로 그럴듯한 부드러운 전환을 생성합니다.
7. 결론
우리는 MusicLM을 소개합니다. 이는 텍스트 조건에 따라 고품질 음악을 24 kHz로 생성하는 모델로, 몇 분 동안 일관된 음악을 생성하며 텍스트 조건 신호에 충실합니다. 우리의 방법이 뮤지션들이 준비한 5.5k 음악-텍스트 쌍의 고품질 데이터셋인 MusicCaps에서 기준 모델들을 능가함을 입증했습니다.
우리 방법의 몇 가지 한계는 MuLan에서 유래했습니다. 예를 들어, 모델이 부정을 오해하거나 텍스트에서 설명된 정확한 시간 순서를 따르지 못하는 문제가 있습니다. 또한, 우리의 정량적 평가 방법도 개선이 필요합니다. 특히, MCC 점수는 MuLan을 기반으로 하기 때문에 우리의 방법에 유리하게 작용합니다.
미래 연구는 가사 생성, 텍스트 조건과 보컬 품질의 개선에 초점을 맞출 수 있습니다. 또 다른 측면은 서곡, 절, 후렴과 같은 고수준의 노래 구조를 모델링하는 것입니다. 더 높은 샘플링 속도로 음악을 모델링하는 것도 추가 목표가 될 수 있습니다.
8. 광범위한 영향
MusicLM은 텍스트 설명을 기반으로 고품질 음악을 생성하며, 창의적인 음악 작업을 돕는 도구 세트를 확장합니다. 그러나 우리 모델과 이를 사용하는 사례에는 몇 가지 위험이 따릅니다. 생성된 샘플은 훈련 데이터에 존재하는 편향을 반영하므로, 훈련 데이터에서 과소 대표된 문화에 대한 음악 생성의 적절성 문제와 문화적 전유 문제에 대한 우려가 제기됩니다.
우리는 이 사용 사례와 관련된 창작 콘텐츠의 부적절한 사용 가능성의 위험을 인식하고 있습니다. 책임 있는 모델 개발 관행에 따라, 우리는 텍스트 기반 대형 언어 모델의 맥락에서 사용된 방법론을 적용하고 확장하여 의미적 모델링 단계에 집중한 암기 연구를 철저히 수행했습니다. 그 결과, 예제의 아주 작은 부분만이 정확히 암기되었고, 약 1%의 예제에서 근사 일치를 확인할 수 있었습니다. 우리는 음악 생성과 관련된 이러한 위험을 해결하기 위한 미래 연구의 필요성을 강하게 강조하며, 현재로서는 모델을 공개할 계획이 없습니다.
'인공지능' 카테고리의 다른 글
| CharacterGen: Efficient 3D Character Generation from Single Imageswith Multi-View Pose Calibration (2) | 2024.07.18 |
|---|---|
| CLIP : Learning Transferable Visual Models From Natural Language Supervision (1) | 2024.07.17 |
| Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning (1) | 2024.07.15 |
| Segment Anything (2) | 2024.07.14 |
| ConvNets Match Vision Transformers at Scale (1) | 2024.07.13 |



