https://arxiv.org/abs/2311.10709
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical desig
arxiv.org
초록
우리는 텍스트-비디오 생성 모델인 EMU VIDEO를 소개합니다. 이 모델은 두 단계로 생성을 분할합니다: 먼저 텍스트를 조건으로 이미지를 생성하고, 그 다음 텍스트와 생성된 이미지를 조건으로 비디오를 생성합니다. 우리는 중요한 설계 결정을 확인했습니다 - 확산을 위한 조정된 노이즈 스케줄과 다단계 훈련 - 이로 인해 이전 작업에서와 같이 모델의 깊은 계단을 요구하지 않고도 고품질과 고해상도의 비디오를 직접 생성할 수 있습니다. 인간 평가에서, 우리의 생성된 비디오는 이전 작업과 비교해 품질이 크게 선호됩니다 - 구글의 Imagen Video와 비교해 81%, 엔비디아의 PYOCO와 비교해 90%, 메타의 Make-A-Video와 비교해 96%가 선호했습니다. 우리의 모델은 RunwayML의 Gen2와 Pika Labs와 같은 상업적 솔루션을 능가합니다. 마지막으로, 우리의 분할 접근 방식은 사용자의 텍스트 프롬프트를 기반으로 이미지를 애니메이션화하는데 자연스럽게 적용되며, 우리의 생성물은 이전 작업보다 96% 선호됩니다.

그림 1. EMU VIDEO는 텍스트 프롬프트를 입력으로 사용하여 고품질 및 시간적 일관성을 가진 비디오를 생성할 수 있습니다(상위 두 줄), 또는 추가적인 사용자 제공 이미지를 사용합니다(하단 줄). 프롬프트: (좌측 상단) 공원에서 정장을 입고 춤추는 여우, (우측 상단) 고층 건물의 높이에서 구름 사이로 해가 비추는 장면, (좌측 중간) 교실에서 발표하는 곰, (우측 중간) 카리브해의 맑은 물 위를 우아하게 항해하는 세련된 요트의 360도 샷, (좌측 하단) 항구를 떠나는 배, (우측 하단) 천천히 생명을 얻는 공룡. 하단 두 예시에서는 사용자 이미지가 추가적인 조건으로 제공되며(파란색 테두리로 표시됨) EMU VIDEO에 의해 생명을 얻습니다. 첫 번째는 RMS 타이타닉이 북아일랜드 벨파스트에서 출항하는 역사적인 사진이며, 두 번째는 티라노사우루스 렉스 화석 사진입니다.
1. 소개
웹 규모의 이미지-텍스트 쌍으로 학습된 대형 텍스트-이미지 모델 [17, 21, 28, 38, 55, 62]은 다양한 고품질 이미지를 생성합니다. 이러한 모델은 비디오-텍스트 쌍을 사용하여 텍스트-비디오 (T2V) 생성으로 추가 적응할 수 있지만 [7, 30, 38, 41, 68], 비디오 생성은 여전히 품질과 다양성 면에서 이미지 생성에 뒤쳐집니다. 이미지 생성에 비해 비디오 생성은 더 높은 차원의 시공간 출력 공간을 모델링해야 하므로 더 도전적입니다. 또한 비디오-텍스트 데이터셋은 이미지-텍스트 데이터셋보다 일반적으로 한 자릿수 이상 작습니다 [17, 38, 68]. 비디오 생성에서 지배적인 패러다임은 확산 모델 [38, 68]을 사용하여 모든 비디오 프레임을 한 번에 생성하는 것입니다.
대조적으로, NLP에서는 긴 시퀀스 생성을 자가회귀 문제 [11]로 공식화하여 이전에 예측된 단어를 조건으로 한 단어를 예측합니다. 따라서 각 후속 예측을 위한 조건 신호가 점점 강해집니다. 우리는 조건 신호를 강화하는 것이 본질적으로 시계열인 고품질 비디오 생성에도 중요하다고 가정합니다. 그러나 확산 모델 [75]을 사용한 자가회귀 디코딩은 이러한 모델에서 단일 프레임을 생성하는 데 많은 반복이 필요하기 때문에 어려운 문제입니다.
우리는 확산 기반 텍스트-비디오 생성을 위한 조건 강화를 위해 명시적인 중간 이미지 생성 단계를 포함하는 EMU VIDEO를 제안합니다. 구체적으로, 우리는 텍스트-비디오 생성을 두 가지 하위 문제로 분할합니다: (1) 입력 텍스트 프롬프트로부터 이미지 생성, (2) 이미지와 텍스트로부터 강력한 조건 신호를 기반으로 비디오 생성. 직관적으로, 모델에 시작 이미지를 제공하고 텍스트를 추가하면 비디오 생성이 더 쉬워지며, 모델은 단순히 이미지가 미래에 어떻게 변화할지 예측하면 됩니다.
비디오-텍스트 데이터셋이 이미지-텍스트 데이터셋보다 훨씬 작기 때문에, 우리는 사전 학습된 텍스트-이미지 (T2I) 모델을 사용하여 우리의 분할 텍스트-비디오 모델을 초기화하고 해당 가중치는 고정된 상태로 유지합니다 [7, 68]. 우리는 중요한 설계 결정 - 확산 노이즈 스케줄의 변경과 다단계 훈련 - 을 통해 512픽셀의 고해상도로 직접 비디오를 생성할 수 있습니다. 직접 T2V 방법 [38, 68]과 달리, 우리의 분할 접근 방식은 추론 시 명시적으로 이미지를 생성하여 텍스트-이미지 모델의 시각적 다양성, 스타일 및 품질을 쉽게 유지할 수 있습니다 (그림 1의 예시). 이를 통해 EMU VIDEO는 동일한 양의 훈련 데이터, 연산, 그리고 학습 가능한 매개변수를 고려할 때도 직접 T2V 방법을 능가합니다.

그림 2. 텍스트-비디오의 비디오 품질과 텍스트 충실도 승률 측면에서 EMU VIDEO와 이전 작업 비교. 대부분의 이전 작업의 모델이 접근 가능하지 않기 때문에, 우리는 각 방법이 공개한 비디오와 관련된 텍스트 프롬프트를 사용합니다. 공개된 비디오는 아마도 가장 좋은 생성물일 것이며, 우리는 우리 자신의 생성물에서 어떤 것도 선택하지 않고 비교합니다. 우리는 또한 상업적 솔루션 (Gen2 [54]와 PikaLabs [47])과 오픈 소스 모델 CogVideo [41]를 [7]의 프롬프트 세트를 사용하여 비교합니다. EMU VIDEO는 두 메트릭 모두에서 모든 이전 작업을 크게 능가합니다.
기여
우리는 텍스트-비디오 (T2V) 생성 품질이 먼저 이미지를 생성하고 생성된 이미지와 텍스트를 사용하여 비디오를 생성하는 방식으로 분할함으로써 크게 향상될 수 있음을 보여줍니다. 우리의 다단계 훈련은 고해상도 512픽셀 비디오를 직접 생성할 수 있게 하여 이전 작업 [38, 68]에서 사용된 깊은 모델 계단의 필요성을 없앴습니다. 우리는 인간 평가 체계 - JUICE - 를 설계하여 평가자들이 선택을 할 때 그들의 선택을 정당화하도록 요청합니다. 그림 2에서 보이듯이, EMU VIDEO는 품질과 텍스트 충실도에서 모든 이전 작업을 포함한 상업적 솔루션을 평균적으로 각각 91.8%, 86.6%의 승률로 크게 능가합니다. T2V를 넘어 EMU VIDEO는 사용자가 제공한 이미지와 텍스트 프롬프트를 기반으로 비디오를 생성하는 이미지-비디오에도 바로 사용할 수 있습니다. 이 설정에서 EMU VIDEO의 생성물은 VideoComposer [77]보다 96% 선호됩니다.
2. 관련 연구
텍스트-이미지 (T2I) 확산 모델. 확산 모델 [69]은 T2I 생성의 최첨단 접근 방식으로, 이전의 GAN [8, 43, 66]이나 자가 회귀 방법 [1, 22, 29, 59]을 능가합니다. 확산 모델은 종종 '노이즈'라고 불리는 정규 분포 변수를 점진적으로 디노이징하여 데이터 분포를 학습합니다. 이전 연구는 픽셀 확산 모델 [19, 36, 37, 56, 60, 63]을 사용하여 픽셀 공간에서 디노이징하거나, 잠재 확산 모델 [17, 62]을 사용하여 저차원 잠재 공간에서 디노이징합니다. 이 연구에서는 비디오 생성을 위해 잠재 확산 모델을 활용합니다.
비디오 생성/예측. 많은 이전 연구는 무조건적 생성 또는 비디오 예측 [45, 46, 53]의 제한된 설정을 목표로 합니다. 이러한 접근 방식에는 VAE [4, 5, 18], 자가 회귀 모델 [25, 41, 42, 61, 82], 마스크 예측 [27, 32, 87], LSTM [67, 78], 또는 GAN [2, 9, 16, 76] 훈련/평가가 포함됩니다. 그러나 이러한 접근 방식은 제한된 도메인에서 훈련/평가됩니다. 이 연구에서는 개방형 텍스트-비디오 (T2V) 생성의 넓은 과제를 목표로 합니다.
텍스트-비디오 (T2V) 생성. 대부분의 이전 연구는 T2I 모델을 활용하여 T2V 생성을 다룹니다. 여러 연구는 T2I 모델에 모션 정보를 주입하여 훈련 없이 영샷 T2V 생성을 위한 방법을 사용합니다 [40, 44, 49, 88]. Tune-A-Video [80]는 단일 비디오로 T2I 모델을 미세 조정하여 원샷 T2V 생성을 목표로 합니다. 이러한 방법은 훈련이 필요 없거나 제한되지만, 생성된 비디오의 품질과 다양성은 제한적입니다.
많은 이전 연구는 T2I 모델에 시간 매개변수를 도입하여 텍스트 조건에서 생성된 비디오로 직접 매핑을 학습하여 T2V 생성을 개선합니다 [7, 30, 33, 39, 41, 48, 72, 74, 75, 79, 83, 85]. Make-A-Video [68]는 사전 학습된 T2I 모델 [60]과 [60]의 사전 네트워크를 활용하여 비디오-텍스트 데이터 없이 T2V 생성을 훈련합니다. Imagen Video [38]는 확산 모델의 계층 구조를 사용하여 Imagen T2I 모델 [63]을 기반으로 합니다 [37, 39]. 높은 차원의 시공간 공간을 모델링하는 문제를 해결하기 위해 여러 연구는 저차원 잠재 공간에서 T2V 확산 모델을 훈련합니다 [3, 7, 24, 30, 31, 34, 81]. Blattmann et al. [7]은 사전 학습된 T2I 모델의 매개변수를 고정하고 새로운 시간 레이어를 훈련합니다. Ge et al. [30]은 [7]을 기반으로 T2V 생성을 위한 노이즈 사전 모델을 설계합니다. 이러한 접근 방식의 한계는 텍스트에서 높은 차원의 비디오 공간으로 직접 매핑을 학습하는 것이 어렵다는 점입니다. 우리는 조건 신호를 강화하기 위해 분할 접근 방식을 취합니다. 이전 연구와 달리, 우리는 비디오의 첫 프레임을 이미지 조건으로 사용하여 조건을 생성하는 모델이 필요하지 않습니다.
분할 생성. EMU VIDEO와 가장 유사한 연구는 CogVideo [41]와 Make-A-Video [68]입니다. CogVideo는 사전 학습된 T2I 모델 [20]을 기반으로 자가 회귀 변환기를 사용하여 T2V 생성을 수행합니다. 자가 회귀 특성은 훈련과 추론 단계 모두에서 우리의 명시적 이미지 조건과 근본적으로 다릅니다. Make-A-Video [68]는 공유 이미지-텍스트 공간에서 학습된 이미지 임베딩 조건을 활용합니다. 우리의 분할 방식은 첫 프레임을 그대로 활용하여 더 강력한 조건을 제공합니다. 또한, Make-A-Video는 사전 학습된 T2I 모델에서 초기화하지만 모든 매개변수를 미세 조정하여 T2I 모델의 시각적 품질과 다양성을 유지할 수 없습니다.

그림 3. 분할 텍스트-비디오 생성은 텍스트 조건 p로 이미지를 생성하고, 더 강력한 조건 - 생성된 이미지와 텍스트 - 을 사용하여 비디오 V를 생성합니다. 우리 모델 F를 이미지 조건으로 만들기 위해, 우리는 이미지를 시간적으로 제로 패딩하고, 어떤 프레임이 제로 패딩되었는지 표시하는 이진 마스크와 노이즈 입력을 연결합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Residual과 비슷한 형식임
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3. 접근 방식
텍스트-비디오 (T2V) 생성의 목표는 텍스트 프롬프트 p를 입력으로 받아 T개의 RGB 프레임으로 구성된 비디오 V를 생성하는 모델 f를 구축하는 것입니다. 최근 방법 [7, 30, 38, 68]은 텍스트 조건만을 사용하여 T개의 비디오 프레임을 한 번에 직접 생성합니다. 우리의 접근 방식은 텍스트와 이미지를 통해 더 강력한 조건을 부여하면 비디오 생성이 개선될 수 있다는 가설에 기반합니다 (cf. § 3.2).

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
일반적인 diffusion 모델
https://junhan-ai.tistory.com/182
What are Diffusion Models?
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ What are Diffusion Models?[Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of several key papers in the references)]. [Updated o
junhan-ai.tistory.com
https://junhan-ai.tistory.com/161
diffusion 논문 유튜브 공유
https://www.youtube.com/watch?v=RGlwzCWJubs
junhan-ai.tistory.com
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.2. EMU VIDEO
우리는 텍스트-비디오 생성을 두 단계로 분할합니다. (1) 텍스트 프롬프트 p를 주어진 첫 번째 프레임(이미지)을 생성하고, (2) 텍스트 프롬프트와 이미지 조건을 활용하여 T개의 비디오 프레임을 생성합니다. 우리는 이 두 단계를 잠재 확산 모델 F를 사용하여 구현하며, 그림 3에 이를 설명하고 있습니다. FF를 사전 학습된 텍스트-이미지 모델로 초기화하여 초기화 시 이미지 생성이 가능하도록 합니다. 따라서 F는 텍스트 프롬프트와 시작 프레임을 조건으로 비디오를 예측하는 두 번째 단계만 훈련하면 됩니다. 우리는 비디오-텍스트 쌍을 사용하여 F를 훈련하고, 시작 프레임 I를 샘플링하여 모델이 텍스트 프롬프트 p와 이미지 I 조건을 사용하여 T개의 프레임을 예측하도록 합니다. 우리는 T개의 RGB 프레임으로 구성된 비디오 V를 공간 차원 H′,W′의 4D 텐서(T x 3 x H′ x W′)로 나타냅니다. 잠재 확산 모델을 사용하기 때문에, 먼저 비디오 V를 프레임별로 적용된 이미지 오토인코더를 사용하여 잠재 공간 X∈R(T×C×H×W)로 변환합니다. 잠재 공간은 오토인코더의 디코더를 사용하여 다시 픽셀 공간으로 변환될 수 있습니다. 비디오의 T 프레임은 독립적으로 노이즈 처리되어 노이즈 입력 X_t를 생성하며, 확산 모델은 이를 디노이즈하도록 훈련됩니다.
이미지 조건부
우리는 시작 프레임 I를 노이즈와 연결하여 조건부로 합니다. 우리의 설계 선택은 조건부로 사용된 의미적 이미지 임베딩으로 인해 이미지 정보를 잃어버리는 다른 선택지 [68, 77]와 달리 모델이 I의 모든 정보를 사용할 수 있도록 합니다. 우리는 I를 단일 프레임 비디오, 즉 T=1로 표현하고, T×C×H×W 텐서를 얻기 위해 제로 패딩합니다. 우리는 시작 프레임의 위치를 나타내기 위해 이진 마스크 m을 사용하며, 이는 첫 번째 시간 위치에서 1로 설정되고 그 외에는 0으로 설정됩니다. 마스크 m, 시작 프레임 I, 그리고 노이즈 처리된 비디오 X_t 모델의 입력으로 채널 단위로 연결됩니다.
모델
우리는 사전 학습된 T2I 모델 [17]을 사용하여 잠재 확산 모델 F를 초기화합니다. 이전 작업 [68]과 같이, 새로운 학습 가능한 시간 매개변수를 추가합니다: 각 공간 컨볼루션 후 1D 시간 컨볼루션, 각 공간 주의 레이어 후 1D 시간 주의 레이어. 원래의 공간 컨볼루션과 주의 레이어는 T 프레임 각각에 독립적으로 적용되며, 이는 고정된 상태로 유지됩니다. 사전 학습된 T2I 모델은 이미 텍스트 조건부로 되어 있으며, 위에서 설명한 이미지 조건부와 결합하여 F는 텍스트와 이미지 둘 다를 조건부로 합니다.
Zero terminal-SNR 노이즈 스케줄
우리는 이전 연구 [17, 62]에서 사용된 확산 노이즈 스케줄이 학습-테스트 불일치를 가져와 고품질 비디오 생성을 방해함을 발견했습니다([12, 51]에 보고됨). 학습 시 노이즈 스케줄은 약간의 잔여 신호를 남기며, 즉 최종 확산 시간 단계 N에서도 신호 대 잡음비 (SNR)가 0이 아닙니다. 이는 실제 데이터에 대한 신호가 없는 임의의 가우시안 노이즈로부터 샘플링할 때 확산 모델이 테스트 시 일반화하는 것을 방해합니다. 잔여 신호는 공간과 시간 전반에 걸쳐 중복된 픽셀로 인해 고해상도 비디오 프레임에서 더 높습니다. 우리는 노이즈 스케줄을 조정하고 최종 α_N=0으로 설정하여 이 문제를 해결합니다 [51]. 이는 학습 시 최종 시간 단계 N에서도 0 SNR을 가지게 합니다. 우리는 이 설계 결정이 고해상도 비디오 생성에 중요함을 발견했습니다.
보간 모델
우리는 T 프레임의 저 프레임률 비디오를 T_p 프레임의 고 프레임률 비디오로 변환하기 위해 F와 구조적으로 동일한 보간 모델 I를 사용합니다. 보간 모델은 T_p × C × H × W 입력/출력으로 작동합니다. 프레임 조건을 위해 입력 T 프레임을 제로-인터리브하여 T_p 프레임을 생성하고, T 프레임의 존재를 나타내는 이진 마스크 m을 노이즈 처리된 입력과 연결합니다 (F의 이미지 조건과 유사). 모델은 T_p 프레임의 비디오 클립에서 T 프레임을 입력으로 사용하여 훈련됩니다. 효율성을 위해 I를 F로부터 초기화하고 보간 작업을 위해 모델 I의 시간 매개변수만 훈련합니다.
구현의 간단함
EMU VIDEO는 표준 비디오-텍스트 데이터셋을 사용하여 훈련할 수 있으며, 고해상도 비디오 생성을 위해 [38]의 7개 모델과 같은 깊은 모델 계단을 필요로 하지 않습니다. 추론 시 텍스트 프롬프트를 주어지면, 시간 레이어 없이 F를 실행하여 이미지 I를 생성합니다. 그런 다음 I와 텍스트 프롬프트를 입력으로 사용하여 F로 T 비디오 프레임을 고해상도로 직접 생성합니다. 우리는 I를 사용하여 비디오의 fps를 증가시킬 수 있습니다. 공간 레이어는 사전 학습된 T2I 모델에서 초기화되고 고정된 상태로 유지되므로, 우리의 모델은 대형 이미지-텍스트 데이터셋에서 학습한 개념적 및 스타일적 다양성을 유지하고 이를 사용하여 I를 생성합니다. 이는 이미지와 비디오 데이터를 공동 미세 조정하는 [38] 접근 방식과 달리 추가적인 훈련 비용이 들지 않습니다. 많은 직접 T2V 접근 방식 [7, 68]도 사전 학습된 T2I 모델에서 초기화되고 공간 레이어를 고정된 상태로 유지합니다. 그러나 이들은 우리의 이미지 기반 분할 방식을 사용하지 않아 T2I 모델의 품질과 다양성을 유지하지 못합니다.
강력한 인간 평가 (JUICE)
최근 연구 [17, 38, 57, 68]와 유사하게, 우리는 자동 평가 지표 [73]가 품질 향상을 반영하지 않는다는 것을 발견했습니다. 우리는 주로 인간 평가를 사용하여 T2V 생성 성능을 두 가지 독립적인 측면에서 측정합니다 - (a) 비디오 생성 품질을 나타내는 품질(Q)과 (b) 생성된 비디오의 텍스트 프롬프트에 대한 정합성 또는 '충실도'(F). 우리는 평가자들에게 다른 생성을 선택할 때 그들의 선택을 정당화하도록 요청함으로써 (JUICE) 주석자 간의 일치도를 크게 향상시켰습니다 (자세한 내용은 부록 C 참조). 평가자들은 선택을 정당화하기 위해 하나 이상의 미리 정의된 이유를 선택합니다. 품질에 대한 선택 이유는: 픽셀 선명도, 움직임 부드러움, 인식 가능한 객체/장면, 프레임 일관성, 움직임의 양입니다. 충실도에 대해서는 두 가지 이유를 사용합니다: 공간적 텍스트 정렬 및 시간적 텍스트 정렬.
3.3. 구현 세부 사항
우리는 보충 부록 A에 전체 구현 세부 사항을 제공하며, 다음에 중요한 세부 사항을 강조합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
U-Net 아키텍처
Input Shape: [17, T, 64, 64]
|
v
Intermediate Layers (U-Net)
|
v
Output Shape: [8, T, 64, 64]VAE 아키텍처
Input Shape: [H, W, 3] (Frame-by-frame)
|
v
VAE Encoder (Downsamples spatially by 8x8)
|
v
Latent Space: 8 channels
|
v
VAE Decoder
|
v
Output Shape: [H, W, 3] (Reconstructed frame-by-frame)
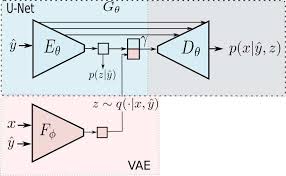
출처 : AVariational U-Net for Conditional Appearance and Shape Generation
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
아키텍처 및 초기화
우리는 [17]의 텍스트-이미지 U-Net 아키텍처를 우리 모델에 맞게 수정하고 모든 공간 매개변수를 사전 학습된 모델로 초기화합니다. 사전 학습된 모델은 8채널 64×64 잠재 공간을 사용하여 512px 정사각형 이미지를 생성하며, 오토인코더는 공간적으로 8배 다운샘플링합니다. 이 모델은 고정된 T5-XL [15]와 고정된 CLIP [58] 텍스트 인코더를 사용하여 텍스트 프롬프트에서 특징을 추출합니다. U-Net의 개별 교차 주의 레이어는 각 텍스트 특징에 주의를 기울입니다. 초기화 후, 우리의 모델은 27억 개의 고정된 공간 매개변수와 학습되는 17억 개의 시간 매개변수를 포함합니다.
시간 매개변수는 신원 연산으로 초기화됩니다: 컨볼루션의 신원 커널과 시간 주의 블록의 최종 MLP 레이어의 제로화. 우리의 예비 실험에서 신원 초기화는 모델 수렴을 2배 개선했습니다. 이미지 조건으로 인해 모델 입력에 추가된 채널에 대해, 우리는 첫 번째 공간 컨볼루션 레이어의 커널에 C + 1 개의 추가 학습 가능한 채널(제로 초기화)을 추가합니다. 우리의 모델은 T = 8 또는 16 프레임의 512px 정사각형 비디오를 생성하며, 8fps 또는 4fps로 샘플링된 1, 2 또는 4초의 정사각형 중심 자르기 비디오 클립으로 훈련됩니다. 우리는 배치 크기 512로 모든 모델을 훈련하며, 다음에 세부 사항을 설명합니다.
효율적인 다단계 다중 해상도 훈련
계산 복잡성을 줄이기 위해 두 단계로 훈련합니다. (1) 대부분의 훈련 반복 (70K)에서 더 간단한 작업: 256px 8fps 1초 비디오를 훈련하여, 공간 해상도 감소로 인해 반복당 시간을 3.5배 줄입니다. (2) 그런 다음 4fps 2초 비디오에서 원하는 512px 해상도로 모델을 15K 반복 동안 훈련합니다. 공간 해상도의 변화는 1D 시간 레이어에 영향을 미치지 않습니다. 고정된 공간 레이어는 이미 512px에서 사전 학습되었으므로, 추론 시 해상도를 256px로 변경해도 생성 품질에는 영향을 미치지 않았습니다. 우리는 256px 훈련을 위해 [62]의 노이즈 스케줄을 사용하고, 512px 훈련을 위해 v-예측 목표 [64]를 사용하여 N = 1000 단계의 확산 훈련을 수행하며, 최종 SNR을 0으로 설정합니다. 우리는 250단계의 DDIM [70]을 사용하여 모델에서 샘플링합니다. 선택적으로, 지속 시간을 늘리기 위해 4초 비디오 클립에서 16 프레임으로 모델을 추가 훈련하여 25K 반복을 수행합니다.
고품질을 위한 미세 조정
이미지 생성에서의 관찰 [17]과 유사하게, 우리는 생성된 비디오의 움직임이 고속 운동 및 고품질 비디오의 작은 부분 집합에서 모델을 미세 조정하여 개선될 수 있음을 발견했습니다. 우리는 H.264 인코딩된 비디오에 저장된 운동 신호를 사용하여 높은 운동성을 가진 훈련 세트에서 1.6K 비디오의 작은 미세 조정 부분 집합을 자동으로 식별합니다. 우리는 표준 관행 [62]을 따르며 미학 점수 [62]와 비디오의 텍스트와 첫 번째 프레임 간의 CLIP [58] 유사성에 기반하여 필터링을 적용합니다.
보간 모델
우리는 비디오 모델 FF에서 보간 모델을 초기화합니다. 우리의 보간 모델은 8 프레임을 입력으로 받아 16fps에서 Tp = 37 프레임을 출력합니다. 훈련 중에는 프레임 조건에 노이즈를 추가하기 위해 무작위로 시간 단계 t∈ {0, ...250}를 샘플링하는 노이즈 증가 [37]를 사용합니다. 추론 시에는 t=100으로 샘플에서 노이즈 증가를 적용합니다.
4. 실험
데이터셋. 우리는 EMU VIDEO를 3400만 개의 라이선스 비디오-텍스트 쌍 데이터셋에서 훈련했습니다. 우리의 비디오는 5-60초 길이이며 다양한 자연 세계 개념을 포함합니다. 비디오는 특정 작업을 위해 큐레이션되지 않았으며 텍스트-프레임 유사성이나 미학적으로 필터링되지 않았습니다. 특별한 언급이 없는 한, 우리는 전체 세트에서 모델을 훈련하며 § 3.3에서 설명한 고속 모션 품질 미세 조정 부분 집합 1600개를 사용하지 않습니다.
인간 평가를 위한 텍스트 프롬프트 세트. 우리는 이전 작업의 텍스트 프롬프트 세트(Appendix Table 10 참조)를 사용하여 비디오를 생성합니다. 프롬프트는 자연스러운 비디오와 환상적인 비디오를 생성하고 다양한 시각적 개념을 구성하는 모델의 능력을 테스트할 수 있는 다양한 카테고리를 포함합니다. 우리는 신뢰할 수 있는 인간 평가를 위해 제안한 JUICE 평가 방식을 사용하며, 각 비교에 대해 5명의 평가자의 다수결 투표를 사용합니다.

Table 1. EMU VIDEO의 주요 설계 결정. 각 표는 품질(Q)과 충실도(F) 측면에서 설계 결정을 채택한 경우와 그렇지 않은 모델의 선호도를 보여줍니다. 우리의 결과는 a) 이미지 및 텍스트 조건을 사용하는 분할 생성이 텍스트 조건만 사용하는 직접 비디오 생성 기본 모델에 비해 선호됨을, b) 높은 해상도 512px 비디오를 직접 생성하기 위한 제로 최종-SNR 노이즈 스케줄 채택이 선호됨을, c) 높은 해상도에서 직접 훈련하는 것과 비교하여 다단계 훈련 설정 채택이 선호됨을, d) 고품질 미세 조정 도입이 선호됨을, e) 공간 매개변수를 고정하는 것이 선호됨을 보여줍니다. 자세한 내용은 § 4.1을 참조하십시오.
4.1. 설계 결정 평가
우리는 8 프레임 생성 설정을 사용하여 설계 결정의 영향을 연구하고, § 3.3의 307 프롬프트 세트를 사용하여 쌍별 비교로 인간 평가 결과를 Table 1에 보고합니다.
분할 생성 vs. 직접 생성. 우리는 텍스트 조건만을 사용하는 직접 T2V 생성 모델과 우리의 분할 생성 모델을 비교합니다. 이 비교를 위해 사전 학습된 T2I 모델, 훈련 데이터, 훈련 반복 횟수 및 학습 가능한 매개변수를 동일하게 유지합니다. Table 1a에 표시된 바와 같이, 분할 생성 모델의 결과는 품질과 충실도에서 모두 강하게 선호됩니다. 품질에서의 강한 선호는 직접 생성 모델이 텍스트-이미지 모델의 스타일과 품질을 유지하지 못하고, 시간적으로도 일관성이 떨어지기 때문입니다(Figure 4의 예시).

Figure 4. EMU VIDEO의 설계 선택. 상단 행: 직접 텍스트-비디오 생성은 낮은 시각적 품질과 일관성 문제를 가집니다. 두 번째 행: 분할 텍스트-비디오 접근 방식은 높은 품질의 비디오를 생성하고 일관성을 개선합니다. 세 번째 행: 512px 생성에서 제로 최종-SNR 노이즈 스케줄을 사용하지 않으면 생성의 일관성에 큰 문제가 발생합니다. 하단 행: HQ 데이터로 모델(두 번째 행)을 미세 조정하면 생성된 비디오의 모션이 증가합니다.
제로 최종-SNR 노이즈 스케줄. 우리는 표준 노이즈 스케줄로 훈련된 모델과 비교하여 높은 해상도 512px 훈련을 위해 제로 최종-SNR을 사용하는 것을 비교합니다. Table 1b는 제로 최종-SNR을 사용하는 생성이 강하게 선호된다는 것을 보여줍니다. 이는 § 3.2에서 설명한 대로 제로 최종-SNR 노이즈 스케줄의 효과가 높은 해상도 비디오 생성을 위한 중요한 역할을 한다는 것을 시사합니다. 우리는 또한 제로 최종-SNR이 분할 생성에 비해 직접 T2V 모델에 더 강한 이점을 가진다는 것을 발견했습니다. 이미지와 유사하게 [51], 직접 T2V의 경우 이 결정은 주로 색상 구성에 영향을 미칩니다. 우리의 분할 접근 방식에서는 이 설계 선택이 객체 일관성과 높은 품질에 중요했습니다(Figure 4의 정성적 결과 참조).
다단계 다중 해상도 훈련. 우리는 훈련 예산의 대부분(4배)을 256px 8fps 단계에 사용하고, 더 높은 해상도로 인해 3.5배 느린 512px 4fps 단계에 사용합니다. 우리는 동일한 훈련 예산으로 512px 단계만 훈련한 기본 모델과 비교합니다. Table 1c는 우리의 다단계 훈련이 훨씬 더 나은 결과를 가져온다는 것을 보여줍니다.
고품질 미세 조정. 우리는 Table 1d에서 자동으로 식별된 고품질 비디오에서 모델을 미세 조정한 효과를 연구합니다. 우리는 이 미세 조정이 두 메트릭에서 모두 개선됨을 발견했습니다. 특히, 미세 조정은 텍스트 프롬프트에서 지정된 모션을 존중하는 모델의 능력을 개선하여 충실도에서 강한 향상을 반영합니다.
매개변수 고정. 우리는 모델의 공간 매개변수를 고정하는 것이 성능에 영향을 미치는지 테스트합니다. 우리는 두 번째 512px 훈련 단계에서 모든 매개변수를 미세 조정하는 모델과 비교합니다. 공정한 비교를 위해, 우리는 동일한 조건 이미지를 우리 모델과 이 기본 모델에 사용합니다. Table 1e는 공간 매개변수를 고정하는 것이 훈련 비용을 줄이면서 더 나은 비디오를 생성함을 시사합니다.
4.2. 이전 작업과의 비교
우리는 EMU VIDEO를 이전 작업과 비교 평가하고, 4초 길이의 16프레임 비디오를 생성하도록 F를 훈련하며, § 4.1에서 최고의 설계 결정을 포함하여 고품질 미세 조정을 사용합니다. 우리는 생성된 비디오에서 16fps 영상을 얻기 위해 I 보간 모델을 사용합니다. 16프레임 비디오를 I로 보간하는 방법에 대한 자세한 내용은 부록 A를 참조하세요.
텍스트-비디오 생성의 인간 평가.
많은 최신 텍스트-비디오 생성 방법이 비공개 소스이므로 [7, 30, 31, 38], 우리는 각 방법에서 공개된 예제를 사용합니다. 공개된 비디오는 각 방법의 '최고' 대표 샘플일 가능성이 높으며, 실패 모드를 포착하지 못할 수 있습니다. Make-A-Video의 경우, 저자들과의 개인 통신을 통해 선별되지 않은 생성물을 얻었습니다. CogVideo [41]의 경우, 우리는 오픈 소스 모델을 사용하여 [7]의 프롬프트 세트에서 T2V 생성을 수행합니다. 우리는 상업적으로 개발된 블랙박스 텍스트-비디오 솔루션인 Gen2 [54]와 PikaLabs [47]와도 비교 벤치마킹하며, 해당 웹사이트에서 [7]의 프롬프트를 사용하여 생성을 얻습니다. 우리는 비디오를 임의의 가우시안 노이즈 시드를 사용하여 생성하며, 이를 최적화하지 않았습니다.

Figure 5. 정성적 비교. EMU VIDEO는 스타일과 일관성 측면에서 Imagen Video [38]와 Align Your Latents [7]보다 더 높은 품질의 생성을 제공합니다.
각 방법이 서로 다른 해상도, 종횡비 및 프레임 속도로 비디오를 생성하므로, 인간 평가에서 편향을 줄이기 위해 각 비교에서 비디오를 후처리하여 이 측면에서 일치하도록 합니다. 이 후처리에 대한 전체 세부 사항과 사용된 텍스트 프롬프트는 부록 D에 있습니다. Figure 2에서 볼 수 있듯이, EMU VIDEO의 생성물은 품질(평균 91.8%)과 충실도(평균 86.6%) 측면에서 상업적 솔루션을 포함한 모든 이전 작업을 크게 능가합니다. 우리는 Figure 5에서 일부 정성적 비교와 Figure 1에서 추가 생성을 보여줍니다. EMU VIDEO는 생성된 비디오의 품질이 상당히 높고, 텍스트에서 지정된 객체와 모션에 대한 전반적인 충실도가 높습니다. 우리의 분할 접근 방식은 명시적으로 이미지를 생성하므로 T2I 모델의 시각적 다양성과 스타일을 유지하여 환상적이고 스타일리시한 프롬프트에서 훨씬 더 나은 비디오를 생성합니다. 또한, EMU VIDEO는 이전 작업보다 훨씬 더 높은 시간적 일관성을 가진 비디오를 생성합니다. 우리는 이미지와 텍스트의 강력한 조건을 사용하기 때문에 모델이 이미지가 미래에 어떻게 변화할지 예측하는 상대적으로 더 쉬운 작업으로 훈련되어 비디오의 시간적 특성을 더 잘 모델링할 수 있다고 가정합니다. 더 많은 정성적 비교는 부록 E를 참조하세요. 후처리되지 않은 비디오가 포함된 인간 평가도 보충 부록 D에 포함되어 있으며, 여기에서도 EMU VIDEO의 생성물이 모든 이전 작업을 크게 능가합니다. 성능 측면에서 가장 가까운 모델은 충실도를 기준으로 측정했을 때 우리의 모델보다 56% 낮은 Imagen Video입니다. Imagen Video의 공개된 프롬프트는 EMU VIDEO에 사용된 잠재 확산 모델의 알려진 실패 모드인 텍스트 문자를 생성하도록 요구합니다 [17, 62].
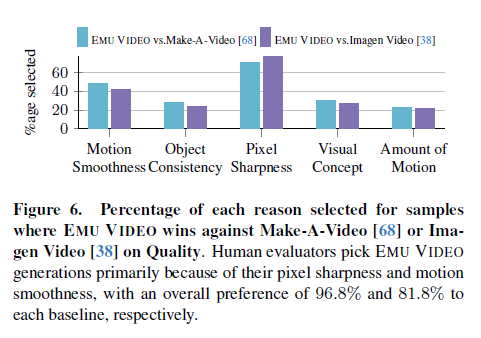
Figure 6. 품질에서 EMU VIDEO가 Make-A-Video [68] 또는 Imagen Video [38]를 이기는 샘플에 대해 선택된 이유의 비율. 인간 평가자는 주로 픽셀 선명도와 모션 부드러움 때문에 EMU VIDEO의 생성을 선택하며, 각각 96.8%와 81.8%로 각 기본 모델보다 선호됩니다.
우리는 Figure 6에서 인간 평가자가 두 가지 강력한 경쟁자인 Make-A-Video [68]와 Imagen Video [38]보다 EMU VIDEO의 생성을 선호하는 이유를 검사합니다. 더 자세한 검사는 부록 C에 제공됩니다. EMU VIDEO의 생성물은 더 나은 픽셀 선명도와 모션 부드러움으로 인해 선호됩니다. 최첨단 기술임에도 불구하고, EMU VIDEO는 더 간단하며 총 60억 개의 매개변수를 가진 두 모델 계층 구조를 가지고 있습니다(공간 레이어의 27억 개 고정 매개변수와 F와 I 각각의 학습 가능한 17억 개 시간 매개변수). 이는 유사한 규모의 데이터를 사용하여 훈련된 Imagen Video (7 모델 계층 구조, 116억 개 매개변수)나 Make-A-Video (5 모델 계층 구조, 96억 개 매개변수)보다 훨씬 간단합니다.

Table 2. UCF101에서 제로 샷 텍스트-비디오 평가를 위한 자동화된 메트릭은 결함이 있습니다. (왼쪽) 우리는 자동화된 메트릭을 제시하며, EMU VIDEO가 이전 작업을 능가하지 못함을 관찰합니다. (오른쪽) 우리는 EMU VIDEO와 Make-A-Video를 비교하는 인간 평가를 사용하며, 여기서 EMU VIDEO는 품질(90.1%)과 충실도(80.5%)에서 Make-A-Video를 크게 능가합니다.
자동화된 메트릭
Table 2에서 우리는 UCF101 데이터셋 [71]에서 제로 샷 T2V 생성 설정 [68]을 사용하여 이전 작업과 비교합니다. EMU VIDEO는 경쟁력 있는 IS 점수 [65]와 더 높은 FVD [73]를 달성합니다. 이전 연구들은 자동화된 메트릭이 결함이 있으며 인간의 선호를 포착하지 못한다고 제안합니다 [6, 14, 17, 38, 57, 68]. 우리는 FVD가 UCF101 비디오와 다른 고품질 생성을 벌점으로 처리한다고 믿으며, IS는 훈련 데이터에 편향되어 있다고 생각합니다 [6, 14]. 이를 확인하기 위해, 우리는 EMU VIDEO와 Make-A-Video를 비교하는 인간 평가를 사용합니다. 우리는 303개의 생성된 비디오(각 UCF101 클래스당 3개의 무작위 샘플) 하위 집합을 사용하여 우리의 생성물이 강하게 선호됨을 발견합니다 (Table 2 오른쪽). 정성적 비교는 부록 E에서 찾을 수 있습니다.

Table 3. 텍스트 조건부 이미지 애니메이션에서 EMU VIDEO와 이전 작업의 인간 평가. 우리는 두 가지 프롬프트 세트에 걸쳐 세 가지 방법과 EMU VIDEO를 비교하며, 시작 이미지는 [57]의 생성물을 사용합니다. EMU VIDEO의 애니메이션 비디오는 모든 기준에서 두 프롬프트 세트에서 강하게 선호됩니다.
이미지 애니메이션
우리의 분할 생성의 장점 중 하나는 동일한 모델을 그대로 사용하여 사용자 제공 이미지를 조건 이미지 I로 제공하여 '애니메이션화'할 수 있다는 것입니다. 우리는 EMU VIDEO의 이미지 애니메이션을 동시 작업 [77] 및 상업적 이미지-비디오(I2V) 솔루션 [47, 54]과 [68] 및 [7]의 프롬프트에서 비교합니다. 모든 방법은 서로 다른 텍스트-이미지 모델 [57]을 사용하여 생성된 동일한 이미지를 보고 텍스트 프롬프트에 따라 비디오를 생성해야 합니다. 우리는 비교에서 [57]의 API를 사용하며, 공식 훈련 데이터와 모델은 사용할 수 없습니다. 우리는 Table 3에서 인간 평가와 부록에서 자동화된 메트릭을 보고합니다 (cf. 부록 Table 9). 인간 평가자는 모든 기준에서 EMU VIDEO의 생성을 강하게 선호합니다. 이러한 결과는 이미지-비디오 작업을 위해 특별히 설계된 방법과 비교하여 EMU VIDEO의 뛰어난 이미지 애니메이션 능력을 보여줍니다.

Figure 7. 더 긴 비디오로 확장. 우리는 원래 비디오의 모든 프레임을 조건으로 하고, 미래 프롬프트를 조건으로 새로운 비디오를 생성하는 EMU VIDEO의 변형을 테스트합니다. 두 가지 다른 미래 프롬프트에 대해, 우리의 모델은 원래 비디오와 미래 텍스트를 존중하는 그럴듯한 확장된 비디오를 생성합니다.
4.3. 분석
최근접 이웃 기준. 우리는 좋은 생성 모델이 최근접 이웃 검색 기준을 능가하고 훈련 세트에 없는 비디오를 생성할 것으로 기대합니다. 우리는 텍스트 프롬프트의 CLIP 특징 유사성을 사용하여 훈련 프롬프트에서 비디오를 검색하는 강력한 최근접 이웃 기준을 구성합니다. [68]의 평가 프롬프트를 사용할 때, 인간 평가자는 실제 비디오보다 EMU VIDEO의 생성을 81.1%의 충실도로 선호하여 EMU VIDEO가 강력한 검색 기준을 능가함을 확인합니다. 우리는 수동으로 검사하여 EMU VIDEO가 훈련 세트에 없는 프롬프트에서도 기준을 능가함을 확인했습니다.
더 긴 텍스트로 비디오 길이 확장. 우리의 모델은 텍스트 프롬프트와 시작 프레임을 조건으로 비디오를 생성합니다. 작은 아키텍처 수정으로 모델을 T 프레임을 조건으로 하여 비디오를 확장할 수 있습니다. 따라서, 우리는 과거 16프레임을 조건으로 미래 16프레임을 생성하는 EMU VIDEO의 변형을 훈련합니다. 비디오를 확장할 때, 우리는 원래 비디오에 사용된 것과 다른 미래 텍스트 프롬프트를 사용하고 Figure 7에서 결과를 시각화합니다. 우리는 확장된 비디오가 원래 비디오와 미래 텍스트 프롬프트를 모두 존중함을 발견했습니다.
5. 한계 및 향후 작업
우리는 강력한 이미지와 텍스트 조건을 활용하는 텍스트-비디오 생성에 대한 분할 접근 방식인 EMU VIDEO를 소개했습니다. EMU VIDEO는 상업적 솔루션을 포함한 모든 이전 작업을 크게 능가합니다. 훈련과 추론에서 모델에 사용되는 이미지 조건에는 차이가 있습니다: 훈련 시, 실제 비디오에서 샘플링된 비디오 프레임을 사용하고, 추론 시에는 모델의 공간 매개변수를 사용하여 생성된 이미지를 사용합니다. 실제로, 대부분의 시나리오에서 이 차이는 생성된 비디오의 품질에 영향을 미치지 않습니다. 그러나, 조건으로 사용된 생성된 이미지가 프롬프트를 대표하지 않는 경우, 우리 모델은 이 오류를 복구할 방법이 없습니다. 우리는 이러한 오류에서 복구하는 모델의 능력을 향상시키는 것이 향후 중요한 연구 방향이라고 믿습니다. 확산 모델을 사용한 순수 자가회귀 디코딩을 통해 비디오 모델의 조건을 강화하는 것은 현재 계산적으로 매력적이지 않습니다. 그러나 추가 연구는 더 긴 비디오 생성을 위한 혜택을 제공할 수 있습니다.
윤리적 고려사항. 우리는 고차원 비디오 출력을 생성하는 방법을 개선하기 위해 생성 방법의 발전을 제안합니다. 생성 방법은 이 작업의 범위를 벗어나는 다양한 용도로 적용될 수 있습니다. 실제 적용 전에 데이터, 모델, 의도된 응용 프로그램, 안전성, 위험, 편향 및 사회적 영향을 신중하게 연구해야 합니다.
감사의 말. 우리는 이 작업을 도와준 Meta의 여러 협력자들에게 감사드립니다. 데이터 및 인프라 지원을 제공한 Baixue Zheng, Baishan Guo, Jeremy Teboul, Milan Zhou, Shenghao Lin, Kunal Pradhan, Jort Gemmeke, Jacob Xu, Dingkang Wang, Samyak Datta, Guan Pang, Symon Perriman, Vivek Pai, Shubho Sengupta에게 감사드립니다. 유익한 토론을 나누어 주신 Uriel Singer, Adam Polyak, Shelly Sheynin, Yaniv Taigman, Licheng Yu, Luxin Zhang, Yinan Zhao, David Yan, Emily Luo, Xiaoliang Dai, Zijian He, Peizhao Zhang, Peter Vajda, Roshan Sumbaly, Armen Aghajanyan, Michael Rabbat, Michal Drozdzal에게도 감사드립니다. 또한 Lauren Cohen, Mo Metanat, Lydia Baillergeau, Amanda Felix, Ana Paula Kirschner Mofarrej, Kelly Freed, Somya Jain의 도움에도 감사드립니다. Ahmad Al-Dahle와 Manohar Paluri의 지원에도 감사드립니다.
'인공지능' 카테고리의 다른 글
| CLIP : Learning Transferable Visual Models From Natural Language Supervision (1) | 2024.07.17 |
|---|---|
| MusicLM: Generating Music From Text (2) | 2024.07.16 |
| Segment Anything (2) | 2024.07.14 |
| ConvNets Match Vision Transformers at Scale (1) | 2024.07.13 |
| QLoRA: Efficient Finetuning of Quantized LLMs (1) | 2024.07.12 |



