https://arxiv.org/abs/2405.05254
You Only Cache Once: Decoder-Decoder Architectures for Language Models
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (K
arxiv.org
요약
우리는 대형 언어 모델을 위한 디코더-디코더 아키텍처인 YOCO를 소개합니다. 이 아키텍처는 키-값 쌍을 한 번만 캐시합니다. YOCO는 두 개의 구성 요소로 이루어져 있습니다. 첫 번째는 자기 디코더(Self-Decoder) 위에 쌓인 교차 디코더(Cross-Decoder)입니다. 자기 디코더는 글로벌 키-값(KV) 캐시를 효율적으로 인코딩하여 교차 디코더가 교차 주의를 통해 이를 재사용합니다. 전체 모델은 마치 디코더 전용 트랜스포머(Transformer)처럼 작동하지만, YOCO는 한 번만 캐시합니다. 이 디자인은 GPU 메모리 요구를 크게 줄이면서도 글로벌 주의(attention) 기능을 유지합니다. 추가로, 계산 흐름은 최종 출력을 변경하지 않고 조기 종료할 수 있도록 사전 채우기(prefilling)를 가능하게 하여 사전 채우기 단계를 크게 가속화합니다. 실험 결과, YOCO는 모델 크기와 학습 토큰 수를 확장하는 다양한 설정에서 트랜스포머와 비교해 유리한 성능을 달성함을 보여줍니다. 또한, YOCO를 100만 문맥 길이(context length)로 확장하여 거의 완벽한 바늘 탐색 정확도를 달성했습니다. 프로파일링 결과는 YOCO가 문맥 길이와 모델 크기 전반에 걸쳐 추론 메모리, 사전 채우기 지연 시간, 처리량을 크게 향상시키는 것을 보여줍니다. 코드 및 자세한 내용은 https://aka.ms/YOCO에서 확인할 수 있습니다.

그림 1: 우리는 대형 언어 모델을 위한 디코더-디코더 아키텍처인 YOCO를 제안합니다. YOCO는 키/값을 한 번만 캐시하며 KV 캐시 메모리와 사전 채우기 시간을 크게 줄이면서도 학습 토큰, 모델 크기, 문맥 길이 면에서 확장 가능합니다. 문맥 길이 512K로 추론 비용이 보고되었으며, 그림 7–10에서는 다양한 길이에 대한 추가 결과를 제공합니다.
1. 소개
디코더 전용 트랜스포머(Transformer) [VSP+17]는 언어 모델을 위한 사실상의 아키텍처가 되었습니다. 언어 모델링에 적합한 아키텍처를 개발하려는 다양한 노력이 계속되고 있습니다. 주요 탐구 방향은 다음과 같습니다. 첫째, BERT [DCLT19]와 같은 인코더 전용 언어 모델은 입력 시퀀스를 양방향으로 인코딩합니다. 둘째, T5 [RSR+20]와 같은 인코더-디코더 모델은 입력을 인코딩하기 위해 양방향 인코더를 사용하고 출력을 생성하기 위해 단방향 디코더를 사용합니다. 위의 두 가지 구성은 양방향성 때문에 자기 회귀 생성에 어려움을 겪습니다. 특히, 인코더는 다음 생성 단계에서 전체 입력 및 출력 토큰을 다시 인코딩해야 합니다. 인코더-디코더는 디코더만 사용하여 출력을 생성할 수 있지만, 출력 토큰은 특히 다중 턴 대화의 경우 인코더의 파라미터를 완전히 활용하지 못합니다. 셋째, GPT [BMR+20]와 같은 디코더 전용 언어 모델은 자기 회귀적으로 토큰을 생성합니다. 이전에 계산된 키/값 벡터를 캐시함으로써 모델은 현재 생성 단계에서 이를 재사용할 수 있습니다. 키-값(KV) 캐시는 각 토큰에 대해 기록을 다시 인코딩하는 것을 방지하여 추론 속도를 크게 향상시킵니다. 이 강력한 기능은 디코더 전용 언어 모델을 표준 옵션으로 자리 잡게 합니다.
그러나 제공하는 토큰의 수가 증가함에 따라 KV 캐시는 많은 GPU 메모리를 차지하여 대형 언어 모델의 추론을 메모리 한계로 만듭니다 [PDC+22]. 예를 들어, 65B 크기의 언어 모델(그룹 쿼리 어텐션 [ALTdJ+23]과 8비트 KV 양자화를 사용한 모델)의 경우 512K 토큰이 약 86GB의 GPU 메모리를 차지하여 H100-80GB GPU 하나의 용량보다 큽니다. 또한, 긴 시퀀스 입력의 사전 채우기 지연 시간은 매우 높습니다. 예를 들어, 4개의 H100 GPU를 사용하여 Flash-Decoding [DHMS23]과 커널 융합이 추가된 7B 언어 모델의 경우 450K 토큰을 사전 채우는 데 약 110초, 1M 길이의 경우 380초가 소요됩니다. 이러한 병목 현상은 긴 문맥 언어 모델을 실용적으로 배포하는 것을 어렵게 만듭니다.
이 연구에서는 대형 언어 모델을 위한 디코더-디코더 아키텍처인 YOCO를 제안합니다. 이 아키텍처는 KV 쌍을 한 번만 캐시합니다. 구체적으로, 우리는 자기 디코더 위에 교차 디코더를 쌓습니다. 입력 시퀀스가 주어지면 자기 디코더는 효율적인 자기 주의를 활용하여 KV 캐시를 획득합니다. 그런 다음 교차 디코더 층은 교차 주의를 사용하여 공유된 KV 캐시를 재사용합니다. 디코더-디코더 아키텍처는 개념적으로 인코더-디코더와 유사하지만, 외부에서는 전체 모델이 디코더 전용 모델처럼 작동합니다. 따라서 언어 모델링과 같은 자기 회귀 생성 작업에 자연스럽게 적합합니다. 첫째, YOCO는 한 번만 캐시하기 때문에 KV 캐시의 GPU 메모리 소비가 크게 줄어듭니다. 둘째, 디코더-디코더 아키텍처의 계산 흐름은 자기 디코더에 진입하기 전에 조기 종료를 위한 사전 채우기를 가능하게 합니다. 이 속성은 사전 채우기 단계를 극적으로 가속화하여 긴 문맥 언어 모델의 사용자 경험을 개선합니다. 셋째, YOCO는 분산된 긴 시퀀스 학습을 위한 더 효율적인 시스템 설계를 가능하게 합니다. 추가로, 우리는 데이터 제어 게이팅 메커니즘으로 유지(retention)를 강화하는 게이티드 유지(self-decoder용)를 제안합니다.
우리는 YOCO가 언어 모델링 성능을 입증하고 추론 효율성 측면에서 많은 장점을 가지고 있음을 보여주는 광범위한 실험을 수행합니다. 실험 결과, YOCO는 더 많은 학습 토큰, 더 큰 모델 크기 및 더 긴 문맥 길이로 확장할 수 있음을 보여줍니다. 구체적으로, 우리는 3B YOCO 모델을 수조 개의 학습 토큰으로 확장하여 StableLM [TBMR]과 같은 저명한 트랜스포머 언어 모델과 동등한 결과를 얻었습니다. 또한, 160M에서 13B까지의 확장 곡선은 YOCO가 트랜스포머와 비교하여 경쟁력 있음을 보여줍니다. 우리는 또한 YOCO의 문맥 길이를 1M 토큰으로 확장하여 거의 완벽한 바늘 탐색 정확도를 달성했습니다. 다중 바늘 테스트에서도 YOCO는 더 큰 트랜스포머와 비교하여 경쟁력 있는 결과를 얻었습니다. 다양한 작업에서의 우수한 성능 외에도 프로파일링 결과는 YOCO가 GPU 메모리 사용량, 사전 채우기 지연 시간, 처리량 및 서비스 용량을 개선함을 보여줍니다. 특히, 65B 모델의 경우 KV 캐시 메모리는 약 80배 감소할 수 있습니다. 3B 모델의 경우에도 32K 토큰의 경우 전체 추론 메모리 소비가 두 배로, 1M 토큰의 경우 아홉 배 이상 감소할 수 있습니다. 1M 문맥의 경우 사전 채우기 단계는 71.8배, 32K 입력의 경우 2.87배 가속화됩니다. 예를 들어, 512K 문맥의 경우 YOCO는 트랜스포머 사전 채우기 지연 시간을 180초에서 6초 미만으로 줄입니다. 이러한 결과는 YOCO를 긴 시퀀스를 기본적으로 지원하는 미래의 대형 언어 모델을 위한 강력한 후보 아키텍처로 위치시킵니다.
그림 2: 디코더-디코더 아키텍처의 개요. 자기 디코더는 글로벌 KV 캐시를 생성합니다. 그런 다음 교차 디코더는 교차 주의를 사용하여 공유된 KV 캐시를 재사용합니다. 자기 디코더와 교차 디코더 모두 인과 마스킹을 사용합니다. 전체 아키텍처는 자기 회귀적으로 토큰을 생성하는 디코더 전용 트랜스포머처럼 작동합니다.
그림 3: YOCO 추론
사전 채우기: 입력 토큰을 병렬로 인코딩합니다. 생성: 출력 토큰을 하나씩 디코딩합니다. 계산 흐름은 최종 출력을 변경하지 않고 사전 채우기를 조기 종료할 수 있게 하여 사전 채우기 단계를 크게 가속화합니다.
표 1: KV 캐시의 추론 메모리 복잡도. N, L, D는 시퀀스 길이, 레이어 수, 숨겨진 차원입니다.
표 2: 주의 모듈의 사전 채우기 시간 복잡도
N, L, D는 위와 동일합니다.
2.3 추론 이점
경쟁력 있는 언어 모델링 결과 외에도 YOCO는 서비스 비용을 크게 절감하고 추론 성능을 향상시킵니다. 섹션 4.4에서 상세한 추론 비교를 보고합니다.

사전 채우기 시간 단축 및 처리량 향상
그림 3에서 보이듯이, 교차 디코더가 자기 디코더의 출력을 재사용하기 때문에 사전 채우기 단계에서 교차 디코더에 진입하기 전에 조기 종료할 수 있습니다. 계산 의존성의 이 흥미로운 특성은 사전 채우기 속도를 크게 가속화합니다.
첫째, 순방향 계산에 필요한 레이어는 절반만 필요하므로 최소한 사전 채우기 지연 시간이 절반으로 줄어듭니다. 둘째, 자기 디코더의 효율적인 어텐션 모듈은 보통 빠릅니다. 예를 들어, 512K 문맥 길이의 경우, 최적화된 추론을 사용하는 트랜스포머(예: Flash-Decoding 및 커널 융합)의 경우 사전 채우기 지연 시간을 180초에서 6초 이하로 줄일 수 있습니다(Figure 9). 32K 길이의 경우에도 YOCO는 사전 채우기 시간에서 약 세 배의 속도 향상을 보입니다. 표 2는 트랜스포머와 YOCO 간의 어텐션 모듈의 사전 채우기 시간 복잡성을 비교합니다.
3. 자기 디코더의 설계 선택
자기 디코더를 위해 다양한 효율적인 자기 주의 방법을 선택할 수 있습니다. 이 모듈이 일정한 추론 메모리만 필요하다면, 자기 디코더의 캐시 메모리 복잡성은 레이어 수에 의존합니다. 또한, 좋은 모듈 선택은 학습 및 배포 비용을 모두 개선합니다. 이 연구에서는 게이티드 유지(섹션 3.1) 또는 슬라이딩-윈도우 주의(섹션 3.2)를 사용합니다.
3.1 게이티드 유지
게이티드 유지(gRet, gRetNet 또는 RetNet-3라고도 함)는 데이터 의존 게이팅 메커니즘으로 유지 [SDH+23]를 강화하여 시퀀스 모델링을 위해 학습 병렬성, 좋은 성능 및 낮은 추론 비용을 동시에 달성합니다. 우리는 실험에서 기본 효율적인 자기 주의 모듈로 gRet을 사용합니다. 이 방법은 병렬, 순환 및 청크 기반 순환 계산 패러다임을 통합합니다. 이 세 가지 표현은 동등하며 동일한 계산 결과를 얻을 수 있습니다. 학습 과정에서는 보통 병렬 또는 청크 기반 순환 패러다임을 사용하며, 추론 단계에서는 일정한 KV 메모리를 위해 순환 패러다임을 사용할 수 있습니다. 세 가지 표현을 다음과 같이 설명합니다:
병렬 표현
게이티드 유지는 다음과 같이 정의됩니다:
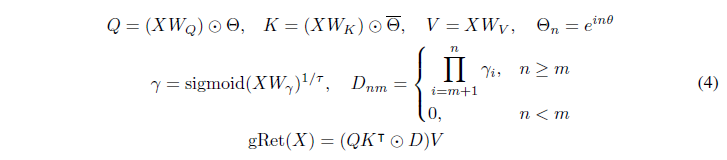

순환 표현
식 (4)와 동등한 게이티드 유지의 출력은 순환적으로 계산할 수 있습니다. n번째 시간 단계에서 출력은 다음과 같이 얻어집니다:
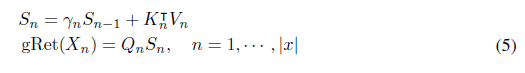


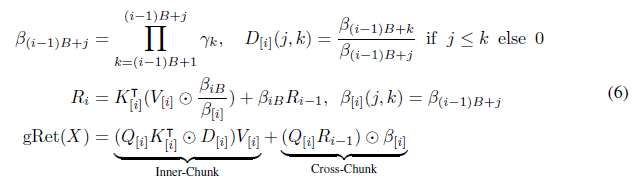

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
식은 다음과 같이 정리할 수 있다. (TODO)




-----------------------------------------------------------------------------------------------------------------------------------------------------------------
다중 헤드 게이티드 유지
다중 헤드 어텐션 [VSP+17] 및 다중 스케일 유지 [SDH+23]와 유사하게, 우리는 각 헤드에 게이티드 유지를 적용하고 출력을 결합합니다.
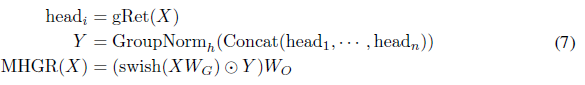

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
GroupNorm은 concat된 애들만 하니 0 ~ 1 값으로 되며 이를 swish를 적용된 것과 곱을하므로 비선형성이 증가된다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------

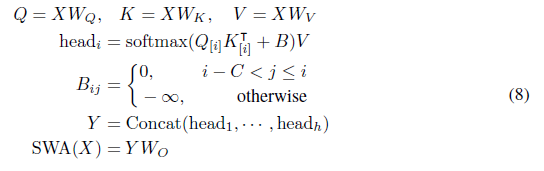

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
j 값을 바탕으로 우리는 softmax에서 원하는 값이 아니라면 - inf로 받기에 해당 주의를 사용할 수 있다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4. 실험
우리는 대형 언어 모델을 위한 YOCO를 다음과 같은 관점에서 평가합니다. 첫째, 우리는 StableLM-3B-4E1T [TBMR] 설정을 따라 학습 토큰을 확장합니다(섹션 4.1). 둘째, 제안된 아키텍처의 확장 곡선을 제시합니다(섹션 4.2). 셋째, YOCO 모델을 100만(1M) 문맥 길이로 확장하고 장기 시퀀스 모델링 능력을 평가합니다(섹션 4.3). 넷째, GPU 메모리 사용량, 서비스 용량, 사전 채우기 시간 및 처리량을 포함한 배포 장점을 분석합니다(섹션 4.4). 실험 결과는 YOCO가 다양한 평가 지표에서 경쟁력 있는 성능을 달성함을 보여줍니다. 더 중요한 것은 제안된 방법이 추론 비용을 크게 줄인다는 것입니다.
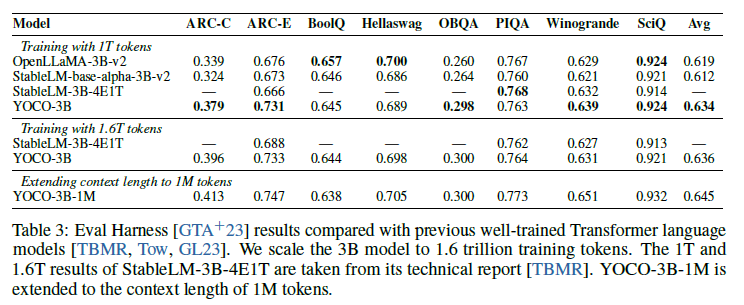
표 3: Eval Harness [GTA+23] 결과
표 3은 이전의 잘 훈련된 트랜스포머 언어 모델 [TBMR, Tow, GL23]과 비교한 Eval Harness [GTA+23] 결과를 보여줍니다. 우리는 3B 모델을 1.6조(1.6T) 학습 토큰으로 확장했습니다. StableLM-3B-4E1T의 1T 및 1.6T 결과는 해당 기술 보고서 [TBMR]에서 가져왔습니다. YOCO-3B-1M은 문맥 길이를 100만(1M) 토큰으로 확장했습니다.
4.1 언어 모델링 평가
우리는 학습 토큰 수를 확장하여 3B 크기의 YOCO 언어 모델을 훈련합니다. 그런 다음 강력한 트랜스포머 기반 언어 모델과 체크포인트를 비교합니다.
설정
StableLM-3B-4E1T [TBMR]에서와 유사한 학습 레시피를 사용합니다. 더 나은 커널 지원을 위해 헤드 차원을 80에서 128로 조정했습니다. 모델 크기를 변경하지 않기 위해 은닉 크기는 3072, 레이어 수는 26으로 설정했습니다. 그룹 쿼리 어텐션 [ALTdJ+23]을 사용하며, 쿼리 헤드 수는 24, 키-값 헤드 수는 8입니다. 우리는 게이티드 유지(섹션 3.1)를 사용하여 YOCO를 훈련합니다. 비임베딩 파라미터 수는 2.8B입니다. 비교를 위해 StableLM-3B-4E1T는 2.7B이고 OpenLLaMA-v2-3B [GL23]는 3.2B입니다. 학습 시퀀스 길이는 4096입니다. 배치 크기는 400만 토큰입니다. AdamW [LH19] 옵티마이저를 β = 0.9, 0.95로 사용합니다. 최대 학습률은 3.2e-4이며, 1000개의 워밍업 스텝과 선형 감소로 1.28e-5까지 감소합니다. 전체 일정은 5T 토큰으로 설정됩니다. 자원 예산을 고려하여 모델을 400k 스텝(즉, 1.6T 토큰)으로 훈련합니다. 큐레이션된 학습 코퍼스는 [TBMR]와 유사합니다. 우리는 tiktoken-cl100k_base를 토크나이저로 사용합니다. 자세한 하이퍼파라미터는 부록 C에 설명되어 있습니다.
결과
표 3은 YOCO 체크포인트를 OpenLLaMA-v2-3B [GL23], StableLMbase-alpha-3B-v2 [Tow], 그리고 StableLM-3B-4E1T [TBMR]와 비교한 것입니다. 우리는 LM Eval Harness [GTA+23]를 사용하여 다양한 다운스트림 작업에서 제로샷 성능을 평가합니다. OpenLLaMA-v2-3B와 StableLMbase-alpha-3B-v2는 1T 토큰으로 훈련되었습니다. StableLM-3B-4E1T의 중간 수치는 기술 보고서 [TBMR]에서 가져왔습니다. 실험 결과, YOCO는 이전에 잘 튜닝된 트랜스포머 언어 모델과 비교하여 유사한 결과를 달성함을 나타냅니다. 1T 토큰과 1.6T 토큰으로 훈련된 체크포인트 모두 일관된 추세를 보입니다. 또한, 결과는 YOCO가 학습 토큰 수 측면에서 확장 가능함을 보여줍니다.
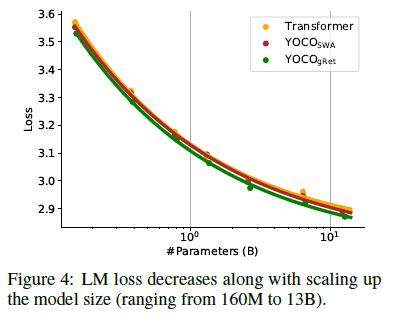
그림 4
그림 4는 모델 크기(160M에서 13B까지)를 확장함에 따라 LM 손실이 감소하는 것을 보여줍니다.
4.2 트랜스포머와의 확장성 비교
우리는 Llama 트랜스포머 [VSP+17, TLI+23], 게이티드 유지가 적용된 YOCO(YOCOgRet; 섹션 3.1), 그리고 슬라이딩-윈도우 어텐션이 적용된 YOCO(YOCOSWA; 섹션 3.2) 간의 확장 곡선을 비교합니다. 동일한 학습 데이터와 설정을 사용하여 다양한 크기의 언어 모델(즉, 160M, 400M, 830M, 1.4B, 2.7B, 6.8B, 13B)을 훈련합니다. 검증 손실(validation loss)을 평가 지표로 사용합니다. 확장 법칙 [KMH+20]은 더 큰 크기의 성능을 추정하기 위한 것입니다.
설정
우리는 Llama [TLI+23]의 개선 사항(RMSNorm [ZS19], SwiGLU [Sha20], 바이어스 제거)을 포함하여 트랜스포머 아키텍처를 보강했습니다. YOCOSWA의 슬라이딩 윈도우 크기는 1,024입니다. FFN 중간 차원을 조정하여 파라미터 수를 맞춥니다. 학습 배치 크기는 0.25M 토큰이며 시퀀스 길이는 2,000입니다. 모델은 40,000 스텝(즉, 10B 토큰)으로 훈련합니다. 실제로 이 설정이 손실 수렴에 효과적이며 확장 법칙이 잘 맞춰질 수 있음을 발견했습니다. 자세한 하이퍼파라미터는 부록 D에 설명되어 있습니다.
결과
그림 4는 다양한 파라미터 수에 따른 검증 손실을 보고합니다. 우리는 [KMH+20]에서와 같이 확장 곡선을 맞춥니다. YOCO는 160M에서 13B까지 Llama 최적화 트랜스포머 아키텍처와 비교하여 유사한 성능을 얻습니다. 이 발견은 YOCO가 모델 크기 측면에서 효과적으로 확장됨을 보여줍니다. 더욱이, YOCOgRet는 트랜스포머와 YOCOSWA보다 뛰어난 성능을 보입니다. 이러한 성과는 주의(attention)와 유지(retention)의 하이브리드 아키텍처에서 비롯되며, 이들의 유도 편향(inductive biases)은 서로 상호 보완적인 경향이 있습니다. 주의 모듈과 유지 모듈을 교차하여 배치(1:3)했을 때 유사한 이득을 관찰했습니다. 최근 하이브리드 아키텍처 [LLB+24]도 유사한 발견을 확인합니다.
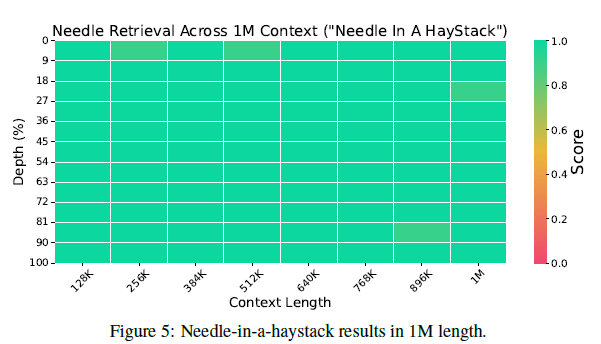
그림 5
그림 5는 100만(1M) 길이에서 "건초 더미에서 바늘 찾기" 결과를 보여줍니다.
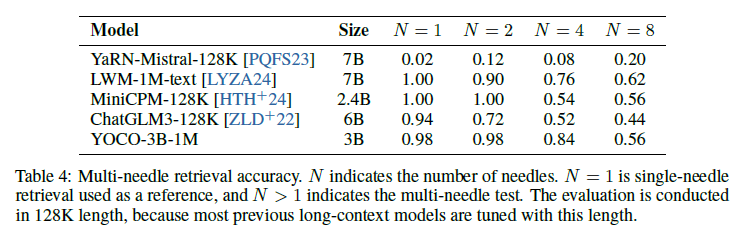
표 4: 다중 바늘 검색 정확도
표 4는 다중 바늘 검색 정확도를 나타냅니다. N은 바늘의 수를 나타냅니다. N=1은 참조로 사용되는 단일 바늘 검색이며, N>1은 다중 바늘 테스트를 나타냅니다. 평가는 대부분의 이전 긴 문맥 모델이 이 길이로 조정되었기 때문에 128K 길이에서 수행됩니다.
4.3 장기 문맥 평가
우리는 YOCO-3B(섹션 4.1)의 문맥 길이를 100만(1M) 토큰으로 확장합니다. 장기 문맥 모델을 바늘 찾기 및 언어 모델링 작업에서 평가합니다.
설정
모델 훈련은 점진적으로 더 긴 길이로 계속됩니다. 길이 일정은 64K, 256K, 그리고 1M 토큰입니다. 배치 크기는 이전과 동일하게 유지됩니다. 학습률과 RoPE [SLP+21] θ는 표 7에 설정된 대로입니다. 학습 데이터는 시퀀스 길이에 따라 업샘플링됩니다 [FPN+24]. 공정한 비교를 위해 장기 지시 조정 데이터를 사용하지 않습니다. 더 자세한 학습 세부 사항은 부록 E에 설명되어 있습니다. YOCO를 위한 청크 병렬 알고리즘은 부록 A에 제안되어 있으며, 이는 1M 길이 실험에서 통신 오버헤드와 GPU 메모리 단편화를 줄입니다.
건초 더미 속의 바늘 찾기
이 압력 테스트는 모델이 긴 문서에서 "바늘"을 찾을 수 있는지를 평가합니다 [Kam23]. 우리는 Gemini 1.5 [RST+24]와 LWM [LYZA24]의 평가 설정을 따릅니다. 바늘은 마법 숫자가 있는 도시로 구성됩니다. 동일한 깊이와 길이에서 10번 실행합니다. 평균 정확도가 보고됩니다. 그림 5는 YOCO-3B-1M이 건초 더미 속의 바늘 테스트를 거의 완벽한 정확도로 통과함을 보여줍니다. 결과는 YOCO가 강력한 장기 문맥 모델링 능력을 가지고 있음을 나타냅니다.
다중 바늘 검색
위의 단일 바늘 검색 외에도, 우리는 다중 바늘 평가를 수행합니다. 우리는 YOCO-3B-1M을 MiniCPM-128K [HTH+24], ChatGLM3-128K [ZLD+22], YaRN-Mistral-128K [PQFS23], 그리고 LWM-1M-text [LYZA24]를 포함한 이전 장기 문맥 언어 모델과 비교합니다. 평가는 대부분의 이전 모델이 이 길이로 조정되었기 때문에 128K 시퀀스 길이에서 수행됩니다.
표 4는 N개의 바늘에 대한 정확도를 보고합니다. 이 모델들 중 LWM-1M-text와 YOCO-3B-1M은 1M 문맥 길이로 훈련되었고, 나머지는 128K 길이로 훈련되었습니다. LWM-1M-text가 Llama-2-7B의 훈련을 계속하였음에도 불구하고, YOCO-3B-1M은 절반 크기의 모델로도 유사한 성능을 달성할 수 있습니다. 더욱이, 위치 보간을 통해 얻어진 7B 크기의 YaRN-Mistral-128K [PQFS23]는 다른 모델보다 뒤처집니다. MiniCPM-128K와 ChatGLM3-128K와 비교하여, YOCO-3B-1M은 이러한 잘 훈련된 언어 모델보다도 우수한 성능을 보입니다.
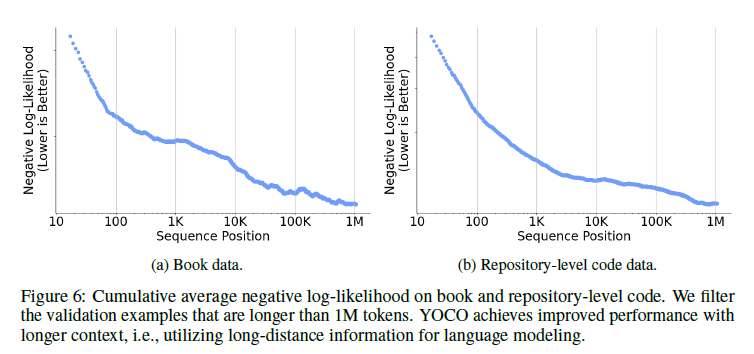
그림 6
그림 6은 책과 저장소 수준의 코드에서의 누적 평균 음의 로그 가능성을 보여줍니다. 우리는 1M 토큰보다 긴 검증 예제를 필터링합니다. YOCO는 더 긴 문맥으로 더 나은 성능을 달성하며, 즉 언어 모델링을 위해 장거리 정보를 활용합니다.
긴 시퀀스에 대한 당혹도
그림 6은 문맥 길이에 따른 누적 평균 음의 로그 가능성(NLL)을 나타냅니다. 우리는 책과 저장소 수준의 코드 데이터를 평가합니다. 우리는 [RST+24]의 설정을 따르며 1M 토큰보다 긴 검증 데이터를 필터링합니다. NLL은 더 긴 시퀀스 길이와 함께 일관되게 감소합니다. 결과는 YOCO가 언어 모델링을 위해 장거리 종속성을 효과적으로 활용할 수 있음을 나타냅니다. 또한, NLL-길이 곡선이 멱 법칙에 맞춰지는 경향이 있으며, 검증 예제 내의 잡음에 의해 격차가 영향을 받는다는 것을 관찰했습니다.
4.4 추론의 장점
우리는 GPU 메모리 사용량, 사전 채우기 지연 시간, 처리량, 그리고 서비스 용량 등 다양한 관점에서 추론 효율성을 분석합니다. YOCO는 특히 긴 시퀀스 추론에서 배포 비용을 몇 배로 줄이며, 사용자 경험(예: 지연 시간)을 개선하고 성능을 유지하면서 비용을 절감합니다. 우리는 YOCOgRet와 트랜스포머를 비교합니다. 기본 모델 구성은 섹션 4.1을 따릅니다. 공정한 비교를 위해 트랜스포머는 그룹 쿼리 어텐션 [ALTdJ+23], Flash-Decoding [DHMS23], 그리고 커널 융합을 사용합니다. 섹션 3.1에서 설명한 대로, 게이티드 유지는 사전 채우기 단계에서 청크-순환 표현을 사용하고 생성 단계에서 순환 표현을 사용합니다. 청크 크기는 256으로 설정됩니다. 우리는 게이티드 유지를 위한 트라이톤 [TC19] 커널을 구현합니다. 평가 시퀀스 길이는 32K에서 1M까지 다양합니다. 마지막 1,024 토큰은 생성되어야 하며, 이전 토큰은 입력 문맥으로 주어집니다. 실험은 H100-80GB GPU 카드를 사용하여 수행됩니다.
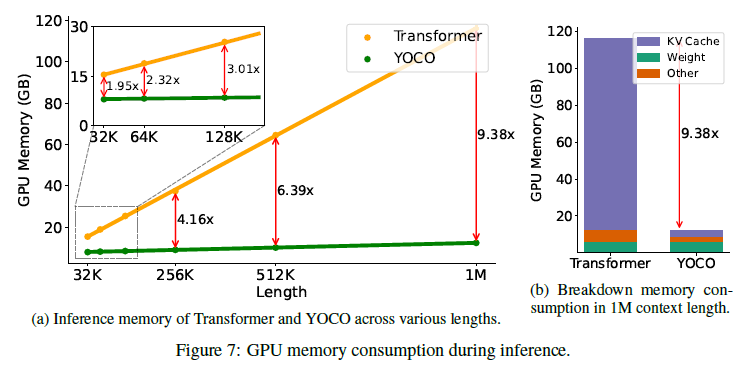
그림 7: 추론 중 GPU 메모리 소비.
- (a) 다양한 길이에 따른 트랜스포머와 YOCO의 추론 메모리.
- (b) 1M 문맥 길이에서 메모리 소비 분류.
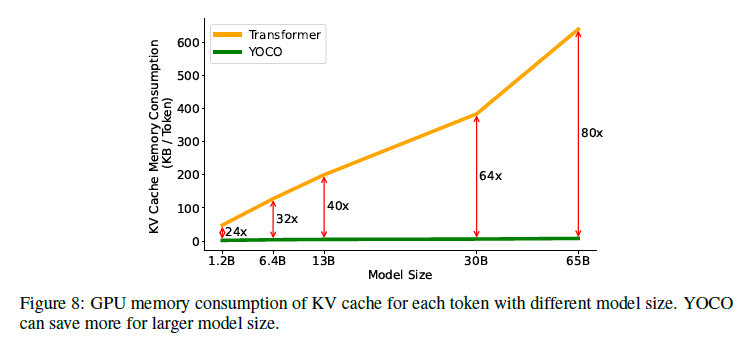
그림 8: 다양한 모델 크기에 따른 각 토큰의 KV 캐시 GPU 메모리 소비. YOCO는 더 큰 모델 크기에서도 더 많은 메모리를 절약합니다.
GPU 메모리
추론 메모리 소비는 모델 가중치, 중간 활성화, 그리고 KV 캐시의 세 부분으로 구성됩니다. 그림 7b는 메모리 프로파일링 결과를 분류하여 보여줍니다. 문맥 길이가 증가함에 따라 주요 메모리 병목은 KV 캐시가 되며, 모델 가중치는 일정한 메모리를 소비합니다. 결과는 YOCOgRet가 활성화 비용과 KV 캐시 메모리 사용량을 완화함을 보여줍니다.
그림 7a에서 보이듯이, YOCO를 사용하면 메모리 비용이 크게 줄어듭니다. 게다가 YOCO의 메모리 소비는 시퀀스 길이에 따라 천천히 증가합니다. 예를 들어, 1M 길이의 경우 전체 추론 메모리 사용량은 12.4GB에 불과하며, 트랜스포머는 9.4배의 GPU 메모리를 차지합니다. YOCO는 고객 수준의 GPU에서 긴 시퀀스 모델링을 배포하는 것을 가능하게 합니다. 32K 시퀀스 길이에서도 YOCO는 트랜스포머보다 약 2배 적은 메모리를 필요로 합니다. 여기서는 3B 크기 모델을 비교하고 있지만, 레이어 수가 증가할수록 감소 비율이 더 커집니다. 그림 8은 각 토큰에 대한 KV 캐시의 GPU 메모리 소비를 보고합니다. YOCO는 글로벌 키-값 쌍의 한 레이어만 캐시하므로 트랜스포머에 비해 약 L배 적은 메모리를 필요로 합니다. 예를 들어, YOCO는 1GB GPU 메모리로 128K 토큰을 서비스할 수 있지만, GQA [ALTdJ+23]를 사용하는 트랜스포머는 65B 모델 크기에서 1.6K 토큰만 지원할 수 있습니다.
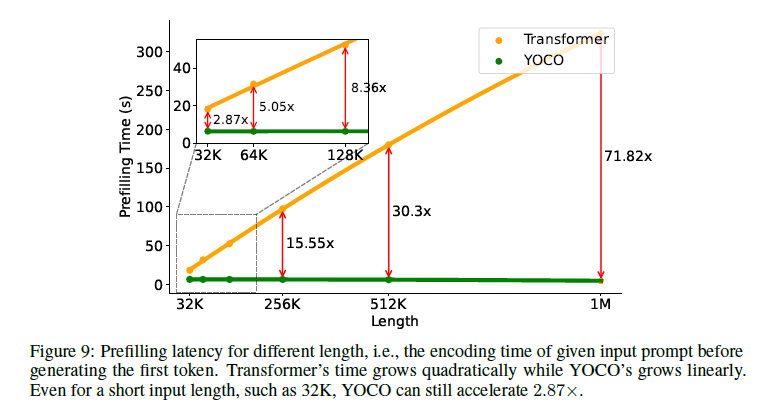
그림 9: 다양한 길이에 따른 사전 채우기 지연 시간, 즉 첫 번째 토큰 생성 전에 주어진 입력 프롬프트의 인코딩 시간. 트랜스포머의 시간은 이차적으로 증가하는 반면, YOCO는 선형적으로 증가합니다. 짧은 입력 길이(예: 32K)에서도 YOCO는 2.87배 더 빠릅니다.

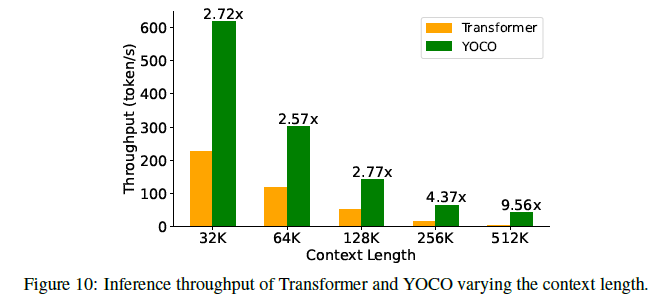
그림 10: 문맥 길이에 따른 트랜스포머와 YOCO의 추론 처리량.
처리량
처리량은 모델이 초당 처리할 수 있는 토큰 수를 나타내며, 사전 채우기와 생성 시간을 모두 포함합니다. 그림 10은 YOCO가 트랜스포머와 비교하여 문맥 길이에 걸쳐 더 높은 처리량을 달성함을 보여줍니다. 예를 들어, 512K 쿼리에서 트랜스포머의 처리량은 초당 4.5 토큰인 반면, YOCO는 43.1 토큰에 도달하여 9.6배의 속도 향상을 달성합니다. 처리량이 향상되는 이유는 다음과 같습니다. 첫째, YOCO는 앞서 설명한 대로 사전 채우기에 필요한 시간을 줄입니다. 둘째, 메모리 소비가 줄어들어 더 큰 배치 크기를 사용할 수 있어 처리량 개선에도 기여합니다.
5. 결론
이 연구에서 우리는 대형 언어 모델링을 위한 디코더-디코더 아키텍처(YOCO)를 제안합니다. YOCO는 트랜스포머와 비교하여 현저히 더 나은 추론 효율성과 경쟁력 있는 성능을 달성합니다. 실험 결과, YOCO는 다양한 설정(예: 학습 토큰 수 확장, 모델 크기 확장, 문맥 길이를 100만(1M) 토큰으로 확장)에서 대형 언어 모델에 대해 우수한 결과를 달성함을 입증합니다. 프로파일링 결과는 특히 장기 시퀀스 모델링에서 YOCO가 추론 효율성을 몇 배로 향상시키는 것을 보여줍니다.
이 연구는 다음과 같은 관점에서 발전될 수 있습니다:
- YOCO + BitNet + Groq: Groq는 모든 것을 SRAM 내에 두어 매우 높은 처리량을 달성합니다. 그러나 메모리 용량 병목이 모델 크기와 입력 토큰 수를 제한합니다. 현재 수백 개의 칩이 하나의 모델을 호스팅하기 위해 연결됩니다. YOCO는 KV 캐시 메모리를 줄이고 BitNet은 모델 가중치 메모리를 줄여 위의 조합을 사용하여 LLM 배포 비용을 몇 배로 줄일 수 있을 것으로 예상됩니다.
- 멀티모달 대형 언어 모델을 위한 YOCO: YOCO 레이아웃은 여러 자기 디코더의 사용에 일반적입니다. 교차 주의 층은 멀티모달 융합에 자연스럽게 적합합니다 [BWD+22, WBD+22]. 자기 디코더의 인과 종속성은 스트리밍 비디오에도 완벽하게 맞습니다. 비동기 멀티모달 대형 언어 모델은 서로 다른 데이터 스트림이 서로를 차단하는 것을 피할 수 있어 로봇 공학과 같은 실시간 응용 프로그램에 중요합니다.
- KV 캐시 모듈을 위한 최적화된 메커니즘: 그림 2는 KV 캐시를 명확히 강조하여 네이티브 메모리 메커니즘 개발의 새로운 기회를 열어줍니다. 첫째, 더 압축된 메모리를 얻기 위해 캐시 압축 메커니즘을 통합할 수 있습니다. 둘째, 효율적인 키-값 검색을 위한 인덱스를 구축할 수 있습니다 [WDC+23]. YOCO가 캐시를 재사용하기 때문에 각 레이어에 인덱스를 만드는 대신 하나의 인덱스만 유지할 수 있습니다. 셋째, 분리된 모델링은 사전 캐싱 문맥을 지원하여 네이티브 RAG 및 LLM-네이티브 검색 엔진에 유용할 수 있습니다.
감사의 말
우리는 GPU 클러스터를 유지 관리한 Ben Huntley에게 감사를 표하고 싶습니다. 장기 시퀀스 훈련은 [LML+23]의 내부 버전인 CUBE를 사용합니다. 우리는 FLA [YZ24]를 기반으로 게이티드 유지의 트라이톤 커널을 구현했습니다.



