https://arxiv.org/abs/2305.10973
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
Synthesizing visual content that meets users' needs often requires flexible and precise controllability of the pose, shape, expression, and layout of the generated objects. Existing approaches gain controllability of generative adversarial networks (GANs)
arxiv.org
요약
사용자 요구를 충족하는 시각적 콘텐츠를 합성하려면 생성된 객체의 자세, 형태, 표정 및 레이아웃을 유연하고 정밀하게 제어할 수 있어야 합니다. 기존 접근법은 수동으로 주석이 달린 학습 데이터나 3D 모델을 사용하여 생성적 적대 신경망(GAN)을 제어하는 방식으로, 유연성, 정밀성 및 일반성이 부족합니다. 본 연구에서는 이미지의 임의 지점을 사용자 상호작용 방식으로 목표 지점으로 정확히 "끌어당기는" GAN 제어 방법을 연구합니다(Fig.1 참조). 이를 위해 우리는 DragGAN을 제안하며, 이는 두 가지 주요 구성 요소로 이루어져 있습니다: 1) 특징 기반 모션 감독을 통해 핸들 포인트가 목표 위치로 이동하도록 유도하며, 2) 판별 가능한 생성기 특징을 활용하여 핸들 포인트 위치를 계속해서 추적하는 새로운 포인트 추적 접근법. DragGAN을 통해 누구나 이미지의 픽셀이 이동하는 위치를 정확히 제어할 수 있어 동물, 자동차, 인간, 풍경 등 다양한 범주의 자세, 형태, 표정, 레이아웃을 조작할 수 있습니다. 이러한 조작은 GAN의 학습된 생성 이미지 매니폴드에서 수행되므로, 가려진 콘텐츠를 환상적으로 생성하거나 객체의 강성을 일관되게 유지하면서 형태를 변형하는 등의 도전적인 시나리오에서도 현실적인 출력을 생성합니다. 질적 및 양적 비교 모두 이미지 조작 및 포인트 추적 작업에서 기존 접근법보다 DragGAN의 우수성을 입증합니다. 또한 GAN 역변환을 통해 실제 이미지 조작도 시연합니다.
GANs, 상호작용 이미지 조작, 포인트 추적

Figure 1. 우리 접근법 DragGAN은 사용자들이 GAN으로 생성된 이미지의 콘텐츠를 "끌어당길" 수 있게 합니다. 사용자는 이미지에 몇 개의 핸들 포인트(빨간색)와 목표 포인트(파란색)를 클릭하기만 하면 되고, 우리 접근법은 핸들 포인트를 정확히 해당 목표 포인트로 이동시킵니다. 사용자는 선택적으로 유연한 영역(밝은 영역)의 마스크를 그려 나머지 이미지를 고정할 수 있습니다. 이러한 유연한 포인트 기반 조작은 다양한 객체 범주에서 자세, 형태, 표정 및 레이아웃 등의 많은 공간적 속성을 제어할 수 있게 합니다. 프로젝트 페이지: 프로젝트 페이지 링크.
- 서론
생성적 적대 신경망(GANs)(Goodfellow et al., 2014)과 같은 딥 생성 모델은 무작위로 현실적인 이미지를 합성하는 데 있어 전례 없는 성공을 거두었습니다. 실제 응용에서 이러한 학습 기반 이미지 합성 방법의 중요한 기능 요구 사항은 합성된 시각적 콘텐츠에 대한 제어 가능성입니다. 예를 들어, 소셜 미디어 사용자들은 캐주얼하게 촬영된 사진에서 사람이나 동물의 위치, 형태, 표정, 자세를 조정하고 싶어할 수 있으며, 영화 사전 시각화 및 미디어 편집에서는 특정 레이아웃으로 장면 스케치를 효율적으로 생성해야 할 수 있습니다. 또한 자동차 디자이너는 자신의 창작물을 대화식으로 수정하고자 할 수 있습니다. 이러한 다양한 사용자 요구를 충족시키기 위해 이상적인 제어 가능한 이미지 합성 접근법은 다음과 같은 특성을 가져야 합니다: 1) 유연성: 생성된 객체나 동물의 위치, 자세, 형태, 표정 및 레이아웃을 제어할 수 있어야 합니다; 2) 정밀성: 공간적 속성을 높은 정밀도로 제어할 수 있어야 합니다; 3) 일반성: 특정 범주에 국한되지 않고 다양한 객체 범주에 적용할 수 있어야 합니다. 이전 연구들은 이 중 한두 가지 특성만을 만족시켰으나, 우리는 이 연구에서 이 모든 특성을 달성하는 것을 목표로 합니다.
이전의 대부분의 접근법은 사전 3D 모델(Tewari et al., 2020; Deng et al., 2020; Ghosh et al., 2020)이나 수동으로 주석이 달린 데이터를 사용하는 지도 학습(Isola et al., 2017; Park et al., 2019; Ling et al., 2021; Shen et al., 2020; Abdal et al., 2021)을 통해 GAN의 제어 가능성을 얻습니다. 따라서 이러한 접근법은 새로운 객체 범주에 일반화되지 못하며, 종종 제한된 범위의 공간적 속성만을 제어하거나 편집 과정에서의 제어가 부족합니다. 최근에는 텍스트 기반 이미지 합성이 주목받고 있습니다(Rombach et al., 2021; Saharia et al., 2022; Ramesh et al., 2022). 그러나 텍스트 가이던스는 공간적 속성을 편집하는 데 있어 정밀성과 유연성이 부족합니다. 예를 들어, 특정 픽셀 수만큼 객체를 이동시키는 데 사용할 수 없습니다.
이 연구에서는 GAN의 유연하고 정밀하며 일반적인 제어 가능성을 달성하기 위해 강력하지만 덜 탐구된 대화형 포인트 기반 조작 방식을 탐구합니다. 구체적으로, 우리는 사용자가 이미지에 원하는 만큼의 핸들 포인트와 목표 포인트를 클릭할 수 있도록 하며, 목표는 핸들 포인트가 해당 목표 포인트에 도달하도록 하는 것입니다. Fig. 1에서 볼 수 있듯이, 이 포인트 기반 조작은 다양한 공간적 속성을 제어할 수 있으며 객체 범주에 무관합니다. 우리의 접근법과 가장 유사한 설정은 UserControllableLT(Endo, 2022)로, 드래그 기반 조작을 연구합니다. 이에 비해, 본 논문에서 연구된 문제는 두 가지 도전 과제를 추가로 가지고 있습니다: 1) 우리는 그들의 접근법이 잘 처리하지 못하는 하나 이상의 포인트 제어를 고려합니다; 2) 우리는 핸들 포인트가 정확히 목표 포인트에 도달하도록 요구합니다. 실험에서 보여주듯이, 하나 이상의 포인트를 정확한 위치 제어로 처리하면 훨씬 더 다양하고 정확한 이미지 조작이 가능합니다.
이러한 대화형 포인트 기반 조작을 달성하기 위해 우리는 DragGAN을 제안하며, 이는 목표를 향해 핸들 포인트를 이동시키는 감독과 편집 과정에서 핸들 포인트의 위치를 추적하는 것을 포함한 두 가지 하위 문제를 해결합니다. 우리의 기술은 GAN의 특징 공간이 모션 감독과 정밀한 포인트 추적을 가능하게 할 만큼 충분히 판별적이라는 주요 통찰에 기반합니다. 구체적으로, 모션 감독은 잠재 코드의 최적화를 통해 이동된 특징 패치 손실을 통해 이루어집니다. 각 최적화 단계는 핸들 포인트가 목표에 더 가까워지도록 하며, 따라서 포인트 추적은 특징 공간에서 최근접 이웃 검색을 통해 수행됩니다. 이 최적화 과정은 핸들 포인트가 목표에 도달할 때까지 반복됩니다. DragGAN은 또한 사용자가 관심 영역을 선택적으로 그려 영역별 편집을 수행할 수 있도록 합니다. DragGAN은 RAFT(Teed 및 Deng, 2020)와 같은 추가 네트워크에 의존하지 않으므로 효율적인 조작을 달성하며, 대부분의 경우 단일 RTX 3090 GPU에서 몇 초 만에 수행됩니다. 이를 통해 사용자는 원하는 출력을 달성할 때까지 다양한 레이아웃을 빠르게 반복할 수 있는 라이브, 대화형 편집 세션을 가질 수 있습니다.
우리는 동물(사자, 개, 고양이, 말), 인간(얼굴 및 전신), 자동차, 풍경을 포함한 다양한 데이터셋에서 DragGAN을 광범위하게 평가합니다. Fig.1에서 볼 수 있듯이, 우리의 접근법은 사용자 정의 핸들 포인트를 목표 포인트로 효과적으로 이동시켜 다양한 객체 범주에서 다양한 조작 효과를 달성합니다. 단순히 왜곡을 적용하는 기존의 형태 변형 접근법과 달리(Igarashi et al., 2005), 우리의 변형은 GAN의 학습된 이미지 매니폴드에서 수행되어 객체 구조를 따르는 경향이 있습니다. 예를 들어, 우리의 접근법은 사자의 입 안의 치아처럼 가려진 콘텐츠를 환상적으로 생성할 수 있으며, 말 다리의 굽힘처럼 객체의 강성을 따르는 변형을 수행할 수 있습니다. 우리는 또한 사용자가 단순히 이미지를 클릭하여 대화형으로 조작을 수행할 수 있는 GUI를 개발했습니다. 질적 및 양적 비교 모두 우리의 접근법이 UserControllableLT보다 우수함을 확인합니다. 또한, 우리의 GAN 기반 포인트 추적 알고리즘은 RAFT(Teed 및 Deng, 2020) 및 PIPs(Harley et al., 2022)와 같은 기존 포인트 추적 접근법보다 GAN 생성 프레임에서 더 우수한 성능을 보입니다. 더욱이, GAN 역변환 기법과 결합함으로써 우리의 접근법은 실제 이미지 편집을 위한 강력한 도구로도 활용될 수 있습니다.
2. 관련 연구
2.1 대화형 콘텐츠 생성을 위한 생성 모델
현재 대부분의 방법은 생성적 적대 신경망(GAN)이나 확산 모델을 사용하여 제어 가능한 이미지 합성을 수행합니다.
비조건부 GANs GAN은 저차원에서 무작위로 샘플링된 잠재 벡터를 포토리얼리스틱 이미지로 변환하는 생성 모델입니다. 이들은 적대적 학습을 통해 훈련되며, 고해상도의 포토리얼리스틱 이미지를 생성할 수 있습니다(Karras et al., 2019, 2021; Goodfellow et al., 2014; Creswell et al., 2018). 대부분의 GAN 모델, 예를 들어 StyleGAN(Karras et al., 2019)은 생성된 이미지의 제어 가능한 편집을 직접적으로 지원하지 않습니다.
조건부 GANs 여러 방법이 이러한 한계를 해결하기 위해 조건부 GAN을 제안했습니다. 여기서 네트워크는 무작위로 샘플링된 잠재 벡터 외에도 세그멘테이션 맵(Isola et al., 2017; Park et al., 2019)이나 3D 변수(Deng et al., 2020; Ghosh et al., 2020)와 같은 조건부 입력을 받습니다. EditGAN(Ling et al., 2021)은 조건부 분포를 모델링하는 대신, 이미지와 세그멘테이션 맵의 공동 분포를 먼저 모델링하고, 편집된 세그멘테이션 맵에 해당하는 새로운 이미지를 계산하여 편집을 가능하게 합니다.
비조건부 GANs를 사용한 제어 가능성 여러 방법이 입력 잠재 벡터를 조작하여 비조건부 GANs를 편집하는 방법을 제안했습니다. 일부 접근법은 수동 주석 또는 사전 3D 모델(Tewari et al., 2020; Shen et al., 2020; Abdal et al., 2021; Patashnik et al., 2021; Leimkühler 및 Drettakis, 2021)로부터 지도 학습을 통해 의미 있는 잠재 방향을 찾습니다. 다른 접근법은 잠재 공간에서 중요한 의미 방향을 비지도 방식으로 계산합니다(Shen 및 Zhou, 2020; Härkönen et al., 2020; Zhu et al., 2023). 최근에는 중간 "블롭"(Epstein et al., 2022)이나 히트맵(Wang et al., 2022b)을 도입하여 거친 객체 위치의 제어 가능성을 달성했습니다. 이러한 접근법들은 외형과 같은 이미지 정렬 의미 속성이나 객체 위치 및 자세와 같은 거친 기하학적 속성의 편집을 가능하게 합니다. Editing-in-Style(Collins et al., 2020)은 일부 공간 속성 편집 능력을 보여주지만, 이는 서로 다른 샘플 간의 지역 의미를 전송함으로써만 가능합니다. 이에 반해, 우리의 접근법은 포인트 기반 편집을 사용하여 공간 속성을 세밀하게 제어할 수 있도록 합니다.
GANWarping(Wang et al., 2022a)도 포인트 기반 편집을 사용하지만, 이 방법은 분포 외 이미지 편집만을 지원합니다. 몇 개의 왜곡된 이미지는 모든 생성된 이미지가 유사한 왜곡을 보여주도록 생성 모델을 업데이트하는 데 사용될 수 있습니다. 그러나 이 방법은 왜곡이 현실적인 이미지를 생성하도록 보장하지 않으며, 객체의 3D 자세를 변경하는 등의 제어도 지원하지 않습니다. 우리와 유사하게, UserControllableLT(Endo, 2022)는 GAN의 잠재 벡터를 변환하여 포인트 기반 편집을 지원합니다. 그러나 이 접근법은 단일 포인트를 이미지에서 끌어 편집하는 것만 지원하며, 다중 포인트 제약을 잘 처리하지 못합니다. 또한, 편집 후 목표 포인트에 도달하지 않는 등 제어가 정밀하지 않습니다.
3D 인식 GANs 여러 방법이 GAN의 아키텍처를 수정하여 3D 제어를 가능하게 합니다(Schwarz et al., 2020; Chan et al., 2021, 2022; Gu et al., 2022; Pan et al., 2021; Tewari et al., 2022; Chen et al., 2022; Xu et al., 2022). 이 모델들은 물리 기반 분석 렌더러를 사용하여 렌더링할 수 있는 3D 표현을 생성합니다. 그러나 우리의 접근법과 달리 제어는 전역 자세나 조명에 제한됩니다.
확산 모델 최근에는 확산 모델(Sohl-Dickstein et al., 2015)이 고품질 이미지 합성을 가능하게 했습니다(Ho et al., 2020; Song et al., 2020, 2021). 이 모델들은 무작위로 샘플링된 노이즈를 점진적으로 제거하여 포토리얼리스틱 이미지를 생성합니다. 최근 모델들은 텍스트 입력을 조건으로 한 표현력 있는 이미지 합성을 보여주었습니다(Rombach et al., 2021; Saharia et al., 2022; Ramesh et al., 2022). 그러나 자연 언어는 이미지의 공간 속성을 세밀하게 제어하지 못하며, 모든 텍스트 조건 방법은 높은 수준의 의미 편집에만 제한됩니다. 또한, 현재 확산 모델은 여러 단계의 노이즈 제거가 필요하므로 느립니다. 효율적인 샘플링을 향한 진전이 이루어지고 있지만, GAN은 여전히 훨씬 더 효율적입니다.
Figure 2. 우리의 파이프라인 개요. GAN으로 생성된 이미지를 기준으로 사용자는 여러 개의 핸들 포인트(빨간 점), 목표 포인트(파란 점), 선택적으로 편집 중에 이동할 수 있는 영역을 나타내는 마스크(밝은 영역)만 설정하면 됩니다. 우리의 접근법은 모션 감독(Sec. 3.2)과 포인트 추적(Sec. 3.3)을 반복적으로 수행합니다. 모션 감독 단계는 핸들 포인트(빨간 점)를 목표 포인트(파란 점)로 이동시키고, 포인트 추적 단계는 이미지 내 객체를 추적하여 핸들 포인트를 업데이트합니다. 이 과정은 핸들 포인트가 해당 목표 포인트에 도달할 때까지 계속됩니다.
2.2 이미지 변형
사용자의 포인트 드래그 명령에 따라 이미지를 변형하는 것은 컴퓨터 그래픽스에서 고전적인 문제입니다. 기존 접근법(Botsch와 Sorkine, 2007)은 일반적으로 이미지를 메쉬로 변환한 다음, 강성(Igarashi et al., 2005; Sorkine 및 Alexa, 2007) 및 라플라스 평활성(Lipman et al., 2004, 2005; Sorkine et al., 2004)과 같은 기하학적 제약을 적용하여 메쉬를 변형합니다. 초기 연구에서는 수작업으로 만든 특징을 기반으로 형태 변형 개념을 제안했습니다(Beier 및 Neely, 2023). 그러나 이러한 기하학적 제약과 수작업 특징은 편집된 객체의 기본 구조와 강성에 대한 지식이 부족하여 종종 최적 이하의 변형을 초래합니다. 또한, 가려진 영역을 합성하는 등 새로운 콘텐츠를 환상적으로 생성할 수 없습니다. 포인트 드래그 편집이 비디오 내비게이션을 통해 근사화될 수 있다는 것도 입증되었지만, 비디오 데이터의 필요성 때문에 적용 가능성이 제한됩니다(Goldman et al., 2008). 반면, 본 연구에서는 객체 구조와 외형에 대한 풍부한 정보를 포착하는 강력한 생성 이미지 프라이어를 기반으로 한 이미지 변형을 연구합니다.
2.3 포인트 추적
비디오에서 포인트를 추적하는 한 가지 명백한 접근법은 연속 프레임 간의 옵티컬 플로우 추정을 통해 이루어집니다. 옵티컬 플로우 추정은 두 이미지 간의 모션 필드를 추정하는 고전적인 문제입니다. 기존 접근법은 수작업 기준으로 최적화 문제를 해결합니다(Brox 및 Malik, 2010; Sundaram et al., 2010). 최근 몇 년 동안 딥러닝 기반 접근법이 더 나은 성능으로 이 분야를 지배하기 시작했습니다(Dosovitskiy et al., 2015; Ilg et al., 2017; Teed 및 Deng, 2020). 이러한 딥러닝 기반 접근법은 일반적으로 진짜 옵티컬 플로우가 있는 합성 데이터를 사용하여 딥 뉴럴 네트워크를 훈련시킵니다. 그중에서 가장 널리 사용되는 방법은 RAFT(Teed 및 Deng, 2020)로, 반복 알고리즘을 통해 옵티컬 플로우를 추정합니다. 최근에 Harley et al. (2022)은 이 반복 알고리즘을 기존의 "입자 비디오" 접근법과 결합하여 PIPs라는 새로운 포인트 추적 방법을 제안했습니다. PIPs는 여러 프레임에 걸쳐 정보를 고려하여 이전 접근법보다 장거리 추적을 더 잘 처리합니다.
본 연구에서는 GAN으로 생성된 이미지에서 앞서 언급한 접근법이나 추가적인 뉴럴 네트워크를 사용하지 않고도 포인트 추적을 수행할 수 있음을 보여줍니다. 우리는 GAN의 특징 공간이 판별적이어서 특징 매칭만으로 추적을 수행할 수 있음을 밝힙니다. 일부 이전 연구들도 의미 분할에서 판별적 특징을 활용했지만(Tritrong et al., 2021; Zhang et al., 2021), 우리는 포인트 기반 편집 문제를 판별적 GAN 특징의 직관과 연결하고 구체적인 방법을 설계한 최초의 연구입니다. 추가 추적 모델을 제거함으로써 우리의 접근법은 대화형 편집을 지원하기 위해 훨씬 더 효율적으로 실행될 수 있습니다. 우리의 접근법의 단순성에도 불구하고, 실험에서 RAFT 및 PIPs를 포함한 최첨단 포인트 추적 접근법보다 우수한 성능을 보임을 입증합니다.
3. 방법
이 연구는 GANs를 위한 대화형 이미지 조작 방법을 개발하는 것을 목표로 합니다. 사용자는 이미지에 클릭하여 (핸들 포인트, 목표 포인트) 쌍을 정의하고 핸들 포인트가 해당 목표 포인트에 도달하도록 할 수 있습니다. 우리의 연구는 StyleGAN2 아키텍처(Karras et al., 2020)를 기반으로 합니다. 여기에서는 이 아키텍처의 기본 사항을 간략히 소개합니다.

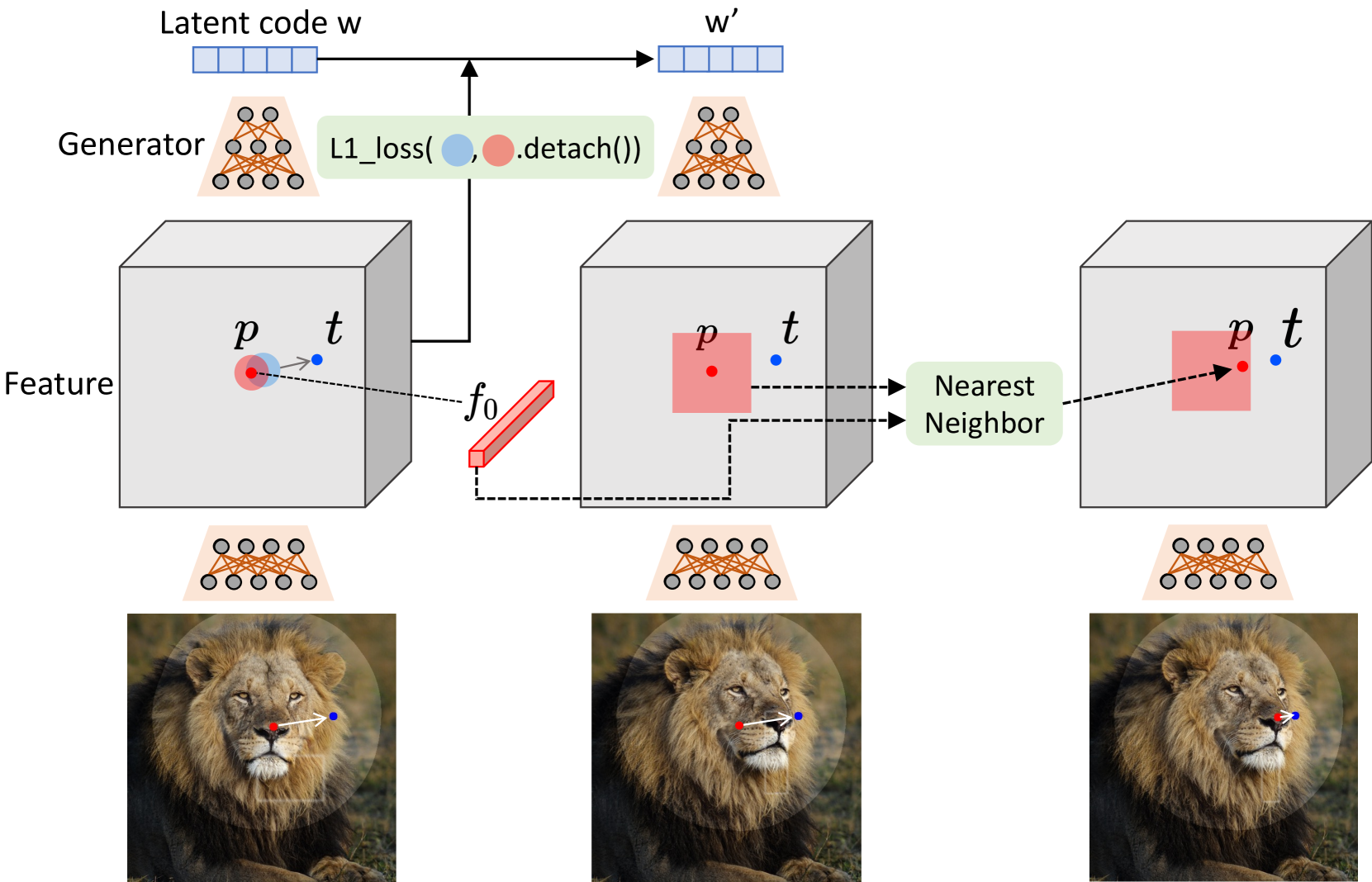
그림 3. 방법
우리의 모션 감독은 생성기의 특징 맵에서 이동된 패치 손실을 통해 이루어집니다. 우리는 동일한 특징 공간에서 최근접 이웃 검색을 통해 포인트 추적을 수행합니다.

그림 4. 질적 비교
핸들 포인트(빨간 점)를 목표 포인트(파란 점)로 이동시키는 작업에서 UserControllableLT(Endo, 2022)와 우리의 접근법을 질적으로 비교한 결과입니다. 우리의 접근법은 다양한 데이터셋에서 더 자연스럽고 우수한 결과를 달성합니다. 더 많은 예시는 그림 10에 제공되어 있습니다.



그림 5. 실제 이미지 조작
실제 이미지가 주어지면, 우리는 GAN 역변환을 적용하여 이를 StyleGAN의 잠재 공간으로 매핑한 다음, 각각의 자세, 머리, 형태 및 표정을 편집합니다.

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.1 대화형 포인트 기반 조작
목표: 사용자가 정의한 핸들 포인트를 목표 포인트로 이동시키는 것.
import torch
import torch.nn.functional as F
from torch.optim import Adam
from stylegan2_pytorch import Model
# StyleGAN2 모델 로드 (사전 훈련된 모델을 사용한다고 가정)
model = Model.load('stylegan2-ffhq-config-f.pt')
# 이미지와 핸들 포인트, 목표 포인트를 설정
image = model.generate_image()
handle_points = [(x1, y1), (x2, y2), ...] # 예시 핸들 포인트
target_points = [(tx1, ty1), (tx2, ty2), ...] # 예시 목표 포인트
# 핸들 포인트와 목표 포인트를 시각적으로 표시
import matplotlib.pyplot as plt
plt.imshow(image)
for (hp, tp) in zip(handle_points, target_points):
plt.plot(*hp, 'ro') # 핸들 포인트 (빨간색 점)
plt.plot(*tp, 'bo') # 목표 포인트 (파란색 점)
plt.show()
3.2 모션 감독
핵심 아이디어: 생성기의 중간 특징 맵을 사용하여 핸들 포인트를 목표 포인트로 이동시키는 것.
# 손실 함수 정의
def motion_supervision_loss(feature_map, handle_points, target_points, r1, lambda_param, mask=None):
loss = 0
for (hp, tp) in zip(handle_points, target_points):
d_i = torch.tensor([tp[0] - hp[0], tp[1] - hp[1]])
d_i = d_i / torch.norm(d_i, p=2) # 정규화된 벡터
for q in omega1(hp, r1): # omega1은 hp 주변의 작은 패치를 나타냄
loss += F.l1_loss(feature_map[q], feature_map[q + d_i])
if mask is not None:
# 재구성 손실 추가
loss += lambda_param * F.l1_loss((feature_map - initial_feature_map) * (1 - mask))
return loss
# Omega1 함수 정의 (hp 주변의 패치)
def omega1(hp, r):
x, y = hp
return [(x + i, y + j) for i in range(-r, r+1) for j in range(-r, r+1)]
# 최적화 설정
optimizer = Adam([latent_code], lr=2e-3)
# 최적화 과정
for step in range(max_steps):
optimizer.zero_grad()
image = model.generate_image(latent_code)
feature_map = model.get_features(image, layer=6) # 6번째 레이어의 특징 맵
loss = motion_supervision_loss(feature_map, handle_points, target_points, r1, lambda_param)
loss.backward()
optimizer.step()
# 새로운 이미지를 시각화
if step % visualize_every == 0:
plt.imshow(image)
for (hp, tp) in zip(handle_points, target_points):
plt.plot(*hp, 'ro')
plt.plot(*tp, 'bo')
plt.show()
3.3 포인트 추적
핵심 아이디어: 최근접 이웃 검색을 통해 핸들 포인트를 정확히 추적.
# 포인트 추적 함수 정의
def track_points(feature_map, handle_points):
new_handle_points = []
for hp in handle_points:
nearest_point = find_nearest(feature_map, hp)
new_handle_points.append(nearest_point)
return new_handle_points
# 최근접 이웃 검색 함수 (단순화된 예시)
def find_nearest(feature_map, point):
# 여기에 최근접 이웃 검색 알고리즘을 구현
# 이 예시는 간단히 임의의 새로운 포인트를 반환
return (point[0] + 1, point[1] + 1)
# 최적화 과정에 포인트 추적 추가
for step in range(max_steps):
optimizer.zero_grad()
image = model.generate_image(latent_code)
feature_map = model.get_features(image, layer=6)
loss = motion_supervision_loss(feature_map, handle_points, target_points, r1, lambda_param)
loss.backward()
optimizer.step()
# 포인트 추적
handle_points = track_points(feature_map, handle_points)
# 새로운 이미지를 시각화
if step % visualize_every == 0:
plt.imshow(image)
for (hp, tp) in zip(handle_points, target_points):
plt.plot(*hp, 'ro')
plt.plot(*tp, 'bo')
plt.show()
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4. 실험
데이터셋
우리는 StyleGAN2(Karras et al., 2020)를 기반으로 다음 데이터셋들에 대해 우리의 접근법을 평가했습니다 (사전 훈련된 StyleGAN2의 해상도가 괄호 안에 표시됨):
- FFHQ (512) (Karras et al., 2019)
- AFHQCat (512) (Choi et al., 2020)
- SHHQ (512) (Fu et al., 2022)
- LSUN Car (512) (Yu et al., 2015)
- LSUN Cat (256) (Yu et al., 2015)
- Landscapes HQ (256) (Skorokhodov et al., 2021)
- Microscope (512) (Pinkney, 2020)
- Lion (512), Dog (1024), Elephant (512) 포함한 self-distilled 데이터셋 (Mokady et al., 2022)
비교 기준
우리의 주요 비교 기준은 UserControllableLT(Endo, 2022)로, 우리의 방법과 가장 유사한 설정을 가지고 있습니다. UserControllableLT는 마스크 입력을 지원하지 않지만, 사용자가 고정된 여러 포인트를 정의할 수 있도록 합니다. 따라서 마스크 입력이 있는 테스트 사례에서는 이미지에서 정규 16×16 그리드를 샘플링하고 마스크 외부의 포인트를 UserControllableLT의 고정 포인트로 사용했습니다. 또한, 우리는 포인트 추적을 위해 RAFT(Teed 및 Deng, 2020)와 PIPs(Harley et al., 2022)와도 비교했습니다. 이를 위해 포인트 추적 부분(Sec.3.3)을 이 두 추적 방법으로 대체한 우리의 접근법의 두 가지 변형을 생성했습니다.

그림 6. 질적 추적 비교
우리의 접근법과 RAFT(Teed 및 Deng, 2020), PIPs(Harley et al., 2022) 및 추적 없이 수행한 결과를 질적으로 비교한 것입니다. 우리의 접근법은 핸들 포인트를 기준선보다 더 정확하게 추적하여 더 정밀한 편집을 생성합니다.
4.1 질적 평가
그림 4는 우리의 방법과 UserControllableLT 간의 질적 비교를 보여줍니다. 우리는 여러 다른 객체 범주와 사용자 입력에 대한 이미지 조작 결과를 보여줍니다. 우리의 접근법은 핸들 포인트를 정확하게 목표 포인트로 이동시켜 동물의 자세를 바꾸거나, 자동차의 형태를 변경하거나, 풍경의 레이아웃을 변경하는 등 다양한 자연스러운 조작 효과를 달성합니다. 반면에, UserControllableLT는 핸들 포인트를 목표로 정확히 이동시키지 못하고 종종 이미지에 원치 않는 변화를 초래합니다. 예를 들어, 사람의 옷이나 자동차의 배경이 변경되는 경우가 있습니다. 또한, UserControllableLT는 고양이 이미지에서 보듯이 마스크되지 않은 영역을 고정하는 데 있어 우리의 방법만큼 효과적이지 않습니다. 그림 10에서 더 많은 비교를 볼 수 있습니다.
그림 6은 우리의 접근법과 PIPs 및 RAFT를 비교한 것입니다. 우리의 접근법은 사자의 코 위의 핸들 포인트를 정확하게 추적하여 이를 목표 위치로 성공적으로 이동시킵니다. PIPs와 RAFT에서는 조작 과정에서 추적된 포인트가 코에서 벗어나기 시작합니다. 그 결과, 잘못된 부분을 목표 위치로 이동시키게 됩니다. 추적이 수행되지 않는 경우, 고정된 핸들 포인트는 몇 단계 후 이미지의 다른 부분(예: 배경)을 이동시키기 시작하여 언제 멈춰야 할지를 알지 못하고, 편집 목표를 달성하지 못합니다.
실제 이미지 편집
실제 이미지를 StyleGAN의 잠재 공간에 임베드하는 GAN 역전환 기법을 사용하여 우리의 접근법을 적용하여 실제 이미지를 조작할 수도 있습니다. 그림 5는 실제 이미지에 PTI 역전환(Roich et al., 2022)을 적용한 다음 일련의 조작을 수행하여 이미지에서 얼굴의 자세, 머리, 형태, 표정을 편집하는 예시를 보여줍니다. 그림 13에서 더 많은 실제 이미지 편집 예시를 볼 수 있습니다.
4.2 정량적 평가
우리는 두 가지 설정, 즉 얼굴 랜드마크 조작과 페어링된 이미지 재구성에서 우리의 방법을 정량적으로 평가합니다.

그림 7. 얼굴 랜드마크 조작
UserControllableLT(Endo, 2022)와 비교했을 때, 우리의 방법은 입력 이미지에서 감지된 랜드마크를 목표 이미지에서 감지된 랜드마크와 더 적은 매칭 오류로 일치시킬 수 있습니다.
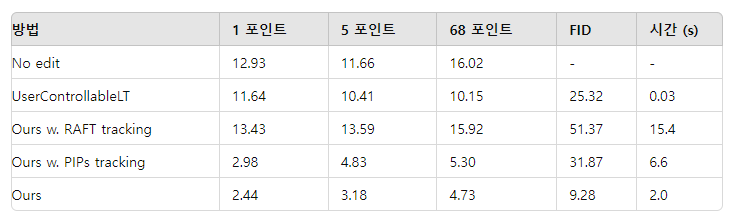
표 1. 얼굴 키포인트 조작에 대한 정량적 평가
편집된 포인트와 목표 포인트 간의 평균 거리를 계산합니다. FID와 시간은 '1 포인트' 설정을 기준으로 보고됩니다.
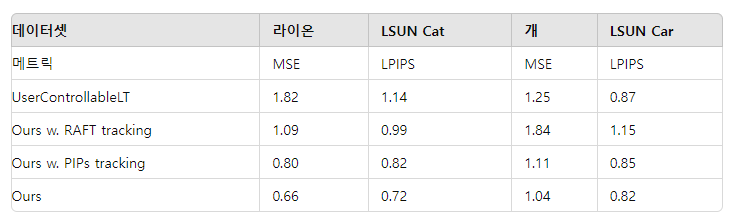
표 2. 페어링된 이미지 재구성에 대한 정량적 평가
우리는 (Endo, 2022)의 평가 방법을 따라 MSE (×10²)↓와 LPIPS (×10)↓ 점수를 보고합니다.

표 3. 사용하는 특징의 영향
x+y는 두 특징의 연결을 의미합니다. 우리는 얼굴 랜드마크 조작 (1 포인트)의 성능 (MD)을 보고합니다.

표 4.
𝑟 1 의 영향
얼굴 랜드마크 조작
얼굴 랜드마크 탐지는 오프 더 셸프 도구(King, 2009)를 사용하여 매우 신뢰할 수 있기 때문에, 우리는 그 예측을 실제 랜드마크로 사용합니다. 구체적으로, 우리는 FFHQ로 훈련된 StyleGAN을 사용하여 두 개의 얼굴 이미지를 무작위로 생성하고, 이들의 랜드마크를 탐지합니다. 목표는 첫 번째 이미지의 랜드마크를 두 번째 이미지의 랜드마크와 일치하도록 조작하는 것입니다. 조작 후, 최종 이미지의 랜드마크를 탐지하고 목표 랜드마크와의 평균 거리(MD)를 계산합니다. 결과는 1000번의 테스트를 평균낸 것입니다. 모든 방법을 평가하기 위해 동일한 테스트 샘플 세트를 사용합니다. 이러한 방식으로 최종 MD 점수는 방법이 랜드마크를 목표 위치로 얼마나 잘 이동시키는지를 반영합니다. 우리는 핸들 포인트의 수에 따른 접근법의 견고성을 보여주기 위해 1, 5, 68개의 랜드마크 설정에서 평가를 수행합니다. 또한, 편집된 이미지와 초기 이미지 간의 FID 점수를 보고하여 이미지 품질을 나타냅니다. 우리 접근법과 그 변형에서는 최대 최적화 단계를 300으로 설정합니다.
결과는 표 1에 제공됩니다. 우리의 접근법은 포인트 수에 상관없이 UserControllableLT를 크게 능가합니다. 질적 비교는 그림 7에 나와 있으며, 우리의 방법은 입을 열고 턱의 형태를 목표 얼굴에 맞추지만 UserControllableLT는 이를 수행하지 못합니다. 또한, 우리의 접근법은 FID 점수에서 나타나듯이 더 나은 이미지 품질을 유지합니다. 더 나은 추적 능력 덕분에, 우리는 RAFT와 PIPs보다 더 정확한 조작을 달성합니다. 부정확한 추적은 과도한 조작을 초래하여 이미지 품질을 악화시키며, 이는 FID 점수에서 볼 수 있습니다. 비록 UserControllableLT가 더 빠르지만, 우리의 접근법은 이 작업의 상한선을 크게 끌어올려 훨씬 더 충실한 조작을 달성하면서도 사용자가 편안하게 사용할 수 있는 실행 시간을 유지합니다.


4.3 토론
마스크의 효과
우리의 접근법은 사용자가 이동 가능한 영역을 나타내는 이진 마스크를 입력할 수 있도록 합니다. 그림 8에서 그 효과를 보여줍니다. 개의 머리 위에 마스크를 적용하면 다른 영역은 거의 고정되고 머리만 움직입니다. 마스크 없이 조작하면 개의 전체 몸이 움직입니다. 이는 포인트 기반 조작이 여러 가능한 해결책을 가지며, GAN은 학습된 이미지 매니폴드에서 가장 가까운 해결책을 찾는 경향이 있음을 보여줍니다. 마스크 기능은 모호성을 줄이고 특정 영역을 고정하는 데 도움을 줄 수 있습니다.
분포 외 조작
지금까지 보여준 포인트 기반 조작은 모두 "분포 내" 조작으로, 즉 훈련 데이터셋의 이미지 분포 내에서 자연스러운 이미지로 조작 요구를 충족할 수 있습니다. 여기서 우리는 그림 9에서 몇 가지 분포 외 조작을 보여줍니다. 우리의 접근법은 훈련 이미지 분포 외부의 이미지를 생성하는 일부 외삽 능력을 가지고 있으며, 예를 들어, 매우 크게 벌어진 입이나 크게 확대된 바퀴와 같은 이미지를 생성할 수 있습니다. 일부 경우 사용자는 이미지를 항상 훈련 분포 내에 유지하고 이러한 분포 외 조작을 방지하고 싶어할 수 있습니다. 이를 달성하는 잠재적인 방법은 잠재 코드 w에 추가 정규화를 적용하는 것입니다. 그러나 이는 이 논문의 주요 초점은 아닙니다.

그림 8. 마스크의 효과
우리의 접근법은 이동 가능한 영역을 마스킹할 수 있도록 합니다. 개의 머리 영역을 마스킹한 후, 나머지 부분은 거의 변하지 않습니다.

그림 9. 분포 외 조작
우리의 접근법은 훈련 이미지 분포 외부의 이미지를 생성하는 외삽 능력을 가지고 있으며, 예를 들어, 매우 크게 벌어진 입과 크게 확대된 바퀴를 생성합니다.
한계점
일부 외삽 능력에도 불구하고, 우리의 편집 품질은 여전히 훈련 데이터의 다양성에 영향을 받습니다. 그림 14(a)에 예시된 것처럼, 훈련 분포에서 벗어나는 인간의 자세를 생성하면 인공물이 생길 수 있습니다. 또한, 텍스처가 없는 영역의 핸들 포인트는 추적 시 더 많은 드리프트를 겪을 수 있습니다(그림 14(b)(c)). 따라서 가능한 한 텍스처가 풍부한 핸들 포인트를 선택할 것을 권장합니다.
사회적 영향
우리의 방법은 이미지의 공간 속성을 변경할 수 있기 때문에, 실제 인물의 가짜 자세, 표정 또는 형태를 생성하는 데 악용될 수 있습니다. 따라서 우리의 접근법을 사용하는 모든 응용 프로그램이나 연구는 인격권과 개인정보 보호 규정을 엄격히 준수해야 합니다.
결론
우리는 직관적인 포인트 기반 이미지 편집을 위한 대화형 접근법인 DragGAN을 제시했습니다. 우리의 방법은 사전 훈련된 GAN을 활용하여 사용자 입력을 정확하게 따르면서도 현실적인 이미지 매니폴드에 머무르는 이미지를 합성합니다. 많은 기존 접근법과 달리, 우리는 도메인 특정 모델링이나 보조 네트워크에 의존하지 않는 일반적인 프레임워크를 제시합니다. 이는 두 가지 새로운 요소를 사용하여 달성됩니다: 잠재 코드의 최적화는 여러 핸들 포인트를 목표 위치로 점진적으로 이동시키고, 포인트 추적 절차는 핸들 포인트의 궤적을 충실히 추적합니다. 두 구성 요소 모두 GAN의 중간 특징 맵의 판별 품질을 활용하여 픽셀 단위의 정확한 이미지 변형과 대화형 성능을 제공합니다. 우리는 우리의 접근법이 GAN 기반 조작에서 최첨단을 능가하며 생성 프라이어를 사용한 강력한 이미지 편집을 위한 새로운 방향을 제시함을 입증했습니다. 앞으로의 연구로 우리는 포인트 기반 편집을 3D 생성 모델로 확장할 계획입니다.
감사의 글
Christian Theobalt는 ERC Consolidator Grant 4DReply(770784)의 지원을 받았습니다. Lingjie Liu는 Lise Meitner Postdoctoral Fellowship의 지원을 받았습니다. 이 프로젝트는 Saarbrücken Research Center for Visual Computing, Interaction and AI의 지원을 받았습니다.



