https://arxiv.org/abs/2408.00653
SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement
We present SF3D, a novel method for rapid and high-quality textured object mesh reconstruction from a single image in just 0.5 seconds. Unlike most existing approaches, SF3D is explicitly trained for mesh generation, incorporating a fast UV unwrapping tech
arxiv.org
요약
우리는 단일 이미지에서 고속으로 고품질의 텍스처 객체 메쉬를 재구성하는 새로운 방법인 SF3D를 소개합니다. SF3D는 0.5초 만에 텍스처 객체 메쉬를 재구성할 수 있습니다. 대부분의 기존 방법과 달리, SF3D는 메쉬 생성을 명시적으로 훈련하며, 버텍스 색상에 의존하지 않고 빠른 UV 언래핑 기술을 사용하여 신속한 텍스처 생성을 가능하게 합니다. 또한, 이 방법은 재구성된 3D 메쉬의 시각적 품질을 향상시키기 위해 재료 매개변수와 노멀 맵을 예측하는 학습을 합니다. 더불어, SF3D는 저주파 조명 효과를 효과적으로 제거하는 디라이트닝 단계를 통합하여 재구성된 메쉬가 새로운 조명 조건에서도 쉽게 사용할 수 있도록 합니다. 실험 결과, SF3D는 기존 기술들보다 우수한 성능을 보여줍니다.
프로젝트 페이지 및 코드와 모델: https://stable-fast-3d.github.io

그림 1: SF3D는 0.5초 만에 단일 이미지에서 재료, 디라이트닝 및 UV 언래핑 텍스처 메쉬를 가진 고품질 객체 메쉬를 생성합니다. 여기서는 다양한 입력 이미지에서 SF3D의 샘플 결과를 보여줍니다. SF3D는 사실적 스타일과 비사실적 스타일 모두 잘 처리합니다.
1. 서론
고품질 객체 메쉬는 영화, 게임, 전자 상거래, AR/VR 등 다양한 용도에서 필수적입니다. 이번 연구에서는 단일 이미지로부터 고품질 3D 객체 메쉬를 생성하는 문제를 다룹니다. 이는 단일 2D 투영(이미지)만으로 객체의 3D 형태와 텍스처를 추론해야 하는, 정식화되지 않고 어려운 문제입니다. 단일 이미지 객체 생성을 통해 번거롭고 수작업이 많은 객체 생성 과정을 단순화할 수 있습니다.
지난 몇 년 동안 트랜스포머 모델[20, 18, 54], 대규모 합성 데이터셋[11], 3D 인식 이미지/비디오 생성 모델[31, 51, 57, 67]의 발전으로 단일 이미지로부터 객체 메쉬를 생성하는 품질이 크게 향상되었습니다. 특히 트랜스포머 기반 재구성 모델[20, 18, 54]은 합성 데이터셋만으로 훈련되었음에도 불구하고 실제 이미지에 대한 뛰어난 일반화 능력을 보여주며, 단일 이미지에서 1초 이내에 3D 자산을 생성할 수 있습니다.

그림 2: SF3D의 다양한 문제에 대한 개선. 여기에서는 TripoSR[54]과 우리의 결과를 비교합니다. 상단은 자산을 재조명할 때 조명이 박힌 효과를 보여줍니다. SF3D는 보다 그럴듯한 재조명을 생성합니다. 버텍스 색상을 사용하지 않기 때문에, 우리의 방법은 더 적은 폴리곤 수로 세밀한 디테일을 인코딩할 수 있습니다. 버텍스 변위는 매칭 큐브에서 계단형 아티팩트를 도입하지 않으면서 매끄러운 형태를 추정할 수 있게 합니다. 마지막으로, 재료 속성 예측을 통해 다양한 표면 유형을 표현할 수 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
"버텍스 색상을 사용하지 않기 때문에"라는 표현은 3D 메쉬 재구성 과정에서 개별 버텍스(정점)에 색상을 직접 지정하지 않는다는 의미
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
서론
빠른 진보에도 불구하고, 이러한 피드포워드 방식의 빠른 3D 재구성 모델들[20, 18, 54]에는 여전히 여러 가지 문제점이 남아 있습니다. 이러한 기술들은 종종 후속 응용 프로그램에서 사용하기 어려운 3D 자산을 생성하거나, 많은 수작업 후처리가 필요합니다. 우리는 이러한 기술들의 여러 주요 문제점을 식별하고, 'Stable Fast 3D'(SF3D)라는 빠른 생성 기법을 제안하여 단일 이미지에서 더 높은 품질과 더 사용 가능한 3D 자산을 생성하면서도 0.5초 내에 H100 GPU에서 생성 속도를 유지합니다. 다음으로, 이러한 문제들과 SF3D에서 이를 해결하는 방법을 간략히 소개합니다.
조명 베이크인: 입력 이미지에 그림자나 기타 조명 효과가 포함되는 것은 일반적입니다. 대부분의 기존 작업은 이러한 효과를 텍스처에 포함시켜, 결과 3D 자산을 덜 사용 가능하게 만듭니다. 일관된 조명은 그래픽 파이프라인에 쉽게 통합될 수 있게 돕습니다. SF3D에서는 구면 가우시안(SG)을 사용한 명시적인 조명과 미분 가능한 음영 모델을 도입하여 조명과 반사 속성을 분해하는 방법을 제안합니다. 그림 2 (상단 행)는 기존 기술에 비해 조명 베이크인이 상당히 줄어든 SF3D의 샘플 결과를 보여줍니다.
버텍스 색상: 대부분의 3D 생성 모델에서 발견된 또 다른 문제는 객체 텍스처를 나타내기 위해 버텍스 색상을 사용하여 높은 버텍스 수를 가지는 메쉬를 생성한다는 점입니다. 이는 게임과 같은 응용 프로그램에서 결과 3D 자산을 비효율적으로 만듭니다. UV 언래핑의 추가 처리 시간이 주요 문제입니다. 예를 들어, xatlas[72]와 geogram[27]은 각각 단일 자산에 대해 최대 30초 또는 10초가 소요될 수 있습니다. 이를 해결하기 위해, 우리는 박스 프로젝션 기반의 고도로 병렬화된 빠른 UV 언래핑 기법을 제안하여 0.5초 생성 시간을 달성합니다. 버텍스 색상 사용 대 UV 언래핑의 효과는 그림 2 (중간 행)에서 볼 수 있으며, TripoSR은 10배 높은 폴리곤 수가 필요함에도 불구하고 SF3D보다 디테일이 적습니다.
마칭 큐브 아티팩트: 피드포워드 네트워크는 종종 마칭 큐브(MC)[35] 알고리즘을 사용하여 메쉬로 변환되는 체적 표현을 생성합니다. MC는 '계단형' 아티팩트를 초래할 수 있으며, 이는 볼륨 해상도를 높임으로써 다소 줄일 수 있지만, 이는 큰 계산 오버헤드를 수반합니다. 이에 반해, SF3D는 더 높은 해상도의 트리플레인을 위한 더 효율적인 아키텍처를 사용하며, 학습된 버텍스 변위와 노멀 맵을 사용하여 DMTet[46]을 통해 메쉬를 생성하여 더 부드러운 메쉬 표면을 제공합니다. 그림 2는 TripoSR과 비교하여 SF3D 메쉬의 부드러움을 보여줍니다.
재료 속성 부족: 이전 피드포워드 기술의 생성물은 다른 조명에서 렌더링될 때 종종 밋밋해 보입니다. 이는 주로 출력 생성물에 명시적인 재료 속성이 없기 때문이며, 이는 빛 반사에 영향을 줄 수 있습니다. 이를 해결하기 위해 우리는 비공간적으로 변화하는 재료 속성을 예측합니다. 이러한 추가 사항은 그림 2 (하단 행)에서 다양한 생성된 객체를 렌더링할 때 명확하게 나타납니다.
이러한 발전으로, SF3D는 단일 이미지로부터 고품질의 3D 메쉬를 생성하여 모양(저폴리곤이면서 매끄러운)과 텍스처(조명 분리된 UV 맵과 재료 속성) 모두에서 여러 응용 프로그램에 유용한 특성을 갖습니다. 3D 자산은 크기가 작고(1MB 이하), 0.5초 내에 생성될 수 있습니다. 텍스트에서 3D 메쉬 생성의 경우, 빠른 텍스트-이미지(T2I) 모델[45]과 SF3D를 결합하여 약 1초 만에 메쉬를 생성할 수 있습니다. 실험 결과는 기존 작업보다 SF3D가 더 높은 품질의 결과를 보여줍니다. 요약하자면, SF3D는 단일 이미지에서 빠르고 고품질의 3D 객체 생성을 위한 종합적인 기술을 제공하여, 실용적인 응용 프로그램에서 속도와 사용성을 모두 해결합니다.
2. 관련 연구
이미지 생성 프라이어를 사용한 3D 재구성: 확산 모델[19, 50]은 다양한 작업에서 강력한 생성 모델임이 입증되었습니다[3, 44, 43, 2, 56, 15]. Zero123[31] 및 기타 연구[11, 51, 25, 80]에서는 3D 생성을 위해 생성 모델을 조정하여 이러한 확산 모델의 객체 프라이어를 활용합니다. Score Distillation Sampling (SDS)[41]은 2D 확산 모델을 사용하여 3D 표현을 최적화하는 데 자주 사용됩니다. 그러나 이미지 프라이어에만 의존하면 일관된 다중 뷰 결과를 항상 생성하지는 못합니다. 이 문제는 후속 연구[49, 32, 37, 47]에서 객체의 여러 뷰를 동시에 생성함으로써 개선되었습니다. 또 다른 접근법으로는 3D 인식을 명시적으로 도입하거나[71, 30, 29], 다중 뷰 확산 과정을 사용하여 3D 객체를 생성하는 방법[49, 62, 34, 26, 2, 36, 57, 14, 79, 33]이 있습니다. 확산 모델은 동영상이나 다중 뷰 이미지를 비교적 빠르게 생성할 수 있지만, 단일 이미지에서 3D 메쉬를 생성하려면 3D 재구성 단계가 필요합니다. 빠른 기술을 사용하더라도 객체 생성에는 여전히 몇 분이 걸립니다. 우리의 연구는 이미지에서 3D로의 빠른 생성 속도인 0.5초에 중점을 둡니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
"이미지 프라이어에만 의존하면 일관된 다중 뷰 결과를 항상 생성하지는 못합니다"라는 문장은 2D 이미지 기반의 생성 모델이 객체의 여러 방향에서 일관된 3D 모습을 생성하는 데 어려움을 겪을 수 있다는 의미
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
피드포워드 3D 재구성: 최근 LRM[20]과 후속 연구[18, 54]에서는 대규모 합성 데이터셋으로 훈련된 피드포워드 네트워크를 사용하여 빠르고 신뢰할 수 있는 3D 생성을 실현할 수 있음을 보여주었습니다. 이 연구들은 큰 트랜스포머 모델을 사용하여 볼륨 표현으로 트리플레인을 직접 예측하며, 이는 NeRF[38]를 사용하여 레이 마칭될 수 있습니다. 이를 통해 이러한 모델들은 다중 뷰 데이터셋에서 렌더링 손실만으로 훈련할 수 있습니다. 후속 연구에서는 다중 뷰 데이터셋에 대한 의존성을 줄이기 위해[65, 58, 23] 여러 가지 방법을 제안합니다. 이러한 방법들은 이미지에서 몇 초 내에 메쉬를 생성할 수 있습니다.
또한, 몇 가지 후속 연구에서는 가우시안 스플래팅[24]을 표현으로 사용하거나[52, 76, 53, 70, 82], 메쉬 예측을 직접 통합하는 방법[81, 68, 66, 60, 73, 63]이 있습니다. 또 다른 그룹의 방법은 트리플레인을 직접 생성하거나[59], LRM을 디노이저로 사용하거나[69], 조건부로 사용하여[61] 확산 모델을 피드포워드 모델과 통합합니다. 단일 이미지 재구성이 어려운 작업이므로, 몇 가지 모델은 피드포워드 모델이 3D 출력을 생성하는 데 사용할 수 있도록 객체의 여러 뷰를 생성하기 위해 광범위한 다중 뷰 확산 모델의 프라이어를 활용합니다[76, 81, 68, 66, 53, 60, 73, 63, 70, 28]. 일반적으로 이러한 모델들은 조명 정보를 객체에 포함시키는 장면의 방사율을 학습합니다. LDM[66]은 음영 정보를 캡처하기 위해 추가적인 음영 색상을 학습함으로써 이를 해결하려고 합니다. 그러나 훈련에는 감독 신호로서의 실제 알베도 색상에 대한 접근이 필요합니다. LDM과 비교하여, 우리의 방법은 조명 모델도 학습하여 일반적인 다중 뷰 데이터셋에서 훈련할 수 있게 하고, 더 많은 재료 속성을 예측합니다. 우리는 또한 빠른 UV 언래핑을 해결하므로, 이전 작업과 달리 버텍스 색상에 의존하지 않으면서 3D 생성 시간을 단축합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
"일반적으로 이러한 모델들은 조명 정보를 객체에 포함시키는 장면의 방사율을 학습합니다"라는 문장은, 모델이 3D 객체를 생성할 때 단순히 형태와 텍스처만을 학습하는 것이 아니라, 해당 객체가 특정 조명 조건 하에서 어떻게 보이는지를 학습하여 더 현실적이고 일관된 3D 모델을 생성한다는 의미
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
재료 분해: 객체의 방사율만 예측하면 재조명 시 설득력 있는 결과를 얻기 어렵습니다. 단일 장면 최적화의 현재 작업은 종종 NeRF[38] 또는 가우시안 스플래팅[24]을 기반으로 하며, 여러 입력 이미지(>50)를 조명과 재료로 분해합니다[4, 5, 6, 13, 75, 39, 17]. 이러한 방법들은 종종 물리 기반 렌더링(PBR) 음영 모델의 재료 속성을 예측합니다. 최근 몇 가지 연구에서는 SDS 손실을 사용하여 재료 속성을 최적화함으로써 UniDream[33]이나 Fantasia3D[10]와 같이 3D 형태와 재료 생성을 공동으로 다룹니다. 그러나 이러한 최적화는 수렴하는 데 몇 시간이 걸립니다. 또 다른 연구들은 확산 모델을 사용하여 기존 객체에 텍스처를 입히는 것을 목표로 합니다[78, 55]. 우리의 연구는 자연 조명 하에서 단일 이미지로부터 동질의 재료 속성을 가진 텍스처 객체를 빠른 생성 속도로 생성합니다.
3. 방법
우리는 단일 객체 이미지를 텍스처가 포함된 UV 언래핑된 3D 모델로 변환하는 SF3D를 제안합니다. 이 모델은 조명이 제거된 알베도와 재료 속성을 포함합니다. 서론에서 설명한 바와 같이, SF3D를 통해 그림 2에 나타난 문제를 해결하고 추가적인 품질 향상을 도입하고자 합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
알베도(albedo)는 어떤 표면이 받는 빛을 얼마나 반사하는지를 나타내는 측정값입니다. 알베도 값은 0에서 1 사이의 값을 가지며, 0은 모든 빛을 흡수하고 아무 것도 반사하지 않는 것을 의미하고, 1은 모든 빛을 반사하고 아무 것도 흡수하지 않는 것을 의미합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
기초 지식: 우리의 방법은 TripoSR[54, 20]을 기반으로 하며, 이는 단일 이미지에서 Triplane[9] 기반 3D 표현을 출력하는 대규모 트랜스포머 기반 네트워크를 훈련합니다. TripoSR은 명시적인 3D 감독 없이 다중 뷰 이미지 데이터셋으로 훈련됩니다. TripoSR에서는 이미지를 DINO[8]를 사용하여 인코딩하고, 트랜스포머 네트워크를 통과시켜 해상도 64×64 의 3D 트리플레인을 생성합니다. 그런 다음 트리플레인 특징을 RGB 색상으로 디코딩하고, 표준 NeRF[38] 렌더링을 사용하여 여러 뷰로 렌더링하여 훈련합니다. TripoSR은 뷰에 독립적인 색상만 학습하며, 반사 객체를 모델링할 수 없습니다. TripoSR(및 다른 유사 네트워크)의 여러 문제는 서론(Fig. 2)에서 설명되었습니다.

그림 3: SF3D 개요. SF3D는 그림 2의 문제를 해결하기 위해 5개의 새로운 모듈로 TripoSR을 개선합니다: 1. 더 높은 해상도의 트리플레인을 위한 향상된 트랜스포머(왼쪽 상단); 2. Material Net을 통한 재료 추정(왼쪽 하단); 3. Light Net을 사용한 명시적 조명 추정(오른쪽 하단); 4. 버텍스 오프셋 및 노멀 추정을 통한 부드러운 메쉬 추출(오른쪽 상단); 마지막으로 5. 빠른 UV 언래핑을 포함한 내보내기 파이프라인(오른쪽).
SF3D 개요: 우리는 TripoSR[54]의 여러 개선점을 제안하여 출력 품질을 다양한 측면에서 향상시키고자 합니다. 그림 3에 설명된 것처럼, SF3D는 5개의 주요 구성 요소로 이루어져 있습니다:
- 고해상도 트리플레인을 예측하는 향상된 트랜스포머 네트워크로, 앨리어싱 아티팩트를 줄이는 데 도움이 됩니다(그림 왼쪽 상단).
- 재료 속성을 예측하여 객체의 반사 속성을 처리하는 데 도움이 되는 재료 추정 네트워크(왼쪽 하단).
- 그림자 없는 균일한 객체를 출력할 수 있도록 조명 분리를 처리하는 조명 예측 모듈(오른쪽 하단).
- 버텍스 오프셋 및 표면 노멀을 예측하여 메쉬를 추출하고 정제하는 모듈로, 더 부드러운 출력 형태와 적은 메쉬 추출 아티팩트를 제공합니다(오른쪽 상단).
- 저폴리곤 메쉬와 고해상도 텍스처를 생성하는 빠른 UV 언래핑 및 내보내기 모듈(오른쪽). 다음으로, 이 각 모듈에 대해 자세히 설명합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
앨리어싱(알리아싱) 아티팩트는 디지털 이미지나 그래픽을 처리할 때 발생하는 왜곡 현상으로, 주로 해상도가 낮을 때 나타납니다. 이는 고주파수 세부 사항을 표현하는 데 필요한 충분한 샘플링이 이루어지지 않아 생기는 문제입니다. 앨리어싱 아티팩트는 여러 형태로 나타날 수 있으며, 일반적으로 다음과 같은 방식으로 설명됩니다:
- 계단 현상(Jaggies): 직선이나 경계선이 계단 모양으로 보이는 현상입니다. 이는 낮은 해상도에서 곡선이나 경사진 선을 표현할 때 발생합니다.
- 모아레 패턴(Moire Patterns): 반복적인 패턴이나 세밀한 텍스처가 겹쳐져서 나타나는 물결 모양의 왜곡 현상입니다.
- 그리드 패턴(Grid Patterns): 세밀한 패턴이나 텍스처가 그리드 모양으로 왜곡되어 보이는 현상입니다.
앨리어싱은 주로 다음과 같은 원인으로 발생합니다:
- 샘플링 부족: 원래의 고해상도 데이터를 저해상도로 변환할 때, 고주파수 정보가 제대로 반영되지 못해 왜곡이 생깁니다.
- 해상도 제한: 해상도가 낮을수록 세밀한 디테일을 표현할 수 있는 능력이 떨어지므로, 복잡한 패턴이나 세부 사항이 왜곡될 수 있습니다.
이러한 아티팩트를 줄이기 위해 다양한 기술이 사용됩니다. 예를 들어, 안티앨리어싱(anti-aliasing) 기법은 이미지의 경계선이나 텍스처를 부드럽게 만들어 앨리어싱 효과를 완화하는 데 사용됩니다.
SF3D에서는 트리플레인의 해상도를 높여 이러한 앨리어싱 아티팩트를 줄이고, 더 부드럽고 디테일한 3D 모델을 생성할 수 있도록 합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.1 향상된 트랜스포머 먼저, 그림 3에서 설명한 것처럼, 우리는 TripoSR에서 사용된 DINO[8]를 개선된 DINOv2[40] 네트워크로 전환하여 트랜스포머를 위한 이미지 토큰을 얻습니다. 우리는 TripoSR 및 다른 네트워크[20, 18]에서 사용된 저해상도( 64×64 ) 트리플레인이 특히 고주파수 및 고대비 텍스처 패턴이 있는 시나리오에서 눈에 띄는 아티팩트를 도입한다는 것을 관찰했습니다. 그림 4(중앙)는 이러한 앨리어싱 아티팩트를 설명합니다. 트리플레인 해상도는 이러한 아티팩트의 존재와 직접적으로 관련이 있으며, 이는 해상도를 증가시켜 완화할 수 있는 앨리어싱 문제로 확인되었습니다. 증가된 용량은 또한 지오메트리를 향상시킵니다.

그림 4: 트리플레인 해상도 앨리어싱: 저해상도 트리플레인은 고주파수 및 고대비 텍스처에서 그리드 모양의 앨리어싱 아티팩트를 생성하는 데 어려움을 겪는다는 것을 발견했습니다. 우리의 방법은 트리플레인 크기를 64^2 에서 384^2 로 증가시켜 이러한 텍스처를 더 적은 아티팩트로 재현할 수 있게 합니다.
고해상도 트리플레인
단순히 트리플레인의 해상도를 증가시키면 트랜스포머의 복잡성이 기하급수적으로 증가합니다. 우리는 최근 PointInfinity[22] 연구에서 영감을 받아, 더 높은 해상도의 트리플레인을 출력하는 향상된 트랜스포머 네트워크를 제안합니다. PointInfinity는 고해상도 트리플레인 토큰에서 자기 주의를 피하여 입력 크기에 비례하여 복잡성을 선형으로 유지하는 아키텍처를 제안합니다. 이 추가 기능을 통해 우리는 1024 채널의 해상도 96×96 의 트리플레인을 생성합니다. 우리는 출력 특징을 차원 간에 섞어서 트리플레인 해상도를 384×384 에서 40채널 특징으로 증가시켰습니다. 아키텍처에 대한 자세한 내용은 부록에서 확인할 수 있습니다. 그림 4 (오른쪽)는 더 높은 해상도의 트리플레인으로 앨리어싱 아티팩트가 적어진 것을 보여줍니다.
3.2 재료 추정
반사 객체의 출력 메쉬 외관을 향상시키기 위해 SF3D는 금속성과 거칠기 매개변수의 재료 속성도 출력합니다. 이상적으로는 3D 출력 위치에서 공간적으로 변화하는 재료 속성을 추정하고자 하지만, 이는 본질적으로 어려운 학습 문제로, 공간적으로 변화하는 고품질 3D 데이터를 많이 필요로 합니다. 이러한 문제를 극복하기 위해, 우리는 전체 객체에 대해 단일 금속성과 거칠기 값을 추정하여 재료 추정 문제를 단순화하는 방법을 제안합니다. 비록 이 비공간적으로 변화하는 재료는 주로 균질한 객체에 적용되지만, 이는 우리의 메쉬 예측의 시각적 품질을 크게 향상시킵니다. 특히, 그림 3에서 설명한 것처럼, 우리는 입력 이미지로부터 금속성과 거칠기 값을 예측하는 ‘Material Net’을 제안합니다.
Material Net의 사전 훈련을 위해, 합성 훈련 데이터셋에서 PBR 재료 속성을 가진 3D 객체의 하위 집합을 선택하고, 이를 다양한 조명과 시점에서 렌더링했습니다. 재료 값을 직접 회귀하면 네트워크가 항상 거칠기 값 0.5 와 금속성 값 0 를 예측하는 훈련 붕괴로 이어진다는 것을 관찰했습니다. 이를 해결하기 위해, 우리는 베타 분포의 매개변수를 예측하고 훈련 중 로그 가능도를 최소화하는 확률적 예측 접근법을 제안합니다. 이는 이 모호한 재료 추정 작업에서 불확실성을 허용하여 훈련을 안정화하고, 직접 회귀에서 관찰된 붕괴를 방지합니다. SF3D의 추론 및 훈련 중에는 분포를 샘플링하지 않고 분포의 모드를 계산합니다.
우리는 이미지를 의미론적으로 의미 있는 잠재 변수를 추출하기 위해 고정된 CLIP 이미지 인코더[42]를 통해 먼저 통과시키고, 3개의 숨겨진 층과 512의 너비를 가진 2개의 별도 MLP를 통해 분포의 매개변수를 출력하여 Material Net을 구현합니다.
3.3 조명 모델링
입력 이미지에서 조명을 명시적으로 추정하여 그림자 등 다양한 음영을 고려하는 방법을 제안합니다. 그렇지 않으면, 그림 2에서 설명한 것처럼, 3D 출력은 RGB 색상에 조명 효과가 포함되어 있게 됩니다. 이를 위해, 우리는 추정된 트리플레인에서 구면 가우시안(SG) 조명 맵을 예측하는 Light Net(그림 3 오른쪽 하단)을 제안합니다. 여기서의 논리는 트리플레인이 입력 객체의 전반적인 구조와 외관을 인코딩하고, 객체 표면의 3D 공간 관계와 조명 변화를 고려해야 한다는 것입니다. 우리는 트랜스포머에서 해상도 96×96 의 트리플레인을 사용하고, 이를 2개의 CNN 층을 통과시키며, 맥스 풀링과 최종 MLP를 통해 모든 층의 특징 차원 512 로 설정된 3개의 숨겨진 층을 거칩니다. Light Net은 24개의 SG에 대해 소프트플러스 활성화로 양수 값을 보장하는 그레이스케일 진폭 값을 출력합니다. 이러한 SG의 축과 샤프니스 값은 고정되어 전체 구를 덮도록 설정됩니다. 이러한 진폭 값은 NeRD[4]에서 사용된 것과 유사한 지연 물리 기반 렌더링 접근법을 구현할 수 있게 합니다.
우리의 방법은 또한 훈련 단계에서 Hasselgren et al.[17]과 Voleti et al.[57]의 연구에서 영감을 받은 조명 변조 손실 ℒDemod 을 통합합니다. 이 손실 함수는 완전히 흰색 알베도를 가진 객체의 조명이 입력 이미지의 휘도와 밀접하게 일치하도록 보장합니다. 변조 손실은 학습된 조명과 훈련 데이터에서 관찰된 조명 조건 간의 일관성을 보장합니다. 이는 외관과 음영 간의 모호성을 해결하기 위한 편향으로 볼 수 있습니다[1].

그림 5: 내보내기 파이프라인. 우리의 내보내기 프로세스는 메쉬로 시작하여 UV 언래핑, 점유 및 월드 포지션 베이킹, 재료 쿼리, UV 아일랜드 마진으로 이어집니다.
3.5 빠른 UV 언래핑 및 내보내기
SF3D의 마지막 단계는 최종 3D 메쉬와 해당 UV 아틀라스를 출력하는 내보내기 파이프라인입니다. 우리의 내보내기 파이프라인은 3D 모델을 효율적이고 효과적으로 처리하기 위해 여러 단계를 거칩니다. 이러한 단계들의 개요는 그림 5에 제공되어 있으며, 첫 번째 단계로 빠른 UV 언래핑이 수행됩니다. 그런 다음 우리는 UV 아틀라스에 월드 포지션과 점유를 베이킹하여 알베도와 노멀 쿼리에 사용합니다. 이를 통해 최종 텍스처가 적용된 3D 메쉬를 얻습니다. 전체 내보내기 과정은 단 150ms가 소요됩니다.
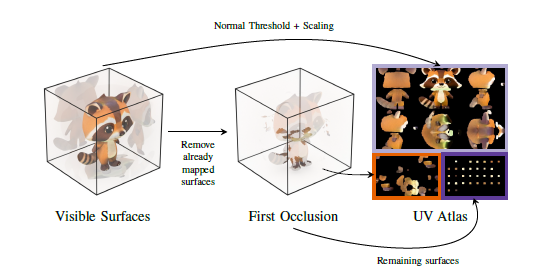
그림 6: UV 언래핑. 우리의 UV 언래핑 기술은 투영 매핑을 사용하여 각 면이 독립적으로 투영을 선택할 수 있게 하여 병렬 처리가 용이합니다. 단순한 접근 방식은 폐색으로 인해 서로 다른 버텍스에 동일한 UV 좌표가 할당되는 문제를 초래할 수 있습니다. 우리는 2D 매핑된 표면에서 폐색으로 인한 잠재적인 겹침을 식별하고, 이를 UV 아틀라스 내의 다른 영역으로 이동시킵니다. 남은 영역은 UV 아틀라스의 오른쪽 하단에 배치됩니다. 이 방법은 왜곡을 최소화하고 대부분의 표면이 연결된 영역 내에 보존되도록 보장합니다.
UV 언래핑
UV 언래핑은 전통적으로 계산 집약적인 과정입니다. 기존 방법들은 UV 언래핑에 몇 초가 소요되는데, 이는 초 단위 생성 속도를 목표로 할 때 비현실적입니다. 이러한 비효율성을 해결하기 위해, 우리는 큐브 투영 기반 언래핑 방법을 제안합니다. 이 접근 방식의 주요 장점은 병렬 처리가 가능하다는 점입니다. 메쉬의 각 면은 표면 노멀을 기준으로 독립적으로 투영할 큐브 면을 결정할 수 있습니다.
우리의 UV 언래핑 과정은 그림 6에 설명되어 있습니다. 우리는 먼저 큐브 투영 좌표 시스템과 가장 지배적인 축을 기준으로 출력 메쉬를 정렬합니다. 각 메쉬 면이 적절한 큐브 방향을 선택한 후에는 잠재적 폐색 문제를 해결합니다. 폐색을 관리하지 않으면 서로 다른 면이 동일한 UV 좌표를 공유하여 텍스처에 아티팩트가 생길 수 있습니다. 우리는 2D 삼각형-삼각형 교차 테스트를 수행하여 UV 아틀라스에서 폐색을 감지합니다. 이 과정을 효율적으로 만들기 위해 삼각형 중심에 대한 근접성으로 삼각형을 필터링합니다. 교차가 감지되면, 교차 삼각형을 평면에서의 깊이에 따라 정렬하여 첫 번째 교차 삼각형을 유지하고 다른 삼각형을 다른 UV 아틀라스 영역으로 재할당하도록 표시합니다. 첫 번째 교차 삼각형은 UV 아틀라스의 상단 1/3에, 두 번째 교차 삼각형은 왼쪽 하단 영역에 배치됩니다. 나머지 삼각형은 아틀라스의 오른쪽 하단 섹션에 그리드로 정리됩니다. 우리는 또한 음영 이음새를 최소화하기 위해 각 섬을 방사형 z 접선 방향으로 회전시킵니다. 그런 다음 각 면을 UV 아틀라스의 위치에 할당합니다(그림 6 참조).
다음으로, 우리는 월드 포지션과 점유 데이터를 UV 언래핑과 함께 최종 UV 아틀라스에 베이킹합니다. 이를 통해 트리플레인에서 월드 포지션을 쿼리하고 알베도와 표면 노멀을 추가 텍스처로 디코딩할 수 있습니다. 우리는 월드 공간 노멀 맵을 접선 공간 노멀 맵으로 변환하기 위해 접선 및 비접선 벡터를 사용합니다. UV 섬 경계에서 보이는 이음새를 방지하기 위해 UV 아틀라스에 여백을 추가합니다. 이는 반복적인 과정으로 이루어집니다: 각 반복에서 점유 영역을 기반으로 3×3 부분 컨볼루션을 수행하여 커널의 유효 영역을 사용합니다. 그런 다음 3×3 최대 풀링 연산을 사용하여 UV 아틀라스의 점유 영역을 확장하고, 원래 영역을 보존하면서 새로 확장된 영역에 평균 값을 배치합니다. 이 반복적 확장은 텍스처가 부드럽게 바깥쪽으로 블렌딩되도록 보장합니다.
우리는 이미지 추정기의 금속성과 거칠기 값을 통합하고, 모든 것을 GLB 파일에 패킹하여 다양한 응용 프로그램에서 효율적으로 렌더링하고 사용할 준비를 합니다.
3.6 전체 훈련 및 손실 함수
메쉬 렌더링으로 직접적으로 우리의 방법을 훈련시키는 것은 만족스럽지 않은 결과를 낳았습니다. 따라서 우리는 NeRF 작업에 대한 사전 훈련을 수행했습니다. 이 사전 훈련 후, 우리는 메쉬 훈련으로 전환하여 NeRF 렌더링을 미분 가능한 메쉬 렌더링과 SG 기반 음영으로 대체했습니다. 조명 추정을 도입한 결과, 더 큰 배치 크기를 사용하는 것이 수렴에 도움이 된다는 것을 발견했습니다. 우리는 배치 크기 192와 128×128 해상도로 훈련을 시작하여 10K 스텝 동안 훈련합니다. 다음 단계에서는 배치 크기를 128로 줄이고 해상도를 256×256으로 증가시키며, 20K 스텝 동안 훈련을 계속합니다. 마지막 단계에서는 512×512 해상도에서 80K 스텝 동안 배치 크기 96으로 훈련합니다.
손실 함수는 모든 메쉬 훈련 단계에서 일관되게 유지됩니다. 우리는 주로 렌더링 및 음영 복원을 GT 이미지 𝑰 와 비교하기 위해 이미지 기반 메트릭을 사용합니다. 여기에는 ℒ MSE 및 LPIPS[77]의 ℒ LPIPS 손실이 포함됩니다. 우리는 또한 GT 마스크 M 와 예측 불투명도 M ^ 사이의 마스크 손실 ℒ Mask 를 포함합니다. 이는 MSE 손실로 정의됩니다. 우리는 렌더링, 메쉬 정규화, 음영을 위한 세 가지 손실 공식을 정의합니다.

총 손실 함수는 다음과 같이 정의됩니다:

4. 결과

그림 7: GSO와 OmniObject3D 비교. 우리의 재구성이 상세한 텍스처와 매끄러운 음영으로 일관된 결과를 생성하는 것을 확인할 수 있습니다.

표 1: 최첨단 성능을 보여주는 3D 메트릭 비교. 모든 다른 방법들이 훨씬 더 높은 폴리곤 수를 가진 메쉬를 생성한다는 점에 주목할 필요가 있습니다. 이는 그들이 우리의 저폴리곤 메쉬보다 표면을 더 밀접하게 따를 수 있게 합니다. 그러나 우리는 학습된 버텍스 오프셋을 사용하여 다른 방법들보다 더 우수한 성능을 발휘할 수 있습니다. 또한 우리의 방법은 효율적인 추출 파이프라인 덕분에 이미지를 기반으로 메쉬를 생성하는 가장 빠른 방법 중 하나입니다.
데이터셋. 비교를 위해, 우리는 GSO[12]와 OmniObject3D[64]를 주요 평가 데이터셋으로 선택했습니다. GSO에서 278개의 랜덤 씬과 OmniObject3D에서 308개의 씬을 선택하여 비교를 수행했습니다. 객체 주위를 16개의 뷰로 렌더링하고 전면 뷰를 조건부 뷰로 선택했습니다.
기준선. 우리는 단일 이미지에서 빠른 3D 객체 재구성을 위한 몇 가지 최신 방법들과 비교했습니다. 다양한 기술들 간에 일관된 평가 프로토콜을 유지하기 위해 주로 빠른 재구성 모델들에 집중했습니다. 우리는 주로 메쉬를 출력으로 고려하고 메쉬에 대한 평가를 수행했습니다. 모든 기준선에 대해 공식 구현을 사용했으며, 동일한 프로토콜 하에 모든 방법을 평가했습니다. 비교를 위해 소스 코드가 공개된 여러 최신 및 동시 연구들을 선택했습니다. 구체적으로, 우리는 OpenLRM[18], TripoSR[54], LGM[53], CRM[59], InstantMesh[68], ZeroShape[21]와 비교했습니다. OpenLRM의 경우, 우리는 대형 Objaverse 1.1 모델을 선택했습니다. 비교에는 H100 GPU를 사용했습니다.

그림 8: 분해 결과. 여기에서는 Polyhaven[74]에서 고품질 객체를 사용하여 자연 조명 하에 렌더링했습니다. 이러한 조명은 재료 추정을 매우 어렵게 만듭니다. 그럼에도 불구하고 우리 모델은 설득력 있는 재조명을 가능하게 하는 합리적인 재료 속성을 추정합니다.

그림 9: 이미지에서 메쉬로 변환 시간 vs. 재구성 품질. 우리의 방법은 가장 빠른 재구성 방법 중 하나일 뿐만 아니라 매우 정확한 지오메트리를 생성할 수 있습니다.

표 2: 소거 실험. 우리의 모델은 TripoSR을 기반으로 구축되었기 때문에 이를 기준선으로 사용합니다. 향상된 트랜스포머가 없는 경우에도 우리의 메쉬 훈련은 TripoSR보다 이미 개선되었습니다. 아키텍처 개선으로 인해 기준선을 크게 능가합니다.
평가. 런타임 비교를 위해 우리는 메쉬를 최종 출력으로 간주하고 입력 이미지에서 최종 메쉬로 가는 전체 런타임을 계산합니다. 그런 다음 형상 품질에 대한 별도 평가를 수행합니다. 몇몇 모델은 본질적 및 외재적 카메라 매개변수에 조건을 걸 수 없기 때문에 정렬 단계를 수행할 것을 제안합니다. 우리는 메쉬를 정규화하고, 무차별 회전 정렬 테스트를 수행한 다음, 가장 낮은 챔퍼 거리(CD)를 가진 회전을 선택합니다. 그런 다음 반복 최근접 점(ICP)을 사용하여 또 다른 정렬 단계를 실행하여 회전 및 번역을 추가로 최적화합니다. 그런 다음 CD와 F-점수(FS)의 표준 형상 메트릭스를 이 정렬 후 계산합니다. 이 정렬은 대칭 객체의 재렌더링을 여전히 잘못 정렬할 수 있습니다. 따라서 보충 자료에 지시적인 렌더링 메트릭스만 보고합니다.
삼각형 수. 각 방법을 기본 구성으로 실행합니다. 삼각형 수는 3D 메쉬에 따라 크게 다르기 때문에 여기에서 단일 메쉬에 대한 삼각형 수를 보고합니다: InstantMesh 57.3K, CRM 24.1K, LGM 42.1K, TripoSR 32.1K, OpenLRM 662K, 우리의 방법 27.4K.
결과. 표 1에서 우리는 모든 기준선과 우리의 방법을 비교합니다. 여기서 우리의 방법은 CD와 F-점수 모두에서 현재 및 동시 기준선을 능가합니다. 이는 우리의 모델이 다른 기준선보다 폴리곤이 적음에도 불구하고 정확한 형상을 재구성할 수 있음을 나타냅니다. 그림 7의 시각적 비교에서 볼 수 있듯이, SF3D의 정확한 형상 재구성은 3D 자산의 시각적 품질로도 잘 반영됩니다. 여기서 주목할 점은 SF3D가 안경과 같은 정밀한 지오메트리를 잘 처리하며 SOTA 방법보다 더 자세한 텍스처를 가지고 일관된 형상을 생성한다는 것입니다. 또한, 그림 8에서 볼 수 있듯이 결과는 합리적인 재료 속성과 알베도를 보여줍니다. 이는 객체가 자연 조명 하에서만 렌더링되기 때문에 매우 도전적입니다. 조명에 대한 지식 없이 재료 속성을 추정하는 것은 매우 모호한 문제입니다.
추론 속도 vs. 재구성 품질. 그림 9에서 우리는 다른 기술에 대한 추론 속도와 재구성 품질을 플로팅합니다. 최고 성능의 방법은 좌측 상단 코너에 위치해야 합니다. 우리의 방법은 TripoSR보다 약간 느리지만, SF3D의 재구성 정확도는 훨씬 더 좋습니다. 또한 그림 7에서 볼 수 있듯이, 우리의 재구성은 덜 두드러진 마칭 큐브 아티팩트로 더 부드러운 음영을 가지고 있습니다. 따라서 최종적으로 보이는 자산의 품질은 우리의 방법이 더 높습니다.
소거 실험. 우리는 표 2에서 기준선 모델과 우리의 추가 사항을 평가합니다. 우리의 방법은 TripoSR을 기반으로 구축되었기 때문에 이를 초기 기준선으로 사용합니다. 메쉬 훈련과 재조명을 미세 조정 단계로 추가하면, '향상된 트랜스포머 없는 SF3D'가 이미 TripoSR을 개선한 것을 볼 수 있습니다. 이러한 개선은 주로 효율적인 렌더링 덕분에 훈련 중에 더 높은 해상도의 감독을 가능하게 하고 버텍스 오프셋에서 더 부드러운 메쉬를 생성합니다. 향상된 트랜스포머를 사용하여 고해상도 트리플레인을 추가하면 SF3D는 기준선을 훨씬 능가합니다.
제한 사항 및 전망. 그림 7(상단 행)에서 볼 수 있듯이 컵의 알베도가 완벽하게 일치하지 않습니다. 이는 LDR 입력과 관련이 있으며, 어두운 부분에는 유용한 정보가 포함되지 않습니다. 또한, 우리의 거칠기와 금속성 속성은 균질하여 공간적으로 변화하는 여러 다른 재료를 포함하는 객체에는 유용성이 제한됩니다. 또한, 우리의 방법은 명시적 감독 없이 재료 예측과 디라이트닝을 도입합니다. 이러한 매개변수의 명시적 감독이 필요하지 않기 때문에 우리의 방법은 실제 데이터셋에서 훈련하도록 확장될 수 있으며, 이는 미래 작업으로 남겨둡니다. 마찬가지로, UV 언래핑은 추가 개선을 위해 기존 데이터셋을 활용할 수 있습니다.
결론
우리는 빠른 단일 뷰에서 UV 언래핑된 텍스처 객체 재구성 방법인 SF3D를 제시합니다. 우리의 빠른 추출 파이프라인 외에도, 우리는 피드포워드 기반 3D 재구성 방법에 여러 아키텍처 개선 사항을 도입하여 모델이 매우 상세한 지오메트리와 텍스처를 생성할 수 있도록 돕습니다. 광범위한 평가에서 우리의 방법이 속도와 품질 모두에서 기존 및 동시 기준선을 능가한다는 것을 보여줍니다.

그림 A1: 향상된 트랜스포머 아키텍처
우리의 새로운 백본은 더 높은 해상도의 출력 트리플레인을 생성합니다. 우리는 추가로 픽셀 셔플링[48]을 사용하여 이를 업스케일합니다. 이는 그림 4에서와 같이 앨리어싱을 줄이면서 고주파수, 고대비 텍스처를 포착하는 데 도움을 줍니다.
A1 향상된 트랜스포머
앨리어싱 아티팩트를 줄이기 위해, 우리는 트랜스포머 백본을 업그레이드하여 해상도 384×384 의 트리플레인을 생성합니다. 그러나 TripoSR[54]에서 트리플레인 토큰을 단순히 증가시키는 것은 자기 주의의 기하급수적 복잡성 때문에 계산적으로 금지됩니다. PointInfinity[22]에서 영감을 받아, 우리는 토큰 수에 대해 선형 복잡성을 가지는 이중 스트림 트랜스포머를 활용합니다. 그림 A1에 설명된 것처럼, 우리의 아키텍처는 트리플레인 스트림과 잠재 스트림의 두 가지 처리 스트림으로 구성됩니다. 트리플레인 스트림은 처리될 원시 트리플레인 토큰으로 구성됩니다. 각 이중 스트림 유닛(그림 A1의 회색 상자)에서, 잠재 스트림은 교차 주의를 사용하여 트리플레인 스트림에서 정보를 가져오고, 일정 크기의 잠재 토큰 세트를 대상으로 주요 계산을 수행합니다. 그런 다음 잠재 스트림은 처리된 잠재 토큰으로 트리플레인 스트림을 업데이트합니다. 우리의 전체 아키텍처는 네 개의 이러한 이중 스트림 유닛으로 구성됩니다. 이 계산적으로 분리된 설계로 인해, 우리의 트랜스포머는 96×96 해상도와 1024 채널의 트리플레인을 생성할 수 있습니다. 해상도를 더 높이고 앨리어싱을 줄이기 위해, 우리는 픽셀 셔플링 작업[48]을 통합하여 트리플레인 해상도를 384×384 로 높이고 특징 차원을 40으로 확장했습니다.

A2 이미지 메트릭
이미지 메트릭을 위해, 우리는 형상 메트릭 계산의 파이프라인을 따릅니다. 우리는 정규화된 객체를 실제 GT 스케일로 다시 스케일링하고, 세부 스케일을 조정하기 위해 더 정밀한 ICP 최적화를 실행합니다. 이 변환을 사용하여 메쉬를 렌더링합니다. 이것은 여전히 매우 대칭적인 객체의 경우 텍스처 정렬 오류를 초래할 수 있으므로, 우리는 이미지 메트릭을 자산 재구성의 최종 품질을 평가하기 위한 보조 메트릭으로 취급합니다. 따라서, 우리는 이 메트릭을 보충 자료에서만 보고합니다. 표 A1은 또한 본 논문에서 렌더링 시 개선된 시각적 품질을 지원합니다.
결론
'인공지능' 카테고리의 다른 글
| Feature Pyramid Networks for Object Detection (2) | 2024.08.08 |
|---|---|
| U-Net: Convolutional Networks for Biomedical Image Segmentation (1) | 2024.08.07 |
| (DIT)Scalable Diffusion Models with Transformers (1) | 2024.08.05 |
| Beyond Memorization: The Challenge of Random Memory Access in Language Models (1) | 2024.08.04 |
| The Pile: An 800GB Dataset of Diverse Text for Language Modeling (2) | 2024.08.03 |



