https://arxiv.org/abs/2212.09748
Scalable Diffusion Models with Transformers
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our D
arxiv.org
요약
우리는 트랜스포머 아키텍처를 기반으로 한 새로운 클래스의 확산 모델을 탐구합니다. 우리는 흔히 사용되는 U-Net 백본을 트랜스포머로 대체하여 잠재 패치에서 작동하는 이미지를 위한 잠재 확산 모델을 훈련시킵니다. 우리는 Gflops로 측정된 순방향 패스 복잡성의 관점에서 우리의 확산 트랜스포머(DiTs)의 확장성을 분석합니다. 트랜스포머의 깊이/너비 증가 또는 입력 토큰 수 증가를 통해 Gflops가 높은 DiTs가 일관되게 더 낮은 FID를 가지는 것을 발견했습니다. 확장성 측면에서 우수한 성능을 가질 뿐만 아니라, 우리의 가장 큰 DiT-XL/2 모델은 클래스 조건부 ImageNet 512x512 및 256x256 벤치마크에서 모든 이전 확산 모델을 능가하여 후자에서 2.27의 최첨단 FID를 달성했습니다.

그림 1. 트랜스포머 백본을 가진 확산 모델은 최첨단 이미지 품질을 달성합니다. 우리는 각각 512x512 및 256x256 해상도로 ImageNet에서 훈련된 클래스 조건부 DiT-XL/2 모델의 선택된 샘플을 보여줍니다.
서론
머신 러닝은 트랜스포머에 의해 주도되는 르네상스를 경험하고 있습니다. 지난 5년 동안 자연어 처리 [8, 42], 비전 [10] 및 여러 다른 도메인을 위한 신경 아키텍처는 주로 트랜스포머 [60]에 의해 대체되었습니다. 그러나 이미지 수준 생성 모델의 많은 클래스는 여전히 이 트렌드를 따르지 않고 있습니다. 트랜스포머는 자가회귀 모델 [3, 6, 43, 47]에서 널리 사용되고 있지만, 다른 생성 모델링 프레임워크에서는 덜 채택되고 있습니다. 예를 들어, 확산 모델은 최근 이미지 수준 생성 모델의 진보를 주도해 왔지만 [9, 46], 모두 기본 백본으로 컨볼루션 U-Net 아키텍처를 채택하고 있습니다.

그림 2. 확산 트랜스포머(DiTs)를 사용한 ImageNet 생성. 버블 면적은 확산 모델의 플롭 수를 나타냅니다. 왼쪽: DiT 모델의 400K 학습 반복 시 FID-50K(낮을수록 좋음). 모델의 플롭 수가 증가함에 따라 FID 성능이 꾸준히 개선됩니다. 오른쪽: 우리의 최고 모델인 DiT-XL/2는 계산 효율적이며, ADM 및 LDM과 같은 모든 이전 U-Net 기반 확산 모델을 능가합니다.
Ho 등 [19]의 기념비적인 연구는 확산 모델에 U-Net 백본을 처음 도입했습니다. 픽셀 수준의 자가회귀 모델과 조건부 GAN [23]에서 초기 성공을 거둔 후, U-Net은 Pixel-CNN++ [52, 58]에서 몇 가지 변경 사항을 포함하여 계승되었습니다. 이 모델은 주로 ResNet [15] 블록으로 구성된 컨볼루션 모델입니다. 표준 U-Net [49]과는 달리, 트랜스포머의 필수 구성 요소인 추가적인 공간적 자가 주의 블록이 저해상도에서 삽입됩니다. Dhariwal과 Nichol [9]은 조건부 정보를 주입하기 위한 적응형 정규화 계층 [40]의 사용과 컨볼루션 계층의 채널 수와 같은 U-Net의 여러 아키텍처 선택 사항을 제거했습니다. 그러나 Ho 등에서 유래된 U-Net의 고수준 설계는 크게 변하지 않았습니다.
이 연구에서는 확산 모델에서 아키텍처 선택의 중요성을 해명하고 미래의 생성 모델링 연구를 위한 실증적 기준을 제시하는 것을 목표로 합니다. 우리는 U-Net 유도 편향이 확산 모델의 성능에 필수적이지 않으며, 표준 설계(예: 트랜스포머)로 쉽게 대체될 수 있음을 보여줍니다. 결과적으로, 확산 모델은 다른 도메인에서 최선의 관행과 학습 방법을 계승하고 확장성, 견고성 및 효율성과 같은 유리한 특성을 유지하면서 최근 아키텍처 통합 트렌드의 이점을 누릴 수 있습니다. 표준화된 아키텍처는 또한 교차 도메인 연구를 위한 새로운 가능성을 열어줄 것입니다.
이 논문에서는 트랜스포머를 기반으로 한 새로운 클래스의 확산 모델에 초점을 맞춥니다. 우리는 이를 확산 트랜스포머, 줄여서 DiTs라고 부릅니다. DiTs는 Vision Transformers (ViTs) [10]의 최선의 관행을 따르며, 이는 전통적인 컨볼루션 네트워크(예: ResNet [15])보다 시각적 인식을 더 효과적으로 확장하는 것으로 나타났습니다.
더 구체적으로, 우리는 네트워크 복잡도와 샘플 품질에 대한 트랜스포머의 확장 동작을 연구합니다. 우리는 잠재 확산 모델 (LDMs) [48] 프레임워크에서 확산 모델이 VAE의 잠재 공간 내에서 훈련되는 DiT 설계 공간을 구성하고 벤치마킹하여 U-Net 백본을 트랜스포머로 성공적으로 대체할 수 있음을 보여줍니다. 우리는 또한 DiTs가 확산 모델을 위한 확장 가능한 아키텍처임을 보여줍니다. 네트워크 복잡도(Gflops로 측정)와 샘플 품질(FID로 측정) 사이에는 강한 상관관계가 있습니다. DiT를 단순히 확장하고 고용량 백본(118.6 Gflops)으로 LDM을 훈련함으로써, 클래스 조건부 256x256 ImageNet 생성 벤치마크에서 2.27 FID의 최첨단 결과를 달성할 수 있습니다.
2. 관련 연구
트랜스포머. 트랜스포머 [60]는 언어, 비전 [10], 강화 학습 [5, 25], 메타 학습 [39] 등 여러 도메인에서 도메인 특화 아키텍처를 대체했습니다. 트랜스포머는 언어 도메인 [26]에서 모델 크기, 학습 연산 및 데이터 증가에 따라 놀라운 확장 특성을 보여주었으며, 일반적인 자가회귀 모델 [17] 및 ViTs [63]로서도 뛰어난 성능을 발휘했습니다. 언어를 넘어서, 트랜스포머는 픽셀을 자가회귀적으로 예측하도록 훈련되었습니다 [6, 7, 38]. 또한, 트랜스포머는 자가회귀 모델 [11, 47] 및 마스킹 생성 모델 [4, 14]로서 이산 코드북 [59]에 대해 훈련되었습니다. 전자는 최대 200억 개의 파라미터로 뛰어난 확장성을 보여주었습니다 [62]. 마지막으로, 트랜스포머는 DDPM에서 비공간 데이터를 합성하는 데 탐구되었습니다. 예를 들어, DALL-E 2 [41, 46]에서 CLIP 이미지 임베딩을 생성하기 위해 사용되었습니다. 이 논문에서는 이미지 확산 모델의 백본으로 사용될 때 트랜스포머의 확장 특성을 연구합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
강화학습에서 쓰려고 노력했지만, 제대로 적용이 안되것으로 아는데... 흠...
-----------------------------------------------------------------------------------------------------------------------------------------------------------------

그림 3. 확산 트랜스포머 (DiT) 아키텍처. 왼쪽: 우리는 조건부 잠재 DiT 모델을 훈련시킵니다. 입력 잠재 공간은 패치로 분해되어 여러 DiT 블록에 의해 처리됩니다. 오른쪽: 우리의 DiT 블록 세부 사항. 우리는 적응형 레이어 정규화, 교차 주의 및 추가 입력 토큰을 통해 조건부를 도입하는 표준 트랜스포머 블록의 변형을 실험합니다. 적응형 레이어 정규화가 가장 효과적입니다.
잡음 제거 확산 확률 모델 (DDPMs).
확산 모델 [19, 54]과 스코어 기반 생성 모델 [22, 56]은 특히 이미지 생성 모델로서 성공적이었으며 [35, 46, 48, 50], 많은 경우 이전에 최첨단이었던 생성적 적대 신경망(GANs) [12]을 능가했습니다. 지난 2년 동안 DDPM의 발전은 주로 향상된 샘플링 기법 [19, 27, 55]에 의해 이루어졌으며, 특히 분류기 없는 가이드 [21], 픽셀 대신 노이즈를 예측하도록 확산 모델을 재구성하는 것 [19], 저해상도 기본 확산 모델이 업샘플러와 병렬로 훈련되는 캐스케이드 DDPM 파이프라인 [9, 20]이 주목할 만합니다. 위에 나열된 모든 확산 모델의 경우, 컨볼루션 U-Net [49]이 사실상의 기본 백본 아키텍처로 사용됩니다. 동시 진행된 연구 [24]는 DDPM을 위한 주의 기반의 새로운 효율적인 아키텍처를 도입했으며, 우리는 순수 트랜스포머를 탐구합니다.
아키텍처 복잡성.
이미지 생성 문헌에서 아키텍처 복잡성을 평가할 때, 파라미터 수를 사용하는 것이 일반적인 관행입니다. 일반적으로 파라미터 수는 이미지 해상도 등 성능에 큰 영향을 미치는 요소를 고려하지 않기 때문에 이미지 모델의 복잡성을 잘 나타내지 못할 수 있습니다 [44, 45]. 대신, 이 논문의 많은 모델 복잡성 분석은 이론적 Gflops의 관점에서 이루어집니다. 이는 복잡성을 측정하기 위해 Gflops가 널리 사용되는 아키텍처 설계 문헌과 일치합니다. 실제로, 황금 복잡성 메트릭은 여전히 논쟁 중이며, 이는 종종 특정 응용 시나리오에 따라 달라집니다. 확산 모델을 개선하는 Nichol과 Dhariwal의 기념비적인 연구 [9, 36]는 우리와 가장 관련이 깊으며, 그들은 U-Net 아키텍처 클래스의 확장성과 Gflop 특성을 분석했습니다. 이 논문에서는 트랜스포머 클래스에 초점을 맞춥니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Gflop(Gigaflop)은 "Giga Floating Point Operations per Second"의 약자로, 컴퓨터 시스템의 연산 능력을 측정하는 단위입니다. 1 Gflop은 10억 번의 부동 소수점 연산을 의미합니다. Gflop은 주로 다음과 같은 용도로 사용됩니다:
- 프로세서 성능 측정: CPU, GPU 등의 성능을 평가하는 데 사용됩니다. 더 높은 Gflop 수치는 더 많은 연산을 빠르게 처리할 수 있음을 나타냅니다.
- 모델 복잡성 평가: 머신 러닝 및 딥러닝 모델의 복잡성을 평가하는 데 사용됩니다. 모델이 수행하는 연산의 양을 나타내며, 더 높은 Gflop 수치는 더 복잡한 모델을 의미합니다.
- 효율성 비교: 서로 다른 모델이나 시스템의 효율성을 비교하는 데 사용됩니다. 동일한 작업을 수행하는 데 필요한 Gflop 수를 비교함으로써 어느 시스템이 더 효율적인지 평가할 수 있습니다.
Gflop은 특히 딥러닝 모델에서 중요한 지표로, 모델의 크기나 복잡성, 연산 성능을 비교하는 데 유용합니다. 예를 들어, 더 높은 Gflop 수치를 가지는 모델은 더 많은 연산 자원을 필요로 하며, 일반적으로 더 높은 성능을 기대할 수 있지만, 이는 더 많은 연산 비용을 수반할 수 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3. 확산 트랜스포머
3.1. 기초 지식


분류기 없는 가이드.

잠재 확산 모델.
고해상도 픽셀 공간에서 직접 확산 모델을 훈련하는 것은 계산 비용이 매우 높을 수 있습니다. 잠재 확산 모델(LDMs) [48]은 이 문제를 두 단계 접근 방식으로 해결합니다: (1) 학습된 인코더 E를 사용하여 이미지를 더 작은 공간 표현으로 압축하는 오토인코더를 학습합니다; (2) 이미지 x의 확산 모델 대신 표현 z=E(x)의 확산 모델을 훈련합니다 (이때 E는 고정됩니다). 새로운 이미지는 확산 모델에서 표현 z를 샘플링하고, 이를 학습된 디코더 D를 사용하여 이미지 x=D(z)로 디코딩하여 생성할 수 있습니다.
그림 2에서 볼 수 있듯이, LDMs는 ADM과 같은 픽셀 공간 확산 모델의 일부 Gflops만 사용하면서도 좋은 성능을 달성합니다. 우리는 계산 효율성에 관심이 있기 때문에, 이것은 아키텍처 탐색을 위한 매력적인 출발점이 됩니다. 이 논문에서는 DiTs를 잠재 공간에 적용하지만, 수정 없이 픽셀 공간에도 적용할 수 있습니다. 이는 우리의 이미지 생성 파이프라인을 하이브리드 기반 접근 방식으로 만듭니다. 우리는 기존의 컨볼루션 VAE와 트랜스포머 기반 DDPM을 사용합니다.
3.2. 확산 트랜스포머 설계
공간 우리는 확산 모델을 위한 새로운 아키텍처인 확산 트랜스포머(DiTs)를 소개합니다. 우리는 트랜스포머의 확장 특성을 유지하기 위해 표준 트랜스포머 아키텍처에 최대한 충실하고자 합니다. 우리의 초점은 이미지(특히 이미지의 공간 표현)의 DDPM을 훈련하는 것이므로, DiT는 패치 시퀀스에서 작동하는 비전 트랜스포머(ViT) 아키텍처를 기반으로 합니다 [10]. DiT는 ViTs의 많은 최선의 관행을 유지합니다. 그림 3은 전체 DiT 아키텍처의 개요를 보여줍니다. 이 섹션에서는 DiT의 순방향 패스와 DiT 클래스의 설계 공간 구성 요소를 설명합니다.
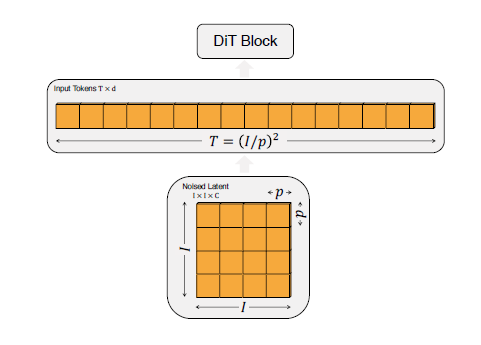

DiT 블록 설계.
패치화 후, 입력 토큰은 일련의 트랜스포머 블록에 의해 처리됩니다. 노이즈가 추가된 이미지 입력 외에도, 확산 모델은 때때로 노이즈 타임스텝 t, 클래스 레이블 c, 자연어 등 추가적인 조건부 정보를 처리합니다. 우리는 조건부 입력을 다르게 처리하는 네 가지 변형의 트랜스포머 블록을 탐구합니다. 이러한 설계는 표준 ViT 블록 설계에 작지만 중요한 수정 사항을 도입합니다. 모든 블록의 설계는 그림 3에 나와 있습니다.
– 컨텍스트 내 조건부 처리.
우리는 단순히 t와 c의 벡터 임베딩을 두 개의 추가 토큰으로 입력 시퀀스에 추가하고, 이를 이미지 토큰과 다르게 처리하지 않습니다. 이는 ViT에서 cls 토큰과 유사하며, 수정 없이 표준 ViT 블록을 사용할 수 있게 합니다. 최종 블록 이후에 조건부 토큰을 시퀀스에서 제거합니다. 이 접근 방식은 모델에 거의 새로운 Gflops를 도입하지 않습니다.
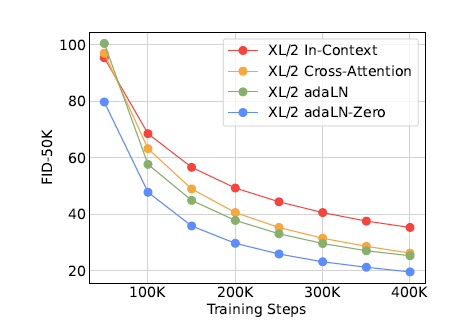
그림 5. 다양한 조건부 처리 전략 비교. adaLNZero는 모든 학습 단계에서 교차 주의와 컨텍스트 내 조건부 처리보다 뛰어납니다.
– 적응형 레이어 정규화(adaLN) 블록.
GAN [2, 28]과 UNet 백본을 사용하는 확산 모델 [9]에서 적응형 정규화 계층 [40]이 널리 사용됨에 따라, 우리는 트랜스포머 블록의 표준 레이어 정규화 계층을 적응형 레이어 정규화(adaLN)로 대체하는 것을 탐구합니다. 차원별 스케일 및 시프트 파라미터 γ와 β를 직접 학습하는 대신, 우리는 와 의 임베딩 벡터의 합으로부터 이를 회귀(regress)합니다. 우리가 탐구하는 세 가지 블록 설계 중에서 adaLN은 가장 적은 Gflops를 추가하므로 가장 계산 효율적입니다. 또한 모든 토큰에 동일한 기능을 적용하는 유일한 조건부 메커니즘입니다.
– adaLN-Zero 블록.
이전의 ResNet 연구에서는 각 잔여 블록을 항등 함수로 초기화하는 것이 유익하다는 것을 발견했습니다. 예를 들어, Goyal 등은 각 블록의 최종 배치 정규화 스케일 팩터 γ를 제로로 초기화하는 것이 지도 학습 환경에서 대규모 훈련을 가속화한다고 발견했습니다 [13]. 확산 U-Net 모델은 유사한 초기화 전략을 사용하며, 잔여 연결 전에 각 블록의 최종 컨볼루션 계층을 제로로 초기화합니다. 우리는 동일한 작업을 수행하는 adaLN DiT 블록의 수정된 버전을 탐구합니다. γ와 β를 회귀하는 것 외에도, DiT 블록 내의 잔여 연결 전에 즉시 적용되는 차원별 스케일 파라미터 α도 회귀합니다. 우리는 MLP를 모든 α에 대해 제로 벡터를 출력하도록 초기화하여, 전체 DiT 블록을 항등 함수로 초기화합니다. 기본 adaLN 블록과 마찬가지로, adaLN-Zero는 모델에 거의 새로운 Gflops를 추가하지 않습니다.
우리는 DiT 설계 공간에 컨텍스트 내, 교차 주의, 적응형 레이어 정규화 및 adaLN-Zero 블록을 포함시킵니다.
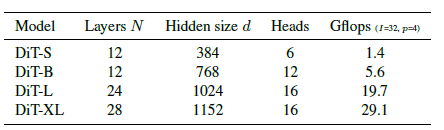
표 1. DiT 모델의 세부 사항. 우리는 Small (S), Base (B) 및 Large (L) 변형에 대해 ViT [10] 모델 구성을 따르며, 가장 큰 모델로 XLarge (XL) 구성을 도입합니다.
모델 크기.
우리는 숨겨진 차원 크기 d에서 작동하는 N개의 DiT 블록 시퀀스를 적용합니다. ViT를 따르며, 우리는 N, d, 주의(heads)를 함께 확장하는 표준 트랜스포머 구성을 사용합니다 [10, 63]. 구체적으로, 우리는 네 가지 구성을 사용합니다: DiT-S, DiT-B, DiT-L, DiT-XL. 이들은 0.3에서 118.6 Gflops까지 다양한 모델 크기와 연산 할당량을 포함하여 확장 성능을 평가할 수 있게 합니다. 표 1에는 구성의 세부 사항이 나와 있습니다.
우리는 DiT 설계 공간에 B, S, L, XL 구성을 추가합니다.
트랜스포머 디코더. 마지막 DiT 블록 이후, 우리는 이미지 토큰 시퀀스를 출력 노이즈 예측 및 출력 대각 공분산 예측으로 디코딩해야 합니다. 이 두 출력은 원래의 공간 입력과 동일한 형태를 가집니다. 이를 위해 우리는 표준 선형 디코더를 사용합니다; 최종 레이어 정규화(adaLN을 사용하는 경우 적응형)를 적용하고, 각 토큰을 p×p×2C 텐서로 선형 디코딩합니다. 여기서 C는 DiT에 대한 공간 입력의 채널 수입니다. 마지막으로, 디코딩된 토큰을 원래의 공간 레이아웃으로 재배열하여 예측된 노이즈와 공분산을 얻습니다.
우리가 탐구하는 완전한 DiT 설계 공간은 패치 크기, 트랜스포머 블록 아키텍처 및 모델 크기입니다.
4. 실험 설정
우리는 DiT 설계 공간을 탐구하고 모델 클래스의 확장 특성을 연구합니다. 우리의 모델은 구성과 잠재 패치 크기 에 따라 이름이 지정됩니다. 예를 들어, DiT-XL/2는 XLarge 구성과 p=2를 나타냅니다.
훈련.
우리는 ImageNet 데이터셋 [31]에서 256x256 및 512x512 이미지 해상도로 클래스 조건부 잠재 DiT 모델을 훈련합니다. ImageNet은 매우 경쟁력 있는 생성 모델링 벤치마크입니다. 우리는 최종 선형 계층을 제로로 초기화하고, 그 외에는 ViT에서 사용된 표준 가중치 초기화 기법을 사용합니다. 모든 모델은 AdamW [29, 33]로 훈련합니다.
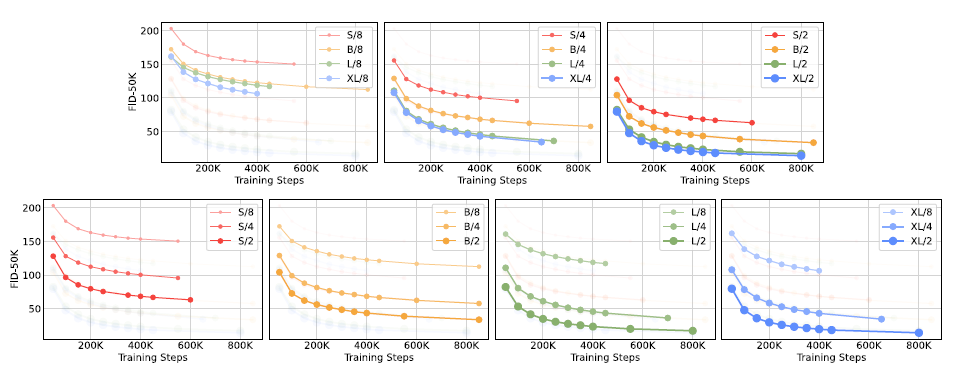
그림 6. DiT 모델의 확장은 훈련의 모든 단계에서 FID를 개선합니다. 우리는 12개의 DiT 모델에 대한 훈련 반복에 따른 FID-50K를 보여줍니다. 상단 행: 패치 크기를 일정하게 유지하면서 FID를 비교합니다. 하단 행: 모델 크기를 일정하게 유지하면서 FID를 비교합니다. 트랜스포머 백본의 확장은 모든 모델 크기와 패치 크기에서 더 나은 생성 모델을 제공합니다.
우리는 학습률 1 x 10^-4, 가중치 감쇠 없음, 배치 크기 256을 사용합니다. 우리가 사용하는 유일한 데이터 증강은 수평 플립입니다. ViT [57, 61]을 사용한 이전 작업과 달리, 우리는 DiT를 높은 성능으로 훈련하는 데 학습률 웜업이나 정규화가 필요하지 않음을 발견했습니다. 이러한 기술 없이도 모든 모델 구성에서 훈련이 매우 안정적이었고, 트랜스포머를 훈련할 때 흔히 보이는 손실 급증 현상을 관찰하지 않았습니다. 생성 모델링 문헌에서 흔히 사용되는 관행을 따라, 우리는 0.9999의 감쇠를 가진 DiT 가중치의 지수 이동 평균(EMA)을 유지합니다. 보고된 모든 결과는 EMA 모델을 사용합니다. 우리는 모든 DiT 모델 크기와 패치 크기에 대해 동일한 학습 하이퍼파라미터를 사용합니다. 우리의 학습 하이퍼파라미터는 거의 전적으로 ADM에서 유지됩니다. 우리는 학습률, 감쇠/웜업 일정, Adam β1/β2 또는 가중치 감쇠를 튜닝하지 않았습니다.
확산.
우리는 Stable Diffusion [48]에서 사전 훈련된 VAE(변형 오토인코더) 모델 [30]을 사용합니다. VAE 인코더는 8의 다운샘플 팩터를 가지고 있으며, 256 x 256 x 3 형태의 RGB 이미지 xx에 대해 z=E(x)는 32 x 32 x 4 형태를 가집니다. 이 섹션의 모든 실험에서 우리의 확산 모델은 이 Z-공간에서 작동합니다. 확산 모델에서 새로운 잠재 변수를 샘플링한 후, 우리는 VAE 디코더 x=D(z)를 사용하여 픽셀로 디코딩합니다. 우리는 ADM [9]에서 확산 하이퍼파라미터를 유지합니다. 구체적으로, 우리는 1 x 10^-4에서 2 x 10^-2까지 범위의 tmax = 1000 선형 분산 스케줄을 사용하며, ADM의 공분산 Σθ 매개 변수화 및 입력 타임스텝과 레이블을 임베딩하는 방법을 사용합니다.
평가 지표.
우리는 이미지 생성 모델을 평가하는 표준 지표인 프레셰 인셉션 거리(FID) [18]로 확장 성능을 측정합니다. 이전 작업과 비교할 때 관례를 따르며, 250 DDPM 샘플링 단계를 사용하여 FID-50K를 보고합니다. FID는 작은 구현 세부 사항에 민감한 것으로 알려져 있습니다 [37]; 정확한 비교를 보장하기 위해, 이 논문에 보고된 모든 값은 샘플을 내보내고 ADM의 TensorFlow 평가 도구 [9]를 사용하여 얻었습니다. 이 섹션에서 보고된 FID 값은 특별히 언급하지 않는 한 분류기 없는 가이드를 사용하지 않습니다. 우리는 추가적으로 Inception Score [51], sFID [34] 및 Precision/Recall [32]을 보조 지표로 보고합니다.
계산.
우리는 모든 모델을 JAX [1]로 구현하고 TPU-v3 팟을 사용하여 훈련합니다. DiT-XL/2, 가장 계산 집약적인 모델은 TPU v3-256 팟에서 전역 배치 크기 256으로 대략 초당 5.7 회 반복 훈련됩니다.
5. 실험
DiT 블록 설계.
우리는 네 가지 다른 블록 설계를 사용하여 가장 높은 Gflop의 DiT-XL/2 모델 네 개를 훈련합니다—컨텍스트 내(119.4 Gflops), 교차 주의(137.6 Gflops), 적응형 레이어 정규화(adaLN, 118.6 Gflops) 또는 adaLN-zero(118.6 Gflops). 우리는 훈련 과정 동안 FID를 측정합니다. 그림 5는 결과를 보여줍니다. adaLN-Zero 블록은 교차 주의와 컨텍스트 내 조건부 처리보다 더 낮은 FID를 제공하면서 가장 계산 효율적입니다. 400K 훈련 반복 시, adaLN-Zero 모델로 달성된 FID는 컨텍스트 내 모델의 거의 절반으로, 조건부 메커니즘이 모델 품질에 중요한 영향을 미친다는 것을 보여줍니다. 초기화도 중요합니다—각 DiT 블록을 항등 함수로 초기화하는 adaLN-Zero는 일반 adaLN보다 현저히 뛰어납니다. 논문의 나머지 부분에서는 모든 모델이 adaLN-Zero DiT 블록을 사용할 것입니다.

그림 7. 트랜스포머 순방향 패스 Gflops를 증가시키면 샘플 품질이 향상됩니다. 확대해서 보는 것이 좋습니다. 우리는 동일한 입력 잠재 노이즈와 클래스 레이블을 사용하여 400K 훈련 단계 후 모든 12개의 DiT 모델에서 샘플을 생성합니다. 모델의 Gflops를 증가시키면—트랜스포머의 깊이/너비를 증가시키거나 입력 토큰 수를 증가시킴으로써—시각적 충실도가 크게 향상됩니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
patch를 줄이면 더 정교하게 표현가능한거고 transformer도 크기 법칙에 의해 성능이 증가하니 맞다
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
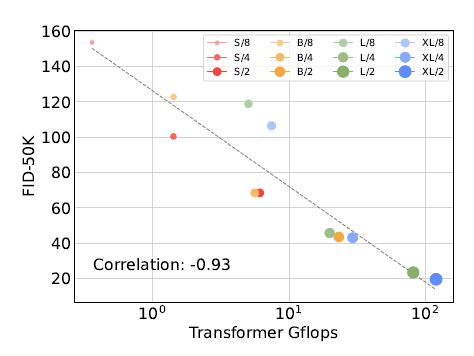
그림 8. 트랜스포머 Gflops와 FID는 강한 상관관계를 가집니다. 우리는 각 DiT 모델의 Gflops와 400K 훈련 단계 후 각 모델의 FID-50K를 플로팅합니다.
모델 크기와 패치 크기 확장.
우리는 모델 구성(S, B, L, XL)과 패치 크기(8, 4, 2)를 조정하여 12개의 DiT 모델을 훈련합니다. DiT-L과 DiT-XL은 다른 구성보다 상대적인 Gflops 면에서 서로 상당히 가깝습니다. 그림 2(왼쪽)는 각 모델의 Gflops와 400K 훈련 반복에서의 FID 개요를 보여줍니다. 모든 경우에서, 우리는 모델 크기를 증가시키고 패치 크기를 줄이면 확산 모델이 상당히 개선되는 것을 발견했습니다. 그림 6(상단)은 모델 크기를 증가시키고 패치 크기를 일정하게 유지했을 때 FID가 어떻게 변하는지 보여줍니다. 모든 네 가지 구성에서, 트랜스포머를 더 깊고 넓게 만듦으로써 훈련의 모든 단계에서 FID가 크게 개선됩니다. 마찬가지로, 그림 6(하단)은 패치 크기를 줄이고 모델 크기를 일정하게 유지했을 때의 FID를 보여줍니다. 우리는 파라미터를 대략 고정한 상태에서 DiT가 처리하는 토큰 수를 단순히 확장함으로써 훈련 동안 상당한 FID 개선을 다시 한번 관찰합니다.
DiT Gflops는 성능 개선에 중요합니다. 그림 6의 결과는 파라미터 수가 DiT 모델의 품질을 고유하게 결정하지 않는다는 것을 시사합니다. 모델 크기를 일정하게 유지하고 패치 크기를 줄이면 트랜스포머의 총 파라미터 수는 사실상 변경되지 않으며(실제로는 총 파라미터가 약간 감소함), 오직 Gflops만 증가합니다. 이러한 결과는 모델 Gflops의 확장이 실제로 성능 개선의 핵심이라는 것을 나타냅니다. 이를 더 조사하기 위해, 우리는 그림 8에서 400K 훈련 단계에서 모델 Gflops에 대한 FID-50K를 플로팅합니다. 결과는 총 Gflops가 유사할 때 서로 다른 DiT 구성들이 유사한 FID 값을 얻는다는 것을 보여줍니다(예: DiT-S/2와 DiT-B/4). 우리는 모델 Gflops와 FID-50K 사이에 강한 음의 상관관계를 발견하여 추가적인 모델 연산이 DiT 모델 개선의 중요한 요소임을 시사합니다. 그림 12(부록)에서는 Inception Score와 같은 다른 지표에서도 이 추세가 유지됨을 발견했습니다.
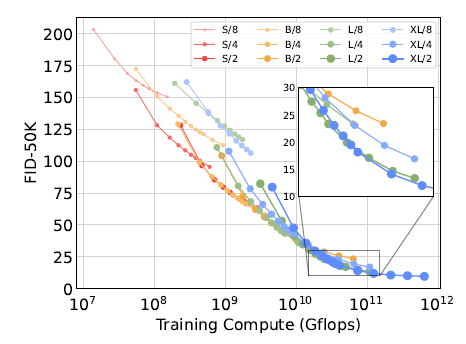
그림 9. 더 큰 DiT 모델은 큰 연산을 더 효율적으로 사용합니다. 우리는 총 훈련 연산량에 따른 FID를 플로팅합니다.
더 큰 DiT 모델은 더 계산 효율적입니다. 그림 9에서 우리는 모든 DiT 모델에 대해 총 훈련 연산량에 따른 FID를 플로팅합니다. 우리는 훈련 연산량을 모델 Gflops × 배치 크기 × 훈련 단계 × 3으로 추정합니다. 여기서 3이라는 계수는 역방향 패스가 순방향 패스보다 두 배 더 연산 무겁다는 것을 대략적으로 근사한 것입니다. 우리는 작은 DiT 모델이 더 오래 훈련되더라도, 더 적은 단계로 훈련된 더 큰 DiT 모델에 비해 결국 계산 효율성이 떨어진다는 것을 발견했습니다. 마찬가지로, 패치 크기만 다른 동일한 모델들이 훈련 Gflops를 제어했을 때도 성능 프로필이 다르다는 것을 발견했습니다. 예를 들어, XL/4는 약 10^10 Gflops 이후 XL/2에 의해 능가됩니다.
스케일링 시각화.
우리는 그림 7에서 샘플 품질에 대한 스케일링의 영향을 시각화합니다. 400K 훈련 단계에서, 우리는 동일한 시작 노이즈 x_{tmax}, 샘플링 노이즈 및 클래스 레이블을 사용하여 12개의 DiT 모델 각각에서 이미지를 샘플링합니다. 이를 통해 스케일링이 DiT 샘플 품질에 미치는 영향을 시각적으로 해석할 수 있습니다. 실제로 모델 크기와 토큰 수를 모두 확장하면 시각적 품질이 크게 향상됩니다.
5.1. 최첨단 확산 모델 256x256 ImageNet.
우리의 스케일링 분석을 따라, 우리는 가장 높은 Gflops 모델인 DiT-XL/2를 700만 단계까지 계속 훈련합니다. 우리는 그림 1에서 모델의 샘플을 보여주며, 최첨단 클래스 조건부 생성 모델과 비교합니다. 우리는 표 2에서 결과를 보고합니다. 분류기 없는 가이드를 사용할 때, DiT-XL/2는 모든 이전 확산 모델을 능가하여 LDM이 달성한 이전 최고 FID-50K 3.60을 2.27로 낮춥니다. 그림 2(오른쪽)는 DiT-XL/2(118.6 Gflops)가 LDM-4(103.6 Gflops)와 같은 잠재 공간 U-Net 모델에 비해 계산 효율적이며, ADM(1120 Gflops) 또는 ADM-U(742 Gflops)와 같은 픽셀 공간 U-Net 모델에 비해 상당히 더 효율적임을 보여줍니다.
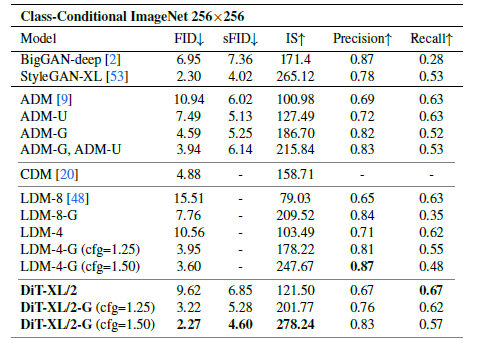
표 2. ImageNet 256x256에서 클래스 조건부 이미지 생성을 벤치마킹합니다. DiT-XL/2는 최첨단 FID를 달성합니다.
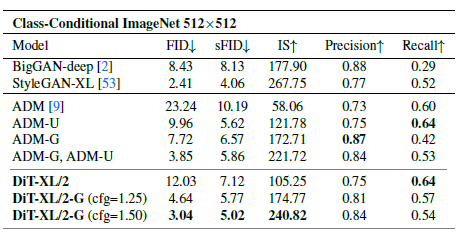
표 3. ImageNet 512x512에서 클래스 조건부 이미지 생성을 벤치마킹합니다. 이전 연구 [9]는 512x512 해상도에서 1000개의 실제 샘플을 사용하여 Precision과 Recall을 측정합니다. 일관성을 위해 우리도 동일하게 합니다.
우리의 방법은 이전의 모든 생성 모델, 포함하여 이전 최첨단이었던 StyleGANXL [53]을 포함한 모든 모델 중에서 가장 낮은 FID를 달성합니다. 마지막으로, 우리는 DiT-XL/2가 LDM-4와 LDM-8과 비교했을 때 테스트한 모든 분류기 없는 가이드 스케일에서 더 높은 리콜 값을 달성한다는 것을 관찰했습니다. 단지 235만 단계(ADM과 유사) 동안 훈련되었을 때도 XL/2는 FID 2.55로 모든 이전 확산 모델을 능가합니다.
512x512 ImageNet.
우리는 512x512 해상도에서 ImageNet을 대상으로 새로운 DiT-XL/2 모델을 300만 회 반복으로 동일한 하이퍼파라미터를 사용하여 훈련합니다. 패치 크기 2로, 이 XL/2 모델은 64x64x4 입력 잠재 공간을 패치화한 후 총 1024개의 토큰을 처리합니다(524.6 Gflops). 표 3은 최첨단 방법들과의 비교를 보여줍니다. XL/2는 이 해상도에서도 모든 이전 확산 모델을 다시 능가하여, ADM이 달성한 이전 최고 FID 3.85를 3.04로 개선했습니다. 토큰 수가 증가해도 XL/2는 계산 효율성을 유지합니다. 예를 들어, ADM은 1983 Gflops, ADM-U는 2813 Gflops를 사용합니다; XL/2는 524.6 Gflops를 사용합니다. 우리는 고해상도 XL/2 모델의 샘플을 그림 1과 부록에 보여줍니다.
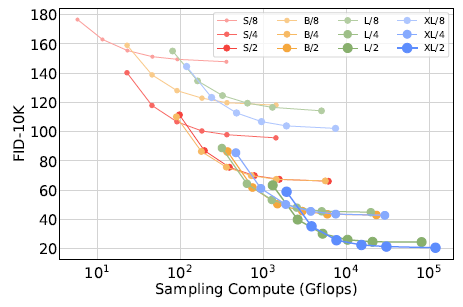
그림 10. 샘플링 연산을 확장한다고 해서 모델 연산 부족을 보상할 수는 없습니다. 400K 반복 훈련된 각 DiT 모델에 대해 [16, 32, 64, 128, 256, 1000] 샘플링 단계를 사용하여 FID-10K를 계산합니다. 각 단계 수에 대해, 우리는 FID와 각 이미지를 샘플링하는 데 사용된 Gflops를 플로팅합니다. 작은 모델은 큰 모델보다 더 많은 테스트 시점 Gflops를 사용하더라도 성능 격차를 해소할 수 없습니다.
5.2. 모델 연산 대 샘플링 연산 확장
확산 모델은 이미지 생성 시 샘플링 단계를 증가시켜 훈련 후 추가 연산을 사용할 수 있는 독특한 특성을 가지고 있습니다. 모델 Gflops가 샘플 품질에 미치는 영향을 감안할 때, 이 섹션에서는 더 많은 샘플링 연산을 사용하여 작은 모델 연산 DiT가 더 큰 모델을 능가할 수 있는지 연구합니다. 우리는 400K 훈련 단계 후 모든 12개의 DiT 모델에 대해 각 이미지당 [16, 32, 64, 128, 256, 1000] 샘플링 단계를 사용하여 FID를 계산합니다. 주요 결과는 그림 10에 있습니다. DiT-L/2가 1000 샘플링 단계를 사용하는 경우와 DiT-XL/2가 128 단계를 사용하는 경우를 고려해 보십시오. 이 경우 L/2는 각 이미지를 샘플링하는 데 80.7 Tflops를 사용하고, XL/2는 각 이미지를 샘플링하는 데 5배 적은 연산(15.2 Tflops)을 사용합니다. 그럼에도 불구하고 XL/2는 더 나은 FID-10K(23.7 대 25.9)를 가지고 있습니다. 일반적으로 샘플링 연산을 확장한다고 해서 모델 연산 부족을 보상할 수는 없습니다.
6. 결론
우리는 이전 U-Net 모델을 능가하고 트랜스포머 모델 클래스의 뛰어난 확장 특성을 계승하는 간단한 트랜스포머 기반 백본인 확산 트랜스포머(DiTs)를 소개합니다. 이 논문에서의 유망한 확장 결과를 바탕으로, 향후 연구는 더 큰 모델과 토큰 수로 DiT를 계속 확장해야 합니다. DiT는 DALL·E 2 및 Stable Diffusion과 같은 텍스트-이미지 모델을 위한 백본으로도 탐구될 수 있습니다.
감사의 말. 우리는 Kaiming He, Ronghang Hu, Alexander Berg, Shoubhik Debnath, Tim Brooks, Ilija Radosavovic, Tete Xiao에게 유익한 논의에 대해 감사드립니다. William Peebles는 NSF GRFP의 지원을 받습니다.



