https://arxiv.org/abs/1905.11946
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing n
arxiv.org
초록
합성곱 신경망(ConvNets)은 일반적으로 고정된 자원 예산에서 개발되며, 더 많은 자원이 확보될 경우 더 나은 정확도를 위해 확장됩니다. 본 논문에서는 모델 확장을 체계적으로 연구하여, 네트워크의 깊이, 너비, 해상도를 신중하게 조정하면 성능이 향상될 수 있음을 확인했습니다. 이러한 관찰에 기반해, 우리는 깊이/너비/해상도의 모든 차원을 간단하면서도 매우 효과적인 복합 계수를 사용하여 균일하게 확장하는 새로운 방법을 제안합니다. 우리는 이 방법의 효과를 MobileNets와 ResNet의 확장에 적용하여 입증했습니다.
더 나아가, 우리는 신경망 구조 탐색을 사용하여 새로운 기본 네트워크를 설계하고, 이를 확장하여 EfficientNets라는 모델 군을 만들었습니다. 이 모델들은 이전의 ConvNets보다 훨씬 더 나은 정확도와 효율성을 달성했습니다. 특히, 우리 모델 EfficientNet-B7은 ImageNet에서 최첨단의 84.3%의 top-1 정확도를 달성했으며, 기존 최고의 ConvNet보다 8.4배 더 작고 추론 속도는 6.1배 더 빠릅니다. 또한, EfficientNets는 전이 학습에서도 우수한 성능을 보였으며, CIFAR-100(91.7%), Flowers(98.8%) 및 3개의 다른 전이 학습 데이터셋에서 최첨단 정확도를 달성하면서도 파라미터 수는 훨씬 적습니다. 소스 코드는 https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet에서 확인할 수 있습니다.
기계 학습, ICML


Figure 1: 모델 크기 vs. ImageNet 정확도. 모든 숫자는 단일 크롭, 단일 모델 기준입니다. 우리의 EfficientNets는 다른 합성곱 신경망(ConvNets)보다 훨씬 뛰어난 성능을 보여줍니다. 특히, EfficientNet-B7은 새로운 최첨단인 84.3%의 top-1 정확도를 달성하면서도 GPipe보다 8.4배 더 작고 6.1배 더 빠릅니다. EfficientNet-B1은 ResNet-152보다 7.6배 더 작고 5.7배 더 빠릅니다. 자세한 내용은 표 2와 표 4에 나와 있습니다.
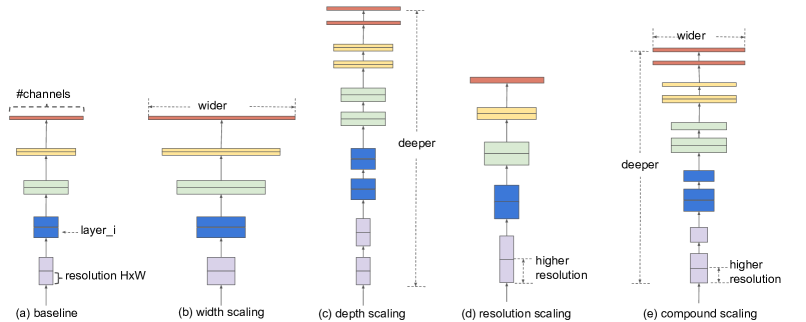
Figure 2: 모델 확장. (a)는 기본 네트워크의 예시입니다. (b)-(d)는 네트워크의 너비, 깊이 또는 해상도 중 하나의 차원만을 증가시키는 기존 확장 방법입니다. (e)는 우리가 제안한 복합 확장 방법으로, 고정된 비율로 세 가지 차원(너비, 깊이, 해상도)을 균일하게 확장합니다.
1. 서론
합성곱 신경망(ConvNets)을 확장하는 것은 더 나은 정확도를 달성하기 위해 널리 사용됩니다. 예를 들어, ResNet(He et al., 2016)은 더 많은 레이어를 추가함으로써 ResNet-18에서 ResNet-200으로 확장할 수 있습니다. 최근에는 GPipe(Huang et al., 2018)가 기본 모델을 네 배로 확장하여 ImageNet에서 84.3%의 top-1 정확도를 달성했습니다. 그러나 ConvNets 확장 과정은 잘 이해되지 않았으며, 이를 수행하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 ConvNets의 깊이(He et al., 2016)나 너비(Zagoruyko & Komodakis, 2016)를 확장하는 것입니다. 또 다른 방법으로는 이미지 해상도를 확장하는 방법(Huang et al., 2018)이 있으며, 이는 점점 더 인기를 얻고 있습니다. 이전 연구에서는 깊이, 너비, 이미지 크기라는 세 가지 차원 중 하나만 확장하는 것이 일반적이었습니다. 두 가지 또는 세 가지 차원을 임의로 확장할 수도 있지만, 이는 수작업으로 미세 조정해야 하며, 종종 최적의 정확도와 효율성을 얻지 못하게 됩니다.
이 논문에서는 ConvNets 확장 과정을 재검토하고자 합니다. 특히, 우리가 탐구하는 핵심 질문은 다음과 같습니다: 더 나은 정확도와 효율성을 달성할 수 있는 체계적인 ConvNets 확장 방법이 있을까요? 우리의 실험적 연구는 네트워크의 너비, 깊이, 해상도 모두를 균형 있게 조정하는 것이 중요하며, 놀랍게도 이러한 균형은 각 차원을 일정 비율로 확장함으로써 달성될 수 있음을 보여줍니다. 이러한 관찰에 기반하여, 우리는 간단하지만 효과적인 복합 확장 방법(compound scaling method)을 제안합니다. 기존의 임의 확장 방식과 달리, 우리의 방법은 고정된 확장 계수를 사용하여 네트워크의 너비, 깊이, 해상도를 균일하게 확장합니다. 예를 들어, 계산 자원을 2배 더 많이 사용하고 싶다면, 네트워크의 깊이를 αN, 너비를 βN, 이미지 크기를 γN으로 늘릴 수 있습니다. 여기서 α, β, γ는 원래 작은 모델에서의 작은 그리드 검색을 통해 결정된 상수 계수입니다. Figure 2는 우리의 확장 방법과 기존 방법의 차이점을 설명합니다.
직관적으로, 복합 확장 방법은 합리적입니다. 입력 이미지가 더 크면, 네트워크는 수용 영역을 늘리기 위해 더 많은 레이어가 필요하고, 더 큰 이미지에서 세밀한 패턴을 포착하기 위해 더 많은 채널이 필요하기 때문입니다. 사실, 이전의 이론적 연구(Raghu et al., 2017; Lu et al., 2018)와 실험적 결과(Zagoruyko & Komodakis, 2016) 모두 네트워크 너비와 깊이 사이에 일정한 관계가 존재함을 보여주었으나, 우리가 알기로는 네트워크 너비, 깊이, 해상도라는 세 가지 차원의 관계를 실험적으로 정량화한 것은 우리가 처음입니다.
우리는 이 확장 방법이 기존의 MobileNets(Howard et al., 2017; Sandler et al., 2018)와 ResNet(He et al., 2016)에서도 잘 작동함을 입증했습니다. 특히, 모델 확장의 효과는 기본 네트워크에 크게 의존합니다. 이를 더욱 발전시키기 위해, 우리는 신경망 구조 탐색(Zoph & Le, 2017; Tan et al., 2019)을 사용하여 새로운 기본 네트워크를 개발하고, 이를 확장하여 EfficientNets라는 모델 군을 만들었습니다. Figure 1은 ImageNet 성능을 요약한 것으로, 우리의 EfficientNets는 다른 ConvNets보다 훨씬 더 뛰어난 성능을 보입니다. 특히, EfficientNet-B7은 기존의 최고의 GPipe 정확도(Huang et al., 2018)를 능가하면서도 8.4배 더 적은 파라미터를 사용하고 추론 속도는 6.1배 더 빠릅니다. 널리 사용되는 ResNet-50(He et al., 2016)과 비교했을 때, EfficientNet-B4는 FLOPS가 비슷하면서도 top-1 정확도를 76.3%에서 83.0%(+6.7%)로 향상시켰습니다. 또한 EfficientNets는 ImageNet뿐만 아니라 8개의 널리 사용되는 데이터셋 중 5개에서 최첨단의 정확도를 달성했으며, 기존 ConvNets보다 파라미터 수를 최대 21배까지 줄였습니다.
2. 관련 연구
ConvNet의 정확도:
AlexNet(Krizhevsky et al., 2012)이 2012년 ImageNet 대회에서 우승한 이후로, 합성곱 신경망(ConvNets)은 규모가 커지면서 점점 더 정확해졌습니다. 예를 들어, 2014년 ImageNet 우승자인 GoogleNet(Szegedy et al., 2015)은 약 6.8M(백만)개의 파라미터로 74.8%의 top-1 정확도를 달성했고, 2017년 ImageNet 우승자인 SENet(Hu et al., 2018)은 145M개의 파라미터로 82.7%의 top-1 정확도를 기록했습니다. 최근 GPipe(Huang et al., 2018)는 557M개의 파라미터를 사용하여 최첨단 ImageNet top-1 검증 정확도를 84.3%까지 끌어올렸습니다. GPipe는 매우 커서 네트워크를 여러 가속기에 분할하여 각각의 파트를 처리하는 특수한 파이프라인 병렬 라이브러리를 통해서만 학습이 가능합니다. 이러한 모델들은 주로 ImageNet을 위해 설계되었으나, 최근 연구에서는 더 나은 ImageNet 모델들이 다양한 전이 학습 데이터셋(Kornblith et al., 2019)과 객체 탐지와 같은 다른 컴퓨터 비전 작업(He et al., 2016; Tan et al., 2019)에서도 더 나은 성능을 보인다는 사실을 밝혔습니다. 더 높은 정확도가 많은 애플리케이션에서 중요하지만, 하드웨어 메모리 한계에 도달했기 때문에 더 높은 정확도를 얻기 위해서는 더 나은 효율성이 필요합니다.
ConvNet의 효율성:
딥러닝 합성곱 신경망(ConvNets)은 종종 과다하게 파라미터화되어 있습니다. 모델 압축(Han et al., 2016; He et al., 2018; Yang et al., 2018)은 효율성을 위해 정확도를 일부 희생하면서 모델 크기를 줄이는 일반적인 방법입니다. 스마트폰이 대중화되면서, SqueezeNets(Iandola et al., 2016; Gholami et al., 2018), MobileNets(Howard et al., 2017; Sandler et al., 2018), ShuffleNets(Zhang et al., 2018; Ma et al., 2018)와 같은 효율적인 모바일 크기의 ConvNets를 직접 설계하는 것이 일반적입니다. 최근에는 신경망 구조 탐색(Neural Architecture Search)이 점점 인기를 얻고 있으며, 네트워크 너비, 깊이, 합성곱 커널 유형과 크기를 세밀하게 조정함으로써 수작업으로 설계된 모바일 ConvNets보다 더 나은 효율성을 달성하고 있습니다(Tan et al., 2019; Cai et al., 2019). 그러나 이러한 기술을 더 큰 모델에 적용하는 방법은 아직 명확하지 않으며, 더 큰 설계 공간과 더 높은 튜닝 비용이 필요합니다. 이 논문에서는 최첨단 정확도를 능가하는 초대형 ConvNets의 모델 효율성을 연구하는 것을 목표로 합니다. 이를 위해 우리는 모델 확장에 주목했습니다.
모델 확장:
ConvNet을 다양한 자원 제약에 맞추어 확장하는 방법은 여러 가지가 있습니다. ResNet(He et al., 2016)은 네트워크의 깊이(레이어 수)를 조정하여 축소(예: ResNet-18) 또는 확장(예: ResNet-200)할 수 있으며, WideResNet(Zagoruyko & Komodakis, 2016)과 MobileNets(Howard et al., 2017)은 네트워크 너비(채널 수)를 조정하여 확장할 수 있습니다. 또한 더 큰 입력 이미지 크기가 정확도 향상에 기여하며, 그에 따른 더 많은 연산 비용(FLOPS)이 발생한다는 것도 잘 알려져 있습니다. 이전 연구(Raghu et al., 2017; Lin & Jegelka, 2018; Sharir & Shashua, 2018; Lu et al., 2018)는 네트워크 깊이와 너비가 ConvNets의 표현력에 모두 중요하다는 사실을 밝혔으나, 효율성과 정확도를 개선하기 위해 ConvNet을 효과적으로 확장하는 방법은 여전히 해결되지 않은 문제로 남아 있습니다. 본 연구에서는 네트워크의 너비, 깊이, 해상도라는 세 가지 차원을 모두 포함한 ConvNet 확장을 체계적이고 실험적으로 연구했습니다.
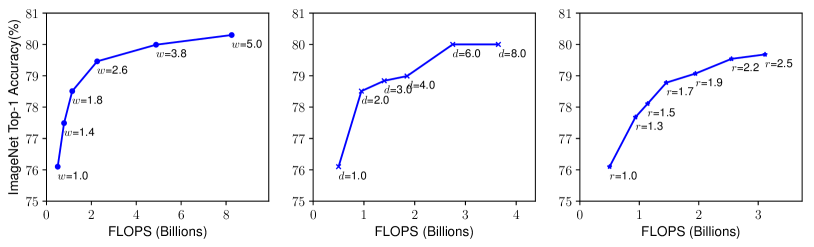
Figure 3: 기본 모델을 다양한 네트워크 너비( w ), 깊이( d ), 해상도( r ) 계수를 사용하여 확장
더 큰 네트워크, 즉 더 큰 너비, 깊이, 또는 해상도를 가진 네트워크는 일반적으로 더 높은 정확도를 달성하는 경향이 있지만, 정확도가 80%에 도달한 후에는 정확도 증가가 빠르게 포화됩니다. 이는 단일 차원 확장의 한계를 보여줍니다. 기본 네트워크에 대한 설명은 표 1에 나와 있습니다.
3. 복합 모델 확장
이 섹션에서는 확장 문제를 공식화하고, 다양한 접근법을 연구하며, 새로운 확장 방법을 제안하겠습니다.
3.1 문제 정의
합성곱 신경망(ConvNet)에서 레이어 ii는 함수로 정의될 수 있습니다:
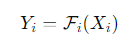




3.2 확장 차원
문제 2에서 주요 어려움은 최적의 d, w, r 값들이 서로 의존하며, 자원 제약 조건에 따라 값이 변한다는 점입니다. 이 어려움 때문에, 기존 방법들은 주로 이 세 가지 차원 중 하나만을 확장합니다:
- 깊이( d ):
네트워크의 깊이를 확장하는 것은 많은 ConvNet들이 사용하는 가장 일반적인 방법입니다(He et al., 2016; Huang et al., 2017; Szegedy et al., 2015, 2016). 직관적으로, 더 깊은 ConvNet은 더 풍부하고 복잡한 특징을 포착할 수 있으며, 새로운 작업에 대해 잘 일반화됩니다. 그러나 더 깊은 네트워크는 소멸 기울기 문제(vanishing gradient problem)로 인해 훈련하기가 더 어렵습니다(Zagoruyko & Komodakis, 2016). 스킵 연결(skip connections)(He et al., 2016)이나 배치 정규화(batch normalization)(Ioffe & Szegedy, 2015)와 같은 여러 기술이 훈련 문제를 완화시키긴 하지만, 매우 깊은 네트워크에서는 정확도 향상이 제한됩니다. 예를 들어, ResNet-1000은 더 많은 레이어를 가지고 있음에도 불구하고 ResNet-101과 비슷한 정확도를 보입니다. Figure 3 (중앙)은 서로 다른 깊이 계수 d로 기본 모델을 확장한 실험 결과를 보여주며, 매우 깊은 ConvNet에서 정확도 증가가 감소하는 것을 제안합니다. - 너비( w ):
네트워크의 너비를 확장하는 것은 소형 모델에서 흔히 사용됩니다(Howard et al., 2017; Sandler et al., 2018; Tan et al., 2019). 일부 문헌에서는 채널 수를 확장하는 것을 "깊이 곱셈기(depth multiplier)"라고 부르기도 하지만, 이는 우리가 말하는 너비 계수 w와 동일한 의미입니다. 넓은 네트워크는 더 세밀한 특징을 포착할 수 있으며 훈련이 더 쉽다는 점이 Zagoruyko & Komodakis(2016)에서 논의되었습니다. 그러나 너무 넓고 얕은 네트워크는 고차원 특징을 포착하는 데 어려움을 겪는 경향이 있습니다. Figure 3 (왼쪽)에서 보듯이, 네트워크가 더 넓어질수록 정확도는 빠르게 포화됩니다. - 해상도( r ):
더 높은 해상도의 입력 이미지를 사용하면 ConvNet이 더 세밀한 패턴을 포착할 수 있습니다. 초기 ConvNet들은 224x224 해상도를 사용했으나, 현대 ConvNet들은 더 나은 정확도를 위해 299x299(Szegedy et al., 2016) 또는 331x331(Zoph et al., 2018) 해상도를 주로 사용합니다. 최근에는 GPipe(Huang et al., 2018)가 480x480 해상도로 최첨단 ImageNet 정확도를 달성했습니다. 600x600과 같은 더 높은 해상도는 객체 탐지 ConvNet에서도 널리 사용됩니다(He et al., 2017; Lin et al., 2017). Figure 3 (오른쪽)은 네트워크 해상도를 확장한 결과를 보여주며, 높은 해상도가 정확도를 향상시키지만 매우 높은 해상도에서는 그 효과가 감소하는 것을 나타냅니다( r=1.0은 224x224 해상도, r=2.5는 560x560 해상도를 의미합니다).
위 분석을 통해 우리는 첫 번째 관찰을 도출할 수 있습니다:
관찰 1 – 네트워크의 너비, 깊이, 해상도 중 어느 한 차원을 확장하면 정확도가 향상되지만, 더 큰 모델에서는 정확도 향상이 점점 감소합니다.
3.3 복합 확장
우리는 실험적으로 다양한 확장 차원이 서로 독립적이지 않다는 것을 관찰했습니다. 직관적으로, 더 높은 해상도의 이미지를 처리할 때는 네트워크의 깊이를 늘려야 합니다. 이는 더 큰 수용 영역이 더 큰 이미지에서 더 많은 픽셀을 포함한 유사한 특징을 포착할 수 있도록 돕기 때문입니다. 마찬가지로, 더 높은 해상도에서는 더 세밀한 패턴을 포착하기 위해 네트워크의 너비도 늘려야 합니다. 이러한 직관은 기존의 단일 차원 확장이 아닌, 다양한 확장 차원을 조정하고 균형을 맞출 필요가 있음을 시사합니다.
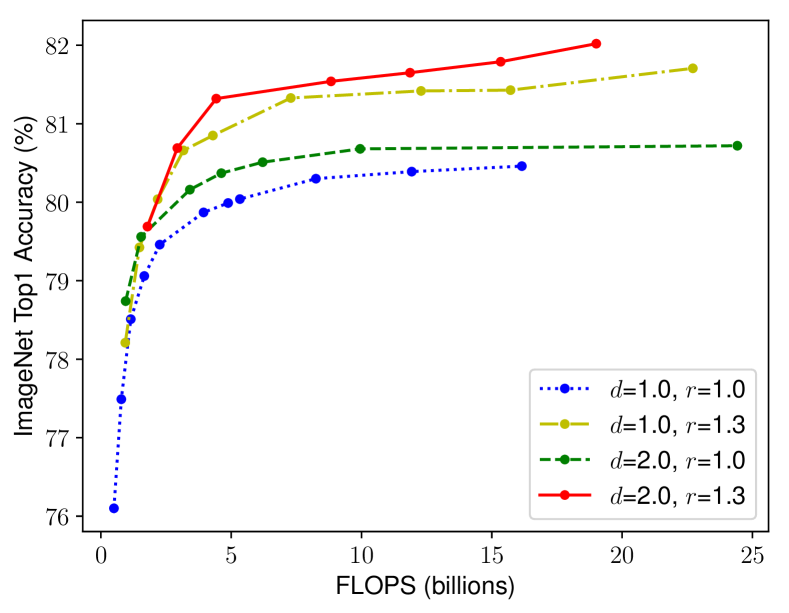
Figure 4: 서로 다른 기본 네트워크에 대한 네트워크 너비 확장. 각 선의 점은 다른 너비 계수 w를 가진 모델을 나타냅니다. 모든 기본 네트워크는 표 1에서 가져왔습니다. 첫 번째 기본 네트워크는 d=1.0, r=1.0이며, 18개의 합성곱 레이어와 해상도 224x224를 가지고 있습니다. 반면, 마지막 기본 네트워크는 d=2.0, r=1.3이며, 36개의 레이어와 해상도 299x299을 가지고 있습니다.
우리의 직관을 검증하기 위해, 서로 다른 네트워크 깊이와 해상도에서 너비 확장을 비교했습니다(Figure 4 참조). 만약 네트워크의 깊이 d=1.0와 해상도 r=1.0을 유지한 채로 너비 w만 확장하면, 정확도는 빠르게 포화됩니다. 그러나 더 깊은 네트워크(d=2.0)와 더 높은 해상도(r=2.0)를 사용하면, 동일한 FLOPS 비용 하에서 너비 확장이 훨씬 더 나은 정확도를 달성합니다. 이러한 결과는 다음과 같은 두 번째 관찰을 이끌어냅니다:
관찰 2
더 나은 정확도와 효율성을 추구하기 위해서는 ConvNet 확장 시 네트워크의 너비, 깊이, 해상도라는 모든 차원의 균형을 맞추는 것이 중요합니다.
실제로, 이전의 몇몇 연구(Zoph et al., 2018; Real et al., 2019)에서는 네트워크의 너비와 깊이를 임의로 조정하려고 했으나, 이러한 방법들은 모두 번거로운 수작업 조정이 필요했습니다.
이 논문에서는 새로운 복합 확장 방법(compound scaling method)을 제안합니다. 이 방법은 복합 계수 ϕ를 사용하여 네트워크의 너비, 깊이, 해상도를 체계적으로 균일하게 확장합니다:


-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Depth (d)는 네트워크의 레이어 수, Width (w)는 각 레이어의 필터 수, Resolution (r)는 이미지의 해상도와 관련이 있으며, 이는 이미지의 x (너비) 및 y (높이) 차원과 직접적으로 연관, Batch Size는 연관 x
필터는 커널(kernel)이라고도 하며, 주로 이미지나 피처맵에서 패턴을 탐지하기 위해 사용되는 작은 행렬
import tensorflow as tf
from tensorflow.keras import layers, models
# 입력 이미지 크기: 224x224x3 (RGB 이미지)
input_shape = (224, 224, 3)
# CNN 모델 생성
model = models.Sequential()
# 첫 번째 Conv 레이어: 필터(커널) 수 32 (Width)
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
# 첫 번째 MaxPooling 레이어
model.add(layers.MaxPooling2D((2, 2)))
# 두 번째 Conv 레이어: 필터(커널) 수 64로 증가 (Width 증가)
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 세 번째 Conv 레이어: 필터(커널) 수 128로 증가 (Width 증가)
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 네 번째 Conv 레이어: 필터(커널) 수 256로 증가 (Width 증가)
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 플래튼(flatten) 레이어와 Dense 레이어 추가
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax')) # 10개의 클래스 분류
# 모델 요약 출력
model.summary()
model.summary 시
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 222, 222, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 111, 111, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 109, 109, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2D)(None, 54, 54, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 52, 52, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2D)(None, 26, 26, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 24, 24, 256) 295168
_________________________________________________________________
max_pooling2d_3 (MaxPooling2D)(None, 12, 12, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 36864) 0
_________________________________________________________________
dense (Dense) (None, 64) 2359360
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 2,746,426
Trainable params: 2,746,426
Non-trainable params: 0
_________________________________________________________________
Batch size는 한 번에 처리되는 데이터의 양을 의미하며, loss를 한 번에 업데이트하는 데이터의 개수를 결정
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4. EfficientNet 아키텍처
모델 확장이 기본 네트워크에서 레이어 연산자 를 변경하지 않기 때문에, 좋은 기본 네트워크를 갖추는 것이 매우 중요합니다. 우리는 기존의 ConvNet을 사용하여 확장 방법을 평가할 것이지만, 우리의 확장 방법의 효과를 더 잘 입증하기 위해 EfficientNet이라는 새로운 모바일 크기의 기본 네트워크도 개발했습니다.

이 탐색 과정에서 우리는 EfficientNet-B0라는 효율적인 네트워크를 만들어냈습니다. 우리는 (Tan et al., 2019)와 동일한 탐색 공간을 사용했기 때문에 아키텍처는 MnasNet과 유사하지만, 우리의 EfficientNet-B0는 더 큰 FLOPS 목표(400M FLOPS)로 인해 약간 더 큽니다. Table 1은 EfficientNet-B0의 아키텍처를 보여줍니다. 주요 구성 요소는 MobileNet에서 사용된 모바일 인버티드 병목 MBConv(Sandler et al., 2018; Tan et al., 2019)이며, 여기에는 squeeze-and-excitation 최적화(Hu et al., 2018)도 추가되었습니다.

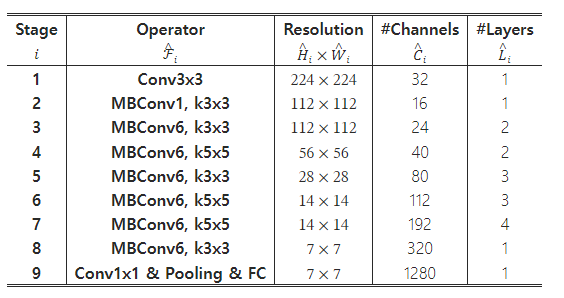
기본 EfficientNet-B0에서 시작하여, 우리는 두 단계로 복합 확장 방법을 적용하여 모델을 확장합니다:

주목할 점은, 큰 모델 주변에서 α, β, γ를 직접 검색하면 더 나은 성능을 달성할 수 있지만, 더 큰 모델에서는 검색 비용이 지나치게 비싸집니다. 우리의 방법은 작은 기본 네트워크에서 한 번만 검색을 수행(step 1)하고, 그 후 동일한 확장 계수를 모든 다른 모델에 적용(step 2)하여 이 문제를 해결합니다.
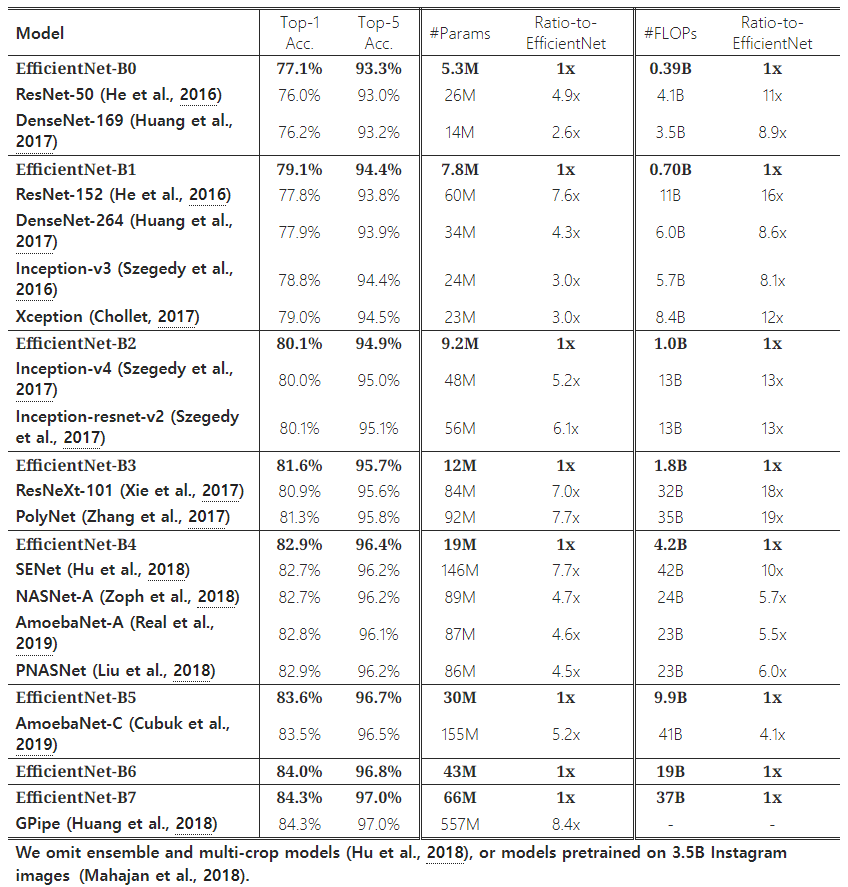
Table 2: ImageNet에서의 EfficientNet 성능 결과 (Russakovsky et al., 2015). 모든 EfficientNet 모델은 서로 다른 복합 계수 ϕ를 사용하여 기본 EfficientNet-B0에서 확장되었습니다. 유사한 top-1/top-5 정확도를 가진 ConvNet들은 효율성 비교를 위해 그룹화되었습니다. 우리가 확장한 EfficientNet 모델들은 기존 ConvNet들보다 파라미터 수와 FLOPS를 한 자릿수 이상 줄였으며(최대 8.4배 파라미터 감소, 최대 16배 FLOPS 감소), 일관되게 성능을 향상시켰습니다.
5. 실험
Table 3: MobileNets와 ResNet의 확장.
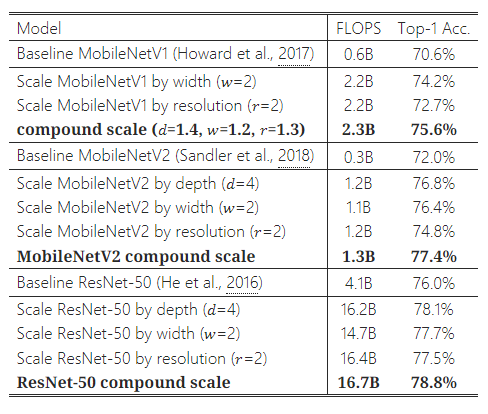
이 섹션에서는 먼저 기존의 ConvNet과 새로 제안된 EfficientNet에 대해 우리의 확장 방법을 평가할 것입니다.
5.1 MobileNets와 ResNets 확장
개념 증명으로서, 우리는 먼저 널리 사용되는 MobileNets(Howard et al., 2017; Sandler et al., 2018)와 ResNet(He et al., 2016)에 우리의 확장 방법을 적용했습니다. Table 3은 다양한 방식으로 확장한 후 이 모델들의 ImageNet 결과를 보여줍니다. 다른 단일 차원 확장 방법들과 비교했을 때, 우리의 복합 확장 방법은 모든 모델에서 정확도를 향상시켰으며, 이는 기존 ConvNet들에 대해서도 우리의 제안된 확장 방법이 효과적임을 시사합니다.

Table 4: 추론 지연 시간 비교 – 지연 시간은 Intel Xeon CPU E5-2690의 단일 코어에서 배치 크기 1로 측정되었습니다.
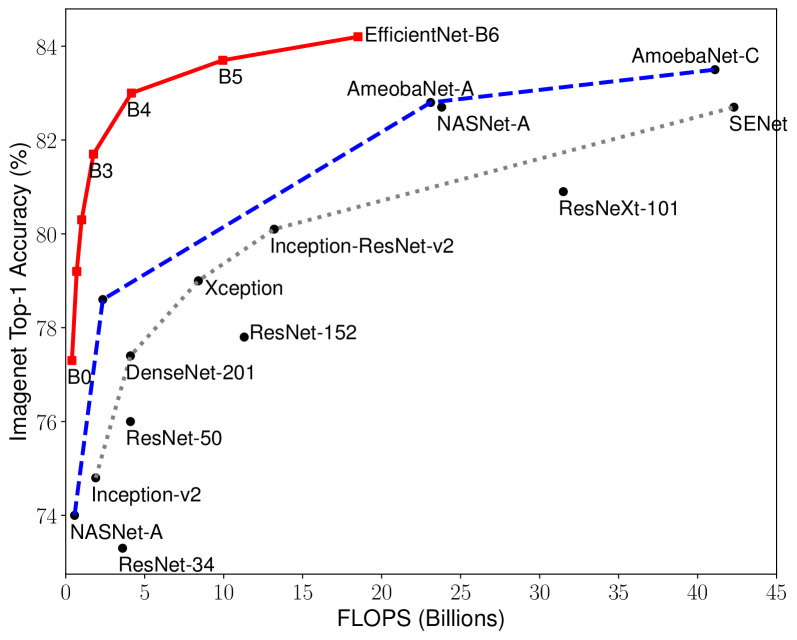
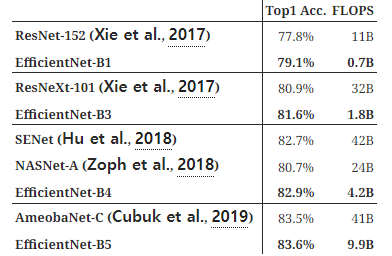
Figure 5: FLOPS 대 ImageNet 정확도 – Figure 1과 유사하지만, 모델 크기 대신 FLOPS를 비교합니다.
Table 5: 전이 학습 데이터셋에서의 EfficientNet 성능 결과. 우리의 확장된 EfficientNet 모델은 8개의 데이터셋 중 5개에서 새로운 최첨단 정확도를 달성했으며, 평균적으로 9.6배 더 적은 파라미터를 사용했습니다.
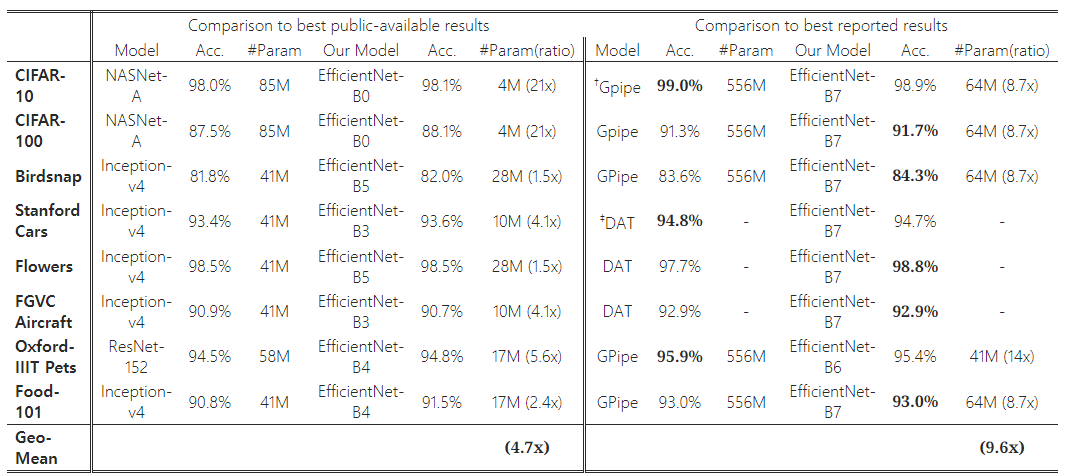
†GPipe(Huang et al., 2018)는 특수한 파이프라인 병렬 처리 라이브러리를 사용하여 거대한 모델을 학습합니다.
‡DAT는 도메인 적응 전이 학습(Domain Adaptive Transfer Learning)을 의미합니다(Ngiam et al., 2018). 여기서는 ImageNet을 기반으로 한 전이 학습 결과만 비교합니다. NASNet(Zoph et al., 2018), Inception-v4(Szegedy et al., 2017), ResNet-152(He et al., 2016)의 전이 학습 정확도 및 파라미터 수는 (Kornblith et al., 2019)에서 인용되었습니다.
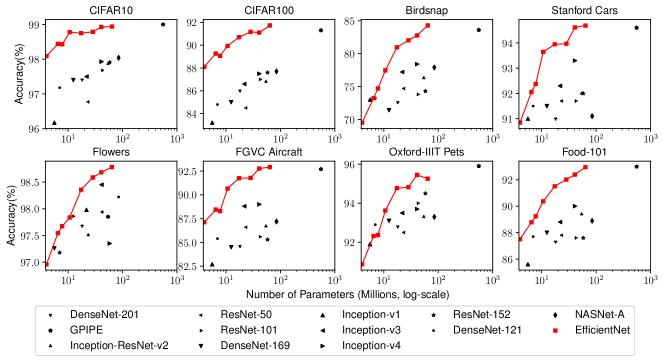
Figure 6: 모델 파라미터 대 전이 학습 정확도 – 모든 모델은 ImageNet에서 사전 학습된 후 새로운 데이터셋에서 미세 조정되었습니다.
5.2 ImageNet에서의 EfficientNet 결과
우리는 EfficientNet 모델을 ImageNet에서 (Tan et al., 2019)와 유사한 설정으로 훈련했습니다. 설정은 다음과 같습니다: RMSProp 옵티마이저(감쇠율 0.9, 모멘텀 0.9), 배치 정규화 모멘텀 0.99, 가중치 감쇠율 1e-5, 초기 학습률 0.256으로 2.4 에포크마다 0.97씩 감소하는 방식입니다. 또한 SiLU(Swish-1) 활성화 함수(Ramachandran et al., 2018; Elfwing et al., 2018; Hendrycks & Gimpel, 2016), AutoAugment(Cubuk et al., 2019), 확률적 깊이(Huang et al., 2016)를 사용했으며, 생존 확률은 0.8로 설정했습니다. 더 큰 모델이 더 많은 정규화를 필요로 한다는 점은 잘 알려져 있어, 우리는 드롭아웃 비율(Srivastava et al., 2014)을 EfficientNet-B0에서는 0.2에서 B7에서는 0.5로 선형적으로 증가시켰습니다. 우리는 훈련 세트에서 무작위로 선택한 25,000개의 이미지를 미니밸리셋으로 예약하고, 이 미니밸리셋에서 일찍 중단을 수행했습니다. 그 후 원래의 검증 세트에서 조기 중단된 체크포인트를 평가하여 최종 검증 정확도를 보고했습니다.
Table 2는 동일한 기본 EfficientNet-B0에서 확장된 모든 EfficientNet 모델의 성능을 보여줍니다. 우리의 EfficientNet 모델들은 유사한 정확도를 가진 다른 ConvNet들에 비해 파라미터 수와 FLOPS를 자릿수 단위로 줄였습니다. 특히, EfficientNet-B7은 66M 파라미터와 37B FLOPS로 84.3%의 top-1 정확도를 달성했으며, 이전 최고 성능 모델인 GPipe(Huang et al., 2018)보다 8.4배 더 작으면서도 더 높은 정확도를 기록했습니다. 이러한 성능 향상은 더 나은 아키텍처, 더 나은 확장 방법, 그리고 EfficientNet에 맞춘 더 나은 훈련 설정 덕분입니다.
Figure 1과 Figure 5는 대표적인 ConvNet들의 파라미터-정확도 곡선과 FLOPS-정확도 곡선을 보여줍니다. 여기에서 우리의 확장된 EfficientNet 모델들은 다른 ConvNet들보다 훨씬 적은 파라미터와 FLOPS로 더 높은 정확도를 달성했습니다. 특히, EfficientNet 모델들은 작을 뿐만 아니라 계산 비용도 저렴합니다. 예를 들어, EfficientNet-B3는 ResNeXt-101(Xie et al., 2017)보다 18배 적은 FLOPS로 더 높은 정확도를 달성했습니다.
추론 지연 시간을 확인하기 위해, 우리는 몇 가지 대표적인 ConvNet들의 실제 CPU에서의 추론 지연 시간을 측정했습니다(Table 4 참조). 20번의 실행에 걸친 평균 지연 시간을 보고했으며, EfficientNet-B1은 널리 사용되는 ResNet-152보다 5.7배 빠르게 실행되었고, EfficientNet-B7은 GPipe(Huang et al., 2018)보다 약 6.1배 빠르게 실행되었습니다. 이는 우리의 EfficientNet 모델들이 실제 하드웨어에서도 빠르다는 것을 시사합니다.
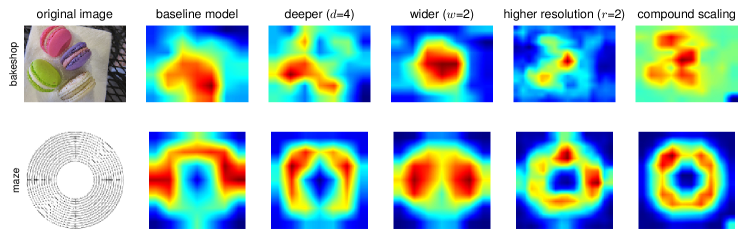
Figure 7: 서로 다른 확장 방법을 적용한 모델들의 클래스 활성화 맵(CAM)(Zhou et al., 2016) – 우리의 복합 확장 방법을 사용한 확장된 모델(마지막 열)은 더 많은 객체 세부 사항과 함께 더 관련 있는 영역에 집중할 수 있도록 합니다. 모델 세부 사항은 Table 7에 나와 있습니다.
5.3 EfficientNet의 전이 학습 결과
Table 6: 전이 학습 데이터셋.
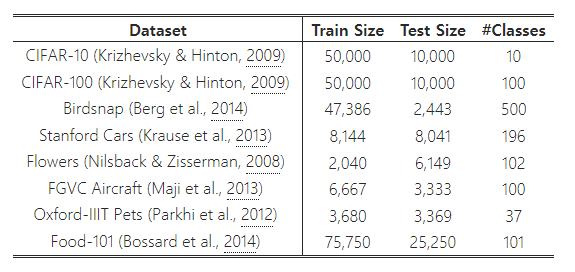
우리는 Table 6에 나와 있는 일반적으로 사용되는 전이 학습 데이터셋에 대해 EfficientNet을 평가했습니다. (Kornblith et al., 2019) 및 (Huang et al., 2018)에서 사용된 훈련 설정을 차용하여, ImageNet에서 사전 학습된 체크포인트를 가져와 새로운 데이터셋에서 미세 조정(finetuning)했습니다.
Table 5는 전이 학습 성능을 보여줍니다:
- 공개된 모델들(NASNet-A(Zoph et al., 2018) 및 Inception-v4(Szegedy et al., 2017) 등)과 비교했을 때, 우리의 EfficientNet 모델은 평균 4.7배(최대 21배) 적은 파라미터로 더 나은 정확도를 달성했습니다.
- 동적 데이터 합성(DAT)(Ngiam et al., 2018)과 특수한 파이프라인 병렬 처리를 사용해 훈련된 GPipe(Huang et al., 2018)를 포함한 최첨단 모델들과 비교했을 때, 우리의 EfficientNet 모델은 8개의 데이터셋 중 5개에서 더 나은 정확도를 기록하면서도 9.6배 적은 파라미터를 사용했습니다.
Figure 6은 다양한 모델에 대한 정확도와 파라미터 수의 관계를 비교합니다. 일반적으로 우리의 EfficientNet 모델은 ResNet(He et al., 2016), DenseNet(Huang et al., 2017), Inception(Szegedy et al., 2017), NASNet(Zoph et al., 2018) 등 기존 모델들보다 파라미터 수가 자릿수 단위로 적으면서도 일관되게 더 나은 정확도를 달성합니다.
6. 논의
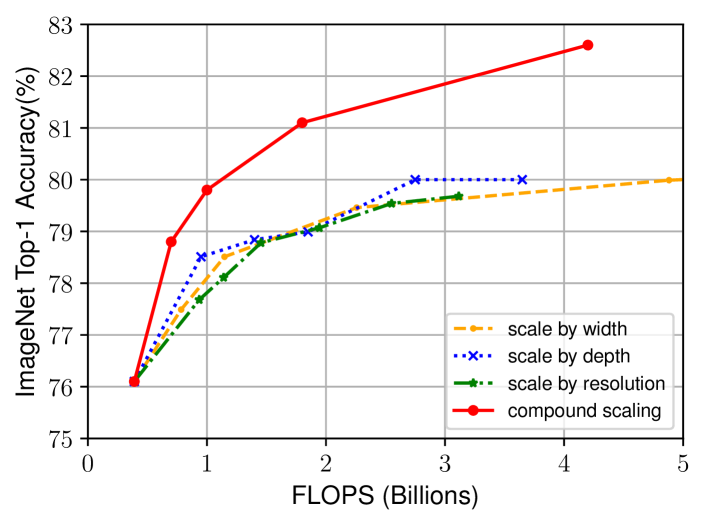
Figure 8: EfficientNet-B0를 다양한 방법으로 확장한 결과를 비교한 그림입니다.
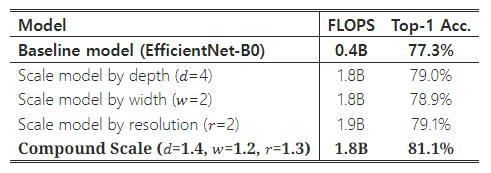
Table 7: Figure 7에서 사용된 확장된 모델들의 세부 사항을 나타냅니다.
6. 논의
우리의 제안된 확장 방법이 EfficientNet 아키텍처에 미치는 기여를 분리하기 위해, Figure 8은 동일한 EfficientNet-B0 기본 네트워크에 대해 다양한 확장 방법을 비교한 ImageNet 성능을 보여줍니다. 일반적으로 모든 확장 방법은 더 많은 FLOPS를 사용하여 정확도를 향상시키지만, 우리의 복합 확장 방법은 다른 단일 차원 확장 방법보다 최대 2.5% 더 높은 정확도를 제공하여 복합 확장의 중요성을 보여줍니다.
왜 우리의 복합 확장 방법이 다른 방법들보다 나은지 이해하기 위해, Figure 7에서는 서로 다른 확장 방법을 사용한 대표 모델들의 클래스 활성화 맵(Zhou et al., 2016)을 비교했습니다. 이 모델들은 모두 동일한 기본 네트워크에서 확장되었으며, 그 통계는 Table 7에 나와 있습니다. 이미지는 ImageNet 검증 세트에서 무작위로 선택되었습니다. 그림에서 볼 수 있듯이, 복합 확장된 모델은 더 많은 객체 세부 사항과 더 관련 있는 영역에 집중하는 반면, 다른 모델들은 객체 세부 사항이 부족하거나 이미지 내의 모든 객체를 포착하지 못하고 있습니다.
7. 결론
이 논문에서는 ConvNet 확장에 대해 체계적으로 연구하였으며, 네트워크의 너비, 깊이, 해상도의 균형을 신중하게 맞추는 것이 더 나은 정확도와 효율성을 방해하는 중요한 누락된 요소임을 확인했습니다. 이 문제를 해결하기 위해, 우리는 간단하면서도 매우 효과적인 복합 확장 방법을 제안했으며, 이를 통해 기본 ConvNet을 자원 제약에 맞춰 더 원칙적으로 확장하면서도 모델 효율성을 유지할 수 있습니다. 이 복합 확장 방법을 통해 모바일 크기의 EfficientNet 모델이 매우 효과적으로 확장될 수 있으며, ImageNet과 다섯 개의 일반적인 전이 학습 데이터셋에서 자릿수 단위로 더 적은 파라미터와 FLOPS로 최첨단 정확도를 능가하는 성과를 보여주었습니다.
감사의 글
우리는 Ruoming Pang, Vijay Vasudevan, Alok Aggarwal, Barret Zoph, Hongkun Yu, Jonathon Shlens, Raphael Gontijo Lopes, Yifeng Lu, Daiyi Peng, Xiaodan Song, Samy Bengio, Jeff Dean, 그리고 Google Brain 팀에게 그들의 도움에 대해 감사드립니다.
부록
2017년 이후 대부분의 연구 논문은 ImageNet 검증 정확도만 보고하고 비교하며, 이 논문도 더 나은 비교를 위해 이러한 관례를 따랐습니다. 추가적으로, 우리는 http://image-net.org에 100k개의 테스트 세트 이미지에 대한 예측을 제출하여 테스트 정확도를 검증했으며, 결과는 Table 8에 나와 있습니다. 예상대로, 테스트 정확도는 검증 정확도와 매우 근접했습니다.
Table 8: ImageNet 검증 vs. 테스트 Top-1/5 정확도.
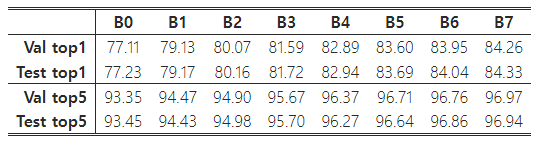
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
항상 오랜 친구 같은 모델...
Transformer 논문의 경우
1. "Scaling Vision Transformers" (Dosovitskiy et al., 2020)
2. "Scaling Laws for Neural Language Models" (Kaplan et al., 2020)
3. "Efficient Transformers: A Survey" (Tay et al., 2020)
4. "Scaling Transformers to 1M Tokens and Beyond" (Press et al., 2021)
이 있다.



