https://arxiv.org/abs/2104.00298
EfficientNetV2: Smaller Models and Faster Training
This paper introduces EfficientNetV2, a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. To develop this family of models, we use a combination of training-aware neural architecture
arxiv.org
초록
이 논문은 EfficientNetV2라는 새로운 계열의 컨볼루션 신경망을 소개합니다. 이 모델들은 이전 모델들에 비해 더 빠른 학습 속도와 향상된 파라미터 효율성을 제공합니다. 이러한 모델을 개발하기 위해, 우리는 학습 인식 신경망 구조 검색과 스케일링을 결합하여 학습 속도와 파라미터 효율성을 공동으로 최적화했습니다. 특히 Fused-MBConv와 같은 새로운 연산을 추가한 검색 공간에서 모델을 검색했습니다. 실험 결과, EfficientNetV2 모델은 최첨단 모델들보다 학습 속도가 훨씬 빠르면서도 최대 6.8배 더 작았습니다.
또한, 학습 속도는 학습 중 이미지 크기를 점진적으로 증가시키면 더 빨라질 수 있지만, 이는 종종 정확도 하락을 초래합니다. 이러한 정확도 하락을 보완하기 위해, 우리는 이미지 크기와 함께 정규화(예: 데이터 증강)를 적응적으로 조정하는 개선된 점진적 학습 방법을 제안합니다.
점진적 학습을 사용한 EfficientNetV2는 ImageNet, CIFAR, Cars, Flowers 데이터셋에서 이전 모델보다 뛰어난 성능을 보였습니다. 동일한 ImageNet21k에서 사전 학습된 EfficientNetV2는 ImageNet ILSVRC2012에서 87.3%의 Top-1 정확도를 달성하며, 최근의 ViT를 2.0%의 정확도 차이로 능가하면서도 동일한 컴퓨팅 자원을 사용하여 5배에서 11배 빠른 학습 속도를 기록했습니다. 코드는 여기에서 확인할 수 있습니다.
Machine Learning, ICML
- 서론

(a) 학습 효율성

(b) 파라미터 효율성
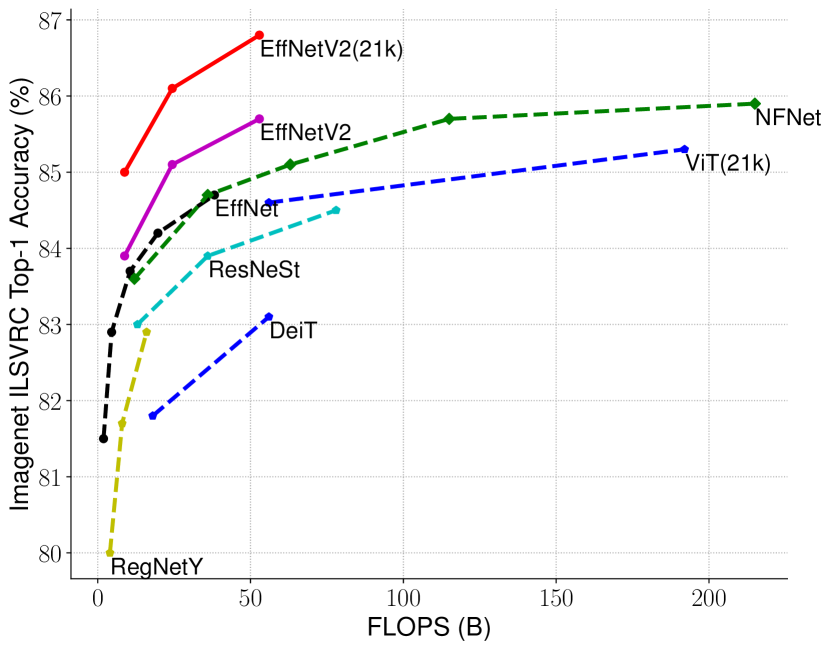
그림 1: ImageNet ILSVRC2012의 Top-1 정확도 대 학습 시간 및 파라미터 비교 - 21k로 표시된 모델은 ImageNet21k로 사전 학습된 것이고, 나머지는 ImageNet ILSVRC2012에서 직접 학습된 모델입니다. 학습 시간은 32 TPU 코어로 측정되었습니다. 모든 EfficientNetV2 모델은 점진적 학습 방식을 사용하여 학습되었습니다. 우리의 EfficientNetV2는 다른 모델들보다 5배에서 11배 더 빠르게 학습하면서도 최대 6.8배 적은 파라미터를 사용합니다. 자세한 내용은 표 7과 그림 5에 나와 있습니다.
학습 효율성은 모델 크기와 학습 데이터 크기가 점점 커지면서 딥러닝에서 중요한 요소가 되고 있습니다. 예를 들어, GPT-3(Brown et al., 2020)는 매우 큰 모델과 많은 학습 데이터를 통해 몇 샷 학습에서 뛰어난 성능을 보여주지만, 수천 개의 GPU로 몇 주간 학습해야 하므로 재학습하거나 개선하는 것이 어려워집니다.
최근 학습 효율성에 대한 관심이 크게 증가했습니다. 예를 들어, NFNets(Brock et al., 2021)은 비용이 많이 드는 배치 정규화를 제거하여 학습 효율성을 개선하려고 시도했으며, 몇몇 최신 연구(Srinivas et al., 2021)는 컨볼루션 신경망(ConvNets)에 어텐션 레이어를 추가하여 학습 속도를 개선하려고 했습니다. Vision Transformers(Dosovitskiy et al., 2021)는 Transformer 블록을 사용하여 대규모 데이터셋에서 학습 효율성을 개선했습니다. 하지만 이러한 방법들은 종종 큰 파라미터 크기로 인해 많은 오버헤드를 발생시키는 단점이 있습니다(그림 1(b) 참고).
이 논문에서는 학습 속도와 파라미터 효율성을 개선하기 위해 학습 인식 신경망 구조 검색(NAS)과 스케일링을 결합한 방법을 사용했습니다. EfficientNets(Tan & Le, 2019a)의 파라미터 효율성에 기반하여, 우리는 EfficientNets에서의 학습 병목 현상을 체계적으로 연구했습니다. 연구 결과, EfficientNets에서 (1) 매우 큰 이미지 크기로 학습하는 것은 느리며, (2) 초기 레이어에서 깊이별 컨볼루션이 느리고, (3) 모든 단계에서 동일하게 확장하는 것은 최적이 아님을 발견했습니다. 이러한 관찰을 바탕으로, 우리는 Fused-MBConv와 같은 추가 연산을 포함한 검색 공간을 설계하고, 학습 인식 NAS와 스케일링을 적용하여 모델 정확도, 학습 속도 및 파라미터 크기를 공동으로 최적화했습니다. 우리가 발견한 네트워크인 EfficientNetV2는 이전 모델보다 최대 4배 더 빠르게 학습되며, 파라미터 크기는 최대 6.8배 더 작습니다(그림 3).
학습 중 이미지 크기를 점진적으로 증가시키면 학습 속도를 더욱 높일 수 있습니다. 이전 연구들, 예를 들어 Progressive Resizing(Howard, 2018), FixRes(Touvron et al., 2019), Mix&Match(Hoffer et al., 2019)은 작은 이미지 크기를 학습에 사용했지만, 보통 모든 이미지 크기에 동일한 정규화를 적용하여 정확도 하락을 초래했습니다. 우리는 동일한 네트워크에서 작은 이미지 크기는 작은 네트워크 용량을 초래하므로 약한 정규화가 필요하고, 반대로 큰 이미지 크기는 과적합을 방지하기 위해 더 강한 정규화가 필요하다고 주장합니다(4.1절 참조). 이러한 통찰을 바탕으로, 우리는 개선된 점진적 학습 방법을 제안합니다. 학습 초기 에포크에서는 작은 이미지 크기와 약한 정규화(예: 드롭아웃 및 데이터 증강)를 사용하고, 점진적으로 이미지 크기를 증가시키고 더 강한 정규화를 추가합니다. Progressive Resizing(Howard, 2018)에 기반하면서도 정규화를 동적으로 조정하여, 우리의 접근 방식은 정확도 하락 없이 학습 속도를 높일 수 있습니다.
개선된 점진적 학습 방법을 통해 EfficientNetV2는 ImageNet, CIFAR-10, CIFAR-100, Cars, Flowers 데이터셋에서 뛰어난 성능을 보였습니다. ImageNet에서 우리는 이전 모델보다 3배에서 9배 더 빠르고, 파라미터 크기는 최대 6.8배 더 작은 상태에서 85.7%의 Top-1 정확도를 달성했습니다(그림 1). 또한, EfficientNetV2와 점진적 학습은 더 큰 데이터셋에서 모델을 더 쉽게 학습할 수 있게 해줍니다. 예를 들어, ImageNet21k(Russakovsky et al., 2015)는 ImageNet ILSVRC2012보다 약 10배 더 큰 데이터셋이지만, EfficientNetV2는 32 TPUv3 코어를 사용하여 이틀 만에 학습을 완료할 수 있습니다. Public ImageNet21k에서 사전 학습한 EfficientNetV2는 ImageNet ILSVRC2012에서 87.3%의 Top-1 정확도를 기록하며, 최근 ViT-L/16보다 2.0% 더 높은 정확도를 달성하면서도 학습 속도는 5배에서 11배 더 빠릅니다(그림 1).
우리의 기여는 세 가지로 요약됩니다:
- 우리는 EfficientNetV2라는 더 작고 빠른 모델 계열을 소개했습니다. 학습 인식 NAS와 스케일링으로 발견된 EfficientNetV2는 이전 모델들보다 학습 속도와 파라미터 효율성에서 뛰어난 성능을 보였습니다.
- 우리는 이미지 크기와 함께 정규화를 적응적으로 조정하는 개선된 점진적 학습 방법을 제안했습니다. 이 방법은 학습 속도를 높이는 동시에 정확도를 향상시킵니다.
- 우리는 ImageNet, CIFAR, Cars, Flowers 데이터셋에서 최대 11배 더 빠른 학습 속도와 최대 6.8배 더 나은 파라미터 효율성을 이전 연구보다 보여주었습니다.
2. 관련 연구
학습 및 파라미터 효율성:
여러 연구들은 DenseNet(Huang et al., 2017)와 EfficientNet(Tan & Le, 2019a)처럼 파라미터 효율성에 초점을 맞추고 있으며, 더 적은 파라미터로 더 나은 정확도를 달성하려고 합니다. 최근의 몇몇 연구들은 파라미터 효율성보다는 학습 또는 추론 속도를 개선하려고 합니다. 예를 들어, RegNet(Radosavovic et al., 2020), ResNeSt(Zhang et al., 2020), TResNet(Ridnik et al., 2020), EfficientNet-X(Li et al., 2021) 같은 모델들은 GPU 및/또는 TPU에서의 추론 속도에 중점을 두고 있으며, NFNets(Brock et al., 2021)와 BoTNets(Srinivas et al., 2021)는 학습 속도 개선에 집중하고 있습니다. 그러나 이들의 학습 또는 추론 속도 개선은 종종 더 많은 파라미터를 요구합니다. 이 논문은 이전 연구들보다 학습 속도와 파라미터 효율성을 모두 크게 개선하는 것을 목표로 합니다.
점진적 학습:
이전 연구들에서는 GANs(Karras et al., 2018), 전이 학습(Karras et al., 2018), 적대적 학습(Yu et al., 2019), 그리고 언어 모델(Press et al., 2021)과 같은 다양한 영역에서 학습 설정이나 네트워크를 동적으로 변화시키는 점진적 학습 방법들이 제안되었습니다. Progressive Resizing(Howard, 2018)은 우리의 접근 방식과 가장 관련이 있으며, 학습 속도를 높이는 것을 목표로 하지만, 보통 정확도 하락이라는 대가를 치릅니다. Mix&Match(Hoffer et al., 2019)라는 또 다른 관련 연구는 각 배치마다 무작위로 다른 이미지 크기를 샘플링하는 방식입니다. Progressive Resizing과 Mix&Match는 모두 모든 이미지 크기에 동일한 정규화를 적용하여 정확도 하락을 초래합니다. 본 논문에서 우리의 주된 차이점은 이미지 크기뿐만 아니라 정규화도 적응적으로 조정하여 학습 속도와 정확도를 모두 개선할 수 있다는 것입니다. 또한, 우리의 접근은 쉬운 것부터 어려운 것으로 학습 예제를 스케줄링하는 커리큘럼 학습(Bengio et al., 2009)에서 부분적으로 영감을 받았습니다. 우리의 방법은 더 많은 정규화를 추가함으로써 학습 난이도를 점차 증가시키지만, 학습 예제를 선택적으로 고르는 방식은 사용하지 않습니다.
신경망 구조 검색(NAS):
네트워크 설계 과정을 자동화함으로써, NAS는 이미지 분류(Zoph et al., 2018), 객체 탐지(Chen et al., 2019; Tan et al., 2020), 분할(Liu et al., 2019), 하이퍼파라미터(Dong et al., 2020) 및 기타 응용 프로그램(Elsken et al., 2019)을 위한 네트워크 아키텍처 최적화에 사용되었습니다. 이전 NAS 연구들은 대부분 FLOPs 효율성(Tan & Le, 2019b, a)이나 추론 효율성(Tan et al., 2019; Cai et al., 2019; Wu et al., 2019; Li et al., 2021)을 개선하는 데 초점을 맞췄습니다. 이 논문은 이전 연구들과 달리 NAS를 사용하여 학습 속도와 파라미터 효율성을 최적화했습니다.
3. EfficientNetV2 아키텍처 설계
이 섹션에서는 EfficientNet(Tan & Le, 2019a)의 학습 병목 현상을 분석하고, 학습 인식 신경망 구조 검색(NAS)과 스케일링, 그리고 EfficientNetV2 모델을 소개합니다.
3.1 EfficientNet 개요
EfficientNet(Tan & Le, 2019a)은 FLOPs(연산 복잡도)와 파라미터 효율성을 최적화한 모델 계열입니다. EfficientNet은 NAS를 활용하여 더 나은 정확도와 FLOPs 간의 균형을 가진 기본 모델인 EfficientNet-B0를 검색합니다. 이후 이 기본 모델은 복합 스케일링 전략을 사용하여 B1부터 B7까지의 모델 계열로 확장됩니다. 최근 연구들은 학습 속도나 추론 속도에서 큰 향상을 주장했지만, 대부분의 경우 파라미터 및 FLOPs 효율성 측면에서는 EfficientNet보다 열등합니다(표 1 참조). 이 논문에서는 파라미터 효율성을 유지하면서 학습 속도를 개선하는 것을 목표로 합니다.
표 1: EfficientNet은 파라미터와 FLOPs 효율성에서 우수한 성능을 보입니다.

3.2 학습 효율성 이해
우리는 EfficientNet(Tan & Le, 2019a)의 학습 병목 현상을 분석하고, 학습 속도를 개선하기 위한 몇 가지 간단한 기술을 제시합니다. EfficientNet은 이후 EfficientNetV1이라고도 불립니다.
큰 이미지 크기로 학습하는 것은 느리다:
이전 연구들(Radosavovic et al., 2020)에서 지적한 바와 같이, EfficientNet은 큰 이미지 크기로 인해 상당한 메모리 사용량을 유발합니다. GPU/TPU의 총 메모리는 고정되어 있으므로, 이러한 모델을 학습할 때 더 작은 배치 크기를 사용해야 하며, 이는 학습 속도를 크게 저하시킵니다. 간단한 개선 방법은 FixRes(Touvron et al., 2019)를 적용하여, 추론 때보다 작은 이미지 크기로 학습하는 것입니다. 표 2에서 볼 수 있듯이, 더 작은 이미지 크기는 계산량을 줄이고 더 큰 배치 크기를 사용할 수 있게 하여, 학습 속도를 최대 2.2배까지 향상시킵니다. 특히 (Touvron et al., 2020; Brock et al., 2021)에서 지적한 바와 같이, 더 작은 이미지 크기로 학습하는 것은 약간 더 나은 정확도를 가져다주기도 합니다. 그러나 (Touvron et al., 2019)과 달리, 우리는 학습 후 어떤 레이어도 추가로 미세 조정하지 않습니다.
표 2: EfficientNet-B6의 배치 크기와 이미지 크기에 따른 정확도와 학습 처리량.

4절에서는 학습 중 이미지 크기와 정규화를 점진적으로 조정하는 더 진보된 학습 방식을 탐구할 것입니다.
깊이별 컨볼루션은 초기 레이어에서 느리지만, 후반 단계에서는 효과적이다:
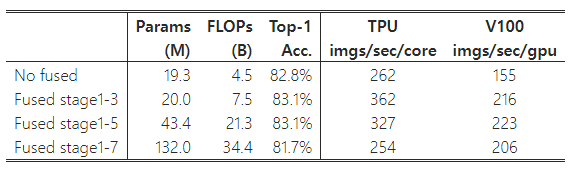
EfficientNet의 또 다른 학습 병목 현상은 광범위한 깊이별 컨볼루션(Sifre, 2014)에서 발생합니다. 깊이별 컨볼루션은 일반적인 컨볼루션보다 파라미터와 FLOPs(연산량)가 적지만, 종종 최신 가속기를 완전히 활용하지 못합니다. 최근에는 Fused-MBConv가 (Gupta & Tan, 2019)에서 제안되었으며, 이후 (Gupta & Akin, 2020; Xiong et al., 2020; Li et al., 2021)에서 모바일 또는 서버 가속기를 더 잘 활용하기 위해 사용되었습니다. 이 방식은 MBConv(Sandler et al., 2018; Tan & Le, 2019a)에서 사용되는 깊이별 컨볼루션 3x3과 확장 컨볼루션 1x1을 하나의 일반적인 컨볼루션 3x3으로 대체합니다(그림 2 참조). 이 두 가지 빌딩 블록을 체계적으로 비교하기 위해, 우리는 EfficientNet-B4에서 기존 MBConv를 Fused-MBConv로 점진적으로 교체했습니다(표 3). 초기 단계(1-3단계)에서 Fused-MBConv를 적용하면 파라미터와 FLOPs에 약간의 오버헤드가 발생하지만, 학습 속도는 향상됩니다. 그러나 모든 블록을 Fused-MBConv로 교체하면(1-7단계), 파라미터와 FLOPs가 크게 증가하고 학습 속도도 느려집니다. MBConv와 Fused-MBConv의 올바른 조합을 찾는 것은 간단하지 않으며, 이로 인해 우리는 최적의 조합을 자동으로 검색하기 위해 신경망 구조 검색(NAS)을 활용하게 되었습니다.
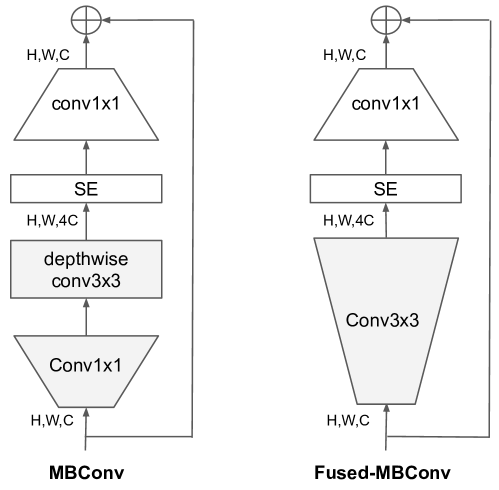
그림 2: MBConv와 Fused-MBConv의 구조.
표 3: MBConv를 Fused-MBConv로 교체한 경우. "No fused"는 모든 단계에서 MBConv를 사용한 것을 의미하며, "Fused stage1-3"은 단계 2, 3, 4에서 MBConv를 Fused-MBConv로 교체한 것을 의미합니다.
모든 단계를 동일하게 확장하는 것은 최적이 아니다:
EfficientNet은 단순한 복합 확장 규칙을 사용하여 모든 단계를 동일하게 확장합니다. 예를 들어, 깊이 계수가 2인 경우 네트워크의 모든 단계에서 레이어 수가 두 배로 증가합니다. 그러나 이러한 단계들이 학습 속도와 파라미터 효율성에 동일하게 기여하지는 않습니다. 본 논문에서는 균일하지 않은 확장 전략을 사용하여 후반 단계에 더 많은 레이어를 점진적으로 추가하는 방식을 제안합니다. 또한, EfficientNet은 이미지 크기를 과도하게 확장하여 메모리 사용량이 크고 학습 속도가 느려집니다. 이를 해결하기 위해, 우리는 확장 규칙을 약간 수정하고 최대 이미지 크기를 더 작은 값으로 제한합니다.
3.3 학습 인식 NAS와 스케일링
이 목표를 달성하기 위해, 우리는 학습 속도를 개선하기 위한 여러 설계 선택을 학습했습니다. 이러한 선택들의 최적 조합을 찾기 위해, 우리는 이제 학습 인식 NAS(신경망 구조 검색)를 제안합니다.
NAS 검색:
우리의 학습 인식 NAS 프레임워크는 이전 NAS 연구(Tan et al., 2019; Tan & Le, 2019a)를 주로 기반으로 하지만, 정확도, 파라미터 효율성, 학습 효율성을 현대 가속기에서 공동으로 최적화하는 것을 목표로 합니다. 구체적으로, 우리는 EfficientNet을 백본으로 사용합니다. 우리의 검색 공간은 (Tan et al., 2019)과 유사한 단계 기반의 분리된 공간으로, {MBConv, Fused-MBConv}와 같은 컨볼루션 연산 유형, 레이어 수, 커널 크기 {3x3, 5x5}, 확장 비율 {1, 4, 6}의 설계 선택들로 구성됩니다. 한편, 우리는 검색 공간의 크기를 줄이기 위해 (1) 원래 EfficientNet에서 사용되지 않는 풀링 스킵 연산과 같은 불필요한 검색 옵션을 제거하고, (2) 이미 검색된 백본에서 채널 크기를 재사용합니다(Tan & Le, 2019a). 검색 공간이 더 작아졌기 때문에, 우리는 강화 학습(Tan et al., 2019) 또는 단순한 랜덤 검색을 적용하여 EfficientNet-B4와 유사한 크기의 더 큰 네트워크에서 검색을 수행할 수 있습니다. 구체적으로, 우리는 최대 1000개의 모델을 샘플링하고 각 모델을 약 10 에포크 동안 축소된 이미지 크기로 학습시킵니다. 우리의 검색 보상은 모델의 정확도 A , 정규화된 학습 단계 시간 S , 파라미터 크기 P 를 결합하여 단순한 가중치 곱 A ⋅ S w ⋅ P v 으로 계산합니다. 여기서 w = -0.07, v = -0.05는 (Tan et al., 2019)와 유사하게 상호 타협을 균형 있게 맞추기 위해 경험적으로 결정된 값입니다.
EfficientNetV2 아키텍처:
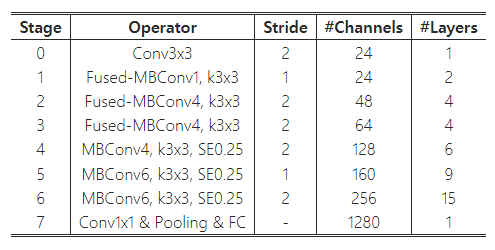
표 4는 검색된 모델 EfficientNetV2-S의 아키텍처를 보여줍니다. EfficientNet 백본과 비교했을 때, 검색된 EfficientNetV2는 몇 가지 주요 차이점이 있습니다:
(1) 첫 번째 차이점은 EfficientNetV2가 초기 레이어에서 MBConv(Sandler et al., 2018; Tan & Le, 2019a)와 새롭게 추가된 Fused-MBConv(Gupta & Tan, 2019)를 광범위하게 사용하는 것입니다.
(2) 두 번째로, EfficientNetV2는 MBConv에서 더 작은 확장 비율을 선호합니다. 이는 작은 확장 비율이 메모리 접근 오버헤드를 줄이는 경향이 있기 때문입니다.
(3) 세 번째로, EfficientNetV2는 더 작은 3x3 커널 크기를 선호하지만, 커널 크기가 작아짐에 따라 줄어든 수용 범위를 보완하기 위해 더 많은 레이어를 추가합니다.
(4) 마지막으로, EfficientNetV2는 원래 EfficientNet에 있던 마지막 stride-1 단계를 완전히 제거했는데, 이는 아마도 해당 단계가 큰 파라미터 크기와 메모리 접근 오버헤드를 야기하기 때문일 것입니다.
표 4: EfficientNetV2-S 아키텍처 – MBConv와 Fused-MBConv 블록에 대한 설명은 그림 2에 나와 있습니다.
EfficientNetV2 확장:
EfficientNetV2-S를 확장하여 EfficientNetV2-M/L을 얻기 위해, (Tan & Le, 2019a)에서 사용된 것과 유사한 복합 확장 전략을 사용하되 몇 가지 추가적인 최적화를 적용했습니다:
(1) 우리는 매우 큰 이미지가 메모리 및 학습 속도에서 큰 오버헤드를 유발하는 경우가 많기 때문에 최대 추론 이미지 크기를 480으로 제한했습니다.
(2) 또한, 경험적 방법으로 네트워크의 실행 시간 오버헤드를 많이 추가하지 않으면서 네트워크 용량을 늘리기 위해 후반 단계(예: 표 4의 5단계와 6단계)에 점진적으로 더 많은 레이어를 추가했습니다.
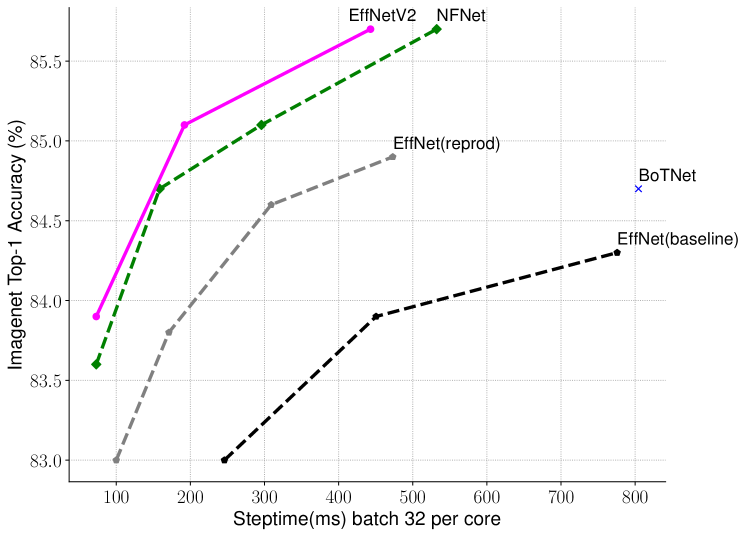
그림 3: TPUv3에서 ImageNet 정확도와 학습 단계 시간 – 낮은 단계 시간이 더 좋습니다. 모든 모델은 점진적 학습 없이 고정된 이미지 크기로 학습되었습니다.
학습 속도 비교:
그림 3은 새로운 EfficientNetV2의 학습 단계 시간을 비교한 것입니다. 모든 모델은 고정된 이미지 크기로 학습되었으며, 점진적 학습은 적용되지 않았습니다. EfficientNet(Tan & Le, 2019a)에 대해서는 두 가지 곡선을 보여줍니다: 하나는 원래의 추론 이미지 크기로 학습된 것이고, 다른 하나는 EfficientNetV2와 NFNet(Touvron et al., 2019; Brock et al., 2021)과 동일하게 약 30% 더 작은 이미지 크기로 학습된 것입니다. 모든 모델은 350 에포크로 학습되었고, NFNets만 360 에포크로 학습되어 모든 모델이 유사한 학습 단계 수를 가집니다. 흥미롭게도, 적절히 학습되었을 때 EfficientNets는 여전히 강력한 성능의 트레이드오프를 보여줍니다. 더 중요한 것은, 우리의 학습 인식 NAS와 스케일링을 통해 제안된 EfficientNetV2 모델이 최근의 다른 모델들보다 훨씬 빠르게 학습된다는 점입니다. 이 결과는 표 7과 그림 5에서 제시된 추론 결과와도 일치합니다.
4. 점진적 학습
4.1 동기
3장에서 논의된 바와 같이, 이미지 크기는 학습 효율성에 중요한 역할을 합니다. FixRes(Touvron et al., 2019) 외에도 많은 연구들이 학습 중에 이미지 크기를 동적으로 변경하는 방법을 사용했습니다(Howard, 2018; Hoffer et al., 2019). 그러나 이러한 방법은 종종 정확도 하락을 유발합니다.
우리는 정확도 하락이 불균형한 정규화에서 비롯된다고 가정합니다. 다른 이미지 크기로 학습할 때, 이전 연구들처럼 고정된 정규화를 사용하는 대신 정규화 강도도 이에 맞춰 조정해야 합니다. 사실, 큰 모델일수록 과적합을 방지하기 위해 더 강한 정규화가 필요합니다. 예를 들어, EfficientNet-B7은 B0보다 더 큰 드롭아웃과 강력한 데이터 증강을 사용합니다. 이 논문에서는 동일한 네트워크에서도 작은 이미지 크기가 더 작은 네트워크 용량을 가져와 약한 정규화를 필요로 하고, 반대로 큰 이미지 크기는 더 많은 계산과 더 큰 용량을 요구하여 과적합에 더 취약해진다고 주장합니다.
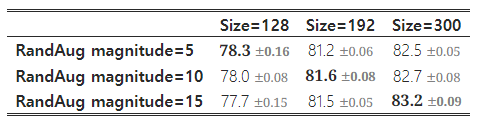
이 가설을 검증하기 위해, 우리는 검색 공간에서 샘플링한 모델을 사용하여 다양한 이미지 크기와 데이터 증강을 적용해 학습했습니다(표 5). 작은 이미지 크기일 때는 약한 증강을 사용할 때 가장 높은 정확도를 보였으며, 더 큰 이미지에서는 강한 증강을 사용할 때 더 나은 성능을 보였습니다. 이러한 통찰은 학습 중 이미지 크기에 따라 정규화를 적응적으로 조정해야 한다는 점을 시사하며, 이를 바탕으로 우리는 개선된 점진적 학습 방법을 제안합니다.
표 5: ImageNet의 top-1 정확도. RandAug(Cubuk et al., 2020)을 사용했으며, 3회 실행한 평균과 표준편차를 보고합니다.
4.2 정규화 적응형 점진적 학습
그림 4는 개선된 점진적 학습 과정의 훈련 과정을 보여줍니다. 초기 학습 에포크에서는 작은 이미지와 약한 정규화를 사용하여 네트워크가 간단한 표현을 쉽게 빠르게 학습할 수 있게 합니다. 그 후 점차 이미지 크기를 증가시키면서, 더 강한 정규화를 추가해 학습을 더 어렵게 만듭니다. 우리의 접근 방식은 이미지 크기를 점진적으로 변경하는 (Howard, 2018)의 방법을 기반으로 하지만, 여기에 정규화도 적응적으로 조정하는 방식을 추가했습니다.
정식으로 설명하면, 전체 학습 단계가 N 일 때, 목표 이미지 크기는 S_e 이고, 정규화 강도 목록은 Φ_e = {ϕ_e^k} 입니다. 여기서 k 는 드롭아웃 비율이나 믹스업 비율 같은 정규화 유형을 나타냅니다. 학습은 M 개의 단계로 나뉘며, 각 단계 1 ≤ i ≤ M 에서 모델은 이미지 크기 S_i 와 정규화 강도 Φ_i = {ϕ_i^k} 로 학습됩니다. 마지막 단계인 M 에서는 목표 이미지 크기 S_e 와 정규화 Φ_e 를 사용합니다. 단순성을 위해, 초기 이미지 크기 S_0 와 정규화 Φ_0 를 경험적으로 선택하고, 각 단계의 값을 결정하기 위해 선형 보간법을 사용합니다. 알고리즘 1은 이 절차를 요약합니다. 각 단계가 시작될 때 네트워크는 이전 단계에서 학습한 모든 가중치를 상속받습니다. 트랜스포머와 달리, 트랜스포머의 가중치(예: 위치 임베딩)는 입력 길이에 의존할 수 있지만, ConvNet의 가중치는 이미지 크기와 독립적이므로 쉽게 상속할 수 있습니다.

알고리즘 1: 정규화 적응형 점진적 학습

그림 4: 개선된 점진적 학습에서의 훈련 과정 – 작은 이미지 크기와 약한 정규화로 시작(에포크=1)하고, 점진적으로 더 큰 이미지 크기와 더 강한 정규화(예: 더 큰 드롭아웃 비율, RandAugment 강도, mixup 비율)를 적용하여 학습 난이도를 높입니다(에포크=300).
우리의 개선된 점진적 학습은 기존의 정규화 방식과 일반적으로 호환됩니다. 단순성을 위해, 이 논문은 다음 세 가지 주요 정규화 유형에 대해 주로 연구했습니다:
- Dropout (Srivastava et al., 2014): 네트워크 수준의 정규화 방식으로, 채널을 무작위로 드롭하여 과적응을 줄입니다. 우리는 드롭아웃 비율 γ 를 조정할 것입니다.
- RandAugment (Cubuk et al., 2020): 이미지별 데이터 증강 방식으로, 강도 ϵ 를 조정할 수 있습니다.
- Mixup (Zhang et al., 2018): 교차 이미지 데이터 증강 방식입니다. 두 이미지와 라벨 ( x_i , y_i )와 ( x_j , y_j )을 주고, mixup 비율 λ 에 따라 다음과 같이 결합합니다: x_i~ = λx_j (1−λ)x_i , y_i~ = λy_j + (1−λ)y_i . 우리는 학습 중에 mixup 비율 λ 를 조정할 것입니다.
5. 주요 결과
이 섹션에서는 우리의 실험 설정, ImageNet에서의 주요 결과, 그리고 CIFAR-10, CIFAR-100, Cars, Flowers에 대한 전이 학습 결과를 제시합니다.
5.1 ImageNet ILSVRC2012
설정:
ImageNet ILSVRC2012(Russakovsky et al., 2015)에는 약 128만 장의 학습 이미지와 5만 장의 검증 이미지가 있으며, 총 1000개의 클래스가 있습니다. 아키텍처 검색 또는 하이퍼파라미터 튜닝 중에는 학습 세트에서 약 2%인 25,000장의 이미지를 미니 검증 세트(minival)로 예약하여 정확도 평가에 사용합니다. 우리는 미니 검증 세트를 사용해 조기 종료(early stopping)를 수행합니다. 우리의 ImageNet 학습 설정은 EfficientNets(Tan & Le, 2019a)를 주로 따릅니다: RMSProp 옵티마이저(감쇠율 0.9, 모멘텀 0.9), 배치 정규화 모멘텀 0.99, 가중치 감쇠율 1e-5. 각 모델은 총 배치 크기 4096으로 350 에포크 동안 학습됩니다. 학습률은 처음에 0에서 0.256까지 워밍업되며, 그 후 매 2.4 에포크마다 0.97씩 감소합니다. 우리는 0.9999의 감쇠율로 지수 이동 평균(exponential moving average)을 사용하고, RandAugment(Cubuk et al., 2020), Mixup(Zhang et al., 2018), Dropout(Srivastava et al., 2014), 확률적 깊이(stochastic depth)(Huang et al., 2016)와 0.8의 생존 확률을 사용합니다.
표 6: EfficientNetV2의 점진적 학습 설정.
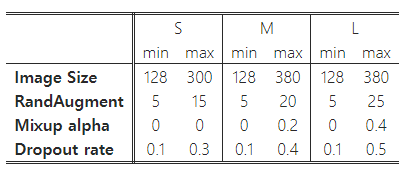
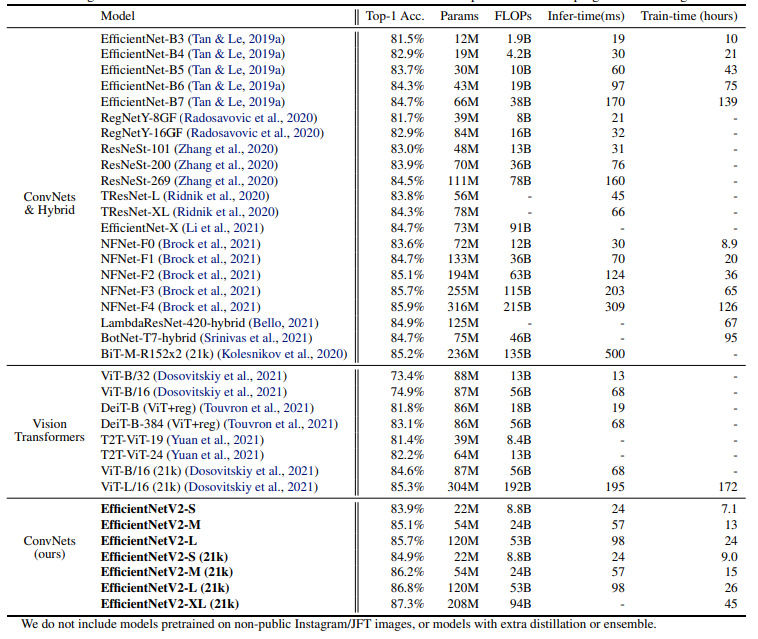
표 7: EfficientNetV2의 ImageNet에서의 성능 결과 (Russakovsky et al., 2015) – 추론 시간은 V100 GPU FP16에서 배치 크기 16으로 동일한 코드베이스(Wightman, 2021)를 사용하여 측정되었습니다. 학습 시간은 32 TPU 코어에 대해 정규화된 총 학습 시간을 나타냅니다. 21k로 표시된 모델들은 1300만 장의 이미지로 이루어진 ImageNet21k에서 사전 학습된 것이며, 그 외의 모델들은 128만 장의 이미지로 이루어진 ImageNet ILSVRC2012에서 처음부터 직접 학습되었습니다. 모든 EfficientNetV2 모델은 개선된 점진적 학습 방법을 사용해 학습되었습니다.
우리는 비공개된 Instagram/JFT 이미지로 사전 학습된 모델이나 추가적인 증류(distillation) 또는 앙상블을 사용한 모델을 포함하지 않았습니다.
점진적 학습에서는 학습 과정을 네 단계로 나누며, 각 단계는 약 87 에포크로 구성됩니다. 초기 단계에서는 작은 이미지 크기와 약한 정규화를 사용하고, 후반 단계에서는 더 큰 이미지 크기와 더 강한 정규화를 사용합니다(알고리즘 1 참조). 표 6은 첫 번째 단계에서의 최소값과 마지막 단계에서의 최대값으로 설정된 이미지 크기와 정규화 값을 보여줍니다. 단순성을 위해, 모든 모델은 동일한 최소 크기와 정규화 값을 사용하지만, 각 모델은 서로 다른 최대값을 채택합니다. 이는 더 큰 모델일수록 과적합을 방지하기 위해 더 많은 정규화가 필요하기 때문입니다. (Touvron et al., 2020)의 연구를 따라, 우리의 학습에 사용된 최대 이미지 크기는 추론 때보다 약 20% 더 작지만, 우리는 학습 후 어떤 레이어도 추가로 미세 조정하지 않습니다.
(a) 파라미터
(b) FLOPs
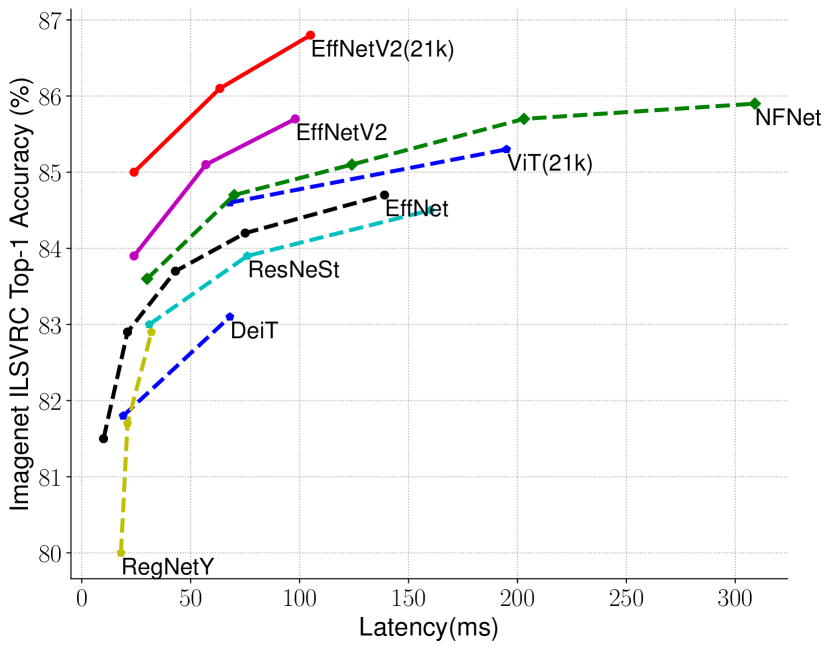
(c) GPU V100 지연 시간(배치 크기 16)
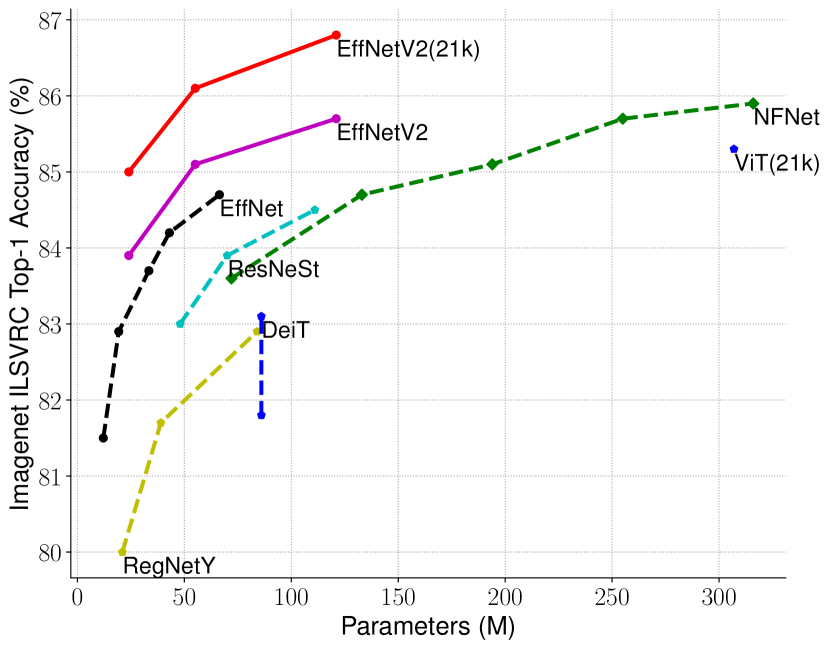
그림 5: 모델 크기, FLOPs, 및 추론 지연 시간 – 지연 시간은 V100 GPU에서 배치 크기 16으로 측정되었습니다. 21k는 ImageNet21k 이미지로 사전 학습된 모델을 나타내며, 나머지는 ImageNet ILSVRC2012에서 학습된 모델입니다. 우리의 EfficientNetV2는 파라미터 효율성 면에서 EfficientNet과 약간 더 나은 성능을 보이지만, 추론 속도는 3배 더 빠릅니다.
결과:
표 7에서 볼 수 있듯이, 우리의 EfficientNetV2 모델은 이전의 ConvNet과 Transformer 모델들보다 ImageNet에서 훨씬 더 빠르고, 더 나은 정확도와 파라미터 효율성을 달성했습니다. 특히, EfficientNetV2-M은 EfficientNet-B7과 유사한 정확도를 기록하면서도 동일한 컴퓨팅 자원을 사용해 11배 더 빠르게 학습되었습니다. 또한, EfficientNetV2 모델은 정확도와 추론 속도에서 최근의 RegNet과 ResNeSt 모델들을 모두 크게 능가합니다. 그림 1은 학습 속도와 파라미터 효율성에 대한 비교를 시각화한 것입니다. 이 속도 향상은 점진적 학습과 더 나은 네트워크 설계가 결합된 결과이며, 각 요소의 개별적인 영향을 제거 연구(ablation study)를 통해 분석할 것입니다.
최근 Vision Transformers(ViT)는 ImageNet에서 인상적인 정확도와 학습 속도를 보여주었습니다. 그러나 이 연구에서는, 적절히 설계된 ConvNet과 개선된 학습 방법이 여전히 Vision Transformers를 정확도와 학습 효율성에서 크게 능가할 수 있음을 증명합니다. 특히, EfficientNetV2-L은 85.7%의 Top-1 정확도를 달성하며, 더 큰 ImageNet21k 데이터셋에서 사전 학습된 더 큰 Transformer 모델인 ViT-L/16(21k)을 능가합니다. 여기서 ViT는 ImageNet ILSVRC2012에서 충분히 튜닝되지 않은 반면, DeiT는 ViT와 동일한 아키텍처를 사용하되, 더 많은 정규화를 추가하여 더 나은 결과를 얻었습니다.
EfficientNetV2 모델은 학습을 최적화했지만, 추론 성능에서도 뛰어난 결과를 보입니다. 이는 학습 속도가 종종 추론 속도와 연관이 있기 때문입니다. 그림 5는 표 7을 기반으로 모델 크기, FLOPs, 추론 지연 시간을 시각화한 것입니다. 지연 시간은 하드웨어와 소프트웨어에 따라 달라지기 때문에, 여기서는 동일한 PyTorch Image Models 코드베이스(Wightman, 2021)를 사용하고, 동일한 머신에서 배치 크기 16으로 모든 모델을 실행했습니다. 전반적으로 우리의 모델은 EfficientNet에 비해 파라미터/FLOPs 효율성이 약간 더 좋지만, 추론 지연 시간은 EfficientNet보다 최대 3배 더 빠릅니다. GPU에 최적화된 최근의 ResNeSt와 비교했을 때, EfficientNetV2-M은 0.6% 더 나은 정확도를 기록하면서도 추론 속도는 2.8배 더 빠릅니다.
5.2 ImageNet21k
설정:
ImageNet21k(Russakovsky et al., 2015)은 약 1300만 장의 학습 이미지와 21,841개의 클래스로 구성되어 있습니다. 원래 ImageNet21k에는 학습/평가 분할(train/eval split)이 없으므로, 우리는 무작위로 선택된 100,000장의 이미지를 검증 세트로 사용하고 나머지를 학습 세트로 사용합니다. 학습 설정은 주로 ImageNet ILSVRC2012와 동일하지만 몇 가지 변경 사항이 있습니다:
(1) 학습 시간을 줄이기 위해 학습 에포크 수를 60 또는 30으로 변경하고, 추가 튜닝 없이도 다양한 단계에 적응할 수 있는 코사인 학습률 감소(cosine learning rate decay)를 사용합니다.
(2) 각 이미지에는 여러 라벨이 있으므로, softmax 손실을 계산하기 전에 라벨의 합이 1이 되도록 정규화합니다. ImageNet21k에서 사전 학습된 후, 각 모델은 ILSVRC2012에서 코사인 학습률 감소를 사용해 15 에포크 동안 미세 조정됩니다.
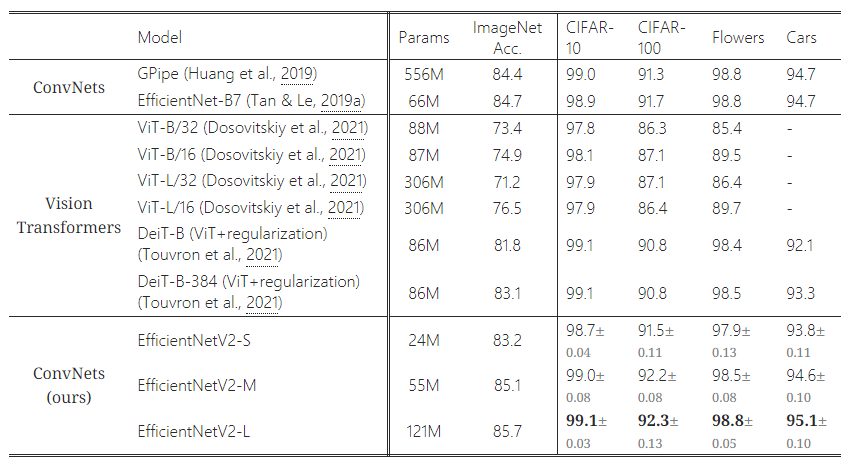
표 8: 전이 학습 성능 비교 – 모든 모델은 ImageNet ILSVRC2012에서 사전 학습되었고, 하위 데이터셋에서 미세 조정되었습니다. 전이 학습 정확도는 다섯 번의 실행에 대한 평균값을 보고합니다.
결과:
표 7는 성능 비교를 보여줍니다. 여기서 "21k"로 표시된 모델들은 ImageNet21k에서 사전 학습된 후 ImageNet ILSVRC2012에서 미세 조정되었습니다. 최근의 ViT-L/16(21k)와 비교했을 때, 우리의 EfficientNetV2-L(21k)는 파라미터를 2.5배 적게 사용하고, FLOPs를 3.6배 적게 사용하면서도, 학습 및 추론 속도에서 6배에서 7배 더 빠르게 작동하며, Top-1 정확도는 1.5% 더 높습니다(85.3% vs. 86.8%).
우리는 몇 가지 흥미로운 관찰 결과를 강조하고 싶습니다:
- 데이터 크기 확장이 모델 크기 확장보다 고정밀 상황에서 더 효과적이다: Top-1 정확도가 85%를 넘으면, 모델 크기를 단순히 키우는 것만으로는 과적합 문제 때문에 성능을 더 향상시키기 어렵습니다. 그러나 추가적인 ImageNet21k 사전 학습은 정확도를 크게 개선할 수 있습니다. 대규모 데이터셋의 효과는 이전 연구들(Mahajan et al., 2018; Xie et al., 2020; Dosovitskiy et al., 2021)에서도 관찰되었습니다.
- ImageNet21k에서의 사전 학습은 매우 효율적일 수 있다: ImageNet21k가 10배 더 많은 데이터를 가지고 있음에도 불구하고, 우리의 학습 방법을 통해 EfficientNetV2의 사전 학습을 32 TPU 코어를 사용해 이틀 내에 완료할 수 있었습니다(반면 ViT의 경우 몇 주가 걸립니다). 이는 ImageNet에서 더 큰 모델을 학습시키는 것보다 효율적입니다. 우리는 대규모 모델에 대한 미래 연구에서 공개된 ImageNet21k를 기본 데이터셋으로 사용할 것을 제안합니다.
5.3 전이 학습 데이터셋
설정:
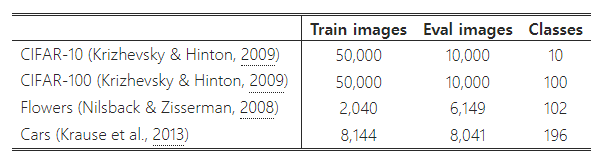
우리는 네 가지 전이 학습 데이터셋(CIFAR-10, CIFAR-100, Flowers, Cars)에서 우리의 모델을 평가했습니다. 표 9는 이러한 데이터셋의 통계를 포함하고 있습니다.
표 9: 전이 학습 데이터셋.
실험 설정:
이 실험에서는 ImageNet ILSVRC2012에서 학습된 체크포인트를 사용했습니다. 공정한 비교를 위해 ImageNet21k 이미지는 사용되지 않았습니다. 우리의 미세 조정 설정은 대부분 ImageNet 학습 설정과 동일하나, (Dosovitskiy et al., 2021; Touvron et al., 2021)과 유사하게 몇 가지 수정 사항이 있습니다: 배치 크기를 512로 줄였고, 초기 학습률은 코사인 감소를 사용하여 0.001로 설정했습니다. 모든 데이터셋에서 각 모델은 고정된 10,000 스텝 동안 학습되었습니다. 각 모델은 매우 적은 스텝으로 미세 조정되므로, 가중치 감쇠(weight decay)를 비활성화하고 단순한 cutout 데이터 증강을 사용했습니다.
결과:
표 8은 전이 학습 성능을 비교한 것입니다. 일반적으로, 우리의 모델은 이들 데이터셋에서 이전의 ConvNet과 Vision Transformer 모델을 능가하며, 경우에 따라서는 상당한 차이를 보입니다. 예를 들어, CIFAR-100에서 EfficientNetV2-L은 이전의 GPipe/EfficientNets보다 0.6% 더 높은 정확도를, ViT/DeiT 모델보다 1.5% 더 높은 정확도를 달성했습니다. 이러한 결과는 우리의 모델이 ImageNet을 넘어도 잘 일반화된다는 것을 시사합니다.
6. 제거 연구(Ablation Studies)
6.1 EfficientNet과의 비교
이 섹션에서는 동일한 학습 및 추론 설정에서 EfficientNetV2(V2)와 EfficientNets(Tan & Le, 2019a)(V1)을 비교합니다.
동일한 학습에서의 성능:
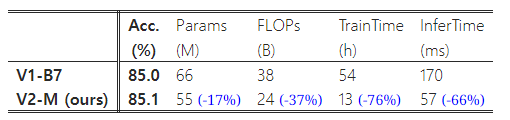
표 10은 동일한 점진적 학습 설정을 사용한 성능 비교를 보여줍니다. 동일한 점진적 학습을 EfficientNet에 적용했을 때, 학습 속도는 139시간에서 54시간으로 단축되고, 정확도는 84.7%에서 85.0%로 개선되었습니다. 그러나 표 10에서 볼 수 있듯이, 우리의 EfficientNetV2 모델은 여전히 EfficientNets보다 훨씬 더 뛰어난 성능을 보입니다: EfficientNetV2-M은 파라미터를 17% 줄이고 FLOPs를 37% 줄이면서, 학습 속도는 4.1배, 추론 속도는 3.1배 더 빠릅니다. 동일한 학습 설정을 사용하고 있으므로, 이러한 성능 향상은 EfficientNetV2 아키텍처에 기인한다고 볼 수 있습니다.
표 10: 동일한 학습 설정에서의 비교 – 우리의 새로운 EfficientNetV2-M은 더 적은 파라미터로 더 빠르게 작동합니다.
모델 크기 축소:
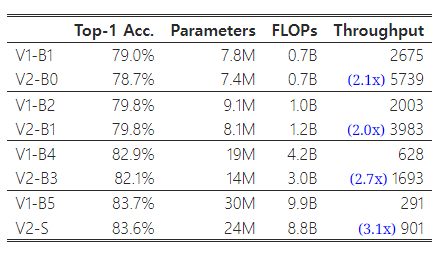
이전 섹션에서는 주로 대규모 모델에 중점을 두었지만, 여기서는 EfficientNet 복합 스케일링을 사용하여 EfficientNetV2-S를 축소하여 작은 모델들을 비교합니다. 비교를 쉽게 하기 위해, 모든 모델은 점진적 학습 없이 학습되었습니다. 작은 크기의 EfficientNet(V1)과 비교했을 때, 우리의 새로운 EfficientNetV2(V2) 모델은 일반적으로 더 빠르면서도 유사한 파라미터 효율성을 유지합니다.
표 11: 모델 크기 축소 – 우리는 V100 FP16 GPU에서 배치 크기 128로 추론 처리량(초당 이미지 수)을 측정했습니다.
6.2 다양한 네트워크에 대한 점진적 학습
우리는 다양한 네트워크에 대해 점진적 학습의 성능을 분석했습니다. 표 12는 동일한 ResNet과 EfficientNet 모델을 사용하여, 우리의 점진적 학습과 기존의 학습 방식 간의 성능 비교를 보여줍니다. 여기서, 기존 ResNet 모델은 원래 논문(He et al., 2016)보다 더 높은 정확도를 보이는데, 이는 더 많은 에포크와 더 나은 옵티마이저를 사용한 우리의 개선된 학습 설정(5장 참조) 덕분입니다. 또한, ResNet의 네트워크 용량과 정확도를 높이기 위해 이미지 크기를 224에서 380으로 증가시켰습니다.
표 12: ResNet과 EfficientNet에 대한 점진적 학습 – (224)와 (380)은 추론 시 이미지 크기를 나타냅니다. 우리의 점진적 학습은 모든 네트워크에서 정확도와 학습 시간을 모두 개선했습니다.
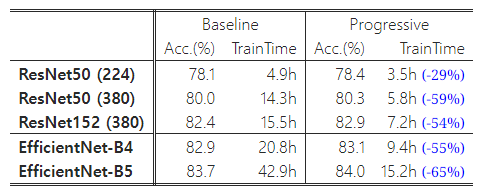
표 12에서 볼 수 있듯이, 우리의 점진적 학습은 다양한 네트워크에서 학습 시간을 단축하면서도 정확도를 향상시킵니다. 예상할 수 있듯이, 기본 이미지 크기가 매우 작은 경우(예: 224x224 크기의 ResNet50(224)), 학습 속도 향상은 제한적입니다(1.4배 속도 향상). 그러나 기본 이미지 크기가 더 크고 모델이 더 복잡할수록, 우리의 접근 방식은 정확도와 학습 효율성에서 더 큰 향상을 가져옵니다. 예를 들어, ResNet152(380)에서는 우리의 방법이 학습 속도를 2.1배 향상시키면서 정확도도 약간 향상되었고, EfficientNet-B4에서는 학습 속도가 2.2배 향상되었습니다.
6.3 적응형 정규화의 중요성
우리의 학습 방식에서 중요한 통찰 중 하나는 적응형 정규화입니다. 이는 이미지 크기에 따라 정규화를 동적으로 조정하는 방식입니다. 이 논문에서는 단순한 점진적 접근 방식을 선택했지만, 이는 다른 방법들과 결합할 수 있는 일반적인 방법이기도 합니다.
표 13에서는 두 가지 학습 설정에서 우리의 적응형 정규화를 연구했습니다. 첫 번째는 작은 이미지 크기에서 큰 크기로 점진적으로 이미지 크기를 증가시키는 방법(Howard, 2018)이고, 두 번째는 각 배치마다 다른 이미지 크기를 무작위로 샘플링하는 방법(Hoffer et al., 2019)입니다. TPU는 각 새로운 이미지 크기에 대해 그래프를 다시 컴파일해야 하므로, 우리는 각 배치마다가 아닌 8 에포크마다 한 번씩 이미지 크기를 무작위로 샘플링했습니다. 모든 이미지 크기에 동일한 정규화를 사용하는 기본적인 점진적 또는 무작위 크기 조정 방식과 비교했을 때, 우리의 적응형 정규화는 정확도를 0.7% 향상시켰습니다. 그림 6은 점진적 접근 방식의 학습 곡선을 추가로 비교합니다. 우리의 적응형 정규화는 학습 초기 에포크에서 작은 이미지에 훨씬 더 약한 정규화를 사용하여 모델이 더 빠르게 수렴하고 더 나은 최종 정확도를 달성할 수 있게 합니다.
표 13: 적응형 정규화 – 세 번의 실행 평균을 기반으로 ImageNet의 top-1 정확도를 비교합니다.
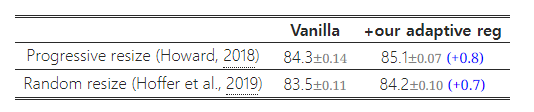
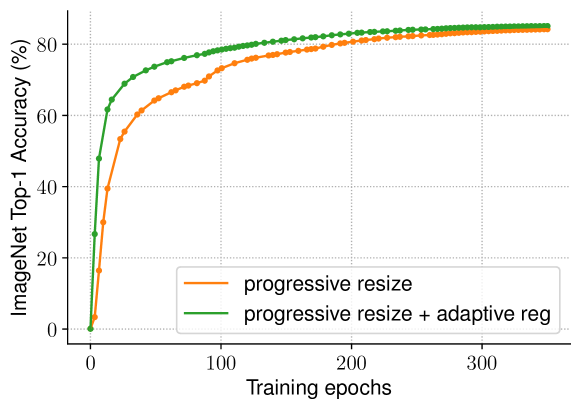
그림 6: 학습 곡선 비교 – 우리의 적응형 정규화는 더 빠르게 수렴하고 더 나은 최종 정확도를 달성합니다.
7. 결론
이 논문은 이미지 인식을 위한 더 작고 빠른 신경망 계열인 EfficientNetV2를 제시합니다. 학습 인식 NAS와 모델 스케일링을 통해 최적화된 EfficientNetV2는 이전 모델보다 훨씬 더 빠르고 파라미터 면에서 효율적이면서도 성능이 크게 향상되었습니다. 학습 속도를 더욱 높이기 위해, 우리는 학습 중에 이미지 크기와 정규화를 함께 증가시키는 개선된 점진적 학습 방법을 제안합니다. 광범위한 실험을 통해 EfficientNetV2가 ImageNet 및 CIFAR/Flowers/Cars 데이터셋에서 뛰어난 성능을 보여준다는 것을 확인했습니다. EfficientNet 및 최신 연구들과 비교할 때, 우리의 EfficientNetV2는 최대 11배 더 빠르게 학습되며, 파라미터 크기는 최대 6.8배 더 작습니다.
감사의 말
오픈 소스화에 도움을 준 Lucas Sloan에게 특별히 감사드립니다. 또한 Ruoming Pang, Sheng Li, Andrew Li, Hanxiao Liu, Zihang Dai, Neil Houlsby, Ross Wightman, Jeremy Howard, Thang Luong, Daiyi Peng, Yifeng Lu, Da Huang, Chen Liang, Aravind Srinivas, Irwan Bello, Max Moroz, Futang Peng에게 피드백을 주신 것에 대해 감사드립니다.
'인공지능' 카테고리의 다른 글
| Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency (14) | 2024.09.14 |
|---|---|
| An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (VIT) (부록 추가 필요) (1) | 2024.09.11 |
| Diffusion Models Are Real-Time Game Engines (부록 추가 필요) (1) | 2024.09.09 |
| Deep Learning using Rectified Linear Units (ReLU) (2) | 2024.09.05 |
| Gaussian Error Linear Units (GELUs) (2) | 2024.09.04 |



