https://arxiv.org/abs/2409.02634
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited contr
arxiv.org
초록
확산 기반 비디오 생성 기술의 도입으로 인해, 최근 오디오 조건의 인간 비디오 생성은 동작의 자연스러움과 초상 디테일의 합성에서 상당한 돌파구를 이루었습니다. 인간의 동작을 구동하는 데 있어 오디오 신호의 제어가 제한적이기 때문에, 기존 방법들은 종종 움직임을 안정화하기 위해 보조적인 공간 신호를 추가하는데, 이는 동작의 자연스러움과 자유로움을 저해할 수 있습니다. 본 논문에서는 Loopy라는 이름의 엔드투엔드 오디오 전용 조건의 비디오 확산 모델을 제안합니다. 구체적으로, 우리는 클립 간 및 클립 내 시간 모듈과 오디오-잠재 공간 모듈을 설계하여, 모델이 데이터로부터 장기적인 동작 정보를 활용하여 자연스러운 동작 패턴을 학습하고 오디오와 초상 움직임의 상관관계를 향상시킬 수 있도록 했습니다. 이 방법은 추론 과정에서 동작을 제약하기 위해 기존 방법에서 사용되던 수동으로 지정된 공간 동작 템플릿의 필요성을 제거합니다. 광범위한 실험 결과, Loopy는 최근의 오디오 기반 초상 확산 모델을 능가하여 다양한 시나리오에서 더욱 생동감 있고 고품질의 결과를 제공합니다.
1. 서론
비디오 합성 분야에서 GAN과 확산 모델의 급속한 발전(Bar-Tal et al., 2024; Blattmann et al., 2023a; b; Guo et al., 2023; Zhou et al., 2022; Gupta et al., 2023; Wang et al., 2023; Ho et al., 2022; Brooks et al., 2022; Wang et al., 2020; Singer et al., 2022; Li et al., 2018; Villegas et al., 2022)으로 인해, 인간 비디오 합성(Siarohin et al., 2019; 2021; Xu et al., 2024b; Hu, 2024; Corona et al., 2024)은 품질 면에서 실용적인 사용 가능성의 문턱에 점차 접근하게 되었으며, 최근 몇 년간 상당한 주목을 받고 있습니다. 이 중에서, 제로샷 오디오 기반 초상 합성은 진입 장벽이 낮아 대화형 헤드 비디오를 생성할 수 있는 능력 덕분에(He et al., 2023; Tian et al., 2024; Xu et al., 2024a; Wang et al., 2024; Chen et al., 2024; Xu et al., 2024b; Stypulkowski et al., 2024) 2020년경부터 연구가 폭발적으로 증가했습니다. 지난해부터는 확산 모델 기술이 도입되면서, 엔드투엔드 오디오 기반 모델들(Tian et al., 2024; Xu et al., 2024a; Chen et al., 2024)이 기존 방법들에 비해 더 생생한 합성 결과를 보여주고 있습니다.
그러나 오디오와 초상 동작 간의 상관관계가 약하기 때문에, 엔드투엔드 오디오 기반 방법들은 합성된 비디오의 시간적 안정성을 보장하기 위해 일반적으로 공간적 동작과 관련된 추가 조건을 도입합니다. 얼굴 위치 지정자(face locators)나 속도 계층(speed layers)과 같은 조건들(Tian et al., 2024; Xu et al., 2024a; Chen et al., 2024)은 초상 움직임의 범위와 속도를 제한하여 최종 출력의 표현력을 저해할 수 있으며, 이는 그림 1에 나타나 있습니다. 사전 설정된 동작 템플릿의 도입은 이러한 문제를 완화할 수 있지만, 템플릿 선택, 오디오-동작 동기화, 반복적인 템플릿 움직임과 관련된 복잡성도 함께 도입됩니다. 모델 관점에서 이러한 한계는 비디오 확산 모델이 생생한 동작을 생성하는 데 있어 잠재력을 충분히 발휘하는 것을 방해합니다. 본 논문은 공간적 템플릿 없이 데이터로부터 자연스러운 동작 패턴을 학습할 수 있도록 하는 오디오 전용 조건의 초상 확산 모델을 제안하여 이 문제를 해결하고자 합니다.

Figure 1: 기존 방법과의 시각적 비교. 기존 방법들은 자연스러운 움직임을 생성하는 데 어려움을 겪고 있으며, 참조 이미지와 비교했을 때 움직임, 자세, 표정이 참조 이미지와 유사하거나 거의 정지 상태에 있는 경우가 많습니다. 이는 보조적인 공간 조건 때문입니다. 반면에 Loopy는 오직 오디오만을 사용하여 자세한 머리 움직임과 표정을 포함한 자연스러운 인체 움직임을 효과적으로 생성합니다. 동영상 결과는 부록 자료에 제공됩니다.
우리는 먼저 얼굴 위치 결정자와 속도 레이어 같은 구조를 제거해 보았습니다. 그 결과, 합성된 동영상에서 갑작스러운 시간적 떨림, 프레임 손상, 증가된 자가회귀 열화, 부자연스러운 시간적 세부 사항과 같은 바람직하지 않은 움직임 패턴이 더 자주 발생하여 전체적인 품질이 저하되었습니다. 실제로, 현재 확산 기반 프레임워크에서 움직임에 영향을 미치는 조건은 오디오뿐만 아니라 모션 프레임도 포함됩니다. 오디오는 움직임 패턴과 다대다로 매핑되어 있으며, 이를 통해 움직임을 완벽하게 정의하는 것은 어렵습니다. 반면, 모션 프레임은 이전 클립에서의 외형 정보를 제공하며, 움직임 생성에 강한 영향을 미칩니다. 그러나 현재의 방법은 대개 마지막 클립에서 4개의 모션 프레임과 현재 클립에서 10개 이상의 목표 프레임을 기반으로 생성됩니다. 일반적인 25fps에서 이 시간은 총 0.5초에 해당하며, 모션 프레임은 단 0.2초만을 다룹니다. 이러한 짧은 모션 프레임은 모델이 시간적 움직임 정보보다 외형 정보에 더 의존하게 만듭니다. 예를 들어, 눈 깜박임의 경우 0.2초의 정보는 깜박임이 발생해야 하는지 여부를 결정하기에 충분하지 않습니다(깜박임이 이전에 발생했는지 알 수 없으므로 깜박임이 확률적 사건이 되어 오랜 시간 동안 깜박임이 없는 동영상이 생성될 수 있습니다). 오디오와 모션 프레임을 통해 움직임 스타일을 결정하기 어려울 때, 움직임은 무작위성을 나타내며, 얼굴 상자나 움직임 속도와 같은 공간 조건의 추가 지도가 필요합니다. 우리는 모션 프레임의 길이를 늘리는 시도를 했고, 이 방법이 어느 정도 더 크고 유연한 움직임을 생성할 수 있음을 발견했지만, 불안정성이 증가할 수 있다는 것을 알게 되었습니다. 이 관찰은 시간적 수용 범위를 적절하게 늘리는 것이 움직임 패턴을 더 효과적으로 포착하고 자연스러운 움직임을 생성하는 데 도움이 될 수 있음을 상기시켜 줍니다. 또한, 현재의 방법들은 오디오 특징을 확산 모델에 직접 크로스 어텐션을 통해 주입하는데, 이로 인해 모델이 오디오와 초상화 움직임 간의 관계를 학습하는 것이 어려워지고, 대신 오디오와 모든 비디오 픽셀 간의 관계를 모델링하게 됩니다. 이 현상은 Hallo(Xu et al., 2024a) 연구에서도 언급되었습니다. 오디오와 초상화 간의 약한 상관관계는 무작위적이고 불만족스러운 움직임을 생성할 가능성을 높이며, 오디오와 잘 일치하는 자연스러운 움직임을 생성하는 데 어려움을 줍니다.
위의 관찰과 고려를 바탕으로, 우리는 Loopy를 제안합니다. 이는 템플릿이 필요 없는 오디오 기반 초상화 비디오 생성용 확산 모델로, 장기적인 움직임 종속성을 활용하여 생생한 초상화 비디오를 생성합니다. 구체적으로 시간적 측면에서는: 우리는 클립 간 및 클립 내 시간 모듈을 설계했습니다. 모션 프레임은 클립 간 시간적 관계를 포착하기 위해 별도의 시간 레이어로 모델링되며, 원래 시간 모듈은 클립 내 시간적 모델링에 집중합니다. 또한, 클립 내 레이어에 시간 세그먼트 모듈을 도입하여 수용 범위를 100프레임 이상으로 확장했습니다(25fps에서 약 5초를 커버하며, 이는 원래의 30배입니다). 오디오 측면에서는: 우리는 오디오와 얼굴 움직임 관련 특징(랜드마크, 머리 움직임 변동, 표정 움직임 변동)을 공통 특징 공간에 기반하여 모션 잠재 변수로 변환하는 오디오-모션 잠재 모듈을 도입했습니다. 이러한 잠재 변수는 디노이징 네트에 조건으로 삽입됩니다. 테스트 시, 모션 잠재 변수는 오직 오디오만을 사용하여 생성됩니다. 이 접근법은 약한 상관 관계의 오디오가 강한 상관 관계의 움직임 조건을 활용할 수 있게 하여 오디오와 초상화 움직임 간의 관계 모델링을 강화합니다. 광범위한 실험을 통해 우리의 설계가 움직임의 자연스러움과 비디오 합성의 안정성을 효과적으로 개선함을 검증했습니다. 요약하면, 우리의 기여는 다음과 같습니다:
(1) 우리는 초상화 비디오 생성을 위한 템플릿이 필요 없는 오디오 기반 확산 모델을 제안하며, 클립 간 및 클립 내 시간 모듈을 특징으로 하여 장기적인 움직임 종속성을 활용해 자연스러운 움직임 패턴을 학습합니다. 또한, 오디오-잠재 모듈을 통해 훈련 중 강한 상관관계의 조건을 사용하여 오디오와 초상화 움직임 간의 상관관계를 강화합니다.
(2) 우리는 공공 데이터셋에서 우리의 방법의 효과를 검증했으며, 여러 응용 시나리오(다양한 유형의 이미지와 오디오 포함)에서 모델의 성능을 평가하여 기존 방법과 비교했을 때 더 생생하고 안정적인 합성 결과를 달성함을 입증했습니다.
2. 관련 연구
오디오 기반 초상화 비디오 생성은 최근 몇 년간 많은 주목을 받으며, 여러 연구들이 이 분야를 발전시켜 왔습니다. 이러한 방법들은 비디오 합성 기술에 따라 크게 GAN 기반과 확산 기반 접근 방식으로 나눌 수 있습니다.
GAN 기반 방법(Zhou et al., 2020; Prajwal et al., 2020; Zhang et al., 2023b; Liang et al., 2022)은 일반적으로 두 가지 주요 구성 요소로 이루어져 있습니다: 오디오-모션 모델과 모션-비디오 모델입니다. 이 모델들은 보통 독립적으로 구현됩니다. 예를 들어, MakeItTalk(Zhou et al., 2020)은 LSTM 모듈을 사용해 오디오에 대응하는 랜드마크 좌표를 예측하고, 이를 워프 기반 GAN 모델이 랜드마크 신호를 비디오 이미지로 변환하는 방식입니다. SadTalker(Zhang et al., 2023b)는 기존의 FaceVid2Vid(Wang et al., 2021) 방법을 이미지 생성기로 사용하며, ExpNet과 PoseVAE를 통해 오디오 특징을 FaceVid2Vid에 필요한 입력으로 변환해 오디오-비디오 생성을 완성합니다. 확산 기법이 도입된 이후, 일부 방법들은 오디오-모션 모듈을 확산 모델로 구현하면서도, 여전히 모션-비디오 모듈은 독립적으로 구현합니다. 예를 들어, GAIA(He et al., 2023)는 VAE를 사용해 모션을 모션 잠재 변수로 표현하고, 모션 잠재 변수-비디오 생성 모델을 구현합니다. 또한, 확산 모델을 설계해 오디오-모션 잠재 변수를 생성하여 오디오-비디오 생성을 가능하게 합니다. DreamTalk(Ma et al., 2023), Dream-Talk(Zhang et al., 2023a), VASA-1(Xu et al., 2024b)은 유사한 아이디어를 제안하며, 각각 PIRender(Ren et al., 2021), FaceVid2Vid(Wang et al., 2021), MegaPortrait(Drobyshev et al., 2022)를 모션-비디오 모델로 사용하며, 오디오-모션 표현 모델을 설계해 오디오-초상화 비디오 생성 과정을 완성합니다.
위의 방법들과는 별개로, EMO Portrait(Tian et al., 2024)은 오디오-모션 모듈과 모션-비디오 모델의 2단계 독립적 설계를 대체하며, 단일 확산 모델을 사용해 오디오-초상화 비디오 생성을 구현합니다. Hallo(Xu et al., 2024a), EchoMimic(Chen et al., 2024), VExpress(Wang et al., 2024) 등은 유사한 오디오-비디오 확산 프레임워크를 기반으로 오디오-비디오 모델링을 개선하였습니다. 이러한 엔드 투 엔드 방식은 생생한 초상화 비디오를 생성할 수 있지만, 안정성을 위해 머리 움직임을 제한하는 얼굴 위치 결정자와 속도 레이어 같은 공간적 조건 모듈을 도입해야만 하며, 이로 인해 실질적인 응용에서 모션 모델의 다양성을 제한하고 확산 모델의 잠재력을 충분히 발휘하는 데 방해가 됩니다.
3. 방법론
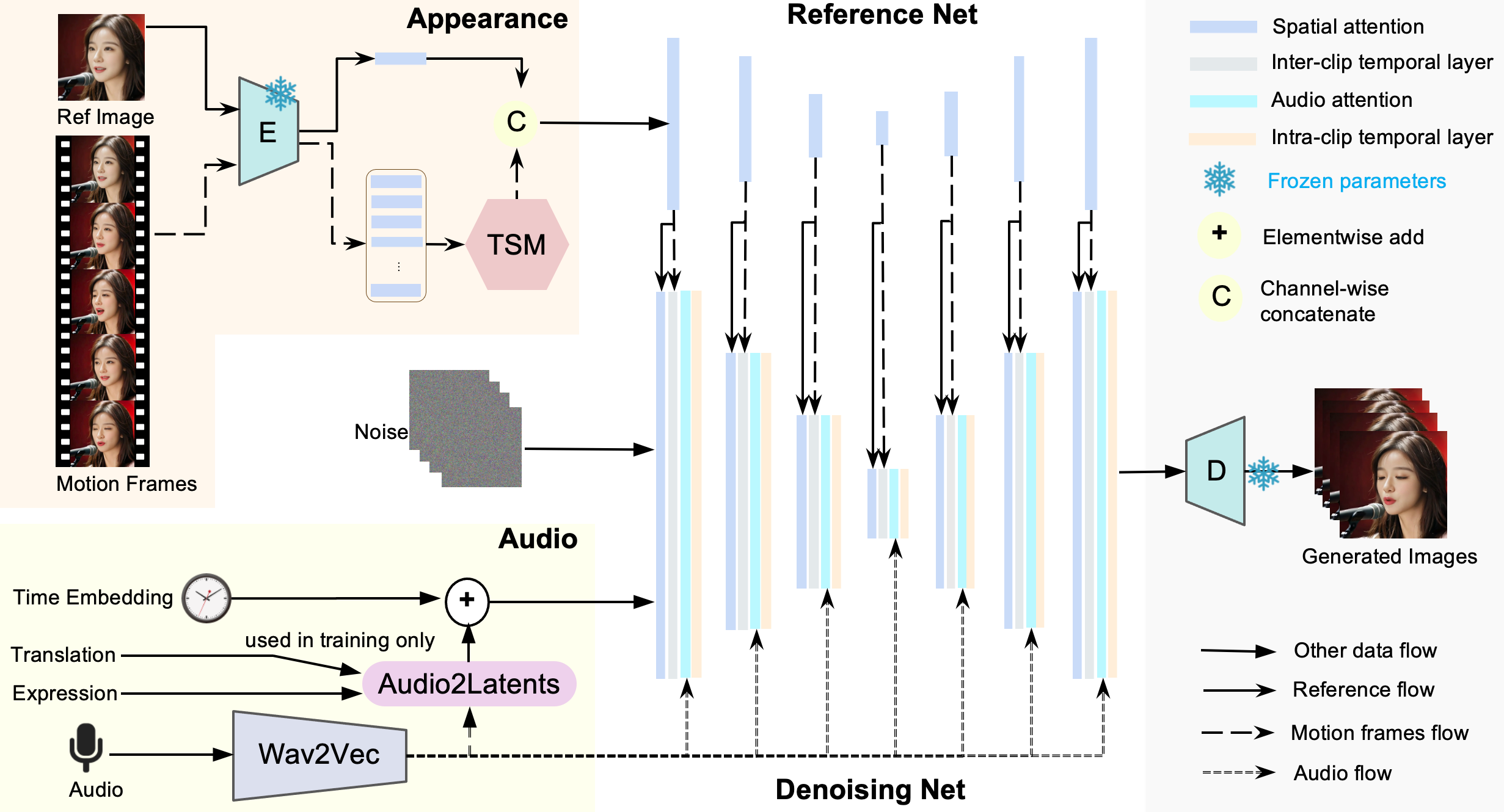
Figure 2: Loopy의 프레임워크는 기존 방법에서 일반적으로 사용되는 얼굴 위치 결정자와 속도 레이어 모듈을 제거했습니다. 대신, Loopy는 제안된 클립 간/내 시간 레이어와 오디오-잠재 모듈을 통해 유연하고 자연스러운 움직임 생성을 달성합니다.
이 섹션에서는 우리의 방법론인 Loopy를 소개합니다. 먼저, Loopy의 프레임워크에 대한 개요를 제공하며, 여기에는 입력, 출력, 그리고 Loopy의 핵심 구성 요소가 포함됩니다. 두 번째로, 클립 간/내 시간 모듈의 설계에 중점을 두며, 이 중 시간 세그먼트 모듈도 포함됩니다. 세 번째로, 오디오 조건 모듈의 구현에 대해 자세히 설명하겠습니다. 마지막으로, Loopy의 훈련 및 테스트 과정에서의 구현 세부 사항을 설명할 것입니다.
3.1 프레임워크



3.2 클립 간/내 시간 레이어 설계
여기서는 제안된 클립 간/내 시간 모듈의 설계를 소개합니다. 기존 방법들(Tian et al., 2024; Xu et al., 2024a; Chen et al., 2024; Wang et al., 2024)은 모션 프레임 잠재 변수와 노이즈가 포함된 잠재 변수의 특징을 단일 시간 레이어를 통해 동시에 처리하지만, Loopy는 두 개의 시간적 주의(attention) 레이어를 사용합니다: 클립 간 시간 레이어와 클립 내 시간 레이어입니다. 클립 간 시간 레이어는 모션 프레임 잠재 변수와 노이즈가 포함된 잠재 변수 사이의 클립 간 시간적 관계를 먼저 처리하며, 클립 내 시간 레이어는 현재 클립의 노이즈가 포함된 잠재 변수 내에서의 시간적 관계에 집중합니다.

클립 내 시간 레이어는 모션 프레임 잠재 변수의 특징을 포함하지 않는다는 점에서 다릅니다. 이 레이어는 오직 현재 클립의 노이즈가 포함된 잠재 변수의 특징만을 처리합니다. 이러한 이중 시간 레이어를 분리함으로써 모델은 클립 간 시간적 관계에서 다른 의미적 시간 특징을 더 잘 통합할 수 있습니다.
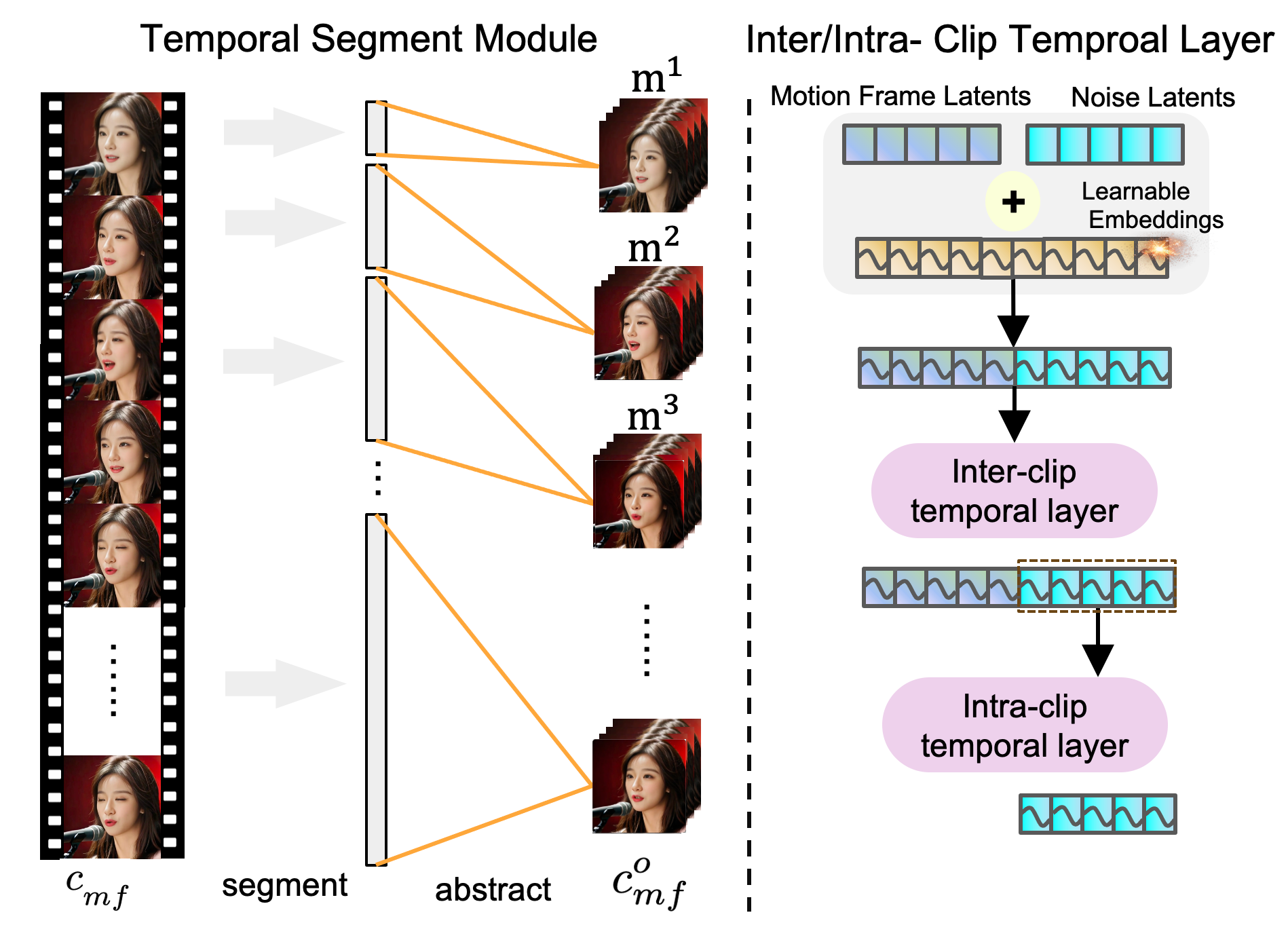
Figure 3: 시간 세그먼트 모듈과 클립 간/내 시간 레이어의 설명. 전자는 모션 프레임을 100프레임 이상 확장할 수 있게 해주며, 후자는 장기적인 움직임 종속성을 모델링할 수 있게 합니다.



시간 세그먼트 모듈은 클립 간 시간 레이어로 입력되는 모션 프레임의 시간 범위를 빠르게 확장하면서도 계산 복잡성을 허용 가능한 수준으로 유지합니다. 가까운 프레임의 경우 낮은 확장 비율을 사용해 더 많은 세부 사항을 유지하고, 먼 프레임의 경우 더 높은 확장 비율을 사용해 더 긴 시간을 다룹니다. 이 접근 방식은 모델이 장기적인 정보를 기반으로 움직임 스타일을 더 잘 포착하고, 공간적 템플릿 없이 시간적으로 자연스러운 움직임을 생성하는 데 도움을 줍니다.
3.3 오디오 조건 모듈

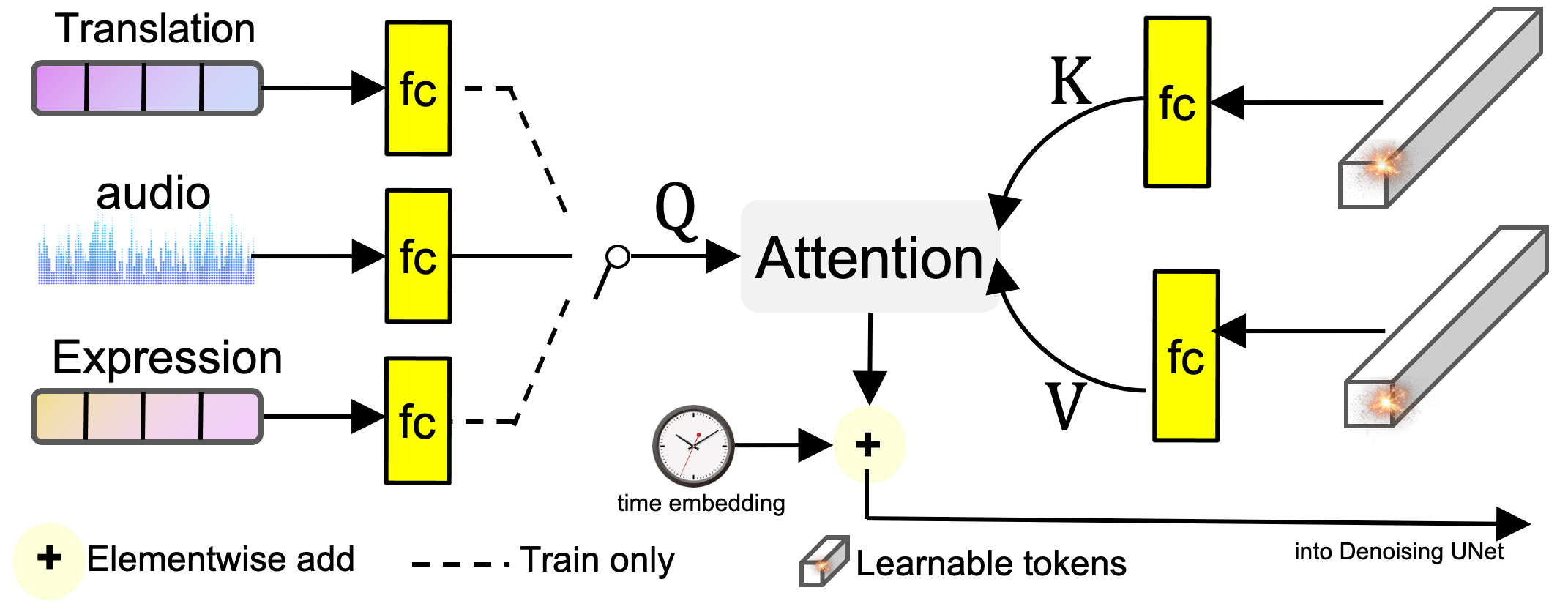
Figure 4: 오디오-잠재 변수 모듈
추가적으로, Figure 4에서 설명한 바와 같이, 우리는 오디오-잠재 변수(Audio-to-Latents) 모듈을 도입합니다. 이 모듈은 오디오와 같은, 초상화 움직임과 강한 상관관계를 가지는 조건들을 공통된 모션 잠재 공간에 매핑합니다. 이렇게 매핑된 조건들은 최종 조건 특징으로 사용되어, 모션 잠재 변수에 기반한 오디오와 초상화 움직임 간의 관계 모델링을 강화합니다.
구체적으로, 우리는 학습 가능한 임베딩 세트를 유지합니다. 각 입력 조건에 대해, 우리는 완전 연결(FC) 레이어를 사용해 해당 조건을 쿼리 특징으로 매핑하며, 학습 가능한 임베딩은 주의(attention) 계산을 위한 **키(key)**와 값(value) 특징으로 작동합니다. 이를 통해 학습 가능한 임베딩에 기반한 새로운 특징을 얻습니다. 이 새로운 특징은 모션 잠재 변수로 불리며, 이후 계산에서 입력 조건을 대체하게 됩니다. 이 모션 잠재 변수는 FC 레이어를 통해 차원이 변환된 후, 시간 단계 임베딩 특징에 더해져 이후 네트워크 계산에 사용됩니다.
훈련 중에는, 오디오 임베딩과 얼굴 움직임 관련 특징(랜드마크, 얼굴 절대 움직임 변동, 얼굴 표정 움직임 변동)에서 오디오-잠재 변수 모듈로 입력 조건을 동일한 확률로 샘플링합니다. 테스트 중에는 오직 오디오만을 입력하여 모션 잠재 변수를 생성합니다. 이 모듈은 초상화 움직임과 강한 상관관계를 가진 특징들을 활용해 학습 가능한 임베딩을 통해 움직임을 제어합니다. 그 결과, 오디오 임베딩을 모션 잠재 변수로 변환하는 것은 초상화 움직임에 더 직접적인 영향을 미칠 수 있게 합니다.
3.4 훈련 전략

다단계 훈련: AnimateAnyone(Hu, 2024)과 EMO(Tian et al., 2024)의 방식을 따르며, 우리는 2단계 훈련 과정을 사용합니다. 첫 번째 단계에서는 시간 레이어와 오디오 조건 모듈 없이 모델을 훈련합니다. 이때 모델의 입력은 목표하는 단일 프레임 이미지와 참조 이미지 잠재 변수의 노이즈가 있는 잠재 변수로, 모델은 이미지 수준에서 자세 변동 작업에 집중합니다. 첫 번째 단계를 완료한 후, 두 번째 단계로 넘어가며, 여기서 모델은 첫 번째 단계의 참조 네트워크와 디노이징 U-Net으로 초기화됩니다. 그런 다음 클립 간/내 시간 레이어와 오디오 조건 모듈을 추가하여 최종 모델을 위한 전체 훈련을 진행합니다.

3.5 실험
데이터셋: 훈련 데이터로, 우리는 인터넷에서 헤드 토킹 비디오 데이터를 수집했으며, 입술 동기화 점수가 낮거나, 머리 움직임이 과도하거나, 극단적인 회전, 또는 머리 노출이 불완전한 비디오는 제외했습니다. 이를 통해 160시간의 정제된 훈련 데이터를 확보했습니다. 또한, HDTF(Zhang et al., 2021)와 같은 공공 데이터셋을 추가로 훈련 데이터에 보충했습니다. 테스트 세트로는 CelebV-HQ(Zhu et al., 2022)에서 무작위로 100개의 비디오를 샘플링했고, RAVDESS(Kaggle)에서 감정이 풍부한 고화질 실내 토킹 씬 데이터를 추가했습니다. 확산 기반 모델의 일반화 능력을 테스트하기 위해, 실제 인물, 애니메이션, 측면 얼굴, 다양한 재질의 인간형 작품 등을 포함한 20개의 초상화 테스트 이미지와, 연설, 노래, 랩, 감정이 풍부한 음성을 포함한 20개의 오디오 클립을 수집했습니다. 이 테스트 세트를 오픈셋 테스트 세트라고 명명했습니다.
구현 세부 사항: 우리는 24개의 Nvidia A100 GPU를 사용하여 배치 크기 24로 모델을 훈련했으며, AdamW(Loshchilov & Hutter, 2017) 옵티마이저와 학습률 1e-5를 사용했습니다. 생성된 비디오의 길이는 12프레임으로 설정되었으며, 모션 프레임 길이는 현재 12프레임 비디오의 이전 124프레임을 나타냅니다. 시간 압축 후, 이는 20개의 모션 프레임 잠재 변수로 압축되었습니다. 훈련 중 참조 이미지는 비디오 클립 내의 임의의 프레임에서 선택되었습니다. 오디오-모션 모듈을 훈련하기 위해 필요한 얼굴 움직임 정보를 위해, 우리는 DWPose(Yang et al., 2023)를 사용하여 현재 12프레임에 대한 얼굴 랜드마크를 감지했습니다. 이 12프레임 동안 코 끝의 절대 위치 변동을 절대 머리 움직임 변동으로 사용했으며, 얼굴 상부의 37개의 랜드마크의 코 끝에 대한 변위를 표정 변동으로 사용했습니다. 훈련 비디오는 25fps로 균일하게 처리되었으며, 512x512 해상도의 초상화 비디오로 잘렸습니다.
평가 지표: 우리는 이미지 품질을 IQA(Wu et al., 2023) 지표로, 비디오 움직임을 VBench의 Smooth 지표(Huang et al., 2024)로 평가했으며, 오디오-비주얼 동기화는 SyncC와 SyncD(Prajwal et al., 2020)를 사용했습니다. CelebV-HQ와 RAVDESS 테스트 세트는 대응하는 실제 비디오 데이터가 있어, 우리는 FVD(Unterthiner et al., 2019), E-FID(Tian et al., 2024), FID 지표도 비교를 위해 계산했습니다. 또한, 초상화의 전체 움직임(Glo)과 동적 표정(Exp)을 비교하기 위해, 우리는 코와 얼굴 상부의 랜드마크를 기반으로 변동 값을 계산했으며, 입 주변은 제외했습니다. 참고를 위해 실제 비디오의 값을 기준으로 비교했습니다. 실제 비디오 참조가 없는 오픈셋 테스트 세트에서는 주관적인 평가를 실시했습니다. 열 명의 경험 있는 사용자들이 신원 일관성, 비디오 합성 품질, 오디오-감정 매칭, 움직임 다양성, 움직임의 자연스러움, 그리고 립싱크 정확성의 6가지 주요 차원을 평가했습니다. 각 경우에, 참가자들은 각 차원에서 최고 성능을 보인 방법을 식별해야 했습니다.
3.5.1 결과 및 분석
복잡한 시나리오에서의 성능: CelebV-HQ는 유명인들이 다양한 시나리오에서 말하는 비디오를 포함하고 있습니다. 여기에는 영화, 인터뷰, 실내 및 실외에서의 다양한 초상화 자세가 포함되어 있어, 이 데이터셋에서의 테스트는 실제 사용 조건을 효과적으로 시뮬레이션합니다. Table 1에 나타난 바와 같이, 우리의 방법은 대부분의 지표에서 비교된 방법들보다 현저하게 뛰어납니다. 비교 비디오들은 부록 자료에 제공되어 있습니다.
움직임 관련 지표에서는 비록 최고는 아니지만, 우리의 결과는 부드러움 측면에서 실제 데이터와 유사한 수준입니다. **동적 표정 지표(Exp)**에서 우리의 방법은 다른 비교된 방법들보다 실제 데이터(GT)에 더 가깝습니다. **전체 움직임(Glo)**에서는 EchoMimic과 유사한 성능을 보였습니다. 그러나 비디오 합성 품질과 립싱크 정확성 면에서 우리의 방법이 뚜렷한 우위를 차지하고 있음을 알 수 있습니다.
Table 1: CelebV-HQ 테스트 세트에서 기존 방법들과의 비교.
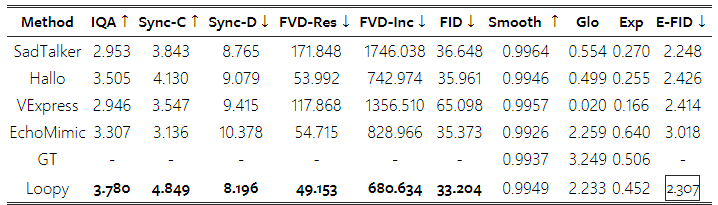
Table 2: RAVDESS 테스트 세트에서 기존 방법들과의 비교.
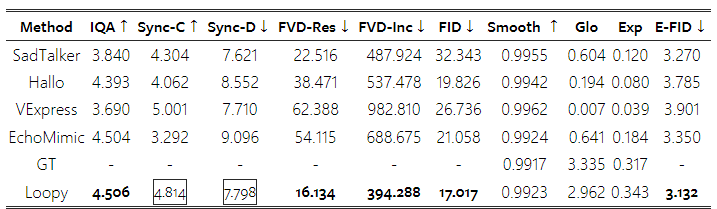

Figure 5: 오픈셋 테스트 세트에서 사용자 투표 비교. 첫 번째 행은 다양한 카테고리의 입력 이미지에 대한 실험 결과를 포함하며, 두 번째 행은 다양한 카테고리의 입력 오디오에 대한 실험 결과를 포함합니다.
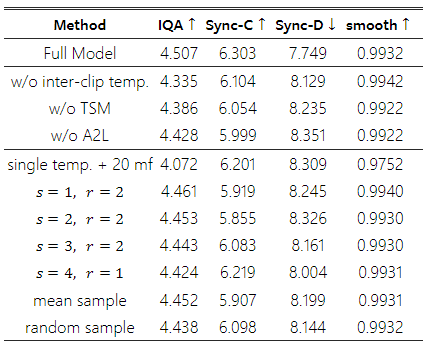
Table 3: 제안된 모듈들의 효과에 대한 실험.
감정 표현에서의 성능: RAVDESS는 감정의 강도가 다른 고화질의 토킹 씬 데이터셋으로, 감정 표현에서의 방법 성능을 효과적으로 평가합니다. E-FID(Tian et al., 2024) 지표에 따르면, 우리의 방법은 비교된 다른 방법들보다 우수한 성능을 보였습니다. 이는 Glo와 Exp와 같은 움직임 동역학 지표에서도 확인되며, 우리의 결과가 실제 데이터에 더 가깝습니다. 비록 립싱크 정확성은 VExpress보다 약간 낮지만, VExpress가 생성한 결과는 일반적으로 Glo, Exp, E-FID 지표에서 나타난 바와 같이 역동적인 움직임이 부족합니다. 이러한 정적인 특성은 SyncNet을 사용한 립싱크 정확성 측정에서 유리하게 작용할 수 있습니다.
오픈셋 시나리오에서의 성능: 우리는 다양한 입력 스타일(실제 인물, 애니메이션, 인간형 작품, 측면 얼굴)과 여러 유형의 오디오(연설, 노래, 랩, 감정이 담긴 오디오)를 비교하여 방법의 강건성을 평가했습니다. Table 3에 나타난 바와 같이, Loopy는 이러한 다양한 시나리오에서 비교된 다른 방법들보다 일관되게 우수한 성능을 보여주었습니다.
3.5.2 소거 실험
핵심 구성 요소 분석: 우리는 Loopy의 두 가지 핵심 구성 요소인 클립 간/내 시간 레이어와 오디오-잠재 변수 모듈의 영향을 분석했습니다. 첫 번째로는 두 가지 실험을 수행했습니다: (1) 듀얼 시간 레이어 디자인을 제거하고 마지막 클립과 현재 클립 간의 시간 관계를 처리하기 위해 단일 시간 레이어만을 유지한 실험(이 방식은 EMO나 Hallo와 유사함); (2) 시간 세그먼트 모듈을 제거하고 다른 방법들처럼 4개의 모션 프레임을 사용하는 실험. 두 번째로는 오디오-잠재 변수 모듈을 제거하고, 오디오 특징 주입을 위한 크로스 어텐션만을 유지한 실험을 진행했습니다. Table 3에 나타난 결과에 따르면, 듀얼 시간 레이어 디자인은 시간적 안정성과 이미지 품질을 향상시키며, 이를 제거하면 성능이 저하됩니다. 시간 세그먼트 모듈을 제거하면 장기적인 움직임 종속성에서 움직임 스타일 정보를 학습하는 데 어려움을 겪게 되어, 표현력과 시간적 안정성을 포함한 전체적인 움직임 품질이 떨어집니다. 오디오-잠재 변수 모듈을 제거하면 합성된 시각적 품질과 움직임의 전체적인 품질이 저하됩니다. 이는 오디오-잠재 변수 모듈 훈련 중 공간적 조건이 혼합 훈련에 추가되기 때문이며, 공간적 조건이 오디오만으로는 어려운 명확한 움직임 지침을 제공해 모델 수렴을 용이하게 합니다. 이러한 결과는 우리의 방법의 유효성을 입증합니다.
장기적 시간 종속성의 영향: 우리는 장기적인 움직임 종속성이 결과에 미치는 영향을 조사했으며, 결과는 Table 3에 나열되어 있습니다. 먼저, 단일 시간 레이어 설정에서 모션 프레임 길이를 20으로 확장한 효과를 비교했습니다. 이 방법은 모델 출력의 역동성을 향상시키지만, 전반적인 이미지 품질을 크게 저하시켰습니다. 반면, 20 모션 프레임(s=4, r=1) 설정을 사용한 전체 모델에서는 클립 간/내 시간 레이어를 추가함으로써 전반적인 결과가 향상되었습니다. s와 r 설정과 관련하여, 우리는 다양한 값을 실험했습니다. r=2를 고정하고 실험한 결과, s 값이 작을수록 전체 성능이 저하되었습니다. 이는 목표 프레임과 모션 프레임 간의 FPS 차이로 인해, 모션 프레임 비율이 낮아짐으로써 클립 간 시간적 모델링이 어려워졌기 때문입니다. s 값이 증가함에 따라 모션 프레임의 수도 증가하여, 클립 간 시간 레이어가 클립 간 시간 관계를 효과적으로 모델링할 수 있어 전반적인 성능이 크게 향상되었습니다. 동일한 s=4에서 r의 효과를 비교한 결과, r=1에서는 성능이 약간 저하되었으며, 이는 r=2가 포함된 전체 모델보다 좁은 시간 범위를 제공하기 때문입니다. 마지막으로, 우리는 시간 세그먼트 모듈 내에서 모션 프레임을 샘플링하는 다양한 전략을 비교했습니다(평균 풀링, 임의의 단일 프레임 샘플링 등). 전체 모델의 균일 샘플링 접근법이 더 효과적인 것으로 나타났으며, 이는 안정적인 간격 정보를 제공하여 클립 간 시간 레이어가 장기적인 움직임 정보를 학습하는 데 유리하기 때문으로 보입니다.

Figure 6: 다양한 시나리오에서 Loopy로 생성된 비디오의 시각화.
3.5.3 시각적 결과 분석
Figure 6에서는 오픈셋 시나리오에 대한 시각적 분석을 제공합니다. 다른 방법들과 비교했을 때, Loopy는 ID 보존, 움직임의 진폭, 이미지 품질에서 상당한 이점을 보여줍니다. 또한, 흔치 않은 이미지에서도 우수한 성능을 발휘합니다. 추가적인 비디오 결과는 부록 자료에서 확인할 수 있습니다.
4. 결론
이 논문에서는 공간적 조건을 필요로 하지 않으며, 장기적인 움직임 종속성을 활용해 데이터를 통해 자연스러운 움직임 패턴을 학습하는 LOOPY라는 오디오 기반 초상화 비디오 생성 프레임워크를 제안합니다. 구체적으로, 우리는 클립 간/내 시간 레이어 디자인과 오디오-잠재 변수 모듈을 도입하여 모델이 시간적 및 오디오 차원에서 오디오와 초상화 움직임 간의 상관관계를 더 잘 학습할 수 있도록 했습니다. 광범위한 실험을 통해 우리의 방법이 시간적 안정성, 움직임 다양성, 전반적인 비디오 품질에서 기존 방법들보다 상당한 개선을 달성했음을 검증했습니다.
'인공지능' 카테고리의 다른 글
| DeepNet: Scaling Transformers to 1,000 Layers (부록 추가 필요) (2) | 2024.09.15 |
|---|---|
| Scaling Vision Transformers (부록 추가 필요) (2) | 2024.09.15 |
| An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (VIT) (부록 추가 필요) (1) | 2024.09.11 |
| EfficientNetV2: Smaller Models and Faster Training (4) | 2024.09.10 |
| Diffusion Models Are Real-Time Game Engines (부록 추가 필요) (1) | 2024.09.09 |



