https://www.eyelinestudios.com/research/diffrelight.html
DifFRelight
Diffusion-Based Facial Performance Relighting
www.eyelinestudios.com
https://arxiv.org/abs/2410.08188
DifFRelight: Diffusion-Based Facial Performance Relighting
We present a novel framework for free-viewpoint facial performance relighting using diffusion-based image-to-image translation. Leveraging a subject-specific dataset containing diverse facial expressions captured under various lighting conditions, includin
arxiv.org
초록
우리는 확산 기반의 이미지-이미지 변환을 사용한 자유 관점 얼굴 성능 재조명을 위한 새로운 프레임워크를 제시합니다. 다양한 조명 조건(평조명과 하나씩 조명을 사용하는 OLAT 시나리오 포함)에서 포착된 다양한 얼굴 표정을 포함하는 주제별 데이터셋을 활용하여, 우리는 확산 모델을 훈련하여 정확한 조명 제어를 가능하게 하고, 평조명 입력으로부터 고충실도의 재조명된 얼굴 이미지를 생성합니다. 우리의 프레임워크는 평조명 캡처와 랜덤 노이즈의 공간적으로 정렬된 조건부 정보에 통합된 조명 정보를 포함하여 전역적인 조명 제어를 제공합니다. 이 과정에서 사전 훈련된 Stable Diffusion 모델의 선험 지식을 활용합니다. 해당 모델은 일관된 평조명 환경에서 포착된 동적 얼굴 표현에 적용되며, 확장 가능한 동적 3D 가우시안 스플래팅(Gaussian Splatting) 방법을 사용하여 새로운 관점의 합성에 적용되어, 재조명 결과의 품질과 일관성을 유지합니다. 추가적으로, 우리는 새로운 영역 조명 표현을 방향 조명과 통합하여 조명의 크기와 방향을 공동으로 조정할 수 있는 통합된 조명 제어를 소개합니다. 또한 여러 방향 조명을 사용하는 고동적 범위 이미징(HDRI) 합성을 가능하게 하여 복잡한 조명 조건하에서 동적 시퀀스를 생성할 수 있습니다. 우리의 평가 결과, 모델이 정확한 조명 제어를 달성하는 효율성을 입증하였으며, 다양한 얼굴 표정에 대해 일반화하면서도 피부 질감과 머리카락과 같은 세부 특징을 유지함을 확인했습니다. 모델은 눈의 반사, 피하 산란, 자기 그림자, 반투명성 등과 같은 복잡한 조명 효과를 정확히 재현하여, 우리 프레임워크 내에서 사실성을 한 단계 끌어올립니다.
키워드: 재조명, Stable Diffusion, 이미지-이미지 변환, 얼굴 표현, 데이터 기반, HD 얼굴 데이터 캡처, OLATs, HDRI 재구성
- 출판연도: 2024
- 저작권: ACM 라이선스
- 컨퍼런스: SIGGRAPH Asia 2024 컨퍼런스 논문; 2024년 12월 3-6일; 일본 도쿄
- 출판 서명: SIGGRAPH Asia 2024 컨퍼런스 논문 (SA Conference Papers '24), 2024년 12월 3-6일, 일본 도쿄
- DOI: 10.1145/3680528.3687644
- ISBN: 979-8-4007-1131-2/24/12
- 제출 ID: 701
- CCS(컴퓨팅 분류 체계):
- 일반 및 참조
- 컴퓨팅 방법론: 재구성
- 컴퓨팅 방법론: 이미지 표현
- 컴퓨팅 방법론: 장면 이해
- 컴퓨팅 방법론: 생체 인식

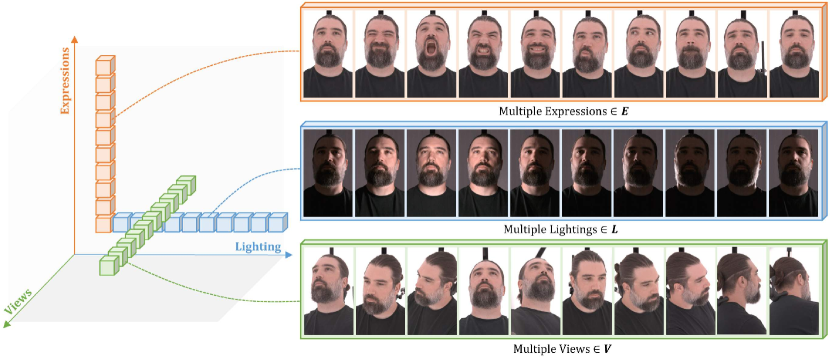
그림 1.
평조명 입력과 우리 확산 기반 재조명 방법의 결과. 상단 행: 평조명된 네 명의 피사체가 다채로운 다방향 조명으로 변환된 결과. 평조명 이미지는 다중 시점 비디오에서 동적 3D 가우시안 스플래팅 확장을 통해 생성된 새로운 시점입니다. 하단 행: 동적 평조명 시퀀스에서 선택된 프레임들과 해당 조명이 애니메이션으로 변경된 재조명 결과들이 나란히 배치되어 있습니다. 얼굴의 세부 묘사는 우리 방법의 고충실도 재조명 효과를 보여주며, 눈의 반사, 반투명성, 자기 그림자 등이 포함됩니다.
설명
평조명으로 캡처된 피사체들이 새로운 표정과 새로운 시점에서 재조명된 모습.
1. 서론
오늘날, 사실적인 디지털 휴먼은 종종 실사 배우들과 나란히 주연으로 등장하며, 비디오 게임과 가상 현실에서도 점점 더 높은 충실도로 나타납니다. 그러나 사실적인 디지털 휴먼 모델을 구축하는 것은 어렵고 비용이 많이 들며, 성능 캡처 데이터를 사용하더라도 이를 사실적으로 애니메이션화하는 것은 여전히 어려우며 오류가 발생하기 쉽습니다.
볼류메트릭 성능 캡처(volcap) 시스템은 내부로 향하는 카메라 배열을 사용하여 인간의 동적 성능을 3차원으로 기록함으로써 전통적인 3D 캐릭터 모델링, 리깅, 애니메이션 작업의 필요성을 없앱니다. Volcap은 모든 퍼포먼스의 세부 사항을 캡처하여, 이를 모든 각도에서 3D 장면으로 렌더링할 수 있도록 합니다. 하지만 대부분의 캡처 기술은 피사체를 단일 평조명 조건 하에서만 기록하며, 이는 시네마틱한 조명 효과의 달성을 어렵게 하고, 새로운 장면으로의 캐릭터의 매끄러운 통합을 복잡하게 만듭니다. 이를 해결하기 위해 일부 고급 시스템(Guo et al., 2019)은 시간 다중화 조명을 사용하여 프레임마다 번갈아가며 여러 조명 조건 하에서 퍼포먼스를 기록합니다. 이 접근 방식은 데이터 기반 재조명을 가능하게 하며, 때로는 머신러닝 추론에 의해 강화되기도 합니다(Meka et al., 2020; Zhang et al., 2021a).
본 연구에서는 그림 1과 같이 볼류메트릭으로 캡처된 얼굴 성능의 고품질 재조명을 달성합니다. 이를 위해 주제별 재조명 예제를 사용해 확산 기반 이미지-이미지 변환 모델을 미세 조정합니다. 평조명 하에서 성능을 캡처하는 것 외에도 다양한 얼굴 표정에 대해 밀집 배열의 조명 방향 하에서 각 피사체를 기록합니다. 우리는 확산 모델을 훈련하여 정확한 조명 제어를 가능하게 하며, 평조명 입력으로부터 고충실도의 재조명된 얼굴 이미지를 생성합니다. 이 과정에서는 평조명 캡처와 랜덤 노이즈의 공간적으로 정렬된 조건부 정보가 통합된 조명 정보와 함께 사용되며, 사전 훈련된 Stable Diffusion 모델의 선험 지식을 활용합니다. 추가적으로, 우리는 동적 3D 가우시안 스플래팅(3DGS)을 사용하여 성능을 새로운 관점으로 외삽합니다.
우리 연구는 다음과 같은 기여를 포함합니다:
(1) 주제별 쌍 데이터셋으로 훈련하여 새로운 조명 조건에 일반화하고, 자유로운 관점과 보지 못한 얼굴 표정에서 재조명을 가능하게 하는 새로운 얼굴 성능 재조명 프레임워크.
(2) 평조명 입력 이미지를 공간적으로 조건화하고, 조명 정보를 전역 제어로 활용하여 고품질의 재조명 결과를 생성하는 확산 기반 재조명 모델.
(3) 긴 시퀀스를 재구성하고 재조명 모델의 일관된 추론을 위해 평조명 입력의 시간적 일관성을 보장하는 확장 가능한 동적 3DGS 기법.
(4) 새로운 영역 조명 표현과 방향 조명을 결합한 통합 조명 제어, 복잡한 환경 조명 합성을 가능하게 하고 다양한 조명 제어를 제공.
그림 2.
제안된 재조명 파이프라인의 개요에는 동적 성능 재구성과 확산 기반 재조명이 포함됩니다. 중립적인 환경에서 피사체의 다중 시점 성능 데이터를 시작으로, 우리는 변형 가능한 3DGS를 훈련하여 동적 시퀀스의 새로운 관점 렌더링을 생성합니다. 이 렌더링은 지정된 조명을 기반으로 평조명 입력 이미지를 재조명 결과로 변환하기 위해 쌍 데이터로 훈련된 확산 기반 재조명 모델의 입력으로 사용됩니다. 여기서 우리는 확산 모델의 추론 단계를 보여주며, 평조명 이미지의 잠재 표현이 랜덤 노이즈와 결합되어 확산 U-Net의 입력으로 사용됩니다. SH 인코딩과 텍스트 임베딩으로 인코딩된 조명 정보가 확산 과정을 조절합니다.
-----
SH 인코딩은 Spherical Harmonics Encoding(구면 고조파 인코딩)의 약자로, 3D 그래픽스와 컴퓨터 비전 분야에서 많이 사용되는 수학적 기법입니다. 이 기법은 주로 조명과 관련된 데이터를 효율적으로 표현하고, 복잡한 조명 환경을 저차원의 표현으로 압축하여 조명을 효과적으로 다루기 위해 사용됩니다.
-----
2. 관련 연구
2.1 비-확산 기반 재조명 기법
매개변수 반사율 모델링은 피사체의 기하학적 구조와 반사 속성을 다양한 시점과 조명 방향에서 측정합니다. 그러나 이러한 기법은 복잡한 재료와 동적 피사체를 다루는 데 어려움을 겪습니다(Sato et al., 1997; Goesele et al., 2004; Weyrich et al., 2006). 특히 머리카락과 같은 복잡한 재료를 다루기 어렵고, 여러 조명 조건에서의 관찰이 필요하기 때문에 동적 피사체에 적용하기가 어렵습니다.
이미지 기반 재조명은 피사체를 다양한 조명 조건에서 촬영하여 새로운 조명 시나리오를 생성하는 방법입니다. 이는 효과적이지만 비용이 많이 들고 동적 피사체에 대해 도전적인 기술입니다(Nimeroff et al., 1995; Debevec et al., 2000; Einarsson et al., 2006; Peers et al., 2007).
내재 이미지 재조명(Intrinsic Image Relighting)은 이미지를 내재적 요소(예: 반사, 그림자 등)로 분해한 다음, 변경된 조명으로 다시 조합하는 방식입니다(Wang et al., 2008; Barron and Malik, 2014; Shu et al., 2017b; Sengupta et al., 2018; Le and Kakadiaris, 2019; Tewari et al., 2021b; Zhou et al., 2019; Sun et al., 2019; Tewari et al., 2020, 2021a; Mei et al., 2024; Shih et al., 2014; Luan et al., 2017; Shu et al., 2017a; Li et al., 2018). 이러한 방법들은 발전을 이루었지만, 여전히 복잡한 음영 효과와 세부 보존에 어려움을 겪고 있습니다. 최근 Kim et al.(2024)은 물리 기반 렌더링 모델을 제안하여 확산 반사와 반사 반사광을 계산하였으며, 이는 (Pandey et al., 2021)에서 영감을 받았습니다. 이 모델은 새로운 피사체에 일반화할 수 있으나 피부와 머리카락 반사에 대한 세부 표현이 부족하며, 신경 렌더러를 사용하여 세부 사항을 개선하였습니다. Rao et al.(2022)은 OLAT 이미지로 훈련된 반사율 네트워크를 사용하여 단일 사진으로부터 조명 조건에 따라 학습된 볼륨 반사 필드를 생성하는 모델을 개발하였지만, 이는 정적 얼굴에만 제한되며 동적 시퀀스를 다루지 못합니다.
신경 기반 재조명 접근법(Neural Relighting Approaches)은 **신경 방사 필드(NeRFs)**를 사용하여 재료 속성과 조명 효과를 3D로 재구성하지만, 새로운 자세와 세부 보존에 어려움을 겪습니다(Mildenhall et al., 2020; Wang et al., 2023a; Boss et al., 2021; Zhang et al., 2021b; Liu et al., 2023; Li et al., 2023b; Zeng et al., 2023; Sarkar et al., 2023; Srinivasan et al., 2021; Yao et al., 2022; Zhang et al., 2023b; Xu et al., 2023b). 또는 **3D 가우시안 스플래팅(3DGS)**을 재조명에 도입하여 세부적인 재구성을 달성합니다(Kerbl et al., 2023; Gao et al., 2023). 최근 재조명 가능한 머리 아바타에 관한 연구는 OLAT 데이터와 다양한 기하학적 표현을 사용하여 렌더링 품질을 향상하고 있습니다. 이러한 기법은 볼류메트릭 프리미티브(Yang et al., 2023), 신경 필드(Xu et al., 2023a), 3DGS(Saito et al., 2023)와 같은 기법을 사용합니다. 피사체별 모델(Saito et al., 2023)은 학습 가능한 방사 전이 기반의 재조명 가능한 외관 모델과 3D 가우시안을 결합하여 유망한 얼굴 성능 재조명을 달성하였습니다. 그러나 이는 표정에 대해 매우 밀집된 캡처 설정을 필요로 하며, 얼굴 메쉬와 시선의 움직임을 정확히 추적하고, 얼굴과 눈을 명시적으로 모델링해야 하므로 이 방법의 일반화가 어렵습니다.
2.2. 확산 기반 재조명 기법
확산 모델(Song et al., 2020b, a; Rombach et al., 2022; Karras et al., 2022; Preechakul et al., 2022; Zhang et al., 2023a; Wang et al., 2023b; Ke et al., 2023)은 학습된 이미지 분포로부터 샘플링하여 고품질 이미지를 생성하는 데 놀라운 능력을 보여주었으며, 특히 이미지-이미지 변환을 통한 공간적 제어에 조건부로 사용될 때 그 효과가 더욱 두드러졌습니다(Meng et al., 2021; Parmar et al., 2023; Brooks et al., 2023; Wang et al., 2023b; Ke et al., 2023).
최근 연구자들은 조건부 확산 모델을 재조명에 활용하고 있습니다(Ding et al., 2023; Ponglertnapakorn et al., 2023; Zeng et al., 2024). 이러한 모델들은 다양한 조명 조건 하에서 이미지 대규모 데이터셋을 사전 학습한 일반화 가능한 생성 사전(prior)을 활용하여 복잡한 조명 상호작용을 학습합니다. 또한, 평조명-재조명 이미지 쌍을 사용해 **세부 조정(fine-tuning)**을 거쳐 조정 가능성에서 이점을 얻습니다. DiffusionRig(Ding et al., 2023)은 표면 법선, 알베도, 확산 음영 처리된 3D 변형 가능한 모델을 사용하여 **컴퓨터 생성 이미지(CGI)**를 실제 이미지로 매핑하는 학습을 통해 조명과 그 이상의 요소를 조작하는 방식을 제안합니다. DiFaReli(Ponglertnapakorn et al., 2023)은 기존의 조명 추정기, 3D 변형 가능한 모델, 피사체의 정체성, 카메라 매개변수, 전경 마스크를 활용하며, 조건부 확산 네트워크를 훈련하여 새로운 조명 아래에서 확산된 렌더링 모델을 처리합니다. 비슷하게, DiLightNet(Zeng et al., 2024)은 유사한 접근 방식을 채택하며, 확산 및 반사광과 같은 다중 방사선 힌트를 제공하지만, 실제 촬영된 입력 사진이 필요하지 않으며 인간이나 얼굴 데이터셋에서 훈련되지 않았습니다.
우리의 접근 방식은 원샷 방법과는 다릅니다. 우리는 다중 시점 및 다중 포즈 데이터를 사용하여 다양한 조명 조건 하에서 피사체를 캡처하며, 이러한 데이터를 기반으로 고충실도 정체성 보존 재구성에 중점을 둡니다. 우리는 임의의 시점, 재조명 조건, 보지 못한 포즈에 대해 일반화할 수 있기를 목표로 하며, 피사체의 정체성 보존을 우선시합니다.
-----
- 한 장의 사진만으로 처리하는 것이 아니라, 여러 각도와 자세에서 찍은 사진들을 활용
- 목표:
- 원본과 최대한 비슷하게 재현
- 어떤 각도에서 보아도 자연스럽게 보이도록 함
- 새로운 조명 조건에서도 잘 작동하도록 함
- 보지 못했던 자세에서도 자연스럽게 표현
- 대상의 고유한 특징을 잘 보존
입력 이미지의 분해 과정
- 하나의 2D 이미지를 입력받아서
- 이미지에서 다양한 특징(feature)들을 추출합니다:
- 표면 법선(surface normal): 물체 표면의 방향성
- 알베도(albedo): 물체 고유의 색상과 재질 특성
- 깊이 정보(depth): 3차원 공간상의 거리 정보
- 물체의 기하학적 구조(geometry)
- 조명 정보(lighting conditions)
특징 활용 방법
- 추출된 특징들을 사용해 3D 모델로 재구성
- 이를 통해 다음과 같은 작업이 가능해집니다:
- 다른 각도에서의 모습 생성
- 새로운 조명 조건 적용
- 다른 포즈로 변형
장점
- 단일 이미지로도 풍부한 3D 정보 획득 가능
- 다양한 변형과 조작이 가능
- 원본의 정체성(특징)을 잘 보존
-----
3. 방법
그림 2는 두 가지 주요 구성 요소인 동적 3D 성능 재구성과 확산 기반 재조명을 포함한 우리의 동적 얼굴 성능 재조명 파이프라인을 설명합니다. 우리의 접근 방식은 평조명 환경에서 다중 시점 성능 시퀀스를 획득하는 것에서 시작합니다. 확장 가능한 동적 3D 가우시안 스플래팅(3DGS) 방식을 사용하여, 우리는 먼저 변형 가능한 3D 가우시안을 재구성하여 새로운 관점에서 시퀀스를 렌더링합니다. 그 후, 확산 기반 재조명 모델을 사용하여 렌더링된 이미지 시퀀스에 대해 지정된 조명 방향에 따라 새로운 조명을 생성합니다. 이 모델은 맞춤형 LED 패널 스테이지를 사용하여 캡처한 평조명 이미지와 OLAT 이미지로 구성된 주제별 쌍 데이터로 훈련되었습니다(섹션 3.1). 평조명 이미지와 조명 방향을 공간적 조건과 전역 조건으로 사전 훈련된 잠재 확산 모델에 입력하는 새로운 설계를 포함하고 있습니다(섹션 3.2). 동적 재조명에서 시간적 일관성을 유지하기 위해, 우리는 긴 시퀀스에 대해 시간적으로 일관된 3DGS를 훈련하기 위한 분할 및 결합 스킴을 도입하고, 동적 재조명 결과에 대해 시간적 블렌딩을 적용합니다(섹션 3.3). 또한 다양한 조명 구성에 대해 다양한 조명 유형을 더욱 제어할 수 있도록 가변 크기의 영역 조명 표현을 새롭게 도입했습니다(섹션 3.4).
3.1 얼굴 데이터 캡처

(a) 캡처 스테이지 (피사체 유/무의 내부 및 외부)
(b) 캡처된 데이터의 시각화
그림 3. 캡처 스테이지와 데이터
(a) LED 패널을 기반으로 한 LED 패널 볼캡 스테이지의 내부 및 외부, 피사체가 있을 때와 없을 때.
(b) 수집된 훈련 데이터의 예시로, 표정(𝐄), 조명(𝐋), 시점(𝐕)의 변화를 포함함.
캡처 설정
확산 기반 재조명 모델을 감독하고, 평조명에서 임의의 조명으로 얼굴 반사율 변환을 학습하기 위해서는 조명만이 변화하는 쌍 훈련 데이터가 필요합니다. 우리는 그림 3(a)와 같이 LED 패널로 덮인 원통형 구조 안에 다중 시점 카메라 배열을 배치한 볼륨 캡처 스테이지를 사용합니다. 서로 다른 LED 패널을 켜서 같은 피사체를 다양한 조명 조건에서 캡처합니다. 또한 LED 패널의 표시 패턴을 사용자 지정하여 다양한 배경과 이미지 기반 조명 환경에서 피사체를 기록할 수 있습니다. 우리는 이 스테이지를 기성품 ROE BP2v2 LED 패널과 75개의 동기화된 4K Z-CAM e2 시네마 카메라를 사용해 원통형 캡처 장치로 구성했습니다. 이 장치는 16×5 배열의 50 cm × 50 cm 패널(16개의 열, 각 열에 5개의 패널)로 구성되며, 약 250 cm 높이와 276 cm 직경의 캡처 볼륨을 형성합니다. 천장은 6×5 배열의 패널로 덮여 있으며, 바닥에는 10개의 추가 패널이 있어 다양한 조명 각도를 제공합니다. 카메라는 벽과 천장에 있는 5cm 간격의 틈을 통해 들여다봅니다.
조명 설정
LeGendre et al. (2020)을 따라, 우리는 반사 필드를 OLAT 이미지로 캡처하며, 각 패널을 순차적으로 단일 광원으로 사용하여 카메라 배열과 동기화된 초당 24프레임으로 촬영합니다. Debevec과 LeGendre (2022)가 보여준 바와 같이, LED 패널은 배우에 대한 이미지 기반 조명에 효과적이기 때문에, 우리는 LED 패널 하나가 하나의 광원(=OL)에 해당하는 방식으로 OLAT을 시뮬레이션하는 데 사용합니다. 각 패널은 스테이지 중심에서 약 20도 콘을 근사하며, 점광원보다 적은 계단 현상 그림자를 생성하면서도 눈의 하이라이트와 날카로운 반사광을 포착합니다. 우리는 충분한 조명을 유지하면서도 패널의 크기를 최소화하고, 크기와 형태의 균일성을 보장하려고 합니다. 각 패널의 큰 각도 범위에도 불구하고, 실제로 우리의 OLAT 기반 프레임워크는 환경 조명으로의 일반화 시 합리적으로 잘 작동하며, 이는 그림 7과 그림 16에서 볼 수 있습니다. 또한 확산 기반 재조명 모델의 훈련을 위해 평조명 데이터도 캡처했습니다.
데이터 수집
우리는 네 명의 개인에 대해 각각 30개의 표정과 머리 자세를 포함하는 OLAT 시퀀스를 수집했습니다. 각 OLAT 시퀀스에는 123개의 조명 조건과 그 사이에 배치된 13개의 평조명 추적 프레임이 포함되어 있습니다. 동일한 평조명 조명은 동적 얼굴 성능을 캡처하는 데 사용되었습니다. 추가적으로, 배경 제거를 용이하게 하기 위해 피사체가 없는 깨끗한 장면의 OLAT 시퀀스를 하나 더 기록했습니다. OLAT 시퀀스 동안 피사체의 약간의 움직임을 보정하기 위해, 우리는 Meka et al. (2019)을 따라 각 시점에서 평조명 프레임을 기준으로 이미지 공간에서 광학 흐름 정렬을 수행합니다. 재조명 모델을 훈련할 때, 우리는 선형 이미지를 sRGB 색 공간으로 변환하여 사전 훈련된 모델 가중치와의 호환성을 높입니다.
3.2. 확산 기반 재조명


이미지 생성 프레임워크를 이미지-이미지 변환 모델로 전환하고 평조명 이미지의 공간적 정보를 더 효과적으로 활용하기 위해, 우리는 U-Net을 수정하여 평조명 이미지의 잠재 변수와 무작위 노이즈 맵을 연결합니다. 이로 인해 네트워크 구조에 약간의 변경이 필요합니다. 특히, 첫 번째 합성곱 계층의 입력 채널 수를 두 배로 늘리는 것입니다. 이러한 최소한의 조정으로 Stable Diffusion의 사전 훈련된 가중치를 최대한 보존할 수 있습니다. 또한, 잠재 변수와 무작위 노이즈를 연결함으로써 재조명 결과와 입력 간의 공간 구조 정렬이 개선됩니다.
평조명 이미지 외에도, 조명 정보는 결과 이미지 전체에 영향을 미치는 중요한 전역 제어 신호 역할을 합니다. 우리는 조명 방향 d을 고차원으로 인코딩하고, 이를 크로스 어텐션을 통해 U-Net에 도입하여 텍스트 임베딩을 대체합니다. 조명의 주파수 대역을 증가시키고 조건화를 강화하기 위해, 우리는 **구면 고조파(Spherical Harmonics, SH)**를 사용해 d를 인코딩하며, 이는 Tancik et al.(2023)의 기법과 유사합니다. 또한, SH 인코딩의 길이를 텍스트 임베딩과 맞추기 위해 제로 패딩을 사용합니다:

우리는 각 피사체에 대해 수집된 데이터를 사용하여 개인화된 모델을 미세 조정합니다. 추론 시, 우리는 동일한 피사체의 평조명 이미지를 얼굴 표정, 카메라 자세, 조명 방향의 임의 조합 하에서 재조명할 수 있습니다.
3.3. 동적 성능 재조명
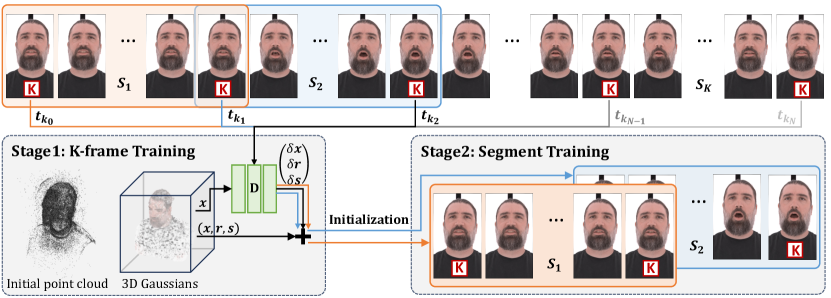



이 웜업 훈련을 통해 가우시안은 전환 지점의 키프레임 변형에 제한되면서도 자유롭게 변형하여 움직임을 재구성할 수 있습니다. 이 단계 후, 대부분의 가우시안이 올바른 위치에 있게 되며, 우리는 제약을 완화하여 가우시안이 복제, 분할, 가지치기하여 세부적인 재구성을 수행할 수 있도록 합니다(기본적으로 10000회 반복). 밀집화(densification) 후, 우리는 가우시안의 수를 고정하고 변형 네트워크와 가우시안을 공동으로 최적화합니다. 두 단계 훈련 방법의 분석 결과는 보충 자료에 포함되어 있습니다.
비록 우리의 재조명 모델에 입력으로 사용되는 재구성된 평조명 시퀀스에서 시간적 일관성을 보장하더라도, 이미지 기반 확산 모델은 여전히 시간적으로 일관되지 않은 고주파수를 생성할 수 있습니다. 이를 해결하기 위해, 우리는 Jamriška et al.(2019)의 방법을 채택하여 시간적 블렌딩 접근법을 적용하고, 키프레임 간의 재조명 결과를 보간합니다. 우리는 작은 단계 크기 4를 사용해 키프레임을 샘플링하여 세부 사항과 조명 정확도를 유지합니다.
3.4. 통합 조명 제어
사용자에게 유연한 조명 제어를 제공하기 위해, 우리는 조명 방향과 가변 광원 크기를 포함하는 새로운 영역 조명 표현을 제안합니다. 이는 우리의 방향성 조명과 통합되어 확산 기반 재조명 모델을 안내하는 통합 조명 제어로 작동합니다. 단일 조명 추론을 기반으로 우리는 여러 단일 조명 추론을 합성하여 HDRI 환경 조명 재구성을 가능하게 합니다.
-----
단일 광원의 특성 학습
↓
여러 광원으로 확장 가능
↓
HDRI 환경 조명까지 구현-----
영역 조명 훈련

HDRI 재구성
우리 모델을 사용하여 단일 조명 조건에서 HDRI 환경에서의 성능을 재조명하기 위해, 우리는 먼저 HDRI 위도-경도(lat-long) 표현을 OLAT들에 매핑합니다. 각 OLAT의 가중치 계수는 해당 영역의 HDRI 위도-경도에서 평균값으로 계산됩니다. 추론 시, 우리는 각 OLAT 방향에 대해 이미지를 생성하고, 이러한 OLAT들의 가중합을 선형 공간에서 계산합니다. 또한, HDRI 맵은 조명 방향과 크기 모두에 조건화된 우리 모델을 사용해 재구성할 수 있으며, 먼저 **구면 가우시안(SG)**을 HDRI 위도-경도 표현에 맞추고, 각 조명 방향과 크기에 대해 추론합니다. OLAT의 경우와 마찬가지로, 우리는 이러한 구면 가우시안의 피팅된 계수를 사용하여 예측값의 가중합을 계산합니다. HDRI가 애니메이션된 경우, 우리는 OLAT 또는 구면 가우시안의 조건화된 방향을 HDRI의 회전에 맞춰 조정합니다.
4. 실험
우리는 다양한 실험을 통해 확산 기반 재조명 모델의 성능을 평가했습니다. 특히 새로운 조명, 표정, 시점과 같은 여러 차원에서의 일반화 능력을 중점적으로 살펴보았습니다. 우리는 관련 연구에서 사용된 다양한 네트워크 구조를 기반으로 구축한 두 가지 베이스라인 모델과 우리의 모델을 비교했습니다. 또한 시스템 내 여러 기술 설계의 타당성을 확인하기 위해 **부분 실험(ablations studies)**을 수행하고, 새로운 피사체에 대한 모델의 일반화 능력을 평가하기 위한 간단한 확장 실험을 진행했습니다. 동적 성능 재조명과 자세한 실험에 대한 추가 결과는 동영상 및 보충 자료를 참조하십시오.
4.1. 구현 세부 사항

4.2. 결과
우리는 네 명의 캡처된 피사체에 대한 테스트 데이터에서 확산 기반 재조명 방법의 효과를 입증했습니다. 그림 1, 그림 10, 그림 11에 나와 있는 시각적 결과는 우리의 방법이 사실적인 피부 질감과 반사, 눈 하이라이트, 섬세한 머리카락 구조를 재현하면서 피사체의 개별적 정체성 특징을 유지하는 것을 보여줍니다. 새로운 조명 애니메이션은 얼굴 전체에서 그림자와 음영의 사실적인 상호작용을 만들어냅니다. 그림 11은 방향 조명과 영역 조명 모두를 활용한 통합 조명 제어를 보여주며, 조명 제어의 응용 예시로 그림 7은 HDRI 환경 맵에 의해 재조명된 결과를 보여줍니다. 다양한 조명 조건 외에도, 표정 변화는 그림 10에서 설명되어 있습니다.
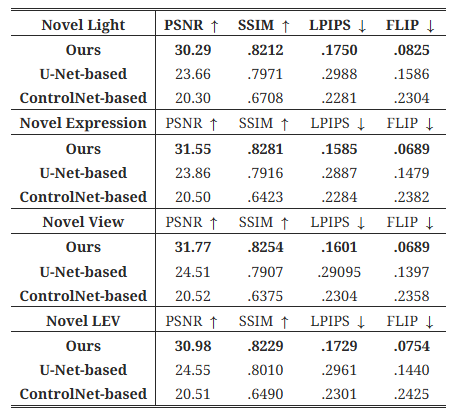
표 1. 다양한 재조명 방법에 대한 정량적 비교.
4.3. 비교
기존의 연구 중 우리 방법과 동일한 훈련 및 테스트 설정을 사용하는 연구가 없기 때문에, 우리는 두 가지 다른 네트워크 구조를 사용하여 베이스라인을 설정했습니다. 하나는 ControlNet(Zhang et al., 2023a)을 기반으로 구축한 확산 기반 모델이며, 다른 하나는 최신 이미지 기반 재조명 기법(Pandey et al., 2021)에서 영감을 받은 U-Net 기반 모델입니다. 우리는 ControlNet을 3채널 평조명 이미지와 1채널 확산 음영 맵에 조건화하도록 조정했습니다. 이 확산 음영 맵은 조명 방향과 광도 법선(photometric normals) 간의 내적을 사용하여 생성됩니다. 광도 법선은 그라디언트 조명 하에서 캡처된 피사체에 대해 표준 방법(Ma et al., 2007)을 사용하여 계산됩니다. 이 모델은 우리의 모델과 동일한 설정에서 1080×1920 해상도로 A100 GPU 8개를 사용해 100K회 반복으로, 배치 크기 8로 훈련되었습니다. 다른 베이스라인인 U-Net 기반 이미지-이미지 변환 네트워크는 조명 방향에 직접 조건화되며, 참조된 아키텍처에서 사용된 **내재적 특징들(법선, 알베도, 반사광)**을 사용하는 대신, 작은 데이터셋에서 부정확한 내재적 분해로 인한 부정적인 영향을 최소화하기 위해 이러한 특징들을 사용하지 않습니다. 두 모델 모두 동일한 데이터를 사용하여 훈련되었으며, 우리는 모든 방법을 네 가지 검증 구성에서 평가했습니다: 새로운 조명(Novel Light), 새로운 표정(Novel Expression), 새로운 시점(Novel View), **새로운 조명+표정+시점(LEV)**으로, 한 차원 혹은 세 차원에서 복잡성을 도입하여 평가했습니다. 우리는 재조명된 이미지와 기준 이미지 간의 차이를 **PSNR, SSIM, LPIPS(Zhang et al., 2018), FLIP(Andersson et al., 2020)**을 계산하여 정량화했습니다. 자세한 결과는 표 1에 나와 있으며, 이들 방법과 기준 이미지의 시각적 비교는 그림 15에 표시되어 있습니다.
-----
[평조명 이미지] ─┐
│─→ ControlNet ─→ [재조명된 이미지]
[확산 음영 맵] ──┘-----
정량적 결과는 ControlNet 기반 방법이 공간적 세부 사항과 색상 정확도 보존에 있어서 PSNR, SSIM, FLIP 점수가 가장 낮아 성능이 떨어진다는 것을 보여줍니다. 이는 이 모델이 희소한 공간 정보만을 활용하기 때문입니다. 또한, 이 모델은 색상 변화에 덜 민감하여 눈에 띄는 색상 차이를 초래합니다. U-Net 기반 방법은 평조명 이미지와의 공간적 정렬이 더 잘 맞지만, 흐릿한 결과를 생성하는 경향이 있어 픽셀 수준의 지표는 향상되지만 사진 사실성은 LPIPS에 의해 측정된 대로 감소합니다. 우리의 방법은 정량적 결과에서 최고의 성과를 달성하였으며, 조명 정확성, 색상 충실도, 전체 이미지 품질을 크게 향상시켰습니다.
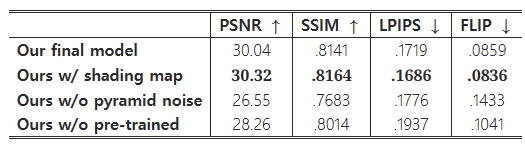
표 2. 부분 실험의 정량적 결과. 음영 맵 조건을 포함한 우리의 방법이 가장 좋은 결과를 얻었지만, 추가 입력으로 광도 법선이 필요하여 데이터 캡처 비용이 증가합니다.

GT( Ground Truth ) | Our | s w/o pyramid noise
그림 5. 피라미드 노이즈를 훈련 중 사용한 경우와 사용하지 않은 경우의 시각적 비교. 피라미드 노이즈를 사용하면 예측과 GT 사이의 색상 일관성이 개선됩니다. 우리는 오차를 강조하기 위해 이미지의 밝기를 20% 증가시켰습니다.

GT( Ground Truth ) | Our | s w/o pyramid noise
그림 6. 사전 훈련된 모델 가중치 사용에 대한 부분 실험. 우리는 사전 훈련된 모델에서 가중치를 로드하는 대신 모델 가중치를 무작위로 초기화하여 우리의 방법을 평가했습니다(사전 훈련 없음). 결과는 사전 훈련된 Stable Diffusion 모델을 로드하면 **인공물(artifacts)**이 적고 사진 사실적인 결과를 생성하는 데 도움이 된다는 것을 보여줍니다.
4.4. 부분 실험(Ablation Studies)
4.4.1. 확산 기반 재조명에 대한 부분 실험
우리는 확산 기반 재조명 모델의 주요 기술 설계를 평가하기 위해 다양한 부분 실험을 수행했습니다. 먼저, 모델에 조명 제어를 통합하는 여러 가지 방법을 시도했습니다. 모델에 거친 음영 추정을 제공하는 방식으로 시도했으며, 이는 ControlNet 기반 재조명 모델에서 사용한 전략과 유사하게 조명 방향과 **광도 법선(photometric normal)**의 내적을 사용해 음영 맵을 생성하는 방식입니다. 법선과 음영 맵의 시각화는 그림 14에서 확인할 수 있습니다. 그 후, 우리는 음영 맵의 잠재 변수와 평조명 잠재 변수, 무작위 노이즈를 결합하여 확산 U-Net의 입력으로 사용했습니다. 우리는 음영 맵과 SH 인코딩을 사용한 조명 조건을 비교했으며, 결과는 그림 14와 표 2에 나와 있습니다. 수치 결과는 음영 맵을 조건으로 사용한 모델이 풍부한 음영과 기하학적 세부 사항을 공간적 제어로 사용하여 우리 모델보다 약간 더 나은 성능을 보임을 나타냅니다. 그러나 다중 시점의 동적 설정에서 광도 법선을 캡처하는 것은 하드웨어 제약으로 인해 어려운 점이 있습니다. 특히, 우리의 방법은 성능 캡처 동안 시간 다중화 조명이 필요하지 않으므로 편안한 평조명을 사용할 수 있으며, 고속 글로벌 셔터 카메라의 필요성을 없애 비용을 절감할 수 있습니다. 따라서, 우리의 접근 방식은 광도 법선에 의존하지 않고도 유사한 성능을 달성할 수 있어 더 많은 응용에 적합합니다.
색상 충실도와 전체 결과 품질에 가장 크게 기여하는 요소를 확인하기 위해, 우리는 피라미드 노이즈를 사용하는 훈련 전략("w/o pyramid noise")을 비활성화하고, 사전 훈련된 Stable Diffusion을 사용하는 초기화를 제거했습니다("w/o pre-trained"). 정량적 결과는 표 2에 자세히 나와 있습니다. 피라미드 노이즈 없이 모델의 성능은 모든 평가 지표에서 감소하는 것으로 나타났습니다. 그림 5에서의 시각적 비교는 피라미드 노이즈가 더 어두운 픽셀의 예측을 더 정확하게하고 색상 이동을 줄이는 데 도움이 된다는 것을 보여주며, 이는 우리 방법이 색상 충실도를 더 잘 유지하는 이유를 설명할 수 있습니다. 또한, 사전 훈련된 Stable Diffusion을 기반으로 네트워크를 미세 조정하는 것이 매우 중요하며, 이는 사진 사실적인 재조명 결과를 생성하기 위한 강력한 사전 지식을 제공합니다. 사전 훈련된 가중치 없이 모델은 더 많은 **인공물(artifacts)**을 생성하는 경향이 있으며, 이는 그림 6에 설명되어 있습니다.
표 3. 동적 3DGS의 다양한 모델에 대한 정량적 비교.
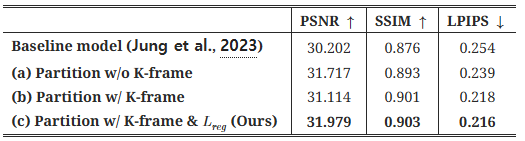
4.4.2. 확장 가능한 동적 3D 가우시안 스플래팅에 대한 부분 실험


그림 7. HDRI 재조명 예시. 우리는 HDRI를 여러 OLAT 또는 영역 조명에 처음 통합하여 피사체를 어떤 HDR 환경에서도 재조명할 수 있습니다. 그 후, 각 OLAT을 통해 확산 기반 재조명 방법을 사용하여 피사체를 개별적으로 재조명하고, 최종 결과를 이미지 공간에서 합성합니다.

기준 진실(Ground Truth) | 피사체별 모델 | 단일 피사체 모델 | 세 피사체 모델
그림 8. 일반화 능력. 우리는 새로운 피사체에 대해 평가하여 모델의 일반화 능력을 테스트했습니다. 피사체별 모델은 같은 피사체에 대해 훈련하고 테스트할 때 가장 잘 정체성을 보존합니다. 흥미롭게도, 단일 피사체 모델은 새로운 피사체를 재조명할 수 있지만 피부 질감이나 입술 색상과 같은 훈련된 피사체의 특징을 계승할 수 있습니다. 세 명의 다른 피사체에 대해 훈련된 경우, 모델은 새로운 피사체의 고유한 특징을 더 잘 보존할 수 있지만 여전히 색상과 세부 사항에 눈에 띄는 변화가 있습니다.
-----
A. 피사체별 모델
- 한 사람의 데이터로만 학습
- 같은 사람에 대해 테스트
B. 단일 피사체 모델
- 한 사람의 데이터로만 학습
- 다른 사람에 대해 테스트
C. 세 피사체 모델
- 세 명의 데이터로 학습
- 새로운 사람에 대해 테스트A. 피사체별 모델
장점: 그 사람의 특징을 가장 잘 유지함
한계: 다른 사람에게는 적용 못함
B. 단일 피사체 모델
장점: 다른 사람에게도 적용 가능
문제점: 학습된 사람의 특징이 묻어남
(예: 피부톤이나 입술색이 학습된 사람과 비슷해짐)
C. 세 피사체 모델
장점: 새로운 사람의 특징을 더 잘 보존
문제점: 약간의 색상과 디테일 변화 있음-----
5. 실제 HDRI 재조명
우리의 방법은 모든 시점에서 OLAT 이미지를 **기준 진실(GT)**과 가깝게 추론할 수 있기 때문에, (Debevec et al., 2000)의 방법을 따르며 HDRI 맵을 사용하여 실제 조명 조건을 재현할 수 있습니다. 이를 평가하기 위해, 우리는 훈련된 피사체 중 한 명의 참조 이미지를 복잡한 실내 및 실외 환경에서 촬영하고, HDRI 맵을 사용해 조명을 재구성했습니다. 비교를 위해, 비슷한 시점에서 평조명된 피사체를 렌더링하고 이를 재조명 모델에 입력했습니다. 각 HDRI 맵에 대해 두 가지 결과를 생성했습니다: 하나는 OLAT 기반 모델을 사용한 것이고, 다른 하나는 영역 조명 모델을 사용한 것입니다. OLAT 기반 재조명에서는 123 OLAT의 결과를 선형 결합하고, 영역 조명 재조명에서는 **15개의 구면 가우시안(SG)**을 사용해 HDRI 맵을 근사하고, 각 SG에 대해 추론한 후 그 결과를 결합합니다. LED와 실제 조명 간의 스펙트럼 차이를 고려하기 위해, 두 환경에서 컬러 차트를 촬영하고, 상수 3채널 스케일링 인자를 계산하여 재조명된 이미지를 보정했습니다. 그림 16은 복잡한 조명 조건에서 우리의 결과가 참조 이미지와 비교할 만한 수준임을 보여줍니다.
6. 모델 일반화
우리 모델은 주로 피사체별 데이터로 훈련되어 새로운 피사체에 대한 일반화 능력이 제한되지만, 모델은 평조명에서 방향성 조명으로의 변환을 학습하며, 이는 다소 피사체에 구애받지 않는 과정입니다. 그러나 모델의 피사체별 정보, 특히 고주파 세부 사항은 여전히 결과에 남아 있을 수 있으며, 이는 그림 8에서 확인할 수 있습니다. 여러 피사체의 데이터를 사용해 훈련하면 이러한 피사체별 정보를 줄일 수 있는지 평가하기 위해, 우리는 세 명의 피사체 데이터를 사용해 모델을 훈련했습니다. 이 모델은 새로운 피사체에 대해 정체성을 더 잘 보존하는 향상된 성능을 보였지만, 색상 변화는 여전히 두드러졌습니다. 이는 더 많은 피사체를 사용한 훈련으로 일반 재조명 모델을 개발할 가능성을 시사합니다.
원본 출력 | 프레임 1 | 프레임 2 | 프레임 3
그림 9. 제한 사항. 포스트 프로세싱 키프레임 보간은 빠른 카메라 움직임으로 인한 부정확한 왜곡 때문에 셔츠에 이중 줄무늬와 같은 인공물을 발생시킬 수 있으며, 이는 광학 흐름 추정의 정확도에 영향을 미칩니다.
7. 제한 사항
우리 기술에는 몇 가지 제한 사항이 있습니다. 첫째, 비디오 훈련 데이터의 부재로 인해 이미지 기반 확산 모델의 시간적 일관성 문제를 완전히 해결하지 못하며, 광학 흐름 포스트 프로세싱은 가끔 빠른 움직임 중에 인공물을 유발합니다(그림 9 참조). 비디오 확산 모델의 발전은 이 문제를 해결할 가능성이 있습니다. 둘째, 우리의 피사체별 훈련은 새로운 피사체에 대해 일반화하도록 설계되지 않았으며, 재조명 결과에서 정체성 특징이 변할 수 있습니다(우리의 확장 실험 참조). 우리는 이 제한을 다양한 다인 데이터셋을 사용하여 훈련하거나 정체성 분리 기법을 구현하여 해결할 수 있을 것으로 믿습니다. 마지막으로, 전신 성능에 우리의 재조명 기술을 적용하려면 전신 훈련 데이터를 추가해야 합니다.
8. 결론
제안된 방법은 피사체별 OLAT 훈련 데이터를 사용하여 자유로운 시점의 평조명 얼굴 성능을 다양한 조명 조건으로 재조명하는 데 있어 유망한 결과를 보여줍니다. 이는 이전의 단일 확산 조명 조건에서 시작하는 이미지 기반 방법에 비해 눈 하이라이트, 피부 광택, 머리카락 세부 사항을 복제하는 성능을 향상시킵니다. 기저 확산 모델을 활용함으로써 피사체별 데이터로 미세 조정하여 원래 피사체의 외형과 정체성을 유지하면서 잘 조건화된 결과를 달성할 수 있었습니다. 이러한 발견은 재조명 가능한 볼류메트릭 캡처 제작을 발전시키고 평조명 푸티지의 후처리 재조명을 용이하게 하는 유망한 방향을 시사합니다.
감사의 말
우리는 Stephan Trojansky와 Jeffrey Shapiro에게 초기 기획과 지속적인 지원에 대해, Gabriel Dedic에게는 이미지 작업에 대한 귀중한 도움에 대해 감사드립니다. Jon Milward, Samuel Price에게는 스테이지 운영에 대해, Connie Siu, Amir Shachar, Kevin Williams, Marc Thorineaux, Alex Chun에게는 스테이지 조정에 대해, Rafe Sacks, Scott Wilson에게는 데이터 전처리에 대해 감사드립니다. Sunny Koya, Daniel Heckenberg, Pablo Delgado, Elliot Chow에게는 기술 지원에 대해, 소프트웨어 부서에게는 스테이지 소프트웨어 유지 관리에 대해, Brian Tong에게는 비디오 편집에 대해 감사드립니다. 마지막으로 우리의 연기자들인 Kevin Williams, Mary Carr, Zorianna Kit, Naz Lang에게 감사드립니다.

그림 10. 회전된 방향성 조명 아래의 새로운 얼굴 표정. 각 행은 특정 배우의 120 프레임으로 구성된 성능 시퀀스에서 12번째 프레임마다 새로운 얼굴 표정을 보여줍니다.

그림 11. 방향성 조명과 영역 조명을 결합한 통합 조명 제어. 이미지 시퀀스는 고정된 시점에서 영역 조명이 애니메이션된 성능 시퀀스를 보여줍니다. 영역 조명은 **방향성 조명(0도 영역 조명)**에서 360도 영역 조명 사이를 직선적으로 앞뒤로 움직입니다. 영역 조명의 반사 필드를 계산하기 위해, 캡처된 OLAT 이미지들이 가중치를 가지고 선형 결합됩니다.

그림 12. 수평 180도 회전 경로를 따라 새로운 방향성 조명 아래에서 본 피사체.

그림 13. 피사체 주위를 180도 회전하며 10개의 새로운 시점에서 본 피사체.

입력 | 광도 법선(Photometric normal) | 음영 맵(Shading map) | 우리의 방법(음영 맵 사용) | 우리의 방법(SH 인코딩 사용) | GT
그림 14. 음영 맵과 SH 인코딩을 사용한 다양한 조명 조건 방법 비교. 또한 광도 법선과 음영 맵을 시각화했습니다. 음영 맵은 광도 법선과 조명 방향 간의 내적입니다. 두 방법 모두 비교 가능한 시각적 품질을 달성하지만, 음영 맵에 조건화된 방법은 추가 입력으로 광도 법선을 필요로 합니다.

GT | 우리의 방법 | ControlNet 기반 | U-Net 기반 | GT | 우리의 방법 | ControlNet 기반 | U-Net 기반
그림 15. ControlNet 기반 재조명, U-Net 기반 재조명, 우리의 방법으로 생성된 결과 비교. U-Net 기반 모델은 전경 마스크로 훈련되어 전경 재조명에 집중하며 검은색 배경을 생성하지만, 나머지 두 방법은 훈련 시 마스크를 사용하지 않으며 대신 3DGS를 사용해 생성됩니다. 우리는 지표 계산 시 다른 방법의 결과에서 배경을 제거했습니다.

참조 이미지 | 영역 조명 모델 | OLAT 기반 모델 | 참조 이미지 | 영역 조명 모델 | OLAT 기반 모델
그림 16. 실제 HDRI 재조명. 우리는 네 개의 실제 환경에서 촬영된 참조 이미지와 비교하여 HDRI 재조명 결과를 보여줍니다. 각 HDRI 재조명 예시에는 참조 이미지, 두 가지 재조명 결과(하나는 영역 조명 모델을 사용하고 다른 하나는 OLAT 기반 모델을 사용한 것), 그리고 캡처된 HDRI 맵과 그에 대한 15개의 구면 가우시안(SG) 및 123개의 OLAT의 근사가 이미지에 오버레이된 형태로 제시됩니다. 두 모델 모두 참조 이미지와 비교할 만한 수준의 결과를 달성합니다.
부록 A 부록
A.1. 방법
A.1.1. 배경 분할을 통한 3D 가우시안 스플래팅 재구성
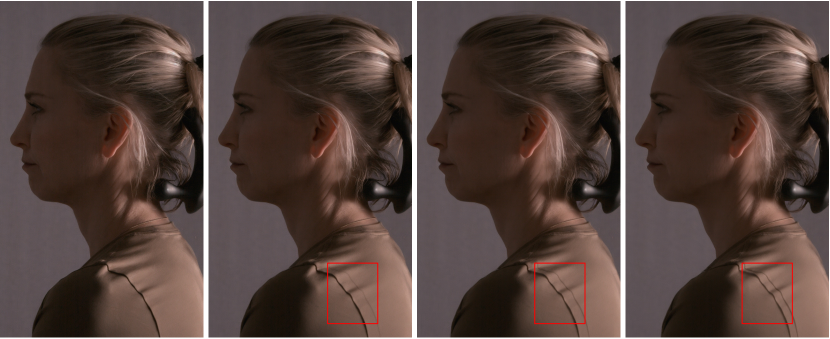
HDR 환경 조명 생성이나 U-Net 기반 네트워크의 훈련 데이터와 같은 일부 후처리 작업에서는 **전경 매팅(foreground matting)**이 필요하기 때문에, 우리는 3DGS 재구성에서 우리의 스테이지가 캡처한 깨끗한 배경을 알려진 배경으로 사용하도록 제안합니다. 구현 세부 사항은 아래에 제공됩니다.



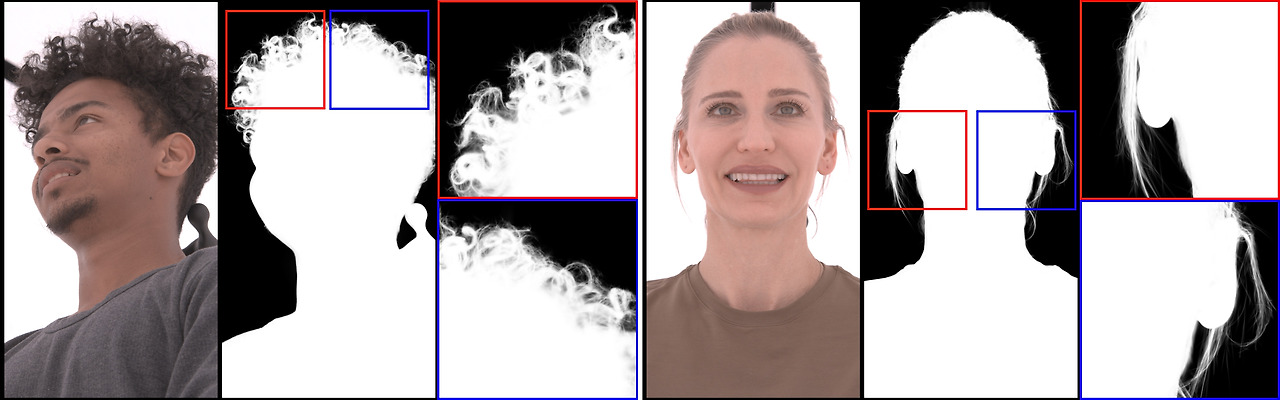
그림 17. 깨끗한 장면을 활용한 3D GS 재구성으로 생성된 알파 매트. 각 예시는 입력 이미지와 함께 생성된 알파 매트를 포함하고 있습니다. 확대된 세부 사항은 깨끗한 장면을 사용하여 명확하게 분리된 머리카락과 같은 특정 요소를 강조합니다.
A.2. 추가 결과
그림 18은 우리의 DifFRelight 방법이 생성하는 복잡한 빛의 전달 효과를 보여줍니다. 이러한 복잡한 조명 효과는 부분적으로 **Stable Diffusion 사전 모델(prior)**에서 기인하지만, 대부분은 우리의 모델이 피사체별 실제 반사 데이터에서 다양한 조명 조건을 적용하는 미세 조정 과정에서 학습한 것입니다. 이러한 효과를 물리 기반 렌더링으로 정확하게 모델링하는 것은 매우 어렵고, 다층 재료에서의 빛의 전달 및 **피하 산란(subsurface scattering)**을 시뮬레이션하기 위해 복잡한 계산 모델이 필요합니다. 예를 들어, 인간의 피부 자체는 표피(epidermis), 진피(dermis), 탄성 연골(elastic cartilage), 지방 조직(fatty tissue) 등 여러 층으로 구성되어 있으며, 이들 층은 빛을 확산시킵니다. 또한 다양한 크기의 혈관이 귀 조직을 관통하여, 빨간 스펙트럼의 빛을 흡수하고, 이를 통해 빛이 투과되면서 붉은 색조를 생성합니다.
그림 18. 복잡한 빛의 전달 효과. 우리 방법은 투명한 귀를 통해 빛이 산란하고 전달되는 효과와 함께, 가장자리 각도에서의 날카로운 반사광 및 머리카락 가닥의 미묘한 반사를 보여주며, 보지 못한 시점과 조명 방향에서 이와 같은 효과를 달성합니다.
A.3. 비교
다음으로 U-Net 기반 재조명 베이스라인의 구현 세부 사항을 제공하고, 제로-샷 재조명 방법과의 새로운 두 가지 비교를 추가로 제시합니다.
A.4. U-Net 훈련 파이프라인
우리의 U-Net(Ronneberger et al., 2015) 기반 아키텍처를 훈련하기 위해, 확산 기반 훈련 파이프라인과 유사하게 평조명으로 캡처된 이미지 쌍과 OLAT 이미지 쌍을 사용하고, 캡처된 카메라 공간의 조명 방향을 입력으로 사용합니다. 추가적으로, 우리는 GS 재구성에서 얻은 마스크를 사용하여 모델이 배경 학습을 건너뛰도록 했습니다. 이는 평조명 이미지와 목표 배경 사이의 변환이 전경 피사체보다 더 모호하기 때문에 수렴을 돕습니다. U-Net의 인코더 아키텍처는 ResNet-50(He et al., 2016) 아키텍처를 기반으로 합니다. 이 아키텍처를 일치시키면 사전 훈련된 모델로부터 가중치 초기화를 사용할 수 있지만, 우리는 이 가중치를 고정된 상태로 사용하지 않기로 결정했습니다. 이 초기화 전략으로 수렴이 상대적으로 빨라졌지만, 랜덤 가중치 초기화를 사용할 경우 더 긴 훈련 시간 동안 유사한 수렴을 보였습니다. 디코더로는 **StyleGAN2(Karras et al., 2020)**에서 설명된 **스타일 변조(style modulation)**를 사용합니다. 스타일 코드는 조명 방향에 사용되며, 두 개의 숨겨진 층 각각에 128개의 뉴런을 가진 다층 퍼셉트론이 3차원 조명 방향을 디코더의 CNN 계층별 필요한 형태로 매핑하여 변조를 수행합니다. 디코더 가중치는 StyleGAN2 체크포인트에서 초기화하지 않고 무작위로 초기화했습니다. 우리는 이 모델을 각 퍼포머별로 약 30 에포크 동안 훈련하여 수렴시켰으며, 확산 기반 훈련 방법보다 수렴하는 데 상당히 더 많은 시간이 소요되었습니다. 4개의 NVIDIA A100G 카드를 사용한 멀티 GPU 훈련이 진행되었고, 원래의 4K 해상도에서 2K 크롭을 사용했습니다. 비교를 위해 데이터셋의 20%를 유지하여 다른 훈련 설정과 일치시켰습니다. 훈련은 하루 미만이 소요되는 확산 기반 훈련과 달리, 여러 주가 걸렸고, 그 결과는 상당히 열등한 출력이었습니다. 확산 기반 훈련 파이프라인과 달리, 우리는 GS 재구성에서 얻은 마스크를 사용하여 캡처된 OLAT 이미지와 예측값 간의 L2 노름을 계산하기 전에 배경을 제거했습니다. Adam 옵티마이저를 3e-4의 학습률로 최적화에 사용했습니다. 눈의 하이라이트를 재구성하기 위해 목표 이미지의 강도를 두 배로 곱하여 노출을 증가시키는 방법이 더 나은 결과를 얻는 데 도움이 되었습니다. 추론 시간은 인터랙티브하며, 상용 CUDA 지원 그래픽 카드에서 초당 16~24 프레임의 속도로 모델이 예측 결과를 보여주는 인터랙티브 애플리케이션을 구축할 수 있었습니다. 그러나 이 추론 시간의 개선은 결과의 품질과 수렴을 위한 훈련 시간을 고려했을 때 정당화되지 않았습니다. 더 다양한 데이터와 더 큰 데이터셋을 사용하여 이 방법으로 사전을 구축하면 더 나은 결과를 얻을 수 있을 것으로 믿습니다. 그러나 Stable Diffusion 기반 방법은 이미 사용할 수 있는 사전을 가지고 있으며, 확산 기반 모델이 고주파 세부 사항에 대해 더 표현력이 있는 것으로 보입니다. U-Net 방법은 모델이 그림자 모양이나 특정 하이라이트 위치에 대해 확신을 갖지 못해 시간적 안정성에서도 문제가 발생합니다. 이러한 문제는 스테이지에서 더 밀집된 조명 및 카메라 설정으로 개선될 수 있을 것으로 보이며, 이는 또한 캡처 과정을 더 비용이 많이 들게 만듭니다. 적대적 손실(adversarial loss)을 사용한 추가 탐색은 생략되었습니다. 이는 이 훈련 방법이 합리적인 수렴을 위한 튜닝이 어렵고, 많은 감독 없이도 각 퍼포머마다 일관되게 작동해야 하는 생산 도구에는 적합하지 않기 때문입니다.
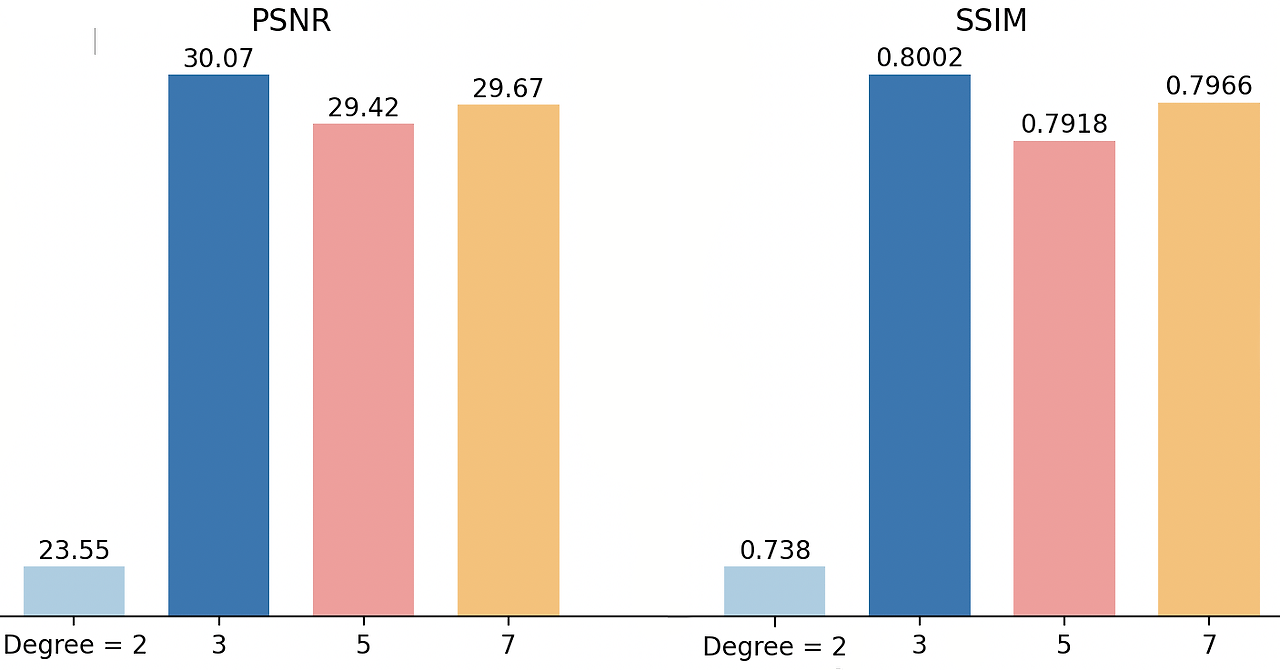
그림 19. 다양한 SH 차수가 재조명 결과의 PSNR 및 SSIM에 미치는 영향을 테스트했습니다. 다른 모든 실험에서는 차수 = 3을 사용했습니다.
A.5. 제로-샷 재조명 방법과의 비교

그림 20. 우리의 방법과 Kim et al.(2024)의 방법을 사용한 제품 SwitchLight Studio 간의 비교. 마지막 행은 HDRI 환경 조명을 보여줍니다.
우리는 그림 20에서 **SwitchLight(Kim et al., 2024)**와 비교를 제공합니다. 이는 가장 최근의 최신 전통 재조명 방법 중 하나로, 우리의 방법과 동일한 조명 정보 및 입력 평조명 이미지를 사용해 생성된 결과와 함께 결과를 보여줍니다. 피사체별 실제 데이터로 미세 조정을 하고, 렌더링 모델에 의존하지 않고 최종 이미지를 생성하기 때문에, 우리의 방법으로 생성된 피부 색상은 더 자연스럽고 세밀하게 표현되며, 피부와 눈에 있는 반사광이 조금 더 뚜렷합니다. SwitchLight의 물리 기반 렌더링 접근법은 HDRI 피부 반사의 색조를 자연스럽게 재현하는 것의 어려움을 강조합니다. SwitchLight와 같은 방식으로 기하학적 특성을 재구성하기 위한 일반 모델을 학습하는 것은 큰 도전이며, 법선과 알베도 품질에서 몇 가지 단점이 있습니다. 그러나 SwitchLight는 어떤 피사체에도 일반화할 수 있으며, 일반적인 재조명 도구로 사용할 수 있습니다.
최근에, **IC-Light(Zhang et al., 2024)**가 Stable Diffusion을 기반으로 하는 제로-샷 재조명 알고리즘으로 출시되었습니다. 이 방법은 전경 이미지의 조명을 주어진 배경과 조화시키는 기능을 갖추고 있으며, 배경이 출력 이미지의 조명을 제어합니다.
그림 21과 그림 22에서 정성적 결과를 보여줍니다. IC-Light는 시간적으로 일관되지 않으며, 주어진 방향에서 정확한 조명을 생성하지 못합니다. 또한 배경 이미지만을 입력으로 받기 때문에, 360도 HDRI 맵을 사용하여 피사체를 재조명하는 데 사용할 수 없습니다. 선택한 프롬프트나 배경에 상관없이, IC-Light는 피사체의 눈에 반사광을 추가하지 못해 흐릿하고 생기 없는 외형을 초래합니다. 반면, 우리의 방법은 고해상도로 반사광을 정확하게 재현합니다. 이러한 결과는 **피사체별 공식화(subject-specific formulation)**의 중요성을 보여줍니다.

그림 21. 우리의 방법과 IC-Light(Zhang et al., 2024) 간의 비교. IC-Light는 눈의 하이라이트와 반사를 생성하지 못하며, 이마 주름도 완전히 없습니다. 첫 번째 IC-Light 이미지는 왼쪽에서의 재조명을 위해 공식 구현의 기본 설정을 사용하여 생성되었으며, 오른쪽 끝 이미지는 포함된 사이버펑크 배경과 프롬프트를 사용하여 생성되었습니다.

그림 22. IC-Light는 시간적으로 일관되지 않으며, 피사체를 정확하게 조명하지 못합니다. y축은 조명의 각도이며, 가장 왼쪽 열은 사용된 배경 이미지입니다. x축은 피사체가 3D로 회전된 각도를 나타냅니다.
A.6. 추가 부분 실험(Ablation Studies)
A.6.1. SH 차수에 대한 부분 실험
우리 방법에서의 하이퍼 파라미터 중 하나는 조명 방향을 텍스트 임베딩으로 인코딩하는 데 사용되는 SH 차수입니다. 우리는 한 피사체에 대해 다양한 SH 차수를 실험하고, 그림 19에 PSNR 및 SSIM 지표를 SH 차수 2, 3, 5, 7로 나타냈습니다. 차수가 2일 때, 우리 방법은 조명 방향에 대한 추론과 고품질 결과를 생성하는 데 어려움을 겪는 것으로 보이는데, 이는 조명 조건의 저주파 대역 때문인 것으로 보입니다. 차수가 2보다 클 때, 모델은 훨씬 더 나은 성능을 보여주며, 차수가 3일 때 최고의 성능을 달성합니다. 이는 우리가 다른 모든 실험에서 선택한 최종 설정입니다. 이 특정 값은 대략 데이터셋의 모든 가능한 조명 방향의 각도 샘플링 비율과 일치합니다. 따라서, 적절한 SH 차수를 선택하는 것은 우수한 피사체별 재조명 모델을 훈련하는 데 중요합니다.
A.6.2. 확장 가능한 동적 3DGS에 대한 부분 실험
우리는 제안된 동적 3DGS에 대한 부분 실험의 시각적 결과를 그림 23에 보여줍니다.
GT

(a)

(b)

(c)

(d)

그림 23. 다양한 동적 3DGS 모델에 대한 시각적 비교: (a) 기준 모델(Jung et al., 2023), (b) 긴 시퀀스를 세그먼트로 분할하여 개별 훈련한 모델, (c) 변형 오프셋 정규화 없이 우리의 K-프레임 초기화를 사용한 모델, (d) K-프레임 초기화와 변형 오프셋 정규화를 결합한 모델. 오렌지와 파란색 프레임은 (b), (c), (d)에서 두 세그먼트가 겹치는 전환 지점을 나타냅니다. 오렌지 프레임은 이전 세그먼트 모델에 의해 학습되었으며, 파란색 프레임은 다음 세그먼트 모델에서 나온 것으로, 더 큰 유사성을 통해 세그먼트 간 일관성이 더 나아졌음을 나타냅니다. **GT와 (a)**에서는 이들이 중복되어 동일함을 보여줍니다.
'인공지능' 카테고리의 다른 글
| Language models generalize beyond natural proteins (2) | 2024.11.15 |
|---|---|
| Multi-Resolution Noise for Diffusion Model Training (7) | 2024.11.14 |
| Augmented Physics: Creating Interactive and Embedded Physics Simulations from Static Textbook Diagrams (4) | 2024.11.14 |
| Unbounded: A Generative Infinite Game of Character Life Simulation (2) | 2024.11.13 |
| Neural Ordinary Differential Equations (2) | 2024.11.12 |



