Multi-Resolution Noise for Diffusion Model Training
Fixing a potential issue with current approaches to diffusion model training by using a new noising approach. Made by Jonathan Whitaker using W&B
wandb.ai
잠재적 문제를 해결하는 새로운 노이즈 접근법을 사용한 확산 모델 훈련 개선 조나단 휘태커 작성일: 2월 28일 | 마지막 수정일: 5월 8일 댓글

스테이블 디퓨전(왼쪽)은 매우 어두운 이미지를 생성할 수 없지만, 우리의 새로운 트릭을 적용하면(오른쪽) 가능합니다!
이 보고서는 확산 모델 훈련 중 이미지나 잠재 이미지에 다중 해상도 노이즈를 추가하는 새로운 노이즈 접근법을 제안합니다. 이 기법으로 훈련된 모델은 기존 확산 모델 출력과는 매우 다른 미적 느낌을 가진 놀라운 이미지를 생성할 수 있습니다. 이는 향후 연구에 있어 유망한 방향으로 보입니다. 노이즈 스케줄에 어떤 의미가 있을까? 팅 첸의 '확산 모델에서 노이즈 스케줄의 중요성에 대한 연구'와 같은 최근 연구는 확산 모델 훈련에서 종종 간과되는 측면인 노이즈 스케줄과 이미지 해상도 및 입력 스케일링의 관계에 주목하고 있습니다. 첸의 논문(그리고 동시 발표된 '단순 확산' 연구)에서 보이듯이, 이러한 미묘한 설계 결정을 다루면 확산 모델의 품질과 훈련 안정성이 크게 향상될 수 있습니다.
노이즈 스케줄에 무엇이 들어 있을까?
팅 첸의 '확산 모델에서 노이즈 스케줄의 중요성에 관한 연구'와 같은 최근의 연구들은 확산 모델 훈련에서 종종 간과되는 측면인 노이즈 스케줄, 그리고 그것이 이미지 해상도와 입력 스케일링과의 관계에 대해 주목하고 있습니다. 첸의 논문(그리고 동시 발표된 '심플 디퓨전' 연구)에서 보이듯이, 이러한 미묘한 설계 결정을 다루는 것이 확산 모델의 품질과 훈련 안정성에 큰 향상을 가져올 수 있습니다.

다른 해상도의 이미지에 동일한 양의 노이즈를 추가하면 해상도가 '신호 대 잡음' 비율에 어떤 영향을 미치는지, 그리고 그로 인해 정보가 얼마나 빠르게 소멸되는지 잘 보여줍니다.
여기서 핵심적인 문제 중 하나는 확산 과정에서 사용되는 랜덤 노이즈가 본질적으로 고주파라는 점입니다. 반면 이미지에는 많은 저주파 성분이 포함되어 있어 인접한 픽셀들 간에 높은 중복성을 가지고 있습니다. 신호 대 잡음 비율을 조정하기 위해 노이즈 스케줄을 조정하면 문제의 일부는 해결되지만, 근본적인 문제는 여전히 남아 있습니다: 고주파 세부 정보가 저주파 세부 정보보다 훨씬 더 빠르게 소멸된다는 점입니다.
이 보고서에서는 '오프셋 노이즈'라는 아이디어를 기반으로, 다중 해상도 노이즈를 사용하여 이미지 신호의 모든 요소를 저하시키는 새로운 노이즈 접근법을 소개합니다. 이를 통해 정규 스테이블 디퓨전보다 더욱 다양한 이미지를 생성할 수 있으며, 이전에는 많은 샘플링 단계를 사용하지 않고는 생성하기 어려웠던 극도로 밝거나 어두운 이미지도 생성할 수 있습니다.
오프셋 노이즈 오프셋 노이즈의 아이디어는 니콜라스 구텐베르그의 블로그 게시물에서 소개되었습니다. 아래 비디오는 이 주제를 잘 설명하고 있으며, 이 덕분에 저는 오프셋 노이즈에 대해 더 깊이 살펴보게 되었습니다(이전에는 큰 차이를 만들지 않을 것이라고 생각하고 넘어갔었습니다).
https://www.youtube.com/watch?v=cVxQmbf3q7Q
니콜라스가 제안한 해결책은 노이즈 함수를 noise = torch.randn_like(latents)에서 noise = torch.randn_like(latents) + 0.1 * torch.randn(latents.shape[0], latents.shape[1], 1, 1)로 다시 작성하는 것입니다. 이렇게 하면 모델이 "영주파 성분"(즉, 이미지의 평균 색상)을 훨씬 더 빠르게 변경하도록 학습하게 되어, 매우 어두운 이미지나 매우 밝은 이미지를 생성하는 데 더 많은 자유를 갖게 됩니다. 다음은 블로그 게시물에서 일부 예시 프롬프트에 대해 적용 전(왼쪽)과 적용 후(오른쪽)를 비교한 결과입니다.

스테이블 디퓨전(SD)으로 생성된 이미지(왼쪽)와 오프셋 노이즈로 파인 튜닝된 버전(오른쪽). 왼쪽 이미지는 결코 매우 밝거나 어둡지 않다는 점을 유의하세요.
니콜라스는 글의 마지막에 다음과 같은 요청을 남겼습니다: "대규모 모델을 훈련하는 관계자들에게 이 글을 통해 하나의 요청을 남기고자 합니다. 다음에 큰 훈련을 진행할 때 이번에 제시한 오프셋 노이즈와 같은 기법을 조금만이라도 적용해 보세요. 이는 모델의 표현 범위를 크게 확장시켜, 로고, 컷아웃 인물, 자연스럽게 밝거나 어두운 장면, 강렬한 색조의 조명이 있는 장면 등에서 훨씬 더 나은 결과를 낼 수 있을 것입니다. 아주 간단한 트릭입니다!" 커뮤니티는 곧 이 요청에 응답했고, 얼마 지나지 않아 일루미나티 디퓨전 v1.1이 멋진 이미지를 생성하는 데 사용되었습니다.
다양한 주파수의 노이즈 오프셋 노이즈 트릭은 매우 고주파 노이즈와 극저주파 노이즈(오프셋)를 효과적으로 결합함으로써 문제의 일부를 해결합니다. 하지만 더 나은 방법이 있을 것 같았습니다. 여러 주파수에서 노이즈를 혼합해 모든 신호를 더 쉽게 지울 수 있는 방법 말입니다. 그래서 등장한 것이 '피라미드 노이즈'입니다.
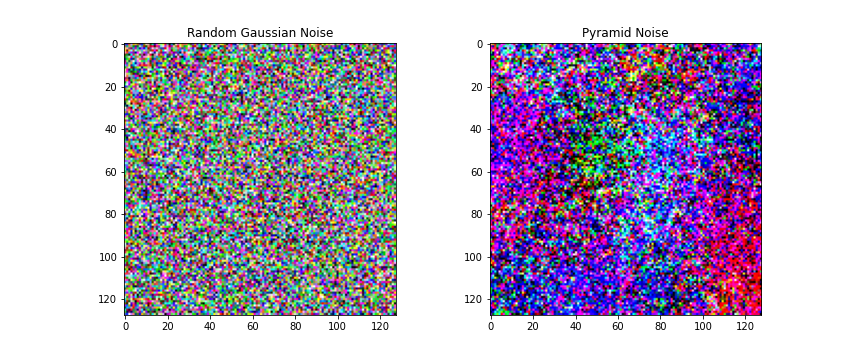
일반적인 확산 모델(DM) 훈련에서 사용되는 노이즈(왼쪽)와 피라미드 노이즈(오른쪽)의 비교
아이디어는 다양한 해상도로 노이즈를 생성하고 이를 쌓은 다음, 선택적으로 낮은 해상도의 노이즈를 특정 계수에 따라 축소하는 것입니다. 다음은 이 아이디어를 코드로 구현한 알고리즘입니다:
def pyramid_noise_like(x, discount=0.9):
b, c, w, h = x.shape # EDIT: w와 h는 덮어쓰여지므로 다른 변형에서는 이름을 바꿔야 합니다!
u = nn.Upsample(size=(w, h), mode='bilinear')
noise = torch.randn_like(x)
for i in range(10):
r = random.random() * 2 + 2 # 항상 2배로 가지 않는 대신, 랜덤 값을 사용
w, h = max(1, int(w / (r ** i))), max(1, int(h / (r ** i)))
noise += u(torch.randn(b, c, w, h).to(x)) * discount ** i
if w == 1 or h == 1:
break # 최소 해상도는 1x1
return noise / noise.std() # 대략 단위 분산으로 다시 스케일 조정
이것은 그저 제가 떠올린 첫 번째 아이디어일 뿐입니다. 퍼린 노이즈(Perlin Noise)를 사용하거나, 자신만의 방법을 고안해 볼 수도 있습니다. 인공지능 예술 커뮤니티에서 저와 다른 사람들이 '퍼린 초기화(perlin init)'를 2020년부터 CLIP-유도 확산과 함께 실험하고 있었으며, 그 이전에도 ImStack 라이브러리를 사용해 서로 다른 레벨의 노이즈를 쌓고 있었습니다. 따라서 다중 해상도 이미지 스택이나 다중 해상도 노이즈를 다루는 아이디어들은 꽤 오랫동안 존재했지만 크게 주목받지 못하고 있었습니다...
훈련 초기 테스트를 위해, 저는 Hugging Face의 파인튜닝 예제를 따르면서 원래의 훈련 스크립트에 몇 가지 작은 수정만을 적용했습니다:
- 훈련 중 이미지에 노이즈를 추가할 때 torch.randn_like(latents) 대신 pyramid_noise_like(latents)를 사용하여 노이즈를 생성
- W&B에 일부 통계를 로깅. 나중에 알았는데, 스크립트가 이미 W&B 로깅을 지원하므로 --report_to=wandb를 전달하는 것으로 충분했을 것 같네요!
- 데이터로더 코드를 제가 가지고 있던 데이터 형식에 맞게 조정
제 훈련 설정의 정확한 내용은 실행 세부 사항에서 확인할 수 있습니다. 업데이트: 피라미드 노이즈의 할인 계수를 0.8로 하고, 더 낮은 학습률과 더 큰 배치 크기로 진행한 두 번째 훈련은 결과가 훨씬 더 좋았던 것 같습니다.
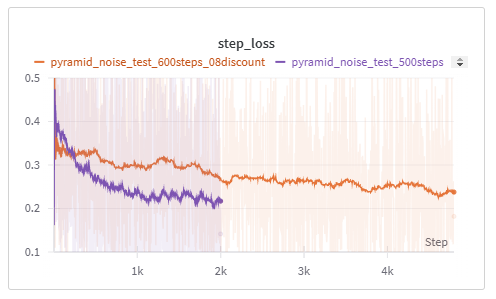
니콜라스처럼, 저는 이걸 더 깊이 탐구하는 어려운 일은 시간이 많고 컴퓨팅 자원이 풍부한 분들께 맡기려고 합니다 ;)
결과 몇 분만 훈련을 해도 모델은 기본 스테이블 디퓨전보다 훨씬 더 어둡거나 밝은 이미지를 생성할 수 있었습니다.

프롬프트 "하얀 이미지" - 초기 테스트 실행에서 몇백 번의 훈련 단계 후
어려운 부분은 기본 SD 모델의 강력함을 유지하면서 과적합을 피하는 것이었습니다. 저는 학습률을 상당히 낮게 유지하고, EMA를 사용하여 훈련 중에 심각한 문제가 발생하지 않도록 했으며, 모델이 훈련 중 같은 이미지를 두 번 이상 보지 않도록 충분히 큰 이미지 데이터셋을 사용했습니다.
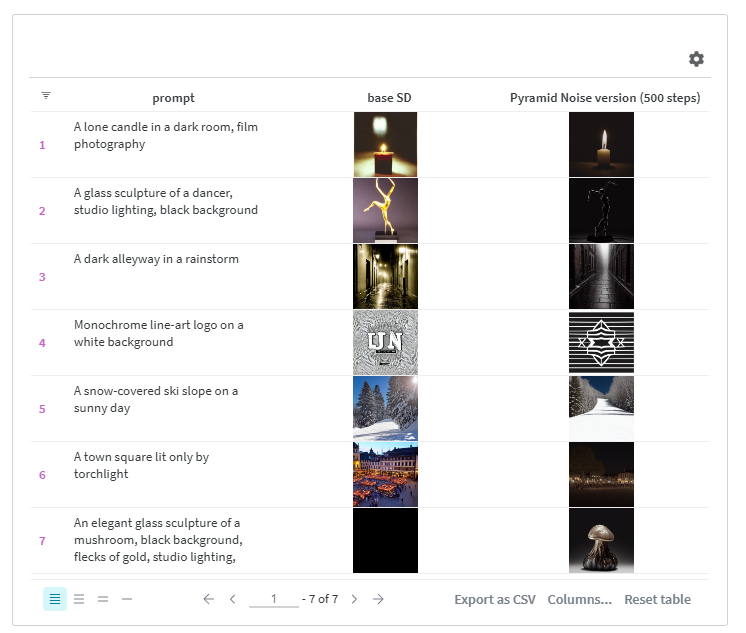
위에는 바닐라 스테이블 디퓨전과 피라미드 노이즈로 파인튜닝한 제 버전을 통해 실행된 프롬프트들이 있습니다. 일부는 조금 오류가 있지만, 저는 어두운 횃불로 비춘 거리들을 정말 좋아합니다! 여러분은 어떤 것을 더 선호하시나요?
결론 모델을 사용해보고 싶다면, Hugging Face에서 찾을 수 있습니다 (업데이트: 더 나은 모델은 여기). 현재 이 버전은 대부분 개념 증명용입니다. 이 아이디어를 기반으로 구축한다면, 이 보고서를 인용하고 저에게 메시지를 보내거나 트위터에서 저를 태그해 주세요(@johnowhitaker). 이 아이디어가 유용했는지 알고 싶어요!
이 글이 어떻게 하면 확산 모델을 최적의 방식으로 훈련할 수 있는지에 대해 우리가 여전히 배울 점이 많다는 것을 보여주었기를 바랍니다. 후속 작업에 영감을 주기를 바라며, 함께 이 놀라운 도구들을 계속해서 더 나아지게 할 수 있기를 바랍니다 :)
추신 이 주제를 탐구하신다면, 몇 가지 추가적인 메모: 긴 훈련에서 이 방법을 성공적으로 테스트하지는 않았습니다. 분산 유지, 샘플링 접근 방식 조정 (초기 잠재 변수에도 피라미드 노이즈를 사용해 더 다양한 출력을 얻는 것과 같은 것들)에 대한 고민이 필요합니다.
할인 계수를 더 낮게 설정하는 것(0.8 또는 0.6, 편집: 0.5와 같은 더 낮은 값도 좋습니다!)이 도움이 되는 것을 관찰했습니다 - 이는 당연한 일입니다 - 현재 상태로는 원래의 노이즈 구성보다 이미지를 훨씬 더 많이 손상시키고 있습니다. 실제 노이즈 스케줄에 대해서도 재고해 볼 가치가 있을 것 같고, 이는 앞으로의 실험에서 결정해야 할 부분입니다.
이 피라미드 노이즈는 제가 구현한 첫 번째 간단한 아이디어일 뿐입니다 - 핑크 노이즈, 퍼린 노이즈, 다양한 주파수에서 노이즈를 손상시키는 다른 방법들도 살펴보세요...
IlluminatiAI 디스코드에서 이와 관련된 일부 논의와 실험이 진행 중입니다.
아직 처음부터 새로 만든 확산 모델에서는 이 방법을 시도해보지 않았지만, 시도하게 되면 여기에 업데이트할 예정입니다.



