https://arxiv.org/abs/2410.18978
Framer: Interactive Frame Interpolation
We propose Framer for interactive frame interpolation, which targets producing smoothly transitioning frames between two images as per user creativity. Concretely, besides taking the start and end frames as inputs, our approach supports customizing the tra
arxiv.org
초록
우리는 상호작용 프레임 보간을 위한 "Framer"를 제안합니다. 이는 사용자의 창의성에 따라 두 이미지 간의 부드럽게 전환되는 프레임을 생성하는 것을 목표로 합니다. 구체적으로, 시작 및 종료 프레임을 입력으로 사용하는 것 외에도, 선택된 일부 키포인트의 궤적을 조정하여 전환 과정을 사용자 맞춤형으로 수정할 수 있습니다. 이러한 설계는 두 가지 명확한 이점을 제공합니다. 첫째, 인간의 상호작용을 포함함으로써 한 이미지에서 다른 이미지로 변환되는 수많은 가능성에서 발생하는 문제를 완화하고, 결과적으로 로컬 모션에 대한 세밀한 제어를 가능하게 합니다. 둘째, 가장 기본적인 상호작용 형태인 키포인트를 사용하여 프레임 간의 대응 관계를 설정함으로써 시작 및 종료 프레임의 객체가 서로 다른 형태와 스타일을 가질 때에도 모델이 이러한 도전적인 사례를 처리할 수 있도록 향상시킵니다. 주목할 만한 점은, 본 시스템이 "자동 조종" 모드를 제공한다는 것입니다. 여기에서 우리는 키포인트를 추정하고 궤적을 자동으로 개선하는 모듈을 도입하여 실제 사용에서의 편리성을 높였습니다. 광범위한 실험 결과는 이미지 변형, 타임랩스 비디오 생성, 만화 보간 등의 다양한 응용에서 Framer의 매력적인 성능을 입증합니다. 코드, 모델 및 인터페이스는 후속 연구를 촉진하기 위해 공개될 예정입니다.
프로젝트 페이지:
𝚊𝚒𝚖-𝚞𝚘𝚏𝚊.𝚐𝚒𝚝𝚑𝚞𝚋.𝚒𝚘/𝙵𝚛𝚊𝚖𝚎𝚛

그림 1: Framer로 생성된 결과물을 보여줍니다. Framer는 로컬 모션의 세밀한 맞춤화를 가능하게 하며 동일한 시작 및 종료 프레임 쌍을 입력으로 주었을 때 다양한 보간 결과를 생성할 수 있습니다(처음 3개의 행). 또한, Framer는 도전적인 사례도 처리하며 부드러운 이미지 변형을 실현할 수 있습니다(마지막 2개의 행). 입력된 궤적은 프레임 위에 중첩되어 표시됩니다.
1. 서론
프레임 간의 원활하고 시각적으로 매력적인 전환을 만드는 것(Dong et al., 2023)은 이미지 변형(Aloraibi, 2023), 슬로우 모션 비디오 생성(Reda et al., 2022), 만화 보간(Xing et al., 2024) 등 다양한 응용에서 중요한 요구 사항입니다. 사용자는 종종 특정 결과를 달성하기 위해 보간된 프레임의 모션 궤적, 변형 역학, 시간적 일관성을 제어해야 합니다. 따라서 프레임 보간 프레임워크에 상호작용 기능을 통합하는 것은 실제 적용 가능성을 확대하는 데 매우 중요합니다.
전통적인 비디오 프레임 보간 방법(Jiang et al., 2018; Xu et al., 2019; Liu et al., 2020; Niklaus & Liu, 2020; Sim et al., 2021; Lee et al., 2020; Ding et al., 2021)은 종종 중간 프레임을 결정론적으로 예측하기 위해 광류(Optical Flow)나 모션을 추정하는 방식에 의존합니다. 이 분야에서 상당한 진전이 있었지만, 큰 움직임이나 객체 외형의 변화가 큰 경우에는 부정확한 광류 추정으로 인해 이러한 접근법이 어려움을 겪습니다. 게다가 하나의 이미지를 다른 이미지로 변환할 때, 객체와 장면이 전환될 수 있는 수많은 가능한 방법이 존재할 수 있습니다. 결정론적인 결과는 사용자 기대나 창의적인 의도와 일치하지 않을 수 있습니다.
기존 방법과는 달리, 우리는 두 이미지 간의 부드럽게 전환되는 프레임을 생성하는 인터랙티브 프레임 보간 프레임워크인 "Framer"를 제안합니다. 우리의 접근법은 사용자가 선택한 키포인트의 궤적을 조정함으로써 전환 과정을 사용자 맞춤형으로 변경할 수 있도록 하여, 장면 내 객체의 모션과 변형에 직접적인 영향을 미칩니다. 이러한 설계는 두 가지 주요 이점을 제공합니다. 첫째, 키포인트 기반의 상호작용을 통합함으로써 한 이미지를 다른 이미지로 변환하는 데 내재된 모호성을 해결하고, 이미지의 특정 영역이 어떻게 움직이고 변화하는지를 정밀하게 제어할 수 있습니다. 그림 1a에 표시된 바와 같이, 사용자는 간단하고 직관적인 상호작용을 통해 개의 발과 머리의 움직임을 제어할 수 있습니다. 둘째, 키포인트 궤적은 프레임 간의 명확한 대응 관계를 설정하며, 특히 객체가 형태, 스타일, 심지어 의미까지 변화하는 어려운 경우에 유리합니다. 그림 1b에 나타난 바와 같이, 키포인트 궤적은 다양한 형태의 포켓몬의 키포인트 간의 대응 관계를 설정하고, 포켓몬의 부드러운 "진화" 과정을 만드는 데 도움을 줍니다.
구체적으로, 우리는 비디오 프레임 보간을 생성적인 관점에서 보고, 오픈 도메인 비디오 데이터셋(Nan et al., 2024)에서 대규모로 사전 학습된 이미지-비디오 확산 모델(Blattmann et al., 2023a)을 미세 조정하여 비디오 프레임 보간을 촉진합니다. 추가로 마지막 프레임 조건은 미세 조정 과정에서 도입됩니다. 이후 추가적인 포인트 궤적 입력을 받는 포인트 궤적 제어 브랜치를 도입하여 비디오 보간 과정을 안내합니다. 추론 시, Framer는 사용자 입력 포인트 궤적을 따르는 사용자 맞춤형 비디오 프레임 보간을 위한 "상호작용" 모드를 지원합니다.
수동 키포인트 주석이 항상 바람직하지 않을 수 있음을 이해하고, 우리는 Framer에 "자동 조종" 모드를 제공합니다. 기술적으로, 우리는 양방향 포인트 추적 방법을 새롭게 제안하며, 프레임 간 전방 및 후방 움직임을 모두 분석하여 전체 비디오 시퀀스에서 일치하는 포인트의 궤적을 추정합니다. 이를 통해 키포인트 궤적을 얻는 과정을 자동화하여, 광범위한 사용자 입력 없이도 Framer가 자연스러운 모션과 시간적으로 일관된 보간 결과를 생성할 수 있게 합니다. "자동 조종" 모드는 포인트 궤적이 제공하는 향상된 대응성을 유지하면서 워크플로를 단순화합니다.
우리는 Framer의 성능을 이미지 변형, 타임랩스 비디오 생성, 만화 보간 등 다양한 응용에서 평가하기 위해 광범위한 실험을 수행합니다. 결과는 Framer가 부드럽고 시각적으로 매력적인 전환을 생성하며, 특히 복잡한 모션과 외형 변화가 큰 경우에 기존 방법들을 능가한다는 것을 보여줍니다. 생성 모델의 강점과 사용자 안내 상호작용을 결합함으로써, Framer는 보간된 프레임의 품질과 제어 가능성을 모두 향상시킵니다.
2 관련 연구
2.1 비디오 프레임 보간
비디오 프레임 보간(VFI)의 목표는 연속적인 두 비디오 프레임 사이에서 중간 프레임을 합성하는 것입니다. 대부분의 이전 방법은 VFI를 프레임 간에 중간 정도의 움직임이 있다고 가정하고 저수준의 작업으로 간주합니다. 이러한 방법들은 대략적으로 광류 기반 방법과 커널 기반 방법으로 분류될 수 있습니다. 구체적으로, 광류 기반 방법은 프레임 합성을 위해 추정된 광류(Optical Flow)를 활용합니다 (Jiang et al., 2018; Xu et al., 2019; Liu et al., 2020; Niklaus & Liu, 2020; 2018; Sim et al., 2021; Huang et al., 2020; Jin et al., 2023; Xue et al., 2019; Park et al., 2020; 2021; Kong et al., 2022). 반면에, 커널 기반 방법은 공간 적응 커널을 사용하여 보간된 픽셀을 합성합니다 (Lee et al., 2020; Cheng & Chen, 2022; Ding et al., 2021; Niklaus et al., 2017; Cheng & Chen, 2020; Gui et al., 2020; Lu et al., 2022). 전자는 부정확한 광류 추정에 의한 문제가 발생할 가능성이 있지만, 후자는 커널 크기에 의해 종종 제약을 받습니다. 이 두 접근 방식의 장점을 결합하기 위해 일부 방법들은 광류 및 커널 기반 방법을 결합하여 엔드 투 엔드 비디오 프레임 보간을 수행합니다 (Bao et al., 2019; 2021; Danier et al., 2022; Li et al., 2022). 이러한 방법들에 대한 더 포괄적인 조사에 대해서는 (Dong et al., 2023)을 참조하십시오.
최근에는 대규모 사전 학습된 비디오 확산 모델의 생성 능력에서 영감을 받아 일부 방법들이 VFI를 생성적인 관점에서 해결하려고 시도하고 있습니다 (Danier et al., 2024; Feng et al., 2024; Jain et al., 2024; Xing et al., 2023; Wang et al., 2024a). 예를 들어, LDMVFI (Danier et al., 2024)는 VFI를 조건부 생성 문제로 구성하고 잠재 확산 모델을 사용하여 지각 지향적인 비디오 프레임 보간을 수행합니다. 유사하게, VIDIM (Jain et al., 2024)은 비선형 움직임을 가진 고품질의 보간 비디오를 생성하기 위해 계단식 확산 모델을 활용합니다. 이러한 방법들이 진전을 이루었지만, 여전히 시작 및 종료 프레임 간의 큰 차이를 다루는 데 어려움이 있습니다. 또한, 이들은 비디오 프레임 보간을 위한 단일 결정론적인 솔루션을 생성하는 데 중점을 두며 제어 가능성을 제공하지 않습니다. 반면에, 우리는 큰 움직임 변화에서도 여러 개의 가능한 솔루션을 생성할 수 있으며, 사용자 의도에 따른 보간 결과를 위해 간단하고 직관적인 드래그 상호작용을 허용합니다.
2.2 비디오 확산 모델
대규모로 사전 학습된 비디오 확산 모델(Brooks et al., 2024; Blattmann et al., 2023b; Ge et al., 2023; Chen et al., 2023; 2024; Wang et al., 2023a; Blattmann et al., 2023a)은 시각적 품질, 다양성, 사실성 면에서 전례 없는 생성 결과를 보여주었습니다. 이러한 방법들은 텍스트나 시작 이미지 제어를 활용하지만, 이는 종종 정밀성과 상호작용성이 부족합니다. 제어 가능한 이미지 생성에서의 성공(Zhang et al., 2023; Mou et al., 2024b)에서 영감을 받아, 여러 연구들은 비디오 확산 모델에 추가적인 제어 기능을 추가하려고 시도하고 있습니다. 초기 탐구(Wang et al., 2023b; Guo et al., 2023)는 스케치와 깊이 맵과 같은 구조적 제어를 비디오 생성에 활용했습니다. 그러나 이러한 제어 신호는 샘플링 과정에서 얻기 어려운 경우가 많아 실제 적용에 한계가 있습니다. 반면, 최근 연구들은 모션 제어에 집중하고 객체 모션을 위한 궤적 제어(Wu et al., 2024; Mou et al., 2024a; Yin et al., 2023)와 카메라 모션을 위한 카메라 포즈 제어(Wang et al., 2024b; He et al., 2024; Bahmani et al., 2024)를 도입하고 있습니다. 이 두 가지 제어 신호는 모두 쉽고 직관적인 사용자 상호작용을 통해 얻을 수 있습니다. 본 논문에서는 비디오 프레임 보간 과정의 창의적 잠재력과 유연성을 강화하여, 사용자가 자신이 제어하는 대로 그럴듯한 프레임 보간 결과를 생성할 수 있도록 합니다.
3. 방법


그림 2: Framer는 (a) 사용자 맞춤형 점 궤적을 위한 사용자 상호작용 모드와 (b) 궤적 입력 없이 비디오 프레임 보간을 위한 "자동 조종" 모드를 지원합니다. 학습 중에는 (d) 비디오 프레임 보간을 위해 사전 학습된 비디오 확산 모델의 3D-UNet을 미세 조정합니다. 이후, (c) 3D-UNet을 고정하고 제어 브랜치를 미세 조정하여 점 궤적 제어를 도입합니다.
3.1 모델 아키텍처
대규모로 사전 학습된 비디오 확산 모델은 열린 세계의 객체의 외형, 구조, 그리고 움직임에 대해 강력한 시각적 선행 지식을 가지고 있습니다 (Brooks et al., 2024). 우리의 접근법은 이러한 선행 지식을 활용하기 위해 비디오 확산 모델을 기반으로 합니다. Image-to-Video (I2V) 확산 모델이 자연스럽게 첫 번째 프레임 조건을 지원한다는 점을 고려하여, 대표적인 I2V 확산 모델인 Stable Video Diffusion (SVD) (Blattmann et al., 2023a)을 기본 모델로 선택하였습니다 (그림 2d 참조).

3.2 상호작용 프레임 보간
시작 프레임과 종료 프레임만 주어졌을 때, 특히 두 프레임 간의 차이가 클 경우 여전히 모호성이 남아 있습니다. 그 이유는 동일한 입력 쌍에 대해 조건부 분포 P(I∣I0,In)에서 비디오를 샘플링하여 여러 가능한 보간 결과를 얻을 수 있기 때문입니다. 사용자 의도에 더 잘 맞추기 위해, 우리는 맞춤형 점 궤적 지도를 위한 제어 브랜치를 도입했습니다.
기술적으로, 우리는 점 궤적 기반 제어 브랜치를 대응성 모델링을 위해 학습하며, 이는 그림 2c에 나타나 있습니다. 학습 중에는 다음의 단계를 통해 제어 신호로 사용할 점 궤적을 얻습니다. 첫째, 첫 번째 프레임의 고정된 희소 격자 주변에서 일부 샘플링된 점들을 무작위로 초기화하고, Co-Tracker (Karaev et al., 2023)를 사용하여 전체 비디오에서 이 점들의 궤적을 얻습니다. 둘째, 비디오 프레임의 절반 이상에서 보이지 않는 궤적들은 제거합니다. 마지막으로, 더 큰 움직임을 가진 점 궤적을 더 높은 확률로 샘플링합니다. 사용자가 보통 소수의 점 궤적만 입력한다는 점을 고려하여, 학습 시 1에서 10개 사이의 궤적만 유지합니다. 자세한 내용은 부록 A를 참조하십시오.
샘플링된 점 궤적을 얻은 후, 우리는 DragNUWA (Yin et al., 2023)와 DragAnything (Wu et al., 2024)을 따라 점 좌표를 가우시안 히트맵으로 변환하며, 이를 c_traj으로 표시하고 제어 모듈의 입력으로 사용합니다. 우리는 ControlNet (Zhang et al., 2023)의 조건부 메커니즘을 따라 궤적 제어를 통합합니다. 구체적으로, 우리는 3D-UNet의 인코더를 복사하여 궤적 지도를 인코딩하고, 이를 제로 컨볼루션 이후에 U-Net의 디코더에 추가합니다 (Zhang et al., 2023). 이 학습 과정은 다음과 같이 표현될 수 있습니다:


논의. 점 궤적 제어의 도입은 사용자 상호작용을 촉진할 뿐만 아니라 서로 다른 프레임의 점들 간의 대응성을 강화합니다. 실험에서 보여준 바와 같이, 이 접근 방식은 시작과 종료 프레임이 크게 다른 경우와 같은 도전적인 사례를 효과적으로 처리할 수 있도록 모델을 개선합니다.
3.3 "자동 조종" 모드 프레임 보간
실제 응용에서 사용자는 항상 수동 드래그 제어를 선호하지 않을 수 있습니다. 이러한 이유로, 우리는 Framer의 사용 편의성을 높이기 위해 "자동 조종" 모드를 제안합니다. 이는 주로 궤적 초기화와 궤적 업데이트 과정으로 구성되며, 그림 2b에 나타나 있습니다.
궤적 초기화

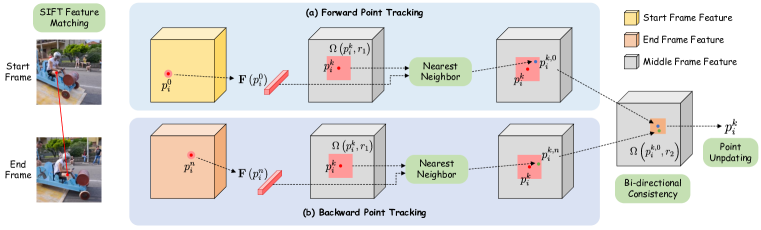
그림 3: 점 궤적 추정. 점 궤적은 일치하는 키포인트의 좌표를 보간하여 초기화됩니다. 각 디노이징 단계에서, 우리는 각각 시작 및 종료 프레임에서 키포인트의 가장 가까운 이웃을 찾는 방식으로 점 추적을 수행합니다. 마지막으로, 점 좌표를 업데이트하기 전에 양방향 추적 일관성을 확인합니다.
궤적 업데이트
초기 궤적이 시간적으로 일관된 점 대응을 제공하더라도, 첫 번째와 마지막 프레임의 점들을 연결하여 얻은 궤적은 정확하지 않을 수 있습니다. DragGAN (Pan et al., 2023)과 DragDiffusion (Shi et al., 2023)에서 영감을 받아, 우리는 U-Net 내 중간 특징을 사용하여 궤적을 업데이트하는 점 추적을 수행합니다. 구체적으로, 각 디노이징 단계에서 U-Net의 특징을 이미지 해상도로 보간하며, 이를 F로 표시합니다. 여기서 우리는 U-Net에서 마지막으로 업샘플링된 블록의 바로 이전 특징을 사용합니다. 이는 특징 해상도와 분별력 간의 좋은 균형을 제공하기 때문입니다. 우리는 점 p의 특징을 나타내기 위해 F(p)를 사용하며, 이 특징은 좌표가 정수가 아닐 수 있기 때문에 이중 선형 보간을 통해 얻습니다.
각 디노이징 단계에서 우리는 중간 프레임 점들의 좌표를 업데이트하기 위해 점 추적을 적용합니다. 우리는 점 주변의 특징 패치에서 가장 가까운 이웃을 찾는 방식으로 수행합니다. 특징 패치는 점 p와의 거리가 r 미만인 점들의 집합을 나타내며, 이는 다음과 같이 표기됩니다:

4 실험
4.1 구현 세부사항

4.2 비교

그림 4: 정성적 비교. 'GT'는 실제(Ground Truth)를 나타냅니다. 각 방법에 대해, 우리는 7개의 보간된 프레임 중 중간 프레임만을 제시합니다. 전체 결과는 부록의 그림 S4와 그림 S5에서 확인할 수 있습니다.

그림 5: 사용자 선호도에 대한 결과.
기존 방법들은 드래그-사용자 상호작용을 지원하지 않습니다. 따라서, 우리는 Framer의 "자동 조종" 모드를 사용하여 공정한 비교를 진행했습니다. 우리는 두 가지 다른 범주에서 기준선을 선택했습니다. 첫 번째 범주는 최신의 일반 확산 기반 비디오 보간 모델을 포함하며, 여기에는 LDMVFI (Danier et al., 2024), DynamicCrafter (Xing et al., 2023), SVDKFI (Wang et al., 2024a)가 있습니다. 두 번째 범주는 전통적인 비디오 보간 방법들을 포함하며, AMT (Li et al., 2023), RIFE (Huang et al., 2020), FLAVR (Kalluri et al., 2023), FILM (Reda et al., 2022)가 이에 속합니다. 우리는 두 가지 공개 데이터셋인 DAVIS (Pont-Tuset et al., 2017)와 UCF101 (Soomro et al., 2012)에서 정량적 및 정성적 분석, 그리고 사용자 연구를 진행했습니다.
정성적 비교
그림 4에서 볼 수 있듯이, 우리 방법은 기존의 보간 기술에 비해 훨씬 더 선명한 텍스처와 자연스러운 모션을 생성합니다. 특히 입력 프레임 간의 차이가 큰 시나리오에서 전통적인 방법들이 정확하게 콘텐츠를 보간하는 데 실패하는 경우, 우리 방법이 특히 우수한 성능을 발휘합니다. LDMVFI와 SVDKFI 같은 다른 확산 기반 방법과 비교할 때, Framer는 도전적인 사례에 대한 우수한 적응력을 보여주며 더 나은 제어 기능을 제공합니다.
정량적 비교
VIDIM (Jain et al., 2024)에서 논의된 바와 같이, PSNR, SSIM, LPIPS와 같은 재구성 메트릭은 보간된 프레임의 품질을 정확히 반영하지 못하며, 원본 비디오와 픽셀 정렬이 맞지 않는 다른 그럴듯한 보간 결과를 불리하게 평가합니다. FID와 같은 생성 메트릭이 일부 개선을 제공하긴 하지만, 여전히 시간적 일관성을 고려하지 않고 프레임을 개별적으로 평가한다는 한계가 있습니다. 그럼에도 불구하고, 우리는 두 데이터셋에 대한 다양한 설정에서 정량적 메트릭을 제시하며, Tab. 1에서 볼 수 있듯이 우리 방법이 모든 기준선 중에서 가장 우수한 FVD 점수를 달성했습니다. 우리는 또한 Co-Tracker를 사용하여 추정한 실제 비디오의 5개의 랜덤 점 궤적을 사용하여 Framer를 평가했습니다. 보시다시피, "Co-Tracker와 함께한 Framer"는 재구성 메트릭에서도 우수한 성능을 보였습니다. 품질에 대한 보다 포괄적인 평가를 위해 보충 비교 비디오를 검토하는 것을 권장드립니다.

표 1: 모든 7개의 생성된 프레임에 대해 기존 비디오 보간 방법들과의 정량적 비교. 재구성 및 생성 메트릭으로 평가됨.
-----
이 표는 두 개의 공개 데이터셋, DAVIS-7 및 UCF101-7에 대해 다양한 비디오 보간 방법의 성능을 정량적으로 비교한 것입니다. 표에는 PSNR, SSIM, LPIPS, FID, FVD와 같은 지표를 사용해 각 방법의 성능이 나열되어 있습니다. 각 지표의 설명은 다음과 같습니다:
- PSNR (Peak Signal-to-Noise Ratio): 영상 품질을 평가하는 주요 척도로, 값이 클수록 더 높은 품질을 의미합니다.
- SSIM (Structural Similarity Index Measure): 원본 영상과 보간된 영상 간의 구조적 유사성을 평가하는 지표로, 1에 가까울수록 더 유사합니다.
- LPIPS (Learned Perceptual Image Patch Similarity): 지각적 유사성을 측정하는 지표로, 값이 낮을수록 더 높은 지각적 품질을 의미합니다.
- FID (Fréchet Inception Distance): 생성된 영상의 품질과 원본 영상 간의 분포 차이를 나타내며, 낮을수록 품질이 좋습니다.
- FVD (Fréchet Video Distance): 시간적 일관성 및 생성된 비디오의 품질을 평가하는 지표로, 낮을수록 더 나은 성능을 의미합니다.
DAVIS-7 데이터셋에서의 결과:
- PSNR 및 SSIM: 대부분의 방법들은 비슷한 PSNR(21 이상)을 보입니다. 그중 "Framer with Co-Tracker"가 22.75로 가장 높은 PSNR 값을 기록했으며, SSIM도 0.7931로 다른 방법들에 비해 높은 수치를 보입니다. 이는 "Framer with Co-Tracker"가 원본과 가장 유사한 품질을 유지했음을 의미합니다.
- LPIPS: LPIPS 값은 낮을수록 원본에 더 가깝다는 것을 의미합니다. Framer와 Framer with Co-Tracker는 각각 0.2525와 0.2199를 기록했으며, 특히 "Framer with Co-Tracker"가 가장 낮은 값을 보였습니다. 이는 더 나은 지각적 품질을 제공했음을 나타냅니다.
- FID 및 FVD: FID와 FVD 지표에서 "Framer with Co-Tracker"는 각각 27.43과 102.31을 기록하며 가장 우수한 성능을 보였습니다. 특히 FVD의 경우, 다른 방법들과 비교했을 때 큰 차이로 낮은 값을 기록하여 시간적 일관성이 매우 뛰어나다는 것을 보여줍니다.
UCF101-7 데이터셋에서의 결과:
- PSNR 및 SSIM: UCF101-7에서도 "Framer with Co-Tracker"가 가장 높은 PSNR(27.08)과 SSIM(0.9024)을 기록하여 우수한 성능을 보였습니다. 이는 이 방법이 다른 방법들에 비해 원본 영상과 구조적으로 더 유사한 비디오를 생성했음을 나타냅니다.
- LPIPS: LPIPS 값에서 Framer와 "Framer with Co-Tracker"는 모두 0.1714를 기록했으며, 이는 다른 방법들보다 높은 지각적 품질을 보여줍니다.
- FID 및 FVD: "Framer with Co-Tracker"는 FID 값이 32.37이고, FVD 값은 159.87로 기존의 모든 방법들보다 우수한 결과를 보여줍니다. 이는 생성된 영상의 시간적 일관성과 품질이 매우 뛰어나다는 것을 의미합니다.
비교 분석:
- 전통적인 비디오 보간 방법과의 비교:
- 전통적인 방법들(AMT, RIFE, FLAVR, FILM)은 PSNR 및 SSIM에서 상당히 높은 성능을 보였으나, 특히 FVD에서 높은 값을 기록하며 시간적 일관성 면에서 Framer보다 뒤떨어지는 결과를 보였습니다. 예를 들어, FLAVR은 FVD가 296.37로 높은 수치를 기록하여, 생성된 비디오의 품질이 다소 떨어졌음을 시사합니다.
- 확산 기반 방법과의 비교:
- 확산 기반 방법들(LDMVFI, DynamicCrafter, SVDKFI)은 상대적으로 낮은 SSIM과 높은 FVD 값을 보였습니다. 특히 DynamicCrafter는 FVD가 468.78로 매우 높은 값을 기록했는데, 이는 큰 모션 차이가 있는 장면에서 시간적 일관성을 유지하는 데 어려움이 있었음을 나타냅니다.
- 우리의 방법 (Framer 및 Framer with Co-Tracker):
- Framer: 기본적인 Framer 역시 다른 방법들보다 전반적으로 우수한 성능을 보였으며, 특히 FVD 값이 낮아 전통적 및 확산 기반 방법들보다 뛰어난 시간적 일관성을 제공합니다.
- Framer with Co-Tracker: Co-Tracker를 사용한 Framer는 모든 지표에서 가장 우수한 성능을 보였으며, 이는 Co-Tracker를 사용하여 얻은 점 궤적이 보간 결과의 품질과 일관성에 크게 기여했음을 보여줍니다.
결론적으로, "Framer with Co-Tracker"는 대부분의 지표에서 기존 방법들보다 우수한 성능을 기록하며, 특히 시간적 일관성과 시각적 품질 면에서 뛰어난 결과를 보여주었습니다. 이는 제안된 "자동 조종" 모드와 Co-Tracker 기반의 궤적 제어가 보간된 프레임의 품질을 크게 향상시켰음을 시사합니다.
-----

그림 6: 사용자 상호작용에 대한 결과. 첫 번째 행은 드래그 입력 없이 생성된 것이며, 나머지 두 행은 서로 다른 드래그 제어를 사용하여 생성된 것입니다. 맞춤형 궤적은 프레임 위에 중첩되어 표시됩니다.

그림 7: 정적(1번째 행) 및 동적 장면(2번째 행) 모두에 대한 새로운 시점 합성 결과.
사용자 연구
정량적 메트릭이 비디오 품질을 반영하는 데 한계가 있기 때문에, 우리는 사용자 연구를 통해 우리 방법의 성능을 추가로 평가했습니다. 이 연구에서 참가자들은 기존 방법들과 Framer가 동일한 입력 프레임 쌍에서 생성한 비디오 세트를 검토했습니다. 참가자들은 최대 100개의 무작위 순서의 비디오 세트를 평가하고 가장 현실적이라고 생각되는 비디오를 선택했습니다. 총 20명의 참가자가 이 비디오 세트에 대해 1,000개의 평가를 제공했습니다. 그림 5에 나타난 바와 같이, 결과는 인간 평가자들이 우리 방법이 생성한 출력물에 대해 강한 선호를 가지고 있음을 보여줍니다.
4.3 응용
선택적 드래그 제어
동일한 시작 및 종료 프레임을 주었을 때, 여러 가지 그럴듯한 결과가 비디오 보간의 목표를 만족할 수 있습니다. Framer를 사용하면 사용자는 간단한 드래그를 통해 입력 프레임에 있는 객체의 움직임을 원하는 방향으로 유도하거나, 드래그 없이 기본 보간 결과를 얻을 수 있습니다. 그림 6에 나타난 것처럼, 동일한 입력 프레임에서 바다표범이 여러 방향으로 움직이는 결과를 볼 수 있습니다.

그림 8: 만화(첫 번째 행) 및 스케치(두 번째 행) 보간에 대한 응용 결과.

그림 9: 타임랩스 비디오 생성에 대한 응용 결과.
새로운 시점 합성 (NVS)
새로운 시점 합성은 고전적인 3D 비전 작업으로, 다양한 응용을 가지고 있습니다. 비디오의 시작과 종료 프레임으로 각각 다른 시점에서 촬영된 이미지를 사용하여, 비디오 보간을 수행함으로써 희소한 시점 입력에서 NVS를 실현할 수 있습니다. 그림 7에 나타난 것처럼, 우리의 방법은 정적 장면(첫 번째 행)과 동적 장면(두 번째 및 세 번째 행) 모두에서 만족스러운 NVS 결과를 달성합니다. 두 번째 행을 예로 들면, 카메라가 앞으로 이동하면서 집이 장면 밖으로 점차 사라집니다. 동시에 자동차는 카메라와 반대 방향으로 움직이며 프레임에서 점차 더 큰 비율을 차지하게 됩니다.

그림 10: 슬로우 모션 비디오 생성 응용. 비디오 프레임에서 빨간색으로 강조된 y-t 슬라이스가 오른쪽에 시각화되어 있습니다.
만화와 스케치 보간
수작업으로 제작된 만화 이미지를 보간하여 만화 비디오 제작 과정을 대폭 단순화할 수 있습니다. 이를 위해 우리는 만화 데이터를 사용해 방법을 테스트했습니다. 우리 방법은 만화 비디오에 대해 특별히 학습된 것은 아니지만, 그림 8에 보이듯이 색상 이미지와 스케치 드로잉 프레임 보간 모두에서 매력적인 만화 비디오 결과를 생성합니다. 예를 들어, 첫 번째 행에서는 앞 차량이 옆으로 당겨지고 뒷 차량이 따라가는 두 개체의 움직임을 성공적으로 모델링했습니다. 세 번째 행에서는 손이 들어 올려지는 스케치 드로잉의 부드러운 움직임을 Framer가 생성했습니다.
타임랩스 비디오 생성
타임랩스 촬영은 맨눈으로 감지하기 어려운 느린 변화를 생동감 있게 보여줍니다. 일반적으로, 이를 위해서는 많은 양의 이미지 데이터를 저장하기 위한 충분한 저장 공간과 이미지를 정리하고 편집하기 위한 복잡한 후처리 과정이 필요합니다. 비디오 보간은 몇 장의 주요 순간 이미지만으로 타임랩스 비디오를 얻는 간단하고 효과적인 방법을 제공합니다. 그림 9에서 보듯이, Framer는 달의 차고 기우는 부드러운 변화를 생성했습니다.
슬로우 모션 비디오 생성
슬로우 모션 비디오 생성은 세부 사항을 강조하여 시각적 효과를 향상시키고 빠른 현상을 더 자세히 관찰할 수 있게 합니다. Framer는 기본적으로 빠른 프레임 보간을 지원하며, 그림 10에서 보여준 것처럼 부드러운 슬로우 모션 효과를 제공하여 영화와 애니메이션에 적합합니다.

그림 11: 이미지 변형에 대한 응용 결과. 맞춤형 궤적이 종료 프레임 위에 중첩되어 표시되었습니다.
이미지 모핑 (Image Morphing)
이미지 모핑(Aloraibi, 2023)은 컴퓨터 비전과 컴퓨터 그래픽스에서 널리 사용되는 인기 있는 이미지 변환 기법입니다. 두 개의 위상적으로 유사한 이미지가 주어졌을 때, 이는 일련의 합리적인 중간 이미지를 생성하는 것을 목표로 합니다. Framer는 두 이미지를 시작과 종료 프레임으로 사용하여 자연스럽고 부드러운 이미지 모핑 결과를 생성할 수 있습니다. 예를 들어, 그림 1에서는 포켓몬의 "진화" 과정을 보여줍니다. 더 많은 사례는 그림 S13에서 확인할 수 있습니다.
4.4 소멸 연구 (Ablation Studies)
우리는 Framer의 개별 구성 요소들의 효과를 검증하기 위해 소멸 연구를 수행했습니다. 결과는 그림 12에 나타나 있습니다. 우리의 관찰 내용은 다음과 같습니다. 첫째, 궤적 가이드를 제거했을 때(“w/o traj.”로 표시), 전경에 있는 오토바이가 상당한 왜곡을 보였습니다. 이는 그림 12의 첫 번째 행에 나타나 있습니다. 반대로, 궤적 가이드를 포함한 경우, 비디오의 시간적 일관성이 현저히 향상되었으며 이는 두 번째 행에 나타나 있습니다. 우리는 이것이 프레임 간의 점 대응 모델링이 강화된 덕분이라고 믿습니다. 둘째, 궤적 업데이트를 제거하거나(“w/o traj. update”) 양방향 일관성 검증 없이 궤적을 업데이트했을 때(“w/o bi-directional”), 출력 비디오의 바퀴 영역에 블러링이 발생했습니다. 우리는 이러한 블러링이 부정확한 궤적으로 인한 부자연스러운 움직임의 지도로 인해 발생했으며, 이는 사전 학습된 확산 모델의 생성 선행 지식과 충돌하여 국소적인 블러링을 일으켰다고 생각합니다. 반면, 우리의 방법은 자연스러운 움직임과 부드러운 시간적 일관성을 갖춘 비디오 프레임 보간 결과를 생성합니다. 부록 B의 표 S1과 S2에 제시된 정량적 결과도 이러한 소멸 실험의 정성적 결과와 유사한 경향을 보이며 이를 뒷받침합니다.

그림 12: 각 구성 요소에 대한 소멸 연구. “w/o trajectory”는 점 궤적의 지도가 없는 추론을 의미하고, “w/o traj. update”는 궤적 업데이트가 없는 추론을, “w/o bi”는 양방향 일관성 검증 없이 궤적을 업데이트하는 것을 나타냅니다.
5 결론 및 향후 연구
본 논문에서는 사용자가 정의한 점 궤적에 따라 두 이미지 간의 부드럽게 전환되는 프레임을 생성하기 위해 설계된 상호작용 프레임 보간 파이프라인인 Framer를 소개했습니다. 우리는 시작 및 종료 프레임에서 사용자 입력 점 제어를 활용하여 비디오 보간 과정을 효과적으로 안내합니다. 또한, 우리 방법은 키포인트를 자동으로 추정하고 궤적을 수동 입력 없이 정제하는 모듈을 도입한 "자동 조종" 모드를 제공합니다. 광범위한 실험과 사용자 연구를 통해 우리는 보간된 프레임의 품질과 제어 가능성 면에서 우리 방법의 우수성을 입증했습니다. 그러나 여전히 도전 과제가 남아 있으며, 특히 서로 다른 클립 간의 전환에서 어려움이 있습니다. 잠재적인 해결책으로는 클립을 여러 키프레임으로 나눈 후 이 키프레임들을 순차적으로 보간하는 방법이 있습니다. 향후 연구에서는 이러한 도전 과제를 해결하는 데 중점을 둘 예정입니다.
부록
부록 A: 추가 구현 세부사항
훈련 중에는 비디오에서 연속된 14개의 프레임을 샘플링하며, 공간 해상도는 512×320입니다. 구체적으로, 비디오를 중심에서 잘라 512/320의 가로세로 비율로 맞춘 후, 비디오 프레임을 512×320의 해상도로 리사이즈합니다. 데이터 증강을 위해 랜덤 가로 뒤집기를 사용합니다. 시간 차원에서 비디오를 샘플링할 때는 프레임 간 간격을 2로 설정합니다. 점 궤적 기반 ControlNet의 학습을 위해서는 더 큰 움직임을 가진 1에서 10개의 궤적을 샘플링하여 학습에 사용합니다. 구체적으로, 우리는 ReVideo (Mou et al., 2024a)를 따라 궤적의 정규화된 길이를 샘플링 확률로 설정하여 궤적을 샘플링합니다. "자동 조종" 모드 샘플링 중에는 총 30개의 확산 단계를 가진 오일러 샘플러(Euler sampler)를 사용합니다. 3.3절에서의 점 추적에서는 3D-UNet의 두 번째 디코더 블록의 출력 특징을 사용합니다. 비디오의 짧은 변을 길이 512로 리사이즈한 후, 비디오를 중심에서 잘라 512×320의 해상도로 맞춥니다.
부록 B: 더 상세한 소멸 결과
소멸 연구의 정성적 결과
그림 12에서 우리는 소멸 연구에 대한 정성적 결과를 보여줍니다. 이러한 결과를 보충하기 위해 표 S1 및 표 S2에서 정량적 결과를 추가하였으며, 이는 정성적 소멸 실험과 유사한 경향을 보입니다.

표 S1: 각 구성 요소에 대한 소멸 연구 결과로, 생성된 모든 7개의 프레임을 평가합니다. "w/o trajectory"는 점 궤적의 지도가 없는 추론을 의미하며, "w/o traj. updating"은 궤적 업데이트가 없는 추론을, "w/o bi"는 양방향 일관성 검증 없이 궤적을 업데이트하는 것을 나타냅니다.

표 S2: 각 구성 요소에 대한 소멸 연구 결과로, 생성된 7개의 프레임 중 중간 프레임만을 평가합니다. "w/o trajectory"는 점 궤적의 지도가 없는 추론을 의미하며, "w/o traj. updating"은 궤적 업데이트가 없는 추론을, "w/o bi"는 양방향 일관성 검증 없이 궤적을 업데이트하는 것을 나타냅니다.
점 추적을 위한 확산 특징에 대한 소멸 연구
3.3절에서 자세히 설명한 것처럼, 우리는 점 궤적 업데이트를 위해 확산 특징을 사용하여 점 추적을 수행합니다. 여기서는 확산 특징 선택에 대한 소멸 실험을 수행했습니다. 결과는 그림 S1에 나타나 있습니다. DAVIS-7과 UCF-7 모두에서 두 번째 확산 블록의 출력 특징을 사용한 점 추적이 FVD에서 가장 우수한 성능을 보인다는 것을 확인할 수 있습니다.

그림 S1: 테스트 시 점 추적을 위한 확산 특징에 대한 소멸 연구. 실험은 DAVIS-7(왼쪽)과 UCF101-7(오른쪽)에서 수행되었습니다.
대응 지도를 위한 확산 단계에 대한 소멸 연구
우리는 초기 단계나 후기 단계에서만 확산 샘플링 중 지도를 적용함으로써 대응 지도를 위한 확산 단계를 소멸했습니다. 결과는 그림 S2에 나타나 있습니다. 보시다시피, 초기 단계가 후기 단계보다 대응 모델링에서 더 중요한 경우가 많습니다. 예를 들어, DAVIS-7에서 0-18 확산 단계에서만 지도를 수행해도 만족스러운 FVD를 얻을 수 있습니다. 반면, 18-30 확산 단계에서만 지도를 수행하는 것은 거의 개선을 가져오지 않습니다. 이는 초기 확산 단계가 비디오의 구조적 정보에 중점을 두는 반면, 후기 확산 단계는 텍스처와 세부 사항에 중점을 두기 때문이라고 추측됩니다(Xue et al., 2023). 초기 단계에서의 대응 지도가 이미 모델이 합리적인 비디오 구조를 얻는 데 도움이 됩니다. 구현에서는 하이퍼파라미터에 대한 상세한 검색 없이 모든 확산 단계에서 대응 지도를 간단히 적용합니다.

그림 S2: 대응 지도를 위한 시작 및 종료 확산 단계에 대한 소멸 연구. 실험은 DAVIS-7(왼쪽)과 UCF101-7(오른쪽)에서 수행되었습니다. 총 30개의 샘플링 단계를 사용합니다.
대응 지도를 위한 궤적 수에 대한 소멸 연구
3.3절에서 설명된 바와 같이, 우리는 샘플링 중 대응 지도를 위해 m개의 궤적을 사용합니다. 여기서 이 하이퍼파라미터에 대한 소멸 실험을 수행하였으며, 결과는 그림 S3에 나타나 있습니다. 5개의 궤적을 샘플링하는 것이 가장 우수한 성능을 보이는 것을 확인할 수 있습니다. 따라서 기본 설정으로 m=5로 설정합니다.
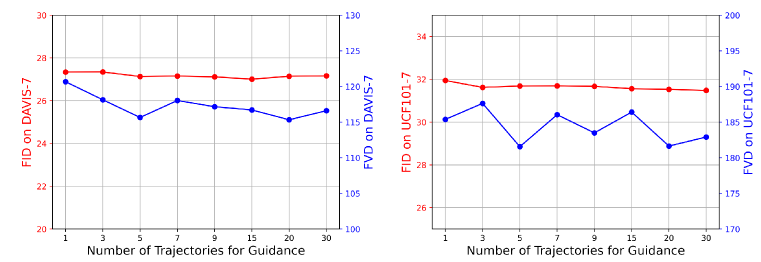
그림 S3: 샘플링 중 지도를 위한 궤적 수에 대한 소멸 연구. 실험은 DAVIS-7(왼쪽)과 UCF101-7(오른쪽)에서 수행되었습니다.
부록 C: 기존 방법들과의 비교에 대한 추가 세부사항
벤치마크
우리는 VIDIM (Jain et al., 2024)의 관행을 따르며, DAVIS-7과 UCF101-7 데이터셋에서 재구성 및 생성 메트릭을 사용해 정량적 평가를 수행합니다. DAVIS-7과 UCF101-7은 각각 해당 데이터셋에서 연속된 7개의 비디오 프레임을 샘플링하여 얻습니다. 우리는 DAVIS 데이터셋의 모든 비디오와 UCF101 데이터셋의 400개 비디오 하위 집합을 사용합니다.
비교에 대한 추가 결과
표 S3에서 우리는 7개의 보간된 비디오 프레임 중 중간 프레임을 기준으로 한 정량적 비교를 제공합니다. 또한, 그림 S4, 그림 S5, 그림 S6, 그림 S7에서는 기존 방법들과의 더 많은 정성적 비교를 보여줍니다.
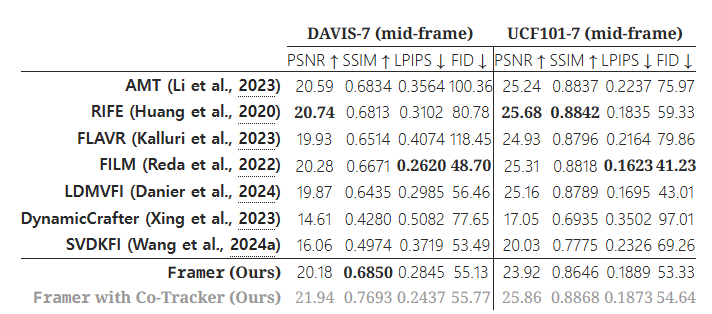
표 S3: 기존 비디오 보간 방법들과의 재구성 및 생성 메트릭에 대한 정량적 비교, 생성된 7개의 프레임 중 중간 프레임에 대해서만 평가함.
부록 D: 더 많은 정성적 결과
우리는 드래그 제어, 새로운 시점 합성, 만화 및 스케치 보간, 타임랩스 비디오 생성, 슬로우 모션 비디오 생성, 이미지 모핑에 대한 더 많은 정성적 결과를 각각 그림 S8, 그림 S9, 그림 S10, 그림 S11, 그림 S12, 그림 S13에 제공합니다.
부록 E: 제한 사항에 대한 논의
Framer는 대규모로 사전 학습된 비디오 확산 모델을 기반으로 하여, 사전 학습된 모델의 제한 사항을 계승합니다. 또한, Framer의 점 궤적은 복잡한 움직임을 보간하기 위해 입력 이미지 쌍 간의 일치하는 점에 의존합니다. 이는 단순한 움직임만을 처리할 수 있는 현재 모델에 비해 한 단계 진보한 것이지만, 앞뒤 프레임 간의 차이가 너무 커서 일치하는 점을 전혀 찾을 수 없는 경우, 우리 방법도 여전히 어려움을 겪습니다. 따라서, 우리는 더 강력한 사전 학습된 비디오 확산 모델을 탐색하고, 더 큰 규모의 비디오 데이터에서 비디오 보간 모델을 학습하는 방향으로 나아갈 것입니다. 마지막으로, 현재 우리 방법은 드래그 제어만 지원하며, 다른 상호작용 방법은 탐색하지 않았습니다. 앞으로 우리는 텍스트 제어나 카메라 포즈 제어와 같은 사용자 친화적인 다른 제어 방법도 계속 탐색할 것입니다.

그림 S4: 기존 방법들과의 더 많은 정성적 비교. "GT"는 실제(Ground Truth)를 의미합니다.

그림 S5: 기존 방법들과의 더 많은 정성적 비교. "GT"는 실제(Ground Truth)를 의미합니다.

그림 S6: 기존 방법들과의 더 많은 정성적 비교. "GT"는 실제(Ground Truth)를 의미합니다.

그림 S7: 기존 방법들과의 더 많은 정성적 비교. "GT"는 실제(Ground Truth)를 의미합니다.

그림 S8: 사용자 상호작용에 대한 더 많은 결과. 동일한 입력 이미지 쌍에 대해 두 개의 궤적 제어 결과를 보여줍니다.

그림 S9: 새로운 시점 합성에 대한 더 많은 결과. 첫 번째 행과 두 번째 행은 각각 정적 장면과 동적 장면에 대한 결과를 보여줍니다.

그림 S10: (a) 만화 및 (b) 스케치 보간에 대한 더 많은 결과.

그림 S11: 타임랩스 비디오 생성에 대한 더 많은 결과.

그림 S12: 슬로우 모션 비디오 생성에 대한 더 많은 결과. 비디오 프레임에서 빨간색으로 강조된 x-t 슬라이스가 오른쪽에 시각화되어 있습니다.

그림 S13: 이미지 모핑에 대한 더 많은 결과.



