https://arxiv.org/abs/2402.17485
EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techn
arxiv.org
https://humanaigc.github.io/emote-portrait-alive/
EMO
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
humanaigc.github.io
초록
본 연구에서는 오디오 신호와 얼굴 움직임 사이의 동적이고 섬세한 관계에 집중하여, 말하는 얼굴(토킹 헤드) 비디오 생성의 사실성과 표현력을 향상시키는 문제에 도전합니다. 기존 기술들이 인간의 표정의 전체 스펙트럼과 개별적인 얼굴 스타일의 고유성을 충분히 포착하지 못하는 한계를 식별했습니다. 이러한 문제를 해결하기 위해, 우리는 중간 3D 모델이나 얼굴 랜드마크를 거치지 않고 직접 오디오에서 비디오로 변환하는 새로운 프레임워크인 EMO를 제안합니다. 우리의 방법은 영상 내에서 원활한 프레임 전환과 일관된 정체성 유지를 보장하여 매우 표현력 있고 사실적인 애니메이션을 생성할 수 있습니다. 실험 결과에 따르면, EMO는 기존 최첨단 방법론에 비해 표현력과 사실성 면에서 현저히 뛰어난 성능을 보이며, 단순히 말하는 비디오뿐만 아니라 다양한 스타일의 노래하는 비디오까지도 설득력 있게 생성할 수 있음을 보여줍니다.
키워드: 확산 모델, 비디오 생성, 토킹 헤드

그림 1: 우리는 EMO라는 표현력 있는 오디오 기반 초상화 비디오 생성 프레임워크를 제안했습니다. 단일 참조 이미지와 목소리 오디오(예: 말하기 및 노래하기)를 입력하면, 우리 방법은 표현력 있는 얼굴 표정과 다양한 머리 자세를 가진 보컬 아바타 비디오를 생성할 수 있으며, 입력 오디오의 길이에 따라 어떤 길이의 비디오든 생성할 수 있습니다.
1. 서론
최근 몇 년간 이미지 생성 분야는 확산 모델(Diffusion Models) [8, 20, 25, 4, 16]의 등장과 성공 덕분에 놀라운 발전을 목격했습니다. 이 모델들은 고품질 이미지를 생성할 수 있는 능력 덕분에 찬사를 받고 있으며, 이는 대규모 이미지 데이터셋에 대한 광범위한 훈련과 점진적인 생성 접근 방식에 기인합니다. 이러한 혁신적인 방법론은 타의 추종을 불허하는 세부성과 사실성을 가진 이미지 생성을 가능하게 하여 생성 모델의 새로운 기준을 세웠습니다. 확산 모델의 응용은 정적 이미지에 국한되지 않고 있으며, 비디오 생성에 대한 증가하는 관심으로 인해 이러한 모델의 잠재력을 동적이고 설득력 있는 시각적 내러티브 창작에 활용하고자 하는 연구가 이어지고 있습니다 [6, 9]. 이러한 선구적인 노력은 비디오 생성 분야에서 확산 모델의 광대한 가능성을 강조합니다.
일반적인 비디오 합성뿐만 아니라, 인간 중심의 비디오 생성, 특히 말하는 얼굴(토킹 헤드) 생성이 연구의 초점이 되어 왔습니다. 토킹 헤드의 목표는 사용자가 제공한 오디오 클립으로부터 얼굴 표정을 생성하는 것입니다. 이러한 표정들을 만들어내기 위해서는 인간 얼굴 움직임의 미묘함과 다양성을 포착해야 하며, 이는 비디오 합성에서 상당한 도전 과제를 제시합니다. 전통적인 접근법은 이러한 작업을 단순화하기 위해 최종 비디오 출력에 제약을 가하는 경우가 많습니다. 예를 들어, 일부 방법은 3D 모델을 사용하여 얼굴의 주요 지점을 제한하거나, 다른 방법은 기본 비디오에서 머리 움직임의 시퀀스를 추출하여 전체 움직임을 유도합니다. 이러한 제약들은 비디오 생성의 복잡성을 줄이기는 하지만, 결과적인 얼굴 표정의 풍부함과 자연스러움을 제한하는 경향이 있습니다.
본 논문에서는 사실적인 얼굴 표정의 넓은 스펙트럼을 포착하고 자연스러운 머리 움직임을 가능하게 하여 생성된 얼굴 비디오에 탁월한 표현력을 부여하는 혁신적인 토킹 헤드 프레임워크를 확립하는 것을 목표로 합니다. 이를 달성하기 위해, 우리는 주어진 이미지와 오디오 클립으로부터 캐릭터 얼굴 비디오를 직접 합성할 수 있는 확산 모델의 생성력을 활용하는 방법을 제안합니다. 이 접근 방식은 중간 표현이나 복잡한 사전 처리 과정을 제거하여 시각적, 감정적으로 높은 충실도를 보이는 토킹 헤드 비디오의 생성을 간소화합니다. 오디오 신호는 얼굴 표정과 관련된 풍부한 정보를 담고 있어 이론적으로 모델이 다양한 표현력 있는 얼굴 움직임을 생성할 수 있게 합니다. 그러나 오디오와 확산 모델의 통합은 오디오와 얼굴 표정 간의 매핑에 내재된 모호성 때문에 간단하지 않습니다. 이 문제는 모델이 생성하는 비디오에 불안정을 초래할 수 있으며, 이는 얼굴 왜곡이나 프레임 간의 떨림으로 나타날 수 있으며, 심한 경우 비디오의 완전한 붕괴로 이어질 수도 있습니다. 이러한 문제를 해결하기 위해 우리는 생성 과정에서 안정성을 높이기 위해 모델에 안정적 제어 메커니즘을 도입했습니다. 이는 속도 제어기와 얼굴 영역 제어기로, 이 두 제어기는 하이퍼파라미터로 작용하여 최종 생성된 비디오의 다양성과 표현력을 손상시키지 않는 미세한 제어 신호로 기능합니다. 또한, 생성된 비디오의 캐릭터가 입력 참조 이미지와 일관되도록 보장하기 위해, ReferenceNet 접근 방식을 채택하고 개선하여, 캐릭터의 정체성을 비디오 전반에 걸쳐 유지하기 위한 FrameEncoding 모듈을 설계했습니다.
마지막으로, 모델을 훈련시키기 위해 250시간 이상의 영상과 1억 5천만 장 이상의 이미지를 수집하여 방대한 오디오-비디오 데이터셋을 구축했습니다. 이 데이터셋은 연설, 영화 및 TV 클립, 노래 공연 등을 포함하는 다양한 콘텐츠를 아우르며, 중국어와 영어 등 여러 언어를 포함하고 있습니다. 말하기 및 노래하는 비디오의 풍부한 다양성은 우리 훈련 자료가 인간의 다양한 표정과 음성 스타일을 포착할 수 있도록 하여 EMO 개발에 견고한 토대를 제공합니다. 우리는 HDTF 데이터셋에서 광범위한 실험과 비교를 수행하였으며, 그 결과 우리 방법이 DreamTalk, Wav2Lip, SadTalker 등 현재 최첨단(SOTA) 방법들을 FID, SyncNet, F-SIM, FVD와 같은 여러 지표에서 뛰어넘었음을 확인했습니다. 정량적 평가 외에도 종합적인 사용자 연구와 질적 평가를 수행했으며, 그 결과 우리 방법이 매우 자연스럽고 표현력 있는 말하기 및 노래하는 비디오를 생성할 수 있으며, 현재까지 최고의 결과를 달성함을 보여주었습니다.
2. 관련 연구
확산 모델
확산 모델(Diffusion Models)은 이미지 합성[4, 8], 이미지 편집[10, 24], 비디오 생성[6, 9], 심지어 3D 콘텐츠 생성[17, 12]을 포함한 다양한 도메인에서 놀라운 능력을 입증했습니다. 그중에서도 Stable Diffusion(SD)[20]은 대표적인 예로서, 대규모 텍스트-이미지 데이터셋에 대한 광범위한 훈련을 통해 탁월한 텍스트-이미지 생성 능력을 갖추고 UNet 아키텍처를 사용해 반복적으로 이미지를 생성합니다[23]. 이러한 사전 훈련된 모델들은 다양한 이미지 및 비디오 생성 작업에서 널리 사용되었습니다[9, 6]. 또한 최근의 일부 연구들은 Transformer를 통합한 시간 모듈과 3D 컨볼루션을 사용해 UNet을 변경한 DiT(Diffusion-in-Transformer)[16]을 도입하여, 더 큰 규모의 데이터와 모델 파라미터를 지원합니다. 이 방법은 텍스트-비디오 모델 전체를 처음부터 훈련하여 뛰어난 비디오 생성 결과를 달성했습니다[14]. 또한, 일부 연구들은 말하는 얼굴(토킹 헤드) 생성에 확산 모델을 적용하는 시도를 하였으며, 이러한 모델이 사실적인 말하는 얼굴 비디오를 만드는 데 있어서의 가능성을 보여주는 유망한 결과를 내놓았습니다[27, 15].
오디오 기반 말하는 얼굴 생성
오디오 기반 말하는 얼굴 생성은 크게 두 가지 접근 방식으로 분류할 수 있습니다: 비디오 기반 방법[30, 5, 18]과 단일 이미지 기반 방법[33, 28, 15]. 비디오 기반 말하는 얼굴 생성은 입력된 비디오 부분에 직접 편집을 허용합니다. 예를 들어, Wav2Lip[18]은 오디오를 기반으로 비디오에서 입술 움직임을 재생성하며, 오디오와 입술의 싱크를 맞추기 위해 판별자를 사용합니다. 그러나 이 방법의 한계는 기본 비디오에 의존하기 때문에 고정된 머리 움직임과 입술 움직임만을 생성한다는 점에서 사실감이 제한될 수 있다는 것입니다.
단일 이미지 기반 말하는 얼굴 생성에서는 참조 사진을 이용해 해당 사진의 모습을 반영한 비디오를 생성합니다. 예를 들어, [28]에서는 블렌드셰이프와 머리 자세를 학습하여 머리 움직임과 얼굴 표정을 독립적으로 생성하는 방법을 제안합니다. 이를 통해 3D 얼굴 메시를 생성하고, 이는 최종 비디오 프레임 생성을 유도하는 중간 표현으로 사용됩니다. 비슷하게, [33]은 말하는 얼굴 비디오 생성을 위해 중간 표현으로 3D Morphable Model(3DMM)을 사용합니다. 이러한 방법들의 공통적인 문제는 3D 메시의 제한된 표현 능력으로 인해 생성된 비디오의 전체적인 표현력과 사실성이 제한된다는 것입니다. 또한, 두 방법 모두 비확산 모델을 기반으로 하기 때문에 생성된 결과의 성능에도 한계가 있습니다. [15]는 말하는 얼굴 생성에 확산 모델을 사용하는 시도를 했지만, 이미지 프레임에 직접 적용하는 대신 3DMM의 계수를 생성하는 데 사용됩니다. 이전의 두 방법과 비교했을 때 Dreamtalk은 결과에서 일부 개선을 이루었지만, 여전히 매우 자연스러운 얼굴 비디오 생성을 달성하는 데에는 미치지 못합니다.
3. 방법
단일 참조 이미지가 주어졌을 때, 우리의 접근 방식은 입력된 음성 오디오 클립과 동기화된 비디오를 생성할 수 있으며, 자연스러운 머리 움직임과 생동감 있는 표정을 유지하여 주어진 음성 오디오의 톤 변화와 조화를 이룹니다. 연속적이고 매끄러운 비디오 시리즈를 생성함으로써, 우리 모델은 현실적인 응용을 위해 중요한 요소인 일관된 정체성과 일관된 움직임을 가진 장시간의 말하는 초상화 비디오를 생성할 수 있습니다.
3.1 기초 개념
3.2 네트워크 파이프라인
그림 2: 제안된 방법의 개요. 우리의 프레임워크는 주로 두 단계로 구성됩니다. 초기 단계에서는 Frames Encoding이라 불리며, ReferenceNet을 배치하여 참조 이미지와 모션 프레임에서 특징을 추출합니다. 이후 Diffusion Process 단계에서는 사전 훈련된 오디오 인코더가 오디오 임베딩을 처리합니다. 얼굴 영역 마스크는 다중 프레임 노이즈와 결합되어 얼굴 이미지를 생성하는 과정을 제어합니다. 그 다음으로 Backbone Network가 노이즈 제거 작업을 수행하도록 합니다. Backbone Network에서는 두 가지 형태의 주의 메커니즘이 적용됩니다: Reference-Attention과 Audio-Attention. 이 메커니즘들은 각각 캐릭터의 정체성 보존과 캐릭터의 움직임 조정을 위해 필수적입니다. 또한, Temporal Modules을 활용해 시간적 차원을 조작하고 움직임의 속도를 조정합니다.
우리 방법의 개요는 그림 2에 나와 있습니다. Backbone Network는 다중 프레임 노이즈 잠재 입력을 받아 각 시간 단계에서 이를 연속적인 비디오 프레임으로 디노이징합니다. Backbone Network는 원래의 SD 1.5와 유사한 UNet 구조 구성을 가지고 있습니다. 1) 이전 연구와 유사하게 생성된 프레임 간의 연속성을 보장하기 위해, Backbone Network에는 시간 모듈이 내장되어 있습니다. 2) 생성된 프레임에서 초상화의 ID 일관성을 유지하기 위해, Backbone과 병렬로 ReferenceNet이라는 UNet 구조를 배치하며, 이는 참조 이미지를 입력받아 참조 특징을 추출합니다. 3) 캐릭터의 말하는 움직임을 유도하기 위해, 오디오 레이어를 사용하여 음성 특징을 인코딩합니다. 4) 말하는 캐릭터의 움직임을 제어 가능하고 안정적으로 만들기 위해, 얼굴 로케이터와 속도 레이어를 사용하여 약한 조건을 제공합니다.
3.2.1 Backbone Network
우리 작업에서는 프롬프트 임베딩을 사용하지 않으므로, SD 1.5 UNet 구조의 교차 주의 레이어를 참조 주의 레이어로 수정했습니다. 이러한 수정된 레이어들은 이제 텍스트 임베딩 대신 ReferenceNet에서 가져온 참조 특징을 입력으로 사용합니다.
3.2.2 오디오 레이어
음성의 발음과 톤은 생성된 캐릭터의 움직임을 주도하는 주요 신호입니다. 사전 훈련된 wav2vec[22]의 다양한 블록에서 입력된 오디오 시퀀스로부터 추출된 특징들은 연결되어 오디오 표현 임베딩 A(f) 을 번째 프레임에 대해 생성합니다. 그러나, 움직임은 미래 또는 과거 오디오 세그먼트에 영향을 받을 수 있습니다. 예를 들어, 말을 하기 전에 입을 열거나 숨을 들이마시는 동작이 포함될 수 있습니다. 이를 해결하기 위해 각 생성된 프레임의 음성 특징을 인접 프레임들의 특징들과 연결하여 정의합니다:
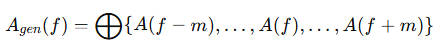
여기서 m 은 한쪽에서 가져올 추가 특징의 개수입니다. 음성 특징을 생성 절차에 주입하기 위해, 우리는 Backbone Network의 각 참조 주의 레이어(ref-attention layers) 뒤에 잠재 코드와 A_gen 간의 교차 주의 메커니즘을 수행하는 오디오 주의 레이어(audio-attention layers)를 추가합니다.
3.2.3 ReferenceNet
ReferenceNet은 Backbone Network와 동일한 구조를 가지며, 입력 이미지에서 세부적인 특징을 추출하는 역할을 합니다. ReferenceNet과 Backbone Network는 모두 동일한 원래 SD 1.5 UNet 아키텍처에서 파생되었기 때문에, 이 두 구조가 특정 레이어에서 생성하는 특징 맵은 유사성을 보일 가능성이 높습니다. 따라서 이것은 Backbone Network가 ReferenceNet이 추출한 특징들을 통합하는 데 도움을 줍니다. 이전 연구[35, 9]는 유사한 구조를 사용하는 것이 목표 객체의 정체성 일관성을 유지하는 데 강력한 영향을 미친다는 점을 강조했습니다. 본 연구에서는 ReferenceNet과 Backbone Network 모두 원래 SD UNet의 가중치를 상속받습니다. 타겟 캐릭터의 이미지는 ReferenceNet에 입력되어 자가 주의 레이어로부터 참조 특징 맵을 추출합니다. Backbone 네트워크의 디노이징 과정에서, 대응하는 레이어의 특징은 추출된 특징 맵과 함께 참조 주의 레이어를 거칩니다. ReferenceNet은 주로 개별 이미지를 처리하도록 설계되어 있으므로, Backbone에서 발견되는 시간적 레이어는 없습니다.
3.2.4 시간 모듈 (Temporal Modules)

백본 네트워크는 노이즈가 있는 프레임을 디노이징하기 위해 여러 번 반복될 수 있지만, 타겟 이미지와 모션 프레임은 ReferenceNet에 한 번만 연결되고 입력됩니다. 따라서 추출된 특징은 전체 과정에서 재사용되어 추론 시 계산 시간의 실질적인 증가를 방지합니다.
3.2.5 얼굴 위치 지정자와 속도 레이어
시간 모듈은 생성된 프레임의 연속성과 비디오 클립 간의 매끄러운 전환을 보장할 수 있지만, 독립적인 생성 과정으로 인해 생성된 캐릭터의 움직임의 일관성과 안정성을 보장하기에는 충분하지 않습니다. 이전 연구들은 캐릭터의 움직임을 제어하기 위해 스켈레톤[9], 블렌드셰이프[33], 또는 3DMM[28] 같은 신호를 사용합니다. 그러나 이러한 제어 신호는 자유도가 제한적이어서 생생한 얼굴 표정과 행동을 만드는 데 적합하지 않을 수 있으며, 훈련 단계에서의 불충분한 라벨링으로 인해 얼굴의 전체 역동성을 포착하기에 부족할 수 있습니다. 또한 동일한 제어 신호가 서로 다른 캐릭터들 사이에서 일관되지 않을 수 있으며, 개별적인 미세한 차이를 반영하지 못할 수 있습니다. 제어 신호의 생성을 가능하게 하는 접근 방식은 유효할 수 있으나[28], 생생한 움직임을 만들어내는 것은 여전히 어려운 문제로 남아 있습니다. 따라서 우리는 "약한" 제어 신호 접근 방식을 선택했습니다.


또한, 지정된 얼굴 영역과 할당된 속도가 강력한 제어 조건을 구성하지 않는다는 점을 유의해야 합니다. Face Locator의 맥락에서 M 은 전체 비디오 클립의 연합 영역이기 때문에 얼굴 움직임이 허용되는 큰 영역을 나타내며, 따라서 머리가 정적 자세에 고정되지 않도록 보장합니다. 속도 레이어와 관련해서는, 데이터셋 라벨링을 위해 인간의 머리 회전 속도를 정확하게 추정하는 것이 어렵기 때문에, 예측된 속도 시퀀스는 본질적으로 노이즈가 섞여 있습니다. 결과적으로 생성된 머리 움직임은 지정된 속도 수준을 대략적으로 근사할 수밖에 없습니다. 이러한 한계는 우리의 속도 버킷 프레임워크 설계의 동기를 부여합니다.
3.3 훈련 전략
훈련 과정은 세 가지 단계로 구조화되어 있습니다. 첫 번째 단계는 이미지 사전 훈련으로, 이 단계에서는 Backbone Network, ReferenceNet, 그리고 Face Locator를 훈련에 포함시킵니다. 이 단계에서 Backbone은 단일 프레임을 입력으로 받으며, ReferenceNet은 동일한 비디오 클립에서 무작위로 선택된 다른 프레임을 처리합니다. Backbone과 ReferenceNet 모두 원래 SD로부터 가중치를 초기화합니다. 두 번째 단계에서는 비디오 훈련을 도입하며, 여기서 시간 모듈과 오디오 레이어가 통합됩니다. 비디오 클립에서 n+f 개의 연속적인 프레임이 샘플링되며, 시작된 n 개의 프레임은 모션 프레임입니다. 시간 모듈은 AnimateDiff[6]에서 가중치를 초기화합니다. 마지막 단계에서는 속도 레이어를 통합하며, 이 단계에서는 시간 모듈과 속도 레이어만을 훈련합니다.
이 전략적 결정은 의도적으로 오디오 레이어를 훈련 과정에서 제외합니다. 이는 말하는 캐릭터의 표정, 입 움직임, 머리 움직임의 빈도가 주로 오디오에 의해 영향을 받기 때문입니다. 결과적으로 이러한 요소들 사이에 상관관계가 존재하는 것으로 보이며, 모델은 오디오 대신 속도 신호에 기반해 캐릭터의 움직임을 유도할 수 있습니다. 우리의 실험 결과에 따르면 속도 레이어와 오디오 레이어를 동시에 훈련하는 것은 오디오가 캐릭터의 움직임에 미치는 유도 능력을 약화시키는 것으로 나타났습니다.
4.2 실험 설정
방법 비교를 위해, 우리는 HDTF 데이터셋을 10%는 테스트 세트로 할당하고 나머지 90%는 훈련용으로 사용하여 분할했습니다. 두 하위 집합 간에 캐릭터 ID가 겹치지 않도록 주의했습니다.
우리는 우리의 방법을 이전 연구들인 Wav2Lip[18], SadTalker[33], DreamTalk[15]과 비교했습니다. 또한, 공개된 Diffused Heads[27]의 코드를 사용해 결과를 생성했습니다. 그러나 이 모델은 녹색 배경만 포함된 CREMA[1] 데이터셋으로 훈련되었기 때문에, 생성된 결과는 최적화되지 않았습니다. 더군다나, 생성된 프레임들 간의 오류 누적으로 인해 결과의 품질이 저하되었습니다. 따라서 Diffused Heads 접근법과는 정성적 비교만을 수행했습니다. DreamTalk의 경우, 우리는 원 저자들이 제시한 말하는 스타일 매개변수를 사용했습니다.
제안된 방법의 우수성을 입증하기 위해, 우리는 모델을 여러 정량적 지표로 평가했습니다. 생성된 프레임의 품질을 평가하기 위해 Fréchet Inception Distance (FID)[7]를 사용했습니다[32]. 추가적으로, 결과에서 정체성 유지 정도를 평가하기 위해, 생성된 프레임과 참조 이미지 간의 얼굴 특징을 추출하여 얼굴 유사도(F-SIM)를 계산했습니다. 단일, 변하지 않는 참조 이미지를 사용하는 것은 F-SIM 점수를 부정확하게 완벽하게 만들 수 있음을 유의해야 합니다. 일부 방법[18]은 입 부분만 생성하고 나머지 프레임은 참조 이미지와 동일하게 유지할 수 있어 결과를 왜곡할 수 있습니다. 따라서 우리는 F-SIM을 인구-참조 지표로 취급하며[27], 대응하는 실제 값(GT)에 더 가까운 값이 더 나은 성능을 나타냅니다. 우리는 또한 비디오 수준의 평가를 위해 Fréchet Video Distance (FVD)[29]를 사용했습니다. 입술 동기화 품질을 평가하기 위해 SyncNet[2] 점수를 사용했으며, 이는 말하는 얼굴 응용 프로그램에 있어 중요한 측면입니다. 생성된 비디오에서 얼굴 표정의 표현력을 평가하기 위해, 우리는 Expression-FID (E-FID) 메트릭을 도입했습니다. 이는 [3]에서 설명된 얼굴 재구성 기술을 통해 표정 매개변수를 추출한 후, 이러한 표정 매개변수의 FID를 계산하여 합성된 비디오의 표정과 실제 데이터셋의 표정 간의 차이를 정량적으로 측정하는 것입니다.
4.3 정성적 비교

그림 3: 여러 말하는 얼굴 생성 작업과의 정성적 비교.
그림 3은 이전 접근 방식들과 함께 우리의 방법의 시각적 결과를 보여줍니다. Wav2Lip은 일반적으로 흐릿한 입 부분을 합성하며, 단일 참조 이미지가 입력으로 제공될 때 고정된 머리 자세와 최소한의 눈 움직임을 특징으로 하는 비디오를 생성하는 것을 볼 수 있습니다. DreamTalk[15]의 경우, 저자들이 제공한 스타일 클립이 원래 얼굴을 왜곡할 수 있으며, 얼굴 표정과 머리 움직임의 역동성을 제한할 수도 있습니다. SadTalker와 DreamTalk과 달리, 우리의 제안된 방법은 더 넓은 범위의 머리 움직임과 더 역동적인 얼굴 표정을 생성할 수 있습니다. 우리는 블렌드셰이프나 3DMM과 같은 직접적인 신호를 사용하지 않고 캐릭터의 움직임을 제어하므로, 이러한 움직임은 오디오에 의해 직접적으로 구동됩니다. 이는 이후의 사례들에서 자세히 논의될 것입니다.

그림 4: 서로 다른 초상화 스타일을 기반으로 한 우리의 방법의 정성적 결과. 여기에서는 동일한 음성 오디오 클립에 의해 구동되는 14개의 생성된 비디오 클립을 보여줍니다. 각 생성된 클립의 길이는 약 8초입니다. 공간 제약으로 인해 각 클립에서 네 개의 프레임만 샘플링했습니다.
우리는 다양한 초상화 스타일에 걸쳐 말하는 얼굴 비디오 생성도 탐구했습니다. 그림 4에 나타난 것처럼, 참조 이미지는 Civitai에서 가져왔으며, 이는 서로 다른 텍스트-이미지(T2I) 모델들에 의해 합성된 것으로, 사실적, 애니메이션, 3D와 같은 다양한 스타일의 캐릭터를 포함합니다. 이러한 캐릭터들은 동일한 음성 오디오 입력을 사용하여 애니메이션화되었으며, 다양한 스타일에서 대략 일관된 입술 동기화를 보여줍니다. 비록 우리의 모델이 사실적인 비디오에서만 훈련되었지만, 다양한 초상화 유형에 대해 말하는 얼굴 비디오를 생성하는 데 능숙함을 보입니다.

그림 5: 강한 음성 톤 특성을 가진 오디오에 대한 우리의 방법으로 생성된 결과. 각 클립에서 캐릭터는 강한 음성 톤 특성(예: 노래)을 가진 오디오에 의해 구동되며, 각 클립의 길이는 약 1분입니다.
그림 5는 우리 방법이 뚜렷한 음성 톤 특성을 가진 오디오를 처리할 때 더 풍부한 얼굴 표정과 움직임을 생성할 수 있음을 보여줍니다. 예를 들어, 세 번째 행의 예시에서 높은 음의 음성 톤이 캐릭터로부터 더 강렬하고 역동적인 표정을 이끌어내는 것을 볼 수 있습니다. 또한 모션 프레임을 활용하여 생성된 비디오의 길이를 확장할 수 있으며, 입력 오디오의 길이에 따라 긴 비디오를 생성할 수 있습니다. 그림 5와 그림 6에 나타난 것처럼, 우리의 접근 방식은 상당한 움직임이 있는 경우에도 긴 시퀀스 동안 캐릭터의 정체성을 유지합니다.

그림 6: Diffused Heads[27]와의 비교. 생성된 클립의 길이는 6초이며, Diffused Heads의 결과는 낮은 해상도를 가지고 있으며 생성된 프레임들 간의 오류 누적으로 인해 품질이 저하되었습니다.
4.4 정량적 비교
표 1: 여러 말하는 얼굴 생성 작업과의 정량적 비교.
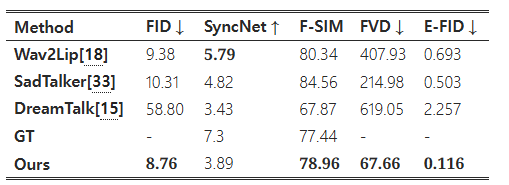
표 1에 나타난 것처럼, 우리의 결과는 비디오 품질 평가에서 상당한 우위를 보여주며, 이는 낮은 FVD 점수로 입증됩니다. 또한, 우리의 방법은 향상된 FID 점수를 통해 개별 프레임 품질 면에서도 다른 방법들을 능가합니다. SyncNet 지표에서 최고 점수를 달성하지는 못했지만, 우리의 접근 방식은 E-FID를 통해 입증된 바와 같이 생생한 얼굴 표정을 생성하는 데 뛰어납니다.
-----
각 지표에 대해 설명드리겠습니다:
- FID (Fréchet Inception Distance, ↓):
- FID는 생성된 프레임의 품질을 평가하는 지표로, 값이 낮을수록 생성된 이미지가 원본과 유사하다는 것을 의미합니다.
- 우리의 방법(Ours)은 8.76으로 가장 낮은 FID 값을 보였으며, 이는 Wav2Lip(9.38)과 SadTalker(10.31)보다 더 나은 품질의 프레임을 생성했음을 나타냅니다. DreamTalk는 58.80으로 높은 값을 보여 품질 면에서 상당히 떨어졌습니다.
- SyncNet (↑):
- SyncNet 점수는 입술 동기화의 품질을 평가하는 지표로, 값이 높을수록 더 잘 동기화되었다는 것을 의미합니다.
- GT(Ground Truth)는 7.3으로 가장 높은 점수를 보였으며, 이는 실제 데이터와 가장 잘 동기화된 상태를 나타냅니다. 우리의 방법은 3.89로 SadTalker(4.82)와 Wav2Lip(5.79)보다는 낮았지만, DreamTalk(3.43)보다는 높은 결과를 보였습니다. 이는 우리의 방법이 입술 동기화 품질 면에서는 다소 개선의 여지가 있음을 시사합니다.
- F-SIM:
- F-SIM은 생성된 프레임과 참조 이미지 간의 얼굴 유사도를 평가하는 지표입니다.
- 가장 높은 점수는 SadTalker가 84.56으로, 얼굴 유사도가 가장 잘 유지되었음을 의미합니다. 우리의 방법은 78.96으로 GT(77.44)에 가까운 점수를 보였으며, 이는 일정 수준 이상의 얼굴 정체성 유지를 보장하고 있음을 나타냅니다. DreamTalk은 67.87로 가장 낮은 점수를 보여 얼굴 정체성 유지 면에서 문제가 있음을 시사합니다.
- FVD (Fréchet Video Distance, ↓):
- FVD는 비디오 수준에서의 품질을 평가하는 지표로, 값이 낮을수록 더 부드럽고 자연스러운 비디오를 의미합니다.
- 우리의 방법은 67.66으로 가장 낮은 FVD 값을 기록했으며, 이는 매우 부드럽고 일관된 비디오 품질을 제공함을 의미합니다. SadTalker는 214.98, Wav2Lip은 407.93, DreamTalk은 619.05로 상대적으로 높은 값을 보였습니다. 이는 우리의 방법이 비디오의 연속성과 일관성 면에서 매우 우수하다는 것을 보여줍니다.
- E-FID (Expression FID, ↓):
- E-FID는 생성된 비디오에서 얼굴 표정의 표현력을 평가하는 지표로, 값이 낮을수록 원본 데이터와 유사한 표현력을 가졌음을 의미합니다.
- 우리의 방법은 0.116으로 가장 낮은 값을 기록하여 가장 자연스럽고 사실적인 표정을 생성할 수 있음을 보여줍니다. SadTalker는 0.503, Wav2Lip은 0.693, DreamTalk은 2.257로 모두 우리의 방법보다 높은 값을 보여 상대적으로 표현력이 부족함을 시사합니다.
요약하자면, 우리의 방법은 비디오의 연속성과 일관성(FVD), 개별 프레임 품질(FID), 얼굴 표정의 표현력(E-FID)에서 우수한 성능을 보였습니다. 입술 동기화 품질(SyncNet)에서는 다소 아쉬운 점이 있지만, 전체적인 비디오 품질과 얼굴 정체성 유지 측면에서 경쟁 방법들보다 훨씬 나은 결과를 보였습니다.
-----
5 제한 사항
우리 방법에는 몇 가지 제한이 있습니다. 첫째, 확산 모델에 의존하지 않는 방법들에 비해 시간이 더 많이 소요됩니다. 둘째, 명시적인 제어 신호를 사용하지 않기 때문에 캐릭터의 움직임을 통제하는 데 어려움이 있어, 손과 같은 다른 신체 부위가 의도치 않게 생성되어 비디오에 아티팩트가 발생할 수 있습니다. 이 문제에 대한 잠재적 해결책은 특정 신체 부위를 제어하기 위해 제어 신호를 사용하는 것입니다.
'인공지능' 카테고리의 다른 글
| AlphaProteo generates novel proteins for biology and health research (1) | 2024.11.22 |
|---|---|
| VASA-1: Lifelike Audio-Driven Talking FacesGenerated in Real Time (3) | 2024.11.21 |
| Framer: Interactive Frame Interpolation (2) | 2024.11.21 |
| Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks (2) | 2024.11.21 |
| Scalable watermarking for identifying large language model outputs (2) | 2024.11.20 |



