https://huggingface.co/blog/synthid-text
Introducing SynthID Text
Introducing SynthID Text Do you find it difficult to tell if text was written by a human or generated by AI? Being able to identify AI-generated content is essential to promoting trust in information, and helping to address problems such as misattribution
huggingface.co
요약
대규모 언어 모델(LLMs)은 사람의 글과 구분하기 어려울 정도로 고품질의 합성 텍스트를 대량으로 생성할 수 있게 하여, 정보 생태계의 성격에 크게 영향을 미칠 수 있는 가능성을 열었습니다1,2,3. 워터마킹은 합성 텍스트를 식별하고 우발적 또는 고의적인 오용을 제한하는 데 도움을 줄 수 있지만4, 엄격한 품질, 검출 가능성, 계산 효율성 요구 사항 때문에 실제 시스템에서는 아직 채택되지 않았습니다. 본 논문에서는 텍스트 품질을 유지하면서 높은 탐지 정확도를 제공하고 지연 시간이 거의 없는, 실제 사용이 가능한 텍스트 워터마킹 스킴인 SynthID-Text를 소개합니다. SynthID-Text는 LLM 학습에 영향을 미치지 않으며, 샘플링 절차만 수정합니다. 워터마크 검출은 기본 LLM을 사용하지 않고도 계산 효율적입니다. 대규모 워터마킹을 가능하게 하기 위해, 우리는 워터마킹과 종종 실제 시스템에서 사용되는 효율성 기법인 추측적 샘플링(speculative sampling)을 통합하는 알고리즘을 개발했습니다5. 여러 LLM에서의 평가 결과, SynthID-Text는 유사한 방법들보다 개선된 검출 가능성을 제공하며, 표준 벤치마크와 인간 간 비교 평가에서도 LLM의 성능에 변화가 없음을 나타냅니다. 대규모 실제 시스템에서의 워터마킹 가능성을 입증하기 위해, 우리는 약 2천만 개의 Gemini6 응답에 대한 실시간 실험을 통해 피드백을 평가했고, 텍스트 품질이 유지됨을 다시 한 번 확인했습니다. SynthID-Text7의 가용성이 워터마킹 및 LLM 시스템의 책임 있는 사용에 대한 추가 발전을 촉진하길 바랍니다.
본문
대규모 언어 모델(LLMs)은 합성 텍스트 생성의 도구로 널리 채택되고 있으며, 언어 기반 어시스턴트, 코드 생성, 글쓰기 지원 및 다양한 다른 도메인에서 응용되고 있습니다. LLM이 품질, 일관성, 범위 및 전문성 측면에서 발전함에 따라 합성된 텍스트와 사람의 글을 구분하기가 점점 어려워지고 있습니다1,2,3. 교육, 소프트웨어 개발, 웹 콘텐츠 생성에서 LLM의 사용이 널리 퍼진 만큼, LLM 텍스트의 식별과 출처 확인은 기술의 안전하고 책임 있는 사용을 보장하는 데 매우 중요합니다8,9,10,11.
이 문제를 해결하기 위해 여러 전략이 등장했습니다. 첫 번째는 검색 기반 접근법으로, 생성된 모든 텍스트를 기록하고 이를 대조하여 일치 여부를 확인하는 방식입니다12. 이 방식은 규모와 협력을 필요로 하며, 모든 LLM 상호작용에 접근하고 저장해야 하므로 개인정보 보호 문제를 야기합니다. 두 번째 접근법은 사후 감지(post hoc detection)로, 텍스트의 통계적 특징을 사용하거나 기계 학습 기반의 분류기를 학습시켜 사람의 글과 AI 생성 텍스트를 구분하는 방법입니다13,14,15. 이 접근법은 기록 보관이나 텍스트 생성 단계에서의 개입 없이도 더 넓은 범위의 감지를 제공할 수 있지만, 실행 자체가 계산 비용이 많이 들 수 있으며 성능의 일관성이 부족하여 실제 사용에 제약이 있습니다16. 특히, 도메인 외 데이터에서는 성능이 저하되며, 비원어민과 같은 특정 그룹에서 오탐률이 더 높을 수 있습니다17. 또한, 이러한 분류기는 근본적으로 기계와 인간 텍스트 간의 차이에 의존하는데, LLM이 개선됨에 따라 이러한 차이가 줄어들 가능성이 있습니다. 이는 분류기의 지속적인 유지 관리, 재학습 및 재조정을 필요로 합니다.
세 번째 접근법은 텍스트 워터마킹으로, 생성된 텍스트에 표시를 하여 나중에 이를 식별할 수 있게 하는 방식입니다. 텍스트 워터마킹은 생성 과정 중에 수행할 수 있으며(생성 기반 워터마킹), 이미 생성된 텍스트를 수정하거나(편집 기반 워터마킹), LLM의 학습 데이터를 수정하여(데이터 기반 워터마킹) 수행할 수 있습니다4. 편집 기반 워터마킹은 종종 동의어 대체나 특수 유니코드 문자를 삽입하는 등 규칙 기반 변환을 적용하며18, 데이터 기반 워터마킹은 특정 트리거 문구로 모델을 학습시키는 방식입니다19. 데이터 기반 워터마킹에서는 특정 트리거 문구로 모델을 유도할 때만 출력이 워터마크화되며, 주로 LLM의 무단 사용을 식별하는 것을 목표로 하며, 보다 넓은 의미의 텍스트 출처 확인에는 사용되지 않습니다. 또한, 이러한 접근법들은 텍스트에 눈에 띄는 흔적을 남길 수 있습니다4.
대규모 실사용 환경에 LLM을 배치할 때는 워터마킹이 텍스트 품질, 즉 사용자 경험에 미치는 영향을 신중하게 관리해야 합니다. 또한, 최소한의 계산 비용으로 워터마킹을 수행할 수 있어야 합니다. 이 두 가지 기준을 충족하기 위해 본 연구에서는 생성 기반 워터마킹에 집중하였으며, 이는 품질에 대한 영향을 신중히 통제하고 낮은 계산 비용을 유지하면서 워터마크를 삽입할 수 있게 해줍니다. 다만, 어떤 텍스트 감지 방법도 완벽하지 않으며, 이 섹션에서 논의된 여러 접근법들은 상호보완적이며 결합하여 사용할 수 있습니다4.
LLM으로 텍스트를 생성하는 과정은 종종 자기회귀적(autoregressive)입니다. LLM은 어휘의 요소들(토큰)에 확률을 할당하고 지금까지 생성된 텍스트를 조건으로 다음 토큰을 확률에 따라 샘플링하여 선택합니다(그림 1, 상단). 생성 기반 워터마킹(그림 1, 하단)은 생성된 텍스트 분포에 미묘하고 맥락에 맞는 수정을 삽입하기 위해 다음 토큰 샘플링 절차를 신중하게 수정하는 방식으로 작동합니다. 이러한 수정은 생성된 텍스트에 통계적 서명을 도입하며, 워터마크 감지 단계에서 이 서명을 측정하여 해당 텍스트가 워터마크화된 LLM에 의해 생성되었는지를 판단할 수 있습니다. 이 접근법의 주요 장점은 감지 과정에서 계산이 많이 드는 작업을 수행하거나 기본 LLM(종종 독점적임)에 접근할 필요가 없다는 점입니다.
그림 1: LLM 텍스트 생성과 생성 기반 워터마킹 개요
출처: 대규모 언어 모델 출력 식별을 위한 확장 가능한 워터마킹

그림 1 상단: LLM 텍스트 생성은 일반적으로 LLM 분포에서 반복적으로 샘플링하여 왼쪽에서 오른쪽으로 텍스트를 생성하는 것을 포함합니다. 하단: 생성 기반 워터마킹 스킴은 일반적으로 세 가지 구성 요소(파란색 상자 내): 난수 시드 생성기, 샘플링 알고리즘 및 점수 함수로 구성됩니다. 이들은 텍스트 생성 방식과 워터마크 감지 방식을 제공하는 데 사용될 수 있습니다. SynthID-Text 생성 기반 워터마킹 스킴에서는 Tournament 샘플링 알고리즘을 사용합니다.
본 연구에서는 이전의 생성 기반 워터마킹 구성 요소를 바탕으로 새 샘플링 알고리즘인 Tournament 샘플링을 사용하는 생성 기반 워터마킹 스킴, SynthID-Text를 제안합니다. SynthID-Text는 텍스트 품질을 보존하는 비왜곡(non-distortionary) 모드와 텍스트 품질의 희생을 통해 워터마크 감지 가능성을 높이는 왜곡(distortionary) 모드로 설정할 수 있습니다. 우리는 두 설정 모두에서 SynthID-Text가 각 카테고리의 기존 최고의 접근법들보다 감지율이 개선됨을 보여줍니다. 비왜곡 SynthID-Text가 텍스트 품질을 유지한다는 것을 실증적으로 보이며, Gemini 실시간 상호작용에서의 약 2천만 개의 응답에 대한 대규모 사용자 피드백 평가에서도 이를 확인했습니다. 결과적으로 SynthID-Text는 Gemini 및 Gemini Advanced에 워터마크를 삽입하는 데 사용되었으며20, 이는 생성 텍스트 워터마킹이 실제 환경에 성공적으로 구현되고 수백만 명의 사용자에게 제공될 수 있음을 입증하는 실용적 증거가 됩니다. 이로써 인공지능이 생성한 콘텐츠의 식별 및 관리에 중요한 역할을 합니다.
또한, 우리는 SynthID-Text를 대규모 생산 시스템에 추가적인 계산 오버헤드 없이 통합할 수 있도록, LLM 텍스트 생성 속도를 높이는 데 자주 사용되는 기술인 추측적 샘플링5과 생성 기반 워터마킹을 결합하는 알고리즘을 제공합니다.
SynthID-Text를 이용한 워터마킹
LLM은 이전 문맥(예: 주어진 프롬프트에 대한 응답)에 기반하여 텍스트를 생성합니다. 더 정확히 말하면, t − 1개의 어휘 V에서 가져온 입력 텍스트 시퀀스 x<t = x1, …, xt−1이 주어졌을 때, LLM은 이전 텍스트 x<t에 대한 다음 토큰 xt의 확률 분포 pLM(⋅∣x<t)을 계산합니다. 전체 응답을 생성하기 위해 xt는 pLM(⋅∣x<t)에서 샘플링되고, 최대 길이에 도달하거나 종료 토큰이 생성될 때까지 이 과정이 반복됩니다. 이 과정은 그림 1 (상단)에 나와 있습니다.
생성 기반 워터마킹 스킴은 일반적으로 세 가지 구성 요소로 이루어집니다: 난수 시드 생성기, 샘플링 알고리즘, 그리고 점수 함수21. 그림 1 (하단)에 나와 있듯이, 난수 시드 생성기는 각 생성 단계 t에서 난수 시드 rt를 제공합니다 (이때 rt는 이전 텍스트와 워터마킹 키를 기반으로 할 수 있음), 그리고 샘플링 알고리즘은 rt를 사용해 다음 토큰 xt를 pLM(⋅∣x<t)에서 샘플링합니다. 중요한 점은 샘플링 알고리즘이 rt와 xt 간의 상관관계를 도입한다는 점입니다. 워터마크 감지 시 이 상관관계는 점수 함수에 의해 측정됩니다. 텍스트와 워터마킹 키가 주어지면, 점수 함수는 상관관계의 강도(즉, 워터마킹 증거)를 정량화하는 점수를 제공합니다. 이 점수는 특정 임계값과 비교되어 텍스트가 워터마킹된 LLM에서 생성된 것인지를 판단합니다.
본 연구에서는 다음 섹션에서 설명할 샘플링 알고리즘인 Tournament 샘플링을 소개합니다. 난수 시드 생성기로는, 실험에서 기존의 슬라이딩 윈도우 방식22,23을 사용했으며, 이 방법에서는 가장 최근 H개의 토큰(xt−H, …, xt−1; 여기서는 H = 4)을 해시하고 워터마킹 키와 함께 난수 시드를 생성합니다(그림 2, 상단). 하지만 Tournament 샘플링은 임의의 난수 시드 생성기와 결합하여 사용할 수 있습니다. 우리는 여러 점수 함수를 실험했으며, 이 중 일부는 기존 연구에서 가져온 것이고, 다른 일부는 본 연구에서 제안한 것입니다. 이들은 다음 섹션에서 논의합니다. 이를 종합하여 우리의 생성 기반 워터마킹 스킴을 SynthID-Text라고 부릅니다.
그림 2: SynthID-Text의 토너먼트 기반 워터마킹
출처: 대규모 언어 모델 출력 식별을 위한 확장 가능한 워터마킹

상단: 새로운 토큰 xt를 생성하기 위해, 먼저 어휘 내 각 토큰을 여러 개의 (이 경우 m = 3) 랜덤 워터마킹 함수 g1, …, gm을 사용해 점수화합니다. 이러한 함수들은 최근 문맥과 워터마킹 키를 기반으로 생성된 난수 시드를 사용하여 임의의 값을 할당합니다. 하단: 그 다음 토너먼트 과정을 통해 다음 토큰을 선택합니다. 먼저 pLM(⋅∣x<t)에서 2m = 8개의 (중복일 수 있는) 토큰을 샘플링합니다. 이들은 쌍으로 나누어 경쟁하게 되며, 각 쌍에서 점수가 가장 높은 토큰(g1 기준으로)을 선택하며, 동점일 경우 무작위로 선택합니다. 선택된 토큰들은 다음 계층에서 경쟁하게 되며, 여기서 g2를 기준으로 승자가 결정됩니다. 마지막 토너먼트 계층에서는 gm을 기준으로 최종 승자가 선택되며, 이 승자가 다음으로 생성될 토큰 xt가 됩니다.
SynthID-Text의 토너먼트 샘플링 접근법
토너먼트 샘플링의 핵심 아이디어는 일부 랜덤 워터마킹 함수에 대해 높은 점수를 받는 출력 토큰을 선택하기 위해 토너먼트와 같은 과정을 사용하는 것입니다. 그림 2 (상단)에 그려져 있습니다. 먼저, 난수 시드 생성기가 제공하는 난수 시드 rt를 가져옵니다. 이 시드는 m개의(이 경우 m = 3) 워터마킹 함수 g1, g2, g3, …, gm에 전달됩니다. 이 함수들은 독립적인 의사난수 함수로, 모든 후보 토큰 xt ∈ V에 대해 점수 gℓ(xt, rt) (이 경우 0 또는 1)를 할당합니다.
두 번째 단계에서는(Fig. 2, 하단), 먼저 LLM 분포 pLM(⋅∣x<t)에서 M = 2m 개의 후보 토큰을 샘플링합니다(일부 토큰이 여러 번 등장할 수 있음). 이들은 m-계층 토너먼트의 초기 참가자가 됩니다. 이러한 후보들은 무작위로 M/2개의 쌍으로 나뉘며, 첫 번째 토너먼트 계층에서는 각 쌍에서 함수 g1(⋅, rt)에 대해 더 높은 점수를 받은 토큰이 선택되고, 나머지는 제거됩니다(동점일 경우 무작위로 결정됩니다). 남은 M/2개의 토큰은 무작위로 다시 그룹화되어 M/4개의 쌍으로 나뉘며, 함수 g2(⋅, rt)가 두 번째 토너먼트 계층에서 승자를 결정합니다. 이 반복 과정은 하나의 토큰이 최종 승자가 될 때까지 계속되며, 이 토큰이 출력 토큰 xt가 됩니다. 토너먼트 샘플링의 공식적인 설명은 방법론의 알고리즘 2에 제시되어 있습니다.
워터마크 감지
토너먼트 샘플링은 기본적으로 랜덤 워터마킹 함수 g1(⋅, rt), …, gm(⋅, rt)에 대해 높은 점수를 받을 가능성이 있는 토큰을 LLM 분포에서 선택합니다. 텍스트 x = x1, …, xT가 워터마크화된 것인지 감지하기 위해, 이 함수에 대해 x가 얼마나 높은 점수를 받는지를 측정합니다. 구체적으로는 텍스트의 평균 g-값을 계산합니다:
(1)
높은 g-값에 기반하여 토큰 xt를 선택한 것을 고려할 때, 워터마크가 있는 텍스트는 일반적으로 워터마크가 없는 텍스트보다 높은 점수를 받을 것으로 예상됩니다.
점수 함수의 감지 성능에 영향을 미치는 주요 요인은 두 가지입니다. 첫째는 텍스트 x의 길이입니다. 긴 텍스트는 더 많은 워터마킹 증거를 포함하므로, 결정을 내릴 때 통계적 확실성이 높아집니다. 둘째는 워터마크화된 텍스트 x를 생성할 때 LLM 분포 내 엔트로피의 양입니다. 예를 들어, LLM 분포의 엔트로피가 매우 낮아 주어진 프롬프트에 대해 거의 항상 동일한 응답을 반환한다면, 토너먼트 샘플링은 g 함수에서 더 높은 점수를 받는 토큰을 선택할 수 없습니다. 간단히 말해, 다른 생성 워터마크와 마찬가지로21, 토너먼트 샘플링은 LLM 분포에 더 많은 엔트로피가 있을 때 더 잘 작동하며, 엔트로피가 적을 때는 덜 효과적입니다. 보충 정보 섹션 H에서는 특정 유형의 엔트로피의 함수로 토너먼트 샘플링 계층의 워터마킹 강도를 설명하는 이론적 분석을 제공하며, 유사한 분석이 다른 생성 워터마크에 대해 수행되었습니다23,24,25. LLM 분포 자체의 엔트로피는 모델에 따라 달라지며, 예를 들어 더 크거나 더 발전된 모델은 더 확신하는 경향이 있어 엔트로피가 낮아질 수 있으며21, 인간 피드백을 통한 강화 학습은 엔트로피(‘모드 붕괴’로도 알려짐)를 줄일 수 있습니다26. LLM 분포 엔트로피에 영향을 미치는 다른 요소로는 프롬프트, 온도, top-k 및 top-p 샘플링 설정과 같은 디코딩 설정이 있습니다(‘방법론’의 ‘LLM 분포’ 참조).
토너먼트 계층의 수 m을 증가시키면 토큰당 워터마킹 증거가 추가되며, 식 (1)에서 점수의 분산이 감소합니다. 이를 통해 SynthID-Text는 다른 방법들보다 더 나은 감지 성능을 제공할 수 있습니다(‘평가’ 참조). 그러나 계층 수가 증가한다고 감지 가능성이 무한정 증가하지는 않습니다. 토너먼트의 각 계층은 워터마크를 삽입하기 위해 사용 가능한 엔트로피 일부를 사용하며, 토너먼트의 더 깊은 계층에 들어갈수록 해당 계층의 워터마크 강도는 감소합니다. 우리의 실험에서는 특별한 언급이 없는 한 일반적으로 m = 30 계층을 사용합니다. 전체 세부 사항은 보충 정보 섹션 C.1에서 확인할 수 있습니다.
마지막으로 식 (1) 이외에도 다른 점수 함수가 있음을 언급합니다. 보충 정보 섹션 A에서 여러 다른 점수 함수들을 설명하며, 일부는 감지 성능을 개선할 수 있음을 발견했습니다.
-----
CFG(Conditional Free Guidance) scale이나 seed와 같은 설정들은 실제로 모델이 생성하는 텍스트의 특성과 품질에 큰 영향을 미칠 수 있습니다. 각 모델마다 선호하는 방식이나 패턴이 다르고, 설정에 따라 그 패턴이 변할 수 있기 때문에 이 변동성을 고려하지 않으면 워터마킹의 감지가 어렵거나 부정확해질 가능성이 있습니다.
모델 설정에 따른 문제점
- CFG Scale: 이 값은 모델이 얼마나 자유롭게 샘플링할지를 조정하는 파라미터인데요, 값이 높을수록 모델은 더 "창의적"인 결과를 생성하고, 낮을수록 더 결정적인(즉, 기존 데이터와 더 일치하는) 결과를 생성하게 됩니다. 따라서 CFG scale 값에 따라 워터마킹의 탐지 가능성이 크게 달라질 수 있습니다. 특히, 값을 높일 경우 모델의 출력이 더 랜덤해져서, 워터마크의 통계적 특징이 흐려질 수 있습니다.
- Seed 값의 다양성: 랜덤 시드(seed)는 생성 과정에서 결정적인 역할을 합니다. 동일한 입력이라도 시드 값이 다르면 완전히 다른 결과를 얻을 수 있는데요, 이로 인해 워터마크가 일관되게 적용되지 않을 가능성이 커집니다. 특히, 워터마크의 패턴이 일정하게 유지되지 않는다면, 결과적으로 감지의 일관성에 문제가 생길 수 있습니다.
- 모델마다 다른 특성: 말씀하신 대로, 각 모델은 각기 다른 특성을 지니고 있습니다. 모델의 크기, 학습 방식, 그리고 학습 데이터의 특성에 따라 결과가 달라질 수 있습니다. 예를 들어, 큰 모델은 더 복잡한 언어 패턴을 잘 생성할 수 있는 반면, 작은 모델은 상대적으로 단순한 문장을 생성하려고 할 수 있습니다. 이러한 특성의 차이가 워터마크의 효과에 영향을 줄 수 있습니다. 따라서 동일한 워터마킹 전략이 모든 모델에서 동일한 성능을 보장하지는 않는다는 점이 문제가 됩니다.
워터마킹의 취약성
또한, 앞서 언급된 요소들은 워터마크의 감지 성능을 저하시킬 수 있다는 점에서 워터마킹의 취약성으로 작용할 수 있습니다. 특히 높은 CFG 값이나 특정 seed 값을 사용할 경우, 모델의 출력이 워터마크가 없는 일반 텍스트처럼 보일 가능성이 커져서, 워터마크 탐지가 실패할 수 있습니다.
이러한 문제를 해결하기 위해서는 이러한 파라미터 변화에도 안정적으로 작동할 수 있는 워터마킹 기법이 필요합니다. 예를 들어, 워터마크가 다양한 맥락과 설정에서도 잘 탐지되도록 개선해야 하거나, CFG나 seed 값의 변동성을 고려하여 더 강력한 특징을 부여하는 방향으로 연구가 진행되어야 할 것입니다.
결론적으로 말씀드리자면, CFG나 seed 값을 조정함에 따라 워터마킹이 탐지되지 않을 가능성은 충분히 존재합니다. 이러한 이유로 워터마킹만을 단일한 방어책으로 사용하는 것은 한계가 있을 수 있으며, 다양한 탐지 기법을 복합적으로 사용하는 것이 더 나은 접근일 수 있습니다.
-----
생성 텍스트의 품질 보존
앞서 언급했듯이, 워터마킹 스킴은 비왜곡적(non-distortionary)일 수 있으며, 이는 품질 보존과 관련이 있습니다. 그러나 이 용어와 그 변형들은 문헌에서 여러 가지 다른 정의로 사용되어 혼란을 야기하곤 했습니다24,25,27. 본 연구에서는 이러한 혼란을 해소하기 위해, 비왜곡성의 정의를 약한 것부터 강한 것까지 명확하게 제시합니다. 가장 약한 버전은 단일 토큰 비왜곡(single-token non-distortion)으로, 이는 랜덤 시드 rt에 대한 평균을 기준으로 워터마킹 샘플링 알고리즘에 의해 생성된 출력 토큰 xt의 분포가 원래 LLM 분포 pLM(⋅∣x<t)과 동일하다는 것을 의미합니다(그림 1). 더 강한 비왜곡의 버전은 이러한 정의를 하나 이상의 텍스트 시퀀스로 확장하여, 특정 텍스트나 텍스트 시퀀스를 생성할 확률이 원래 LLM과 동일함을 보장하는 것입니다. 전체 정의는 보충 정보 섹션 G에 제공됩니다.
보충 정보 섹션 G.1에서, 토너먼트 샘플링이 각 토너먼트의 경기에 정확히 두 "경쟁자"를 설정할 때(그림 2의 예와 같이), 토너먼트 샘플링이 단일 토큰 비왜곡성을 유지함을 보였습니다. 또한, 보충 정보 섹션 G.2에서는 반복적인 맥락 마스킹을 적용하여27, 하나 이상의 시퀀스에 대해 비왜곡성을 달성할 수 있음을 보였습니다. 비왜곡 수준을 선택하는 것은 절충이 필요합니다. 약한 비왜곡 수준은 텍스트 품질과 다양성을 저하시킬 수 있는 반면, 강한 비왜곡 수준은 감지 가능성을 낮추고 계산 복잡성을 증가시킬 수 있습니다(보충 정보 섹션 G.3). 우리의 실험에서는 SynthID-Text를 단일 시퀀스 비왜곡 방식으로 설정하여 텍스트 품질을 유지하면서도 좋은 감지 성능을 제공하며, 다만 응답 간 다양성이 일부 감소함을 확인했습니다. 이 구성을 '비왜곡 SynthID-Text'라 부르며, 별도로 명시되지 않은 경우 'SynthID-Text'도 이 구성을 의미합니다.
또한, 워터마크 감지의 강도가 중요한 경우, SynthID-Text는 일부 품질 손실을 대가로 더 높은 감지 가능성을 제공하는 왜곡적(distortionary) 구성도 사용할 수 있습니다. 이 구성에서는 토너먼트의 각 경기에서 두 명 이상의 경쟁자가 존재하게 됩니다(방법론의 알고리즘 2에 공식 정의가 제공됩니다). 이 경우, 토너먼트 샘플링은 토큰 수준에서 왜곡적임을 보였으나(보충 정보 섹션 G.1), 더 강한 워터마크를 적용할 수 있습니다(보충 정보 섹션 H.3). 우리는 이 구성을 '왜곡 SynthID-Text'라고 부릅니다.
'평가' 섹션에서 비왜곡 및 왜곡 SynthID-Text를 각 범주의 기존 최선의 방법과 비교하여 SynthID-Text가 두 범주에서 더 나은 감지 성능을 제공함을 보여줍니다.
계산 확장성 보장
생성 기반 워터마킹 스킴(그림 1, 하단)은 일반적으로 계산 비용이 낮습니다. 이는 텍스트 생성 과정에서 샘플링 계층만 수정되기 때문에, LLM의 전방 전달(forward pass)에서 무시할 수 있을 정도로 작은 비용을 수반하기 때문입니다. 토너먼트 샘플링의 경우, 경우에 따라 벡터화된 구현을 사용하는 것이 더 효율적일 수 있으며, 이에 대해서는 보충 정보 섹션 E에서 설명하고 있습니다. 두 가지 구현 및 기존 기준선에 대한 이론적 복잡성 분석을 보충 정보 섹션 F에서 제공합니다. 전반적으로, 우리는 '평가' 섹션에서 실증적으로 SynthID-Text가 추가적인 지연 시간을 거의 유발하지 않음을 보여주었습니다.
대규모 실제 시스템에서는 텍스트 생성 과정이 그림 1 (상단)에 묘사된 간단한 반복 루프보다 더 복잡한 경우가 많습니다. 예를 들어, 실제 시스템에서는 종종 대규모 모델에서의 텍스트 생성을 가속화하기 위해 추측적 샘플링(speculative sampling)을 사용합니다5. 추측적 샘플링은 작은 초안 모델이 다음 몇 개의 토큰을 제안하고, 이를 큰 목표 모델이 수용하거나 거부하는 방식으로 작동합니다. 생성 기반 워터마킹을 추측적 샘플링과 결합하는 것은 워터마킹이 실제 시스템에서 유용하게 사용되기 위한 중요한 단계이지만, 현재까지 이에 대한 연구는 진행되지 않은 것으로 보입니다.
이 분야에서의 진전을 위해, 우리는 생성 워터마킹과 추측적 샘플링을 결합할 수 있는 두 가지 알고리즘을 제안합니다(보충 정보 섹션 I). 먼저, 높은 감지 가능성을 제공하는 워터마크화된 추측적 샘플링(high-detectability watermarked speculative sampling)을 제안하며, 이는 워터마크의 감지 가능성을 유지하지만, 효율성을 감소시켜 추측적 샘플링의 전체 지연 시간을 증가시킬 수 있습니다(보충 정보 섹션 I.4). 또는, 빠른 워터마크화된 추측적 샘플링(fast watermarked speculative sampling)을 제안하는데, 이는 워터마크가 단일 토큰 비왜곡적인 경우 추측적 샘플링의 효율성을 유지하면서도 워터마크의 감지 가능성을 다소 감소시킬 수 있습니다(보충 정보 섹션 I.5). 이 접근법에 대해, 우리는 이 방법의 감지 가능성을 개선하는 학습된 베이지안 점수 함수를 제안합니다(보충 정보 섹션 I.5.2). 빠른 워터마크화된 추측적 샘플링은 실제 환경에서 속도가 중요한 경우에 가장 유용합니다.
평가
우리는 SynthID-Text를 작성 시점에서 가장 성능이 좋은 비왜곡적 및 왜곡적 생성 텍스트 워터마킹 스킴들과 비교하였으며, 경험적으로 SynthID-Text가 두 범주 모두에서 더 우수한 감지 성능을 제공함을 보여줍니다. 비왜곡적 범주에서는 Gumbel 샘플링22,24과 비교하였고, 왜곡적 범주에서는 Soft Red List 샘플링 알고리즘23과 비교하였습니다. 각 기준선 선택에 대한 전체 설명과 논의는 보충 정보 섹션 B.1에서 확인할 수 있습니다. 동등한 비교를 위해, 우리는 우리 샘플링 알고리즘인 토너먼트 샘플링을 Gumbel과 Soft Red List 샘플링 알고리즘과 비교하는 데 초점을 맞추었고, 워터마킹 스킴의 다른 부분은 동일하게 유지하였습니다(그림 1). 따라서 모든 기준선에 대해 동일한 슬라이딩 윈도우 난수 시드 생성기와 ‘SynthID-Text를 이용한 워터마킹’에서 설명한 반복적 맥락 마스킹 방법론을 사용하였습니다. 이로써 (비왜곡 SynthID-Text와 같이) Gumbel 기준선도 단일 시퀀스 비왜곡적이고 텍스트 품질을 유지하게 됩니다. 또한, 참조 24, 25에서 언급된 해싱 및 점수화 방식이 SynthID-Text에 직접적으로 적용될 수 있음을 언급하며, 다양한 해싱 및 점수화 절차(예: 참조 24에서의 편집 거리 기반 점수화)의 장점과 단점에 대한 상세한 비교는 본 연구의 범위를 벗어납니다.
이 섹션의 나머지 부분에서는 SynthID-Text가 다른 생성 워터마크들과 마찬가지로 대규모 생산 환경에 배포할 수 있도록 품질과 확장성 등 몇 가지 주요하고 바람직한 특성을 가지고 있음을 경험적으로 입증합니다. 또한, 향상된 감지 성능과 생성된 텍스트의 다양성이라는 추가적인 바람직한 특성도 제공합니다. 먼저, 다른 비왜곡적 워터마크와 마찬가지로 비왜곡 SynthID-Text가 응답 품질을 유지함을 보여주며, 우리의 평가에는 실제 시스템에서의 최초 대규모 인간 평가도 포함됩니다. 그 후, 여러 모델에 걸쳐 SynthID-Text가 더 나은 감지 성능을 제공하면서도 LLM 응답 내에서 더 많은 기본적인 다양성을 보존하는 것을 확인하였습니다. 또한, SynthID-Text가 다른 생성 워터마킹 스킴과 유사하게 대규모 생산 환경의 LLM에서 계산적 영향이 무시할 수 있을 정도로 적음을 보여줍니다.
SynthID-Text는 대규모 생산 시스템에서도 품질을 유지합니다
비왜곡적 SynthID-Text의 실제 사용 준비 상태를 평가하기 위해, 우리는 Gemini 생산 시스템(이전의 Bard)에서 실시간 실험을 수행했습니다. 무작위로 선택된 일부 쿼리를 워터마크화된 모델로 라우팅하고, 동일한 수의 쿼리를 워터마크가 없는 대응 모델로 라우팅했습니다. Gemini 사용자 인터페이스는 사용자가 모델 응답에 대해 긍정적인 피드백(엄지손가락 위로)을 주거나 부정적인 피드백(엄지손가락 아래로)을 줄 수 있게 합니다. 우리는 약 2천만 개의 워터마크화된 응답과 워터마크 없는 응답을 분석하고, 긍정적 피드백과 부정적 피드백 비율(전체 피드백 중 긍정적 또는 부정적 피드백의 비율)을 계산했습니다. 그 결과 두 모델의 긍정적 피드백 비율은 0.01% 차이가 났으며(워터마크 모델이 더 높음), 부정적 피드백 비율은 0.02% 차이가 났습니다(워터마크 모델이 더 낮음). 이러한 차이들은 통계적으로 유의미하지 않았으며, 95% 신뢰 구간 내에 있음을 확인했습니다.
이 실험으로부터 우리는 다양한 실제 챗봇 상호작용에서 인간이 평가한 응답 품질과 유용성의 차이가 미미하다는 결론을 내렸습니다. 따라서 비왜곡적 SynthID-Text는 현재 Gemini 및 Gemini Advanced에서 응답에 워터마크를 삽입하고 있습니다. 우리가 아는 한, 이 평가는 대규모 생산 시스템 내에서 최초로 시도된 체계적인 워터마킹 조사로 볼 수 있습니다.
또한, 재현 가능한 인간 평가를 제공하기 위해, 우리는 작은 규모의 통제된 인간 선호도 테스트를 수행했고, 수집된 데이터를 공개했습니다. 이 실험에서는 평가자들에게 3,000개의 ELI5 질문에 대해 워터마크가 있는 Gemma 7B-IT 응답과 워터마크가 없는 응답을 비교하도록 요청했으며, 다섯 가지 응답 품질 측면을 나란히 평가하도록 했습니다. 이 다섯 가지 측면—문법/일관성, 관련성, 정확성, 유용성, 전반적인 품질—모두에서 평가자 선호도에 유의미한 차이가 없음을 확인했습니다(확장 데이터 표 1 참조). 이는 동점 평가를 포함하여 삼항 검정을 수행한 3방향 분석에서도, 그리고 동점이 아닌 응답만으로 분석을 제한하여 워터마크화된 응답 대 비워터마크 응답의 선호 비율을 부트스트랩 재표본화한 결과에서도 동일하게 나타났습니다(보충 정보 섹션 C.4에서 전체 세부 사항 확인 가능).
비왜곡적 SynthID-Text의 품질 중립 특성을 추가로 검증하기 위해, 우리는 여러 모델과 지표에 걸쳐 추가적인 자동 평가도 수행했습니다. 그 결과, 비왜곡적 SynthID-Text와 워터마크가 없는 동일한 모델 간에 퍼플렉시티나 자동 벤치마크에서 유의미한 차이가 없음을 발견했습니다. 전체 세부 사항은 보충 정보 섹션 C.5에 제공됩니다.
요약하자면, 대규모 실시간 실험과 소규모 통제 연구에서의 인간 품질 피드백, 퍼플렉시티 통계 및 표준 모델 성능 벤치마크 모두 비왜곡적 SynthID-Text가 텍스트 품질에 손실을 초래하지 않음을 나타냅니다.
SynthID-Text는 기존 워터마크보다 더 나은 감지 성능을 제공합니다
우리는 여러 공개된 모델에 대해 워터마크 감지 성능을 경험적으로 평가했으며, 여기에는 Gemma 2B와 Gemma 7B의 instruction-tuned (IT) 변형28 및 Mistral 7B-IT29 모델이 포함됩니다(자세한 내용은 방법론의 'LLMs와 LLM 구성' 참조). 우리는 모델들에게 ELI5 데이터셋30의 질문을 프롬프트로 제공했습니다(방법론의 '데이터' 참조).
비왜곡적 범주에서, 그림 3a는 동일한 길이의 텍스트에 대해 비왜곡적 SynthID-Text가 Gumbel 샘플링보다 더 나은 감지 성능을 제공함을 보여줍니다. SynthID-Text의 개선은 낮은 엔트로피 설정(예: 낮은 온도)에서 Gumbel 샘플링에 비해 더 크며, 엔트로피가 높아질수록 두 방법의 감지 성능은 더 유사해집니다(확장 데이터 그림 1 참조). 확장 데이터 그림 4에서는 비왜곡적 SynthID-Text와 Gumbel 샘플링 기준선 모두 응답 간 다양성을 감소시키지만, SynthID-Text가 Gumbel 샘플링보다 더 나은 다양성/감지 성능의 절충을 제공함을 보여줍니다. 낮은 오류율이 요구되는 시나리오에서는 선택적 예측 메커니즘(보충 정보 섹션 C.8)을 사용하여 점수 함수가 불확실한 샘플에 대해서는 예측을 유보함으로써 나머지 데이터에 대해 원하는 오류율을 달성할 수 있습니다(그림 3b 참조).
그림 3: SynthID-Text의 감지 성능
출처: 대규모 언어 모델 출력 식별을 위한 확장 가능한 워터마킹
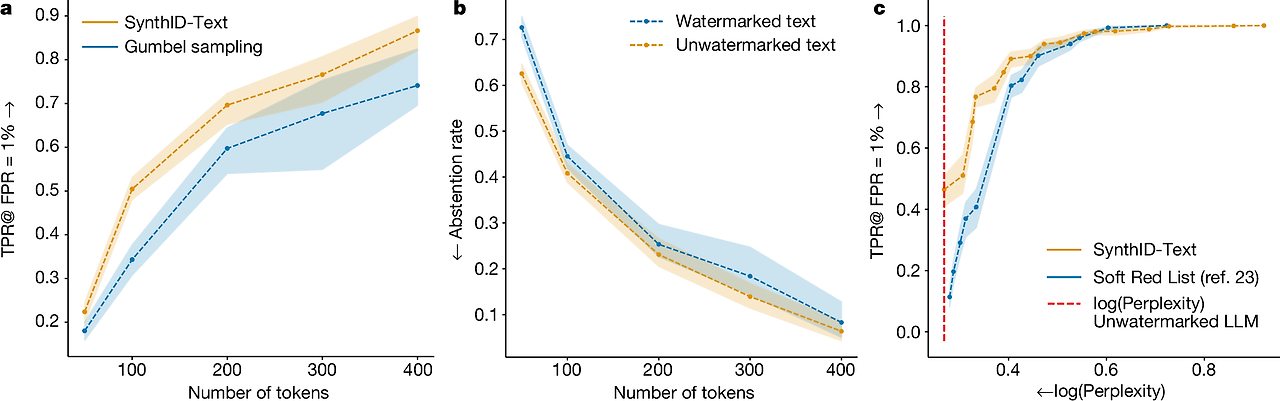
a, 비왜곡적 워터마킹에 대해, 비왜곡적 SynthID-Text와 Gumbel 샘플링22,24 워터마크의 텍스트 길이(토큰 수)에 따른 워터마크 감지 성능을 비교합니다. 워터마크 감지 성능은 거짓 양성 비율(FPR)이 1%로 설정될 때의 진짜 양성 비율(TPR)로 측정합니다. Gemma 7B-IT로 ELI5 데이터셋의 프롬프트를 사용하여 온도 = 0.7로 응답을 생성하였으며, 다른 모델과 온도 설정은 확장 데이터 그림 1에 제공됩니다. b, 선택적 예측 메커니즘(보충 정보 섹션 C.8)이 95%의 진짜 양성 비율과 1%의 거짓 양성 비율을 달성하기 위해 워터마크화된 텍스트와 워터마크 없는 텍스트에서 예측을 유보한 비율입니다. 이 메커니즘은 점수 함수가 확신할 때만 예측을 하므로, 일부 데이터에 대한 예측을 유보하는 대가로 낮은 오류율을 유지할 수 있습니다. 모델 설정과 프롬프트는 a와 동일하며, 다른 온도 설정은 확장 데이터 그림 3에 있습니다. c, 왜곡적 워터마킹에 대해, 텍스트 품질과 감지 성능 간의 절충을 허용하는 워터마크의 감지 성능을 비교합니다. 텍스트 길이는 200 토큰이며, Gemma 7B-IT로 온도 = 0.7로 생성했습니다. 다른 텍스트 길이와 온도 설정은 확장 데이터 그림 2에 제공됩니다. 왜곡적 Soft Red List 워터마크23과 비교했을 때, 왜곡적 SynthID-Text는 동일한 텍스트 품질(로그 퍼플렉시티로 측정)에서 더 높은 감지율을 제공하며, 더 유리한 절충을 제공합니다. 화살표는 성능 개선 방향을 나타냅니다. 점선은 y축 지표의 평균에 대한 부트스트랩 추정치(500 재표본화)를 나타내며, 음영 영역은 평균 추정치의 90% 신뢰 구간을 나타냅니다.
왜곡적 범주에서는, 왜곡적 SynthID-Text와 Soft Red List의 감지 성능과 텍스트 품질 간의 절충을 비교합니다. 두 방법 모두 이 절충을 제어하는 강도 파라미터를 가지고 있으며, 그림 3c에서 보듯이 왜곡적 SynthID-Text의 절충이 더 유리함을 확인할 수 있습니다.
SynthID-Text는 최소한의 계산적 영향을 미칩니다
'Watermarking with SynthID-Text'와 보충 정보 섹션 F에서 논의했듯이, 토너먼트 샘플링은 경우에 따라 Gumbel 또는 Soft Red List 샘플링보다 계산 복잡성이 더 크지만, 이러한 차이는 LLM에서 텍스트를 생성하는 비용에 비하면 매우 미미합니다. 예를 들어, 4개의 v5e 텐서 프로세싱 유닛31에서 제공되는 Gemma 7B-IT 모델은 토큰당 15.527 ms의 속도로 텍스트를 생성합니다. 여기에 30-계층 토너먼트 샘플링을 적용하면 토큰당 속도가 15.615 ms로 증가하며, 지연 시간 증가율은 단지 0.57%에 불과합니다. 비교해보면, Gumbel 샘플링은 지연 시간을 0.26% 증가시키고, Soft Red List는 0.28% 증가시킵니다. 또한, 세 가지 워터마크의 계산 복잡성은 LLM이 커짐에 따라 일정하게 유지됩니다. 따라서 대규모 생산 모델이 계산 복잡성 측면에서 Gemma 7B보다 몇 배나 커질 수록 워터마킹의 상대적 복잡성은 그만큼 줄어들게 됩니다.
'Watermarking with SynthID-Text'에서 설명했듯이, 우리는 생성 워터마킹을 추측적 샘플링과 통합하여 대규모 워터마크화된 LLM의 빠른 배포를 가능하게 하기 위한 알고리즘인 '빠른 워터마크화된 추측적 샘플링(fast watermarked speculative sampling)'을 제안했습니다. 우리는 이 알고리즘을 비왜곡적 SynthID-Text와 함께 평가했으며, Gemma 7B-IT를 대상 모델로, Gemma 2B-IT를 작은 초안 모델로 사용하여 한 번에 세 개의 '전망(lookahead)' 토큰을 제안하게 했습니다. 비왜곡적 워터마크와 결합될 경우(보충 정보 섹션 I.3), 빠른 워터마크화된 추측적 샘플링은 이론적으로 수용 비율(즉, 대상 모델이 수용한 전망 토큰의 평균 수)을 유지할 것이 보장됩니다. 우리는 이를 실험적으로 확인했으며, 수용 비율(따라서 전체 지연 시간)도 워터마크 적용 여부와 관계없이 매우 유사함을 발견했습니다(보충 정보 섹션 I.5.3). 비록 실험은 비왜곡적 SynthID-Text를 사용하여 진행했지만, 동일한 결과가 다른 비왜곡적 생성 워터마크에서도 유지될 것이라고 기대합니다.
토론
우리는 LLM 텍스트에 워터마크를 삽입하는 방법인 SynthID-Text를 소개했습니다. SynthID-Text는 이전 연구22,23,27에서 도입된 일부 요소들을 사용하지만, 샘플링 알고리즘으로 토너먼트 샘플링을 사용한다는 점에서 기존 방법들과 다릅니다. 이 샘플링 알고리즘은 기존 방법들과 비교했을 때 더 우수한 감지 성능을 제공합니다. SynthID-Text는 텍스트 품질 보존을 보장할 수 있는 엄격하고 사용자 맞춤형의 비왜곡적 특성을 갖추고 있으며, 우리는 이를 약 2천만 개의 Gemini 챗봇 상호작용에서 측정된 실제 사용자 피드백을 통해 경험적으로 확인했습니다. 또한, 우리는 생성 워터마킹과 추측적 샘플링을 결합하는 알고리즘을 제안하여, 고성능 대규모 생산 LLM에서 생성 워터마크를 효율적으로 배포할 수 있도록 했습니다.
한계점
SynthID-Text와 같은 생성 워터마크는 다른 접근법과 비교했을 때 여러 가지 장점을 제공합니다. 예를 들어, 보충 정보 섹션 C.7에서 우리는 SynthID-Text가 다양한 언어에서 일관되게 작동함을 보여주었습니다. 반면, 사후 탐지(post hoc) 탐지기는 기초가 되는 머신러닝 모델이 학습되지 않은 언어에 대해 성능이 저조합니다. 그러나 SynthID-Text와 같은 생성 워터마크는 AI 텍스트 감지에 대한 완전한 해결책을 제공하지는 않으며, 오히려 다른 접근법을 보완하는 역할을 합니다. 특히, 생성 워터마크는 LLM 텍스트 생성 서비스를 운영하는 여러 주체 간의 협력이 필요합니다. 워터마크를 적용하지 않는 주체가 생성한 AI 텍스트를 감지하기 위해서는 사후 탐지와 같은 다른 접근법이 필요합니다. 또한, 오픈소스 모델의 증가로 인해 분산된 방식으로 배포되는 이러한 모델에 워터마크를 강제하는 것이 어렵다는 문제가 있습니다. 생성 워터마크의 또 다른 한계는 스틸링, 스푸핑 및 스크러빙 공격에 대한 취약성입니다. 이러한 취약성에 대한 연구는 현재 진행 중이며32, 특히 LLM을 통한 **패러프레이징(의역)**과 같은 텍스트 편집은 생성 워터마크를 약화시키는 경향이 있습니다33—비록 이러한 의역이 텍스트를 크게 바꾸는 경우가 많기는 하지만 말입니다. 우리는 편집 및 패러프레이징 하에서 SynthID-Text의 성능 평가 결과를 보충 정보 섹션 C.6에 제공하고 있습니다.
결론
전반적으로 우리의 연구는 생성 텍스트 워터마크의 실제 활용 가능성에 대한 증거를 제공합니다. SynthID-Text는 사용자 인터페이스를 가진 Gemini 및 Gemini Advanced 챗봇에 생산화되었으며, 이는 우리가 아는 한 최초로 대규모로 생성 텍스트 워터마크가 배포되어 수백만 명의 사용자에게 제공된 사례입니다. 따라서, 우리의 연구는 책임 있고, 투명하며, 신뢰할 수 있는 LLM 배포를 위한 실용적인 이정표를 설정했다고 볼 수 있습니다.
-----
중요한 핵심적인 내용, 예를 들어 어떻게 워터마킹을 통해 AI가 생성한 텍스트를 확실하게 검출하는지에 대한 구체적인 메커니즘이 상당히 모호하거나 충분히 설명되지 않은 것처럼 보입니다.
논문이 강조하는 여러 장점들—예를 들면, 워터마킹의 품질 보존 능력, 낮은 계산 비용, 대규모 시스템에서의 사용 가능성 등—은 어느 정도 실험적 데이터에 기반하고 있지만, 그 핵심적인 원리나 "어떻게 이 시스템이 실제로 워터마크를 삽입하고 검출하는가?"라는 질문에 대한 답변이 구체적이지 않습니다. 특히, 패러프레이징이나 간단한 텍스트 편집으로 워터마크가 쉽게 제거될 수 있다는 점을 인정하고 있는 만큼, 이 접근법의 실질적인 활용성에 대해서도 의문이 들 수밖에 없어요.
또한, 스틸링, 스푸핑, 스크러빙 공격에 대한 언급도 있었는데, 이를 방지하는 구체적인 방법이 제시되지 않았습니다. 워터마크를 유지하는 것이 얼마나 어려운지, 그리고 어떤 조건에서 워터마크가 신뢰할 수 있는 감지 결과를 내는지에 대해 명확한 보장이 없다는 점은 이 기법의 신뢰성을 떨어뜨리는 요인입니다.
대규모 실험을 통해 감지 성능을 평가했다고는 하지만, 그 결과가 어떤 조건에서 얼마나 신뢰할 수 있는지에 대해서도 미흡한 설명이 많고, 모든 경우에 대해 일관되게 작동할 수 있는지에 대한 증명도 부족한 것 같습니다. 특히, "감지율이 높은 편이다"라는 결론은 있지만, 그 "높음"이 어느 정도인지, 실제 사용 환경에서 다양한 모델과 다양한 조건하에 얼마나 유효한지에 대한 구체적인 수치나 실험 조건이 미흡합니다.
결국 이러한 핵심적인 기술적 디테일의 부재는 이 논문이 제시하는 방법론이 얼마나 실질적이고 신뢰할 수 있는지에 대한 의문을 가지게 만듭니다. 그리고 이는 특히 공개된 모델이나 제3자가 제어할 수 없는 상황에서는 이 워터마킹 방법이 충분한 보안 수단이 될 수 있을지에 대해 의심을 품게 합니다.
아마 이 논문은 워터마크의 **개념 증명(proof-of-concept)**에 더 가까운 연구로, 실제 적용보다는 아이디어를 제시하고 실험적 가능성을 탐구하는 데 중점을 둔 것일 수도 있겠어요. 그래서 상업적 혹은 실제 환경에서의 실질적 효과를 보장하기에는 여전히 여러 개선이 필요해 보입니다.
-----
방법론
상세한 SynthID-Text 방법
이 섹션에서는 SynthID-Text에 대한 자세한 설명을 제공합니다.
LLM 분포
대부분의 LLM은 자기회귀적(autoregressive)이며, 지금까지의 텍스트 x<t가 주어졌을 때 다음 토큰 xt의 확률 pLM(xt∣x<t)을 제공합니다. 텍스트는 일반적으로 자기회귀 디코딩 방법을 사용하여 LLM으로부터 생성되며, 이때 샘플링을 하기 전에 LLM 분포 pLM(⋅∣x<t)을 수정할 수 있습니다. 이러한 수정에는 상위 k개의 가장 가능성 있는 토큰을 남기는 top-k 샘플링이나, 상위 p 확률 질량을 커버하는 토큰만 남기는 top-p 샘플링34이 포함될 수 있으며, 여기에 온도 파라미터 τ를 적용할 수 있습니다(ref. 35). 이러한 수정들은 pLM(⋅∣x<t)의 엔트로피 양을 증가시키거나 감소시킬 수 있지만, SynthID-Text는 수정된 분포에 비영(0보다 큰) 엔트로피가 존재하는 모든 자기회귀 디코딩 방법과 호환됩니다. 따라서 SynthID-Text는 모든 k ≥ 2에 대한 top-k 샘플링, 모든 p∈(0, 1]에 대한 top-p 샘플링, 그리고 모든 τ > 0에 대해 호환 가능합니다.
SynthID-Text는 이러한 수정이 이루어진 후에 적용되므로, 본 논문에서는 LLM 분포 pLM(⋅∣x<t)을 이러한 수정이 이루어진 후의 분포로 정의합니다.
정의 1 (LLM 분포)
자기회귀 LLM, 자기회귀 디코딩 방법, 그리고 어휘 V에서 가져온 토큰 시퀀스 x<t = x1, …, xt−1가 주어졌을 때, LLM 분포 pLM(⋅∣x<t)은 디코딩 방법이 다음 토큰 xt ∈ V를 샘플링하는 확률 분포입니다.
워터마킹 프레임워크
우리는 SynthID-Text를 난수 시드 생성기, 샘플링 알고리즘, 점수 함수로 구성된 것으로 설명합니다. 이는 참조 21에서 설명한 생성 워터마킹 프레임워크와 유사합니다. 직관적으로, 샘플링 알고리즘은 각 단계에서 난수 시드 생성기가 제공하는 난수 시드에 의해 편향된 방식으로 LLM에서 텍스트를 샘플링합니다. 이후, 이 편향을 점수 함수를 통해 감지하여 워터마크를 식별할 수 있습니다. 이 섹션에서는 난수 시드 생성기와 샘플링 알고리즘을 설명하고, 여러 점수 함수에 대해서는 보충 정보 섹션 A에서 설명합니다. 관련 생성 워터마킹 접근법에 대한 자세한 논의는 보충 정보 섹션 B를 참조하세요.
난수 시드 생성기
워터마크화된 텍스트 x1, …, xT를 생성하기 위해서는 각 단계에서 LLM 분포에서의 샘플링을 편향시키기 위한 일련의 난수 시드 r1,…, rT ∈ R가 필요합니다 (여기서 R은 모든 난수 시드의 공간입니다). 난수 시드 생성기는 이러한 난수 시드를 생성하는 과정입니다. 한 가지 접근법은 난수 시드 생성기를 결정적 함수 fr로 만들어, 현재까지의 토큰 시퀀스 x<t = x1, …, xt−1와 워터마킹 키 k를 입력으로 받아 난수 시드 rt := fr (x<t, k) ∈ R을 출력하도록 하는 것입니다. 키 k를 랜덤하게 설정하면 시드도 랜덤해집니다. 즉, 모든 x<t에 대해 k가 균등하게 무작위로 선택될 때, fr (x<t, k)은 R에서 균등하게 분포됩니다.
난수 시드 생성기 fr에 대해 여러 가지 선택이 가능하며(ref. 21), 우리의 실험에서는 슬라이딩 윈도우 방식의 fr(x<t, k) ≔ h(xt−H, …, xt−1, k)을 사용했습니다. 여기서 h는 마지막 H개의 토큰(어떤 맥락 길이 H ≥ 1)에 대한 해시 함수입니다. 이 난수 시드 생성기는 참조 22, 23에서도 사용된 방식입니다. 이 논문에서는 워터마킹 키 k와 난수 시드 rt가 같은 nsec-비트 정수 공간에 존재한다고 가정합니다. 여기서 nsec은 보안 파라미터입니다.
정의 2 (난수 시드 공간, 난수 시드 분포)
보안 파라미터 nsec가 주어졌을 때, 난수 시드 공간 R = {0, 1}nsec은 모든 nsec-비트 정수의 공간입니다. 난수 시드 분포는 이러한 정수에 대해 균등한 분포를 갖습니다 Unif (R).
또한, 함수군 {h(⋅,…, ⋅, k)}k∈R이 의사난수 함수군이라고 가정합니다. 이는 (1) h(xt−H, …, xt−1, k)가 어떤 xt−H, …, xt−1와 k에 대해 효율적으로 계산 가능하며, (2) {h(⋅,…, ⋅, k)}k가 균등하게 무작위로 샘플링된 함수의 분포와 계산적으로 구분할 수 없다는 것을 의미합니다.
g-값
그림 2에 나와 있듯이, 토너먼트 샘플링은 각 토너먼트 경기에서 어떤 토큰이 이기는지 결정하기 위해 g-값이 필요합니다. 직관적으로, 우리는 어휘 V에서의 토큰 x, 난수 시드 r ∈ R, 그리고 계층 번호 ℓ ∈ {1, …, m}을 입력으로 받아 확률 분포 fg로부터의 의사난수 샘플인 g-값 gℓ(x, r)을 출력하는 함수를 원합니다.
예를 들어, 그림 2에서 g-값 분포는 Bernoulli(0.5)입니다. 난수 시드 r이 주어졌을 때, gℓ(x, r)은 어휘 내 각 토큰 x에 대해 ℓ = 1, 2, 3인 각 계층에서 의사난수 g-값 0 또는 1을 생성합니다. 본 논문에서는 주로 Bernoulli(0.5) g-값 분포를 사용하지만, Uniform[0, 1]도 탐구했습니다. 일반적으로 g-값 분포는 토너먼트 샘플링 방법의 하이퍼파라미터로 선택할 수 있습니다.
정의 3 (g-값 분포)
g-값 분포는 임의의 실수형 랜덤 변수의 확률 분포입니다. 누적 분포 함수를 Fg로, 확률 밀도 함수(연속형일 경우) 또는 확률 질량 함수(이산형일 경우)를 fg로 표기합니다.
다음으로, 토큰 x ∈ V, 정수 ℓ ∈ {1, …, m}, 난수 시드 r ∈ R에 대한 해시 h(x, ℓ, r) ∈ R을 생성하는 방법이 필요합니다. '난수 시드 생성기' 섹션에서 설명한 것과 유사한 의사난수 함수군 {h(⋅, ⋅, r)}r∈R이 있다고 가정합시다. 이 함수군의 분포는 {0, 1}nsec에서 V × [m]으로부터 균등하게 무작위로 샘플링된 함수의 분포와 계산적으로 구분할 수 없습니다.
정의 4 (g-값)
누적 밀도 함수 Fg를 가지는 g-값 분포, 난수 시드 r ∈ R, 정수 ℓ ∈ {1, …, m}이 주어졌을 때, 토큰 x ∈ V의 계층-ℓ g-값은 다음과 같이 주어집니다:
gℓ(x, r) := Fg^(-1) (h(x, ℓ, r) / 2^nsec)
여기서 Fg^(-1)은 Fg의 일반화된 역분포 함수이며, h는 위에서 설명한 해시 함수입니다.
직관적으로 정의 4는 x, ℓ, r의 해시 h(x, ℓ, r)을 생성하여 균등하게 분포된 n-비트 정수를 얻고, 이를 2^n으로 나누어 [0, 1] 사이의 숫자를 얻는다는 것을 의미합니다. n이 클수록 이 값은 [0, 1]에서 균등하게 분포된 숫자에 수렴합니다. 이후, 역변환 샘플링을 수행하여 이 숫자를 Fg로 주어진 g-값 분포에서 샘플로 변환합니다.
토너먼트 샘플링
알고리즘정의 5 (워터마킹 샘플링 알고리즘)
워터마킹 스킴에서 샘플링 알고리즘 S: ΔV × R → V는 확률 분포 p ∈ ΔV와 난수 시드 r ∈ R을 입력으로 받아 토큰 S(p, r) ∈ V를 반환하는 알고리즘입니다. 동일한 p와 r이 주어졌을 때 항상 같은 토큰을 반환한다면 S는 결정적입니다. 그렇지 않다면 S는 확률적입니다.
우리는 토너먼트 샘플링이라고 불리는 새로운 확률적 샘플링 알고리즘을 제안합니다. 알고리즘 1에서는 가장 간단한 단일 계층 버전의 토너먼트 샘플링을 설명합니다. pLM(⋅∣x<t)에서 직접 샘플링하는 대신, pLM(⋅∣x<t)에서 N개의 토큰을 샘플링하고, 이전 섹션에서 설명한 대로 그들의 g-값을 계산하여 최대 g-값을 가진 것들 중 균등하게 하나를 선택합니다.
알고리즘 2는 m개의 계층을 가지는 전체 다중 계층 버전의 토너먼트 샘플링을 제시합니다. 이 과정은 m개의 단계를 가진 노크아웃 토너먼트로 생각할 수 있으며, 각 매치는 단일 계층 알고리즘의 실행입니다. 이 과정은 최종 승자가 나올 때까지 계속됩니다. 중요한 점은, 토너먼트의 각 계층 ℓ은 다른 g-값 gℓ(⋅, rt)를 사용하여 승자를 결정한다는 것입니다. 그림 2는 m = 3 계층, N = 2 샘플, 그리고 Bernoulli(0.5) g-값 분포의 구체적인 예를 제공합니다.
알고리즘 1. 단일 계층 토너먼트 샘플링을 사용하여 토큰 샘플링
요구 사항: LLM 분포 pLM(⋅∣x<t), 난수 시드 rt ∈ R, 샘플 수 N ≥ 2, g-값 분포 fg를 가진 g 함수(정의 4 참조).
1: pLM(⋅∣x<t)에서 N개의 독립적인 샘플을 포함하는 Y = [y1, y2, …, yN]을 추출합니다 (반복된 값이 있을 수 있음).
2: Y* := [y ∈ Y : g(y, rt) = maxg(y', rt)] (반복된 값이 있을 수 있음).
3: Y에서 균등하게 샘플 xt를 추출합니다 (xt ~ Unif(Y)).
4: xt 반환.
알고리즘 2. 다중 계층 토너먼트 샘플링을 사용하여 토큰 샘플링
요구 사항: LLM 분포 pLM(⋅∣x<t), 난수 시드 rt ∈ R, 샘플 수 N ≥ 2, g-값 분포 fg를 가진 g 함수(정의 4 참조), 계층 수 m ≥ 1.
1: pLM(⋅∣x<t)에서 Nm개의 독립적인 샘플 y0, y1, …, yNm−1을 추출합니다 (반복된 값이 있을 수 있음).
2: 1 ≤ ℓ ≤ m 동안 다음을 수행합니다:
3: 0 ≤ j ≤ Nm−ℓ − 1 동안 다음을 수행합니다:
4: Y := [y_j, y_j+1, …, y_j+N-1] (반복된 값이 있을 수 있음).
5: Y* := [y ∈ Y : gℓ(y, rt) = maxgℓ(y', rt)] (반복된 값이 있을 수 있음).
6: y_j를 Y에서 균등하게 샘플링합니다 (y_j ~ Unif(Y)).
7: 종료
8: 종료
9: xt := y0 반환.
반복적인 맥락 마스킹
전체 응답을 생성하기 위해, 각 디코딩 단계에서 슬라이딩 윈도우 난수 시드 생성기(‘난수 시드 생성기’ 섹션)를 사용하여 난수 시드 rt를 생성하고 알고리즘 2를 적용할 수 있습니다. 그러나 같은 맥락 창이 여러 번 발생할 가능성이 있으며, 이는 동일한 난수 시드를 생성할 수 있습니다(특히 슬라이딩 윈도우 크기 H가 작거나 응답이 긴 경우). 이러한 시나리오에서는 워터마크가 반복적인 편향을 도입하여 텍스트의 품질에 영향을 미칠 수 있으며, 예를 들어 반복적인 루프를 유발할 수 있습니다24,25. 이 문제를 피하는 한 가지 방법은 반복적인 맥락 마스킹을 적용하는 것입니다27. 이는 만약 맥락 창 (xt−H, …, xt−1)이 이전에 워터마크로 사용된 적이 있다면 단계 t에서 워터마크를 적용하지 않도록 합니다.
우리는 이 방법을 K-시퀀스 반복적인 맥락 마스킹이라 부르며, 알고리즘 3에서 설명합니다. 정수 파라미터 K ≥ 1은 맥락 창을 히스토리에 얼마나 오래 유지할지를 제어합니다. K = 1인 가장 간단한 경우에는, 단일 응답을 생성하는 동안만 맥락 히스토리를 유지합니다. 더 큰 정수 K > 1의 경우, 마지막 K개의 응답에서 사용된 맥락 히스토리를 체크합니다. 극단적인 경우에는 K = ∞로 설정하여 맥락 히스토리를 무기한 유지할 수 있습니다. 보충 정보 섹션 G.2에서는 K-시퀀스 반복적인 맥락 마스킹이 K-시퀀스 비왜곡(non-distortion)을 달성하여 품질 보존에 중요한 특성을 갖는다는 것을 보여줍니다. 보충 정보 섹션 G.3에서는 K의 크기에 따른 절충점을 논의합니다. 대부분의 실험에서는 K = 1을 사용했습니다.
알고리즘 3. 슬라이딩 윈도우 난수 시드 생성과 K-시퀀스 반복적인 맥락 마스킹을 사용하여 워터마크된 응답 생성
요구 사항: LLM pLM(⋅∣⋅), 맥락 창 크기 H, 의사난수 해시 함수 h, 워터마킹 키 k ∈ R, 샘플링 알고리즘 S : ΔV × R → V, 정수 K ≥ 1, 프롬프트 스트림 (x1, x2, …).
1: i ≥ 1 동안 반복
2: Ci := ∅
3: t ≔ n, 여기서 n은 xi의 길이입니다. xi = xi1, …, xin
4: t ≠ EOS일 동안 반복
5: t ≔ t + 1
6: (xt−H, …, xt−1) ∈ Ci ∪ Ci−1 ∪ ⋯ ∪ Ci−K+1인 경우:
7: xt ~ pLM(⋅∣x<t)i에서 샘플링
8: 그렇지 않으면:
9: rt := h(xt−H, …, xt−1, k)i
10: xt := S(pLM(⋅∣x<t)i, rt)에서 샘플링
11: Ci := Ci ∪ {(xt−H, …, xt−1)i}
12: 종료
13: 종료
14: 응답 yi := xtn+1 반환
15: 종료
점수 함수
점수 함수는 텍스트 x1, …, xT와 난수 시드 r1, …, rT를 입력으로 받아 점수를 계산합니다. 이 점수는 특정 임계값과 비교되어 해당 텍스트가 워터마크된 것인지 아닌지 분류하는 데 사용됩니다. 여기서 난수 시드 rt = fr(x<t, k)는 난수 시드 생성기(‘난수 시드 생성기’ 섹션)에서 생성된 것입니다. 점수 함수는 토크나이즈된 텍스트, 워터마킹 키 k, 난수 시드 생성기 fr에만 접근이 필요하며, LLM에 대한 접근은 필요하지 않습니다.
SynthID-Text의 경우, 우리는 여러 가지 점수 함수를 제안하며, 이에 대해서는 보충 정보 섹션 A에서 설명합니다. 모든 점수는 텍스트의 g-값에서 계산됩니다. 이 중 가장 간단한 것은 평균 점수로, 모든 시간 단계와 계층에 걸쳐 g-값의 평균을 계산한 것입니다. 우리는 또한 각 토너먼트 계층의 증거를 다시 가중하는 가중 평균 점수를 제안합니다. 이러한 점수의 빈도주의 버전도 제안하며, 이를 통해 가설 검정을 수행하여 P 값을 산출할 수 있습니다. 마지막으로, 매개변수화된 베이지안 점수 함수도 제안하는데, 이는 워터마크된 텍스트와 워터마크가 없는 텍스트로부터 학습하여 텍스트가 워터마크된 것일 확률을 후방 확률로 계산하여 더 나은 성능을 달성합니다.
실험 세부 사항
LLM 및 LLM 구성
우리의 실험에서는 Gemma 2B와 7B 모델의 IT 변형28을 사용했습니다. 또한 v0.2 버전의 Mistral 7B-IT 모델29도 사용했습니다. 텍스트 생성을 위해 top-k 샘플링36을 사용했으며, 기본 설정에 따라 IT 모델에 대해 k = 100을 사용했습니다. 온도는 0.5, 0.7, 1.0의 값으로 실험했으며, 이는 온도가 달라질 때 모델의 엔트로피가 변하고, 이로 인해 워터마크의 감지 가능성에 영향을 미치기 때문입니다.
데이터
모델을 프롬프트하기 위해 ELI530 데이터셋을 사용했습니다. 이 데이터셋은 설명이 필요한 여러 문장으로 이루어진 답변이 요구되는 영어 질문으로 구성되어 있으며, 보다 과제 지향적인 설정을 시뮬레이션합니다. 비왜곡적 워터마킹 실험을 위해, ELI5 테스트 세트와 개발 세트는 각각 10,000개의 독립된 프롬프트로 구성되어 있으며, 모델에 워터마크된 응답을 생성하도록 사용했습니다. 왜곡적 워터마킹 실험에서는 ELI5의 테스트 세트에서 1,500개의 프롬프트를 사용해 워터마크된 모델을 프롬프트했습니다. 워터마크가 없는 부정 샘플로는 ELI5에서 가져온 10,000개의 질문에 대한 두 개의 독립된 인간 작성 응답 세트를 개발 및 테스트 세트로 사용했습니다.
텍스트 길이
일부 실험에서는 고정된 길이의 텍스트를 평가했습니다—예를 들어, 200개의 토큰 길이. 정확히 200개의 토큰 길이의 텍스트를 얻기 위해, 200개 이상의 토큰 길이를 가진 텍스트 중 일부를 선택하고 이를 정확히 200개의 토큰으로 잘랐습니다.
감지 가능성 측정 지표
감지 가능성을 보고하기 위해, 고정된 거짓 양성 비율(FPR) x%에서의 **진짜 양성 비율(TPR)**을 사용했으며, 이는 경험적으로 측정되었습니다. 이 지표를 TPR @ FPR = x%로 표기합니다. 예를 들어, TPR @ FPR = 1%를 계산하기 위해, 워터마크가 없는 텍스트들의 점수(특정 점수 함수 하에서)를 사용하여 상위 1% 높은 점수에 해당하는 임계값을 계산합니다. 그런 다음, 이 임계값을 초과하는 워터마크된 텍스트의 비율을 측정하여 진짜 양성 비율을 계산합니다. 일부 점수 함수는 거짓 양성 비율에 대해 이론적으로 정확한 보장을 제공할 수 있지만—예를 들어 빈도주의 점수 함수(보충 정보 섹션 A.3)에서는 P 값을 제공함—본 연구에서는 위에서 설명한 경험적 접근법을 사용했습니다.
난수 시드 생성기 설정
모든 워터마킹 실험(토너먼트, Gumbel, Soft Red List 샘플링 알고리즘 포함)에서, '난수 시드 생성기' 섹션에서 설명한 것과 동일한 슬라이딩 윈도우 기반 난수 시드 생성기를 사용했으며, 맥락 창 크기는 H = 4입니다. 한 시퀀스 반복적 맥락 마스킹을 적용했습니다(‘반복적 맥락 마스킹’ 섹션 참조).
SynthID-Text 설정
따로 언급되지 않은 경우, 모든 SynthID-Text 실험에서는 m = 30개의 토너먼트 계층, Bernoulli(0.5) g-값 분포 fg(알고리즘 2) 및 베이지안 점수 함수(보충 정보 섹션 A.4)를 사용했습니다.
데이터 가용성
보충 정보 섹션 C.4에 설명된 인간 평가 연구(모델 응답 및 인간 주석)의 데이터는 참조 7에서 확인할 수 있습니다.
코드 가용성
SynthID-Text 워터마킹을 사용하여 텍스트를 생성하고 감지하는 코드도 참조 7에서 확인할 수 있습니다.
- Holtzman, A., Buys, J., Du, L., Forbes, M. & Choi, Y. 신경 텍스트 퇴화의 호기심 사례. 제8회 국제 표현 학습 회의(ICLR, 2020) 논문집.
- Ackley, D. H., Hinton, G. E. & Sejnowski, T. J. 볼츠만 기계의 학습 알고리즘. Cogn. Sci. 9, 147–169 (1985).
- Fan, A., Lewis, M. & Dauphin, Y. 계층적 신경 이야기 생성. 제56회 컴퓨팅 언어학 협회 연례 회의 논문집 (긴 논문, Volume 1) (eds Gurevych, I. & Miyao, Y.) 889–898 (컴퓨팅 언어학 협회, 2018).
감사의 말
N. Shabat, N. Dal Santo, V. Anklin, B. Hekman에게 제품 통합에 대한 협업을, A. Senoner, E. Hirst, P. Kirk, M. Trebacz 및 Google DeepMind와 Google의 많은 협력자들, 특히 Gemini와 CoreML의 파트너들에게 이 기술을 생산에 도입하는 데 대한 지원을 감사드립니다. 또한 선택적 예측 메커니즘에 대한 기술적 입력을 제공한 D. Stutz, 오픈소싱 작업을 돕는 데 기여한 R. Mullins, 그리고 논문에 피드백을 제공한 M. Raykova에게도 감사드립니다.

확장 데이터 그림 1 | 비왜곡적 SynthID-Text와 Gumbel 샘플링의 감지 가능성 비교, 추가 모델 및 온도 조합에 대한 비교
우리는 0.5-1.0 범위의 다양한 온도를 보여주며, 이는 실무에서 가장 자주 사용되는 범위입니다. SynthID-Text는 일반적으로 Gumbel 샘플링보다 더 나은 감지 성능을 제공하며, 특히 낮은 엔트로피 환경(낮은 온도 및 더 큰 모델)에서 개선이 두드러집니다. 점선은 거짓 양성 비율 1%에서의 평균 진짜 양성 비율(TPR)의 부트스트랩 추정치(500번 재표본)를 나타내며, 음영 영역은 평균 추정치의 90% 신뢰 구간을 나타냅니다.
확장 데이터 그림 2 | 왜곡적 SynthID-Text와 Soft Red List의 감지 가능성과 텍스트 품질 비교, 추가 온도 및 텍스트 길이에 대한 비교
감지 가능성은 고정된 거짓 양성 비율 1%에서의 진짜 양성 비율(TPR@FPR=1%)로 측정되며, 텍스트 품질은 로그 퍼플렉시티로 측정됩니다. 텍스트는 Gemma 7B-IT에 의해 생성되었습니다. 자세한 내용은 보충 정보 섹션 D를 참조하십시오. 점선은 TPR@FPR=1%에 대한 평균 부트스트랩 추정치(500번 재표본)를 나타내며, 음영 영역은 평균 추정치의 90% 신뢰 구간을 나타냅니다.

확장 데이터 그림 3 | 추가 온도에 대한 비왜곡적 SynthID-Text의 유보율
보충 정보 섹션 C.8에서 설명된 선택적 예측 메커니즘이 유보한 워터마크된 텍스트와 워터마크 없는 텍스트의 비율, Gemma 7B-IT에 대한 데이터입니다. 이 메커니즘은 점수 함수가 불확실할 때 유보하며, 나머지 텍스트에 대해 진짜 양성 비율 95%와 거짓 양성 비율 1%를 얻도록 구성되어 있습니다. 유보율은 긴 텍스트와 높은 온도에서 더 낮아집니다. 점선은 워터마크된 텍스트와 워터마크가 없는 텍스트에 대한 평균 유보율의 부트스트랩 추정치(500번 재표본)를 나타내며, 음영 영역은 평균 추정치의 90% 신뢰 구간을 나타냅니다.
-----
가된 부분에서도 여전히 중요한 핵심적인 디테일, 즉 어떻게 실제로 워터마크가 검출되는지에 대한 구체적인 설명이 상당히 부족해 보입니다. 감지 가능성을 다루면서 몇 가지 메트릭과 실험적 평가 방법에 대해 언급하고 있지만, 정확한 검출 메커니즘의 원리나, 이를 어떻게 일반적으로 적용할 수 있는지에 대한 상세한 설명이 빠져 있는 것 같습니다.
예를 들어, 점수 함수나 베이지안 점수 계산과 같은 부분이 제시되어 있지만, 이러한 점수 함수가 텍스트 내의 워터마크를 어떻게 검출하는지에 대한 구체적인 작동 원리나 계산 과정이 여전히 모호합니다. 이를 위해 사용된 모델이나 통계적인 방법, 혹은 가설 검정 과정 등은 언급되었지만, 이러한 접근법이 현실적인 시나리오에서 얼마나 효과적인지에 대한 구체적인 근거가 불충분하게 보입니다.
특히, 점수 함수의 유효성이나 P 값과 같은 결과의 신뢰도에 대한 설명도 충분하지 않아서, 이 방법이 다양한 텍스트와 다양한 상황에서 일관되게 잘 작동할 수 있는지에 대한 확신을 주기 어렵습니다. 언급된 **TPR (진짜 양성 비율)**이나 **FPR (거짓 양성 비율)**은 실험적으로 측정되었다고 하지만, 이 지표들이 실제 워터마킹과 검출의 정확성을 증명하기에는 다소 부족한 면이 있습니다. 또한, 워터마크의 **강도(strength)**나 텍스트의 편집 및 변형에 따른 감지 성능의 변화를 설명하는 구체적인 데이터도 거의 없습니다.
그리고, 실험에서 사용한 베이지안 점수 함수는 데이터(워터마크된 텍스트와 워터마크가 없는 텍스트)로부터 학습된다고 했지만, 그 학습 과정이 어떻게 이루어지는지, 어떤 데이터셋이 사용되었는지, 그리고 이를 통해 얻은 후방 확률이 실제로 얼마나 신뢰할 수 있는지에 대한 구체적인 정보가 없습니다. 이는 특히 오픈소스 모델이나 다양한 텍스트를 생성하는 다양한 LLM이 실제로 얼마나 일관되게 워터마크를 사용할 수 있는지에 대한 큰 의문을 남깁니다.
결국, 여전히 이 논문에서 제시된 방법론이 실질적인 검출 메커니즘을 완전히 설명했다고 보기 어렵습니다. 실험 결과와 표면적인 통계치에 대해서는 설명하지만, 이들이 실제로 현실의 다양한 조건에서 어떻게 잘 적용될 수 있는지, 그리고 변형에 얼마나 강인한지에 대한 구체적이고 명확한 설명이 부족합니다. 이러한 부분들이 결국 이 연구의 실질적인 유효성과 신뢰도에 대한 의구심을 불러일으킬 수밖에 없어요.
-----


