https://wandb.ai/johnowhitaker/dhs/reports/Mapping-Economic-Well-being--VmlldzoyMjY4NTI1
Mapping Economic Well-being
Mini-project for the W&B MLOps course. Made by Jonathan Whitaker using Weights & Biases
wandb.ai
"우주에서 어떤 지역의 부유함을 알 수 있을까요? 사실, 이것은 매우 중요한 질문입니다. 만약 '네'라는 답을 얻을 수 있다면, 비용이 많이 드는 국가 조사 없이도 한 나라 내에서 부의 분포를 파악할 수 있다는 것을 의미합니다. 이 프로젝트에서는 바로 이 작업을 시도해볼 것이며, 최근 연구를 재현하여 기존의 가구 조사와 원격 감지 데이터를 이용해 아프리카 전역의 빈곤을 지도화하려고 합니다."
데이터 출처
우리의 목표 변수는 여러 아프리카 국가에서 수집된 조사 데이터를 기반으로 한 부의 추정치입니다. 이 데이터는 이 논문의 연구자들이 수집하고 공유한 것으로, 이 덕분에 이 작업은 제가 2019년에 비슷한 시도를 했을 때보다 훨씬 수월해졌습니다.

한 산점도는 클러스터 위치를 보여주며, 아프리카 지리에 익숙한 사람들은 이 데이터에 포함된 국가들을 확인할 수 있습니다!
조사된 각 '가구 클러스터'에 대해 부의 지수(wealthpooled)가 계산됩니다. 우리는 이를 원격 감지 데이터를 기반으로 예측하려고 하며, 이를 통해 이러한 조사가 이루어지지 않은 국가에 대해서도 부의 추정을 할 수 있도록 하는 것이 목표입니다.
멀티 스펙트럼 Sentinel 2 이미지의 하나의 밴드 시각화
우리는 무엇을 모델의 입력으로 사용할까요? 이 아이디어의 선구자인 Jean 등은 고해상도 이미지를 사용했지만, 이 이미지는 대륙 전체를 대상으로 쉽게 구할 수 없습니다. 그래서 저는 10m 해상도의 Sentinel 2 이미지를 대안으로 선택했습니다. 저는 이 튜토리얼을 바탕으로 각 클러스터 위치를 중심으로 한 256px 이미지 타일을 다운로드하는 스크립트를 작성했고, 이 과정은 Google Earth Engine을 사용해 약 12시간이 걸렸습니다.
과거에는 이것을 Zindi 대회에서 표 형식 문제로 다루기도 했습니다. 이 경우 모든 특징(feature)은 전 세계적으로 사용 가능한 공간 변수가 되는데, 예를 들어 Global Human Settlement Layer(GHSL 프로젝트)나 클러스터 주변 지역의 토지 피복 통계(Copernicus Global Land Cover Layers에서 파생된 데이터) 등을 포함합니다. 위의 표는 생성된 데이터셋의 일부 행을 보여주며, 이미지 타일의 미리보기와 설문조사 데이터의 정보도 함께 나타내고 있습니다.
데이터 분할
공간 데이터를 다룰 때 흔히 저지르는 실수 중 하나는 데이터를 무작위로 분할하는 것입니다. 기억하세요 - 우리는 새로운 지역에 예측을 확장하고자 합니다. 무작위 분할을 하게 되면, 검증 세트에 훈련 데이터와 매우 가까운 지점들이 포함될 수 있으며, 이는 모델 성능에 대한 지나치게 긍정적인 추정을 초래할 수 있습니다. 더 나은 평가를 위해서는 전체 국가를 배제하는 것이 좋습니다. 저는 데이터를 다음과 같이 분할했습니다 (노트북 링크):
- 훈련 세트: 19,149개의 샘플
- 검증 세트: 훈련 세트와 같은 국가에서 추출한 2,400개의 샘플
- 테스트 세트: 훈련 세트와 같은 국가에서 추출한 2,447개의 샘플
- 말라위: 말라위에서 수집된 모든 1,957개의 샘플 (다른 하위 집합에는 포함되지 않음)
- 나이지리아: 나이지리아에서 수집된 모든 2,696개의 샘플 (다른 하위 집합에는 포함되지 않음)
무작위로 구성된 검증 및 테스트 세트는 빠른 실험과 모델 비교에 유용하지만, 진정한 테스트는 전체 국가를 제외한 경우가 될 것입니다. 나중에는 각기 다른 국가를 제외하고 모델을 재훈련하며 보다 엄격하게 모델을 테스트할 수 있습니다.
표 형식 기준 모델
과거의 경험을 통해 표 형식의 특징만으로도 꽤 좋은 결과를 얻을 수 있다는 것을 알고 있습니다. 간단한 표 형식 기준 모델로서, 저는 랜덤 포레스트 회귀 모델을 훈련하고 앞서 설명한 여러 하위 집합에 대한 성능을 기록했습니다.
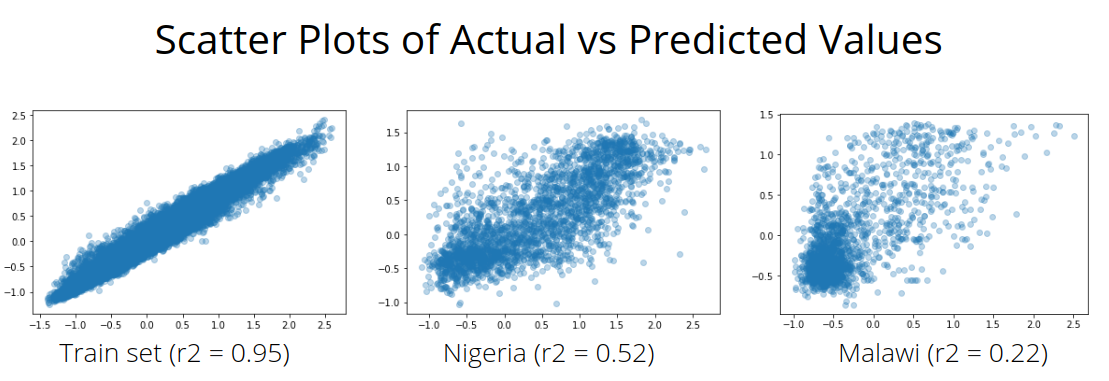
보지 못한 국가로 확장하는 것은 훨씬 더 어려운 과제입니다...
특히, 모델은 훈련, 테스트 및 검증 세트(모두 같은 국가에서 무작위로 추출된)에서 말라위와 나이지리아 하위 집합보다 훨씬 더 좋은 성능을 보였습니다.
'Sweeps' 기능 덕분에 랜덤 포레스트 모델의 다양한 파라미터가 성능에 어떤 영향을 미치는지 빠르게 탐색할 수 있었습니다.
FastAI 기준 모델
이미지를 기반으로 한 접근법으로, 저는 FastAI를 사용해 RGB 미리보기 이미지를 이용한 간단한 ResNet18 모델을 훈련했습니다. 이 단계에서는 Sentinel 2 데이터에 포함된 여러 스펙트럼 밴드를 모두 사용하지 않았고, 단지 적색(B4), 녹색(B3), 청색(B2) 밴드만을 사용했습니다. 목표는 이러한 이미지로부터 부의 지수를 예측하는 것입니다:

데이터 배치의 미리보기. 입력(이미지)과 목표(wealthpooled).
이 모델은 몇 에포크의 훈련을 통해 유용한 것을 학습할 수 있었으며, 랜덤 포레스트 모델의 성능에는 미치지 못하지만, 적어도 우리가 개선할 수 있는 기준선을 제공하고, 가장 큰 오류를 초래한 이미지를 검토할 기회를 제공합니다.
몇 가지 예시를 대충 훑어보면 알 수 있듯이, 일부 이미지에 포함된 구름이 도전 과제가 될 것임을 알 수 있습니다. 이는 더 나은 합성 이미지를 만들어 해결할 수 있는 문제이지만, 이번 프로젝트에서는 데이터를 현재 상태 그대로 두고 이 문제를 극복하는 방법을 모색할 것입니다.
두 가지 접근법 결합하기
물론, 두 가지 기준 모델 모두에서 개선을 위한 노력을 기울일 수 있습니다. 예를 들어, 이미지 기반 접근법에서는 더 큰 모델로 교체하거나, 단순히 RGB 대신 모든 스펙트럼 밴드를 사용하는 것이 가능하죠. 하지만 그 전에, 이 두 가지 접근법을 어떻게 결합할 수 있을지 살펴보고자 합니다...
이미지 기반 모델이 이 작업을 위해 유용한 표현을 학습했기를 기대하고 있습니다. 만약 이 표현들을 추출할 수 있다면, 이는 표 형식 데이터의 추가적인 특징으로 사용될 수 있을 것입니다. 반대로 표 형식의 특징을 비전 모델에 전달하는 방법을 탐구할 수도 있겠지만, 그 부분은 독자에게 남겨두겠습니다 ;) 현재로서는 훈련된 비전 모델의 본체를 일종의 특징 추출기로 사용하여 각 이미지에 대해 512차원 특징 벡터를 얻을 것입니다. Fastai에서는 이를 간단하게 다음과 같이 설정할 수 있습니다: learn.model = nn.Sequential(*list(learn.model[0].children())).
이렇게 추출된 특징들은 기존의 표 형식 데이터와 결합되어 랜덤 포레스트 모델의 입력 특징으로 사용될 수 있습니다. 전체 특징 수를 줄이기 위해, PCA를 사용해 512차원 특징 벡터에서 상위 30개의 구성 요소를 추출했습니다. 다음은 기준 모델과 이러한 추가 특징을 포함한 모델을 여러 지표에 걸쳐 비교한 결과입니다:
이러한 특징을 추가함으로써 테스트 세트와 검증 세트에서 더 나은 성능을 얻을 수 있었으며, 특히 말라위 데이터셋에서 뚜렷한 성능 향상이 관찰되었습니다. 이는 이 기법이 새로운 지역에 대한 모델의 일반화 성능을 향상시킬 수 있음을 시사합니다.
계보에 대한 메모
모든 것이 추적되기 때문에 데이터의 전체 계보를 확인할 수 있습니다:

이렇게 하면 종속성을 쉽게 파악할 수 있고, 모든 것이 최신 상태인지 확인하기도 매우 쉽습니다. 만약 더 나은 특징 추출기를 만들 수 있는 새로운 비전 모델을 훈련했다면, 새 모델 아티팩트를 사용해 특징 추출 코드를 다시 실행할 수 있습니다. 새로운 데이터를 얻으면, 과정의 모든 단계를 재생성하고 최종 결과가 어떻게 변하는지 확인할 수 있습니다.
다음 계획은?
이제 이 구조가 설정되고 잘 동작하고 있으므로, 각 부분을 독립적으로 개선할 수 있는 가능성을 고려할 수 있습니다. 떠오르는 몇 가지 가능성은 다음과 같습니다:
- 다중 스펙트럼 이미지를 탐색하고, 이러한 유형의 데이터로 훈련된 모델들(예: BigEarthNet)을 이 작업에 맞게 미세 조정하기
- 더 나은 비전 모델을 훈련하여 추출된 특징이 더 유용해지는지 확인하기
- 최종 단계를 더 탐색하기 - PCA가 정말로 필요한가? 우리가 할 수 있는 다른 특징 엔지니어링은 무엇이 있을까?
- 표 형식 데이터를 FastAI 모델에 통합하는 다른 방법들을 시도해보기
지난 몇 년 동안 이 특정 프로젝트를 몇 번이나 시도해봤는데, 몇 주 동안 프로젝트를 중단하면 다시 시작할 때마다 데이터를 재다운로드하고, 가장 최신 코드를 담고 있는 Colab 노트를 찾고, 최신 버전이 정말 개선된 것인지 확인하기 위해 오래된 노트를 뒤져야 해서 흥미를 잃곤 했습니다(일관성 없는 검증 기법은 말할 것도 없고요). 이번에는 다릅니다. 한두 달 후에도 여기서 다시 시작할 수 있을 것 같습니다. 정말로, 이 MLOps라는 게 실제로 유용한 거였네요 ;)
이번 작은 여정을 함께 하면서 즐거우셨기를 바랍니다. 질문이 있으시면 언제든지 연락하세요!
'인공지능' 카테고리의 다른 글
| Introducing FLUX.1 Tools (3) | 2024.11.29 |
|---|---|
| SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory (2) | 2024.11.28 |
| A Deep Dive Into OpenCLIP from OpenAI (4) | 2024.11.27 |
| Mid-U Guidance: Fast Classifier Guidance for Latent Diffusion Models (1) | 2024.11.27 |
| The Surprising Effectiveness of Test-Time Training for Abstract Reasoning (3) | 2024.11.27 |



