https://arxiv.org/abs/2411.11922
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
The Segment Anything Model 2 (SAM 2) has demonstrated strong performance in object segmentation tasks but faces challenges in visual object tracking, particularly when managing crowded scenes with fast-moving or self-occluding objects. Furthermore, the fix
arxiv.org
초록
Segment Anything Model 2 (SAM 2)는 객체 분할 작업에서 강력한 성능을 보여주었지만, 군중이 밀집된 장면에서 빠르게 움직이거나 자가 가려짐이 있는 객체들을 관리할 때 시각적 객체 추적에서 어려움을 겪고 있습니다. 또한, 원래 모델에서 사용된 고정 창 메모리 접근 방식은 다음 프레임의 이미지 특징을 조건화하기 위해 선택된 메모리의 품질을 고려하지 않기 때문에 비디오에서 오류가 축적되는 문제가 발생합니다. 이 논문은 SAM 2를 시각적 객체 추적에 특화되도록 개선한 SAMURAI를 소개합니다. 제안된 모션 인식 메모리 선택 메커니즘을 통해 시간적인 움직임 단서를 통합하여 SAMURAI는 객체의 움직임을 효과적으로 예측하고 마스크 선택을 개선함으로써 재학습이나 미세 조정 없이도 강력하고 정확한 추적을 달성합니다. SAMURAI는 실시간으로 작동하며 다양한 벤치마크 데이터셋에서 강력한 제로샷 성능을 보여주며, 미세 조정 없이도 일반화할 수 있는 능력을 입증합니다. 평가 결과, SAMURAI는 기존 추적기들에 비해 성공률과 정밀도에서 상당한 개선을 달성했으며, LaSOT에서 7.1%의 AUC 향상과 GOT-10k에서 3.5%의 AO 향상을 보여주었습니다. 또한, 완전 지도 학습 방식과 비교하여 LaSOT에서 경쟁력 있는 결과를 얻으며 복잡한 추적 시나리오에서도 견고함을 보여주고, 동적 환경에서의 실제 응용 가능성을 강조합니다. 코드와 결과는 https://github.com/yangchris11/samurai에서 확인할 수 있습니다.
1. 서론
Segment Anything Model (SAM) [26]은 세분화 작업에서 인상적인 성능을 보여주었습니다. 최근 SAM 2 [35]는 스트리밍 메모리 아키텍처를 도입하여 비디오 프레임을 순차적으로 처리하면서 긴 시퀀스 동안 문맥을 유지할 수 있게 했습니다. SAM 2는 Video Object Segmentation (VOS [46]) 작업에서 영상 시퀀스 전반에 걸쳐 객체의 정밀한 픽셀 단위 마스크를 생성하는 뛰어난 능력을 보였지만, Visual Object Tracking (VOT [36]) 시나리오에서는 여전히 한계에 직면하고 있습니다.
VOT에서의 주요 문제는 객체가 가려지거나 외형이 변하거나 유사한 객체들이 존재함에도 불구하고 일관된 객체의 정체성과 위치를 유지하는 것입니다. 그러나 SAM 2는 종종 다음 프레임의 마스크를 예측할 때 움직임 단서를 무시하는 경향이 있어, 빠르게 이동하는 객체나 복잡한 상호작용이 있는 시나리오에서는 부정확한 결과를 초래합니다. 이러한 제한점은 특히 군중이 많은 장면에서 두드러지는데, SAM 2는 공간적 및 시간적 일관성보다 외형의 유사성을 우선시하여 추적 오류를 일으키는 경향이 있습니다. 그림 1에서 볼 수 있듯이, 흔히 나타나는 두 가지 실패 패턴은 혼잡한 장면에서의 혼동과 가려짐이 발생하는 동안의 비효율적인 메모리 활용입니다.
이러한 제한점을 해결하기 위해 우리는 SAM 2의 예측 과정에 움직임 정보를 통합할 것을 제안합니다. 객체 궤적의 역사를 활용함으로써, 시각적으로 유사한 객체들을 구분하고 가려짐이 발생하는 상황에서도 추적 정확도를 유지할 수 있는 모델의 능력을 향상시킬 수 있습니다. 또한, SAM 2의 메모리 관리 최적화도 필수적입니다. 현재 방식 [35, 14]인 최근 프레임을 메모리 뱅크에 무분별하게 저장하는 것은 가려짐이 발생하는 동안 무관한 특징들을 도입하여 추적 성능을 저하시킵니다. SAM 2의 풍부한 마스크 정보를 견고한 비디오 객체 추적에 적응시키기 위해 이러한 문제를 해결하는 것이 중요합니다.
이를 위해 우리는 SAMURAI, 즉 모션 인식 인스턴스 수준 메모리를 갖춘 SAM 기반 통합적이고 견고한 제로샷 시각 추적기를 제안합니다. 제안된 방법은 두 가지 주요 개선 사항을 포함합니다: (1) 복잡한 시나리오에서 보다 정확한 객체 위치 예측을 가능하게 하는 마스크 선택을 정제하는 움직임 모델링 시스템, (2) 원래의 마스크 유사도, 객체, 움직임 점수를 결합한 하이브리드 점수 시스템을 활용하여 보다 관련성 있는 역사 정보를 보존하고 모델의 전체 추적 신뢰성을 향상시키는 최적화된 메모리 선택 메커니즘입니다.
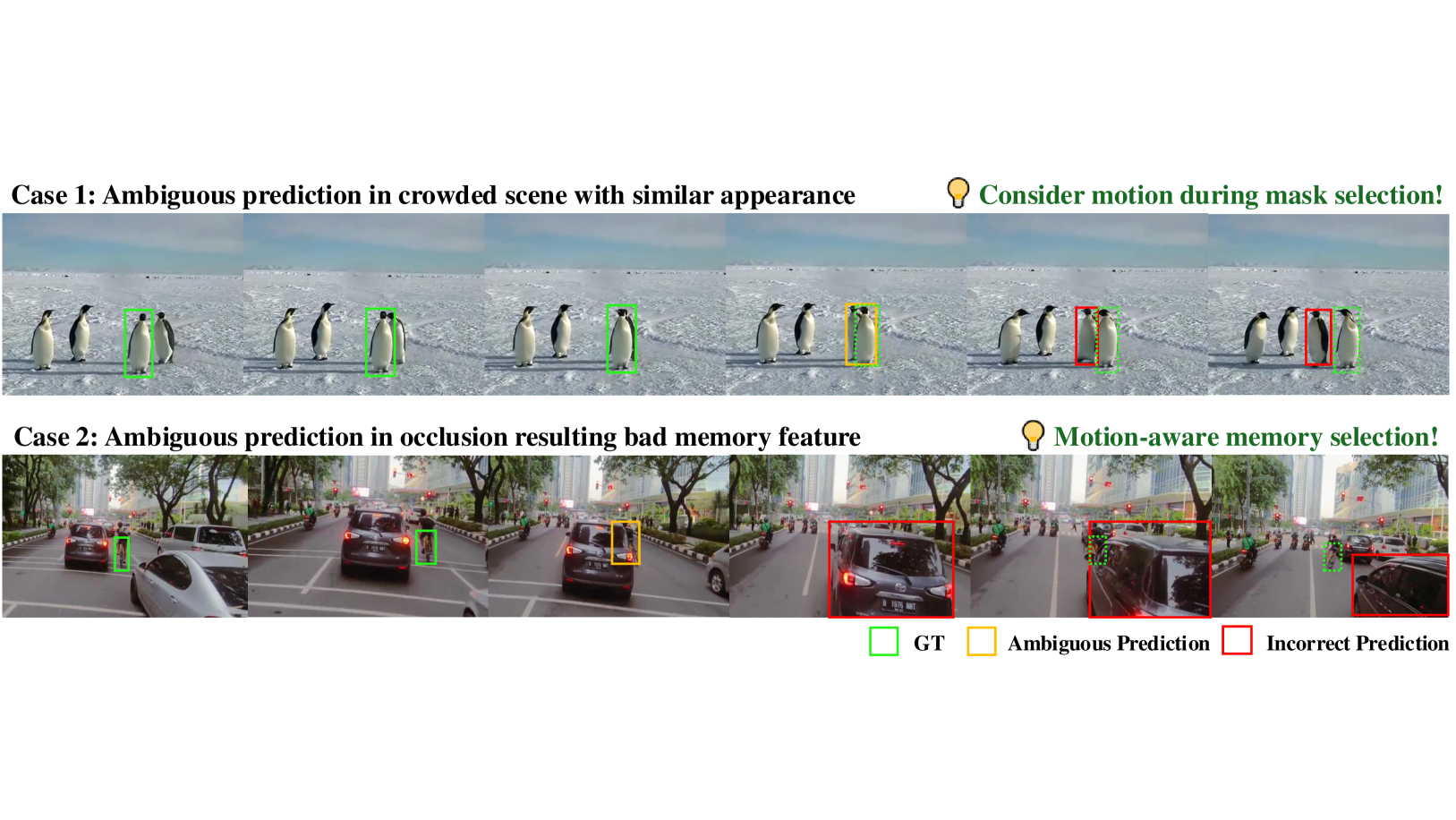
캡션 참조 그림 1: SAM 2를 사용한 시각적 객체 추적에서 흔히 발생하는 두 가지 실패 사례의 예시: (1) 목표 객체와 배경 객체의 외형이 유사한 혼잡한 장면에서 SAM 2는 움직임 단서를 무시하고 마스크의 IoU 점수가 높은 위치를 예측하는 경향이 있음. (2) 원래 메모리 뱅크는 단순히 이전 n 개의 프레임을 메모리 뱅크에 저장하여 가려짐 동안 나쁜 특징들이 도입되는 문제를 초래함.
결론적으로, 본 논문은 다음과 같은 기여를 합니다:
• 빠르게 움직이고 가려진 객체들을 효과적으로 처리하기 위해 움직임 모델링을 통해 SAM 2의 시각적 추적 정확도를 향상시켰습니다.
• 움직임 및 유사도 점수의 혼합으로 결정된 관련 프레임을 선택적으로 저장함으로써, 원래의 고정 창 메모리와는 달리 혼잡한 장면에서 오류를 줄이는 모션 인식 메모리 선택 메커니즘을 제안했습니다.
• 우리의 제로샷 SAMURAI는 추가적인 학습이나 미세 조정 없이 LaSOT, LaSOT ext , GOT-10k 및 기타 VOT 벤치마크에서 최첨단 성능을 달성하며, 제안된 모듈이 다양한 데이터셋에서 강력한 일반화를 이룰 수 있음을 입증했습니다.
2.관련 연구
2.1 시각적 객체 추적 (VOT)
시각적 객체 추적 (VOT) [36]은 객체의 크기 변화, 가려짐, 복잡한 배경 등을 포함한 도전적인 비디오 시퀀스에서 객체를 추적하여 추적 알고리즘의 견고성과 정확성을 높이는 것을 목표로 합니다. 시암 네트워크 기반 [10, 52]와 트랜스포머 기반 [12, 47] 추적기는 임베딩 유사도를 학습하는 일반적인 접근 방식입니다. 그러나 이러한 추적기들은 단일 전방 패스 평가 방식에서 자기 수정 기능이 부족하기 때문에 쉽게 방해 요소로 인해 드리프트할 수 있습니다. 이를 해결하기 위해 최근 연구들 [49, 18]은 메모리 뱅크와 어텐션을 도입하여 현재 프레임과 과거 정보 간의 더 나은 매핑을 찾고자 했습니다.
2.2 Segment Anything Model (SAM)
Segment Anything Model (SAM) [26]은 도입 이후 많은 후속 연구를 촉발했습니다. SAM은 사용자가 점, 경계 상자, 텍스트 등을 입력하여 모델이 이미지 내의 모든 객체를 분할하도록 안내할 수 있는 프롬프트 기반 분할 접근 방식을 도입했습니다. SAM은 비디오 이해 [7, 38, 39]와 편집 [6]과 같은 광범위한 응용 분야를 가지고 있습니다. 이후 여러 연구가 SAM을 기반으로 확장되었습니다. 예를 들어, SAM 2 [35]는 모델의 기능을 비디오 세분화 [11]로 확장하여 동적 비디오 시퀀스에서 다중 프레임에 걸쳐 객체를 추적할 수 있는 메모리 메커니즘을 도입했습니다. 또한, 자원 제한 환경에서 SAM의 계산 부담을 줄이기 위한 더 효율적인 변형을 만들기 위한 노력도 있었습니다 [45, 54]. 의료 영상 연구에서도 SAM이 특화된 작업에 채택되었습니다 [30]. 최근 SAM2Long [14]은 긴 비디오의 객체 분할을 향상시키기 위해 트리 기반 메모리를 사용하고 있습니다. 그러나 더 높은 FPS의 비디오 시퀀스와 더 깊은 메모리 트리 아키텍처는 정확한 경로와 시간 제약 메모리 경로를 저장해야 하는 오버헤드 때문에 기하급수적으로 더 많은 연산 능력과 메모리 저장을 필요로 합니다. 반면, 우리가 제안하는 SAM 2 기반의 SAMURAI 모델은 이러한 문제를 극복하고 우수한 성능과 일반화 능력을 보장하기 위해 대규모 세분화 데이터셋으로 학습되었습니다.
2.3 움직임 모델링
움직임 모델링은 추적 작업에서 중요한 구성 요소로, 휴리스틱 접근 방식과 학습 가능한 접근 방식으로 구분할 수 있습니다. 휴리스틱 방법으로는 널리 사용되는 칼만 필터 (KF) [24]가 있으며, 이는 고정된 움직임 선행값과 사전에 정의된 하이퍼파라미터를 사용하여 객체 궤적을 예측합니다. KF는 많은 추적 벤치마크에서 효과적임을 입증했지만, 급격하거나 강렬한 움직임이 있는 시나리오에서는 실패하는 경우가 많습니다. 다른 방법들 [1]은 전통적인 KF 기반 예측을 적용하기 전에 카메라 움직임을 보정하여 강렬하거나 급격한 객체 움직임을 상쇄하려고 시도합니다. 그러나 표준 및 노이즈 스케일 적응형 (NSA) 칼만 필터 [15]는 다수의 하이퍼파라미터를 포함하고 있어 특정 종류의 움직임 시나리오에 그 효과가 제한될 수 있습니다. 반면, 학습 가능한 움직임 모델은 데이터 중심의 특성으로 인해 점점 더 많은 관심을 끌고 있습니다. Tracktor [2]는 Faster-RCNN에서 RoI(Region of Interest)로 궤적 상자를 사용하여 특징을 추출하고 프레임 간 객체의 위치를 회귀 분석하는 최초의 모델입니다. MotionTrack [43]은 과거 궤적 표현을 학습하여 미래 움직임을 예측함으로써 추적을 향상시킵니다. MambaTrack [22]은 트랜스포머 [40] 및 상태 공간 모델 (SSM) [21]과 같은 다양한 학습 기반 움직임 모델 아키텍처를 추가로 탐구합니다. 우리의 접근 방식도 향상된 휴리스틱 체계를 갖춘 학습 기반 움직임 모델링입니다.
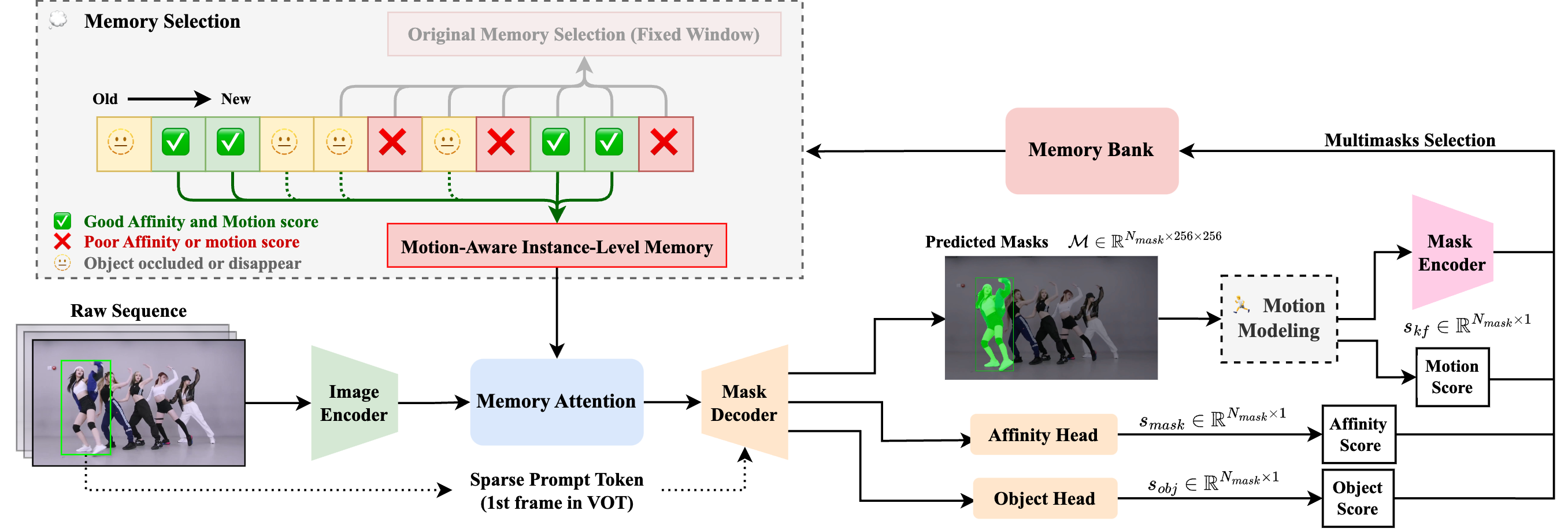
그림 2: 우리의 SAMURAI 시각적 객체 추적기의 개요.
3. Segment Anything Model 2 재방문
Segment Anything Model 2 [34]는 (1) 이미지 인코더, (2) 프롬프트 인코더가 포함된 마스크 디코더, (3) 메모리 어텐션 레이어, (4) 메모리 인코더를 포함합니다. 우리는 SAM 2의 기초 사항을 소개하고 SAMURAI가 추가되는 부분을 구체적으로 설명하겠습니다.
프롬프트 인코더

마스크 디코더




그러나 유사도 점수는 시각적 추적의 경우 특히 비슷한 객체들이 서로 가려지는 복잡한 상황에서 매우 견고한 지표가 아닙니다. 우리는 목표의 움직임을 추적하고 예측 선택을 돕기 위해 추가적인 움직임 점수를 제공하는 추가 움직임 모델링을 도입했습니다.
메모리 어텐션 레이어
메모리 어텐션 블록은 먼저 프레임 임베딩으로 자기 어텐션을 수행한 후 이미지 임베딩과 메모리 뱅크의 내용 간에 크로스 어텐션을 수행합니다. 따라서 무조건적인 이미지 임베딩은 이전 출력 마스크, 이전 입력 프롬프트, 객체 포인터와 함께 문맥화됩니다.
메모리 인코더와 메모리 뱅크
마스크 디코더가 출력 마스크를 생성한 후, 출력 마스크는 메모리 인코더를 통과하여 메모리 임베딩을 얻습니다. 새로운 메모리는 각 프레임이 처리된 후 생성됩니다. 이러한 메모리 임베딩은 비디오 디코딩 중 생성된 최신 메모리들로 이루어진 FIFO(선입선출) 큐인 메모리 뱅크에 추가됩니다. 시퀀스의 주어진 시간 t에, 우리는 메모리 뱅크 B_t를 다음과 같이 구성할 수 있습니다:

이는 과거 N_ 프레임의 출력 m을 메모리 뱅크의 구성 요소로 사용합니다.
이와 같은 단순한 고정 창 메모리 구현은 객체가 잘못 인코딩되거나 낮은 신뢰도의 객체가 포함되어 있을 수 있으며, 이는 긴 시퀀스의 시각적 추적 작업에서 오류가 상당히 누적될 수 있습니다. 우리가 제안하는 모션 인식 메모리 선택은 기존 메모리 뱅크 구성을 대체하여 더 나은 메모리 특징이 유지되고 이미지 특징에 조건화될 수 있도록 합니다.
4. 방법론
SAM 2는 기본적인 시각적 객체 추적(VOT) 및 비디오 객체 분할(VOS) 작업에서 강력한 성능을 보여주었습니다. 그러나 원래 모델은 잘못된 객체나 신뢰도가 낮은 객체를 잘못 인코딩할 수 있어, 장기 시퀀스 VOT에서 상당한 오류 전파를 초래할 수 있습니다.
이러한 문제를 해결하기 위해 우리는 칼만 필터(KF) 기반의 움직임 모델링을 다중 마스크 선택(4.1 절) 위에 적용하고, 유사도와 움직임 점수를 결합한 하이브리드 점수 시스템을 기반으로 한 향상된 메모리 선택(4.2 절)을 제안합니다. 이러한 개선 사항은 복잡한 비디오 시나리오에서 모델의 객체 추적 능력을 강화하도록 설계되었습니다. 중요한 점은 이 접근 방식이 미세 조정을 요구하지 않으며 추가적인 학습도 필요하지 않고, 기존 SAM 2 모델에 직접 통합될 수 있다는 것입니다. 예측된 마스크의 선택을 개선하면서도 추가적인 계산 부담 없이 이 방법은 온라인 VOT를 위한 신뢰성 있는 실시간 솔루션을 제공합니다.
4.1 움직임 모델링
움직임 모델링은 Visual Object Tracking (VOT) 및 다중 객체 추적(MOT) [51, 5, 1]에서 연관성 모호성을 해결하는 데 오랜 기간 동안 효과적인 접근 방식이었습니다. 우리는 추적 정확도 향상에 움직임 모델링을 통합하는 예시로 선형 기반의 칼만 필터 [24]를 사용했습니다.
우리의 시각적 객체 추적 프레임워크에서, 우리는 칼만 필터를 통합하여 경계 상자 위치와 크기 예측을 향상시키고, 이를 통해 M에서 N개의 후보 마스크 중 가장 신뢰도가 높은 마스크를 선택하도록 돕습니다. 상태 벡터 x는 다음과 같이 정의됩니다:





그런 다음 KF-IoU 점수와 원래의 유사도 점수의 가중 합을 최대화하는 마스크를 선택합니다:

마지막으로 다음과 같은 업데이트가 수행됩니다:


4.2 모션 인식 메모리 선택
표 1: LaSOT [16], LaSOText_{ext} [17], 그리고 GOT-10k [23]에서의 시각적 객체 추적 결과.
† LaSOText_{ext}는 LaSOT로 학습된 추적기에서 평가됩니다.
‡ GOT-10k 프로토콜은 해당 데이터셋의 학습 분할만을 사용해 학습된 추적기만 허용합니다.
T, S, B, L은 ViT 기반 백본의 크기를 나타내며, 하위 첨자는 검색 영역을 의미합니다. 굵은 글씨는 최고의 성능을, 밑줄은 두 번째 성능을 나타냅니다.

원래의 SAM 2는 이전 프레임에서 N_을 선택하여 현재 프레임의 조건부 시각 특징을 준비합니다. [34]에서는 단순히 타겟의 품질을 기준으로 가장 최근의 N_ 프레임을 선택하는 구현을 사용합니다. 하지만 이 접근 방식은 시각적 객체 추적 작업에서 흔히 발생하는 장기 가려짐이나 변형을 처리할 수 없다는 약점이 있습니다.


여기서 N_는 과거로 돌아갈 수 있는 최대 프레임 수를 의미합니다. 모션 인식 메모리 뱅크 B_t는 이후 메모리 어텐션 레이어를 통해 전달되며, 현재 타임스탬프에서 마스크 디코더 D_로 보내져 마스크 디코딩을 수행합니다. 우리는 SAM 2가 이러한 특정 메모리 뱅크 설정에서 학습되었기 때문에 N_mem=7을 따릅니다.
제안된 움직임 모델링과 메모리 선택 모듈은 재학습 없이도 시각적 객체 추적을 크게 향상시킬 수 있으며, 기존 파이프라인에 추가적인 계산 부담을 가하지 않습니다. 또한 모델에 구애받지 않으며, SAM 2를 넘어 다른 추적 프레임워크에도 적용될 가능성이 있습니다. 움직임 모델링과 지능적인 메모리 선택을 결합함으로써 효율성을 희생하지 않으면서도 도전적인 실제 응용에서의 추적 성능을 향상시킬 수 있습니다.
5. 실험
5.1 벤치마크
우리는 다음의 VOT 벤치마크에서 SAMURAI의 제로샷 성능을 평가합니다:
LaSOT [16]
LaSOT는 70개의 다양한 객체 카테고리에 걸쳐 총 1,400개의 비디오로 구성된 시각적 객체 추적 데이터셋으로, 평균 시퀀스 길이는 2,500 프레임입니다. 이 데이터셋은 학습 및 테스트 세트로 나뉘며, 각각 1,120개와 280개의 시퀀스로 구성되어 있습니다. 각 카테고리당 16개의 학습 시퀀스와 4개의 테스트 시퀀스를 포함합니다.
LaSOText_ [17]
LaSOText_는 원래 LaSOT 데이터셋의 확장으로, 15개의 새로운 객체 카테고리에 걸쳐 추가된 150개의 비디오 시퀀스를 도입합니다. 이러한 새로운 시퀀스는 가려짐 및 작은 객체의 변화를 집중적으로 다루기 위해 설계되었으며, 더 도전적입니다. 표준 프로토콜은 LaSOT로 학습된 모델을 LaSOText_에 직접 평가하는 것입니다.
GOT-10k [23]
GOT-10k는 10,000개 이상의 실제 세계에서 움직이는 객체들의 비디오 세그먼트를 포함하며, 560개 이상의 객체 클래스와 80개 이상의 움직임 패턴을 다룹니다. GOT-10k의 핵심 특징은 지정된 학습 분할만으로 학습된 추적기를 평가하는 원샷 평가 프로토콜을 요구하며, 테스트용으로 170개의 비디오가 예약되어 있습니다.
TrackingNet [33]
TrackingNet은 자연 환경에서의 다양한 컨텍스트에서 광범위한 객체 클래스를 다루는 대규모 추적 데이터셋입니다. 총 30,643개의 비디오로 구성되며, 30,132개의 학습 비디오와 511개의 테스트 비디오로 나뉩니다.
NFS [25]
NFS는 실세계 시나리오에서 고속 카메라(240 FPS)로 촬영된 총 380,000 프레임의 100개의 비디오로 구성되어 있습니다. 우리는 다른 VOT 연구들과 마찬가지로 인위적인 모션 블러가 추가된 30 FPS 버전의 데이터를 사용합니다.
OTB100 [42]
OTB100은 속성 태그로 주석이 달린 시퀀스를 포함하는 초기 시각 추적 벤치마크 중 하나입니다. 총 100개의 시퀀스로 구성되어 있으며, 평균 길이는 590 프레임입니다.
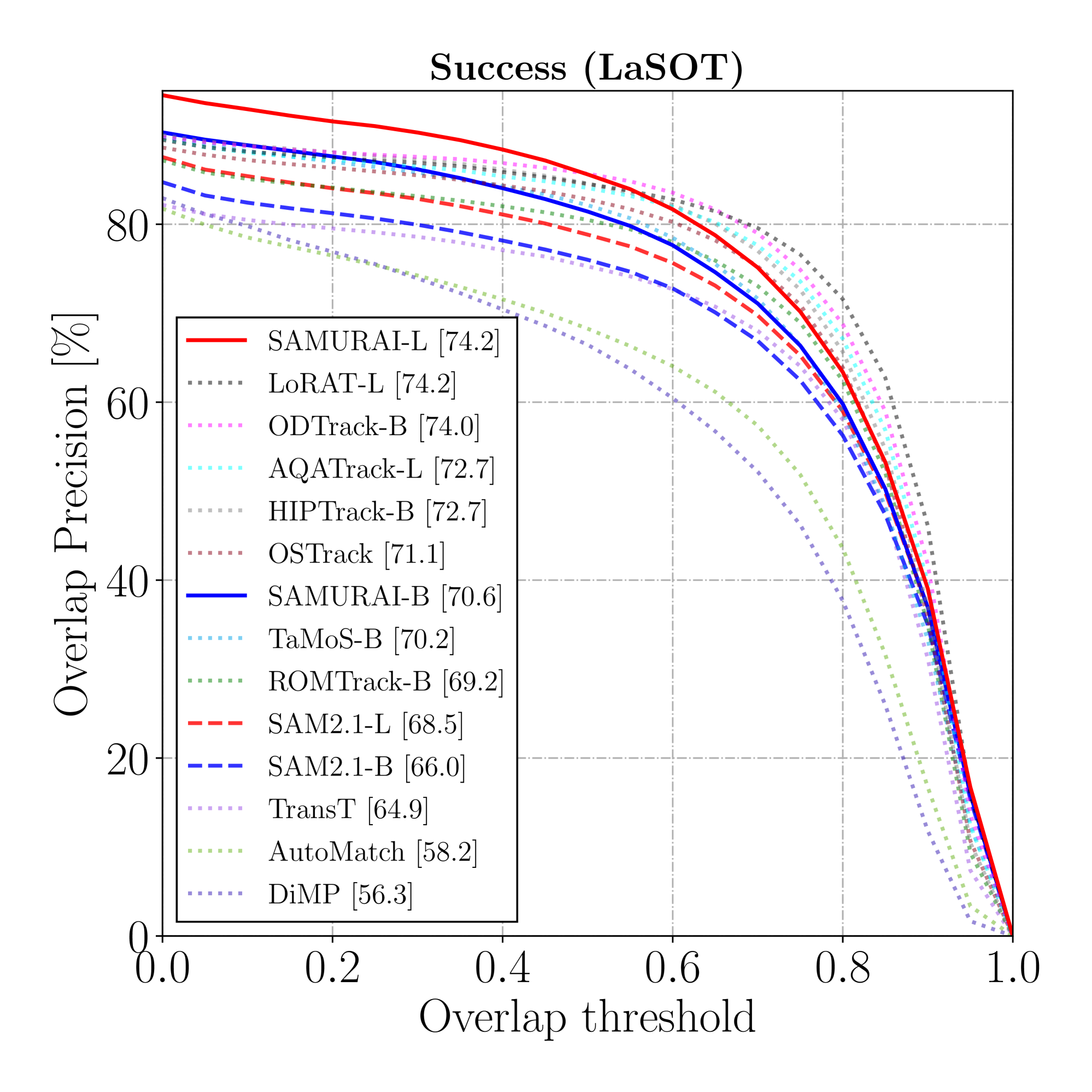

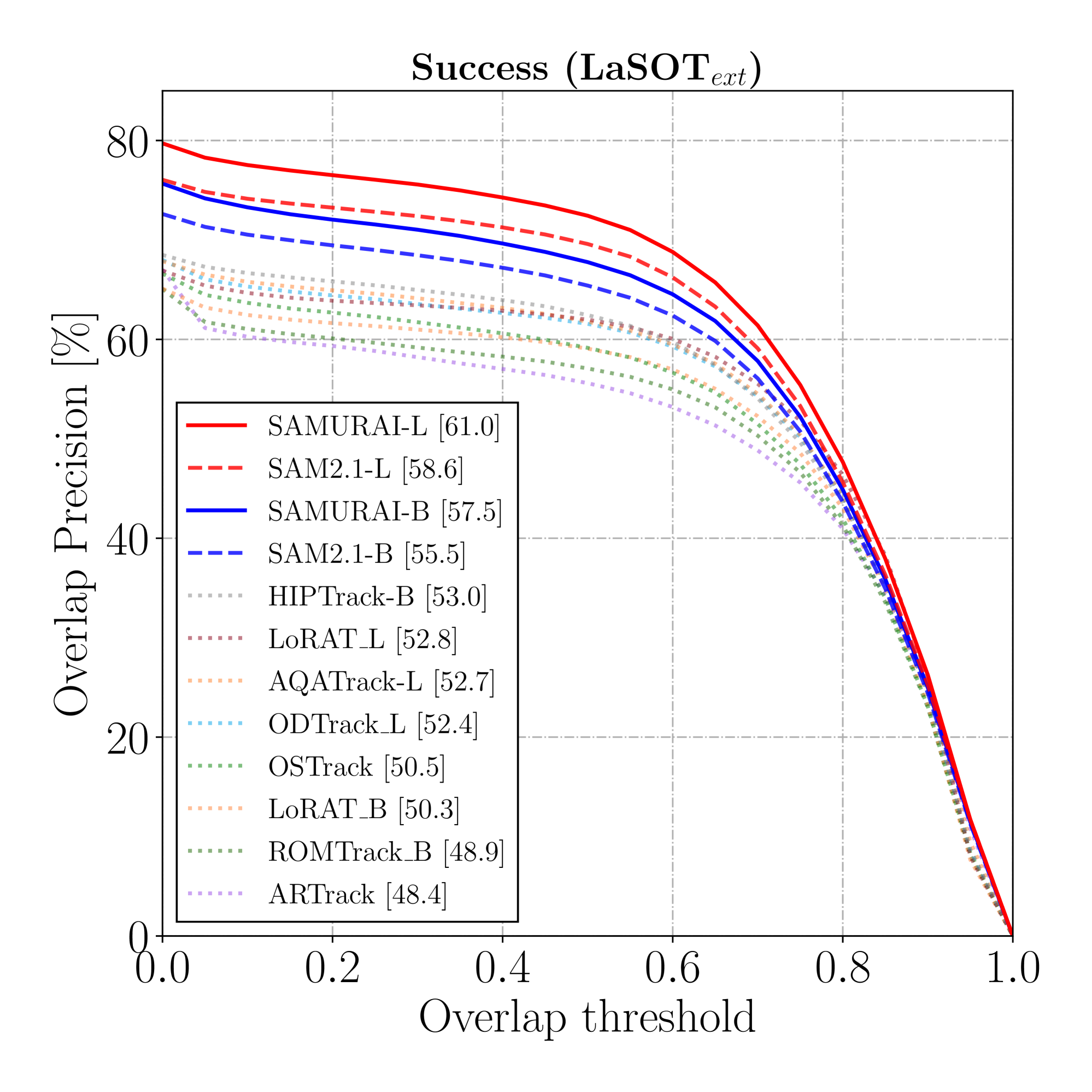
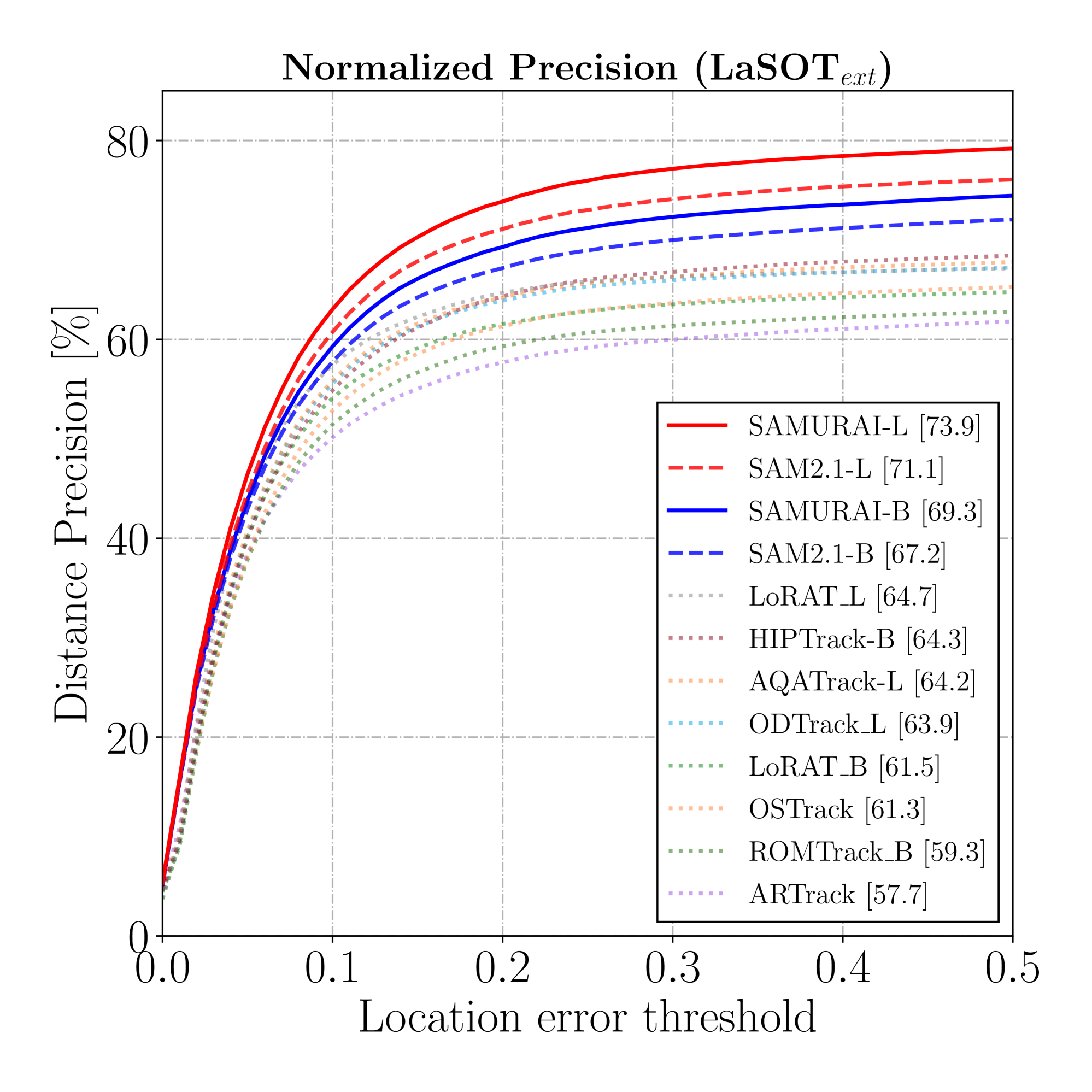
그림 3: LaSOT와 LaSOText_의 SUC 및 P_ 그래프.
5.2 정량적 결과
LaSOT와 LaSOText_ 결과
표 1은 LaSOT와 LaSOText_ 데이터셋에서의 시각적 객체 추적 결과를 보여줍니다. 우리의 방법인 SAMURAI는 제로샷 및 지도 학습 방법 모두에서 세 가지 모든 지표에서 유의미한 개선을 보여줍니다 (그림 3에 표시됨). 지도 학습된 VOT 방법들([55, 29]와 같은)이 상당히 인상적인 결과를 보여주지만, 제로샷 SAMURAI는 이와 대조적으로 뛰어난 일반화 능력을 갖추어 비교할 만한 제로샷 성능을 보여줍니다. 또한, 모든 SAMURAI 모델은 LaSOText_에서 모든 지표에 대해 최첨단 성능을 초과했습니다.
표 2: TrackingNet [33], NFS [25], 그리고 OTB100 [42] 데이터셋에서 제안된 방법과 최첨단 방법의 AUC(%)를 비교한 시각적 객체 추적 결과. 굵은 글씨는 최고의 성능을, 밑줄은 두 번째 성능을 나타냅니다.

표 3: 제안된 모듈의 효과에 대한 소거 실험.

표 4: 모션 가중치 α_kf의 민감도에 대한 소거 실험.
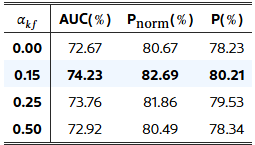
표 5: 제안된 SAMURAI와 기본 SAM 기반 추적 방법의 시각적 객체 추적 결과 비교.

표 6: LaSOT [16]와 LaSOText_ [17]의 속성별 AUC(%) 결과.

GOT-10k 결과
표 1은 또한 GOT-10k 데이터셋에서의 시각적 객체 추적 결과를 보여줍니다. GOT-10k 프로토콜은 해당 학습 분할만을 사용하여 추적기를 학습시키는 것을 허용하며, 일부 논문에서는 이를 원샷 방법이라고 언급할 수 있습니다. SAMURAI-B는 SAM2.1-B 대비 AO에서 2.1%, OP0.5에서 2.9%의 개선을 보여주었으며, SAMURAI-L은 AO에서 0.6%, OP0.5에서 0.7%의 개선을 보여주었습니다. 모든 SAMURAI 모델은 GOT-10k에서 모든 지표에 대해 최첨단 성능을 초과했습니다.
TrackingNet, NFS, OTB100 결과
표 2는 널리 비교되는 네 개의 벤치마크에서의 시각적 객체 추적 결과를 보여줍니다. 우리의 제로샷 SAMURAI-L 모델은 AUC에서 지도 학습된 최첨단 방법과 비교할 만하거나 이를 초과할 수 있음을 보여주며, 다양한 데이터셋에서의 모델의 능력과 일반화 능력을 입증하고 있습니다.
5.3 소거 연구
개별 모듈의 효과
표 3에서 다양한 설정에서 메모리 선택 여부에 따른 효과를 보여줍니다. 제안된 두 모듈 모두 SAM 2 모델에 긍정적인 영향을 미쳤으며, 두 모듈을 결합할 경우 LaSOT 데이터셋에서 AUC 74.23%와 P_ 82.60%로 최고의 AUC를 달성할 수 있었습니다.
모션 가중치의 효과
표 4에서는 신뢰할 마스크를 결정하는 점수의 가중치 효과를 보여줍니다. 모션 점수와 마스크 유사도 점수 간의 균형이 추적 성능에 상당한 영향을 미친다는 것을 시사합니다. 실험 결과, 모션 가중치 α_motion=0.2로 설정했을 때 LaSOT 데이터셋에서 가장 좋은 AUC 및 P_ 점수를 기록했으며, 이는 정확도와 견고성 모두에서 최적의 균형을 제공함을 의미합니다.

그림 4: SAMURAI와 기존 방법을 비교한 추적 결과 시각화.
(상단) 기존 VOT 방법들은 타겟 객체가 유사한 외형을 가진 객체들로 둘러싸여 있는 혼잡한 상황에서 종종 어려움을 겪음.
(하단) 기본 SAM 기반 방법은 고정 창 메모리 구성으로 인해 ID 전환이 발생하며, 이는 오류 전파와 추적 정확도 저하를 초래함.
기준 비교
SAMURAI에서 제안한 모션 모델링과 모션 인식 메모리 선택 메커니즘의 효과를 입증하기 위해, 우리는 LaSOT와 LaSOText_에서 모든 백본 변형에 대해 SAM 2 [34]와 자세한 비교 실험을 수행했습니다. 기준 SAM 2는 원래의 메모리 선택을 사용하고 IoU 점수가 가장 높은 마스크를 직접 예측합니다. 표 5는 제안된 방법이 모든 세 가지 지표에서 기준 방법을 꾸준히 향상시키는 것을 보여주며, 이는 다양한 모델 구성에서 우리의 접근 방식이 견고하고 일반화 가능함을 강조합니다.
속성별 성능 분석
우리는 LaSOT와 LaSOText_를 [16, 17]에서 정의한 14개의 속성을 기반으로 분석했습니다. 표 6에서 SAMURAI는 두 데이터셋의 모든 속성에서 원래의 기준 방법보다 꾸준한 성능 향상을 보여주었지만, LaSOText_의 조명 변이(IV) 속성에서는 그렇지 않았습니다. 모션 점수를 고려함으로써 CM(카메라 움직임) 및 FM(빠른 움직임)과 같은 속성에서의 성능 향상이 가장 크게 나타났으며, SAMURAI는 LaSOText_ 데이터셋에서 CM에서 16.5%, FM에서 9.9%의 성능 향상을 보여주었습니다. 이 데이터셋은 VOT에서 가장 도전적인 데이터셋 중 하나로 여겨집니다. 또한, FOC(전체 가림) 및 POC(부분 가림)과 같은 가림 관련 속성들도 제안된 모션 인식 인스턴스 수준 메모리 선택을 통해 크게 이익을 얻었으며, 모든 모델 변형 및 데이터셋에서 꾸준한 개선을 보여주었습니다. 이러한 결과는 SAMURAI가 단순한 모션 추정을 통합하여 글로벌 카메라 움직임이나 급격한 객체 움직임을 더 잘 반영하여 추적 성능을 향상시킬 수 있음을 시사합니다.
런타임 분석
모션 모델링과 향상된 메모리 선택 방법을 추적 프레임워크에 통합함으로써 최소한의 계산 오버헤드가 도입되었으며, NVIDIA RTX 4090 GPU에서의 런타임 측정은 기준 모델과 일치하는 것으로 나타났습니다.
5.4 정성적 결과
SAMURAI와 다른 방법들 [34, 3, 29] 간의 정성적 비교가 그림 4에 표시되어 있습니다. SAMURAI는 비디오에서 유사한 외형을 가진 다수의 객체가 존재하는 장면에서 우수한 시각적 객체 추적 결과를 보여줍니다. 이러한 예시에서 단기적인 가림은 기존 VOT 방법들이 동일한 객체를 지속적으로 예측하거나 위치를 지정하는 데 어려움을 겪게 만듭니다. 또한, SAMURAI와 원래의 기준 방법 간의 시각화된 마스크 비교는 모션 모델링 및 메모리 선택 모듈 추가로 얻어진 개선을 보여주며, 예측된 마스크는 항상 메모리로 사용하기에 신뢰할 수 있는 출처가 아니므로 어떤 마스크를 신뢰할지를 체계적으로 결정하는 방식이 유용함을 나타냅니다. 이러한 개선 사항은 모델을 재학습하거나 미세 조정하지 않아도 시각적 추적을 위한 더 나은 지침을 제공하여 기존 프레임워크에 이점을 제공합니다.
6. 결론
우리는 SAMURAI라는 시각적 객체 추적 프레임워크를 제안합니다. 이는 객체의 자가 가림 및 급격한 움직임을 처리하기 위해 더 나은 마스크 예측 및 메모리 선택을 위해 모션 기반 점수를 도입하여 Segment Anything 모델 위에 구축된 것입니다. 제안된 모듈은 여러 VOT 벤치마크에서 모든 지표에서 SAM 모델의 모든 변형에서 일관된 성능 향상을 보여주었습니다. 이 방법은 재학습이나 미세 조정을 필요로 하지 않으며, 여러 VOT 벤치마크에서 실시간 온라인 추론 성능을 보여줍니다.
'인공지능' 카테고리의 다른 글
| Mistral has entered the chat (4) | 2024.11.29 |
|---|---|
| Introducing FLUX.1 Tools (3) | 2024.11.29 |
| Mapping Economic Well-being (3) | 2024.11.27 |
| A Deep Dive Into OpenCLIP from OpenAI (4) | 2024.11.27 |
| Mid-U Guidance: Fast Classifier Guidance for Latent Diffusion Models (1) | 2024.11.27 |



