Develop Multilingual and Cross-Lingual Information Retrieval Systems with Efficient Data Storage | NVIDIA Technical Blog
Efficient text retrieval is critical for a broad range of information retrieval applications such as search, question answering, semantic textual similarity, summarization, and item recommendation.
developer.nvidia.com
다국어 및 교차 언어 정보 검색 시스템 개발: 효율적인 데이터 저장 방식을 활용하여
2024년 12월 17일
작성자: Ronay AK, Isabel Hulseman, Benedikt Schifferer, Nave Algarici

효율적인 텍스트 검색은 검색, 질문 응답, 의미적 텍스트 유사성, 요약, 아이템 추천 등 다양한 정보 검색 애플리케이션에 있어 필수적입니다. 이는 또한 대규모 언어 모델(LLMs)이 기본 매개변수를 수정하지 않고 외부 컨텍스트에 접근할 수 있게 하는 기법인 검색-증강 생성(RAG)에서도 핵심적인 역할을 합니다.
RAG는 LLM이 생성하는 응답의 품질을 높이는 데 매우 효과적이지만, 많은 임베딩 모델이 주로 영어 데이터셋으로 훈련되었기 때문에 여러 언어에서 정확한 데이터를 검색하는 데 어려움을 겪고 있습니다. 이로 인해 다른 언어로 정확하고 유익한 텍스트 응답을 생성하는 데 한계가 발생하며, 글로벌 사용자와의 효과적인 소통이 저해됩니다.
다국어 정보 검색은 생성된 텍스트의 사실적 정확성과 일관성을 높이고, 언어 장벽을 허물어 정보를 보다 쉽게 접근할 수 있도록 하는 지역화된 상황 인지형 응답을 가능하게 합니다. 이러한 기능은 의료진과 환자의 의사소통 개선, 기술 문제 해결, 맞춤형 리테일 경험 제공 등 다양한 산업에서의 응용 가능성을 열어줍니다.
그러나 대규모 데이터 플랫폼을 위한 이러한 시스템을 구축하는 데는 방대한 데이터 볼륨 관리, 저지연 검색 보장, 다양한 다국어 데이터셋에서의 높은 정확도 유지와 같은 고유한 과제가 따릅니다.
이 글에서는 이러한 복잡성을 해결하고 NVIDIA NeMo Retriever 임베딩 및 재랭킹 마이크로서비스를 사용하여 강력한 다국어 정보 검색 시스템을 구축하는 방법을 설명합니다. NVIDIA NIM을 기반으로 한 NeMo Retriever는 다양한 데이터 환경에서 AI 애플리케이션 배포를 원활하게 지원하며, 뛰어난 정확도, 확장성 및 응답성을 갖춘 대규모 다국어 검색 처리를 가능하게 합니다. 이를 통해 글로벌 조직이 정보를 활용하는 방식을 혁신합니다.
NVIDIA NeMo Retriever는 높은 정확도와 데이터 프라이버시를 제공하는 마이크로서비스 모음으로, 기업이 실시간 비즈니스 인사이트를 생성할 수 있도록 지원합니다.
NVIDIA AI Enterprise 소프트웨어 플랫폼의 일부인 NVIDIA NIM은 생성형 AI 모델을 플랫폼 전반에 걸쳐 간소화된 방식으로 배포할 수 있도록 하며, 팀이 LLM을 자체 호스팅하면서 표준 API를 통해 애플리케이션을 구축할 수 있도록 합니다. 자세한 내용은 NVIDIA NIM for Developers를 참조하세요.
다단계 다국어 정보 검색 시스템 요구 사항
다국어 정보 검색 시스템을 개발하려면 다국어 지식 베이스에서 데이터를 가져올 수 있는 강력한 검색 구성 요소를 통합해야 합니다. 이렇게 검색된 데이터는 생성 프로세스를 보강하여 정확하고 상황에 맞는 응답을 보장하는 데 사용됩니다.
정보 검색 시스템의 핵심은 임베딩 모델 또는 밀집 검색 모델(dense retrieval models)입니다. 이 모델은 쿼리와 콘텐츠(예: 문단이나 문서)를 의미적으로 인코딩하여 그 의미를 포착한 벡터 표현으로 변환합니다.
최근 몇 년간 다양한 크기와 기능을 가진 여러 밀집 임베딩 모델이 소개되었습니다(MTEB 검색 리더보드 참고). 그러나 이 모델들 대부분은 다국어 검색을 효과적으로 수행하는 데 한계가 있습니다.
다국어 RAG 시스템을 구축하려면 임베딩 모델이 다양한 언어를 지원해야 하며, 서로 다른 언어적 출처의 쿼리와 컨텍스트를 정확히 임베딩하여 공통 의미 공간에 매핑할 수 있어야 합니다.
더 고도화된 다국어 검색 시스템을 위해서는 다단계 다국어 검색 파이프라인이 필요할 수 있습니다. 이 파이프라인에는 밀집 검색 모델뿐만 아니라, 검색된 문서의 순위를 보다 정확하게 재조정하여 결과를 세부적으로 정제하는 재랭킹(reranking) 모델도 포함됩니다.
NVIDIA NeMo Retriever로 데이터 플랫폼 혁신
이러한 파이프라인 구축의 도전 과제와 요구 사항을 해결하기 위해 NVIDIA는 NVIDIA NIM을 기반으로 한 세계적 수준의 다국어 및 교차 언어 텍스트 검색을 위한 두 가지 새로운 커뮤니티 기반 NeMo Retriever 마이크로서비스를 도입했습니다.
- NeMo Retriever Llama 3.2 임베딩: llama-3.2-nv-embedqa-1b-v2
- NeMo Retriever Llama 3.2 재랭킹: llama-3.2-nv-rerankqa-1b-v2
이 새로운 다국어 모델은 다국어 및 교차 언어 질문 응답 검색을 가능하게 할 뿐만 아니라, 데이터 플랫폼에서 효율성과 확장성을 통해 스토리지, 성능, 적응성 측면에서 중요한 과제들을 해결합니다.
다음과 같은 기술을 통해 벡터 데이터베이스에 더 많은 데이터를 저장할 수 있으며, 실시간 검색 및 생성 기능이 강화됩니다:
- 긴 컨텍스트 지원: 최대 8192 토큰의 컨텍스트를 지원하여 광범위한 문서를 처리하고 이해하며, 데이터 처리 능력을 향상시킵니다.
- 동적 임베딩 크기 조정: 유연한 임베딩 크기를 제공하여 저장 및 검색 프로세스를 최적화하며, 차원을 줄이면서도 정확성을 유지합니다.
- 저장 효율성: 임베딩 차원을 384로 줄이고 컨텍스트 길이를 확장하여 저장 용량을 35배 절감, 더 큰 지식 베이스를 단일 서버에 저장할 수 있게 합니다.
- 성능 최적화: 긴 컨텍스트 지원과 차원 축소를 결합하여 높은 정확도를 유지하면서도 뛰어난 저장 효율성을 제공합니다.
그림 1. llama-3.2-nv-embedqa-1b-v2가 긴 컨텍스트 지원, 동적 임베딩 크기 조정, 효율적인 저장 방식을 통해 벡터 저장 볼륨에 미치는 영향.
그림 1에서는 동적 임베딩 크기 조정과 긴 토큰 길이 지원을 통해 저장 공간을 35배 줄이는 성과를 보여줍니다. 이를 통해 대규모 데이터셋을 효율적으로 처리할 수 있으며, 특히 클라우드 자동 확장을 사용할 수 없는 온프레미스 고객에게 유용하여 더 많은 데이터를 정확하고 효율적으로 저장하고 검색할 수 있습니다.
다국어 및 교차 언어 텍스트 검색 벤치마크: 최적화된 임베딩 및 재랭킹 모델
다국어 및 교차 언어 질문 응답 검색 작업을 위해 이 임베딩 및 재랭킹 모델을 어떻게 최적화했는가?
- 기반 모델 변경
- 디코더 전용 모델인 Meta-Llama/Llama-3.2-1B를 기반 모델로 채택하여 인코더 모델로 변환.
- 이 모델은 공식적으로 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어를 지원하며, 이 8개 언어 외에도 더 광범위한 언어를 학습함.
- 자체 주의 메커니즘 수정
- 단방향(원인 기반)에서 양방향으로 변경하여 각 토큰이 양쪽(왼쪽과 오른쪽)의 다른 토큰을 참조할 수 있도록 개선.
- 다국어 성능 개선
- 공개된 영어 및 다국어 데이터셋을 내부적으로 조합한 데이터로 모델을 파인튜닝하여 기존 다국어 성능을 향상.
- 대조 학습을 통한 최적화
- 긍정 인식 하드 네거티브 마이닝(Positive-aware Hard-Negative Mining) 기법을 사용하여 수집한 하드 네거티브를 활용해 임베딩 및 재랭킹 모델을 대조 학습으로 파인튜닝.
- 자세한 내용은 NV-Retriever: Improving Text Embedding Models with Effective Hard-Negative Mining 참고.
NVIDIA는 두 개의 새로운 10억 매개변수 검색 모델을 도입하여, 다국어 검색에서 높은 정확도와 효율적인 색인 처리량, 낮은 서비스 지연 시간 간의 균형을 제공합니다.
모델 평가
- 데이터셋과 평가 환경
- 18개의 MIRACL 개발 데이터셋, 11개의 번역된 언어 데이터셋, 그리고 49개의 교차 언어 MLQA 데이터셋에서 모델을 평가.
- 모든 모델은 동일한 인프라 및 데이터셋에서 평가되었으며, 평가 속도를 높이기 위해 MIRACL 개발 데이터셋을 하위 샘플링함.
- 결과: NVIDIA Llama 3.2 모델의 정확도 성능
그림 2: NVIDIA Llama 3.2 임베딩 및 재랭킹 모델이 검색 정확도(Recall@5)에서 뛰어난 성능을 보이며, 특히 다단계 검색 시스템에서 더욱 탁월함.
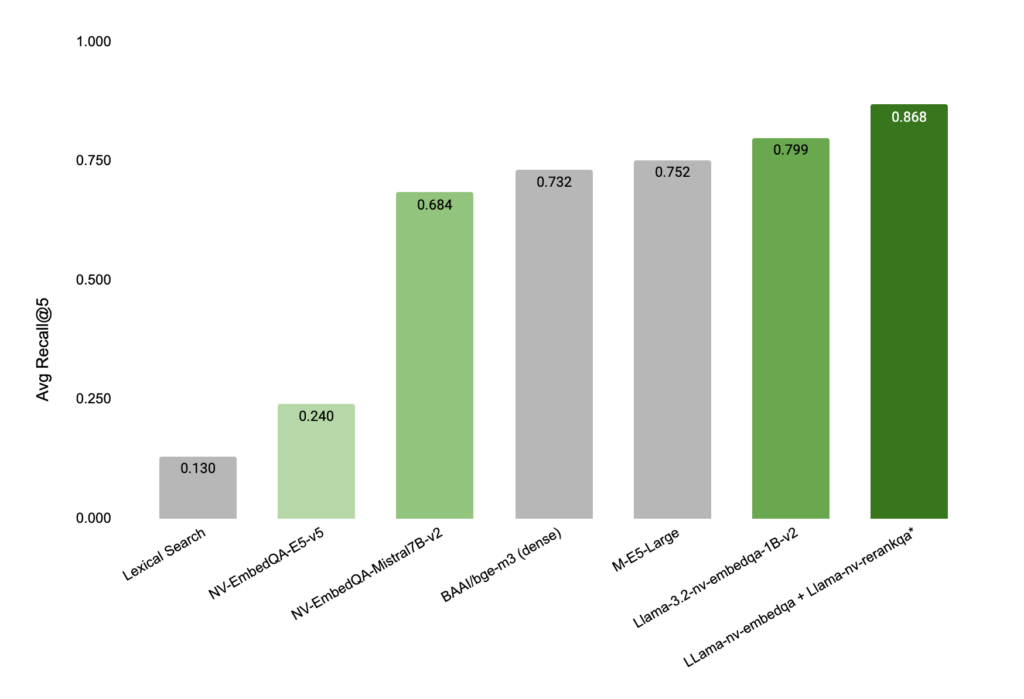
그림 3: NVIDIA Llama 3.2 임베딩 및 재랭킹 모델이 다국어 및 교차 언어 텍스트 검색 벤치마크에서 새로운 최고 성능(State-of-the-Art)을 달성.
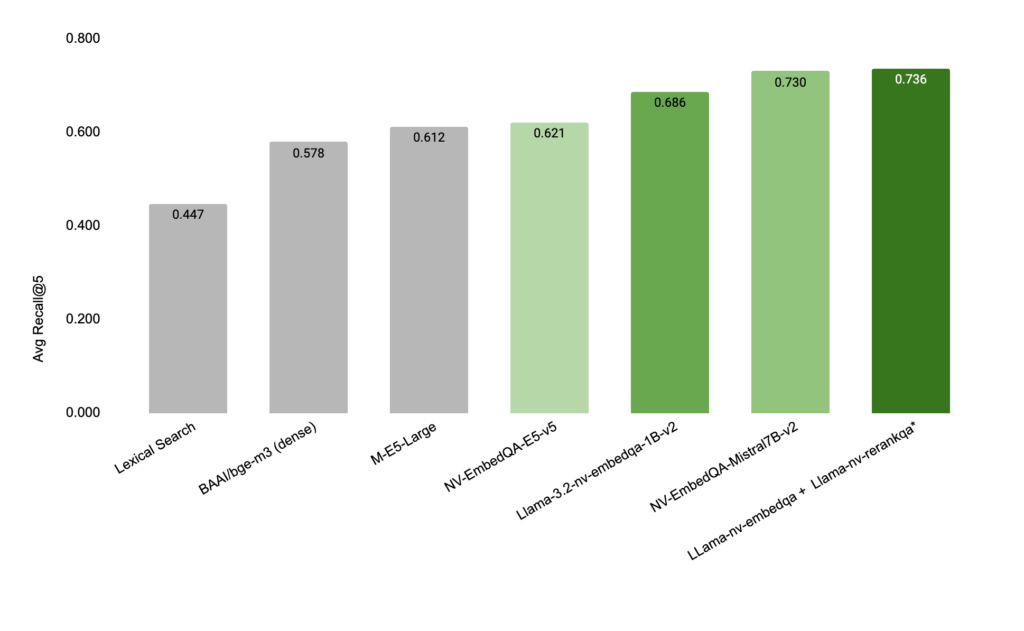
그림 4: 영어 전용 TextQA 벤치마크 데이터셋에서도 경쟁 모델보다 더 정확한 검색 결과를 생성. 이 평가는 NQ, HotpotQA, FiQA(금융 질문 응답), TechQA 등 BeIR 벤치마크 데이터셋에서 수행됨.
세계적 수준의 정보 검색 파이프라인 구축 방법
- NVIDIA API 카탈로그 활용
- NVIDIA API 카탈로그에서 llama-3.2-nv-embedqa-1b-v2 및 llama-3.2-nv-rerankqa-1b-v2를 포함한 다양한 검색 마이크로서비스에 액세스 가능.
- 사용자 정의 모델을 비즈니스 데이터와 연결하여 높은 정확도의 응답을 제공.
- NVIDIA Developer Program 활용
- 연구, 개발 및 테스트를 위해 NIM을 무료로 제공하며, 이메일을 통해 맞춤형 옵션 사용 가능.
- NVIDIA LaunchPad와 GitHub 예제
- NVIDIA LaunchPad에서 NeMo Retriever 실습 랩을 통해 엔터프라이즈 데이터를 활용하거나, AI 챗봇을 구축하는 RAG 랩 체험 가능.
- GitHub에서 생성형 AI 통합 예제 및 샘플 애플리케이션 코드 확인 가능.
관련 자료
- GTC 세션
- RAG 시스템의 효과를 개선하는 기술
- Oracle과 Qdrant 벡터 데이터베이스를 활용한 LLM 응답 품질 개선
- Red Hat OpenShift AI와 NVIDIA AI Enterprise를 활용한 RAG 사용법
- NGC 컨테이너
- chain-server
- 웹 세미나
- 생성형 AI를 위한 세계적 수준의 텍스트 검색 정확도 달성
- AI를 활용한 의료 워크플로우 혁신: CLLM 심층 분석
태그
생성형 AI | 일반 | NeMo Retriever | NIM | 중급 기술 | 심층 분석 | LLM 기술 | Retrieval Augmented Generation (RAG)
NVIDIA NeMo Retriever: 다국어 및 교차 언어 텍스트 검색의 혁신 요약
1. 핵심 내용
NVIDIA는 다국어 및 교차 언어 텍스트 검색을 위해 최적화된 두 가지 NeMo Retriever 모델을 도입:
- 임베딩 모델: llama-3.2-nv-embedqa-1b-v2
- 재랭킹 모델: llama-3.2-nv-rerankqa-1b-v2
이 모델들은 검색 정확도와 효율성을 동시에 만족하며, 다국어 질문 응답 검색과 대규모 데이터 플랫폼에 적합하도록 설계됨.
2. 주요 기술 특징
- 기반 모델 변경: Llama 3.2를 인코더 모델로 변환 및 양방향(Self-Attention) 메커니즘 추가.
- 다국어 성능 강화: 영어 및 다국어 데이터셋으로 파인튜닝하여 정확도 향상.
- 효율적 데이터 처리:
- 긴 컨텍스트 지원(최대 8192 토큰).
- 동적 임베딩 크기 조정(차원 축소 및 저장 공간 절약).
- 35배 저장 효율 개선, 대규모 데이터 적합.
- 대조 학습: 하드 네거티브 마이닝 기법으로 임베딩 및 재랭킹 모델 최적화.
3. 성능 평가
- 벤치마크 데이터셋: 18개 MIRACL, 11개 번역 데이터셋, 49개 MLQA 데이터셋에서 평가.
- 결과:
- 다국어/교차 언어 검색 정확도: Recall@5 기준 경쟁 모델 대비 우수.
- **영어 전용 벤치마크(NQ, HotpotQA, FiQA, TechQA)**에서도 높은 성능.
- 다단계 검색 시스템(임베딩 + 재랭킹) 조합 시 최고 성능 달성.
4. 활용 방법
- NVIDIA API 카탈로그: 검색 마이크로서비스 활용으로 비즈니스 데이터와의 통합 지원.
- NVIDIA Developer Program: 무료로 NIM 접근 및 연구, 개발, 테스트 가능.
- LaunchPad 및 GitHub: RAG 기반 AI 챗봇 및 엔터프라이즈 데이터 활용 실습 제공.
5. 관련 자료 및 교육 기회
- RAG, LLM 기술 개선 관련 GTC 세션 및 웹 세미나.
- chain-server 컨테이너 및 GitHub 예제 코드 제공.
이 모델들은 다양한 언어 환경에서의 정보 검색 정확도를 대폭 향상시키며, 대규모 데이터셋을 다루는 조직에 최적의 솔루션을 제공합니다.
'Article' 카테고리의 다른 글
| Security for Data Privacy in Federated Learning with CUDA-Accelerated Homomorphic Encryption in XGBoost (1) | 2024.12.19 |
|---|---|
| Satellite powered estimation of global solar potential (1) | 2024.12.18 |
| 2025년 이후의 기술 예측 (2) | 2024.12.18 |
| Whisk: Visualize and remix ideas using images and AI (1) | 2024.12.18 |
| Working with tabular data in Python (2) | 2024.12.18 |


