https://arxiv.org/abs/2412.19437
DeepSeek-V3 Technical Report
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and Deep
arxiv.org
초록
우리는 토큰당 37B가 활성화되고 총 671B 파라미터를 갖춘 강력한 Mixture-of-Experts(MoE) 언어 모델인 DeepSeek-V3를 소개한다. 효율적인 추론과 비용 효율적인 학습을 위해 DeepSeek-V3는 Multi-head Latent Attention(MLA) 및 DeepSeekMoE 아키텍처를 채택했으며, 이는 DeepSeek-V2에서 철저히 검증되었다. 또한 DeepSeek-V3는 부가 손실(auxiliary loss) 없이 로드 밸런싱을 달성하는 전략을 처음 도입하고, 더 강력한 성능을 위해 다중 토큰 예측(multi-token prediction) 학습 목표를 설정하였다. 우리는 DeepSeek-V3를 14.8조 개의 다양하고 고품질 토큰에 대해 사전 학습한 뒤, 지도 학습(Supervised Fine-Tuning) 및 강화 학습(Reinforcement Learning)을 거쳐 모델의 역량을 극대화하였다. 종합 평가 결과, DeepSeek-V3는 다른 오픈소스 모델들을 능가하며, 선도적인 폐쇄형 모델들과 견줄 만한 성능을 보여준다. 우수한 성능에도 불구하고 DeepSeek-V3는 전체 학습에 단 2.788M H800 GPU 시간이 필요하다. 더욱이 학습 과정이 매우 안정적이어서, 전체 학습 기간 동안 되돌릴 수 없는 손실 스파이크가 발생하거나 롤백 조치가 필요했던 적이 전혀 없었다. 모델 체크포인트는 https://github.com/deepseek-ai/DeepSeek-V3에서 확인할 수 있다.

Figure 1: DeepSeek-V3 및 유사 모델들의 벤치마크 성능.

1 서론
최근 몇 년간 대규모 언어 모델(LLM)은 급속도로 발전하며 (OpenAI, 2024a; Anthropic, 2024; Google, 2024), 범용 인공지능(Artificial General Intelligence, AGI)에 한 걸음씩 다가가고 있다. 폐쇄형 모델뿐 아니라 DeepSeek 계열(DeepSeek-AI, 2024b, c; Guo et al., 2024; DeepSeek-AI, 2024a), LLaMA 계열(Touvron et al., 2023a, b; AI@Meta, 2024a, b), Qwen 계열(Qwen, 2023, 2024a, 2024b), Mistral 계열(Jiang et al., 2023; Mistral, 2024) 등 여러 오픈소스 모델들 역시 빠르게 발전하여, 이들 폐쇄형 모델들과의 격차를 좁히고자 노력하고 있다. 이러한 오픈소스 모델 역량의 한계를 한층 더 확장하기 위해, 우리는 모델을 대규모로 확장하여 토큰당 37B가 활성화되고 총 671B 파라미터를 갖춘 대규모 Mixture-of-Experts(MoE) 모델인 DeepSeek-V3를 소개한다.
미래지향적 관점에서 우리는 항상 강력한 모델 성능과 경제적인 비용의 균형을 추구한다. 이에 따라 DeepSeek-V3는 추론 효율을 위해 Multi-head Latent Attention(MLA)(DeepSeek-AI, 2024c)을, 그리고 비용 효율적인 학습을 위해 DeepSeekMoE(Dai et al., 2024)를 여전히 채택한다. 이 두 아키텍처는 DeepSeek-V2(DeepSeek-AI, 2024c)에서 검증되어, 효율적인 학습과 추론을 유지하면서도 견고한 모델 성능을 제공함이 입증되었다. 또한 기본 아키텍처 외에도 모델 역량을 더욱 향상하기 위해 두 가지 추가 전략을 구현하였다. 첫째, DeepSeek-V3는 부가 손실(auxiliary loss)을 사용하지 않고 로드 밸런싱을 달성하는 전략(Wang et al., 2024a)을 새롭게 도입하여, 로드 밸런싱을 촉진하는 과정에서 발생할 수 있는 모델 성능 저하를 최소화한다. 둘째, DeepSeek-V3는 멀티 토큰 예측(multi-token prediction) 학습 목표를 채택하여 전체적인 평가 지표에서 모델 성능을 향상시킨다는 사실을 확인하였다.
효율적인 학습을 달성하기 위해, 우리는 FP8 혼합 정밀도(mixed precision) 학습을 지원하고 학습 프레임워크에 대한 종합적인 최적화를 구현하였다. 저정밀도 학습은 (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022) 효율적 학습을 위한 유망한 해법으로 대두되고 있으며, 이는 하드웨어 기술 발전(Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a)과 맞물려 빠르게 발전하고 있다. 본 논문에서는 FP8 혼합 정밀도 학습 프레임워크를 도입하고, 초대형 규모 모델에서 FP8 학습이 실제로 가능하고 효과적임을 처음으로 검증하였다. FP8 계산 및 저장을 지원함으로써 학습 속도 가속과 GPU 메모리 사용량 감소 효과를 모두 얻었다. 학습 프레임워크 측면에서는 파이프라인 병렬화를 효율적으로 수행하기 위해 DualPipe 알고리즘을 설계하였고, 이를 통해 파이프라인 버블을 줄이고 대부분의 통신을 학습 과정 중에 연산과 겹치도록(overlap) 처리한다. 이런 겹침으로 인해 모델 규모가 더 커져도 일정한 연산 대 통신 비율을 유지하기만 하면, 여러 노드에 걸쳐 파인 그레이닝(fine-grained)된 전문가들을 배치하더라도 거의 0에 가까운 all-to-all 통신 오버헤드로 학습을 진행할 수 있다. 또한 우리는 InfiniBand(IB)와 NVLink 대역폭을 최대한 활용하기 위해 효율적인 노드 간 all-to-all 통신 커널을 개발하였다. 아울러 메모리 사용량을 꼼꼼하게 최적화하여, 비용이 많이 드는 텐서 병렬성(tensor parallelism)을 사용하지 않고도 DeepSeek-V3를 학습할 수 있도록 하였다. 이로써 학습 효율을 크게 끌어올릴 수 있었다.
사전 학습 단계에서는 14.8조 개의 다양하고 높은 품질의 토큰을 학습에 활용하였다. 학습 과정은 매우 안정적으로 진행되어, 전체 훈련 기간 동안 되돌릴 수 없는 수준의 손실(spike)이 발생하거나 롤백을 수행해야 하는 상황이 한 번도 없었다. 이후 DeepSeek-V3에 대해 두 단계로 맥락 길이(context length)를 확장하였다. 첫 번째 단계에서 최대 맥락 길이를 32K로 확장하고, 두 번째 단계에서 이를 128K까지 늘렸다. 그 뒤, DeepSeek-V3의 베이스(base) 모델을 대상으로 한 지도 학습(Supervised Fine-Tuning, SFT)과 강화 학습(RL) 단계를 진행하여 사람의 선호도와 더욱 정교하게 정렬(alignment)시키고 모델의 잠재력을 극대화하였다. 이 과정에서 DeepSeek-R1 계열 모델로부터 추론 능력을 증류(distillation)하는 한편, 모델 정확도와 생성 길이 간 균형도 신중히 유지하였다.
우리는 DeepSeek-V3를 다양한 벤치마크에서 평가하였다. 경제적인 학습 비용에도 불구하고, 종합 평가 결과 DeepSeek-V3-Base는 코드와 수학 영역에서 특히 강력한 성능을 보이며 현재 공개된 베이스 모델 중 가장 우수한 성능을 보여준다. Chat 버전 또한 다른 오픈소스 모델들을 상회하고, GPT-4o 및 Claude-3.5-Sonnet과 같은 선도적인 폐쇄형 모델들과의 성능 격차를 상당히 좁혀준다.

Table 1: DeepSeek-V3의 전체 학습 비용 추정. H800 GPU 대여 비용을 GPU 시간당 $2로 가정.
마지막으로, Table 1에 정리한 바와 같이 알고리즘·프레임워크·하드웨어를 함께 최적화한 결과, DeepSeek-V3의 학습 비용은 매우 경제적이다. 사전 학습 단계에서 매 1조 토큰당 약 18만 H800 GPU 시간이 필요하며, 이는 2048대의 H800 GPU를 운용할 경우 약 3.7일 만에 처리 가능하다. 따라서 전체 사전 학습(14.8조 토큰)을 완료하는 데 약 2,664K GPU 시간이 소요되어 두 달이 채 걸리지 않는다. 이후 맥락 길이 확장에 119K GPU 시간, 후속 포스트 트레이닝에 5K GPU 시간이 추가로 들며, 결과적으로 DeepSeek-V3 전체 학습에는 총 2.788M GPU 시간이 소요된다. H800 GPU 대여 비용을 시간당 $2로 가정하면, 총 학습 비용은 약 $5.576M에 불과하다. 단, 이는 DeepSeek-V3의 공식 학습에 필요한 비용만을 산정한 것이며, 아키텍처·알고리즘·데이터 관련 사전 연구나 소규모 실험에 소요된 비용은 포함되지 않았다.
주요 기여
아키텍처: 혁신적 로드 밸런싱 전략 및 학습 목표
- DeepSeek-V2의 효율적인 아키텍처를 기반으로, 부가 손실(auxiliary loss)을 배제한 로드 밸런싱 전략을 처음으로 도입하여, 로드 밸런싱을 촉진하는 과정에서 발생할 수 있는 성능 저하를 최소화한다.
- 멀티 토큰 예측(Multi-Token Prediction, MTP) 학습 목표를 적용해 모델 성능이 향상됨을 확인하였으며, 이는 추론 속도를 높이는 speculative decoding에도 활용 가능하다.
사전 학습: 궁극의 학습 효율 추구
- FP8 혼합 정밀도 학습 프레임워크를 설계하고, 초대형 모델 규모에서 FP8 학습이 실제로 가능하고 효과적임을 처음으로 검증하였다.
- 알고리즘·프레임워크·하드웨어를 공동으로 설계하여, 노드 간 MoE 학습에서 발생하는 통신 병목을 극복하고 연산-통신 겹침을 극대화하였다. 이를 통해 학습 효율을 크게 높이고 비용을 절감하여, 추가 오버헤드 없이 모델 규모를 더욱 확장할 수 있게 되었다.
- H800 GPU 시간 2.664M만으로 14.8조 토큰에 대한 사전 학습을 완료함으로써, 현재 공개된 모델 중 가장 강력한 오픈소스 베이스 모델을 생산하였다. 사전 학습 이후 단계인 맥락 길이 확장과 포스트 트레이닝에는 약 0.1M GPU 시간만 필요하다.
포스트 트레이닝: DeepSeek-R1로부터의 지식 증류
- 길이가 긴 Chain-of-Thought(CoT)를 사용하는 모델인 DeepSeek R1 계열로부터 추론 능력을 일반 LLM(특히 DeepSeek-V3)에 증류하는 새로운 방식을 제안하였다. 이 파이프라인을 통해 R1의 검증과 반추(reflection) 패턴을 DeepSeek-V3에 자연스럽게 접목함으로써 추론 성능을 크게 향상시키면서도, DeepSeek-V3의 출력 스타일과 길이를 필요에 따라 제어할 수 있게 하였다.
핵심 평가 결과 요약
- 지식(한국어·영어 등):
- MMLU, MMLU-Pro, GPQA와 같은 교육 분야 벤치마크에서 DeepSeek-V3는 MMLU 88.5, MMLU-Pro 75.9, GPQA 59.1 점수를 기록하며 다른 오픈소스 모델을 능가한다. 동시에 GPT-4o 및 Claude-Sonnet-3.5와 유사한 수준의 성능을 보이며, 이 영역에서 오픈소스와 폐쇄형 모델 간 격차를 좁힌다.
- 사실성 평가(factuality) 벤치마크인 SimpleQA, Chinese SimpleQA에서도 오픈소스 모델 중 가장 뛰어난 성능을 보여준다. 영어 사실성(SimpleQA) 측면에서는 GPT-4o와 Claude-Sonnet-3.5에 약간 뒤처지나, 중국어 사실성(Chinese SimpleQA)에서는 이들을 능가하며 중국어 팩트 지식 측면에서의 우수성을 드러낸다.
- 코드, 수학, 추론:
- 수학 관련 벤치마크에서, DeepSeek-V3는 모든 비-장문 CoT(non-long-CoT) 오픈소스·폐쇄형 모델 중 최상위 성능을 기록한다. 특히 MATH-500과 같은 특정 벤치마크에서 o1-preview 모델을 상회하며, 강력한 수학적 추론 역량을 보여준다.
- 코딩 관련 태스크(예: LiveCodeBench)에서도 DeepSeek-V3는 경쟁 모델 중 가장 높은 점수를 획득하며, 이 분야를 선도하는 모델로 자리매김한다. 엔지니어링 관련 태스크에서도 Claude-Sonnet-3.5보다 약간 뒤처지긴 하지만, 다른 모델들과 비교했을 때는 상당히 앞서는 성능을 발휘하여 다양한 기술적 벤치마크에서 경쟁력을 입증한다.
이하 본문에서는 먼저 DeepSeek-V3 모델 아키텍처를 상세히 설명한다(2장). 이후 우리의 컴퓨팅 클러스터, 학습 프레임워크, FP8 학습 지원, 추론 배포 전략, 차세대 하드웨어 설계에 대한 제언 등 인프라 전반을 소개한다(3장). 다음으로 사전 학습 과정—데이터 구성, 하이퍼파라미터, 맥락 길이 확장 기법, 평가 및 논의—을 다룬다(4장). 이어 포스트 트레이닝 단계인 지도 학습(SFT)과 강화 학습(RL), 이와 관련된 평가와 논의에 대해 논한다(5장). 마지막으로 DeepSeek-V3의 한계점을 짚고 향후 연구 방향을 제시하며 본 논문을 마무리한다(6장).
2 아키텍처
본 장에서는 먼저 효율적인 추론을 위한 Multi-head Latent Attention(MLA)(DeepSeek-AI, 2024c)와 경제적인 학습을 위한 DeepSeekMoE(Dai et al., 2024)로 구성된 DeepSeek-V3의 기본 아키텍처를 소개한다. 이후 다양한 평가 지표에서 모델 성능을 향상시키는 것으로 확인된 Multi-Token Prediction(MTP) 학습 목표에 대해 설명한다. 명시적으로 언급되지 않은 기타 세부 사항은 DeepSeek-V2(DeepSeek-AI, 2024c)와 동일하다.

Figure 2: DeepSeek-V3의 기본 아키텍처를 그림으로 나타낸다. DeepSeek-V2와 마찬가지로, 효율적인 추론을 위해 MLA를, 경제적인 학습을 위해 DeepSeekMoE를 채택하였다.
2.1 기본 아키텍처
DeepSeek-V3의 기본 아키텍처는 여전히 Transformer(Vaswani et al., 2017) 프레임워크 내에 있다. 효율적인 추론과 경제적인 학습을 위해, DeepSeek-V3는 DeepSeek-V2에서 철저히 검증된 MLA와 DeepSeekMoE를 채택한다. DeepSeek-V2와 비교했을 때 가장 큰 차이는, DeepSeekMoE에 대해 부가 손실 없이(auxiliary-loss-free) 로드 밸런싱을 달성할 수 있는 전략(Wang et al., 2024a)을 추가 도입하여, 로드 밸런싱 과정에서 초래되는 성능 저하를 줄였다는 점이다. 그림 2는 DeepSeek-V3의 기본 아키텍처를 나타내며, 이하 본 절에서는 MLA와 DeepSeekMoE에 대한 세부 내용을 간략히 검토한다.
2.1.1 Multi-Head Latent Attention











Node-Limited Routing
DeepSeek-V2에서 사용된 device-limited routing과 유사하게, DeepSeek-V3도 학습 중 통신 비용을 제한하기 위해 라우팅을 제약하는 메커니즘을 쓴다. 구체적으로, 각 토큰은 최대 M개의 노드로만 전송되는데, 이는 해당 노드에 배치된 전문가 중 상위 K_r M개의 친화도 합이 가장 큰 노드들을 기준으로 결정된다. 이를 통해 분산 MoE 학습에서 연산과 통신 간 겹침(overlap)을 거의 전부 실현할 수 있다.
No Token-Dropping
로드 밸런싱 전략이 효과적으로 작동하기 때문에, DeepSeek-V3는 학습 전체 기간 동안 토큰을 드롭(drop)할 필요가 없었다. 더 나아가 추론 시에도 특화된 배포 전략을 적용하여 로드 밸런스를 유지하기 때문에, DeepSeek-V3는 추론 시에도 토큰을 드롭하지 않는다.

Figure 3: Multi-Token Prediction(MTP)의 구현 방식을 나타낸다. 각 깊이(depth)에서 토큰을 예측할 때, 인과적(causal) 연결고리를 모두 유지한다.






2.2 멀티 토큰 예측(Multi-Token Prediction, MTP)
Gloeckle et al. (2024)에서 영감을 받아, 우리는 DeepSeek-V3에 대해 멀티 토큰 예측(MTP) 학습 목표를 연구하고 설정하였다. 이는 각 위치에서 다수의 미래 토큰을 예측 범위에 포함시킨다. 한편으로, MTP 학습 목표는 학습 신호를 조밀화(densify)하여 데이터 효율성을 높일 수 있으며, 다른 한편으로는 모델이 미래 토큰 예측을 위해 사전에 표현을 구성(pre-plan)하는 데 도움이 될 수 있다. 그림 3은 우리의 MTP 구현 방식을 보여준다. Gloeckle et al. (2024)는 독립적인 출력 헤드를 통해 추가 토큰 D개를 병렬로 예측한 것과 달리, 우리는 추가 토큰을 순차적으로 예측하면서 각 예측 깊이(depth)에서 완전한 인과적 사슬(causal chain)을 유지하도록 구현하였다. 본 절에서는 MTP 구현에 대한 세부 사항을 소개한다.


추론에서의 MTP(MTP in Inference)
우리의 MTP 전략은 주로 메인 모델의 성능 향상을 목적으로 하므로, 추론 시에는 MTP 모듈을 버리고(사용하지 않고) 메인 모델만 독립적으로 사용해도 전혀 문제가 없다. 추가적으로, 원한다면 MTP 모듈을 재활용하여 추론 속도를 더욱 높이기 위한 speculative decoding에 활용할 수도 있다.


3 인프라(Infrastructures)
3.1 컴퓨팅 클러스터(Compute Clusters)
DeepSeek-V3는 2048개의 NVIDIA H800 GPU가 탑재된 클러스터에서 학습된다. H800 클러스터의 각 노드에는 NVLink와 NVSwitch로 연결된 8개의 GPU가 장착되어 있으며, 노드 간 통신은 InfiniBand(IB) 인터커넥트를 통해 이루어진다.
3.2 학습 프레임워크(Training Framework)
DeepSeek-V3의 학습은 우리 엔지니어들이 기초 단계부터 직접 설계한, 효율적이고 가벼운 학습 프레임워크인 HAI-LLM에 의해 지원된다. 전반적으로, DeepSeek-V3는 16-way 파이프라인 병렬화(Pipeline Parallelism, PP)(Qi et al., 2023a), 8개 노드에 걸친 64-way 전문가 병렬화(Expert Parallelism, EP)(Lepikhin et al., 2021), 그리고 ZeRO-1 데이터 병렬화(Data Parallelism, DP)(Rajbhandari et al., 2020)를 적용한다.
DeepSeek-V3의 효율적인 학습을 위해, 우리는 정교한 엔지니어링 최적화를 구현하였다. 첫째, 파이프라인 병렬화를 효율적으로 수행하기 위해 DualPipe 알고리즘을 고안했다. 기존 PP 방식과 비교했을 때 DualPipe는 파이프라인 버블이 더 적고, 특히 순전파(forward)와 역전파(backward) 과정에서 연산과 통신을 겹쳐(Overlap) 처리함으로써 노드 간 전문가 병렬화가 초래하는 막대한 통신 오버헤드를 완화한다. 둘째, 노드 간 all-to-all 통신을 효율적으로 처리하기 위한 전용 커널을 개발하여 IB와 NVLink 대역폭을 최대한 활용하고, 통신에 할당되는 스트리밍 멀티프로세서(SM) 점유를 절감하였다. 마지막으로, 학습 과정에서 메모리 사용량을 철저히 최적화하여, 비용이 큰 텐서 병렬화(Tensor Parallelism, TP)를 사용하지 않고도 DeepSeek-V3를 학습할 수 있도록 했다.
3.2.1 DualPipe와 연산-통신 겹치기(Computation-Communication Overlap)

Figure 4: 개별 순방향(forward) 청크와 역방향(backward) 청크 쌍에 대한 겹치기 전략을 나타낸다. (트랜스포머 블록의 경계와 정렬되지 않음) 주황색은 순방향, 녹색은 “역방향 입력”, 파란색은 “역방향 가중치”, 보라색은 PP(pipeline parallelism) 통신, 빨간색은 배리어(Barriers)를 뜻한다. all-to-all 및 PP 통신 모두 완전히 감출(hide) 수 있다.
DeepSeek-V3에서는 노드 간 전문가 병렬화로 인해 발생하는 통신 오버헤드 때문에 연산 대비 통신 비율이 대략 1:1로 비효율적이다. 이를 해결하기 위해 우리는 DualPipe라는 혁신적인 파이프라인 병렬화 알고리즘을 고안하였다. DualPipe는 순방향 및 역방향 단계에서 연산과 통신을 효과적으로 겹치도록 함으로써 학습 속도를 가속할 뿐 아니라, 파이프라인 버블도 줄여준다.
DualPipe의 핵심 아이디어는 하나의 순방향 청크와 역방향 청크 쌍에서 연산과 통신을 서로 겹치도록 하는 것이다. 구체적으로, 각 청크를 어텐션, all-to-all 디스패치(dispatch), MLP, 그리고 all-to-all 컴바인(combine) 네 가지 구성 요소로 나눈다. 특히 역방향 청크의 어텐션과 MLP는 ZeroBubble(Qi et al., 2023b) 방식과 마찬가지로 “역방향 입력(backward for input)”과 “역방향 가중치(backward for weights)”로 각각 두 부분으로 분할한다. 또한 우리는 PP 통신 단계를 추가 구성한다. 그림 4에서 보이듯이, 순방향 청크와 역방향 청크 쌍에 대해 이들을 재배치하고, GPU SM(Streaming Multiprocessor) 중 통신에 배정되는 비중 대비 연산에 배정되는 비중을 수동으로 조정한다. 이를 통해 all-to-all과 PP 통신이 실행 중에 완전히 감춰질(hide) 수 있다. 이처럼 효율적으로 겹치는 전략 덕분에 DualPipe의 전체 스케줄링은 그림 5와 같이 이뤄진다. 쌍방향 파이프라인 스케줄링을 적용해, 마이크로 배치를 파이프라인 양 끝에서 동시에 투입하면서 통신 대부분을 겹칠 수 있다. 이렇게 함으로써 모델 규모가 더욱 커져도, 연산 대비 통신 비율을 일정하게 유지하기만 하면, 노드 전체에 걸쳐 파인 그레인(fine-grained) 전문가를 사용하면서도 all-to-all 통신 오버헤드를 거의 0에 가깝게 만들 수 있다.

Figure 5: 8개 PP 랭크와 20개 마이크로 배치를 양방향으로 처리하는 DualPipe 스케줄링 예시. 역방향 방향에 있는 마이크로 배치는 순방향 방향과 대칭적 구조이므로, 이해를 돕기 위해 배치 ID는 생략했다. 검은색 테두리로 둘러싸인 두 칸은 서로 연산과 통신이 겹치는 부분을 의미한다.
나아가, 통신 부담이 그리 크지 않은 일반적인 시나리오에서도 DualPipe는 여전히 효율성 측면에서 이점을 보인다. 표 2는 다른 PP 기법과 비교했을 때, 파이프라인 버블과 메모리 사용량을 요약한 것이다. 표에서 보듯이 ZB1P(Qi et al., 2023b)나 1F1B(Harlap et al., 2018)와 비교했을 때, DualPipe는 파이프라인 버블을 크게 줄이면서도 활성화(activation) 메모리 사용량은 1/FP배만 증가시킨다. 또한 DualPipe는 모델 파라미터를 2개 복제해야 하지만, 학습 시 EP(Expert Parallelism)의 크기가 커서 메모리 사용량 자체가 크게 늘어나지는 않는다. Chimera(Li and Hoefler, 2021)와 달리, DualPipe는 “파이프라인 스테이지와 마이크로 배치 개수가 2로 나누어떨어질 것”만 요구할 뿐, “마이크로 배치가 파이프라인 스테이지의 개수로 나누어떨어져야 한다”는 조건을 요구하지 않는다. 또한 DualPipe에서는 마이크로 배치 수가 증가해도 버블이나 활성화 메모리가 늘어나지 않는다.

Table 2: 다양한 파이프라인 병렬 기법 간 파이프라인 버블 및 메모리 사용량 비교. F는 순방향 청크 실행 시간, B는 전체 역방향 청크 실행 시간, W는 “역방향 가중치(backward for weights)” 청크의 실행 시간, F&B는 상호 겹치는 순방향 및 역방향 청크 두 개의 실행 시간을 나타낸다.
3.2.2 노드 간 All-to-All 통신의 효율적 구현(Efficient Implementation of Cross-Node All-to-All Communication)
DualPipe의 계산 성능을 충분히 확보하기 위해, 우리는 노드 간 all-to-all 통신(디스패칭 및 컴바인)을 효율적으로 처리하기 위한 전용 커널을 구현했다. 이는 통신 전용 SM(Streaming Multiprocessor) 사용량을 최소화하기 위해 설계된 것으로, MoE 게이팅 알고리즘과 클러스터의 네트워크 토폴로지에 맞춰 공동 설계되었다. 구체적으로, 우리 클러스터에서 노드 간 GPU는 IB(InfiniBand)로 완전히 연결되어 있고, 노드 내 통신은 NVLink로 처리된다. NVLink 대역폭(160 GB/s)은 IB(50 GB/s)의 약 3.2배다. 이러한 서로 다른 대역폭을 최대한 활용하기 위해 각 토큰은 최대 4개 노드까지만 디스패치하도록 제약하며, 이로써 IB 트래픽을 줄였다. 토큰이 라우팅 결정을 마친 뒤에는 먼저 IB를 통해 대상 노드 중 동일한 노드 내 인덱스(in-node index)를 갖는 GPU로 전송된다. 대상 노드에 도착하면, 해당 토큰이 이후 도착하는 다른 토큰에 의해 차단되지 않고 즉시 NVLink로 필요한 전문가가 있는 GPU에 전달되도록 설계했다. 이 방식으로 IB와 NVLink 통신이 완전히 겹치며, 각 토큰은 추가 NVLink 오버헤드 없이 노드당 평균 3.2개의 전문가에게 효율적으로 분산될 수 있다. 결과적으로 DeepSeek-V3는 실질적으로 8개의 라우팅 전문가만을 선택하지만, 최대 13개(4개 노드 × 3.2 전문가/노드) 전문가까지 확장하더라도 NVLink 측면에서 동일한 통신 비용을 유지할 수 있다. 이런 전략하에서 전체 IB와 NVLink 대역폭을 완전히 활용하기 위해서는 SM 20개면 충분하다.
구체적으로, 우리는 워프 특화(warp specialization)(Bauer et al., 2014) 기법을 사용해 SM 20개를 10개의 통신 채널로 분할한다. 디스패칭 과정에서 (1) IB 송신, (2) IB→NVLink 포워딩, (3) NVLink 수신은 각각 독립된 워프(warp)들이 담당한다. 워크로드 분포에 따라 워프 할당 개수를 동적으로 조정하며, 이는 전체 SM에서 통신 작업을 효율적으로 나누어 처리하기 위함이다. 컴바인 과정에서도 (1) NVLink 송신, (2) NVLink→IB 포워딩 및 누산, (3) IB 수신 및 누산을 마찬가지 방식으로 동적으로 워프에 할당한다. 또한 디스패칭과 컴바인 커널은 연산 스트림과 겹치도록 설계되어 있어, 다른 SM 연산 커널에 미치는 영향도 고려한다. 구체적으로는 PTX(Parallel Thread Execution) 명령어를 맞춤 구현하고, 통신 청크 크기를 자동 튜닝하여 L2 캐시 사용량을 대폭 줄이고 다른 SM과의 간섭도 최소화했다.
3.2.3 극단적 메모리 절감과 미미한 오버헤드(Extremely Memory Saving with Minimal Overhead)
학습 중 메모리 사용량을 줄이기 위해, 우리는 다음과 같은 기법들을 적용했다.
- RMSNorm 및 MLA 업-프로젝션 재계산(Recomputation of RMSNorm and MLA Up-Projection)
역전파(back-propagation) 시 모든 RMSNorm 연산과 MLA 업-프로젝션을 재계산함으로써, 이들의 출력 활성화(activation)를 지속적으로 저장할 필요가 없도록 했다. 이는 약간의 계산 오버헤드를 감수하는 대신 활성화 메모리 사용량을 크게 줄여준다. - CPU에서의 지수이동평균(Exponential Moving Average) 처리
학습 중 모델 파라미터에 대한 지수이동평균(EMA)을 CPU 메모리에 저장하고, 각 스텝이 끝날 때마다 비동기적으로 업데이트한다. 이를 통해 별도의 GPU 메모리나 추가 계산 시간을 거의 소모하지 않고서도 EMA 파라미터를 유지해, 학습률 감소 후 모델 성능을 조기에 추정할 수 있다. - 멀티 토큰 예측용 임베딩 및 출력 헤드 공유(Shared Embedding and Output Head for Multi-Token Prediction)
DualPipe 전략을 적용할 때, 모델의 가장 얕은 레이어(임베딩 레이어 포함)와 가장 깊은 레이어(출력 헤드 포함)를 동일한 PP 랭크에 배치했다. 이렇게 하면, MTP 모듈과 메인 모델 사이에서 공유 임베딩·출력 헤드 파라미터 및 그라디언트를 물리적으로 함께 쓸 수 있어, 메모리 효율이 더욱 향상된다.
1. InfiniBand(IB)
1) 무엇을 하는가?
- 서버(노드) 간 데이터를 전달하는 네트워크 인터페이스
- 일반적으로 **Ethernet(이더넷)**보다 훨씬 빠른 대역폭과 낮은 지연(latency)을 제공
- HPC(슈퍼컴퓨터나 클러스터) 분야에서 주로 쓰이며, GPU 클러스터에서도 노드 간 통신에 많이 사용됨
2) 왜 필요한가?
- 여러 노드(서버)들이 한꺼번에 대규모 연산(예: 대규모 AI 모델 학습)을 수행할 때, 노드끼리 상태나 데이터를 주고받아야 함
- 일반적인 이더넷으로는 속도나 지연이 HPC 요건을 만족하기 힘들 수 있으므로, 더 빠르고 안정적인 통신을 위해 IB를 도입
3) 특징
- 고속, 저지연: 동급 이더넷 대비 대역폭이 크고(예: 25Gb, 40Gb, 100Gb, 200Gb 등), 지연이 낮음
- RDMA(Remote Direct Memory Access) 가능: CPU 관여 없이 직접 GPU 메모리에 쓰기/읽기 같은 동작을 지원 → 통신 효율 높임
- 가격 및 설치 복잡도: 이더넷보다 비용이 높고, 스위치·케이블·드라이버 설정도 전문성이 필요
2. NVLink
1) 무엇을 하는가?
- GPU와 GPU 간, 혹은 GPU와 NVSwitch 간 데이터를 초고속으로 주고받기 위한 인터커넥트
- NVIDIA에서 개발한 기술로, 여러 GPU가 같은 노드(서버) 안에 있을 때 GPU들끼리 데이터를 교환할 때 쓰임
2) 왜 필요한가?
- 노드 내부에서 여러 GPU가 병렬 연산을 하려면, 서로 간 데이터 교환이 자주 일어남
- PCIe(보통 CPU와 GPU를 잇는 일반적인 연결 방식)보다 대역폭이 훨씬 크고, 지연이 낮음 → GPU들끼리 빠른 통신 필요
3) 특징
- 고속(수백 GB/s급) 대역폭: 같은 노드 내에서 GPU가 직접 연결되거나 NVSwitch를 통해 통신하므로, 매우 빠르고 안정적
- GPU 전용 인터커넥트: CPU 관여 없이, GPU 메모리끼리 직접 데이터를 주고받음
- NVSwitch: NVLink를 더 확장한 스위치 구조로, 여러 GPU가 마치 모두 서로 연결되어 있는 듯이 고속 통신 가능
3. IB vs NVLink 요약
- IB(InfiniBand):
- 노드(서버) 간 연결
- 상대적으로 속도가 낮고(예: 50
200Gb/s, 1초에 수 GB수십 GB 수준), 지연이 클 수 있음 - 이더넷보다 여전히 빠르지만, 노드 내부에서 쓰기는 다소 부족
- HPC나 클라우드 데이터센터에서 대규모 클러스터 구성 시 필수적인 고속 네트워킹
- NVLink:
- 한 노드 내부에서 GPU들 간 연결
- 가장 빠른 수준(예: 대당 600GB/s 이상)으로 데이터 전송 가능
- 노드 내부에서만 사용(외부로는 안 나감)
즉, 노드 간 통신에는 InfiniBand가, 노드 내부 GPU 간 통신에는 NVLink가 사용된다고 보면 됩니다.
4. 왜 둘 다 필요한가?
- 대규모 GPU 클러스터 환경에서는, 여러 노드에 GPU가 수십~수백 개씩 나누어 배치되어 있을 수 있음
- 노드 내부에서는 GPU끼리 빠른 NVLink로 연결
- 노드와 노드 사이는 InfiniBand로 이어져야 데이터 교환 가능
- 예를 들어 8개의 GPU가 있는 서버 여러 대가 있을 때:
- 서버 1 내부의 8개 GPU들은 NVLink로 고속 연결
- 서버 1과 서버 2 간에는 InfiniBand를 통해 데이터 이동
- 이런 식으로 각 노드 내부와 노드 간을 모두 고속화해야 병렬 연산 성능이 극대화됨
5. 결론
- InfiniBand(IB):
- 노드(서버) 간 초고속 네트워킹
- 이더넷보다 빠르고 저지연이며, HPC/AI 클러스터 구축에 자주 쓰임
- NVLink:
- 한 노드 내부 GPU들 간 초고속 연결
- PCIe보다 훨씬 빠른 속도, GPU-메모리 간 직접 접근 가능
- 대규모 딥러닝 훈련에서는 “노드 내부(GPU-GPU)는 NVLink” + “노드 간(서버-서버)은 InfiniBand” 조합으로 구성해, 전체 클러스터의 병렬 처리 효율을 높입니다.
GPU 클러스터 환경에서 노드 간 all-to-all 통신(dispatch/combination)은 모델 아키텍처와 데이터 파티셔닝 방식(특히 MoE처럼 토큰을 라우팅해야 하는 경우)에 따라 매우 많은 통신량이 발생할 수 있습니다. 기본적으로 “노드 A에 있는 토큰 중 일부가 노드 B에 있는 특정 전문가(Expert)로 보내져야 하고, 거기서 처리된 결과가 다시 노드 A로 돌아와야 하는” 과정을 수행하므로, 각 노드 간에는 끊임없이 대량의 데이터가 오갈 수밖에 없습니다.
이때 오버헤드(통신 지연, GPU SM 자원 낭비)가 커지면, 학습 속도는 물론이고 클러스터 전체의 효율이 급격히 떨어지게 됩니다. 특히 최근 트랜스포머 모델들은 매우 크고, MoE 구조도 수많은 라우팅이 필요해 통신 병목이 쉽게 발생합니다.
3.2 장의 핵심 요점
1) 노드 간 통신 부담을 줄이기 위해 (토큰→전문가) 라우팅을 제한함
- 본문에서 말하듯, “각 토큰이 최대 4개 노드까지만 갈 수 있게 제한한다.”
- 즉, 토큰이 원격 노드 전부로 무작정 분산되지 않도록 하여 InfiniBand(IB) 사용량을 통제하는 것.
- 노드 내부(NVLink) 통신은 IB보다 3.2배 정도 빠르므로, 토큰이 노드 내부에서 이동하는 것은 비교적 큰 문제는 아니다.
2) IB와 NVLink를 완전히 겹치도록(Overlap) 통신한다
- 먼저 토큰이 IB로 노드에 도착하면, 곧바로 NVLink로 전문가 GPU에 옮겨 버린다(차단되지 않고 즉시).
- 이 과정을 병렬/겹치기하면서, “IB로 전달 → 도착 GPU → NVLink로 최종 목적지로 전달” 전 과정을 파이프라인처럼 운영해, 대기 시간을 줄임.
3) SM(Streaming Multiprocessor) 자원을 효율적으로 쓴다 (Warp Specialization + Auto Tuning)
- 통신 처리(송수신, 포워딩, 누산 등)에 필요한 스레드 워프들을 20개 SM으로 묶어서 운영.
- “IB 송신, IB→NVLink 포워딩, NVLink 수신” 등 단계별로 필요한 워크로드 비율에 맞춰 워프를 동적으로 분배.
- 이를 통해 연산을 수행해야 할 다른 SM들과의 충돌(자원 경쟁)을 최소화하고, 통신 과정도 빠르게 끝냄.
- 또, PTX 명령어 수준에서 커스텀 코드를 작성하여, L2 캐시 사용량을 줄이고 SM 간 간섭을 억제.
“왜 대단한가?”를 알기 위해 짚어볼 포인트
- 토큰을 여러 노드로 라우팅하는 MoE 구조에서 통신 오버헤드는 굉장히 치명적입니다.
- 토큰 수가 엄청나고, 각 토큰은 자신에게 맞는 전문가(expert)로 보내야 함 → “all-to-all” 형태의 통신 폭발이 일어날 수 있음.
- 이런 통신 폭발을 제어하지 못하면, 모델 크기가 커질수록 학습 속도가 기하급수적으로 느려집니다.
- “노드 제한 라우팅” (토큰당 최대 4개 노드)이라는 규칙을 설계해 IB 트래픽을 막고, NVLink처럼 더 빠른 노드 내부 통신을 적극 이용하게끔 했습니다.
- IB는 보통 클러스터 스케일(노드 간) 통신을 담당하므로 병목이 되기 쉽고, NVLink는 노드 내부에 국한되어 있지만 훨씬 빠름.
- “토큰을 최대한 적은 노드에 배정하고, 노드 내부에서는 NVLink를 통해 처리”하는 방식이 효율적.
- 통신 오퍼레이션을 GPU 내부 스케줄링 측면(워프 할당, PTX 레벨 최적화)에서 세밀하게 튜닝한 사례가 흔치 않습니다.
- 대부분의 프레임워크는 NVIDIA의 NCCL, MPI 같은 라이브러리에 의존하고, 커널 레벨에서 깊은 최적화를 하기 쉽지 않음.
- 여기서는 엔지니어들이 직접 “SM 20개, 10개 통신 채널”을 구성하여 각 단계(송신, 포워딩, 수신)를 구분하고 워프를 동적으로 할당 → GPU 연산 자원과 통신 자원을 효율적으로 안배.
- 이걸 통해 통신 시간이 거의 숨겨지고(overlapped), 모델이 학습 연산을 최대한 쉬지 않고 진행할 수 있음.
- **결과적으로 “노드 간 all-to-all 통신이 거의 0에 가까운 오버헤드”**가 되도록 만들었다는 점이 중요한 성과입니다.
- 일반적으로 “노드 간 통신은 무겁다”라는 게 정설인데, 이런 구조적/세밀한 최적화로 통신 병목을 해결해냈으니, 모델 크기가 훨씬 커져도 확장성(scalability)에서 이점을 가진다는 의미.
3.3 FP8 학습(FP8 Training)

Figure 6: FP8 데이터 형식을 사용하는 혼합 정밀도(mixed precision) 프레임워크의 전체 구조. 이해를 돕기 위해 Linear 연산자만 표시했다.

3.3.1 혼합 정밀도 프레임워크(Mixed Precision Framework)
기존 저정밀도 학습 기술(Kalamkar et al., 2019; Narang et al., 2017)에 기반해, 우리는 FP8 학습을 위한 혼합 정밀도 프레임워크를 제안한다. 이 프레임워크에서, 연산량이 큰 대부분의 연산은 FP8로 처리하고, 일부 핵심 연산만 원래의 데이터 형식을 유지해 학습 효율과 수치 안정성을 균형 있게 맞췄다. 전체 구조는 그림 6에 요약되어 있다.
먼저, 모델 학습 속도를 높이기 위해 대부분의 핵심 연산 커널(즉, GEMM 연산)을 FP8 정밀도로 구현한다. 이들 GEMM 연산은 FP8 텐서를 입력받아 BF16 또는 FP32 형식으로 출력을 만든다. 그림 6과 같이 Linear 연산자에 해당하는 Fprop(순전파), Dgrad(활성화 역전파), Wgrad(가중치 역전파) 등 세 가지 GEMM을 모두 FP8로 수행하도록 설계했다. 이는 기존의 BF16 방식 대비 이론상 2배 빠른 연산 속도를 낼 수 있다. 또, FP8로 Wgrad를 수행함으로써 역전파 시 필요한 활성화를 FP8 형식으로 저장해 둘 수 있으므로, 메모리를 크게 절약할 수 있다.
비록 FP8이 효율적이긴 하지만, 일부 연산은 저정밀도에 민감하기 때문에 더 높은 정밀도가 요구되며, 일부 저비용 연산도 높은 정밀도를 사용해도 전체 학습 비용에는 큰 영향이 없다. 이런 이유로, 우리는 임베딩 모듈, 출력 헤드, MoE 게이팅 모듈, 정규화 연산, 그리고 어텐션 연산에는 BF16이나 FP32 같은 원래의 정밀도를 유지하기로 결정했다. 이러한 선택적 고정밀도 유지가 DeepSeek-V3의 학습을 안정적으로 만드는 주요 요인이다. 또한 수치 안정성을 보장하기 위해, 마스터 가중치와 그라디언트, 옵티마이저 상태는 더 높은 정밀도로 저장한다. 이로 인해 다소 메모리가 추가로 소모되지만, 분산 학습 환경에서 여러 DP 랭크 간에 효율적으로 샤딩(sharding)하면 그 부담을 최소화할 수 있다.

Figure 7: (a) 활성화의 이상치(outlier)로 인한 양자화 오류를 줄이기 위해 우리는 세밀화된 양자화(fine-grained quantization) 기법을 제안했다(도움말을 위해 순전파(Fprop)만 표시). (b) 이 양자화 전략과 함께 FP8 GEMM 정밀도를 높이기 위해, 높은 정밀도 누산을 위한 N_C=128 요소마다 한 번씩 CUDA 코어로 승격(promote)시키는 방식을 적용한다.
3.3.2 양자화와 곱셈 과정에서의 정밀도 개선(Improved Precision from Quantization and Multiplication)
우리의 FP8 혼합 정밀도 프레임워크를 기반으로, 우리는 양자화 방식과 곱셈 과정 양측에서 저정밀도 학습 정확도를 높이는 여러 전략을 제안한다.
세밀화된 양자화(Fine-Grained Quantization)
FP8 형식은 지수 비트가 적어 동적 범위가 제한적이므로, 오버플로/언더플로 문제가 자주 발생한다. 전형적으로 입력 텐서 분포의 최대 절댓값을 FP8 포맷의 표현 범위에 맞춰 스케일링하는 방식을 사용하지만(Narang et al., 2017), 이는 활성화에서 발생하는 이상치에 매우 민감하여 양자화 정확도를 심하게 떨어뜨릴 수 있다. 이에 대응해, 우리는 보다 세밀한 수준에서 스케일링을 적용하는 세밀화된 양자화(fine-grained quantization)를 제안한다. 그림 7(a)에서 보듯이,
- 활성화의 경우, 1×128 타일 단위(즉, “한 토큰당 128 채널”)로 모아서 스케일링,
- 가중치의 경우, 128×128 블록 단위(즉, “128개 입력 채널 × 128개 출력 채널”)로 모아서 스케일링한다.
이를 통해 양자화 과정이 보다 작은 범위의 요소들에 맞춰 스케일을 조절함으로써 이상치를 효과적으로 수용할 수 있다. 부록 B.2에서는 가중치 양자화와 동일한 방식으로 활성화를 블록 단위로 그룹핑할 경우 발생하는 학습 불안정에 대해 추가 논의한다.
우리 방법의 핵심 변경 사항 중 하나는 GEMM 연산의 내부 차원(K축)에 따라 그룹별 스케일링 팩터를 도입했다는 점이다. 이는 표준 FP8 GEMM에서는 직접 지원되지 않는 기능이지만, 우리의 정밀한 FP32 누산 전략과 결합해 효율적으로 구현할 수 있다.
주목할 만한 점은, 본 세밀화된 양자화 전략이 마이크로스케일링(microscaling) 포맷(Rouhani et al., 2023b)과 매우 유사하다는 것이다. 실제로 NVIDIA의 차세대 GPU(Blackwell 시리즈)는 더 작은 양자화 그라뉴얼리티를 갖는 마이크로스케일링 포맷을 지원한다고 발표했다(NVIDIA, 2024a). 우리의 설계가 향후 최신 GPU 아키텍처에 맞춰진 연구의 참고가 되길 바란다.





누산 정밀도 증가(Increasing Accumulation Precision)
저정밀도 GEMM 연산은 언더플로 문제에 취약하며, 이를 보완하기 위해 보통 고정밀 누산(FP32)을 사용한다(Kalamkar et al., 2019; Narang et al., 2017). 그러나 우리의 관찰에 따르면, NVIDIA H800 GPU에서 FP8 GEMM의 누산 정밀도는 사실상 14비트 수준에 머물러 FP32 정밀도보다 훨씬 낮다. 이는 대규모 모델 훈련에서 자주 볼 수 있는 큰 K값(배치 크기나 모델 폭이 클 때)에서 더욱 문제가 된다(Wortsman et al., 2023). 예컨대 K=4096인 무작위 행렬 곱셈을 테스트해본 결과, 텐서 코어(Tensor Core)의 제한된 누산 정밀도로 인해 최대 상대 오차가 2%에 육박했다. 그럼에도 불구하고 일부 FP8 프레임워크(NVIDIA, 2024b)에서는 이 제한된 누산 정밀도가 기본 옵션으로 사용되어, 학습 정확도를 크게 제약한다.
이 문제를 해결하기 위해, 우리는 더 높은 정밀도를 위해 CUDA 코어로 승격(promote)하는 방식을 채택했다(Thakkar et al., 2023). 그림 7(b)에 나타난 것처럼, 텐서 코어에서 MMA(Matrix Multiply-Accumulate) 실행 시 일시적으로 제한된 비트 폭으로 누산하고, 내부 연산이 N_C만큼 진행되면(예: 128개 요소마다) 이 부분 누산 결과를 FP32 레지스터가 있는 CUDA 코어로 복사하여 전체 정밀도의 FP32 누산을 수행한다. 또, 앞서 언급한 대로 우리 세밀화된 양자화 전략은 K축 그룹별 스케일링 팩터를 적용하는데, 이 스케일 팩터들도 CUDA 코어에서 디양자화 연산을 하면서 저비용으로 곱셈 처리할 수 있다.
물론 이 변경 사항 때문에 단일 워프그룹에서의 WGMMA(Warpgroup-level Matrix Multiply-Accumulate) 명령어 발행 빈도가 감소한다. 하지만 H800 아키텍처에서는 보통 두 개의 WGMMA가 동시에 계속 실행되며, 한 워프그룹이 승격 작업을 수행하는 동안 다른 워프그룹은 MMA를 진행할 수 있어, 두 연산이 겹칠(Overlap) 수 있다. 이를 통해 텐서 코어 활용률을 높게 유지한다. 실험 결과, N_C=128 요소(4번의 WGMMA에 해당)를 누산 간격으로 설정했을 때, 오버헤드가 크지 않으면서 정밀도를 크게 개선할 수 있었다.
“승격(promote)한다”는 말은, 초기 입력(행렬 요소)이나 내부 연산은 FP8(저정밀) 상태로 시작하더라도, 곱셈 결과(중간 누산값)는 더 높은 정밀도(예: FP32)에 올려서 처리한다는 뜻입니다.
- FP8 × FP8 → (내부적으로) FP32 누산
- 예시로 드신 것처럼 0.1234567 × 0.2135487 등의 곱셈을 훨씬 정밀하게 계산할 수 있습니다.
- 텐서 코어 하드웨어가 기본적으로 “FP8 * FP8 → FP16(또는 더 낮은 정밀도) 누산” 정도까지만 구현되어 있다면, 일정 간격마다(N_C만큼 누적한 뒤) CUDA 코어로 옮겨와 FP32로 누산을 이어가는 식입니다.
따라서 승격을 통해 곱셈 이후 누산 과정은 FP32 정밀도로 이뤄지고, 그 결과 오차가 크게 줄어들게 됩니다.
지수보다 가수(mantissa)에 중점을 둔 형식(Mantissa over Exponents)
이전 연구(NVIDIA, 2024b; Peng et al., 2023b; Sun et al., 2019b)에서는 E4M3(지수 4비트, 가수 3비트)와 E5M2(지수 5비트, 가수 2비트)를 각각 순전파와 역전파에 사용한다. 우리는 모든 텐서에 대해 E4M3만 사용하여, 보다 높은 가수 정밀도를 확보했다. 이는 세밀화된 양자화 전략(타일·블록 단위 스케일링) 덕분에 가능해졌다고 볼 수 있는데, 소규모 그룹으로 나눈 요소들 간에 지수 비트를 공유하는 방식으로, 제한된 동적 범위가 주는 영향을 줄였기 때문이다.
FP8에는 여러 변형이 있지만, 딱 8비트만 가지고 지수(exponent)와 가수(mantissa)를 어떻게 배분하느냐에 따라 E4M3, E5M2 등 여러 포맷이 생깁니다. 여기서 “E4M3”는 “지수 4비트 + 가수 3비트”, “E5M2”는 “지수 5비트 + 가수 2비트”를 의미합니다. 실제로는 부호(sign) 1비트까지 포함해 총 8비트를 구성하지만, 보통 줄여서 E4M3, E5M2라고 부릅니다.
아래에서는 두 포맷을 간단히 비교하고, 가능한 수 표현 범위(동적 범위)와 정밀도(가수 비트)가 어떻게 다른지 예시와 함께 설명합니다.
FP8에서는 보통 1비트를 부호(sign)로 쓰고, 나머지 7비트를 지수와 가수로 나눕니다.
- E4M3: 부호(1) + 지수(4) + 가수(3)
- E5M2: 부호(1) + 지수(5) + 가수(2)
아래는 가상의 8비트 패턴 예시입니다.
E4M3 예시
[부호 1비트] [지수 4비트] [가수 3비트]
예: 0 1010 011 (총 8비트)
- 부호 = 0 (양수)
- 지수 필드 = 1010₂ (= 10 decimal) → 실제 지수 = (10 - 바이어스)
- 가수 필드 = 011₂ → 실제 가수는 1.011₂ ~ 1.375 decimal (정규화 가정 시)
- 최종 값 = + (1.011₂) × 2^(지수값)E5M2 예시
[부호 1비트] [지수 5비트] [가수 2비트]
예: 1 11001 01 (총 8비트)
- 부호 = 1 (음수)
- 지수 필드 = 11001₂ (= 25 decimal) → 실제 지수 = (25 - 바이어스)
- 가수 필드 = 01₂ → 실제 가수는 1.01₂ ~ 1.25 decimal (정규화 가정 시)
- 최종 값 = - (1.25) × 2^(지수값)결론적으로
- E4M3(지수 4비트, 가수 3비트)는 소수점 표현이 조금 더 세밀해 “정밀도”에서 이점이 있으나, 동적 범위는 좁음.
- E5M2(지수 5비트, 가수 2비트)는 범위가 넓어 오버플로/언더플로 상황에 좀 더 강하지만, 소수점 정밀도는 더 낮음.
실전에서는 “순전파 때 E4M3 / 역전파 때 E5M2”처럼 혼합 사용하기도 하고, 혹은 모든 텐서를 E4M3로 통일한 뒤 “세밀화된 양자화”를 적용해 동적 범위를 보완하기도 합니다. 어떤 방식을 택하든, 저정밀도 포맷의 장단점을 어떻게 보완하느냐가 핵심 과제가 됩니다.
온라인 양자화(Online Quantization)
기존 텐서 단위 양자화 프레임워크(NVIDIA, 2024b; Peng et al., 2023b)에서는 지연 양자화(delayed quantization)를 사용해 이전 스텝들의 최대 절댓값 이력을 토대로 현재 스케일을 추정한다. 반면 우리는 매 1×128 활성화 타일 또는 128×128 가중치 블록마다 최대 절댓값을 실시간으로 계산해 스케일 팩터를 구하고, 바로 FP8 형식으로 양자화(quantize)한다. 이를 통해 스케일이 매우 정확해지고, 프레임워크 구조도 단순해진다.
원래 양자화는 내가 생각하는 대로 분포도를 0을 기준으로해서 다시 만들어주는데, 온라인은 그걸 실시간으로 하니까, 정밀도 내려가는게 줄어들고 추가로 학습과정의 일부니 정밀도 유지가 된다는거네
- 일반적인 양자화(특히 사후 양자화·PTQ)에서는
- 미리 측정된 분포(혹은 과거 스텝의 통계치)를 토대로, “0 중심의 분포로 스케일링”을 정합니다.
- 그래서 현재 배치에서 갑자기 이상치(outlier)가 튀어나오면 반영이 느려, 양자화 정밀도가 떨어질 여지가 있습니다.
- 온라인 양자화(Online Quantization) 방식은
- “현재 타일/블록에서 최대 절댓값(max_abs)을 실시간으로 찾고, 그 값에 맞춰 스케일링 후 즉시 양자화”를 수행합니다.
- 그 결과, “현재 실제 분포”에 훨씬 더 잘 적합한 스케일로 양자화하게 되므로,
- 분포 변화(이상치 등장, 다이나믹 레인지 변동)를 즉각 반영해, 정밀도 손실이 최소화될 수 있죠.
- 학습 과정에서 이를 수행하면
- 모델이 “해당 양자화 방식”에 자연스럽게 적응하며 파라미터를 업데이트하므로,
- 전반적으로 정밀도를 더 안정적으로 유지하면서도 FP8 등의 저정밀 포맷을 사용할 수 있게 됩니다.
결국, 온라인 양자화는 각 스텝(또는 각 타일)에서 “실제 데이터 분포”를 즉시 반영하므로, “이전 스텝 통계를 활용하는 지연 양자화” 대비 양자화 오차를 크게 줄이고, 학습 시에도 유연하고 안정적인 정밀도를 확보할 수 있는 접근법이라 할 수 있습니다.
3.3.3 저정밀도 스토리지 및 통신(Low-Precision Storage and Communication)
FP8 학습 프레임워크와 결합해, 우리는 캐싱된 활성화와 옵티마이저 상태를 저정밀도 형식으로 압축하여 메모리 사용량과 통신 오버헤드를 추가로 줄였다.
저정밀도 옵티마이저 상태(Low-Precision Optimizer States)
옵티마이저로 AdamW(Loshchilov and Hutter, 2017)를 사용할 때, 1·2차 모멘트는 FP32 대신 BF16으로 추적해도 성능 저하는 관찰되지 않았다. 하지만 수치 안정성을 위해, 마스터 가중치(옵티마이저가 저장)와 그라디언트(배치 크기 누적용)는 여전히 FP32로 유지한다.
저정밀도 활성화(Low-Precision Activation)
그림 6에서 보듯, Wgrad 연산을 FP8로 수행하기 위해, 역전파 시 사용될 활성화를 FP8로 캐싱하는 것은 자연스러운 선택이다. 다만 몇몇 연산자에 대해서는 다음과 같이 특별 처리를 하여, 저비용 고정밀 학습을 유지한다:
- 어텐션 연산 뒤의 Linear 입력
- 이 활성화는 어텐션 역전파에서도 사용되므로 정밀도에 민감하다. 따라서 이 부분에는 E5M6 형식을 전용으로 사용한다.
- 또한 역전파 시 1×128 타일에서 128×1 타일로 전환한다. 양자화 오차를 줄이기 위해 스케일 팩터는 2의 거듭제곱 단위(=반올림해 정수 지수로)로 설정한다.
- MoE의 SwiGLU 연산 입력
- 메모리 비용을 더 줄이기 위해, 역전파 시 SwiGLU의 출력을 재계산하도록, 입력 활성화를 캐싱한다.
- 이 활성화 또한 세밀화된 양자화 방식을 사용해 FP8로 저장함으로써, 메모리 효율과 연산 정확도 간 균형을 맞췄다.
저정밀도 통신(Low-Precision Communication)
MoE 모델의 학습에서 통신 대역폭은 중요한 병목이다. 이를 해소하기 위해, 우리는 활성화를 FP8로 양자화한 뒤 MoE 업-프로젝션으로 디스패치한다. 이는 FP8 순전파(Fprop)와 호환된다. 어텐션 이후 Linear 입력과 마찬가지로, 이 활성화의 스케일 팩터도 2의 거듭제곱 단위로 설정한다. 역전파 시 MoE 다운-프로젝션 직전의 활성화 그라디언트 또한 유사한 방식으로 처리한다. 포워드/백워드 컴바인(combine) 단계는 학습 파이프라인의 핵심 영역이므로 BF16으로 유지하여 학습 정밀도를 보존했다.
해당 부분의 핵심 의도는 “모델 병목인 통신 대역폭을 줄이기 위해, 통신할 데이터를 FP8로 줄여서 보내자”는 데 있습니다. 즉, MoE 구조상 “업-프로젝션(전문가로 토큰을 보내는 단계)”와 “다운-프로젝션(전문가로부터 결과를 합치는 단계)”에서 토큰의 활성화나 그라디언트가 노드 간에 오가야 하는데, 이때 데이터 양이 많아 통신 병목이 발생하기 쉽습니다.
1) 왜 통신을 저정밀도(FP8)로 처리하나?
- MoE 특성
- MoE(Mixture-of-Experts)는 “토큰→전문가” 라우팅으로 인해 노드 간 통신이 대규모로 발생합니다.
- 전문가가 여러 노드에 분산되므로, 각 토큰(활성화)과 그라디언트가 노드 간을 왕복해야 하는 경우가 많습니다.
- 통신 대역폭이 병목
- 대규모 모델, 대규모 배치(batch)일수록 통신해야 하는 데이터 양이 기하급수적으로 늘어납니다.
- GPU-노드 간 통신(InfiniBand)은 NVLink보다도 느리고, 병목이 되기 쉽습니다.
- 저정밀도(FP8) 양자화의 장점
- FP8로 활성화를 양자화하면, 전송해야 할 데이터 양(비트 수)이 크게 줄어듭니다.
- 예: FP16(16비트) 대비 절반, BF16(16비트) 대비 절반, FP8(8비트)이므로 통신 사용량 절반 수준
- 덕분에 통신 지연(latency)과 대역폭 부담이 감소해 전체 학습 속도를 높일 수 있습니다.
2) 왜 “업-프로젝션” 구간만 FP8로 처리하고 “컴바인(combine)” 구간은 BF16으로 남겨두나?
- 업-프로젝션(Dispatch) 단계
- 활성화(또는 그라디언트)를 각 전문가로 보내는 단계이므로, 통신량이 많음
- 여기서 FP8로 양자화하면 병목 해소에 큰 이점
- 또한, FP8 순전파(Fprop)와의 호환성을 고려해 설계했으므로, 수치 안정성(정확도)이 크게 나빠지지 않음
- 컴바인(Combine) 단계
- 전문가들이 처리한 출력을 다시 합치는 단계. 모델 파이프라인 전체에서 중추적 역할을 하며, 역전파(Backward) 시에도 중요한 그라디언트를 다루는 영역
- BF16 정도의 정밀도를 유지해야, “최종 결과의 정확도”에 문제가 생기지 않음(특히 역전파 그라디언트에서 누적 오차 방지)
- 따라서 이 영역은 저정밀도 양자화로 인해 성능이 크게 하락할 수 있으므로, BF16을 사용해 안전성을 높임
3) 스케일 팩터를 “2의 거듭제곱 단위”로 잡는 이유
- 빠르고 단순한 양자화/디양자화
- 2의 거듭제곱(예: 2⁰, 2¹, 2⁻¹ 등)으로 스케일을 맞추면, 실제 하드웨어 연산 시 “곱셈/나눗셈” 대신 시프트 연산만으로 처리가 가능하거나, 오차를 줄이기 쉽습니다.
- GPU 파이프라인에서 반올림이나 추가 연산을 최소화할 수 있고, 효율적입니다.
- “어텐션 이후 Linear 입력”과 동일한 정책
- 같은 방식으로 스케일을 잡으면, 일관된 양자화 흐름을 유지할 수 있어 전체 파이프라인 구현이 단순해지고, 수치 안정성도 올라갑니다.
4) 결론적으로…
- 의도: MoE 모델 학습에서 **가장 큰 병목(통신)**을 극복하기 위해, “MoE 업-프로젝션 구간(Dispatch)”에 한해 FP8로 활성화(및 그라디언트)를 양자화하여 전송.
- 컴바인(Combine) 단계는 모델 정확도에 미치는 영향이 크므로 BF16을 유지해 안정성을 확보.
- 동시에, “2의 거듭제곱 스케일”을 쓰면 양자화/디양자화를 빠르게 처리하며, 하드웨어 구현도 단순화 가능.
즉, 통신량을 절반 이하로 줄여 학습 속도를 높이고, 중요한 구간에서는 BF16 정밀도를 유지함으로써 성능(정확도)과 효율(통신) 사이의 균형을 맞추는 설계가 주된 의도라고 보시면 됩니다.
3.4 추론 및 배포(Inference and Deployment)
우리는 DeepSeek-V3를 H800 클러스터 위에 배포한다. 이때 각 노드 내 GPU들은 NVLink로 연결되고, 클러스터 전체에 걸쳐서는 IB(InfiniBand)로 완전한 상호연결을 이룬다. 온라인 서비스에 대한 SLO(Service-Level Objective)와 높은 처리량(throughput)을 동시에 보장하기 위해, 프리필(prefilling) 단계와 디코딩(decoding) 단계를 분리하는 배포 전략을 적용한다.
3.4.1 프리필(prefilling)
프리필 단계의 최소 배포 단위는 4개 노드, 즉 32개의 GPU이다. 어텐션 부분은 시퀀스 병렬화(Sequence Parallelism, SP)가 결합된 4-way 텐서 병렬화(TP4) 방식과, 8-way 데이터 병렬화(DP8)를 사용한다. 텐서 병렬화 크기를 4로 작게 유지하여 TP 통신 오버헤드를 제한한다.
MoE 부분에서는 32-way 전문가 병렬화(EP32)를 적용하여, 각 전문가가 충분히 큰 배치 크기를 처리하도록 함으로써 계산 효율을 높인다. MoE의 all-to-all 통신은 학습 때와 동일한 방식, 즉 먼저 토큰을 IB를 통해 노드 간 전송하고, 그 후 노드 내부에서 NVLink를 통해 필요한 GPU로 전달하는 방식을 쓴다. 특히 얕은 레이어(shallow layer)에 있는 밀집(dense) MLP에 대해서는 텐서 병렬화를 1-way로 설정하여 TP 통신량을 절감한다.
MoE 부분에서 여러 전문가 간 로드 밸런스를 달성하기 위해서는, 각 GPU가 처리하는 토큰 수가 대체로 비슷해야 한다. 이를 위해, 우리는 중복 전문가(redundant experts) 배포 전략을 적용한다. 부하가 높은(high-load) 전문가를 복제하여 중복 배치하는 방식이다. 해당 전문가들은 온라인 배포 도중 수집된 통계를 바탕으로 주기적으로(예: 10분마다) 감지된다. 중복 전문가 집합이 정해지면, 노드 내 GPU 간 전문가 재배치를 신중히 수행하여, 노드 간 all-to-all 통신 오버헤드를 늘리지 않으면서도 GPU 간 로드를 최대한 균등화한다. DeepSeek-V3의 프리필 단계에서는 32개의 중복 전문가를 사용하며, 각 GPU는 원래 호스팅하던 8개 전문가 외에 추가로 1개의 중복 전문가를 더 호스팅한다.
나아가, 프리필 단계에서는 처리량을 높이고 all-to-all 및 TP 통신 오버헤드를 감추기(hide) 위해, 비슷한 연산 부하를 가진 두 마이크로배치(micro-batch)를 동시에 처리한다. 즉, 한 마이크로배치의 어텐션과 MoE 연산을 다른 마이크로배치의 디스패치(dispatch)와 컴바인(combine) 단계와 겹치도록 실행한다.
끝으로, 우리는 전문가에 대해 동적인 중복(dynamic redundancy)을 적용하는 방안도 연구 중이다. 예컨대 각 GPU가 16개 전문가를 호스팅하되, 실제 인퍼런스 스텝마다 그중 9개만 활성화한다. 레이어별 all-to-all 연산이 시작되기 전에 전체적으로 최적의 라우팅 방안을 계산(on the fly)하는 방식이다. 프리필 단계의 연산량이 워낙 커서, 이 라우팅 계획을 계산하는 오버헤드는 거의 무시할 수 있다.
3.4.2 디코딩(decoding)
디코딩 단계에서는 공유 전문가(shared expert)를 라우팅 전문가로 취급한다. 즉, 라우팅 과정에서 각 토큰은 9개의 전문가를 선택하되, 공유 전문가는 항상 선택되는 “heavy-load” 전문가로 간주한다. 디코딩 단계의 최소 배포 단위는 40개 노드, 즉 320개의 GPU다. 어텐션 부분은 TP4+SP와 DP80을 결합해 사용하고, MoE 부분에서는 EP320을 사용한다. MoE 부분에 대해서는 각 GPU가 전문가를 1개씩만 호스팅하며, 64개의 GPU가 중복 전문가와 공유 전문가를 호스팅한다. 디스패치와 컴바인 시의 all-to-all 통신은 지연(latency)을 최소화하기 위해 IB 상에서 직접 P2P(point-to-point) 방식으로 수행한다. 추가로 IBGDA(NVIDIA, 2022) 기술을 활용해 지연을 더욱 줄이고 통신 효율을 높인다.
프리필과 마찬가지로, 일정 주기마다(예: 특정 인터벌) 온라인 서비스에서 수집한 통계적 전문가 부하를 기반으로 중복 전문가 집합을 결정한다. 다만 디코딩 단계에서는 각 GPU가 전문가를 단 1개씩만 호스팅하므로, 재배치를 따로 할 필요는 없다. 디코딩에서도 동적 중복 전략을 모색 중이지만, 전역적으로 최적의 라우팅을 계산하는 알고리즘과 디스패치 커널의 융합(fusion)을 통해 오버헤드를 줄이는 추가 최적화가 필요하다.
또한, 디코딩 단계에서도 처리량을 높이고 all-to-all 통신 오버헤드를 감추기 위해, 비슷한 연산 부하를 가진 두 마이크로배치를 동시에 처리하는 방안을 연구 중이다. 다만 프리필과 달리 디코딩에서는 어텐션 부분이 차지하는 시간이 더 크다. 따라서 한 마이크로배치의 어텐션 연산을 다른 마이크로배치의 디스패치+MoE+컴바인 과정과 겹치도록 실행한다. 디코딩 단계에서는 전문가마다 배치 크기가 상대적으로 작아(보통 256 토큰 이내) 병목은 연산보다는 메모리 접근이 된다. 그리고 MoE 부분은 한 번에 단 하나의 전문가 파라미터만 불러오면 되므로 메모리 접근 오버헤드가 미미하고, SM(Streaming Multiprocessor)을 적게 써도 전체 성능에 큰 영향을 주지 않는다. 따라서 어텐션 연산 속도에 지장을 주지 않기 위해, 디스패치+MoE+컴바인 과정에 SM 자원을 조금만 할당해도 충분하다.
1) 프리필 단계의 중복 전문가(redundant experts) 배포 전략 (3.4.1)
(1) MoE 구조와 전문가 부하 불균형
- MoE(Mixture-of-Experts) 모델에서 “토큰→전문가” 라우팅이 이루어지다 보면,
- 어떤 전문가에게는 토큰이 몰리고(“heavy-load”),
- 어떤 전문가는 상대적으로 일이 적어서(“light-load”) 부하 불균형이 발생할 수 있습니다.
- 이렇게 되면 “heavy-load” 전문가가 있는 GPU는 다른 GPU보다 훨씬 많은 토큰을 처리해야 해서 병목이 생기고, 전체 처리량이 떨어집니다.
(2) 중복 전문가(redundant experts)로 부하 분산
- 중복 전문가란, “특정 전문가(heavy-load)를 여러 GPU에 복제해서 동시에 처리”할 수 있게 만드는 기법입니다.
- 예: 원래 GPU1에만 있던 ‘Expert A’를, GPU2에도 복제(동일 파라미터 공유)해 두면, ‘Expert A’를 필요로 하는 토큰들을 GPU1과 GPU2가 나누어 병렬로 처리합니다.
- 이렇게 하면 부하가 높은 전문가를 여러 GPU가 분산 처리하므로, 토큰이 특정 GPU에 몰리는 문제를 완화할 수 있습니다.
(3) 왜 주기적 재배치(rearranging)가 필요한가?
- 온라인 서비스(실시간 인퍼런스) 환경에서는, 시간에 따라 입력 분포나 토큰 패턴이 바뀌면서 어떤 전문가가 더 자주 선택되는지 달라집니다.
- 따라서 한 번 정해진 중복 전문가 구성만으로는 부하가 완전히 균등화되지 않을 수 있어, “10분마다” 등 일정 주기로 다시 통계를 모아 “누가 heavy-load인지”를 파악하고,
- 그때마다 중복 배치를 조정(redundant experts를 새로 지정·이동)해서 부하 균형을 유지하는 것입니다.
1) 전문가가 “복제”되어도 파라미터는 동일함
- 중복 전문가란, 어떤 전문가가 호스팅된 GPU를 여러 개로 늘리는 것이지, 서로 다른 파라미터를 갖는 “새로운 전문가”를 만드는 게 아닙니다.
- 실제 파라미터는 전부 동일(동기화)하게 유지되어, 모델이 학습한 “특화 지식”이 그대로 존재합니다.
- 토큰이 “Expert A”로 라우팅될 때, “GPU1의 Expert A” 혹은 “GPU2의 Expert A(복제본)” 중에서 물리적으로 더 여유 있는 곳이 그 토큰을 처리하게 됩니다.
- 결국 논리적으로는 같은 전문가가 분산 처리되는 것이므로, 해당 전문가의 “특화”가 사라지거나 약화되지 않습니다.
하나의 노드에 동일한 expert를 여러개 만들어서 이에 대한 학습은 노드단위로 expert가 진행되는거군
“하나의 논리적(논리적으로 동일한) Expert”를 서로 다른 GPU(동일 노드 내 여러 GPU, 혹은 여러 노드)에 여러 개로 복제해두고, 결국에는 하나의 파라미터(동일 Expert의 가중치)로 동기화되는 방식입니다. 즉,
- 물리적으로는 Expert가 여러 “복제본” 형태로 배치되어, 부하를 분산해 처리하지만,
- 논리적으로는 하나의 Expert이므로, 학습 시 여러 복제본이 처리한 그라디언트를 합쳐(집계) 동일한 파라미터를 업데이트합니다.
2) 디코딩 단계에서 MoE 부분은 한 번에 하나의 전문가 파라미터만 로드하므로 메모리 오버헤드가 미미 (3.4.2)
(1) 디코딩 시 어텐션 연산이 메인 병목
- 프리필(prefilling) 단계는 전체 문맥(context)을 한 번에 입력받아 대규모 행렬 곱 연산이 일어나, MoE 연산도 많은 계산 비중을 차지합니다.
- 디코딩(decoding) 단계는 이미 프리필로 “맥락”이 주어진 상태에서, 토큰을 한두 개씩 생성해 나갑니다.
- 이 과정에서는 어텐션 연산(특히 캐시 업데이트 등)이 상대적으로 더 복잡하고, 많은 시간이 소요됨.
- 반면, MoE 부분은 배치 크기도 작고, 토큰당 실제 연산량이 크지 않아 주된 병목이 되지 않습니다.
(2) “한 번에 한 전문가만 로드한다”는 말의 의미
- MoE 레이어는 “토큰을 선택한 K개의 전문가”에서 처리하게 됩니다.
- 그러나 디코딩 시 배치(batch) 크기가 작게 쪼개져 들어오다 보니, 실제 한 시점(timestep)의 토큰 집합 중에서 각 전문가당 토큰 수가 매우 작습니다(보통 256개 미만이라 설명).
- 그 결과, 어떤 GPU가 호스팅 중인 특정 전문가 파라미터만 로드하면, 그 전문가가 맡은 토큰들은 모두 처리할 수 있으므로, 추가적인 큰 메모리 접근이 불필요해집니다.
(3) SM 자원을 많이 안 써도 되는 이유
- MoE 처리 자체가 상대적으로 적은 계산(토큰 수가 작음) + 메모리 접근도 크지 않음이므로,
- 이걸 위해 **전체 GPU SM(Streaming Multiprocessor)**를 다 동원할 필요가 없습니다.
- 즉, SM 중 일부만 MoE 쪽에 할당해도 충분하며,
- 나머지 리소스를 어텐션 연산에 집중할 수 있게 함으로써, 디코딩 단계 전반의 성능을 극대화할 수 있다는 뜻입니다.
3.5 하드웨어 설계에 대한 제언(Suggestions on Hardware Design)
DeepSeek-V3의 all-to-all 통신 및 FP8 학습 방식을 구현한 경험을 토대로, 우리는 AI 하드웨어 벤더들에게 다음과 같은 칩 설계 방향을 제안한다.
3.5.1 통신 하드웨어(Communication Hardware)
DeepSeek-V3에서는 연산과 통신을 겹쳐(Overlap) 처리하여, 순차적으로 연산 후 통신을 수행할 때 발생하는 통신 지연을 감춘다. 이는 통신 대역폭 의존도를 크게 줄여주지만, 현재 구현된 통신 방식은 값비싼 SM(Streaming Multiprocessor)을 사용하는 데 기반한다(예: H800 GPU에서 사용 가능한 132개 SM 중 20개를 통신 전용으로 할당). 이로 인해 계산 처리량이 제한되고, 텐서 코어가 유휴 상태로 남아 비효율성이 커진다.
현재 SM들이 all-to-all 통신에서 담당하는 작업은 크게 다음과 같다.
- IB(InfiniBand)와 NVLink 도메인 간 데이터를 포워딩하면서, 단일 GPU에 도착한 IB 트래픽을 노드 내 여러 GPU 대상으로 집계
- RDMA 버퍼(등록된 GPU 메모리 공간)와 입력/출력 버퍼 간 데이터 전송
- all-to-all 컴바인(combine) 연산에서의 리듀스(reduce) 연산
- IB와 NVLink 도메인에 걸쳐 여러 전문가(expert)에게 청크 단위 데이터를 전송하기 위한 미세 메모리 레이아웃 관리
향후 하드웨어가 SM 대신 통신 작업을 전담하는 GPU 코프로세서나 네트워크 코프로세서(예: NVIDIA SHARP (Graham et al., 2016)와 유사)를 탑재해 주길 기대한다. 또한 프로그래밍 복잡도를 줄이기 위해, 계산 유닛(Computation Unit) 관점에서 IB(확장-아웃)와 NVLink(확장-업) 네트워크를 통합적으로 다룰 수 있는 구조를 희망한다. 이런 단일화된 인터페이스를 갖추면, 계산 유닛은 단순한 프리미티브 기반 통신 요청만으로 IB-NVLink 통합 도메인에서의 읽기/쓰기/멀티캐스트/리듀스를 간편하게 수행할 수 있을 것이다.
M(연산 장치) 중 일부를 통신 전담으로 할당해 다음과 같은 작업을 수행하고 있습니다:
- IB(InfiniBand) ↔ NVLink 간 데이터 포워딩
- 개념: 노드 간 통신을 담당하는 IB 네트워크와, 노드 내부 GPU 간 통신을 담당하는 NVLink 네트워크가 분리되어 있습니다.
- 이 작업: “다른 노드에서 IB로 들어온 데이터(토큰·그라디언트·중간 활성화 등)를, 해당 노드의 NVLink 망을 통해 각 GPU로 다시 중계(포워딩)해주는 것”
- 왜 필요한가: IB로 한 GPU에 데이터가 일단 도착하더라도, 최종적으로는 이 데이터가 노드 내 다른 GPU로도 흩어져야 할 수 있습니다(예: 모듈 병렬화, MoE 전문가 라우팅 등). 따라서 GPU1 → GPU2로 NVLink 전송이 필요함.
- RDMA 버퍼(등록된 GPU 메모리) ↔ I/O 버퍼 간 데이터 전송
- 개념: RDMA(Remote Direct Memory Access)는 네트워크 통신 시 CPU 개입 없이 GPU 메모리를 직접 읽고 쓰는 기술입니다.
- 이 작업: “네트워크로 받을(or 보낼) 데이터를 ‘RDMA 전용 등록 영역(registered GPU memory)’에서 가져오거나, 결과물을 다시 I/O 버퍼로 옮기는” 등의 메모리 복사(copy) 작업
- 왜 필요한가: RDMA 동작을 위해서는 네트워크 카드(NIC)와 직접 연결된 특정 GPU 메모리 범위가 있어야 하고, 실제 연산(MLP, 어텐션 등)은 또 다른 GPU 메모리 공간에서 이뤄집니다. 이 둘을 연결하려면 일부 복사가 필요합니다.
- all-to-all 컴바인(combine) 연산에서의 리듀스(reduce)
- 개념: all-to-all 통신에서, 노드 여러 개에 분산된 데이터를 모아서(혹은 나눠서) 처리해야 할 때, “컴바인(combine)” 단계에서 여러 요소를 리듀스(sum/mean/concat 등)합니다.
- 이 작업: “각 GPU에서 받은 데이터를 합산, 혹은 특정 연산을 통해 합치는 과정”
- 왜 필요한가: MoE 구조에서 ‘토큰→전문가’ 디스패치 후, 결과를 다시 합쳐야(combine) 최종 출력을 만들 수 있습니다. 이때 단순 데이터 복사만 아니라, “누산/평균” 등 리듀스 연산이 함께 이뤄집니다.
- IB·NVLink 도메인에 걸쳐 여러 전문가에게 청크 단위 데이터 전송 시, 미세 메모리 레이아웃 관리
- 개념: MoE 모델은 “토큰→전문가” 라우팅 시, 각 토큰이 고른 전문가가 노드·GPU 상 여러 곳에 분산. 따라서 데이터를 작은 청크(chunk) 단위로 쪼개서, 올바른 전문가가 있는 GPU로 전송해야 합니다.
- 이 작업: “토큰별 라우팅 정보를 기반으로, ‘어떤 청크를 어떤 노드/GPU로 보낼 것인가’를 SM이 결정하여 메모리를 재배치(메모리 레이아웃), 한꺼번에(또는 효율적으로) 전송”
- 왜 필요한가: 토큰별 라우팅 목적지가 제각각이므로, 단순히 하나의 큰 버퍼로 보내기 어렵고, 작은 덩어리들을 정확히 묶어 보내야 합니다.
핵심 의도: “통신 전담 하드웨어가 따로 있으면 좋겠다”
- 현재는 **SM(연산 장치)**가 위 작업들을 직접 수행하여, “연산을 맡아야 할 텐서 코어는 놀고, SM은 통신 작업으로 소모”되는 현상이 발생합니다.
- 문서에서 제안하는 바는, **“이런 통신 업무를 전담하는 별도의 코프로세서(NIC 측)나 GPU 내부 전문 하드웨어”**를 두면 SM을 아낄 수 있다는 것입니다.
- 예: “NVIDIA SHARP”처럼 네트워크 측에서 리듀스/포워딩 등을 지원하는 모델, 또는 “GPU 내부 통신 유닛”이 독립적으로 데이터 라우팅과 리듀스를 수행
- 그렇게 하면, SM은 온전히 연산에 집중해 텐서 코어 활용률을 높일 수 있고, 통신-연산 겹침 시에도 SM 리소스가 소모되지 않아 전체 성능이 올라갑니다.
정리하자면, “IB ↔ NVLink 포워딩, RDMA 버퍼 ↔ I/O 버퍼 전송, 리듀스, 미세 메모리 레이아웃 관리” 등은 모두 “노드 간+노드 내”를 넘나드는 데이터 트래픽 조율을 위해 SM이 수행해야 하는 작업인데,
- 이런 통신 로직을 “전담 하드웨어”로 빼주면, SM은 모델 연산에만 전념하고, 통신은 별도 코어가 맡아 처리 → 효율과 속도가 훨씬 좋아진다는 게 문서가 주장하는 핵심입니다.
3.5.2 계산 하드웨어(Compute Hardware)
텐서 코어에서의 더 높은 FP8 GEMM 누산 정밀도(Higher FP8 GEMM Accumulation Precision in Tensor Cores)
현재 NVIDIA Hopper 아키텍처의 텐서 코어(Tensor Core)는 FP8 GEMM에서 고정소수점 방식을 사용해, 덧셈 전에 최대 지수(exponent)에 맞춰 맨티사(mantissa) 곱을 오른쪽 시프트로 정렬한다. 실험 결과, 부호 보정을 위한 오른쪽 시프트 후 약 14비트만 사용되고 범위를 초과하는 비트들은 잘려나간다. 예컨대 32개의 FP8×FP8 곱셈을 FP32 수준으로 누산하려면 최소 34비트 정밀도가 필요한데, 현행 방식은 이를 만족하지 못한다.
따라서 향후 칩 설계에서는 텐서 코어의 누산 정밀도를 확대해 완전 정밀도(accumulate)나, 적어도 학습/추론 알고리즘에 필요한 요구사항을 충족하는 누산 비트 폭을 선택하기를 권장한다. 이로써 계산 효율성을 유지하면서도 오차를 허용 가능한 범위 내로 제어할 수 있을 것이다.
타일·블록 단위 양자화 지원(Support for Tile- and Block-Wise Quantization)
현행 GPU는 텐서 단위(per-tensor) 양자화만 기본적으로 지원하며, 우리 방식처럼 타일(1×128)·블록(128×128) 단위의 세밀화된 양자화는 네이티브 지원이 없다. 현재 구현에서는 N_C 간격에 도달할 때마다 텐서 코어에서 CUDA 코어로 부분 누산값(partial result)을 복사하고, 그 스케일 팩터를 곱해 FP32 레지스터에 더해야 한다. 정밀한 FP32 누산 전략 덕분에 디양자화 오버헤드는 많이 완화됐지만, 텐서 코어↔CUDA 코어 간 빈번한 데이터 이동이 여전히 계산 효율을 제한한다.
이에 우리는 텐서 코어가 스케일 팩터를 직접 입력받아 그룹 단위 스케일링을 수행(MMA with group scaling)할 수 있길 권장한다. 그렇게 되면 부분 합(accumulation)과 디양자화가 텐서 코어 내부에서 최종 출력까지 바로 이뤄져, 잦은 데이터 이동을 피하고 성능을 높일 수 있을 것이다.
온라인 양자화 지원(Support for Online Quantization)
현재 GPU 구현들은 온라인 양자화를 효과적으로 지원하지 못한다. 예컨대 128개의 BF16 활성화 값을 HBM(High Bandwidth Memory)에서 읽어와 양자화한 뒤, FP8 값으로 다시 HBM에 쓰고, 그 뒤 MMA를 위해 다시 읽는 식으로 처리해야 한다. 우리는 FP8 캐스팅(cast)과 TMA(Tensor Memory Accelerator) 접근을 하나의 결합된 연산으로 통합해, 활성화를 글로벌 메모리에서 공유 메모리로 옮기는 과정에서 양자화를 완료함으로써 불필요한 메모리 왕복을 줄이길 권장한다. 또한 warp 단위의 캐스트(cast) 명령어를 지원해 레이어 정규화(layer normalization)와 FP8 캐스트의 융합 효율을 높이는 방안도 제시한다. 대안으로 HBM 근방에 연산 로직을 배치해(BF16→FP8 변환을 메모리 바로 옆에서 수행) 오프칩(off-chip) 메모리 접근을 약 50% 줄이는 근접-메모리 연산(near-memory computing) 접근도 고려해볼 만하다.
전치된 GEMM 연산 지원(Support for Transposed GEMM Operations)
현재 아키텍처에서는 행렬 전치(matrix transposition)와 GEMM 연산을 융합하기가 어렵다. 우리의 워크플로에서 순전파 시 활성화를 1×128 FP8 타일로 양자화해 저장했다가, 역전파 시 이 행렬을 읽어 디양자화하고 전치한 뒤 128×1 타일로 다시 양자화해 HBM에 저장하는 과정을 거친다. 이러한 반복적 메모리 연산을 줄이려면, 주요 정밀도(학습/추론에 필요한)에서 MMA 수행 전, 공유 메모리에서 행렬을 직접 전치해 읽는 기능을 제공하기를 권장한다. FP8 포맷 변환과 TMA 접근을 융합하면, 양자화 워크플로가 훨씬 단순화될 것이다.
맨티사(mantissa)는 부동소수점(floating-point) 수에서 “실제 유효숫자(significant digits)”를 저장하는 부분입니다. 예를 들어, 일반적인 IEEE 754 표준의 부동소수점 수는 다음과 같은 필드로 구성됩니다.
- 부호 비트(Sign bit): 양수/음수를 나타냅니다.
- 지수 비트(Exponent bits): 수의 크기를 크게(또는 작게) 만드는 데 사용되며, 2의 몇 제곱인지 나타냅니다.
- 맨티사(가수) 비트(Mantissa bits): 실제 유효숫자(significand)를 저장합니다. (가수라고도 불립니다)
예컨대 32비트 단정밀도(FP32)는
- 1비트 부호(sign)
- 8비트 지수(exponent)
- 23비트 맨티사(mantissa)
형식으로 나뉘죠.
"전치(transpose)나 양자화/디양자화 같은 전·후처리 과정을 소프트웨어적으로 반복할 게 아니라, 하드웨어가 자동으로 지원해주면 좋겠다”는 게 문서의 주장입니다.
- 전치 행렬 자동화
- 지금은 예컨대 1×128 → 128×1 전환이 필요할 때, GPU 커널을 따로 짜거나 공유 메모리에 복사해 전치하는 과정을 거칩니다.
- 하지만 하드웨어 차원에서 “행렬 읽기/쓰기 시 자동 전치”를 지원하면, 소프트웨어 레벨에서 전치 커널을 작성할 필요가 없어져 메모리 접근·개발 복잡도가 크게 줄어듭니다.
- 디양자화(Dequantization) 하드웨어 지원
- FP8 같은 저정밀도 형식에서, 매번 “FP8 → FP32” 변환(디양자화)을 소프트웨어적으로 하면, 스케일 팩터 곱·반올림 등을 모두 커널로 구현해야 합니다.
- 문서에서는 “텐서 코어(또는 TMA, Shared Memory) 단계에서 이 과정을 내부적으로 처리”하길 제안합니다.
- 즉, ‘true/false 혹은 간단한 파라미터 설정’으로 디양자화 여부를 결정해, 매번 추가 커널 작성 없이 하드웨어가 스스로 수행할 수 있도록 하자는 것이죠.
- 왜 어려운가?
- 말씀하신 대로, 디양자화는 단순히 “곱하기 스케일 + 반올림”으로 끝나지 않을 수 있습니다.
- 특히 세밀화된 양자화(tile/block-wise scaling)나 온라인 양자화(activation마다 스케일 달리 적용) 같은 기능을 고려하면,
- 하드웨어가 “다양한 스케일링 전략”을 동시에 지원해야 하므로 설계가 복잡해집니다.
- 그래도 이를 하드웨어에서 제공하면, 소프트웨어 입장에선 “스케일 팩터만 세팅 → 자동 디양자화”가 가능해지니, 성능과 개발 편의성이 크게 향상된다는 거죠.
정리하면, 하드웨어 차원에서 ‘자동 전치 + (디)양자화 처리’ 지원을 해주면, 현재 소프트웨어적으로 반복 구현해야 할 전치 연산·스케일링/반올림 처리 등이 투명하게 이뤄질 수 있어, “성능(메모리 접근 감소, 병렬화 증대)”과 “개발 효율(코드 간소화, 버그 감소)” 모두 개선된다는 뜻입니다.
4 사전 학습(Pre-Training)
4.1 데이터 구성(Data Construction)
DeepSeek-V2와 비교했을 때, 우리는 사전 학습 코퍼스에서 수학과 프로그래밍 샘플의 비중을 높이고, 영어와 중국어 외에도 다국어 범위를 확장하였다. 또한 데이터 처리 파이프라인을 개선해, 코퍼스의 다양성을 유지하면서 중복을 최소화했다. Ding et al. (2024)를 참고하여 문서 무결성(document integrity)을 위해 문서 패킹(document packing) 기법을 적용했지만, 학습 중 크로스-샘플 어텐션 마스킹(cross-sample attention masking)은 적용하지 않았다. 최종적으로 DeepSeek-V3의 사전 학습에 사용되는 코퍼스는 토크나이저 기준 14.8T개의 다양하고 높은 품질의 토큰으로 구성되었다.
DeepSeekCoder-V2(DeepSeek-AI, 2024a)를 학습하는 과정에서, Fill-in-Middle(FIM) 전략이 모델의 다음 토큰 예측(next-token prediction) 능력에 지장을 주지 않으면서, 맥락 정보를 활용해 중간 텍스트를 정확히 예측하게 만들어 준다는 점을 확인했다. 이에 따라 DeepSeekCoder-V2와 동일하게, DeepSeek-V3 사전 학습에도 FIM 전략을 적용하였다. 구체적으로는 Prefix-Suffix-Middle(PSM) 프레임워크를 사용해 데이터를 다음과 같은 구조로 구성한다.
<|fim_begin|>
f_pre
<|fim_hole|>
f_suf
<|fim_end|>
f_middle
<|eos_token|>
.이 구조는 문서 수준에서 사전 패킹(pre-packing) 과정의 일부로 적용되며, FIM 전략은 PSM 프레임워크와 동일하게 0.1의 비율로 적용된다.
DeepSeek-V3의 토크나이저는 Byte-level BPE(Shibata et al., 1999)를 사용하며, 12만8천(128K)개의 토큰을 포함하도록 어휘 목록을 확장했다. 우리는 다국어 압축 효율을 높이기 위해 프리토크나이저(pretokenizer)와 토크나이저 학습 데이터를 수정하였다. 또한 DeepSeek-V2와 비교했을 때, 새로운 프리토크나이저는 문장부호와 줄바꿈(line breaks)을 결합한 토큰을 추가로 도입하였다. 그러나 이러한 방법은 몇 가지 특수 상황—특히 종단 줄바꿈(terminal line break)이 없는 다중 줄 프롬프트에 대해, 모델이 few-shot 평가 시 토큰 경계 편향(token boundary bias; Lundberg, 2023)을 일으킬 수 있다. 이를 완화하기 위해, 우리는 학습 과정에서 이러한 결합 토큰 중 일부를 무작위로 분할하여 모델이 보다 다양한 특수 사례에 노출되도록 하였으며, 이로써 해당 편향을 완화했다.
**문서 패킹(document packing)**과 **크로스-샘플 어텐션 마스킹(cross-sample attention masking)**은 대규모 언어 모델을 학습할 때 데이터를 어떻게 배열하고 모델이 어디까지 시야를 가질 수 있게 하느냐와 관련된 기법입니다.
1) 문서 패킹(document packing)
- 개념: 하나의 시퀀스(예: 최대 4K 토큰)에 여러 문서를 이어 붙여, 불필요한 패딩(padding)을 최소화하는 기법입니다.
- 예: “문서 A”를 다 넣고 남는 길이가 있으면, 이어서 “문서 B”를 넣고… 이런 식으로 최대 시퀀스 길이를 최대한 활용.
- “문서 무결성(document integrity)”: 각 문서를 인위적으로 잘라내거나 뒤섞지 않고, 문서 단위는 그대로 보존해서 한 시퀀스 안에 배치. 즉, 문서 A 안의 토큰 순서는 그대로 유지하고, 중간에 다른 문서가 섞여 들어오지 않도록 함.
이렇게 하면 한 시퀀스 내 “문서 A → 구분 토큰 → 문서 B → 구분 토큰 → 문서 C” 같은 식으로 서로 다른 문서들이 연달아 배치될 수 있습니다.
2) 크로스-샘플 어텐션 마스킹(cross-sample attention masking)
- 개념: 시퀀스 안에 여러 문서(샘플)가 들어 있을 때, 문서 경계 바깥(즉, 다른 문서)에 대한 어텐션(attention)을 막는 기법입니다.
- 예: 문서 A의 토큰들은 A 안에서만 어텐션을 하도록 하고, 문서 B의 토큰들은 B 안에서만 보도록 마스킹
- 이렇게 하면 모델이 “서로 다른 문서들 간 정보”를 참조하지 못하게 됩니다.
- 왜 하는가?:
- 여러 문서를 한 시퀀스에 넣었지만, 각각은 독립된 텍스트이므로 “A와 B를 이어 붙인 경계”가 실제로 의미 없는 연결일 수 있음.
- 모델이 “문서 간 경계를 인지하지 못한 채” 잘못된 전이(transition)나 문맥 혼동을 학습하는 것을 방지.
3) “문서 패킹은 했지만, 학습 중 크로스-샘플 어텐션 마스킹은 하지 않았다”의 의미
- 문서 패킹만 적용:
- 시퀀스 내부에 “문서 A + [구분 토큰] + 문서 B + …”처럼 여러 문서를 이어 붙이는 구성
- 각 문서의 내부 구조(순서)는 깨뜨리지 않고, “문서 무결성”을 지킴
- 크로스-샘플 어텐션 마스킹은 미적용:
- 모델이 이 시퀀스 내에서 “문서 A와 B를 구분하는 마스킹”을 사용하지 않음 → 즉, 문서 경계 넘어도 어텐션을 자유롭게 할 수 있음
- 모델 입장에서는 그냥 하나의 긴 텍스트로 보고 학습
즉, “문서를 여러 개 이어붙여 한 시퀀스에 넣되, 문서 경계 바깥으로 어텐션을 차단하지 않았다”는 뜻입니다. 다른 연구나 기법에서는 “문서 경계를 넘는 어텐션을 막아야 한다”고 주장하기도 하지만, 여기서는 굳이 마스킹을 추가로 적용하지 않고 그냥 통합된 긴 텍스트로 학습시키는 방식을 택했습니다.
왜 이런 선택을 했을까?
- 단순화: 크로스-샘플 마스킹 로직을 추가하면 구현 복잡도가 올라가고, 파이프라인도 복잡해짐.
- 효과 실험: 어떤 모델은 문서 경계를 넘어 확장된 문맥을 보는 게 도움이 될 수도 있음.
- 학습 비용: 마스킹을 잘못 적용하면 어텐션 계산이 더 복잡해지거나, 모델이 문서 경계를 학습에 제대로 활용하지 못할 수도 있음.
요약하면, **“문서 패킹을 통해 시퀀스 내 여러 문서를 효율적으로 배치하되, 문서 경계를 굳이 차단하지 않기로 했다”**는 문장입니다. 이를 통해 “문서 무결성”은 지키면서도 “인접 문서로의 어텐션”도 허용한다는 설계 의도를 파악하시면 됩니다.
- Fill-in-Middle(FIM)은 “중간에 누락된 텍스트”를 채우도록 모델을 훈련시키는 전략이며,
- 문서나 코드의 중간 삽입/수정 시나리오 대응력이 커지고, 양방향 맥락 활용도 높일 수 있다는 장점 때문에 최근 여러 코드/문서 모델에서 활용되고 있습니다.
- 해당 논문(DeepSeek 시리즈)에서는, 모델이 중간 텍스트 생성 능력을 가지도록 FIM을 사전 학습 과정에 도입했다고 보시면 됩니다.
- MLM
- 보통 “랜덤하게 골라진 여러 위치”에 마스크를 씌우고, 각 위치 단어를 복원
- 마스크가 분산될 수 있으며, 여러 [MASK]가 따로 존재 가능 → 다중 마스킹
- 본질적으로는 “토큰 단위 복원”에 가깝다
- FIM/Infilling
- 앞·뒤 문맥이 고정된 상황에서 “연속된 구간”을 통째로 가림 → 그 구간의 텍스트를 생성
- “중간 구간 전체”를 한 덩어리(span)로 예측
- 예: 코드 작성 시 “함수 시그니처와 함수 호출부는 존재하지만, 함수 본문은 비어 있음 → 함수 본문 생성”과 유사
- 생성(generative) 관점이 더 강함
4.2 하이퍼파라미터(Hyper-Parameters)




Figure 8: “Needle In A Haystack”(NIAH) 테스트 결과. DeepSeek-V3는 최대 128K 컨텍스트 윈도 길이에서 모두 우수한 성능을 보인다.

4.4 평가(Evaluations)
4.4.1 평가 벤치마크(Evaluation Benchmarks)
DeepSeek-V3 베이스(base) 모델은 다국어 코퍼스(영어, 중국어 중심)로 사전 학습되었으므로, 주로 영어와 중국어 벤치마크, 그리고 다국어 벤치마크를 통해 성능을 평가한다. 우리의 평가 작업은 HAI-LLM 프레임워크에 내장된 내부 평가 툴을 사용해 진행한다. 사용된 벤치마크는 다음과 같이 범주별로 나누어 정리했으며, 밑줄(단일 밑줄)은 중국어, 이중 밑줄은 다국어 벤치마크를 의미한다.
- 다중 과목 객관식(multi-subject multiple-choice) 데이터셋: MMLU (Hendrycks et al., 2020), MMLU-Redux (Gema et al., 2024), MMLU-Pro (Wang et al., 2024b), MMMLU (OpenAI, 2024b), C-Eval (Huang et al., 2023), CMMLU (Li et al., 2023).
- 언어 이해 및 추론(language understanding and reasoning) 데이터셋: HellaSwag (Zellers et al., 2019), PIQA (Bisk et al., 2020), ARC (Clark et al., 2018), BigBench Hard (BBH) (Suzgun et al., 2022).
- 폐쇄형 질의응답(closed-book question answering) 데이터셋: TriviaQA (Joshi et al., 2017), NaturalQuestions (Kwiatkowski et al., 2019).
- 독해(reading comprehension) 데이터셋: RACE (Lai et al., 2017), DROP (Dua et al., 2019), C3 (Sun et al., 2019a), CMRC (Cui et al., 2019).
- 참조(disambiguation) 데이터셋: CLUEWSC (Xu et al., 2020), WinoGrande (Sakaguchi et al., 2019).
- 언어모델링(language modeling) 데이터셋: Pile (Gao et al., 2020).
- 중국어 이해·문화(Chinese understanding and culture) 데이터셋: CCPM (Li et al., 2021).
- 수학(math) 데이터셋: GSM8K (Cobbe et al., 2021), MATH (Hendrycks et al., 2021), MGSM (Shi et al., 2023), CMath (Wei et al., 2023).
- 코드(code) 데이터셋: HumanEval (Chen et al., 2021), LiveCodeBench-Base (0801-1101) (Jain et al., 2024), MBPP (Austin et al., 2021), CRUXEval (Gu et al., 2024).
- 표준화 시험(standardized exams): AGIEval (Zhong et al., 2023). 이 중 AGIEval은 영어와 중국어 하위 집합을 모두 포함한다.
이전 연구(DeepSeek-AI, 2024b, c)와 마찬가지로, HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, MMLU-Redux, MMLU-Pro, MMMLU, ARC-Easy, ARC-Challenge, C-Eval, CMMLU, C3, CCPM 등에는 perplexity 기반 평가를 적용하고, TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, MGSM, HumanEval, MBPP, LiveCodeBench-Base, CRUXEval, BBH, AGIEval, CLUEWSC, CMRC, CMath 등에는 생성(generation) 기반 평가를 적용한다. 또한, Pile-test에 대해서는 언어 모델링 기반 평가를 수행하고, 다른 토크나이저를 사용하는 모델들과의 공정한 비교를 위해 지표로 Bits-Per-Byte(BPB)를 활용한다.

Table 3: DeepSeek-V3-Base와 다른 주요 오픈소스 베이스 모델들을 비교한 결과. 모든 모델은 동일한 내부 평가 설정에서 평가된다. 점수 차이가 0.3 이하인 경우 동일 수준으로 간주한다. DeepSeek-V3-Base는 대부분의 벤치마크(특히 수학·코드 태스크)에서 최고의 성능을 기록한다.
4.4.2 평가 결과(Evaluation Results)
표 3에서는 DeepSeek-V3 베이스 모델을 최첨단 오픈소스 베이스 모델들과 비교한다. 여기에는 이전에 공개했던 DeepSeek-V2-Base (DeepSeek-AI, 2024c), Qwen2.5 72B Base (Qwen, 2024b), 그리고 LLaMA-3.1 405B Base (AI@Meta, 2024b)가 포함된다. 이 모든 모델은 동일한 내부 평가 프레임워크 설정에서 비교한다. (DeepSeek-V2-Base의 경우, 과거 보고 대비 평가 프레임워크 변경으로 인해 약간의 성능 차이가 발생했음을 참고 바란다.)
종합적으로 볼 때, DeepSeek-V3-Base는 DeepSeek-V2-Base와 Qwen2.5 72B Base를 능가하며, 대부분의 벤치마크에서 LLaMA-3.1 405B Base도 넘어서는 성능을 보여준다. 사실상 가장 강력한 오픈소스 베이스 모델 지위에 오른 셈이다.
더 구체적으로 각 모델을 비교해보면,
- DeepSeek-V2-Base 대비: 모델 아키텍처 개선, 모델 크기 확대, 학습 토큰 증가, 데이터 품질 향상의 영향으로, DeepSeek-V3-Base가 예측한 대로 훨씬 더 우수한 성능을 나타낸다.
- Qwen2.5 72B Base 대비: 중국어 분야에서 가장 앞선 오픈소스 모델임에도, 활성화되는 파라미터 수가 Qwen2.5 절반 수준인 DeepSeek-V3-Base가 영어, 다국어, 코드, 수학 등에서 두드러진 우위를 보인다. 중국어 벤치마크 중 CMMLU를 제외하면 DeepSeek-V3-Base가 더 나은 성능을 낸다.
- LLaMA-3.1 405B Base 대비: 활성화 파라미터가 11배나 많은 거대 모델이지만, DeepSeek-V3-Base는 다국어, 코드, 수학 벤치마크에서 훨씬 우수한 성능을 보인다. 영어 및 중국어 벤치마크에서도 경쟁력 혹은 더 뛰어난 결과를 나타내며, 특히 BBH, MMLU 계열, DROP, C-Eval, CMMLU, CCPM에서 두드러진다.
한편, 효율적인 아키텍처와 종합적인 엔지니어링 최적화를 통해, DeepSeek-V3의 학습 효율은 매우 높다. 본 학습 프레임워크와 인프라 하에서, DeepSeek-V3의 매 1조 토큰 학습 비용은 H800 GPU 시간 18만(180K) 시간에 불과한데, 이는 72B나 405B급의 밀집(dense) 모델을 학습하는 것보다 훨씬 저렴하다.

Table 4: MTP(Multi-Token Prediction) 전략에 대한 에블레이션(ablations) 결과. 대부분의 평가 벤치마크에서 MTP 전략은 모델 성능을 일관되게 향상시킨다.
4.5 논의(Discussion)
4.5.1 멀티 토큰 예측(MTP)에 대한 에블레이션 연구(Ablation Studies for Multi-Token Prediction)
표 4에서는 MTP 전략에 대한 에블레이션(단일 요소를 제거하고 비교 실험을 수행하는 연구) 결과를 제시한다. 구체적으로, 우리는 두 가지 서로 다른 규모의 베이스라인 모델에 대해 MTP 전략을 검증하였다.
- 소규모 모델: 총 157억(15.7B) 파라미터를 가진 MoE 모델을 1.33조(1.33T) 토큰으로 학습.
- 대규모 모델: 총 2,287억(228.7B) 파라미터를 가진 MoE 모델을 5400억(540B) 토큰으로 학습.
두 모델 각각에 대해, 학습 데이터와 다른 아키텍처 요소들은 그대로 두고, 1단계(depth=1)의 MTP 모듈을 추가로 붙여서 MTP 전략을 적용한 모델을 새로 학습한 뒤 결과를 비교했다. 주목할 점은 추론 시, MTP 모듈을 바로 버려(discard) 버리므로, 원래 모델과 추론 비용은 동일하다는 점이다.
표 결과에서 확인할 수 있듯이, MTP 전략은 대부분의 평가 벤치마크에서 모델 성능을 일관되게 향상시킴을 알 수 있다.
쉽게 말해, MTP(Multi-Token Prediction) 모듈은 학습 단계에서만 추가로 사용하는 보조 서브네트워크(혹은 추가 출력 헤드)라는 뜻입니다.
- 학습 시: 모델이 바로 다음 토큰 뿐 아니라, 2스텝 뒤 토큰(또는 그 이상)을 예측하도록 병렬로 학습하며, 학습 신호(손실)를 더 얻어 모델을 강화합니다.
- 추론 시: 실제로는 “1스텝 뒤”(기본 next token 예측)만 사용하므로, MTP 모듈을 아예 쓰지 않아도 문제 없으며, 제거해도(“버려버려도”) 정상 동작합니다.
즉,
- MTP 모듈이 있든 없든, 최종 다음 토큰을 예측하는 메인 경로(기존 언어모델 경로)는 똑같이 존재합니다.
- 추론 단계에서 MTP 모듈은 호출/계산되지 않으므로, 추가 연산 비용이 0에 가깝습니다.
- 결과적으로 “MTP 모듈로 인해 파라미터가 늘어나도”, 추론 비용은 원래 모델과 동일하게 유지됩니다.
이와 달리, 일반적으로 모델에 새로운 레이어나 출력 헤드를 추가하면 추론 때도 계산이 필요해 비용이 늘어나지만, MTP는 추론 때 사용하지 않고 버린다는 점이 다릅니다. Therefore, 학습 시에는 MTP를 통해 더 풍부한 학습 신호를 받고, 추론 시에는 오버헤드 증가 없이 기존 모델과 동일한 비용으로 추론을 수행할 수 있게 되는 것입니다.
MTP(Multi-Token Prediction) 학습을 도입하는 주된 이유는, 모델 학습 단계에서 더 풍부한 학습 신호를 얻어 모델의 전반적인 표현 및 예측 능력을 향상시키기 위해서입니다. 간단히 요약하면 다음과 같은 효과가 있습니다.
- 더 많은 학습 신호
- 일반적인 언어 모델은 “다음 토큰 하나”에 대한 오류 신호(손실)만 주어집니다.
- 반면 MTP에서는 “다다음 토큰(또는 그 이상 스텝 뒤 토큰)”도 동시에 예측하게 함으로써, 학습 단계에서 토큰 하나당 추가적인 교정 신호를 받습니다.
- 이렇게 손실이 촘촘해지면(densify), 모델이 문맥 이해, 문장 패턴 학습 등에 있어서 학습 효율이 올라갈 수 있습니다.
- 장기 의존성(Long-range dependency) 이해
- MTP 학습을 통해 모델은 “단일 스텝”을 넘어선 미래 토큰을 예측하려고 시도하게 됩니다.
- 이를 통해, 모델 내부 표현이 “앞뒤 맥락을 좀 더 넓게” 반영하도록 훈련될 수 있으며, 결과적으로 정확도가 높아지거나 추론 시 더 자연스러운 문장을 만들어낼 수 있습니다.
- 추론 비용 증가 없음
- MTP 모듈은 학습 과정에만 관여하고, 추론 시에는 아예 사용하지 않아도 됩니다(“버린다/disable”).
- 따라서 학습 시에는 MTP가 제공하는 부가 학습 신호로 모델을 강화하지만, 추론 시에는 기존 모델과 똑같은 비용으로 inference를 진행하게 됩니다.
결과적으로, MTP 학습은 “추론 비용 증가 없이 모델 학습을 더욱 풍부하게 만들어, 정확도나 표현력을 개선”하는 데 목적이 있습니다.
4.5.2 보조 손실 없는(auxiliary-loss-free) 로드 밸런싱 전략에 대한 에블레이션 연구(Ablation Studies for the Auxiliary-Loss-Free Balancing Strategy)
표 5에서는 보조 손실 없이 로드 밸런싱을 달성하는 전략(auxiliary-loss-free balancing)에 대한 에블레이션 결과를 보여준다. 우리는 서로 다른 규모의 두 베이스라인 모델에 대해 이 전략을 검증하였다.
- 소규모 모델: 총 157억(15.7B) 파라미터를 가진 MoE 모델을 1.33조(1.33T) 토큰으로 학습.
- 대규모 모델: 총 2,287억(228.7B) 파라미터를 가진 MoE 모델을 5780억(578B) 토큰으로 학습.
이 두 베이스라인 모델은 모두 로드 밸런싱을 위해 순수하게 보조 손실(auxiliary loss)만 사용하며, 시그모이드 게이팅(sigmoid gating)에 top-K 친화도 정규화(top-K affinity normalization)를 적용한다. 보조 손실 강도를 제어하는 하이퍼파라미터는 각각 DeepSeek-V2-Lite 및 DeepSeek-V2에서 사용한 것과 동일하다. 이후, 학습 데이터와 나머지 아키텍처 요소들을 그대로 둔 채 모든 보조 손실을 제거하고, 보조 손실 없는 로드 밸런싱 전략을 도입해 새 모델을 학습하였다.
표의 결과를 보면, 보조 손실 없는(auxiliary-loss-free) 전략이 대부분의 평가 벤치마크에서 더 나은 모델 성능을 꾸준히 달성함을 알 수 있다.

Table 5: 보조 손실 없이 수행하는 로드 밸런싱 전략에 대한 에블레이션 결과. 순수하게 보조 손실만 사용하는 방식과 비교해, 보조 손실 없는 전략이 대부분의 평가 벤치마크에서 지속적으로 더 뛰어난 성능을 낸다.
4.5.3 배치 단위 로드 밸런싱 vs. 시퀀스 단위 로드 밸런싱(Batch-Wise Load Balance VS. Sequence-Wise Load Balance)
보조 손실 없는 로드 밸런싱(auxiliary-loss-free)과 시퀀스 단위(sequence-wise) 보조 손실을 비교했을 때, 두 방식의 차이는 로드 밸런싱 범위—즉, 배치 단위와 시퀀스 단위—에 있다. 시퀀스 단위 보조 손실은 각 시퀀스 내부에서 균형을 강제하지만, 배치 단위 로드 밸런싱은 이보다 더 유연하게, 도메인별 특화(specialization)를 허용할 수 있다. 이를 검증하기 위해, 우리는 160억(16B) 파라미터 규모의 보조 손실 기반 베이스라인 모델과, 160억 파라미터 규모의 보조 손실 없는 모델을 Pile 테스트 세트 내 다른 도메인에서의 전문가 로드를 기록·분석하였다. 그림 9에서 확인할 수 있듯, 보조 손실 없는 모델은 더 강한 전문가 특화 패턴을 보임을 관찰할 수 있다.
이 유연성과 모델 성능 우세 간의 상관관계를 추가로 조사하기 위해, 우리는 “시퀀스 단위가 아니라, 각 학습 배치(batch) 단위로 로드 밸런스를 유도하는” 배치 단위 보조 손실(batch-wise auxiliary loss)을 추가로 설계·검증하였다. 실험 결과, 비슷한 수준의 배치 단위 로드 밸런스를 달성하는 경우, 배치 단위 보조 손실 역시 보조 손실 없는 방식과 유사한 모델 성능을 얻을 수 있었다. 구체적으로, 10억(1B) 규모 MoE 모델 실험에서 검증 손실(validation loss)은 시퀀스 단위 보조 손실이 2.258, 보조 손실 없는 방식이 2.253, 배치 단위 보조 손실 역시 2.253을 기록하였다. 30억(3B) 규모 MoE 모델에서도 유사한 결과를 얻어, 시퀀스 단위 보조 손실 모델 검증 손실이 2.085, 보조 손실 없는/배치 단위 보조 손실 모델은 모두 2.080이었다.
한편, 배치 단위 로드 밸런싱은 성능 우세를 보이지만, 다음과 같은 효율성 측면의 잠재적 문제도 안고 있다.
- 특정 시퀀스나 작은 배치 내에서의 불균형
- 추론 시 도메인 전환(domain-shift)으로 인한 불균형 발생
첫 번째 이슈는 대규모 전문가 병렬화 및 데이터 병렬화를 사용하는 학습 프레임워크에서 자연스럽게 해결된다. 이는 각 마이크로배치(micro-batch)가 충분히 커서 불균형을 완화할 수 있기 때문이다. 두 번째 이슈에 대해서는, 3.4절에서 설명한 중복 전문가(redundant expert) 배치를 사용하는 효율적인 추론 프레임워크를 구현해 이를 극복한다.

Figure 9: Pile 테스트 세트의 세 가지 도메인에서 보조 손실 없는 모델(auxiliary-loss-free)과 보조 손실 기반 모델(auxiliary-loss-based) 간 전문가 로드를 비교한 그래프. 보조 손실 없는 모델이 상대적으로 더 뚜렷한 전문가 특화(expert specialization) 패턴을 보인다. 그래프의 세로축에 표시된 “상대적 전문가 로드(relative expert load)”는, 실제 전문가 로드량을 이론적 균형 로드량으로 나눈 비율이다. 공간 제약상 두 개 레이어의 결과만 예시로 제시했으며, 모든 레이어에 대한 결과는 부록 C에 제공한다.
5. 포스트 트레이닝(Post-Training)
5.1 지도 학습(Supervised Fine-Tuning)
우리는 다양한 도메인을 아우르는 150만 건의 인스트럭션 튜닝(instruction-tuning) 데이터셋을 큐레이션하여, 각 도메인별 특성에 맞는 데이터 생성 기법을 적용하였다.
추론(Reasoning) 관련 데이터
수학, 코드 대회 문제, 논리 퍼즐 등 추론 관련 데이터셋에 대해서는, 내부의 DeepSeek-R1 모델을 활용해 데이터를 생성한다. 구체적으로, R1이 만들어낸 데이터는 높은 정확도를 보여주지만, 과도한 사고(“overthinking”), 불량한 포맷, 지나치게 긴 답변 등을 포함하는 문제가 있다. 우리의 목표는 R1이 생성하는 높은 정확도와, 일반적으로 깔끔한 형식의 간결한 추론 데이터를 적절히 균형화하는 것이다.
우리는 먼저 코드, 수학, 일반 추론 등 특정 도메인에 특화된 전문가 모델(expert model)을, 지도 학습(SFT)과 강화 학습(RL)을 결합한 파이프라인으로 학습한다. 이 전문가 모델은 최종 모델의 데이터 생성원(data generator) 역할을 한다. 학습 과정에서, 각 인스턴스마다 두 가지 형태의 SFT 샘플을 만든다. 첫째, 문제와 원본 응답을 결합하는 <문제, 원본 응답> 형식이며, 둘째, 시스템 프롬프트(system prompt)와 함께 문제, R1 응답을 포함하는 <시스템 프롬프트, 문제, R1 응답> 형식이다.
시스템 프롬프트는 모델이 반추(reflection)와 검증(verification) 기제를 담아낸 응답을 생성하도록 유도하는 지침을 꼼꼼히 설계한다. RL 단계에서는, 모델이 고온 탐색(high-temperature sampling)을 사용해 R1 및 원본 데이터 양쪽 패턴을 통합한 응답을 생성하되, 명시적 시스템 프롬프트가 없더라도 이를 활용할 수 있게 한다. 수백 스텝의 RL을 거치면서, 중간 RL 모델은 R1 패턴을 흡수하여 전반적인 성능을 전략적으로 높이게 된다.
RL 학습이 끝나면, 전문가 모델들을 데이터 생성원으로 활용하여 거부 샘플링(rejection sampling) 방식으로 고품질의 SFT 데이터를 선별한다. 이 방식은 DeepSeek-R1의 강점을 유지하면서도 간결하고 효율적인 답변을 생성할 수 있는 최종 학습 데이터를 확보하게 해준다.
추론 외 데이터(Non-Reasoning Data)
창의적 글쓰기, 롤플레이, 간단한 질의응답과 같은 추론과 무관한 데이터에 대해서는, DeepSeek-V2.5를 이용해 응답을 생성하고, 휴먼 어노테이터들이 정확성을 검증하여 데이터 품질을 보장한다.

5.2 강화 학습(Reinforcement Learning)
5.2.1 보상 모델(Reward Model)
우리의 RL 과정에서는 규칙 기반(rule-based) 보상 모델과 모델 기반(model-based) 보상 모델을 모두 활용한다.
규칙 기반 RM(Rule-Based RM)
특정 규칙을 사용해 정답 여부를 검증할 수 있는 문제의 경우, 우리는 규칙 기반 보상 시스템을 통해 피드백을 결정한다. 예를 들어, 일부 수학 문제는 결정론적(deterministic) 해답을 갖고, 지정된 형식(예: 상자 안에 최종 답안 표시)을 요구하므로, 이를 충족하는지 여부로 정답을 판별할 수 있다. 이와 유사하게, LeetCode 문제에서는 컴파일러를 사용해 테스트 케이스 결과에 기반한 피드백을 생성 가능하다. 이러한 규칙 기반 검증을 적용할 수 있는 경우가 늘어날수록, 보상 모델이 조작이나 취약점을 악용당할 우려가 낮아져 신뢰도가 향상된다.
모델 기반 RM(Model-Based RM)
자유 형식(free-form)의 정답을 갖는 질문(ground-truth가 명시된 경우)에 대해서는, 보상 모델이 “답변이 실제 정답과 일치하는지”를 판단한다. 반면, 명확한 정답이 없는 창의적 쓰기 등과 같은 질문의 경우, 모델은 “질문과 해당 답변”을 함께 입력받아 적절한 피드백을 산출한다. 이 보상 모델은 DeepSeek-V3 SFT 체크포인트에서 파생된 모델을 학습해 얻는다. 보상 모델의 신뢰도를 높이기 위해, 우리는 최종 보상 값뿐 아니라, 보상이 산출되는 과정(Chain-of-Thought)도 포함하는 선호 데이터(preference data)를 구성한다. 이러한 접근은 특정 태스크에서 발생할 수 있는 보상 조작(reward hacking) 위험을 줄여준다.

5.3 평가(Evaluations)
5.3.1 평가 설정(Evaluation Settings)
평가 벤치마크(Evaluation Benchmarks)
베이스 모델 테스트에 사용했던 벤치마크 외에도, 우리는 지시문(instruction)을 수행하는 모델을 다음의 추가 벤치마크로 평가한다: IFEval (Zhou et al., 2023), FRAMES (Krishna et al., 2024), LongBench v2 (Bai et al., 2024), GPQA (Rein et al., 2023), SimpleQA (OpenAI, 2024c), C-SimpleQA (He et al., 2024), SWE-Bench Verified (OpenAI, 2024d), Aider¹, LiveCodeBench (Jain et al., 2024) (2024년 8월~11월 문제), Codeforces², Chinese National High School Mathematics Olympiad (CNMO 2024)³, American Invitational Mathematics Examination 2024 (AIME 2024)(MAA, 2024).
¹ https://aider.chat
² https://codeforces.com
³ https://www.cms.org.cn/Home/comp/comp/cid/12.html
数学竞赛 - 中国数学会
中国数学会是中国数学工作者的学术性法人社会团体,是中国科学技术协会的组成部分。中国数学会的宗旨是团结广大数学工作者,为促进数学的发展,繁荣我国的科学技术事业,促进科学技术
www.cms.org.cn
비교 베이스라인(Compared Baselines)
우리는 내부 챗(chat) 모델을 DeepSeek-V2-0506, DeepSeek-V2.5-0905, Qwen2.5 72B Instruct, LLaMA-3.1 405B Instruct, Claude-Sonnet-3.5-1022, GPT-4o-0513 등 강력한 베이스라인과 폭넓게 비교한다. DeepSeek-V2 계열 모델 중에서는 가장 대표적인 버전을 선정하였다. 폐쇄형 모델(예: GPT-4o, Claude)은 각 모델의 API를 통해 평가를 진행한다.
상세 평가 설정(Detailed Evaluation Configurations)
- MMLU, DROP, GPQA, SimpleQA: simple-evals 프레임워크⁴의 평가 프롬프트 사용
- MMLU-Redux: Zero-Eval 프롬프트 포맷(Lin, 2024)을 적용해 zero-shot 설정으로 평가
- 기타 데이터셋: 해당 데이터셋 제작자가 제공한 기본(prompt) 설정과 오리지널 평가 프로토콜 준수
- 코드 및 수학 태스크: HumanEval-Mul 데이터셋에 파이썬, 자바, C++, C#, 자바스크립트, 타입스크립트, PHP, Bash 등 8개 주류 프로그래밍 언어 포함
- LiveCodeBench(2024년 8~11월 문제)는 CoT 방식과 non-CoT 방식 둘 다로 모델 성능 평가
- Codeforces 데이터셋은 “competitors 대비 백분율” 지표 사용
- SWE-Bench Verified는 agentless 프레임워크(Xia et al., 2024)로 평가
- Aider 관련 벤치마크는 “diff” 포맷으로 평가
- 수학 평가 중 AIME, CNMO 2024는 온도(temperature)=0.7로 설정해 16회 평균 결과, MATH-500은 그리디 디코딩(greedy decoding)
- 모든 모델: 각 벤치마크당 최대 8192 토큰까지 출력하도록 허용

Table 6: DeepSeek-V3와 다른 대표 챗 모델 비교. 모든 모델은 출력 길이를 8K로 제한한 환경에서 평가. 샘플 수가 1000 미만인 벤치마크는 온도를 달리해 여러 번 측정하고 결과를 종합. DeepSeek-V3는 현재 공개된(open-source) 모델 중 최고 성능을 보이며, 최전선 폐쇄형 모델과도 경쟁력 있는 성능을 낸다.
5.3.2 표준 평가(Standard Evaluation)
표 6의 결과에서, DeepSeek-V3는 오픈소스 모델 중 최고 성능을 보이며, GPT-4o나 Claude-3.5-Sonnet 같은 최전선 폐쇄형 모델에도 견줄 만한 경쟁력을 갖추고 있음을 알 수 있다.
- 영어 벤치마크(English Benchmarks)
- MMLU: 폭넓은 지식과 작업을 평가하는 표준 벤치마크. DeepSeek-V3는 LLaMA-3.1-405B, GPT-4o, Claude-Sonnet 3.5 등 최상위 모델과 비슷한 수준의 성능을 보이면서 Qwen2.5 72B를 크게 앞선다.
- MMLU-Pro: 더 어려운 교육 분야 지식 벤치마크로, Claude-Sonnet 3.5 바로 뒤를 바짝 추격.
- MMLU-Redux: 라벨이 수정된 버전. DeepSeek-V3가 동급 모델을 넘어서는 성능을 기록.
- GPQA-Diamond(PhD급 테스트베드): Claude 3.5 Sonnet에 이어 2위를 차지하며, 다른 모델들과 큰 격차를 보인다.
- 코드·수학 벤치마크(Code and Math Benchmarks)
- 엔지니어링 중심 코드 태스크(SWE-Bench-Verified, Aider)에서 DeepSeek-V3는 Claude-Sonnet-3.5-1022에 못 미치지만, 다른 오픈소스 모델은 크게 상회한다. 오픈소스 모델로서 이 정도 역량을 공개하면, 소프트웨어 엔지니어링·알고리즘 분야에서 더 광범위한 발전이 기대된다.
- 알고리즘 중심 코드 태스크(HumanEval-Mul, LiveCodeBench)에서는 DeepSeek-V3가 모든 베이스라인을 능가해 최고 성능을 보인다. 이는 고급 지식 증류 기법을 활용해 코드 생성 및 문제 해결 능력이 강화된 덕분이다.
- 수학 태스크에서도 DeepSeek-V3는 비-o1 계열 모델 중 압도적 성능을 보이며, AIME, MATH-500, CNMO 2024에서 2위 모델(Qwen2.5 72B)과 10% 이상의 점수 차이를 기록한다. 이는 DeepSeek-R1로부터 이끌어낸 증류(distillation) 기법이 큰 효과를 발휘했음을 보여준다.
- 중국어 벤치마크(Chinese Benchmarks)
- Qwen, DeepSeek 두 시리즈 모두 중영(中英) 양언어 지원에 강점이 있다. Chinese SimpleQA에서 DeepSeek-V3는 Qwen2.5-72B보다 16.4점 높게 나오며, 이는 Qwen2.5가 DeepSeek-V3 대비 20% 많은 18조(18T) 토큰을 학습했다는 점을 고려하면 더 인상적이다.
- C-Eval, CLUEWSC 등 중국어 교육 지식 평가에서는 DeepSeek-V3와 Qwen2.5-72B가 비슷한 수준을 보이며, 두 모델 모두 복잡한 중문 추론·교육 태스크에 최적화된 결과다.

Table 7: 영어 오픈형 대화(open-ended conversation) 평가. AlpacaEval 2.0에서는 length-controlled win rate를 지표로 사용.
5.3.3 자유형 평가(Open-Ended Evaluation)
우리는 표준 벤치마크 외에도, LLM을 심사관으로 활용하는 오픈형 생성 태스크 평가를 수행했으며, 표 7에 그 결과를 정리했다. 구체적으로 AlpacaEval 2.0 (Dubois et al., 2024)과 Arena-Hard (Li et al., 2024a)의 원본 설정을 따랐으며, GPT-4-Turbo-1106을 판정(judge)으로 쓰는 페어와이즈 비교 방식을 채택했다.
- Arena-Hard에서, DeepSeek-V3는 기존 GPT-4-0314 대비 86% 이상의 승률을 달성하며, Claude-Sonnet-3.5-1022 등 최상위 모델과 대등한 모습을 보인다. 이는 코드·디버깅 등 복잡 프롬프트 처리가 강력함을 입증하며, DeepSeek-V3가 오픈소스 모델 최초로 Arena-Hard에서 85%를 넘겨 오픈소스와 폐쇄형 모델 간 성능 격차를 크게 줄였음을 뜻한다.
- AlpacaEval 2.0에서도 DeepSeek-V3는 폐쇄형 모델은 물론, 다른 오픈소스 모델들을 상회하며, 특히 문장 작성 및 단순 질의응답에서 뛰어난 숙련도를 보여준다. DeepSeek-V2.5-0905 대비 20% 이상의 향상을 나타내어, 간단한 태스크에도 훨씬 향상된 성능을 보임을 증명한다.
5.3.4 보상 모델로 활용되는 생성형 DeepSeek-V3(DeepSeek-V3 as a Generative Reward Model)
우리는 DeepSeek-V3의 판별(judgment) 능력을 최첨단 모델인 GPT-4o, Claude-3.5와 비교하였다. 표 8의 RewardBench(Lambert et al., 2024) 결과에 따르면, DeepSeek-V3는 GPT-4o-0806 및 Claude-3.5-Sonnet-1022 최고 버전과 대등한 수준의 성능을 보이고, 다른 버전들보다 우위에 있다. 또한 투표(voting) 기법을 더하면, DeepSeek-V3의 판별 능력이 추가로 향상될 수 있음이 관찰되었다. 따라서 우리는 DeepSeek-V3와 투표 방식을 결합해, 오픈형 질문에서의 자가 피드백(self-feedback)을 제공하도록 만들어, 정렬(alignment) 과정을 보다 효과적이고 견고하게 만들고 있다.
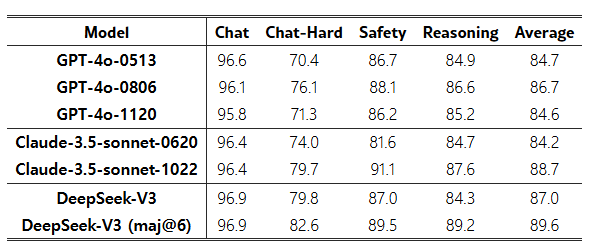
Table 8: GPT-4o, Claude-3.5-Sonnet, DeepSeek-V3의 RewardBench 성능 비교.
5.4 논의(Discussion)
5.4.1 DeepSeek-R1로부터의 증류(Distillation from DeepSeek-R1)
우리는 DeepSeek-V2.5 기반 실험에서, DeepSeek-R1로부터 지식을 증류(distillation)하는 방안이 얼마나 기여하는지를 분석한다. 베이스라인 모델은 짧은 Chain-of-Thought(CoT) 데이터로 학습했으며, 비교 대상은 위에서 언급한 전문가 체크포인트(expert checkpoints)가 생성한 데이터를 사용했다.

표 9는 이런 증류 데이터의 효과를 보여주며, LiveCodeBench와 MATH-500 두 벤치마크 모두에서 성능이 크게 향상되었음을 알 수 있다. 실험 결과, 증류는 더 나은 성능을 제공하지만 동시에 평균 응답 길이를 상당히 늘린다는 흥미로운 트레이드오프가 있음을 확인했다. 모델 정확도와 계산 효율 간 균형을 유지하기 위해, 우리는 DeepSeek-V3의 증류 설정을 신중하게 조정했다.
이 결과로부터, 추론(reasoning) 모델로부터의 지식 증류는 포스트 트레이닝(post-training) 최적화를 위한 유망한 연구 방향임을 시사한다. 본 연구는 주로 수학 및 코드 분야에서 생성된 데이터를 증류했으나, 이러한 접근이 복잡한 추론이 필요한 다른 작업 전반으로도 확장 가능할 것으로 보인다. 특정 영역에서 확인된 장점을 바탕으로, 복잡한 인지 능력이 요구되는 다양한 태스크에 대해서도 장문의 CoT 증류를 활용하는 연구가 더욱 활발히 이루어질 것으로 기대된다.
5.4.2 셀프 리워딩(Self-Rewarding)
강화 학습(RL)에서 보상은 최적화 과정을 이끄는 핵심이다. 코드나 수학처럼 외부 도구를 통해 검증하기 쉬운 분야에서는 RL이 특히 뛰어난 효과를 보인다. 하지만 일반적 시나리오에서는 하드코딩된 피드백 메커니즘을 만들기 어렵다. DeepSeek-V3 개발 시, 이런 광범위 문맥에 대해서는 헌법적 AI(constitutional AI)(Bai et al., 2022) 접근을 채택해, DeepSeek-V3 스스로의 투표 결과(voting evaluation)를 피드백 소스로 활용했다. 이 방법은 주관적 평가에서 의미 있는 정렬(alignment) 효과를 낳아, DeepSeek-V3의 성능을 크게 높였다. 추가 헌법 정보(constitutional input)를 도입함으로써, DeepSeek-V3가 헌법적 방향성에 맞춰 최적화되도록 유도한 것이다.
이처럼 LLM을 피드백 소스로 삼아 다양한 시나리오에서 비정형 정보를 보상(reward)으로 변환하는 패러다임이 매우 중요하다고 본다. LLM은 범용 프로세서(general-purpose processor) 역할을 하여, 최종적으로 LLM 자기 개선(self-improvement)을 가능케 한다. 셀프 리워딩 외에도, 일반적이며 확장 가능한 리워딩 기법을 발굴해 모델 역량을 지속적으로 높이는 방법을 모색하고 있다.
5.4.3 멀티 토큰 예측(MTP) 평가(Multi-Token Prediction Evaluation)
DeepSeek-V3는 다음 단일 토큰만이 아니라, MTP 기법을 통해 다음 2개 토큰을 동시에 예측한다. 이를 추론 가속 기법인 speculative decoding(Leviathan et al., 2023; Xia et al., 2023)과 결합하면, 모델 디코딩 속도를 크게 높일 수 있다. 여기서 자연스럽게 제기되는 질문은 “추가로 예측된 토큰을 수용(accept)할 비율이 얼마나 되느냐”이다. 우리의 평가에 따르면, 주제별 토큰 생성 상황에서 2번째 토큰 예측의 수용률이 85~90% 정도로 꾸준히 유지되었다. 이처럼 높은 수용률 덕분에 DeepSeek-V3는 디코딩 속도를 크게 개선해, 초당 토큰 처리량(TPS, Tokens Per Second)이 약 1.8배 향상되는 효과를 얻었다.
6 결론, 한계, 그리고 향후 방향(Conclusion, Limitations, and Future Directions)
본 논문에서는 총 6710억(671B) 파라미터를 보유하고 토큰당 370억(37B)이 활성화되는 대규모 MoE 언어 모델인 DeepSeek-V3를 소개하였다. 14.8조(14.8T) 토큰으로 학습된 DeepSeek-V3는 MLA와 DeepSeekMoE 아키텍처 외에도, 로드 밸런싱을 위한 보조 손실 없는(auxiliary-loss-free) 전략을 개척하고, 더 강력한 성능을 위해 멀티 토큰 예측(multi-token prediction) 학습 목표를 설정하였다. FP8 학습과 정교한 엔지니어링 최적화를 통해 DeepSeek-V3의 학습 비용은 매우 경제적이다. 포스트 트레이닝 과정 역시 DeepSeek-R1 계열 모델의 추론 역량을 성공적으로 증류(distillation)하여 모델 성능을 한층 끌어올렸다. 광범위한 평가 결과, DeepSeek-V3는 현재 공개된(open-source) 모델 중 가장 뛰어난 성능을 보이며, GPT-4o 및 Claude-3.5-Sonnet 등 선도적인 폐쇄형 모델과도 견줄 만한 수준에 이르렀다. 뛰어난 성능에도 불구하고 사전 학습·맥락 길이 확장·포스트 트레이닝을 모두 포함하는 전체 학습 과정에 단 278만8천(H800 GPU) 시간만을 필요로 하며, 이는 경제성도 함께 유지하고 있음을 보여준다.
그러나 DeepSeek-V3가 우수한 성능과 비용 효율성을 갖추었음에도, 배포 측면에서 몇 가지 한계를 지니고 있다. 첫째, 추론 효율을 보장하기 위해 DeepSeek-V3의 권장 배포 단위가 비교적 크다는 점은 소규모 팀에게 부담이 될 수 있다. 둘째, DeepSeek-V3의 배포 전략을 통해 이전 버전인 DeepSeek-V2 대비 2배 이상의 End-to-End 생성 속도를 달성했지만, 여전히 더 개선될 여지가 존재한다. 다행히 이 같은 한계들은 향후 하드웨어 발전에 따라 자연스럽게 해소될 것으로 기대된다.
DeepSeek 프로젝트는 오픈소스 모델을 지향하며, 장기적 관점에서 AGI(범용 인공지능) 목표에 꾸준히 다가가고자 한다. 앞으로는 다음과 같은 영역에서 전략적 연구 투자를 추진할 계획이다.
- 지속적인 모델 아키텍처 연구 및 고도화
학습·추론 효율을 한층 더 높이고, 무한대에 가까운 맥락 길이를 효율적으로 지원하는 방안을 모색한다. 더 나아가, Transformer의 구조적 한계를 뛰어넘어 모델링 역량을 극대화하는 새로운 아키텍처를 탐색할 예정이다. - 학습 데이터 양과 질의 지속적 확장
더욱 다양한 차원에서 데이터 규모를 확대하고, 추가적인 학습 신호 소스를 접목하는 방안을 모색함으로써, 데이터 측면에서의 확장을 이끌어낼 것이다. - 모델의 심층 추론(Deep Thinking) 역량 강화
모델의 추론 길이와 깊이를 확장하여 지능과 문제 해결 능력을 높이는 방향으로, 모델의 심층 사고 능력을 개선하기 위한 연구를 이어간다. - 다차원적이고 종합적인 모델 평가 기법 탐색
한정된 벤치마크에 최적화하는 편향을 막고, 모델 역량에 대한 왜곡된 인상을 피하기 위해, 더 폭넓은 측면에서 평가하는 방법을 연구·개발할 계획이다. 이는 모델 평가의 기반을 강화하는 핵심적인 방안이 될 것이다.
'인공지능' 카테고리의 다른 글
| Large Language Diffusion Models (2) | 2025.02.18 |
|---|---|
| Layer Normalization (4) | 2025.02.17 |
| DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2) | 2025.02.12 |
| Instance Normalization: The Missing Ingredient for Fast Stylization (3) | 2025.01.30 |
| Group Normalization (2) | 2025.01.24 |



