https://openai.com/index/introducing-o3-and-o4-mini/
지금까지 출시된 모델 가운데 가장 스마트하고 강력한 기능 ― 완전한 도구 접근
오늘 저희는 o‑시리즈의 최신작인 OpenAI o3와 o4‑mini를 공개합니다. 이 모델들은 응답 전에 더 깊이 사고하도록 학습된, 지금까지 선보인 모델 중 최고 성능을 자랑합니다. 호기심 많은 사용자부터 고급 연구자까지 모두에게 ChatGPT의 능력을 한 단계 도약시키는 획기적인 진전입니다.
이번에 처음으로, 우리의 추론 모델이 ChatGPT 안의 모든 도구를 능동적으로 조합해 사용할 수 있습니다—웹 검색, Python으로 업로드한 파일·데이터 분석, 시각 입력에 대한 심층 추론, 이미지 생성까지 포함됩니다. 특히 모델 스스로 언제 어떤 도구를 써야 하는지를 판단해, 보통 1 분 이내에 복합 문제에 대한 상세하고도 깊이 있는 답변을 올바른 형식으로 제시합니다.
이 덕분에 다면적인 질문을 훨씬 효율적으로 해결하며, 사용자를 대신해 작업을 독립적으로 수행할 수 있는 보다 에이전트적인 ChatGPT를 향한 중요한 발걸음을 내딛게 되었습니다. 최첨단 추론 능력과 전 도구 접근성의 결합은 학술 벤치마크와 실제 과제 모두에서 크게 향상된 성능을 보여 주며, 지능과 유용성 면에서 새로운 기준을 세웁니다.
무엇이 달라졌나요
OpenAI o3
- 가장 강력한 추론 모델
o3는 코딩·수학·과학·시각 지각 등 전 영역에서 전례 없는 성능을 보여 줍니다. Codeforces, SWE‑bench(모델 전용 스캐폴드 없이), MMMU 등 여러 벤치마크에서 최신 최고 기록(SOTA)을 세웠습니다. - 복합 분석과 이미지 이해에 특화
다층적인 분석이 필요한 질문이나 답이 바로 떠오르지 않는 문제를 해결하는 데 이상적이며, 이미지·차트·그래픽 등 시각 과제에서도 특히 강합니다. - 실제 업무 기준 20 % 오류 감소
외부 전문가 평가에 따르면, 까다로운 현실 과제에서 o3는 이전 모델(o1)보다 주요 오류가 20 % 적었습니다. 프로그래밍, 비즈니스/컨설팅, 창의적 아이디어 구상 분야에서 뛰어난 성능을 보였습니다. - 사고 파트너로서의 분석력
초기 테스터들은 o3가 생물학·수학·공학 맥락에서 새로운 가설을 생성하고 비판적으로 검증하는 능력을 강조했습니다.
OpenAI o4‑mini
- 작지만 빠르고 경제적인 추론 모델
o4‑mini는 크기 대비 놀라운 성능을 제공하며, 특히 수학·코딩·시각 과제에서 강점을 보입니다. AIME 2024·2025 벤치마크에서 최고 성적을 기록했습니다. - 전 세대 대비 광범위한 향상
비(非)‑STEM 및 데이터 과학 영역에서도 이전 모델(o3‑mini)을 능가했습니다. - 높은 처리량
효율성이 뛰어나 사용 한도가 o3보다 훨씬 높아, 대량·고속 추론이 필요한 작업에 최적입니다.
공통 개선점
- 향상된 지침 준수와 검증 가능성
외부 전문가들은 두 모델 모두 이전 세대보다 지시를 더 잘 따르고, 출처가 명확한 유용한 답변을 제공한다고 평가했습니다. - 더 자연스러운 대화
메모리와 과거 대화를 적극적으로 참조하여 개인화된, 맥락에 맞는 응답을 생성합니다.




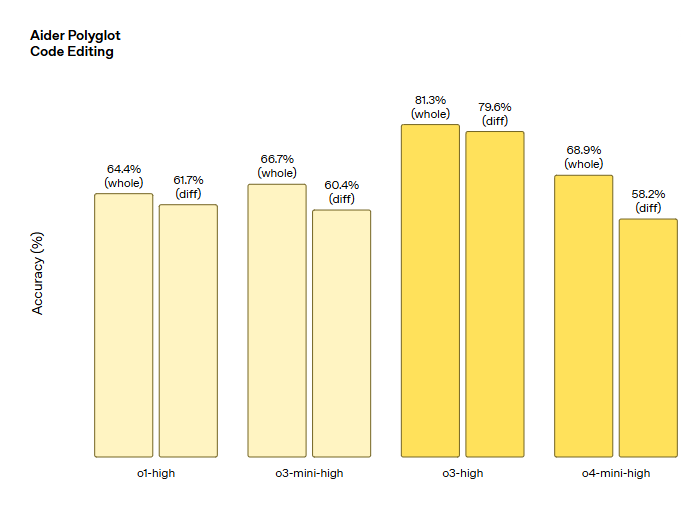


모든 모델은 ‘o4‑mini‑high’와 같은 변형에서 사용되는 높은 “reasoning effort” 설정으로 평가되었습니다.
강화 학습(재)확장
OpenAI o3 개발 과정에서 우리는 대규모 강화 학습(RL)에서도 GPT 계열 프리트레이닝과 마찬가지로 “더 많은 연산 = 더 높은 성능”이라는 스케일링 법칙이 그대로 적용됨을 확인했습니다. 이번에는 RL 영역에서 같은 스케일링 경로를 다시 밟으면서, 훈련 계산량과 추론‑시간(reasoning) 연산량을 모두 한 단계(10배) 더 끌어올렸음에도 성능이 계속 향상되는 것을 확인했습니다. 모델에 더 오래 “생각할” 시간을 주면 성능이 꾸준히 상승한다는 사실을 검증한 셈입니다.
- 동일 지연 시간·비용 대비 더 높은 성능
OpenAI o1과 같은 지연(latency)·비용 조건에서 o3는 ChatGPT 내부 테스트에서 더 높은 성능을 보여 주었습니다. 또, 추론 시간을 늘려 주면 성능이 계속 상승한다는 점도 확인했습니다.
도구 사용 능력 강화
두 모델(o3, o4‑mini)은 강화 학습을 통해 “도구(tool) 사용”을 학습했습니다.
- 어떻게 도구를 쓰는지만이 아니라, 언제 써야 하는지를 추론하도록 훈련했습니다.
- 목표 결과에 따라 적절한 도구를 선택·배치할 수 있어, 특히 시각 추론이나 다단계 워크플로처럼 열린 상황에서 더 강력해졌습니다.
이러한 개선은 학술 벤치마크와 실제 과제 모두에서 early tester들이 보고한 성능 향상으로 입증되었습니다.
이미지를 ‘생각’하는 모델

- 시각 정보 통합 추론
이번 모델들은 이미지를 단순히 “보는” 수준을 넘어, 사고 과정에 직접 통합합니다. 텍스트·시각 정보를 결합해 문제를 풀 수 있어, 다중 모달 벤치마크에서 최첨단 성능을 기록했습니다. - 다양한 이미지 해석
화이트보드 사진, 교과서 도식, 손그림 스케치 등 어떤 이미지를 올려도 해상도가 낮거나, 뒤집혀 있거나, 흐릿해도 이해할 수 있습니다. - 도구를 활용한 실시간 이미지 조작
모델은 추론 과정에서 이미지를 즉석에서 회전·확대·변형하면서 분석합니다. - 업계 최고 수준의 시각 인식 정확도
이전에는 해결하기 어려웠던 시각‑기반 질문도 처리할 수 있습니다. 자세한 내용은 시각 추론 연구 블로그에서 확인해 보세요.
에이전트형 도구 사용(Agentic Tool Use)을 향하여
OpenAI o3와 o4‑mini는 ChatGPT 내부의 모든 도구뿐 아니라, API의 function calling을 통해 연결한 사용자 정의(custom) 도구에도 완전히 접근할 수 있습니다. 두 모델은 문제 해결 과정을 스스로 설계하면서, 언제 어떻게 도구를 활용해야 할지 추론하도록 훈련되었습니다. 덕분에 여러 도구 호출을 연쇄적으로 엮어 1 분 이내에 상세하고 깊이 있는 답변을 올바른 형식으로 제시할 수 있습니다.
예시 ‑ 사용자가 “캘리포니아의 올여름 에너지 사용량은 작년과 어떻게 비교될까?”라고 묻는 경우
모델은
- 공공 전력 데이터를 찾아 웹 검색을 수행하고,
- Python 코드를 작성해 수요 예측을 만들며,
- 그래프나 이미지를 생성해 시각화하고,
- 예측의 핵심 요인을 설명
하는 과정을 일련의 도구 호출로 자동 구성할 수 있습니다.
추론 능력 덕분에 모델은 얻은 정보에 따라 실시간으로 전략을 조정합니다. 예를 들어, 검색 결과가 부족하면 다른 검색어로 다시 시도하고, 필요 시 추가 데이터를 탐색할 수 있습니다.
이처럼 유연하고 전략적인 접근 덕분에, 모델은 자체 파라미터에 내장된 지식을 넘어서는 최신 정보 접근이 필요한 작업, 장기적 추론·통합·멀티모달 결과 생성이 요구되는 복잡한 과제도 해결할 수 있습니다.
위 예시를 포함한 모든 데모는 OpenAI o3로 수행되었습니다.

OpenAI o3는 별도의 웹 검색 없이도 정답을 도출하지만, o1은 정확한 응답을 내놓지 못합니다.
비용 대비 성능이 한 단계 상승
— o3 및 o4‑mini가 그리는 새 Cost‑Performance 프런티어



- 가장 똑똑하면서도 더 경제적
실제 활용에서 o3 / o4‑mini ▶ o1 / o3‑mini보다 대체로 더 높은 정확도와 더 낮은 실행 비용을 동시에 제공할 것으로 예상됩니다. - 사례: 2025 AIME
동일 비용 구간에서 o3가 o1을 완전히 능가해, “더 싸고 더 똑똑한” 새로운 전면(Frontier)을 형성했습니다. o4‑mini도 o3‑mini 대비 같은 패턴을 보여 줍니다. - 실무에 주는 시사점
모델 선택 시 비용과 응답 지연 제약이 있더라도, 최신 세대(o3·o4‑mini)가 이전 세대보다 우월한 선택이 되는 경우가 많습니다—특히 수학·코딩·시각 추론 등 고난도 작업일수록 차이가 두드러집니다.
요약하면, o3와 o4‑mini는 지능뿐 아니라 비용 효율성에서도 전 세대를 넘어서는 새로운 기준을 세웠습니다.
안전·보안 강화 ― o3 / o4‑mini 세대에서 무엇이 달라졌나?
- 안전 학습 데이터 전면 재구성
- 바이오리스크(Biorisk), 악성코드 생성, 탈옥(jailbreak) 시도 등 새 거부(Refusal) 프롬프트를 대폭 추가하여 학습.
- 그 결과, 내부 거부 벤치마크(Instruction Hierarchy·Jailbreak 테스트 등)에서 강력한 거부 성능을 달성.
- 시스템 레벨 완화책(System‑level mitigations)
- 프런티어 위험 영역(생물·화학 위협, 사이버보안, AI 자기개선) 관련 위험 프롬프트를 자동 감지하도록 설계.
- 이미지 생성 안전 필터 개발 경험을 확장해, 이해 가능한 안전 명세를 바탕으로 LLM 모니터를 훈련.
- 인간 레드 팀이 설계한 ‘바이오리스크 시나리오’의 약 99 %를 사전 차단.
- 가장 엄격한 사내 안전 스트레스 테스트
- Preparedness Framework(업데이트판)에 따라 세 가지 핵심 역량 영역을 평가:
- 생물·화학
- 사이버보안
- AI 자기개선
- o3와 o4‑mini 모두 세 영역에서 프레임워크가 정의한 ‘High’(높음) 임계값 아래로 판정.
- Preparedness Framework(업데이트판)에 따라 세 가지 핵심 역량 영역을 평가:
- 투명성
- 위 평가의 세부 결과는 시스템 카드에 공개해 이해관계자들이 검증할 수 있도록 함.
요약: 모델 능력이 좋아질수록 안전 대비도 강화되어야 한다는 원칙 아래, o3 / o4‑mini는 거부 학습 데이터 확충·위험 프롬프트 차단 모니터·엄격한 준비성 평가를 통해 이전 세대보다 한층 높은 안전 기준을 충족했습니다.
Codex CLI — 터미널에서 만나는 최첨단 추론 에이전트

활용 아이디어
- CI/CD 파이프라인 어시스턴트: 테스트 실패 로그를 스크린샷으로 전달해 자동 수정 PR 생성
- 데이터 과학 실험: 로컬 CSV를 읽어 분석 코드·시각화를 즉석에서 생성
- 교육용 코딩 튜터: 학생이 찍은 화이트보드 수식·다이어그램을 바탕으로 파이썬 예제 코드 제공
요약: Codex CLI는 “모델 → 내 컴퓨터” 연결을 극도로 간소화해, 강력한 추론 능력을 코드 작성·분석 워크플로에 즉시 불어넣어 줍니다. 오픈 소스 프로젝트이므로 자유롭게 확장·기여할 수 있으며, 혁신적 활용 아이디어가 있다면 그랜트 프로그램으로 자금·API 크레딧 지원까지 노려보세요.
접근 방법 & 출시 일정 핵심 정리

추가 라인업 & 계획
- o3‑pro
‑ 몇 주 내 출시 예정
‑ 풀 툴 액세스 지원 예정 (현재 Pro 사용자는 o1‑pro 계속 이용 가능) - 개발자 API
‑ 오늘부터 Chat Completions API·Responses API로 o3 / o4‑mini 사용 가능
‑ 일부 조직은 조직 인증(verify) 필요
‑ Responses API:- 추론 요약(token & $ 비용 절감)
- 함수 호출 주변 추론 토큰 보존
- 곧 웹 검색, 파일 검색, 코드 인터프리터 같은 내장 도구 지원 예정 ‑ 시작 가이드는 공식 문서 참고
향후 방향 (What's next)
- o‑시리즈의 고도화된 추론 + GPT‑시리즈의 자연스러운 대화·도구 사용을 단일 모델로 통합하는 로드맵
- 목표: 사용자와 끊김 없는 대화를 유지하면서도 능동적(tool‑driven) 문제 해결을 동시에 수행하는 차세대 모델
주: 4 월 16 일
Charxiv‑r, MathVista 점수는 시스템 프롬프트 변경을 반영해 업데이트되었습니다.
'Article' 카테고리의 다른 글
| Understanding and Coding the KV Cache in LLMs from Scratch (3) | 2025.06.19 |
|---|---|
| Qwen3: Think Deeper, Act Faster (1) | 2025.04.30 |
| MONAI Integrates Advanced Agentic Architectures to Establish Multimodal Medical AI Ecosystem (1) | 2025.04.16 |
| 물리 AI로 헬스케어 혁신 주도하는 NVIDIA와 GE HealthCare (0) | 2025.04.16 |
| On the Biology of a Large Language Model (2) | 2025.04.11 |



