https://arxiv.org/abs/2504.09858
Reasoning Models Can Be Effective Without Thinking
Recent LLMs have significantly improved reasoning capabilities, primarily by including an explicit, lengthy Thinking process as part of generation. In this paper, we question whether this explicit thinking is necessary. Using the state-of-the-art DeepSeek-
arxiv.org
초록
최근의 대형 언어 모델(LLM)은 명시적이고 긴 사고 과정(Thinking process) 을 생성 과정에 포함함으로써 추론 능력을 크게 향상시켜 왔습니다. 본 논문에서는 이러한 명시적인 사고 과정이 과연 필수적인지를 의문을 제기합니다. 최신 모델인 DeepSeek-R1-Distill-Qwen을 활용하여, 단순한 프롬프트를 통해 사고 과정을 생략하는 방식, 즉 NoThinking이 의외로 효과적일 수 있음을 확인했습니다.
토큰 수를 동일하게 맞춘 조건에서, NoThinking은 수학 문제 해결, 정형 정리 증명, 코딩 등 다양한 고난이도 추론 과제로 구성된 7개 데이터셋 전반에서 Thinking 방식을 능가하였습니다. 특히 리소스가 제한된 환경에서는 그 차이가 두드러졌습니다 (예: ACM 23에서 700 토큰 기준, NoThinking 51.3 vs. Thinking 28.9).
또한 pass@k 지표에서 k가 커질수록 NoThinking의 성능은 더욱 경쟁력을 갖추는 경향을 보였습니다. 이 관찰을 바탕으로, NoThinking을 사용하여 N개의 출력을 독립적으로 생성한 뒤 병렬로 결합(aggregate) 하는 병렬 스케일링(parallel scaling) 접근이 매우 효과적임을 입증했습니다.
결합 방식으로는 가능한 경우 과제별 검증기(task-specific verifier) 를 사용하거나, 간단한 best-of-N 전략(예: confidence 기반 선택)을 적용했습니다. 우리의 방법은 Thinking 방식을 사용한 여러 베이스라인 대비 유사한 지연(latency)에서 더 뛰어난 성능을 보였으며, 지연 시간이 최대 9배 더 긴 Thinking 방식과도 비슷한 성능을 나타냈습니다.
이 연구는 길고 복잡한 사고 과정의 필요성에 대한 재고를 촉구함과 동시에, 낮은 예산 또는 짧은 지연 시간 환경에서 병렬 스케일링을 통해 강력한 추론 성능을 달성할 수 있는 하나의 경쟁력 있는 기준점을 제시합니다.
1 서론
최근의 대형 추론 모델들—예: DeepSeek-R1 (DeepSeek-AI et al., 2025), OpenAI o1 (OpenAI, 2024), 그리고 그 외의 모델들(Qwen Team, 2025; Muennighoff et al., 2025; Li et al., 2025a; Ye et al., 2025)—은 추론 시점의 연산량(inference-time compute) 을 증가시킴으로써 성능을 크게 향상시켰습니다 (Snell et al., 2024; Brown et al., 2024 참조).
그림 1에서 볼 수 있듯, 이러한 모델들은 복잡한 작업에 접근할 때 먼저 긴 사고 연쇄(thought chain) 를 생성합니다. 이는 성찰(reflection), 되돌아가기(backtracking), 자기 검증(self-validation) 과 같은 탐색 과정을 포함하며, "Thinking" 단계(파란 박스 상단)에 해당합니다. 그 후에 최종 풀이 단계와 정답("Final Solution") 이 이어집니다 (파란 박스 하단).
이러한 추론 능력은 일반적으로 검증된 보상에 기반한 강화학습 또는 추론 과정을 증류(distillation)한 데이터를 활용한 파인튜닝(fine-tuning) 을 통해 학습됩니다. 이 과정은 명시적인 사고 과정(explicit reasoning process) 이 성능 향상에 기여한다고 여겨지며, 결과적으로 추론 시점 연산량을 확장하는 패러다임(즉, 더 많은 토큰 사용과 높은 지연 시간 비용을 감수하고 추론 성능을 향상시키는 방법)이 널리 받아들여지게 되었습니다.
최근에는 사고 과정 중 사용하는 토큰 수를 줄이는 방식으로 추론 효율을 높이는 연구도 활발히 진행되고 있습니다. 예를 들어, 길이 기반 보상을 활용한 강화학습(Aggarwal & Welleck, 2025), 또는 가변 길이의 Chain-of-Thought(CoT) 데이터를 활용한 지도 학습(Sui et al., 2025) 이 그 예입니다. 그러나 대부분의 접근 방식은 여전히 명시적인 Thinking 단계에 의존하고 있습니다.
이 논문에서는, 고급 추론에 명시적인 Thinking 과정이 정말 필요한가라는 근본적인 질문을 던집니다. 우리는 이미 강력한 추론 성능을 입증한 모델인 DeepSeek-R1-Distill-Qwen을 기반으로, 간단한 프롬프트 기법을 사용하여 이 사고 과정을 비활성화했습니다 (그림 1의 주황색 박스 참조).
우리의 방법은 NoThinking이라고 하며, Assistant 응답을 가상의 사고 블록(dummy Thinking block) 으로 미리 채워 넣고, 그 이후부터 모델이 바로 솔루션을 생성하도록 합니다.
우리는 이 접근을 수학 문제 풀이(AIME 2024, AIME 2025, AMC 2023) (He et al., 2024), 코딩(Jain et al., 2025), 정형 정리 증명(formal theorem proving) (Zheng et al., 2022; Azerbayev et al., 2023) 등 다양한 벤치마크에 걸쳐 철저히 평가하였습니다.

그림 1:
기존 방식인 Thinking은 최종 풀이 단계 이전에, 전용 사고 박스 내에서 성찰, 백트래킹, 자기 검증 등의 탐색 과정을 포함하는 긴 사고 연쇄(thought chain) 를 생성합니다. 반면, NoThinking은 이 박스를 더미(dummy)로 채운 뒤, 바로 풀이를 생성합니다.

그림 2:
토큰 예산이 800으로 동일할 때, NoThinking이 Thinking보다 더 높은 성능을 보임을 보여줍니다.
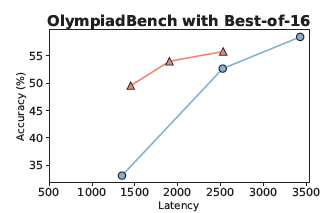
그림 3:
지연 시간(latency)을 동일하게 맞춘 조건에서도 NoThinking이 Thinking을 현저히 능가하는 결과를 나타냅니다. 이때는 best-of-N 샘플 선택 전략을 적용한 결과입니다.
우리의 실험 결과에 따르면, NoThinking은 놀라울 정도로 효과적입니다. 이는 pass@k 지표 (1 ≤ k ≤ 64) 에서 확인할 수 있습니다. 처음부터 NoThinking은 Thinking보다 2.0~5.1배 적은 토큰을 사용하면서도, 모든 k 값에 대해 Thinking과 동일한 수준의 성능을 보이거나, k=1에서는 다소 뒤처지지만 k가 커질수록 빠르게 따라잡고 때로는 Thinking을 능가하기도 합니다.
이러한 성능 패턴은 추론 모델을 학습할 때 사용된 기반(base) 모델들에서는 나타나지 않습니다. 게다가 예산 강제 기법(budget forcing technique, Muennighoff et al., 2025) 을 통해 두 접근 방식의 토큰 사용량을 동일하게 통제하면, 특히 낮은 예산(low-budget) 환경에서 NoThinking이 pass@1 정확도에서 Thinking을 자주 능가하며, k가 증가할수록 그 성능 차이는 더욱 커집니다(그림 2 참조).
효율성을 체계적으로 평가하기 위해, 우리는 pass@k와 평균 토큰 사용량 사이의 파레토 전선(Pareto frontier) 을 분석했습니다. 그 결과, NoThinking은 일관되게 Thinking보다 우수한 효율성을 보였습니다. 이는 명시적인 사고 과정을 생략했음에도, NoThinking이 더 나은 정확도-비용(trade-off) 균형을 다양한 예산 구간에서 달성함을 시사합니다.
NoThinking의 pass@k 성능 우위는 기존의 Thinking 기반 순차 추론 방식보다 더 나은 정확도와 지연 시간을 달성할 수 있는 새로운 추론 전략을 가능하게 합니다. 이를 입증하기 위해, 우리는 NoThinking 기반의 병렬 스케일링(parallel scaling) 을 실험했습니다. 여기서는 여러 출력을 병렬로 샘플링한 후, best-of-N 방식(Kang et al., 2025; Wang et al., 2023) 을 통해 응답을 집계합니다.
우리는 두 가지 유형의 작업을 고려했습니다:
- 완전 검증기가 있는 과제(예: 정형 정리 증명)는 정답 여부를 자동으로 판별할 수 있으며,
- 검증기가 없는 과제(예: 일반 문제 해결)는 confidence 기반 선택 전략에 의존합니다.
정형 증명과 같이 검증 가능한 과제에서는, 병렬 스케일링을 적용한 NoThinking이 병렬 여부와 관계없이 Thinking을 모두 능가했습니다. 이 경우, 지연 시간은 7배 낮고, 총 토큰 사용량은 4배나 적었습니다.
또한, 검증기가 없는 일부 과제에서도 NoThinking은 강력한 성능을 보였습니다. 예를 들어, 수학 올림피아드 벤치마크(OlympiadBench)에서는 Thinking보다 정확도가 높으면서도 지연 시간은 9배 더 낮은 결과를 기록했습니다.
그림 3에 나타난 것처럼, 다양한 벤치마크에서 NoThinking + 병렬 스케일링 방식은 정확도와 지연 시간 사이에서 탁월한 trade-off를 제공합니다.
이 결과는 많은 과제에서 추론 모델 제공자가 Thinking 방식 없이도, 더 낮은 지연 시간과 비슷하거나 더 나은 품질의 성능을 병렬 스케일링 기반 NoThinking 방식으로 달성할 수 있음을 시사합니다.
요약하자면, 본 연구는 현재의 추론 모델들이 따르는 사고 과정(thinking process)이 반드시 높은 성능을 위한 필수 요소는 아니라는 점을 처음으로 밝혀냈습니다. 이는 구조화된 추론 방식에 맞춰 학습된 모델들조차도 해당됩니다.
더 나아가, 우리는 이 단순한 NoThinking 프롬프트 방식이 테스트 시점에서 병렬 연산(parallel test-time compute) 과 결합될 수 있으며, 이를 통해 기존의 순차적 추론 방식보다 더 나은 지연 시간 대비 정확도(latency-vs-accuracy) 를 달성할 수 있음을 보였습니다.
전반적으로 본 연구는 길고 복잡한 사고 과정의 필요성에 대한 재고를 촉구하며, 낮은 예산(low-budget) 또는 짧은 지연 시간(low-latency) 환경에서도 강력한 추론 성능을 낼 수 있는 경쟁력 있는 기준(baseline) 을 제시합니다.
2 관련 연구 및 배경
언어 모델의 테스트 시점 스케일링(Test-Time Scaling)
추론 시점 연산량(inference-time compute) 을 확장하는 것은 대형 언어 모델(LLM)의 추론 능력을 향상시키는 효과적인 전략으로 자리 잡고 있습니다. 기존 방법들은 크게 두 가지 범주로 나뉩니다.
첫 번째는 순차적 접근(sequential approaches) 으로, 대표적인 예로는 OpenAI의 o1, DeepSeek R1, Qwen QwQ 등이 있습니다 (DeepSeek-AI et al., 2025; OpenAI, 2024; Qwen Team, 2025). 이러한 모델들은 되돌아가기(backtracking) 와 검증(self-verification) 을 포함한 구조화된 Chain-of-Thought(CoT) 응답을 하나의 전방 패스(forward pass) 내에서 생성합니다.
이러한 능력을 확보하기 위해서는 강화학습(RL) 이나 반복적인 자기 개선 과정(iterative self-improvement) 과 같은 비용이 많이 드는 훈련 과정이 필요합니다 (Zelikman et al., 2022; Lambert et al., 2025; Yuan et al., 2024). 예를 들어, DeepSeek R1은 전체 훈련이 RL 기반으로 이루어졌으며, RLVR (Lambert et al., 2025)과 PRIME (Yuan et al., 2024)은 검증 가능한 피드백(verifiable feedback) 이나 잠재적 감독 신호(latent supervision) 을 활용하여 추론 품질을 향상시킵니다.
두 번째 범주는 병렬적 접근(parallel approaches) 입니다. 이는 여러 출력을 샘플링한 뒤 이를 집계하는 방식으로, Best-of-N 샘플링, Monte Carlo Tree Search(MCTS) 등의 탐색 기반 디코딩 기법이 여기에 해당합니다 (Snell et al., 2024; Brown et al., 2024). 이 방식은 다수의 후보 출력을 생성하고, 탐색 알고리즘, 보상 모델, 외부 검증기(external verifiers) 등을 통해 선택적으로 집계합니다.
기존 연구들은 대부분 명시적인 사고 과정이 강력한 성능을 위해 필수적이라고 전제하고 있지만, 본 연구는 이 사고 과정을 비활성화(disabling explicit thinking) 하는 것이 오히려 정확도-비용(accuracy-budget) trade-off를 개선할 수 있는 유망한 방법임을 보여줍니다.
우리가 제안하는 프롬프트 기반 방법(prompting-based method) 은 단순하지만 간과되어 온 방식으로, 추가적인 훈련(training), 보상 신호(reward signals), 추론 과정에 대한 감독(process supervision) 없이도 경쟁력 있는 성능을 달성할 수 있습니다.
우리는 Best-of-N 방법을 사용하여 이 접근 방식의 효과를 입증하였지만, 본 연구의 목적은 샘플링 기법 자체를 혁신하는 것이 아니라, 저예산(low-budget) 환경에서 실용적이고 강력한 베이스라인을 제시하는 데에 있습니다.
효율적인 추론 (Efficient Reasoning)
추론 모델에서의 순차적 스케일링(sequential scaling) 에 따른 연산 비용이 증가함에 따라, 최근 연구들은 대형 언어 모델(LLM) 내 추론을 더욱 효율적으로 수행하기 위한 다양한 전략을 탐색하고 있습니다. 이러한 접근 방식들은 생성되는 추론 시퀀스의 길이를 최적화하고 불필요한 단계를 제거함으로써, 간결하고 효율적인 추론(smart and concise reasoning) 을 유도하는 것을 목표로 하며, 이는 최근 설문 조사(Sui et al., 2025)에도 정리되어 있습니다.
일부 방법들은 여전히 전체 길이의 Chain-of-Thought(CoT) 최적화를 위해 추론 모델을 훈련시키는 방식을 따릅니다. 예를 들어, 길이 기반 보상(length-based rewards) 을 명시적으로 활용한 강화학습(RL) (Aggarwal & Welleck, 2025; Luo et al., 2025; Shen et al., 2025b; Arora & Zanette, 2025; Qu et al., 2025)이나, best-of-N 샘플링을 통해 얻은 가변 길이 또는 간결한 추론 과정에 대해 파인튜닝하는 방식(Xia et al., 2025; Kang et al., 2024; Ma et al., 2025; Munkhbat et al., 2025; Yu et al., 2024; Liu et al., 2024; Cui et al., 2025)이 이에 해당합니다.
또 다른 접근들은 출력 방식 자체(output paradigm) 를 변경하여 간결한 추론을 유도합니다. 예를 들어, 잠재 표현(latent representations) 을 활용하도록 LLM을 학습시키는 방식(Hao et al., 2024; Cheng & Durme, 2024; Shen et al., 2025a; Xu et al., 2025b; Su et al., 2025; Saunshi et al., 2025; Shen et al., 2025c)이나, 추론 전략을 안내하기 위해 적절한 기준(criteria) 을 선택하는 비학습(training-free) 기법(Fu et al., 2024; Wu et al., 2025b; Aytes et al., 2025; Liao et al., 2025; Sun et al., 2024; Li et al., 2025b; Ding et al., 2025; Wang et al., 2025; Zhang et al., 2025; Yan et al., 2025)이 있습니다.
또한 일부 연구는 LLM이 더 적은 수의 추론 단계를 생성하도록 명시적으로 지시합니다(Han et al., 2025; Xu et al., 2025a; Lee et al., 2025; Renze & Guven, 2024; Wu et al., 2025a). 예를 들어, 프롬프트 내에 토큰 예산(token budget) 을 설정하는 방식이 여기에 해당합니다. 혹은 입력 난이도에 따라 동적으로 라우팅하여(reasoning complexity를 제어) 추론 복잡도를 조절하는 방법도 있습니다(Ong et al., 2025; Chuang et al., 2025a;b).
이러한 방법들 중 일부는 효과적인 것으로 입증되었지만, 우리의 접근은 완전히 직교적(orthogonal) 입니다.
즉, 추론 과정(thinking process)을 아예 비활성화하는 것만으로도 놀라운 효과를 얻을 수 있음을 우리는 보여줍니다.
3. NoThinking은 Thinking보다 더 나은 정확도-예산 균형을 제공한다
이 절에서는 NoThinking이 놀라울 정도로 효과적일 수 있으며, budget forcing 하에서도 Thinking을 능가하며 더 나은 정확도-예산(accuracy-budget) trade-off를 제공함을 보입니다. 먼저 Thinking과 NoThinking을 정의하고(3.1절), 실험 설정을 설명한 뒤(3.2절), 실험 결과를 제시합니다(3.3절).
3.1 방법론 (Method)
대부분의 최신 추론 모델들(R1, R1-Distill-Qwen 등)은 유사한 생성 구조를 따릅니다.
즉, 생성된 응답은 다음과 같은 순서로 구성됩니다:
- 사고 과정(thinking process): <|beginning of thinking|> 와 <|end of thinking|> 사이에 위치
- 최종 풀이(final solution)
- 최종 정답(final answer)
이 구조를 기반으로, 우리는 두 가지 방식—Thinking과 NoThinking—을 다음과 같이 정의합니다:
- Thinking:
기본적인 질의 방식으로, 모델이 사고 과정(thinking box 내 reasoning process), 최종 풀이, 최종 정답을 차례로 생성합니다 (그림 1의 파란 박스 참조). - NoThinking:
명시적인 사고 과정을 프롬프트를 통해 생략하고, 곧바로 최종 풀이 및 정답만을 생성하는 방식입니다.
이를 위해 디코딩 과정 중 thinking box를 비워둔 상태로 고정합니다 (그림 1의 주황색 박스 참조).
<|beginning of thinking|>
Okay, I think I have finished thinking.
<|end of thinking|>우리가 실제로 사용한 프롬프트 예시는 부록 C(Appendix C) 에서 확인할 수 있습니다.
두 방식의 토큰 사용량을 제어하기 위해, 우리는 Muennighoff et al. (2025)에서 제안한 budget forcing 기법을 채택했습니다.
모델이 지정된 토큰 예산(token budget) 에 도달하면, 즉시 "Final Answer:"를 생성하도록 강제하여 최종 정답이 출력되도록 합니다. 만약 예산 내에서 여전히 사고 박스 내에 있다면, <|end of thinking|> 태그를 삽입한 후 최종 정답을 생성하도록 유도합니다.
이 budget forcing을 효과적으로 구현하기 위해, 우리는 작업(task)별로 소폭의 구현 수정을 적용하였습니다. 세부 사항은 부록 A.1(Appendix A.1) 을 참고하십시오.
3.2 평가 설정 (Evaluation Setup)
모델 (Models)
우리는 주 모델로 DeepSeek-R1-Distill-Qwen-32B (DeepSeek-AI et al., 2025)를 사용합니다. 이 모델은 DeepSeek-R1의 디스틸(distill) 버전으로, Qwen-32B로 초기화한 뒤, DeepSeek-R1이 생성한 데이터를 활용해 훈련되었습니다.
이 모델은 순차적 테스트 시점 스케일링(sequential test-time scaling) 을 사용하는 최신 추론 모델 중 하나이며, 리포트에 따르면 더 큰 모델인 DeepSeek-R1-Distill-Llama-70B 와 유사한 수준의 성능을 보입니다.
추가적인 비교 기준으로, Qwen-32B-Instruct (Qwen et al., 2025)도 포함했습니다. 이 모델은 같은 아키텍처를 사용하지만 구조화된 추론(structured reasoning)에 특화되지는 않은 범용 instruction-tuned 모델입니다.
또한 우리는 AIME 태스크에서 더 작은 규모의 R1 시리즈 모델들(7B, 14B) 도 실험해 보았으며, 이들 역시 본 실험에 사용된 32B 모델과 유사한 동작 양상을 보였습니다. 해당 결과는 부록 B.2에 추가되어 있습니다.
비공개 모델(closed-source models)은 직접 개입이 불가능하여, Thinking-Solution 포맷(1장에서 설명한 구조)을 따르는 타사 모델에 대한 탐색은 향후 과제로 남겨둡니다.
태스크 및 벤치마크 (Tasks and Benchmarks)
우리는 수학, 코딩, 올림피아드 문제, 정형 정리 증명 등 다양한 고난도 추론 벤치마크를 포함하여 평가를 수행했습니다.
- 수학 문제 해결 (Mathematical problem solving):
일반적인 문제부터 올림피아드 수준 문제까지 포함했습니다.- 표준 수학 문제로는 AIME 2024, AIME 2025, AMC 2023을 사용하였으며, 이는 추론 모델 평가에서 널리 사용되는 벤치마크입니다 (DeepSeek-AI et al., 2025; OpenAI, 2024).
- 더 고차원적인 추론을 위해, OlympiadBench (He et al., 2024) 의 수학 서브셋을 사용했습니다. 이는 AIME나 AMC보다 훨씬 더 어려운 문제들로 구성되어 있습니다.
- 코딩 (Coding):
LiveCodeBench (Jain et al., 2025, release v2)를 사용했습니다. 이는 홀리스틱(hollistic) 하면서도 오염되지 않은(순수한) 벤치마크로, 시간이 지남에 따라 새로운 문제들을 지속적으로 수집합니다. - 정형 정리 증명 (Formal theorem proving):
- 수학적 추론을 위한 MiniF2F (Zheng et al., 2022),
- 논리 및 정리 증명을 위한 ProofNet (Azerbayev et al., 2023)을 사용했습니다.
이 두 데이터셋은 정형 언어(formal languages) 를 이용한 정리 증명 태스크에서 가장 널리 사용되는 벤치마크 중 하나입니다.

그림 4: Thinking vs. NoThinking vs. Qwen-Instruct (토큰 예산 미제한 상태)
파란색, 주황색, 초록색은 각각 Thinking, NoThinking, Qwen-Instruct를 나타냅니다.
각 서브그림의 범례에는 각 접근 방식에서 사용된 평균 토큰 수가 표시되어 있습니다.

그림 5: Thinking vs. NoThinking (토큰 예산 제한 상태)
주황색과 파란색은 각각 NoThinking과 Thinking을 나타냅니다.
동일한 토큰 예산 조건 하에서, NoThinking은 k가 증가할수록 지속적으로 Thinking을 능가합니다.
지표 (Metrics)
우리는 pass@k를 보고합니다. 이 지표는 문제당 생성된 n개의 응답 중에서 무작위로 선택한 k개 안에 최소 하나 이상의 정답이 포함될 확률을 나타냅니다.
pass@k는 다음과 같이 정의됩니다:
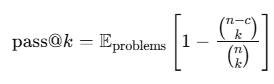
여기서
- n은 문제당 생성된 전체 응답 수,
- c는 그중 정답의 수입니다 (Chen et al., 2021).
사용한 k 값의 설정은 다음과 같습니다:
- 정형 정리 증명 데이터셋(MiniF2F, ProofNet):
k = {1, 2, 4, 8, 16, 32} (표준 설정) - 작은 규모의 수학 데이터셋(AIME24, AIME25, AMC23):
k = {1, 2, 4, 8, 16, 32, 64} - 큰 규모의 데이터셋(OlympiadBench, LiveCodeBench):
k = {1, 2, 4, 8, 16}
특히,
- 정형 정리 증명 벤치마크에서는 pass@32가 표준,
- 수학 및 코딩 벤치마크에서는 pass@1(즉, 정확도)이 가장 일반적으로 사용됩니다.
3.3 결과 (Results)
토큰 예산 미제한 상태에서의 Thinking vs. NoThinking vs. Qwen-Instruct 비교
그림 4는 budget forcing 없이 세 가지 모델의 pass@k 값을 다양한 k에 대해 비교한 것입니다.
먼저, MiniF2F와 ProofNet에서는 NoThinking이 Thinking과 모든 k 값에서 유사한 성능을 보였습니다(두 모델 모두 Qwen-Instruct를 크게 능가함).
이는 특히 주목할 만한데, NoThinking이 Thinking보다 3.3~3.7배 적은 토큰만을 사용했기 때문입니다.
다른 데이터셋에서는 결과가 다소 혼재되어 있습니다.
- k = 1에서는 NoThinking이 Thinking보다 성능이 낮았으나,
- k가 증가할수록 그 격차는 점차 줄어들고,
- 결국 가장 큰 k 값에서는 NoThinking이 Thinking과 비슷한 수준에 도달합니다. 이때에도 NoThinking은 2.0~5.1배 적은 토큰만을 사용합니다.
AIME24, AIME25, LiveCodeBench의 경우, Thinking과 NoThinking 모두 Qwen-Instruct를 크게 앞섰습니다.
그러나 AMC23과 OlympiadBench에서는 Qwen-Instruct도 Thinking 및 NoThinking과의 성능 차이를 상당 부분 좁히는 모습을 보였습니다.
다양한 작업과 접근 방식에 대한 입력 및 출력 예시는 부록 C(Appendix C) 에 포함되어 있습니다.
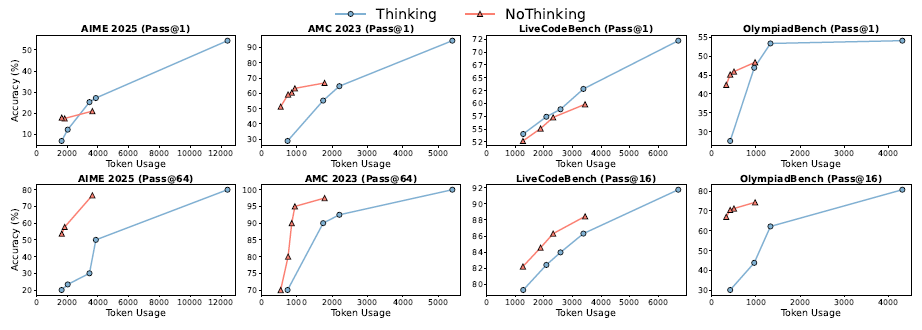
그림 6:
pass@k 값과 평균 토큰 사용량을 벤치마크별로 나타낸 그래프입니다.
각 곡선은 서로 다른 방식을 나타냅니다:
- 파란색은 Thinking
- 주황색은 NoThinking
각 벤치마크에 대해 k = 1과 해당 벤치마크에서의 최대 k 값 모두를 사용해 비교하였습니다.
토큰 예산이 제한된 상태에서의 Thinking vs. NoThinking 비교
MiniF2F와 ProofNet을 제외한 다른 데이터셋에서는 NoThinking이 Thinking보다 성능이 낮았지만, 사용한 토큰 수는 훨씬 적었습니다.
따라서 우리는 앞서 3.1절에서 설명한 budget forcing 기법을 통해 토큰 예산을 통제한 상태에서 두 방식을 공정하게 비교했습니다.
그림 5에서 보듯이, 토큰 사용량이 동일할 경우, NoThinking이 일반적으로 Thinking보다 더 나은 성능을 보였습니다.
특히, 예산이 적은 환경(예: 3,000 토큰 미만)에서는 k 값에 관계없이 NoThinking이 일관되게 우수한 성과를 내며,
k가 커질수록 그 성능 차이는 더욱 벌어졌습니다.
반면, 토큰 예산이 더 높아졌을 때(예: 약 3,500 토큰),
- pass@1에서는 Thinking이 더 나은 성능을 보였지만,
- k = 2부터는 NoThinking이 빠르게 성능을 역전했습니다.
그림 6은 이러한 결과를 더욱 명확히 보여줍니다. x축에는 토큰 사용량, y축에는 pass@1 및 해당 벤치마크에서 가능한 가장 큰 k에 대한 pass@k 값을 표시했습니다.
- pass@k (k > 1) 기준으로는 NoThinking이 예외 없이 모든 예산 구간에서 Thinking보다 뛰어난 성능을 보였습니다.
- pass@1 기준으로는, 저예산 구간에서는 NoThinking이 더 우수, 고예산 구간에서는 Thinking이 더 우수했습니다.
단, LiveCodeBench는 예외입니다. 이 벤치마크에서는 저예산 구간에서도 Thinking이 NoThinking보다 높은 pass@1 성능을 보였습니다.
이는 해당 데이터셋에서 Thinking box를 제거해도 토큰 사용량이 크게 줄지 않기 때문인 것으로 보입니다.
또한 데이터 오염(data contamination)의 가능성을 줄이기 위해, 최근 공개되어 기존 모델의 사전학습 데이터에는 포함되었을 가능성이 낮은 AIME 2025를 포함시켰습니다.
중요하게도, 우리의 실험 결과는 새로운 벤치마크와 기존 벤치마크 모두에서 일관된 경향을 보였습니다.
이는 관측된 성능 차이가 단순한 암기 효과가 아니라 모델의 일반화 가능한 추론 경향임을 시사합니다.
요약 (Summary)
Thinking box는 현대 추론 모델의 핵심 구성 요소 중 하나이지만, 이를 제거했음에도 NoThinking은 놀라울 만큼 효과적입니다.
- 정리 증명 벤치마크에서는 Thinking보다 3.3~3.7배 적은 토큰만으로도 유사한 성능을 달성했고,
- 다른 벤치마크에서는 동일한 토큰 예산 하에서 Thinking을 능가했으며,
- 특히 저예산 환경에서는 그 차이가 두드러졌습니다 (예: AMC23에서 700 토큰 사용 시 NoThinking 51.3 vs. Thinking 28.9).
또한, k > 1인 pass@k 기준으로는 NoThinking이 전체 예산 범위에서 항상 Thinking보다 우수했으며,
k가 커질수록 그 우위는 더 커지는 경향을 보였습니다.
3.4 논의 및 분석 (Discussions and Analyses)
과제별 NoThinking 성능의 차이 (Task-Specific Differences in NoThinking Performance)
3.3절에서 일관된 성향이 관찰되었지만, 각 개별 벤치마크에서는 NoThinking의 성능에 미묘한 차이가 존재합니다.
그림 4를 보면, AMC 2023에서는 세 가지 설정 모두에서 성능 격차가 거의 없이 수렴하는 모습을 보여줍니다. 이는 이 벤치마크에 대해 모델들이 포화(saturation) 상태에 도달했을 가능성을 시사합니다.
또한, MiniF2F와 ProofNet에서는 놀라운 현상이 나타납니다.
NoThinking이 pass@1 기준으로 Thinking과 유사한 정확도를 달성했으며, 사용한 토큰 수는 현저히 적었습니다.
그러나 이는 해당 과제가 간단하다는 의미로 해석되어서는 안 됩니다.
실제로, 우리의 평가에 따르면, OpenAI의 강력한 모델인 o1조차도 MiniF2F에서 단 30%의 정확도만을 기록하였고,
ProofNet 역시 모든 방법에서 일관되게 낮은 점수를 보여주었습니다.
이러한 결과는 다음의 두 가지를 강조합니다:
- NoThinking의 효과는 과제(task) 특성에 따라 달라질 수 있음
- 일부 벤치마크에서 NoThinking이 강력한 성능을 보이는 이유는 아직 명확히 밝혀지지 않았으며, 이는 향후 연구 과제로 남아 있음.
k 값 증가가 NoThinking 성능에 미치는 영향
k가 증가함에 따라 NoThinking 성능이 향상되는 원인을 간략히 탐색하며, 생성된 정답의 다양성(diversity) 에 초점을 맞춥니다.
우리는 각 질문에 대한 정답 분포의 엔트로피(entropy) 를 계산함으로써 다양성을 측정합니다.
특정 질문의 정답 분포가 {p₁, p₂, ..., pₙ}일 때, 엔트로피는 다음과 같이 정의됩니다:

여기서 p_i는 i번째 고유한 정답이 등장할 경험적 확률(empirical probability) 입니다.
우리는 질문 전체에 대해 엔트로피의 평균(mean)과 표준편차(std)를 계산하여 다양성을 요약합니다.
- 높은 평균 엔트로피는 전반적인 다양성이 크다는 것을 의미하며,
- 낮은 표준편차는 질문 간 다양성의 일관성이 높다는 것을 뜻합니다.
본 분석은 그림 5에서 비교한 Thinking vs. NoThinking 성능 결과를 기반으로 하며, 정확한 정답이 없는 LiveCodeBench는 제외하였습니다.
표 1: Thinking과 NoThinking 모드에서 다양한 토큰 예산 하에 측정된 평균(±표준편차) 다양성 지표 비교
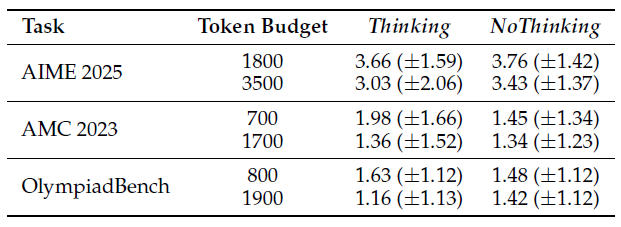
표 1의 결과에 따르면, 평균 다양성 측면에서 어느 방식이 우위에 있는지는 일관되지 않습니다.
- 어떤 설정에서는 NoThinking이 더 높은 평균 엔트로피를 보였고 (예: AIME 2025),
- 다른 설정에서는 Thinking이 더 높은 값을 기록했습니다 (예: AMC 2023).
그러나 모든 경우에서 NoThinking은 질문 간 다양성의 분산(표준편차)이 더 낮은 경향을 보였습니다.
이는 NoThinking이 다양한 예제들에 대해 보다 균일한 수준의 다양성을 갖춘 응답을 생성한다는 것을 시사합니다.
우리는 이러한 다양성의 일관성이 pass@k 성능 향상에 기여했을 가능성이 있다고 가정합니다.
다만, 다양성만으로 성능 차이를 완전히 설명할 수는 없으며, 이는 복합적인 요인에 기반한 결과일 수 있습니다.
4. NoThinking은 병렬 테스트 시점 연산을 더 효과적으로 만든다
3장에서 확인한 바와 같이, k가 증가할수록 NoThinking의 pass@k 성능 이점은 더욱 두드러지게 나타납니다.
이러한 결과는 NoThinking이 병렬 스케일링(parallel scaling) 기법과 효과적으로 결합될 수 있음을 시사합니다.
즉, N개의 출력을 병렬로 독립적으로 생성한 후, 그 중 가장 우수한(best-of-N) 결과를 선택하는 방식입니다.
본 장에서는 이러한 병렬 방식이 정확도 vs. 지연 시간(latency) 관점에서 Thinking 기반 구성보다 더 뛰어난 성능을 낼 수 있음을 보여줍니다.

그림 7:
모든 벤치마크에서의 pass@1 결과 비교.
병렬 스케일링 사용 여부와 NoThinking vs. Thinking 방식에 따른 성능 차이를 보여줍니다.
4.1 동기 및 방법 (Motivation and Methods)
병렬 스케일링 vs. 순차적 스케일링 (Parallel Scaling vs. Sequential Scaling)
병렬 스케일링(parallel scaling) 은 본질적으로 낮은 지연 시간(low latency) 을 제공합니다.
이는 여러 개의 모델 호출을 동시에 실행할 수 있기 때문이며, API 호출이나 로컬 모델 서빙을 통해 구현할 수 있습니다.
구체적으로는, 멀티 GPU 환경 또는 단일 GPU에서의 배치 처리(batch processing) 를 통해 구현할 수 있으며,
이러한 방식은 순차적 스케일링(sequential scaling) 에 비해 GPU 활용률을 더 높일 수 있습니다.
전체 지연 시간은 개별 응답 중 가장 오래 걸리는 하나의 응답 시간에 의해 결정됩니다.
우리는 앞선 분석을 통해 다음과 같은 사실을 확인했습니다:
- NoThinking은 저예산 환경에서 더 정확한 결과를 생성하며,
- k가 증가할수록 pass@k 성능이 점점 향상된다는 점입니다.
이를 바탕으로, 우리는 간단한 best-of-N 방식과 결합된 병렬 샘플링(parallel sampling) 을 통해
NoThinking이 정확도를 크게 향상시킬 수 있음을 보입니다.
이 방식은 다음을 능가합니다:
- 비슷한 지연 시간을 가진 대안들 (예: Thinking + budget forcing + 병렬 샘플링)
- 전체 사고 과정을 포함한 full Thinking (budget forcing 없이 Thinking) 방식이 순차적 스케일링 하에서 달성하는 pass@1 성능까지도 능가합니다.
이는 훨씬 더 낮은 지연 시간으로 이루어졌음에도 불구하고 달성된 결과입니다.
방법 (Methods)
병렬 샘플링(parallel sampling) 은 N개의 독립적인 응답을 하나의 최종 예측으로 집계하는 방법, 즉 best-of-N 방식을 필요로 합니다.
형식적으로, N개의 예측 결과 P = {p_1, p_2, ..., p_N} 가 주어졌을 때, best-of-N 방식은 이 중에서 하나의 p∈P 를 최종 출력으로 선택합니다.
- MiniF2F와 ProofNet과 같은 과제에서는, 각 예측 p∈P 가 정답인지 여부를 정확히 판단할 수 있는 완벽한 검증기(perfect verifier) 가 존재한다고 가정합니다.
여기서 사용되는 검증기는 Lean 컴파일러입니다 (Moura & Ullrich, 2021). - 하지만 이러한 검증기가 존재하지 않는 다른 과제들에 대해서는, 다음과 같은 방법들을 실험했습니다:


지표 (Metrics)
우리는 지연 시간(latency) 을 다음과 같이 정의합니다:
각 데이터셋에서 N개의 병렬 샘플링 결과 중 생성된 토큰 수의 최댓값을 평균한 값입니다.
이 지표는 실제 애플리케이션에서 매우 중요한 요소입니다.
왜냐하면, 낮은 지연 시간은 더 빠른 응답 시간으로 이어지기 때문이며, 이는 현실 세계의 사용자 경험 측면에서 핵심 목표가 되기 때문입니다.


4.2 결과 (Results)
그림 7은 모든 벤치마크에 대해 Thinking과 NoThinking의 pass@1 결과를 보여줍니다.
- 단일 샘플 응답의 성능은 병렬 스케일링 없이의 pass@1으로 간주되며,
- 여러 샘플에 대해 Best-of-N 선택을 수행한 정확도는 병렬 스케일링을 적용한 pass@1으로 간주됩니다.
검증기(verifier)가 없는 태스크들의 경우, 우리는 그림에서 confidence 기반 결과를 사용하였으며,
선택된 실험들에 대한 ablation 결과는 표 2에 제시했습니다.
이 표는 4.1절에서 설명한 Best-of-N 선택 방법들을 비교한 것으로, confidence 기반 선택 방식이 일반적으로 다수결보다 우수한 성능을 보였습니다.
또한, 병렬 스케일링을 사용할 때 pass@1의 이론적 상한선으로서 pass@k 정확도도 함께 보고하였으며, 이 값도 표 2에 포함되어 있습니다.
확장된 표는 부록 B.3에서 확인할 수 있습니다.
완벽한 검증기(perfect verifiers)가 있는 경우
NoThinking은 병렬 스케일링과 결합될 때, 전통적인 순차적 접근 방식에 비해 훨씬 더 효율적인 대안이 됩니다.
즉, 훨씬 낮은 지연 시간과 토큰 사용량으로 비슷하거나 더 높은 정확도를 달성할 수 있습니다.
그림 7의 첫 번째와 두 번째 플롯을 보면, NoThinking은 Thinking보다 훨씬 낮은 지연 시간으로
유사하거나 더 높은 성능을 보여줍니다.
- 병렬 스케일링 없이도, NoThinking은 Thinking과 거의 유사한 정확도를 훨씬 적은 지연 시간으로 달성합니다.
- 만약 완벽한 검증기가 존재한다면, k개의 샘플 중에서 가장 좋은 응답을 선택함으로써 pass@k 정확도를 달성할 수 있습니다.
병렬 스케일링과 결합하면, NoThinking은
budget forcing 없이 병렬 스케일링도 사용하지 않은 Thinking—즉, 대표적인 순차적 스케일링 베이스라인—과 동일한 수준의 정확도를 달성하면서도,
지연 시간은 7배 감소합니다.
또한, MiniF2F와 ProofNet 데이터셋 모두에서, NoThinking은 4배 적은 출력 토큰만으로 동일한 정확도를 달성,
그 계산 효율성(computational efficiency) 을 강조합니다.
이러한 결과는 검증기가 사용 가능한 환경에서 병렬 샘플링의 효과성을 강하게 뒷받침합니다.
추가적인 세부 사항은 부록 B.1에서 확인할 수 있습니다.
단순 Best-of-N 방법 (Simple Best-of-N Methods)
NoThinking은 병렬 스케일링과 confidence 기반 선택 방식이 결합될 때, 대부분의 벤치마크에서 낮은 토큰 예산 조건 하에 Thinking을 일관되게 능가합니다.
그림 7의 마지막 다섯 개 플롯은 여러 벤치마크에서 Thinking과 NoThinking을 토큰 수를 맞춰 비교한 confidence 기반 선택 결과를 보여줍니다.
우리가 저예산(low-budget) 구간에 집중하는 이유는 다음 두 가지입니다:
- 효율적인 추론(inference efficiency) 에 대한 본 연구의 주 관심사와 일치하며,
- 토큰 최대 길이를 너무 높게 설정하면, 출력이 지나치게 길고 일관성 없는 "중얼거림(babbling)"으로 이어져,
지연 시간만 늘고 비교의 의미가 사라지기 때문입니다.
예상대로 병렬 스케일링은 Thinking과 NoThinking 모두의 pass@1 성능을 향상시켰습니다.
그러나 모든 수학 벤치마크에서 NoThinking은 병렬 스케일링이 적용된 Thinking보다 항상 더 우수한 Pareto frontier를 형성하며,
더 나은 정확도–예산 균형(accuracy–budget tradeoff) 을 입증했습니다.
AMC 2023과 OlympiadBench에서는, 병렬 스케일링 적용 여부와 무관하게 NoThinking이 항상 Thinking을 능가했습니다.
특히, full Thinking(budget forcing 없이 Thinking)과 비교했을 때도,
NoThinking은 pass@1 점수가 더 높았으며 (55.79 vs. 54.1), 지연 시간은 9배나 줄었습니다.
다만, LiveCodeBench에서는 NoThinking의 성능이 떨어졌으며, 예외적인(outlier) 결과로 보입니다.
이는 코딩 과제에서는 정확히 일치하는 정답이 없으면 voting 전략을 쓸 수 없어 confidence 기반 선택 방식의 한계가 드러났기 때문일 수 있습니다.
이런 경우에는 confidence가 가장 높은 응답을 선택하는 fallback 전략을 사용하지만, 이 방식은 신뢰도가 낮습니다.
표 2에서 확인할 수 있듯, 이 방식은 voting을 사용할 수 있는 과제에서는 일관되게(종종 큰 차이로) 열등한 성능을 보였습니다.
종합적으로 보면, 검증기가 없는 환경에서도, 병렬 샘플링 및 강력한 선택 전략과 결합된 NoThinking은 매우 효과적인 방법임을 보여줍니다.
요약 (Summary)
NoThinking은 k가 증가할수록 놀라운 pass@k 성능을 보이며,
병렬 스케일링을 통해 이를 더욱 활용하면, 비슷하거나 훨씬 낮은 지연 시간(최대 9배 감소) 으로 향상된 pass@1 성능을 달성할 수 있습니다.
또한, 완벽한 검증기가 존재하는 과제에서는, 정확도를 유지하거나 더 높은 정확도를 달성하면서도 전체 토큰 사용량을 최대 4배까지 줄일 수 있습니다.
5 결론 (Conclusion)
지금까지 대형 언어 모델들은 최종 해답을 생성하기 전에 긴 “사고(thinking)” 과정을 거침으로써 추론 과제에서 높은 성능을 보여 왔습니다.
그러나 본 논문에서는 이러한 사고 과정이 과연 필요한지를 다시 질문하며, 이를 대신할 간단하면서도 효과적인 프롬프트 기반 접근법인 NoThinking을 제안했습니다.
우리는 동일한 모델이라도 긴 사고 체인 없이도,
pass@k 기준으로는 기존 Thinking 방식보다 성능이 동등하거나 더 우수하며,
사용하는 토큰 수는 훨씬 적을 수 있음을 보였습니다.
동일한 토큰 예산 조건에서도, NoThinking은 대부분의 k 값에서 기존 Thinking 결과를 꾸준히 능가했습니다.
또한, 우리는 NoThinking을 Best-of-N 선택 전략과 결합하여
표준 Thinking 방식보다 더 나은 정확도–지연 시간 균형을 달성할 수 있음을 보여주었습니다.
본 연구가 긴 사고 과정의 필요성에 대한 재고를 유도하고,
저예산 및 저지연 환경에서 강력한 추론 성능을 위한 실용적 기준선을 제공하길 바랍니다.
감사의 글 (Acknowledgements)
이 연구는 UC 버클리 Sky Computing Lab의 지원을 받아 수행되었습니다.
Databricks로부터 컴퓨팅 자원을 제공받았으며, Jonathan Frankle에게 리소스 접근을 도와준 점에 감사드립니다.
또한, Kaylo Littlejohn(UC Berkeley), Zhaoyu Li(University of Toronto)에게 초안에 대한 소중한 피드백을 제공해 주신 점을 감사드립니다.
'인공지능' 카테고리의 다른 글
| EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications (2) | 2025.04.30 |
|---|---|
| LLMs can see and hear without any training (3) | 2025.04.28 |
| Antidistillation Sampling (3) | 2025.04.24 |
| BitNet b1.58 2B4T Technical Report (3) | 2025.04.24 |
| Gaussian Mixture Flow Matching Models (4) | 2025.04.22 |



