https://arxiv.org/abs/2501.18096
LLMs can see and hear without any training
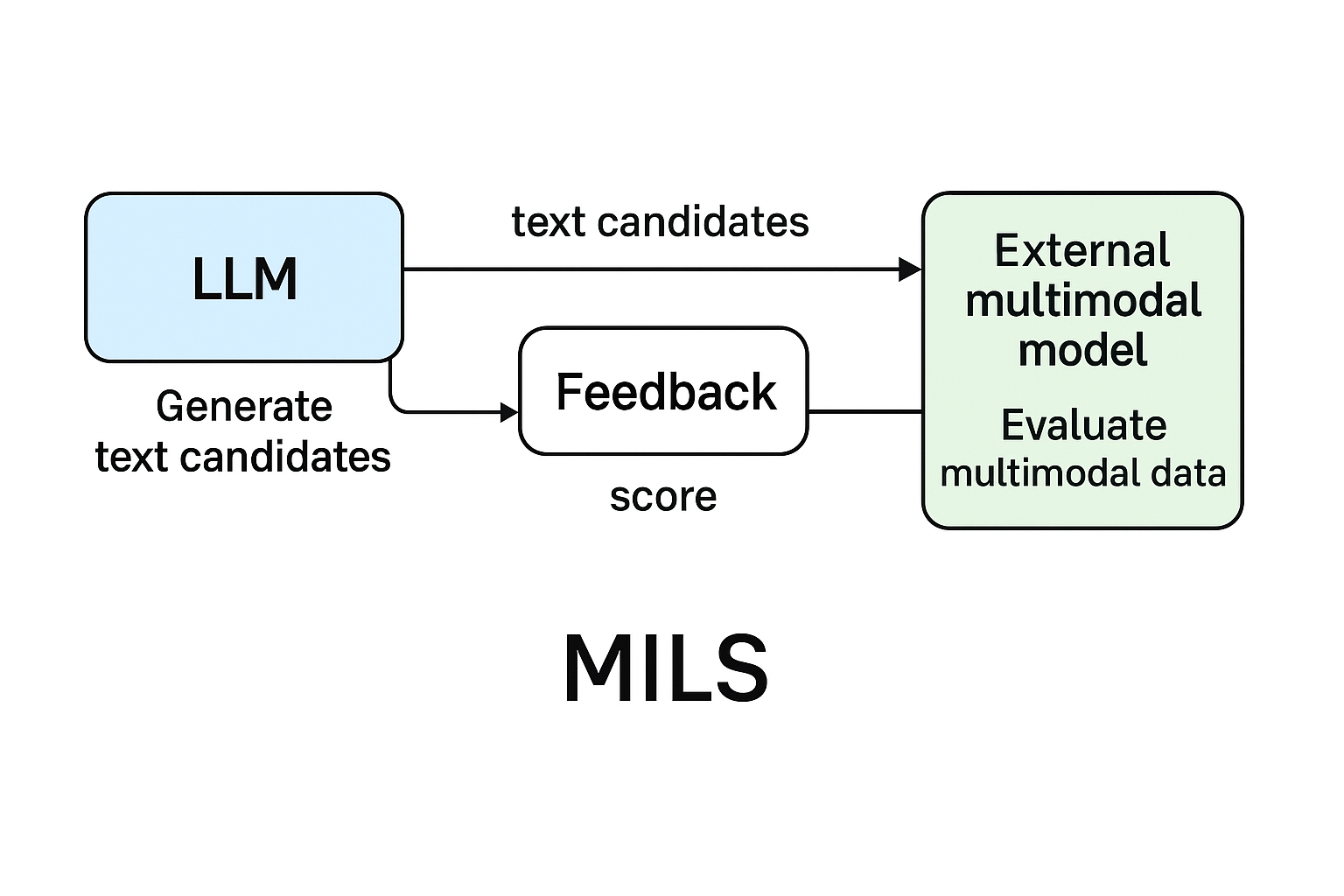
We present MILS: Multimodal Iterative LLM Solver, a surprisingly simple, training-free approach, to imbue multimodal capabilities into your favorite LLM. Leveraging their innate ability to perform multi-step reasoning, MILS prompts the LLM to generate cand
arxiv.org
초록
우리는 MILS(Multimodal Iterative LLM Solver)를 소개합니다. MILS는 놀라울 정도로 간단하면서도 학습이 필요 없는 접근 방식으로, 여러분이 선호하는 대형 언어 모델(LLM)에 멀티모달 기능을 부여할 수 있게 합니다. LLM의 본질적인 다단계 추론(multi-step reasoning) 능력을 활용하여, MILS는 LLM이 후보 출력을 생성하도록 유도하고, 각 후보에 점수를 매긴 뒤 이를 반복적으로 피드백하여 최종적으로 과제에 대한 해답을 생성합니다. 이 방법을 통해, 일반적으로 과제별 데이터에 특화된 모델 학습이 필요한 다양한 응용을 수행할 수 있습니다.
특히, 우리는 emergent zero-shot 이미지, 비디오, 오디오 캡셔닝(emergent zero-shot image, video and audio captioning) 분야에서 새로운 최첨단(state-of-the-art) 성과를 달성했습니다. MILS는 미디어 생성(media generation)에도 자연스럽게 적용되어, 텍스트-투-이미지(text-to-image) 생성 품질을 향상시키기 위한 프롬프트 재작성(prompt rewrites)을 찾아내고, 스타일 전환(style transfer)을 위한 프롬프트 수정까지 수행할 수 있습니다!
마지막으로, MILS는 그래디언트 없이 최적화하는 방식(gradient-free optimization approach)이기 때문에, 멀티모달 임베딩(multimodal embeddings)을 텍스트로 복원할 수도 있어, 크로스모달 산술(cross-modal arithmetic)과 같은 응용이 가능합니다.

Figure 1 설명
우리가 제안하는 방법인 MILS는 이미지, 비디오, 오디오 캡셔닝부터 텍스트-투-이미지 생성 품질 향상, 스타일 전환과 같은 이미지 편집, 다양한 모달리티를 텍스트로 변환하여 수행하는 산술 연산에 이르기까지 다양한 응용을 가능하게 합니다. 이러한 모든 작업을, 과제별 학습이나 데이터 수집 없이, 순수하게 테스트 시간 최적화(test-time optimization)만으로 수행합니다!
1. 서론
대형 언어 모델(LLMs)의 테스트 시점 추론 능력(test-time reasoning ability)은 어려운 과제를 해결하는 강력한 도구로 떠오르고 있습니다. 최근 OpenAI는 O1(OpenAI)을 소개했는데, 이는 테스트 시점 연산(test-time compute)을 활용하여 점진적으로 더 나은 결과를 얻기 위해 강화 학습(reinforcement learning)으로 훈련된 모델입니다. 특히 복잡한 수학 및 코딩 과제에서 두드러진 성과를 보였습니다. 추가 학습 없이도, LLM들은 체인-오브-생각(Chain-of-Thought, CoT) 추론 방식을 통해 테스트 시점 연산을 활용하여 인상적인 성능 향상을 보여주었으며, 사용자 질문에 답하기 위해 실행 계획(execution plan)을 전개하는 형태로 작동합니다(Wei et al., 2022; Kojima et al., 2022).
본 연구에서는, LLM이 지닌 이러한 본질적인 추론 능력을 활용하여, 학습 없이 멀티모달 이해(multimodal understanding) 및 생성(generation) 과제를 해결하는 방법을 제안합니다! 우리의 접근법인 MILS(Multimodal Iterative LLM Solver)는, LLM을 “생성기(GENERATOR)”로 사용하여 주어진 과제에 대한 후보 솔루션을 생성하고, 기성(multimodal) 모델을 “채점기(SCORER)”로 사용하여 각 후보 솔루션의 품질을 평가합니다.
SCORER의 출력 결과는 GENERATOR로 다시 전달되어 피드백을 제공하고, 다음 단계에서 과제를 해결할 가능성이 더 높은 새로운 후보들을 생성하도록 돕습니다. 이 반복(iterative) 과정을 수렴할 때까지, 또는 정해진 횟수만큼 수행한 후, 최종적으로 과제에 대한 출력을 생성하게 됩니다.
우리는 이 단순한 방법이 놀랍도록 강력하고 범용적이며, 다양한 과제와 모달리티에 걸쳐 잘 작동한다는 사실을 발견했습니다. 다양한 조합의 GENERATOR와 SCORER를 사용함으로써, MILS는 멀티모달 캡셔닝(captioning), 생성(generation), 편집(editing), 멀티모달 산술(multimodal arithmetic) 등 다양한 과제를 해결할 수 있습니다.
대부분의 기존 연구들은 이러한 과제들을 위해 해당 과제에 맞게 선별된 데이터로 훈련된 특수한 모델들을 사용합니다. 예를 들어, 제로샷 이미지 캡셔닝(zero-shot image captioning) 모델들도 여전히 이미지-캡션 쌍 데이터에 대해 학습되는 경우가 많습니다. 반면, MILS는 이러한 별도의 학습이 전혀 필요 없으며, 자연적으로(emergent) 제로샷 능력을 발휘합니다.
예를 들어 이미지 캡셔닝의 경우, MILS는 표준 Llama (Dubey et al., 2024) LLM을 GENERATOR로 사용하고, CLIP (Radford et al., 2021)을 SCORER로 사용합니다. 주목할 점은, CLIP이 이미지-텍스트 데이터로 학습되긴 했지만, 일반적인 캡셔닝 모델들이 사용하는 정제된 이미지-캡션 데이터로 학습된 것은 아니라는 것입니다. 대부분의 비전-언어 모델(vision-language models)은 CLIP을 초기화 용도로만 사용하며, 이후에는 캡셔닝 데이터에 대해 추가 학습(post-training)을 필요로 합니다.
따라서, 기존 모델들은 테스트 시점에서 새로운 데이터 분포에 대해 제로샷 일반화(zero-shot generalization)를 보일 수 있지만, MILS는 새로운 과제인 "캡셔닝" 자체에 대해 emergent한 제로샷 일반화를 보여줍니다.
또한, 캡셔닝 데이터 없이 캡션을 생성하는 접근 방식(Salewski et al., 2023; Tewel et al., 2022; Shaharabany et al., 2023; Zeng et al., 2024)도 일부 존재하지만, 이들은 특정 모달리티와 과제에만 한정되어 있습니다. 대부분 이러한 방법들은 CLIP의 그래디언트(gradient)를 활용하여 다음 토큰 예측을 유도하는데, 이는 캡셔닝 작업에만 국한되는 한계가 있습니다.
반면, MILS는 GENERATOR와 SCORER 모듈만 교체함으로써 새로운 과제나 모달리티에도 자연스럽게 일반화(generalization)할 수 있습니다. 예를 들어, 단순히 LLM과 텍스트-투-이미지(Text-to-Image, T2I) 모델을 연결하여 만든 GENERATOR는, LLM을 "프롬프트 리라이팅(prompt rewriting)" 도구로 활용하여 기존 최첨단 T2I 모델의 성능을 향상시킬 수 있습니다. 이는 기존 접근법에서는 제공되지 않던 능력입니다.
본 연구에서는 MILS의 적용 가능성을 시각적 및 비시각적 세 가지 모달리티(이미지, 비디오, 오디오)와 세 가지 과제(캡셔닝, 생성, 편집)에서 보여줍니다. 추가로, MILS는 그래디언트가 필요 없는(gradient-free) 접근법이기 때문에, 멀티모달 임베딩(multimodal embeddings)을 이산 텍스트(discrete text)로 복원하는 데 사용할 수 있음을 입증합니다.
이는 기존 연구(Kazemi et al., 2024)에서 그래디언트 기반 방법을 사용해 임베딩을 연속적 공간(continuous spaces, 예: 이미지)으로 복원했던 것과 대조됩니다. MILS의 이러한 능력은 멀티모달 샘플을 텍스트로 복원하고, 이를 결합하여 다시 생성하는 방식을 통해, 멀티모달 산술(multimodal arithmetic) 과 같은 새로운 응용을 가능하게 합니다.
우리는 Figure 1에서 이러한 기능들의 일부를 시각화하여 제시합니다.
2. 관련 연구 (Related Work)
멀티모달 임베딩 공간(multimodal embedding spaces)은 일반적으로 인터넷에서 수집한 대규모 멀티모달 페어 데이터(주로 이미지와 텍스트)를 통해 학습됩니다. 각 모달리티에 대해 인코더(encoders)를 학습시키는데, 이때 쌍(pairwise) 간 유사도(similarity)를 최대화하는 목표(Objective)를 사용합니다(Radford et al., 2021; Ilharco et al., 2021; Zhai et al., 2023; Li et al., 2023a).
이러한 모델들은 텍스트와 추가 모달리티를 짝지은 데이터(Wang et al., 2023; Guzhov et al., 2022)나, 임베딩 공간 내 다른 모달리티와 연결된 데이터(Girdhar et al., 2023; Gong et al., 2023)를 수집하여 추가적인 모달리티로 확장될 수 있습니다.
이러한 임베딩들은 제로샷 인식(zero-shot recognition)(Radford et al., 2021; Girdhar et al., 2023), 오픈월드 객체 탐지(open-world object detection)(Zhou et al., 2022), 이미지 생성(image generation)(Ramesh et al., 2022) 등 다양한 응용을 가능하게 했습니다.
우리는 이러한 임베딩을 활용하여 모달리티 간 유사도 점수(similarity score)를 계산하고, 이를 최적화(optimization)에 활용하여 원래 시각 및 청각 능력이 없는(즉, 멀티모달 입력을 처리할 수 없는) LLM에 멀티모달 기능을 부여합니다.
생성 모델(Generative models)은 최근 제로샷(zero-shot)으로 새로운 과제에 일반화할 수 있는 능력 덕분에 인기를 얻고 있습니다.
LLMs(Dubey et al., 2024; Jiang et al., 2023; Team et al., 2024)은 텍스트와 같은 이산(discrete) 입력을 처리하기 위한 대표적인 모델로 자리잡았습니다.
이들은 방대한 데이터 코퍼스(corpora)로 대규모 학습을 수행한 후, 인간 피드백을 포함한 고품질 데이터로 지침 튜닝(instruction tuning)을 거쳐 다양한 과제에서 강력한 성능을 발휘합니다.
또한 체인 오브 싱킹(chain-of-thought prompting)(Wei et al., 2022; Kojima et al., 2022; Menon et al., 2024)과 최근 LLM의 추론 능력을 강화하는 훈련(OpenAI)을 통해, 복잡한 수학 및 코딩 과제에서도 더욱 뛰어난 성능을 보이고 있습니다.
그러나 지침 튜닝은 목표 과제와 모달리티에 맞추어 LLM을 학습 또는 미세조정(finetuning)하는 과정을 필요로 합니다.
반면 MILS는 학습 없이 추론 시간(inference-time) 동안 최적화를 수행하는 방식입니다.
최근 연구에서는 LLM의 추론 능력을 반복적으로(iteratively) 활용하여 최적화(optimization)(Yang et al., 2023) 및 생성(generation)(Mañas et al., 2024) 과제를 해결하려는 시도도 있었습니다. 그러나 이러한 방법들은 시각적 과제(visual tasks)에는 평가되지 않았거나(Yang et al., 2023), emergent한 제로샷 능력을 보여주지는 못했습니다(Mañas et al., 2024).
또 다른 범주의 생성 모델로는 연속적(continuous) 도메인, 특히 이미지(Rombach et al., 2022; Betker et al., 2023; Dai et al., 2023; Saharia et al., 2022)나 비디오(Polyak et al., 2024; Girdhar et al., 2024; Ho et al., 2022; Blattmann et al., 2023)에서 주로 사용되는 디퓨전(diffusion)(Nichol & Dhariwal, 2021) 또는 플로우 매칭(flow-matching)(Lipman et al., 2022) 기반 생성 모델들이 있습니다.
이러한 모델들은 미디어 생성(media generation) 능력을 극적으로 향상시켰으며, 최근에는 LLM을 활용해 학습 데이터 캡셔닝 품질을 높이거나, 추론 시점 프롬프트 재작성(prompt rewrites)에도 사용되고 있습니다(Betker et al., 2023; Polyak et al., 2024).
제로샷 멀티모달 이해(zero-shot multimodal understanding)는 두 가지 형태로 연구되고 있습니다. 하나는 데이터 분포 간 제로샷(zero-shot across data distributions), 다른 하나는 emergent 제로샷(emergent zero-shot)(Girdhar et al., 2023)입니다.
후자는 모델이 단순히 새로운 데이터에만 일반화하는 것이 아니라, 완전히 새로운 과제에도 일반화하는 경우를 의미합니다.
멀티모달 확장 버전의 대표적인 LLM들(Dubey et al., 2024; Agrawal et al., 2024; Li et al., 2023b)은 대부분 전자의 경우에 해당합니다. 이들은 보통 테스트 시점에 주어지는 데이터 유형에 대해 미리 학습되거나 튜닝되어 있습니다.
본 연구의 초점은 후자에 있으며, 우리는 MILS가 테스트 시점에 완전히 새로운 과제에 대해 일반화할 수 있음을 보여줍니다.
이전 연구들(Tewel et al., 2022; Zeng et al., 2023; 2024; Salewski et al., 2023; Shaharabany et al., 2023)도 이러한 설정을 시도한 바 있으나, 이는 특정 모달리티에 대해 특수화된 기법을 사용하여 제한적으로 수행되었습니다.
반면, MILS는 다양한 모달리티에 대해 이해(understanding) 및 생성(generation) 과제를 모두 자연스럽게 일반화할 수 있습니다.
3. MILS
이제 MILS를 사용하여 멀티모달 과제를 해결하는 우리의 간단한 접근법을 설명합니다.
MILS는 학습이 필요 없는(training-free) 방법이기 때문에, 테스트 샘플(test sample)만 입력으로 받습니다. MILS는 두 가지 핵심 모듈에 의존하는데, 이를 각각 GENERATOR와 SCORER라고 부릅니다.
이름에서 알 수 있듯이, GENERATOR는 주어진 과제에 대한 후보 솔루션(candidate solutions)을 생성하고, SCORER는 이 후보들을 평가하여 다시 GENERATOR로 피드백을 보냅니다. 이 과정을 통해 더 나은 후보 세트를 생성하게 됩니다.
특정 과제에서는, 초기 후보 세트에 대한 점수를 사용하여 부트스트랩(bootstrapping)할 수도 있습니다.
이 최적화 과정은 수렴(convergence)하거나, 정해진 횟수만큼 반복(iterations)한 뒤 종료되며, 최종적으로 과제에 대한 해답을 생성합니다.
Figure 2는 이 전체 과정을 도식화한 것입니다.

Figure 2 설명
MILS는 GENERATOR와 SCORER라는 두 가지 핵심 모듈을 활용하여 멀티모달 과제를 해결합니다.
GENERATOR는 여러 개의 텍스트 후보(candidates)를 생성하는데, 예를 들어 이미지 캡셔닝(image captioning)에서는 캡션(captions), 텍스트-투-이미지(Text-to-Image, T2I) 과제에서는 프롬프트(prompts)를 생성합니다.
각 후보들은 SCORER에 의해 점수화(scoring)되고, 그 결과가 피드백으로 다시 GENERATOR에 전달되어 다음 후보군을 생성하는 데 사용됩니다.
이 과정을 반복하여 최종적으로 입력 테스트 샘플(test sample)에 대한 최종 출력을 만들어냅니다.
GENERATOR
GENERATOR의 목표는 주어진 과제를 해결할 수 있는 후보 출력(Candidates, C)을 생성하는 것입니다.
입력으로는 과제 설명을 담은 텍스트(T)와, 이전 최적화 단계에서 SCORER로부터 받은 점수(S, 있을 경우)를 함께 받습니다.
GENERATOR는 이 입력 신호를 활용해 다음 후보 세트를 생성합니다.
일반적으로 GENERATOR는 텍스트를 입력으로 받아 이를 기반으로 추론할 수 있는 LLM을 이용해 모델링됩니다. 그러나 출력은 텍스트에 한정되지 않습니다.
생성된 후보들은 다른 모달리티를 생성하는 모델을 호출하는 프롬프트로 사용될 수 있습니다. 예를 들어, 텍스트-투-이미지(Text-to-Image, T2I) 모델인 Emu(Dai et al., 2023)를 이용해 이미지를 생성할 수도 있습니다.
또한, 일부 GENERATOR는 테스트 샘플(test sample) 자체를 입력으로 사용할 수도 있습니다. 예를 들어 이미지 편집(image editing)이나 스타일 전환(stylization) 과제에서는 이러한 방식이 사용될 수 있습니다.
SCORER
SCORER의 목표는, GENERATOR가 생성한 후보(Candidates, C)에 대해 스칼라 점수(scalar score) S ∈ ℝ를 계산하는 것입니다.
SCORER는 입력으로 테스트 샘플(test sample)과 후보군 C를 받아 이 둘을 비교합니다.
SCORER는 다양한 방식으로 구현할 수 있습니다.
예를 들어, 두 이미지의 텍스처(texture)를 비교하는 저수준(low-level) 이미지 처리 함수가 될 수도 있고, CLIP(Radford et al., 2021; Ilharco et al., 2021)과 같은 학습된 머신러닝 모델이 될 수도 있습니다.
SCORER는 모든 후보를 점수에 따라 정렬한 후, 상위 K개(top-K candidates)와 해당 점수를 반환합니다.
또한, GENERATOR의 입력 용량(컨텍스트 길이, context length)에 따라 전체 점수 목록을 반환할 수도 있고, ε-탐욕(ϵ-greedy) 전략을 사용해 점수가 낮은 후보 일부를 포함할 수도 있습니다.
초기 실험에서는, 단순한 탐욕적(top-K) 선택이 가장 좋은 성능을 보였기 때문에, 본 연구에서는 이 방식을 사용합니다.
SCORER의 출력은 텍스트 형태(T)로 포맷되어 다시 GENERATOR로 전달됩니다.
최적화 과정(Optimization process)
MILS는 SCORER의 비용 함수(cost function) 하에서 최적의 생성물(candidate generation, C)을 탐색합니다.
이 최적화 과정은 N 스텝 동안 수행되거나, 수렴(convergence)할 때까지 반복됩니다.
수렴은 후보군 C가 연속된 스텝 사이에서 유사해지는 것으로 정의할 수 있습니다.
과제(task)에 따라, 최적화는 초기 후보 세트(initial candidate set)를 부트스트랩(bootstrapping)하여 시작할 수도 있습니다.
예를 들어 이미지 캡셔닝의 경우, GENERATOR가 생성한 다양한 가능한 캡션 후보군을 초기 세트로 사용할 수 있습니다.
반면, T2I(Text-to-Image)와 같은 과제에서는 이러한 초기 세트가 필요 없습니다.
정리하면:
- MILS에서 사용하는 LLM 자체는 멀티모달 모델이 아닙니다.
→ 이 LLM은 텍스트 입력만 처리할 수 있고, 텍스트 출력만 생성합니다. (예: LLaMA, GPT 계열처럼 일반 텍스트 LLM) - 그런데 MILS는 멀티모달 과제(이미지 캡셔닝, 이미지 생성, 오디오 설명 등) 를 풀기 위해 필요할 때 외부 멀티모달 도구를 함께 사용합니다.
- 예를 들어:
- 이미지 생성(Text-to-Image, T2I)을 하고 싶으면,
→ LLM이 프롬프트(prompt)를 텍스트로 작성하고,
→ 그 프롬프트를 외부 T2I 모델(예: Emu, Stable Diffusion 같은 모델) 에 넘겨서 이미지를 생성합니다. - 반대로, 이미지를 평가(Scoring)할 때도
→ 생성한 이미지와 목표 이미지/조건을 비교하기 위해 CLIP 같은 멀티모달 모델을 사용합니다.
- 이미지 생성(Text-to-Image, T2I)을 하고 싶으면,
요약
MILS 안에서는:
- LLM → 텍스트 생성만 담당 (후보 생성, 프롬프트 수정 등)
- 멀티모달 모델 (T2I, CLIP 등) → 이미지 생성이나 이미지-텍스트 유사도 평가를 담당
→ 둘을 반복적으로 연결하면서, 멀티모달 과제를 "학습 없이" 해결하는 구조입니다.
4. 실험(Experiments)
이제 우리는 MILS를 실험적으로 평가하고, 이를 통해 수행할 수 있는 일부 멀티모달 이해 및 생성 과제에서 기존 방법들과 비교합니다.
각 다운스트림 응용 사례에 대해, GENERATOR, SCORER, 벤치마크(benchmarks), 평가 설정(evaluation setup)을 설명한 뒤, 주요 결과(key results)를 제시합니다.
마지막으로 4.7절에서는 MILS의 다양한 설계 선택(design choices)에 대한 분석(ablation)을 수행합니다.
MILS는 테스트 시점 최적화(test-time optimization) 방식이며, emergent 제로샷 행동(emergent zero-shot behavior)(Girdhar et al., 2023)을 나타낸다는 점에 유의해야 합니다.
즉, 새로운 테스트 데이터 분포뿐만 아니라 새로운 과제와 모달리티 자체에 대해 일반화할 수 있습니다.
이는 기존 제로샷 연구와 대비되는데, 대부분의 기존 연구들은 과제/모달리티에 특화된 데이터 수집(task/modality-specific data curation)이나 학습(training)을 필요로 합니다.
대부분의 기존 방법이 후자 유형이기 때문에, MILS와의 공정한 비교는 어렵습니다.
그럼에도 불구하고, 우리는 가장 유사한 제로샷 방법들과 비교를 시도하며, MILS가 해당 과제나 모달리티에 맞춰 조정된 기존 방법들보다도 경쟁력이 있거나 더 우수하다는 것을 보여줍니다.

Figure 3 설명
MILS를 사용한 이미지 캡셔닝(Image Captioning) 결과를, 기존 최첨단 제로샷 접근법인 MeaCap(Zeng et al., 2024)과 비교한 것입니다.
MILS는 훨씬 간단한 접근법임에도 불구하고, 이미지에 대해 더 정확하고 문법적으로 올바른 캡션을 생성합니다.
Table 1 설명
MSCOCO 데이터셋(Karpathy & Fei-Fei, 2015)에서 제로샷 이미지 캡셔닝 성능을 비교한 표입니다.
MILS는 기존 방법들보다 훨씬 간단함에도 불구하고, 모든 자동 평가 지표(automatic metrics)에서 경쟁력 있는 성능을 보이며, 특히 의미적 유사성(semantic similarity)을 고려하는 METEOR 및 SPICE 지표에서는 뛰어난 성과를 보입니다.
(*) 표시는 제공된 코드를 실행하여 얻은 결과임을 나타냅니다.

4.1. 이미지 캡셔닝(Image Captioning)
우리는 주어진 이미지에 대해 텍스트 캡션을 생성하는 기본적인 이미지 이해 과제부터 시작합니다.
GENERATOR
우리는 Llama 3.1 8B(Dubey et al., 2024) LLM을 기본 생성 모듈로 사용합니다.
초기 최적화 과정을 부트스트랩(bootstrap)하기 위해, 30,000개의 초기 프롬프트(prompt) 리스트를 생성합니다.
이 초기 세트의 다양성(diversity)을 확보하기 위해, LLM에 다양한 객체 카테고리(object categories)를 제공하여 여러 종류의 프롬프트를 생성하고, 이를 결합하는 방식을 사용합니다. 이는 (Gandelsman et al., 2024)과 유사한 방법입니다.
그 다음, 각 최적화 단계마다 SCORER에서 점수가 가장 높은 상위 50개의 후보를 선택하고, 이들을 텍스트 프롬프트로 변환합니다. 사용된 프롬프트는 부록(Appendix B)에서 자세히 설명되어 있습니다.
최적화 과정은 총 10단계(steps) 동안 수행합니다.
SCORER
우리는 후보 캡션들을 테스트 이미지와 비교하여 이미지-텍스트 유사도(image-text similarity) 모델인 SigLIP(Zhai et al., 2023)을 사용해 점수화합니다.
여기서 주목할 점은, 기존 이미지 캡셔닝 모델들(Karpathy & Fei-Fei, 2015)이 정제된 이미지-텍스트 페어를 활용하는 반면, SigLIP은 자체적으로 캡셔닝(captioning)을 수행할 수 없는 모델이라는 것입니다(Shen et al., 2022).
그럼에도 불구하고, MILS와 결합하면 효과적인 캡셔닝 도구로 활용될 수 있음을 다음에서 보여줍니다.
벤치마크 및 평가 지표(Benchmarks and Metrics)
우리는 MILS를 MSCOCO 캡셔닝 테스트 세트(MSCOCO captioning test set)(Karpathy & Fei-Fei, 2015)에서 평가합니다.
이 세트는 MSCOCO 데이터셋(Lin et al., 2014)에서 샘플링된 5,000개의 이미지로 구성되어 있습니다.
우리는 BLEU(Papineni et al., 2002), METEOR(Banerjee & Lavie, 2005), CIDEr(Vedantam et al., 2015), SPICE(Anderson et al., 2016) 등 표준 캡셔닝 평가 지표를 사용합니다.
특히 우리는 METEOR와 SPICE 지표에 주목하는데, 이들은 단순한 단어 일치가 아니라 의미적 유사성(semantic similarity)을 평가하며, 인간 선호(human preference)와 더 높은 상관관계를 보이기 때문입니다(Anderson et al., 2016).
이는 MILS처럼 주어진 벤치마크나 모달리티에 사용된 어휘(vocabulary)를 학습하지 않은 emergent zero-shot 접근법에서는 특히 중요합니다.
결과(Results)
우리는 Table 1에서 MILS를 기존 베이스라인(baselines)과 비교합니다.
예를 들어, ZeroCap(Tewel et al., 2022) 같은 일부 베이스라인도 LLM과 CLIP 유사 모델을 함께 활용합니다.
하지만 ZeroCap은 현재 생성 결과를 기반으로 최적의 다음 토큰을 찾기 위해 그래디언트 기반 최적화(gradient-based optimization) 과정을 제안합니다.
또 다른 방법인 MeaCap(Zeng et al., 2024) 은 메모리 모듈에서 핵심 개념(key concepts)을 필터링하고, 여러 텍스트 및 멀티모달 인코더들을 활용하여 다단계(multi-step) 과정을 통해 캡션을 생성합니다.
이에 비해, MILS는 개념적으로도 구현 측면에서도 훨씬 간단하며, 더 나은 결과를 얻습니다.
우리는 Figure 3에서 MILS로 생성한 캡션 예시를 보여주고, 이를 MeaCap과 비교합니다.
MILS는 캡셔닝 데이터나 캡셔닝 특화 학습을 한 번도 경험하지 않았음에도 불구하고, 신뢰할 수 있고 문법적으로 정확한 캡션을 생성할 수 있음을 보여줍니다.

Table 2 설명
MSR-VTT(Xu et al., 2016) 데이터셋에서의 제로샷 비디오 캡셔닝(zero-shot video captioning) 성능을 비교한 표입니다.
MILS는 HowTo100M 데이터셋으로 학습된 (Nagrani et al., 2022) 방법보다 더 높은 성능을 보이며, 훨씬 더 정제된 VideoCC3M 데이터셋으로 학습된 경우에도 경쟁력 있는 성능을 보입니다. 특히 METEOR 지표에서는 더 나은 성과를 기록합니다.
표에서는 (Nagrani et al., 2022) 결과를 회색 처리했는데, 이는 해당 방법이 비디오 캡셔닝을 위해 학습된 반면, MILS는 별도의 학습 없이 수행되었기 때문입니다.
4.2. 비디오 캡셔닝(Video Captioning)
MILS는 그 단순성과 범용성 덕분에 별다른 수정 없이 비디오에도 자연스럽게 적용할 수 있습니다.
우리는 4.1절(이미지 캡셔닝)에서 설명한 것과 동일한 GENERATOR와 동일한 초기 프롬프트 세트(initial prompt set)를 사용합니다.
SCORER로는, 8개의 비디오 프레임을 입력으로 받아 비디오와 캡션 간의 유사도 점수를 반환하는 ViCLIP(Wang et al., 2023) ViT-L/14 모델을 사용합니다.
우리는 MSR-VTT(Xu et al., 2016) 테스트 세트에서 실험을 진행합니다. 이 세트는 2,990개의 비디오로 구성되어 있으며, 각 비디오는 길이가 10~30초입니다.
실험 결과는 Table 2에 보고합니다.
대부분의 기존 비디오 캡셔닝 연구는 비디오-캡션 훈련 데이터(video-caption training data)를 활용하기 때문에, 우리는 MILS를 (Nagrani et al., 2022) 방법과 비교합니다.
(Nagrani et al., 2022)는 HowTo100M(Miech et al., 2019)이나 VideoCC3M(Nagrani et al., 2022) 데이터셋을 사용하여 비전-언어 모델(vision-language model)을 학습하고, MSR-VTT에서 성능을 보고했습니다.
우리는 기존 연구와 동일하게 CIDEr(Vedantam et al., 2015)와 METEOR(Banerjee & Lavie, 2005) 지표를 사용하여 평가합니다.
그 결과, 비디오 캡셔닝을 위해 한 번도 학습된 적이 없음에도 불구하고, MILS는 HowTo100M에서 학습된 (Nagrani et al., 2022) 방법보다 두 지표 모두에서 더 뛰어난 성능을 보였습니다.
또한, 훨씬 정제된(cleaner) VideoCC3M 데이터로 학습된 경우와 비교하더라도, MILS는 의미적 인식을 반영하는 METEOR 지표에서 더 높은 성능을 기록했습니다.
이러한 결과는 비디오 캡셔닝 모델에서 학습 데이터의 중요성을 보여줍니다.
MILS는 비디오 캡셔닝 훈련 없이도 이러한 모델들과 경쟁할 수 있어 매우 고무적입니다.
정성적 결과(qualitative results)는 부록 C에 제시했습니다.

Table 3 설명
Clotho(Drossos et al., 2020) 데이터셋에서의 제로샷 오디오 캡셔닝(zero-shot audio captioning) 성능을 비교한 표입니다.
MILS는 기존 제로샷 오디오 캡셔닝 방법인 ZerAuCap과 경쟁력 있는 성능을 보였으며, 특히 METEOR 및 SPICE처럼 의미 인식을 평가하는 지표에서는 ZerAuCap을 능가했습니다.
또한 MILS는 더 간단하고, 다른 다양한 모달리티와 과제에도 적용 가능하다는 장점을 가집니다.

Figure 4 설명
MILS를 활용한 향상된 텍스트-투-이미지(Text-to-Image, T2I) 생성 결과입니다.
우리는 MILS를 최신 최첨단 T2I 모델 두 가지, 즉 라텐트 디퓨전 모델(LDM)과 FLUX.1schnell 에 적용했습니다.
MILS의 출력을 초기 모델들의 생성 결과와 비교하기 위해, 인간 평가자(human annotators)가 평가를 수행했습니다.
200개의 프롬프트로 구성된 DrawBench 데이터셋에서 평가한 결과,
두 모델 모두에서 전체 품질(overall quality)과 텍스트 충실도(text faithfulness) 측면에서 평가자들이 명확히 MILS의 생성 결과를 선호했습니다.

Figure 5 설명
MILS를 활용한 이미지 생성 품질 향상 결과입니다.
동일한 기본 모델(이 경우 라텐트 디퓨전 모델, Latent Diffusion Model, LDM)을 사용하는 GENERATOR에 MILS를 적용하면 훨씬 더 높은 품질의 이미지를 얻을 수 있습니다.
그림에서는 원래 입력 프롬프트(original input prompt), 기본 모델(base model)로부터 생성된 이미지, 그리고 MILS를 적용하여 생성된 이미지를 함께 보여줍니다.
4.3. 오디오 캡셔닝(Audio Captioning)
비디오와 마찬가지로, MILS는 오디오 캡셔닝(audio captioning)에도 자연스럽게 확장할 수 있습니다.
우리는 4.1절(이미지 캡셔닝)과 동일한 GENERATOR를 사용하고, LLM을 이용해 생성한 5만 개(50K)의 초기 오디오 프롬프트(initial audio prompts)를 활용합니다(자세한 내용은 부록 B 참고).
SCORER로는, 오디오와 텍스트를 포함한 여러 모달리티를 공통 임베딩 공간(shared embedding space)으로 매핑하는 ImageBind(Girdhar et al., 2023) 모델을 사용합니다.
우리는 인기 있는 오디오 캡셔닝 데이터셋인 Clotho(Drossos et al., 2020) 에서 우리의 방법을 평가합니다.
평가에는 기존 연구들에서 사용된 자동 캡셔닝 지표(automatic captioning metrics)를 사용하며, 이는 4.1절에서 설명된 내용과 동일합니다.
성능 결과는 Table 3에 보고합니다.
MILS는 유사한 제로샷 방법인 ZerAuCaps(Salewski et al., 2023) 와 비교하여 강력한 성능을 보이며, 특히 METEOR 및 SPICE와 같이 의미 인식(semantics-aware)을 반영하는 지표에서는 더 나은 성과를 기록했습니다.
다른 오디오 캡셔닝 접근법들도 제안된 바 있으나, 이들은 오디오-캡션 데이터(audio-caption data)에 대한 학습을 필요로 합니다(Kong et al., 2024).
정성적 결과(qualitative results)는 부록 C에서 확인할 수 있습니다.
4.4. 고품질 이미지 생성(High-Quality Image Generation)
앞서 언급했듯이, MILS는 지금까지 설명한 멀티모달 이해 과제에만 국한되지 않습니다.
이번에는 MILS가 멀티모달 생성 과제(multimodal generation tasks) 에 어떻게 활용될 수 있는지를 설명하며, 텍스트-투-이미지(Text-to-Image, T2I) 생성 모델의 성능을 개선하는 사례부터 시작합니다.
GENERATOR
고품질 이미지를 생성하기 위해, 우리는 LLM과 T2I 모델을 연결(chain) 합니다.
구체적으로, 우리는 두 가지 최첨단(state-of-the-art) 모델을 사용해 실험합니다:
- Latent Diffusion Model (LDM) (Rombach et al., 2022)
- FLUX.1 [schnell] (Labs)
이때 LLM의 목표는,
- T2I 모델에 전달되는 프롬프트를 "재작성(rewrite)"하여,
- 최종적으로 생성되는 이미지의 품질을 향상시키되,
- 원래 텍스트 프롬프트에 대한 충실도(faithfulness)를 유지하거나 개선하는 것입니다.
주목할 점은, 이 GENERATOR는 초기 프롬프트 세트(initial prompt set)를 따로 부트스트랩할 필요가 없다는 것입니다.
SCORER
생성된 이미지들은 PickScore(Kirstain et al., 2023) 를 이용해 점수화(scoring)합니다.
PickScore는 CLIP 스타일 모델로,
- 이미지와 텍스트 프롬프트를 입력으로 받아,
- 해당 이미지가 해당 프롬프트에 대해 인간(human)이 선호할 가능성(likelihood)을 예측합니다.
우리는 각 GENERATOR 출력물에 대해 입력 프롬프트와 함께 PickScore 점수를 계산하고, 각 생성 결과에 대한 점수를 반환합니다.
그 외 나머지 최적화 과정은 이전 섹션들과 동일하게 진행됩니다.
벤치마크 및 평가 지표(Benchmarks and Metrics)
우리는 Imagen(Saharia et al., 2022)에서 제공하는 DrawBench 프롬프트 세트(200개의 텍스트 프롬프트)를 사용하여 생성 결과를 평가합니다.
미디어 생성(media generation) 작업에서 자동 평가 지표가 매우 노이즈가 심하다는 점(Girdhar et al., 2024; Ge et al., 2024; Jayasumana et al., 2024)을 고려하여, 우리는 Amazon Mechanical Turk의 인간 평가자(human annotators)를 통해 평가를 진행합니다.
평가 방식은 JUICE 프레임워크(Girdhar et al., 2024) 를 따릅니다.
미디어 생성 분야 표준 관행(Dai et al., 2023; Girdhar et al., 2024)에 맞춰, 우리는 생성 결과를 두 가지 축(axis)으로 평가합니다:
- 품질 또는 시각적 매력(visual appeal)
- 입력 텍스트에 대한 충실도(faithfulness)
각 평가 항목마다 웹 인터페이스를 구성하여, 평가자에게 두 개의 이미지를 보여줍니다. 하나는 베이스라인 모델로 생성한 것이고, 다른 하나는 MILS로 개선한 것입니다.
텍스트 충실도 평가 시에는 원래의 텍스트 프롬프트도 함께 제시됩니다.
평가자는 둘 중 어느 이미지를 선호하는지 선택합니다.
각 이미지는 3명의 평가자가 평가하며, 다수결(majority vote)을 통해 각 모델의 승률(win%)을 계산합니다.
자세한 인간 평가 세부사항은 부록 A를 참고하십시오.
결과(Results)
우리의 인간 평가 결과는 Figure 4에 요약되어 있습니다.
승률(win-rate)에서 볼 수 있듯이, 인간 평가자들은 MILS로 개선된 생성 결과를 기본(base) 모델 결과보다 명확하게 더 선호했습니다.
또한, Figure 5에서는 MILS를 적용했을 때의 미적 품질(aesthetic quality) 개선이 명확히 드러나는 정성적 비교를 보여줍니다.
우리는 MILS가 복잡한 프롬프트를 단순화하고, 전체 품질과 충실도를 향상시키는 미적 디테일을 추가하는 데에도 효과적임을 발견했습니다.
최근 연구들(Betker et al., 2023; Polyak et al., 2024)에서도 LLM 기반 프롬프트 재작성(prompt rewriting)이 미디어 생성 성능을 향상시킬 수 있음을 보여주었습니다.
그러나 기존 방법들은 다양한 리라이팅 프롬프트를 수작업으로 실험해야 하는 번거로운 과정을 필요로 했습니다.
MILS는 이 과정을 자동화하거나, 전문 프롬프트 엔지니어가 다듬을 수 있도록 후보 리라이팅을 제안할 수 있습니다.
주목할 점은, 앞서 비교했던 기존 방법들(Tewel et al., 2022; Salewski et al., 2023)에서는 이러한 기능을 쉽게 제공하지 못한다는 것입니다.
그러한 방법들은, LLM이 다음에 생성해야 할 토큰을 추정하기 위해 다단계 디퓨전 프로세스(multi-step diffusion process) 전체를 통해 그래디언트(gradient)를 계산해야 합니다.
반면, MILS는 그래디언트 없이 최적화(gradient-free optimization)하는 접근법이기 때문에, 단순한 프레임워크 안에서도 다양한 응용을 쉽게 가능하게 합니다.

Figure 6 설명
스타일 전환(Style Transfer)
Gram Matrix 거리(Gatys, 2015) 를 SCORER로 사용하면, MILS는 주어진 스타일을 이미지에 적용하기 위한 편집 프롬프트(edit prompt)를 발견할 수 있습니다.

Figure 7 설명
크로스 모달 산술(Cross-modal Arithmetic)
MILS는 다양한 모달리티를 텍스트로 변환한 뒤, 이를 결합하고 다시 이미지로 매핑함으로써 크로스 모달 산술을 수행할 수 있게 합니다.
4.5. 스타일 전환(Style Transfer)
이미지 생성(image generation)을 넘어, MILS는 이미지 편집(image editing) 작업에도 적용될 수 있습니다.
여기서는 특히 스타일 전환(style transfer) 과제를 다루는데, 주어진 테스트 이미지(test image)와 스타일 이미지(style image)를 바탕으로,
- 테스트 이미지의 내용(content) 은 유지하고,
- 스타일 이미지의 스타일(style) 을 적용한 새로운 이미지를 생성하는 것이 목표입니다.
GENERATOR
4.4절과 유사하게, 우리는 LLM의 출력을 이미지 생성 모델에 연결(chain) 하여 GENERATOR를 구현합니다.
하지만 4.4절과는 달리, 여기서는 테스트 샘플(test sample)과 동일한 내용을 생성해야 하기 때문에, GENERATOR가 테스트 샘플도 입력으로 받습니다.
따라서 우리는 이미지 생성 모듈로 이미지 편집 모델(Sheynin et al., 2024) 을 사용합니다.
이 모델은 테스트 샘플과 LLM이 생성한 편집 프롬프트(edit prompt)를 입력받아, 스타일이 적용된 이미지를 생성합니다.
SCORER
스타일 전환 품질을 평가하기 위해,
- 생성된 이미지와 스타일 이미지 간의 색상(color) 및 텍스처(texture) 유사도를 추정하는 간단한 접근법을 사용합니다.
- 구체적으로, 이미지 특징(feature)들의 Gram Matrix 거리(distance) 를 계산하는 방법(Gatys, 2015)을 사용합니다.
우리는 VGG19(Simonyan & Zisserman, 2015) CNN의 다양한 레이어(feature layer)로부터 특징을 추출하여 거리를 계산합니다.
- 하위 레이어(lower layers)는 스타일 충실도(stylistic faithfulness) 를 보장하고,
- 상위 레이어(higher layers)는 내용 충실도(content faithfulness) 를 보장합니다.
MILS는 이 스타일 손실과 내용 손실을 모두 최소화하는 방향으로 최적화합니다.
결과(Results)
Figure 6은 MILS를 이용해 생성한 스타일 전환 결과 샘플을 보여줍니다.
MILS는 이 새로운 과제에도 완전히 제로샷(zero-shot) 으로 일반화하여 정확하게 스타일이 적용된 이미지를 생성합니다.
특히 주목할 점은, MILS는 어떠한 학습(training)도 없이, 그리고 LLM이 테스트 샘플이나 스타일 이미지의 특징(feature) 을 직접 보는 일 없이 이러한 편집을 수행했다는 것입니다!

Figure 8 설명
최적화 과정 동안 생성된 캡션(Image captioning over steps)
최적화 과정의 여러 단계(#)에서 MILS가 생성한 캡션을 보여주며, 점진적으로 더 정확해지는 모습을 볼 수 있습니다.
4.6. 크로스 모달 산술(Cross-Modal Arithmetic)
마지막으로, 우리는 MILS를 통해 가능해진 흥미로운 응용 사례를 탐구합니다.
기존 연구(Kazemi et al., 2024)가 임베딩을 연속적 이미지 공간(continuous image space)으로 매핑하는 접근을 취했던 것과 달리,
MILS는 그래디언트 없는 방식(gradient-free approach) 을 통해 이러한 임베딩을 이산적 텍스트 공간(discrete text space) 으로 복원(invert)할 수 있습니다.
이것은 4.1절부터 4.3절까지 제시된 결과들에서도 이미 입증되었습니다.
이를 통해 크로스 모달 산술(cross-modal arithmetic) 이라는 흥미로운 응용이 가능해집니다.
우리는 ImageBind(Girdhar et al., 2023)에서 영감을 얻었습니다. ImageBind는 여러 다양한 모달리티를 공통된 이미지 임베딩 공간(image embedding space)으로 매핑하여,
- 모달리티를 결합하거나(combine modalities)
- 그 조합을 기반으로 이미지를 생성 또는 검색(generate or retrieve images)할 수 있도록 했습니다.
MILS는 이보다 더 유연합니다.
텍스트로 복원할 수 있기 때문에, 훨씬 더 다양한 모델들과 상호작용할 수 있습니다.
예를 들어, ImageBind는 오디오를 이미지로 생성하는(audio-to-image generation) 결과를 보여주었는데, 이는 DALLE-2 스타일 T2I 모델(Ramesh et al., 2022) 을 활용해 가능했습니다.
이는 ImageBind가 CLIP 임베딩 공간과 정렬되어 있었기 때문에 가능한 일이었고, DALLE-2도 같은 CLIP 공간을 사용했기 때문입니다.
하지만, ImageBind는 다른 T2I 모델 — 예를 들어 Latent Diffusion Model(Rombach et al., 2022) 과는 호환되지 않았습니다.
반면, 텍스트 표현(textual representation) 을 사용하는 방식은,
- 임베딩 공간에 텍스트 입력을 점(point)으로 매핑하지 않는
- 모든 종류의 T2I 모델과 함께 사용할 수 있습니다.
Figure 7 설명
우리는 이미지 모달리티와 오디오 모달리티를 결합하는 예시를 보여줍니다.
- 먼저, 이미지는 4.1절 방식으로, 오디오는 4.3절 방식으로 각각 텍스트로 복원(invert)합니다.
- 그런 다음, 두 텍스트 출력을 LLM을 사용해 결합(combine)합니다 (자세한 내용은 부록 B 참고).
- 마지막으로, 4.4절에서 설명한 방법을 따라 프롬프트를 고품질 이미지로 변환합니다.
그 결과 생성된 이미지는,
두 모달리티의 의미적 개념(semantic concepts)을 모두 결합한 결과를 보여줍니다.
4.7. 구성 요소 분석(Ablations)
이제 MILS의 주요 설계 선택(design choices)에 대해 분석(ablation)을 진행합니다.
대부분의 분석은 이미지 캡셔닝(image captioning) 과제에 초점을 맞추고, 일부 분석에서는 이미지 생성(image generation) 향상에 초점을 둡니다.
계산 효율성을 위해,
- 이미지 캡셔닝에서는 MSCOCO 데이터셋에서 1,000장의 이미지를 무작위로 샘플링하고,
- 이미지 생성에서는 DrawBench 프롬프트 200개 세트를 사용하여 테스트 세트를 구성했습니다.
이 분석에서는 CLIP 유사도(CLIP similarity)와 PickScore를 포함한 모든 평가 지표를 이 세트들에 대해 평균 내어 보고합니다.
최적화 스텝 동안의 성능 변화(Performance over optimization steps)
Figure 9에서 두 과제 모두에 대해 평가합니다.
우리 설정에서는,
- SCORER 출력은 일종의 "훈련 손실(training loss)"로 볼 수 있으며,
- 다운스트림 지표(downstream metric)도 함께 보고합니다.
구체적으로:
- 이미지 캡셔닝은 SPICE(Anderson et al., 2016) 점수를 사용하고,
- T2I에서는 원래 입력 프롬프트에 대해 생성된 결과와의 인간 평가(human evaluation) 를 사용합니다.
T2I 평가에서는 ±4포인트 오차(error bars)도 함께 표시하는데, 이는 인간 평가에서 관찰된 일반적인 무작위 편차(random variance) 범위입니다.
Figure 9를 보면,
- SCORER 출력과 다운스트림 지표 모두 최적화 스텝이 진행됨에 따라 향상되며,
- 약 10~20 스텝 후 수렴(convergence)하는 것을 알 수 있습니다.
또한, 최적화 목표(SCORER 출력)와 다운스트림 성능 간에 좋은 상관관계(correlation) 가 있음을 확인했습니다.
마지막으로, 이러한 결과를 캡셔닝과 생성 각각에 대해 Figure 8과 11에서 정성적으로(qualitatively) 시각화했습니다.
두 경우 모두 출력 품질이 스텝이 지남에 따라 향상되며, MILS의 효과를 보여줍니다.
초기 후보 세트의 영향(Impact of the initial candidate set)
Figure 10에서 이를 평가합니다.
초기 세트의 크기를 다르게 샘플링하여 실험한 결과,
- 초기 세트 크기와 최종 성능 간에 강한 양의 상관관계(strong positive correlation) 가 있음을 발견했습니다.
이는, GENERATOR가 충분히 다양한 후보를 생성하고(local minima를 피하기 위해) 초기 부트스트래핑 세트가 매우 중요하다는 것을 시사합니다.
GENERATOR와 SCORER 크기의 영향(Size of the GENERATOR and SCORER)
Figure 12에서는 이미지 캡셔닝 과제에 대해,
- GENERATOR(예: Llama 3)와
- SCORER(예: MetaCLIP (Xu et al., 2024))
모델의 파라미터 수(parameter size) 가 성능에 미치는 영향을 평가합니다.
결과적으로,
- 더 큰 모델(larger models) 이 대체로 더 나은 성능을 보였으며,
- 특히 LLM 크기 확장(scaling) 이 가장 눈에 띄는 성능 향상을 가져왔습니다.
또한 다양한 종류의 GENERATOR와 SCORER 조합에 대해서도 부록 C(Appendix C)에서 추가 실험을 진행했습니다.

Figure 9 설명
캡셔닝(왼쪽)과 이미지 생성(오른쪽)에서 최적화 스텝 수에 따른 성능 변화를 보여줍니다.
- 최적화 지표(optimization metric)인 SCORER 출력값(CLIP Similarity 및 PickScore)과
- 다운스트림 지표(downstream metric)인 SPICE(Anderson et al., 2016) 및 품질에 대한 인간 평가 승률(win%) 을 각각 나타냅니다.
두 지표 모두 최적화 스텝이 진행될수록 향상되며, 서로 강한 상관관계를 보입니다.

Figure 10 설명
초기 세트(initial set) 크기가 커질수록 성능이 향상됨을 보여줍니다.
이는 GENERATOR 부트스트랩(bootstrapping) 에서 초기 세트가 매우 중요함을 시사합니다.
(CLIP*은 수렴 시의 CLIP 유사도를 의미합니다.)

Figure 11 설명
최적화 스텝 동안의 이미지 생성 품질 향상을 보여줍니다.
최적화 스텝(#)이 증가함에 따라 출력 이미지 품질이 점진적으로 개선됩니다.
또한, GENERATOR 내 LLM이 생성하는 프롬프트도 함께 제시하며, 이 프롬프트가 T2I 모델로 전달되어 이미지를 생성합니다.
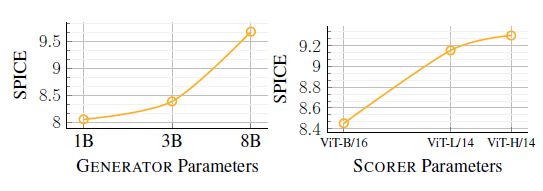
Figure 12 설명
GENERATOR(왼쪽) 와 SCORER(오른쪽) 모델 크기의 영향을 보여줍니다.
모델 크기에 따라 CLIP 유사도는 비교하기 어려울 수 있어, 두 경우 모두 다운스트림 지표로 SPICE 점수를 보고합니다.
GENERATOR와 SCORER 모두 다양한 크기의 Llama 또는 MetaCLIP 모델을 사용했습니다.
그래프에서 확인할 수 있듯이, 모델이 클수록 성능이 향상됩니다.
5. 결론 및 향후 연구(Conclusion and Future Work)
우리는 이번 연구에서,
특정 과제에 대한 데이터 수집이나 학습 없이 멀티모달 과제를 해결할 수 있는 간단한 접근법인 MILS를 제안했습니다.
MILS는 다양한 과제와 모달리티에 대해 emergent한 제로샷 일반화(emergent zero-shot generalization) 능력을 보였습니다.
특히,
- 이미지,
- 비디오,
- 오디오
세 가지 모달리티에 걸쳐 캡셔닝 성능이 뛰어남을 보여주며, LLM이 학습 없이도 "보고 듣는" 역할을 수행할 수 있음을 입증했습니다.
또한, 이를 통해
- 이미지 생성(image generation),
- 이미지 편집(image editing, 예: 스타일 전환),
- 크로스 모달 산술(cross-modal arithmetic)
등 다양한 미디어 생성 작업도 개선하거나 가능하게 했습니다.
한계와 향후 방향
MILS는 매우 유망하지만 몇 가지 한계도 존재합니다:
- GENERATOR가 충분히 다양한 후보를 생성하는 능력,
- SCORER가 정확한 피드백을 제공하는 능력
에 의해 성능이 제한됩니다.
예를 들어:
- 스타일 전환에서는, Gram matrix 거리의 해상도 한계 때문에 미세한 텍스처 유사성 감지가 어렵고,
- LLM이 잠재적 스타일을 묘사하는 능력에도 한계가 있습니다.
하지만, LLM과 멀티모달 모델들이 지속적으로 개선되고 있기 때문에(OpenAI; Fang et al., 2024), MILS도 자연스럽게 함께 발전할 것입니다.
또한, 최적화 과정 속도 역시 현재 한계점입니다.
- LLM의 속도와 효율이 향상되고,
- 컨텍스트 길이(context length)(Munkhdalai et al., 2024) 및 추론 능력(reasoning ability)(OpenAI)이 개선되면,
- 필요한 최적화 스텝 수가 줄어들어 이 문제도 해결될 수 있습니다.
마지막으로,
공간(spatial) 및 3D 과제와 같은 새로운 모달리티 및 과제에 MILS를 적용하는 것도 흥미로운 연구 방향이 될 것입니다.
영향 성명(Impact Statement)
우리의 연구는 LLM 및 기타 멀티모달 모델을 기반으로 구축되었습니다.
따라서 MILS를 사용할 때 이들 모델의 강점과 약점(예: 내재된 편향성)도 함께 반영될 수 있습니다.
하지만, MILS는 학습이 필요 없는(training-free) 접근법이기 때문에, 새로운 편향을 학습하지 않으며,
- 더 나은, 덜 편향된 LLM이나 멀티모달 모델이 등장하면,
- 재학습 없이 손쉽게 업그레이드할 수 있습니다.
우리는 MILS 자체가 직접적으로 부정적인 사회적 영향을 초래할 것으로 예상하지는 않습니다.
하지만 실제 환경에 배포하기 전에는 추가적인 안전성 평가(safety evaluations)가 고려되어야 합니다.
'인공지능' 카테고리의 다른 글
| Traveling Waves Integrate Spatial Information Through Time (3) | 2025.05.02 |
|---|---|
| EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications (2) | 2025.04.30 |
| Reasoning Models Can Be Effective Without Thinking (2) | 2025.04.25 |
| Antidistillation Sampling (3) | 2025.04.24 |
| BitNet b1.58 2B4T Technical Report (3) | 2025.04.24 |



