https://arxiv.org/abs/2103.03206
Perceiver: General Perception with Iterative Attention
Biological systems perceive the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc. The perception models used in deep learning on the other hand are designed for individual
arxiv.org
MLA 개념의 최초 제안
초록
생물학적 시스템은 시각, 청각, 촉각, 고유 감각(proprioception) 등 다양한 양식(modality)으로부터의 고차원 입력을 동시에 처리함으로써 세상을 인지합니다. 반면, 딥러닝에서 사용하는 인지(perception) 모델들은 보통 개별 모달리티에 맞춰 설계되며, 대부분 기존 시각 모델들이 활용하는 지역 격자 구조(local grid structure)와 같은 도메인 특화 가정(domain-specific assumption)에 의존합니다. 이러한 사전 지식(prior)은 유용한 귀납적 편향(inductive bias)을 제공하지만, 동시에 모델을 특정 모달리티에 묶어두는 제약이 됩니다.
본 논문에서는 Perceiver라는 모델을 소개합니다. 이 모델은 Transformer 구조를 기반으로 하여 입력 간 관계에 대한 구조적 가정을 거의 하지 않으며, 동시에 ConvNet처럼 수십만 개의 입력을 처리할 수 있도록 확장 가능합니다. Perceiver는 비대칭적 주의(attention) 메커니즘을 활용해, 입력을 반복적으로 압축된 잠재 표현(latent bottleneck)으로 정제(distill)함으로써 매우 큰 입력도 처리할 수 있도록 설계되었습니다.
우리는 이 아키텍처가 다양한 모달리티(이미지, 포인트 클라우드, 오디오, 비디오, 비디오+오디오)에 걸친 분류 작업에서 강력한 특화 모델들과 경쟁하거나 이를 능가함을 보여줍니다. Perceiver는 2D 컨볼루션을 사용하지 않고도 50,000개의 픽셀에 직접 주의를 기울임으로써 ImageNet에서 ResNet-50 및 ViT 수준의 성능을 달성합니다. 또한 AudioSet을 포함한 모든 모달리티에서도 경쟁력 있는 성능을 보입니다.
키워드:
Perceiver, Transformer, Attention, Cross-attention, Image Transformer, Vision Transformer, 멀티모달(Multimodal), ImageNet, Permuted ImageNet, AudioSet, ModelNet
1. 서론 (Introduction)
초기 시각 처리에서의 공간적 지역성(spatial locality)과 같은 귀납적 편향(inductive bias)은 인지(perception) 모델의 학습 효율을 획기적으로 높이는 데 명백히 유용하며, 그 가치가 잘 알려져 있습니다. 하지만 점점 더 많은 대규모 데이터셋이 사용 가능해지고 있는 오늘날, 이러한 편향을 모델 안에 강하게 구조화된 형태로 주입하는 것이 과연 옳은 선택일까요? 아니면 가능한 한 많은 유연성을 확보하고, 데이터 자체가 말하도록 두는 것이 더 나은 접근일까요? (LeCun et al., 2015)
강한 구조적 사전(architectural prior)의 문제점 중 하나는 그것이 종종 모달리티 특화(modality-specific) 라는 점입니다. 예를 들어, 입력이 단일 이미지라고 가정하면 우리는 그 2차원 격자 구조(2D grid structure)를 이용해 2D 컨볼루션 연산에 기반한 효율적인 아키텍처를 설계할 수 있습니다. 하지만 입력이 스테레오 이미지 쌍으로 바뀌면, 두 센서의 픽셀을 어떻게 함께 처리할 것인지 결정해야 합니다. 예컨대, early fusion을 사용할지 late fusion을 사용할지(Karpathy et al., 2014), 또는 피처를 더할지(concatenate) 혹은 합할지(sum) 선택해야 합니다. 오디오로 전환하면 2D 격자 구조의 장점은 더 이상 명확하지 않으며, 대신 1D 컨볼루션이나 LSTM(Hochreiter & Schmidhuber, 1997; Graves et al., 2013)과 같은 다른 종류의 모델이 더 적합할 수 있습니다. 포인트 클라우드(point cloud)를 처리하고자 한다면(예: 라이다 센서를 탑재한 자율주행차), 저해상도의 고정 격자에 최적화된 기존 모델에 의존할 수 없습니다. 요컨대, 기존 도구를 사용하면 입력이 바뀔 때마다 아키텍처를 새로 설계해야 하는 문제가 있습니다.

[그림 1 캡션]
Perceiver는 시각, 비디오, 오디오, 포인트 클라우드 및 멀티모달 입력 등 고차원 입력을 처리할 수 있도록 설계된 주의(attention) 기반 아키텍처입니다. 도메인 특화 가정을 하지 않으면서도 범용적인 확장성을 갖추고 있습니다. Perceiver는 고차원 입력 바이트 배열을 고정 차원의 잠재 병목(latent bottleneck)으로 투영하기 위해 교차 주의(cross-attention) 모듈을 사용합니다 (입력 인덱스 수 M이 잠재 인덱스 수 N보다 훨씬 큼). 이후 Transformer 스타일의 self-attention 블록을 잠재 공간에서 깊게 쌓아 입력을 처리합니다. Perceiver는 cross-attention과 latent self-attention을 교차 적용하여 입력 바이트 배열을 반복적으로 주의(attend)합니다.
본 논문에서는 Perceiver라는 모델을 소개합니다. 이 모델은 다양한 모달리티 구성(configurations)을 단일 Transformer 기반 아키텍처로 처리할 수 있도록 설계되었습니다. Transformer(Vaswani et al., 2017)는 입력에 대해 거의 가정을 하지 않으면서도 매우 유연한 구조적 블록이지만, 입력 수가 증가할수록 메모리와 연산 측면에서 제곱 비율(quadratic)로 확장되는 문제가 있습니다. 최근 연구에서는 이미지에 Transformer를 성공적으로 적용했지만, 대부분 픽셀의 격자 구조를 활용해 연산량을 줄였습니다. 예를 들어, 먼저 2D 컨볼루션을 적용하거나(Dosovitskiy et al., 2021; Touvron et al., 2020), 행과 열로 인자를 분해하거나(Ho et al., 2019; Child et al., 2019), 매우 강한 다운샘플링을 수행하는 방식(Chen et al., 2020a)입니다. 이에 반해, 우리는 입력 구성이 어떻게 되든 유연하게 처리할 수 있으면서도 고차원 입력을 효과적으로 다룰 수 있는 새로운 메커니즘을 제안합니다.
우리의 핵심 아이디어는 입력이 반드시 통과해야 하는 작은 수의 잠재 유닛(latent unit)을 도입해 주의 병목(attention bottleneck)을 형성하는 것입니다 (그림 1 참고). 이를 통해 Transformer의 전통적인 all-to-all attention에서 발생하는 제곱 확장을 제거하고, 네트워크 깊이를 입력 크기와 독립적으로 설계할 수 있어 매우 깊은 모델 구성이 가능해집니다. Perceiver는 입력에 반복적으로 주의를 기울임으로써, 제한된 용량을 가장 관련성 높은 입력에 집중시킬 수 있으며, 각 단계의 결과를 기반으로 정보를 점진적으로 축적합니다.
하지만 많은 모달리티에서는 공간적/시간적 정보가 핵심이며, 멀티모달 상황에서는 입력이 어떤 모달리티에서 온 것인지 구분하는 것도 매우 중요합니다. 명시적인 구조가 없는 우리의 아키텍처에서는 모든 입력 요소(예: 픽셀 하나하나나 오디오 샘플 등)에 위치 및 모달리티 특화 특성(position- and modality-specific features)을 연관시켜 이를 보완할 수 있습니다. 이들은 학습되거나, 고해상도 푸리에 특성(high-fidelity Fourier features; Mildenhall et al., 2020; Tancik et al., 2020; Vaswani et al., 2017)을 통해 구성할 수 있습니다. 이는 생물학적 신경망에서 특정 유닛의 활동을 의미적 또는 공간적 위치와 연관시키는 지형 및 감각 간 지도(topographic and cross-sensory maps) 전략과 유사한 방식입니다 (Kandel et al., 2012, 21장).
우리는 Perceiver가 다음과 같은 다양한 작업에서 강력한 모델들과 경쟁할 수 있음을 보여줍니다:
- ImageNet 분류에서 ResNet-50 및 ViT와 유사한 성능 달성
- AudioSet 소리 이벤트 분류에서 오디오, 비디오 또는 멀티모달 입력으로 경쟁력 있는 성능 달성
- ModelNet-40 포인트 클라우드 분류에서도 기존 접근법들과 비교해 우수한 성능 확보
2. 관련 연구 (Related Work)

[그림 2 캡션]
우리는 Perceiver 아키텍처를 ImageNet(Deng et al., 2009)의 이미지(왼쪽), AudioSet(Gemmeke et al., 2017)의 비디오 및 오디오(단일 모달과 멀티모달 모두 고려, 중앙), 그리고 ModelNet40(Wu et al., 2015)의 3D 포인트 클라우드(오른쪽)에서 학습시켰습니다. 다양한 입력 데이터를 처리함에 있어 모델 구조를 본질적으로 변경할 필요가 없습니다.
ConvNet과의 비교
ConvNet(Fukushima, 1980; LeCun et al., 1998; Cireşan et al., 2011; Krizhevsky et al., 2012)은 지난 10년 동안 인지(perceptual) 작업에서 뛰어난 성능과 확장성 덕분에 지배적인 아키텍처로 자리 잡아왔습니다. ConvNet은 2D 컨볼루션을 통해 가중치를 공유하고 각 유닛의 연산을 지역적인 2D 이웃으로 제한함으로써, 고해상도 이미지를 상대적으로 적은 파라미터와 연산량으로 처리할 수 있습니다. 그러나 앞서 언급했듯이, ConvNet은 다양한 신호를 결합할 때 유연성이 부족합니다. 이는 언어 분야에서 Transformer(Vaswani et al., 2017)와 같은 주의(attention) 기반 모델이 지배적인 것과 대조적입니다.
효율적인 Attention 아키텍처
Transformer는 매우 유연한 구조를 갖지만, 입력 크기에 따라 모든 self-attention 레이어가 동일한 수의 입력을 가지므로 메모리와 연산 비용이 제곱 비율(quadratic)로 증가하는 단점이 있습니다. 그럼에도 불구하고, self-attention은 빠르게 시각 인지 분야로 확산되고 있으며, 이는 이미지(Bello et al., 2019; Cordonnier et al., 2020; Srinivas et al., 2021)와 비디오(Wang et al., 2018; Girdhar et al., 2019) 모델에서 부분적으로 적용되는 형태로 나타납니다.
입력이 너무 큰 도메인에서도 Transformer를 적용할 수 있도록, 입력 크기를 줄이는 다양한 전략이 제안되었습니다. 예를 들어, 입력을 다운샘플링하거나(Chen et al., 2020a), 사전 처리로 컨볼루션을 사용하는 방식(Wu et al., 2020)입니다. ViT (Vision Transformer; Dosovitskiy et al., 2021)는 이러한 전략을 따릅니다. 이 모델은 2D 컨볼루션 계층(해당 논문에서는 “평탄화된 패치의 선형 투영”이라 지칭)을 통해 입력을 약 200개 정도로 줄인 뒤, BERT(Devlin et al., 2019)에서 사용하는 class token과 함께 Transformer에 입력합니다. ViT는 ImageNet에서 인상적인 성능을 보이지만, 이러한 사전 처리 전략은 입력이 격자 형태(grid-like)를 가지는 이미지 기반 도메인으로 제한된다는 한계가 있습니다.
Transformer 구조 내부의 효율 개선 연구
Transformer의 self-attention 모듈 내부를 개선하여 효율성을 높이려는 시도도 여럿 있었습니다 (자세한 내용은 부록 A 섹션 참고). 이 중 Perceiver와 가장 유사한 연구는 Set Transformer (Lee et al., 2019)입니다. Set Transformer는 cross-attention을 통해 대규모 입력 배열을 더 작은 배열로 투영하며, 이를 통해 연산량을 줄이거나 입력을 타깃 출력 형태로 변환할 수 있습니다(예: 입력 집합을 로짓으로 매핑). Perceiver 역시 이와 유사하게, 보조적인 저차원 배열을 활용한 cross-attention을 통해 attention 복잡도를 입력 크기에 대해 선형(linear)으로 낮춥니다.
비슷한 맥락에서 Linformer(Wang et al., 2020b)는 cross-attention 없이도, key와 value를 입력보다 작은 크기의 배열로 투영하여 self-attention의 계산 복잡도를 선형으로 낮추는 방법을 제시합니다. 하지만 Perceiver는 단순히 선형 복잡도를 달성하는 것뿐 아니라, 네트워크의 깊이를 입력 크기와 분리(decouple)한다는 점에서 차별점을 가집니다. 이는 단순한 확장성 이상의 효과를 만들어내며, 다양한 도메인에서 높은 성능을 위한 매우 깊은 아키텍처 구성을 가능하게 해줍니다 (자세한 내용은 3절에서 논의). Perceiver와 Set Transformer 및 관련 모델과의 관계는 부록 A에서 더 자세히 다룹니다.
멀티모달 아키텍처
현재 멀티모달 처리 방식은 보통 각 모달리티별로 별도의 feature extractor를 사용하는 구조입니다(Kaiser et al., 2017; Arandjelovic & Zisserman, 2018; Wang et al., 2020c; Chen et al., 2020b; Alayrac et al., 2020; Lee et al., 2020; Xiao et al., 2020). 예를 들어, 오디오 스펙트로그램이나 원시 오디오 파형을 이미지와 단순히 결합(concatenate)한 뒤 ConvNet에 넣는 것은 일반적으로 합리적이지 않습니다.
이 접근법은 언제 모달리티를 융합할지 등 다양한 아키텍처 선택지를 필요로 하며, 각 애플리케이션마다 이를 재조정해야 하는 불편이 있습니다. 그 결과, 비전에서 최적화된 아키텍처는 모든 도메인에 적용될 수 없으며, 포인트 클라우드(Qi et al., 2017; Guo et al., 2020)처럼 특수한 도메인을 위해 별도의 모델이 개발되었습니다.
반면, Perceiver는 처음부터 다양한 입력 모달리티를 매우 유연하게 처리할 수 있도록 설계되었습니다. 특히 이미지나 오디오처럼 대역폭이 높은 입력(high-bandwidth inputs)도 별다른 구조 변경 없이 처리할 수 있습니다 (그림 2 참조).
3. 방법 (Methods)
3.1 Perceiver 아키텍처
개요 (Overview)
우리는 Perceiver 아키텍처를 두 가지 구성 요소로 설계합니다:
(i) 크로스 어텐션 모듈(cross-attention module) – 바이트 배열(예: 픽셀 배열)과 잠재 배열(latent array)을 입력받아 잠재 배열로 매핑
(ii) Transformer 타워(Transformer tower) – 잠재 배열을 입력받아 또 다른 잠재 배열로 매핑
바이트 배열의 크기는 입력 데이터에 의해 결정되며 일반적으로 매우 큽니다 (예: 224 해상도의 ImageNet 이미지는 50,176개의 픽셀을 가짐). 반면 잠재 배열의 크기는 하이퍼파라미터로, 일반적으로 훨씬 작습니다 (예: ImageNet에서는 512개의 latent를 사용).
우리 모델은 cross-attention 모듈과 Transformer를 번갈아가며 적용합니다. 즉, 고차원 바이트 배열을 낮은 차원의 어텐션 병목(attention bottleneck)을 통해 투영한 후, 깊은 Transformer로 처리하고, 그 결과 표현을 이용해 다시 입력을 질의(query)하는 방식입니다. 이 모델은 잠재 위치(latent position)를 클러스터 중심으로 사용하여 입력을 end-to-end 방식으로 군집화하는 것으로도 볼 수 있으며, 이는 비대칭적인 cross-attention을 통해 수행됩니다.
Transformer 타워 간의 파라미터를 공유하고(선택적으로), 첫 번째를 제외한 cross-attention 모듈들 간에도 파라미터를 공유하기 때문에, 이 모델은 시간 차원이 아니라 깊이 차원에서 펼쳐진 순환 신경망(RNN)으로 해석될 수 있습니다. Perceiver의 모든 attention 모듈은 비인과적(non-causal)이며 마스크를 사용하지 않습니다. 아키텍처 구성은 그림 1에 나와 있습니다.
cross-attention을 통한 제곱 복잡도의 제어
Perceiver는 입력 구조에 대한 가정이 거의 없으면서도 강력한 성능을 보여주는 attention 기반 아키텍처를 중심으로 설계되었습니다. 주요 과제는 매우 크고 일반적인 입력에서도 attention 연산이 확장 가능하도록 만드는 것입니다. Cross-attention과 Transformer 모듈은 모두 QKV (query-key-value) attention 구조에 기반합니다 (Graves et al., 2014; Weston et al., 2015; Bahdanau et al., 2015). QKV attention은 일반적으로 MLP를 사용하는 query, key, value 네트워크를 각각의 입력 요소에 적용해, 동일한 인덱스 차원(또는 시퀀스 길이) M을 유지하는 세 개의 배열을 생성합니다.
Transformer의 주요 병목은 QKV self-attention이 입력 차원 M에 대해 O(M²) 복잡도를 가진다는 점입니다. 예를 들어 224×224 이미지에서는 M = 50,176입니다. 오디오의 경우도 유사하게, 1초 길이의 오디오는 약 50,000개의 샘플로 구성되므로 마찬가지 문제가 발생합니다. 멀티모달 입력에서는 이 문제가 더욱 심각해집니다.
이 문제를 피하기 위해 기존 연구들은 QKV attention을 직접 입력 픽셀 배열에 적용하지 않고(자세한 내용은 2절과 부록 A 참조), 사전 처리 등을 사용합니다. 반면, 우리는 attention 연산에 비대칭성(asymmetry)을 도입함으로써 이를 해결합니다.
보다 구체적으로,

일 때, 기본 QKV 연산 softmax(QKᵀ)V는 두 번의 큰 행렬 곱셈을 포함하므로 O(M²) 복잡도를 갖습니다. (채널 차원 C와 D는 M에 비해 작기 때문에 무시합니다.)
이를 해결하기 위해 우리는 Q를 학습된 잠재 배열(latent array)로부터 투영하고, K와 V는 입력 바이트 배열에서 투영하도록 비대칭 구조를 도입합니다. 잠재 배열의 인덱스 차원 N은 M보다 훨씬 작으며, 하이퍼파라미터입니다. 이렇게 하면 cross-attention 연산의 복잡도는 O(MN)이 됩니다.
잠재 Transformer를 통한 깊이 분리(uncoupling)
cross-attention 모듈의 출력은 Q의 입력과 동일한 형태를 가집니다. 즉, cross-attention은 병목 구조(bottleneck)를 유도합니다. 우리는 이 병목 구조를 활용하여 잠재 공간(latent space)에서 깊고 표현력 높은 Transformer를 구성합니다. 이 경우 연산 비용은 O(N²)로 매우 저렴해집니다.
이 설계를 통해 Perceiver는 입력 크기와 무관하게 매우 깊은 Transformer를 사용할 수 있게 되며, 이는 domain-specific한 가정 없이도 가능합니다. 바이트 기반 Transformer는 L 레이어일 때 O(LM²)의 복잡도를 가지지만, latent 기반 Transformer는 O(LN²) 복잡도를 가지므로, N ≪ M인 상황에서는 매우 유리합니다.
이 결과로 Perceiver의 전체 복잡도는 O(MN + LN²)가 되며, 이는 중요한 설계 포인트입니다. 입력 크기와 네트워크 깊이를 분리함으로써, 입력 크기와 무관하게 더 많은 Transformer 블록을 추가할 수 있게 되어 대규모 데이터에 적합한 모델 구성이 가능해집니다. 예를 들어, ImageNet 실험에서는 48개의 latent Transformer 블록을 사용하였으며, 이는 입력 크기와 깊이가 결합되어 있는 구조에서는 현실적으로 불가능합니다 (표 5 참고).
우리의 latent Transformer는 GPT-2 아키텍처(Radford et al., 2019)를 기반으로 하며, 이는 Transformer의 디코더(Vaswani et al., 2017)를 기반으로 합니다. 실험에서는 N ≤ 1024의 값을 사용하였으며, 이는 자연어 처리에서 사용되는 모델들과 유사한 입력 크기입니다. 잠재 배열은 학습된 위치 인코딩(position encoding)으로 초기화됩니다 (Gehring et al., 2017, 자세한 내용은 부록 C 참고).
반복적 cross-attention 및 weight sharing
잠재 배열의 크기를 통해 픽셀을 직접 모델링하고 깊은 Transformer를 구성할 수 있지만, 병목 구조의 강도는 입력 신호에서 필요한 모든 정보를 완전히 포착하는 데 제한이 될 수 있습니다. 이를 완화하기 위해 Perceiver는 여러 개의 cross-attention 레이어를 반복적으로 구성할 수 있습니다. 이는 잠재 배열이 입력 이미지에서 필요한 정보를 점진적으로 추출할 수 있도록 합니다.
이 방식은 정보가 많은 cross-attention(연산량 많음)과 반복적인 latent self-attention(연산량 적음) 간의 균형 조정을 가능하게 합니다. 부록 표 6에서 보이듯이, cross-attention 레이어를 더 많이 사용할수록 성능은 향상되지만, 입력 크기에 선형적으로 비례하는 연산량이 증가합니다.
마지막으로, 반복적인 구조 덕분에 cross-attention 및 latent Transformer 블록 간에 가중치 공유(weight sharing)를 통해 파라미터 효율을 크게 높일 수 있습니다. cross-attend가 하나뿐일 경우, latent self-attention 블록들만 공유해도 충분합니다. ImageNet 실험에서는 가중치 공유를 통해 파라미터 수를 약 10배 줄였으며, 이는 과적합을 줄이고 검증 성능을 향상시켰습니다.
결과적으로, Perceiver는 cross-attention 입력 투영, 병목화된 잠재 표현, 그리고 Transformer 기반 반복 구조를 갖춘 RNN과 같은 형태의 모델로 해석될 수 있습니다. 이러한 가중치 공유 기법은 기존 Transformer 연구(Dehghani et al., 2019; Lan et al., 2020)에서도 유사한 목적으로 활용된 바 있습니다.


50,176명의 사람들이 있고, 512명의 요약 담당자(latents)가 각각 중요한 사람들 이야기를 들은 다음 요약하는 방식입니다.
사람 수(입력 크기)는 줄지 않지만, 중요한 정보는 요약자들이 담아서 소수의 벡터로 압축하는 구조인 거죠.
Cross-Attention 단계에서 줄어듭니다.
(입력) Byte array (M×C) ← M = 224×224 = 50,176
↓
Cross Attention (Q=latent, K,V=input) ← 바로 이 단계가 복잡도 O(MN)
↓
Latent Transformer (self-attention) ← 복잡도 O(N²), N ≪ M
↓
Cross Attention (다시 입력에서 정보 뽑음)
↓
Latent Transformer
↓
...
↓
평균화 (Average)
↓
Logits










3.2 위치 인코딩(Position encodings)

표 1: ImageNet에서의 Top-1 검증 정확도(%).
2D 컨볼루션을 사용하는 모델들은 도메인 특화된 격자 구조(grid structure)를 아키텍처적으로 활용하는 반면, 글로벌 어텐션만 사용하는 모델들은 그렇지 않습니다. 첫 번째 블록은 문헌에서 보고된 픽셀 기반의 표준 성능을 보여줍니다. 두 번째 블록은 입력이 RGB 값과 2D 푸리에 특징(FF)을 연결한 경우의 성능으로, 이는 Perceiver가 받는 입력과 동일합니다. 이 블록은 저자들이 직접 구현한 베이스라인을 사용했습니다. Perceiver는 도메인 특화된 아키텍처적 가정 없이도 ImageNet에서 기존 베이스라인들과 경쟁할 수 있습니다.

표 2: 정규(raw) 및 무작위 순열(permuted)된 ImageNet에서의 Top-1 검증 정확도(%).
괄호 안의 위치 인코딩은 순열 이전에 구성됨. 글로벌 어텐션만 사용하는 모델은 입력 순서 변화에 강인하지만, 2D 컨볼루션으로 지역 정보를 처리하는 모델은 그렇지 않습니다. 입력의 지역 수용 영역(RF)은 픽셀 단위로 나타냅니다.
순열 불변성과 위치 정보
어텐션은 순열 불변(permutation-invariant) 연산이며, 이 특성은 Perceiver와 Set Transformer(Lee et al., 2019) 같은 관련 모델에서도 유지됩니다. 순수한 어텐션 기반 모델은 입력 순서에 관계없이 동일한 출력을 생성하므로, 입력 순서에 대한 정보는 출력에 전혀 남지 않습니다. 이 특성 덕분에 어텐션 기반 아키텍처는 특정 공간적 관계나 대칭에 대한 가정을 하지 않고도 다양한 데이터에 적합합니다.
반면, ResNet(He et al., 2016)과 같은 일반적인 컨볼루션 네트워크는 2D 공간 구조를 다양한 방식으로 강하게 반영합니다. 예를 들어:
- 필터는 지역적인 영역만을 바라보며,
- 공간 차원에서 가중치를 공유하고,
- 반복적인 작은 필터를 적용함으로써,
픽셀 간의 근접 관계는 잘 포착하고, 위치 불변성과 스케일 불변성을 강화합니다.
하지만 순열 불변성은 Perceiver 아키텍처 자체가 입력 내의 공간적 관계를 활용하지 못한다는 한계를 의미합니다. 공간 정보는 감각 추론에서 본질적으로 중요하므로(Kant, 1781), 이 제약은 근본적인 문제입니다.
따라서 어텐션 문헌에서는 보통 입력 특징에 위치 인코딩을 덧붙여 공간 정보를 삽입합니다 (Vaswani et al., 2017). 본 논문에서도 같은 전략을 사용합니다. 언어에서 위치 인코딩은 보통 시퀀스 상의 위치를 나타내지만, 우리는 이를 공간, 시간, 모달리티 정보까지 포함하도록 일반화합니다.
확장 가능한 푸리에 특징 (Scalable Fourier features)
우리는 최근 다시 주목받고 있는 전략인 푸리에 기반 위치 인코딩(Fourier feature position encoding)을 사용합니다 (Stanley, 2007; Vaswani et al., 2017; Parmar et al., 2018; Tancik et al., 2020; Mildenhall et al., 2020). 이 방법은 다음의 특징을 가집니다:
- 입력 데이터의 위치 구조를 직접 표현 (1D 시간, 2D 공간, 3D 시공간)
- 주파수 밴드 수와 cutoff 주파수를 독립적으로 제어 가능
- 목표 해상도까지의 주파수를 균일하게 샘플링
우리는 다음과 같은 형태의 푸리에 특징을 사용합니다:

- f_k는 1부터 μ/2 사이에 균등하게 분포된 주파수 밴드 중 k번째 주파수
- μ/2는 목표 샘플링 주파수 μ에 대응하는 나이퀴스트 주파수(Nyquist frequency)로 해석 가능
- x_d는 d차원 위치 (예: 이미지면 d=2, 비디오면 d=3), 범위는 [-1, 1]
- 최종 위치 표현은 x_d 값 자체도 연결하여 크기 = d * (2K + 1)인 벡터로 구성
이 구조는 NeRF의 위치 인코딩(Mildenhall et al., 2020)과 유사하나, NeRF에서는 2^k 식의 지수적 증가를 사용합니다. 이 경우, 밴드 수가 많아질수록 주파수가 지나치게 커져 수치적 불안정성이 생길 수 있어, 일반적으로 k=15 이상에서는 문제가 발생할 수 있습니다.
위치 인코딩 결합 방식
언어 모델링에서는 입력 인코딩과 위치 인코딩을 더하기(addition)로 결합하는 것이 일반적입니다. 그러나 우리는 입력 특징과 위치 인코딩을 연결(concatenate)하는 방식이 더 효과적이라는 것을 발견했습니다. 이는 언어 입력은 일반적으로 희소하고 차원이 크기 때문일 수 있습니다.
위치 인코딩은 일반적인 방식이다
"위치 인코딩을 사용한다면, 우리는 여전히 도메인 특화된 구조를 쓰는 게 아닌가?"라는 질문에 대해, 저자들은 다음 세 가지 이유로 그렇지 않다고 말합니다:
- 학습 가능한 인코딩은 구조를 고정하지 않고, 네트워크가 위치 정보를 활용할지 무시할지 스스로 학습하게 하므로 일반성을 보장합니다 (Sutton, 2019).
- 구조적 prior를 직접 설계하는 방식(예: 비디오, 오디오, 군대칭 기반 모델)은 시간이 오래 걸리고 복잡합니다. 반면, Fourier 위치 인코딩은 입력 차원만 알면 즉시 적용 가능합니다.
- 멀티모달 데이터에서도 손쉽게 확장 가능합니다. 각 모달리티에 적합한 차원의 위치 인코딩을 적용하고, 도메인 구분을 위한 학습된 인코딩을 붙이면 됩니다. 우리는 AudioSet 멀티모달 실험에서 이 방식을 사용했습니다 (4.2절 참고).


4. 실험 (Experiments)
다음 몇 개의 하위 섹션은 사용된 모달리티(modality)에 따라 구성되어 있으며, 이는 그림 2에 시각적으로 나타나 있습니다. ImageNet 분류에 대한 모델 구성 및 하이퍼파라미터의 영향을 평가한 결과는 부록 B에서 다룹니다.
비교 기준(baseline)으로는 ResNet-50(He et al., 2016)을 사용합니다. ResNet-50은 시각과 오디오 모두에서 매우 널리 사용되는 모델로, 지금까지 제안된 모델 중 가장 일반적인 인지(perceptual) 아키텍처에 가까운 모델이라 할 수 있습니다.
또한, 최근 제안된 ViT (Vision Transformer)(Dosovitskiy et al., 2021)와 기본적인 Transformer 스택 구조(Vaswani et al., 2017)도 함께 비교 대상으로 사용합니다.
모든 실험은 JAX(Bradbury et al., 2018)와 DeepMind의 JAX 생태계(Babuschkin et al., 2020)를 기반으로 수행되었습니다.
4.1 이미지 – ImageNet
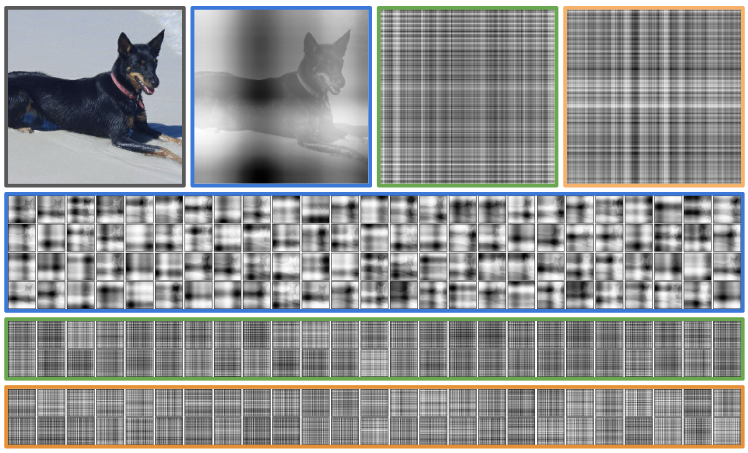
[그림 3 캡션]
ImageNet에 대해 cross-attention 모듈 8개로 구성된 모델의 첫 번째, 두 번째, 여덟 번째(최종) cross-attention layer에서 시각화된 attention map. 이 모델은 cross-attention 모듈 2~8 사이에서 가중치를 공유합니다.
- 1행: 원본 이미지와 각 레이어에서 선택된 attention map의 클로즈업
- 2~4행: 각 cross-attention 모듈의 attention map 전체
attention map은 입력 이미지를 다양한 공간 주파수에서 격자 무늬(tartan-like) 방식으로 스캔하는 것처럼 보입니다.
이 attention map들은 입력 이미지에 overlay된 것이 아니라, 이미지 구조 자체가 attention map에 반영된 것입니다 (예: 첫 번째 attention map에서는 개가 뚜렷하게 보임).
우리는 먼저 ILSVRC 2012 버전의 ImageNet(Deng et al., 2009)을 사용하여 단일 이미지 분류(single-image classification) 작업을 다룹니다. ImageNet은 이미지 인식 아키텍처 발전에 있어 핵심적인 기준점 역할을 해왔으며 (Krizhevsky et al., 2012; Simonyan & Zisserman, 2015; Szegedy et al., 2015; He et al., 2016), 최근까지도 ConvNet 기반 구조들이 우세를 점해왔습니다.
ImageNet의 각 이미지는 단일 라벨을 가지므로, 우리는 softmax 출력과 cross-entropy loss를 사용하여 분류 작업을 학습합니다. 표준 관례에 따라, 모델 성능은 test set이 비공개이므로 validation set에서의 top-1 정확도로 평가합니다.
이미지 전처리는 Inception 스타일(Szegedy et al., 2015)을 따라 224×224 픽셀 crop을 사용하고, 훈련 시에는 RandAugment(Cubuk et al., 2020)를 통해 이미지 증강을 적용했습니다.
위치 인코딩
위치 인코딩은 224×224 입력 crop 상의 (x, y) 좌표를 기반으로 생성하며, 각 축은 [-1, 1]로 정규화됩니다 (부록 그림 4 참고). Inception-style crop은 비율 왜곡이 있을 수 있으며, 이로 인해 (x, y) 좌표 역시 왜곡될 수 있습니다.
초기 실험에서는 이미지 전체 좌표계를 위치 인코딩에 사용했지만, 그 결과는 오버피팅을 초래했습니다. 이는 Perceiver 아키텍처가 훈련 이미지의 특정 픽셀(예: RGB + 위치)을 기억하는 방식으로 과적합할 수 있기 때문이라 추측됩니다. Crop 기반 위치 인코딩은 다양한 위치 및 비율로의 증강 효과를 주어, RGB와 위치 간 상관관계를 깨고 오버피팅을 방지합니다.
최적화 및 하이퍼파라미터
ConvNet은 일반적으로 SGD로 학습되지만, Perceiver는 Transformer에 최적화된 LAMB 옵티마이저(You et al., 2020)를 사용하는 것이 더 안정적이었습니다. 총 120 에폭 동안 학습하며, 초기 학습률은 0.004로 설정하고 [84, 102, 114] 에폭 시점에 10배씩 감소시켰습니다.
ImageNet에서 가장 성능이 좋았던 Perceiver 모델은 총 8번 입력 이미지 전체(50,176 픽셀)를 cross-attention으로 처리하며,
각 cross-attend 뒤에 latent Transformer (6개 블록, 각 블록에 single-head cross-attend 1개)를 거칩니다. 첫 번째 cross-attend 이후로는 모두 가중치를 공유합니다 (첫 번째는 독립적). Transformer block 내의 dense subblock은 bottleneck을 사용하지 않습니다.
- Latent array: 인덱스 512개, 채널 1024
- 위치 인코딩: 주파수 밴드 64개, 최대 해상도 224
ImageNet에서는 weight sharing 없이 학습하면 과적합되기 때문에, 첫 번째 cross-attend와 latent Transformer만 제외하고 나머지는 가중치 공유합니다. 총 파라미터 수는 약 4,500만 개로, ImageNet에 쓰이는 ConvNet과 유사한 수준입니다.
표준 ImageNet 실험 결과
표 1에서 보듯이, Perceiver는 이미지 처리를 위해 설계된 전통적인 모델들과 경쟁 가능한 성능을 보여줍니다. ResNet-50 결과는 RandAugment를 적용한 (Cubuk et al., 2020)의 설정을 인용하여 비교를 맞췄습니다.
Perceiver는 Fourier features를 입력으로 사용하므로, baseline 모델들도 동일한 입력으로 학습해 비교했습니다. Fourier feature 기반 입력은 RGB 단독보다 성능이 약간 낮거나 비슷한 수준을 보였습니다.
또한, pure Transformer도 실험했습니다. 하지만 Transformer는 ImageNet 크기의 입력을 직접 다룰 수 없기 때문에, 입력을 64×64로 downsample한 후 적용했고, 96×96도 실험했지만 학습 시간이 오래 걸리고 메모리도 더 많이 소모되어 레이어 수를 줄여야 했습니다.
이 Transformer는 Perceiver의 latent Transformer 구조와 동일하며, 하이퍼파라미터만 다릅니다 (자세한 내용은 부록 참조). 참고로, pretraining 없이 ImageNet에서 달성된 최신 top-1 정확도는 86.5%입니다 (Brock et al., 2021 기준).
Permuted ImageNet
입력 격자(grid) 구조에 대한 도메인 특화 가정이 성능에 얼마나 중요한지를 확인하기 위해, 모든 모델을 permuted ImageNet에서 평가했습니다. 모든 이미지에 동일한 permutation 패턴을 사용하며, permutation은 위치 인코딩 생성 후에 수행합니다.
이렇게 하면 모델은 여전히 위치 정보를 통해 공간 관계를 추론할 수는 있지만, 2D convolution이 가진 inductive bias는 활용하지 못하도록 제한됩니다.
즉, 2D convolution 기반 모델은 이 조건 하에서 local neighbor 구조를 활용하지 못하고, Transformer나 Perceiver처럼 feature 기반 reasoning만 가능해야 합니다.
표 2 결과:
- Transformer, Perceiver는 순열 여부와 무관하게 성능이 일정
- ViT, ResNet은 성능이 크게 하락
- 위치 인코딩을 갖고 있음에도 불구하고, 구조적 inductive bias에 의존함
- ViT는 ResNet보다 더 안정적임 (ViT는 수용영역이 큰 16×16 conv 사용, ResNet은 7×7)
구조가 없는 위치 인코딩 실험
Perceiver 자체는 입력의 공간 구조에 대한 가정을 하지 않지만, Fourier 위치 인코딩은 공간 구조를 전제로 합니다. 그래서 128차원의 학습 가능한 위치 인코딩으로 대체하여, 공간 구조에 대한 사전 지식 없이 학습이 가능한지 평가했습니다.
이 위치 인코딩은 완전히 무작위로 초기화되며, 네트워크와 함께 end-to-end로 학습됩니다 (부록 C 참고). 이 인코딩은 입력 구조를 모르므로, permutation이 어느 시점에 일어나든 성능에 영향을 주지 않습니다.
그러나 이 구조는 8개의 cross-attend를 사용할 경우 학습 안정성에 문제가 있었기 때문에, 1개의 cross-attend만 사용한 버전의 결과만 보고합니다 (표 2 하단 참조).
표 3: AudioSet에서 Perceiver 성능 (mAP, 높을수록 좋음)

이 실험은 다소 인위적으로 느껴질 수 있습니다. “입력 구조를 알고 있는데, 왜 굳이 permute하나?”라는 의문이 들 수 있지만, 이 설정은 격자 구조가 명확하지 않거나, 다중 모달리티 간 구조가 다른 경우 (예: 이미지+언어, 영상+오디오 등)에 대한 모델 일반화 능력을 평가하는 데 유용합니다.
Attention map 분석
그림 3은 ImageNet 샘플 이미지에 대한 여러 cross-attention 단계의 attention map을 시각화한 것입니다. 각 attention map은 latent index 512개와 입력 픽셀 간의 QKᵀ 연산 결과를 보여줍니다.
- Softmax 이전 값을 시각화한 이유: softmax 결과는 너무 sparse해서 해석이 어려움
- 초기 cross-attention은 독립 가중치를 사용, 이후 모듈은 공유
- 초기 layer의 attention은 입력 이미지의 구조(예: 개의 형태)를 명확히 반영
- 후속 layer의 attention은 고주파 격자(lattice) 구조로 변함
- attention map 간 구조는 유사하지만, 세부는 다름 → 각 단계마다 다른 부분에 주의 집중
Fourier 위치 인코딩의 주파수 구조가 이 격자형 attention 분포에 반영되어 있으며, 이는 학습된 위치 인코딩을 사용하는 모델에서는 나타나지 않음. 따라서 이 구조는 Fourier 기반 인코딩의 직접적인 영향일 가능성이 높습니다.
4.2 오디오 및 비디오 – AudioSet
우리는 AudioSet(Gemmeke et al., 2017)을 사용하여 비디오 내 오디오 이벤트 분류 실험을 진행했습니다. AudioSet은 527개의 클래스와 170만 개의 10초짜리 학습 비디오로 구성된 대규모 데이터셋입니다. 비디오에는 다수의 라벨이 포함될 수 있으므로, sigmoid cross-entropy loss를 사용하고, 평가에는 mean average precision (mAP)을 사용합니다.
Perceiver는 다음 세 가지 입력 설정으로 평가했습니다:
- 오디오 (원시 파형 또는 mel 스펙트로그램)
- 비디오
- 오디오 + 비디오
학습 시에는 32프레임 클립(25fps 기준 1.28초)을 샘플링하고, 평가 시에는 전체 10초를 커버하는 16개의 겹치는 32프레임 클립으로 나눈 뒤 점수를 평균했습니다. 모델은 총 100 에폭 동안 학습했습니다.
모델 설정
데이터셋 규모를 고려해, ImageNet용 Perceiver보다 더 가벼운 버전을 사용했습니다:
- cross-attention은 8회 → 2회로 축소
- 각 Transformer 블록 내 self-attention layer는 6개 → 8개로 증가
- weight sharing은 사용하지 않음 (모델이 더 작기 때문)
또한, 시간 순서대로 frame을 하나씩 처리하는 temporal unrolling 실험도 진행했습니다. 이 방식은 비디오에서는 잘 작동했지만, 오디오에서는 성능이 저하되었습니다.
→ 오디오는 더 긴 attention context가 필요할 수 있습니다.
오디오 전용 (Audio only)
- 샘플링률: 48kHz
- 1.28초 동안 약 61,440개의 오디오 샘플
두 가지 입력 방식 실험:
- Raw audio 분할:
- 128 샘플 단위로 분할 → 총 480개의 128차원 벡터
- Perceiver의 입력으로 사용
- Mel 스펙트로그램:
- 스펙트로그램을 평탄화하여 총 4,800개의 입력 벡터로 변환하여 사용
증강 방법:
- raw audio: 비디오 샘플링과 동일하게 시간 상에서 샘플링
- mel spectrogram: SpecAugment(Park et al., 2019) 사용
비디오 (Video)
- 전체 32프레임 클립, 해상도 224×224 → 총 픽셀 수 200만 이상
- 작은 시공간 패치(2×8×8)로 나눔 → 총 12,544개의 입력 생성
- Fourier 위치 인코딩은 시간, 수평, 수직 좌표에 대해 계산하고 RGB 값과 연결함
- Perceiver 구조는 오디오 실험과 동일하되, 입력만 공간-시간 패치로 변경
영상 증강:
- 색상 증강
- Inception 스타일 리사이징
- 무작위 수평 뒤집기
- 224×224 crop
오디오 + 비디오
이 실험에서는 Perceiver에 12,544개의 시공간 패치 + 오디오 입력(raw 480개 또는 스펙트로그램 4,800개)을 함께 입력합니다.
멀티모달 융합을 위한 처리:
- 오디오와 비디오가 동일한 채널 수를 가져야 하므로, 각 입력에 모달리티 특화 인코딩을 연결
- 비디오 쪽은 임베딩 크기 4로 고정하고, 오디오는 그에 맞게 확장
- 이 인코딩은 모달리티 특화 위치 인코딩으로도 작용하며 (3.2절 참고), 단순히 선형 projection하는 방식보다 더 나은 성능을 보임
추가 기법 – 비디오 드롭아웃:
- 훈련 중 일정 확률로 비디오 스트림 전체를 0으로 설정
- batch 내 각 예제마다 30% 확률로 적용
- 오디오셋에서는 영상이 정보량은 많지만 판별력은 떨어지기 때문에, 과적합 방지에 효과적
- 이 기법을 통해 성능이 3% 이상 개선됨

추가로, 카메라 레디 이후, mel spectrogram 모델을 더 튜닝하여 specaugment 비활성화 + 10% 확률로 spectrogram 자체 드롭 → mAP 44.2 달성
실험 결과
표 3에서 확인할 수 있듯, Perceiver는 오디오 전용, 비디오 전용 모두에서 준 SOTA 수준의 성능을 보입니다.
- Raw audio: Perceiver는 mAP 38.4로, 대부분의 ConvNet보다 높음
- CNN-14(Kong et al., 2020)만 AugMix(Hendrycks et al., 2019)와 class balance를 적용하여 더 높음
- 이 추가 기법 없으면 CNN-14는 37.5 mAP로 오히려 낮음
- Spectrogram 없이도 raw audio만으로 경쟁력 있는 성능 가능
- Audio + Video 융합:
- 단일 모달리티보다 성능 개선
- 기존의 전용 융합 최적화 구조들(Wang et al., 2020c)보다도 성능 우수
- 그러나 late fusion 구조를 쓰는 SOTA(Fayek & Kumar, 2020)보다는 아직 낮음
- 추후 이 부분 개선 예정
비디오와 오디오의 attention map 시각화는 부록 E에 포함되어 있습니다.
4.3 포인트 클라우드 – ModelNet40
ModelNet40(Wu et al., 2015)은 3D 삼각형 메시(triangular mesh)에서 유도된 포인트 클라우드 데이터셋으로, 40개의 객체 카테고리를 포함합니다. 과제는 약 2000개의 3D 공간상의 점 좌표를 입력으로 받아 객체의 클래스를 예측하는 것입니다.
ModelNet은 우리가 사용한 다른 데이터셋에 비해 작으며, 총 9,843개의 학습 예제, 2,468개의 테스트 예제로 구성되어 있습니다.
모델 적용을 위해, 포인트 클라우드는 먼저 영점 중심(zero-centering)으로 전처리합니다. 훈련 시 증강으로는 각 포인트에 대해 0.99~1.01 사이의 랜덤 스케일링을 적용한 후, zero-mean 및 unit-cube 정규화를 수행합니다.
정확도 비교 (표 4)

표 4: ModelNet40 테스트셋에서의 Top-1 분류 정확도. 높을수록 좋음.
각 모델 종류에서 테스트셋 정확도가 가장 높은 결과만을 보고합니다. 이 데이터셋에는 RGB 특징이나 자연스러운 격자 구조가 존재하지 않습니다. 우리는 Fourier 위치 인코딩을 사용한 이전 섹션의 일반적 베이스라인들과 비교하며, 전문 모델인 PointNet++(Qi et al., 2017)도 포함했습니다.
PointNet++은 추가적인 기하학적 특징과 고급 증강(예: 표면 적합, face normal 추가)을 사용하지만, 본 논문에서는 이러한 기법을 사용하지 않았습니다. 파란색 모델들은 모두 그러한 기법 없이 학습된 것입니다.
Perceiver에는 cross-attention 2개와 self-attention 레이어 6개로 구성된 블록을 사용했고, 기타 아키텍처 설정은 ImageNet과 동일하게 유지했습니다. 포인트 클라우드는 불규칙하게 샘플링되므로, 이미지보다 더 높은 주파수를 설정해 최대 주파수를 1120 (ImageNet의 10배)로 설정했습니다.
- 최적 성능: 주파수 밴드 64개
- 256개 이상에서는 과적합이 심해졌음
- 배치 크기: 512
- 옵티마이저: LAMB, 학습률 1e-3 (고정)
- 5만 스텝 이내에 성능 수렴
참고로, 이 벤치마크에서 SOTA 모델은 보통 매우 작고 특화되어 있으며, 포인트 클라우드에 표면을 적합시키거나, face normal을 추가하는 등 복잡한 feature engineering을 수행합니다. 우리는 여기서 ImageNet 베이스라인과 같이 일반적인 모델들이 격자 구조가 없는 데이터를 어떻게 처리하는지를 평가하는 데 목적이 있습니다.
우리는 각 포인트 클라우드를 무작위로 2D 격자에 정렬한 뒤, 모델에 입력했습니다. ViT에서는 입력 패치 크기를 다양하게 바꿔 실험했습니다.
5. 논의 (Discussion)
우리는 본 논문에서 Perceiver를 제안했습니다. 이는 Transformer 기반 구조로, 수십만 개의 입력까지 확장 가능하며, 입력 구조에 거의 가정을 하지 않고도 범용 인지 아키텍처로 작동할 수 있습니다. 또한 다양한 수준에서 정보를 융합할 수 있는 유연함도 제공합니다.
그러나 높은 유연성은 종종 과적합을 동반하며, 우리의 여러 설계 선택은 이를 완화하는 데 초점을 맞췄습니다. 향후에는 대규모 데이터셋으로 사전 학습(pretraining)된 모델을 사용해 성능을 향상시키는 방향을 고려하고자 합니다 (Dosovitskiy et al., 2021 참고).
우리는 AudioSet에서 강력한 결과를 얻었으며, Perceiver는 오디오, 비디오, 멀티모달 설정 모두에서 최근 SOTA 모델과 경쟁하거나 능가했습니다. ImageNet에서도 ResNet-50 및 ViT와 비슷한 수준의 성능을 달성했습니다.
논문에서 다룬 다양한 모달리티와 조합 전반에서 비교했을 때, Perceiver는 전반적으로 가장 뛰어난 결과를 보여주었습니다.
우리는 모델 내에서 모달리티 특화된 사전 지식(prior)을 줄이려 노력했지만, 여전히 모달리티별 증강과 위치 인코딩은 사용했습니다. 완전히 end-to-end 모달리티 비의존 학습은 앞으로의 흥미로운 연구 방향입니다.
감사의 글 (Acknowledgements)
본 논문의 초안 검토에 도움을 준 Sander Dieleman과 Matt Botvinick에게 감사드립니다. 또한 AudioSet 관련 실험을 도와준 Adrià Recasens Continente와 특히 평가 버그를 식별해준 Luyu Wang에게 깊이 감사드립니다.
DeepMind의 Chris Burgess, Fede Carnevale, Mateusz Malinowski, Loïc Matthey, David Pfau, Adam Santoro, Evan Shelhamer, Greg Wayne, Chen Yan, Daniel Zoran 및 기타 팀원들과의 유익한 대화와 제안에도 감사드립니다.
이 외에도 Irwan Bello, James Betker, Andreas Kirsch, Christian Szegedy, Weidi Xie 등 여러 분들께서 초기 초안에 유익한 피드백을 주셨습니다. 감사드립니다.



