https://arxiv.org/abs/2506.14761
From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
Tokenization imposes a fixed granularity on the input text, freezing how a language model operates on data and how far in the future it predicts. Byte Pair Encoding (BPE) and similar schemes split text once, build a static vocabulary, and leave the model s
arxiv.org
초록 (Abstract)
토크나이제이션(tokenization)은 입력 텍스트에 고정된 세분화 수준을 강제로 부여하며, 이는 언어 모델이 데이터를 처리하는 방식과 미래를 예측하는 범위를 고정시킵니다. Byte Pair Encoding(BPE) 및 유사한 방식들은 텍스트를 한 번 나누고, 정적인 어휘집을 구축한 뒤, 모델을 그 선택에 묶어둡니다. 본 논문에서는 이러한 경직성을 완화하기 위해, 학습 과정에서 자체 토큰을 임베딩하는 방법을 학습하는 오토리그레시브 U-Net(Autoregressive U-Net)을 제안합니다.
이 네트워크는 원시 바이트(raw bytes)를 읽은 뒤, 이를 단어 단위로 풀링(pooling)하고, 그 다음에는 단어 쌍(pair of words), 더 나아가 최대 4단어까지 점진적으로 결합하여 시퀀스의 다중 스케일 표현(multi-scale representation)을 생성합니다. 모델이 더 깊은 단계로 들어갈수록, 더 멀리 있는 미래—즉, 다음 바이트가 아닌 다음 여러 단어를 예측해야 하므로, 깊은 단계에서는 더 넓은 의미적 패턴(semantic pattern)을 포착하고, 얕은 단계에서는 미세한 세부 사항(fine detail)을 처리하게 됩니다.
사전학습(pretraining) 연산량을 정밀하게 조정하고 제어하면, 얕은 계층 구조는 강력한 BPE 기준 모델들과 유사한 성능을 보이며, 더 깊은 계층 구조는 유망한 성능 향상 추세를 나타냅니다. 이제 토크나이제이션이 모델 내부에 포함되기 때문에, 동일한 시스템이 문자 수준(character-level)의 작업도 처리할 수 있고, 저자원 언어 간에도 지식을 공유할 수 있게 됩니다.
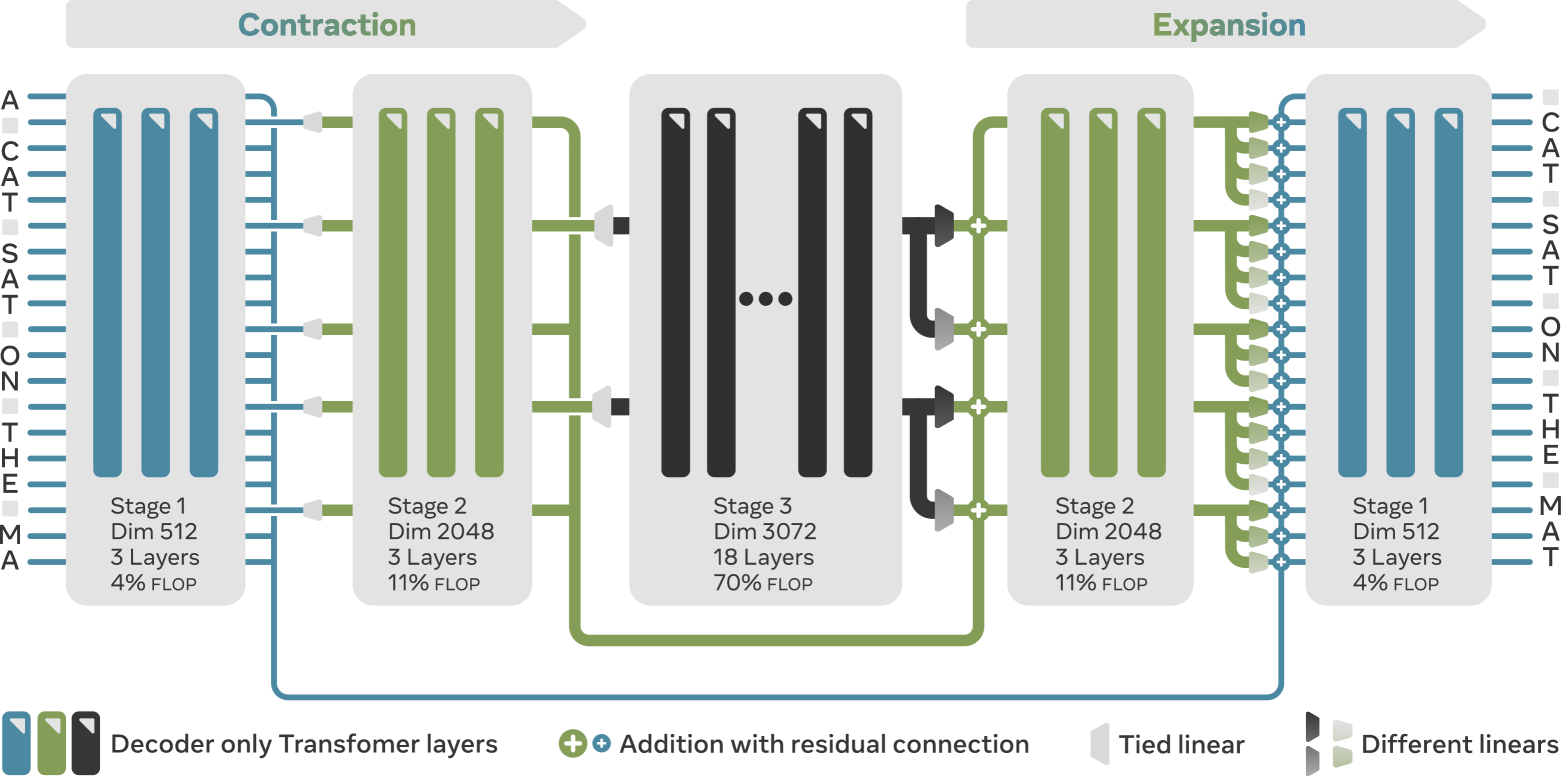
그림 1: 세 단계로 구성된 오토리그레시브 U-Net (AU-Net)
모델은 왼쪽에서 오른쪽 방향으로 실행됩니다. 수축 경로(contracting path)는 시퀀스를 두 단계에 걸쳐 압축합니다:
- 1단계(Stage 1)에서는 원시 바이트를 처리하고,
- 2단계(Stage 2)에서는 각 단어 경계에서의 벡터만 유지하며,
- 3단계(Stage 3)에서는 두 단어당 하나의 벡터만 유지합니다.
각 수축 및 확장 단계는 임의의 풀링(pooling) 및 업샘플링(upsampling) 패턴을 지원합니다. 가장 깊은 단계 이후에는, 확장 경로(expanding path)가 수축 경로를 역으로 따라가며 각 조밀한(coarse) 벡터를 복제하고, 위치별 선형 레이어를 적용합니다. 이들은 수축 경로에서의 skip connection과 결합되어 시퀀스 길이를 점진적으로 복원하고, 상위 수준의 정보를 혼합합니다. 깊은 단계는 더 먼 미래를 예측하고 넓은 의미론을 포착하며, 얕은 단계는 지역적인 세부 사항을 정제합니다.
1. 서론 (Introduction)
언어 모델의 본질은 시퀀스 내에서 패턴을 발견해 다음에 올 것을 예측하는 데 있다. 그러나 그 전에, 우리는 그 시퀀스를 구성하는 단위—즉 토큰(token)—이 무엇인지 먼저 정의해야 한다. 이 선택은 보통 학습이 시작되기 훨씬 전, 원시 텍스트(raw text)를 개별 단위로 자르는 토크나이저(tokenizer)에 의해 고정된다.
예를 들어, 문장 “The quick brown fox.”를 생각해보자.
- 문자 수준(character-level) 토크나이저는 {T, h, e, ␣, q, u} 같은 스트림을 모델에 제공하고, 다음 글자 i를 예측하도록 요구한다.
- 반면에 단어 수준(word-level) 토크나이저는 {The, quick}을 넘겨주고, 모델이 한 번에 brown을 예측하길 기대한다.
세분화가 정밀할수록 시퀀스는 길어지고 모델이 미리 볼 수 있는 창(window)은 짧아진다. 반대로, 세분화가 거칠수록 시퀀스는 짧아지지만, 각 토큰은 더 희귀해지고 서로 비교하거나 예측하기가 어려워진다. 세분화 수준과 무관하게, 어떤 형태든 토크나이제이션은 필수다—Transformer 모델이 실행되기 위해서는 반드시 시퀀스가 먼저 존재해야 하기 때문이다.
Byte Pair Encoding(BPE)은 단순한 임베딩 테이블과 함께 사용되며, 가장 널리 쓰이는 접근법이다. 이 방법은 학습 텍스트 내에서 가장 자주 등장하는 바이트 시퀀스를 반복적으로 병합하여, 설정된 어휘 크기까지 계속 확장해 나간다. 이 과정에서 연구자들은 직관적인 두 개의 조절 요소만 다룬다:
- 학습 코퍼스(training corpus): 어떤 텍스트를 넣느냐—영어 문장, 소스코드, 다국어 혼합—에 따라 병합되는 패턴이 달라지고, 최종 토큰 모양도 결정된다.
- 어휘 크기(vocabulary size): 이 값을 높이면 병합 과정을 더 많이 반복할 수 있어, 더 긴 토큰과 짧은 시퀀스를 얻을 수 있지만, 더 큰 임베딩 테이블과 출력 소프트맥스가 필요해진다.
토크나이제이션의 대부분 문제는 텍스트 분할 자체보다 임베딩 과정에서 비롯된다. 각 토큰은 보통 독립된 벡터에 매핑되며, 이로 인해 네트워크는 불투명한 식별자(예: "strawberry" vs. "strawberries")만 보고, 두 단어가 9개의 문자를 공유한다는 사실조차도 다시 학습해야 한다. 이러한 고립된 임베딩 의존성은 기호 수준의 추론을 방해하고, 방언이나 희귀 언어로의 전이를 어렵게 만든다. 게다가 이 분할은 대부분 사전 처리(preprocessing) 단계에서 수행되기 때문에, 이후 모든 모델 계층이 하나의 고정된 세분화 수준에 묶이게 된다 (2.2절 참고).
이러한 한계를 해결하기 위해, 우리는 오토리그레시브 U-Net(Autoregressive U-Net, 2.1절) 또는 AU-Net(발음: 오우-넷 /óU nEt/) 을 제안한다. 이 모델은 원시 바이트(raw byte)로부터 직접 정보를 임베딩하며, 여러 단계의 분할(multi-stage splitting)을 허용한다.
임베딩의 목적은 토큰을 벡터로 매핑하는 것이다. 기존의 테이블 기반 룩업 대신, 우리는 self-attention을 직접 사용해 토큰을 임베딩한다. Self-attention은 어떤 위치의 벡터든 전체 앞선 컨텍스트를 요약할 수 있게 해준다. 이 특성을 활용해, 우리는 다음과 같은 단순한 풀링 메커니즘을 구성한다:
- 단어 경계에서 벡터를 선택(AU-Net-2)
- 단어 쌍에서 선택(AU-Net-3)
- 4단어 단위로 선택(AU-Net-4)
이렇게 해서 다단계 임베딩 계층 구조(multi-stage embedding hierarchy)를 만든다. 이 U-Net 구조는 시퀀스를 점차 압축하는 수축 경로(contracting path)를 따르고, skip connection으로 세부 정보를 유지한 뒤, 다시 확장 경로(expanding path)를 통해 시퀀스를 복원한다. 이 확장 과정에서는, 거친(coarse) 정보를 나타내는 벡터가 미세한(fine-grained) 표현으로 다시 주입된다.
깊은 단계는 압축된 표현에서 작동하기 때문에, 본질적으로 여러 단어를 미리 예측해야 하며, 이는 보조 손실 없이 multi-token 예측(Gloeckle et al., 2024)과 유사하다. 이 구조는 깊은 단계가 의미 수준에서 얕은 단계를 안내하게 하고, 얕은 단계는 철자 등 세부 사항을 담당하도록 한다.
기여 요약 (Section 3에서 정량적으로 평가됨):
- C1. 적응형 다단계 계층 구조: 고정된 풀링 또는 얕은 계층 구조에 의존했던 기존 연구와 달리, 임의의 사용자 정의 분할 함수와 함께 최대 4단계 임베딩을 종단(end-to-end) 학습한다.
- C2. 무한한 어휘 크기: 원시 바이트 단위로 작동하기 때문에, 사전 정의된 어휘나 메모리를 많이 사용하는 임베딩 테이블이 필요 없어지고, 무한한 수의 고유 토큰을 다룰 수 있다.
- C3. 강력한 성능 및 확장성: 동일한 사전 학습 자원 내에서, 단일 계층 모델은 강력한 BPE 기준과 대등하며, 두세 단계 모델은 유망한 확장 추세(scaling trend)를 보인다. 결과 일부는 표 2에 제시된다.
- C4. 실용적 효율성: 이론적 계산량이 아니라, 실제 GPU 처리량을 기준으로 벽시계 시간(wall-clock time)에서 성능을 유지한다. 코드는 Meta Lingua (Videau et al., 2024)에서 공개되어 있다.
- C5. 안정적인 스케일링 법칙: 토큰 수준에서 바이트 수준으로 넘어가면서 새로운 배치 크기 및 학습률 공식이 필요함을 보이고, 이를 통해 매끄러운 최적화가 가능해진다.
✏️ 요약하면
초록은 “기존 방식의 rigid함을 완화했다”는 말로 추상적으로 표현되어 있지만,
실제로는 토크나이저를 완전히 없애고, 바이트부터 4단어 단위까지 모델 내부에서 동적으로 처리한다는 점이 혁신적입니다.
또한 self-attention 기반으로 토큰을 임베딩하고, multi-scale 계층 구조를 통해 깊은 계층이 의미 수준을, 얕은 계층이 철자 수준을 처리하는 방식은 Transformer 이후 나온 많은 구조 중에서도 기존 임베딩 방식의 한계를 깨려는 시도로 볼 수 있습니다.
2 방법 (Method)
2.1 오토리그레시브 U-Net (Autoregressive U-Net)
우리는 U-Net 기반 아키텍처(Ronneberger et al., 2015; Nawrot et al., 2022)에서 영감을 받아, 그림 1에 나타난 바와 같이 언어 모델링을 위한 오토리그레시브 계층적 모델(autoregressive hierarchical model)을 제안한다. 이 아키텍처는 입력 시퀀스를 압축하는 수축 경로(contracting path)와 이를 복원하는 확장 경로(expanding path)로 구성된다.
두 경로는 모두 완전히 적응적(adaptive)이며, 고정된 풀링(pooling) 또는 업샘플링(upsampling) 크기를 요구하지 않는다. 풀링과 업샘플링 연산은 독립적으로 설계될 수 있으며, 본 논문에서는 대칭적으로 설계하였지만 필수는 아니다. 유일한 요구 조건은 시퀀스 내에서 풀링이 수행될 위치를 지정하는 분할 함수(splitting function)이다. 이 함수에 대해서는 2.2절에서 자세히 설명한다.
우리의 아키텍처는 모놀리식(monolithic)하다. 최근의 접근 방식들(Pagnoni et al., 2024; Neitemeier et al., 2025)이 로컬 모델(local model)을 사용하는 것과 달리, 우리는 각 단계에서 글로벌 attention (또는 슬라이딩 윈도우 내에서)을 적용하여 모든 입력이 앞선 입력들을 참조할 수 있도록 한다. 이를 통해 단어나 단어 그룹이 고립된 채 처리되지 않도록 보장한다.
또한 시퀀스 압축 과정에서 손실될 수 있는 세부 정보(fine-grained information)를 보존하기 위해, Ronneberger et al. (2015) 및 Nawrot et al. (2022)의 접근법을 따라 단계 간 skip connection을 도입하였다. 더불어 시퀀스를 압축해 갈수록 숨겨진 차원(hidden dimension)을 수축 비율에 비례해 점진적으로 증가시켜, 더 풍부한 표현이 가능하도록 한다.
마지막으로, 가장 긴 시퀀스를 처리하는 바이트 수준 단계(Stage 1)에서는 계산 복잡도를 제어하기 위해 attention 범위를 윈도우로 제한한다.
2.1.1 풀링(Pooling)과 업샘플링(Upsampling)
우리의 풀링과 업샘플링은 적응형(adaptive)이므로, 고정된 윈도우 크기에 의존할 수 없다. 이를 해결하기 위해 여러 풀링 및 업샘플링 전략을 실험했으며, 이 섹션에서는 본문에 보고된 모든 실험에 사용된 방법을 설명한다. 대체 방법들과 제거 실험(ablation) 결과에 대한 전체 설명은 부록 8에 제시되어 있다.
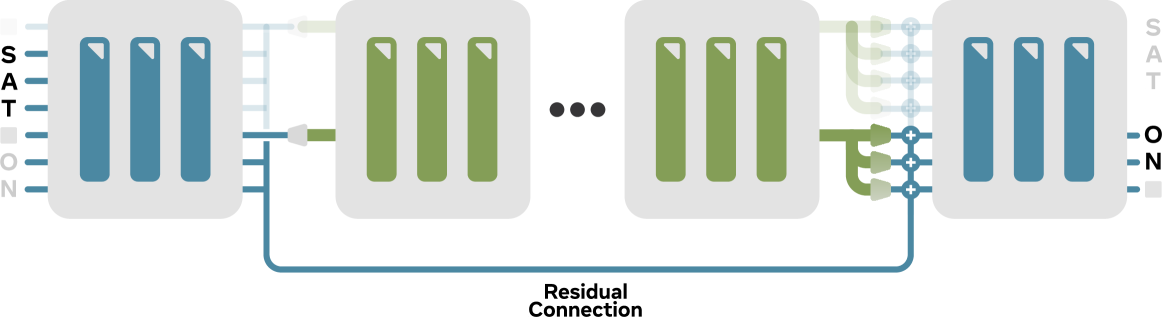
그림 2 캡션:
풀링(pooling)은 단순히 분할 함수(splitting function)에 의해 지정된 위치의 벡터들을 선택한다. 이후 업샘플링(upsampling)은 각 풀링된 벡터를 다음 세그먼트(segment)의 길이에 맞게 확장하며, 각 위치에 대해 별도의 선형 계층(linear layer)을 적용한다. 예를 들어, ‘SAT␣’라는 단어를 나타내는 풀링된 벡터는 이후 ‘ON␣’을 예측하는 데 사용된다. 이러한 오프셋 구조는 더 깊은 단계가 시퀀스 상에서 더 먼 미래를 예측할 수 있도록 해준다. 예컨대 4단계 모델을 사용할 경우, 가장 깊은 단계는 다음 네 단어 예측에 기여하게 된다.
Pooling (풀링):
우리는 가장 단순한 풀링 전략을 채택했다:
분할 함수가 지정한 인덱스를 선택한 뒤, 해당 벡터를 선형 계층을 통해 다음 단계의 차원(dimensionality)으로 투영한다. 이전 계층들에는 이미 self-attention 메커니즘이 포함되어 있으므로, Nawrot et al. (2022), Pagnoni et al. (2024)에서 사용한 명시적 cross-attention 대신, 우리는 암묵적인 attention 기반 풀링에 의존한다.
Upsampling (업샘플링):
업샘플링 단계는 조밀(coarse)한 표현을 더 정밀(fine)한 다음 단계 표현으로 변환하는 역할을 한다. 그림 2에서 보여주듯, 우리는 각 조밀한 벡터를 복제하여 다음 세그먼트의 길이에 맞추고, 각 복제본에 대해 위치별로 다른 선형 변환(position-specific linear transformation)을 적용한다. 이러한 변환은 세그먼트 전체에 걸쳐 공유되지만, 세그먼트 내의 위치별로는 다르기 때문에, 우리는 이 방식을 Multi-Linear Upsampling이라 부른다.
실험 결과, 업샘플링 전략의 선택은 특히 다단계 모델에서 성능에 민감하게 작용한 반면, 풀링은 다양한 전략이 대체로 유사한 성능을 보였다.
2.1.2 생성 (Generation)
학습 중에는, 전체 입력 시퀀스를 병렬로 처리하며 모든 단계가 동시에 활성화된다. 반면, 추론 시에는 생성이 오토리그레시브(autoregressive)하게 이루어진다:
- 바이트 수준 단계(Stage 1)는 매 스텝마다 활성화되며,
- 더 깊은 단계는 풀링 패턴에 따라 간헐적으로 활성화된다.
Skip connection은 각 단계에서 위쪽으로 정보를 전달하므로, 깊은 단계들도 미세한 정보(fine-grained details)를 통합할 수 있다. 이와 같은 단계적이고 조건부적인 활성화(cascading, conditional activation)는 효율적인 추론을 가능하게 한다:
계산 비용이 큰 고수준 단계는 드물게 활성화되지만, 여전히 하위 단계의 세부 예측을 의미적으로 효과적으로 안내할 수 있다.
실제 구현에서는, 각 단계 출력에서 가장 최근의 벡터를 캐시해두어야만, 더 깊은 단계의 출력이 올바르게 전파될 수 있다.
2.2 분할 함수 (Splitting Function)
AU-Net 아키텍처는 계층별 풀링 지점을 정의하기 위한 유연한 분할 전략(splitting strategy)을 지원한다. 주요 제약 조건은, 선택한 분할 함수가 우측 삽입(rightward insertion)에 대해 안정적이어야 한다는 점이다. 즉, 새로운 바이트가 뒤에 추가되더라도 이전의 풀링 결정에는 영향을 주지 않아야 하며, 이를 통해 일관된 오토리그레시브 생성이 가능해진다.
고정 윈도우(Nawrot et al., 2022), 엔트로피 기반(Pagnoni et al., 2024), 학습된 규칙 등 다양한 방법이 존재하며, 본 연구에서는 각 단계마다 서로 다른 정규 표현식(regular expression)을 활용해 공백(space) 기준으로 분할을 수행한다 (자세한 내용은 부록 7(Appendix 7) 참고).
이 전략은 다음과 같은 계층 구조(hierarchy)를 정의한다:
- 1단계(Stage 1): 원시 바이트(raw bytes)를 처리
- 2단계(Stage 2): 단어 경계(정규식 기반)를 기준으로 풀링
- 3단계(Stage 3): 두 단어마다 (또는 문장 끝에서) 풀링
- 4단계(Stage 4): 네 단어마다 (또는 문장 끝에서) 풀링
이러한 규칙 기반 접근 방식은 GPT-4o 시스템(Dagan et al., 2024)과 같은 모델의 사전 토크나이제이션(pre-tokenization)에서 영감을 받았으며, 라틴 문자 스크립트(Latin scripts)에서는 효과적으로 작동한다. 반면, 명확한 구분자가 없는 언어들에까지 이 방법을 확장하는 것은 앞으로의 과제로 남아 있다.
기존의 Pagnoni et al. (2024), Neitemeier et al. (2025), Slagle (2024) 등의 접근은 이러한 분할을 단일 계층(single-stage)에서 BPE 대체 용도로 사용한 반면, AU-Net은 사용자 정의 분할 규칙을 다단계 계층 처리에 적극 활용한다는 점에서 차별화된다.
2.3 다양한 스케일에서의 평가
대규모 언어 모델은 매우 예측 가능하게 스케일링되는 것으로 알려져 있다(Kaplan et al., 2020; Hoffmann et al., 2022; Bi et al., 2024). 이러한 특성 덕분에, 우리는 큰 연산량(compute budget)이 주어졌을 때 모델의 성능을 어느 정도 사전에 추정할 수 있다. 더욱 흥미로운 점은, 이를 통해 실제 실험보다 훨씬 큰 모델에 대한 최적 하이퍼파라미터도 예측할 수 있다는 것이다.
Bi et al. (2024)은 작은 모델들에 대해 다양한 학습률과 배치 크기를 탐색(sweep)한 후, 그 결과를 바탕으로 큰 모델에 대한 최적의 하이퍼파라미터를 예측할 수 있음을 보였다. 우리는 이들의 방법론을 따라, 우리의 설정에서의 데이터와 계층적 모델(hierarchical model)의 구조로 인해 하이퍼파라미터가 다르게 진화함을 보여준다. 이 하이퍼파라미터를 이용해, 다양한 연산량에 대해 스케일링 법칙(scaling laws)을 실험하고, 기준 아키텍처(BPE 기반 Transformer)와 AU-Net을 비교한다.






3 실험 결과
3.1 실험 설정
데이터
모든 실험에서 우리는 사전학습 데이터셋으로 DCLM(Li et al., 2024)을 사용하였으며, 아주 일부만 검증용으로 제외하였다. 전체 학습 데이터는 약 4조(GPTNeoXTokenizer 기준) 토큰이다. 이 코퍼스는 대부분 영어 기반이며, 주로 자연어 이해(NLU) 작업을 목표로 하므로, 코드나 수학 콘텐츠는 아주 적은 비율만 포함되어 있다.
기준 모델(Baselines)
우리의 접근 방식은 다음 세 가지 기준 모델과 비교된다:
- LLaMa 3의 BPE 토크나이저를 사용한 Transformer
- 바이트 단위로 직접 학습한 Transformer
- 바이트 단위로 학습한 Mamba 모델 (Gu and Dao, 2024)
비교의 공정성을 위해, 모든 기준 모델은 동일한 데이터 양 또는 연산량(compute)으로 학습되었다.
예를 들어, AU-Net이나 바이트 기반 모델을 2730억 바이트 학습 데이터로 학습했다면, 이는 DCLM 기준 압축률 4.56을 반영해 600억 토큰으로 변환하여 LLaMa 3 토크나이저 기반 Transformer에 사용되었다(Grattafiori et al., 2024).
하이퍼파라미터
하이퍼파라미터에 대한 세부 내용은 부록 9(Appendix 9)에 수록되어 있다.
2.3절에서 설명했듯이, 우리는 25M부터 500M 규모의 모델에 대해 배치 크기와 학습률을 sweep한 뒤, 이를 바탕으로 주어진 연산량에 대한 최적의 하이퍼파라미터를 외삽한다.
평가 지표 (Evaluation Metrics)
모든 모델은 제로샷(zero-shot) 설정으로 다양한 다운스트림 작업에서 평가되며, 경우에 따라 프롬프트 내에 소수의 인컨텍스트 예시가 포함될 수 있다.
작업 유형은 크게 두 가지로 나뉜다:
- 객관식(MCQ) 과제: 정답은 normalized negative log-likelihood(음의 로그 우도 / 문자 수)가 가장 낮은 선택지를 정답으로 판단 (Brown et al., 2020).
- 주관식 생성(Open-ended generation) 과제: 모델이 자유롭게 응답을 생성할 수 있음.
AU-Net의 강점을 부각시키기 위해, 다음과 같은 특화 벤치마크도 포함시켰다:
- 문자 수준 조작(character-level manipulation): CUTE (Edman et al., 2024, 섹션 10)
- 저자원 언어 번역(low-resource language translation): FLORES-200 (Costa-jussa et al., 2024, 섹션 3.4)
주요 벤치마크 보고
명확한 비교를 위해, 핵심 벤치마크에 대한 결과만 본문 표에 포함하였다.
포함된 항목: Hellaswag, ARC-Easy, ARC-Challenge, MMLU, NQ, TQA, GSM8K
모든 테이블에는 95% 신뢰구간이 bootstrap 방식으로 함께 보고되며, 전체 평가 결과는 부록 11(Appendix 11)에 자세히 제공된다.
추가적으로 각 모델에 대해 다음 정보도 함께 제공한다:
- 총 학습 연산량(FLOPs)
- GPU당 초당 바이트 처리 속도(bps), 기준: H100 80GB GPU (내부 클러스터 환경)
구현 세부사항
대규모 언어 모델에서 스케일링이 성능에 핵심이므로, 우리는 효율성과 단순함 사이의 균형을 추구했다.
- 전체 attention을 유지한 채 시퀀스 패킹(sequence packing)을 사용했으며, 이는 downstream 성능에 거의 영향을 주지 않는 것으로 알려져 있다 (Li et al., 2024).
- GPU 메모리 압박을 줄이기 위해, 모든 실험은 Fully Sharded Data Parallelism (FSDP)을 사용하였다.
추가 속도 향상을 위해, 전체 모델은 torch.compile로 컴파일되었다.
그러나 컴파일에는 정적 연산 그래프(static computation graph)가 필요하며, 이는 적응형 풀링(adaptive pooling)에서 발생하는 가변 시퀀스 길이와 충돌한다. 예를 들어, 단어당 바이트 수는 문장마다 다르기 때문이다.
이 문제는 각 계층별 최대 시퀀스 길이를 고정하여 해결한다:
- 초과하는 시퀀스는 잘라내고(truncated)
- 짧은 시퀀스는 패딩 처리한다.
이러한 절충을 통해, 컴파일이 가능한 정적 그래프를 유지하면서도 계층적 풀링 구조를 실제로 지원할 수 있게 된다.
표 2:
AU-Net과 BPE/바이트 기반 기준 모델 간의 다운스트림 결과 비교. 핵심 벤치마크에 대한 정확도(accuracy)를 95% 신뢰구간과 함께 보고하며, 기존 문헌 모델들은 이탤릭체로 표시되었다. 모든 모델은 별도 명시가 없으면 동일한 코퍼스에서 학습되었다. AU-Net은 계층 수에 따라 여러 변형이 존재하며, 연산량 및 GPU 처리 속도(bytes/sec)도 함께 보고된다.
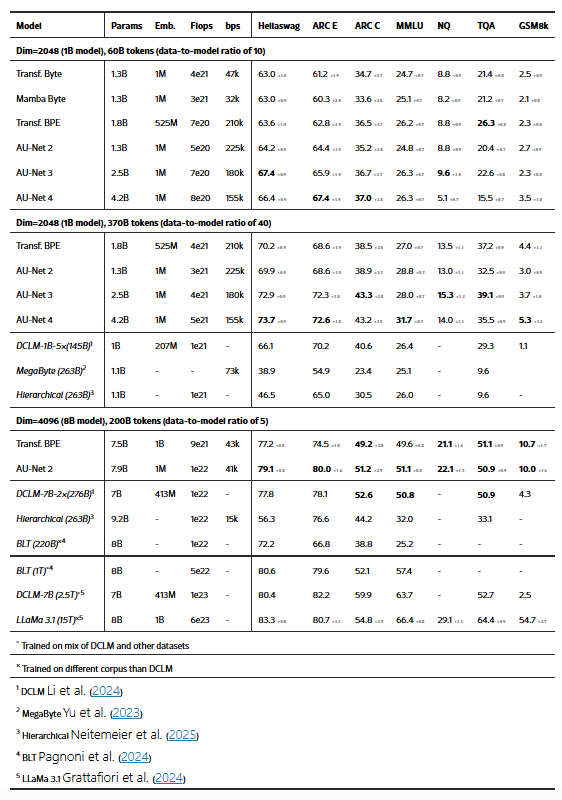
3.2 동일한 데이터 예산 하에서의 결과
우리는 모델의 주요 hidden dimension을 2048로 고정하고, 전체 학습 데이터 예산을 동일하게 유지한 상태에서 계층적 풀링(hierarchical pooling)의 효과를 평가하였다. 각 단계에서의 hidden dimension은 수축 비율(contraction ratio)에 비례하여 조정되며, 이는 2.1절에서 설명한 방식이다.
예를 들어:
- 바이트 수준 단계는 2048 / 4 = 512 차원 사용
- 단어 수준 단계는 2048 차원
- 2단어 수준은 1.5 × 2048 = 3072 차원
- 이후 단계도 이와 같은 방식으로 증가
우리는 파라미터 수 10억(1B) 규모에서 2, 3, 4단계 모델의 다운스트림 성능을 측정했고, 8B 모델에 대해서는 현재 1단계 구성만 평가했다. 모든 AU-Net 변형은 동일한 hidden dimension을 사용하는 LLaMA 3 BPE 기반 Transformer와 비교된다. 각 단계당 층 수 및 풀링 관련 추가 제거 실험은 부록 8에 포함되어 있다.
표 2의 결과에 따르면, 계층 구조를 갖는 모델들은 일관되게 BPE 기반 모델과 동등하거나 더 우수한 성능을 보인다. 이러한 경향은 다양한 구성 전반에서 나타나며, 계층 단계를 추가할수록 더 두드러진다. 특히, 다단계 AU-Net 모델(AU-Net 3, AU-Net 4)은 여러 벤치마크에서 BPE 기준 모델을 능가한다.
다만, 예외적으로 TQA 벤치마크에서는 AU-Net 모델과 바이트 수준 기준 모델들이 BPE 모델보다 일관되게 낮은 성능을 보인다.
TQA는 지식 기반 생성(generation)을 요구하는 과제이기 때문에, 이 성능 차이는 단순히 계층 구조 때문이라기보다는 다른 요인(예: 데이터 표현력, 어휘 범위 등)의 영향일 수 있다. 그러나 모델 규모와 학습 데이터량이 충분히 커질 경우(예: 1B/8B 모델, 370B 토큰 수준), 이 차이는 거의 사라지는 경향을 보인다.
또한, 일정한 계층 깊이를 넘어서면 성능 향상이 줄어드는 초기 징후도 관찰된다. 예를 들어, AU-Net 4는 ARC-C나 GSM8K처럼 추론이 중요한 작업에서는 개선을 보이지만, Hellaswag, TQA와 같은 과제에서는 일관된 이득이 없다. 이러한 현상은 계층 구조 그 자체보다는, 더 깊은 계층 구조가 더 많은 데이터가 있어야 진가를 발휘하는 데이터 효율성 문제로 해석될 수 있다.
실제로, AU-Net 2와 AU-Net 4는 추가 학습 데이터가 주어졌을 때 성능이 크게 향상되며, MMLU, GSM8K 등의 과제에서는 모델 스케일이 고정되어 있어도 계층 수 증가에 따라 성능이 계속 향상되는 모습을 보인다.
마지막으로, 문헌의 동급 모델들과 비교해도 AU-Net은 경쟁력 있는 성능을 보인다. 예를 들어, BLT (1T)는 AU-Net 8B 모델보다 약 5배 더 많은 연산량을 사용했음에도, MMLU 외에는 성능 우위가 없다. 또한, 비교의 공정성을 위해, 모든 문헌 모델은 동일한 DCLM 코퍼스를 기반으로 학습되었으며, 예외적으로 BLT(220B)와 LLaMA 3.1 (15T)만 다른 데이터량을 사용하였다.
AU-Net의 구조를 더 정량적으로 평가하기 위해, 이제 우리는 스케일링 법칙(scaling laws)을 살펴본다. 비교 대상은 BPE 기반 Transformer이며, AU-Net 2 및 AU-Net 3에 집중한다. 우리는 데이터-대-모델 비율(γ)을 2로 고정하는데, 이는 AU-Net 3에서 AU-Net 4로 갈 때 수익 감소 현상(diminishing returns)이 관찰되었기 때문이다.
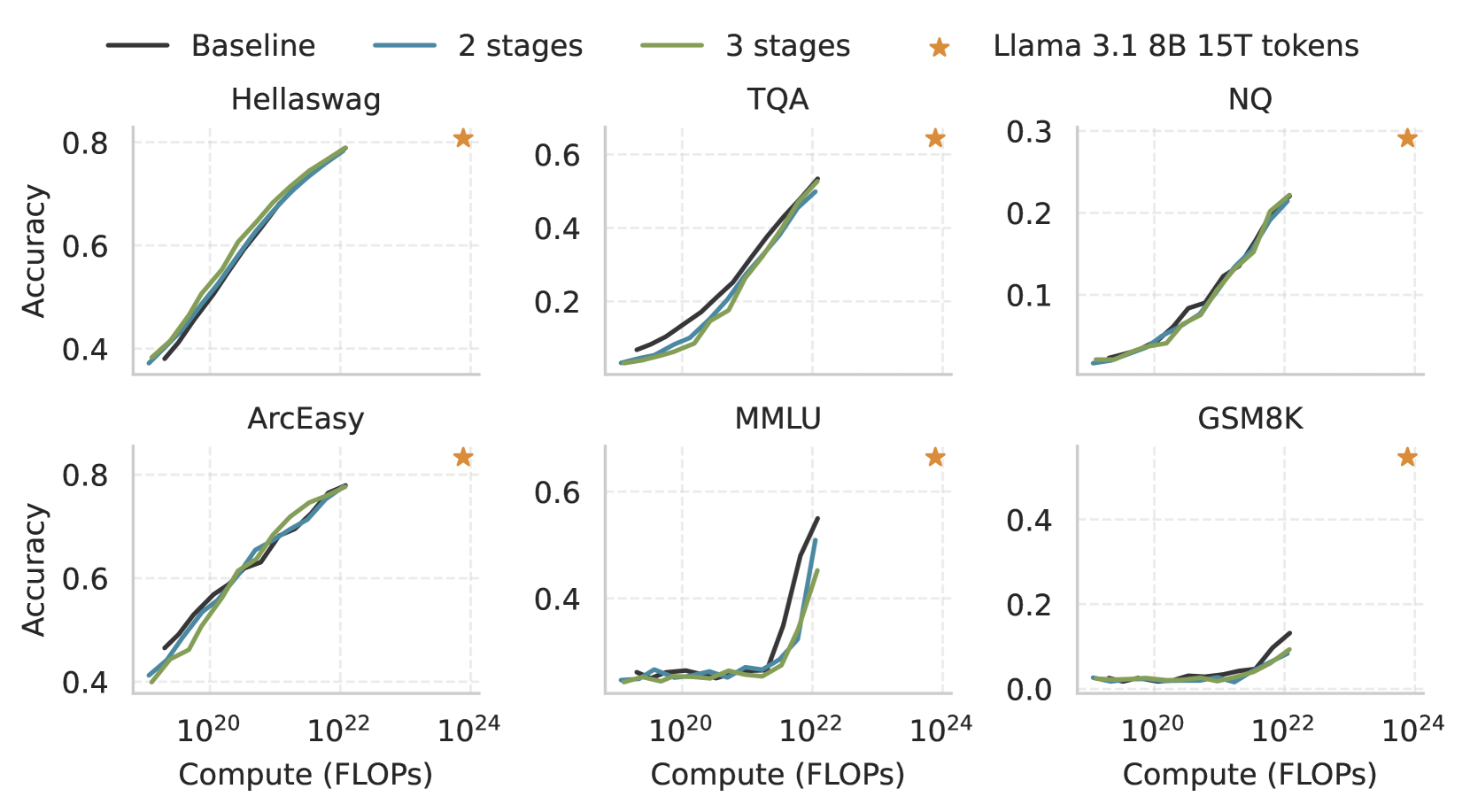
그림 3 캡션:
다운스트림 과제 성능이 연산량(1e19 ~ 1e22 FLOPs)에 따라 스케일링되는 모습. AU-Net(2단계 / 3단계)은 일반적으로 강력한 BPE Transformer 기준선과 유사하게 성능이 상승하며, 이 기준선은 LLaMA 3.1 8B 모델(15T 토큰, 연산량 100배 이상)과도 경쟁이 가능하다.
AU-Net은 Hellaswag, ARC-Easy와 같은 작업에서 기준선과 대등하며, TQA는 더 많은 연산량에서 따라잡는다. 다만, MMLU 및 GSM8K에서는 성능 상승 시작점이 더 늦게 나타나는 경향이 있다. 또한 GSM8K 성능 저하는 DCLM 사전학습 데이터셋 내에 수학 데이터가 제한적이라는 점과 관련되어 있다.
3.3 스케일링 법칙 (Scaling Laws)
학습률과 배치 크기 공식(2.3절 참고)을 사용하여, 우리는 1e19에서 1e22 FLOP에 이르는 다양한 연산량(compute budget)에 대해 사전학습을 수행했다. 이는 약 1억 5천만(150M)에서 53억(5.3B)개의 임베딩을 제외한 파라미터를 가진 모델에 해당하며,
데이터-대-모델 비율(data-to-model ratio)은 10으로 설정되었다. 이는 Kaplan et al. (2020)에서 제시한 최적 비율의 약 2배에 해당한다.
각 연산 예산에 따라 선택된 모델 목록은 부록 12(Appendix 12)에 자세히 나와 있다. 그림 3은 AU-Net과 BPE 기준 모델의 다운스트림 작업 6개에 대한 성능 변화 추이를 보여준다.
여기서 주요하게 관찰되는 사실은 다음과 같다:
- 2단계 및 3단계 AU-Net 모델은 연산량을 엄격히 통제할 경우, BPE 기준선과 동등한 성능을 달성할 수 있다.
→ 예: Hellaswag, ARC-Easy, NQ - TQA의 경우, AU-Net(2단계, 3단계 모두)은 초기에는 성능 차이가 존재하지만,
→ 3단계 모델은 1e22 FLOP 수준에서 성능을 따라잡는다. - 반면, GSM8K와 MMLU에서는 1e22 FLOP 수준에서도
→ AU-Net(2/3단계) 모델 모두 BPE 기준 모델에 미치지 못한다.
대부분의 다운스트림 작업은 시그모이드(s-shaped) 패턴을 따른다:
- 초기에는 성능이 거의 랜덤 수준이다가,
- 연산량이 증가하면 급격히 향상되고,
- 이후 일정 수준에서 성능이 평평하게 수렴(plateau)하는 경향.
특히 GSM8K와 MMLU와 같은 작업에서는
→ AU-Net 모델의 성능 전환 지점이 다소 늦게 나타나며,
→ 이는 깊은 계층 구조의 이점이 더 큰 스케일에서 두드러질 수 있음을 시사한다.
그럼에도 불구하고, 많은 벤치마크에서 우리의 AU-Net 모델들과 BPE 기준선 모두
→ LLaMA 3.1 8B와 매우 근접한 성능을 달성하였다.
(LLaMA 3.1 8B는 15조 토큰으로 사전학습되었으며, 이는 본 논문에서 실험한 가장 큰 모델보다 100배 더 많은 연산량에 해당)
이러한 근접성은 BPE 기준선의 강력함을 보여주며,
→ AU-Net이 이를 따라잡거나 근접하는 성능을 보인다는 점은 특히 주목할 만하다.
다만, GSM8K는 예외적으로 AU-Net이 기준선과의 격차가 확연히 드러나는 과제이며,
→ 이는 모든 모델에서 일관되게 관찰되므로,
→ 사전학습 코퍼스의 특성(DCLM 내 수학 데이터 부족)에 기인한 것으로 추정된다.
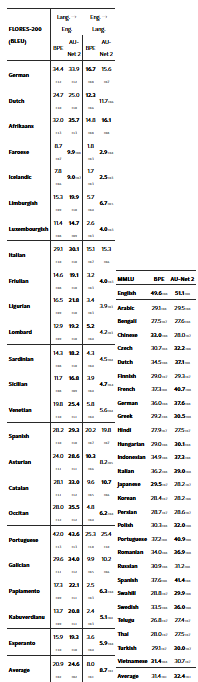
표 3: 다국어 평가 결과
- 왼쪽: FLORES-200 벤치마크에서의 BLEU 점수 (여러 언어에 걸친 번역 품질 측정)
→ 점수가 높을수록 더 나은 번역 성능을 의미 - 오른쪽: MMLU 정확도(Exact Match, %), 26개 비영어 언어에 대해 측정
→ 모든 작업에 대해 언어별 평균 성능을 보고함
3.4 확장된 평가 (Extended Evaluations)
우리는 AU-Net의 바이트 수준 학습(byte-level training)이 BPE 기반 Transformer에 비해 가지는 두 가지 주요 이점에 주목한 평가 결과를 제시한다:
- 다국어 벤치마크에서의 향상된 성능 (표 3 및 3)
- 문자 수준 조작 과제에서의 강점 (부록 10의 표 7)
표 3 및 표 3에서 확인할 수 있듯, 모델들이 대부분 영어로 구성된 학습 코퍼스(DCLM)를 사용했음에도 불구하고, 비영어 언어에서도 놀라울 정도로 좋은 성능을 보인다.
언어 계열 내의 교차 언어 일반화(Cross-lingual generalization)
다국어 MMLU 벤치마크(표 3 오른쪽)에서는 라틴 문자(Latin script)를 사용하는 언어들이 일관되게 바이트 수준 모델링의 이점을 받는다. 우리는 관련 언어 간의 강력한 전이 효과(positive transfer)를 관찰하였다.
예를 들어:
- 게르만계 언어 (독일어, 스웨덴어, 네덜란드어 등)는 평균 +3.0포인트 향상
- 로망스어 계열 (이탈리아어, 스페인어, 포르투갈어, 프랑스어 등)는 약 +4.0포인트 향상
이러한 결과는 바이트 수준에서 작동하는 모델이 철자적(orthographic)·형태론적(morphological) 패턴을 공유하는 언어들 간의 특징을 잘 포착할 수 있음을 시사한다.
저자원 언어에 대한 전이(Transfer to low-resource languages)
FLORES-200 벤치마크(표 3 왼쪽)는 학습 데이터에 거의 포함되지 않았거나 전혀 포함되지 않은 저자원 언어 및 지역 언어들을 다룬다. 이 설정은 서브워드 형태소(subword morphology)나 공통된 언어학적 뿌리에 기반해 모델이 얼마나 일반화할 수 있는지를 테스트할 수 있게 해준다.
바이트 수준 모델링은 다음과 같은 장점을 제공한다:
- 해당 언어가 토크나이저나 학습 코퍼스에 포함되어 있지 않아도 의미 있는 표현을 생성할 수 있는 유연성
- 특히 영어로 번역하는 작업에서는 소스 언어 이해가 핵심이기 때문에, 일관된 성능 향상이 관찰됨
- 동일 계열의 강세 언어(예: 프랑스어 등)와 통사론(syntax)이나 형태론(morphology)을 공유하는 언어일수록 이점이 더 뚜렷함
- 학습 중 등장하지 않은 OOV(어휘 밖) 단어에 대해서도 의미 있는 번역을 생성할 수 있음 → 모델의 강건성(robustness)을 강조
반면, 영어 → 저자원 언어 방향으로의 생성은 여전히 더 도전적인 과제로 남아 있다.
4 관련 연구 (Related Work)
전통적인 토크나이제이션(tokenization) 방식은 연산 효율성 측면에서 여전히 중요하다(Ali et al., 2024; Rajaraman et al., 2024; Gu et al., 2024; Lester et al., 2024). 그러나 이들은 고정된 세분화 수준(fixed granularity)을 강제한다는 한계가 있다. 이러한 경직성을 극복하려는 초기 시도들은 적응형 어휘(adaptive vocabularies)(Zheng et al., 2024), n-그램 조합(n-gram combinations)(Deiseroth et al., 2024), 또는 엔트로피 기반 분할 기준(entropy-based splitting)(Pagnoni et al., 2024) 등을 탐색해왔다.
본 연구에서 제안한 AU-Net은 이보다 한 걸음 더 나아가, 토크나이제이션과 표현 학습(representation learning)을 통합한 다단계(multi-level)의 오토리그레시브 U-Net 구조를 제안하며, 원시 바이트(raw bytes)에서 직접 작동하는 것이 핵심이다.
AU-Net의 계층적(hierarchical)이며 적응형 풀링(adaptive pooling) 기반 설계는 기존 연구들과 명확히 구분된다. 예를 들어, Megabytes(Yu et al., 2023)는 로컬 모델을 사용하는 2단계 LLM을 제안했지만, 고정 크기 토큰 블록을 사용한다는 점에서 입력에 적응하는 AU-Net의 풀링 방식과는 다르다.
또한,
- Neitemeier et al. (2025),
- Byte Latent Transformers (BLT) (Pagnoni et al., 2024),
- SpaceByte (Slagle, 2024) 역시 바이트 단위 처리 또는 특수 분할 함수를 사용하지만,
→ 이들은 대부분 단일 처리 단계에서 BPE를 대체하거나, 로컬 어텐션(local attention)을 사용한다.
반면, AU-Net은 사용자 정의 분할(user-defined splits)을 활용하여,
→ 각 단계마다 다른 풀링 전략을 사용하는 다단계 아키텍처를 구축하며,
→ 이는 Nawrot et al. (2022), Pagnoni et al. (2024)에서 사용하는 cross-attention 방식과도 다르다.
참고로 Nawrot et al. (2022)은 유사한 U-Net 구조를 제안했으나,
- 풀링 방식이 고정되어 있으며,
- 모델 크기가 훨씬 작고,
- 평가 기준도 perplexity 위주였다.
5 결론 (Conclusion)
이 논문에서는 AU-Net을 소개하였다. 이는 원시 바이트(raw bytes)를 입력으로 받아 계층적인 토큰 표현(hierarchical token representations)을 학습하는 오토리그레시브 U-Net이다.
AU-Net은 바이트를 단어 및 다단어 청크(multi-word chunks)로 동적으로 풀링함으로써,
→ 사전 정의된 어휘(vocabulary)나 대규모 임베딩 테이블의 필요성을 없앤다.
실험 결과,
- AU-Net은 제한된 연산 예산 하에서 강력한 BPE 기준 모델과 동등한 성능을 보이며,
- 더 깊은 계층 구조일수록 유망한 스케일링 경향을 나타낸다.
또한,
- 바이트 단위 연산 방식 덕분에 문자 수준 작업에서 더 나은 성능을 보이며,
- 저자원 언어(low-resource languages)에 대한 일반화 능력도 향상된다.
이러한 접근 방식은 기존 토크나이제이션 방법에 대한 유연하고 효율적인 대안을 제공하며,
→ 더 적응력 있고 다양한 언어 모델을 위한 기반을 마련한다.
한계점과 후속 연구 방향 (Limitations and Further Work)
- 본 연구는 영어 전용 데이터셋인 DCLM을 사용하였다.
→ 따라서 공백(space)을 기준으로 하지 않는 언어들, 예: 중국어 등은 직접적으로 지원되지 않으며,
→ 사전 정의된 분할 함수(splitting function)가 필요하다는 제한이 있다. - 실제로 중국어 MMLU 점수는 BPE 기준 모델보다 낮게 나타났다.
- 하나의 확장 방향은 분할 함수를 모델이 직접 학습하도록 설계하는 것이다.
- 소프트웨어 측면에서는,
→ 계층 수(stage 수)가 증가함에 따라 모델 파라미터 수가 늘어나고,
→ FSDP(Fully Sharded Data Parallelism)는 3~4단계에서도 계산-통신 오버랩에 어려움을 겪는다.
→ 충분한 입력 시퀀스 길이가 있어야 오버랩이 완전히 가능하다는 실용적 제약도 존재한다.
'인공지능' 카테고리의 다른 글
| OmniGen2: Exploration to Advanced Multimodal Generation (3) | 2025.07.02 |
|---|---|
| Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought (4) | 2025.07.01 |
| STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis (2) | 2025.06.17 |
| How much do language models memorize? (8) | 2025.06.13 |
| XXt Can Be Faster (4) | 2025.06.07 |



