https://github.com/VectorSpaceLab/OmniGen2
GitHub - VectorSpaceLab/OmniGen2: OmniGen2: Exploration to Advanced Multimodal Generation.
OmniGen2: Exploration to Advanced Multimodal Generation. - VectorSpaceLab/OmniGen2
github.com
https://arxiv.org/abs/2506.18871
OmniGen2: Exploration to Advanced Multimodal Generation
In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features t
arxiv.org
초록
본 연구에서는 텍스트-투-이미지, 이미지 편집, 문맥 기반 생성 등 다양한 생성 작업을 위한 통합 솔루션을 제공하는 다재다능하고 오픈소스인 생성 모델인 OmniGen2를 소개한다. 기존 OmniGen과 달리, OmniGen2는 텍스트와 이미지 모달리티를 위한 두 개의 독립적인 디코딩 경로를 갖추고 있으며, 공유되지 않은 파라미터와 분리된 이미지 토크나이저(decoupled image tokenizer)를 사용한다. 이러한 설계는 기존 멀티모달 이해 모델을 기반으로 하면서도 VAE 입력을 다시 적응시킬 필요 없이 사용할 수 있도록 하여, 원래의 텍스트 생성 능력을 유지할 수 있게 한다.
OmniGen2의 학습을 위해, 우리는 이미지 편집 및 문맥 기반 생성 데이터를 포함하는 포괄적인 데이터 구축 파이프라인을 개발하였다. 또한 이미지 생성 작업에 특화된 리플렉션 메커니즘(reflection mechanism)을 도입하고, OmniGen2 기반으로 구성된 전용 리플렉션 데이터셋도 함께 구축하였다.
OmniGen2는 비교적 작은 파라미터 수를 가짐에도 불구하고 텍스트-투-이미지 및 이미지 편집을 포함한 여러 작업 벤치마크에서 경쟁력 있는 성능을 보인다. 문맥 기반 생성(in-context generation), 즉 주제 기반(subject-driven) 작업의 성능을 보다 체계적으로 평가하기 위해, 우리는 새로운 벤치마크인 OmniContext를 제안한다. OmniGen2는 일관성(consistency) 측면에서 오픈소스 모델 중 최고 수준의 성능을 달성하였다.
본 연구에서는 향후 관련 연구를 지원하기 위해 모델, 학습 코드, 데이터셋, 데이터 구축 파이프라인 전반을 공개할 예정이다.
- 프로젝트 페이지: https://vectorspacelab.github.io/OmniGen2
- GitHub 링크: https://github.com/VectorSpaceLab/OmniGen2
1. 서론

OmniGen2와 리플렉션 모델이 갖는 다재다능한 능력 개요
최근 몇 년간 통합 이미지 생성(unified image generation)은 큰 주목을 받아왔다 [80; 92; 73; 48]. 예를 들어, OmniGen [80]은 별도의 플러그인이나 전처리기 없이 다양한 이미지 생성 작업을 수행할 수 있는 간결한 트랜스포머(Transformer) 아키텍처를 제안하였다. 최근 Gemini-2.0-flash [22], GPT-4o [53] 등의 모델이 등장하면서 이 분야의 잠재력이 더욱 부각되었고, 전문화된 모델들 [3; 33]에서 강력하고 통합된 시스템으로 패러다임이 전환되고 있다. 예컨대 Chameleon [72], Emu3 [76]는 모든 모달리티에 걸쳐 이산 자기회귀(discrete autoregressive) 방식을 사용하고, Janus 시리즈 [78; 11]는 이해 및 생성 작업을 위한 이중 이미지 인코더를 도입하였다. Transfusion은 자기회귀와 확산(diffusion) 과정을 하나의 Transformer 프레임워크 내에서 결합한다. 그러나 이들 모델이 실제로 지원하는 이미지 생성 작업의 범위는 여전히 제한적이다.
이 논문에서는, 다양한 생성 작업에 대해 경쟁력 있는 성능을 보여주는 오픈소스 생성 모델 OmniGen2를 소개한다. 기존 모델인 OmniGen [80]과 달리, 우리의 관찰에 따르면 단순한 파라미터 공유만으로는 자기회귀 기반 텍스트 모델링과 확산 기반 이미지 모델링을 동시에 처리하기에 충분하지 않다. 이를 해결하기 위해, OmniGen2는 자기회귀 작업과 확산 작업을 위한 별도의 아키텍처 경로(distinct architectural pathways)를 채택하였다.
GPT-4o [53]와 같은 모델들이 뛰어난 프롬프트 처리 능력을 보이지만, 정밀한 이미지 편집이나 문맥 기반 생성(in-context generation)에서의 일관성(consistency)은 부족한 경우가 많다. 우리는 이러한 일관성 결여가, 고수준 의미 정보(semantic information)에만 의존하는 인코더 기반 모델의 구조적 한계에서 기인한다고 추측한다. 이들은 세밀한 시각적 정보를 잘 포착하지 못하기 때문이다. 이를 보완하기 위해, OmniGen2는 저수준 시각 정보를 위한 VAE 기반 특징(VAE features)을 활용하는 기존 전략을 강화하였다.
최근 Mogao [40], BAGEL [13] 등의 모델들도 텍스트와 이미지 모달리티에 대해 파라미터를 공유하지 않고, 이미지 처리를 위해 VAE [31]와 ViT [15]라는 이중 비전 토크나이저를 사용하는 방식이 시도되고 있다. 그러나 OmniGen2는 이들과 달리, VAE에서 추출된 특징을 MLLM(Multimodal Large Language Model)이 아닌, 오직 확산 모델로만 전달한다. 이러한 설계는 VAE 인코딩의 영향을 피함으로써 MLLM의 본래 멀티모달 이해 능력을 유지하고, 중복된 이미지 표현을 줄이는 효과도 있다. 결과적으로, OmniGen2는 원래의 MLLM이 갖는 단순한 구조와 강력한 텍스트 생성 능력을 유지할 수 있다.
우리는 모델 설계 외에도, 이 분야의 발전을 저해하는 데이터와 평가의 근본적 문제에 주목하였다. 먼저, 관련된 오픈소스 데이터셋을 수집하고 재구성하였지만, 이미지 편집과 문맥 기반 생성 작업에서는 품질 한계가 뚜렷하게 존재한다. 이러한 한계는 상용 모델 대비 오픈소스 모델의 성능 격차를 만드는 주된 요인이기도 하다. 이에 우리는 비디오 소스를 기반으로 이미지 편집 및 문맥 기반 데이터셋을 생성하는 포괄적인 파이프라인을 구축하였으며, 이를 커뮤니티에 공개할 계획이다. 추가로, 생성과정을 반복하며 이미지 생성에 대한 반성(reflection) 데이터를 구축하였으며, 이는 LLM의 추론 및 반성 능력을 멀티모달 생성에 통합하려는 목적을 가진다.
OmniGen2에 대한 광범위한 실험 결과, 텍스트-투-이미지(T2I), 이미지 편집, 문맥 기반 생성 등의 다양한 작업에서 경쟁력 있는 성능을 보였다. 특히 문맥 기반 생성 작업은 현재까지도 모델 간의 핵심 능력을 체계적으로 비교할 수 있는 퍼블릭 리더보드가 부족한 상황이다. 예컨대 DreamBench [64]와 같은 기존 벤치마크는 실제 시나리오의 복잡성을 충분히 반영하지 못한다. 이에 우리는 새로운 벤치마크인 OmniContext를 제안하며, 개인, 객체, 장면 등의 일관성을 평가할 수 있도록 8개의 과제 유형을 포함하고 있다. 실험 결과, OmniGen2는 오픈소스 모델 중에서 일관성 면에서 최고 성능을 달성하였다.
본 연구의 주요 기여는 다음과 같다:
- OmniGen2를 오픈소스로 공개하며, 다양한 이미지 생성 작업에서 탁월한 성능을 보여주는 강력한 멀티모달 생성 모델을 제시하였다. 텍스트 생성 성능 또한 유지되며, 여기에 멀티모달 리플렉션 메커니즘 적용을 확장하였다.
- 고급 이미지 편집 및 문맥 기반 학습 작업에서 데이터 부족 문제를 해결하기 위해, 비디오 기반 고품질 데이터셋을 생성하는 새로운 데이터 생성 파이프라인을 설계하고 구현하였다.
- OmniContext 벤치마크를 통해, 다양한 시나리오에서 문맥 기반 시각 생성 능력을 엄격하게 측정하고 표준화할 수 있는 포괄적인 평가 도구를 제안하였다.
또한, 중요한 점은 OmniGen2의 텍스트 생성 능력이 전체 모델의 엔드투엔드 학습 결과가 아니라, 분리된 구조 내 MLLM 구성 요소에서 비롯된다는 점이다. (단, 특수 토큰이 삽입된 점을 제외하고) MLLM 자체는 OmniGen2 베이스 모델에서 엔드투엔드로 전체 파라미터 학습되지는 않는다. 전체 파라미터의 엔드투엔드 학습은 오직 리플렉션 모델에서만 수행된다. 따라서 OmniGen2는 텍스트와 이미지를 동시에 출력할 수 있는 멀티모달 생성 모델로 간주되어야 하며, 원천적으로 멀티모달로 설계된 모델은 아니다.
2. 모델

그림 2 OmniGen2의 아키텍처
OmniGen2는 자기회귀(autoregressive)와 확산(diffusion)을 위해 서로 분리된 트랜스포머 아키텍처를 사용한다. 또한 두 개의 이미지 인코더가 활용되며, ViT는 텍스트 트랜스포머에 입력될 이미지를 인코딩하고, VAE는 확산 트랜스포머에 입력될 이미지를 인코딩한다.
2.1 설계 원칙 (Design Principle)
기존 OmniGen [80] 프레임워크에서는, 텍스트 생성을 위해 자기회귀 모델링(autoregressive modeling)을, 이미지 생성을 위해 확산 기반(diffusion-based) 방식을 채택하였으며, 두 작업 모두 phi-3 [1]로 초기화된 트랜스포머 아키텍처 내에서 구현되었다.
OmniGen 발표 이후, 우리는 여러 후속 실험을 진행하였다.
첫째, phi-3를 더 강력한 Qwen 모델로 교체해보았는데, 더 우수한 LLM을 사용했음에도 불구하고 이미지 생성 품질이 하락하는 결과를 얻었다.
둘째, LMfusion [68]과 유사한 방식으로 텍스트와 이미지의 파라미터를 독립적으로 라우팅하는 MoE(Mixture-of-Experts) 전략을 실험하였다. 그러나 이미지 브랜치를 텍스트 브랜치에서 가져온 파라미터로 초기화할 경우, 랜덤 초기화한 경우보다 오히려 성능이 저조하였다.
이러한 결과는 텍스트에 최적화된 파라미터는 이미지 모델링에는 적합하지 않다는 사실을 시사한다. 따라서 OmniGen2에서는 확산 과정을 분리(decouple)하고, 해당 파라미터를 랜덤으로 초기화하는 방식을 채택하였다.
최근의 MetaQuery [55] 및 BLIP-3o [7]와 같은 접근법은, 확산 기반 생성에서 조건 정보를 인코딩하기 위해 학습 가능한 쿼리 토큰(query token)을 활용한다. 그러나 이 방식은 모든 조건 정보를 고정된 수의 토큰에 압축함으로써, 표현력 한계 및 정보 손실 문제를 초래한다. 또한, 이러한 쿼리 토큰 기반 압축은 긴 텍스트를 처리하는 데 어려움이 있는 것으로 나타났다.
이에 OmniGen2는 고정된 쿼리 토큰 집합에 의존하는 대신, MLLM이 생성한 멀티모달 조건의 hidden state를 확산 디코더의 입력으로 활용한다. 향후 연구 방향으로는, 조건의 hidden state와 쿼리 토큰을 결합하는 방법을 고려할 수 있다.
또 하나의 중요한 고려 사항은 VAE 인코더의 통합 방식이다.
기존 MLLM들은 대부분 이미지 모델링에 ViT(Vision Transformer)를 사용하지만, ViT는 세밀한 시각 정보를 잘 포착하지 못해 이미지 생성 시 화질이 저하되는 한계가 있다. ViT 특징을 end-to-end로 학습하면 이 문제를 일부 완화할 수 있지만, 이는 이미지 이해와 생성 간의 균형을 맞추는 데 추가적인 복잡성을 초래한다.
최근 BAGEL [13], Mogao [40]는 이 문제를 해결하기 위해, 이미지에 대해 VAE와 ViT를 동시에 인코딩하는 이중 인코딩 전략을 채택하였다. 그러나 이러한 방식은 구조적인 대대적인 수정 및 복잡한 어텐션 메커니즘 도입이 필요하며, 모델의 이미지 이해 능력을 복구하기 위한 재학습(retraining)이 필수적이다.
이러한 여러 문제를 고려하여, OmniGen2는 VAE를 오직 확산 디코더의 입력으로만 사용하고, MLLM 자체에는 통합하지 않는 전략을 택하였다. 이로써 MLLM의 구조적 단순성을 유지하면서도, 멀티모달 이해 능력을 추가적인 재학습 없이 보존할 수 있다.
2.2 멀티모달 대형 언어 모델 (Multimodal Large Language Model)
그림 2에서 보이는 바와 같이, OmniGen2는 기본 MLLM 트랜스포머를 활용하여 텍스트와 이미지 입력을 모두 처리한다. 텍스트 생성 작업에는 자기회귀 언어 헤드(autoregressive language head)가 사용되며, 이미지 생성은 전용 확산 모듈(diffusion module)을 통해 수행된다.
트랜스포머 백본은 Qwen2.5-VL-3B [3]로 초기화되며, 출력 시퀀스 내에서 이미지 생성을 명시적으로 지시하기 위해 특수 토큰 “<|img|>”이 도입된다. 모델이 이 토큰을 만나면, 확산 디코더(diffusion decoder)가 작동하여 해당 이미지를 합성하게 된다.
MLLM이 생성한 hidden state는 확산 디코더의 조건 입력(conditional input)으로 활용된다. 그러나 이러한 hidden state는 세밀한 시각 정보를 충분히 담지 못할 수 있으므로, 이를 보완하기 위해 입력 이미지에서 추출한 VAE 기반 특징(VAE-derived features)을 디코더에 추가로 제공한다. 이후 확산 디코더는 rectified flow (RF) 방식을 사용하여 이미지를 생성한다.

그림 3 Omni-RoPE의 개념도
Omni-RoPE는 위치 정보를 다음의 세 가지 요소로 분해한다:
- Sequence 및 모달리티 식별자 (id_seq):
하나의 이미지를 하나의 의미 단위(semantic unit)로 간주하여, 해당 이미지 내의 모든 토큰에 공통된 ID를 부여한다. 단, 서로 다른 이미지 간에는 고유한 ID를 가진다. - 2차원 공간 좌표 (h, w):
- h: 이미지 토큰의 수직 좌표 (height)를 나타내며, 각 이미지 내에서 (0,0) 기준으로 로컬하게 계산된다.
- w: 이미지 토큰의 수평 좌표 (width)를 나타내며, 마찬가지로 로컬 기준으로 산출된다.
이 이중 위치 메커니즘은, 각 이미지가 고유한 id_seq를 가지게 하여 서로 다른 이미지를 명확하게 구분하도록 돕는다. 동시에, 공유된 로컬 공간 좌표(h, w)는 이미지 편집과 같은 작업에서 일관성과 변경되지 않은 영역의 보존을 향상시킨다.
2.3 확산 트랜스포머 (Diffusion Transformer)
그림 2에서 나타나듯이, 우리는 MLLM, VAE, 노이즈로부터 추출된 특징들을 직접 연결(concatenate)하여 이들 모달리티에 대해 공동 attention을 수행하는 단순한 확산 트랜스포머 아키텍처를 사용한다.
Lumina-Image 2.0 [57]를 따라, 여러 입력 조건들은 먼저 정렬(alignment)을 보장하기 위해 refiner 네트워크를 거쳐 처리된 뒤 트랜스포머 레이어로 전달된다.
확산 디코더는 총 32개 레이어, 2520의 hidden size, 약 40억 개의 파라미터로 구성된다.
VAE 특징이 명시적으로 통합되어 있기 때문에, MLLM 내 이미지 관련 hidden state의 중요도는 낮아진다. 이에 따라 계산 비용을 줄이기 위해, 우리는 MLLM에서 텍스트 토큰과 관련된 hidden state만 유지하고, 이미지 관련 hidden state는 제거한다.
또한 확산 트랜스포머에는 Qwen mRoPE를 확장한 3D 로터리 위치 임베딩(3D Rotary Position Embedding)이 도입되었다.
멀티모달 로터리 위치 임베딩 (Multimodal Rotary Position Embedding)
최근 멀티모달 위치 임베딩 설계의 발전 [75; 57; 71]에서 영감을 받아, OmniGen2는 복잡하고 다양한 작업, 특히 이미지 편집 및 문맥 기반 생성을 위한 새로운 Omni-RoPE를 설계하였다. 그림 3에 설명된 바와 같이, Omni-RoPE는 다음의 세 가지 구성 요소로 분해된다:
- 시퀀스 및 모달리티 식별자 (id_seq)
- 서로 다른 모달리티 및 시퀀스의 토큰을 구분하는 데 사용된다.
- 각 이미지를 하나의 완전한 의미 단위(semantic unit)로 간주하며, 해당 이미지에 속한 모든 토큰은 공통된 ID를 부여받는다.
- 반면 텍스트 토큰의 경우, 이 ID는 단조롭게 증가하여 표준 1D 위치 인덱스처럼 작동하며, 단어 순서를 보존한다.
- 이 구성 요소는 Qwen2-VL [75]의 기존 mRoPE와 동일하다.
- 2D 공간 세로 좌표 (h)
- 이미지 토큰의 정규화된 수직 위치(height)를 나타낸다.
- 2D 공간 가로 좌표 (w)
- 이미지 토큰의 정규화된 수평 위치(width)를 나타낸다.
- 이미지가 아닌 토큰의 경우, (h, w)는 모두 0으로 설정된다.
이 설계의 핵심은 이 세 구성 요소가 어떻게 조화롭게 작동하느냐에 있다. 각 이미지 단위(소스 이미지든 타깃 이미지든)마다, 공간 좌표 (h, w)는 독립적으로 (0,0)부터 계산되며, 동일 위치에 있는 토큰들은 동일한 공간 임베딩을 공유한다. 이는 편집 과정에서의 일관성 유지 및 변경되지 않은 영역의 보존을 강하게 유도한다.
한편, 공간 좌표는 로컬하게 정의되지만, id_seq는 서로 다른 이미지들을 명확히 구분할 수 있게 해준다.
이와 같이 통합적으로 설계된 Omni-RoPE는, 텍스트 전용 입력일 경우 자연스럽게 표준 1D 위치 임베딩으로 축소되므로, 멀티모달 작업 전반을 유연하고 견고하게 지원하는 프레임워크가 된다.

그림 4 이미지 생성을 위한 멀티모달 리플렉션(Multimodal Reflection)의 개념도
2.4 학습 전략 (Training Strategy)
MLLM은 Qwen2.5-VL-3B-Instruct1로 초기화되며, 멀티모달 이해 능력을 유지하기 위해 대부분의 파라미터는 학습 중 고정(frozen) 상태로 유지된다. 학습 과정에서 업데이트되는 것은 새롭게 도입된 특수 토큰 “<|img|>”뿐이다.
확산 모델은 처음부터 학습(train from scratch)되며, 먼저 텍스트-투-이미지(T2I) 생성 작업을 통해 초기 학습을 진행하고, 이후에는 다양한 목적을 수용하기 위한 다중 작업 혼합 학습 전략(mixed-task training strategy)을 적용한다.
리플렉션(reflection) 학습 단계에서는 모든 모델 파라미터를 언프리즈(unfreeze)하여, 모델이 텍스트 기반의 반성적 설명(reflective textual descriptions)을 생성하고, 이미지 출력을 반복적으로 개선(refine)할 수 있도록 한다 (그림 13 참조).
3. 데이터셋 구축 (Dataset Construction)
멀티모달 이해 과제에 대해서는 LLaVA-OneVision [35]에서 제공하는 데이터셋을 활용하였다.
텍스트-투-이미지(T2I) 생성 학습을 위해, 우리는 다음과 같은 공개 소스에서 수집한 약 1억 4천만 장의 이미지로 학습 코퍼스를 구성하였다:
- Recap-DataComp [37]
- SAM-LLaVA [8]
- ShareGPT4V [9]
- LAION-Aesthetic [65]
- ALLaVA-4V [6]
- DOCCI [50]
- DenseFusion [38]
- JourneyDB [69]
- BLIP3-o [7]
이와 더불어, Qwen2.5-VL-72B [3]를 이용하여 합성 어노테이션(synthetic annotation)을 생성한 1천만 장의 독자적인 이미지도 추가로 포함하였다.
이미지 편집(image editing) 작업을 위해서는 다음과 같은 공개 데이터셋들을 수집하였다:
- SEED-Data-Edit [19]
- UltraEdit [91]
- OmniEdit [77]
- PromptFix [86]
- ImgEdit [83]
그러나 이러한 오픈소스 데이터셋들은 종종 이미지 품질이 낮거나, 지시문 정확성이 부족하거나, 작업 다양성이 떨어지는 한계를 지닌다.
이러한 제약을 극복하고 본 연구의 목적에 더 부합하는 데이터셋을 확보하기 위해, 우리는 새롭고 포괄적인 학습용 데이터셋을 정교하게 구축하였다.
다음 절에서는 우리의 데이터 구축 파이프라인에 대해 자세히 설명한다.
3.1 문맥 기반 데이터 (In-Context Data)
문맥 기반 이미지 생성(in-context image generation) 작업 [79; 82; 34; 71]은 입력 이미지로부터 특정 객체, 정체성(identity), 혹은 개인(individual)과 같은 시각적 개념을 추출하고, 이를 새롭게 생성된 이미지 내에 정확히 재현하는 데 중점을 둔다.
이러한 작업은 subject-driven generation [64]이라고도 불리며, 대형 언어 모델에서의 문맥 학습(in-context learning)과 유사한 개념이다. 즉, 이미지 생성 모델은 추가적인 파인튜닝 없이, 주어진 문맥(context)만을 바탕으로 개인화된 출력을 실시간으로 생성한다.
문맥 기반 이미지 생성은 다양한 응용 가능성으로 인해 활발히 연구되고 있지만, 이 작업에 특화된 고품질 데이터셋은 여전히 부족하다는 점이 커뮤니티의 주요 과제로 남아 있다.
3.1.1 문맥 기반 생성 (In-Context Generation)

그림 5 문맥 기반 생성 데이터셋 구축 파이프라인.
최종 입력 이미지는 빨간 테두리로, 타깃 이미지는 파란 테두리로 표시되어 있다.
문맥 기반 생성 과제에서는, 하나의 객체가 다양한 상황에서 어떻게 나타나는지를 모델링할 수 있어야 한다. 이를 위해 우리는 동영상 데이터를 활용하는데, 이는 동일한 피사체(subject)를 시간 축을 따라 다양한 조건에서 자연스럽게 포착하기 때문이다. 이와 같은 시간적 다양성을 활용하면, 의미론적으로 동일하지만 자세, 시점, 조명 조건이 다른 학습용 이미지 쌍을 구성할 수 있다.
그림 5에 나타난 바와 같이, 우리의 데이터 파이프라인은 각 비디오에서 주요 프레임(keyframe)을 추출하고, 기준 프레임(base frame)을 지정하는 것으로 시작된다.
기준 프레임에서는 Qwen2.5-VL-7B-Instruct [3]의 비전-언어 기능을 활용하여 의미론적으로 핵심적인 피사체(subject)를 식별하고, 배경의 불필요한 객체는 필터링한다. 이후 GroundingDINO [45]를 사용하여, 해당 비전-언어 모델이 생성한 태그에 기반하여 피사체의 바운딩 박스를 얻는다.
다음으로, SAM2 [61]를 활용하여 이후 프레임들에서 피사체를 세분화(segment)하고 추적(track)하며, 모든 피사체가 여전히 포함된 가장 마지막 유효 프레임을 선택하여 시각적 다양성을 극대화한다.
추적 과정에서 시각적으로 유사하지만 잘못된 객체가 포함될 위험을 줄이기 위해, 우리는 VLM 기반 필터링 단계를 추가하여 피사체의 일관성(subject consistency)을 검증한다.
또한 시각적 다양성을 더욱 강화하기 위해, FLUX.1-Fill-dev[링크]를 사용하여 입력 프레임의 피사체를 새로운 배경으로 리페인팅(outpainting)한다.
생성된 이미지 중에서 피사체의 외형이 기준과 지나치게 달라진 경우를 걸러내기 위해, DINO [5] 기반 유사도 필터링을 적용하고, Qwen2.5-VL-7B-Instruct를 사용하여 샘플의 의미론적 품질과 일관성을 평가한다.
추가적으로, Qwen2.5-VL-7B-Instruct를 이용해 기준 이미지에 대해 간결한 객체 설명(object description)과 자세한 캡션(caption)을 생성하며, 이는 최종적으로 자연어 지시문(natural language instruction)에 통합된다.
최종 학습 데이터는 다음의 3요소로 구성된 학습 삼중항(training triplet)으로 구성된다:
- 지시문(instruction)
- 리페인팅된 입력 이미지
- 원본 타깃 이미지
이 구조는 의미론적으로 풍부하고, 시각적으로 다양한 감독 신호를 제공함으로써, 다중 피사체 생성 과제에서의 학습 품질을 높인다.
3.1.2 문맥 기반 편집 (In-Context Edit)

그림 6 문맥 기반 편집 데이터셋 구축 파이프라인.
최종 입력 이미지와 타깃 이미지는 그림 5와 동일하게 빨간색과 파란색 테두리로 각각 표시되어 있다.
우리는 문맥 기반 생성(in-context generation) 패러다임을 편집(editing) 작업으로 확장하여, 문맥 기반 편집(in-context editing)이라는 새로운 작업을 도입한다. 이 작업은 그림 6에 나타나 있으며, 모델이 문맥 이미지(context image)에서 관련 요소를 추출하고 이를 활용하여 입력 이미지(input image)를 편집하는 방식이다.
문맥 기반 편집에 사용되는 데이터 소스는 문맥 기반 생성과 유사하다. 즉, 동일한 객체를 포함한 두 개의 프레임을 선택하고, 하나는 문맥 클립(context clip), 다른 하나는 타깃 클립(target clip)으로 사용한다.
먼저, 두 프레임 모두에 대해 SAM2 [61]를 이용하여 객체 마스크(object mask)를 추출한다. 문맥 이미지에서는 FLUX.1-Fill-dev를 사용하여 객체를 새로운 배경 위에 리페인팅(outpainting)함으로써, 모델이 객체 고유의 특징에 주목하도록 유도한다.
그 다음, 동일한 FLUX.1-Fill-dev를 타깃 클립에 적용하여 객체를 제거하고 원래 배경은 그대로 보존하는 방식으로 입력 클립(input clip)을 생성한다.
마지막으로, Qwen2.5-VL-72B-Instruct [3]를 활용하여 입력 클립에서 타깃 클립으로의 변화를 자연어로 설명하는 지시문을 생성하며, 여기에 문맥 클립에서 생성된 객체 설명(object description)을 결합하여 완전한 자연어 지시문(comprehensive natural language instruction)을 구성한다.
3.2 이미지 편집 데이터 (Image Editing Data)
3.2.1 인페인팅 데이터 (Inpaint Data)
기존의 대부분 이미지 편집 데이터셋은 인페인팅(inpainting) 기법을 통해 구축되었지만, 다음과 같은 두 가지 주요 한계를 가진다:
- 낮은 이미지 품질:
- 원본 해상도가 낮고
- 인페인팅 과정에서의 후처리로 인해 품질이 더 저하됨
- 부정확한 편집 지시문:
- 이전 연구들은 편집 지시문을 미리 정의한 뒤, 이를 기반으로 인페인팅 모델로 이미지를 생성하였으나
- 인페인팅 모델은 지시문을 잘 따르지 못하는 경향이 있어,
- 결과적으로 지시문과 생성된 이미지 쌍 간에 불일치가 발생함
본 연구에서는 텍스트-투-이미지 데이터 중 고화질 이미지 소량을 선별하여 데이터 소스로 사용하고, 여기에 FLUX.1-Fill-dev를 적용해 인페인팅을 수행한다.
- 인페인팅된 이미지를 입력,
- 원본 이미지를 타깃으로 사용함으로써, 고품질의 타깃 이미지를 확보한다.
- 또한, 인페인팅 모델에는 어떠한 편집 지시문도 입력하지 않고, 내용을 무작위로 채우게 하여, 지시문 기반 생성 오류를 방지한다.
그 후, 생성된 이미지 쌍을 기반으로 MLLM을 활용해 편집 지시문을 작성한다.
우리는 Qwen2.5-VL과 같은 최신 MLLM이 원본-인페인팅 이미지 쌍에 대한 편집 지시문 생성에 매우 뛰어남을 확인했으며, 이를 통해 정확도가 높은 편집 데이터셋을 구축할 수 있었다.
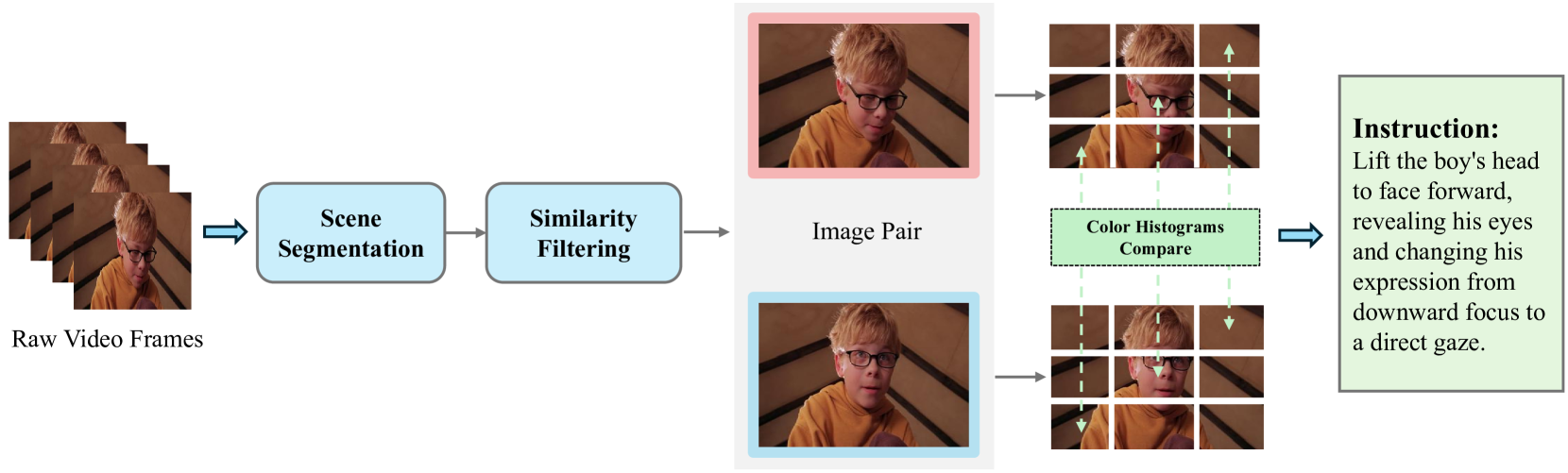
그림 7 비디오에서 이미지 편집 쌍을 생성하는 과정
먼저, 서로 다른 장면에 속하는 프레임들을 필터링하여 문맥적 일관성(contextual consistency)을 확보한 뒤, 시점(viewpoint)이 크게 바뀐 프레임도 제거한다.
3.2.2 비디오 기반 데이터 (Video Data)
기존의 인페인팅 기반 기법은 동작 수정(action modification), 객체 이동(object movement), 표정 변화(expression changes) 등과 같은 다양한 유형의 편집 작업을 생성하는 데 한계가 있다. 이러한 제약을 극복하기 위해, 우리는 비디오 소스로부터 이미지 편집 쌍(editing pairs)을 추가로 추출하였다.
파이프라인은 그림 7에 제시되어 있다.
일반적인 이미지 편집 과제는 국소적인 수정(localized modification)만을 필요로 하며, 주변 문맥은 그대로 보존되어야 한다. 따라서 비디오에서 편집용 이미지 쌍을 구성하려면, 국소적인 변화만 포함된 프레임 쌍을 선별해야 한다.
이를 위해 먼저 비디오를 서로 다른 장면(scene) 단위로 분할한다.
- 장면 경계는 RGB 평균 픽셀 강도를 분석하여 탐지되며,
- HSV 색공간에서의 차이값에 대한 이동 평균을 함께 사용하여 빠른 움직임에 대한 견고성(robustness)도 확보한다.
각 장면 내에서 여러 프레임 쌍을 추출하고,
- DINOv2 [54] 및 CLIP [59]를 이용해 프레임 간 차이를 평가한다.
- 시점 변화(viewpoint change)를 암시하는 큰 차이가 있거나,
- 거의 변화가 없는 무의미한 쌍은 필터링한다.
하지만 하나의 장면 내에서도 카메라 시점이 종종 바뀌므로, 추가 정제가 필요하다.
- 기존의 비전-언어 모델 기반 방법은 계산 비용이 높고 정확도도 불안정하며,
- 색 히스토그램(color histogram)이나 픽셀 수준 유사도 기반 방법은 공간 구조에 둔감하거나 노이즈에 지나치게 민감하다.
이 문제를 해결하기 위해, 우리는 각 이미지를 여러 블록으로 분할하고,
- 각 대응 블록의 색 히스토그램을 비교함으로써 유사도를 평가한다.
- 이 방식은 노이즈의 영향을 줄이면서,
- 각 블록이 얼마나 유사한지를 비율로 계산하여,
- 시점 일관성(viewpoint consistency)의 신뢰도 있는 지표로 활용한다.
이 전략은 계산 효율성을 유지하면서도, 시점 변화가 있는 프레임 쌍을 효과적으로 걸러낸다.
마지막으로, 시점이 일관된 프레임 쌍에 대해 Qwen2.5-VL-72B-Instruct [3]를 사용하여 정확한 편집 지시문(editing instruction)을 생성함으로써, 고품질 이미지 편집 데이터셋을 구축할 수 있다.
3.3 인터리브 데이터 (Interleave Data)
3.3.1 인터리브 프레임 (Interleaved Frames)
먼저, 비디오를 장면 전환(scene transition) 기준으로 분할한 후, 각 구간에서 주요 프레임(key frame)을 추출한다. 이후, 최대 5장의 프레임으로 구성된 두 가지 유형의 프레임 시퀀스를 구축한다:
- 장면 내(inter-scene) 인터리브 시퀀스: 동일한 장면 내에서 추출된 프레임으로 구성
- 장면 간(intra-scene) 인터리브 시퀀스: 서로 다른 장면에서 추출된 프레임으로 구성
프레임 시퀀스를 구성한 뒤, 각 연속된 프레임 쌍에 대해 객체의 동작 및 행동 변화, 환경 및 배경 변화, 객체 외형의 차이 등을 설명하는 캡션을 MLLM을 통해 생성한다.
이때 필요한 어노테이션 양이 매우 많기 때문에, 우리는 경량 모델인 Qwen2.5-VL-7B-Instruct를 사용하여 효율적으로 처리하였다. 그 결과, 약 80만 개의 인터리브 데이터 샘플을 비디오 소스로부터 확보하였으며, 이는 모델의 연속적인 멀티모달 시퀀스 처리 능력을 사전 학습(pretrain)하는 데 사용된다.
3.3.2 리플렉션 데이터 (Reflection Data)
테스트 타임 스케일링(test-time scaling)과 자기 반성(self-reflection)을 통해 대형 언어 모델의 성능을 향상시키는 최근 연구들 [23; 28; 41]에 영감을 받아, 우리는 리플렉션(reflection) 능력을 멀티모달 생성 모델에 통합하는 방법을 탐색하였다. 특히, 테스트 시 반성 능력과 반복 학습이 이미지 생성 품질을 어떻게 개선할 수 있는지를 실험하였다.
이 절에서는 모델 파인튜닝에 사용되는 리플렉션 데이터의 구축 방법에 대해 설명한다.
리플렉션 데이터는 텍스트와 이미지가 교차된 시퀀스 형태로 구성되며, 다음과 같은 순서를 따른다:
- 사용자 지시문 (instruction)
- 모델이 생성한 이미지
- 생성 결과에 대한 단계별 자기 반성(step-by-step reflection)
각 반성은 다음 두 가지 핵심 요소를 포함한다:
- 원래 지시문과 비교하여 미흡하거나 부족한 부분에 대한 분석
- 이전 이미지의 한계를 해결하기 위한 구체적인 개선 방안
리플렉션 데이터를 구축하기 위해, 우리는 학습 데이터 중 텍스트-투-이미지(T2I) 데이터 일부를 선택하고 모델을 통해 이미지를 생성하였다. 이후, 생성된 이미지가 지시문을 충실히 반영하고 있는지를 평가하기 위해 MLLM을 활용한다.
- 만약 지시문 충실도가 낮거나 품질 문제를 보일 경우,
- 모델이 구체적인 오류를 식별하고,
- 수정 방안을 제시한다.
초기에는 DSG [12] 평가 프레임워크를 활용해 지시문-이미지 정렬 상태를 평가해보았으나, 환각(hallucination)이 빈번하게 발생하는 문제가 있었다.
이에 따라, 더 강력한 멀티모달 모델이 직접 이 작업을 수행할 수 있음을 발견하고, Doubao-1.5-pro [16]를 활용하여 문제점과 수정 제안을 추출하였다.
첫 번째 라운드의 리플렉션 결과가 확보되면, 생성된 이미지와 반성 내용을 원래 지시문과 함께 묶어 모델을 파인튜닝한다. 파인튜닝이 완료되면, 첫 번째 라운드의 데이터를 기반으로 다시 이미지를 생성하고, 두 번째 라운드의 반성 데이터를 구축한다. 이러한 반복적(iterative) 학습 과정을 통해 여러 라운드의 자기 반성 데이터(self-reflection data)가 생성된다.
현재까지 멀티모달 생성 모델에서 리플렉션 메커니즘을 통해 이미지 생성 품질을 개선하는 연구는 드물다. 우리는 본 연구가 멀티모달 생성 분야에서의 추론(reasoning) 능력 향상에 기여하길 기대한다.
모델이 현재 리플렉션 데이터를 통해 초기적인 반성 능력을 습득한 이후에는, 온라인 강화학습 알고리즘(online reinforcement learning)을 활용하여 이 능력을 더욱 향상시킬 수 있으며, 이는 향후 연구로 남겨둔다.
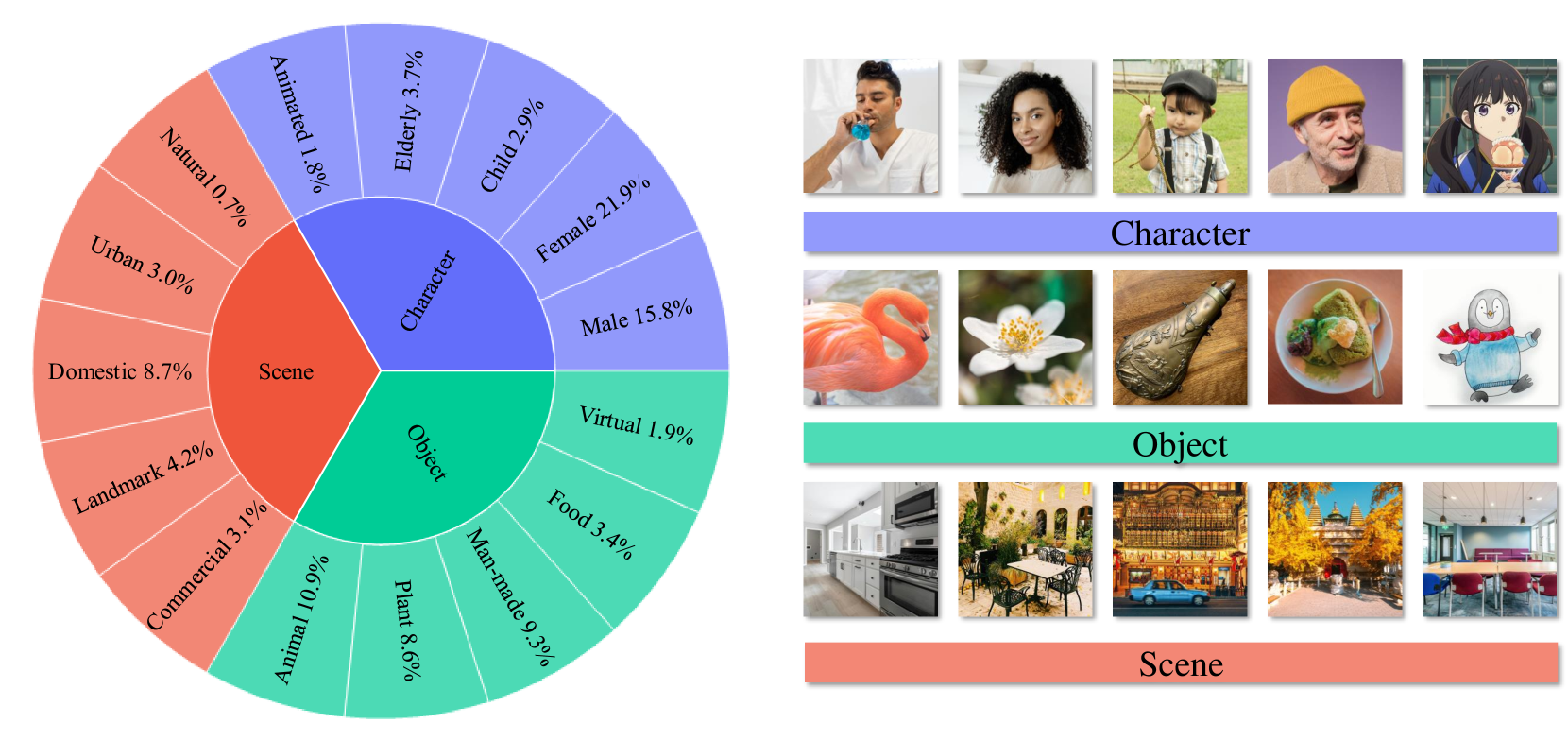
그림 8 OmniContext 벤치마크 개요
- 왼쪽: OmniContext에 포함된 이미지 장르들
- 오른쪽: 각 장르에 대한 예시 이미지들

그림 9 OmniContext 벤치마크에서 출력 이미지를 평가하는 예시
4. OmniContext 벤치마크
OmniGen2의 핵심 목표 중 하나는, 사용자가 제공한 특정 문맥 이미지(context image)에 대해 일관된 이미지 생성을 가능하게 하는 것이다. 이처럼 중요하지만 아직 충분히 벤치마크되지 않은 능력을 엄밀히 평가하기 위해, 우리는 OmniContext라는 새로운 벤치마크를 도입하였다. 이는 모델이 다양한 문맥 속에서도 피사체(subject)의 정체성을 유지하는 능력(subject fidelity)을 평가하는 데 중점을 둔다.
기존의 문맥 기반 이미지 생성 벤치마크들은 현실적 응용 시나리오를 제대로 반영하지 못한다.
- 입력 이미지가 복수개일 수 있는 상황을 고려하지 않고,
- 문맥 이미지 수나 작업 유형의 다양성도 제한적이다.
예컨대 DreamBench [64]는 단 30개의 객체와 25개의 프롬프트 템플릿만을 포함하며,
- 인물이나 장면 단위 문맥(scene-level context)은 다루지 않는다.
또한 기존 벤치마크들은 CLIP-I 및 DINO 기반의 이미지 간 유사도 지표를 사용해 이미지 품질을 평가하는데,
- 이들 평가는 복수 피사체가 포함된 상황에 부적절하고,
- 설명력(explainability)도 부족하다.
이러한 한계를 극복하기 위해, 우리는 고품질 이미지(개인 사진, 오픈소스 이미지, 애니메이션 스틸컷, AI 생성 이미지 등)를 수작업으로 대규모 수집하여 OmniContext를 구성하였다.
(그림 8 참조)
OmniContext는 Character, Object, Scene의 세 가지 문맥 이미지 유형을 포함하며, 다양한 실체(entity)와 환경(environment)을 포괄한다. 우리는 이들을 조합하여 다음과 같은 세 가지 주요 과제 유형과 8개의 세부 과제(subtask)를 정의하였다:
- SINGLE: 단일 문맥 이미지(캐릭터 또는 객체)에 기반한 생성 작업
- MULTIPLE: 복수 문맥 이미지에서 추출된 피사체 간의 구성적 상호작용
- SCENE: 참조 이미지에 제공된 환경적 문맥을 기반으로 한 생성 작업
각 세부 과제는 50개의 예시로 구성된다.
이미지-프롬프트 쌍은 멀티모달 LLM과 수작업 어노테이션을 결합한 하이브리드 방식으로 구축되었다:
- MLLM이 이미지 소스를 분류 및 필터링하여 저품질 샘플 제거
- 사람 전문가가 3가지 기준에 따라 이미지 선별:
- (1) 주요 피사체가 명확히 드러나는가
- (2) 미적 품질이 높은가
- (3) 데이터의 다양성이 확보되었는가
- 프롬프트는 GPT-4o를 통해 자동 생성하고, 어노테이터들이 의미적/구문적 다양성을 확보하도록 필터링 및 정제
(그림 9 참조)
생성된 이미지를 평가하기 위해, 우리는 최신 멀티모달 LLM인 GPT-4.1 [52]을 사용한다.
OmniContext는 세 가지 평가 지표를 포함한다:
- Prompt Following (PF): 프롬프트를 얼마나 잘 따랐는가
- Subject Consistency (SC): 피사체 정체성이 얼마나 잘 유지되었는가
- Overall Score: PF와 SC의 기하 평균(geometric mean)으로 계산
우리는 VIEScore [32]의 방식을 따라 GPT-4.1로부터 0~10 점수와 상세한 평가 근거(rationale)를 함께 생성하게 한다.
OmniContext는 참조 기반(reference-based), 제어 가능한(controllable) 이미지 생성 연구를 촉진하기 위한 유용한 리소스로 기능할 것으로 기대된다.
5. 실험 (Experiments)

표 1: 다양한 모델들의 이해, 생성, 편집, 문맥 기반 생성 작업에 대한 비교.
* : 앞의 숫자는 텍스트 생성을 위한 파라미터 수를, 뒤의 숫자는 이미지 생성을 위한 파라미터 수를 나타냅니다.
† : LLM 리라이터(LLM rewriter)를 사용한 방법을 의미합니다.
이 절에서는 OmniGen2의 다양한 생성 작업 전반에 걸친 통합 능력을 입증하기 위해 포괄적인 평가를 수행한다. 먼저 표 1을 통해 최신 모델들과의 전반적인 비교 결과를 제시하며, 평가 영역은 다음 네 가지 핵심 과제로 구성된다:
- 시각 이해 (visual understanding)
- 텍스트-투-이미지 생성 (text-to-image generation)
- 이미지 편집 (image editing)
- 문맥 기반 생성 (in-context generation)
실험 결과, OmniGen2는 모든 영역에서 우수한 성능 균형을 보여주며, 특히 문맥 기반 생성에서 탁월한 성과를 기록하였다.
5.1 시각 이해 (Visual Understanding)
OmniGen2의 시각 이해 성능은 사전 학습된 30억 파라미터 규모의 MLLM(Qwen2.5-VL-3B-Instruct [3])에 기반하며, 이 모델은 학습 중 고정(frozen) 상태로 유지된다.
표 1에서 보이듯, OmniGen2는 다음과 같은 견고한 성능을 달성하였다:
- MMBench [47]: 79.1
- MMMU [87]: 53.1
- MM-Vet [85]: 61.8
이러한 아키텍처 설계는 다음 두 가지 주요 이점을 제공한다:
- MLLM을 고정(freeze)함으로써, 생성 작업 학습 도중 기존의 강력한 이해 능력이 손상되지 않고 온전히 유지된다.
- 30억 파라미터라는 경량 구조 덕분에, 대규모 MLLM 기반의 통합 모델보다 훈련 비용이 낮고, 실제 환경에서도 훨씬 효율적으로 활용 가능하다.
5.2 텍스트-투-이미지 생성 (Text-to-Image Generation)

표 2: GenEval [21] 벤치마크에서의 텍스트-투-이미지 생성 성능 평가
† : LLM 리라이터를 사용한 방법을 의미합니다.

그림 10: OmniGen2의 정성적 텍스트-투-이미지 생성 결과. 다양한 텍스트 프롬프트에 대한 높은 충실도와 다양한 가로세로 비율을 지원하는 예시를 보여줍니다.
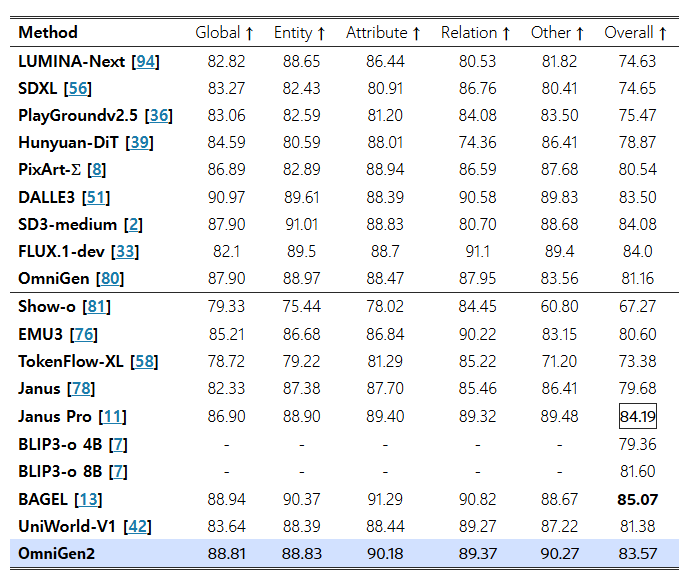
표 3: DPG-Bench [26] 벤치마크에서의 텍스트-투-이미지 생성 성능 평가
우리는 OmniGen2의 T2I(텍스트-투-이미지) 생성 능력을 두 개의 표준 벤치마크에서 평가하였다:
- GenEval [20]: 복합적인 구문(compositional prompt)에 대한 이해 능력을 평가
- DPG-Bench [26]: 긴 프롬프트(long prompt)에 대한 충실도 평가
그림 10에는 정성적인 시각화 결과가 제시되어 있으며, OmniGen2는 특히 자원 효율성을 고려할 때 매우 경쟁력 있는 성능을 보여준다.
GenEval 평가
표 2에서 볼 수 있듯이, OmniGen2는 복잡하고 구성적인 프롬프트로부터 이미지를 생성하는 데 뛰어난 성능을 발휘한다. 특히 LLM 리라이터를 함께 사용할 경우 (OmniGen2†), OmniGen2는 0.86의 우수한 종합 점수를 기록하였다.
이 점수는 다른 강력한 통합 모델인 UniWorld-V1 (0.84)를 능가하며, 최신 최고 성능(State-of-the-Art) 모델인 BAGEL (0.88)에 매우 근접한 수준이다.
중요한 점은, 이와 같은 SOTA급 성능을 탁월한 효율성 하에 달성했다는 것이다.
- OmniGen2는 단 4억 개의 학습 가능한 파라미터와
- 단 1,500만 개의 T2I 페어 데이터만으로 학습되었다.
반면, BAGEL은
- 1,400억 개의 파라미터,
- 16억 개의 T2I 데이터셋을 활용했다는 점에서 자원 격차가 매우 크다.
DPG-Bench 평가
표 3에 따르면, OmniGen2는 DPG-Bench 벤치마크에서 83.57의 종합 점수를 달성하였다. 이는 UniWorld-V1 (81.38)보다 높은 점수이며, 전문 모델인 SD3-medium (84.08)과도 상당히 근접한 수준이다.
이처럼 두 가지 상이한 벤치마크에서 모두 강력한 결과를 보여준다는 것은, OmniGen2가 복잡한 구성형 프롬프트뿐만 아니라 일반적인 긴 프롬프트에도 효과적인 고성능·고효율 생성기임을 입증한다.
5.3 이미지 편집 (Image Editing)
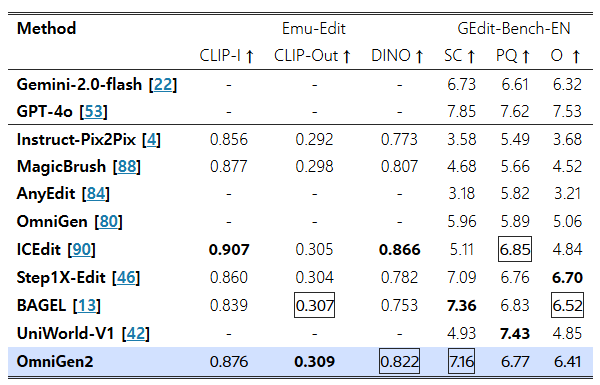
표 4: Emu-Edit [67] 및 GEdit-Bench-EN [46]에서의 정량적 비교 결과
- Emu-Edit에서는 다음 지표들이 사용됨:
- CLIP-I / DINO: 소스 이미지와의 일관성(consistency) 측정
- CLIP-Out: 타깃 이미지의 캡션과의 정렬도(alignment) 측정
- 특징 추출에는 CLIP-B/32 [59], DINO-S/16 [5] 사용
- GEdit-Bench에서는 다음 지표들이 사용됨:
- SC (Semantic Consistency): 지시문 준수 여부 평가
- PQ (Perceptual Quality): 이미지의 자연스러움 및 아티팩트 여부 평가
모든 지표에서 점수가 높을수록 우수함을 의미한다.

표 5: ImgEdit-Bench [83]에서의 비교 결과
- "Overall" 점수는 모든 작업의 평균으로 계산됨

그림 11: OmniGen2를 활용한 다재다능한 이미지 편집 예시
이 모델은 단순한 객체 수정부터 복잡한 동작 변화(motion change), 스타일 변경(stylistic alterations)에 이르기까지 매우 다양한 편집 지시문을 능숙하게 처리하는 모습을 보여준다.
이미지 편집은 OmniGen2의 핵심 기능 중 하나이며, 본 절에서는 이를 Emu-Edit [66], GEdit-Bench-EN [46], ImgEdit-Bench [83]의 세 가지 다양한 벤치마크에서 엄밀하게 평가하였다. 그 결과, OmniGen2는 지시문 기반 이미지 편집에서 매우 강력한 성능을 발휘함을 확인할 수 있다. 정성적 시각화 결과는 그림 11에 제시되어 있다.
표 4에서 확인할 수 있듯이, OmniGen2는 편집 정확도와 원본 보존 간의 탁월한 균형을 보여준다.
- Emu-Edit에서 OmniGen2는 CLIP-Out 점수 0.309로 최고 성능을 기록하였으며,
이는 비교된 모든 모델 중 가장 효과적으로 지시된 편집을 수행했음을 의미한다. - 동시에, 편집되지 않은 영역의 보존을 측정하는 CLIP-I (0.876) 및 DINO (0.822) 점수에서는 각각 두 번째로 높은 성능을 기록하였다.
이러한 결과는 전체 이미지를 해치지 않으면서, 정확하고 국소적인 편집을 수행하는 OmniGen2의 능력을 입증한다.
또한, OmniGen2의 지시문 이해 능력은 GEdit-Bench에서도 다시 한 번 확인된다.
- Semantic Consistency (SC) 점수는 7.16으로 두 번째로 높았으며,
- 전체 점수는 6.41로 상위권에 해당한다.
다만, Portrait Beautification과 Text Modification 등의 특정 세부 작업에서의 상대적 낮은 성능(각각 5.608, 5.141)은 해당 작업에 대한 학습 데이터 부족에 기인한 것으로 판단된다.
그럼에도 불구하고, 일반적인 작업 전반에서 높은 SC 점수는 사용자 지시문을 정확하게 이해하고 실행하는 강건한 능력을 잘 보여준다.
표 5에 따르면, OmniGen2는 ImgEdit-Bench에서 오픈소스 모델 중 새로운 최고 성능(state-of-the-art)을 달성하였다. 특히, BAGEL과 OmniGen2가 Action 벤치마크에서 높은 성능을 기록한 것은, 동작 변화에 대한 풍부한 데이터를 제공하는 비디오 기반 학습의 효과를 보여주는 사례로 볼 수 있다.

그림 12 문맥 기반 생성 및 문맥 기반 편집 작업의 정성적 결과 예시

표 6: OmniContext 벤치마크에서 다양한 이미지 생성 모델의 전체 점수 비교
- "Char. + Obj.": Character + Object 조합을 의미함

표 7: OmniContext의 SINGLE 작업 유형에 대한 비교
- Prompt Following (PF), Subject Consistency (SC), Overall 점수를 보고 (높을수록 우수, ↑)

표 8: OmniContext의 MULTIPLE 작업 유형에 대한 비교
- Prompt Following (PF), Subject Consistency (SC), Overall 점수를 보고 (높을수록 우수, ↑)

표 9: OmniContext의 SCENE 작업 유형에 대한 비교
- Prompt Following (PF), Subject Consistency (SC), Overall 점수를 보고 (높을수록 우수, ↑)
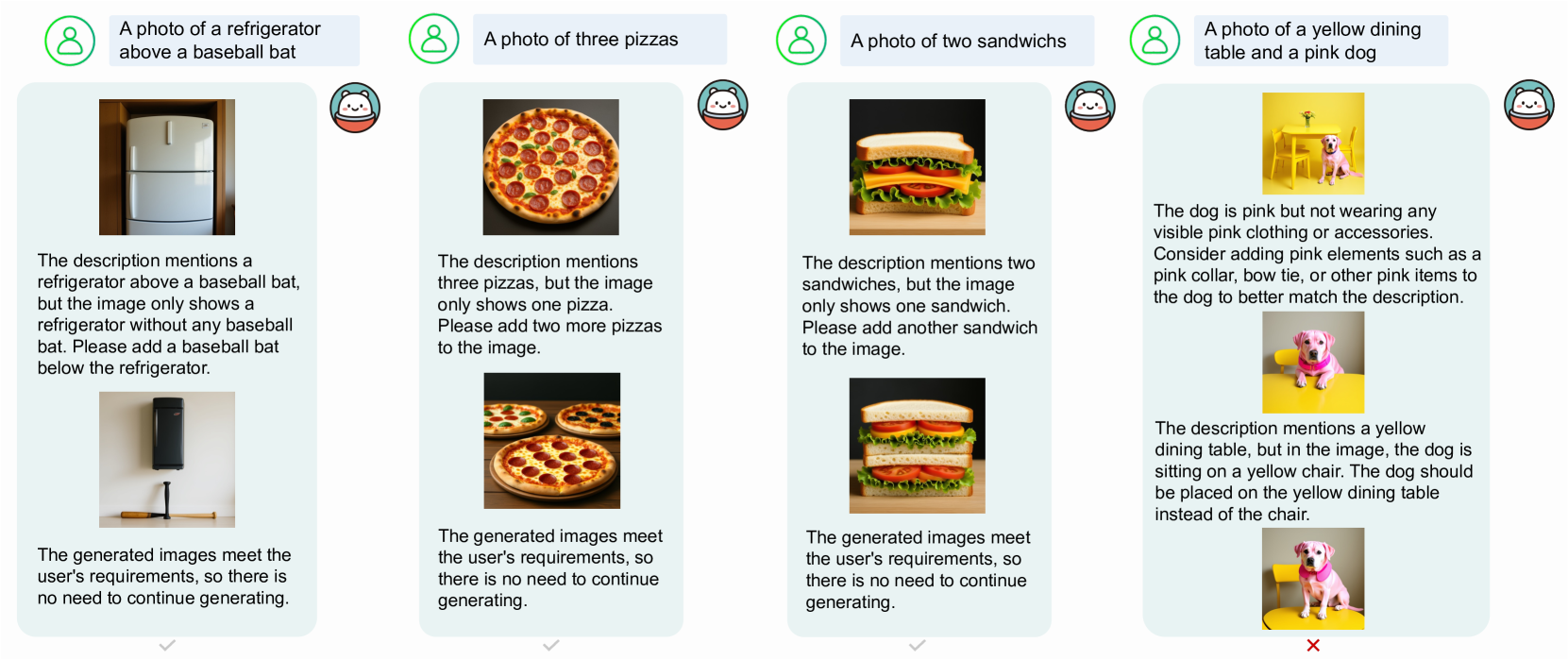
그림 13 OmniGen2를 사용한 리플렉션 기반 생성 예시
- 왼쪽 및 중앙: 1회 리플렉션으로 성공적으로 수정된 결과
- 오른쪽: 과도한 리플렉션(over-reflection)으로 인해 정답이 오답으로 잘못 판단된 실패 사례
5.4 문맥 기반 생성 (In-context Generation)
OmniGen2의 대표적인 강점 중 하나는 문맥 기반 생성(in-context generation) 능력이며, 이에 대한 정성적 시각화 결과는 그림 12에 제시되어 있다. 우리는 이 분야에서 기존 모델들의 성능을 포괄적으로 평가하기 위해 OmniContext 벤치마크를 새롭게 도입하였다.
OmniContext는 총 8개의 세부 과제(subtask)로 구성되어 있으며, 각 과제의 전체 점수는 표 6에 정리되어 있다. 이 벤치마크에서 최초로 평가된 모델로서, OmniGen2는 전체 점수 7.18을 기록하며 강력한 베이스라인을 확립하였다.
이러한 결과는 OmniGen2가 피사체의 정체성을 원래 배경으로부터 효과적으로 분리(disentangle)하고, 새로운 텍스트 지시에 맞게 정확하게 재구성(re-render)할 수 있는 능력을 잘 보여준다.
OmniGen2는 모든 유형의 작업에서 경쟁 모델 대비 뚜렷한 성능 향상을 보여주며, 지시문에 대한 충실도(prompt-following)와 피사체 일관성(subject consistency) 모두에서 우수한 성능을 나타낸다.
각 세부 과제에 대한 상세 평가 지표는 표 7, 8, 9에 수록되어 있으며, 여기서 몇 가지 주목할 만한 점을 도출할 수 있다.
- OmniGen2는 입력이 단일 이미지이든, 복수 이미지이든 관계없이,
모든 평가 지표에서 오픈소스 기준 모델들을 안정적으로 능가한다. - 폐쇄형(closed-source) 모델 중에서는
- GPT-4o [53]가 Overall 점수 및 Prompt Following 항목에서 최고 점수를 기록하고,
- Flux.1 Kontext [34]는 Subject Consistency에서 가장 뛰어난 성능을 보였다.
- 반면, Gemini-2.0-Flash [22]는 해당 벤치마크에서 상대적으로 낮은 성능을 보였다.
5.5 리플렉션 (Reflection)
우리는 리플렉션 데이터셋을 활용하여 OmniGen2를 파인튜닝(fine-tuning)하였고, 그 결과를 그림 13에 제시하였다.
성공적인 사례에서는,
- 모델이 초기 생성 이미지에 대해 스스로 반성(reflect)하고,
- 문제점을 정확히 파악한 뒤,
- 두 번째 생성에서 적절한 수정을 수행함으로써,
- 지시문을 정확히 만족하는 이미지를 생성하였다.
또한, OmniGen2는 생성 과정이 충분하다고 판단되면 적절한 시점에서 중단할 수 있는 능력도 보여주었다.
관찰 결과, 객체의 색상, 수량, 형태와 관련된 오류가 있는 경우, 리플렉션 파인튜닝된 모델이 특히 정확한 수정을 잘 수행하였다.
그러나 리플렉션 모델에는 여전히 몇 가지 중대한 한계가 존재한다:
- 특히 간단한 지시문에 대해 과도하게 반성(over-reflection)하여, 불필요한 요구사항을 생성하거나 이미지에 대해 잘못된 판단을 내리는 경우가 있다.
- 반대로, 모델이 자신의 반성 내용을 제대로 반영하지 못하거나, 오류가 있는 반성 내용을 그대로 따르는 경우도 발생하며, 이는 출력 이미지 품질의 저하로 이어질 수 있다.
이러한 한계는
- 현재 사용 중인 3B 규모 MLLM의 제한된 인지 능력과
- 리플렉션 학습 데이터 부족에서 비롯된 것으로, 편향(bias)이 개입될 여지가 있다.
향후에는
- 더 큰 규모의 MLLM으로 확장하고,
- 강화학습 기반 접근 방식을 활용하여 리플렉션 능력을 더욱 정교하게 개선할 계획이다.
6. 한계점 (Limitations)
그러나 OmniGen2에는 다음과 같은 몇 가지 한계점도 존재함을 확인하였다:
1) 영어와 중국어 프롬프트 간의 성능 격차
- 그림 14의 첫 번째 행에서 볼 수 있듯이, 영어로 작성된 프롬프트가 일반적으로 더 나은 결과를 도출한다.
- 예를 들어, 중국어 프롬프트를 사용할 경우 입력 이미지와 편집된 이미지 간에 사소한 불일치가 발생하기도 한다.
2) 특정 지시문에 대한 일반화의 한계
- 두 번째 행에서는, 사람의 신체 형태를 수정하는 작업에서 OmniGen2가 어려움을 겪는 모습을 보여준다.
- 이는 이와 같은 변형을 포착한 실제 데이터가 부족하기 때문으로 보인다.
3) 입력 이미지 품질에 대한 민감성
- 그림 14에 나타난 바와 같이, 생성 결과는 입력 이미지의 품질에 매우 민감하다.
- 예를 들어, 노이즈를 추가하여 품질을 낮춘 이미지를 입력하면, 결과 이미지에서 세부 묘사가 흐릿해지고 품질이 크게 저하된다.
- 또한, 입력 이미지를 최대 256픽셀로 다운샘플할 경우 명확성과 세부 정보가 손실되고,
지시문을 정확히 따르는 능력도 현저히 저하된다.
4) 복수 이미지 입력에 대한 모호성 처리 한계
- 세 번째 행에서는, 프롬프트가 각 객체와 해당 소스 이미지를 명확히 지정했을 때 (예: “image 1의 새, image 2의 책상”) 성능이 향상되는 것을 볼 수 있다.
- 이는 OmniGen2가 복수 이미지 기반의 모호한 지시문에 민감하게 반응함을 시사한다.
5) 문맥 기반 생성 작업에서 피사체의 완전한 재현 실패 가능성
- 문맥 기반 생성(in-context generation)에서, 모델이 입력된 문맥 이미지의 객체를 완벽히 재현하지 못하는 경우가 간혹 발생한다.
- 이미지의 guidance scale을 높이면 부분적으로 개선되지만, 완전한 해결책은 아니다.
- 이러한 복잡한 작업에서의 근본적인 개선을 위해서는 모델 규모의 추가적인 확장이 필요할 수 있다고 추정한다.

그림 14 OmniGen2의 한계 시각화
- 1행: 중국어 프롬프트 및 저화질 입력 이미지 처리 시 성능 저하
- 2행: 사람 신체 형태 편집 시 부정확한 결과
- 3행: 다중 이미지 소스를 포함한 모호한 지시문에 민감함
7.1 이미지 생성 (Image Generation)
디퓨전 모델(Diffusion models)은 특히 고화질 이미지 생성(high-fidelity image synthesis) 분야에서 놀라운 성과를 거두었다 [17; 8; 14]. Stable Diffusion (SD) 시리즈 [62; 56; 17], DALL·E [60], Imagen [27] 등 선구적인 시스템들은 강력한 텍스트-이미지 생성 능력을 보여주며, 제어 가능하고 확장 가능한 생성의 기반을 마련했다.
생성 제어력을 높이기 위해,
- ControlNet [89], T2I-Adapter [49]는 외부 조건 모듈을 도입했고,
- StyleShot [18], InstructPix2Pix [4], EMU-Edit [67] 등은 세밀한 편집 및 지시 기반 생성에 집중하였다. 이러한 발전은 디퓨전 모델이 다양한 조건부 설정에서 더욱 유연하게 동작하고 있음을 보여준다.
최근에는 다양한 이미지 생성 태스크를 단일 모델로 처리하는 통합 이미지 생성(unified image generation) 방향으로 연구가 확산되고 있다 [80; 48; 10; 73].
예를 들어:
- OmniGen은 텍스트와 이미지를 하나의 Transformer에서 공동 모델링하여 통합 생성 수행
- UniReal은 다양한 태스크를 비디오 예측 문제로 재구성하고, 태스크 구분을 위한 프롬프트 설계 방식을 채택하였다.
또한 최근에는 Chain-of-Thought(CoT) 추론 기법을 이미지 생성 태스크에 접목하려는 시도들도 나타나고 있다 [24; 74; 29].
그러나 이와 달리, "반성(reflection)" 메커니즘을 이미지 생성에 접목한 연구는 아직 부족한 실정이다.
- ReflectionFlow [95]는 최초의 reflection 프레임워크로,
- 기존 T2I 모델,
- instruction 생성을 위한 파인튜닝된 MLLM,
- 이미지 편집 모델을 모듈별로 구성한 구조를 제안한다.
- 단, 이 프레임워크는 단일 instruction-image 쌍만으로 학습함.
- 반면, OmniGen2는 단일 모델 내에서 reflection 및 재생성을 통합한 구조를 채택한다. 특히 다중 회차(multi-turn) reflection 데이터에 대해 파인튜닝되어, 실제 이미지 편집 시나리오의 반복적 본질을 더 잘 포착할 수 있다.
7.2 멀티모달 생성 (Multimodal Generation)
멀티모달 생성 모델(multimodal generation model)은 단일 모달 중심 모델에서 출발하여, 이해(comprehension)와 생성(generation)을 모두 아우르는 통합 구조로 급속히 진화하고 있다.
초기 접근 방식인 Chameleon [72]은 텍스트와 이미지를 대상으로 토큰 기반의 조기 결합(early-fusion) 오토리그레시브 생성을 선보였으며, 이후 Emu2 [70] 및 Emu3 [76]는 이러한 다음 토큰 예측 기반 패러다임을 더욱 발전시켰다. Emu3는 디퓨전 없이도 텍스트, 이미지, 비디오 전반에 걸쳐 일반 멀티모달 지능을 달성할 수 있다고 주장하였다.
한편,
- Show-o [81],
- Transfusion [93] 등의 하이브리드 모델은
- 텍스트는 오토리그레시브 방식으로,
- 이미지는 디퓨전 방식으로 처리하며,
- 두 방식을 하나의 Transformer 안에 통합한다.
- 다만 효율성 문제로 consistency distillation 등 가속화 기법이 필요하다.
또 다른 접근으로는,
- MetaMorph [25]는 Visual-Predictive Instruction Tuning (VPiT) 기법을 도입하여,
LLM이 텍스트 및 시각 토큰 모두를 생성할 수 있도록 조정하였다. - LMFusion [68]은 텍스트 전용 LLM을 멀티모달 생성에 적응시키는 방법으로,
- 병렬적인 모달 전용 모듈을 사용하고,
- 텍스트 컴포넌트를 고정하여 catastrophic forgetting을 방지하였다.
- MetaQueries [55]는 frozen MLLM과 디퓨전 모델 간 효율적 인터페이스를 learnable query를 통해 제공하며,
이해 능력을 유지하면서 지식 기반 이미지 생성을 가능하게 한다. - BLIP3-o [7]는 open-source 계열로,
- 디퓨전 Transformer를 통해 의미론적으로 풍부한 CLIP 이미지 피처를 생성하고,
- 이해와 생성을 모두 강화하는 순차적 사전학습 전략을 사용한다.
- MoGao [40], BAGEL [13]은 모두 interleaved data(텍스트와 이미지가 교차된 데이터)에 대해 대규모 사전 학습을 수행함으로써, 강력한 전이 성능을 다양한 다운스트림 태스크에서 입증하였다.



