DQN을 기반으로 한 다른 연구들을 알아보자.
• 아타리에서의 성공은 심층 신경망을 사용하여 강화학습에서 가치 함수 근사를 수행하는 데 큰 흥미를 불러일으켰습니다.
• 즉시 개선된 몇 가지 방법들 (그 외에도 다른 많은 방법들이 있습니다!)
• Double DQN (Double Q 학습을 이용한 심층 강화학습, Van Hasselt 등, AAAI 2016)
• Prioritized Replay (우선순위 기반 경험 재생, Schaul 등, ICLR 2016)
• Dueling DQN (ICML 2016 최우수 논문) (심층 강화학습을 위한 Dueling 네트워크 아키텍처, Wang 등, ICML 2016)
DQN을 기반으로 한 연구는 계속해서 진화하고 있으며, 다양한 개선 및 변형이 제안되고 있습니다. 그 중 일부는 다음과 같습니다:
1. Double DQN: 기존의 DQN에서 발생하는 과대평가 문제를 해결하기 위해 도입된 알고리즘으로, 두 개의 독립적인 신경망을 사용하여 Q값을 추정합니다.
2. Prioritized Replay: 경험 재생에서 샘플링되는 전이들의 중요도에 따라 학습에 활용되는 방식으로, 보다 중요한 전이들을 우선적으로 학습하도록 합니다.
3. Dueling DQN: 가치 함수의 추정과 상태-액션 가치 함수의 추정을 분리하여 학습하는 방식으로, 학습의 안정성과 효율성을 향상시킵니다.
"Massively Parallel Methods for Deep Reinforcement Learning" [ICML 2015]
• DQN은 단일 기기에만 적용되었습니다.
• 긴 학습 시간 (한 게임에 대해 12~14일 소요)
• 심층 강화학습 알고리즘을 확장해 보겠습니다.
• 심층 학습 연산은 병렬화될 수 있습니다.
• 강화학습의 특성을 고려해보세요.
심층 강화학습에서의 대규모 병렬화 방법에 대한 논문인 "Massively Parallel Methods for Deep Reinforcement Learning"은 DQN을 단일 기기에서만 사용하여 학습 시간이 오래 걸린다는 한계를 극복하기 위해 제안되었습니다. 병렬 처리를 통해 심층 강화학습 알고리즘을 확장하고자 하며, 심층 학습 연산은 병렬화될 수 있는 특성을 가지고 있습니다. 이 논문에서는 강화학습의 특성을 고려하여 대규모 병렬화를 통해 학습 속도와 성능을 향상시키는 방법을 제시하고 있습니다.


실험
• 49개의 Atari 게임에 대해
• 액터(Actor) 수: 100
• 러너(Learner) 수: 100
• 샤드(Shard) 머신 수: 31
• 재생 메모리 크기: 1백만 프레임
• 각 러너는 매 60,000번의 업데이트 후 대상 네트워크의 매개변수를 동기화합니다.
위의 실험에서는 49개의 Atari 게임에 대해 대규모 병렬화를 적용했습니다. 100개의 액터와 100개의 러너를 사용하며, 31개의 샤드 머신을 사용하여 계산을 병렬화합니다. 재생 메모리 크기는 1백만 프레임이며, 각 러너는 60,000번의 업데이트 후 대상 네트워크의 매개변수를 동기화합니다.
평가 결과
• 단일 DQN은 12~14일 동안 학습되었습니다.
• Gorila DQN은 최대 6일 동안 학습되었습니다.
• Gorila DQN은 단일 DQN에 비해 우수한 성능을 보였으며, 49개 게임 중 41개 게임에서 성능이 뛰어났습니다.
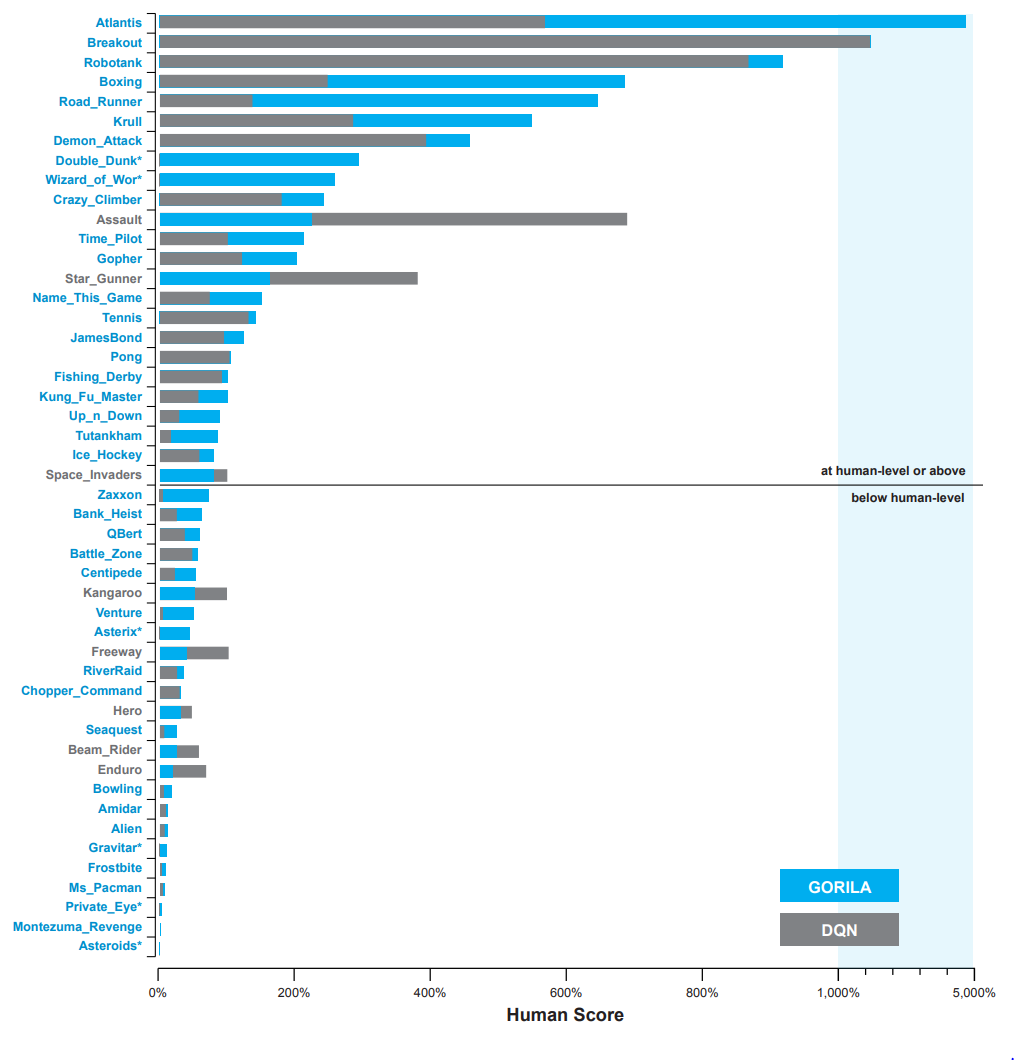
위의 평가 결과에 따르면, 단일 DQN은 12~14일 동안 학습되었고, Gorila DQN은 최대 6일 동안 학습되었습니다. 이 중 Gorila DQN은 단일 DQN에 비해 우수한 성능을 보여주었으며, 49개의 게임 중 41개 게임에서 더 뛰어난 성능을 보였습니다. 이를 통해 Gorila DQN의 병렬화된 학습 방법이 단일 DQN에 비해 효과적임을 확인할 수 있었습니다.
Gorila DQN Summary
• 딥 강화 학습을 위한 최초의 대규모 분산 아키텍처입니다.
• Gorila DQN은 분산 재생 메모리와 분산 신경망을 사용하여 병렬로 행동하고 학습합니다.
• Gorila DQN은 49개 게임 중 41개 게임에서 단일 DQN을 능가하였으며, 학습 시간을 크게 줄였습니다.
Double DQN
Double DQN은 Double Q-Learning을 DQN에 적용한 방식이다.
• 현재의 Q 네트워크 𝑤는 행동을 선택하는 데 사용됩니다.
• 과거의 Q 네트워크 𝑤−는 행동을 평가하는 데 사용됩니다.
기존의 Q 네트워크 𝑤는 행동을 선택하는 데 사용되며, 과거의 Q 네트워크 𝑤−는 행동을 평가하는 데 사용됩니다. 이를 통해 Q-learning에서 발생하는 overestimation bias 문제를 완화할 수 있습니다. Double DQN은 Q 네트워크의 선택과 평가를 분리함으로써 더 정확한 행동 가치를 추정할 수 있습니다.
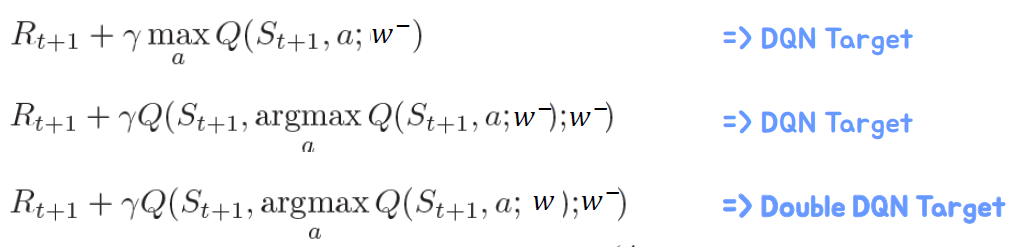

Double DQN Summary
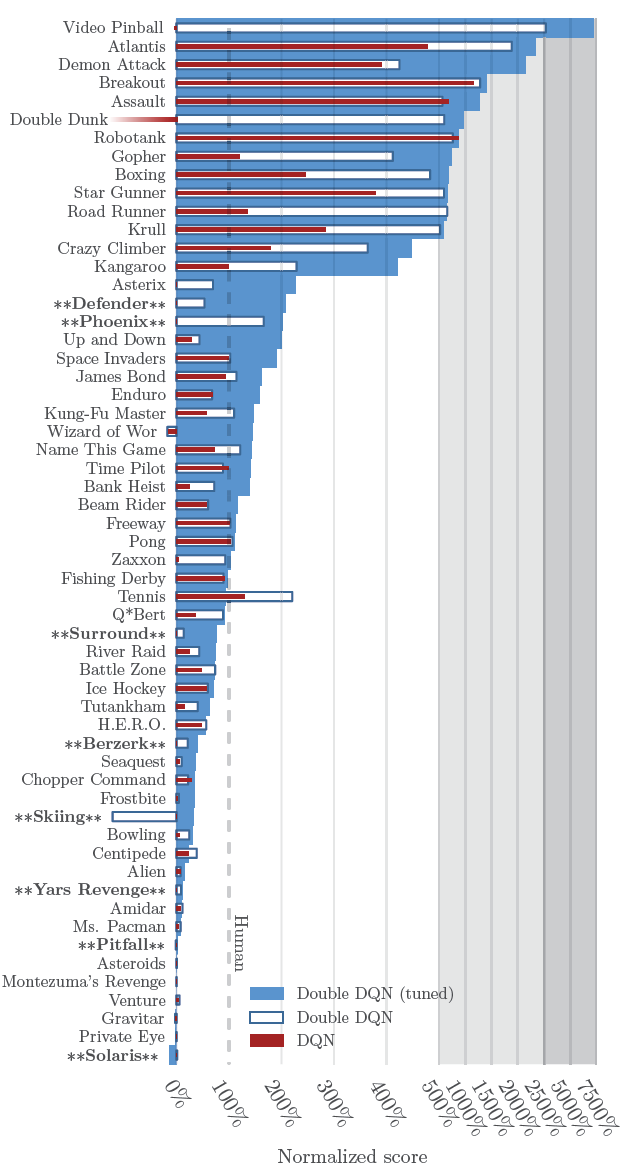
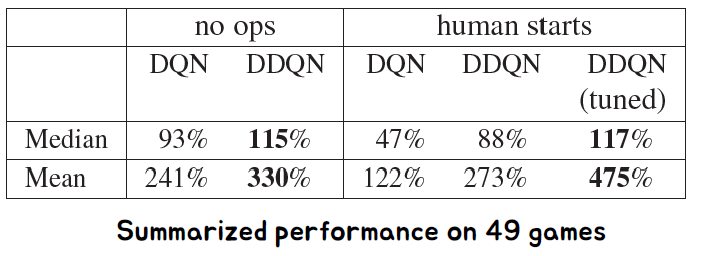
• 실제로 과대평가가 더 자주 발생하고 심각함을 보여줍니다.
• Double Q-learning은 더 안정적이고 신뢰할 수 있는 학습에 성공적으로 사용될 수 있습니다.
• Double DQN은 추가적인 네트워크 없이 기존의 DQN 아키텍처를 사용합니다.
• Double DQN은 단일 DQN보다 더 우수한 성능을 보였습니다.
"Prioritized Experience Replay" [ICLR 2016]
• Experience Replay는 과거의 경험을 기억하고 다시 재생합니다.
• 임의 샘플링을 통해 시간 상의 상관 관계를 깨뜨립니다.
• 경험을 재사용할 수 있습니다.
• 재생 메모리에서 균일하게 샘플링됩니다.
• 경험의 중요성과 상관없이 동일한 빈도로 경험을 재생합니다.
Prioritized Experience Replay (PER)는 경험을 기억하고 재생하는 방법 중 하나입니다. PER은 경험을 재생할 때 임의로 샘플링하여 시간 상의 상관 관계를 깨뜨립니다. 이를 통해 경험을 재사용할 수 있게 됩니다. 또한, PER은 재생 메모리에서 균일하게 샘플링하는 대신 경험의 중요도에 따라 샘플링합니다.
TD 오류에 따른 우선순위 지정
• 경험은 더 놀라운 또는 중요한 경우가 있을 수 있습니다.
• 시간 차이 (TD) 오류의 크기를 측정합니다.
• TD 오류는 경험의 놀라움을 나타냅니다.
• 탐욕스러운 TD 오류 우선순위 지정
• 샘플링 O(1), 우선순위 업데이트 O(log N)
Prioritized Experience Replay (PER)에서는 TD 오류에 따라 경험의 우선순위를 지정합니다. TD 오류는 경험이 얼마나 놀라운지를 나타내는 척도로 사용됩니다. 보통 TD 오류가 큰 경험은 더 중요하거나 놀라운 경험이라고 간주됩니다. 우선순위 지정은 탐욕스러운 방식으로 이루어지며, 우선순위가 높은 경험은 더 자주 샘플링되어 학습에 활용됩니다. 이러한 방식은 O(1)의 시간으로 샘플링하고 우선순위를 업데이트할 수 있어 효율적인 학습이 가능합니다.
확률적 우선순위 지정
• 탐욕스러운 TD 오류 우선순위 지정
• 경험의 작은 부분에 집중합니다.
• TD 오류가 낮은 경험은 오랜 시간 동안 다시 재생되지 않을 수 있습니다.
• 잡음 스파이크에 민감합니다 (보상이 확률적인 경우)
• 확률적인 단조 샘플링을 제안합니다. 경험 우선순위를 유지하면서 0 이상의 확률을 보장합니다.
• 경험 𝑖의 샘플링 확률은 𝑃(𝑖)=𝑝𝑖𝛼/Σ𝑘𝑝𝑘𝛼로 나타낼 수 있습니다. 여기서 𝑝𝑖>0입니다.
• 지수 𝛼∈[0,1]는 우선순위 지정의 정도를 결정합니다. 𝛼=0은 균등한 경우에 해당합니다.)
• 옵션 1 (비례 우선순위 지정) : 𝑝𝑖=𝛿𝑖+𝜖
• 옵션 2 (순위 기반 우선순위 지정) : 𝑝𝑖=1/𝑟𝑎𝑛𝑘(𝑖) 여기서 𝑟𝑎𝑛𝑘(𝑖)는 정렬된 replay memory에서 경험 𝑖의 순위입니다.
편향 보정
• 우선순위 리플레이는 경험 분포를 변경하여 편향을 도입합니다.
• 중요도 샘플링 (IS) 가중치를 사용하여 이러한 편향을 보정할 수 있습니다. 만약 𝛽=1이면 비균등 확률 𝑃(𝑖)를 완전히 보상하는 IS 가중치를 사용합니다.
𝑤𝑖=1/𝑁∙1/𝑃(𝑖)𝛽
• δ𝑖대신 𝑤𝑖δ𝑖를 사용하여 Q 학습 업데이트 수행
• 𝛽를 초기 값 𝛽0에서 1로 선형으로 감소시킴으로써 편향을 보정합니다.

PRIORITIZED EXPERIENCE REPLAY (PER) 알고리즘
- 초기화:
- 재현 메모리 𝐷 초기화
- 𝑤 초기화
- 𝛽, 𝛽0, 𝜖 초기화
- 𝛼, 𝜖₀ 초기화
- 𝐾, 𝑎 초기화
- 경험 샘플링:
- 𝑃(𝑖) = 𝑝𝑖^𝛼 / Σ𝑘 𝑝𝑘^𝛼 (𝑝𝑖는 경험 𝑖의 우선순위)
- 𝑏 = {𝑠, 𝑎, 𝑟, 𝑠′, 𝑑𝑜𝑛𝑒}을 𝑃(𝑖)에 따라 𝑁개 샘플링
- IS 가중치 계산:
- 𝑤𝑖 = (1 / (𝑁 ∙ 𝑃(𝑖)))^𝛽 / 𝑚𝑎𝑥(𝑤𝑖)
- 𝑤𝑖 정규화
- 학습:
- 𝑄(𝑠, 𝑎; 𝑤)의 값 계산
- 𝑄(𝑠′, 𝑎′; 𝑤)의 값 계산 (타겟 네트워크 사용)
- 𝑦 = 𝑟 + 𝛾𝑚𝑎𝑥(𝑄(𝑠′, 𝑎′; 𝑤))
- 𝜃 = 𝑤에 대해 𝑦와 𝑄(𝑠, 𝑎; 𝑤)의 차이를 줄이기 위한 손실 함수 최적화
- 𝑤 업데이트
- 타겟 네트워크 업데이트:
- 일정 주기(𝐾)마다 타겟 네트워크를 현재 네트워크로 업데이트
- 𝛽 업데이트:
- 𝛽 = min(𝛽 + 𝛽0, 1)
- 𝛼, 𝜖₀ 업데이트:
- 𝛼, 𝜖₀ 선형 감소
- 반복:
- 2단계부터 7단계까지 반복

DQN vs. DQN with PER

Double DQN vs. Double DQN with PER

Prioritized Experience Replay Summary
• Prioritized Experience Replay는 학습을 더 효율적으로 만들어주는 메소드입니다.
• 학습 속도를 2배 빠르게 하고 Atari 벤치마크에서의 성능을 향상시킬 수 있습니다.
• 우선순위 샘플링을 통해 중요한 경험들을 더 자주 샘플링하고 학습에 활용합니다.
• 우선순위가 높은 경험들을 더 자주 학습하여 빠른 학습과 더 나은 성능 향상을 이끌어냅니다.
"Dueling Network Architectures for Deep Reinforcement Learning" [ICML 2016, Best paper]
• 모델 프리 강화학습을 위한 새로운 신경망 구조
• 기존 및 미래의 강화학습 알고리즘과 쉽게 결합 가능
이 신경망 구조는 모델 프리 강화학습에 사용되며, 기존 및 미래의 강화학습 알고리즘과 쉽게 결합할 수 있습니다. 이 구조는 상태-가치와 장기-이익을 분리하여 독립적으로 학습할 수 있도록 해줍니다. 이는 강화학습의 학습 과정을 효율적으로 만들어주고 더 나은 학습 성능을 이끌어냅니다.

Dueling Network Architecture는 상태 가치와 행동 이득을 분리하고 공통의 CNN 모듈을 공유하는 구조입니다.
이 구조는 두 개의 스트림을 사용하여 Q 함수를 생성하기 위해 집계 레이어를 통합시킵니다. 상태 가치 스트림은 현재 상태의 가치를 나타내고, 행동 이득 스트림은 각 행동의 상대적인 이득을 나타냅니다.
Dueling Network Architecture의 핵심 아이디어는 각 상태의 가치를 학습하면서 각 행동의 효과를 별도로 학습할 필요 없이 어떤 상태가 가치가 있는지를 학습할 수 있다는 것입니다. 이를 통해 학습 과정이 효율적이며 더 나은 성능을 얻을 수 있습니다.
Dueling Network은 다음과 같은 구조로 설계됩니다:
𝑄𝑠,𝑎=𝑉𝑠+𝐴𝑠,𝑎
이 구조는 𝑉와 𝐴를 구별하기 어렵다는 의미에서 구별불가능(unidentifiable)합니다. 즉, 𝑄가 주어졌을 때 𝑉와 𝐴를 유일하게 복원할 수 없습니다. 예를 들어, 𝑄=4일 때 𝑉+𝐴는 1+3, 2+2, 또는 3+1이 될 수 있습니다.
이러한 구별불가능성은 이 식을 직접 사용할 때 실용적인 성능이 저하된다는 것을 의미합니다.
• 이 식별 가능성 문제를 해결하기 위해
• Option1 : 𝑎가 조치를 취한 경우 강제 𝐴(𝑠,𝑎)=0

• Option2: 평균을 기준선으로 사용(더 안정적)

이로인한 Value and Advantage 예시

단순과제 평가결과

Performance on Atari Games
Baseline : Double DQN vs. Dueling Double DQN

Distributional RL [ICML 2017]
분포적 강화학습은 기존의 단일 값 추정 대신, 강화학습 에이전트의 상태-행동 쌍에 대한 보상의 분포를 모델링하는 방법입니다. 즉, 강화학습 문제를 해결하기 위해 단일 값을 예측하는 대신, 각 상태-행동 쌍에 대한 보상의 확률 분포를 학습하고 활용합니다.

이 방법은 보상의 불확실성을 더 잘 다룰 수 있으며, 확률적인 성격을 갖는 문제에 적용할 수 있습니다. 분포적 강화학습은 기존의 강화학습 알고리즘에 확장하여 더 정확하고 안정적인 결과를 얻을 수 있도록 도와줍니다.
분포적 강화학습은 더 나은 리워드 추정, 더 효과적인 탐색 및 활용, 그리고 보상 분포의 변화에 대한 강건한 학습을 제공할 수 있습니다. 이를 통해 강화학습의 성능과 안정성을 향상시킬 수 있습니다.


Noisy Network [ICLR 2018]
노이즈 네트워크는 딥 뉴럴 네트워크의 가중치에 일정한 노이즈를 주어 더욱 강력한 탐색과 활용 능력을 갖게 하는 방법입니다. 일반적인 딥 뉴럴 네트워크에서는 가중치가 고정된 상태에서 학습이 이루어지지만, 노이즈 네트워크에서는 가중치에 노이즈를 주어 학습 과정에서의 불확실성을 증가시킵니다.

노이즈 네트워크는 강화학습에서의 탐색과 활용 간의 균형을 조절하는 데 도움을 줍니다. 노이즈가 주어진 네트워크는 탐색을 통해 새로운 상태와 행동을 탐색하고, 동시에 활용을 통해 학습한 지식을 활용할 수 있게 됩니다.
이를 통해 노이즈 네트워크는 더욱 안정적인 학습과 더 나은 성능을 제공할 수 있습니다. 또한, 노이즈 네트워크는 모델의 파라미터 공간에서 더 다양한 솔루션을 찾을 수 있어 다양한 문제에 적용할 수 있는 장점이 있습니다.
Noisy Network


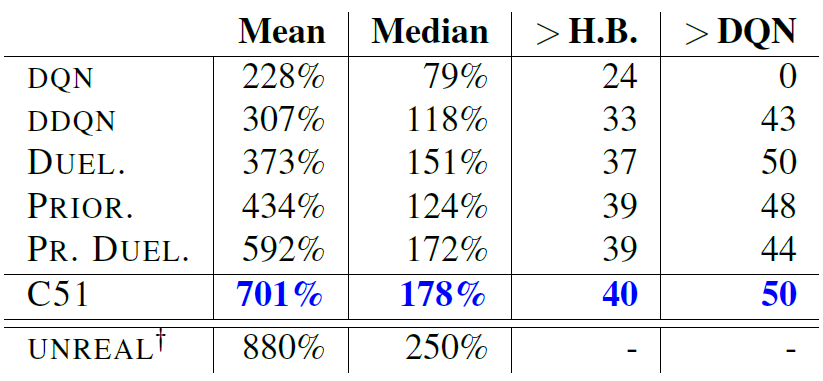
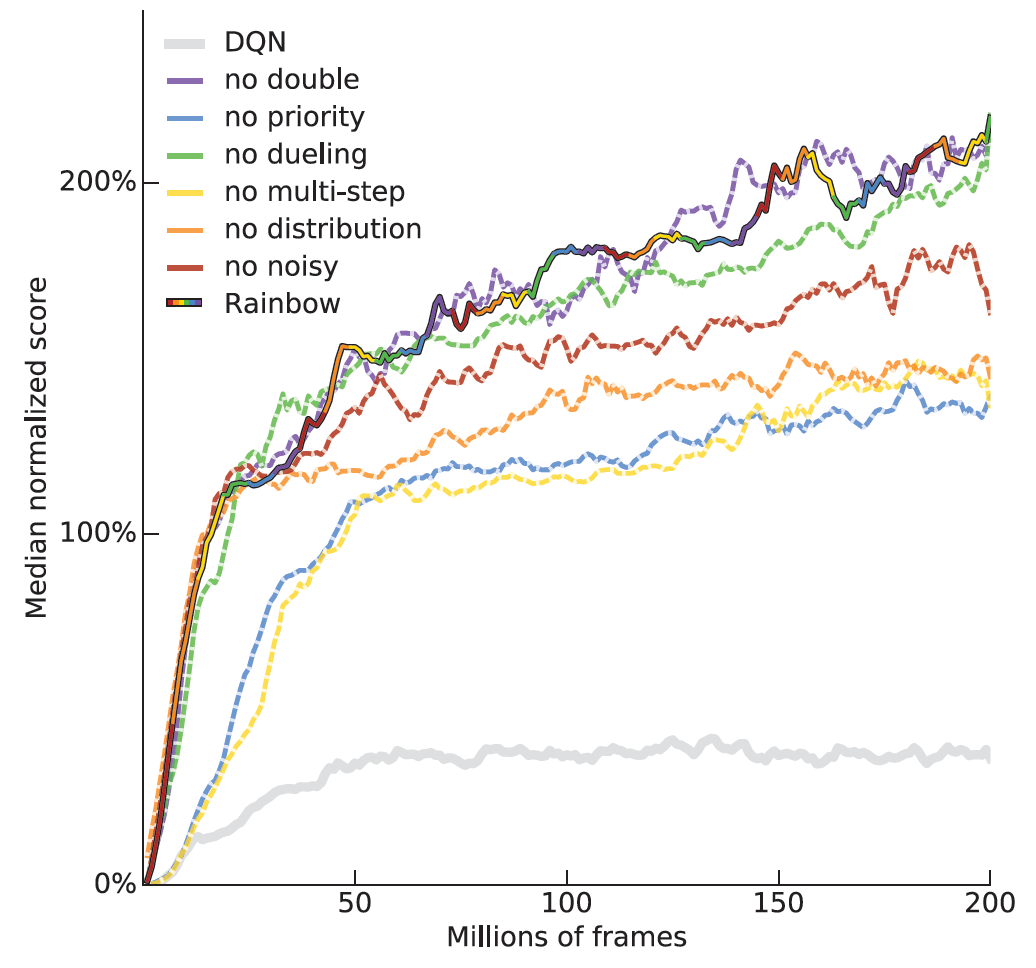
RAINBOW [AAAI 2018]
RAINBOW는 AAAI 2018에서 발표된 연구로, 강화학습에서의 성능을 향상시키기 위한 다양한 기법들을 통합한 알고리즘입니다.
RAINBOW는 DQN(Dueling Deep Q-Network)을 기반으로 하며, 다음과 같은 기법들을 적용하여 성능을 향상시킵니다:
- Double Q-learning: DQN에서 발생하는 값의 과대평가 문제를 완화하기 위해 Double Q-learning을 적용합니다.
- Prioritized Experience Replay: 학습 데이터의 중요도에 따라 샘플링을 조절하여 더 중요한 경험들에 더 많은 학습 기회를 주는 기법입니다.
- Dueling Network Architecture: 상태의 가치와 각 행동의 장점을 분리하여 추정하는 네트워크 구조를 사용합니다. 이를 통해 학습을 더욱 안정화시키고 일부 게임에서 더 높은 성능을 얻을 수 있습니다.
- Multi-step Learning: 다중 단계 학습을 통해 더 긴 시간에 걸친 보상을 고려하여 학습합니다. 이는 더 높은 샘플 효율성과 학습의 안정성을 제공합니다.
- Distributional RL: 강화학습에서의 가치 함수를 확률 분포 형태로 추정하여 더 다양한 정보를 활용합니다.
- Noisy Network: 네트워크의 가중치에 노이즈를 추가하여 더 강력한 탐색 능력을 갖도록 합니다.
RAINBOW는 이러한 다양한 기법들을 통합하여 강화학습 알고리즘의 성능을 향상시킨다는 점에서 주목받는 연구입니다.
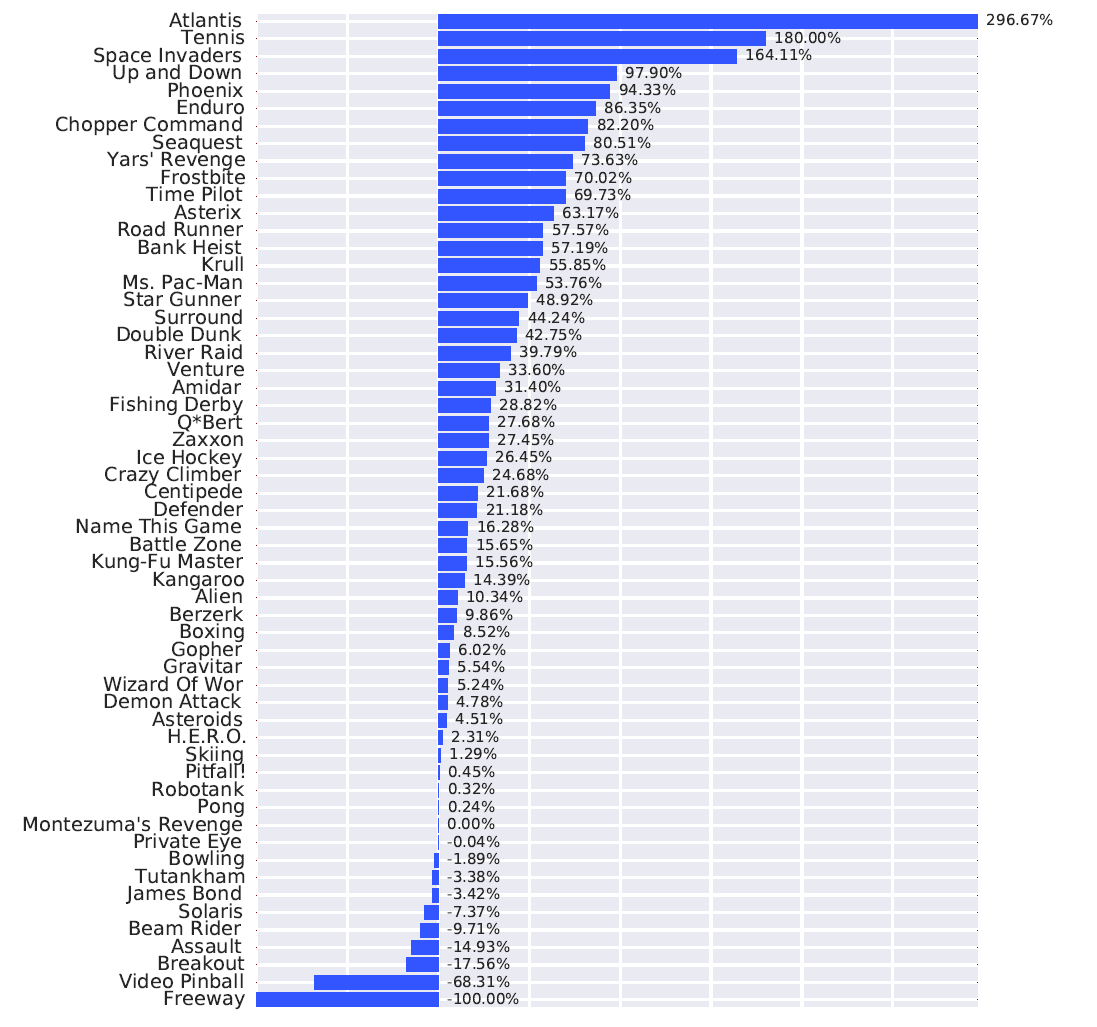
57개 Atari 게임의 성능 비교

성능 분석
Distributed Prioritized Experience Replay [ICLR 2018]
Distributed Prioritized Experience Replay는 ICLR 2018에서 발표된 연구로, Prioritized Experience Replay를 기반으로 한 분산 아키텍처입니다.
이 연구에서는 여러 개의 액터(Actor)가 동시에 작동하며 공유 메모리에 경험을 저장합니다. 각 액터는 𝜖-탐욕적(epsilon-greedy) 방법을 사용하는 데에 있어 다른 엡실론 값을 사용합니다. 주기적으로, 액터들은 학습자(Learner)로부터 𝜃(모델의 가중치)를 복사합니다.
단일 GPU를 사용하는 학습자는 공유 경험 재생 메모리로부터 학습을 수행합니다. 이 학습자는 Prioritized Experience Replay와 Multi Step, 그리고 Dueling Double Q-learning 기법을 함께 사용하여 학습합니다.
Distributed Prioritized Experience Replay는 분산 환경에서 Prioritized Experience Replay를 활용하여 학습 속도를 향상시키고, 여러 액터들이 경험을 공유하면서 학습자가 보다 효율적으로 학습할 수 있도록 하는 아키텍처입니다.

Ape-X Algorithms
Ape-X 알고리즘은 Prioritized Experience Replay와 강화 학습을 결합하여 성능을 향상시키는 방법을 제시합니다. 이 알고리즘은 여러 개의 작은 학습 그룹(learner group)과 대규모의 경험 저장소(replay buffer)로 구성됩니다. 각 학습 그룹은 독립적으로 학습하고, 일정한 간격으로 다른 그룹과 경험을 공유합니다. 이를 통해 경험의 다양성을 확보하고, 효율적인 학습을 진행할 수 있습니다.


Ape-X 알고리즘은 많은 작은 학습 그룹이 각각의 역할을 수행하면서 공동으로 성능을 향상시키는 효과적인 분산 학습 방식을 제공합니다. 이를 통해 학습 속도를 높이고, 안정적인 성능 향상을 이끌어냅니다.
Performance Results



부분 관찰 가능성으로 넘어가보자.
Deep Recurrent Q-Learning for Partially Observable MDPs [AAAI 2015]
Deep Recurrent Q Learning for Partially Observable MDPs (Markov Decision Processes)는 MDP의 일부분만 관찰 가능한 상황에서 강화 학습을 수행하기 위한 알고리즘입니다.
MDP의 한계는 시스템의 전체 상태를 에이전트에게 제공하거나 식별하는 것이 드물다는 점입니다. 일부 상태만을 관찰할 수 있는 부분 관측 MDP의 경우, 에이전트는 현재의 관측값을 기반으로 행동을 선택해야 합니다.
Deep Recurrent Q-Learning은 이러한 부분 관측 MDP에서 강화 학습을 수행하기 위해 순환 신경망(RNN)을 활용합니다. RNN은 이전 상태 정보를 기억하여 현재 관측값을 해석하고, 이를 기반으로 행동을 선택합니다. 이를 통해 에이전트는 부분 관측 상태에서도 효과적으로 학습하고 최적의 행동을 결정할 수 있습니다.
Deep Recurrent Q Learning은 에이전트가 관측 가능한 정보의 제한된 상황에서도 강력한 학습 성능을 발휘할 수 있습니다.
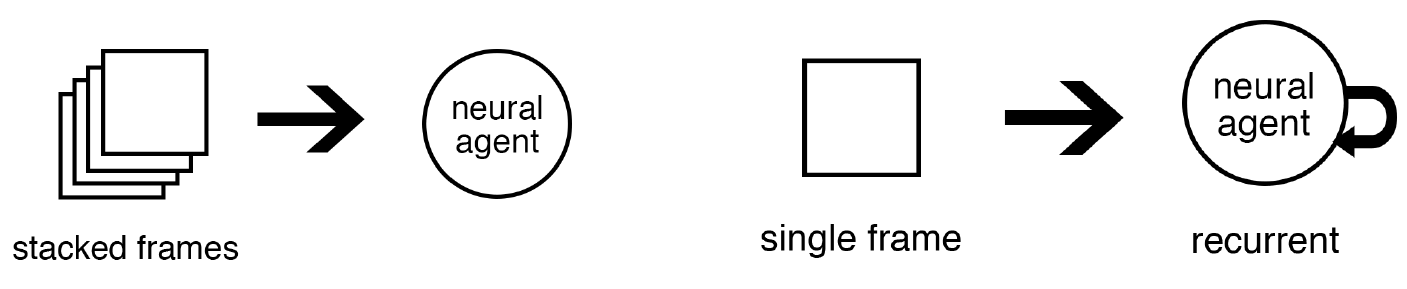
DRQN의 목표는 부분 관측 MDP에서 Deep Q Network에 순환성을 추가하여 𝑄(𝑜,𝑎|𝜃)와 𝑄(𝒔,𝑎|𝜃) 사이의 간격을 줄이는 것입니다.
부분 관측 MDP에서 에이전트는 전체 상태를 관찰하지 못하고 일부 상태만을 관측할 수 있습니다. 이로 인해 에이전트는 현재의 관측값만을 기반으로 행동을 선택해야 합니다. 하지만 이전 상태에 대한 정보가 중요할 수 있습니다.
DRQN은 이전 상태의 정보를 기억하기 위해 순환성을 도입한 Deep Q Network입니다. 순환 신경망(RNN)을 사용하여 에이전트는 이전 상태에 대한 정보를 유지하면서 현재의 관측값을 해석하고, 이를 기반으로 행동을 선택합니다. 이를 통해 에이전트는 부분 관측 상태에서도 보다 정확하게 𝑄값을 추정할 수 있습니다.
DRQN은 부분 관측 MDP에서 𝑄(𝑜,𝑎|𝜃)와 𝑄(𝒔,𝑎|𝜃) 사이의 차이를 줄이는 것을 목표로 하여, 보다 효과적인 학습과 결정을 가능하게 합니다.
DRQN Architecture

순환 업데이트는 다음 두 가지 방식으로 진행됩니다.
- 부트스트랩된 순차 업데이트:
- 에피소드는 재생 메모리에서 무작위로 선택됩니다.
- 업데이트는 에피소드의 시작부터 (초기 순환 상태를 0으로 설정하여) 에피소드의 끝까지 진행됩니다.
- 부트스트랩된 랜덤 업데이트:
- 에피소드는 재생 메모리에서 무작위로 선택됩니다.
- 업데이트는 에피소드 내의 무작위 지점부터 (초기 순환 상태를 0으로 설정하여) unroll_iteration 시간 단계 동안 진행됩니다.
이러한 방식은 DRQN에서 순환 업데이트를 수행하는 방법을 설명합니다. 순환 업데이트는 에피소드의 일부 또는 전체를 사용하여 순환 신경망을 업데이트하는 것입니다. 순차 업데이트는 에피소드의 처음부터 끝까지 순서대로 업데이트를 수행하며, 랜덤 업데이트는 에피소드 내에서 무작위로 시작 지점을 선택하여 해당 지점부터 unroll_iteration 시간 단계 동안 업데이트를 수행합니다.
Experimentation: Flickering Pong
lickering Pong 실험은 각 타임스텝에서 화면이 완전히 드러나거나 완전히 가려지는 경우를 가정합니다. 이 실험에서는 다음과 같은 3 종류의 네트워크를 학습합니다:
- 순환 1 프레임 DRQN:
- 단일 프레임으로 구성된 순환 신경망입니다.
- 화면이 완전히 드러날 때마다 신경망이 학습됩니다.
- 표준 4 프레임 DQN:
- 4개의 연속된 프레임으로 구성된 표준 신경망입니다.
- 화면이 완전히 드러날 때마다 신경망이 학습됩니다.
- 증강 10 프레임 DQN:
- 10개의 연속된 프레임으로 구성된 증강 신경망입니다.
- 화면이 완전히 드러날 때마다 신경망이 학습됩니다.
이러한 네트워크는 Flickering Pong에서 다양한 입력 상황에 대해 학습합니다. 순환 1 프레임 DRQN은 단일 프레임만을 사용하여 학습되며, 표준 4 프레임 DQN은 연속된 4개의 프레임을 사용하여 학습되며, 증강 10 프레임 DQN은 연속된 10개의 프레임을 사용하여 학습됩니다.
Flickering Pong Results

Atari Results

DRQN Summary
DRQN은 POMDP(Partially Observable Markov Decision Processes)의 노이즈와 불완전한 특성을 다루기 위해 LSTM(Long Short-Term Memory)과 DQN을 결합하여 사용합니다.
각 스텝마다 단일 프레임만 사용하는 DRQN은 프레임 간의 정보를 통합하여 관련 정보를 감지합니다. DRQN은 누락된 정보를 처리할 수 있는 견고한 정책을 학습합니다.
DRQN은 LSTM을 사용하여 이전 프레임의 정보를 기억하고 현재 상태에서 행동을 선택하는 데 활용합니다. 이를 통해 DRQN은 POMDP 환경에서 발생하는 노이즈와 불완전한 정보에 대응할 수 있으며, 누락된 정보를 효과적으로 다룰 수 있습니다. DRQN은 프레임 간의 상관 관계를 이용하여 관련 정보를 추출하고 이를 기반으로 강화 학습 정책을 학습합니다. 이렇게 학습된 DRQN은 불완전한 정보에도 견고한 정책을 구축할 수 있게 됩니다.
Recurrent Experience Replay in Distributed Reinforcement Learning [ICLR 2019]
"Recurrent Experience Replay in Distributed Reinforcement Learning"는 ICLR 2019에서 발표된 논문입니다.
이 논문은 분산된 우선순위 기반 경험 재생(replay)에서 RNN(Recurrent Neural Network) 기반 강화학습 에이전트의 훈련을 조사합니다. 이 연구는 매개변수 지연(parameter lag)으로 인해 표현적 변화(representational drift)와 반복적인 상태 불일치(recurrent state staleness)가 발생하는 영향을 연구합니다.
연구 결과, 이 논문은 57개의 Atari 게임 중 52개에서 인간 수준의 성능을 초과한 최초의 기록을 달성했습니다. 이는 RNN을 활용한 강화학습 에이전트가 복잡한 환경에서 잘 수행될 수 있음을 시사합니다.
이 논문은 분산된 환경에서의 RNN 기반 강화학습에 대한 연구로, RNN과 경험 재생의 조합을 통해 효과적인 강화학습 에이전트를 훈련하는 방법에 대한 실용적인 가이드라인을 제시합니다.
Training Recurrent RL with Experience Replay
"Training Recurrent RL with Experience Replay"은 DRQN(Deep Recurrent Q-Network)에서의 경험 재생(experience replay)에 대한 논의입니다.
DRQN에서는 초기에 무작위로 선택된 시퀀스의 시작 상태로 네트워크를 초기화하는 데 사용되는 제로(start) 상태를 사용합니다. 이는 초기 반복 상태의 불일치(initial recurrent state mismatch)를 야기할 수 있습니다.
또한, 전체 에피소드(trajetories)를 경험 재생하는 것은 실용적인, 계산적, 알고리즘적인 문제를 야기할 수 있습니다.
따라서, 이러한 문제에 대한 대안적인 접근 방식을 모색하고 실험하는 것이 중요합니다. 이를 통해 DRQN의 훈련 과정을 개선하고 효율적인 경험 재생 방법을 찾을 수 있습니다.
Proposed Two Strategies
제안된 두 가지 전략은 다음과 같습니다.
- Stored state: 경험 재생(replay)에서 재현 상태(recurrent state)를 저장하고, 이를 훈련 시 네트워크 초기화에 사용하는 것입니다. 이는 '표현 드리프트(representational drift)'로 이어지고 '재현 상태의 오래된 상태(recurrent state staleness)'로 이어질 수 있습니다.
- Burn-in: 경험 시퀀스의 일부를 사용하여 시작 상태를 생성하고, 남은 부분의 시퀀스를 업데이트하는 '버닝 기간(burn-in period)'을 도입하는 것입니다. 이를 통해 초기 반복 상태의 불일치 문제를 완화할 수 있습니다.
이러한 전략은 DRQN에서 경험 재생을 효과적으로 활용하기 위해 고려되는 방법들입니다. 이러한 전략들은 '표현 드리프트'나 '재현 상태의 오래된 상태'와 같은 문제를 해결하고, 네트워크의 훈련과 성능을 개선하는 데 도움을 줄 수 있습니다.
Learning curves on the training strategies

Atari Performance Results
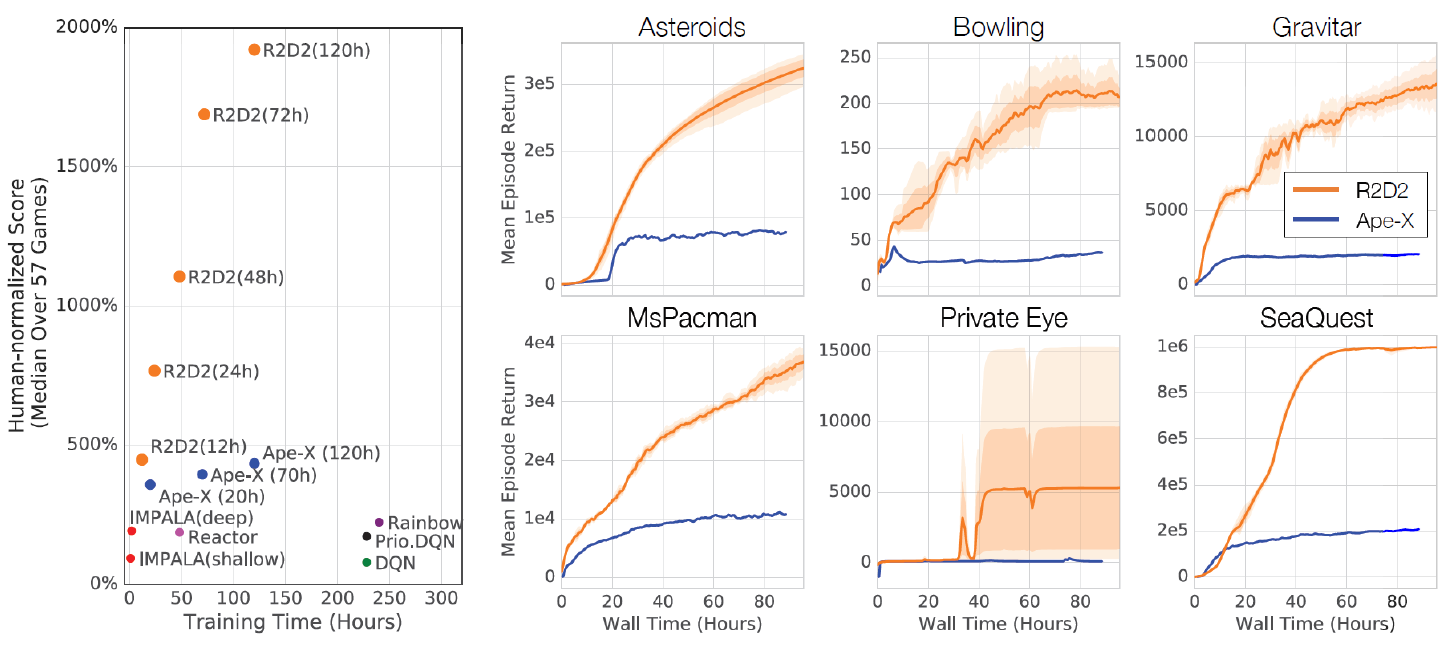
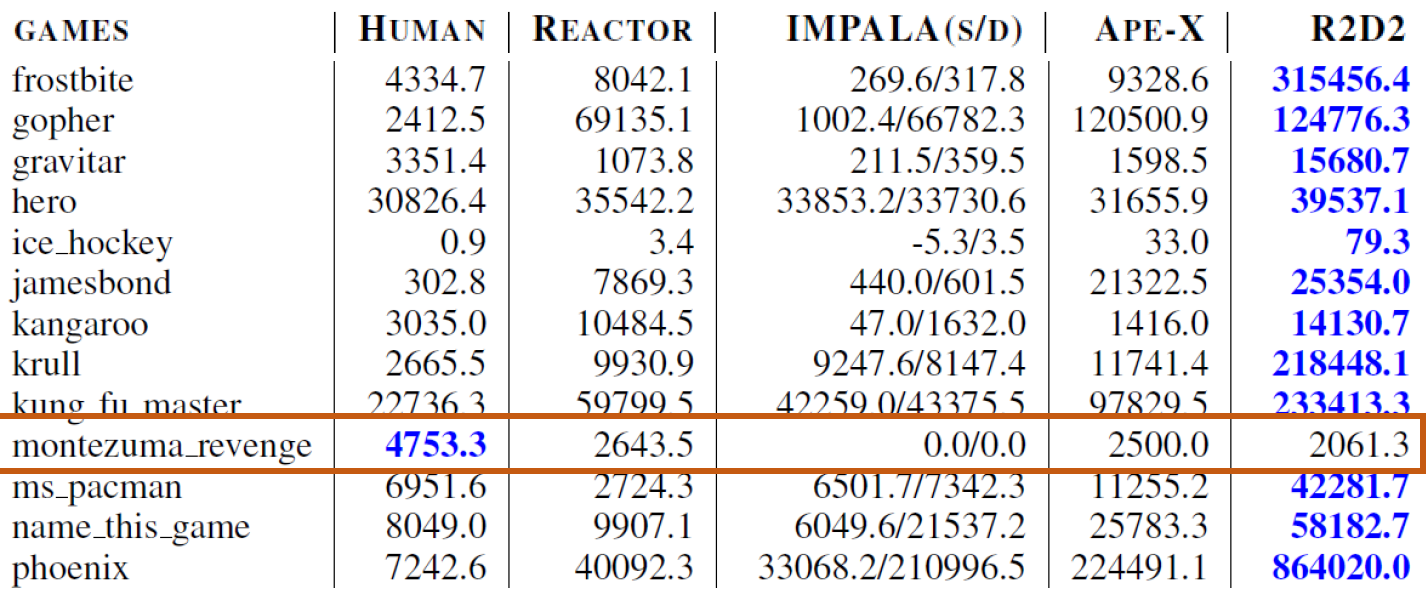
Montezuma Revenge에서는 별로 좋지 않은 평가를 보인다.
Reference

'강화학습' 카테고리의 다른 글
| Chapter 10. Exploration (1) | 2023.05.30 |
|---|---|
| Chapter 9. Policy Gradients (0) | 2023.05.22 |
| Chapter 7. Value Function Approximation (0) | 2023.05.22 |
| Chapter6. Model-Free Control (0) | 2023.05.22 |
| Chapter 5. Model-free Prediction (1) | 2023.05.21 |



