강화학습 알고리즘은 보통 세 가지 유형으로 분류됩니다.
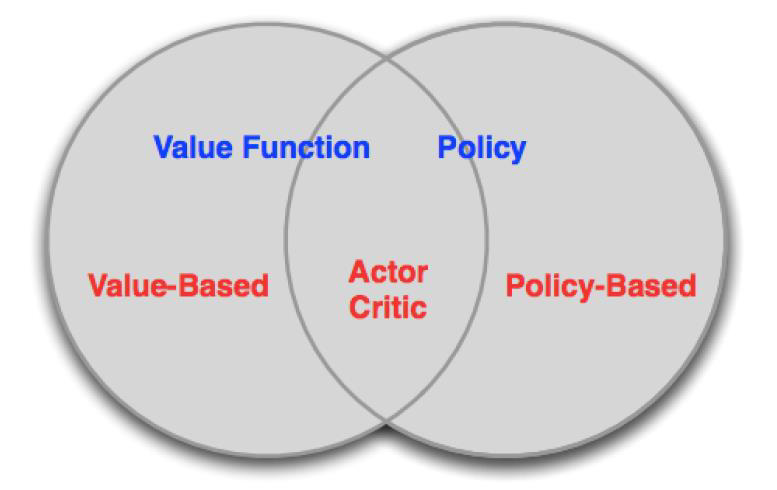
- 값 기반 (Value-based) 알고리즘:
- 학습된 가치 함수 (Value Function)을 기반으로 합니다.
- 암묵적인 정책 (Implicit Policy)을 사용하여 행동을 선택합니다 (예: 𝜀-탐욕 정책).
- 가치 함수를 학습하여 최적의 행동 가치를 추정하고 이를 기반으로 행동을 선택합니다.
- 정책 기반 (Policy-based) 알고리즘:
- 가치 함수를 사용하지 않고, 직접 정책 (Policy)을 학습합니다.
- 학습된 정책을 기반으로 행동을 선택합니다.
- 보상을 최대화하기 위해 정책을 개선하고, 보상에 대한 기대값을 최대화하는 방향으로 학습합니다.
- 액터-크리틱 (Actor-Critic) 알고리즘:
- 값 함수와 정책을 동시에 학습합니다.
- 학습된 가치 함수를 사용하여 행동 가치를 추정하고, 이를 기반으로 정책을 업데이트합니다.
- 가치 함수와 정책이 상호작용하면서 보상을 최대화하는 방향으로 학습합니다.
이러한 알고리즘들은 강화학습에서 다양한 문제에 적용되며, 각각의 특징과 장단점을 가지고 있습니다. 저번 chapter에서는 Value-based 알고리즘을 알아보았다. 이번 chapter에서는 Policy-based 알고리즘을 알아보자.
Policy-based Reinforcement Learning
정책 기반 강화학습은 마지막 강의에서 우리는 매개변수 𝜃를 사용하여 행동 가치 함수를 근사화했습니다. 즉, Q-함수를 근사화했습니다.
Q𝜃(s,a)≈Q𝜋(s,a)
정책은 행동 가치 함수로부터 생성되었습니다. 이번 강의에서는 정책을 직접 매개변수화하는 방법에 대해 집중할 것입니다.
𝜋𝜃(𝑠,𝑎)≈ℙ[𝑎|𝑠]
다시 말해서, 정책을 직접적으로 매개변수화하여 학습합니다. 이번 강의에서는 모델 없는 강화학습에 중점을 둘 것입니다.
Advantages and Disadvantages of Policy-Based RL
정책 기반 강화학습의 장점은 다음과 같습니다:
• 수렴 속성이 더 좋습니다.
• 고차원 또는 연속적인 행동 공간에서 효과적입니다.
• 확률적인 정책을 학습할 수 있습니다.
하지만 정책 기반 강화학습은 아래와 같은 단점도 가지고 있습니다:
• 학습 과정에서 안정성이 떨어질 수 있습니다. (분산이 크기 때문에)
• 샘플 효율이 낮아 더 많은 샘플 데이터가 필요합니다.
Example: Rock-Paper-Scissors
• 가위는 보를 이기고, 바위는 가위를 이기고, 보는 바위를 이깁니다.
• 반복해서 진행되는 게임에서의 정책을 고려해봅시다.
• 결정론적인 정책은 쉽게 이용될 수 있습니다.
• 균일한 무작위 정책은 최적입니다. (즉, 나쉬 균형)

가위바위보 게임은 상대방의 정책에 따라 최적의 전략이 달라질 수 있습니다. 결정론적인 정책은 상대방에게 쉽게 이용될 수 있으므로 예측이 가능한 정책을 사용하는 것이 좋습니다. 반면, 균일한 무작위 정책은 상대방이 예측하기 어려우며, 전략적인 요소가 없는 것으로 알려져 있습니다. 따라서 이러한 요소들을 고려하여 가위바위보 게임에서 최적의 정책을 선택해야 합니다.
Example: Aliased Gridworld
• 에이전트는 회색 상태를 구분할 수 없습니다.
• 다음 형식의 특징을 고려해 봅시다 (모든 N, E, S, W에 대하여): ∅(s) = N 방향 또는 S 방향으로 벽이 있는지 여부
• 근사값 함수를 사용한 값 기반 강화 학습: Q𝜃(s, a) = f(∅(s), a, 𝜃)
• 매개변수화된 정책을 사용한 정책 기반 강화 학습: 𝜋𝜃(s, a) = g(∅(s), a, 𝜃)
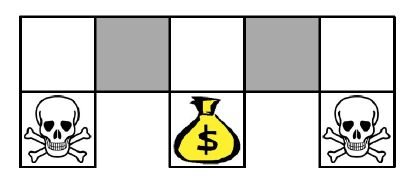
• 에일리어스에 의해, 최적의 결정론적 정책은
• 회색 상태에서 모두 W로 이동하는 것입니다 (빨간색 화살표로 표시)
• 또는 회색 상태에서 모두 E로 이동하는 것입니다
• 어느 경우에도, 이동이 제한되어 돈에 도달할 수 없게 됩니다
• 값 기반 강화 학습은 거의 결정론적인 정책을 학습합니다
• 예를 들어, 탐욕적인 또는 𝜀-탐욕적인 정책
• 따라서 이러한 경우, 회색 상태에서의 이동은 오랜 시간이 걸릴 수 있습니다.
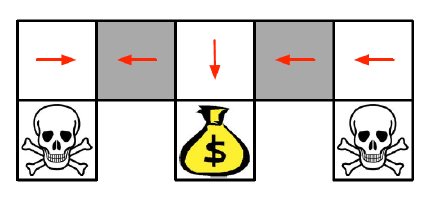
• 최적의 확률적인 정책은 회색 상태에서 무작위로 E 또는 W로 이동합니다.
𝜋𝜃(벽이 N 방향과 S 방향에 있는 상태, E로 이동) = 0.5
𝜋𝜃(벽이 N 방향과 S 방향에 있는 상태, W로 이동) = 0.5
• 이 경우, 고성공 확률로 몇 단계 안에 목표 상태에 도달할 수 있습니다.
• 정책 기반 강화 학습은 최적의 확률적인 정책을 학습할 수 있습니다.
Policy Search
• 파라미터 𝜃를 가진 최적의 정책 𝜋𝜃를 찾아보겠습니다. 이 정책은 최적의 행동의 확률 분포를 출력합니다.

• 하지만, 정책 𝜋𝜃을 개선하기 위해 어떻게 최적화할 수 있을까요?
• 𝐽𝜃라는 점수 함수를 최대화하는 최적의 파라미터 𝜃를 찾아야 합니다.
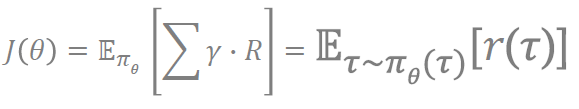
• 정책 기울기 상승법(policy gradient ascent)을 사용하여 정책 𝜋𝜃를 개선하는 최적의 파라미터 𝜃를 찾습니다.
Policy Score (Objective) Functions
우리는 episodic environments에 다음처럼 시작할 수 있습니다.

Average Reward(평균 보상을 최대화하는 정책을 찾기)를 통해 구한다면 다음과 같이 나옵니다.
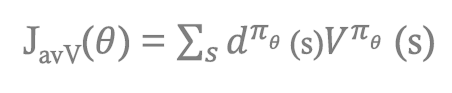
Policy Optimization
• 정책 기반 강화 학습은 최적화 문제입니다.
• 𝜃를 찾아서 J(𝜃)를 최대화하는 것이 목표입니다.
• 우리는 주로 그래디언트 기반 접근법에 초점을 맞춥니다.
정책 최적화는 정책 파라미터 𝜃를 업데이트하여 보상을 최대화하는 것을 목표로 합니다. 이를 위해 주로 그래디언트 기반 접근법을 사용합니다. 그래디언트 기반 접근법은 정책 점수 함수의 그래디언트를 계산하고, 이를 사용하여 정책 파라미터를 조정합니다. 이를 통해 정책이 점점 더 좋아지고 최적 정책에 수렴하도록 학습할 수 있습니다
따라서 우리는 Policy Gradient를 통해 최적화된 해를 찾습니다.


Policy Gradient Ascent
• 점수 함수를 최대화하는 것은 최적의 정책을 찾는 것을 의미합니다.
• 점수 함수 J(𝜃)를 최대화하기 위해 정책 파라미터에 대한 그래디언트 상승을 수행해야 합니다.
• 정책이 상태 분포에 미치는 영향을 어떻게 결정할까요?
• 알려지지 않은 상태 분포에서 (그래디언트)를 어떻게 추정할까요?
정책 그래디언트 상승은 정책 파라미터에 대한 점수 함수의 그래디언트를 계산하여 정책을 최적화하는 방법입니다. 이를 위해 우리는 정책이 상태 분포에 미치는 영향을 결정해야 합니다. 이를 위해 환경에서 행동을 샘플링하여 상태-행동 쌍을 수집하고, 이를 사용하여 상태 분포를 추정할 수 있습니다.
알려지지 않은 상태 분포에서 그래디언트를 추정하기 위해 주로 몬테카를로 추정을 사용합니다. 몬테카를로 추정은 샘플링을 통해 기대값을 추정하는 방법입니다. 여러 상태-행동 쌍을 샘플링하여 점수 함수에 대한 그래디언트의 추정치를 계산합니다. 이 추정치를 사용하여 정책 파라미터를 업데이트하고 점진적으로 점수 함수를 최대화하도록 학습합니다.
Policy Differentiation
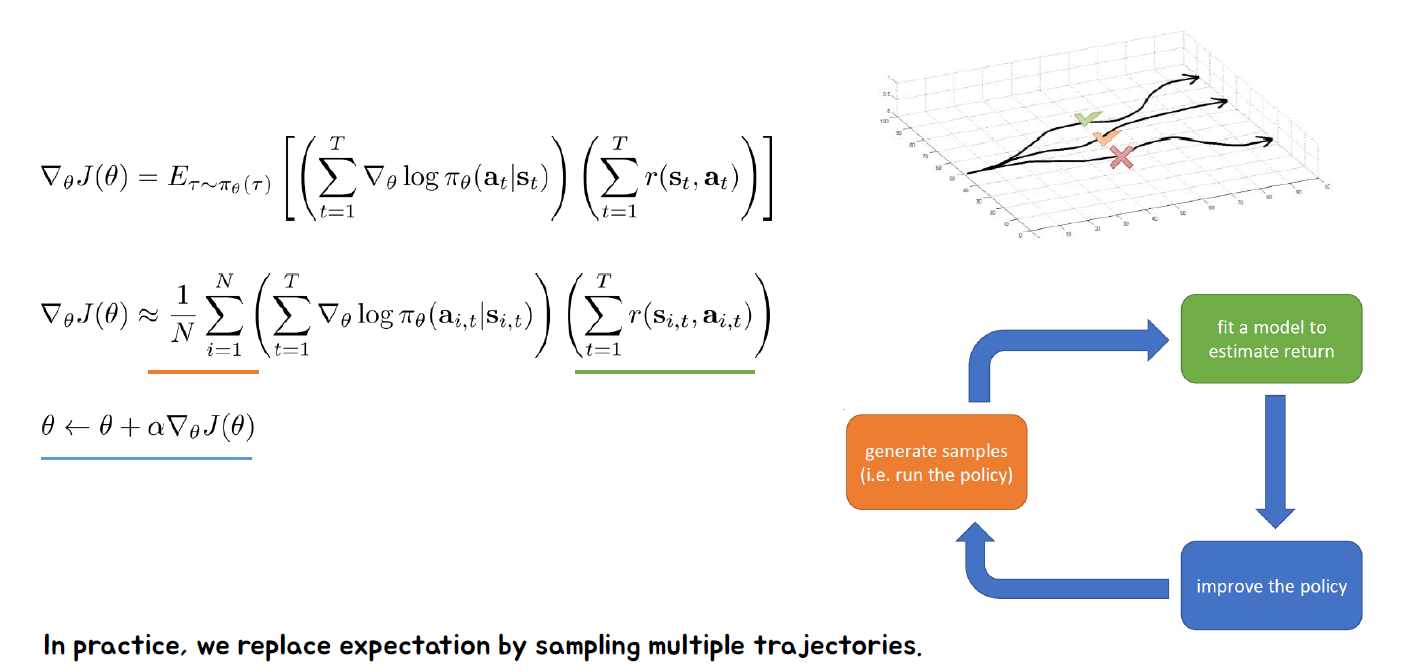
Policy의 최적의 해를 구해보자.

세타를 위에처럼 둘수있는것을 우리는 알고 있습니다. 따라서 J에 적용하면 다음과 같이 나옵니다.
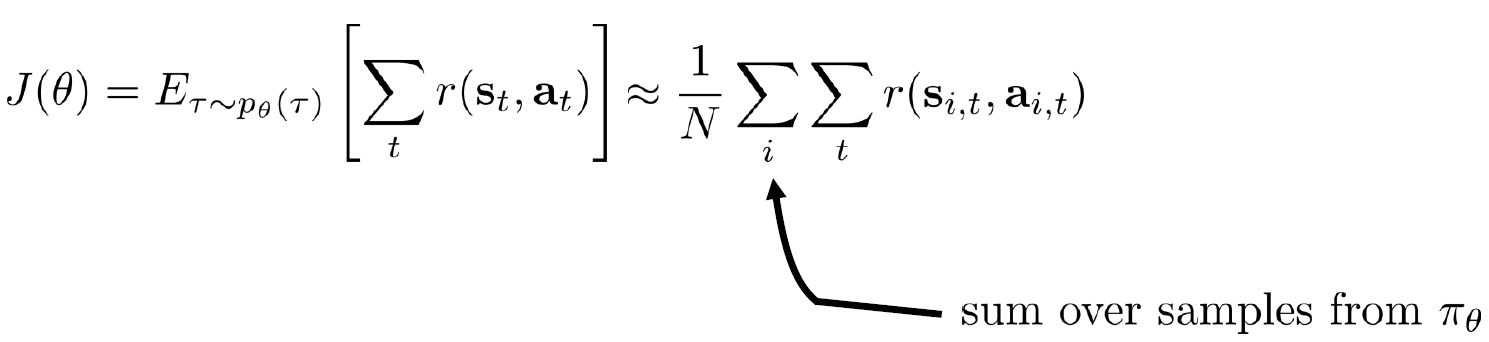
따라서 최적의 해를 구하기위해 식을 미분에 따라 구하면 다음과 같습니다.
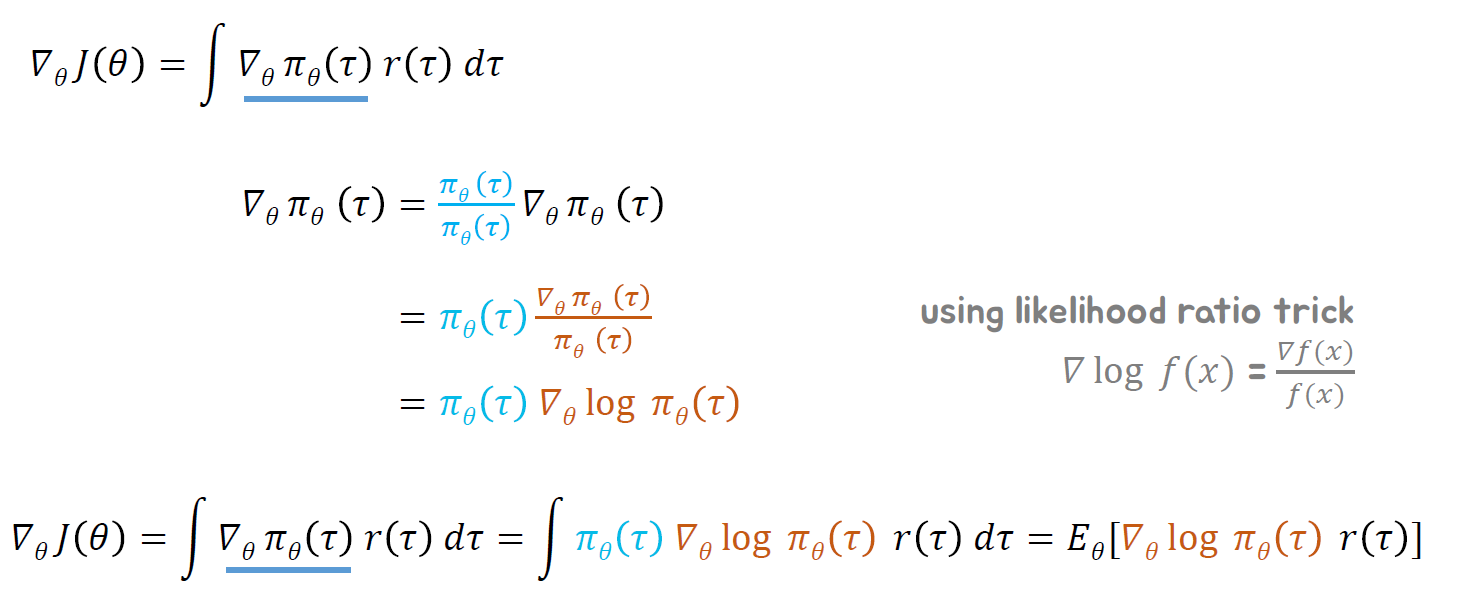


따라서 최종적으로는 다음과 같이 나오며, 오른쪽 아래와 같이 수행될 것입니다.
Differentiable Policy Classes
미분 가능한 정책 클래스들은 다음과 같습니다.
• Discrete action space
• Softmax

•Continuous action space
•Gaussian policy
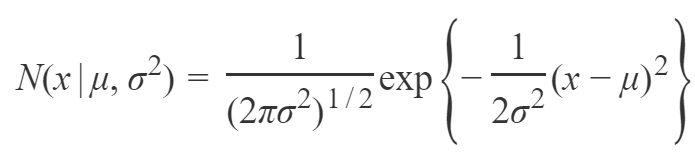
Reducing Variance
분산을 줄이려면 어떻게 해야될까요?
이를 알아보러 갑시다.
먼저, Gradient method를 사용하기 때문에, 다음을 정의하고 가겠습니다.
Monte-Carlo Policy Gradient (REINFORCE)
Monte-Carlo Policy Gradient (REINFORCE) 알고리즘은 정책 기반 강화 학습 알고리즘 중 하나입니다. 이 알고리즘은 보상을 바탕으로 정책을 업데이트하여 최적 정책을 찾는 데 사용됩니다.
REINFORCE 알고리즘은 다음과 같은 단계로 진행됩니다:

- 초기화: 정책 파라미터 𝜃를 임의의 값으로 초기화합니다.
- 에피소드 샘플링: 정책을 따라 환경과 상호작용하여 에피소드를 수집합니다. 각 스텝마다 상태, 액션, 보상을 기록합니다.
- 리턴 계산: 에피소드가 종료될 때까지 얻은 보상들의 합인 리턴을 계산합니다.
- 그래디언트 계산: 각 스텝에서의 그래디언트를 계산합니다. 그래디언트는 리턴과 로그 확률의 곱으로 구성됩니다. 로그 확률은 현재 상태와 선택한 액션에 대한 정책의 로그 확률입니다.
- 파라미터 업데이트: 그래디언트의 평균을 구하여 정책 파라미터를 업데이트합니다. 업데이트 방식은 보통 확률적 경사 상승법(Stochastic Gradient Ascent)을 사용합니다.
- 반복: 위 단계를 여러 번 반복하여 정책을 계속적으로 개선합니다.
REINFORCE 알고리즘은 모든 에피소드를 완료한 후에 그래디언트 업데이트를 수행하므로, 모든 에피소드의 정보를 이용하여 정책을 업데이트합니다. 이 알고리즘은 보상의 기댓값을 추정하기 위해 몬테카를로 추정을 사용하며, 매우 간단하고 직관적인 방법입니다.
Baselines in Policy Gradients
정책 그래디언트에서 "베이스라인"을 사용하는 것은 정책 그래디언트에서 기준 함수 𝐵(𝑠)를 빼는 것을 의미합니다. 이를 통해 기대값을 변경하지 않고 분산을 감소시킬 수 있습니다. 좋은 베이스라인은 상태 가치 함수인 𝐵𝑠=𝑉𝜋𝑠입니다. 이는 정책 학습을 더 빠르고 안정적으로 만들어줍니다.
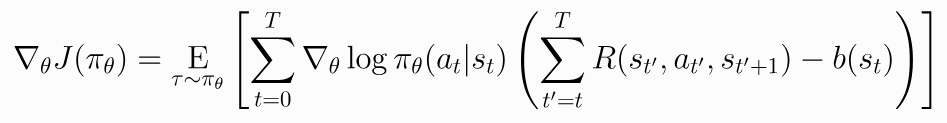
베이스라인을 사용하는 이유는 정책 그래디언트 추정에서 리턴의 변동성을 줄이고, 그래디언트의 분산을 감소시키기 위함입니다. 베이스라인을 사용하면 보상과 베이스라인 사이의 차이를 이용하여 그래디언트를 조정하므로, 기댓값은 변하지 않습니다. 이를 통해 보다 빠르고 안정적인 정책 학습이 가능해집니다.
베이스라인으로 상태 가치 함수를 사용하는 이유는 상태 가치 함수가 현재 상태의 평균적인 보상을 나타내기 때문입니다. 상태 가치 함수를 베이스라인으로 사용하면, 현재 상태의 예상 보상과 실제 보상 사이의 차이를 그래디언트에 반영하여 정책 학습을 개선할 수 있습니다.
Baseline does NOT introduce bias-derivation
다음의 식을 보면 베이스라인 정책 그래디언트 추정에서 리턴의 변동성을 줄이고, 그래디언트의 분산을 감소시키기는 것을 확인할 수 있습니다.

정확한 상태 가치 함수 𝑉𝜋(𝑠)를 계산하기 어려우므로 근사화해야 합니다. 신경망을 사용하여 정책과 동시에 업데이트됩니다. 값 네트워크는 항상 가장 최근 정책의 가치 함수를 근사화합니다. 𝜋𝑘는 k번째 에포크에서의 정책이며, 평균 제곱 오차 목적 함수를 최소화합니다.
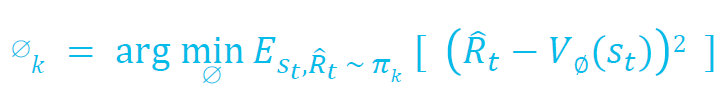
Vanilla Policy Gradient Algorithm [Sutton 2000]
바닐라 정책 그래디언트 알고리즘은 Sutton (2000)에 제안된 정책 그래디언트 방법 중 하나입니다. 이 알고리즘은 다음과 같은 절차로 정책을 학습합니다.
- 초기화: 정책 파라미터 𝜃를 무작위로 초기화합니다.
- 에피소드 반복:
- 환경과 상호작용하여 에피소드 데이터를 수집합니다.
- 수집한 데이터를 기반으로 정책 그래디언트를 계산합니다.
- 정책 파라미터를 업데이트합니다.
- 반복: 원하는 수의 에피소드를 수행하거나 수렴 조건을 만족할 때까지 2단계를 반복합니다.
정책 그래디언트 계산은 다음과 같은 단계로 이루어집니다.
- 에피소드 데이터를 기반으로 정책의 평균 리턴을 계산합니다.
- 에피소드의 각 시간 단계에서의 로그 확률 그래디언트를 계산합니다.
- 로그 확률 그래디언트에 평균 리턴을 곱하여 정책 그래디언트를 얻습니다.
- 정책 파라미터를 정책 그래디언트와 학습률을 이용하여 업데이트합니다.

바닐라 정책 그래디언트 알고리즘은 정책 그래디언트를 사용하여 정책을 학습하는 간단하면서도 효과적인 방법입니다. 하지만 높은 분산을 가지며 샘플 효율성이 낮다는 단점이 있습니다. 이러한 단점을 극복하기 위해 다양한 개선된 정책 그래디언트 알고리즘이 제안되었습니다.
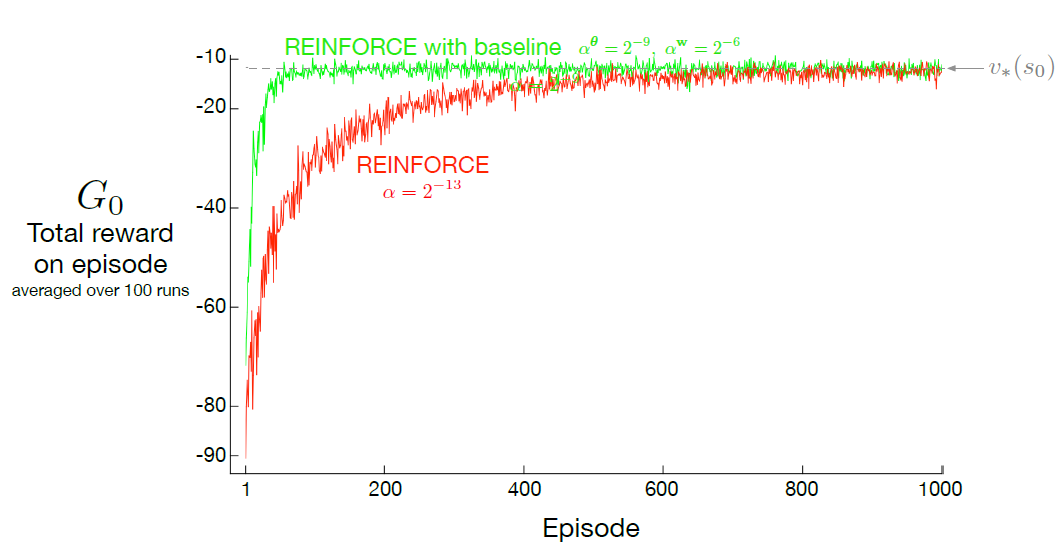
Performance Impact of Baseline
Policy-based 이 부분으로 종료되었다. Actor-Critic을 통해 학습된 가치함수와 배운 정책에 대해서 알아보자.
Problem Example of Policy Gradient Method
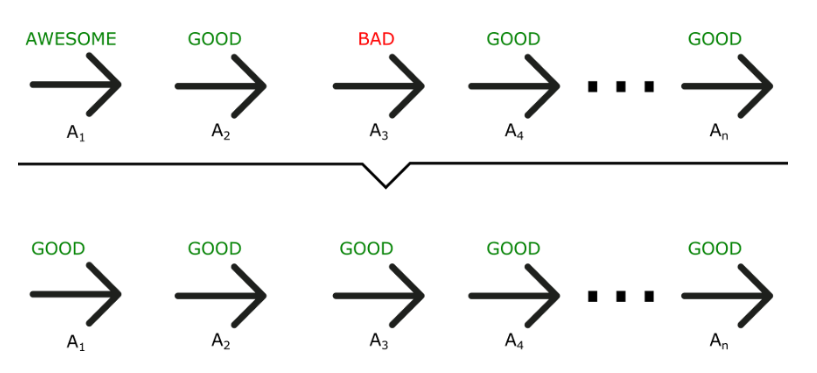
정책 그래디언트 방법은 샘플링에 기반한 학습 방식이기 때문에 초기에는 에피소드를 통해 얻은 샘플들이 무작위성과 불안정성을 가지고 있을 수 있습니다. 따라서 초기에는 정책이 잘못된 방향으로 학습되는 경우가 발생할 수 있습니다.
About Choosing the Target
타깃 선택에 관한 내용은 다음과 같습니다.
몬테카를로 정책 그래디언트 방법은 여전히 높은 분산을 가지고 있습니다. 𝑅(𝜏𝑖)는 단일 롤아웃에서 값을 추정하는 것입니다. 이는 편향은 없지만 분산이 높습니다.
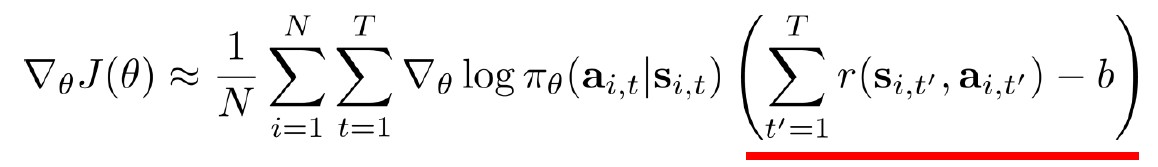
이러한 문제를 해결하기 위해 가치 추정치 (비평가)와 부트스트래핑을 사용할 수 있습니다. 이는 우리가 MC와 TD에서 보았던 것과 유사한 방식입니다. 더 나은 추정치일수록 분산이 낮아지게 됩니다.
즉, 단일 롤아웃으로 추정한 값이 아닌 가치 추정치와 부트스트래핑을 사용하여 타깃을 선택하면 분산을 줄일 수 있습니다. 이를 통해 보다 안정적이고 효과적인 정책 그래디언트 방법을 구현할 수 있습니다.
Reducing Variance Using a Critic
• 우리는 비평가를 사용하여 행동-가치 함수를 추정합니다.

• 액터-비평가 알고리즘은 두 개의 파라미터 집합을 유지합니다.
• 비평가는 행동-가치 함수 파라미터 w를 업데이트합니다.
• 액터는 비평가가 제시한 방향으로 정책 파라미터 𝜃를 업데이트합니다.
• 액터-비평가 알고리즘은 근사적인 정책 그래디언트를 따릅니다.
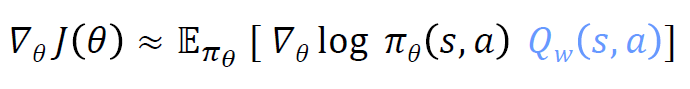
액터-비평가 알고리즘에서는 정책 그래디언트를 추정하기 위해 비평가를 사용하여 분산을 줄입니다. 비평가는 행동-가치 함수를 추정하여 액터가 정책 파라미터를 업데이트할 때 그 방향을 제시합니다. 이렇게 함으로써 분산을 줄이고 보다 안정적인 학습을 이룰 수 있습니다.
Estimating the Advantage Function
• 장점 함수를 추정함으로써 정책 그래디언트의 분산을 크게 줄일 수 있습니다.
• 따라서, 비평가는 실제로 장점 함수를 추정해야 합니다.
• 예를 들어, V(s)와 Q(s, a)를 모두 추정함으로써
• 두 가지 함수 근사치와 두 개의 파라미터 벡터를 사용합니다.
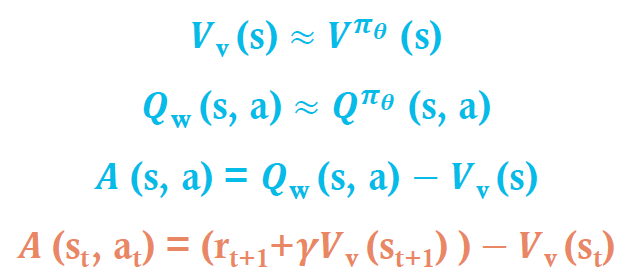
Various Forms of the Policy Gradient
다양한 형태의 정책 기울기는 다음과 같다.

여기서 확인할 수 있다. (https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html#deriving-the-simplest-policy-gradient)
Actor-Critic에 대해서 알아보자. 아래는 Actor-Critic의 구조이다.

Actor-Critic Algorithm
액터-크리틱(Actor-Critic) 알고리즘은 정책 그래디언트 방법과 가치 함수 추정을 결합한 강화학습 알고리즘입니다.

이 알고리즘은 두 개의 주요 구성 요소로 이루어져 있습니다. 첫 번째는 액터(Actor)로써 정책을 파라미터화하고 업데이트하는 역할을 합니다. 두 번째는 크리틱(Critic)으로써 가치 함수를 추정하고 업데이트하는 역할을 합니다.
액터는 정책 그래디언트 방법을 사용하여 환경과 상호작용하면서 행동을 선택하고, 선택된 행동에 대한 보상을 받습니다. 이를 통해 정책 파라미터를 업데이트하고 더 나은 정책을 학습합니다.
크리틱은 가치 함수를 추정하여 상태의 가치를 예측하고, 액터의 행동에 대한 장점(advantage)을 계산합니다. 장점은 현재 상태에서 선택한 행동의 평균적인 가치와 예상 가치의 차이를 나타내며, 액터의 학습에 사용됩니다. 크리틱은 가치 함수의 추정을 통해 액터의 학습을 보조하고, 장점 함수의 추정에 의한 분산 감소 효과를 가져옵니다.
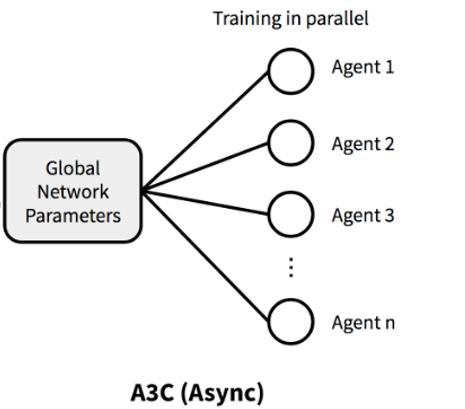
A3C : Asynchronous Advantage Actor-Critic [ICML 2016]
A3C(Asynchronous Advantage Actor-Critic)은 병렬 액터-러너(Actor-Learner)들을 사용하여 비동기적으로 그래디언트 하강법을 수행하는 강화학습 알고리즘입니다. 이 알고리즘은 멀티 스레드를 활용하여 병렬적으로 학습을 수행하며, GPU 대신 단일 다중 코어 CPU를 사용합니다.
A3C에서는 N-step returns를 사용하여 정책(policy)과 가치 함수(value function)를 업데이트합니다. N-step returns는 현재 상태에서 시작하여 N개의 연속된 행동에 대한 반환값을 추정하는 방법으로, 정책과 가치 함수의 학습에 활용됩니다. 이를 통해 장점(advantage)을 계산하고, 이를 이용하여 액터-크리틱 알고리즘의 학습을 수행합니다.
A3C는 이산 및 연속적인 행동 공간에서 모두 동작할 수 있는 장점을 가지고 있습니다. 따라서 다양한 문제에 대한 적용이 가능하며, 학습의 안정성과 효율성을 높일 수 있습니다.
A3C Architecture는 다음과 같다.

A3C에서 개별 에이전트의 교육 워크플로는 다음과 같다.
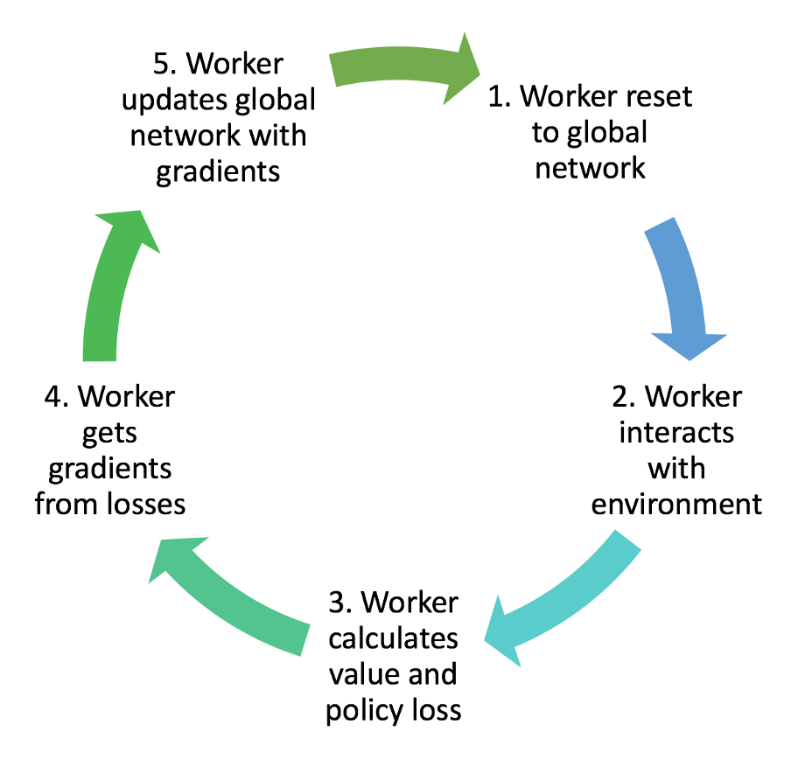
A3C(A3C : Asynchronous Advantage Actor-Critic)에서 개별 에이전트의 학습 워크플로우는 다음과 같습니다:
- 각 워커는 전역 신경망(Global Network)을 초기화합니다. 이는 모든 워커가 동일한 초기 파라미터를 가지고 시작할 수 있도록 합니다.
- 워커는 환경과 상호작용합니다. 각 워커는 자체적으로 상태를 관찰하고, 해당 상태에 대한 행동을 선택하여 환경에 적용합니다.
- 워커는 선택한 행동에 대한 가치와 정책 손실을 계산합니다. 가치 손실은 에이전트의 상태에 대한 가치 함수의 오차를 나타내며, 정책 손실은 선택한 행동에 대한 로그 확률의 음의 가중치입니다.
- 워커는 손실로부터 그래디언트를 계산합니다. 이는 역전파 알고리즘을 통해 그래디언트를 추정하는 과정입니다.
- 워커는 계산된 그래디언트를 사용하여 전역 신경망을 업데이트합니다. 이를 통해 모든 워커가 동시에 전역 신경망을 업데이트하고 공유합니다.
위의 과정을 반복하여 각 워커는 독립적으로 환경과 상호작용하고, 손실을 계산하고, 그래디언트를 업데이트하여 전역 신경망을 개선합니다.
Asynchronous N-step Q-learning
비동기적 단일 스텝 Q-학습(Asynchronous one-step Q-learning)은 다음과 같은 방식으로 진행됩니다:

- 각 워커는 독립적으로 환경과 상호작용합니다. 워커는 현재 상태를 관찰하고, 그에 따른 행동을 선택하여 환경에 적용합니다.
- 워커는 적용한 행동에 대한 보상과 다음 상태를 받습니다.
- 워커는 받은 보상과 다음 상태를 사용하여 Q-값을 업데이트합니다. 일반적으로 Q-학습은 다음과 같은 공식을 사용하여 Q-값을 업데이트합니다: Q(s, a) = Q(s, a) + α(r + γ max(Q(s', a')) - Q(s, a))
- 워커는 업데이트된 Q-값을 사용하여 정책을 개선합니다. 일반적으로 ε-탐욕적인(ε-greedy) 방식을 사용하여 현재 상태에서 가장 높은 Q-값을 가진 행동을 선택합니다.
- 워커는 업데이트된 정책을 사용하여 환경과 상호작용합니다. 이러한 과정을 반복하여 워커들이 독립적으로 환경과 상호작용하고, Q-값과 정책을 업데이트하여 최적의 정책을 학습합니다.
비동기적 단일 스텝 Q-학습은 다중 에이전트 학습에서 효율적으로 사용될 수 있으며, 각 워커가 독립적으로 학습하고 업데이트하기 때문에 학습 속도와 확장성이 향상될 수 있습니다.
Asynchronous N-step Q-learning
비동기적 N-스텝 Q-학습(Asynchronous N-step Q-learning)은 다음과 같은 방식으로 진행됩니다:

- 각 워커는 독립적으로 환경과 상호작용합니다. 워커는 현재 상태를 관찰하고, 그에 따른 행동을 선택하여 환경에 적용합니다.
- 워커는 적용한 행동에 대한 보상과 다음 상태를 받습니다.
- 워커는 받은 보상과 다음 상태를 사용하여 N-스텝 리턴(N-step return)을 계산합니다. N-스텝 리턴은 현재 시점에서 N개의 연속된 보상과 상태를 고려하여 계산됩니다.
- 워커는 N-스텝 리턴을 사용하여 Q-값을 업데이트합니다. Q-값은 일반적으로 다음과 같은 공식을 사용하여 업데이트됩니다: Q(s, a) = Q(s, a) + α(G - Q(s, a)), where G = r_t + γ*r_{t+1} + ... + γ^{N-1} * r_{t+N-1} + γ^N * max(Q(s_{t+N}, a_{t+N}))
- 워커는 업데이트된 Q-값을 사용하여 정책을 개선합니다. 일반적으로 ε-탐욕적인(ε-greedy) 방식을 사용하여 현재 상태에서 가장 높은 Q-값을 가진 행동을 선택합니다.
- 워커는 업데이트된 정책을 사용하여 환경과 상호작용합니다. 이러한 과정을 반복하여 워커들이 독립적으로 환경과 상호작용하고, Q-값과 정책을 업데이트하여 최적의 정책을 학습합니다.
비동기적 N-스텝 Q-학습은 다중 에이전트 학습에서 효율적으로 사용될 수 있으며, N-스텝 리턴을 사용하여 미래의 보상을 고려하므로 학습의 안정성과 효율성이 향상될 수 있습니다.
Asynchronous Advantage Actor-Critic
비동기적 어드밴티지 액터-크리틱(Asynchronous Advantage Actor-Critic, A3C)은 다음과 같은 방식으로 동작합니다:

- 여러 개의 워커(worker)가 병렬적으로 환경과 상호작용합니다. 각 워커는 독립적으로 현재 상태를 관찰하고, 행동을 선택하여 환경에 적용합니다.
- 워커는 선택한 행동에 대한 보상과 다음 상태를 받습니다.
- 워커는 받은 보상과 다음 상태를 사용하여 어드밴티지(advantage)를 계산합니다. 어드밴티지는 현재 상태에서의 예상 보상과 평균적인 보상을 비교하여 계산됩니다.
- 워커는 어드밴티지와 선택한 행동을 사용하여 정책과 가치 함수를 업데이트합니다. 정책은 확률적으로 행동을 선택하는 방식으로 업데이트되며, 가치 함수는 상태의 예상 가치를 추정하는 방식으로 업데이트됩니다.
- 워커는 업데이트된 정책과 가치 함수를 사용하여 환경과 상호작용합니다. 이러한 과정을 반복하여 워커들이 동시에 학습을 진행하고, 정책과 가치 함수를 개선하여 최적의 정책을 학습합니다.
비동기적 어드밴티지 액터-크리틱은 다중 에이전트 학습에서 효율적으로 사용될 수 있으며, 병렬 처리를 통해 학습 속도를 향상시킬 수 있습니다.
Learning Speed Comparison

Performance Comparison on 57 Atari games

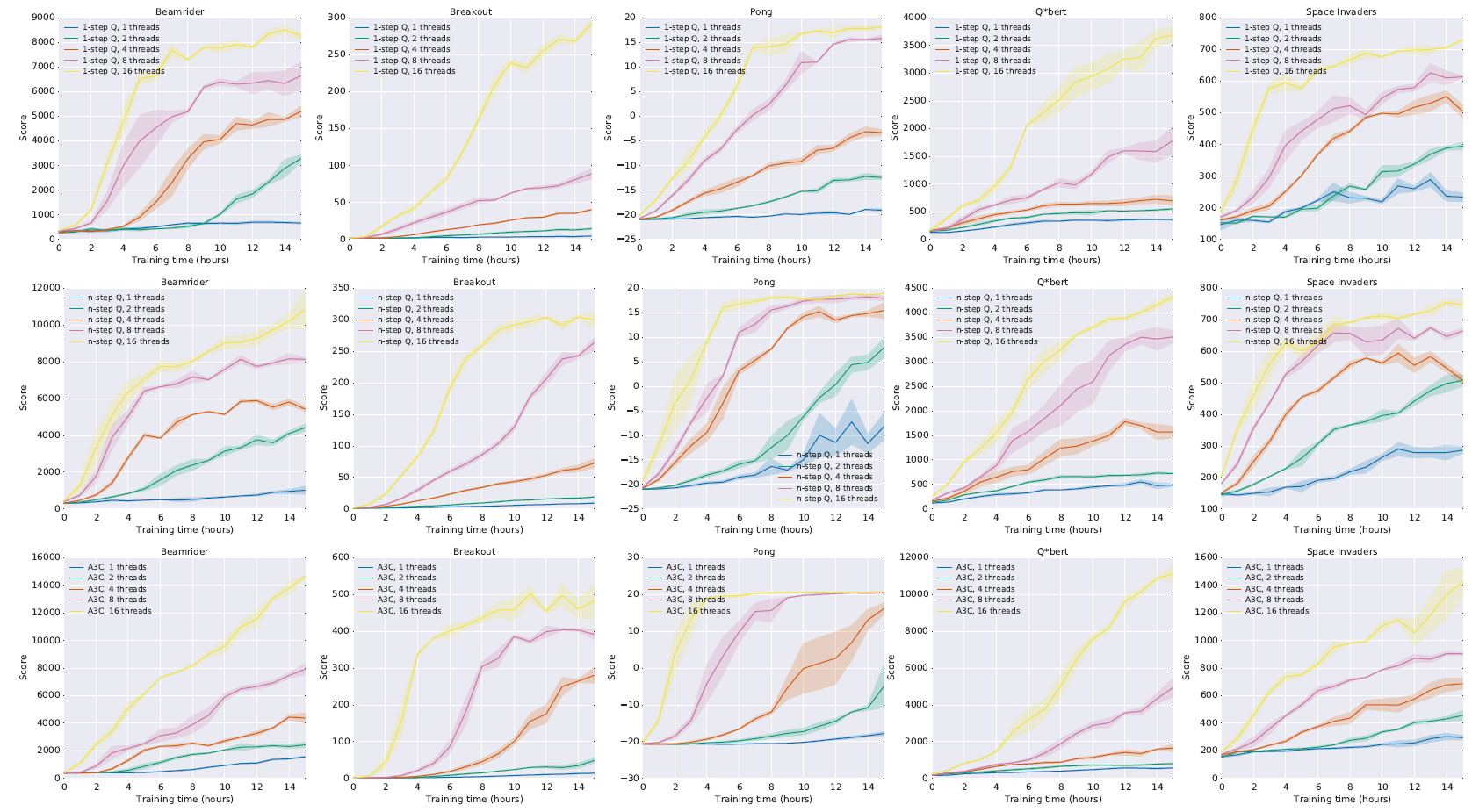
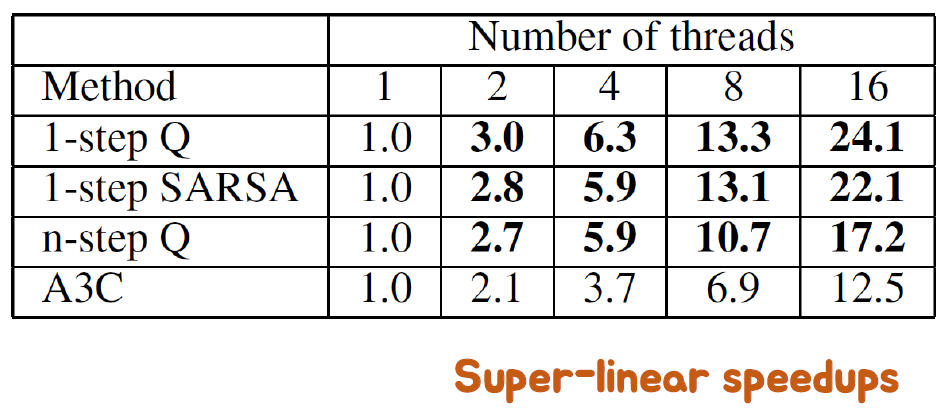
Training speedup for number of threads
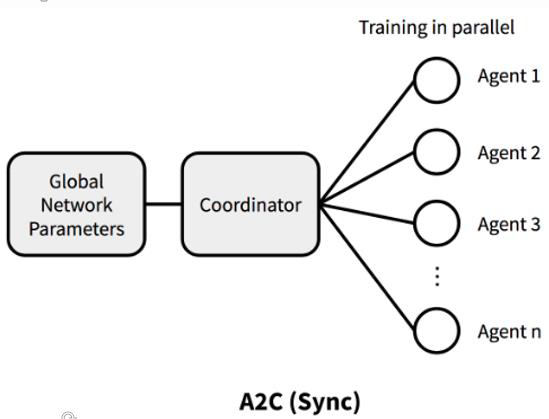
Synchronous version of A3C
A3C의 동기화 버전은 다음과 같은 특징을 가지고 있습니다:
- 전역 파라미터를 공유하는 모든 에이전트들이 동일한 정책을 사용합니다. 에이전트들은 각자의 환경과 상호작용하며 행동을 선택하지만, 정책 업데이트에는 동일한 파라미터를 사용합니다.
- 에이전트들은 동시에 환경과 상호작용하고, 동시에 경험을 수집합니다. 이를 통해 모든 에이전트들이 동일한 환경에서 동일한 데이터를 사용하여 학습을 진행하게 됩니다.
- 경험 수집이 완료되면, 각 에이전트는 자신이 수집한 데이터를 사용하여 정책 업데이트를 진행합니다. 그리고 그 업데이트된 정책은 전역 파라미터와 동기화됩니다.
동기화된 A3C는 에이전트들이 동일한 정책을 사용하고, 경험을 동시에 수집하여 학습에 일관성을 부여합니다.
Policy-Gradient Summary
Policy-Gradient 알고리즘들에 대한 요약입니다:
- REINFORCE: Policy-gradient + Reward To Go
- Reward To Go를 사용한 Policy-gradient 알고리즘입니다.
- Vanilla Policy-gradient: REINFORCE + Baseline
- Baseline을 사용하여 분산을 줄인 Policy-gradient 알고리즘입니다.
- Actor-Critic: Vanilla Policy-gradient + Critic (Bootstrapping)
- Critic을 추가하여 값 함수 추정을 수행하는 Policy-gradient 알고리즘입니다.
- A3C: Actor-Critic + Asynchronous + Advantage + N-step
- 비동기적으로 작동하는 여러 에이전트들이 Actor-Critic 방식을 사용하여 학습하는 알고리즘입니다. Advantage와 N-step 리턴을 사용합니다.
- A3C의 동기화 버전
- 비동기적인 학습 대신, 에이전트들이 동시에 데이터를 수집하고 업데이트를 진행하는 동기화된 버전입니다.
이러한 Policy-Gradient 알고리즘들은 각자의 특징과 장점을 가지고 있으며, 보상을 최대화하기 위한 최적의 정책을 학습하는 데에 사용됩니다.
Policy Gradient and Step Sizes
• Gradient descent 기법은 그레이디언트의 방향으로 가중치를 한 스텝씩 업데이트합니다.
• 정책 그래디언트의 각 스텝이 이전 정책보다 크거나 같은 가치를 가진 업데이트된 정책 𝜋′를 만들어낼 수 있을까요?
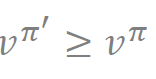
정책 그래디언트 알고리즘은 각 스텝에서 그레이디언트를 이용하여 정책을 업데이트합니다. 이 과정에서 스텝 크기, 즉 학습 속도는 중요한 요소입니다. 학습 속도가 너무 작으면 학습이 느리게 진행되고, 반대로 너무 크면 발산할 수 있습니다.
정책 그래디언트 알고리즘은 목적 함수의 기울기를 따라 정책을 업데이트하므로, 이론적으로는 각 스텝에서 값이 증가하는 정책을 얻을 수 있습니다. 그러나 실제로는 여러 요인에 의해 성능이 달라질 수 있습니다. 스텝 크기의 선택, 초기 정책의 선택, 그리고 환경과의 상호작용은 모두 결과에 영향을 미칠 수 있습니다.
따라서 스텝 크기를 적절하게 선택하여 정책 그래디언트 알고리즘이 좋은 성능을 발휘할 수 있도록 해야 합니다.
Trust Region Policy Optimization [ICML 2015]
강화학습에서는 스텝 크기가 중요한 이유가 있습니다. 스텝 크기는 함수의 최적점을 찾는 모든 문제에서 중요합니다.
감독 학습(Supervised learning)의 경우, 스텝을 너무 멀리 이동해도 다음 업데이트에서 이를 수정할 수 있습니다. 하지만 강화학습에서는 스텝을 너무 멀리 이동하면 좋지 않은 정책으로 수렴할 수 있습니다. 정책은 데이터 수집을 결정하기 때문에 다음 배치에서는 좋지 않은 정책 하에 데이터가 수집될 수 있습니다. 좋지 않은 선택으로 인해 성능이 저하되고 회복하기 어려울 수 있습니다.
따라서 강화학습에서는 적절한 스텝 크기를 선택하는 것이 매우 중요합니다. 적절한 스텝 크기를 선택하면 안정적인 학습을 할 수 있으며 최적의 성능을 얻을 수 있습니다.
정책 그래디언트 방법에서 스텝 크기를 자동으로 조정하여 업데이트된 정책 𝜋′가 이전 정책 𝜋보다 크거나 같은 가치를 갖도록 할 수 있을까요? 이를 위해 스텝 크기를 수정하는 방법을 고려해 보고자 합니다.
스텝 크기를 자동으로 조정하여 업데이트된 정책의 가치가 이전 정책보다 크거나 같도록 하는 것은 일반적으로 어려운 문제입니다. 정책 그래디언트 방법은 매우 복잡한 비선형 문제이기 때문에 이를 자동으로 보장하기는 어렵습니다.

따라서 Trust Region Policy Optimization (TRPO)은 종종 대리 목적 함수를 최적화합니다. 대리 목적 함수는 작은 영역에서만 신뢰할 수 있는 경우가 많습니다.
TRPO는 정책 업데이트를 제한하는 정책 영역을 설정하여 안정적인 학습을 위해 대리 목적 함수를 사용합니다. 이 정책 영역은 원래 정책과의 차이를 제어하고, 안정성을 유지하며 학습을 진행합니다.
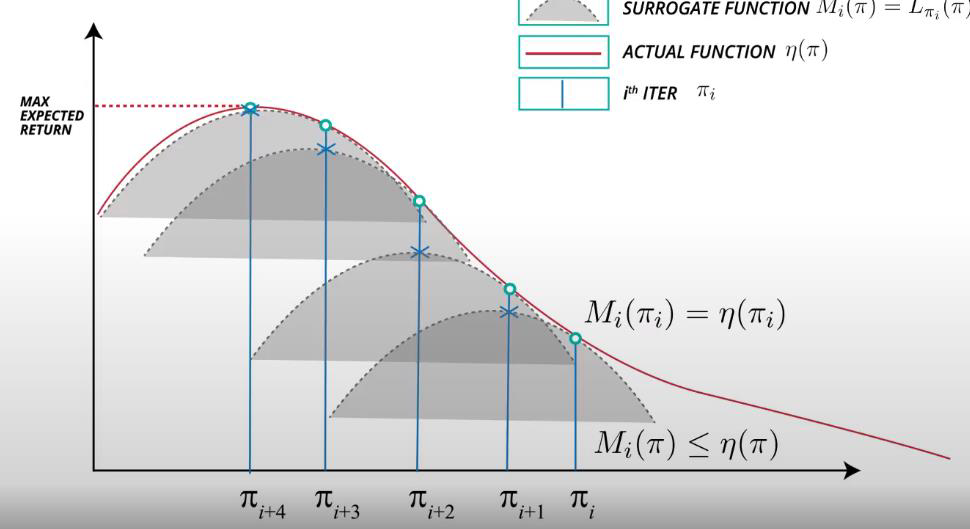
대리 목적 함수가 신뢰 가능한 작은 영역에서만 유효한 이유는 원래 목적 함수를 직접 최적화하는 것이 어려운 경우가 많기 때문입니다. 따라서 대리 목적 함수를 사용하여 원래 목적 함수를 근사화하고, 그 근사치를 최적화하여 정책을 개선하는 것이 일반적입니다.
TRPO는 이러한 제한된 신뢰 영역을 통해 안정적이고 신뢰할 수 있는 정책 학습을 할 수 있게 해줍니다.
이를 위해서 TRPO는 일반적인 확률적 정책에서 하한값을 찾습니다.
• 𝜂(𝜋)를 𝜋의 예상 반환값이라고 가정합시다.
• 𝐿𝜋𝑜𝑙𝑑(𝜋)와 𝜂𝜋 사이의 차이를 제한합니다.
• 이를 통해 단조 증가가 보장됩니다.

일반적인 확률적 정책에서 하한값을 찾기 위해 다양한 방법이 사용될 수 있습니다. 이 방법은 대체로 수학적인 접근 방식을 사용하여 𝐿𝜋𝑜𝑙𝑑(𝜋)와 𝜂𝜋의 차이를 최소화하거나 제한함으로써 학습의 안정성을 보장합니다.
하한값을 찾는 기법은 일반적으로 "Guaranteed Improvement"라고도 불립니다. 이는 정책 개선 과정에서 항상 예상 반환값을 향상시킨다는 보장을 제공합니다.
정책의 개선은 일반적으로 예상 반환값을 최대화하는 것을 목표로 합니다. 하지만 정책 개선 중에는 예상치와 실제 반환값 사이에 불확실성이 존재할 수 있습니다. 이러한 불확실성은 예상치와 실제 값 사이의 차이로 표현됩니다.
"Guaranteed Improvement" 기법은 이러한 불확실성을 고려하여 정책 개선의 단계에서 최소한의 개선을 보장합니다. 즉, 정책을 개선하는 과정에서 예상 반환값이 항상 이전 정책의 값을 초과하도록 보장됩니다.
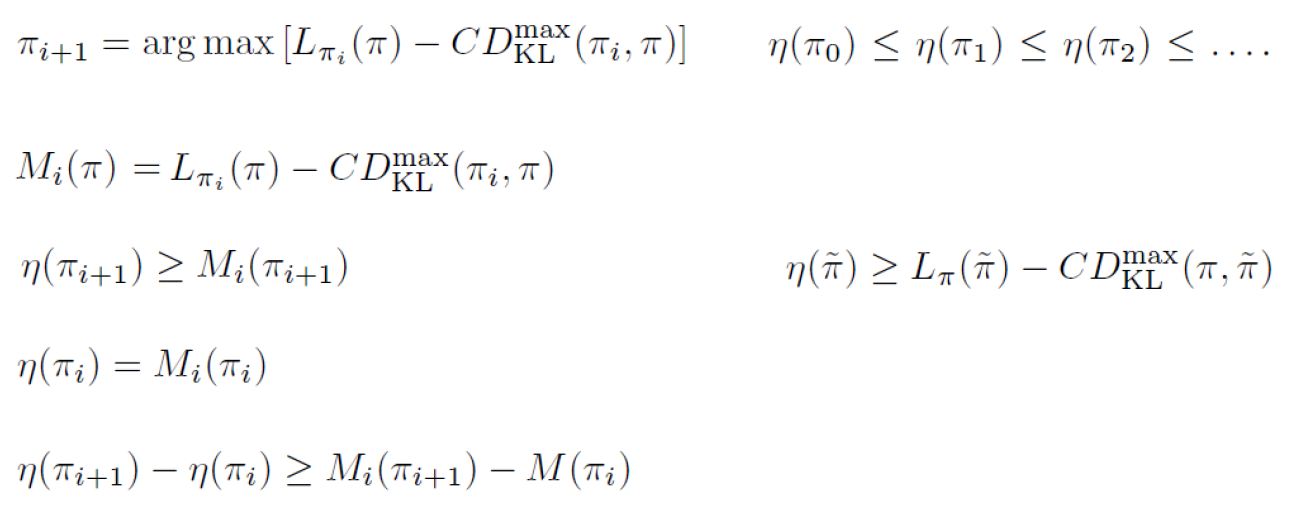
이러한 기법은 학습 과정에서 안정성과 성능 개선을 보장하기 위해 사용됩니다. 보통 KL-방법(Kullback-Leibler method)이나 신뢰 구간(trust region)을 활용하여 하한값을 설정하고, 개선된 정책이 이 하한값을 초과하는지 확인합니다.
Trust Region Policy Optimization Algorithm
TRPO는 보장된 개선(Guaranteed Improvement) 기법을 사용하여 정책을 개선하면서 안정성을 유지합니다.
TRPO는 다음과 같은 주요 단계로 구성됩니다:

- 현재 정책 𝜋를 기반으로 환경에서 몇 가지 경로(trajectories)를 생성합니다.
- 경로를 사용하여 정책의 예상 반환값(estimated return) 및 어드밴티지(advantage)를 계산합니다.
- 경로의 어드밴티지를 이용하여 정책을 개선하는데 사용할 수 있는 수렴된 스텝 크기를 계산합니다.
- 정책을 개선하기 위해 KL-방법(Kullback-Leibler method)을 사용하여 안정성을 보장하는 새로운 정책을 탐색합니다.
- 개선된 정책을 기존 정책과 비교하여 예상 반환값의 상한을 만족하는지 확인합니다.
- 개선된 정책을 현재 정책으로 대체합니다.
- 1부터 6까지의 단계를 반복하여 최적의 정책을 찾습니다.
TRPO는 안정적인 정책 개선을 보장하면서 학습 속도를 조절하는 효과적인 알고리즘입니다. KL-방법을 사용하여 정책의 변화를 제한함으로써 큰 변화로 인한 불안정성을 방지하고, 안정적인 개선을 실현합니다.
TRPO Performance Results

Proximal Policy Optimization [OpenAI2017]
Proximal Policy Optimization (PPO)는 TRPO의 영감을 받아 구현하기 훨씬 간단하며, 일반적인 상황에서 더 효율적으로 동작합니다. PPO는 TRPO의 몇 가지 이점을 가지고 있으며, 구현하기가 간단하고 일반적인 상황에서도 더 좋은 샘플 효율성을 제공합니다.
PPO는 주로 두 가지 개념을 기반으로 합니다:
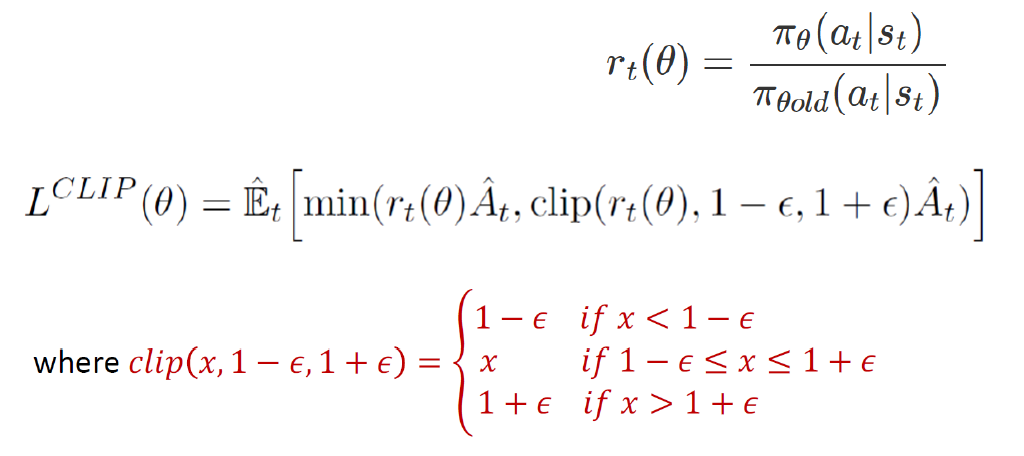

- Clipped Surrogate Objective: PPO는 이전 정책과 새로운 정책 간의 KL-방법 대신 클리핑 기법을 사용하여 정책 업데이트를 제어합니다. 정책 업데이트 시, 새로운 정책의 비율을 이전 정책과 비교하여 클리핑 범위 내에 제한합니다. 이를 통해 큰 변화를 피하면서 안정성을 유지하고 정책의 변화를 제한합니다.
- Multiple Epochs of Mini-Batch Updates: PPO는 여러 번의 미니 배치 업데이트를 사용하여 정책을 학습합니다. 각 에포크에서 여러 개의 미니 배치를 사용하여 경사하강법을 수행하고, 이를 통해 정책 업데이트의 안정성을 향상시킵니다.
PPO는 구현하기가 간단하면서도 TRPO와 유사한 성능을 발휘합니다. 클리핑 기법을 통해 안정성을 제공하면서도 샘플 효율성을 개선하여 보다 빠르고 효과적인 정책 학습을 가능하게 합니다. 이러한 이점으로 인해 PPO는 강화 학습 알고리즘의 널리 사용되는 방법 중 하나입니다.
Comparison on MoJoCoEnvironments

Comparison on the Atari Domain

Performance Comparison
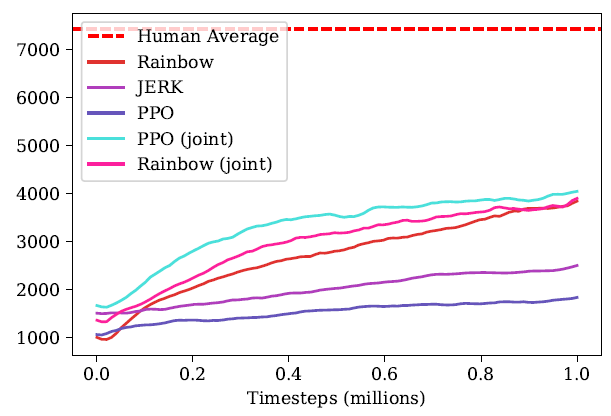
"joint"는 모든 교육 세트에 대한 정책을 교육한 다음 테스트 세트의 초기화로 사용함을 의미합니다.
Implementation Matters in Deep RL: A Case Study on PPO and TRPO [ICLR 2020]
PPO와 TRPO의 경우, 구현 방식은 중요한 역할을 합니다. 이에 대한 사례 연구가 ICLR에서 진행되었습니다.
PPO는 원래 TRPO의 개선 버전으로 개발되었습니다. 그러나 PPO 논문에서는 코드 수준의 최적화에 대한 설명은 제공되지 않습니다. 따라서 이러한 최적화가 성능에 얼마나 영향을 미치는지에 대해 깊이 있는 연구가 필요합니다.
이를 위해 코드 최적화의 영향을 철저히 분석하고 비교하는 연구가 진행되었습니다. 이 연구는 PPO와 TRPO의 성능을 다양한 설정에서 비교하고, 구현의 변형과 최적화가 성능에 미치는 영향을 조사하였습니다.
결과적으로, 코드 수준의 최적화는 PPO와 TRPO의 성능에 큰 영향을 미친다는 것이 밝혀졌습니다.
Code Level Optimization in PPO
PPO에서의 코드 수준 최적화:
- 가치 함수 클리핑: 가치 함수의 출력을 클리핑하여 큰 변화를 제한합니다.
- 보상 스케일링: 보상 값을 조정하여 학습의 안정성을 향상시킵니다.
- 직교 초기화와 레이어 스케일링: 초기화와 스케일링 기법을 사용하여 가중치 초기화를 최적화합니다.
- Adam 학습률 에니얼링: 학습 속도를 조절하기 위해 Adam 옵티마이저의 학습률을 점진적으로 감소시킵니다.
- 보상 클리핑: 보상 값을 클리핑하여 큰 변화를 제한하고 학습의 안정성을 향상시킵니다.
- 관측값 정규화: 관측값을 정규화하여 학습의 안정성을 향상시킵니다.
- 관측값 클리핑: 관측값을 클리핑하여 너무 크거나 작은 값의 영향을 줄입니다.
- 하이퍼볼릭 탄젠트 활성화 함수: 활성화 함수로 하이퍼볼릭 탄젠트를 사용하여 출력 범위를 제한합니다.
- 전역 그래디언트 클리핑: 그래디언트를 클리핑하여 너무 큰 그래디언트의 영향을 제한합니다.
이러한 코드 수준의 최적화는 PPO 알고리즘의 성능 향상에 기여합니다. 각 최적화 기법은 학습의 안정성과 수렴 속도를 향상시키는 역할을 합니다.
Ablation Study on First Four Optimizations
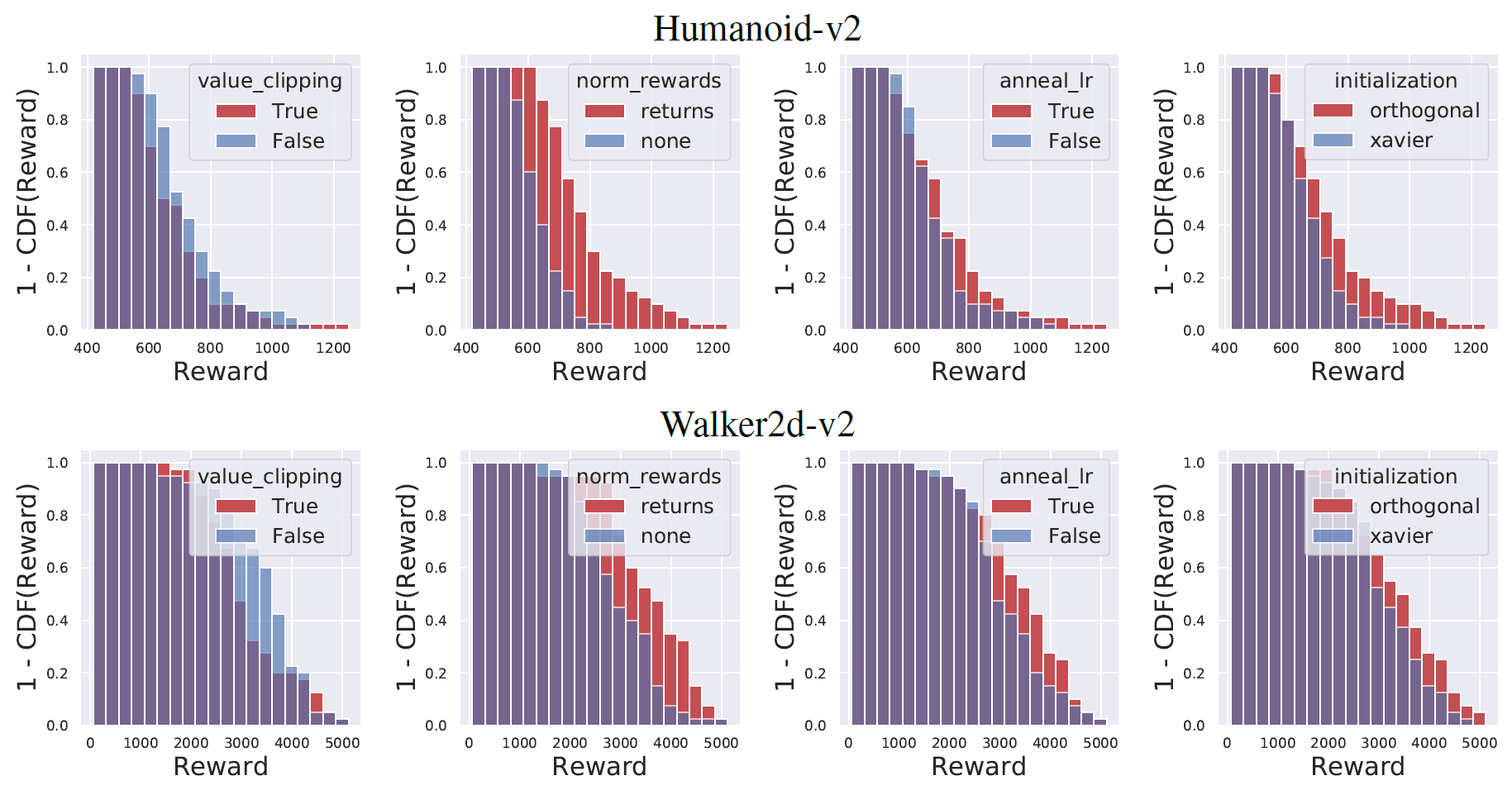
Comparison on Different Models

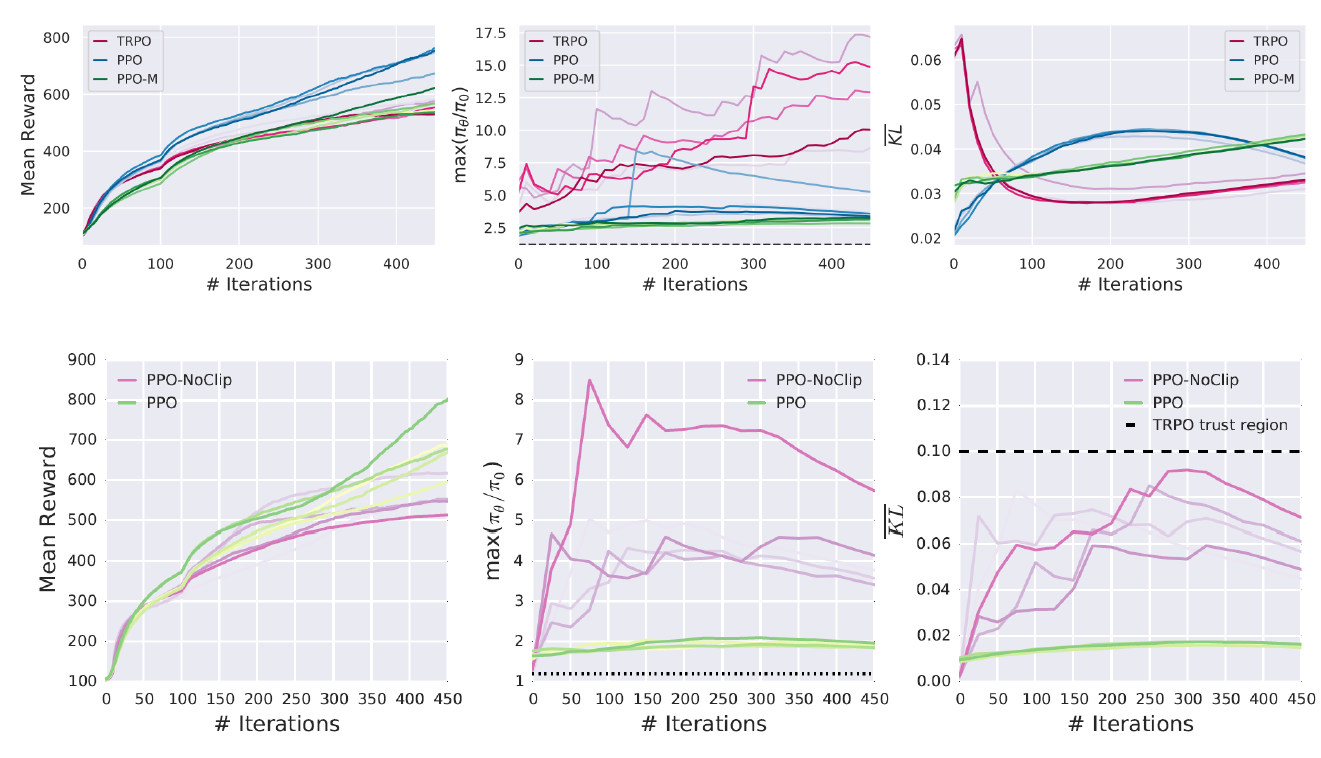

Implementation Matters... Summary
• 코드 수준의 최적화는 성능에 깊은 영향을 미칩니다.
• 이러한 최적화는 알고리즘 간의 엄격한 비교를 어렵게 만듭니다.
• 따라서, 깊은 강화학습 방법을 모듈식으로 설계하여 각 구성 요소의 에이전트 동작과 성능에 미치는 영향을 이해하는 것이 중요합니다.
Continuous Control With Deep Reinforcement Learning [ICLR 2016]
• DQN은 이산적이고 저차원의 행동 공간에서 작동합니다.
• 대부분의 정책 기울기 알고리즘은 정책 방법을 사용합니다 (샘플링).
• 액터-크리틱 접근법을 DQN의 통찰력과 결합하여, 연속적인 행동 공간에서의 오프 폴리시 액터-크리틱 알고리즘을 개발했습니다.
Deterministic Policy Gradient (DPG) algorithm
확정적 정책 기울기 (DPG) 알고리즘은 흔히 사용되는 오프 폴리시 알고리즘인 Q 학습과는 달리, 탐욕 정책을 사용합니다.
𝜇(𝑠)=argmax𝑎𝑄(𝑠,𝑎)
벨만 방정식은 다음과 같이 표현됩니다:
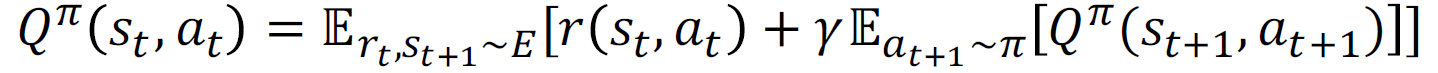
확정적 정책을 사용하는 경우, 벨만 방정식은 다음과 같이 단순화됩니다:

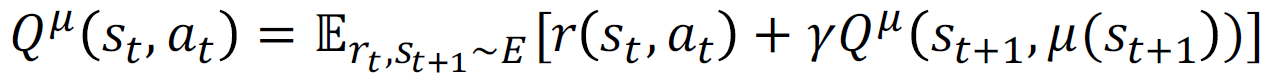
이것은 DPG 알고리즘의 기본 개념입니다.
Deep Deterministic Policy Gradient (DDPG)
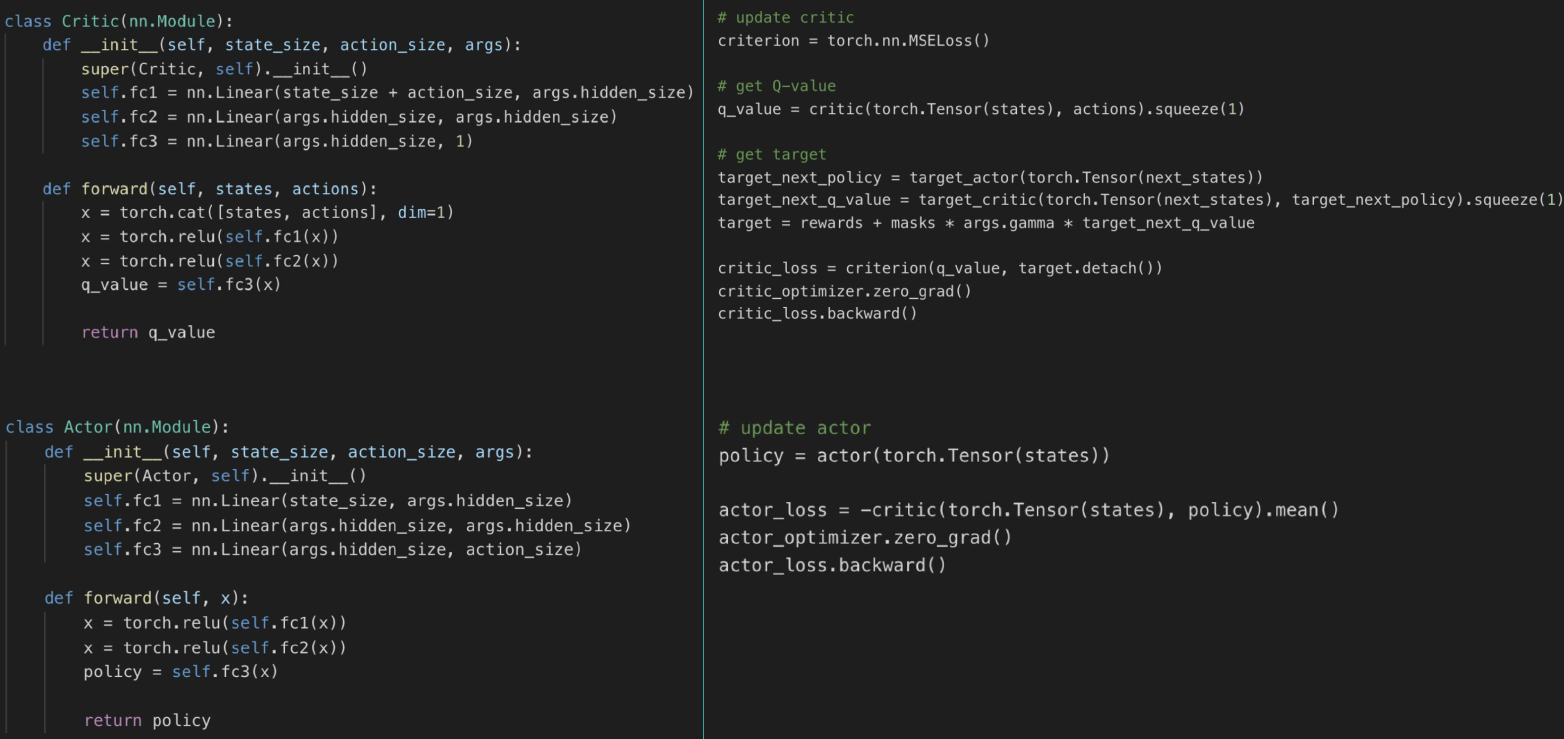
딥 결정론적 정책 기울기 (DDPG) 알고리즘은 크게 두 가지 신경망으로 구성됩니다. 첫 번째는 크리틱 네트워크(가치)이고, 두 번째는 액터 네트워크(정책)입니다.

크리틱 네트워크는 주어진 상태와 액션에 대한 가치 함수를 근사화하는 역할을 담당합니다. 이를 통해 주어진 상태와 액션의 예상 가치를 추정합니다.

액터 네트워크는 주어진 상태에서 최적의 액션을 선택하는 역할을 담당합니다. 이는 주어진 상태를 입력으로 받아 예측된 액션을 출력합니다. 액터 네트워크는 확률론적 정책이 아닌 결정론적 정책을 사용합니다.
DDPG 알고리즘은 이러한 크리틱 네트워크와 액터 네트워크를 결합하여 강화 학습을 수행합니다. 크리틱 네트워크는 TD 학습을 통해 가치 함수를 업데이트하고, 액터 네트워크는 정책 그래디언트를 사용하여 최적의 액션을 선택합니다
Other Components in DDPG
DDPG(Deterministic Policy Gradient)에는 다른 중요한 구성 요소들이 있습니다.
- 경험 재생(Experience Replay)에서 미니배치 샘플링: DDPG는 에이전트의 경험을 저장하고, 이를 재생하며 학습에 사용합니다. 경험 재생 버퍼에서 일정한 크기의 미니배치를 샘플링하여 학습에 사용합니다. 이를 통해 데이터의 재사용과 상관관계를 줄여 안정적인 학습을 도모합니다.
- 소프트 타겟 네트워크 업데이트: DDPG는 타겟 네트워크를 사용하여 크리틱 네트워크의 업데이트를 안정화합니다. 소프트 타겟 업데이트는 주어진 타겟 네트워크의 파라미터를 부드럽게 업데이트하여 학습의 안정성과 수렴 속도를 향상시킵니다.
- 배치 정규화(Batch Normalization): DDPG에는 배치 정규화가 사용될 수 있습니다. 배치 정규화는 신경망의 각 층에서 입력 데이터의 정규화를 수행하여 학습의 안정성과 일반화 능력을 향상시킵니다.
- 탐색(Exploration): DDPG는 액터 네트워크에 의해 선택되는 액션을 탐색하여 새로운 경험을 얻을 수 있도록 합니다. 이를 통해 다양한 상태와 액션을 탐색하며 최적 정책을 찾아갈 수 있습니다.

DDPG Algorithm
DDPG(Deep Deterministic Policy Gradient) 알고리즘은 연속적인 행동 공간에서 동작하는 강화 학습 알고리즘입니다. 다음은 DDPG 알고리즘의 주요 단계입니다:

- 초기화: 크리틱 네트워크와 액터 네트워크의 가중치를 초기화합니다. 또한 타겟 네트워크를 생성하고 초기 가중치를 복사합니다.
- 경험 샘플링: 에이전트는 환경과 상호 작용하며 경험을 수집합니다. 이러한 경험은 경험 재생 버퍼에 저장됩니다.
- 타겟 값 계산: 타겟 네트워크를 사용하여 크리틱 네트워크의 타겟 값을 계산합니다. 이는 현재 상태와 액터 네트워크의 액션을 이용하여 계산됩니다.
- 그라디언트 계산: 크리틱 네트워크와 액터 네트워크의 손실 함수를 사용하여 그라디언트를 계산합니다. 크리틱 네트워크의 그라디언트는 TD 오차를 이용하여 계산되고, 액터 네트워크의 그라디언트는 액터 네트워크의 액션과 크리틱 네트워크의 출력을 이용하여 계산됩니다.
- 네트워크 업데이트: 계산된 그라디언트를 사용하여 크리틱 네트워크와 액터 네트워크의 가중치를 업데이트합니다. 이때, 타겟 네트워크의 가중치도 소프트 타겟 네트워크 업데이트를 통해 업데이트됩니다.
- 탐색: 액터 네트워크는 탐색을 통해 다양한 액션을 시도하고 새로운 경험을 얻을 수 있도록 합니다. 이를 통해 다양한 상태-액션 쌍을 탐색하며 학습을 진행합니다.
- 반복: 위 단계를 여러 번 반복하여 액터 네트워크와 크리틱 네트워크를 학습합니다. 타겟 네트워크의 업데이트 빈도 등 하이퍼파라미터 설정에 따라 알고리즘의 성능이 달라질 수 있습니다.
DDPG 알고리즘은 이러한 단계를 통해 신경망 기반의 정책과 가치 함수를 동시에 학습하여, 연속적인 행동 공간에서 최적의 정책을 찾아냅니다.
Performance Results
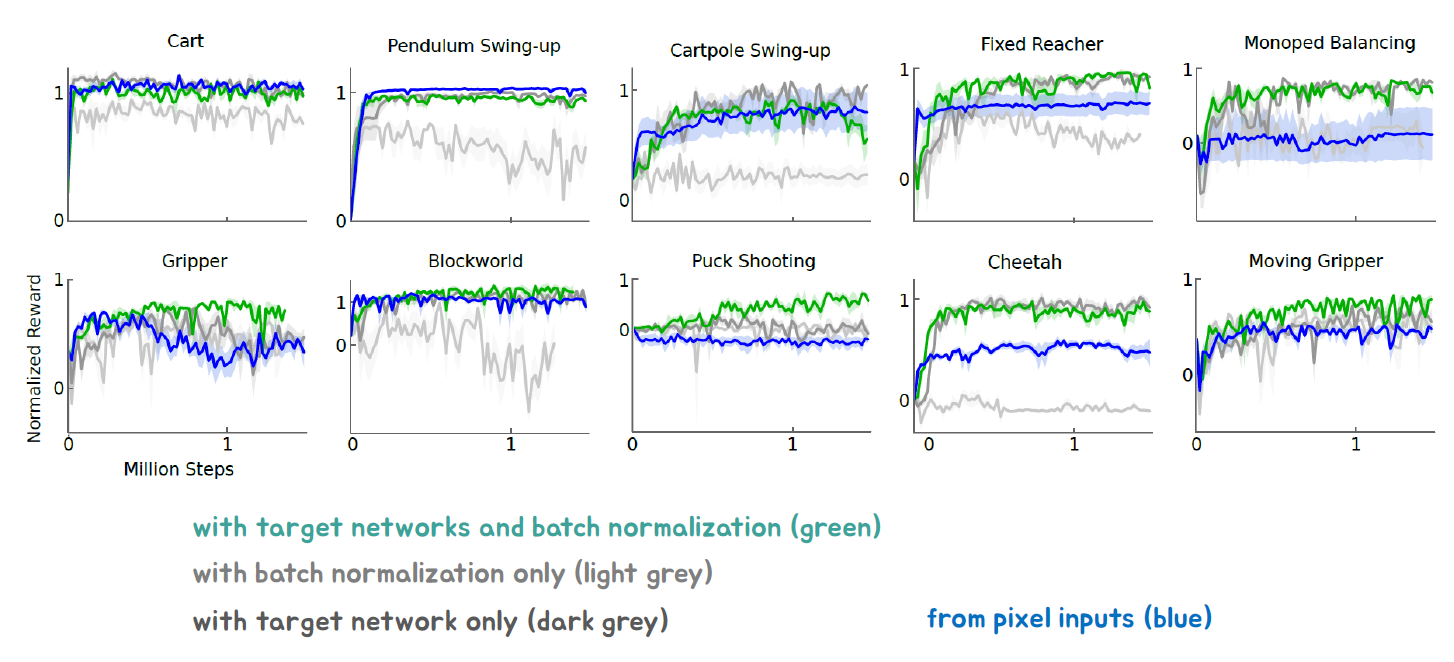
Addressing Function Approximation Error in Actor Critic Methods [2018 IMCL]
"Addressing Function Approximation Error in Actor Critic Methods" 논문은 Q 학습과 DDPG에서 나타나는 과대평가 편향을 해결하기 위한 방법을 제안합니다. 이러한 과대평가 편향은 부적절한 정책 업데이트와 발산하는 행동을 초래할 수 있습니다. 또한 DDPG는 하이퍼파라미터 조정에 너무 민감할 수 있다는 문제가 있습니다. 이를 해결하기 위해 "Twin Delayed Deep Deterministic policy gradient (TD3)" 알고리즘이 제안됩니다.
TD3 알고리즘은 DDPG의 개선된 버전으로, 다음과 같은 특징을 가지고 있습니다:
- Twin Critic Networks: TD3는 두 개의 크리틱 네트워크를 사용하여 Q 값의 과대평가 문제를 완화합니다. 두 개의 크리틱 네트워크 중 작은 값을 선택하여 더 신뢰할 수 있는 Q 값 추정을 수행합니다.
- Delayed Policy Updates: TD3는 정책 업데이트를 지연시킴으로써 Q 값 추정의 불안정성을 완화합니다. 일정한 시간 동안 정책을 고정하고, 크리틱 네트워크를 사용하여 Q 값 추정을 수행한 후 정책을 업데이트합니다.
- Target Policy Smoothing: TD3는 정책의 안정성을 높이기 위해 목표 정책 스무딩을 사용합니다. 정책이 작은 잡음을 가미하여 더 부드럽게 변화하도록 만듭니다. 이는 정책 업데이트의 불안정성을 줄여줍니다.
TD3 알고리즘은 DDPG의 한계를 극복하고 더 안정적인 학습을 제공합니다. 과대평가 편향을 완화하고 발산 문제를 해결하여 효과적인 정책 학습을 가능하게 합니다.
TD3: Clipped Double Q-learning
TD3 알고리즘에서는 "Clipped Double Q learning"을 제안합니다. 이 방법은 덜 편향된 값 추정을 상한으로 제한하는 것을 목표로 합니다. 이를 위해 타겟 값들 중에서 최소값을 선택합니다. 이 업데이트 규칙은 과소평가 편향을 유발할 수 있지만, 과대평가 편향보다는 선호되며 전파되지 않습니다.
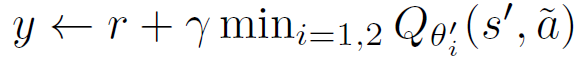
이 방법은 한 크리틱 네트워크의 값 추정만 사용하는 것이 아니라 두 개의 크리틱 네트워크를 사용하여 값을 추정합니다. 이를 통해 더 안정적이고 신뢰할 수 있는 값 추정을 얻을 수 있습니다. 상한을 적용함으로써 과대평가 문제를 완화하고 더 정확한 크리틱 값을 얻을 수 있습니다.

TD3: Delayed Policy Updates
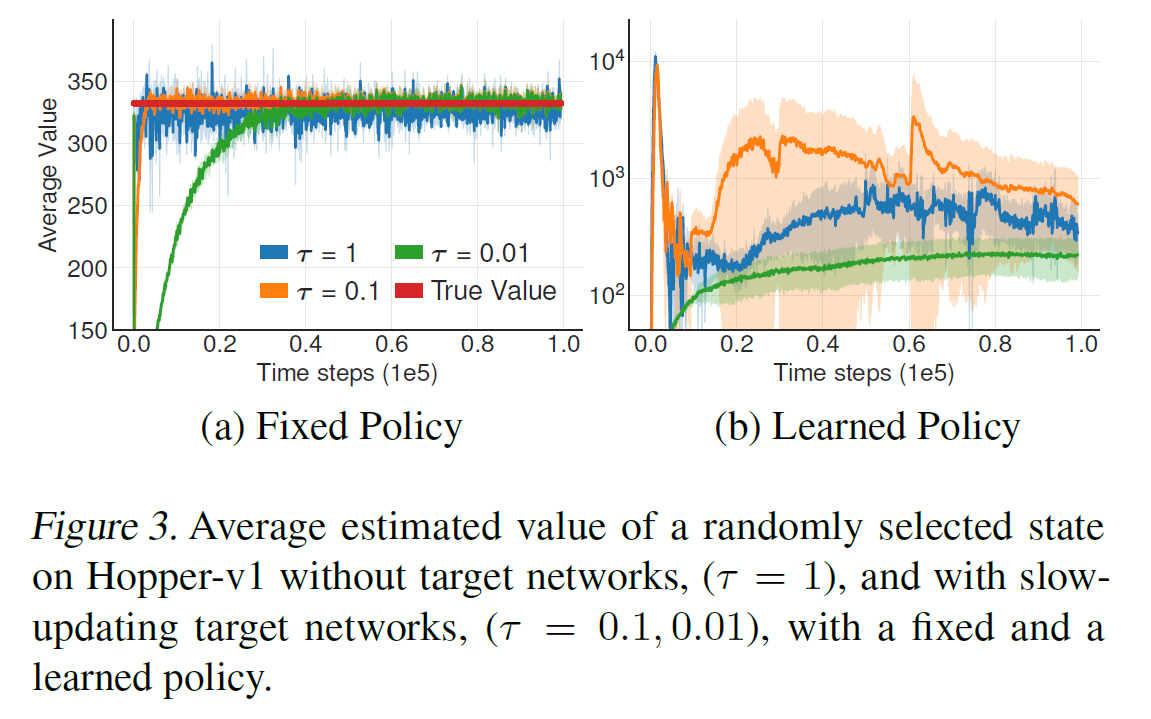
TD3 알고리즘에서는 "Delayed Policy Updates"를 사용합니다. 이는 정책이 좋지 않을 때 값을 과대평가하여 가치 추정이 발산하는 문제를 해결하기 위해 정책 업데이트를 지연시키는 것입니다. 정책이 정확하지 않은 경우 가치 추정이 부정확해지므로, 정책 업데이트를 가능한 작은 값 오차가 될 때까지 지연시킵니다.
TD3: Target Policy Smoothing Regularization
TD3 알고리즘에서는 "Target Policy Smoothing Regularization"을 사용합니다. 이는 결정론적인 정책이 과적합될 수 있는 문제를 해결하기 위해 제안된 방법입니다. 작은 영역 내에서 목표 행동 주변의 가치를 맞추는 것을 제안합니다. 이는 확률적인 환경에서의 성능 향상을 이끌어내게 됩니다.
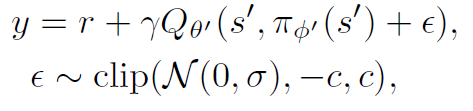
Target Policy Smoothing Regularization은 결정론적인 정책이 과적합되는 것을 방지하기 위해 탐색적인 행동을 촉진하는 역할을 합니다. 작은 영역 내에서 가치를 맞추는 것은 목표 행동 주변에서 일종의 잡음을 생성하는 효과를 가지며, 이는 정책의 탐색적인 행동을 증가시킵니다. 따라서 TD3는 Target Policy Smoothing Regularization을 통해 결정론적인 정책의 과적합을 완화하고 보다 탐색적인 학습을 할 수 있도록 도와줍니다.
TD3 Algorithm
TD3 (Twin Delayed Deep Deterministic Policy Gradient) 알고리즘은 DDPG를 개선한 알고리즘입니다. TD3는 더욱 안정적인 학습과 높은 성능을 달성하기 위해 몇 가지 기술적인 개선을 도입합니다.

- Clipped Double Q-Learning: TD3에서는 두 개의 독립된 Q 네트워크를 사용하여 가치 추정치의 과대평가를 완화합니다. 타겟 가치 네트워크의 값을 예측할 때 두 네트워크 중 작은 값을 선택하고, 이를 이용하여 업데이트를 수행합니다. 이렇게 함으로써 가치 추정치의 과대평가에 의한 부정확한 정책 업데이트를 방지할 수 있습니다.
- Delayed Policy Updates: TD3에서는 정책 업데이트를 가능한 한 가치 오차가 작아질 때까지 지연시킵니다. 가치 추정치의 부정확성으로 인해 정책이 악화되는 것을 방지하기 위해 사용됩니다. 이는 가치 네트워크를 일정 시간 지연시킴으로써 가치 오차의 안정화를 도모합니다.
- Target Policy Smoothing Regularization: 결정론적인 정책의 과적합을 완화하기 위해 목표 정책을 부드럽게 만드는 정규화를 도입합니다. 작은 영역 내에서 목표 행동 주변의 가치를 맞추는 방식으로 탐색적인 행동을 촉진합니다. 이를 통해 TD3는 탐색성을 향상시켜 정책의 다양성과 학습 성능을 향상시킵니다.
이러한 기술들을 통해 TD3는 안정적이고 효과적인 학습을 가능하게 하며, 결정론적인 정책의 과적합을 완화하여 더 나은 성능을 얻을 수 있습니다.
TD3 Performance Results

TD3 Ablation Studies

Soft Actor Critic: Off Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor [2018 ICML] AND Soft Actor Critic Algorithms and Applications [2019]
Soft Actor Critic (SAC)
Soft Actor-Critic (SAC)는 확률적 정책을 오프-폴리시 방식으로 최적화하는 알고리즘입니다. SAC는 샘플 효율성이 높아 하이퍼파라미터에 둔감하며 다양한 랜덤 시드에서 안정적인 성능을 보여주는 특징을 가지고 있습니다. 하지만 실제 세계의 과제에 대해서는 도전적인 문제가 있을 수 있습니다.
SAC는 정책 그레이디언트 알고리즘으로, 목표로 하는 확률적 정책을 학습합니다. 이를 통해 환경의 다양한 상태에서 적절한 행동을 선택하고, 더 나은 탐색과 제어를 가능하게 합니다. SAC는 엔트로피 최대화 항을 포함하여 정책의 탐색적인 성질을 강화합니다. 이를 통해 불확실한 환경에서도 탐색과 활용 사이의 균형을 잘 유지할 수 있습니다.
SAC는 하이퍼파라미터에 대한 민감도가 낮아 조정이 비교적 간단하고, 적은 데이터로도 효과적인 학습이 가능합니다. 또한 다양한 환경에서 안정적인 성능을 보여주며, 학습 결과가 다양한 랜덤 시드에서 일관성을 유지합니다.
Soft Actor-Critic (SAC)는 최대 엔트로피 강화학습입니다. 이 알고리즘에서는 정책을 학습할 때 예상되는 보상과 정책의 무작위성을 나타내는 엔트로피 사이의 균형을 최대화하는 방향으로 학습합니다.
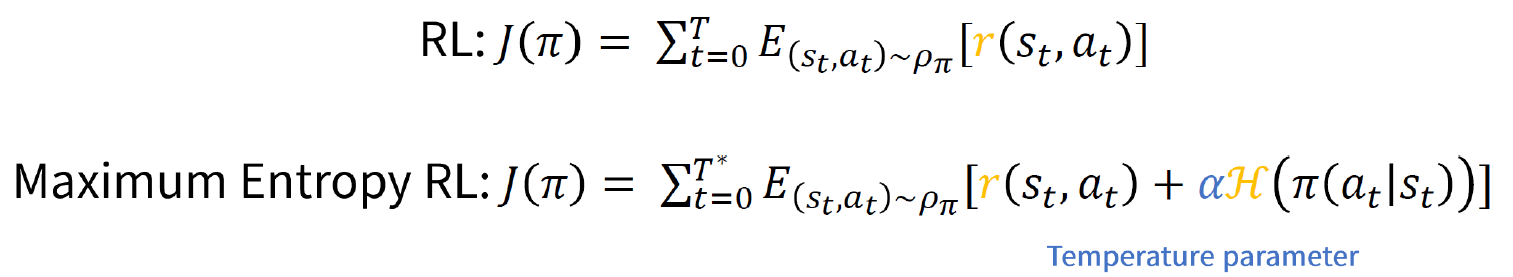
SAC의 목표는 높은 보상을 받으면서도 가능한 많은 상태에서 다양한 행동을 선택할 수 있는 정책을 학습하는 것입니다. 보상을 최대화하기 위해 탐색적인 행동을 촉진하는 엔트로피 항을 최대화하는 방향으로 정책을 학습합니다. 이를 통해 정책은 더 많은 탐색과 새로운 상태를 경험하도록 유도되며, 이는 더 나은 정책 학습을 가능하게 합니다.
SAC의 학습 과정에서는 보상과 엔트로피를 적절하게 균형시키기 위한 가중치 조정이 이루어집니다.
Soft Policy Iteration : Policy Evaluation
소프트 정책 반복(Soft Policy Iteration)은 정책 평가(Policy Evaluation) 단계입니다. 이 단계에서는 현재의 정책에 대한 가치 함수를 평가하여 정책의 품질을 측정합니다.

정책 평가는 주어진 정책에 대한 상태 가치 함수를 추정하는 과정입니다. 상태 가치 함수는 주어진 상태에서 시작하여 정책을 따라갔을 때 얻을 수 있는 기대 반환값을 나타냅니다. 소프트 정책 반복에서는 상태 가치 함수를 평가하는 데에 엔트로피 보너스가 추가됩니다. 엔트로피 보너스는 정책의 무작위성을 증진시키는 역할을 합니다.
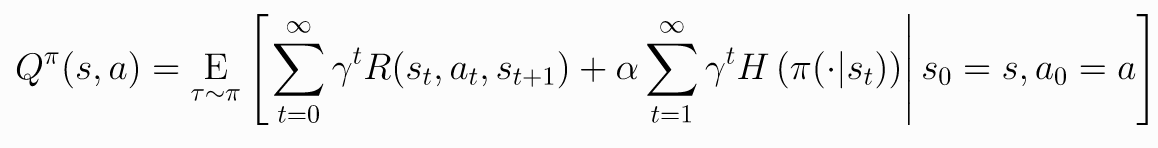
정책 평가는 주어진 정책과 가치 함수 추정치를 사용하여 벨만 방정식을 푸는 과정입니다. 이 방정식은 현재 상태의 가치를 이전 상태의 가치로 업데이트합니다. 이를 반복적으로 수행하여 수렴할 때까지 가치 함수를 업데이트합니다. 소프트 정책 반복에서는 엔트로피 보너스를 고려하여 가치 함수를 업데이트하고, 보다 무작위한 정책을 유지합니다.

정책 평가는 소프트 정책 반복 알고리즘에서 정책 개선(Policy Improvement) 단계에서 사용됩니다. 정책 평가를 통해 얻은 가치 함수를 기반으로 최적의 정책을 개선하는 과정을 진행합니다.
Soft Policy Iteration : Policy Improvement
소프트 정책 반복(Soft Policy Iteration)은 정책 개선(Policy Improvement) 단계입니다. 이 단계에서는 정책 평가를 통해 얻은 가치 함수를 기반으로 현재의 정책을 개선합니다.
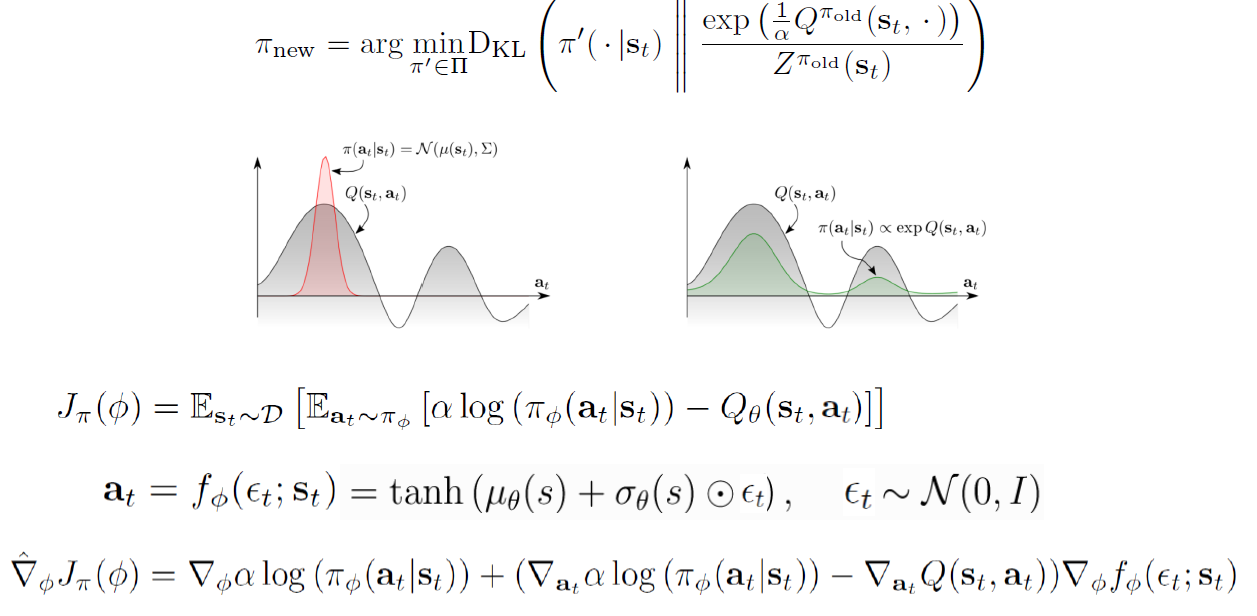
정책 개선은 주어진 가치 함수를 활용하여 현재의 정책을 개선하는 과정입니다. 가치 함수는 각 상태에서의 행동의 가치를 나타내므로, 가치 함수를 기준으로 가장 가치가 높은 행동을 선택하여 정책을 개선합니다. 소프트 정책 반복에서는 엔트로피 보너스를 사용하여 정책을 더 무작위하게 만듭니다.
정책 개선은 가치 함수를 기준으로 행동을 선택하는 정책을 업데이트함으로써 진행됩니다. 일반적으로 가치 함수가 높은 행동에 높은 확률을 할당하고, 가치 함수가 낮은 행동에 낮은 확률을 할당하여 정책을 개선합니다. 이렇게 업데이트된 정책은 더 나은 행동을 선택할 수 있도록 학습됩니다.
정책 개선은 소프트 정책 반복 알고리즘에서 정책 평가(Policy Evaluation) 단계와 번갈아가며 반복적으로 진행됩니다. 정책 평가를 통해 얻은 가치 함수를 기반으로 정책을 개선하고, 다시 정책 평가를 수행하여 최적의 정책을 찾아나갑니다.
소프트 정책 반복은 정책 평가와 정책 개선을 반복하며 점진적으로 더 나은 정책을 찾아나가는 방식으로 최적의 정책을 학습합니다.
SAC Algorithm
소프트 액터-크리틱(Soft Actor-Critic, SAC) 알고리즘은 최대 엔트로피 강화학습 알고리즘입니다. 이 알고리즘은 기댓값에 대한 리턴과 정책의 엔트로피(랜덤성) 사이의 균형을 최대화하는 방향으로 정책을 학습합니다.
SAC 알고리즘은 다음과 같은 단계로 진행됩니다:

- 초기화: 정책과 가치 함수를 초기화합니다.
- 반복 학습:
- 데이터 수집: 환경에서 샘플 데이터를 수집합니다.
- 가치 함수 업데이트: 수집한 데이터를 이용하여 가치 함수를 업데이트합니다.
- 정책 업데이트: 가치 함수를 이용하여 정책을 업데이트합니다. 이때 엔트로피 보너스를 포함하여 무작위성을 유지하고 최대 엔트로피를 추구합니다.
- 타겟 네트워크 업데이트: 가치 함수의 타겟 네트워크를 업데이트합니다. 타겟 네트워크는 가치 함수의 업데이트에 사용됩니다.
- 정책의 타겟 네트워크 업데이트: 정책의 타겟 네트워크를 업데이트합니다. 타겟 네트워크는 정책의 업데이트에 사용됩니다.
- 네트워크 파라미터 업데이트: 네트워크 파라미터를 업데이트합니다. 가치 함수와 정책의 파라미터를 모두 업데이트합니다.
- 종료: 지정된 반복 횟수 또는 학습 목표에 도달할 때까지 반복 학습을 진행한 후 알고리즘을 종료합니다.
SAC 알고리즘은 엔트로피 보너스를 통해 더 탐색적인 정책을 유지하면서 최적의 정책을 학습할 수 있는 장점을 가지고 있습니다. 또한, 하이퍼파라미터에 대한 민감성이 낮아서 다양한 환경에서 안정적인 성능을 보이는 특징이 있습니다.
SAC Performance Results
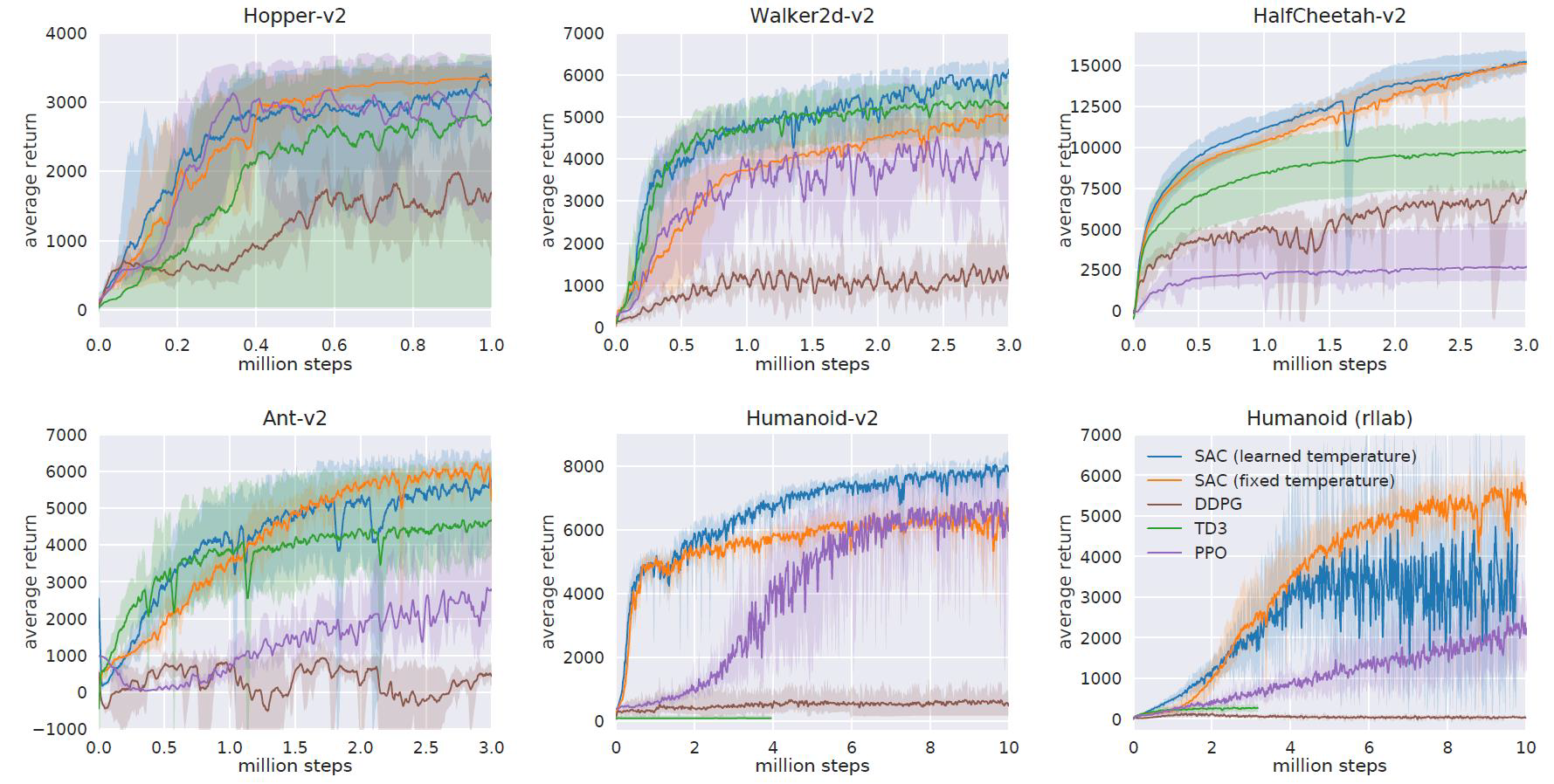
Actor Critic Algorithms을 모아서 표로만들면 다음과 같다.

'강화학습' 카테고리의 다른 글
| Chapter 11. Imitation Learning (0) | 2023.06.02 |
|---|---|
| Chapter 10. Exploration (1) | 2023.05.30 |
| Chapter 8. Advanced Value Function Approximation (0) | 2023.05.22 |
| Chapter 7. Value Function Approximation (0) | 2023.05.22 |
| Chapter6. Model-Free Control (0) | 2023.05.22 |



