https://arxiv.org/abs/2312.10240
Rich Human Feedback for Text-to-Image Generation
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/impla
arxiv.org
요약
최근의 텍스트-이미지(T2I) 생성 모델인 Stable Diffusion과 Imagen은 텍스트 설명에 기반하여 고해상도의 이미지를 생성하는 데 있어 큰 발전을 이루었습니다. 그러나 생성된 많은 이미지들은 여전히 인공물/비현실성, 텍스트 설명과의 불일치, 낮은 미적 품질 등의 문제를 겪고 있습니다. 대형 언어 모델을 위한 인간 피드백을 통한 강화 학습(RLHF)의 성공에서 영감을 받아, 이전 연구들은 생성된 이미지에 대한 인간이 제공한 점수를 피드백으로 수집하고 보상 모델을 훈련하여 T2I 생성을 개선했습니다. 본 논문에서는 (i) 텍스트와 불일치하거나 비현실적인 이미지 영역을 표시하고, (ii) 텍스트 프롬프트에서 이미지에 잘못 표현되거나 누락된 단어들을 주석 달아 이러한 피드백 신호를 더욱 풍부하게 합니다. 우리는 18,000개의 생성된 이미지(RichHF-18K)에 대해 이러한 풍부한 인간 피드백을 수집하고, 멀티모달 트랜스포머를 훈련시켜 자동으로 풍부한 피드백을 예측하게 합니다. 우리는 예측된 풍부한 인간 피드백을 활용하여 이미지 생성을 개선할 수 있음을 보여줍니다. 예를 들어, 고품질의 훈련 데이터를 선택하여 생성 모델을 미세 조정하고 개선하거나, 예측된 히트맵으로 마스크를 만들어 문제 있는 영역을 인페인팅하는 방법 등이 있습니다. 특히, 이러한 개선은 인간 피드백 데이터가 수집된 이미지를 생성한 모델(Stable Diffusion 변형) 외의 모델(Muse)에도 일반화됩니다. RichHF-18K 데이터 세트는 우리의 GitHub 저장소에서 공개될 예정입니다: [GitHub 링크](https://github.com/google-research/google-research/tree/master/richhf_18k).

그림 1. 주석 UI의 그림. 주석 작성자는 텍스트 프롬프트와 관련하여 이미지에 포인트를 표시하여 아티팩트/불가능 영역(빨간색 점) 또는 잘못 정렬된 영역(파란색 점)을 표시합니다. 그런 다음 단어를 클릭하여 잘못 정렬된 키워드(밑줄 및 음영 처리)를 표시하고 타당성, 텍스트-이미지 정렬, 심미성 및 전반적인 품질(밑줄)에 대한 점수를 선택합니다.
1. 서론
텍스트-이미지(T2I) 생성 모델 [12, 17, 41, 42, 56, 58, 59]은 엔터테인먼트, 예술, 디자인, 광고 등 다양한 분야에서 콘텐츠 제작의 핵심으로 빠르게 자리잡고 있으며, 이미지 편집 [4, 27, 44, 50], 비디오 생성 [23, 35, 53] 등 많은 응용 분야로 일반화되고 있습니다. 최근의 중요한 발전에도 불구하고, 생성된 출력물은 여전히 인공물/비현실성, 텍스트 설명과의 불일치, 낮은 미적 품질 등의 문제를 겪고 있습니다 [30, 52, 54]. 예를 들어, 주로 Stable Diffusion 모델 변형에 의해 생성된 이미지들로 구성된 Pick-a-Pic 데이터셋 [30]에서는 많은 이미지들(예: 그림 1)이 왜곡된 인간/동물의 몸(예: 다섯 개 이상의 손가락을 가진 인간의 손), 왜곡된 객체 및 비현실적인 문제(예: 떠 있는 램프)를 포함하고 있습니다. 우리의 인간 평가 실험에서는 데이터셋의 생성된 이미지 중 약 10%만이 인공물과 비현실성이 없는 것으로 나타났습니다. 이와 유사하게, 텍스트-이미지 불일치 문제도 흔히 발생합니다. 예를 들어, 프롬프트가 "강으로 뛰어드는 남자"인데 생성된 이미지는 남자가 서 있는 모습을 보여줍니다.
생성된 이미지에 대한 기존의 자동 평가 지표는 잘 알려진 IS [43]와 FID [20]를 포함하여 이미지 분포에 대해 계산되며 개별 이미지의 미묘한 차이를 반영하지 못할 수 있습니다. 최근 연구에서는 생성된 이미지의 품질을 평가하기 위해 인간의 선호도/평가를 수집하고 이러한 평가를 예측하는 평가 모델을 훈련했습니다 [30, 52, 54], 특히 ImageReward [54] 또는 Pick-a-Pic [30]이 있습니다. 더 집중된 지표이긴 하지만, 이러한 지표도 여전히 한 이미지의 품질을 단일 숫자로 요약합니다. 프롬프트-이미지 정렬 측면에서는 CLIPScore [19]와 같은 초기 단일 점수 지표와 질문 생성 및 답변 파이프라인 [8, 10, 24, 57]이 최근 등장했습니다. 더 정교하고 설명 가능한 모델이긴 하지만, 여전히 이미지에서 불일치 영역을 지역화하지 못합니다.
본 논문에서는 단일 스칼라 점수보다 훨씬 더 풍부한 이미지 품질에 대한 이해를 제공하는 해석 가능하고 귀속 가능한(예: 인공물/비현실성 또는 이미지-텍스트 불일치가 있는 영역에) 세밀하고 다면적인 평가의 데이터셋과 모델을 제안합니다. 첫 번째 기여로, 18,000개의 이미지에 대한 풍부한 인간 피드백(RichHF-18K) 데이터셋을 수집하여 (i) 비현실성/인공물 및 텍스트-이미지 불일치 영역을 강조하는 이미지의 포인트 주석, (ii) 생성된 이미지에서 누락되거나 잘못 표현된 개념을 지정하는 프롬프트의 라벨링된 단어, (iii) 이미지의 현실성, 텍스트-이미지 정렬, 미학, 전반적인 평점을 위한 네 가지 세분화된 점수를 포함합니다.
RichHF-18K를 갖춘 우리는 멀티모달 트랜스포머 모델을 설계하여, 이를 Rich Automatic Human Feedback(RAHF)이라 명명하고, 생성된 이미지와 관련 텍스트 프롬프트에 대한 이러한 풍부한 인간 주석을 예측하도록 학습합니다. 따라서 우리의 모델은 비현실성 및 불일치 영역, 불일치 키워드, 세분화된 점수를 예측할 수 있습니다. 이는 신뢰할 수 있는 평가뿐만 아니라 생성된 이미지의 품질에 대한 더 상세하고 설명 가능한 통찰력을 제공합니다. 우리가 알기로, 이것은 최첨단 텍스트-이미지 생성 모델을 위한 최초의 풍부한 피드백 데이터셋 및 모델로, T2I 생성을 평가하기 위한 자동화되고 설명 가능한 파이프라인을 제공합니다.
이 논문의 주요 기여는 아래와 같이 요약됩니다:
- 18,000개의 Pick-a-Pic 이미지에 대한 생성된 이미지에 관한 첫 번째 풍부한 인간 피드백 데이터셋(RichHF-18K)으로, 세분화된 점수, 비현실성(인공물)/불일치 이미지 영역 및 불일치 키워드를 포함합니다.
- 생성된 이미지에 대한 풍부한 피드백을 예측하는 멀티모달 트랜스포머 모델(RAHF)을 제안하며, 테스트 세트에서 인간 주석과 높은 상관관계를 보임을 보여줍니다.
- 우리는 RAHF의 예측된 풍부한 인간 피드백을 사용하여 이미지 생성을 개선하는 유용성을 추가로 입증합니다: (i) 예측된 히트맵을 마스크로 사용하여 문제 있는 이미지 영역을 인페인팅하고, (ii) 예측된 점수를 사용하여 이미지 생성 모델(Muse [6]과 같은)을 미세 조정하는 데 도움을 주며, 예를 들어 미세 조정 데이터를 선택/필터링하거나 보상 지침으로 사용합니다. 두 경우 모두 원래 모델보다 더 나은 이미지를 얻습니다.
- 우리의 훈련 세트에서 이미지를 생성한 모델과 다른 Muse 모델에서의 개선은 RAHF 모델의 뛰어난 일반화 능력을 보여줍니다.
2. 관련 연구
텍스트-이미지 생성
텍스트-이미지(T2I) 생성 모델은 딥러닝 시대에 여러 인기 있는 모델 아키텍처를 통해 발전하고 반복되었습니다. 초기 작업 중 하나는 생성적 적대 신경망(GAN) [3, 16, 26]으로, 이미지 생성을 위한 생성자와 실제 이미지와 생성된 이미지를 구별하는 판별자를 병렬로 훈련시킵니다(또한 [32, 38, 47, 55, 60, 62] 참조). 또 다른 생성 모델 범주는 변분 오토인코더(VAEs) [21, 29, 48]에서 발전하여 이미지 데이터의 가능성을 위해 증거 하한(ELBO)을 최적화합니다. 최근에는 확산 모델(DMs) [22, 36, 41, 46]이 이미지 생성 [13]의 최첨단(SOTA)으로 떠올랐습니다. DMs는 무작위 잡음에서 점진적으로 이미지를 생성하도록 훈련되며, GAN보다 더 많은 다양성을 포착하고 좋은 샘플 품질을 달성할 수 있습니다 [13]. 잠재 확산 모델 [41]은 더 효율적으로 압축된 잠재 공간에서 확산 과정을 수행하는 추가적인 개선입니다.
텍스트-이미지 평가 및 보상 모델
텍스트-이미지 모델 평가에 대한 최근 연구는 여러 차원에서 이루어졌습니다 [9, 25, 30, 31, 37, 51, 52, 54]. Xu et al. [54]는 사용자가 여러 이미지를 순위 매기고 품질에 따라 평가하도록 요청하여 인간 선호 데이터셋을 수집했습니다. 그들은 ImageReward라는 보상 모델을 훈련하여 인간 선호 학습을 수행했으며, ImageReward 모델을 사용하여 확산 모델을 튜닝하기 위한 보상 피드백 학습(ReFL)을 제안했습니다. Kirstain et al. [30]은 사용자가 생성된 이미지 쌍 중 더 나은 이미지를 선택하도록 하여 인간 선호를 수집하는 웹 애플리케이션을 구축하였고, Stable Diffusion 2.1, Dreamlike Photoreal 2.05, Stable Diffusion XL 변형과 같은 T2I 모델에 의해 생성된 50만 개 이상의 예제를 포함하는 Pick-a-Pic이라는 데이터셋을 만들었습니다. 그들은 인간 선호 데이터셋을 활용하여 CLIP 기반 [39] 스코어링 함수인 PickScore를 훈련시켜 인간 선호를 예측했습니다. Huang et al. [25]는 속성 결합, 객체 관계 및 복잡한 구성을 설명하는 6,000개의 텍스트 프롬프트로 구성된 텍스트-이미지 모델 평가 벤치마크인 T2I-CompBench를 제안했습니다. 그들은 CLIP [39] 및 BLIP [34]와 같은 여러 사전 학습된 비전-언어 모델을 사용하여 여러 평가 지표를 계산했습니다. Wu et al. [51, 52]는 생성된 이미지에 대한 대규모 인간 선택 데이터셋을 수집하고 이 데이터셋을 사용하여 Human Preference Score(HPS)를 출력하는 분류기를 훈련했습니다. 그들은 HPS로 Stable Diffusion을 튜닝하여 이미지 생성이 개선됨을 보여주었습니다. 최근 Lee [31]는 여러 세분화된 지표를 사용하여 T2I 모델에 대한 전체적인 평가를 제안했습니다.
이러한 중요한 기여에도 불구하고, 대부분의 기존 연구는 피드백/보상 구성을 위해 이진 인간 평가 또는 선호도 순위만을 사용하며, 생성된 이미지에서 비현실적 영역, 불일치 영역 또는 불일치 키워드와 같은 상세한 실행 가능한 피드백을 제공할 수 있는 능력이 부족합니다. 우리 연구와 관련된 최근 논문은 Zhang et al. [61]으로, 이미지 합성 작업을 위한 인공물 영역 데이터셋을 수집하고, 인공물 영역을 예측하기 위한 분할 기반 모델을 훈련했으며, 해당 영역을 위한 영역 인페인팅 방법을 제안했습니다. 그러나 그들의 연구는 인공물 영역에만 초점을 맞추고 있는 반면, 본 논문에서는 인공물 영역뿐만 아니라 불일치 영역, 불일치 키워드, 여러 측면에서의 네 가지 세분화된 점수를 포함하는 T2I 생성에 대한 풍부한 피드백을 수집했습니다. 우리가 알기로는, 이것이 텍스트-이미지 모델에 대한 이질적인 풍부한 인간 피드백에 관한 첫 번째 연구입니다.
3. 풍부한 인간 피드백 수집
3.1 데이터 수집 과정
이 섹션에서는 RichHF-18K 데이터셋을 수집하는 절차를 논의합니다. 이 데이터셋에는 두 개의 히트맵(인공물/비현실성과 불일치), 네 가지 세분화된 점수(현실성, 정렬, 미적 품질, 전체 점수), 하나의 텍스트 시퀀스(불일치 키워드)가 포함됩니다.
각 생성된 이미지에 대해 주석자는 먼저 이미지를 검사하고 이를 생성하는 데 사용된 텍스트 프롬프트를 읽습니다. 그런 다음, 주석자는 텍스트 프롬프트와 관련된 비현실성/인공물 또는 불일치의 위치를 나타내기 위해 이미지에 포인트를 표시합니다. 주석자에게는 각 표시된 포인트가 "효과 반경"을 가지고 있으며, 이는 표시된 포인트를 중심으로 가상의 디스크를 형성한다고 설명됩니다(이미지 높이의 1/20). 이 방식으로 비교적 적은 수의 포인트로 결함이 있는 이미지 영역을 커버할 수 있습니다. 마지막으로, 주석자는 불일치 키워드를 라벨링하고 각각 5점 리커트 척도로 현실성, 이미지-텍스트 정렬, 미적 품질, 전체 품질에 대한 네 가지 점수를 매깁니다. 이미지의 비현실성/인공물과 불일치에 대한 자세한 정의는 보충 자료에서 찾을 수 있습니다. 데이터 수집을 용이하게 하기 위해 그림 1에 표시된 것과 같은 웹 UI를 설계했습니다. 데이터 수집 과정에 대한 자세한 내용은 보충 자료에서 확인할 수 있습니다.
3.2. 인간 피드백 통합
생성된 이미지에 대한 수집된 인간 피드백의 신뢰성을 향상시키기 위해, 각 이미지-텍스트 쌍은 세 명의 주석자가 주석을 답니다. 따라서 각 샘플에 대한 여러 주석을 통합해야 합니다. 점수의 경우, 단순히 여러 주석자의 점수를 평균내어 최종 점수를 얻습니다. 불일치 키워드 주석의 경우, 키워드에 대한 가장 빈번한 라벨을 사용하여 다수결 투표를 통해 최종 정렬/불일치 지표 시퀀스를 얻습니다. 점 주석의 경우, 각 주석에 대해 히트맵으로 변환한 후(지난 하위 섹션에서 논의한 대로 각 점을 히트맵에서 디스크 영역으로 변환), 주석자 간 평균 히트맵을 계산합니다. 명백한 비현실성이 있는 영역은 모든 주석자에 의해 주석될 가능성이 높으며 최종 평균 히트맵에서 높은 값을 갖게 됩니다.
3.3. RichHF-18K: 풍부한 인간 피드백 데이터셋
데이터 주석을 위해 Pick-a-Pic 데이터셋에서 이미지-텍스트 쌍의 하위 집합을 선택했습니다. 우리의 방법은 일반적이며 생성된 모든 이미지에 적용 가능하지만, 우리의 데이터셋의 대부분을 사진 실사 이미지로 선택한 이유는 그 중요성과 더 넓은 응용 분야 때문입니다. 또한 우리는 이미지 간 균형 잡힌 카테고리를 가지기를 원했습니다. 균형을 보장하기 위해, Pick-a-Pic 데이터 샘플에서 일부 기본 기능을 추출하기 위해 PaLI 시각 질문 응답(VQA) 모델 [7]을 사용했습니다. 구체적으로, Pick-a-Pic의 각 이미지-텍스트 쌍에 대해 다음 질문을 했습니다: 1) 이미지가 사진 실사인가? 2) 이미지를 가장 잘 설명하는 카테고리는 무엇인가? '인간', '동물', '객체', '실내 장면', '야외 장면' 중 하나를 선택하세요. PaLI의 이러한 두 질문에 대한 답변은 우리의 수동 검토 하에 일반적으로 신뢰할 수 있었습니다. 우리는 이 답변들을 사용하여 Pick-a-Pic에서 다양한 하위 집합을 샘플링하여 17,000개의 이미지-텍스트 쌍을 얻었습니다. 우리는 17,000개의 샘플을 두 개의 하위 집합으로 무작위로 나누어 16,000개의 샘플로 구성된 훈련 세트와 1,000개의 샘플로 구성된 검증 세트를 만들었습니다. 16,000개의 훈련 샘플 속성 분포는 보충 자료에 나와 있습니다. 추가적으로, Pick-a-Pic 테스트 세트에서 고유한 프롬프트와 해당 이미지를 대상으로 풍부한 인간 피드백을 수집하여 테스트 세트로 사용했습니다. 총 18,000개의 Pick-a-Pic 이미지-텍스트 쌍에 대해 풍부한 인간 피드백을 수집했습니다. 우리의 RichHF-18K 데이터셋은 16,000개의 훈련 샘플, 1,000개의 검증 샘플, 1,000개의 테스트 샘플로 구성됩니다.
Figure 3. 우리의 풍부한 피드백 모델의 아키텍처. 우리의 모델은 하나의 비전 스트림과 하나의 텍스트 스트림으로 구성됩니다. 우리는 ViT에서 출력된 이미지 토큰과 텍스트 임베드 모듈에서 출력된 텍스트 토큰에 대해 셀프 어텐션을 수행하여 이미지와 텍스트 정보를 융합합니다. 비전 토큰은 특징 맵으로 재구성되어 히트맵과 점수에 매핑됩니다. 비전 및 텍스트 토큰은 트랜스포머 디코더로 전송되어 텍스트 시퀀스를 생성합니다.
Figure 4. 훈련 세트에서 점수의 최대 차이를 가진 샘플의 수.
현실성 (Plausibility)
이미지가 현실적으로 보이는지 여부를 평가합니다. 이는 이미지가 실제로 존재할 수 있는지, 혹은 비현실적이거나 불가능한 요소를 포함하고 있지 않은지를 판단합니다. 예를 들어, 사람의 손에 다섯 개 이상의 손가락이 있는 경우, 이 이미지는 현실성이 낮다고 평가될 수 있습니다.
정렬 (Alignment)
이미지와 텍스트 설명 간의 일치도를 평가합니다. 텍스트 프롬프트에서 설명한 내용이 이미지에 정확하게 반영되었는지를 판단합니다. 예를 들어, 텍스트 프롬프트가 "강으로 뛰어드는 남자"인 경우, 이미지가 실제로 남자가 강으로 뛰어드는 장면을 보여줘야 합니다.
미적 품질 (Aesthetics)
이미지의 전반적인 미적 품질을 평가합니다. 이는 이미지의 구성, 색상, 조화, 예술적 가치 등을 포함합니다. 이미지는 시각적으로 매력적이고 조화로워야 하며, 미적 기준을 충족해야 합니다.
전체 점수 (Overall)
이미지의 전반적인 품질을 종합적으로 평가합니다. 이는 앞서 언급된 현실성, 정렬, 미적 품질을 포함한 모든 측면을 고려한 최종 점수입니다. 이 점수는 이미지의 전체적인 성공 여부를 판단하는 데 사용됩니다.
4. 풍부한 인간 피드백 예측
4.1. 모델
4.1.1 아키텍처
우리 모델의 아키텍처는 그림 3에 나와 있습니다. 우리는 ViT [14]와 T5X [40] 모델을 기반으로 하는 비전-언어 모델을 채택하였으며, Spotlight 모델 아키텍처 [33]에서 영감을 받아 모델과 사전 학습 데이터셋을 우리 작업에 더 잘 맞도록 수정했습니다. 우리의 작업은 양방향 정보 전파가 필요하므로, PaLI [7]와 유사하게 결합된 이미지 토큰과 텍스트 토큰 간의 셀프 어텐션 모듈 [49]을 사용합니다. 텍스트 정보는 텍스트 불일치 점수 및 히트맵 예측을 위해 이미지 토큰으로 전파되며, 비전 정보는 텍스트 불일치 시퀀스를 디코딩하기 위한 더 나은 비전 인식 텍스트 인코딩을 위해 텍스트 토큰으로 전파됩니다. 더 다양한 이미지에서 모델을 사전 학습하기 위해 WebLI 데이터셋 [7]에서 자연 이미지 캡셔닝 작업을 사전 학습 작업 혼합에 추가했습니다.
구체적으로, ViT는 생성된 이미지를 입력으로 받아들여 이미지 토큰을 고수준 표현으로 출력합니다. 텍스트 프롬프트 토큰은 밀집 벡터로 임베딩됩니다. 이미지 토큰과 임베딩된 텍스트 토큰은 결합되어 T5X의 트랜스포머 셀프 어텐션 인코더에 의해 인코딩됩니다. 인코딩된 결합 텍스트와 이미지 토큰 위에, 우리는 다양한 출력을 예측하기 위해 세 가지 종류의 예측기를 사용합니다. 히트맵 예측을 위해 이미지 토큰은 특징 맵으로 재구성되어 컨볼루션 레이어, 디컨볼루션 레이어, 시그모이드 활성화를 통해 비현실성과 불일치 히트맵을 출력합니다. 점수 예측을 위해 특징 맵은 컨볼루션 레이어, 선형 레이어, 시그모이드 활성화를 통해 전달되어 세분화된 점수로서 스칼라를 출력합니다.
키워드 불일치 시퀀스를 예측하기 위해, 이미지를 생성하는 데 사용된 원본 프롬프트가 모델의 텍스트 입력으로 사용됩니다. 수정된 프롬프트는 T5X 디코더의 예측 목표로 사용됩니다. 수정된 프롬프트는 각 불일치 토큰에 대해 특별한 접미사(' 0')를 가지며, 예를 들어, 생성된 이미지에 검은 고양이가 포함되어 있고 단어 'yellow'가 이미지와 불일치하는 경우 'a yellow 0 cat'이 됩니다. 평가 중에는 특별한 접미사를 사용하여 불일치 키워드를 추출할 수 있습니다.
4.1.2 모델 변형
히트맵과 점수의 예측 헤드에 대해 두 가지 모델 변형을 탐구합니다.
다중 헤드 (Multi-head)
여러 히트맵과 점수를 예측하는 간단한 방법은 각 점수와 히트맵 유형마다 하나의 헤드를 사용하는 여러 예측 헤드를 사용하는 것입니다. 이렇게 하면 총 7개의 예측 헤드가 필요합니다.
증강 프롬프트 (Augmented prompt)
또 다른 접근 방식은 각 예측 유형, 즉 히트맵, 점수, 불일치 시퀀스에 대해 각각 하나의 헤드를 사용하는 것입니다. 이를 통해 총 3개의 헤드가 필요합니다. 모델에 세분화된 히트맵 또는 점수 유형을 알리기 위해 프롬프트에 출력 유형을 추가합니다. 더 구체적으로, 예제의 특정 작업에 대해 프롬프트에 작업 문자열(예: ‘implausibility heatmap’)을 앞에 추가하고 해당 라벨을 훈련 목표로 사용합니다. 추론 중에는 해당 작업 문자열로 프롬프트를 증강하여 단일 히트맵(점수) 헤드가 다양한 히트맵(점수)을 예측할 수 있습니다. 실험에서 보여주듯이, 이 증강 프롬프트 접근 방식은 작업별 비전 특징 맵과 텍스트 인코딩을 생성할 수 있으며, 일부 작업에서 상당히 더 나은 성능을 발휘합니다.
4.1.3 모델 최적화
히트맵 예측을 위해 픽셀 단위의 평균 제곱 오차(MSE) 손실로 모델을 훈련하고, 점수 예측을 위해 MSE 손실로 훈련합니다. 불일치 시퀀스 예측을 위해 모델은 teacher-forcing 교차 엔트로피 손실로 훈련됩니다. 최종 손실 함수는 히트맵 MSE 손실, 점수 MSE 손실, 시퀀스 teacher-forcing 교차 엔트로피 손실의 가중 조합입니다.

Figure 5. 비현실성 히트맵 예제. 프롬프트: 긴 머리를 가진 날씬한 아시아 소녀 발레리나가 흰색 타이츠를 입고 해변에서 뒤돌아 달리는 사진, Nikon D5 사용.

Figure 6. 불일치 히트맵 예제. 프롬프트: 버섯 위의 뱀.
4.2 실험
4.2.1 실험 설정
우리 모델은 16,000개의 RichHF-18K 훈련 샘플로 훈련되었으며, 하이퍼파라미터는 1,000개의 RichHF-18K 검증 세트에서 모델 성능을 기준으로 튜닝되었습니다. 하이퍼파라미터 설정은 보충 자료에서 확인할 수 있습니다.
평가 지표
점수 예측 작업에서는 점수 예측을 위한 일반적인 평가 지표인 Pearson 선형 상관 계수(PLCC)와 Spearman 순위 상관 계수(SRCC)를 보고합니다 [28]. 히트맵 예측 작업의 경우, 결과를 평가하기 위해 NSS/KLD [5]와 같은 표준 주의 히트맵 평가 지표를 차용하는 것이 간단한 방법일 수 있습니다. 그러나 이러한 지표는 모두 그라운드 트루스 히트맵이 비어 있지 않다는 것을 가정하기 때문에, 우리의 경우에는 직접 적용할 수 없습니다. 우리의 경우 비어 있는 그라운드 트루스가 가능하기 때문입니다(예: 인공물/비현실성 히트맵의 경우, 이미지는 어떤 인공물/비현실성도 포함하지 않음을 의미합니다). 따라서 모든 샘플과 비어 있는 그라운드 트루스를 가진 샘플에 대해 각각 MSE를 보고하며, 비어 있지 않은 그라운드 트루스를 가진 샘플에 대해서는 NSS/KLD/AUC-Judd/SIM/CC [5]와 같은 주의 히트맵 평가 지표를 보고합니다. 불일치 키워드 시퀀스 예측의 경우, 토큰 수준의 정밀도, 재현율, F1 점수를 채택합니다. 구체적으로, 정밀도/재현율/F1 점수는 모든 샘플에 대해 불일치 키워드에 대해 계산됩니다.
기준선
비교를 위해 두 개의 ResNet-50 모델 [18]을 훈련하여 여러 개의 완전히 연결된 층과 디컨볼루션 헤드를 사용하여 각각 점수와 히트맵을 예측합니다. 또한, 오프더쉘프 PickScore 모델 [30]을 사용하여 PickScores를 계산하고 우리의 네 가지 그라운드 트루스 점수 각각에 대해 지표를 계산합니다. 오프더쉘프 CLIP 모델 [39]을 기준선으로 사용하여 이미지와 텍스트 임베딩의 코사인 유사도를 계산하고, 텍스트-이미지 정렬 지표를 계산합니다. CLIP 코사인 유사도는 이미지와 프롬프트 간의 정렬을 반영하도록 설계되었습니다. 그 외에도, 우리의 훈련 데이터셋을 사용하여 네 가지 유형의 점수를 예측하기 위해 CLIP 모델을 미세 조정합니다. 불일치 히트맵 예측을 위해 CLIP 그라디언트 [45] 맵을 기준선으로 사용합니다.
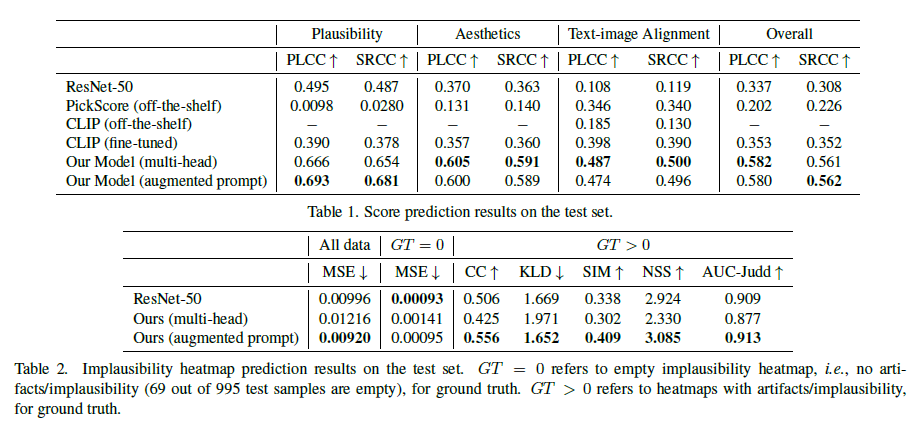
Table 2. 테스트 세트에서의 비현실성 히트맵 예측 결과. GT = 0은 비현실성 히트맵이 비어 있음을 나타내며, 이는 비현실성/인공물이 없음을 의미합니다(995개의 테스트 샘플 중 69개가 비어 있음). GT > 0은 그라운드 트루스에 대한 비현실성/인공물을 포함한 히트맵을 나타냅니다.

Figure 7. 평가 예제. “GT”는 그라운드 트루스 점수(세 명의 주석자로부터의 평균 점수).

Figure 8. 생성 모델에 대한 RAHF의 영향 예시. (a-b): 현실성 점수로 필터링된 예제를 사용하여 미세 조정하기 전과 후의 Muse [6] 생성 이미지, 프롬프트: 신발을 베개로 사용하여 땅에서 자는 고양이. (c-d): 미적 점수가 분류기 가이드 [2]로 사용되지 않은 경우와 사용된 경우의 잠재 확산(LD) [41] 결과, 프롬프트: 종이 클립의 매크로 렌즈 클로즈업.
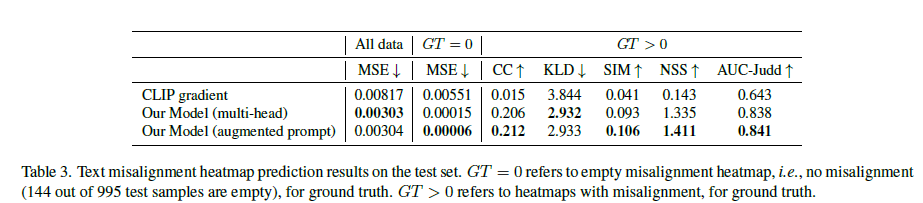
Table 3. 테스트 세트에서의 텍스트 불일치 히트맵 예측 결과. GT = 0은 불일치 히트맵이 비어 있음을 나타내며, 이는 불일치가 없음을 의미합니다(995개의 테스트 샘플 중 144개가 비어 있음). GT > 0은 그라운드 트루스에 대한 불일치 히트맵을 나타냅니다.

Figure 9. Muse [6] 생성 모델을 사용한 영역 인페인팅. 왼쪽에서 오른쪽으로, 네 개의 그림은 각각 Muse에서 인공물이 있는 원본 이미지, 모델에서 예측한 비현실성 히트맵, 히트맵을 처리(임계값 적용, 팽창)하여 생성된 마스크, 마스크를 사용한 Muse 영역 인페인팅에서 나온 새로운 이미지를 나타냅니다.
4.2.2 RichHF-18K 테스트 세트에서의 예측 결과
정량적 분석
우리 모델의 네 가지 세분화된 점수, 비현실성 히트맵, 불일치 히트맵, 불일치 키워드 시퀀스에 대한 예측 결과는 각각 표 1, 표 2, 표 3, 표 4에 제시되어 있습니다. 표 1과 표 3에서, 제안된 모델의 두 가지 변형은 모두 ResNet-50 (또는 텍스트-이미지 정렬 점수의 경우 CLIP)보다 상당히 뛰어납니다. 그러나 표 2에서는 우리 모델의 다중 헤드 버전이 ResNet-50보다 성능이 떨어지지만, 증강된 프롬프트 버전은 ResNet-50보다 성능이 우수합니다. 주요 이유는 다중 헤드 버전에서 예측 작업을 프롬프트에 증강하지 않으면 동일한 프롬프트가 모든 일곱 가지 예측 작업에 사용되므로, 특징 맵과 텍스트 토큰이 모든 작업에 대해 동일하게 된다는 점입니다. 이러한 작업들 사이에서 좋은 절충안을 찾기가 쉽지 않으며, 따라서 비현실성 히트맵과 같은 일부 작업의 성능이 나빠질 수 있습니다. 그러나 예측 작업을 프롬프트에 증강한 후, 특징 맵과 텍스트 토큰이 각 특정 작업에 맞게 조정되어 더 나은 결과를 제공합니다. 추가로, 불일치 히트맵 예측이 일반적으로 비현실성 히트맵 예측보다 결과가 나쁜데, 이는 불일치 영역이 덜 명확하게 정의되어 주석이 더 노이즈가 많을 수 있기 때문입니다.
정성적 예제
우리 모델의 비현실성 히트맵(Fig. 5)에 대한 예측 예제를 보여주며, 모델이 인공물/비현실성 영역을 식별합니다. 불일치 히트맵(Fig. 6)에 대한 예측 예제에서는 모델이 프롬프트와 일치하지 않는 객체를 식별합니다. Fig. 7은 일부 예제 이미지와 그라운드 트루스 및 예측 점수를 보여줍니다. 더 많은 예제는 보충 자료에 있습니다.
5. 풍부한 인간 피드백을 통한 학습
이 섹션에서는 예측된 풍부한 인간 피드백(예: 점수와 히트맵)이 이미지 생성을 개선하는 데 사용될 수 있는지 조사합니다. RAHF 모델의 이점이 생성 모델 패밀리 전반에 걸쳐 일반화될 수 있도록 하기 위해, 우리는 주로 Muse [6]를 개선하기 위한 대상 모델로 사용합니다. Muse는 마스크된 트랜스포머 아키텍처를 기반으로 하여 우리의 RichHF-18K 데이터셋에 있는 Stable Diffusion 모델 변형들과 다릅니다.
예측된 점수를 사용한 생성 모델의 미세 조정
먼저, RAHF 점수를 사용한 미세 조정이 Muse를 개선할 수 있음을 설명합니다. 먼저, 사전 학습된 Muse 모델을 사용하여 12,564개의 프롬프트(프롬프트 세트는 PaLM 2 [1, 11]을 통해 일부 시드 프롬프트로 생성됨)에 대해 각 프롬프트마다 8개의 이미지를 생성합니다. 각 이미지에 대해 RAHF 점수를 예측하고, 각 프롬프트의 이미지 중 최고 점수가 일정 임계값을 초과하면 이를 미세 조정 데이터셋의 일부로 선택합니다. 그런 다음 Muse 모델은 이 데이터셋으로 미세 조정됩니다. 이 접근 방식은 Direct Preference Optimization [15]의 단순화된 버전으로 볼 수 있습니다.
**그림 8 (a)-(b)**에서는 우리가 예측한 현실성 점수(임계값=0.8)로 Muse를 미세 조정한 예를 보여줍니다. Muse 미세 조정에서 얻은 이득을 정량화하기 위해, 100개의 새로운 프롬프트를 사용하여 이미지를 생성하고, 6명의 주석자가 원래 Muse와 미세 조정된 Muse에서 각각 생성된 두 이미지 사이의 현실성 비교를 수행하도록 요청했습니다. 주석자들은 이미지 A가 이미지 B보다 상당히/약간 더 낫다, 거의 같다, 이미지 B가 이미지 A보다 약간/상당히 더 낫다 중에서 선택합니다. 주석자들은 어떤 모델이 이미지 A/B를 생성했는지 알지 못합니다. 표 5의 결과는 RAHF 현실성 점수로 미세 조정된 Muse가 원래 Muse보다 인공물/비현실성이 현저히 적음을 보여줍니다.
또한, **그림 8 (c)-(d)**에서는 RAHF 미적 점수를 Classifier Guidance로 사용하여 Latent Diffusion 모델 [41]을 사용하는 예를 보여줍니다. 이는 Bansal et al. [2]의 접근 방식과 유사하며, 각 세분화된 점수가 생성 모델/결과의 다양한 측면을 개선할 수 있음을 보여줍니다.
예측된 히트맵과 점수를 사용한 영역 인페인팅
모델이 예측한 히트맵과 점수를 사용하여 영역 인페인팅을 수행하여 생성된 이미지의 품질을 개선할 수 있음을 보여줍니다. 각 이미지에 대해 먼저 비현실성 히트맵을 예측한 다음, 히트맵을 처리하여(임계값 적용 및 팽창) 마스크를 생성합니다. Muse 인페인팅 [6]은 마스크된 영역 내에서 적용되어 텍스트 프롬프트와 일치하는 새로운 이미지를 생성합니다. 여러 이미지가 생성되며, 최종 이미지는 우리 RAHF가 예측한 최고 현실성 점수에 따라 선택됩니다.
그림 9에서는 예측된 비현실성 히트맵과 현실성 점수를 사용한 여러 인페인팅 결과를 보여줍니다. 인페인팅 후에 더 적은 인공물과 더 현실적인 이미지가 생성됨을 알 수 있습니다. 이는 RAHF가 RAHF를 훈련하는 데 사용된 이미지와 매우 다른 생성 모델의 이미지에도 잘 일반화됨을 다시 한 번 보여줍니다. 더 많은 세부 사항과 예제는 보충 자료에서 확인할 수 있습니다.
6. 결론 및 한계
이 작업에서 우리는 이미지 생성을 위한 첫 번째 풍부한 인간 피드백 데이터셋인 RichHF-18K를 제공했습니다. 우리는 멀티모달 트랜스포머를 설계하고 훈련하여 풍부한 인간 피드백을 예측했으며, 이러한 풍부한 인간 피드백을 사용하여 이미지 생성을 개선하는 몇 가지 예를 보여주었습니다.
비록 일부 결과가 매우 흥미롭고 유망하지만, 이 작업에는 몇 가지 한계가 있습니다. 첫째, 불일치 히트맵에 대한 모델 성능이 비현실성 히트맵보다 낮은데, 이는 불일치 히트맵의 노이즈 때문일 수 있습니다. 이미지에서 객체가 없는 등의 일부 불일치 사례를 라벨링하는 것이 다소 모호할 수 있습니다. 불일치 라벨 품질을 개선하는 것이 향후 연구 방향 중 하나입니다. 둘째, Pick-a-Pic(Stable Diffusion)을 넘어서 다른 생성 모델에 대한 데이터를 더 많이 수집하고, 그것이 RAHF 모델에 미치는 영향을 조사하는 것이 유용할 것입니다.
더 나아가, 우리는 T2I 생성을 개선하기 위해 모델을 활용하는 세 가지 유망한 방법을 제시했지만, 풍부한 인간 피드백을 활용할 수 있는 다른 많은 방법이 있습니다. 예를 들어, 예측된 히트맵이나 점수를 강화 학습을 통한 생성 모델 미세 조정의 보상 신호로 사용하는 방법, 예측된 히트맵을 가중치 맵으로 사용하는 방법, 예측된 불일치 시퀀스를 학습에서 인간 피드백으로 사용하여 이미지 생성을 개선하는 방법 등 다양한 연구 방향이 있습니다. 우리는 RichHF-18K와 우리의 초기 모델이 이러한 연구 방향을 조사하는 데 영감을 주기를 바랍니다.
추천은 딱히...
import re
from typing import List, Tuple
def match_misalignment_label_to_token(misalignment_label, prompt):
"""Matches the misalignment label to the token.
Args:
misalignment_label: The misalignment label from RichHF-18K dataset.
prompt: The prompt from the Pick-a-pic dataset.
Returns:
A list of pairs of token and misalignment label.
"""
# 구분자를 정의합니다.
delimiters = ',.?!":; '
pattern = '|'.join(map(re.escape, delimiters))
# 정규 표현식을 사용하여 프롬프트를 토큰으로 분리하고 빈 토큰을 제거합니다.
tokens = re.split(pattern, prompt)
tokens = [t for t in tokens if t]
# 불일치 라벨을 정수 리스트로 변환합니다.
misalignment_label = misalignment_label.split(' ')
misalignment_label = [int(l) for l in misalignment_label]
# 토큰과 불일치 라벨의 길이가 같은지 확인합니다.
assert len(tokens) == len(misalignment_label)
# 토큰과 불일치 라벨을 쌍으로 묶어 반환합니다.
return list(zip(tokens, misalignment_label))
if __name__ == '__main__':
text = 'RichHF-18K: a dataset for rich human feedback on generative images.'
label = '0 1 0 0 0 1 0 0 1 0'
pairs = match_misalignment_label_to_token(label, text)
print(pairs)
"""Example script to parse a TFRecord file.""" # TFRecord 파일을 파싱하는 예제 스크립트입니다.
from collections.abc import Sequence # Sequence 타입을 사용하기 위해 collections.abc에서 가져옵니다.
from absl import app # 명령줄 인터페이스를 제공하는 absl 모듈에서 app을 가져옵니다.
import tensorflow as tf # TensorFlow 라이브러리를 tf로 임포트합니다.
def parse_tfrecord_file(filename): # TFRecord 파일을 파싱하는 함수입니다.
"""Parses a TFRecord file and prints the contents.""" # TFRecord 파일을 파싱하고 내용을 출력합니다.
raw_dataset = tf.data.TFRecordDataset(filename) # 주어진 파일 이름으로 TFRecordDataset을 생성합니다.
for raw_record in raw_dataset: # 데이터셋의 각 레코드를 반복합니다.
example = tf.train.Example() # tf.train.Example 객체를 생성합니다.
example.ParseFromString(raw_record.numpy()) # raw_record를 파싱하여 example 객체로 변환합니다.
feat_map = example.features.feature # example 객체에서 피처 맵을 가져옵니다.
# Original filename which can be mapped to images in pick-a-pic dataset.
filename = feat_map['filename'].bytes_list.value[0].decode() # 'filename' 피처를 디코딩하여 원본 파일 이름을 얻습니다.
# 4 fine-grained scores.
aesthetics_score = feat_map['aesthetics_score'].float_list.value[0] # 'aesthetics_score' 피처에서 점수를 가져옵니다.
artifact_score = feat_map['artifact_score'].float_list.value[0] # 'artifact_score' 피처에서 점수를 가져옵니다.
misalignment_score = feat_map['misalignment_score'].float_list.value[0] # 'misalignment_score' 피처에서 점수를 가져옵니다.
overall_score = feat_map['overall_score'].float_list.value[0] # 'overall_score' 피처에서 점수를 가져옵니다.
# Artifact and misalignment heatmaps.
artifact_map = feat_map['artifact_map'].bytes_list.value[0] # 'artifact_map' 피처에서 히트맵 데이터를 가져옵니다.
artifact_map = tf.image.decode_image(artifact_map, channels=1).numpy() # 히트맵 데이터를 디코딩하여 numpy 배열로 변환합니다.
misalignment_map = feat_map['misalignment_map'].bytes_list.value[0] # 'misalignment_map' 피처에서 히트맵 데이터를 가져옵니다.
misalignment_map = tf.image.decode_image( # 히트맵 데이터를 디코딩하여 numpy 배열로 변환합니다.
misalignment_map, channels=1
).numpy()
# Mislignment label, which can be mapped to tokens in original prompt using
# match_label_to_token.py.
token_label = feat_map['prompt_misalignment_label'].bytes_list.value[0] # 'prompt_misalignment_label' 피처에서 불일치 라벨을 가져옵니다.
token_label = token_label.decode() # 불일치 라벨을 디코딩합니다.
# 각 피처를 출력합니다.
print('Filename:', filename) # 파일 이름을 출력합니다.
print('Aesthetics score:', aesthetics_score) # 미적 점수를 출력합니다.
print('Artifact score:', artifact_score) # 인공물 점수를 출력합니다.
print('Misalignment score:', misalignment_score) # 불일치 점수를 출력합니다.
print('Overall score:', overall_score) # 전체 점수를 출력합니다.
# 두 히트맵은 512x512 크기이며 [0, 255] 사이의 값을 가지며, 히트맵 강도를 나타냅니다.
print('Artifact heatmap shape:', artifact_map.shape) # 인공물 히트맵의 크기를 출력합니다.
print('Misalignment heatmap shape:', misalignment_map.shape) # 불일치 히트맵의 크기를 출력합니다.
# 0: 불일치 토큰, 1: 일치 토큰.
print('Misalignment token label:', token_label) # 불일치 토큰 라벨을 출력합니다.
break # 첫 번째 레코드만 처리하고 루프를 종료합니다.
def main(argv): # 메인 함수입니다.
if len(argv) > 1: # 명령줄 인수가 너무 많은지 확인합니다.
raise app.UsageError('Too many command-line arguments.') # 명령줄 인수가 너무 많으면 오류를 발생시킵니다.
# 다운로드한 TFRecord 파일의 경로를 지정합니다.
parse_tfrecord_file('train.tfrecord') # 'train.tfrecord' 파일을 파싱하는 함수를 호출합니다.
if __name__ == '__main__': # 스크립트가 직접 실행될 때만 실행됩니다.
app.run(main) # absl의 app.run()을 호출하여 main 함수를 실행합니다.'인공지능' 카테고리의 다른 글
| BioCLIP: A Vision Foundation Model for the Tree of Life (1) | 2024.07.08 |
|---|---|
| Mip-Splatting: Alias-free 3D Gaussian Splatting (1) | 2024.07.07 |
| Generative Image Dynamics (1) | 2024.07.05 |
| Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild (2) | 2024.07.04 |
| LoRA: Low-Rank Adaptation of Large Language Models (1) | 2024.07.03 |



