https://arxiv.org/abs/2310.16764
ConvNets Match Vision Transformers at Scale
Many researchers believe that ConvNets perform well on small or moderately sized datasets, but are not competitive with Vision Transformers when given access to datasets on the web-scale. We challenge this belief by evaluating a performant ConvNet architec
arxiv.org
많은 연구자들은 ConvNets(Convolutional Neural Networks)이 작은 또는 중간 크기의 데이터셋에서는 잘 작동하지만, 웹 스케일의 데이터셋에서는 Vision Transformers보다 경쟁력이 떨어진다고 믿고 있습니다. 우리는 JFT-4B라는 대규모 레이블링된 이미지 데이터셋에서 사전 학습된 고성능 ConvNet 아키텍처를 평가함으로써 이러한 믿음에 도전합니다. JFT-4B는 주로 기초 모델을 훈련시키는 데 사용되는 데이터셋입니다. 우리는 0.4k에서 110k TPU-v4 코어 컴퓨팅 시간 사이의 사전 학습 계산 예산을 고려하고, NFNet 모델 계열의 깊이와 너비를 증가시키면서 일련의 네트워크를 훈련합니다. 우리는 보류된 손실과 계산 예산 사이에 로그-로그 스케일링 법칙을 관찰했습니다. ImageNet에서 미세 조정한 후, NFNet은 유사한 계산 예산으로 Vision Transformers의 보고된 성능과 일치했습니다. 우리 가장 강력한 미세 조정 모델은 Top-1 정확도 90.4%를 달성했습니다.
Keywords: ConvNets, CNN, Convolution, Transformer, Vision, ViTs, NFNets, JFT, Scaling, Image
도입
Convolutional Neural Networks (ConvNets)은 딥러닝 초기 성공의 많은 부분을 차지했습니다. 딥 ConvNets는 상업적으로 처음 도입된 지 20년이 넘었으며(LeCun et al., 1998), 2012년 ImageNet 챌린지에서 AlexNet의 성공으로 이 분야에 대한 광범위한 관심이 다시 불붙었습니다(Krizhevsky et al., 2017). 거의 10년 동안 ConvNets(주로 ResNets(He et al., 2016a,b))는 컴퓨터 비전 벤치마크를 지배했습니다. 그러나 최근 몇 년 동안 Vision Transformers(ViTs)(Dosovitskiy et al., 2020)가 이를 점차 대체하고 있습니다. 동시에 컴퓨터 비전 커뮤니티는 특정 데이터셋(예: ImageNet)에서 무작위로 초기화된 네트워크의 성능을 주로 평가하던 방식에서, 웹에서 수집된 대규모 범용 데이터셋에서 사전 학습된 네트워크의 성능을 평가하는 방식으로 변화하고 있습니다. 이는 중요한 질문을 제기합니다. Vision Transformers가 유사한 계산 예산으로 사전 학습된 ConvNet 아키텍처보다 뛰어난 성능을 보일까요?
비록 대부분의 연구자들은 Vision Transformers가 ConvNets보다 더 나은 확장성을 보여준다고 믿고 있지만, 이를 뒷받침하는 증거는 놀랍게도 거의 없습니다. 많은 ViTs 관련 연구 논문들은 약한 ConvNet 기준(주로 원래의 ResNet 아키텍처(He et al., 2016a))과 비교합니다. 추가로, 가장 강력한 ViT 모델들은 500k TPU-v3 코어 시간을 초과하는 대규모 계산 예산을 사용하여 사전 학습되었습니다(Zhai et al., 2022). 이는 ConvNets 사전 학습에 사용된 계산량을 훨씬 초과하는 수준입니다.
우리는 NFNet 모델 계열(Brock et al., 2021)의 확장성을 평가합니다. NFNet은 순수한 컨볼루션 아키텍처로, 첫 번째 ViT 논문들과 동시에 발표되었으며 ImageNet에서 새로운 SOTA를 설정한 마지막 ConvNet입니다. 우리는 모델 아키텍처나 훈련 절차를 변경하지 않고(학습률이나 에폭 예산과 같은 간단한 하이퍼파라미터 튜닝을 제외하고), 최대 110k TPU-v4 코어 시간을 계산 예산으로 고려하여, 약 40억 개의 레이블이 붙은 이미지가 30k 클래스에서 수집된 JFT-4B 데이터셋에서 사전 학습합니다(Sun et al., 2017). 우리는 검증 손실과 사전 학습에 사용된 계산 예산 사이에 로그-로그 스케일링 법칙을 관찰했습니다. ImageNet에서 미세 조정한 후, 우리의 네트워크는 유사한 계산 예산을 사용한 사전 학습된 ViTs의 성능과 일치합니다(Alabdulmohsin et al., 2023; Zhai et al., 2022). 이는 그림 1에 나타나 있습니다.
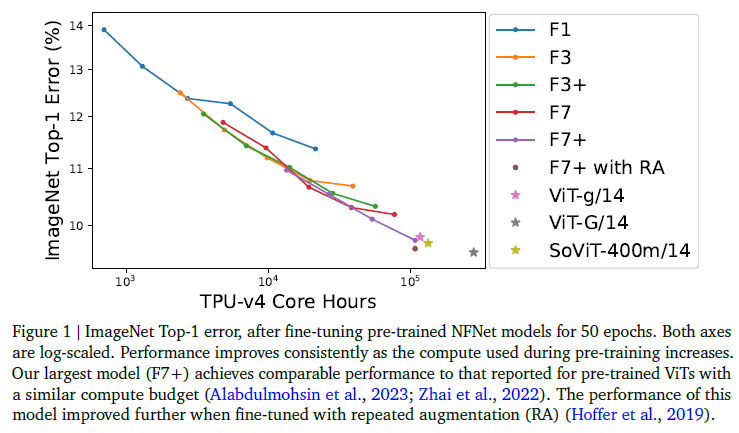
그림 1 | 사전 학습된 NFNet 모델을 50 에폭 동안 미세 조정한 후의 ImageNet Top-1 오류. 양쪽 축은 로그 스케일입니다. 사전 학습 중에 사용된 계산이 증가함에 따라 성능이 일관되게 향상됩니다. 우리의 가장 큰 모델(F7+)은 유사한 계산 예산으로 사전 학습된 ViTs의 보고된 성능과 유사한 성능을 달성합니다(Alabdulmohsin et al., 2023; Zhai et al., 2022). 이 모델의 성능은 반복적인 증강(RA)으로 미세 조정할 때 더 향상되었습니다(Hoffer et al., 2019).
사전 학습된 NFNets의 스케일링 법칙
우리는 JFT-4B에서 깊이와 너비가 다양한 NFNet 모델들을 훈련했습니다. 각 모델은 0.25에서 8 사이의 에폭 예산 범위 내에서 훈련되었으며, 코사인 감소 학습률 스케줄을 사용했습니다. 기본 학습률은 각 에폭 예산에 대해 별도로 작은 로그 스케일 그리드에서 튜닝되었습니다. 그림 2에서는 각 모델을 훈련하는 데 필요한 계산 예산에 대해 130,000개의 이미지가 보류된 검증 손실을 제공합니다. 우리는 F7이 F3과 같은 너비를 가지지만 깊이는 두 배임을 주목합니다. 마찬가지로 F3은 F1의 깊이의 두 배이고, F1은 F0의 깊이의 두 배입니다. F3+와 F7+는 F3과 F7과 동일한 깊이를 가지지만 더 큰 너비를 가집니다. 우리는 배치 크기 4096에서 모멘텀이 있는 SGD와 적응형 그래디언트 클리핑(AGC)을 사용하여 훈련하며, 훈련 시 이미지 해상도는 224×224이고 평가 시에는 256×256을 사용합니다. NFNet 아키텍처와 훈련 파이프라인에 대한 추가 세부 사항은 원 논문(Brock et al., 2021) 및 섹션 6.2에 설명된 JFT 사전 학습 프레임워크를 참조하십시오. 우리는 훈련 전에 JFT-4B에서 ImageNet의 훈련 및 검증 세트에서 이미지의 중복을 제거했습니다(Kolesnikov et al., 2020).
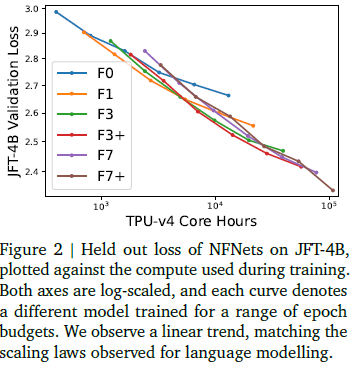
그림 2 | JFT-4B에서 NFNets의 보류된 손실, 훈련 중 사용된 계산에 대해 플로팅. 양쪽 축은 로그 스케일이며, 각 곡선은 다양한 에폭 예산으로 훈련된 다른 모델을 나타냅니다. 우리는 언어 모델링에서 관찰된 스케일링 법칙과 일치하는 선형 추세를 관찰합니다.
그림 2는 검증 손실과 사전 학습 계산 예산 사이의 로그-로그 스케일링 법칙과 일치하는 명확한 선형 추세를 보여줍니다. 이는 언어 모델링에서 관찰된 로그-로그 스케일링 법칙과 일치합니다(Brown et al., 2020; Hoffmann et al., 2022). 최적의 모델 크기와 최적의 에폭 예산(최저 검증 손실을 달성하는)은 계산 예산이 증가함에 따라 모두 증가합니다. 우리는 모델 크기와 훈련 에폭 수를 동일한 비율로 확장하는 것이 신뢰할 수 있는 경험 법칙임을 발견했습니다(Hoffmann et al., 2022). 최적의 에폭 예산은 대략 5,000 TPU-v4 코어 시간을 초과하는 전체 계산 예산에 대해 1보다 큽니다.
그림 3에서는 에폭 예산 범위에 걸쳐 최적의 학습률(검증 손실을 최소화하는)을 3개의 모델에 대해 플로팅합니다. 우리는 2배 간격의 로그 그리드에서 학습률을 튜닝했습니다. NFNet 계열의 모든 모델이 작은 에폭 예산에서는 비슷한 최적의 학습률 𝛼 ≈ 1.6을 보이지만, 에폭 예산이 증가함에 따라 최적의 학습률이 감소하며, 큰 모델에서는 최적의 학습률이 더 빠르게 감소합니다. 실제로 학습률은 모델 크기와 에폭 예산이 증가함에 따라 천천히 하지만 단조롭게 감소한다고 가정하면 2번의 실험 내에서 효율적으로 튜닝할 수 있습니다.
마지막으로, 그림 2에서 일부 사전 학습된 모델이 예상보다 성능이 낮은 것을 주목합니다. 예를 들어, 다른 사전 학습 예산에서 NFNet-F7+ 모델의 곡선이 매끄럽지 않습니다. 이는 데이터 로딩 파이프라인이 훈련이 중단/재시작될 경우 각 훈련 예제가 에폭당 한 번씩 샘플링되도록 보장하지 않았기 때문에 발생한 것으로 보이며, 이로 인해 훈련 예제가 여러 번 재시작될 경우 일부 훈련 예제가 적게 샘플링될 수 있습니다.

그림 3 | 최적의 학습률은 예측 가능하며 튜닝하기 쉽습니다. 모든 모델은 에폭 예산이 작을 때 비슷한 최적의 학습률 𝛼 ≈ 1.6을 보여줍니다. 학습률은 모델 크기와 에폭 예산이 증가함에 따라 천천히 감소합니다.
ImageNet에서 Vision Transformers와 경쟁하는 미세 조정된 NFNets
그림 1에서 우리는 사전 학습된 NFNets를 ImageNet에 대해 미세 조정하고, 사전 학습 중 사용된 계산에 대해 Top-1 오류를 플롯합니다. 우리는 각 모델을 sharpness aware minimization (SAM) (Foret et al., 2020)과 확률적 깊이 및 드롭아웃을 사용하여 50 에폭 동안 미세 조정합니다. 훈련 해상도는 384 × 384이고 평가 해상도는 480 × 480입니다. ImageNet Top-1 정확도는 계산 예산이 증가함에 따라 일관되게 향상됩니다. 우리의 가장 비싼 사전 학습 모델, 8 에폭 동안 사전 학습된 NFNet-F7+는 ImageNet Top-1 정확도 90.3%를 달성하며, 사전 학습에 약 110k TPU-v4 코어 시간이, 미세 조정에 1.6k TPU-v4 코어 시간이 필요합니다. 추가로 미세 조정 동안 반복적인 증강(Fort et al., 2021; Hoffer et al., 2019)을 도입하면 Top-1 정확도는 90.4%에 도달합니다. 비교를 위해, 추가 데이터 없이 ImageNet에서 NFNet의 최고 보고된 Top-1 정확도는 86.8%(Fort et al., 2021)로, 반복적인 증강을 사용한 NFNet-F5에 의해 달성되었습니다. 이는 NFNets가 대규모 사전 학습에서 상당한 이점을 얻는다는 것을 보여줍니다.
두 모델 아키텍처 간의 상당한 차이에도 불구하고, 대규모 사전 학습된 NFNets의 성능은 사전 학습된 Vision Transformers의 성능과 놀라울 정도로 유사합니다. 예를 들어, Zhai et al. (2022)은 JFT-3B에서 210k TPU-v3 코어 시간을 사용하여 사전 학습한 후 ViT-g/14으로 ImageNet에서 90.2%의 Top-1 정확도를 달성하고, JFT-3B에서 500k TPU-v3 코어 시간을 초과하여 사전 학습한 후 ViT-G/14으로 90.45%를 달성했습니다. 최근 연구에서 Alabdulmohsin et al. (2023)은 ViT 아키텍처를 최적화하여 JFT-3B에서 230k TPU-v3 시간을 사용하여 사전 학습한 후 SoViT-400m/14으로 90.3%의 Top-1 정확도를 달성했습니다.
우리는 TPU-v4에서 이러한 모델들의 사전 학습 속도를 평가하고(원 저자의 코드베이스를 사용하여) ViT-g/14은 사전 학습하는 데 120k TPU-v4 코어 시간이, ViT-G/14은 280k TPU-v4 코어 시간이, SoViT-400m/14은 130k TPU-v4 코어 시간이 필요할 것으로 추정합니다. 우리는 이 추정을 사용하여 그림 1에서 ViTs와 NFNets의 사전 학습 효율성을 비교합니다. 그러나 NFNets는 TPU-v4에 최적화되어 있으며, 다른 장치에서 평가할 때는 성능이 떨어질 수 있습니다. 예를 들어, 우리의 코드베이스에서 NFNet-F7+는 8 에폭 동안 사전 학습하는 데 250 TPU-v3 코어 시간이 필요할 것으로 추정됩니다.
마지막으로, JFT-4B에서 가장 낮은 검증 손실을 달성한 사전 학습 체크포인트가 미세 조정 후 항상 ImageNet에서 가장 높은 Top-1 정확도를 달성하지는 않았음을 주목합니다. 특히, 고정된 사전 학습 계산 예산 하에서 미세 조정 체제는 일관되게 약간 더 큰 모델과 약간 더 작은 에폭 예산을 선호했습니다. 직관적으로, 더 큰 모델은 더 많은 용량을 가지고 있어 새로운 작업에 더 잘 적응할 수 있습니다. 일부 경우에는 사전 학습 중 약간 더 큰 학습률이 미세 조정 후 더 나은 성능을 달성했습니다.
토론
우리의 연구는 씁쓸한 교훈을 다시 한번 상기시킵니다. 합리적으로 설계된 모델의 성능을 결정하는 가장 중요한 요소는 훈련에 사용할 수 있는 계산 능력과 데이터입니다(Tolstikhin et al., 2021). ViTs가 컴퓨터 비전에서 보여준 성공은 매우 인상적이지만, 우리의 견해로는 공정하게 평가되었을 때 사전 학습된 ViTs가 사전 학습된 ConvNets를 능가한다는 강력한 증거는 없습니다. 그러나 ViTs는 여러 모달리티에서 유사한 모델 구성 요소를 사용할 수 있는 능력과 같은 특정 상황에서 실질적인 이점을 가질 수 있음을 주목합니다(Bavishi et al., 2023).
감사의 말
Lucas Beyer와 Olivier Henaff에게 이 노트의 초기 초안에 대한 피드백을 제공해주셔서 감사드립니다. 또한, TPU-v4 장치에서 ViT 모델의 훈련 속도 추정치를 제공해주신 Lucas Beyer에게도 감사드립니다.
'인공지능' 카테고리의 다른 글
| Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning (1) | 2024.07.15 |
|---|---|
| Segment Anything (2) | 2024.07.14 |
| QLoRA: Efficient Finetuning of Quantized LLMs (1) | 2024.07.12 |
| Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (1) | 2024.07.11 |
| SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers (1) | 2024.07.10 |



