https://arxiv.org/abs/2304.01373
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same
arxiv.org
요약
대형 언어 모델(LLMs)은 훈련 과정에서 어떻게 발전하고 진화할까? 모델의 규모가 커질수록 이러한 패턴은 어떻게 변화할까? 이러한 질문에 답하기 위해 우리는 Pythia를 소개한다. Pythia는 70M에서 12B 파라미터 범위의 동일한 순서로 공개 데이터를 훈련한 16개의 LLM들로 구성된 모음이다. 우리는 각 16개의 모델에 대해 154개의 체크포인트를 공개적으로 제공하며, 추가 연구를 위해 정확한 훈련 데이터 로더를 다운로드하고 재구성할 수 있는 도구도 제공한다. Pythia는 다양한 연구를 촉진하기 위해 설계되었으며, 메모리제이션, 용어 빈도의 few-shot 성능에 미치는 영향, 성별 편향 감소 등 여러 사례 연구를 제시한다. 우리는 이러한 고도로 통제된 설정이 LLM과 그 훈련 동력학에 대한 새로운 통찰력을 제공할 수 있음을 입증한다. 훈련된 모델, 분석 코드, 훈련 코드, 훈련 데이터는 https://github.com/EleutherAI/pythia 에서 찾을 수 있다.
서론
지난 몇 년간, 대형 트랜스포머 모델은 자연어 처리(NLP)에서 생성 작업을 수행하는 주요 방법론으로 자리 잡았습니다 (Brown et al., 2020; Sanh et al., 2021; Chowdhery et al., 2022). NLP를 넘어, 트랜스포머는 텍스트-이미지 합성(Ramesh et al., 2022; Crowson et al., 2022; Rombach et al., 2022), 단백질 모델링(Jumper et al., 2021; Ahdritz et al., 2022), 컴퓨터 프로그래밍(Chen et al., 2021; Xu et al., 2022; Fried et al., 2022) 등 다양한 분야에서 생성 모델로 큰 주목을 받았습니다. 이러한 성공에도 불구하고, 이러한 모델이 왜 그리고 어떻게 그렇게 성공적인지에 대한 이해는 아직 미흡합니다.
트랜스포머의 기능을 이해하는 데 중요한 것은 이 모델들이 훈련 및 확장 축에서 어떻게 행동하는지를 더 잘 이해하는 것입니다. 훈련된 언어 모델들이 확장될 때 규칙적이고 예측 가능한 패턴이 존재한다는 것은 잘 알려져 있습니다 (Kaplan et al., 2020; Henighan et al., 2020; Hernandez et al., 2021; Mikami et al., 2021; Pu et al., 2021; Sharma & Kaplan, 2020; Ghorbani et al., 2021). 하지만 이러한 "확장 법칙"을 언어 모델의 학습 동역학과 연결하는 기존 연구는 거의 없습니다. 이러한 연구 격차의 주요 원인 중 하나는 이론을 테스트할 적절한 모델 모음에 접근할 수 없다는 점입니다. 공개된 LLM이 과거보다 많아졌지만, 연구자들이 요구하는 공통 기준을 충족하지 못하고 있습니다. 이 논문의 2장에서는 이러한 점에 대해 자세히 다룹니다. 기존 연구 (McGrath et al., 2021; Tirumala et al., 2022; Xia et al., 2022)는 대부분 비공개 모델이나 모델 체크포인트를 대상으로 하고 있어, 과학 연구를 위한 공개 모델 모음의 중요성을 더욱 강조하고 있습니다.
본 논문에서는 이러한 과학적 연구를 촉진하기 위해 설계된 70M에서 12B 파라미터 범위의 디코더 전용 자기회귀 언어 모델 모음인 Pythia를 소개합니다. Pythia 모음은 다음 세 가지 주요 속성을 충족하는 유일한 공개된 LLM 모음입니다:
- 모델 규모가 여러 차례에 걸쳐 다양합니다.
- 모든 모델이 동일한 데이터 순서로 훈련되었습니다.
- 데이터와 중간 체크포인트가 공개적으로 연구 가능합니다.
우리는 Pile (Gao et al., 2020; Biderman et al., 2022) 및 중복 제거 후의 Pile에서 각각 8개의 모델 크기를 훈련하여 비교할 수 있는 2개의 모음을 제공합니다. Pythia의 이러한 주요 속성을 사용하여 성별 편향, 메모리제이션, few-shot 학습과 같은 속성이 훈련 데이터 처리 방식과 모델 규모에 의해 어떻게 영향을 받는지를 처음으로 연구합니다. 우리는 다음 실험들이 Pythia가 가능하게 하는 실험 설정을 보여주는 사례 연구가 되고, 향후 연구 방향을 제시하기를 의도합니다.

표 1. Pythia 모음의 모델 및 선택된 하이퍼파라미터. 하이퍼파라미터의 전체 목록은 부록 E를 참조하십시오. 모델은 총 파라미터 수를 기준으로 이름이 지정되었지만, 대부분의 분석에서는 비임베딩 파라미터 수를 "크기"의 척도로 사용할 것을 권장합니다. "동등"으로 표시된 모델은 동일한 아키텍처와 비임베딩 파라미터 수를 가집니다..
성별 편향 완화
언어 모델이 훈련 데이터에 내재된 편향을 어떻게 반영하는지에 대해 많은 연구가 있습니다. 그러나 일부 연구는 언어 모델의 편향에 대한 미세 조정의 영향을 탐구했거나 (Gira et al., 2022; Kirtane et al., 2022; Choenni et al., 2021), 코퍼스 통계와 측정된 편향 간의 관계를 조사했습니다 (Bordia & Bowman, 2019; Van der Wal et al., 2022b). 연구자들은 일반적으로 다른 크기의 대형 언어 모델에서 훈련 데이터가 편향 학습 동역학에 미치는 역할을 연구할 도구가 부족했습니다. Pythia를 통해 이제 가능한 것을 보여주기 위해, 우리는 언어 모델의 사전 훈련 데이터에서 성별 용어의 빈도를 의도적으로 수정하는 것이 모델의 다운스트림 행동과 편향에 영향을 미칠 수 있는지를 분석합니다. 우리는 모델 모음의 알려진 사전 훈련 데이터와 공개 훈련 코드베이스를 활용하여 모델 훈련의 마지막 7% 및 21% 동안 대명사의 대부분을 남성형이 아닌 여성형으로 수정하여 역으로 훈련합니다. 이러한 개입이 목표 벤치마크에서 편향 측정을 줄이는 데 성공적임을 입증하고, 향후 모델 행동에 훈련 코퍼스가 미치는 영향을 연구하기 위한 주요 도구로서 반사실적 개입과 모델 부분의 재훈련 가능성을 제안합니다.
메모리제이션은 포아송 점 과정이다
대형 언어 모델의 메모리제이션에 관한 광범위한 문헌(Carlini et al., 2019; 2021; Hu et al., 2022)을 바탕으로, 우리는 다음과 같은 질문을 제기합니다: 훈련 데이터셋에서 특정 시퀀스의 위치가 그것이 기억될 가능성에 영향을 미칠까? Pythia의 재현 가능한 데이터 로더 설정을 활용하여 이 질문에 부정적으로 답하고, 더 나아가 훈련 과정에서 기억된 시퀀스의 발생에 대한 포아송 점 과정이 매우 좋은 모델임을 발견합니다.
사전 훈련 빈도의 영향의 출현
최근 연구는 코퍼스 내 특정 사실의 빈도가 모델이 자연어 질문에 그 사실을 적용할 가능성에 중요한 요소임을 확인했습니다 (Razeghi et al., 2022; Elazar et al., 2022; Kandpal et al., 2022; Mallen et al., 2022). 기존 연구는 공개 데이터로 훈련된 GPT-J (Wang & Komatsuzaki, 2021) 및 BLOOM (Scao et al., 2022)과 같은 소수의 모델에 크게 의존했으며, 이 모델들은 빈번한 중간 체크포인트가 부족하여 훈련 과정에서 이 현상의 세밀한 진화를 관찰할 수 없었습니다. 이 문헌의 격차를 해결하기 위해, 우리는 사전 훈련 용어 빈도의 역할이 훈련 과정에서 어떻게 변화하는지 조사합니다. 우리는 훈련 65,000 스텝(훈련의 45%) 이후 중요한 단계 변화가 발생함을 발견합니다: 28억 개 이상의 파라미터를 가진 모델들이 이전 체크포인트에는 없었던 과제 정확도와 과제 관련 용어 발생 사이의 상관관계를 나타내기 시작하며, 이는 더 작은 모델에서는 거의 존재하지 않습니다.

표 2. 일반적으로 사용되는 모델 제품군 및 요구사항에 따른 평가 방법. 자세한 내용은 부록 F.1에서 확인할 수 있습니다.
2. Pythia 모음
Birhane et al. (2021)의 조언을 따라, 이 섹션에서는 Pythia를 설계하고 구현하는 데 있어 우리의 선택, 근거 및 가치를 명확히 문서화하려고 합니다. 우리의 목표는 대형 언어 모델에 대한 과학적 연구를 촉진하는 것이므로, 각 모델의 성능을 최대한 끌어내기보다는 모델 설계의 일관성을 유지하고 가능한 많은 잠재적 변동 원인을 통제하는 데 중점을 둡니다. 예를 들어, 모든 모델에 대해 병렬 주의(attention)와 피드포워드(feedforward) 접근 방식을 사용합니다. 이는 가장 큰 모델에 널리 사용되고 있지만, 일반적으로 60억 개 미만의 파라미터를 가진 모델에는 권장되지 않습니다. 우리의 예상과 달리, 우리는 작은 규모의 모델에서 성능이 저하될 것으로 예상했던 선택을 했음에도 불구하고, 모든 규모에서 우리의 모델이 동일한 파라미터를 가진 OPT 모델과 동일한 성능을 보인다는 것을 발견했습니다. 우리는 2.6절에서 LLM 훈련에 대한 널리 받아들여진 격언과 모순되는 결과에 대해 논의합니다.
2.1. 과학적 LLM 모음을 위한 요구사항
Pythia는 대형 언어 모델의 능력과 한계에 대한 과학적 연구를 가능하게 하고 촉진하는 모음으로 구상되었습니다. 기존 문헌을 조사한 결과, 다음 조건을 모두 충족하는 모델 모음은 없었습니다:
- 공개 접근성: 모델이 공개적으로 배포되며 공개적으로 이용 가능한 데이터로 훈련됩니다.
- 훈련 출처: 중간 체크포인트가 분석을 위해 제공되며, 모든 모델이 동일한 데이터 순서로 훈련되고 중간 체크포인트는 해당 체크포인트까지 본 정확한 데이터와 연결될 수 있습니다. 훈련 절차와 모델 및 훈련 하이퍼파라미터가 잘 문서화되어 있습니다.
- 규모에 따른 일관성: 모델 확장 시퀀스는 최신 대형 모델을 훈련하는 일반적인 관행을 합리적으로 준수하는 일관된 설계 결정을 가져야 합니다. 모델 크기는 여러 차례에 걸쳐 다양한 규모를 포괄해야 합니다.
표 2는 이러한 기준에 따라 여러 인기 있는 언어 모델 모음에 대한 평가를 제공합니다. "체크포인트 수"에 대해서는 체크포인트가 가장 적은 모델 모음을 기준으로 평가했습니다. 일부 모델 모음(GPT-Neo, OPT, BLOOM 등)은 더 많은 체크포인트를 가지고 있는 하위 집합이 있지만, 대부분의 연구 목적에는 충분하지 않습니다. 특히, 일반적으로 더 작은 모델이 더 많은 체크포인트를 가지는 경우가 많아 이러한 문제가 심화됩니다. 위 목록에서 가장 큰 모델이 더 작은 모델보다 더 많은 체크포인트를 가진 유일한 모델 모음은 GPT-Neo입니다.
2.2. 훈련 데이터
우리는 대형 자기회귀 트랜스포머를 훈련하는 데 널리 사용되는 영어 데이터셋 모음인 Pile(Gao et al., 2020; Biderman et al., 2022)에서 모델을 훈련합니다. 이 데이터셋은 다음과 같은 세 가지 주요 장점이 있습니다: 첫째, 무료로 공개적으로 이용 가능합니다. 둘째, 인기 있는 크롤링 기반 데이터셋 C4(Raffel et al., 2020; Dodge et al., 2021)와 OSCAR(Suárez et al., 2019)보다 높은 다운스트림 성능을 보고합니다(Le Scao et al., 2022). 셋째, GPT-J-6B(Wang & Komatsuzaki, 2021), GPT-NeoX-20B(Black et al., 2022), Jurassic-1(Lieber et al., 2021), Megatron-Turing NLG 530B(Smith et al., 2022), OPT(Zhang et al., 2022), WuDao(Tang, 2021) 등 최첨단 모델에 널리 사용되었습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
예를 들어, GPT-3와 같은 언어 모델은 처음에는 대규모 텍스트 코퍼스( 대규모 텍스트 코퍼스는 방대한 양의 텍스트 데이터를 모아놓은 데이터셋 )에서 사전 훈련을 받고, 이후 특정 다운스트림 작업에 맞게 미세 조정됩니다. 이때 다운스트림 성능은 모델이 이러한 실제 작업에서 얼마나 효과적으로 수행되는지를 평가하는 지표입니다. 높은 다운스트림 성능은 사전 훈련이 잘 되었고, 모델이 다양한 언어 작업에서 좋은 결과를 낼 수 있음을 나타냅니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
우리는 Black et al.(2022)이 개발한 BPE 토크나이저를 사용합니다. 이 토크나이저는 Pile에서 특수하게 훈련된 것입니다. 다언어 말뭉치 대신 단일언어 말뭉치에서 훈련하는 것을 고려했지만, 다음과 같은 이유로 최종적으로 그렇게 하지 않았습니다:
- Pile의 내용과 품질에 대해 일반적으로 잘 알고 있지만, 다언어 데이터셋에 대해서는 동일한 확신을 할 수 없습니다. 기존의 대규모 다언어 데이터셋은 품질이 의심스러울 수 있으며(Caswell et al., 2020; Kreutzer et al., 2021), 이를 사용하는 데 있어 발생할 수 있는 문제를 충분히 판단할 자격이 없다고 느꼈습니다. BLOOM(Scao et al., 2022)이 훈련된 ROOTS(Laurençon et al., 2022)는 Pile을 본떠 만들어져 좋은 후보가 될 수 있었지만, 우리가 모델 훈련을 시작할 때는 공개적으로 이용할 수 없었습니다.
- 이 프레임워크가 미래 연구의 기준선으로 사용되도록 의도된 만큼, 현재 널리 받아들여지는 일반적인 관행을 따르는 것이 중요하다고 생각합니다. Pile은 영어 모델을 훈련하는 데 널리 사용되지만, 이에 상응하는 다언어 데이터셋은 없습니다. 특히, ROOTS는 BLOOM 외의 모델을 훈련하는 데 사용된 적이 없습니다.
- Gao et al.(2021)처럼 포괄적인 다언어 평가 프레임워크에 접근할 수 없습니다.
우리는 동일한 아키텍처를 사용하여 Pythia 모음을 두 번 훈련합니다. 각 모음은 8가지 다른 크기를 아우르는 8개의 모델로 구성됩니다. 우리는 Pile에서 8개의 모델로 구성된 모음을 하나 훈련하고, MinHashLSH와 0.87 임계값을 적용하여 중복을 제거한 후 Pile의 사본에서 또 다른 모음을 훈련합니다. 중복 제거된 데이터로 훈련된 LLM이 더 우수하고 데이터를 덜 기억한다는 조언을 따랐습니다(Lee et al., 2021). 중복 제거 후, 중복 제거된 Pile은 약 207B 토큰 크기이며, 원래 Pile은 300B 토큰을 포함합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
MinHashLSH의 구성 요소
- MinHash (Minimum Hashing):
- MinHash는 두 집합 사이의 유사성을 추정하기 위한 해싱 기법입니다. 두 집합의 MinHash 값이 같을 확률은 두 집합의 자카드 유사도(Jaccard similarity)와 같습니다. 즉, MinHash는 유사도 추정치를 제공하여 두 집합이 얼마나 비슷한지 평가합니다.
- 이를 통해 대규모 데이터셋의 문서들 간 유사도를 빠르게 계산할 수 있습니다.
- LSH (Locality-Sensitive Hashing):
- LSH는 유사한 항목을 동일한 버킷으로 해시하는 기법입니다. 이는 유사한 항목이 동일한 해시 값을 가질 확률을 높이는 해싱 방법으로, 유사한 항목들을 빠르게 찾을 수 있도록 도와줍니다.
- LSH는 고차원 데이터에서 유사한 항목들을 효율적으로 검색할 수 있게 합니다.
MinHashLSH의 동작 방식
- 문서 변환: 각 문서를 n-그램 또는 셰잉글(shingle)로 분할합니다.
- MinHash 계산: 각 문서에 대해 여러 개의 해시 함수를 적용하여 MinHash 서명을 생성합니다.
- LSH 적용: MinHash 서명을 여러 개의 버킷에 해시하여 유사한 문서들이 같은 버킷에 들어가도록 합니다.
- 유사 문서 검색: 동일한 버킷에 속한 문서들만 비교하여 유사 문서를 찾습니다. 이를 통해 전체 데이터셋을 비교하는 것보다 훨씬 효율적으로 유사 문서를 식별할 수 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
2.3. 아키텍처
우리의 모델 아키텍처와 하이퍼파라미터는 주로 Brown et al. (2020)를 따르지만, 대형 언어 모델링의 최근 발전에 따른 몇 가지 중요한 변경 사항이 있습니다 (Black et al., 2022; Chowdhery et al., 2022; Zeng et al., 2022):
- Brown et al. (2020)는 희소 및 밀집 어텐션 레이어를 교대로 사용하는 것을 설명하지만, 우리는 후속 연구들을 따라 모델에 완전히 밀집된 레이어를 사용합니다.
- 훈련 중에 장치 처리량을 개선하기 위해 Flash Attention (Dao et al., 2022)을 사용합니다.
- Su et al. (2021)이 도입하고 현재 널리 사용되고 있는 회전 임베딩(rotary embeddings)을 위치 임베딩 타입으로 선택합니다 (Black et al., 2022; Chowdhery et al., 2022; Zeng et al., 2022).
- Wang & Komatsuzaki (2021)가 도입하고 (Black et al., 2022; Chowdhery et al., 2022)가 채택한 병렬화된 어텐션 및 피드포워드 기법과 모델 초기화 방법을 사용합니다. 이는 훈련 효율성을 개선하고 성능을 저해하지 않습니다.
- 이전 연구에서 해석 가능성 연구를 더 쉽게 만든다고 제안된 바와 같이, 결합되지 않은 임베딩/언임베딩 행렬을 사용합니다 (Belrose et al., 2023).
2.4. 훈련
우리의 모델은 EleutherAI가 개발한 오픈 소스 라이브러리 GPT-NeoX (Andonian et al., 2021)를 사용하여 훈련됩니다. 우리는 Adam을 사용하여 훈련하고, Zero Redundancy Optimizer (ZeRO) (Rajbhandari et al., 2020)를 활용하여 다중 기계 설정으로 효율적으로 확장합니다. 또한 데이터 병렬 처리 (Goyal et al., 2017) 및 텐서 병렬 처리 (Shoeybi et al., 2019)를 적절히 활용하여 성능을 최적화합니다. 우리는 하드웨어 처리량을 개선하기 위해 Flash Attention (Dao et al., 2022)을 사용합니다.
표준 훈련 절차와의 가장 큰 차이점은, 소형 언어 모델을 훈련하는 데 일반적으로 사용되는 것보다 훨씬 큰 배치 크기를 사용하는 것입니다. 더 큰 배치 크기를 사용하는 것이 바람직하다는 것은 널리 알려져 있지만 (McCandlish et al., 2018; Zhang et al., 2019; Kaplan et al., 2020; Brown et al., 2020; Hoffmann et al., 2022), 작은 LLM은 수렴 문제를 피하기 위해 더 작은 배치 크기를 필요로 한다고 합니다. 이러한 문헌과는 달리, 우리는 10억 개 미만의 파라미터를 가진 모델에서 표준으로 간주되는 것보다 4배에서 8배 더 큰 배치 크기를 사용하는 데 수렴 문제를 발견하지 못했습니다. 따라서 모든 모델에 대해 배치 크기 1024 샘플과 시퀀스 길이 2048 (2,097,152 토큰)을 사용하여 모든 Pythia 모델 훈련 실행에서 일관성을 유지합니다.
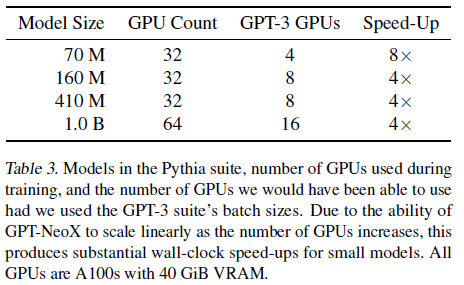
표 3. Pythia 모음의 모델, 훈련 중 사용된 GPU 수 및 GPT-3 모음의 배치 크기를 사용했을 때 사용할 수 있었던 GPU 수를 나타냅니다. GPU 수가 증가함에 따라 GPT-NeoX가 선형적으로 확장할 수 있는 능력 덕분에, 이는 작은 모델에 대해 상당한 벽시계 시간 단축을 제공합니다. 모든 GPU는 40 GiB VRAM을 가진 A100입니다.
대형 배치 크기의 중요성
대형 배치 크기는 모델을 빠르게 훈련하는 데 필수적입니다. GPU나 고품질 인터커넥트의 접근성에 병목이 없는 상황에서는 배치 크기를 두 배로 늘리면 훈련 시간을 절반으로 줄일 수 있습니다. 따라서 최대 배치 크기는 최소 훈련 시간을 직접적으로 의미하며, 계산이 최대한 활용되는 GPU 수를 최대화합니다. 기존 표준을 초과하는 배치 크기를 사용함으로써, 우리는 소형 모델에서 표준 배치 크기와 비교할 때 최대 10배의 속도 향상을 달성했습니다(표 5 참조). 또한, 우리의 모델이 GPT-Neo(Black et al., 2021)나 OPT(Zhang et al., 2022)와 같은 동일한 크기의 널리 사용되는 모델과 동등한 성능을 여전히 보여준다는 점을 언급합니다(공통 벤치마크에 대한 플롯은 부록 G 참조).
우리는 초기화 시점과 매 2,097,152,000 토큰(또는 1,000 반복)마다 모델 체크포인트를 저장하여 훈련 전반에 걸쳐 균일하게 144개의 체크포인트를 생성합니다. 추가로, 훈련 초기에 로그 간격으로 체크포인트를 저장하여 {1, 2, 4, 8, 16, 32, 64, 128, 256, 512} 반복에서 체크포인트를 생성합니다. 이를 통해 모델당 총 154개의 체크포인트를 제공하며, 이는 다른 공개 언어 모델 모음보다 훨씬 많습니다.
우리는 모든 모델을 약 299,892,736,000 ≈ 300B 토큰 동안 훈련하여 원래 GPT-3와 OPT 모델 모음과 토큰 수를 맞춥니다. 표준(중복된) Pile은 GPT-NeoX 토크나이저를 사용하여 334B 토큰을 포함하므로, 일부 데이터는 표준 Pythia 모델에서 보지 못할 수 있습니다. 따라서 Pythia 모델에 대한 훈련 데이터의 영향을 연구하려는 사람들은 정확한 카운트를 보장하기 위해 제공된 데이터 로더를 사용하는 것이 좋습니다. 중복 제거된 Pile은 207B 토큰만 포함하므로 약 1.5 에포크 동안 실행됩니다. 이를 통해 Pythia 모음을 사용하는 사용자들은 에포크 경계 직전의 모델과 약간 후의 모델을 비교하여 중복 제거를 더 자세히 연구할 수 있습니다. 두 번째 에포크가 다양한 벤치마크에서 평가 점수에 부정적인 영향을 미친다는 증거는 없습니다(더 많은 정보는 2.6절 및 부록 G 참조).
우리는 원래 Pile에서 훈련된 모델을 "Pythia-xxx"로 부르며, 여기서 'xxx'는 모델의 총 파라미터 수를 두 자리 숫자로 반올림한 값입니다. 중복 제거된 Pile에서 훈련된 대응 모델은 "Pythia-xxx-deduped"로 부릅니다.
2.5. 평가
이 연구의 주요 초점은 대형 언어 모델의 행동에 대한 과학적 연구를 촉진하는 것이며, 최첨단 성능이 필수 요구사항은 아니지만, Pythia와 Pythia (Deduplicated)가 다양한 NLP 벤치마크에서 OPT와 BLOOM 모델과 매우 유사한 성능을 보인다는 것을 발견했습니다. 이러한 결과는 부록 G에 제시되어 있습니다. 우리는 Language Model Evaluation Harness(Gao et al., 2021)를 사용하여 여덟 개의 공통 언어 모델링 벤치마크에서 평가를 수행합니다(부록 G 참조). 우리는 Pythia와 Pythia (Deduplicated)가 OPT와 BLOOM 모델과 매우 유사한 성능을 보인다는 것을 일관되게 발견했습니다.
2.6. 평가에서의 새로운 관찰
우리는 문헌의 지배적인 서사와 반대되는 세 가지 흥미로운 현상을 발견했습니다.
첫째, 훈련 데이터의 중복 제거가 언어 모델링 성능에 명확한 이점을 주지 않는다는 것을 발견했습니다. 이는 Black et al. (2022)의 결과와 일치하지만 다른 논문들과는 일치하지 않습니다. 이는 Pile의 특정 하위 집합의 업샘플링이 중복된 데이터에 대한 일반적인 가정과 일치하지 않거나, 중복되지 않은 데이터가 중복된 데이터를 능가하는 일반적인 경향이 다른 연구에서 사용된 데이터의 품질에 대한 진술일 수 있음을 나타냅니다.
둘째, 우리는 모든 모델 규모에서 병렬 어텐션 + MLP 서브레이어를 사용했음에도 불구하고 OPT와 동등한(동일한 토큰 수와 동일한 파라미터) 성능을 달성했습니다. Black et al. (2022)와 Chowdhery et al. (2022)는 이 아키텍처 선택이 6B 파라미터 미만의 규모에서 성능 저하를 초래한다고 명시합니다.
셋째, BLOOM에 대해 "다언어성의 저주"(Conneau et al., 2020; Pfeiffer et al., 2022)가 최소화되고 일관되지 않다는 것을 발견했습니다. BLOOM은 LAMBADA, PIQA 및 WSC에서 다른 모델보다 확실히 성능이 떨어지지만, WinoGrande, ARC-easy, ARC-challenge, SciQ 및 LogiQA에서는 그렇지 않은 것으로 보입니다. 이는 기존의 다언어성 저주에 대한 문헌이 보다 다양한 평가 벤치마크를 사용하여 재검토될 필요가 있음을 나타내는 신호로 해석합니다. 이러한 주장들을 뒷받침하는 플롯은 부록 G에 있습니다.
2.7. 공개 및 재현 가능성
우리의 작업이 완전히 재현 가능하도록 하기 위해, 우리는 자유롭고 공개적으로 이용 가능한 코드베이스와 종속성만을 사용하고자 합니다. 앞서 언급한 바와 같이, 우리는 훈련에 오픈 소스 GPT-NeoX 및 DeepSpeed 라이브러리를 사용합니다. 모델 평가를 위해 우리는 Language Model Evaluation Harness (Gao et al., 2021)를 사용하고, 이전 논문에서 주장된 결과를 복사하는 대신 모든 평가를 직접 수행합니다.
우리는 모든 모델과 체크포인트를 Apache 2.0 라이선스 하에 HuggingFace Hub (Wolf et al., 2019)를 통해 공개합니다. 또한 모든 평가에 사용된 코드와 GitHub에 생성된 원시 벤치마크 점수를 공개합니다.
공개된 Pile 데이터셋으로 모델을 훈련하는 것 외에도, 우리는 GPT-NeoX 라이브러리에서 우리의 데이터로더가 사용한 사전 토큰화된 데이터 파일을 다운로드할 수 있는 도구와, 훈련 중 모델이 사용한 정확한 데이터로더를 재현할 수 있는 스크립트를 제공합니다. 이를 통해 연구자들은 각 훈련 단계에서 각 배치의 내용을 읽거나 디스크에 저장할 수 있습니다.
3. 사례 연구
우리는 기존 모델 모음을 사용해서는 수행할 수 없었던 언어 모델링 연구에서 세 가지 사례 연구를 수행합니다. 이 사례 연구들은 다양한 주제 영역을 다루고, 각각의 분야에서 작지만 중요한 질문들을 해결하기 위해 선택되었습니다. 특히, 우리는 이러한 모델들에 대해 이전에 연구되지 않았던 새로운 통찰을 도출하기 위해 공개된 훈련 데이터 순서를 활용하고자 합니다.
3.1. 데이터 편향이 학습된 행동에 어떻게 영향을 미치는가?
대형 언어 모델은 일반적으로 최소한으로 큐레이션된 인간 작성 데이터를 사용하여 훈련됩니다. 모델이 훈련 데이터에 내재된 편향을 학습한다는 것은 널리 알려져 있지만, 이러한 편향이 훈련 과정에서 어떻게 발전하는지에 대한 실제 학습 동역학에 대해서는 거의 알려져 있지 않습니다. 이는 딥러닝 모델에서 편향 연구의 가장 잘 확립된 현상 중 하나인 편향 증폭(bias amplification) 때문에 특히 우려됩니다. 딥러닝 모델의 사회적 편향은 훈련 데이터에서 발견되는 편향보다 더 극단적이라는 사실이 이에 해당합니다 (Zhao et al., 2017; Hirota et al., 2022; Hall et al., 2022). 데이터를 통해 학습된 편향을 완화하기 위해, 이전 연구들은 균형 잡힌 데이터셋으로 미세 조정을 사용하여 언어 모델의 성별 편향을 줄이는 데 어느 정도 성공했습니다 (Levy et al., 2021; Gira et al., 2022; Kirtane et al., 2022). 그러나 사전 훈련 중에 편향이 발생하는 데 있어 특정 말뭉치 통계의 역할에 대해서는 거의 알려져 있지 않습니다.
우리는 반사실적 주장을 조사하고자 합니다. 만약 우리가 다른 특성을 가진 말뭉치로 모델을 훈련했다면, 이러한 모델의 특성은 다운스트림에서 어떻게 변할 것인가? 언어 모델이 학습한 편향에 대한 말뭉치 통계의 영향을 테스트하기 위해, 특정 모델의 사전 훈련 구간을 반복하며 말뭉치 통계를 변경합니다. 특히, 크기가 70M, 410M, 1.4B, 6.9B인 Pythia(중복 제거된) 모델에 대해 훈련 종료 21B 토큰(7%) 전에 체크포인트와 옵티마이저 상태를 저장하고, 훈련 종료까지 동일한 데이터를 보도록 훈련을 재개하되, 형태적으로 남성형 대명사를 여성형 대명사로 대체합니다. 또한, Pythia-1.4B-deduped 모델에 대해서는 훈련 종료 63B 토큰(21%) 전에 동일한 개입을 반복합니다. 그런 다음, WinoBias(Zhao et al., 2018) 벤치마크와 다언어 CrowS-Pairs(Névéol et al., 2022)4의 영어 하위 집합에서 모델 성능을 측정하여, 변경된 사전 훈련 데이터가 다운스트림 성별 편향에 영향을 미치는지 관찰합니다. 이 벤치마크들은 원래 자기회귀 언어 모델이나 텍스트 생성에 사용되도록 설계되지 않았기 때문에, 평가 설정에 대한 우리의 수정 사항은 부록 C.1에 설명되어 있습니다.
Pythia가 제공하는 통제된 설정은 훈련 중에 본 데이터 샘플에 대한 정확한 접근을 통해 사전 훈련에서 대명사 빈도의 영향을 고립시킬 수 있게 합니다. 만약 우리가 두 개의 다른 훈련 데이터셋을 비교하기로 선택했다면, 통제할 수 없는 많은 잠재적 설명 요인을 변경하게 되었을 것입니다. 실제로 데이터 순서와 같은 하이퍼파라미터의 선택조차도 결과적인 편향에 영향을 미칠 수 있다고 제안된 바 있습니다(D’Amour et al., 2020). 따라서 정확히 동일한 데이터 순서로 사전 훈련을 재개할 수 없었다면, 특정 성별 용어 빈도의 영향만을 측정하고 있다는 확신을 가질 수 없었을 것입니다.
WinoBias 구현에 대해(부록 C.1 참조), 그림 2에서 개입의 명확한 효과를 볼 수 있습니다: 각 개입과 모델 규모 전반에 걸쳐 고정 관념적 정확성이 감소합니다. 테스트된 가장 큰 모델인 6.9B에서, 개입을 적용한 결과 모델이 훈련 전반에서 고정 관념적 편향에서 반(反)고정 관념적 편향으로 성공적으로 변화했습니다. 이러한 결과는 더 큰 용량의 모델이 직업과 대명사 사이의 더 복잡한 관계를 학습할 수 있는 능력 덕분에 고정 관념적 편향을 덜 보인다는 것을 나타내며, 유사한 이유로 개입 효과 크기가 규모에 따라 증가한다고 가정합니다.
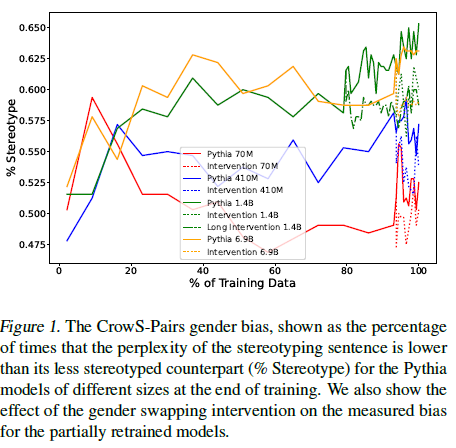
그림 1. CrowS-Pairs 성별 편향
훈련 종료 시점에서 크기가 다른 Pythia 모델에 대해 고정 관념적 문장의 당혹도가 덜 고정 관념적 문장의 당혹도보다 낮은 빈도를 백분율로 나타낸 것입니다(% 고정 관념). 또한, 부분적으로 재훈련된 모델의 측정된 편향에 대한 성별 전환 개입의 효과를 보여줍니다.
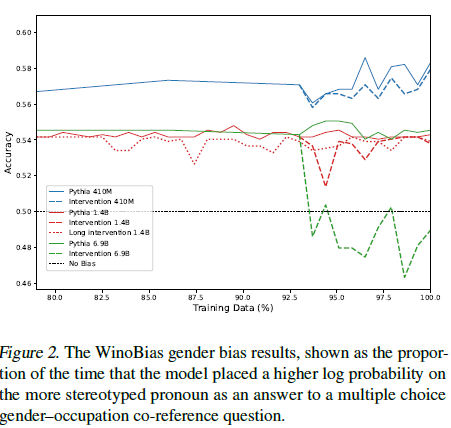
그림 2. WinoBias 성별 편향 결과
모델이 성별-직업 공동 참조 질문에 대한 다중 선택 답변으로 더 고정 관념적 대명사에 높은 로그 확률을 부여한 비율을 나타냅니다.
그림 1은 CrowS-Pairs 성별 편향 지표의 진행 상황과 개입의 효과를 보여줍니다. 우리는 모든 모델 크기에서 마지막 7% 또는 21%의 훈련 동안 성별 대명사를 교체한 결과로 편향이 감소하는 것을 분명히 볼 수 있습니다. 이 효과는 특히 더 큰 모델에서 두드러지며, 이 모델들은 처음부터 더 많은 편향을 보입니다. 우리는 더 큰 모델이 말뭉치 내의 상관 관계와 분포를 더 잘 모델링하기 때문에, 증가된 용량이 편향의 특징을 더 강하게 또는 견고하게 학습하게 만든다고 가정합니다. 또한, 이 개입이 LAMBADA (Paperno et al., 2016)에서 모델 당혹도를 약간 감소시키는 것만을 초래한다는 것을 확인할 수 있습니다(부록 C.1 참조). 이는 편향 완화가 언어 모델링 성능에 큰 영향을 미치지 않고 효과적으로 이루어짐을 나타냅니다. 진행 과정의 노이즈가 실제 언어 모델의 편향 변화인지 아니면 CrowS-Pairs의 신뢰성 부족을 반영하는지는 미래 연구에 남겨둔 열린 질문입니다.
우리는 언어 모델 훈련 데이터의 일부를 수정하고, 재훈련하고, 기본 모델과 비교하는 이러한 개입(interventions)을 편향 증폭 조사 및 새로운 완화 전략 수립을 포함하되 이에 국한되지 않는 다양한 응용 프로그램에 대해 더 연구할 것을 제안합니다. 예를 들어, 이 사례 연구에서는 다루지 않았지만, Pythia가 제공하는 훈련 중 본 데이터에 대한 세부 정보가 특정 훈련 샘플이 인코딩된 편향에 미치는 영향을 추정하는 데 유망한 문헌인 영향 함수에 유용할 수 있다고 생각합니다(Brunet et al., 2019; Silva et al., 2022). 이 사례 연구의 범위를 넘었지만, 우리는 광범위한 체크포인트 가용성, 일관된 훈련 순서, 재훈련 가능성이 기존 편향 측정의 테스트-재테스트 신뢰성을 평가하는 데 유용할 수 있다고 믿습니다(Van der Wal et al., 2022a).
3.2. 훈련 순서가 암기에 영향을 미치는가?
신경 언어 모델에서의 암기는 널리 연구되었지만, 암기의 동역학에 대한 많은 기본적인 질문은 여전히 답변되지 않은 상태로 남아 있습니다. 이전의 암기 동역학 연구는 일반적으로 몇 가지 모델에 국한되거나(Jagielski et al., 2022; Elazar et al., 2022), 연구를 위해 맞춤형 모델을 훈련시키지만 공개하지 않는 논문들(Tirumala et al., 2022; Hernandez et al., 2022)에 한정됩니다. Carlini et al. (2022)는 암기에 대한 확장의 영향을 연구하면서, 그들의 연구에 적합한 모델 모음의 부족을 반복해서 언급합니다. 결국, 그들은 약간 다른 데이터셋으로, 다른 순서로, 일관되지 않은 체크포인트로 훈련된 GPT-Neo 모델 모음(Black et al., 2021; Wang & Komatsuzaki, 2021; Black et al., 2022)에 초점을 맞추게 됩니다.
이 실험에서는 훈련 순서가 암기에 영향을 미치는지 테스트합니다. 이는 명시적으로 이론에 기반한 실험입니다. 여러 저자는 트랜스포머가 새로운 정보를 잠재 공간에 추가한 다음 전체 공간을 처리하여 더 나은 표현을 얻는 방식으로 작동한다고 생각했습니다. 이 정신 모델은 훈련 후반부에 만난 데이터가 더 많이 암기될 것이라고 예측합니다. 이는 모델이 해당 데이터를 표현 공간에 완전히 통합할 시간이 적기 때문입니다. 이 예측이 맞다면, 이는 문자 그대로의 암기가 바람직하지 않은 시퀀스의 암기를 완화하기 위해 모델의 훈련 데이터 순서를 의도적으로 변경하는 데 매우 유용할 수 있습니다.
가설을 테스트하기 위해, 우리는 훈련 말뭉치에서 각 시퀀스의 초기 부분의 암기를 측정합니다. 암기에 대한 여러 합리적인 정의가 있지만, 우리는 문헌에서 상당한 주목을 받은 Carlini et al. (2021)의 정의를 사용합니다(Yoon & Lee, 2021; Huang et al., 2022; Ginart et al., 2022; Ippolito et al., 2022; Biderman et al., 2023). 이 정의에 따르면, 훈련 데이터에서 길이가 k인 문자열로 모델을 프롬프트하면 모델이 훈련 데이터에서 다음 ℓ 토큰을 정확히 생성하게 되면 그 문자열은 (k, ℓ)-암기된 것으로 간주됩니다. 우리는 k = ℓ = 32를 대체로 임의로 선택했으며, 모든 합리적인 (k, ℓ) 쌍을 다루는 것은 모델을 처음부터 다시 훈련시키는 것과 비슷한 계산 비용이 든다는 점을 언급합니다. 잠재적인 공변 효과를 피하기 위해, 우리는 훈련 중에 본 각 문맥의 첫 64 토큰만 사용합니다.
놀랍게도, 우리는 포아송 모델이 데이터를 매우 잘 맞춘다는 것을 발견했습니다(그림 3). 이는 훈련 순서가 암기에 거의 영향을 미치지 않음을 나타냅니다. 이 모델은 암기된 시퀀스가 훈련의 시작이나 끝 부분에 더 밀집되어 있지 않으며, 각 체크포인트 사이에 대략 동일한 수의 암기된 시퀀스를 찾을 수 있음을 의미합니다.
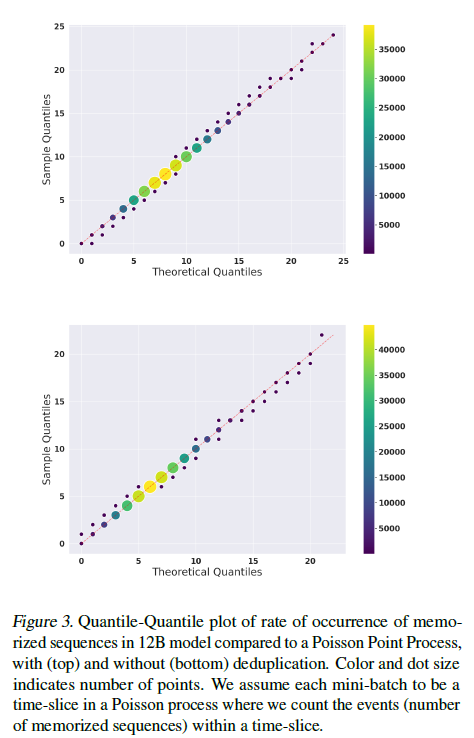
그림 3.
12B 모델에서 암기된 시퀀스 발생률을 포아송 점 과정과 비교한 Q-Q 플롯, 중복 제거 여부를 기준으로 위(중복 제거)와 아래(중복 제거 안함)에 표시됩니다. 색상과 점 크기는 점의 수를 나타냅니다. 우리는 각 미니배치를 포아송 과정의 시간 단위로 간주하고, 해당 시간 단위 내에서 사건(암기된 시퀀스 수)을 셉니다.
포아송 과정은 훈련 데이터 배치 내에서 암기된 시퀀스가 발생하는 사건을 설명합니다. 평가가 훈련 말뭉치 내 모든 시퀀스의 처음 64개 토큰에서, 훈련 순서와 동일한 순서로 수행되었기 때문에 각 배치는 가상의 시간 간격을 나타낸다고 볼 수 있습니다. 여기서 시간 단위는 훈련 말뭉치의 시퀀스를 의미하며, 샘플 분포는 훈련 데이터 배치 내 암기된 시퀀스의 수로 정의되고, 이론적 분포는 샘플로부터 최적의 포아송 분포로 정의됩니다. 우리는 이러한 플롯에 대해 512 시퀀스의 배치 크기를 사용했지만, 다양한 배치 크기에 대해서도 유사한 결과를 관찰했습니다.
카운트(그림 3의 오른쪽 색 막대)는 Q-Q 플롯에서 점의 밀도를 나타내며, 크기로도 표시됩니다. Q-Q 플롯은 훈련 데이터에서 암기된 시퀀스 발생률이 균일하다는 사실을 확인하기 위한 적합도 검사의 역할을 합니다.
이 발견은 모델이 암기할 시퀀스를 제어하려는 실무자들에게 중요합니다. 이는 단순히 암기가 바람직하지 않은 시퀀스를 훈련 시작이나 끝에 배치함으로써 암기 가능성을 성공적으로 줄일 수 없음을 의미합니다. 그러나 우리는 특히 특정 시퀀스의 암기를 우려하는 실무자가 훈련 시작 시점에 이러한 시퀀스를 배치하도록 제안합니다. 이렇게 하면 실무자가 훈련이 완료되기 전에 부분적으로 훈련된 모델에서 바람직하지 않은 암기 행동이 발생하는지 관찰할 가능성이 높아집니다.
3.3. 사전 훈련 용어 빈도가 훈련 전반의 작업 성능에 영향을 미치는가?
최근 연구는 언어 모델 말뭉치의 통계가 다양한 다운스트림 작업에 미치는 영향을 탐구했습니다. Shin et al. (2022)의 연구는 사전 훈련 말뭉치가 few-shot 성능에 어떻게 영향을 미치는지 보여주었고, Razeghi et al. (2022)는 모델이 few-shot 설정에서 수리적 추론을 수행할 수 있는 방법을 조사했습니다. 입력 피연산자와 사전 훈련 말뭉치에서의 빈도를 기반으로 산술 작업의 성능을 도표화하여, 더 자주 발견되는 용어의 정확도가 덜 자주 발견되는 용어보다 높다는 결론을 내렸습니다. 다른 연구들도 사전 훈련 말뭉치가 few-shot 행동에 큰 영향을 미친다고 제안합니다(Elazar et al., 2022; Kandpal et al., 2022). 이러한 연구들은 사실적 질문에 답하는 능력과 사전 훈련 말뭉치에서 발견된 두드러진 엔티티의 빈도 사이에 상관 관계와 인과 관계가 있음을 관찰했습니다.
앞서 언급한 연구들은 다양한 모델 크기로 실험했지만, 훈련 중 언제 그리고 어떤 모델 크기에서 이러한 효과가 발생하는지는 아직 연구되지 않았습니다. 우리는 모델 체크포인트와 모델 크기 전반에 걸쳐 이 현상을 추가로 조사하기 위해 산술 작업(곱셈과 덧셈)과 QA 작업(Kandpal et al., 2022)을 자연어 프롬프트를 사용하여 k-shot 설정에서 평가합니다. 우리는 각 체크포인트가 본 사전 훈련 데이터를 기반으로 관련 용어 빈도를 계산합니다. 이는 각 선택된 훈련 단계까지 모델이 샘플링하고 본 사전 훈련 말뭉치의 각 부분을 통해 계산됩니다. 모델 평가는 Pythia (중복 제거된) 모음을 사용하여 LM Evaluation Harness (Gao et al., 2021)로 수행되었습니다.
Razeghi et al. (2022)를 따르며, 산술 작업의 구성은 입력 피연산자 x1∈[0,99]와 x2∈[1,50] 및 출력 y로 이루어집니다. 입력 피연산자는 "Q what is: x1 # x2? A:"라는 프롬프트 템플릿으로 변환되며, 여기서 #는 덧셈을 위한 "plus"와 곱셈을 위한 "times"입니다. 우리는 모델의 예측을 y와 비교하여 프롬프트 인스턴스의 정확도를 측정합니다. 용어 빈도와 작업 성능의 상관 관계를 측정하기 위해, 동일한 x1 값을 가진 모든 프롬프트의 평균 정확도를 x2의 모든 값에 대해 측정하고, 각 평가된 모델 체크포인트가 본 샘플링된 사전 훈련 데이터에서 x1이 발견된 횟수에 매핑합니다. few-shot 설정에서는 측정되는 x1 값과 다른 숫자의 예제를 샘플링합니다.
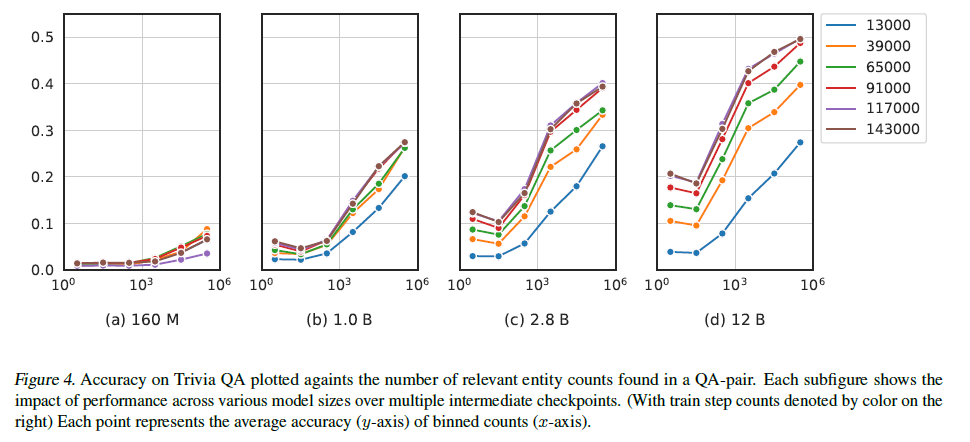
그림 4. Trivia QA 정확도
QA 쌍에서 발견된 관련 엔티티 수와 비교하여 플롯된 Trivia QA 정확도입니다. 각 서브피겨는 다양한 모델 크기에서 여러 중간 체크포인트에 걸친 성능의 영향을 보여줍니다(오른쪽 색상으로 표시된 훈련 단계 수). 각 점은 구간별 빈도의 평균 정확도(y축)를 나타냅니다(x축).
QA 작업에 대한 실험
TriviaQA (Joshi et al., 2017)를 QA 작업으로 사용하여 "Q: x1 \n A: y"라는 간단한 템플릿을 사용합니다. 여기서 x1은 질문이고 y는 답변입니다. y는 few-shot 샘플에서는 포함되고 평가되는 샘플에서는 비워둡니다. 모델 예측은 가능한 답변 세트에 대한 정확한 일치로 평가됩니다. 단일 질문-답변 쌍("QA 쌍")의 용어 빈도는 주어진 체크포인트가 본 샘플링된 사전 훈련 데이터 시퀀스에서 해당 QA 쌍의 모든 중요한 엔티티가 나타나는 횟수를 기반으로 계산됩니다. 우리는 원래 실험을 따라 4-shot을 사용하고, 데이터셋의 훈련 및 검증 분할을 모두 평가합니다. 성능은 로그 간격의 그룹으로 평균화됩니다.
산술 및 QA 실험 모두에서 모델 크기가 평균 성능과 용어 빈도 사이의 상관관계에 영향을 미친다는 것을 관찰했습니다. 이는 이러한 상관관계가 더 큰 모델에서 나타나는 특성임을 나타냅니다. 작은 모델은 최대 16개의 few-shot 예제를 제공받더라도 작업에서 정확한 결과를 거의 생성하지 못합니다. 그림 7에서 10억 개 미만의 모델이 훈련 후반 단계에서도 성능이 좋지 않음을 보여주며, 이는 이러한 모델이 훈련 데이터에서 관련 정보의 빈도에 관계없이 이 작업을 성공적으로 학습하지 못한다는 것을 시사합니다. 유사한 패턴은 훈련이 진행됨에 따라 성능 향상이 주로 더 큰 모델에서만 발생하는 그림 4에서도 볼 수 있습니다. 곱셈 작업의 경우, Razeghi et al. (2022)를 따라 가장 빈도가 높은 상위 10% 입력 피연산자와 가장 빈도가 낮은 하위 10% 입력 피연산자 사이의 성능 차이를 계산합니다(표 4 참조). 우리는 이 성능 격차가 훈련 과정에서 넓어지는 것을 발견했습니다.
Pythia의 용어 빈도가 성능에 미치는 영향 관찰
Pythia는 이전 연구보다 용어 빈도가 성능에 미치는 동역학을 더 명확하게 관찰할 수 있게 해줍니다. 모델 아키텍처, 사전 훈련 데이터셋 및 훈련 하이퍼파라미터의 차이와 같은 혼란 요인을 제거함으로써, 용어 빈도가 모델의 작업 성능에 미치는 영향이 언제 발생하는지 더 잘 이해할 수 있습니다. 실제로, 모델 크기와 중간 체크포인트와 관련된 현상을 관찰하면 향후 훈련에서 더 나은 선택을 할 수 있습니다. 예를 들어, 특정 질문에 대한 답을 모델이 알고 있는지 여부에 대해 신경을 쓴다면, 훈련 데이터에서 해당 정보가 얼마나 자주 발생하는지를 계산하여 X 크기의 모델이 이 정보를 유지하고 회상할 수 있는 가능성을 예측할 수 있습니다.
4. 결론
우리는 여러 규모에 걸쳐 일관된 데이터 순서와 모델 아키텍처로 훈련된 언어 모델 모음인 Pythia를 공개합니다. Pythia를 사용하여 공공 모델 모음에 대해 전례 없는 수준의 세부 실험을 가능하게 하는 방법을 성별 편향 완화, 암기 및 용어 빈도 효과에 대한 새로운 분석과 결과를 통해 시연합니다. 우리는 이러한 분석이 더 복잡한 작업 전반에서 사전 훈련 데이터가 능력 획득과 발현에 어떻게 영향을 미치는지를 보여주는 추가 연구를 촉발하기를 바라며, 이러한 모델과 데이터셋 도구가 다양한 실무자들에게 광범위하게 유용하기를 바랍니다. 또한 LLM에 대한 새로운 실험적 설정의 프레임워크로 이 모음을 사용할 것을 권장합니다.
감사의 말
이 모델을 훈련하는 데 필요한 컴퓨팅 자원을 제공한 Stability AI와 일부 평가를 위해 컴퓨팅 자원을 제공한 CoreWeave에 감사를 표합니다. OW의 기여는 네덜란드 연구 위원회(NWO)가 프로젝트 406.DI.19.059의 일환으로 자금을 지원하였습니다. HB의 기여는 영국RI의 인공지능을 환경 위험 연구에 적용하는 박사 과정 교육 센터(참조 EP/S022961/1)에서 지원을 받았습니다.
Nora Belrose, Tim Dettmers, Percy Liang, Yasaman Razeghi, Mengzhou Xia, 그리고 EleutherAI Discord 서버의 다양한 멤버들에게 피드백을 제공해 주신 것에 대해 감사를 드립니다. 또한 GPT-NeoX, Megatron-DeepSpeed 및 NeMo Megatron 라이브러리의 개발자들에게 그들의 도움과 지원에 대해 감사를 드리며, Flash Attention 구현에 기여하여 모델 훈련 시간을 크게 절약할 수 있게 해준 Vincent Hellendoorn에게도 감사를 드립니다.
'인공지능' 카테고리의 다른 글
| ConvNets Match Vision Transformers at Scale (1) | 2024.07.13 |
|---|---|
| QLoRA: Efficient Finetuning of Quantized LLMs (1) | 2024.07.12 |
| SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers (2) | 2024.07.10 |
| Better & Faster Large Language Models via Multi-token Prediction (2) | 2024.07.09 |
| BioCLIP: A Vision Foundation Model for the Tree of Life (1) | 2024.07.08 |



