https://huggingface.co/Kwai-Kolors/Kolors-IP-Adapter-Plus
Kwai-Kolors/Kolors-IP-Adapter-Plus · Hugging Face
Kolors-IP-Adapter-Plus weights and inference code 📖 Introduction We provide IP-Adapter-Plus weights and inference code based on Kolors-Basemodel. Examples of Kolors-IP-Adapter-Plus results are as follows: Our improvements A stronger image feature extrac
huggingface.co
요약
우리는 Kolors라는 텍스트-이미지 생성용 잠재 확산 모델을 소개합니다. 이 모델은 영어와 중국어에 대한 깊은 이해력과 인상적인 포토리얼리즘을 특징으로 합니다. Kolors 개발에 기여한 세 가지 주요 통찰력이 있습니다.
첫째, Kolors는 Imagen 및 Stable Diffusion 3에서 사용되는 대규모 언어 모델 T5와 달리, 영어와 중국어 이해력을 향상시키는 일반 언어 모델(GLM)을 기반으로 구축되었습니다. 또한, 우리는 정교한 텍스트 이해를 위해 대규모 학습 데이터셋을 재설명하는 멀티모달 대규모 언어 모델을 사용합니다. 이러한 전략들은 Kolors의 복잡한 의미 이해 능력을 크게 향상시키며, 특히 다수의 엔티티를 포함하는 텍스트를 이해하고 고급 텍스트 렌더링 기능을 가능하게 합니다.
둘째, Kolors의 학습을 개념 학습 단계와 고품질 향상 단계로 나눕니다. 개념 학습 단계에서는 광범위한 지식을, 고품질 향상 단계에서는 특별히 선별된 고미적 데이터로 학습합니다. 더 나아가, 우리는 노이즈 스케줄의 중요한 역할을 조사하고, 고해상도 이미지 생성을 최적화하기 위해 새로운 스케줄을 도입했습니다. 이러한 전략들은 생성된 고해상도 이미지의 시각적 매력을 높이는 데 기여합니다.
마지막으로, 우리는 Kolors의 학습과 평가를 위한 지침으로서 카테고리 균형 벤치마크인 KolorsPrompts를 제안합니다. 결과적으로, 일반적으로 사용되는 U-Net 백본을 사용하더라도 Kolors는 인간 평가에서 기존 오픈 소스 모델을 능가하는 뛰어난 성과를 보였으며, 특히 시각적 매력 면에서 Midjourney-v6 수준의 성과를 달성했습니다. 우리는 Kolors의 코드와 가중치를 https://github.com/Kwai-Kolors/Kolors에서 공개할 예정이며, 이는 시각적 생성 커뮤니티의 미래 연구와 응용에 기여할 것입니다.

그림 1: Kolors가 생성한 고품질 샘플로, 영어 및 중국어 텍스트 렌더링, 정확한 프롬프트 준수, 세밀한 디테일 렌더링, 다양한 스타일과 해상도에서의 우수한 이미지 품질을 보여줍니다.
1. 서론
확산 기반 텍스트-이미지(T2I) 생성 모델은 인공지능 및 컴퓨터 비전 분야에서 주요 초점으로 떠오르고 있습니다. Stability AI의 SDXL [27], Google의 Imagen [34], Meta의 Emu [6]와 같은 이전의 방법들은 U-Net [33] 아키텍처를 기반으로 구축되어 텍스트-이미지 생성 작업에서 주목할 만한 성과를 이뤘습니다. 최근에는 PixArt-α [5]와 Stable Diffusion 3 [9]와 같은 Transformer 기반 모델들이 전례 없는 품질의 이미지를 생성하는 능력을 보여주었습니다. 그러나 이러한 모델들은 현재 중국어 프롬프트를 직접 해석할 수 없어, 중국어 텍스트로부터 이미지를 생성하는 데 한계가 있습니다. 중국어 프롬프트의 이해를 개선하기 위해 AltDiffusion [45], PAI-Diffusion [39], Taiyi-XL [42], Hunyuan-DiT [19]와 같은 여러 모델들이 도입되었습니다. 이러한 접근 방식들은 여전히 중국어 텍스트 인코딩을 위해 CLIP에 의존하고 있습니다. 그럼에도 불구하고, 이들 모델들은 중국어 텍스트 준수와 이미지 미적 품질 면에서 여전히 상당한 개선의 여지가 있습니다.
이 보고서에서는 텍스트-이미지 생성을 위해 잠재 공간 [32]에서 일반 언어 모델(GLM) [8]을 통합한 클래식 U-Net 아키텍처 [27]를 포함한 Kolors를 소개합니다. GLM과 멀티모달 대형 언어 모델이 생성한 세밀한 캡션을 통합함으로써, Kolors는 영어와 중국어에 대한 고급 이해력과 뛰어난 텍스트 렌더링 능력을 보입니다. 정교하게 설계된 두 단계의 학습 전략 덕분에 Kolors는 놀라운 포토리얼리즘 능력을 발휘합니다. KolorsPrompts 벤치마크에 대한 인간 평가에서 Kolors는 특히 시각적 매력에서 뛰어난 성과를 달성했습니다. 우리는 Kolors의 코드와 모델 가중치를 공개하여 Kolors를 주류 확산 모델로 자리매김하려고 합니다. 이 작업의 주요 기여는 다음과 같이 요약됩니다:
- Kolors에서 영어와 중국어 텍스트 표현을 위해 GLM을 적절한 대형 언어 모델로 선택했습니다. 또한, 멀티모달 대형 언어 모델이 생성한 상세한 설명으로 학습 이미지를 향상시켰습니다. 그 결과, Kolors는 복잡한 의미를 이해하는 데 뛰어난 능력을 보이며, 특히 다수의 엔티티가 포함된 시나리오에서 우수한 텍스트 렌더링 능력을 보여줍니다.
- Kolors는 개념 학습 단계(광범위한 지식을 사용)와 고품질 향상 단계(정교하게 선별된 고미적 데이터 사용)의 두 단계 접근법으로 학습됩니다. 또한, 고해상도 이미지 생성을 최적화하기 위해 새로운 스케줄을 도입했습니다. 이러한 전략들은 생성된 고해상도 이미지의 시각적 매력을 효과적으로 향상시킵니다.
- 카테고리 균형 벤치마크 KolorsPrompts에 대한 포괄적인 인간 평가에서 Kolors는 Stable Diffusion 3 [9], DALL-E 3 [3], Playground-v2.5 [18]을 포함한 대부분의 오픈 소스 및 클로즈드 소스 모델을 능가했으며, Midjourney-v6에 필적하는 성과를 보여줬습니다.
2. 방법
이 연구에서는 텍스트-이미지 확산 모델의 성능을 향상시키기 위한 여러 중요한 측면에 집중합니다. 보다 진보된 백본을 최적화하는 것이 모델 성능을 향상시킬 수는 있지만, 이는 본 연구의 범위에 포함되지 않습니다. 백본으로는 SDXL [27]에서 사용된 U-Net 아키텍처를 엄격히 준수합니다. 중요한 점은 우리의 방법이 잠재적 U-Net [33]에 국한되지 않고 다양한 확산 모델에서 효과적이라는 것입니다.
2.1 텍스트 신뢰성 향상
2.1.1 텍스트 인코더로서의 대형 언어 모델
텍스트 인코더는 텍스트-이미지 생성 모델의 중요한 구성 요소로, 모델이 생성하는 콘텐츠에 직접적으로 영향을 미치고 제어합니다. 우리는 Kolors와 기존 이미지 생성 모델에서 사용되는 텍스트 인코더를 표 1에서 비교합니다. 일반적으로 CLIP [28]과 T5 [29] 시리즈가 텍스트 인코더로 주로 사용됩니다. SD1.5 [32]와 DALL-E 2 [30]와 같은 전통적인 방법들은 CLIP 모델의 텍스트 브랜치를 텍스트 표현에 사용합니다. 그러나 CLIP는 전체 이미지를 텍스트 설명과 정렬하기 위해 대조적 손실로 훈련되었기 때문에, 여러 주제나 위치, 색상을 포함하는 상세한 이미지 설명을 이해하는 데 어려움을 겪습니다.
일부 방법은 Transformer T5의 인코더-디코더에서 텍스트 임베딩을 추출하여 보다 세밀한 지역 정보를 제공합니다. 예를 들어, Imagen [34]과 PixArt-α [5]가 있습니다. 또한, 다른 방법들은 향상된 텍스트 이해를 위해 여러 텍스트 인코더를 사용합니다. 예를 들어, eDiff-I [2]는 글로벌 및 로컬 텍스트 표현을 위해 CLIP과 T5를 결합한 통합 텍스트 인코더를 제안합니다. SDXL [27]은 두 개의 CLIP 인코더를 사용하여 오픈 소스 커뮤니티에서 유망한 결과를 얻습니다. Stable Diffusion 3 [9]는 모델 아키텍처에 T5-XXL 텍스트 인코더를 추가하여 복잡한 프롬프트를 처리하는 데 필수적입니다. 최근에 LuminaT2X는 사전 훈련된 LLM 모델 LLama2 [38]을 활용하여 텍스트를 모든 모달리티로 변환하는 통합 프레임워크를 제안합니다.
대부분의 텍스트-이미지 생성 모델은 CLIP의 영어 텍스트 인코더 한계로 인해 중국어 프롬프트 처리에 어려움을 겪습니다. HunyuanDiT [19]는 중국어 텍스트-이미지 생성을 위해 이중언어 CLIP과 다중언어 T5 [43] 인코더를 사용하여 이 문제를 해결합니다. 그러나 중국어 텍스트에 대한 학습 코퍼스는 다중언어 T5 데이터셋의 2% 미만을 차지하며, 이중언어 CLIP이 생성하는 텍스트 임베딩은 여전히 복잡한 텍스트 프롬프트를 처리하는 데 부족합니다.
이러한 제한 사항을 해결하기 위해 Kolors의 텍스트 인코더로 General Language Model (GLM) [8]을 선택했습니다. GLM은 영어와 중국어를 동시에 처리할 수 있는 사전 훈련된 언어 모델로, 자연어 이해 및 생성 작업에서 BERT와 T5를 크게 능가합니다. 우리는 사전 훈련된 ChatGLM3-6B-Base 모델이 텍스트 표현에 더 적합하다고 생각하며, 인간 선호도 정렬 훈련을 거친 ChatGLM3-6B는 텍스트 렌더링에 뛰어납니다. 따라서 Kolors에서는 1.4조 이상의 이중언어 토큰으로 사전 훈련된 오픈 소스 ChatGLM3-6B-Base를 텍스트 인코더로 사용하여 중국어 이해 능력을 강화합니다. CLIP의 77개 토큰과 비교하여 ChatGLM3의 텍스트 길이를 256으로 설정하여 복잡한 텍스트 이해를 용이하게 합니다. ChatGLM3의 긴 텍스트 처리 능력 덕분에 긴 텍스트 지원도 쉽게 할 수 있습니다. SDXL을 따라 ChatGLM3의 마지막 출력 전 단계를 텍스트 표현에 사용합니다.
2.1.2 멀티모달 대형 언어 모델을 통한 상세한 캡션 개선
학습 텍스트-이미지 쌍은 종종 인터넷에서 수집되며, 동반되는 이미지 캡션은 불가피하게 노이즈가 많고 부정확합니다. DALL-E 3 [36]는 전문 이미지 캡션 생성기를 사용하여 학습 데이터셋을 다시 캡션하는 방식으로 이 문제를 해결합니다. Kolors의 프롬프트 준수 능력을 향상시키기 위해 우리는 DALL-E 3과 유사한 접근 방식을 채택하여 멀티모달 대형 언어 모델(MLLM)로 텍스트-이미지 쌍을 다시 캡션합니다.
우리는 텍스트 설명의 품질을 다음 다섯 가지 기준에 따라 평가할 것을 제안합니다:
- 길이: 중국어 문자 수.
- 완전성: 텍스트 설명이 전체 이미지를 얼마나 잘 포함하는지. 텍스트가 이미지의 모든 객체를 설명하면 5점, 30% 미만을 설명하면 1점.
- 상관성: 텍스트 설명이 이미지의 전경 요소를 얼마나 정확하게 나타내는지. 텍스트가 모든 전경 객체를 설명하면 5점, 30% 미만을 설명하면 1점.
- 환각: 텍스트에 언급된 세부 사항이나 엔티티 중 이미지에 없는 비율. 텍스트에 환각이 없으면 5점, 텍스트의 50% 이상이 환각적이면 1점.
- 주관성: 텍스트가 이미지의 시각적 내용을 설명하는 대신 주관적인 인상을 전달하는 정도. 예를 들어, "편안하고 평온한 느낌을 주고 사람들을 편안하게 만든다"는 문장은 주관적으로 간주됩니다. 주관적 텍스트가 없으면 5점, 텍스트의 50% 이상이 주관적 문장으로 구성되면 1점.
- 평균: 완전성, 상관성, 환각, 주관성에서 도출된 평균 점수.
우리는 잘 알려진 다섯 개의 MLLM 모델을 선택하고 500개의 이미지를 평가하기 위해 10명의 평가자를 고용했습니다. LLaVA1.5 [22], CogAgent [14], CogVLM [40]이 중국어 텍스트를 지원하지만, 생성된 중국어 캡션이 영어 캡션보다 열등하다는 것을 발견했습니다. 따라서 우리는 먼저 영어 이미지 캡션을 생성하고 나중에 이를 중국어로 번역했습니다. 반면, InternLM-XComposer-7B [49]와 GPT-4V에서는 중국어 프롬프트를 직접 사용했습니다.
표 1: 다양한 이미지 생성 모델에서 사용된 텍스트 인코더.
MethodsText EncoderLanguage| SD1.5 [32] | CLIP ViT-L | English |
| SD2.0 [32] | OpenCLIP ViT-H | English |
| DALL-E 2 [30] | CLIP | English |
| Imagen [34] | T5-XXL | English |
| MUSE [4] | T5-XXL | English |
| PixArt-α [5] | T5-XXL | English |
| LuminaT2X [12] | LLama2-7B | English |
| Kandinsky-3 [1] | Flan-UL2 | Multilingual |
| SDXL [27] | CLIP ViT-L & OpenCLIP ViT-bigG | English |
| Playground-v2.5 [18] | CLIP ViT-L & OpenCLIP ViT-bigG | English |
| eDiff-I [2] | CLIP L & T5-XXL | English |
| HunyuanDiT [19] | mCLIP & mT5-XL | Multilingual |
| Stable Diffusion 3 [9] | CLIP ViT-L & OpenCLIP ViT-bigG & T5-XXL | English |
| Kolors | ChatGLM3-base | Chinese / English |
캡션 성능 요약
다섯 가지 모델의 캡션 성능을 표 2에 요약했습니다. GPT-4V가 가장 높은 성능을 달성했음이 명백합니다. 그러나 수억 개의 이미지를 GPT-4V로 처리하는 것은 비용이 많이 들고 시간이 많이 소요됩니다. 나머지 네 개의 오픈 소스 모델 중에서, LLaVA1.5와 InternLM-XComposer는 CogAgent-VQA와 CogVLM-1.1-chat에 비해 완전성과 상관성 측면에서 현저히 낮은 성능을 보이며, 이는 세부적인 설명의 질이 낮음을 나타냅니다. 또한, CogVLM-1.1-chat이 생성한 캡션은 환각과 주관성 측면에서 적은 사례를 보여줍니다. 이러한 평가를 기반으로, 우리는 광범위한 학습 데이터셋을 위한 합성 세부 캡션을 생성하기 위해 최첨단 비전-언어 모델인 CogVLM-1.1-chat을 선택했습니다. MLLM이 지식 코퍼스에 없는 특정 개념을 이미지에서 식별하지 못할 수 있다는 점을 고려하여, 원본 텍스트와 합성 캡션의 비율을 50:50으로 사용하는 전략을 채택했습니다. 이는 Stable Diffusion 3의 구성과 일치합니다.
정교한 합성 캡션을 활용함으로써, Kolors는 복잡한 중국어 텍스트를 따르는 강력한 능력을 보여줍니다. 그림 2에서 우리는 복잡한 프롬프트에 대한 다양한 텍스트 인코더를 사용한 Kolors의 결과를 제시합니다. GLM을 사용하는 Kolors는 여러 주제와 세부 속성에 걸쳐 우수한 성능을 발휘하는 것을 확인할 수 있습니다. 반면, CLIP을 사용하는 Kolors는 상단 프롬프트에서 판매자와 전화기를 생성하지 못하고, 하단 프롬프트에서 색상에 혼동을 겪습니다.
표 2: 다양한 MLLM 모델의 캡션 성능.
| Methods | Length | Completeness | Correlation | Hallucination | Subjectivity | Avg |
| LLaVA1.5-13B [22] | 33.51 | 3.90 | 4.24 | 4.69 | 4.21 | 4.26 |
| InternLM-XComposer-7B [49] | 64.71 | 3.92 | 4.15 | 4.69 | 4.27 | 4.26 |
| CogAgent-VQA [14] | 129.38 | 4.55 | 4.50 | 4.28 | 4.46 | 4.45 |
| CogVLM-1.1-chat [40] | 99.7 | 4.54 | 4.54 | 4.64 | 4.51 | 4.56 |
| GPT4-V | 43.89 | 4.75 | 4.60 | 4.78 | 4.52 | 4.66 |

그림 2: (a) CLIP을 사용한 Kolors와 (b) GLM을 사용한 Kolors의 정성적 비교.
2.1.3 중국어 텍스트 렌더링 능력 향상
텍스트 렌더링은 오랫동안 텍스트-이미지 생성 분야에서 도전적인 문제로 여겨져 왔습니다. DALL-E 3 [3]와 Stable Diffusion 3 [9]와 같은 고급 방법들은 영어 텍스트 렌더링에서 뛰어난 능력을 보여주었습니다. 그러나 현재 모델들은 중국어 텍스트를 정확하게 렌더링하는 데 상당한 어려움을 겪고 있습니다. 이러한 어려움의 근본적인 이유는 다음과 같습니다:
- 중국어 문자의 방대한 집합과 이러한 문자의 복잡한 질감 때문에 영어에 비해 중국어 텍스트를 렌더링하는 것이 본질적으로 더 어렵습니다.
- 중국어 텍스트와 관련된 이미지가 포함된 충분한 학습 데이터가 부족하여 모델 학습 및 적합 능력이 부족합니다.
이 문제를 해결하기 위해 두 가지 관점에서 접근합니다. 첫째, 중국어 코퍼스의 경우, 우리는 가장 자주 사용되는 50,000개의 단어를 선택하고 데이터 합성을 통해 수천만 개의 이미지-텍스트 쌍으로 구성된 학습 데이터셋을 구축합니다. 효과적인 학습을 보장하기 위해 이러한 합성 데이터는 개념 학습 단계에서만 포함됩니다. 둘째, 생성된 이미지의 현실감을 높이기 위해 OCR 및 멀티모달 언어 모델을 사용하여 포스터 및 장면 텍스트와 같은 실제 이미지에 대한 새로운 설명을 생성하여 약 수백만 개의 샘플을 얻습니다.
우리는 학습 데이터셋의 합성 데이터가 초기에는 현실감이 부족했지만, 실제 데이터와 고품질 텍스트 이미지를 학습 과정에 통합한 후 생성된 텍스트 이미지의 현실감이 크게 향상되는 것을 관찰했습니다. 이러한 향상은 일부 문자가 합성 데이터에만 나타날 때에도 분명합니다. 추가적인 시각화는 그림 3에 제공됩니다.
합성 및 실제 데이터를 통합하여 학습 데이터의 한계를 체계적으로 해결함으로써, 우리의 접근 방식은 중국어 텍스트 렌더링의 품질을 크게 향상시켜 중국어 텍스트 이미지 생성의 새로운 발전을 위한 길을 열었습니다.

그림 3: Kolors의 강력한 텍스트 렌더링 능력, 특히 중국어에서.
2.2 시각적 매력 향상
잠재 확산 모델(LDMs)은 일반 사용자와 전문 디자이너 모두에게 널리 채택되었지만, 이미지 생성 품질은 종종 이미지 업스케일링 및 얼굴 복원과 같은 추가 후처리 단계가 필요합니다. LDMs의 시각적 품질 향상은 여전히 중요한 과제입니다. 이 연구에서는 데이터와 학습 방법론을 개선하여 이 문제를 해결합니다.
2.2.1 고품질 데이터
Kolors의 학습은 개념 학습 단계와 품질 향상 단계의 두 가지로 구분됩니다. 개념 학습 단계에서는 주로 수십억 개의 이미지-텍스트 쌍으로 구성된 대규모 데이터셋에서 포괄적인 지식과 개념을 습득합니다. 이 단계의 데이터는 공공 데이터셋(e.g., LAION [35], DataComp [11], JourneyDB [37])과 독점 데이터셋에서 수집됩니다. 카테고리 균형 전략을 사용하여 이 데이터셋은 광범위한 시각적 개념을 포괄합니다. 품질 향상 단계에서는 고해상도에서 이미지 세부 사항과 미학을 향상시키는 데 중점을 둡니다. 이전 연구들 [6, 18]도 이 단계에서 데이터 품질의 중요성을 강조했습니다.
고품질 이미지-텍스트 쌍을 얻기 위해, 우리는 먼저 전통적인 필터(해상도, OCR 정확도, 얼굴 수, 선명도, 미학 점수)를 데이터셋에 적용하여 약 수천만 개의 이미지로 줄입니다. 그런 다음 이 이미지를 수동으로 주석 처리하고, 주석은 다섯 가지 수준으로 분류됩니다. 주관적 편견을 줄이기 위해 각 이미지는 세 번 주석 처리되며, 최종 수준은 투표 과정을 통해 결정됩니다. 다양한 수준의 이미지 특성은 다음과 같습니다:
- Level 1: 포르노, 폭력, 잔혹, 공포를 묘사하는 이미지를 포함하여 안전하지 않은 내용으로 간주됩니다.
- Level 2: 로고, 워터마크, 검정 또는 흰색 테두리, 스티칭 이미지 등 인공 합성의 징후를 보이는 이미지.
- Level 3: 흐릿함, 과다 노출, 부족한 노출 또는 명확한 주제가 없는 이미지와 같은 매개 변수 오류가 있는 이미지.
- Level 4: 특별히 주의를 기울이지 않고 촬영한 스냅샷과 같은 평범한 사진.
- Level 5: 높은 미적 가치를 지닌 사진으로, 적절한 노출, 대비, 색조 균형, 색채 포화도를 가질 뿐만 아니라 서사를 전달해야 합니다.
이 방법론은 최종적으로 품질 향상 단계에서 사용되는 수백만 개의 Level 5 고미학적 이미지를 생성합니다.
2.2.2 고해상도 학습
확산 모델은 전진 확산 과정에서 이미지가 충분히 분해되지 않아 고해상도에서 성능이 떨어집니다. 그림 4에서 설명한 바와 같이, SDXL [27]에서 제공된 일정에 따라 노이즈를 추가할 때, 저해상도 이미지는 거의 순수한 노이즈로 분해되지만, 고해상도 이미지는 터미널 단계에서 저주파 성분을 유지하는 경향이 있습니다. 모델이 추론 중에 순수한 가우시안 노이즈에서 시작해야 하므로, 이러한 불일치는 고해상도에서 학습과 추론 간의 일관성 문제를 일으킬 수 있습니다. 최근 연구들 [20, 15]은 이 문제를 해결하기 위한 방법을 제안했습니다.

그림 4: 다양한 해상도의 이미지에 대한 표준 확산 노이즈.
Kolors에서의 학습 접근법
Kolors에서는 epsilon 예측 목표를 가진 DDPM 기반 학습 접근법을 채택합니다 [13]. 개념 학습을 위한 저해상도 학습 단계에서는 SDXL [27]과 동일한 노이즈 스케줄을 사용합니다. 고해상도 학습을 위해, 우리는 원래 1000단계에서 1100단계로 단계를 단순히 확장하여 모델이 더 낮은 최종 신호 대 잡음 비율을 달성할 수 있는 새로운 스케줄을 도입합니다. 또한, αt 곡선의 형태를 유지하기 위해 β 값을 조정합니다. αt는 xt = √αtx0 + √(1 - αt)ϵ를 결정합니다. 그림 5에서 설명한 것처럼, 우리의 αt 경로는 기본 스케줄의 경로를 완전히 포함하고 있는 반면, 다른 방법들의 경로는 상당한 편차를 보입니다. 이는 저해상도에서 사용된 기본 스케줄에서 전환할 때, 새로운 스케줄의 적응 및 학습 난이도가 다른 스케줄에 비해 낮아진다는 것을 나타냅니다.
고해상도 학습 기법과 데이터 통합
그림 6에서 설명한 것처럼, 고품질 학습 데이터를 최적화된 고해상도 학습 기법과 통합함으로써 생성된 이미지의 품질이 크게 향상되었습니다. 또한, 모델이 다양한 가로세로 비율을 가진 이미지를 생성할 수 있도록 학습 과정에서 NovelAI의 버킷 샘플링 방법 [25]을 사용합니다. 학습 자원을 절약하기 위해 이 전략은 고해상도 학습 동안에만 적용됩니다. 다양한 해상도의 이미지 예시는 그림 1과 9에 제시되어 있습니다.
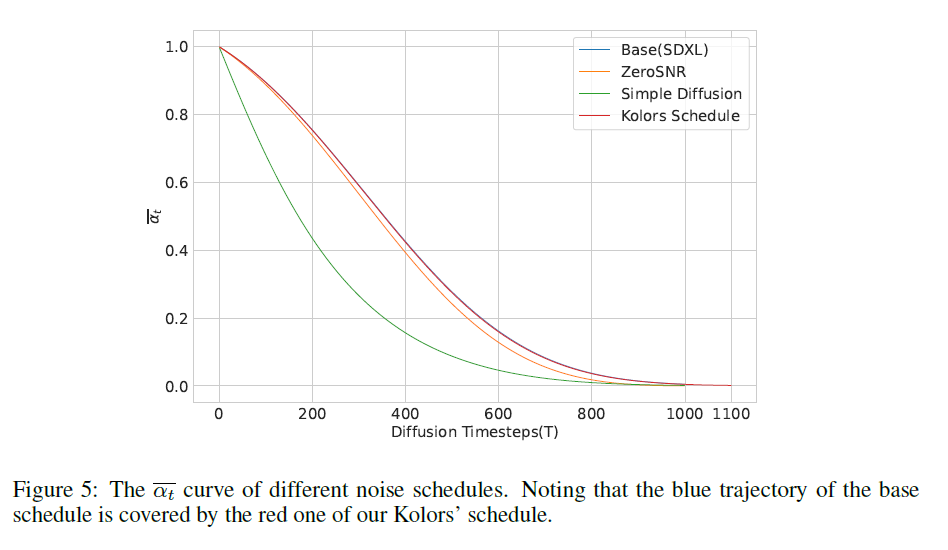
그림 5: 다양한 노이즈 스케줄의 αt 곡선. 파란색 경로의 기본 스케줄이 빨간색 경로의 Kolors 스케줄에 의해 덮여 있음을 주목하십시오.

그림 6: (a) 시각적 매력 향상 전과 (b) 시각적 매력 향상 후의 정성적 비교.
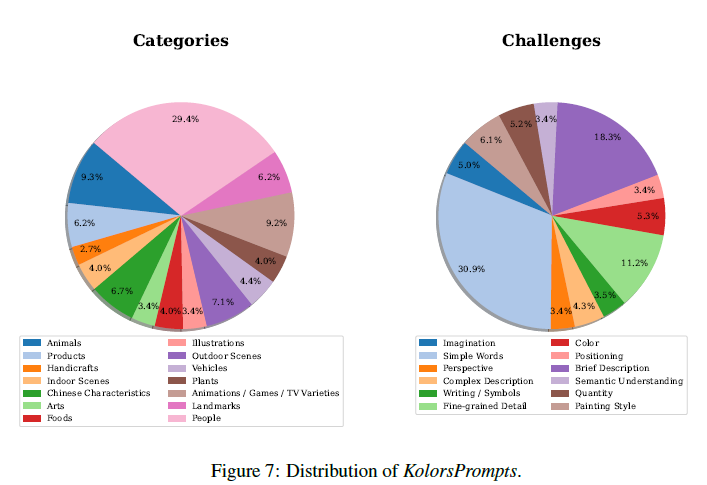
그림 7: KolorsPrompts의 분포.
3 평가
Kolors의 생성 능력을 정확히 평가하기 위해 세 가지 기본 평가 지표를 설정했습니다. 첫째, 여러 카테고리와 다양한 도전을 포함하는 프롬프트 세트인 KolorsPrompts라는 새로운 벤치마크를 도입했습니다. 그런 다음 KolorsPrompts를 사용하여 인간 선호도에 기반한 종합 평가를 수행했습니다. 또한 두 가지 자동 평가 지표를 계산했습니다: (a) 다차원 선호도 점수(MPS) [50]와 (b) 잘 알려진 이미지 품질 평가 지표인 FID. Kolors를 오픈 소스 모델과 시장에서 사용 가능한 독점 시스템과 비교했습니다.
3.1 KolorsPrompts
텍스트-이미지 생성 모델을 종합적으로 평가하기 위해 KolorsPrompts라는 포괄적인 벤치마크를 도입했습니다. KolorsPrompts는 PartiPrompts [47]와 ViLG-300 [10]을 포함한 공개 데이터셋에서 수집된 천 개 이상의 프롬프트와 일부 독점 프롬프트로 구성됩니다. KolorsPrompts는 실세계에서 흔히 볼 수 있는 14개의 시나리오(예: 사람, 음식, 동물, 예술 등)를 포함합니다. 또한, 프롬프트의 특성에 따라 KolorsPrompts를 12개의 고유 도전 과제로 분류했습니다. 각 프롬프트는 중국어와 영어 버전으로 제공됩니다.
KolorsPrompts의 분포는 그림 7에 자세히 설명되어 있습니다. 카테고리와 도전 과제의 분포 설정은 실제 사용을 반영합니다. 그림의 왼쪽은 KolorsPrompts의 카테고리 분포를 나타내며, 사람 카테고리가 29.4%로 가장 큰 비율을 차지합니다. 오른쪽은 도전 과제의 분포를 보여주며, 단순 단어가 30.9%로 가장 많습니다.
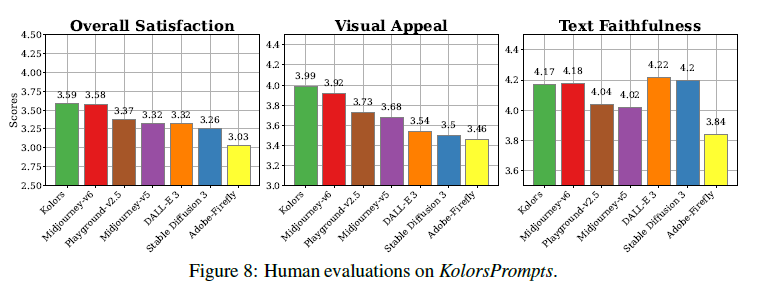
그림 8: KolorsPrompts에 대한 인간 평가.
3.2 인간 평가
모델의 성능을 평가하기 위해 세 가지 인간 평가 지표를 제공합니다:
- 시각적 매력: 시각적 매력은 색상, 모양, 질감, 구성 등 다양한 시각적 요소를 포함하여 생성된 이미지의 전반적인 미적 품질을 나타냅니다. 이 평가에서는 동일한 프롬프트를 사용하여 생성된 여러 모델의 이미지를 텍스트 설명 없이 사용자에게 제시하여, 이미지의 시각적 매력에만 집중할 수 있도록 합니다. 각 평가자는 1에서 5까지의 척도로 이미지를 평가하며, 5는 완벽함을, 1은 가장 낮은 품질을 나타냅니다.
- 텍스트 충실도: 텍스트 충실도는 생성된 이미지가 프롬프트와 얼마나 정확하게 일치하는지를 측정합니다. 평가자들은 이미지 품질을 무시하고 텍스트 설명과 이미지 간의 관련성에만 집중하도록 지시받습니다. 점수는 1에서 5까지의 척도로 평가됩니다.
- 종합 만족도: 종합 만족도는 이미지의 전반적인 평가를 나타냅니다. 이 평가에서는 프롬프트와 이미지를 함께 제시하여, 평가자들이 이미지의 품질, 시각적 매력, 프롬프트와 이미지 간의 일치를 기준으로 평가합니다. 점수는 1에서 5까지의 척도로 평가됩니다.
평가 중인 모델은 프롬프트당 네 개의 이미지를 생성합니다. 우리는 약 50명의 전문 리뷰어를 고용하여 각 이미지를 지정된 지침에 따라 다섯 번씩 평가했습니다. 이미지의 최종 점수는 이 다섯 번의 평가에서 평균 점수로 계산됩니다. 따라서 각 이미지는 시각적 매력, 텍스트 충실도, 종합 만족도에 대해 세 가지 별도의 점수를 받습니다. 모든 이미지는 1024×1024 픽셀 해상도로 렌더링됩니다.
수작업 평가의 높은 비용을 고려하여, 우리의 인간 평가는 Adobe Firefly, DALL-E 3 [3], Stable Diffusion 3 [9], Midjourney-v5, Midjourney-v6, Playground-v2.5 [18]와 같은 최신 텍스트-이미지 모델에 중점을 둡니다. 비교 모델의 최적 성능을 보장하기 위해, 이들 모델에는 영어로 된 프롬프트를 제공하고, Kolors에는 중국어로 된 프롬프트를 제공합니다. 자세한 결과는 그림 8에 제시되어 있습니다. Kolors는 종합 만족도에서 가장 높은 점수를 기록했으며, Midjourney-v6와 같은 독점 모델과 동등한 수준을 달성했습니다. 특히, Kolors는 시각적 매력 측면에서 큰 이점을 보여주었습니다. Kolors가 생성한 추가 예시는 그림 9에 나와 있습니다.

그림 9: Kolors가 생성한 이미지.
3.3 자동 평가 벤치마크
3.3.1 다차원 인간 선호도 점수 (MPS)
현재 텍스트-이미지 모델 평가 지표는 주로 단일 측정치(FID, CLIP Score [28] 등)에 의존하며, 이는 인간의 선호도를 충분히 반영하지 못합니다. 다차원 인간 선호도 점수(MPS) [50]는 텍스트-이미지 모델을 인간의 선호도 여러 측면에서 평가하기 위해 제안되었으며, 텍스트-이미지 평가에서 그 효과가 입증되었습니다. 따라서 우리는 KolorsPrompts 벤치마크에서 MPS를 사용하여 위의 텍스트-이미지 모델들을 평가했습니다.
MPS 결과는 표 3에 제시되어 있습니다. Kolors는 인간 평가와 일치하게 가장 높은 성능을 기록했습니다. 이러한 일관성은 인간의 선호도와 KolorsPrompts 벤치마크에서의 MPS 점수 간의 강한 상관관계를 나타냅니다.
표 3: KolorsPrompts에서의 MPS 총점
모델MPS 총점↑
| Adobe-Firefly | 8.5 |
| Stable Diffusion 3 [9] | 8.9 |
| DALL-E 3 [3] | 9.0 |
| Midjourney-v5 | 9.4 |
| Playground-v2.5 [18] | 9.8 |
| Midjourney-v6 | 10.2 |
| Kolors | 10.3 |
표 4: MSCOCO에서 제로샷 FID-30K를 사용한 성능 비교
방법매개변수 수FID-30K↓
| DALL-E [31] | 12.0B | 27.50 |
| GLIDE [24] | 5.0B | 12.24 |
| DALL-E 2 [30] | 6.5B | 10.39 |
| PixArt-α [5] | 0.6B | 10.65 |
| ParaDiffusion [41] | 1.3B | 9.64 |
| GigaGAN [16] | 0.9B | 9.09 |
| SD [32] | 0.9B | 8.32 |
| Imagen [34] | 3.0B | 7.27 |
| ERNIE-ViLG 2.0 [10] | 22B | 6.75 |
| DeepFloyd-IF [7] | 4.3B | 6.66 |
| RAPHAEL [44] | 3.0B | 6.61 |
| Kolors | 2.6B | 23.15 |
Kolors는 MPS에서 최고의 성능을 기록했으며, 인간 평가와 일치했습니다. 그러나 MSCOCO에서의 제로샷 FID-30K 결과에서는 Kolors가 상대적으로 낮은 성능을 보였습니다. 이는 다양한 측정 지표와 데이터셋에서 모델의 성능이 다를 수 있음을 시사합니다.
3.3.2 COCO 데이터셋에서의 정확도 평가
우리는 Kolors를 텍스트-이미지 생성 작업의 표준 평가 지표인 MS-COCO 256 × 256 [21] 검증 데이터셋에서 Zero-shot FID-30K를 사용하여 평가했습니다. 표 4는 Kolors와 기존 모델 간의 비교를 보여줍니다. Kolors는 약간 높은 FID 점수를 기록했는데, 이는 매우 경쟁력 있는 결과로 보이지 않을 수 있습니다. 그러나 FID가 이미지 품질을 평가하는 데 완전히 적합한 지표가 아닐 수 있으며, 높은 점수가 반드시 우수한 생성 이미지를 의미하지는 않는다고 주장합니다.
수많은 연구들 [5, 7, 27, 17, 50]은 COCO에서의 제로샷 FID가 시각적 미학과 부정적인 상관관계가 있음을 보여주었으며, 텍스트-이미지 모델의 생성 성능은 통계적 지표보다 인간 평가자가 더 정확하게 평가합니다. 이러한 발견은 실제 인간의 선호도와 일치하는 자동 평가 시스템의 필요성을 강조하며, MPS [21]와 같은 시스템이 이를 충족시킬 수 있습니다.
4 결론
이 연구에서는 Kolors라는 클래식 U-Net 아키텍처 [27]를 기반으로 한 잠재 확산 모델을 소개합니다. General Language Model (GLM)과 CogVLM이 생성한 세밀한 캡션을 활용하여 Kolors는 특히 다수의 엔티티를 포함하는 복잡한 의미를 이해하고 우수한 텍스트 렌더링 능력을 보여줍니다. 또한, Kolors는 개념 학습 단계와 품질 향상 단계라는 두 가지 별개의 단계를 통해 학습됩니다. 고미학적 데이터를 활용하고 고해상도 이미지 생성을 위한 새로운 스케줄을 사용하여, 결과 고해상도 이미지의 시각적 매력을 크게 향상시켰습니다. 또한 텍스트-이미지 생성 모델을 종합적으로 평가하기 위해 새로운 카테고리 균형 벤치마크인 KolorsPrompts를 제안합니다. Kolors는 인간 평가에서 뛰어난 성능을 보여주며, Stable Diffusion 3, Playground-v2.5, DALL-E 3와 같은 대부분의 오픈 소스 및 독점 모델을 능가하고 Midjourney-v6와 동등한 성능을 입증했습니다.
우리는 Kolors의 모델 가중치와 코드를 공개할 예정입니다. 향후 연구에서는 ControlNet [48], IP-Adapter [46], LCM [23] 등을 포함한 Kolors의 다양한 응용 프로그램과 플러그인을 점진적으로 공개할 계획입니다. 또한, Transformer 아키텍처 [26]를 기반으로 한 새로운 독점 확산 모델을 출시할 계획입니다. Kolors가 텍스트-이미지 합성 커뮤니티의 발전을 촉진하고 오픈 소스 생태계에 실질적인 기여를 할 수 있기를 기대합니다.
우리도 한국어 모델이 나왔으면 좋겠네요....
'인공지능' 카테고리의 다른 글
| The Llama3 Herd of Models (1) | 2024.07.27 |
|---|---|
| WavMark: Watermarking for Audio Generation (1) | 2024.07.26 |
| Learning to (Learn at Test Time): RNNswith Expressive Hidden States (5) | 2024.07.24 |
| Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (5) | 2024.07.23 |
| You Only Cache Once: Decoder-Decoder Architectures for Language Models (5) | 2024.07.22 |



