https://arxiv.org/abs/2308.12770
WavMark: Watermarking for Audio Generation
Recent breakthroughs in zero-shot voice synthesis have enabled imitating a speaker's voice using just a few seconds of recording while maintaining a high level of realism. Alongside its potential benefits, this powerful technology introduces notable risks,
arxiv.org
초록
최근 무차별 음성 합성의 돌파구는 단 몇 초의 녹음을 사용하여 화자의 음성을 높은 현실성을 유지하면서 모방할 수 있게 되었습니다. 이러한 강력한 기술은 잠재적인 이점과 함께 음성 사기 및 화자 사칭과 같은 상당한 위험을 초래합니다. 기존의 합성 데이터를 감지하는 수동적인 방법에만 의존하는 접근 방식과 달리, 워터마킹은 이러한 다가오는 위험에 대한 적극적이고 강력한 방어 메커니즘을 제공합니다. 이 논문은 단 1초의 오디오 조각 내에 최대 32비트의 워터마크를 인코딩하는 혁신적인 오디오 워터마킹 프레임워크를 소개합니다. 이 워터마크는 인간의 감각으로는 감지할 수 없으며 다양한 공격에 대한 강력한 내성을 보여줍니다. 이는 합성된 음성의 효과적인 식별자로 작용할 수 있으며 오디오 저작권 보호의 더 넓은 응용 가능성을 가지고 있습니다. 또한 이 프레임워크는 높은 유연성을 자랑하여 여러 워터마크 세그먼트를 결합하여 향상된 강건성과 확장된 용량을 달성할 수 있습니다. 10~20초의 오디오를 호스트로 사용할 때, 우리의 접근 방식은 10가지 일반적인 공격에 대해 평균 비트 오류율(BER)이 0.48%로, 최첨단 워터마킹 도구에 비해 BER이 2800% 이상 감소하는 놀라운 결과를 보여줍니다. 우리의 작업 데모는 여기에서 확인할 수 있습니다.

그림 1:
왼쪽: 우리의 프레임워크의 워터마크 인코딩 과정. 호스트 오디오의 1초 세그먼트에 동일한 워터마크를 반복적으로 추가하여 전체 시간 영역 보호를 보장합니다. 워터마크된 오디오가 잘려도, 완전한 워터마크 세그먼트를 사용하여 디코딩이 가능합니다. 오른쪽: 최첨단(SOTA) 워터마킹 도구와의 강건성 비교. 우리의 프레임워크는 주요 워터마킹 도구와 비교할 만한 워터마킹 용량과 감지 불가성을 보여주면서도 10가지 공격 시나리오에서 우수한 강건성을 자랑합니다.
1. 서론
음성 복제 기술의 접근성과 정교함이 높아짐에 따라 음성 합성의 잠재적 오용에 대한 우려가 증가하고 있습니다. 음성 워터마킹은 이러한 음성 복제와 관련된 위험을 완화하는 유망한 방법으로 부상하고 있으며, 오디오 녹음의 무결성을 보호하고 합성 음성이 다양한 맥락에서 윤리적이고 책임감 있게 사용되도록 보장하는 데 중요한 역할을 하고 있습니다. 오디오 신호에 고유한 디지털 서명을 인코딩함으로써 오디오 워터마킹은 음성 녹음의 진위 여부를 확인하고 변조 시도를 감지할 수 있습니다. 이 기술은 저작권 보호, 방송 모니터링 및 인증과 같은 실용적인 응용 분야에서 중요한 도구로서 오디오 녹음의 정확성과 신뢰성을 보장하는 데 가치가 있습니다.
오랜 기간 동안 오디오 워터마킹은 LSB(최소 유의 비트) LSB2004, 에코 히딩 echo_hiding96, 스프레드 스펙트럼 Spread_spectrum1996; Spread_spectrum1997, 패치워크 patchwork2003, 그리고 QIM(양자화 지수 변조) QIM2001와 같은 전통적인 방법이 지배해왔습니다. 이러한 방법은 전문가 지식과 경험적 규칙에 크게 의존하며 구현이 어려워 낮은 인코딩 용량과 제한된 공격 허용성을 제공하는 경향이 있습니다. 최근 몇 년간, 딥 뉴럴 네트워크(DNN)의 오디오 워터마킹 적용은 유망한 가능성을 보여주었습니다 DNN2022DSP; DeAR2023AAAI. 이러한 연구들은 주로 인코더 - 공격 시뮬레이터 - 디코더 구조를 채택하여 사전 정의된 공격에 대한 강건성을 자동으로 학습하고 인코딩 전략 설계의 복잡성을 크게 줄였습니다. 그러나 DNN 기반 오디오 워터마킹은 여전히 초기 단계에 있으며 낮은 용량 DNN2022DSP 및 최적화되지 않은 감지 불가성 DeAR2023AAAI 문제를 겪고 있습니다. 또한, 현재의 방법들 DNN2022DSP; DeAR2023AAAI은 제공된 워터마크 세그먼트에서만 디코딩을 수행할 수 있었습니다. 실제 시나리오에서는 워터마크의 위치를 정확히 찾아야 디코딩이 가능합니다. 따라서 전통적인 동기화 코드 sync2002와 같은 외부 위치 지정 기술이 필요하며, 이는 구현을 복잡하게 하고 시스템의 신뢰성을 저해할 수 있습니다 sync2002.
이 논문은 WavMark라는 오디오 워터마킹 프레임워크를 제안합니다. 그림 1에서 설명한 바와 같이, 이 프레임워크는 1초 오디오를 호스트로 하여 32비트의 정보를 인코딩합니다. 이 워터마크는 인간에게 감지할 수 없으며, 10가지 일반적인 공격 시나리오에 대해 강한 내성을 보여줍니다. 이전 접근 방식에 대한 우리의 발전을 요약한 내용은 표 1에 나와 있습니다.
표 1: 현재 DNN 기반 오디오 워터마킹 기술과 WavMark의 비교. Bps: 초당 비트 수.
현재 DNN 기반 방법WavMark
| 감지 불가성 | 중간 (SNR < 30 dB) |
| 용량 | < 10 bps |
| 워터마크 위치 지정 | × |
| 훈련 데이터 | 단일 유형, < 1k 시간 |
우리는 먼저 가역 신경망(dinh2014nice; realNVP2016)을 오디오 워터마킹에 적용하는 혁신적인 접근 방식을 선보입니다. 이 프레임워크에서는 인코딩과 디코딩이 상호 보완적인 과정으로 간주되며 동일한 매개변수를 공유합니다. 이 특성은 뛰어난 워터마킹 품질을 제공하여 더 나은 감지 불가성을 유지하면서도 인코딩 용량을 세 배로 늘릴 수 있게 합니다. 둘째로, 우리 모델은 외부 위치 지정 기술의 번거로움 없이 자동으로 워터마크 위치를 찾을 수 있습니다. 이는 시스템 구현의 복잡성을 줄일 뿐만 아니라 신뢰성을 향상시킵니다. 셋째로, 이전 작업들이 단일 유형의 수백 시간의 데이터로 훈련된 것과 달리, 우리 모델은 5천 시간의 다양한 데이터셋(음성, 음악, 이벤트 소리 등)으로 훈련되었습니다. 이 데이터셋은 우리 모델의 적응성을 풍부하게 하여 음성 생성 모델의 출력과 같은 미지의 도메인에도 적용할 수 있게 합니다 (valle; musicgen; Spear_TTS).
광범위한 실험을 통해 우리의 프레임워크의 효과가 입증되었습니다. 이전 DNN 기반 솔루션과 비교하여, 우리 모델은 더 높은 감지 불가성(신호 대 잡음비, SNR,에서 6 dB 증가)과 두 배의 강건성을 달성했습니다. 워터마크 위치 지정 테스트에서 우리 모델은 더 나은 안정성을 보였습니다. 부정확한 위치 지정으로 인한 평균 디코딩 오류는 0.54% 비트 오류율(BER)로, 이는 전통적인 위치 지정 접근법의 1/19에 불과합니다. SOTA 오픈소스 워터마킹 도구인 Audiowmark 1과 비교했을 때, 우리 모델은 비슷한 용량과 감지 불가성을 유지하면서도 훨씬 더 높은 강건성을 보여주었습니다. 특히, 10~20초의 오디오로 인코딩할 때, 평균 BER이 0.48%로, 이는 강건성에서 28배의 향상을 보여줍니다.
우리의 기여는 다음과 같이 요약될 수 있습니다:
- 고급 오디오 생성 모델과 관련된 오용 문제를 효과적으로 해결하기 위해, 가역 신경망을 오디오 워터마킹에 사용하는 혁신적인 솔루션을 제시합니다. 가역 신경망을 활용함으로써 워터마크의 조작에 대한 저항성을 보장하면서도 인간 청취자에게는 들리지 않도록 합니다.
- 구현의 간편함과 뛰어난 안정성을 제공하는 새로운 워터마크 위치 지정 솔루션을 제안합니다.
- 교육 학습, 가중 공격 처리, 반복 인코딩을 포함한 다양한 훈련 및 구현 전략을 도입합니다. 이러한 기술들은 훈련 복잡성을 완화하고 구현 효과성을 향상시킵니다. 고급 프레임워크 구조와 결합하여, 우리 모델은 32비트의 인코딩 용량을 달성합니다. 또한, 제안된 모델은 종합적인 공격에 대한 뛰어난 저항성을 보여주면서도 우수한 감지 불가성(SNR=36.85 및 PESQ=4.21)을 유지합니다.
2 관련 연구
2.1 오디오 워터마킹
오디오 워터마킹은 저작권 보호와 콘텐츠 인증을 위한 필수 기술로, 1990년대까지 거슬러 올라갑니다(boney1996digital; cox1997secure). 지난 30여 년 동안 오디오 워터마킹 기술은 에코 히딩(echo_hiding96), 패치워크(patchwork2000; patchwork2003), 스프레드 스펙트럼(cox1997secure), 양자화 지수 변조(QIM2001)와 같은 전통적인 방법이 주도해왔습니다. 이러한 방법은 전문가 지식, 경험적 규칙 및 다양한 휴리스틱에 크게 의존하며, 구현이 어렵고 취약하며 적응성이 제한적입니다. 최근 몇 년간 딥 러닝은 시각적 스테가노그래피(img_steganography2021; xu2022robust; bui2023rosteals) 및 워터마킹(liu2019novel; ma2022towards; luo2023irwart)에서 중요한 성공을 거두어, 인코딩 용량, 감지 불가성 및 강건성 면에서 전통적인 방법을 능가했습니다. DNN의 강력한 모델링 능력 덕분에, 이러한 모델은 공격에 대한 강력한 인코딩 방법을 자동으로 학습할 수 있어 워터마킹 전략 설계의 복잡성을 크게 줄였습니다. 최근 몇몇 연구들은 DNN 프레임워크를 오디오 워터마킹으로 확장했습니다(DeAR2023AAAI; DNN2022DSP). 그러나 이들은 단일 워터마크 세그먼트 내에서만 워터마킹을 다루며, 워터마크 위치 지정 문제는 간과되어 실제 시나리오에 직접 적용할 수 없습니다.
워터마크 위치 지정은 오디오 워터마킹 분야에서 오랜 도전 과제였습니다(sync2001; sync2002; sync2006). 전통적인 오디오 워터마킹에서는 "동기화 코드(sync2002; sync2006)"로 알려진 마커를 워터마크 세그먼트 앞에 추가하여 빠른 위치 지정을 가능하게 합니다. 그러나 이 방법은 속도 변화를 포함한 비동기화 공격에 취약하여 워터마킹 시스템의 전반적인 강건성을 저해합니다. 우리는 전통적인 동기화 코드가 DNN 기반 오디오 워터마킹에 충분한 해결책이 아니라고 믿습니다. 비록 DNN 모델이 자동으로 인코딩 전략을 얻을 수 있지만, 동기화 코드 설계는 여전히 전문가 통찰력에 크게 의존하며, 이는 엔드 투 엔드 오디오 워터마킹 시스템을 구현하는 데 방해가 됩니다.
이 논문에서는 워터마크 위치 지정 문제에 대한 새로운 해결책으로 Brute Force Detection(BFD) 방법을 소개합니다. 이 방법의 본질은 패턴 비트와 페이로드를 결합하여 인코딩된 메시지를 구성하는 것입니다. 디코딩 중에는 모델이 오디오를 따라 이동하며 지속적으로 디코딩을 시도합니다. 패턴 비트는 디코딩된 출력의 유효성을 검사하는 기준으로 사용됩니다. 검출 효율성을 높이기 위해 우리는 프레임워크에 시프트 모듈을 도입합니다. 훈련 시 이 모듈은 워터마크된 오디오에 임의의 시간 이동을 도입하여 모델이 부정확한 워터마크 위치를 사용하여 디코딩하도록 강제합니다. 결과적으로, 모델은 디코딩 위치가 실제 워터마크 위치에서 10% 인코딩 단위 길이(EUL) 거리 내에 떨어지기만 하면 워터마크를 디코딩할 수 있게 됩니다. 5% EUL 슬라이딩 스텝을 채택하면 디코딩을 위해 EUL 거리 내에서 20번의 검출만 필요하여 BFD 방법이 실제 구현에 적합하게 됩니다.
2.2 가역 신경망
가역 신경망(INN)의 개념은 2014년 Dinh에 의해 처음 도입되었으며(dinh2014nice), 이후 Real NVP(realNVP2016)와 Glow(kingma2018glow)와 같은 연구들에 의해 개선되었습니다. INN은 두 가지 과정으로 구성됩니다: 순방향과 역방향. 순방향 과정은 가역 변환을 통해 복잡한 데이터 분포를 단순한 잠재 분포로 매핑하며, 역방향 과정은 단순한 잠재 분포에서 데이터 분포를 생성합니다. 직접적인 가역 매핑을 학습할 수 있는 능력 덕분에 INN은 이미지 변환(van2019reversible), 초해상도 재구성(zhang2022enhancing), 시각적 스테가노그래피(HiNet; mou2023large), 텍스트-음성 변환(waveglow2019; glowtts; vits) 등 다양한 분야에서 광범위한 주목을 받았습니다. 우리는 워터마크 인코딩과 디코딩이 본질적으로 상호 보완적인 과정이라고 믿습니다. 따라서 이상적인 디코딩은 인코딩의 역연산으로 얻어져야 합니다. 그러나 이전 연구들(DNN2022DSP; DeAR2023AAAI)은 주로 인코더와 디코더를 별도의 네트워크로 구현하여 독립적인 구조와 매개변수를 가지며, 좋은 가역성을 달성할 수 없었습니다. 이러한 구조적 결함은 좋은 워터마킹 품질을 달성하기 어렵게 만듭니다. 우리의 연구는 오디오 워터마킹에 INN을 처음으로 적용한 것입니다.
3. 방법
그림 2: 훈련 프레임워크 개요
인코더는 호스트 오디오와 메시지 벡터를 결합하여 워터마크된 오디오를 생성합니다. 시프트 모듈은 작은 거리를 무작위로 이동시켜 디코딩 창을 이동합니다. 그런 다음 무작위 공격이 이동된 오디오에 적용되어 워터마크를 손상시킵니다. 마지막으로 디코더가 공격받은 오디오에서 메시지를 복원합니다.
3.1 전체 아키텍처
우리의 프레임워크 구조는 그림 2에 묘사되어 있으며, 주로 가역 인코더/디코더, 시프트 모듈 및 공격 시뮬레이터로 구성됩니다. 이러한 모듈들은 엔드 투 엔드 방식으로 훈련되어 매끄러운 통합 및 최적화를 가능하게 합니다. 각 구성 요소에 대한 자세한 설명은 다음 섹션에서 제공됩니다.



3.4 공격 시뮬레이터
우리의 프레임워크는 다음과 같은 10가지 일반적인 공격 유형을 고려합니다:
- 랜덤 노이즈 (RN): 평균 신호 대 잡음비(SNR) 34.5 dB를 유지하면서 오디오에 균등하게 분포된 노이즈 신호를 추가합니다.
- 샘플 억제 (SS): 샘플 포인트의 0.1%를 무작위로 0으로 설정합니다.
- 저역 필터 (LP): 5kHz 컷오프 주파수를 사용하여 오디오의 고주파 성분을 제거합니다.
- 중간 필터 (MF): 필터 커널 크기 3을 적용하여 신호를 부드럽게 합니다.
- 재샘플링 (RS): 샘플링 속도를 원래의 두 배 또는 절반으로 변환한 후 원래 주파수로 다시 변환합니다.
- 진폭 스케일링 (AS): 오디오 진폭을 원래의 90%로 줄입니다.
- 손실 압축 (LC): 오디오를 64kbps MP3 형식으로 변환한 후 다시 변환합니다.
- 양자화 (QTZ): 샘플 포인트를 29단계로 양자화합니다.
- 에코 추가 (EA): 오디오 볼륨을 0.3 배로 줄이고 100ms 지연시킨 후 원본과 오버레이합니다.
- 시간 스트레치 (TS): 속도를 1.1배 또는 0.9배로 증가 또는 감소시킵니다.
여러 공격의 학습 난이도가 다르다는 점은 하나의 과제입니다. 이를 해결하기 위해 우리는 학습 과정을 균형 있게 유지하기 위해 가중 공격 전략을 채택했습니다. 훈련 중에는 한 번에 한 가지 공격 유형만 적용합니다. 초기에는 각 공격에 동일한 샘플링 가중치를 할당합니다. 모델을 검증 세트에서 평가한 후, 각 공격에 해당하는 BER 값으로 가중치를 업데이트합니다. 결과적으로 학습이 더 어려운 공격(높은 BER을 가진 공격)은 더 높은 샘플링 가중치를 부여받아 모델이 다양한 공격에 대한 강건성을 적응적으로 학습할 수 있습니다. 또한 샘플링은 항목별로 수행되어 동일한 배치 내에서 다양한 공격 유형을 통해 훈련 안정성을 향상시킵니다.


3.6 커리큘럼 학습 전략
훈련 초기 단계에서 모든 공격과 강한 지각적 제약을 도입하면 모델이 효과적인 인코딩 전략을 학습하기 어렵습니다. 이를 해결하기 위해, 우리는 커리큘럼 학습 접근 방식을 채택하여 모델이 세 가지 명확한 단계를 통해 점진적으로 인코딩 능력을 습득할 수 있도록 합니다. 첫 번째 단계에서는 공격 시뮬레이터를 제외하고 지각성에 대한 약한 제약을 부과하여 모델이 기본 인코딩 전략을 학습하는 데 집중할 수 있도록 합니다. 두 번째 단계에서는 공격 시뮬레이터를 도입하여 모델의 다양한 공격에 대한 강건성을 강화합니다. 그러나 지각성에 대한 약한 제약으로 인해 출력에 눈에 띄는 노이즈가 있을 수 있습니다. 따라서 세 번째 단계에서는 강한 지각적 제약을 부과하여 워터마크로 생성된 노이즈가 감지되지 않도록 보장합니다.
4. 실험 설정
4.1 데이터셋
이전 연구들은 주로 단일 카테고리의 수백 시간 데이터로 훈련을 진행했습니다(DeAR2023AAAI; DNN2022DSP). 다양한 시나리오에서 모델의 적용성을 높이기 위해 우리는 음성, 음악, 이벤트 소리를 포함한 다양한 데이터셋을 결합하여 5,000시간의 훈련 데이터를 구성했습니다.
- LibriSpeech: LibriSpeech는 LibriVox 프로젝트에서 유래된 영어 데이터셋입니다. 약 1,000시간의 음성 데이터를 포함하는 전체 코퍼스를 사용했습니다(panayotov2015librispeech).
- Common Voice: Common Voice는 100개 이상의 언어를 포함하는 대규모 다국어 음성 데이터셋입니다(CV2019). 우리는 10개의 언어를 포함하는 약 1,700시간의 음성 데이터를 선택했습니다.
- Audio Set: Audio Set은 632개의 클래스와 5,790시간 이상의 오디오를 포함하는 일반적인 오디오 이벤트 데이터셋입니다(Audioset2017). 우리는 1,337시간의 데이터를 연구에 사용했습니다.
- Free Music Archive: Free Music Archive(FMA)는 DeAR에서 사용된 고품질 음악 데이터셋입니다(DeAR2023AAAI). 우리는 FMA의 "large" 서브셋을 활용했으며, 이 서브셋은 각각 30초 길이의 106,574개의 트랙을 포함하여 총 888시간의 음악 데이터를 포함합니다(FMA2016).
각 데이터셋에 대해 우리는 400개의 샘플을 추출하여 검증 및 테스트에 사용하고, 나머지는 훈련에 사용했습니다.


5. 실험 결과
이 섹션에서는 다양한 데이터 유형에 대해 모델을 평가하여 이상적인 세그먼트 기반 및 더 복잡한 발화 기반 시나리오에서 모델의 성능을 확인합니다.
5.1 세그먼트 기반 평가
먼저, 모델이 다양한 공격 유형에 대해 강건성을 유지하면서 단일 세그먼트 길이 오디오에 워터마크를 삽입해야 하는 세그먼트 기반 평가를 수행합니다.
표 2: 기존 DNN 기반 방법과의 비교. MEAN: 모든 공격 시나리오(‘공격 없음’ 설정 포함)에서의 평균 BER 값.
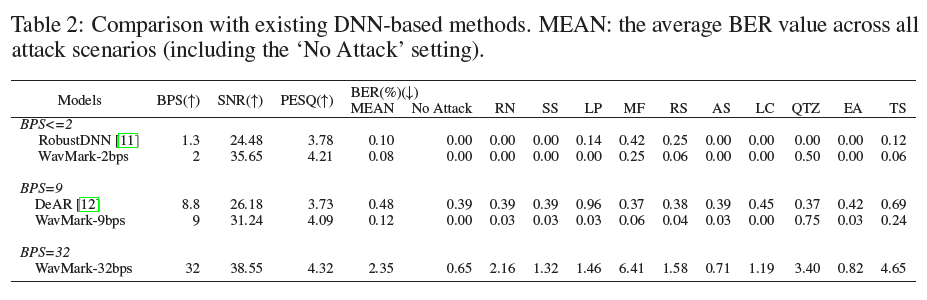
우리는 우리의 모델을 현재의 DNN 기반 방법(RobustDNN DNN2022DSP와 DeAR DeAR2023AAAI)과 비교했습니다. RobustDNN은 1.3 bps의 인코딩 용량을 달성했고, DeAR는 8.8 bps의 용량을 달성했습니다. 워터마킹 기술은 용량, 감지 불가성, 강건성 간의 절충이 필요합니다. 비교를 용이하게 하기 위해, 우리는 추가적으로 2 bps와 9 bps의 두 모델을 훈련시켰습니다. 구체적으로, 우리는 32 bps 모델의 매개변수를 기반으로 하여 메시지 벡터 길이 K를 각각 2와 9로 줄이고, 감지 불가성 제약을 완화하여 미세 조정했습니다. 이 평가에서 우리는 5천 시간 데이터셋의 400개의 테스트 샘플을 사용했습니다. 비교된 연구에서 사용된 데이터셋과 공격 유형이 다르므로, 일관성을 유지하기 위해 공식적으로 발표된 모델을 기반으로 우리 데이터셋과 공격을 사용하여 미세 조정했습니다. 결과는 표 2에 나와 있습니다.
각 용량 그룹 내에서 더 높은 감지 불가성(↑SNR 및 ↑PESQ로 표시)과 더 낮은 디코딩 오류(↓BER)는 우수한 워터마킹 품질을 나타냅니다. RobustDNN DNN2022DSP와 비교하여, 우리의 WavMark-2bps 모델은 더 나은 용량, 감지 불가성 및 강건성을 동시에 달성합니다. SNR 메트릭에서 10 dB 이상의 향상을 이루었고, Median Filter (MF), Re-Sampling (RS), Time Stretching (TS) 메트릭에서 낮은 BER을 달성했습니다. DeAR DeAR2023AAAI와 비교하여, 우리의 WavMark-9bps 모델도 장점을 보여줍니다. 워터마크된 오디오는 더 높은 감지 불가성(↑5.06 SNR, ↑0.36 PESQ)을 가질 뿐만 아니라 거의 모든 공격에 대해 더 높은 강건성을 달성했습니다(Quantization (QTZ) 메트릭 제외). 이는 더 높은 워터마킹 품질을 달성하는 데 있어 우리의 가역 구조의 우수성을 입증합니다.
우리의 다양한 용량 모델을 비교할 때, 더 높은 용량과 감지 불가성을 달성하기 위해 강건성의 절충이 있다는 것을 알 수 있습니다. 38.55 dB SNR과 32 bps 용량을 달성하기 위해, 우리의 32 bps 모델은 평균 메트릭에서 2.35% BER을 기록했습니다. 그러나 이러한 절충은 일반적으로 실제 응용에서 받아들일 수 있습니다. 호스트에 다중 워터마크 세그먼트를 추가하여 중복성을 형성하고 오류 수정 전략을 활용하여 강건성을 더욱 향상시킬 수 있습니다.
5.2 발화 기반 평가

그림 3: 발화 기반 평가의 다이어그램
워터마크 도구는 호스트에 여러 세그먼트를 추가합니다. 그런 다음 첫 번째 워터마크 세그먼트를 잘라내어 손상시키고 남은 오디오를 디코딩에 사용합니다. 노란색 영역은 불완전한 워터마크 세그먼트를 나타냅니다.
설정:
실제 응용에서 오디오 길이가 다양하기 때문에 전체 시간 영역 보호를 달성하기 위해 여러 워터마크 세그먼트를 추가하며, 모델은 디코딩 전에 워터마크 위치를 찾아야 합니다. 따라서 실제 시나리오에서 워터마크 모델의 성능을 평가하기 위해 발화 기반 평가를 수행했습니다. 이 평가에서는 80개의 오디오를 호스트로 샘플링했으며, 각각 10초에서 20초 사이입니다. 우리는 두 가지 설정으로 실험을 진행했습니다: 클립과 노-클립. 클립 설정에서는 워터마크된 오디오의 시작 부분에서 0초에서 1초 사이를 무작위로 잘라내어 첫 번째 워터마크 세그먼트를 손상시켜 오디오 잘라내기 시나리오를 시뮬레이션했습니다. 노-클립 설정에서는 인코딩 후 바로 디코딩을 수행했습니다.
RobustDNN과 DeAR은 발화 기반 시나리오에 직접 적용할 수 없기 때문에, 우리는 우리의 모델을 SOTA 오픈 소스 워터마킹 툴킷인 Audiowmark(westerfeld2020audiowmark)와 비교했습니다. Audiowmark는 전통적인 패치워크 기반 워터마킹(Digital2015)에 의존하며, 주파수 대역의 진폭 관계를 조정하여 비트 정보를 인코딩하고 추가 오류 수정을 위해 BCH 코드를 사용합니다(bose1960class). 우리는 이 툴킷의 기본 설정을 사용하여 동일한 128비트 워터마크를 호스트에 반복적으로 인코딩하고, 여러 세그먼트의 결과를 공동 오류 수정에 사용했습니다. 16kHz 오디오를 호스트로 사용할 때, 성공적인 인코딩에는 평균 6.5초의 길이가 필요함을 발견했습니다. 이는 실제 인코딩 용량이 약 20 bps임을 의미합니다.
우리는 Audiowmark와 비교하기 위해 32 bps 모델을 사용했습니다. 처음 10비트는 패턴으로 사용하고 나머지 22비트는 페이로드로 사용하여 Audiowmark와 비슷한 용량을 제공합니다. 인코딩 시 동일한 워터마크를 호스트에 반복적으로 추가했으며, 각 세그먼트 사이에 10% EUL 간격을 예약했습니다. 각 세그먼트를 인코딩한 후 워터마크된 결과의 SNR을 계산했습니다. SNR이 38 dB 이상이면 더 나은 강건성을 실현하기 위해 반복 인코딩을 수행했습니다(섹션 6.1에서 자세히 설명). 디코딩 동안 우리는 BFD 방법을 사용하여 5% EUL 간격으로 검출을 수행했습니다. 디코딩 결과와 패턴 간의 유사성을 계산하고, 가장 높은 유사성을 가진 결과를 최종 출력으로 선택한 후 페이로드를 기반으로 BER을 계산했습니다.
표 3: 발화 기반 평가의 비교 결과

결과
비교 결과는 표 3에 요약되어 있습니다. 다음과 같은 관찰을 할 수 있습니다:
첫째, 두 방법 모두 클립 및 노-클립 설정에서 비슷한 성능을 보이며, 이는 두 방법이 완전한 워터마크 세그먼트를 효과적으로 찾아 디코딩할 수 있음을 나타냅니다.
둘째, 우리의 모델은 Audiowmark와 비교하여 감지 불가성이 비슷하지만, SNR에서 더 높은 값을 보였고(1.57% 증가), PESQ에서는 약간 낮은 값을 보였습니다(0.14% 감소). 그러나 강건성 측면에서 우리의 모델은 훨씬 뛰어난 성능을 보였습니다. 우리의 모델은 모든 공격 지표에서 Audiowmark를 능가하며, 평균 BER이 클립 설정에서 단 0.48%로 Audiowmark의 14.08%에 비해 1/29에 불과합니다.
셋째, Audiowmark는 시간 스트레치(TS) 공격에 저항할 수 없습니다. 이 공격이 Audiowmark의 동기화 메커니즘을 파괴하여 워터마크를 찾지 못하게 했습니다. 반면, 우리의 모델은 BFD 방법을 기반으로 위치를 찾아내어 이 공격에 의해 약간만 영향을 받았습니다(BER < 2%).
이러한 결과는 실제 응용에서 우리의 모델의 잠재력을 충분히 입증합니다.
5.3 오디오 생성 모델 출력에 대한 평가
표 4: 합성 데이터셋에 대한 발화 기반 평가

이전 섹션의 테스트 샘플은 5천 시간 데이터셋에서 파생되었으며, 이는 훈련 데이터와 동일한 도메인에 속합니다. 모델의 낯선 도메인 처리 능력과 오디오 생성 모델의 잠재적 오용을 방지하는 능력을 보여주기 위해, 우리는 표 4에서 발화 수준의 평가를 확장했습니다.
이번 평가에서 테스트 데이터는 오디오 생성 모델의 출력물입니다: VALL-E, Spear-TTS, MusicGen. 구체적으로, VALL-E와 Spear-TTS는 음성 합성 모델이고, MusicGen은 음악 생성 모델입니다. 각 모델에서 프로젝트 데모 페이지에서 15개의 오디오 샘플을 수집했습니다. 오디오 길이는 4초에서 30초까지 다양합니다. 우리는 섹션 5.2에서 설명한 것과 동일한 인코딩 구성을 사용했습니다. 우리의 모델은 훈련 단계에서 합성 데이터를 전혀 접하지 않았음에도 불구하고, 합성 데이터셋에서 뛰어난 능력을 보여주었습니다. SNR이 36 dB 이상인 상태에서, 거의 모든 공격 지표(샘플 억제(SS) 및 시간 스트레치(TS) 공격 제외)에서 0 BER을 달성했습니다. 이러한 결과는 미지의 도메인에서도 모델의 적응력을 충분히 입증합니다. 또한, 우리의 모델은 오디오 생성 기술의 오용에 대한 사전 대책으로 작용할 수 있습니다.
5.4 워터마크 위치 찾기 테스트
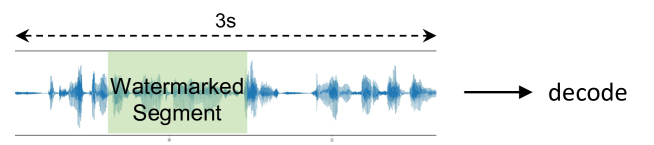
그림 4: 워터마크 위치 찾기 테스트의 다이어그램
설정: 발화에 여러 워터마크를 추가하기 때문에 워터마크를 효과적으로 찾는 방법은 오랜 연구 주제였습니다(sync2001; sync2002; sync2006). 제안된 시프트 모듈과 BFD를 사용하여 이 문제를 해결하기 위해 워터마크 위치 찾기 테스트를 수행했습니다. 이 테스트에서 우리는 3초 오디오 내 임의의 위치에 1초 워터마크를 삽입하고 이후 디코딩을 수행했습니다(그림 4). 총 200개의 샘플이 이 평가에 사용되었습니다.
BFD와 비교하기 위해 우리는 두 가지 설정을 도입했습니다: Oracle과 SyncCode. Oracle은 디코딩을 위한 정확한 위치를 사용하여 로컬라이제이션 알고리즘의 상한 성능을 반영합니다. SyncCode의 경우, 전통적인 시간 도메인 동기화 코드(sync2002) 방법을 사용하여 로컬라이제이션을 수행했습니다. 구체적으로, 워터마크 세그먼트 바로 앞에 12비트 Barker 코드 시퀀스를 호스트에 추가했습니다. 디코딩 중에는 오디오와 Barker 코드 간의 최대 상관 위치를 기준으로 워터마크 위치를 결정할 수 있습니다.
표 5: 다양한 워터마크 로컬라이제이션 방법의 비교
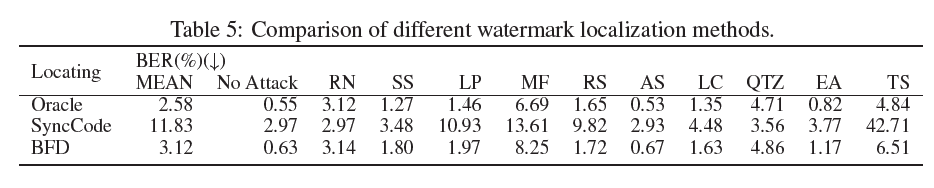
결과
비교 결과는 표 5에 제시되어 있습니다. Oracle 설정과 비교했을 때, SyncCode 위치 지정 방법은 성능 저하를 초래했습니다. MEAN 메트릭에서 BER이 9% 이상 증가했고, Time Stretch (TS)에서는 37% 증가했습니다. 이는 SyncCode가 시스템의 강건성에 약점이 된다는 것을 나타냅니다. SyncCode와 비교했을 때, 우리의 BFD 방법은 우수한 강건성을 보여주었습니다. BFD를 사용한 위치 지정 시, 대부분의 공격에서 BER 증가는 2% 이내로 나타났습니다. 이러한 결과는 동일한 모델이 디코딩과 위치 지정 작업을 모두 수행하는 우리 프레임워크의 독특한 설계 덕분입니다. 따라서 이 두 과정은 다양한 공격에 대해 비슷한 강건성을 갖게 됩니다. 이 접근 방식은 시스템 구현을 단순화할 뿐만 아니라 전체적인 안정성을 향상시킵니다.
6. 제거 연구
6.1 다양한 오디오 도메인 평가
표 6: 각 데이터셋에서 WavMark-32bps 모델의 성능 (세그먼트 기반 평가).

섹션 5.1의 결과는 네 개 데이터셋의 평균값입니다. 표 6에서는 WavMark-32bps 모델의 각 데이터셋별 자세한 성능을 제공합니다. 모델이 인간 음성 데이터셋(LibriSpeech와 CommonVoice)에서 더 나은 성능을 보이며, 낮은 평균 BER(0.29% 및 1.10%)을 달성한 것을 확인할 수 있습니다. 반면, 이벤트 소리(AudioSet)와 음악 장르(FMA)의 경우 BER이 훨씬 더 높았습니다(각각 4.18% 및 3.84%). 모든 공격에서 강건성이 감소했으며, 특히 Median Filter (MF)와 Time Stretch (TS) 메트릭에서 두드러졌습니다. 네 개 데이터셋의 크기가 비슷하고 훈련 중 균일한 샘플링을 수행했기 때문에, 이러한 현상은 데이터 불균형에서 비롯된 것이 아닙니다. 대신, 우리는 이러한 데이터셋들이 학습 난이도가 다르다고 믿습니다.

그림 5: 호스트 오디오 샘플
주황색 영역은 호스트 오디오와 워터마크된 오디오 간의 차이를 나타내며, 명확성을 위해 25배 확대되었습니다
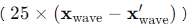
해석
우리는 그림 5에 파형 예제를 제시하여 추가 설명을 제공했습니다. AudioSet과 FMA 데이터셋은 LibriSpeech와 CommonVoice 데이터셋보다 더 큰 진폭과 적은 저역 세그먼트를 보여줍니다. 직관적인 생각은 모델이 인코딩을 위해 무음 영역을 활용하는 경향이 있다는 것입니다. 그러나 그림 6에서 보듯이 수정은 모든 시간 도메인에 걸쳐 분포하며, 모델은 감지 불가성을 보장하기 위해 무음 영역 내에서 미세한 조정을 하는 경향이 있음을 확인할 수 있습니다.
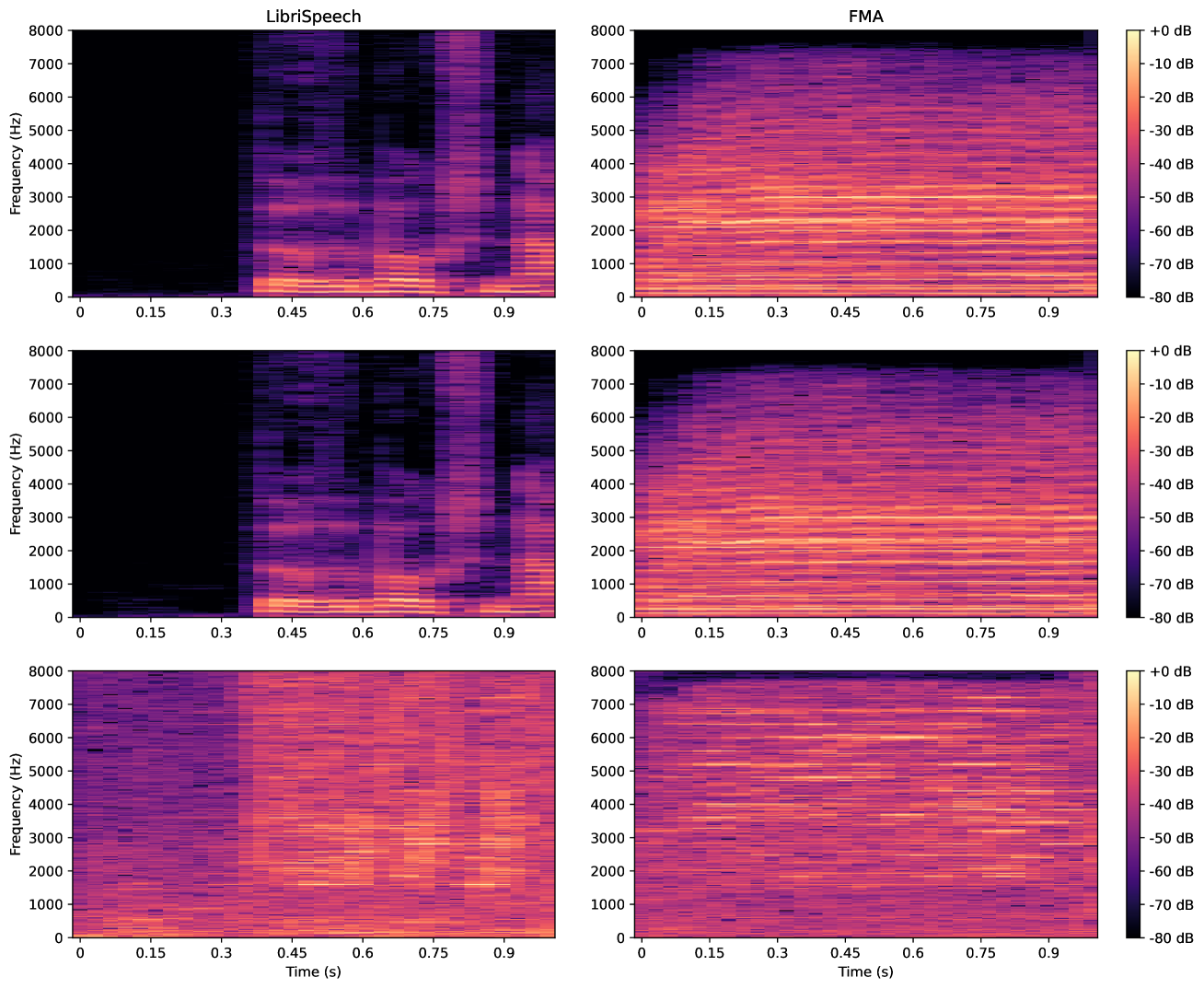
그림 6: 호스트 오디오(상단), 워터마크된 오디오(중간), 그리고 차이(하단)의 스펙트로그램
CommonVoice와 FMA 데이터셋에서 성능이 저하되는 이유를 더 높은 오디오 진폭으로 돌릴 수 있습니다. 이는 성공적인 인코딩을 위해 더 많은 상대적인 수정이 필요하기 때문입니다. 그러나 이러한 수정은 지각 손실(식 10)에 의해 제한되어, 충분한 인코딩과 강력한 강건성을 달성하지 못합니다. 이 한계를 해결하기 위해 반복 인코딩 개념을 통합했습니다. 구체적으로, 인코딩 후 워터마크된 세그먼트의 SNR을 평가합니다. 인코딩이 불충분한 경우(SNR > 38 dB), SNR이 38 dB 미만이 될 때까지 워터마크된 세그먼트에 반복 인코딩을 수행합니다. 테스트를 통해 이 전략이 좋은 감지 불가성(SNR > 36 dB)을 유지하면서 강건성을 효과적으로 향상시키는 것을 확인했습니다. 그럼에도 불구하고 개선의 여지가 있는 잠재적인 방법은 식 10에 의해 부과된 제약 수준을 동적으로 조정하는 것입니다.
6.2 다양한 시프트에서의 디코딩 성능
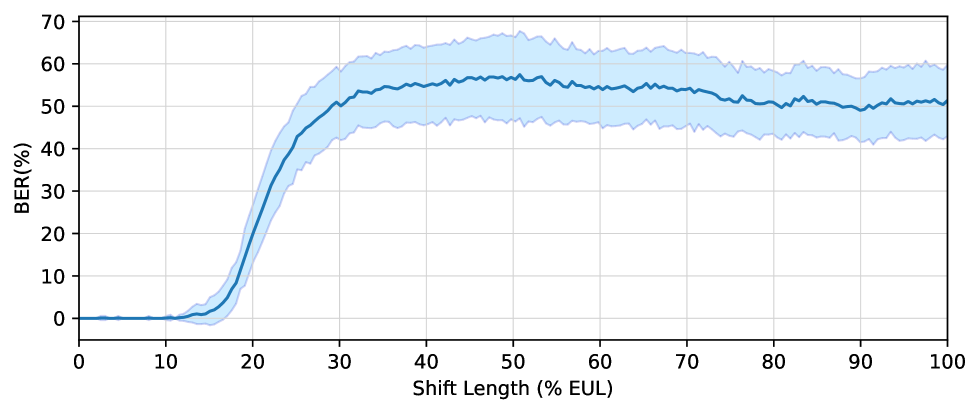
그림 7: 다양한 시프트에서의 디코딩 성능
그림 7에서 음영 처리된 영역은 표준 편차를 나타냅니다.
시프트 모듈을 도입하면 모델이 부정확한 워터마크 위치를 사용하여 디코딩할 수 있습니다. 그림 7에서는 다양한 시프트 길이에서 디코딩 성능을 테스트했습니다. 훈련 시 최대 시프트 범위는 10% EUL로 설정되었기 때문에, 이 설정의 효과를 확인할 수 있습니다. 오프셋이 10% EUL 미만일 때, BER 값은 0에 가깝고 표준 편차가 약간 있습니다. 오프셋이 10% EUL을 초과하면 모델 성능이 점진적으로 감소합니다. 시프트 길이가 35% EUL에 도달하면 성능이 무작위 추측과 비슷해집니다.
6.3 시프트 모듈의 영향

표 7: 시프트 모듈의 영향 (세그먼트 기반 평가)
표 7에서는 시프트 모듈이 성능에 미치는 영향을 비교했습니다. WavMark-32bps 모델을 기반으로 시프트 모듈을 제거하고 미세 조정을 수행하여 시프트가 없는 버전을 얻었습니다. 시프트 모듈을 도입하면 감지 불가성과 강건성에 영향을 미치는 것을 확인할 수 있으며, 특히 랜덤 노이즈(RN), 양자화(QTZ), 시간 스트레치(TS)와 같은 지표에서 두드러집니다. 이는 시프트 모듈이 모델의 학습 난이도를 증가시킨다는 것을 의미합니다. 그러나 워터마크 위치 지정이 필요한 상황에서 이는 보상됩니다. 시프트 모듈의 도입으로 BFD 방법을 위치 지정에 적용할 수 있게 되어 SyncCode 방법(섹션 5.4)과 비교하여 더 높은 강건성을 얻을 수 있습니다.
그림 8: 음소거된 호스트에서 인코딩할 때의 워터마크된 오디오
6.4 모델 크기와 추론 속도
32 bps 모델의 경우, 모델 파라미터 수는 250만 개이며, 메시지 벡터 인코딩 및 디코딩 과정에서 두 개의 선형 계층이 전체 파라미터의 43%(110만 개)를 차지합니다. 인코딩 용량이 증가하면 이 비율도 증가합니다. 이 문제를 해결하기 위한 개선 방안으로는 피처 맵 생성을 위한 파라미터 없는 업샘플링/다운샘플링 기술을 구현하는 것이 있습니다(pixinwav2023).
AMD EPYC 7V13 CPU와 A100 GPU를 장착한 시스템에서 인코딩 속도는 GPU에서 실시간보다 약 54.2배 빠르며, CPU에서는 7.7배 빠릅니다. 디코딩 속도도 인코딩과 유사합니다. BFD를 사용하여 5% EUL의 검출 단계를 이용하면, 1 EUL 거리 내에서 20번의 검출이 수행됩니다. 그 결과, BFD 속도는 CPU에서 실시간의 0.38배에 불과합니다. 그러나 검출 속도는 일반적으로 인코딩보다 덜 중요하며 대부분의 워터마크 응용에서 허용 가능합니다.
7 결론 및 한계
이 논문에서는 가역 네트워크 기반 오디오 워터마킹 프레임워크를 제안했습니다. 이 프레임워크는 32 bps 용량, 높은 감지 불가성을 달성하면서 10가지 일반적인 공격에 대해 강건성을 유지합니다. 또한, 이전 DNN 기반 연구에서 간과된 위치 지정 문제를 효율적으로 해결하여, 실제 응용에서 DNN 기반 오디오 워터마킹의 길을 열었습니다.
기존 DNN 기반 방법 및 확립된 산업 솔루션에 비해 우리의 프레임워크가 명확히 우수하지만, 향후 개선을 위한 가치 있는 방향을 제공하는 한계가 있습니다.
호스트 오디오 품질: 우리는 16kHz 오디오를 호스트로 사용했습니다. 44.1kHz와 같은 더 높은 샘플링 속도로 지원을 확장하는 것이 더 넓은 범위의 오디오 소스를 수용하는 데 중요합니다. 그러나 호스트 길이를 단순히 증가시키면 파라미터 수가 급증할 수 있습니다. 따라서 모델 구조의 개선이 필요합니다.
무음 오디오: 우리의 모델은 무음이 아닌 오디오에서 감지 불가한 인코딩을 달성하는 데 뛰어납니다. 그러나 호스트 오디오가 완전히 무음인 경우(예: 음악의 끝)도 있습니다. 완전히 무음인 호스트 세그먼트에 인코딩할 때 모델의 동작을 조사한 결과, 워터마크된 오디오에서 눈에 띄는 노이즈가 발생했습니다. 이는 모델이 이러한 데이터를 명시적으로 훈련하지 않았기 때문입니다. 실용적인 응용에서 최적의 감지 불가성을 보장하기 위해 무음 세그먼트를 생략하는 것이 좋습니다. 효율적인 접근 방식은 인코딩 후 SNR을 확인하고 품질이 떨어지는 세그먼트(SNR < 25 dB)를 건너뛰는 것입니다. 이러한 선택적 접근 방식은 워터마크의 전체 감지 불가성을 보호합니다.
페이로드 효율성: 우리의 워터마크 위치 지정 방법은 패턴 비트를 사용하여 워터마크 세그먼트를 식별합니다. 32비트 용량에서 10비트를 패턴 식별에 할당하면 전체 용량의 31%를 차지합니다. 잠재적인 개선 방안은 EUL을 확대하여 추가 비트를 인코딩하고 페이로드 효율성을 높이는 것입니다.
실시간 인코딩: 현재, 우리의 모델은 고정된 1초 오디오 세그먼트에서 인코딩을 수행하며, 인코딩 과정 동안 호스트 오디오가 필요합니다. 이 제약은 실시간 워터마킹이 필요한 시나리오에서 도전 과제가 될 수 있습니다.



