https://arxiv.org/abs/2005.08100
Conformer: Convolution-augmented Transformer for Speech Recognition
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interac
arxiv.org
초록
최근 Transformer와 Convolutional Neural Network (CNN) 기반 모델이 자동 음성 인식(ASR)에서 유망한 결과를 보여주며 Recurrent Neural Networks (RNNs)를 능가하고 있습니다. Transformer 모델은 내용 기반의 전역 상호작용을 잘 포착하는 반면, CNN은 지역적 특징을 효과적으로 활용합니다. 이 연구에서는 오디오 시퀀스의 지역적 및 전역적 의존성을 매개변수 효율적인 방식으로 모델링하기 위해 CNN과 Transformer를 결합하는 방법을 연구하여 두 가지 장점을 모두 얻고자 합니다. 이를 위해 음성 인식을 위한 Conformer라는 이름의 convolution-augmented transformer를 제안합니다. Conformer는 이전의 Transformer 및 CNN 기반 모델을 크게 능가하여 최첨단 정확도를 달성합니다. 널리 사용되는 LibriSpeech 벤치마크에서, 우리의 모델은 언어 모델을 사용하지 않고도 테스트/테스트 기타에서 각각 2.1%/4.3%의 WER를 달성했으며, 외부 언어 모델을 사용하면 각각 1.9%/3.9%를 달성했습니다. 또한, 10M 매개변수만으로 구성된 작은 모델에서도 2.7%/6.3%의 경쟁력 있는 성능을 관찰했습니다.
인덱스 용어: 음성 인식, 주의 메커니즘, 합성곱 신경망, 트랜스포머, 종단간 (end-to-end)
1. 소개
신경망을 기반으로 한 종단간 자동 음성 인식(ASR) 시스템은 최근 몇 년 동안 큰 발전을 이루었습니다. 순환 신경망(RNN)은 오디오 시퀀스의 시간적 의존성을 효과적으로 모델링할 수 있어 ASR의 사실상 선택이 되었습니다. 최근에 자기 주의(self-attention)에 기반한 트랜스포머 아키텍처는 긴 거리 상호작용을 포착하고 높은 훈련 효율성 덕분에 시퀀스 모델링에 널리 채택되었습니다. 대안적으로, 합성곱도 ASR에서 성공을 거두었으며, 이는 층별로 지역적 수용 영역을 통해 점진적으로 지역적 컨텍스트를 캡처합니다.
그러나 자기 주의 또는 합성곱을 사용하는 모델은 각각의 한계가 있습니다. 트랜스포머는 장거리 전역 컨텍스트를 모델링하는 데 능하지만, 세밀한 지역적 특징 패턴을 추출하는 데는 덜 능합니다. 반면에 합성곱 신경망(CNN)은 지역적 정보를 활용하여 시각에서 사실상의 계산 블록으로 사용됩니다. CNN은 지역 창에서 번역 등가성을 유지하고 가장자리와 형태와 같은 특징을 캡처할 수 있는 위치 기반의 공유 커널을 학습합니다. 지역적 연결성을 사용하는 한계는 전역 정보를 캡처하기 위해 더 많은 층이나 매개변수가 필요하다는 점입니다. 이 문제를 해결하기 위해, 현대적인 작업인 ContextNet은 각 잔차 블록에 더 긴 컨텍스트를 캡처하기 위해 Squeeze-and-Excitation 모듈을 채택합니다. 그러나 이는 전체 시퀀스에 대해 전역 평균화만 적용하기 때문에 동적인 전역 컨텍스트를 캡처하는 데 여전히 제한이 있습니다.
최근 연구들은 합성곱과 자기 주의를 결합하면 각각을 개별적으로 사용하는 것보다 더 나은 성능을 보인다고 밝혔습니다. 함께 사용하면 위치 기반의 지역 특징을 학습하고 내용 기반의 전역 상호작용을 사용할 수 있습니다. 동시에, 몇몇 논문은 자기 주의에 위치 기반 정보를 추가하여 등가성을 유지하는 방법을 제안했습니다. Wu 등은 입력을 자기 주의와 합성곱으로 나누고 그 출력을 연결하는 다중 브랜치 아키텍처를 제안했습니다. 이들의 작업은 모바일 응용 프로그램을 목표로 했으며, 기계 번역 작업에서 성능 향상을 보여주었습니다.
이 연구에서는 ASR 모델에서 합성곱과 자기 주의를 유기적으로 결합하는 방법을 연구합니다. 우리는 전역 및 지역 상호작용이 매개변수 효율성을 위해 중요하다고 가정합니다. 이를 달성하기 위해, 우리는 자기 주의와 합성곱을 결합한 새로운 방식이 최상의 성능을 발휘할 것이라고 제안합니다. 자기 주의는 전역 상호작용을 학습하고, 합성곱은 상대적 오프셋 기반의 지역 상관관계를 효율적으로 캡처합니다. Wu 등의 연구에 영감을 받아, 우리는 피드 포워드 모듈 쌍 사이에 자기 주의와 합성곱을 샌드위치처럼 배치한 새로운 조합을 도입합니다.
우리의 제안 모델인 Conformer는 LibriSpeech에서 최첨단 결과를 달성하며, 외부 언어 모델을 사용하여 testother 데이터셋에서 이전에 발표된 최상의 트랜스포머 트랜스듀서를 15% 상대적 개선하여 능가합니다. 우리는 10M, 30M, 118M의 모델 매개변수 제한에 기반한 세 가지 모델을 제시합니다. 우리의 10M 모델은 유사한 크기의 현대 작업과 비교하여 test/testother 데이터셋에서 2.7%/6.3%의 개선을 보여줍니다. 중간 크기의 30M 매개변수 모델은 139M 매개변수를 사용하는 [7]에 발표된 트랜스포머 트랜스듀서를 이미 능가합니다. 118M 매개변수를 사용하는 대형 모델은 언어 모델을 사용하지 않고 2.1%/4.3%를 달성하고, 외부 언어 모델을 사용하면 1.9%/3.9%를 달성합니다.
우리는 또한 주의 헤드의 수, 합성곱 커널 크기, 활성화 함수, 피드 포워드 레이어의 위치, 트랜스포머 기반 네트워크에 합성곱 모듈을 추가하는 다양한 전략의 효과를 신중하게 연구하고, 각각이 정확도 향상에 어떻게 기여하는지 밝힙니다.

그림 1: Conformer 인코더 모델 아키텍처
Conformer는 반 스텝 잔차 연결을 가진 두 개의 마카롱과 같은 피드 포워드 레이어 사이에 다중 헤드 자기 주의와 합성곱 모듈을 샌드위치처럼 배치합니다. 이는 이후에 후속 레이어 정규화가 따릅니다.
그림 2: 합성곱 모듈
합성곱 모듈은 확장 계수가 2인 포인트와이즈 합성곱을 포함하여 GLU 활성화 레이어와 함께 채널 수를 투영한 후 1-D 깊이별 합성곱이 따릅니다. 1-D 깊이별 합성곱은 배치 정규화와 스위시 활성화 레이어가 뒤따릅니다.
2. Conformer 인코더
우리의 오디오 인코더는 입력을 먼저 합성곱 서브샘플링 레이어로 처리한 후, 여러 개의 Conformer 블록으로 처리합니다. 이는 그림 1에 나와 있습니다. 우리 모델의 독특한 특징은 Transformer 블록 대신 Conformer 블록을 사용하는 것입니다.
Conformer 블록은 네 개의 모듈로 구성되어 있습니다. 즉, 피드 포워드 모듈, 자기 주의 모듈, 합성곱 모듈, 마지막으로 두 번째 피드 포워드 모듈로 이루어져 있습니다. 섹션 2.1에서는 자기 주의 모듈을, 섹션 2.2에서는 합성곱 모듈을, 섹션 2.3에서는 피드 포워드 모듈을 각각 소개합니다. 마지막으로, 섹션 2.4에서는 이러한 서브 블록들이 어떻게 결합되는지를 설명합니다.
2.1. 다중 헤드 자기 주의 모듈
우리는 다중 헤드 자기 주의(MHSA)를 사용하면서 Transformer-XL [20]의 중요한 기술인 상대적인 사인 파형 위치 인코딩 방식을 통합합니다. 상대적 위치 인코딩은 자기 주의 모듈이 다양한 입력 길이에 대해 더 잘 일반화할 수 있게 하며, 결과적으로 인코더가 발화 길이의 변화에 대해 더 견고해지도록 합니다. 우리는 드롭아웃과 함께 사전 정규화 잔차 유닛(pre-norm residual units)을 사용하여 더 깊은 모델을 훈련하고 정규화하는 데 도움이 됩니다. 아래 그림 3은 다중 헤드 자기 주의 블록을 보여줍니다.
그림 3: 다중 헤드 자기 주의 모듈
우리는 상대적 위치 임베딩을 사용한 다중 헤드 자기 주의를 사전 정규화 잔차 유닛과 함께 사용합니다.
2.2. 합성곱 모듈
[17]에서 영감을 받아, 합성곱 모듈은 게이팅 메커니즘 [23]—포인트와이즈 합성곱과 게이트된 선형 유닛(GLU)으로 시작합니다. 이후 단일 1차원 깊이별 합성곱 레이어가 뒤따릅니다. 합성곱 직후에는 깊은 모델 훈련을 돕기 위해 배치 정규화를 사용합니다. 그림 2는 합성곱 블록을 보여줍니다.
2.3. 피드 포워드 모듈
[6]에서 제안된 트랜스포머 아키텍처는 MHSA 레이어 후에 피드 포워드 모듈을 배치하며, 두 개의 선형 변환과 그 사이에 비선형 활성화로 구성됩니다. 피드 포워드 레이어에는 잔차 연결이 추가되며, 그 후 레이어 정규화가 뒤따릅니다. 이 구조는 트랜스포머 ASR 모델 [7, 24]에서도 채택되었습니다.
우리는 사전 정규화 잔차 유닛 [21, 22]을 따라 첫 번째 선형 레이어 이전에 입력에 레이어 정규화를 적용합니다. 또한 Swish 활성화 [25]와 드롭아웃을 적용하여 네트워크를 정규화하는 데 도움을 줍니다. 그림 4는 피드 포워드(FFN) 모듈을 보여줍니다.
2.4. Conformer 블록
우리의 제안된 Conformer 블록은 그림 1에 나와 있듯이 다중 헤드 자기 주의 모듈과 합성곱 모듈을 샌드위치처럼 두 개의 피드 포워드 모듈 사이에 배치합니다.
이 샌드위치 구조는 마카롱넷(Macaron-Net) [18]에서 영감을 받았으며, 이는 트랜스포머 블록의 원래 피드 포워드 레이어를 주의 레이어 이전과 이후에 각각 반 스텝 피드 포워드 레이어 두 개로 대체할 것을 제안합니다. 마카롱넷처럼 우리는 피드 포워드(FFN) 모듈에 반 스텝 잔차 가중치를 사용합니다. 두 번째 피드 포워드 모듈 후에는 최종 레이어 정규화 레이어가 뒤따릅니다. 수학적으로, Conformer 블록 i의 입력 xi에 대해 블록의 출력 yi는 다음과 같습니다:
여기서 FFN은 피드 포워드 모듈을, MHSA는 다중 헤드 자기 주의 모듈을, Conv는 앞서 설명한 합성곱 모듈을 나타냅니다.
섹션 3.4.3에서 논의된 우리의 제거 연구에서는 이전 작업에서 사용된 일반적인 FFN과 마카롱 스타일 반 스텝 FFN을 비교합니다. 우리는 주의 및 합성곱 모듈 사이에 반 스텝 잔차 연결이 있는 두 개의 마카롱넷 스타일 피드 포워드 레이어를 갖는 것이 Conformer 아키텍처에서 단일 피드 포워드 모듈을 갖는 것보다 유의미한 개선을 제공한다는 것을 발견했습니다.
합성곱과 자기 주의의 결합은 이전에 연구된 바 있으며, 이를 달성하는 다양한 방법을 상상할 수 있습니다. 섹션 3.4.2에서는 자기 주의를 통해 합성곱을 증강하는 다양한 옵션을 연구했습니다. 우리는 자기 주의 모듈 후에 쌓인 합성곱 모듈이 음성 인식에 가장 적합하다는 것을 발견했습니다.
그림 4: 피드 포워드 모듈
첫 번째 선형 레이어는 확장 계수가 4이고, 두 번째 선형 레이어는 이를 다시 모델 차원으로 투영합니다. 우리는 swish 활성화와 사전 정규화 잔차 유닛을 피드 포워드 모듈에 사용합니다.
3. 실험
3.1. 데이터
우리는 제안된 모델을 970시간의 라벨링된 음성과 언어 모델을 구축하기 위한 추가적인 8억 단어 토큰의 텍스트 전용 코퍼스를 포함하는 LibriSpeech [26] 데이터셋에서 평가합니다. 우리는 25ms 윈도우와 10ms 스트라이드로 계산된 80채널 필터뱅크 특징을 추출했습니다. SpecAugment [27, 28]를 사용하여 마스크 파라미터(F = 27)와 최대 시간 마스크 비율(pS = 0.05)의 열 시간 마스크를 적용하였으며, 시간 마스크의 최대 크기는 발화 길이의 pS 배로 설정했습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
우리가 사용하는 오디오 데이터는 일정한 길이의 작은 구간으로 나눠서 분석됩니다. 여기서 각각의 작은 구간을 윈도우(window)라고 부릅니다. 각 윈도우는 25밀리초(ms) 동안의 오디오 데이터를 포함하고 있습니다. 그리고 다음 윈도우는 이전 윈도우의 끝에서 10밀리초(ms)만큼 겹쳐서 시작됩니다. 이를 스트라이드(stride)라고 부릅니다.
이렇게 나눈 각 구간의 오디오 데이터를 80개의 채널로 나누어, 필터뱅크(filterbank)라는 방식으로 특징을 추출합니다. 필터뱅크 특징은 오디오 신호의 주파수 성분을 분석하여 다양한 주파수 대역에서 에너지를 측정한 값들을 의미합니다.
즉, 우리는 25밀리초 길이의 오디오 구간마다 80개의 주파수 대역에서 에너지를 측정하고, 10밀리초 간격으로 이러한 과정을 반복하여 오디오 데이터를 분석한 것입니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.2. Conformer Transducer
우리는 네트워크 깊이, 모델 차원, 주의 헤드 수의 다양한 조합을 검토하여 모델 매개변수 크기 제한 내에서 가장 성능이 좋은 소형, 중형, 대형 모델(각각 10M, 30M, 118M 매개변수)을 식별했습니다. 모든 모델에 단일 LSTM 레이어 디코더를 사용했습니다. 표 1은 이들의 아키텍처 하이퍼 파라미터를 설명합니다.
정규화를 위해 각 모듈의 출력을 모듈 입력에 추가하기 전에 Conformer의 각 잔차 유닛에 드롭아웃 [29]을 적용했습니다. 드롭아웃 비율은 Pdrop = 0.1입니다. 모델 정규화를 위해 변동 노이즈 [5, 30]가 도입되었습니다. 모든 학습 가능한 가중치에 대해 1e-6의 가중치를 갖는 `2 정규화도 추가되었습니다. 우리는 Adam 옵티마이저 [31]를 사용하여 모델을 훈련했으며, β1 = 0.9, β2 = 0.98, ε = 10-9와 트랜스포머 학습률 일정 [6]을 사용하여 10k 워밍업 스텝과 피크 학습률을 0.05/√d로 설정했습니다. 여기서 d는 Conformer 인코더의 모델 차원입니다.
우리는 LibriSpeech 언어 모델 코퍼스와 LibriSpeech 960h 전사본을 추가하여 학습된 너비 4096의 3층 LSTM 언어 모델(LM)을 사용했습니다. 이 LM은 LibriSpeech 960h에서 구축된 1k WPM으로 토큰화되었습니다. LM은 dev-set 전사본에서 단어 수준의 당혹도를 63.9로 기록했습니다. 얕은 융합을 위한 LM 가중치 λ는 dev-set를 통해 그리드 탐색으로 조정되었습니다. 모든 모델은 Lingvo 툴킷 [32]으로 구현되었습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
언어 모델 설명
- 퍼플렉시티(Perplexity):
- 퍼플렉시티는 언어 모델의 성능을 측정하는 지표입니다. 값이 낮을수록 모델이 더 잘 예측하고 있다는 것을 의미합니다.
- 여기서 언어 모델은 dev-set 전사본에서 단어 수준의 퍼플렉시티 63.9를 기록했습니다. 이는 언어 모델이 해당 데이터셋에서 비교적 좋은 성능을 보였음을 나타냅니다.
- 얕은 융합(Shallow Fusion):
- 얕은 융합은 음성 인식 시스템에서 언어 모델을 통합하는 방법 중 하나입니다. 음성 인식 결과를 디코딩할 때, 음향 모델의 출력과 언어 모델의 출력을 결합하여 최종 결과를 만듭니다.
- 여기서 언어 모델 가중치 λ는 얕은 융합에서 중요한 역할을 합니다. 이 가중치는 음향 모델과 언어 모델의 출력을 결합할 때의 비율을 조정합니다.
- 가중치 λ를 최적화하기 위해 dev-set에서 그리드 탐색(grid search)을 사용했습니다. 그리드 탐색은 다양한 가중치 값을 시험해 보면서 최적의 가중치를 찾는 방법입니다.
- 일반적인 그리드 탐색
- Lingvo 툴킷:
- 모든 모델은 Google에서 개발한 Lingvo라는 툴킷을 사용하여 구현되었습니다. Lingvo는 음성 인식, 번역 등 다양한 시퀀스 모델링 작업을 지원하는 딥러닝 라이브러리입니다.
- https://github.com/tensorflow/lingvo
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.3. LibriSpeech 결과
표 2는 LibriSpeech의 test-clean/test-other에서의 모델 성능(WER)을 ContextNet [10], Transformer Transducer [7], QuartzNet [9] 등 최신 모델과 비교한 것입니다. 모든 평가 결과는 소수점 첫째 자리까지 반올림되었습니다.
언어 모델 없이도 중형 모델의 성능은 이미 test/test-other에서 각각 2.3/5.0의 경쟁력 있는 결과를 달성하여, 가장 잘 알려진 트랜스포머, LSTM 기반 모델 또는 유사한 크기의 합성곱 모델을 능가합니다. 언어 모델을 추가하면, 우리 모델은 모든 기존 모델 중 가장 낮은 단어 오류율을 달성합니다. 이는 단일 신경망에서 트랜스포머와 합성곱을 결합하는 것의 효과를 명확히 보여줍니다.
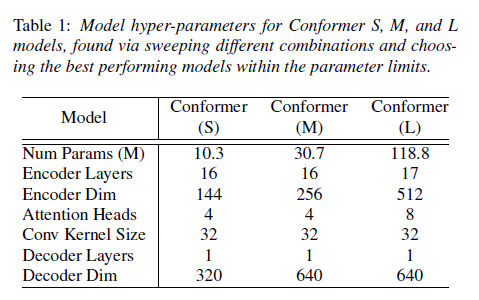
표 1: Conformer S, M, L 모델의 하이퍼 파라미터는 다양한 조합을 통해 찾아낸 결과로, 매개변수 제한 내에서 최고의 성능을 발휘하는 모델을 선택했습니다.
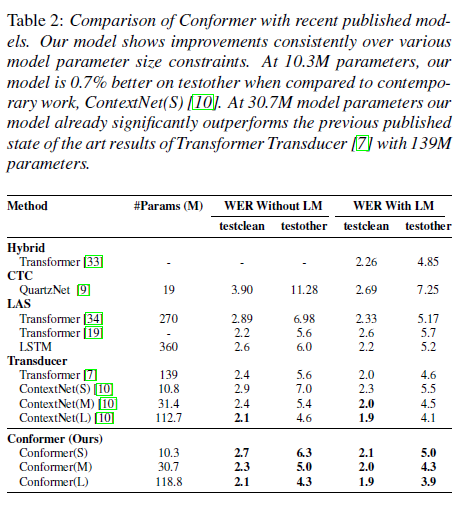
표 2: 최근 발표된 모델들과 Conformer의 비교. 우리 모델은 다양한 모델 매개변수 크기 제한 내에서 일관된 개선을 보여줍니다. 10.3M 매개변수에서 우리 모델은 contemporary work, ContextNet(S) [10]과 비교할 때 test-other에서 0.7% 더 나은 성능을 보여줍니다. 30.7M 모델 매개변수에서 우리 모델은 이미 139M 매개변수를 사용하는 이전에 발표된 최첨단 트랜스포머 트랜스듀서 [7]의 결과를 크게 능가합니다.
3.4. 절단 연구 (Ablation Studies)
3.4.1. Conformer 블록 대 Transformer 블록
Conformer 블록은 여러 면에서 Transformer 블록과 다릅니다. 특히, 합성곱 블록을 포함하고 Macaron 스타일로 블록을 둘러싼 한 쌍의 FFNs를 갖고 있습니다. 아래에서는 매개변수의 총 수를 동일하게 유지하면서 Conformer 블록을 Transformer 블록으로 변형시켜 이러한 차이의 효과를 연구합니다. 표 3은 Conformer 블록에 대한 각 변경의 영향을 보여줍니다. 모든 차이 중에서 합성곱 서브 블록이 가장 중요한 기능이며, Macaron 스타일의 FFN 쌍을 갖는 것이 동일한 매개변수 수의 단일 FFN보다 더 효과적입니다. Swish 활성화를 사용하는 것이 Conformer 모델에서 더 빠른 수렴을 이끌어냈습니다.
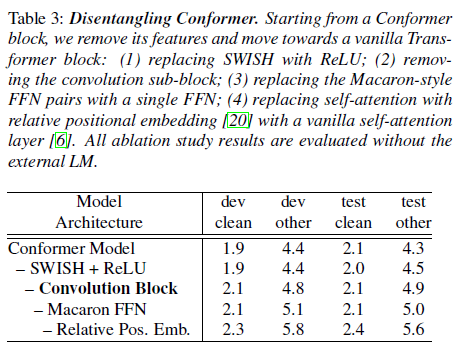
표 3: Conformer 분석. Conformer 블록에서 시작하여 그 기능을 제거하고 일반적인 Transformer 블록으로 이동합니다: (1) SWISH를 ReLU로 교체; (2) 합성곱 서브 블록 제거; (3) Macaron 스타일의 FFN 쌍을 단일 FFN으로 교체; (4) 상대적 위치 임베딩이 있는 자기 주의를 일반적인 자기 주의 레이어로 교체 [6]. 모든 절단 연구 결과는 외부 언어 모델 없이 평가되었습니다.
3.4.2. 합성곱과 Transformer 모듈의 조합
우리는 다중 헤드 자기 주의(MHSA) 모듈과 합성곱 모듈을 결합하는 다양한 방법의 효과를 연구합니다. 먼저, 합성곱 모듈의 깊이별 합성곱을 경량 합성곱 [35]으로 교체하려고 시도했으며, 특히 dev-other 데이터셋에서 성능이 크게 떨어지는 것을 확인했습니다. 두 번째로, Conformer 모델에서 합성곱 모듈을 MHSA 모듈 앞에 배치하는 방법을 연구했으며, 이는 dev-other에서 성능이 0.1만큼 저하되는 것을 발견했습니다. 또 다른 가능한 아키텍처는 입력을 다중 헤드 자기 주의 모듈과 합성곱 모듈의 병렬 브랜치로 나누고, 그 출력을 결합하는 것입니다 [17]. 우리는 이 방법이 제안된 아키텍처에 비해 성능을 악화시키는 것을 확인했습니다.

표 4의 결과는 Conformer 블록에서 합성곱 모듈을 자기 주의 모듈 후에 배치하는 것이 이점이 있음을 시사합니다.
표 4: Conformer 주의 합성곱 블록의 절단 연구. 다중 헤드 자기 주의와 합성곱 블록의 조합을 다양하게 변화시킴: (1) Conformer 아키텍처; (2) Conformer의 합성곱 블록에서 깊이별 합성곱 대신 경량 합성곱 사용; (3) 다중 헤드 자기 주의 전의 합성곱; (4) 출력이 결합된 상태로 병렬로 배치된 합성곱과 MHSA [17].
3.4.3. 마카롱 피드 포워드 모듈
트랜스포머 모델에서 주의 블록 후에 단일 피드 포워드 모듈(FFN)을 사용하는 대신, Conformer 블록은 자기 주의 및 합성곱 모듈을 샌드위치처럼 둘러싸는 한 쌍의 마카롱 스타일 피드 포워드 모듈을 가지고 있습니다. 또한, Conformer 피드 포워드 모듈은 반 스텝 잔차를 사용합니다. 표 5는 Conformer 블록을 단일 FFN 또는 전체 스텝 잔차를 사용하도록 변경했을 때의 영향을 보여줍니다.
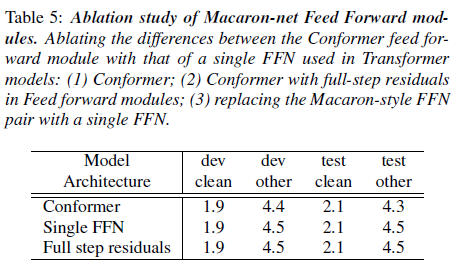
표 5: 마카롱넷 피드 포워드 모듈의 절단 연구. Conformer 피드 포워드 모듈과 트랜스포머 모델에서 사용된 단일 FFN의 차이를 절단: (1) Conformer; (2) 피드 포워드 모듈에서 전체 스텝 잔차를 사용한 Conformer; (3) 마카롱 스타일의 FFN 쌍을 단일 FFN으로 교체.
3.4.4. 주의 헤드의 수
자기 주의(self-attention)에서 각 주의 헤드(attention head)는 입력의 다른 부분에 집중하도록 학습하여 단순 가중 평균을 넘어 예측을 개선할 수 있게 합니다. 우리는 대형 모델에서 주의 헤드의 수를 4개에서 32개까지 다양하게 변경하여 실험을 수행하였으며, 모든 층에서 동일한 수의 헤드를 사용했습니다. 표 6에 나와 있듯이, 주의 헤드를 16개까지 늘리면 정확도가 향상되며, 특히 dev-other 데이터셋에서 두드러집니다.
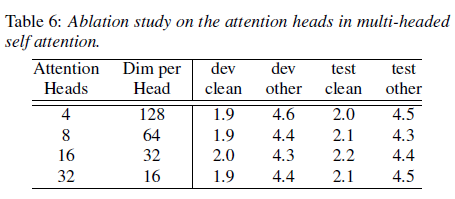
표 6: 다중 헤드 자기 주의에서 주의 헤드 수에 대한 절단 연구.
3.4.5. 합성곱 커널 크기
깊이별 합성곱에서 커널 크기의 효과를 연구하기 위해, 우리는 대형 모델에서 모든 층에 동일한 커널 크기를 사용하여 커널 크기를 {3, 7, 17, 32, 65}로 다양하게 변경하며 실험을 수행했습니다. 표 7에 나와 있듯이, 성능은 커널 크기가 17 및 32일 때까지 향상되지만, 커널 크기가 65일 경우 성능이 악화되는 것을 발견했습니다. dev WER에서 소수점 둘째 자리까지 비교한 결과, 커널 크기 32가 나머지보다 더 나은 성능을 보였습니다.
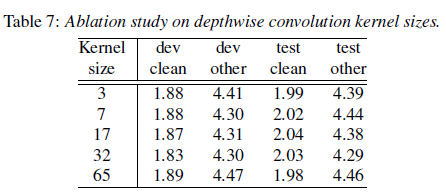
표 7: 깊이별 합성곱 커널 크기에 대한 절단 연구.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
왜 kernel size가 17, 65일까? 3, 7, 32이는 일반적으로 사용되서 이해가 된다
코드 확인 필요
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4. 결론
이 연구에서 우리는 CNN과 트랜스포머의 구성 요소를 통합하여 종단간 음성 인식을 위한 아키텍처인 Conformer를 소개했습니다. 각 구성 요소의 중요성을 연구하고, 합성곱 모듈의 포함이 Conformer 모델의 성능에 중요한 역할을 한다는 것을 입증했습니다. 이 모델은 LibriSpeech 데이터셋에서 이전 작업보다 적은 매개변수로 더 나은 정확도를 보였으며, test/testother에서 각각 1.9%/3.9%로 새로운 최첨단 성능을 달성했습니다.
'인공지능' 카테고리의 다른 글
| SAM 2: Segment Anything in Images and Videos (4) | 2024.07.30 |
|---|---|
| Neural General Circulation Models for Weather and Climate (2) | 2024.07.29 |
| The Llama3 Herd of Models (1) | 2024.07.27 |
| WavMark: Watermarking for Audio Generation (1) | 2024.07.26 |
| Kolors: Effective Training of Diffusion Model forPhotorealistic Text-to-Image Synthesis (중국 모델) (2) | 2024.07.25 |



