https://arxiv.org/abs/2403.03206
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative
arxiv.org
요약
디퓨전 모델은 데이터를 노이즈로 변환하는 경로를 역으로 따라가면서 노이즈로부터 데이터를 생성하며, 이미지나 비디오와 같은 고차원 지각 데이터를 생성하는 강력한 생성 모델링 기술로 떠올랐습니다. 정류된 흐름(Rectified Flow)은 데이터와 노이즈를 직선으로 연결하는 최근의 생성 모델 공식입니다. 이 모델은 이론적으로 더 우수하고 개념적으로 더 간단함에도 불구하고 아직 표준 관행으로 확립되지 않았습니다. 본 연구에서는 정류된 흐름 모델을 훈련시키기 위한 기존의 노이즈 샘플링 기법을 향상시키기 위해 지각적으로 관련된 스케일로 편향시켰습니다. 대규모 연구를 통해 고해상도 텍스트-이미지 합성에서 이 접근 방식이 기존의 디퓨전 공식보다 우수한 성능을 보임을 입증했습니다. 추가로, 이미지와 텍스트 토큰 사이에 양방향 정보 흐름을 가능하게 하여 텍스트 이해, 타이포그래피, 인간 선호도 평가를 개선하는 텍스트-이미지 생성용 새로운 트랜스포머 기반 아키텍처를 제시합니다. 이 아키텍처는 예측 가능한 확장 경향을 따르며 다양한 지표와 인간 평가에 의해 측정된 텍스트-이미지 합성 향상과 관련된 낮은 검증 손실을 나타냅니다. 우리의 최대 모델들은 최신 모델들을 능가하며, 실험 데이터, 코드 및 모델 가중치를 공개할 예정입니다.
머신 러닝, ICML
Stability AI
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
"지각적으로 관련된 스케일로 편향시켰다"는 것은 인간의 시각적 지각 특성을 반영하여 노이즈 샘플링을 조정했다는 의미입니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------

Figure 1
고해상도 샘플: 우리의 8B 정류된 흐름 모델이 타이포그래피, 정확한 프롬프트 수행 및 공간 추론, 세부 사항에 대한 주의, 다양한 스타일에서 높은 이미지 품질을 보여줍니다.
1. 소개
디퓨전 모델은 노이즈로부터 데이터를 생성합니다 (Song et al., 2020). 이 모델들은 데이터를 무작위 노이즈로 변환하는 경로를 역으로 따르도록 훈련되며, 신경망의 근사화 및 일반화 속성을 활용하여 훈련 데이터에 없는 새로운 데이터 포인트를 생성할 수 있습니다 (Sohl-Dickstein et al., 2015; Song & Ermon, 2020). 이 생성 모델링 기술은 이미지와 같은 고차원 지각 데이터를 모델링하는 데 매우 효과적임이 입증되었습니다 (Ho et al., 2020). 최근 몇 년간, 디퓨전 모델은 자연어 입력으로부터 고해상도 이미지와 비디오를 생성하는 사실상 표준 접근 방식이 되었습니다 (Saharia et al., 2022b; Ramesh et al., 2022; Rombach et al., 2022; Podell et al., 2023; Dai et al., 2023; Esser et al., 2023; Blattmann et al., 2023b; Betker et al., 2023; Blattmann et al., 2023a; Singer et al., 2022). 반복적인 특성과 관련된 계산 비용 및 추론 시 긴 샘플링 시간 때문에, 이러한 모델의 효율적인 훈련 및/또는 빠른 샘플링을 위한 연구가 증가하고 있습니다 (Karras et al., 2023; Liu et al., 2022).
데이터에서 노이즈로 가는 경로를 지정하는 것은 효율적인 훈련을 가능하게 하지만, 어떤 경로를 선택할지에 대한 문제가 제기됩니다. 이 선택은 샘플링에 중요한 영향을 미칠 수 있습니다. 예를 들어, 모든 노이즈를 제거하지 못하는 전진 과정은 훈련 및 테스트 분포 간의 불일치를 초래하고 회색 이미지 샘플과 같은 아티팩트를 유발할 수 있습니다 (Lin et al., 2024). 특히, 전진 과정의 선택은 학습된 후진 과정 및 샘플링 효율성에도 영향을 미칩니다. 곡선 경로는 많은 통합 단계를 필요로 하지만, 직선 경로는 단일 단계로 시뮬레이션할 수 있으며 오류 누적 가능성이 적습니다. 각 단계는 신경망의 평가에 해당하므로, 이는 샘플링 속도에 직접적인 영향을 미칩니다.
특정 전진 경로 선택은 이른바 정류된 흐름입니다 (Liu et al., 2022; Albergo & Vanden-Eijnden, 2022; Lipman et al., 2023). 이는 데이터와 노이즈를 직선으로 연결합니다. 이 모델 클래스는 이론적으로 더 나은 속성을 가지고 있지만, 아직 실무에서 결정적으로 확립되지 않았습니다. 지금까지는 소규모 및 중간 규모의 실험에서 몇 가지 이점이 실증되었지만 (Ma et al., 2024), 대부분 클래스 조건부 모델에 국한됩니다. 본 연구에서는 노이즈 예측 디퓨전 모델과 유사하게 정류된 흐름 모델에서 노이즈 스케일을 재조정하는 새로운 방법을 도입하여 이를 변경합니다. 대규모 연구를 통해 우리의 새로운 공식이 기존 디퓨전 공식보다 우수함을 입증합니다.
텍스트-이미지 합성을 위한 널리 사용되는 접근 방식, 즉 고정된 텍스트 표현을 모델에 직접 입력하는 방식(e.g., 크로스 어텐션 (Vaswani et al., 2017; Rombach et al., 2022))이 이상적이지 않음을 보여주고, 텍스트와 이미지 토큰 간의 양방향 정보 흐름을 가능하게 하는 학습 가능한 스트림을 통합한 새로운 아키텍처를 제시합니다. 이를 개선된 정류된 흐름 공식과 결합하여 확장성을 조사합니다. 검증 손실의 예측 가능한 확장 경향을 보여주고, 낮은 검증 손실이 자동 및 인간 평가 모두에서 텍스트-이미지 합성 성능 향상과 강한 상관관계가 있음을 입증합니다.
우리의 최대 모델들은 최신 오픈 모델들(e.g., SDXL (Podell et al., 2023), SDXL-Turbo (Sauer et al., 2023), Pixart-α (Chen et al., 2023))과 닫힌 소스 모델(e.g., DALL-E 3 (Betker et al., 2023))보다 프롬프트 이해 및 인간 선호도 평가에서 뛰어납니다.
핵심 기여
- 다양한 디퓨전 모델 및 정류된 흐름 공식에 대한 대규모 체계적 연구를 수행하여 최적의 설정을 식별했습니다. 이를 위해 성능을 향상시키는 새로운 노이즈 샘플러를 도입했습니다.
- 네트워크 내에서 텍스트 및 이미지 토큰 스트림 간의 양방향 혼합을 가능하게 하는 새로운 확장 가능한 텍스트-이미지 합성 아키텍처를 고안했습니다. 기존의 UViT (Hoogeboom et al., 2023) 및 DiT (Peebles & Xie, 2023) 백본과 비교하여 그 이점을 보여주었습니다.
- 모델의 확장 연구를 수행하여 예측 가능한 확장 경향을 따름을 입증했습니다. 낮은 검증 손실이 T2I-CompBench (Huang et al., 2023), GenEval (Ghosh et al., 2023) 및 인간 평가와 같은 지표를 통해 평가된 텍스트-이미지 성능 향상과 강하게 상관관계가 있음을 보여주었습니다. 우리의 결과, 코드 및 모델 가중치를 공개할 예정입니다.



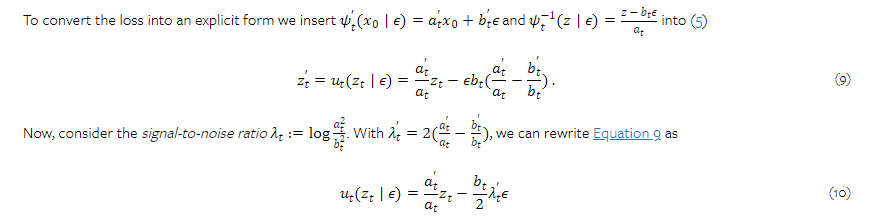

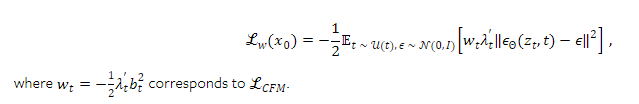
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
직접 적어볼 곳
-----------------------------------------------------------------------------------------------------------------------------------------------------------------



-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Cosine 식은 대학교때도 많이 보던 식
-----------------------------------------------------------------------------------------------------------------------------------------------------------------





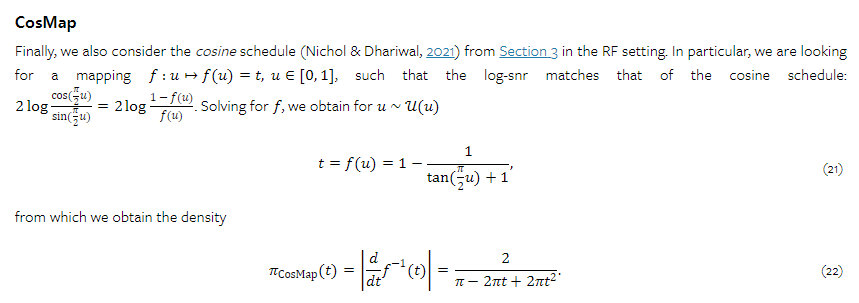
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
손으로 풀어보기 필요
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4. 텍스트-이미지 아키텍처
(a) 모든 구성 요소의 개요
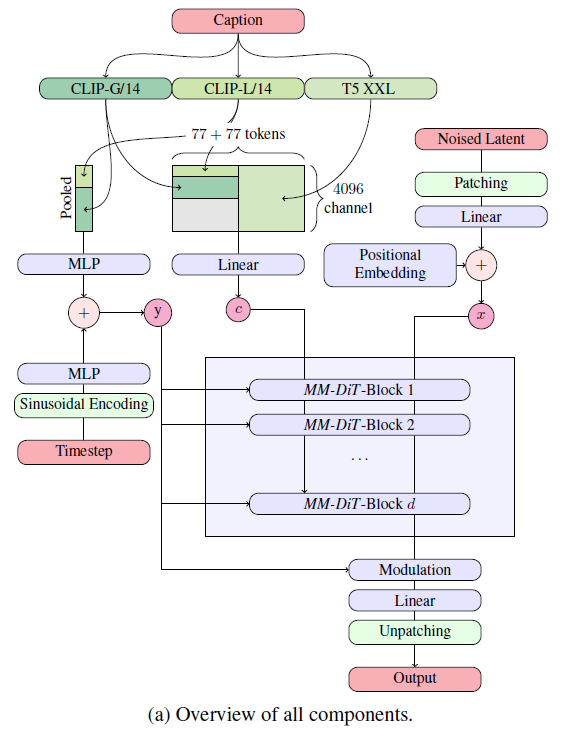
(b) 하나의 MM-DiT 블록
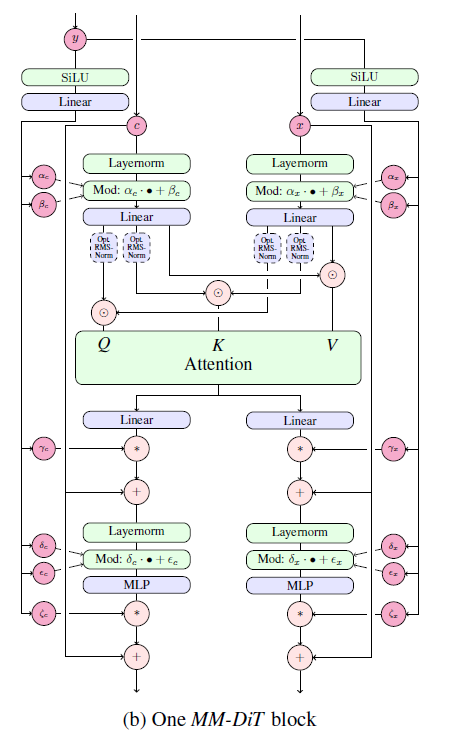
Figure 2: 우리 모델 아키텍처. 연결(Concatenation)은 ⊙로, 요소별 곱(Element-wise multiplication)은 *로 표시됩니다. Q와 K에 대한 RMS-Norm은 훈련 안정화를 위해 추가할 수 있습니다. 확대하여 보는 것이 가장 좋습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
positional encoder를 쓰는 이유는 더 긴 text에 대응하기 위함이다. 요세 추세는 ffn 형식이었지만, text length에 대응하기에는 positional encoder가 아직 우세하다고 함
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
이미지의 텍스트 조건 샘플링을 위해, 우리 모델은 텍스트와 이미지 두 가지 모달리티를 고려해야 합니다. 적절한 표현을 도출하기 위해 사전 학습된 모델을 사용한 후, 디퓨전 백본의 아키텍처를 설명합니다. 이에 대한 개요는 Figure 2에 나와 있습니다.
우리의 일반적인 설정은 사전 학습된 오토인코더의 잠재 공간에서 텍스트-이미지 모델을 훈련하기 위해 LDM(Rombach et al., 2022)을 따릅니다. 이미지의 잠재 표현으로의 인코딩과 유사하게, 이전 접근 방식(Saharia et al., 2022b; Balaji et al., 2022)을 따르고, 사전 학습된 텍스트 모델을 사용하여 텍스트 조건 c을 인코딩합니다. 자세한 내용은 섹션 B.2에 있습니다.
멀티모달 디퓨전 백본
우리의 아키텍처는 DiT (Peebles & Xie, 2023) 아키텍처를 기반으로 합니다. DiT는 클래스 조건부 이미지 생성만을 고려하며, 네트워크를 디퓨전 과정의 시간 단계와 클래스 레이블에 조건화하는 변조 메커니즘을 사용합니다. 마찬가지로, 우리는 시간 단계 t와 c_vec의 임베딩을 변조 메커니즘의 입력으로 사용합니다. 그러나 집합된 텍스트 표현은 텍스트 입력에 대한 거친 정보를 유지하기 때문에 (Podell et al., 2023), 네트워크는 시퀀스 표현 c_ctxt로부터의 정보도 필요합니다.

텍스트와 이미지 임베딩은 개념적으로 매우 다르기 때문에, 두 모달리티에 대해 두 개의 별도 가중치 세트를 사용합니다. Figure 1(b)에 표시된 것처럼, 이는 각 모달리티에 대해 두 개의 독립적인 트랜스포머를 갖는 것과 동일하지만, 주의 연산을 위해 두 모달리티의 시퀀스를 결합하여 두 표현이 각각의 공간에서 작동하면서도 서로를 고려할 수 있게 합니다.
우리의 스케일링 실험을 위해, 모델의 크기는 모델의 깊이 d (즉, 주의 블록의 수)로 매개변수화하며, 숨겨진 크기를 64⋅d (MLP 블록에서 4⋅64⋅d 채널로 확장)로 설정하고, 주의 헤드의 수는 d와 동일하게 설정합니다.
5. 실험
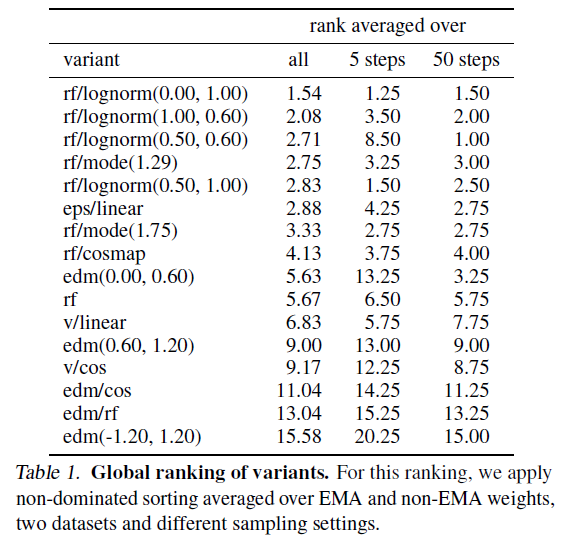
Table 1: 변형의 전역 순위
이 순위를 위해, EMA(Exponential Moving Average) 및 non-EMA 가중치, 두 데이터셋 및 다양한 샘플링 설정을 평균하여 비지배 정렬을 적용합니다.
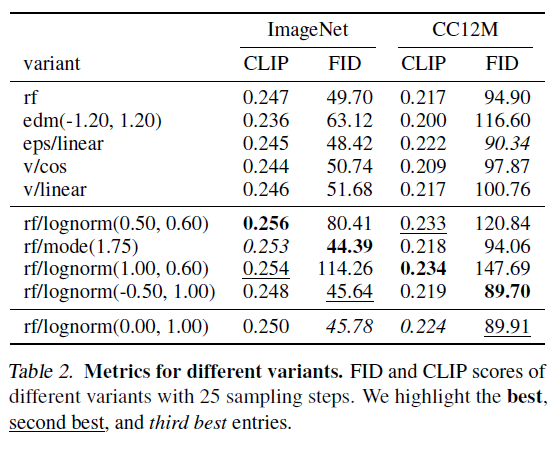
Table 2: 다양한 변형의 메트릭스
다양한 변형의 25 샘플링 스텝에 대한 FID와 CLIP 점수. 최상의 항목, 두 번째로 좋은 항목, 세 번째로 좋은 항목을 강조합니다.
5.1 정류된 흐름 개선
우리는 정상화 흐름의 시뮬레이션 없는 훈련을 위한 다양한 접근법 중 어떤 것이 가장 효율적인지를 이해하고자 합니다. 다른 접근법 간의 비교를 가능하게 하기 위해, 최적화 알고리즘, 모델 아키텍처, 데이터셋 및 샘플러를 통제합니다. 또한, 다양한 접근법의 손실은 비교할 수 없으며 출력 샘플의 품질과 반드시 상관관계가 있는 것도 아니기 때문에, 접근법 간의 비교를 허용하는 평가 메트릭이 필요합니다. 우리는 ImageNet(Russakovsky et al., 2014)과 CC12M(Changpinyo et al., 2021)에서 모델을 훈련하고, 검증 손실, CLIP 점수(Radford et al., 2021; Hessel et al., 2021) 및 FID(Heusel et al., 2017)를 사용하여 훈련 중 모델의 훈련 가중치와 EMA 가중치를 평가합니다. 다양한 샘플러 설정(다양한 가이드 스케일 및 샘플링 스텝)에서 평가합니다. FID는 Sauer et al.(2021)이 제안한 대로 CLIP 특징에서 계산합니다. 모든 메트릭은 COCO-2014 검증 분할(Lin et al., 2014)에서 평가합니다. 훈련 및 샘플링 하이퍼파라미터에 대한 전체 세부 사항은 섹션 B.3에 제공됩니다.
5.1.1 결과
우리는 두 데이터셋에서 61개의 다른 공식을 각각 훈련시켰습니다. 다음은 섹션 3에서 포함된 변형들입니다:

각 실행마다 EMA 가중치를 사용하여 평가된 최소 검증 손실 단계를 선택한 후, EMA 가중치를 사용한 경우와 사용하지 않은 경우 모두 6개의 다른 샘플러 설정으로 얻은 CLIP 점수와 FID를 수집합니다.
샘플러 설정, EMA 가중치 및 데이터셋 선택의 24가지 조합에 대해, 비지배 정렬 알고리즘을 사용하여 다양한 공식을 순위 매깁니다. 이를 위해, CLIP 및 FID 점수에 따라 파레토 최적의 변형을 반복적으로 계산하고, 해당 변형에 현재 반복 인덱스를 할당한 후, 해당 변형을 제거하고 남은 변형으로 계속 진행하여 모든 변형이 순위를 얻을 때까지 진행합니다. 마지막으로, 24가지 다른 제어 설정에 대한 순위를 평균화합니다.
결과는 표 1에 제시되어 있으며, 여기에는 다양한 하이퍼파라미터로 평가된 변형 중 상위 두 가지 변형만을 표시합니다. 또한, 샘플러 설정을 5단계와 50단계로 제한하여 평균화한 순위도 보여줍니다.
우리는 rf/lognorm(0.00, 1.00)이 일관되게 좋은 순위를 차지한다는 것을 관찰합니다. 이는 균일한 시간 단계 샘플링을 사용하는 정류된 흐름 공식 (rf)보다 우수하며, 중간 시간 단계가 더 중요하다는 우리의 가설을 확인시켜줍니다. 모든 변형 중에서 수정된 시간 단계 샘플링을 사용하는 정류된 흐름 공식만이 이전에 사용된 LDM-Linear (Rombach et al., 2022) 공식 (eps/linear)보다 우수한 성능을 보입니다.
또한, 일부 변형은 특정 설정에서 잘 수행되지만 다른 설정에서는 성능이 떨어지는 것을 관찰합니다. 예를 들어, rf/lognorm(0.50, 0.60)은 50 샘플링 스텝에서는 가장 성능이 좋지만, 5 샘플링 스텝에서는 평균 순위가 8.5로 매우 나쁩니다. 표 2에서도 유사한 행동을 관찰할 수 있습니다. 첫 번째 그룹은 대표적인 변형과 25 샘플링 스텝으로 두 데이터셋에서의 메트릭을 보여줍니다. 다음 그룹은 최고의 CLIP 및 FID 점수를 달성한 변형을 보여줍니다. rf/mode(1.75)를 제외하고, 이러한 변형은 일반적으로 한 메트릭에서는 매우 잘 수행되지만 다른 메트릭에서는 상대적으로 나쁜 성능을 보입니다. 반면, rf/lognorm(0.00, 1.00)은 메트릭과 데이터셋 전반에서 좋은 성능을 보이며, 네 번 중 두 번 세 번째로 좋은 점수, 한 번 두 번째로 좋은 성능을 얻었습니다.
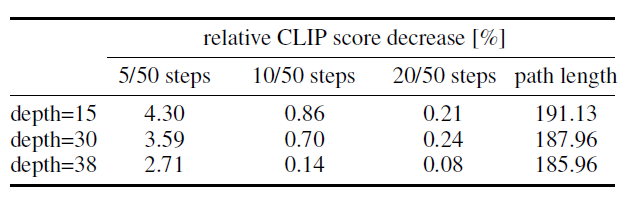
마지막으로, Figure 3에서는 다양한 공식의 정성적 행동을 보여줍니다. 여기서 다양한 공식 그룹(edm, rf, eps 및 v)에 대해 다른 색상을 사용합니다. 정류된 흐름 공식은 일반적으로 좋은 성능을 보이며, 다른 공식과 비교하여 샘플링 스텝 수를 줄일 때 성능 저하가 적습니다.
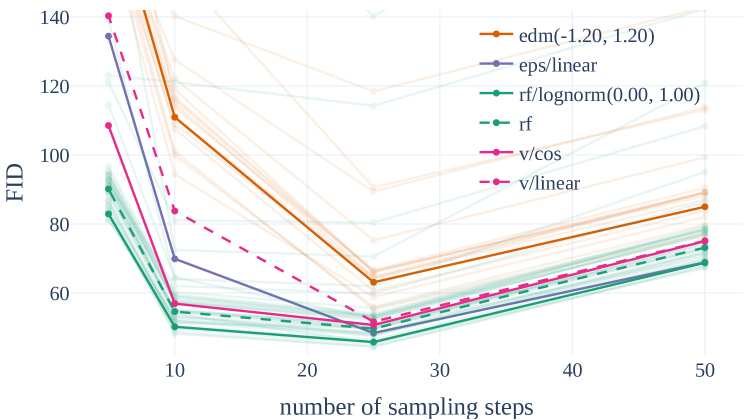
Figure 3: 정류된 흐름은 샘플 효율적입니다. 정류된 흐름은 다른 공식보다 샘플링 스텝이 적을 때 더 나은 성능을 보입니다. 25 스텝 이상에서는 rf/lognorm(0.00, 1.00)만이 eps/linear에 경쟁력 있게 남습니다.
5.2 모달리티 특정 표현의 개선
이전 섹션에서 정류된 흐름 모델이 LDM-Linear (Rombach et al., 2022)나 EDM (Karras et al., 2022)과 같은 기존의 디퓨전 공식과 경쟁할 뿐만 아니라 이를 능가할 수 있는 공식을 찾은 후, 이제 우리는 이 공식을 고해상도 텍스트-이미지 합성에 적용하려고 합니다. 따라서, 알고리즘의 최종 성능은 훈련 공식뿐만 아니라 신경망을 통한 매개변수화와 우리가 사용하는 이미지 및 텍스트 표현의 품질에 달려 있습니다. 다음 섹션에서는 최종 방법을 섹션 5.3에서 확장하기 전에 이러한 모든 구성 요소를 어떻게 개선했는지 설명합니다.

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
d = 16이 좋다는 의견이 많아지는데, 논문들에서, 이는 GPU 구조와 관련있어보인다
-----------------------------------------------------------------------------------------------------------------------------------------------------------------

Table 3: 개선된 오토인코더
다양한 채널 구성에 대한 재구성 성능 메트릭. 모든 모델의 다운샘플링 팩터는 f=8입니다.
이로써, 우리는 고해상도 텍스트-이미지 합성을 위한 모델의 성능을 개선하기 위해 오토인코더의 채널 수를 늘려 재구성 품질을 향상시켰음을 알 수 있습니다.

5.2.2 개선된 캡션
Betker et al. (2023)은 합성으로 생성된 캡션이 대규모로 훈련된 텍스트-이미지 모델의 성능을 크게 향상시킬 수 있음을 보여주었습니다. 이는 대규모 이미지 데이터셋에 첨부된 인간이 생성한 캡션이 종종 단순하고 이미지 주제에만 과도하게 집중하며, 배경이나 장면의 구성, 표시된 텍스트를 설명하는 세부 사항을 생략하는 경향이 있기 때문입니다 (Betker et al., 2023). 우리는 그들의 접근 방식을 따르고, 최첨단 비전-언어 모델인 CogVLM (Wang et al., 2023)을 사용하여 대규모 이미지 데이터셋에 대한 합성 주석을 생성합니다. 합성 캡션이 VLM의 지식 범위에 없는 특정 개념을 텍스트-이미지 모델이 잊게 만들 수 있으므로, 우리는 원본 캡션 50%와 합성 캡션 50%의 비율을 사용합니다.
이 캡션 혼합물에 대한 훈련 효과를 평가하기 위해, 우리는 두 개의 d=15 M-DiT 모델을 250,000 스텝 동안 훈련시켰습니다. 하나는 원본 캡션만으로, 다른 하나는 50/50 혼합물로 훈련되었습니다. 우리는 Table 4에서 GenEval 벤치마크 (Ghosh et al., 2023)를 사용하여 훈련된 모델을 평가했습니다. 결과는 합성 캡션을 추가하여 훈련된 모델이 원본 캡션만을 사용하는 모델보다 명확히 더 우수하다는 것을 보여줍니다. 따라서, 우리는 이 연구의 나머지 부분에서 50/50 합성/원본 캡션 혼합물을 사용합니다.
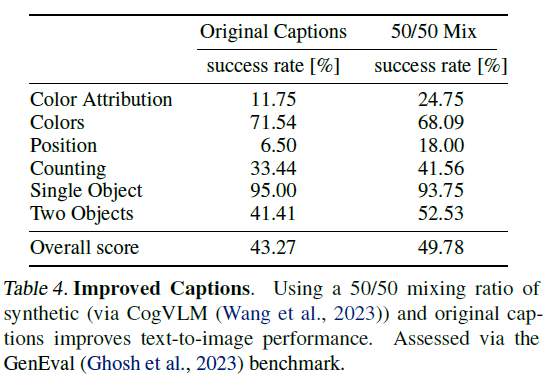
Table 4: 개선된 캡션
CogVLM (Wang et al., 2023)을 통해 생성된 합성 캡션과 원본 캡션을 50/50 비율로 혼합하면 텍스트-이미지 성능이 향상됩니다. GenEval (Ghosh et al., 2023) 벤치마크를 통해 평가되었습니다.
5.2.3 개선된 텍스트-이미지 백본
이 섹션에서는 기존의 트랜스포머 기반 디퓨전 백본과 섹션 4에서 소개된 새로운 멀티모달 트랜스포머 기반 디퓨전 백본인 MM-DiT의 성능을 비교합니다. MM-DiT는 텍스트와 이미지 토큰이라는 서로 다른 도메인을 처리하기 위해 두 개의 다른 학습 가능한 모델 가중치 세트를 사용하도록 설계되었습니다. 구체적으로, 섹션 5.1의 실험 설정을 따르며, CC12M에서 DiT, CrossDiT(텍스트 토큰에 시퀀스별 연결 대신 교차 주의를 사용하는 DiT (Chen et al., 2023)) 및 우리의 MM-DiT의 텍스트-이미지 성능을 비교합니다. MM-DiT의 경우, 두 개의 가중치 세트와 세 개의 가중치 세트를 가진 모델을 비교하며, 후자는 CLIP (Radford et al., 2021) 및 T5 (Raffel et al., 2019) 토큰을 별도로 처리합니다(섹션 4 참조). DiT(섹션 4에서 텍스트와 이미지 토큰을 연결한 경우)는 모든 모달리티에 대해 하나의 공유 가중치 세트를 사용하는 MM-DiT의 특수한 경우로 해석될 수 있습니다. 마지막으로, UViT (Hoogeboom et al., 2023) 아키텍처를 널리 사용되는 UNets와 트랜스포머 변형의 하이브리드로 간주합니다.
이들 아키텍처의 수렴 행동을 Figure 4에서 분석합니다: 기본 DiT는 UViT보다 성능이 낮습니다. 교차 주의 DiT 변형인 CrossDiT는 UViT보다 더 나은 성능을 달성하지만, UViT는 초기 학습 속도가 더 빠른 것으로 보입니다. 우리의 MM-DiT 변형은 교차 주의 및 기본 변형보다 훨씬 뛰어난 성능을 보입니다. 두 개의 파라미터 세트 대신 세 개의 파라미터 세트를 사용할 때는 작은 성능 향상이 있지만(파라미터 수와 VRAM 사용량 증가의 비용이 따름), 따라서 이 연구의 나머지 부분에서는 전자의 옵션을 선택합니다.
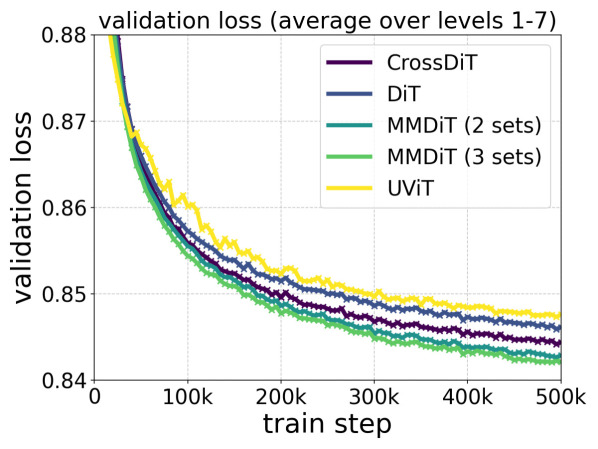
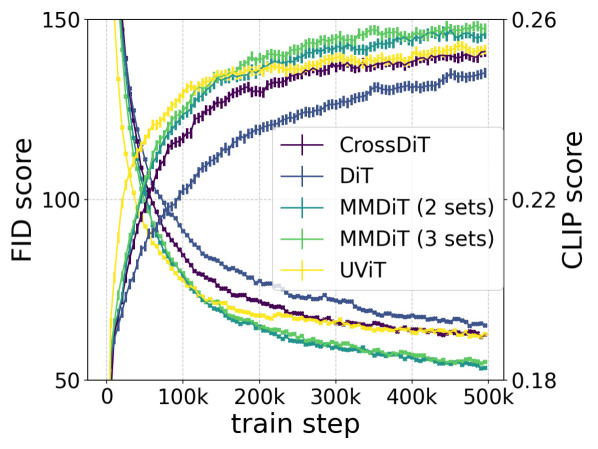
Figure 4: 모델 아키텍처의 훈련 동력학
CC12M에서 DiT, CrossDiT, UViT, 및 MM-DiT의 검증 손실, CLIP 점수 및 FID에 대한 비교 분석. 우리가 제안한 MM-DiT는 모든 메트릭에서 우수한 성능을 보입니다.
5.3 대규모 훈련
규모를 확장하기 전에 안전하고 효율적인 사전 훈련을 위해 데이터를 필터링하고 미리 인코딩합니다. 그런 다음, 이전의 디퓨전 공식, 아키텍처 및 데이터에 대한 모든 고려사항이 마지막 섹션에서 8B 파라미터로 모델을 확장하는 데 결합됩니다.
5.3.1 데이터 전처리
사전 훈련 완화 조치
훈련 데이터는 생성 모델의 능력에 크게 영향을 미칩니다. 따라서 데이터 필터링은 바람직하지 않은 기능을 제한하는 데 효과적입니다 (Nichol, 2022). 대규모 훈련 전에, 우리는 데이터를 다음 범주로 필터링합니다:
- 성적 콘텐츠: NSFW 감지 모델을 사용하여 명시적 콘텐츠를 필터링합니다.
- 미학: 평가 시스템이 낮은 점수를 예측하는 이미지를 제거합니다.
- 반복: 클러스터 기반 중복 제거 방법을 사용하여 훈련 데이터에서 지각적 및 의미적 중복을 제거합니다. 자세한 내용은 섹션 E.2를 참조하세요.
이미지 및 텍스트 임베딩의 사전 계산
우리 모델은 여러 사전 학습된 고정된 네트워크의 출력을 입력으로 사용합니다 (오토인코더 잠재 변수 및 텍스트 인코더 표현). 이 출력은 훈련 중에 일정하므로, 전체 데이터셋에 대해 한 번만 사전 계산합니다. 우리의 접근 방식에 대한 자세한 논의는 섹션 E.1에 있습니다.
5.3.2 고해상도에서의 파인튜닝
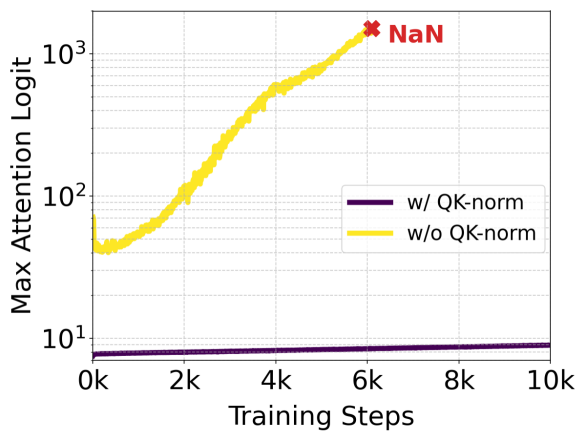
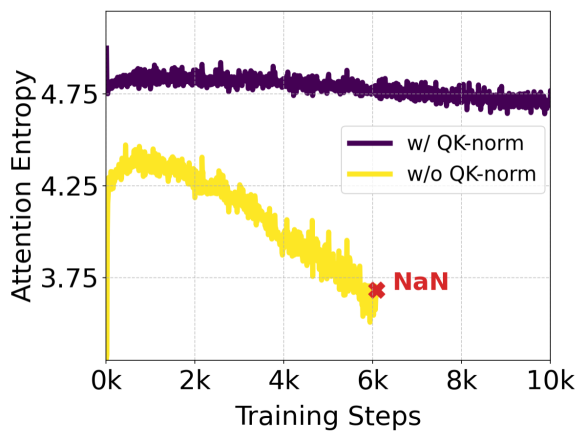
Figure 5: QK-정규화의 효과. 주의(attention) 행렬을 계산하기 전에 Q- 및 K-임베딩을 정규화하면 주의 로그잇 성장 불안정성(왼쪽)을 방지합니다. 이 불안정성은 주의 엔트로피의 붕괴(오른쪽)를 유발하며, 이는 이전에 판별적인 ViT 문헌에서 보고되었습니다 (Dehghani et al., 2023; Wortsman et al., 2023). 이러한 이전 연구와 달리, 우리는 네트워크의 마지막 트랜스포머 블록에서 이 불안정성을 관찰합니다. 최대 주의 로그잇과 주의 엔트로피는 2B (d=24) 모델의 마지막 5개 블록에 걸쳐 평균화되어 표시됩니다.
Q- 및 K-임베딩을 정규화하면 주의 행렬의 계산에서 발생할 수 있는 불안정성을 방지할 수 있습니다. 이로 인해 모델의 성능이 더 안정적이고 일관되게 유지됩니다. Figure 5는 이러한 정규화의 효과를 시각적으로 보여줍니다.


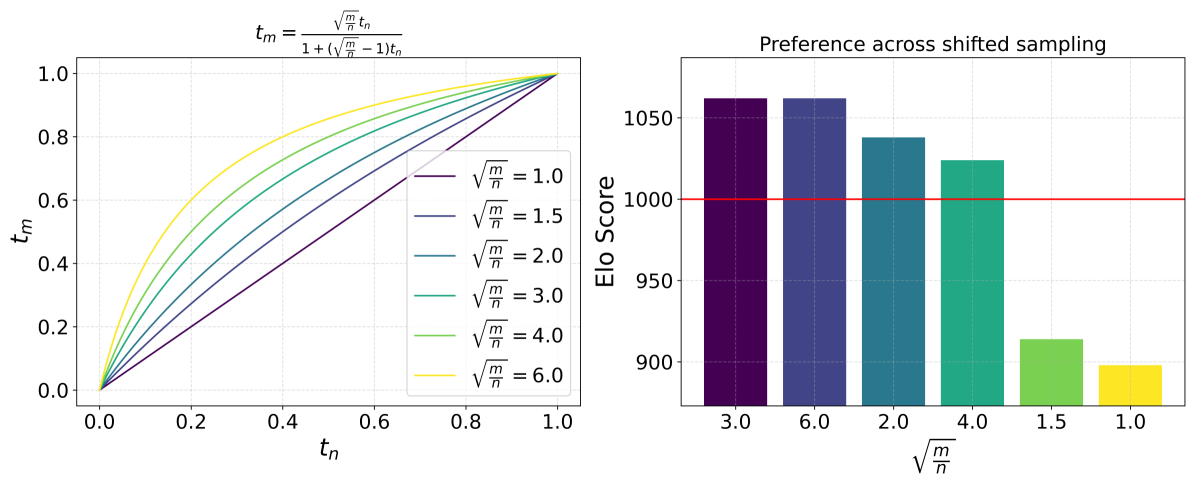





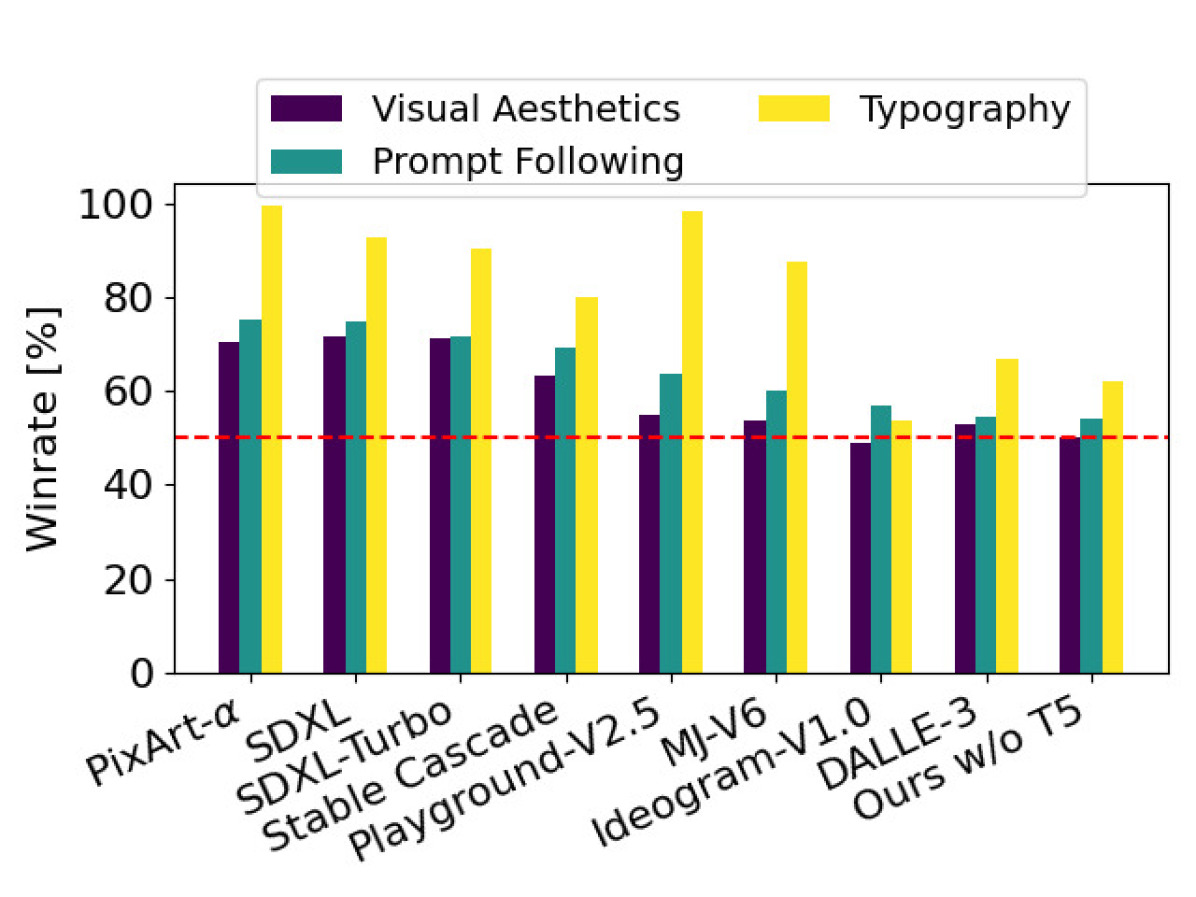
Figure 7: 인간 선호도 평가
최신 공개 및 비공개 SOTA 생성 이미지 모델과 비교한 인간 선호도 평가. 우리 8B 모델은 시각적 품질, 프롬프트 준수, 타이포그래피 생성 등의 카테고리에서 parti-prompts(Yu et al., 2022)를 사용한 평가에서 현재의 최신 텍스트-이미지 모델과 비교하여 우수한 성능을 보입니다.

5.3.3 결과
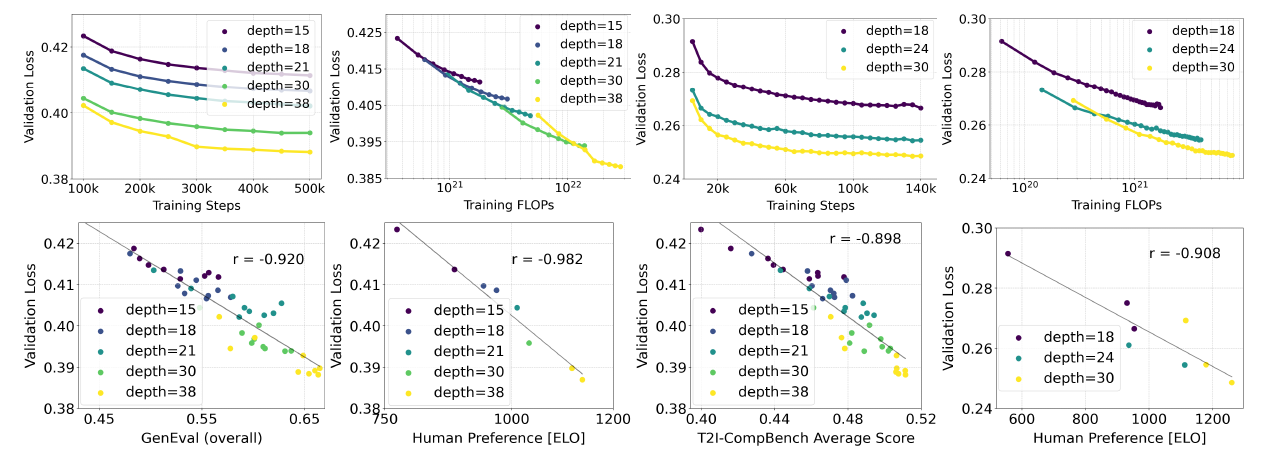


이미지와 비디오 도메인 모두에서 모델 크기와 훈련 단계를 증가시킬 때 검증 손실이 부드럽게 감소하는 것을 관찰합니다. 검증 손실이 종합적인 평가 메트릭(CompBench (Huang et al., 2023), GenEval (Ghosh et al., 2023)) 및 인간 선호도와 높은 상관관계를 보임을 발견했습니다. 이 결과는 검증 손실이 모델 성능의 간단하고 일반적인 측정치임을 지지합니다. 우리의 결과는 이미지나 비디오 모델에서 포화 현상을 보여주지 않습니다.
Figure 12는 더 큰 모델을 더 오랜 시간 훈련할 때 샘플 품질에 미치는 영향을 보여줍니다. 표 5는 GenEval의 전체 결과를 보여줍니다. 섹션 5.3.2에서 제시된 방법을 적용하고 훈련 이미지 해상도를 높이면, 우리의 가장 큰 모델이 대부분의 카테고리에서 뛰어난 성과를 내며, 전반적인 점수에서 현재 최첨단인 DALLE 3 (Betker et al., 2023)을 능가합니다.

Figure 9: T5의 영향
우리는 T5가 높은 세부 사항이나 더 긴 텍스트(2, 3열)와 같은 복잡한 프롬프트에 중요하다는 것을 관찰합니다. 그러나 대부분의 프롬프트에서는 추론 시 T5를 제거해도 여전히 경쟁력 있는 성능을 달성합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
positional encoding 사용 이유
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
해석
우리의 d=38 모델은 Parti-prompts 벤치마크(Yu et al., 2022)에서 시각적 미학, 프롬프트 준수, 타이포그래피 생성 카테고리에서 현재의 비공개 (Betker et al., 2023; ide, 2024) 및 공개 (Sauer et al., 2023; pla, 2024; Chen et al., 2023; Pernias et al., 2023) 최신 생성 이미지 모델을 인간 선호도 평가에서 능가합니다(Figure 7 참조). 이 카테고리에서 인간 선호도를 평가하기 위해, 평가자들은 두 모델의 쌍별 출력을 보고 다음 질문에 답하도록 요청받았습니다:
- 프롬프트 준수: 어느 이미지가 위의 텍스트를 더 잘 표현하고 충실하게 따르나요?
- 시각적 미학: 주어진 프롬프트에 대해, 어느 이미지가 더 높은 품질과 미학적으로 더 만족스럽나요?
- 타이포그래피: 위의 설명에서 지정된 텍스트를 더 정확하게 표시하는 이미지는 어느 것인가요? 더 정확한 철자가 선호됩니다! 다른 측면은 무시하세요.
마지막으로, 표 6은 흥미로운 결과를 강조합니다: 더 큰 모델이 더 나은 성능을 발휘할 뿐만 아니라, 최대 성능에 도달하는 데 필요한 단계도 적다는 점입니다.
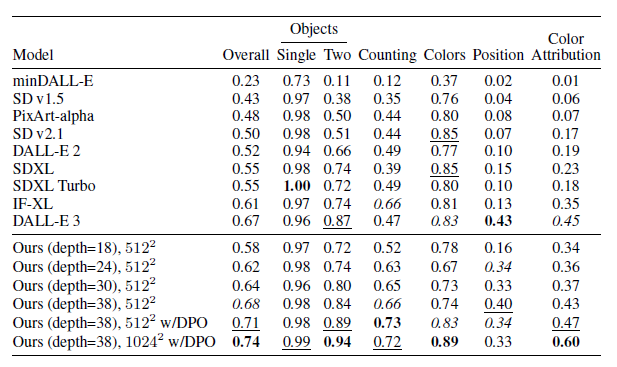
표 5: GenEval 비교
우리의 가장 큰 모델(깊이=38)은 GenEval(Ghosh et al., 2023)에서 모든 현재 공개 모델과 DALLE-3(Betker et al., 2023)을 능가합니다. 최고, 두 번째, 세 번째 항목을 강조합니다. DPO에 대한 내용은 부록 C를 참조하세요.

유연한 텍스트 인코더
여러 텍스트 인코더를 사용하는 주요 동기는 전체 모델 성능을 향상시키는 것(Balaji et al., 2022)이지만, 이는 추론 중 MM-DiT 기반 정류된 흐름의 유연성을 추가로 증가시킵니다. 섹션 B.3에서 설명한 바와 같이, 우리는 각기 46.3%의 드롭아웃율을 가진 세 개의 텍스트 인코더로 모델을 훈련시켰습니다. 따라서 추론 시, 세 개의 텍스트 인코더 중 임의의 하위 집합을 사용할 수 있습니다. 이는 특히 VRAM을 많이 필요로 하는 4.7B 파라미터의 T5-XXL (Raffel et al., 2019)의 메모리 효율성을 향상시키기 위해 모델 성능을 조정할 수 있는 수단을 제공합니다. 흥미롭게도, 텍스트 프롬프트에 대해 T5 임베딩을 0으로 대체하고 두 개의 CLIP 기반 텍스트 인코더만 사용하는 경우 성능 저하가 제한적이라는 것을 관찰했습니다. Figure 9에서 이를 시각적으로 보여줍니다. 장면의 매우 세부적인 설명이나 더 많은 양의 텍스트가 포함된 복잡한 프롬프트의 경우, 세 개의 텍스트 인코더를 모두 사용할 때 성능이 크게 향상됩니다. 이러한 관찰은 인간 선호도 평가 결과(Figure 7, Ours w/o T5)에서도 확인됩니다. T5를 제거해도 미학적 품질 평가에는 영향을 미치지 않으며(승률 50%), 프롬프트 준수에는 작은 영향만 미치며(승률 46%), 반면에 텍스트 생성 능력에는 더 큰 영향을 미칩니다(승률 38%).
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
성능 저하가 제한적인 이유를 추론해보면, T5쪽 인코더가 더 뒤에 위치하기 때문이다. Position에 영향을 받는 것으로 볼 수도 있다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------

광범위한 영향
이 논문은 기계 학습 분야, 특히 이미지 합성 분야를 발전시키는 것을 목표로 하는 연구를 제시합니다. 이 연구에는 여러 잠재적인 사회적 결과가 있지만, 이곳에서 특별히 강조해야 할 필요는 없다고 생각합니다. 디퓨전 모델의 일반적인 영향에 대한 광범위한 논의는 관심 있는 독자들을 위해 (Po et al., 2023)을 참조하십시오.
'인공지능' 카테고리의 다른 글
| The Pile: An 800GB Dataset of Diverse Text for Language Modeling (2) | 2024.08.03 |
|---|---|
| GLM: General Language Model Pretraining with Autoregressive Blank Infilling (1) | 2024.08.02 |
| GraphCast: Learning skillful medium-range global weather forecasting (1) | 2024.07.31 |
| SAM 2: Segment Anything in Images and Videos (4) | 2024.07.30 |
| Neural General Circulation Models for Weather and Climate (2) | 2024.07.29 |



