https://arxiv.org/abs/2103.10360
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
There have been various types of pretraining architectures including autoencoding models (e.g., BERT), autoregressive models (e.g., GPT), and encoder-decoder models (e.g., T5). However, none of the pretraining frameworks performs the best for all tasks of
arxiv.org
초록
자동인코딩 모델(예: BERT), 자기회귀 모델(예: GPT), 인코더-디코더 모델(예: T5) 등 다양한 유형의 사전 학습 아키텍처가 존재해 왔습니다. 그러나 자연어 이해(NLU), 무조건적 생성, 조건부 생성의 세 가지 주요 카테고리의 모든 작업에서 최상의 성능을 발휘하는 사전 학습 프레임워크는 없습니다. 우리는 이러한 문제를 해결하기 위해 자기회귀적 빈칸 채우기에 기반한 일반 언어 모델(GLM)을 제안합니다. GLM은 2D 위치 인코딩을 추가하고 임의의 순서로 스팬을 예측할 수 있게 하여 빈칸 채우기 사전 학습을 개선함으로써 NLU 작업에서 BERT와 T5보다 성능을 향상시킵니다. 한편, GLM은 빈칸의 수와 길이를 변화시켜 다양한 유형의 작업을 위해 사전 학습될 수 있습니다. NLU, 조건부 생성, 무조건적 생성 등 다양한 작업에서 GLM은 동일한 모델 크기와 데이터로 BERT, T5, GPT보다 뛰어난 성능을 발휘하며, BERTLarge의 1.25배의 매개변수를 가진 단일 사전 학습 모델로 최고의 성능을 달성하여 다양한 다운스트림 작업에 대한 일반화 가능성을 입증합니다.
해석
1. 도입
라벨이 없는 텍스트로 사전 학습된 언어 모델은 자연어 이해(NLU)에서 텍스트 생성에 이르기까지 다양한 NLP 작업에서 최첨단 성능을 크게 향상시켰습니다 (Radford et al., 2018a; Devlin et al., 2019; Yang et al., 2019; Radford et al., 2018b; Raffel et al., 2020; Lewis et al., 2019; Brown et al., 2020). 다운스트림 작업의 성능과 매개변수의 규모도 지난 몇 년 동안 지속적으로 증가해 왔습니다.

그림 1: GLM의 설명 그림. 우리는 텍스트 스팬(녹색 부분)을 빈칸으로 만들고 이를 자기회귀적으로 생성합니다. (일부 주의 엣지는 생략되었습니다; 그림 2를 참조하십시오.)
일반적으로 기존의 사전 학습 프레임워크는 자기회귀 모델, 자동인코딩 모델, 인코더-디코더 모델의 세 가지로 분류할 수 있습니다. GPT(Radford et al., 2018a)와 같은 자기회귀 모델은 왼쪽에서 오른쪽으로 학습하는 언어 모델입니다. 이들은 긴 텍스트 생성에서 성공을 거두었고 수십억 개의 매개변수로 확장되었을 때 소수 샷 학습 능력을 보여주었지만(Radford et al., 2018b; Brown et al., 2020), 고유의 단방향 주의 메커니즘으로 인해 NLU 작업에서 문맥 단어 간의 의존성을 완전히 포착하지 못하는 단점이 있습니다. BERT(Devlin et al., 2019)와 같은 자동인코딩 모델은 노이즈 제거 목표를 통해 양방향 문맥 인코더를 학습합니다. 예를 들어, 마스킹 언어 모델(MLM)입니다. 인코더는 자연어 이해 작업에 적합한 문맥화된 표현을 생성하지만, 텍스트 생성에 직접 적용될 수는 없습니다. 인코더-디코더 모델은 인코더에 양방향 주의를, 디코더에 단방향 주의를, 그 사이에 교차 주의를 적용합니다(Song et al., 2019; Bi et al., 2020; Lewis et al., 2019). 이 모델들은 일반적으로 텍스트 요약 및 응답 생성과 같은 조건부 생성 작업에 사용됩니다. T5(Raffel et al., 2020)는 인코더-디코더 모델을 통해 NLU와 조건부 생성을 통합하지만, RoBERTa(Liu et al., 2019) 및 DeBERTa(He et al., 2021)와 같은 BERT 기반 모델의 성능과 일치시키기 위해 더 많은 매개변수가 필요합니다.
이러한 사전 학습 프레임워크는 모든 NLP 작업에서 경쟁력 있게 수행할 만큼 유연하지 않습니다. 이전 연구들은 다중 작업 학습을 통해 다양한 프레임워크의 목표를 결합하여 통합하려고 시도했으나(Dong et al., 2019; Bao et al., 2020), 자동인코딩과 자기회귀 목표는 본질적으로 다르기 때문에 단순한 통합으로는 두 프레임워크의 장점을 완전히 계승할 수 없습니다.
이 논문에서는 자기회귀 빈칸 채우기를 기반으로 한 GLM(General Language Model)이라는 사전 학습 프레임워크를 제안합니다. 우리는 입력 텍스트에서 연속적인 토큰 스팬을 무작위로 비워 자동인코딩의 아이디어를 따르고, 모델이 이 스팬을 순차적으로 재구성하도록 학습하여 자기회귀 사전 학습의 아이디어를 따릅니다(그림 1 참조). T5(Raffel et al., 2020)에서는 텍스트 간 사전 학습을 위해 빈칸 채우기를 사용했지만, 우리는 스팬 셔플링과 2D 위치 인코딩이라는 두 가지 개선점을 제안합니다. 실험적으로, 동일한 매개변수와 계산 비용으로 GLM은 SuperGLUE 벤치마크에서 BERT를 4.6%에서 5.0%까지 크게 능가하며, 유사한 크기의 코퍼스(158GB)로 사전 학습된 RoBERTa 및 BART를 능가합니다. GLM은 또한 더 적은 매개변수와 데이터로 NLU 및 생성 작업에서 T5를 크게 능가합니다.
패턴 활용 학습(PET)(Schick and Schütze, 2020a)에서 영감을 받아, 우리는 NLU 작업을 사람의 언어를 모방한 수동 제작 클로즈 질문으로 재구성했습니다. PET에서 사용된 BERT 기반 모델과 달리, GLM은 자기회귀 빈칸 채우기를 통해 클로즈 질문에 대해 다중 토큰 응답을 자연스럽게 처리할 수 있습니다.
또한, 빈칸의 수와 길이를 변화시켜 자기회귀 빈칸 채우기 목표가 조건부 및 무조건부 생성을 위해 언어 모델을 사전 학습할 수 있음을 보여줍니다. 다양한 사전 학습 목표를 다중 작업 학습을 통해 단일 GLM은 NLU와 (조건부 및 무조건부) 텍스트 생성 모두에서 뛰어난 성능을 발휘할 수 있습니다. 실험적으로, 단독 기준 모델과 비교하여, 다중 작업 사전 학습을 통한 GLM은 매개변수를 공유함으로써 NLU, 조건부 텍스트 생성, 언어 모델링 작업에서 모두 개선을 달성합니다.
2. GLM 사전 학습 프레임워크
우리는 새로운 자기회귀 빈칸 채우기 목표에 기반한 일반적인 사전 학습 프레임워크인 GLM을 제안합니다. GLM은 작업 설명을 포함하는 클로즈 질문으로 NLU 작업을 공식화하며, 이는 자기회귀 생성으로 답변할 수 있습니다.
2.1 사전 학습 목표
2.1.1 자기회귀 빈칸 채우기


우리는 각 빈칸의 토큰을 항상 왼쪽에서 오른쪽 순서로 생성합니다. 즉, 스팬 s_를 생성할 확률은 다음과 같이 분해됩니다:


우리는 길이가 포아송 분포를 따르는 스팬들을 무작위로 샘플링합니다 (λ=3). 원래 토큰의 최소 15%가 마스킹될 때까지 새로운 스팬을 반복적으로 샘플링합니다. 경험적으로, 15% 비율이 다운스트림 NLU 작업에서 좋은 성능을 발휘하는 데 중요한 것으로 나타났습니다.
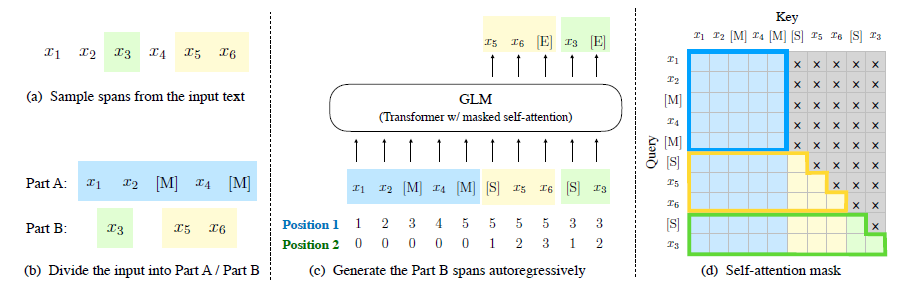
그림 2: GLM 사전 학습. (a) 원래 텍스트는 [x1; x2; x3; x4; x5; x6]입니다. 두 개의 스팬 [x3]과 [x5; x6]이 샘플링됩니다. (b) 샘플링된 스팬을 Part A에서 [M]으로 대체하고, Part B에서 스팬을 셔플합니다. (c) GLM은 자기회귀 방식으로 Part B를 생성합니다. 각 스팬은 입력으로 [S], 출력으로 [E]로 시작됩니다. 2D 위치 인코딩은 스팬 간 및 스팬 내 위치를 나타냅니다. (d) 셀프 어텐션 마스크. 회색 영역은 마스킹됩니다. Part A의 토큰은 자신에게만 주의를 기울일 수 있지만(파란색 프레임), Part B에는 주의를 기울일 수 없습니다. Part B의 토큰은 Part A와 Part B 내의 선행 토큰에 주의를 기울일 수 있습니다(노란색 및 녹색 프레임은 두 스팬에 해당합니다). [M] = [MASK], [S] = [START], [E] = [END].
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
얀 루큰의 jest와 비슷한 느낌임
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
2.1.2 다중 작업 사전 학습
이전 섹션에서 GLM은 짧은 스팬을 마스킹하며 NLU 작업에 적합합니다. 그러나 우리는 NLU와 텍스트 생성을 모두 처리할 수 있는 단일 모델의 사전 학습에 관심이 있습니다. 따라서 우리는 빈칸 채우기 목표와 함께 긴 텍스트 생성이라는 두 번째 목표를 공동으로 최적화하는 다중 작업 사전 학습 설정을 연구합니다. 우리는 다음 두 가지 목표를 고려합니다:
- 문서 수준: 원래 길이의 50%에서 100% 사이의 균일 분포에서 길이를 샘플링한 단일 스팬을 샘플링합니다. 이 목표는 긴 텍스트 생성을 목표로 합니다.
- 문장 수준: 마스킹된 스팬은 반드시 전체 문장이어야 합니다. 여러 스팬(문장)을 샘플링하여 원래 토큰의 15%를 커버합니다. 이 목표는 예측이 종종 완전한 문장 또는 단락인 시퀀스 투 시퀀스 작업을 목표로 합니다.
새로운 두 목표는 원래 목표와 동일한 방식으로 정의됩니다, 즉 Eq. 1입니다. 유일한 차이점은 스팬의 수와 스팬 길이입니다.
2.2 모델 아키텍처
GLM은 아키텍처에 몇 가지 수정이 가해진 단일 트랜스포머를 사용합니다: (1) 우리는 층 정규화와 잔여 연결의 순서를 재조정하여 대규모 언어 모델에서 수치 오류를 피하는 데 중요함을 보여주었습니다(Shoeybi et al., 2019); (2) 출력 토큰 예측을 위해 단일 선형 층을 사용합니다; (3) ReLU 활성화 함수 대신 GeLU를 사용합니다(Hendrycks and Gimpel, 2016).
2.2.1 2D 위치 인코딩

우리의 인코딩 방법은 모델이 스팬을 재구성할 때 마스킹된 스팬의 길이를 인지하지 못하게 보장합니다. 이는 다른 모델과 비교했을 때 중요한 차이점입니다. 예를 들어, XLNet(Yang et al., 2019)은 원래 위치를 인코딩하여 누락된 토큰의 수를 인지할 수 있으며, SpanBERT(Joshi et al., 2020)는 스팬을 여러 개의 [MASK] 토큰으로 대체하고 길이를 유지합니다. 우리의 설계는 생성된 텍스트의 길이를 미리 알 수 없는 경우가 많은 다운스트림 작업에 적합합니다.

그림 3: GLM을 사용한 감정 분류 작업의 빈칸 채우기 공식화.
2.3 GLM 파인튜닝

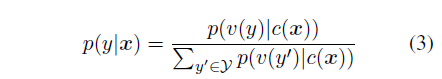
따라서 문장이 긍정적인지 부정적인지의 확률은 빈칸에 "good" 또는 "bad"를 예측하는 것과 비례합니다. 그런 다음 교차 엔트로피 손실을 사용하여 GLM을 파인튜닝합니다(그림 3 참조).
텍스트 생성 작업의 경우 주어진 문맥이 입력의 Part A를 구성하며, 끝에 마스크 토큰이 추가됩니다. 모델은 Part B의 텍스트를 자기회귀 방식으로 생성합니다. 우리는 사전 학습된 GLM을 무조건적 생성에 직접 적용할 수 있거나, 다운스트림 조건부 생성 작업에 맞게 파인튜닝할 수 있습니다.
2.4 논의 및 분석
이 섹션에서는 GLM과 다른 사전 학습 모델 간의 차이점을 논의합니다. 우리는 주로 이들이 다운스트림 빈칸 채우기 작업에 어떻게 적응할 수 있는지에 대해 관심을 가집니다.
BERT(Devlin et al., 2019)와의 비교
(Yang et al., 2019)이 지적한 바와 같이, BERT는 MLM의 독립성 가정으로 인해 마스킹된 토큰의 상호 의존성을 포착하지 못합니다. BERT의 또 다른 단점은 여러 토큰의 빈칸을 적절히 채울 수 없다는 점입니다. BERT는 길이 l의 답변 확률을 추론하기 위해 l개의 연속된 예측을 수행해야 합니다. 길이 ll이 알려지지 않은 경우, BERT는 [MASK] 토큰의 수를 길이에 따라 변경해야 하기 때문에 모든 가능한 길이를 열거해야 할 수도 있습니다.
XLNet(Yang et al., 2019)과의 비교
GLM과 XLNet은 모두 자기회귀 목표로 사전 학습되지만, 두 가지 차이점이 있습니다. 첫째, XLNet은 손상되기 전의 원래 위치 인코딩을 사용합니다. 추론 중에는 BERT와 동일한 문제로 답변의 길이를 알거나 열거해야 합니다. 둘째, XLNet은 정보 누출을 방지하기 위해 오른쪽 이동 대신 두 스트림 셀프 어텐션 메커니즘을 사용합니다. 이는 사전 학습의 시간 비용을 두 배로 늘립니다.
T5(Raffel et al., 2020)와의 비교
T5는 인코더-디코더 트랜스포머를 사전 학습하기 위해 유사한 빈칸 채우기 목표를 제안합니다. T5는 인코더와 디코더에 독립적인 위치 인코딩을 사용하며, 마스킹된 스팬을 구분하기 위해 여러 센티널 토큰에 의존합니다. 다운스트림 작업에서는 센티널 토큰 중 하나만 사용되어 모델 용량의 낭비와 사전 학습과 파인튜닝 간의 불일치를 초래합니다. 또한, T5는 항상 왼쪽에서 오른쪽 순서로 스팬을 예측합니다. 결과적으로, GLM은 섹션 3.2 및 3.3에서 설명한 바와 같이 더 적은 매개변수와 데이터로 NLU 및 seq2seq 작업에서 T5보다 훨씬 뛰어난 성능을 발휘할 수 있습니다.
UniLM(Dong et al., 2019)과의 비교
UniLM은 양방향, 단방향, 교차 어텐션 간의 어텐션 마스크를 변경하여 자동인코딩 프레임워크 하에 다양한 사전 학습 목표를 결합합니다. 그러나 UniLM은 항상 마스킹된 스팬을 [MASK] 토큰으로 대체하여, 마스킹된 스팬과 그 문맥 간의 의존성을 모델링하는 능력을 제한합니다. GLM은 이전 토큰을 입력으로 제공하고 다음 토큰을 자기회귀적으로 생성합니다. 다운스트림 생성 작업에서 UniLM을 파인튜닝하는 것도 마스킹된 언어 모델링에 의존하여 효율성이 떨어집니다. UniLMv2(Bao et al., 2020)는 NLU 작업을 위해 자동인코딩 목표와 함께 생성 작업을 위해 부분적으로 자기회귀 모델링을 채택합니다. 반면, GLM은 자기회귀 사전 학습을 통해 NLU와 생성 작업을 통합합니다.
3. 실험
이제 우리의 사전 학습 설정과 다운스트림 작업 평가에 대해 설명합니다.
3.1 사전 학습 설정
BERT(Devlin et al., 2019)와의 공정한 비교를 위해, 우리는 BooksCorpus(Zhu et al., 2015)와 영어 Wikipedia를 사전 학습 데이터로 사용합니다. BERT의 30k 어휘를 가진 uncased wordpiece 토크나이저를 사용합니다. 우리는 BERTBase와 BERTLarge와 동일한 아키텍처를 가진 GLMBase와 GLMLarge를 각각 110M 및 340M 매개변수로 학습합니다. 다중 작업 사전 학습을 위해, 우리는 빈칸 채우기 목표와 문서 수준 또는 문장 수준 목표의 혼합으로 두 개의 Large 크기 모델(GLMDoc과 GLMSent)을 학습합니다. 추가로, 410M(30 레이어, 히든 사이즈 1024, 16 어텐션 헤드) 및 515M(30 레이어, 히든 사이즈 1152, 18 어텐션 헤드) 매개변수를 가진 더 큰 GLM 모델(GLM410M 및 GLM515M)을 문서 수준 다중 작업 사전 학습으로 학습합니다.
최첨단 모델과의 비교를 위해, 우리는 동일한 데이터, 토크나이징 및 하이퍼파라미터로 RoBERTa(Liu et al., 2019)와 같은 Large 크기 모델(GLMRoBERTa)을 학습합니다. 자원 제한으로 인해, 우리는 모델을 RoBERTa와 BART의 학습 단계의 절반인 250,000 단계만 사전 학습하며, T5의 학습된 토큰 수와 유사합니다. 더 자세한 실험 정보는 부록 A에서 확인할 수 있습니다.
3.2 SuperGLUE
우리의 사전 학습된 GLM 모델을 평가하기 위해, SuperGLUE 벤치마크(Wang et al., 2019)에서 실험을 수행하고 표준 지표를 보고합니다. SuperGLUE는 8개의 도전적인 NLU 작업으로 구성되어 있습니다. 우리는 PET(Schick and Schütze, 2020b)를 따라 분류 작업을 사람이 제작한 클로즈 질문을 통한 빈칸 채우기로 재구성합니다. 그런 다음 섹션 2.3에서 설명한 대로 각 작업에 대해 사전 학습된 GLM 모델을 파인튜닝합니다. 클로즈 질문과 기타 세부 사항은 부록 B.1에서 확인할 수 있습니다.
GLMBase와 GLMLarge와의 공정한 비교를 위해, 우리는 BERTBase와 BERTLarge를 우리의 기준 모델로 선택합니다. 이들은 동일한 코퍼스에서 유사한 시간 동안 사전 학습되었습니다. 우리는 표준 파인튜닝 성능([CLS] 토큰 표현에서의 분류)을 보고합니다. 클로즈 질문과 함께한 BERT의 성능은 섹션 3.4에 보고됩니다. GLMRoBERTa와 비교하기 위해, 우리는 T5, BARTLarge, RoBERTaLarge를 기준 모델로 선택합니다. T5는 BERTLarge와 매개변수 수가 직접 일치하지 않기 때문에, 우리는 T5Base(220M 매개변수)와 T5Large(770M 매개변수)의 결과를 모두 제시합니다. 다른 모든 기준 모델은 BERTLarge와 유사한 크기입니다.
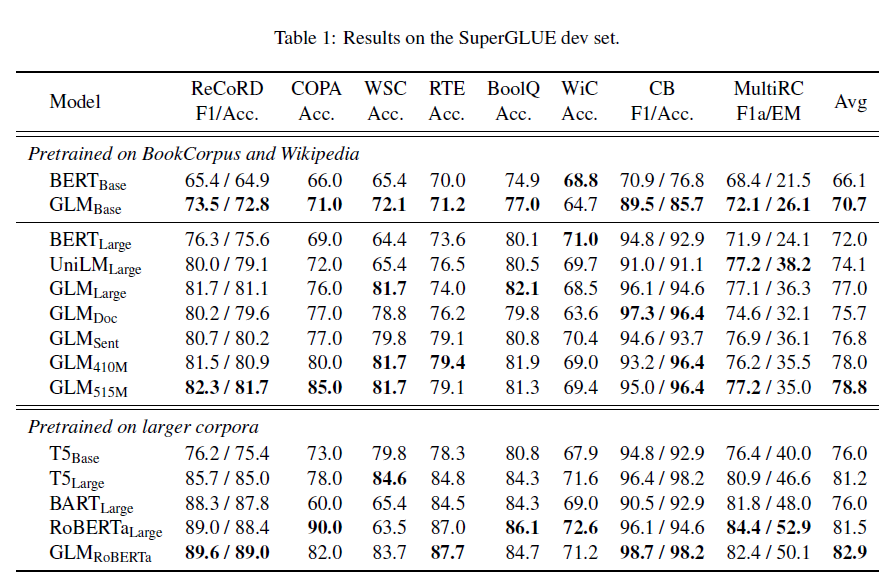
표 1: SuperGLUE 개발 세트의 결과.
표 1은 결과를 보여줍니다. 동일한 양의 학습 데이터로 GLM은 대부분의 작업에서 base 또는 large 아키텍처를 사용하여 BERT보다 일관되게 우수한 성능을 발휘합니다. 유일한 예외는 WiC(단어 의미 구분)입니다. 평균적으로, GLMBase는 BERTBase보다 4.6% 높은 점수를, GLMLarge는 BERTLarge보다 5.0% 높은 점수를 기록합니다. 이는 NLU 작업에서 우리의 방법의 장점을 명확히 보여줍니다. RoBERTaLarge 설정에서 GLMRoBERTa는 여전히 기준 모델보다 개선을 이룰 수 있지만, 그 차이는 더 작습니다. 구체적으로, GLMRoBERTa는 T5Large보다 우수하지만, 크기는 절반에 불과합니다. 우리는 또한 BART가 SuperGLUE 벤치마크에서 잘 수행되지 않는다는 것을 발견했습니다. 이는 인코더-디코더 아키텍처의 낮은 매개변수 효율성과 노이즈 제거 시퀀스-투-시퀀스 목표 때문이라고 추정됩니다.
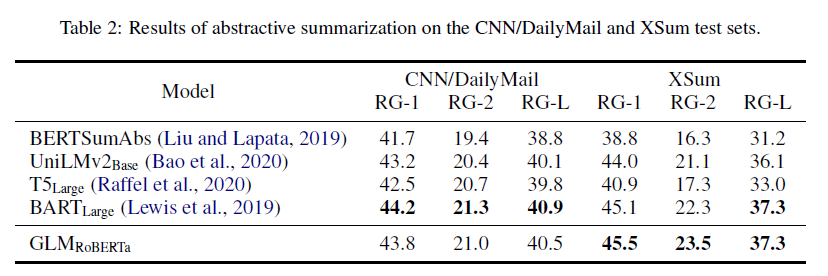
표 2: CNN/DailyMail과 XSum 테스트 세트에서의 추상적 요약 결과.
3.3 다중 작업 사전 학습
다음으로 우리는 다중 작업 설정에서 GLM의 성능을 평가합니다(섹션 2.1). 하나의 학습 배치 내에서, 짧은 스팬과 긴 스팬(문서 수준 또는 문장 수준)을 동일한 확률로 샘플링합니다. 우리는 다중 작업 모델을 NLU, 시퀀스-투-시퀀스(seq2seq), 빈칸 채우기, 제로 샷 언어 모델링에 대해 평가합니다.
SuperGLUE. NLU 작업의 경우, 우리는 SuperGLUE 벤치마크에서 모델을 평가합니다. 결과는 표 1에도 나와 있습니다. 다중 작업 사전 학습을 통해 GLMDoc와 GLMSent가 GLMLarge보다 약간 낮은 성능을 보이지만, 여전히 BERTLarge와 UniLMLarge를 능가하는 것을 관찰할 수 있습니다. 다중 작업 모델 중에서 GLMSent가 평균적으로 GLMDoc보다 1.1% 더 우수합니다. GLMDoc의 매개변수를 410M(1.25배 BERTLarge)으로 늘리면 GLMLarge보다 더 나은 성능을 발휘합니다. 515M 매개변수(1.5배 BERTLarge)를 가진 GLM은 더 나은 성능을 발휘할 수 있습니다.
시퀀스-투-시퀀스(seq2seq)
사용 가능한 기준 결과를 고려하여, 우리는 기가워드(Gigaword) 데이터셋(Rush et al., 2015)을 추상적 요약을 위해, 그리고 SQuAD 1.1 데이터셋(Rajpurkar et al., 2016)을 질문 생성(Du et al., 2017)을 위한 벤치마크로 사용합니다. 추가적으로, 우리는 더 큰 코퍼스에서 사전 학습된 모델들의 벤치마크로 CNN/DailyMail(See et al., 2017)과 XSum(Narayan et al., 2018) 데이터셋을 사용합니다.
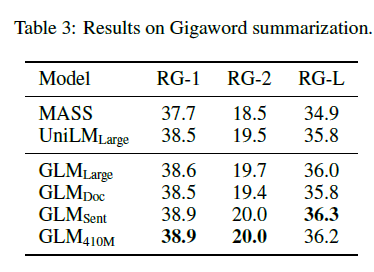
표 3: 기가워드 요약의 결과.
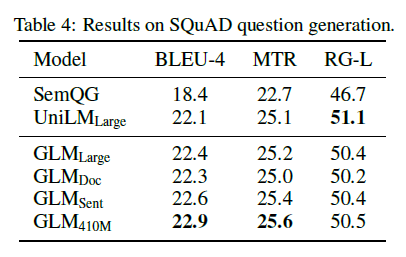
표 4: SQuAD 질문 생성의 결과.
BookCorpus와 Wikipedia에서 학습된 모델의 결과는 표 3과 4에 나와 있습니다. 우리는 GLMLarge가 두 가지 생성 작업에서 다른 사전 학습 모델과 성능을 맞출 수 있음을 관찰했습니다. GLMSent는 GLMLarge보다 더 나은 성능을 발휘할 수 있는 반면, GLMDoc는 GLMLarge보다 약간 낮은 성능을 보입니다. 이는 주어진 문맥을 확장하는 것을 가르치는 문서 수준 목표가 문맥에서 유용한 정보를 추출하는 것을 목표로 하는 조건부 생성에 덜 도움이 된다는 것을 나타냅니다. GLMDoc의 매개변수를 410M으로 늘리면 두 작업에서 최고의 성능을 발휘합니다. 더 큰 코퍼스에서 학습된 모델의 결과는 표 2에 나와 있습니다. GLMRoBERTa는 seq2seq BART 모델과 성능을 맞출 수 있으며, T5와 UniLMv2를 능가합니다.
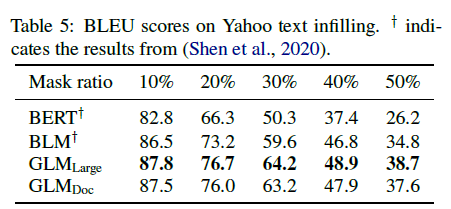
표 5: Yahoo 텍스트 인필링의 BLEU 점수. y는 (Shen et al., 2020)에서의 결과를 나타냅니다.
텍스트 인필링(Text Infilling)
텍스트 인필링은 주변 문맥과 일치하는 누락된 텍스트 스팬을 예측하는 작업입니다(Zhu et al., 2019; Donahue et al., 2020; Shen et al., 2020). GLM은 자기회귀 빈칸 채우기 목표로 학습되었으므로 이 작업을 간단히 해결할 수 있습니다. 우리는 Yahoo Answers 데이터셋(Yang et al., 2017)에서 GLM을 평가하고, 텍스트 인필링을 위해 특별히 설계된 모델인 Blank Language Model(BLM)(Shen et al., 2020)과 비교합니다. 표 5의 결과에서 볼 수 있듯이, GLM은 이전 방법들을 큰 차이(1.3에서 3.9 BLEU)로 능가하며 이 데이터셋에서 최첨단 결과를 달성합니다. 우리는 GLMDoc이 GLMLarge보다 약간 낮은 성능을 보인다는 것을 주목했는데, 이는 seq2seq 실험에서 관찰한 바와 일치합니다.
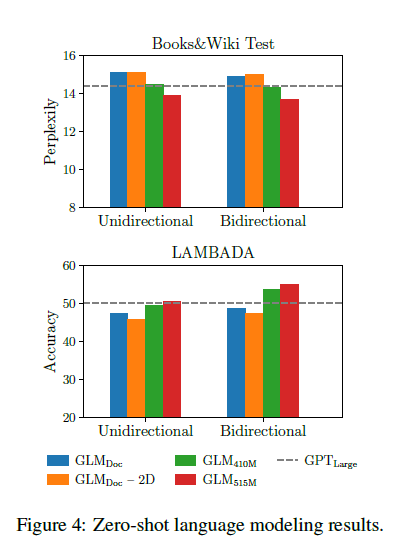
그림 4: 제로샷 언어 모델링 결과.
언어 모델링
대부분의 언어 모델링 데이터셋(예: WikiText103)은 이미 우리의 사전 학습 데이터셋에 포함된 Wikipedia 문서로 구성되어 있습니다. 따라서 우리는 사전 학습 데이터셋의 보류된 테스트 세트(약 2000만 토큰 포함)인 BookWiki에서 언어 모델링 perplexity를 평가합니다. 또한 우리는 LAMBADA 데이터셋(Paperno et al., 2016)에서 GLM을 평가합니다. LAMBADA는 시스템이 텍스트에서 장거리 의존성을 모델링하는 능력을 테스트하는 데이터셋으로, 주어진 단락의 마지막 단어를 예측하는 과제입니다. 기준 모델로서 우리는 GLMLarge와 동일한 데이터와 토크나이징을 사용하여 GPTLarge 모델(Radford et al., 2018b; Brown et al., 2020)을 학습합니다.
결과는 그림 4에 나와 있습니다. 모든 모델은 제로샷 설정에서 평가되었습니다. GLM은 양방향 주의를 학습하므로, 문맥을 양방향 주의로 인코딩하는 설정에서도 GLM을 평가합니다. 사전 학습 중 생성 목표가 없는 경우, GLMLarge는 언어 모델링 작업을 완료할 수 없으며, perplexity가 100보다 큽니다. 동일한 매개변수를 가진 경우, GLMDoc는 GPTLarge보다 성능이 낮습니다. 이는 GLMDoc이 또한 빈칸 채우기 목표를 최적화하기 때문에 예상된 결과입니다. 모델의 매개변수를 410M(1.25배 GPTLarge)으로 늘리면 GPTLarge에 근접한 성능을 발휘합니다. GLM515M(1.5배 GPTLarge)은 GPTLarge를 능가할 수 있습니다. 동일한 매개변수로 문맥을 양방향 주의로 인코딩하면 언어 모델링 성능이 향상될 수 있습니다. 이 설정에서 GLM410M은 GPTLarge를 능가합니다. 이는 단방향 GPT보다 GLM의 장점입니다. 우리는 또한 긴 텍스트 생성에 대한 2D 위치 인코딩의 기여를 연구했습니다. 2D 위치 인코딩을 제거하면 언어 모델링에서 정확도가 낮아지고 perplexity가 높아지는 것을 발견했습니다.
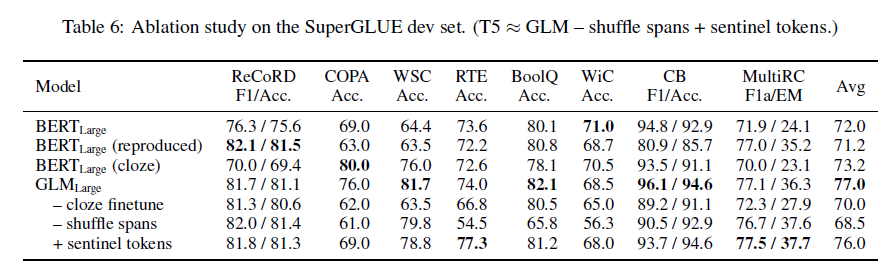
표 6: SuperGLUE 개발 세트에서의 소거 연구. (T5 GLM – 스팬 셔플링 + 센티넬 토큰.)
요약
위의 내용을 종합하면, GLM은 자연어 이해와 생성 작업 전반에 걸쳐 모델 매개변수를 효과적으로 공유하며, 단독 BERT, 인코더-디코더, 또는 GPT 모델보다 더 나은 성능을 달성합니다.
3.4 소거 연구
표 6은 GLM에 대한 소거 분석 결과를 보여줍니다. 먼저, BERT와 공정한 비교를 위해, 우리는 우리의 구현, 데이터, 하이퍼파라미터로 BERTLarge 모델을 학습했습니다(2행). 성능은 공식 BERTLarge보다 약간 낮고, GLMLarge보다 훨씬 낮습니다. 이는 NLU 작업에서 GLM이 Masked LM 사전 학습보다 우수하다는 것을 확인시켜 줍니다. 둘째, 우리는 시퀀스 분류기로서 파인튜닝된 GLM의 SuperGLUE 성능(5행)과 클로즈 스타일 파인튜닝된 BERT(3행)를 보여줍니다. 클로즈 스타일 파인튜닝된 BERT와 비교할 때, GLM은 자기회귀 사전 학습에서 이점을 얻습니다. 특히, 여러 토큰으로 구성된 언어화 도구(verbalizer)가 있는 ReCoRD와 WSC에서 GLM은 일관되게 BERT보다 우수합니다. 이는 가변 길이 빈칸 처리를 다루는 GLM의 장점을 입증합니다. 또 다른 관찰 결과는 클로즈 공식화가 NLU 작업에서 GLM의 성능에 중요하다는 것입니다. 대형 모델의 경우, 클로즈 스타일 파인튜닝은 성능을 7포인트 향상시킬 수 있습니다. 마지막으로, 우리는 다른 사전 학습 디자인을 가진 GLM 변형들을 비교하여 그 중요성을 이해합니다. 6행은 스팬 셔플링을 제거하면(항상 왼쪽에서 오른쪽으로 마스킹된 스팬을 예측) SuperGLUE에서 성능이 크게 떨어진다는 것을 보여줍니다. 7행은 여러 센티넬 토큰 대신 단일 [MASK] 토큰을 사용하여 다양한 마스킹된 스팬을 나타냅니다. 이 모델은 표준 GLM보다 성능이 낮습니다. 이는 다운스트림 작업에서 하나의 빈칸만 사용하는 경우, 다양한 센티넬 토큰을 학습하는 데 모델링 용량이 낭비된다고 가정합니다. 그림 4에서는 2D 위치 인코딩의 두 번째 차원을 제거하면 긴 텍스트 생성 성능에 부정적인 영향을 미친다는 것을 보여줍니다.
T5는 유사한 빈칸 채우기 목표로 사전 학습되었습니다. GLM은 세 가지 측면에서 다릅니다: (1) GLM은 단일 인코더로 구성됩니다, (2) GLM은 마스킹된 스팬을 셔플링합니다, (3) GLM은 여러 센티넬 토큰 대신 단일 [MASK]를 사용합니다. GLM과 T5를 학습 데이터와 매개변수 수의 차이로 인해 직접 비교할 수는 없지만, 표 1과 6의 결과는 GLM의 장점을 입증합니다.
4 관련 연구
사전 학습된 언어 모델
대규모 언어 모델의 사전 학습은 다운스트림 작업의 성능을 크게 향상시킵니다. 사전 학습된 모델은 세 가지 유형이 있습니다. 첫째, 자동인코딩 모델은 노이즈 제거 목표를 통해 자연어 이해를 위한 양방향 문맥 인코더를 학습합니다(Devlin et al., 2019; Joshi et al., 2020; Yang et al., 2019; Liu et al., 2019; Lan et al., 2020; Clark et al., 2020). 둘째, 자기회귀 모델은 왼쪽에서 오른쪽으로 언어 모델링 목표를 통해 학습됩니다(Radford et al., 2018a,b; Brown et al., 2020). 셋째, 인코더-디코더 모델은 시퀀스-투-시퀀스 작업을 위해 사전 학습됩니다(Song et al., 2019; Lewis et al., 2019; Bi et al., 2020; Zhang et al., 2020).
인코더-디코더 모델 중 BART(Lewis et al., 2019)는 동일한 입력을 인코더와 디코더에 입력하고 디코더의 최종 숨겨진 상태를 사용하여 NLU 작업을 수행합니다. 반면, T5(Raffel et al., 2020)는 대부분의 언어 작업을 텍스트-투-텍스트 프레임워크로 공식화합니다. 그러나 두 모델 모두 RoBERTa(Liu et al., 2019)와 같은 자동인코딩 모델보다 우수한 성능을 발휘하려면 더 많은 매개변수가 필요합니다. UniLM(Dong et al., 2019; Bao et al., 2020)은 다양한 주의 마스크로 마스킹된 언어 모델링 목표 하에 세 가지 사전 학습 모델을 통합합니다.
생성으로서의 NLU
이전에 사전 학습된 언어 모델은 학습된 표현에서 선형 분류기를 사용하여 NLU 분류 작업을 완료했습니다. GPT-2(Radford et al., 2018b)와 GPT-3(Brown et al., 2020)는 생성 언어 모델이 과제 지시 또는 몇 가지 라벨링된 예제를 제공받았을 때 파인튜닝 없이도 질문 응답과 같은 NLU 작업을 직접 예측할 수 있음을 보여주었습니다. 그러나 생성 모델은 단방향 주의의 한계로 인해 더 많은 매개변수가 필요합니다. 최근 PET(Schick and Schütze, 2020a,b)는 입력 예제를 소수 샷 설정에서 사전 학습 코퍼스와 유사한 패턴의 클로즈 질문으로 재구성할 것을 제안했습니다. 이는 경사 기반 파인튜닝과 결합하면 PET이 GPT-3보다 0.1%의 매개변수로 더 나은 성능을 달성할 수 있음을 보여주었습니다. 유사하게 Athiwaratkun et al. (2020)과 Paolini et al. (2020)은 시퀀스 태그 및 관계 추출과 같은 구조화된 예측 작업을 시퀀스 생성 작업으로 변환합니다.
빈칸 채우기 언어 모델링
Donahue et al. (2020)와 Shen et al. (2020)은 또한 빈칸 채우기 모델을 연구했습니다. 이들의 연구와 달리 우리는 빈칸 채우기 목표로 언어 모델을 사전 학습하고 다운스트림 NLU와 생성 작업에서 그 성능을 평가합니다.
5 결론
GLM은 자연어 이해와 생성을 위한 일반적인 사전 학습 프레임워크입니다. 우리는 NLU 작업이 조건부 생성 작업으로 공식화될 수 있으며, 따라서 자기회귀 모델로 해결할 수 있음을 보여줍니다. GLM은 다양한 작업의 사전 학습 목표를 혼합된 주의 마스크와 새로운 2D 위치 인코딩을 사용한 자기회귀 빈칸 채우기로 통합합니다. 실험적으로 우리는 GLM이 이전 방법보다 NLU 작업에서 우수한 성능을 발휘하며, 다양한 작업에 대해 효과적으로 매개변수를 공유할 수 있음을 보여줍니다.
감사의 글
이 연구는 NSFC의 젊은 석학 지원(61825602)과 베이징 인공지능 아카데미(BAAI)의 지원을 받았습니다.



